

Очень важно выбрать правильный инструмент для анализа данных. На форумах Kaggle.com, где проводятся международные соревнования по Data Science, часто спрашивают, какой инструмент лучше. Первые строчки популярноcти занимают R и Python. В статье мы расскажем про альтернативный стек технологий анализа данных, сделанный на основе языка программирования Scala и платформы распределенных вычислений Spark.
Как мы пришли к этому? В Retail Rocket мы много занимаемся машинным обучением на очень больших массивах данных. Раньше для разработки прототипов мы использовали связку IPython + Pyhs2 (hive драйвер для Python) + Pandas + Sklearn. В конце лета 2014 года приняли принципиальное решение перейти на Spark, так как эксперименты показали, что мы получим 3-4 кратное повышение производительности на том же парке серверов.
Еще один плюс — мы можем использовать один язык программирования для моделирования и кода, который будет работать на боевых серверах. Для нас это было большим преимуществом, так как до этого мы использовали 4 языка одновременно: Hive, Pig, Java, Python, для небольшой команды это серьезная проблема.
Spark хорошо поддерживает работу с Python/Scala/Java через API. Мы решили выбрать Scala, так как именно на нем написан Spark, то есть можно анализировать его исходный код и при необходимости исправлять ошибки, плюс — это JVM, на котором крутится весь Hadoop. Анализ форумов по языкам программирования под Spark свел к следующему:
Scala:
+ функциональный;
+ родной для Spark;
+ работает на JVM, а значит родной для Hadoop;
+ строгая статическая типизация;
— довольно сложный вход, но код читабельный.
Python:
+ популярный;
+ простой;
— динамическая типизация;
— производительность хуже, чем у Scala.
Java:
+ популярность;
+ родной для Hadoop;
— слишком много кода.
Более подробно по выбору языка программирования для Spark можно прочитать здесь.
Должен сказать, что выбор дался не просто, так как Scala никто в команде на тот момент не знал.
Известный факт: чтобы научиться хорошо общаться на языке, нужно погрузиться в языковую среду и использовать его как можно чаще. Поэтому для моделирования и быстрого анализа данных мы отказались от питоновского стека в пользу Scala.
В первую очередь нужно было найти замену IPython, варианты были следующие:
1) Zeppelin — an IPython-like notebook for Spark;
2) ISpark;
3) Spark Notebook;
4) Spark IPython Notebook от IBM.
Пока выбор пал на ISpark, так как он простой, — это IPython для Scala/Spark, к нему относительно легко удалось прикрутить графики HighCharts и R. И у нас не возникло проблем с подключением его к Yarn-кластеру.
Наш рассказ о среде анализа данных на Scala состоит из трех частей:
1) Несложная задача на Scala в ISpark, которая будет выполняться локально на Spark.
2) Настройка и установка компонент для работы в ISpark.
3) Пишем Machine Learning задачу на Scala, используя библиотеки R.
И если эта статья будет популярной, я напишу две другие. ;)
Задача
Давайте попробуем ответить на вопрос: зависит ли средний чек покупки в интернет-магазине от статичных параметров клиента, которые включают в себя населенный пункт, тип браузера (мобильный/Desktop), операционную систему и версию браузера? Сделать это можно с помощью «Взаимной информации» (Mutual Information).
В Retail Rocket мы много где используем энтропию для наших рекомендательных алгоритмов и анализа: классическую формулу Шеннона, расхождение Кульбака-Лейблера, взаимную информацию. Мы даже подали заявку на доклад на конференцию RecSys по этой теме. Этим мерам посвящен отдельный, хоть и небольшой раздел в известном учебнике по машинному обучению Мерфи.
Проведем анализ на реальных данных Retail Rocket. Предварительно я скопировал выборку из нашего кластера к себе на компьютер в виде csv-файла.
Загрузка данных
Здесь мы используем ISpark и Spark, запущенный в локальном режиме, то есть все вычисления происходят локально, распределение идет по ядрам. Собственно в комментариях все написано. Самое главное, что на выходе мы получаем RDD (структура данных Spark), которая представляет собой коллекцию кейс-классов типа Row, который определен в коде. Это позволит обращаться к полям через ".", например _.categoryId.
На входе:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.tribbloid.ispark.display.dsl._
import scala.util.Try
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
// Объявляем CASE class, он нам понадобится для dataframe
case class Row(categoryId: Long, orderId: String ,cityId: String, osName: String,
osFamily: String, uaType: String, uaName: String,aov: Double)
// читаем файл в переменную val с помощью sc (Spark Context), его объявляет Ipython заранее
val aov = sc.textFile("file:///Users/rzykov/Downloads/AOVC.csv")
// парсим поля
val dataAov = aov.flatMap { line => Try { line.split(",") match {
case Array(categoryId, orderId, cityId, osName, osFamily, uaType, uaName, aov) =>
Row(categoryId.toLong + 100, orderId, cityId, osName, osFamily, osFamily, uaType, aov.toDouble)
} }.toOption }
На выходе:
MapPartitionsRDD[4] at map at <console>:28Теперь посмотрим на сами данные:

В данной строке используется новый тип данных DataFrame, добавленный в Spark в версии 1.3.0, он очень похож на аналогичную структуру в библиотеке pandas в Python. toDf подхватывает наш кейс-класс Row, благодаря чему получает названия полей и их типы.
Для дальнейшего анализа нужно выбрать какую-нибудь одну категорию желательно с большим количеством данных. Для этого нужно получить список наиболее популярных категорий.
На входе:
//Наиболее популярная категория
dataAov.map { x => x.categoryId } // выбираем поле categoryId
.countByValue() // рассчитываем частоту появления каждой categoryId
.toSeq
.sortBy( - _._2) // делаем сортировку по частоте по убыванию
.take(10) // берем ТОП 10 записейНа выходе мы получили массив кортежей (tuple) в формате (categoryId, частота):
ArrayBuffer((314,3068), (132,2229), (128,1770), (270,1483), (139,1379), (107,1366), (177,1311), (226,1268), (103,1259), (127,1204))Для дальнейшей работы я решил выбрать 128-ю категорию.
Подготовим данные: отфильтруем нужные типы операционных систем, чтобы не засорять графики мусором.
На входе:
val interestedBrowsers = List("Android", "OS X", "iOS", "Linux", "Windows")
val osAov = dataAov.filter(x => interestedBrowsers.contains(x.osFamily)) //оставляем только нужные ОС
.filter(_.categoryId == 128) // фильтруем категории
.map(x => (x.osFamily, (x.aov, 1.0))) // нужно для расчета среднего чека
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.map{ case(osFamily, (revenue, orders)) => (osFamily, revenue/orders) }
.collect()На выходе массив кортежей (tuple) в формате OS, средний чек:
Array((OS X,4859.827586206897), (Linux,3730.4347826086955), (iOS,3964.6153846153848), (Android,3670.8474576271187), (Windows,3261.030993042378))Хочется визуализации, давайте сделаем это в HighCharts:

Теоретически можно использовать любые графики HighCharts, если они поддерживаются в Wisp. Все графики интерактивны.
Попробуем сделать то же самое, но через R.
Запускаем R клиент:
import org.ddahl.rscala._
import ru.retailrocket.ispark._
def connect() = RClient("R", false)
@transient
val r = connect()Строим сам график:

Так можно строить любые графики R прямо в блокноте IPython.
Взаимная информация
На графиках видно, что зависимость есть, но подтвердят ли нам этот вывод метрики? Существует множество способов это сделать. В нашем случае мы используем взаимную информацию (Mutual Information) между величинами в таблице. Она измеряет взаимную зависимость между распределениями двух случайных (дискретных) величин.
Для дискретных распределений она рассчитывается по формуле:
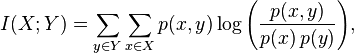
Но нас интересует более практичная метрика: Maximal Information Coefficient (MIC), для расчета которой для непрерывных переменных приходится идти на хитрости. Вот как звучит определение этого параметра.
Пусть D = (x, y) — это набор из n упорядоченных пар элементов случайных величин X и Y. Это двумерное пространство разбивается X и Y сетками, группируя значения x и y в X и Y разбиения соответственно (вспомните гистограммы!).

где B(n) — это размер сетки, I?(D, X, Y ) — это взаимная информация по разбиению X и Y. В знаменателе указан логарифм, который служит для нормализации MIC в значения отрезка [0, 1]. MIC принимает непрерывные значения в отрезке [0,1]: для крайних значений равен 1, если зависимость есть, 0 — если ее нет. Что можно еще почитать по этой теме перечислено в конце статьи, в списке литературы.
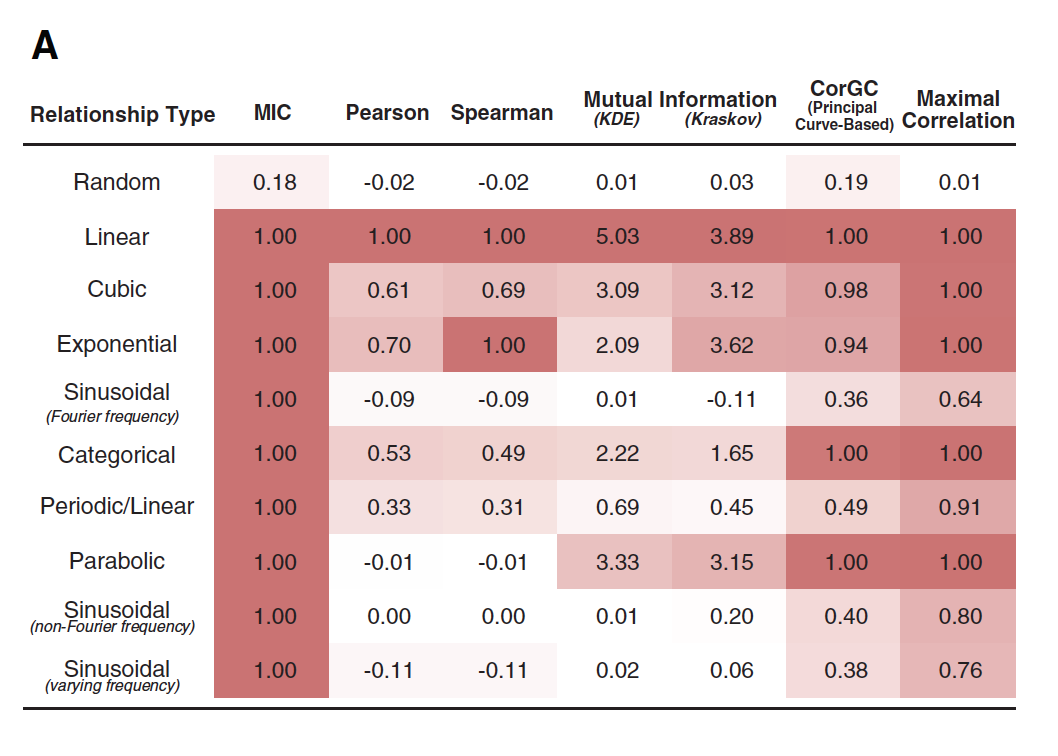
В книге MIC (взаимная информация) названа корреляцией 21-го века. И вот почему! На графике ниже приведены 6 зависимостей (графики С — H). Для них были вычислены корреляция Пирсона и MIC, они отмечены соответствующими буквами на графике слева. Как мы видим, корреляция Пирсона практически равна нулю, в то время как MIC показывает зависимость (графики F, G, E).

Первоисточник: people.cs.ubc.ca
В таблице ниже приведен ряд метрик, которые были вычислены на разных зависимостях: случайной, линейной, кубической и т.д. Из таблицы видно, что MIC ведет себя очень хорошо, обнаруживая нелинейные зависимости:
Еще один интересный график иллюстрирует воздействие шумов на MIC:

В нашем случае мы имеем дело с расчетом MIC, когда переменная Aov у нас непрерывная, а все остальные дискретны с неупорядоченными значениями, например тип браузера. Для корректного расчета MIC понадобится дискретизация переменной Aov. Мы воспользуемся готовым решением с сайта exploredata.net. Есть с этим решением одна проблема: она считает, что обе переменные непрерывны и выражены в значениях Float. Поэтому нам придется обмануть код, кодируя значения дискретных величин во Float и случайно меняя порядок этих величин. Для этого придется сделать много итераций со случайным порядком (мы сделаем 100), а в качестве результата возьмем максимальное значение MIC.
import data.VarPairData
import mine.core.MineParameters
import analysis.Analysis
import analysis.results.BriefResult
import scala.util.Random
//Кодируем дискретную величину, случайно изменяя порядок "кодов"
def encode(col: Array[String]): Array[Double] = {
val ns = scala.util.Random.shuffle(1 to col.toSet.size)
val encMap = col.toSet.zip(ns).toMap
col.map{encMap(_).toDouble}
}
// функция вычисления MIC
def mic(x: Array[Double], y: Array[Double]) = {
val data = new VarPairData(x.map(_.toFloat), y.map(_.toFloat))
val params = new MineParameters(0.6.toFloat, 15, 0, null)
val res = Analysis.getResult(classOf[BriefResult], data, params)
res.getMIC
}
//в случае дискретной величины делаем много итераций и берем максимум
def micMax(x: Array[Double], y: Array[Double], n: Int = 100) =
(for{ i <- 1 to 100} yield mic(x, y)).max Ну вот мы близки к финалу, теперь осуществим сам расчет:
val aov = dataAov.filter(x => interestedBrowsers.contains(x.osFamily)) //оставляем только нужные ОС
.filter(_.categoryId == 128) // фильтруем категории
//osFamily
var aovMic = aov.map(x => (x.osFamily, x.aov)).collect()
println("osFamily MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//orderId
aovMic = aov.map(x => (x.orderId, x.aov)).collect()
println("orderId MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//cityId
aovMic = aov.map(x => (x.cityId, x.aov)).collect()
println("cityId MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//uaName
aovMic = aov.map(x => (x.uaName, x.aov)).collect()
println("uaName MIC =" + mic(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//aov
println("aov MIC =" + micMax(aovMic.map(_._2), aovMic.map(_._2)))
//random
println("random MIC =" + mic(aovMic.map(_ => math.random*100.0), aovMic.map(_._2)))На выходе:
osFamily MIC =0.06658
orderId MIC =0.10074
cityId MIC =0.07281
aov MIC =0.99999
uaName MIC =0.05297
random MIC =0.10599Для эксперимента я добавил случайную величину с равномерным распределением и сам AOV.
Как мы видим, практически все MIC оказались ниже случайной величины (random MIC), что можно считать «условным» порогом принятия решения. Aov MIC равен практически единице, что естественно, так как корреляция самой к себе равна 1.
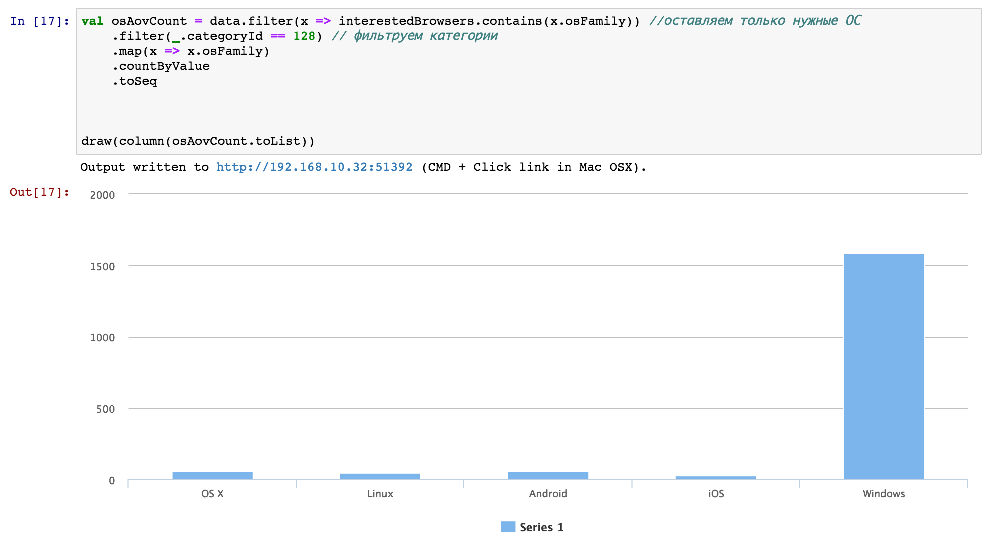
Возникает интересный вопрос: почему мы на графиках видим зависимость, а MIC нулевой? Можно придумать множество гипотез, но скорее всего для случая os Family все довольно просто — количество машин с Windows намного превышает количество остальных:
Заключение
Надеюсь, что Scala получит свою популярность среди аналитиков данных (Data Scientists). Это очень удобно, так как есть возможность работать со стандартным IPython notebook + получить все возможности Spark. Этот код может спокойно работать с терабайтными массивами данных, для этого нужно просто изменить строчку конфигурации в ISpark, указав URI вашего кластера.
Кстати, у нас открыты вакансии по этому направлению:
Полезные ссылки:
Научная статья, на базе которой разрабатывался MIC.
Заметка на KDnuggets про взаимную информацию (есть видео).
Библиотека на C для расчета MIC с обертками для Python и MATLAB/OCTAVE.
Сайт автора научной статьи, который разработал MIC (на сайте есть модуль для R и библиотека на Java).
Комментарии (21)

kronos
26.05.2015 15:16+2Очень интересно услышать что-то на тему Clojure vs Scala для Bigdata. Особенно у кого есть опыт

Stas911
27.05.2015 22:45Очень интересная статья, спасибо!
А было что-то из Python стека (IPython + Pandas + Sklearn), чего совсем не хватало перехода на Scala? Например, DF from pandas же драматически, вроде, отличается от RDD?
rzykov Автор
28.05.2015 10:56Мне очень не хватало графиков в ipython интерфейсах. DF особо не пользуюсь, все-таки case классы и функциональный подход тоже дают похожий эффект, но конечно не такой как Pandas
Stas911
28.05.2015 22:54Очень понравился Zeppelin. Вы его пробовали? Если да, чем не угодил?
rzykov Автор
29.05.2015 11:23Я очень много работал с Zeppelin, сейчас я могу сказать, что не понимаю, почему проект попал под крыло Apache.
Недостатки следуюшие:
- очень неудобно строить графики, если вы посмотрите в статье, то увидите, что они намного гибче, можно использовать или R или HighCharts. Не нужно использовать SQL
- когда вы пишите код через pipe, т.е. добавляете операторы через ".", в Zeppelin нужно ставить ее в конце предыдущей строки, а не в начале. Выглядит ужасно
- ISpark — это ipyhton плагин, он очень легковесный и простой, Zeppelin — это «дирижабль кода», заново изобретенный велосипед. Ipython намного лучше
- В Zeppelin одно ядро, когда у вас много пользователей и что-то пошло не так, то перезапуск ядра убьет блокноты других пользователей, в ipython на каждый блокнот пользователя запускается отдельное ядро.
rzykov Автор
29.05.2015 11:23Я очень много работал с Zeppelin, сейчас я могу сказать, что не понимаю, почему проект попал под крыло Apache.
Недостатки следующие:
- очень неудобно строить графики, если вы посмотрите в статье, то увидите, что они намного гибче, можно использовать или R или HighCharts. Не нужно использовать SQL
- когда вы пишите код через pipe, т.е. добавляете операторы через ".", в Zeppelin нужно ставить ее в конце предыдущей строки, а не в начале. Выглядит ужасно
- ISpark — это ipyhton плагин, он очень легковесный и простой, Zeppelin — это «дирижабль кода», заново изобретенный велосипед. Ipython намного лучше
- В Zeppelin одно ядро, когда у вас много пользователей и что-то пошло не так, то перезапуск ядра убьет блокноты других пользователей, в ipython на каждый блокнот пользователя запускается отдельное ядро.

gricom
29.05.2015 17:50Я не до конца понял, делаете ли вы какое-либо предположение о причинно-следственной связи на основании корреляции (или MIC)? Или наличие корреляции само по себе является целью ваших поисков? И можно ли полагаться на то, что такая корреляция сохранится в долгосрочном периоде? Все-таки бизнес будет принимать решения на основе ваших выводов.
nehaev
Да, Spark очень радует тем, что постепенно перетягивает народ с других платформ на Scala. Сколько же, если не секрет, занял процесс обучения и перехода к продуктивной разработке на Scala для команды, где изначально этот язык никто не знал?
rzykov Автор
Нам очень помогли курсы по Scala на coursera + книги по Spark, которые опубликованы на O'Reilly.
Тестовый переход занял 2 месяца, на production переходили дольше, т.к. до версии Spark 1.1.1 все было плохо.
Сейчас переписано 90% функционала. Написано около 15 000 строк кода на Scala. Команда три человека.
potan
А был у кого-нибудь в команде опыт программирования на функциональных языках со статической типизацией? Hashell, OCaml, SML, F#
После Haskell и C++ я начал программировать на Scala за несколько дней, при том что с JVM-языками был мало знаком.
rzykov Автор
Со статической типизацией — нет.
akrot
Как сказал один разработчик из моей команды «чтобы понять Spark, нужно начать в него коммитить» — мы постоянно его дописываем, но, надо сказать, в ML задачах стремимся им не пользоваться, а использовать Vowpal Wabbit или пиклить питоновские модели. Для графовых задач — да, тут в основном только спарк
rzykov Автор
У нас очень специфический ML, пишем сами, хотя некоторые методы MLlib используем. Из внешних библиотек я планировал протестировать распределенный R. Python или Vowpal Wabbit использовать не хочется по причине возвращению к зоопарку технологий, как было раньше, это очень хорошо для экспериментов, но плохо для production
akrot
Спарк в продакшне — респект!) А Вы делаете реал-тайм аналитику? Интересно было бы услышать про опыт работы с транзакциями/минибатчами — сравнение Storm vs Spark Streaming на каком-нибудь примере…
rzykov Автор
До streaming пока руки не дошли, нужно с Kafka разобраться. Storm пробовать точно не будем, т.к. мы решили использовать только Spark компоненты.
akrot
У спарка есть отличительная особенность, что в реалтайме он работает с минибатчами, т.е. это не совсем реал-тайм. Интересно будет услышать опыт на каком-нибудь примере. Поделитесь потом?)
А так — очень круто) Мы тоже спарк допиливаем, хотя у нас и нет такой зависимости от него. Вы коммитите уже в него или все пока внутри?
rzykov Автор
У нас есть свой GitHub, там есть один проект для Spark. В Spark коммиты пока не делаем, т.к. это время разработчиков. Мы стартап, который уже самоокупился, поэтому не можем разбрасываться рабочим временем.
akrot
Понял, большое спасибо! Круто, когда есть такие команды на рынке! Успехов Вам!)
gurinderu
А как обстоят дела у команды с познанием внутренностей JVM и Scala компиляцией? Насколько я помню, поведении JMM описано для Java, есть ли такое же для Scala?
rzykov Автор
Для нас нет никакой необходимости познавать внутренности Scala, внутренности Spark для нас более актуальны, т.к. бывает нужно оптимизировать саму реализацию алгорима. А это больше не сама Scala, а Spark!