
Если вы – пользователь Netflix, то, скорее всего, вы замечали, что иногда вам предлагаются фильмы странных жанров. Некоторые из них настолько странные, что выглядят абсурдными. Документальные драматические фильмы про борцов с системой? Пьеса про королевскую семью, основанная на реальных событиях? Зарубежные истории про сатанистов 80-х?
Если Netflix способен выделять такие тонкости каждого фильма для каждого пользователя (а их 40 миллионов), встает вопрос, каким образом устроена система «индивидуальных жанров», описывающая всю вселенную Голливуда?
Простое удивление переросло в восторг, когда я понял, что могу определить каждый из микро-жанров, созданных алгоритмом Netflix. Приложив немалые усилия, мы обнаружили, что Netflix обрабатывает не несколько сотен жанров (даже не несколько тысяч), а имеет 76897 разных способов описания фильмов.
Их оказалось так много, что для полной загрузки и копирования потребовался отдельный скрипт, который я писал больше 20 часов. Следующие несколько недель мы проводили анализ и реверсивный инжиниринг, пытаясь понять лексикон и грамматику Netflix. Мы разбили самые популярные определения на составляющие и выявили самых популярных актеров и режиссёров.
По моим данным (и данным Netflix), никто за пределами компании никогда не собирал подобной информации.
Из проделанной работы можно сделать вывод: Netflix тщательно анализировал и размечал каждый фильм и ТВ-шоу. Они собрали кучу данных о продуктах Голливуда, чего никто и никогда до них не делал. Жанры, которые я выбрал, и которые мы высмеивали выше – это только верхушка айсберга.
Netflix поддержал мое стремление понять, что же такое «альтжанры» (как их называют в компании), и я получил возможность взять интервью у вице-президента по инновациям Тода Йеллина (Todd Yellin), человека, который придумал эту систему. ИТ-профессор Ян Богост (Ian Bogost) из Джорджии, по совместительству пишущий редактор Atlantic, плотно работал со мной над проектом воссоздания грамматики Netflix и программировал волшебный вышеописанный генератор жанров.
Йеллин сам предложил провести реверсивный инжиниринг своего проекта, с целью увидеть более амбициозные результаты. С помощью крупных команд, состоящих из специально обученных смотреть фильмы людей, Netflix анализировал Голливуд. Они платили людям за просмотр фильмов и установление метаданных для каждого из них. Этот процесс оказался настолько сложен, что участники получали 36-страничный учебный документ, в котором было расписано, как оценивать фильмы по наличию сексуального содержания, количеству крови, как определить романтичность фильма и даже оценить уровень актерской игры.
Производилась оценка десятков различных аспектов фильма. Оценивалась даже нравственность персонажей. Главным достижением Netflix стало объединение собранных тегов с миллионами любимых фильмов пользователей. Главной целью компании является обретение и удержание подписчиков, и те жанры, которые видят пользователи – это ключевая часть стратегии. «Интересы подписчиков сервиса сопоставляются с жанрами настолько точно, что приток клиентов увеличивается, когда мы размещаем индивидуальные жанры вверху страницы», – сообщила компания в своем блоге в 2012 году. Чем больше Netflix соответствует вашим желаниям, тем больше шанс, что вы станете его клиентом.
Netflix создал базу данных кинематографических предпочтений американцев, которая оказывается полезным подспорьем в создании собственных телевизионных шоу. Собранные данные не говорят, «как» сделать ТВ-шоу, но могут сказать, «что» нужно делать. Телесериал «Карточный домик» был создан неслучайно.
Вымышленные фильмы вымышленных жанров. Иллюстрация Darth.
Операция: Собрать все данные
Все началось, когда я захотел получить наиболее полный список всех микро-жанров Netflix. Задача выглядела как обычная забава, но, несмотря на это, её решение требовало особого подхода – как и многие другие вариации этой задачи.
Я начал работу, попросив своих подписчиков в Twitter записать категории, которые им предлагает Netflix, в общий документ.
«Насколько я знал, подобного списка не существовало в природе, а зря, – писал я. – Теперь мы можем видеть, что делает для нас Netflix».
Этот призыв о помощи принес мне около 150 жанров, что может казаться большой цифрой, если сравнивать с Blockbuster (покойся с миром). Сара Пэвис (Sarah Pavis), писатель и инженер, заметила, что URL-адреса Netflix пронумерованы по порядку. Можно изменять порядковый номер и записывать жанры с каждой страницы.
Смотрите, ссылка movies.netflix.com/WiAltGenre?agid=1 отсылает нас к «Документальным фильмам о преступной деятельности афроамериканцев», а movies.netflix.com/WiAltGenre?agid=2 к «Культовым ужастикам 1980х годов». И так далее.
После посещения нескольких десятков ссылок, я перешел к довольно большим порядковым номерам.
1000: Фильмы отснятые Отто Премингером;
3000: Драмы с Сильвестром Сталлоне;
5000: Фильмы о преступлениях 1940х годов, которые были тепло встречены критиками;
20000: Фильмы про отношения матери и сына 1970х годов.
Многие порядковые номера были пустыми, но их количество превышало 90000!
Исследование базы данных дало понять три вещи: 1) У Netflix абсурдно большое количество жанров, на порядок или два больше, чем я думал сначала. 2) Все жанры организованы абсолютно непонятным способом. 3) Невозможно перебрать все жанры вручную.
Но я также понял, что есть способ собрать все эти данные. Я как-то натыкался на сложное программное обеспечение под названием UBot Studio, упрощающее написание скриптов для веба. В основном, оно используется спамерами и мошенниками, но я решил использовать его для последовательного копирования жанров Netflix в файл.
Прибегнув к помощи Богоста и отладив программу, я запустил бот, который стал копировать жанры с каждого URL, избавив меня от ручного труда. Потребовался почти целый день, чтобы ноутбук Asus, стоящий в углу на кухне, справился с задачей.
Пока бот работал, я начал знакомиться с получаемыми им данными. Я выбрал случайную часть списка, чтобы вы могли ознакомиться с тем, как выглядит необработанный список жанров:
Независимое кино: эмоциональные фильмы о спорте
Шпионские и приключенческие фильмы 1930х годов
Культовые ужастики со злыми детьми
Культовые спортивные фильмы
Сентиментальные европейские драмы 1970х
Иностранные ностальгические драмы, поражающие красотой
Японские спортивные фильмы
Реалити-шоу телеканала Discovery Channel
Романтические криминальные драмы Китая
Крышесносные культовые ужастики 1980х годов
Мрачный научно-фантастический саспенс
Волнующие вестерны про отмщение
Экшен и приключенческие фильмы 1980х годов с элементами жестокости
Фильмы о путешествиях во времени с Уильямом Хартеллом
Индийские романтические криминальные драмы
Ужастики со злыми детьми
Удивительные приключенческие комедии
Британская научная фантастика и фэнтези 1960х годов
Напряженные гангстерские драмы
Недооцененные фильмы про чувства, которые были признаны критиками
Я сразу обратил внимание, что на сайте есть фильмы не всех представленных жанров. Это последствия постоянно меняющегося каталога фильмов, и пустые жанры показывают, что такие фильмы когда-то существовали. Категория 91300: «Добрые романтические ТВ-шоу на испанском языке» была пустой, категория 91307: «Красивые латиноамериканские комедии» содержала два фильма, а в категории 6307: «Красивые романтические драмы» были представлены 20 фильмов.
Просматривая данные, нужно помнить, что наличие жанра в базе никак не коррелирует с общим количеством фильмов Netflix. Наличие жанра в базе означает, что, по данным алгоритма, такие фильмы могут появиться позже, или уже есть материалы, которые подпадают под описание, но еще не добавлены на сайт.
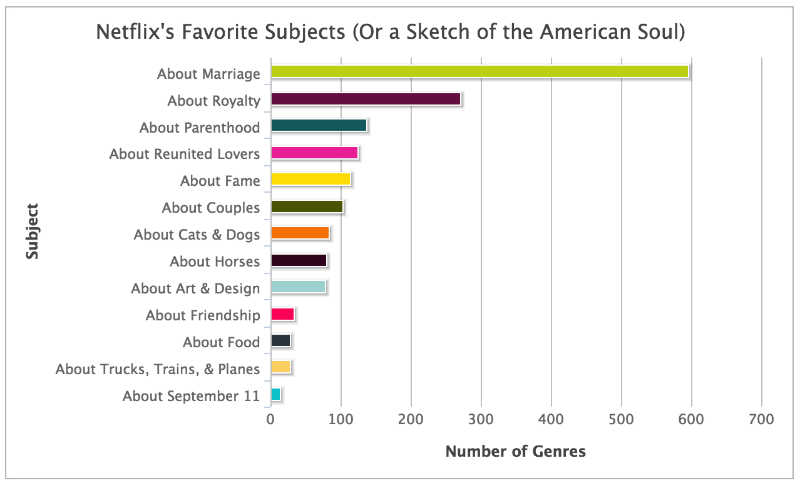
В то время как тысячи жанров появлялись на моем небольшом нетбуке, я начал замечать другие паттерны в данных: Netflix обладал собственным словарем. Одни и те же прилагательные появлялись снова и снова. Постоянно всплывали страны происхождения фильмов и большое количество существительных, описывающих сам жанр (вестерн, слэшер). Также алгоритм описывал, откуда взялась идея для сценария: «из жизни», «из классической литературы», и в каком времени происходят события, например, «времен короля Эдуарда». Разумеется, в заголовках присутствовали временные отрезки, например, «1980х годов», а также рекомендуемый возраст – «для детей от 8 до 10 лет».
Интересно то, что полный список объектов способен продемонстрировать, чего желает американская душа:
Часы шли, и грамматика Netflix – то, как связываются слова и формулируются жанры – становилась все более прозрачной.
Если фильм романтичный и выигрывал Оскар, то информация об Оскаре всегда записывалась вначале: «Оскароносные романтические драмы». Временные же периоды всегда следуют в конце: «Оскароносные романтические драмы 1950х годов».
Прилагательные (например, «романтические») могут просто накапливаться, давая в результате нечто подобное: «Оскароносные романтические фильмы о запретной любви».
Категории, раскрывающие содержание фильма, обычно ставятся в самый конец: «Оскароносные романтические фильмы о свадьбе».
На самом деле, для каждого дескриптора существует строгая иерархия. Короче говоря, жанр формируется по определенному шаблону:
Откуда + Прилагательные + Существительное + Основан на … + Снят в … + От режиссера … + О… + Для возрастов от X до YПериодически тут попадались нешаблонные варианты, как, например, всеми любимые «С женщиной в главной роли» и «Для неисправимых романтиков».
Разумеется, там присутствовали все жанры фильмов и ТВ-шоу, в которых упоминались имена известных актеров и режиссеров.
Но на этом все. Все 76897 жанров, которые нашел мой бот, были созданы из этих основных компонентов. Я не мог понять, как формируются названия жанров целиком, но базовые элементы и логику, которые использовались для их создания, понять было несложно. Теперь я понял, как работает система Neflix.
Должен отметить, что успех моего бота вскружил мне голову. Объединить несколько категорий Netflix – это забавно и увлекательно. Но что делать с 76897 категориями?
Здесь вступил в игру мой коллега Ян Богост, он предложил построить свой собственный генератор, который вы могли видеть в начале страницы.
Декодирование грамматики Netflix
Однако, чтобы построить генератор, от нас требовалось полное понимание грамматики. Я прибегнул к помощи еще одного программного продукта, названного AntConc – это бесплатная программа, разработанная профессором из Японии. Обычно это ПО используется лингвистами в цифровых центрах гуманитарных наук, библиотекарями и людьми, которым нужно обрабатывать большие объемы текста. Инструмент Ngram от Google – это только одна из возможностей, предоставляемых AntConc.
AntConc, по сути, превращает текст в легкоуправляемый набор данных. Программа может посчитать число вхождения слов в текст, например, в базу данных Netflix.
Теперь создание списка из 10 самых распространённых описаний персонализированных жанров фильмов от сервиса Netflix стало тривиальной задачей.
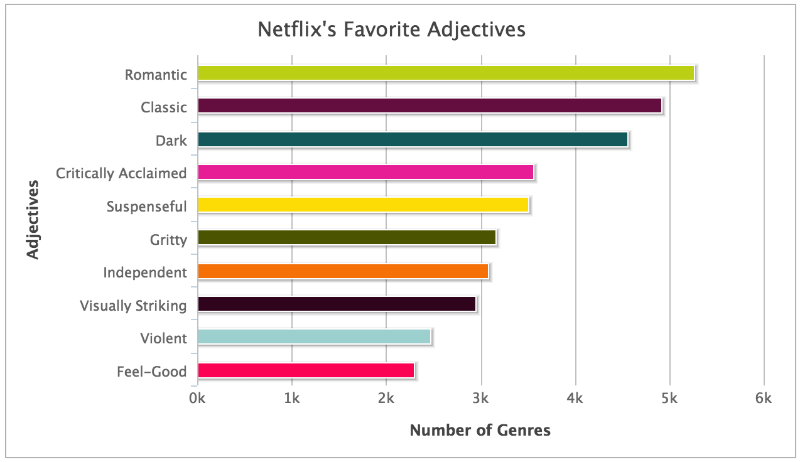
Вы можете посчитать, насколько часто появляется фраза, начинающаяся с указания на время создания фильма. Такая настройка покажет самые распространенные десять жанров, на вершине списка которых (ожидаемо и заслуженно) окажутся фильмы 80х годов. Если запускать поиск по фильмам 80х годов, то только эти фильмы вы и увидите.
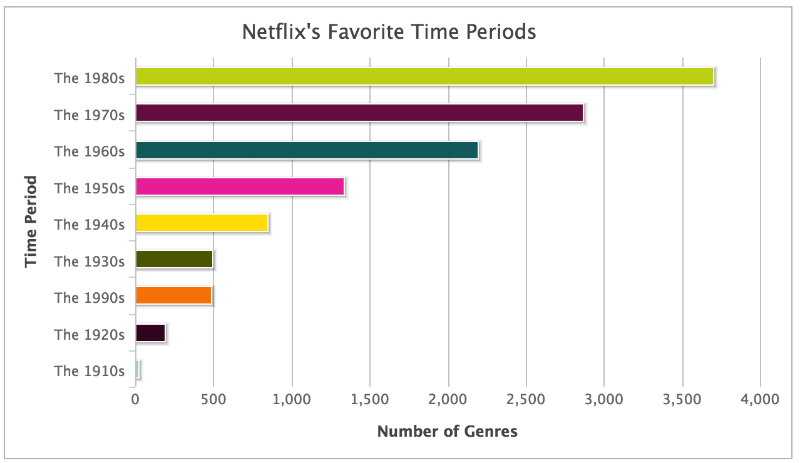
Запустив поиск фраз, содержащих фразу «Снят в…», я нашел все места сьемок фильмов, упомянутые в жанрах:
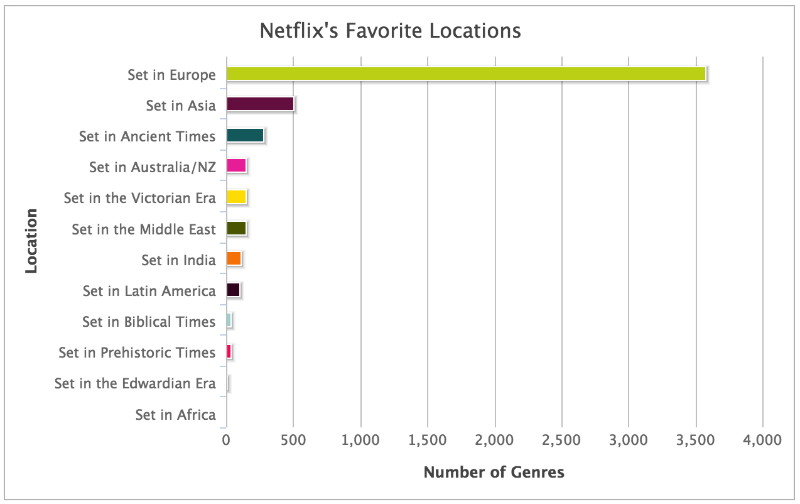
По поиску фраз, начинающихся с «Для…», я сформировал список описаний жанров для определённых возрастов. У Netflix есть контент для детей возрастов от 0 до 2 лет, от 0 до 4, от 2 до 4, от 5 до 7, о 8 до 10 и от 11 до 12 лет.
Я взял все данные о словаре Netflix и создал одну большую таблицу. Я подсчитал самых популярных актеров, режиссёров и авторов, сохранив это в отдельном файле.
Затем Ян взял эти таблицы, чтобы создать несколько различных грамматик. Первый и самый простой способ – это позволить прилагательным беспорядочно соединяться друг с другом, а затем забросить в получившуюся кучу несколько дескрипторов. Эта настройка получила название GONZO. Она выводит потрясающие результаты, которые вы тут же захотите переслать вашим друзьям:
- Глубоководные взаимоотношения отца и сына, фильм, основанный на реальных событиях, снятый на Среднем Востоке для детей
- Социальные драмы про убийства, охоту за наградами и шпионаж, основанные на популярной в Европе серии книг для детей от 8 до 10 лет
- Пост-апокалиптические комедии про дружбу
Боже, это нормально? Кода вы читаете что-то подобное, вы даже не уверены, что хотите, чтобы такой фильм существовал. Вы можете себе представить подобное? Для меня gonzo – это фильмы, которые должны существовать, но никогда не будут. Ну, в крайнем случае, темы, на которые в скором времени может появиться фильм.
Затем мы уменьшили количество допустимых прилагательных в заголовках. И вдруг, мы поняли, что наблюдаем рождение голливудских заголовков. По сути это – бесконечная перестановка одних и тех же тем.
- Классические экшен-фильмы
- Вестерны для всей семьи
- Фильмы про друзей
Наконец, играя с различными грамматическими структурами, мы начали замечать уровень специфичности, свойственный Netflix.
- Похабные и абсурдные слешеры
- Таинственные истории о любовных треугольниках и борьбе с политической системой
- Экшен-триллеры про королевские семьи
В ходе работы над генератором я понимал, что кто-то уже делал это до нас. Человеческий мозг должен был принять решения, которые принимали мы. Как много прилагательных? Насколько они должны быть длинными? Какими должны быть прилагательные? Почему интеллектуальный, а не остроумный? В чем разница между кровавым и жестоким?
Как писатель, я продолжал спрашивать себя: «Почему именно эти прилагательные?» Заумный, гладиаторский (привет, Конан!), запутанный, криминальный, безумный, неудачный, ободряющий и недооцененный?
Слова подбирались очень тщательно. Но кем?
У нас все еще остались вопросы. Из статьи журнала Los Angeles Times мы узнали основы расстановки тегов. Но какое отношение имеют теги к индивидуальным жанрам Netflix? Какой алгоритм превратил кучу тегов в 76897 жанров?
Большинство людей, пытавшихся понять способы построения жанров Netflix, выглядели как слепые, старавшиеся «увидеть» слона. Я чувствовал, что стою напротив зверя, но не вижу его целиком. Нужно было, чтобы кто-нибудь объяснил мне, что стоит за всем этим.
После того, как я сохранил свои данные, я позвонил в PR-службу Netflix голландцу по имени Йорис Эверс (Joris Evers), у которого на столе стоит фигурка ветряной мельницы, и попросил о встрече.
После того, как я рассказал ему все, что сделал, я ожидал, что мой аккаунт Netflix будет навсегда аннулирован. Вместо этого он сказал: «Я полагаю, ты хочешь поговорить с Тоддом Йеллином?»
Йеллин – это вице-президент компании и человек, ответственный за создание системы Netflix. Расстановка тегов была его идеей. Все началось с того, что он написал 24-страничный документ о том, как это делать, а затем лично расписал по тегам несколько фильмов и возглавил создание всех систем.
Разумеется, я хотел встретиться с Йеллином. Он стал моим волшебником из страны Оз, человеком, создавшим машину, чьи возможности и принцип работы я пытался понять.
В ходе нашего интервью Йеллин повернулся ко мне и сказал: «Я несколько лет ждал кого-то, кто попытается разобраться в работе системы».
* * *

Я посетил Netflix в Лос Гатос, Калифорния. Лос Гатос – это город менее известный, чем Кремниевая Долина, но он стал знаменит из-за пожара в центре переработки отходов, во время которого в атмосферу выбрасывались токсины, затем покрывшие всю область залива Сан-Франциско. Небо тогда окрашивалось в странные цвета, а в ноздри бил сильный запах горелого пластика.
Штаб-квартира Netflix расположилась в большом здании итальянского стиля, которое выглядело, как только что открывшийся спа-курорт: желтая отделка, фонтаны, веревочные мосты. Люди живут в номерах прямо за штаб-квартирой и делят тренажерный зал с сотрудниками Netflix.
Штаб-квартира выглядела странно, словно съемочная площадка, только люди на ней занимались совершенно другими делами – это все равно, что прийти на съемочную площадку Universal Studios, и увидеть там филиал Charles Schwab. Люди в таком месте должны отдыхать в бассейне, есть оливки и пить вино, но вместо этого они печатают на клавиатурах в просторных стеклянных кабинках.
Йеллин испытывал схожее чувство. Умный, активный и энергичный, он выглядел как продюсер, что вполне понятно, так как, по его словам, он знает «все стороны киноиндустрии». Он даже похож на актера Майкла Келли (Michael Kelly), который играл Доу Стэмпера, главу администрации Фрэнка Андервуда (Кевин Спейси), в оригинальном сериале Netflix «Карточный домик».
Он создает впечатление человека, который может заставить все работать как надо.
Как только мы сели в конференц-зале, я достал компьютер и начал демонстрировать созданный нами генератор жанров. Я показал ему таблицы и проведенный текстовый анализ.
Хотя он и впечатлился нашим упорством, но терпеливо объяснил, что мы видим только вершину айсберга всей инфраструктуры данных Netflix. В системе используется гораздо больше данных и информации, чем использовали мы.
Он рассказал мне, как все устроено.
«Мей первой задачей было разобрать контент по частям», – сказал он.

Тодд Йеллин в штаб-квартире Netflix
Как систематично разбить на теги тысячи фильмов? Как убедиться в том, что люди, которые помогают в этом непростом деле, обладают тем же пониманием микро-тегов? В 2006 году Йеллин объединился с парой инженеров и потратил несколько месяцев на разработку документации, получившей название «Квантовая теория Netflix», которое Йеллин сейчас называет «нашим претенциозным именем». Оно дает отсылку к тому, что Йеллин называл «квантом», то есть небольшим «пакетом энергии» – составляющим каждого фильма. Теперь он предпочитает название «микро-тег».
Квантовая теория Netflix описывала правила расстановки тегов для концовок фильмов, «социальной приемлемости» ключевых персонажей и десятков других аспектов. Многие величины являются «скалярными» и варьируются от 1 до 5, поэтому рейтинг романтичности получает каждый фильм, а не только помеченные тегом «романтичный» в индивидуальных жанрах. Каждая концовка фильма оценивается как «счастливая», «грустная», или «неочевидная». Описывается каждая часть фильма, даже работа главных героев и место действия в фильме. Все и вся.
Эта информация находится на самой вершине пирамиды. Это базис, который я использовал для создания альт-жанров. Инженеры Netflix взяли микро-теги и создали свой синтаксис для жанров, который имитирует наш генератор.
В этом месте человеческий ум объединялся с машинным интеллектом – алгоритмами. В индивидуальных жанрах Netflix было что-то не совсем человеческое, чувствовалось, что здесь работали не люди.
Например, прилагательное «ободряющий», прикрепляется к фильмам, которые обладают определенным набором особенностей, наиболее важной среди которых является счастливая концовка. Это не прямой тег, который прикрепляют люди, а вычисленная категория, основанная на наборах этих тегов.
Единственный похожий проект, который я могу вспомнить, это когда-то известный Music Genome Project от Pandora, но Netflix отличается тем, что описания фильмов всегда выводятся на первый план. Netflix не просто показывает вам фильмы, которые могут вам понравиться, но и говорит, о чем они. Это своего рода способ самоанализа, хотя и странный.
Старый способ рекомендации контента Netflix сильно отличается от нынешнего. Компания хвалилась, что может предсказать, сколько звезд вы поставите фильму, тем самым призывая пользователей оценивать фильм после просмотра, чтобы использовать эти оценки для создания вашего вкусового профиля.
Они даже предложили приз в $1 миллион команде, которая сможет разработать алгоритм, способный улучшить возможности компании по предсказанию оценок пользователей. Чтобы улучшить алгоритм на 10% потребовалось несколько лет.
Приз был вручен в 2009 году, но Netflix никогда не использовал новую модель. Частично из-за больших издержек на внедрение, частично из-за решения компании отказаться от концепции 5 звезд и переключиться на идею индивидуальных жанров.
Названия жанров, написанные понятным языком, делают рекомендации более точными. «Предсказать, что фильм получит 3.2 звезды – весело, если вы имеете инженерный склад ума, но будет гораздо полезнее говорить о [содержании фильма]: о неблагополучных семьях и вирусных эпидемиях. Мы хотели добавить язык, – сказал Йеллин, – чтобы на первом месте была персонализация, и мы гордимся нашей работой, когда правильный заголовок появляется перед глазами правильного человека в правильное время».
Нет ничего более персонализированного, чем демонстрация вам очень специфического альт-жанра. Почему же они не суперспецифичны? Я имею в виду супердлинные формулировки, которые генерировал наш режим gonzo.
Йеллин сказал, что жанры ограничиваются тремя основными факторами:
1) Из-за особенностей пользовательского интерфейса нужно отображать только 50 знаков в названии, что исключило большинство длинных формулировок.
2) Должна накопиться критическая масса контента, которая бы подошла под описание жанра, хотя бы в расширенном DVD-каталоге Netflix.
3) Запись ведется только для синтаксически «правильных» жанров.
Мы игнорируем все эти ограничения, поэтому наш генератор такой забавный. В мире Netflix нет жанров, состоящих из более чем пяти дескрипторов. Четыре дескриптора очень редки, но их можно встретить: «Культовые ужастики про безумных ученых 1970х годов». Три дескриптора встречаются достаточно часто: «Добрые зарубежные комедии для неисправимых романтиков». Два дескриптора используются очень часто: «Фильмы, насыщенные загадками». Разумеется, используется множество одиночных дескрипторов: «Необычные фильмы»
Я узнал удивительную вещь, оказывается, теги используются не только для создания жанров, но и для повышения уровня персонализации для всех фильмов, показываемых пользователю. Если Netflix знает, что вы любите приключенческие экшен-фильмы с высокими романтическими рейтингами (по шкале от 1 до 5), то сайт порекомендует вам такие фильмы, но не внесет их в категорию «романтические приключенческие экшен-фильмы».
«Мы оцениваем, насколько романтичен фильм, но не говорим, какую оценку он получил, – говорит Йеллин. – Он появится в строке рекомендаций, но количество «романтизма» в предлагаемом фильме будет зависеть от информации, которой мы о вас располагаем».
В ходе общения с Йеллином я понял, что Netflix построил систему, имеющую только один аналог в мире: фид Facebook. Вместо того, чтобы предоставлять вам новости из интернета, которые, по мнению алгоритма, вам понравятся, Netflix предлагает вам фильмы.
Это делает систему гибридом человеческого и машинного интеллекта, что очень впечатляюще. Они могли пользоваться чистыми машинными вычислениями, например, рекомендовать пользователю фильмы, которые понравились другому человеку с похожими предпочтениями (Netflix использует и такую систему), но они пошли дальше и стали учитывать содержание.
«За созданием системы стоят машинное обучение, алгоритмы и синтаксис, – сказал Йеллин, – а также кучка гиков, которые любят копнуть поглубже».
Как вам такой эксперимент: представьте, что Facebook разобьет на теги все вебсайты, воспользовавшись 36-страничной инструкцией, и поймет, что действительно любят люди в Atlantic или Popular Science, или 4chan, или ViralNova.
С веб-содержимым это невозможно. Но если бы система Netflix не существовала, то многие сочли бы, что и её создание нереально.
Загадка Перри Мейсона

Рэймонд Бёрр в фильме «Пожалуйста, убей меня»
Когда наше интервью подошло к концу, я убрал свой компьютер и показал Йеллину последний график. Взгляните на него. Кое-что сразу бросается в глаза.
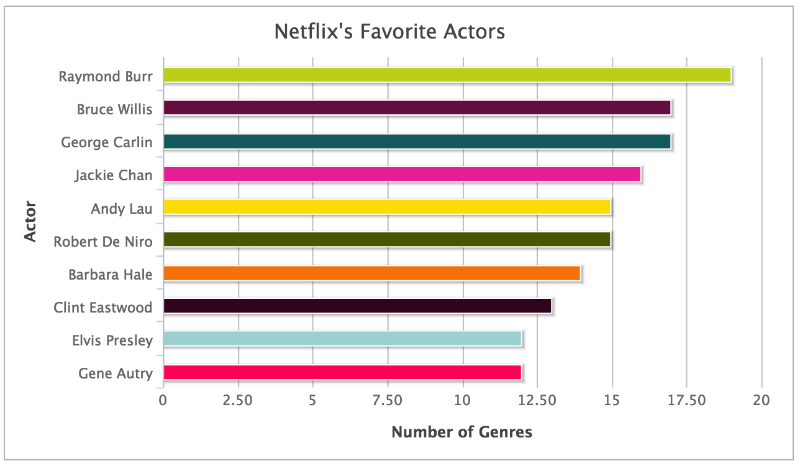
На вершине списка самых популярных звезд Голливуда расположился Рэймонд Бёрр, который снимался в сериале 1950х годов «Пэрри Мейсон».
Как могли Хэйл и Бёрр обогнать Мерил Стрип и Дорис Дэй, не говоря уже про Самюэля Л. Джексона, Николаса Кейджа, Фреда Астера, Шона Коннери и десяток других актеров?
Список не выглядит таким уж абсурдным. Было бы легко сказать, что «Генератор жанров Netflix по участию актеров» не работает. Но здесь дело в другом. Остальные актеры в списке располагаются на своих местах, даже если их положение не до конца соответствует данным бокс-офиса.
Взгляните на список 15 режиссёров. Вероятно, вы не узнали его по имени. Кристиан И. Найби II снимал несколько эпизодов Пэрри Мейсона в 1980х годах (Его отец, Кристиан И. Найби, также снимал несколько эпизодов оригинального сериала).
Christian I. Nyby II
Manny Rodriguez
Takashi Miike
Woody Allen
Ernst Lubitsch
Jim Wynorski
John Woo
Joseph Kane
Norman Taurog
Peter Jackson
Akira Kurosawa
Ingmar Bergman
R.G. Springsteen
Ridley Scott
Roger Corman
Все выглядит вполне нормально, кроме странного местоположения режиссера Пэрри Мейсона.
Предположим, что все альт-жанры с Рэймондом Бёрром и Барбарой Хэйл не означают, что пользователи постоянно видят фильмы с их участием в списке рекомендуемых. Гораздо более вероятно, что они будут получать рекомендации посмотреть фильмы с Брюсом Уиллисом.
Но зачем тогда все эти жанры?
Детективы с Рэймондом Бёрром
Фильмы с Рэймондом Бёрром
Драмы с Рэймондом Бёрром
Триллеры с Рэймондом Бёрром
Остросюжетные фильмы с Рэймондом Бёрром
Остросюжетные драмы с Рэймондом Бёрром
Интеллектуальные триллеры с Рэймондом Бёрром
Интеллектуальные драмы с Рэймондом Бёрром
Интеллектуальные остросюжетные драмы с Рэймондом Бёрром
Интеллектуальные детективы с Рэймондом Бёрром
Интеллектуальные остросюжетные фильмы с Рэймондом Бёрром
Интеллектуальные фильмы с Рэймондом Бёрром
Детективные истории про убийства с Рэймондом Бёрром
Недооцененные фильмы с Рэймондом Бёрром
Недооцененные остросюжетные драмы с Рэймондом Бёрром
Недооцененные остросюжетные фильмы с Рэймондом Бёрром
Недооцененные детективы с Рэймондом Бёрром
Недооцененные триллеры с Рэймондом Бёрром
Недооцененные драмы с Рэймондом Бёрром
В чем причина? Я спросил об этом Йеллина.
Вообще, у меня родилась теория, которую я поведал ему. «В эпоху DVD фанаты Перри Мейсона заказывали копии сериала просто в громадных количествах, – сказал я. – Это создало достаточный спрос, чтобы вы, ребята, решили ввести новые категории».
Это довольно грубая теория, сказал мне Йеллин. И сервис работает не таким образом.
С одной стороны никто, даже Йеллин, не уверен, почему появилось такое количество альт-жанров с участием Рэймонда Бёрра и Барбары Хейл. Это необъяснимо с точки зрения человеческой логики. Просто так получилось.
Я пытался дать название феномену Перри Мейсона: призрак, гремлин, не-совсем-баг. Как вы назовете что-то в коде и данных, что привело к появлению этих микро-жанров?
Напрашивается неприятный и важный вывод о том, что когда компании объединяют человеческий разум и машинный интеллект, это может вести к вещам, которые никто не может объяснить.
«Позвольте мне пофилософствовать. Мы не можем спрогнозировать в нашей жизни все, – поведал мне Йеллин. – Чем сложнее становится машинный мир, тем сложнее спрогнозировать результат. Загадке Пэрри Мейсона было суждено родиться. Призраки «из машины» всегда будут присутствовать как побочный продукт увеличения их [алгоритмов] сложности. Иногда мы называем их багами, а иногда – особенностями».
Сериал «Перри Мейсон» был известен своими поворотными моментами в суде, когда Мейсон предоставлял важную улику, складывал воедино всю картину и выигрывал дело.
Сейчас реальность закодирована в данных для машин, которые затем декодируются в описания для людей. В ходе нашей жизни способность людей понимать, что происходит, сходит на нет. Когда мы ищем причины и ответы, то редко находим единственное доказательство, которое находил Перри Мейсон. Потому что все это не имеет никакого смысла.
Может Netflix и решил вечную проблему «что посмотреть?», но обрел свои собственные небольшие тайны.
Которые иногда называются багами, а иногда особенностями.
Комментарии (10)

fenrirgray
25.05.2015 23:15-1Довольно странный подход к категоризации.
Почему вместо жанра «оскарносные романтические комедии 1950х» не сделать тэги oscar, romantic comedy, 1950?
Это же в разы уменьшит количество сущностей которые нужно хранить в базе. Хотя вполне возможно что они так и записывают все раздельно, а пользователям просто показывают объединенные тэги для красивости.
Но если так то я не очень вижу в чем новизна подхода, разнообразие тэгов это весьма старая идея, у нетфликса возможно подход более основательный, но не более.ToSHiC
26.05.2015 01:57+9Например потому, что жанр «оскарносные романтические комедии 1950х» — это на самом деле название кластера в многомерном пространстве параметров фильма. Каждый фильм, после проставления ему всех параметров по тому 36-страничному документа, это точка в N-мерном пространстве (судя по всему, там больше 100 параметров, то есть больше 100 измерений). Каким-то образом, на основе уже имеющейся базы оценок, точки объединяются в кластера, и для названия кластера выбираются наиболее значимые измерения.
Когда пользователь смотрит фильмы, рекомендательная система вырисовывает области предпочтений в том N-мерном пространстве, и ищет наиболее близлежащие кластера, и их подсовывает пользователю.


mrjj
26.05.2015 01:06+1Это самое интересное из того, что я читал за месяц.
Очень понравилась идея, что в контенте есть некие «пакеты энергии» эмоционального характера.
С загадкой Берра ставлю на то, что на каком то этапе все серии запроцессились как отдельный фильм, таким образом их общие черты получили мощный множитель.

grokinn
26.05.2015 08:53+1У меня есть теория про Бёрра: дело в том, что про фильмы с Мерил Стрип можно и без того подобрать множество эпитетов, не обязательно каждый раз упоминать ее имя, в вот про фильмы с этим Бёрром сказать больше нечего кроме того что это фильм с Бёрром, вот и ставят на его фильмы этот тег постоянно те кто занимается там их присваиванием.

my_own_parasite
26.05.2015 12:13+1Я думаю, что всем фильмам автоматом добавляются в параметры все звезды, которые в нем играли. это же самое простое, что можно автоматизировать, решая задачу категоризацию фильмов.

samodum
26.05.2015 12:42Интересно, а происходит ли потом коррекция пользовательских предпочтений? Ведь вкусы меняются.

edelweiss76
26.05.2015 19:52Спасибо за материал. Интересно как российские компании решают подобные задачи

ShiawasenaHoshi
Отличная статья! Как детектив. Прочитал на одном дыхании. Спасибо за перевод.