
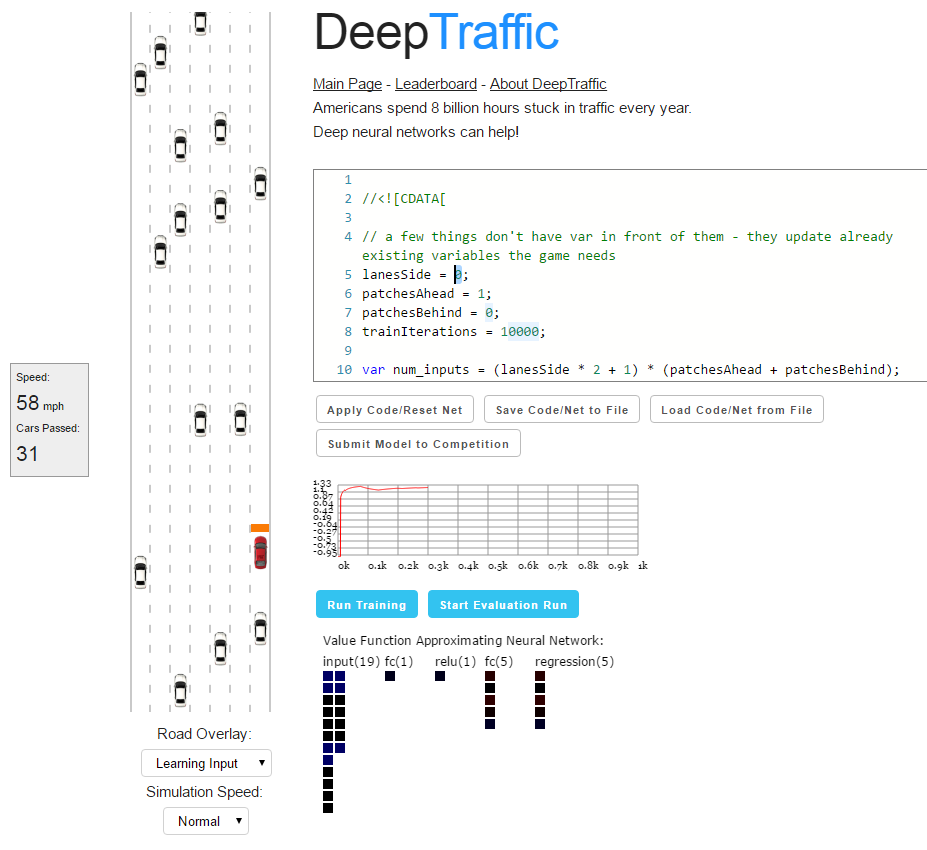
DeepTraffic — интересная интерактивная игра, поучаствовать в которой может любой желающий, а студенты Массачусетского технологического института (МТИ), которые изучают курс глубинного обучения в беспилотных автомобилях, обязаны показать хороший результат в этой игре, чтобы им засчитали выполненное задание.
Участникам предлагают спроектировать агента ИИ, а именно, спроектировать и обучить нейронную сеть, которая покажет себя лучше конкурентов в плотном дорожном потоке. В управление агенту даётся один автомобиль (красного цвета). Он должен научиться маневрировать в потоке наиболее эффективным способом.
По условиям игры, в автомобиль изначально встроена система безопасности, то есть он не сможет врезаться или улететь с дороги. Задача игрока — только управлять разгоном/торможением и сменой полос. Агент будет делать это с максимальной эффективностью, но не врезаясь в другие автомобили.
Изначально предлагается базовый код агента, который можно модифицировать прямо в игровом окне — и сразу запускать на исполнение, то есть на обучение нейросети.
//<![CDATA[
// a few things don't have var in front of them - they update already existing variables the game needs
lanesSide = 0;
patchesAhead = 1;
patchesBehind = 0;
trainIterations = 10000;
var num_inputs = (lanesSide * 2 + 1) * (patchesAhead + patchesBehind);
var num_actions = 5;
var temporal_window = 3;
var network_size = num_inputs * temporal_window + num_actions * temporal_window + num_inputs;
var layer_defs = [];
layer_defs.push({
type: 'input',
out_sx: 1,
out_sy: 1,
out_depth: network_size
});
layer_defs.push({
type: 'fc',
num_neurons: 1,
activation: 'relu'
});
layer_defs.push({
type: 'regression',
num_neurons: num_actions
});
var tdtrainer_options = {
learning_rate: 0.001,
momentum: 0.0,
batch_size: 64,
l2_decay: 0.01
};
var opt = {};
opt.temporal_window = temporal_window;
opt.experience_size = 3000;
opt.start_learn_threshold = 500;
opt.gamma = 0.7;
opt.learning_steps_total = 10000;
opt.learning_steps_burnin = 1000;
opt.epsilon_min = 0.0;
opt.epsilon_test_time = 0.0;
opt.layer_defs = layer_defs;
opt.tdtrainer_options = tdtrainer_options;
brain = new deepqlearn.Brain(num_inputs, num_actions, opt);
learn = function (state, lastReward) {
brain.backward(lastReward);
var action = brain.forward(state);
draw_net();
draw_stats();
return action;
}
//]]>Слева от кода на странице представлена реальная симуляция дороги, по которой движется агент, с текущем состоянием нейросети. Там же некоторая базовая информация, вроде текущей скорости автомобиля и количества других машин, которые он обогнал.
При обучении нейросети и оценке результата измеряется количество фреймов, так что производительность компьютера или скорость анимации не оказывают влияния на результат.
Разные режимы Road Overlay позволяют понять, как работает и обучается нейросеть. В режиме Full Map вся дорога представлена в виде ячеек сетки, а в режиме Learning Input показано, какие ячейки учитываются на входе нейросети для решения о манёвре.
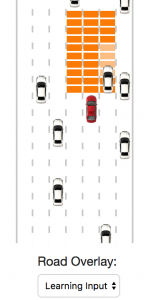
Размер «контрольной зоны» на входе нейросети определяется следующими переменными:
lanesSide = 1;
patchesAhead = 10;
patchesBehind = 0;
trainIterations = 10000;Чем больше зона, тем больше информации об окружающем трафике получает нейросеть. Но зашумляя нейросеть лишними данными, мы мешаем ей обучиться действительно эффективным манёврам, то есть усвоить правильные стимулы. Для обработки площади большего размера, вероятно, следует увеличить количество итераций при обучении (
trainIterations).Переключившись в режим Safety System можно посмотреть, как работает базовый алгоритм нашего автомобиля. Если ячейки сетки становятся красными, то автомобилю запрещено перемещаться в этом направлении. Перед впереди идущими автомобилями агент тормозит.
Управление автомобилем осуществляет функция
learn, которая учитывает текущее состояние агента (аргумент state), награду за предыдущий шаг (lastReward, средняя скорость в милях/ч) и возвращает одно из следующих значений:var noAction = 0;
var accelerateAction = 1;
var decelerateAction = 2;
var goLeftAction = 3;
var goRightAction = 4;То есть не предпринимать никаких действий (0, держаться своей полосы и скорости), ускориться (1), затормозить (2), перестроиться влево (3), перестроиться вправо (4).
Снизу от блока с кодом — некоторая служебная информация о состоянии нейросети, кнопки для начала обучения нейросети и для запуска испытаний.
Результатом испытательного заезда станет средняя скорость, которую показал агент на трассе (в милях/час). Свой результат вы можете сравнить с результатами других программистов. Но следует учитывать, что «испытательный заезд» показывает только примерную ориентировочную скорость, с небольшим элементом случайности. Во время этого теста нейросеть прогоняют через десять 30-минутных заездов с вычислением средней скорости в каждом заезде, а потом результат вычисляется как средняя медианная скорость десяти скоростей в этих заездах. Если отправить нейросеть на конкурс, то организаторы соревнований запустят свой собственный тест и определят истинную скорость, которую показывает беспилотный автомобиль.
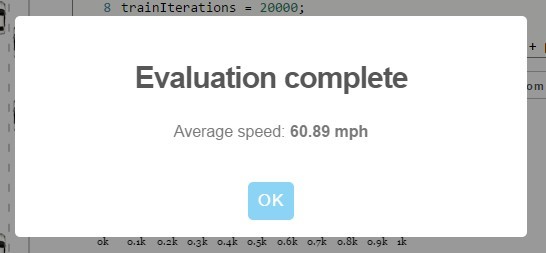
Результат с 5 полосами, 10 клетками впереди, 3 сзади, 20000 итераций, 12 нейронами
Судя по всему, кроме базовых параметров нужно ещё изменить количество нейронов в скрытом слое в этом фрагменте кода:
layer_defs.push({
type: 'fc',
num_neurons: 1,
activation: 'relu'
});Пока что максимальные результаты на конкурсе показали преподаватель курса Лекс Фридман (74,45 мили/ч) и хабраюзер Антон Печенко parilo (74,41 мили/ч). Возможно, в комментариях parilo объяснит, с какими настройками он это сделал. Интересно, изменял ли он код каким-то образом, или ограничился подбором четырёх базовых параметров и количества нейронов в скрытом слое.
Идеи более продвинутой оптимизации нейросети можно получить из комментариев в коде фрагмента нейросети на Github.
Студенты курса 6.S094: Deep Learning for Self-Driving Cars обязаны показать в игре результат минимум 65 миль в час, чтобы преподаватель Лекс Фридман засчитал им это задание.
Комментарии (32)

Jeiwan
19.01.2017 10:57+2Меж тем Антон уже вышел на первое место с большим отрывом:
 https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.png
https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.png
alek0585
19.01.2017 16:52-3Я был большего мнения о преподавателях МИТ… А тут какой-то Печенко из ниоткуда показал лучшие результаты.
Респект нашим!)

shadowkas
19.01.2017 11:56что то кажется все таки с нейронами играть нельзя ибо слишком просто получается.
Jeiwan
19.01.2017 12:26+1Набрал 71.32 на дефолтной модели, увеличив область видимости и количество нейронов на fc-слое. Больше набрать не получается, наверное надо менять архитектуру сети.
Кстати, там ещё есть DeepTesla http://selfdrivingcars.mit.edu/deepteslajs/
El_bruja_de_la_tristefigu
19.01.2017 14:1269 вышло очень легко — опять же бессистемным изменением параметров и количества нейронов.

roller
19.01.2017 18:53Как сказать нейросети «Если справа открывается два окна по диагонали — прыгай туда»
Veliant
19.01.2017 22:51Сделал прямоугольник 3*5 перед машиной, и в learn анализировал три средне-арифметических по каждому из столбцов. Если перед машиной сумма < 1 значит кого-то догоняем. Считаем суммы по соседним рядам. Где сумма больше получается, там и свободнее — перестраиваемся туда. Средняя скорость вышла ~71.5.
Правда при этом не учитывается скорость соседних рядов.
В идеале форма анализируемых клеток должна быть по форме близкая к символам X и V, т.е. приближенная к реальным условиям. Реальный водитель или лидар на три машины вперед врядли сможет видеть
sim31r
20.01.2017 02:51Лидары теоретически могут соединятся между собой по беспроводной сети и делится наблюдениями, там не так много информации нужно передавать. Таким образом у автопилота будет больше информации, чем у живого водителя.

Sadler
20.01.2017 06:145x3 (ШxВ) на расстоянии в 3-4 клетки впереди машины, fc размера 30-50 с relu и 100k итераций дают стабильно в районе 72-72.5. Честно, не очень понимаю, как получить больше, у меня даже при ручном управлении машинкой не выходит 75. Возможно, следует использовать набор conv-слоёв, но в варианте js уж слишком медленно оно работает.
erwins22
20.01.2017 15:0472 получается если просто увеличить до числа столбцов скрытый слой и убрать из него relu

Alex20129
22.01.2017 10:39Игра не так проста, как кажется. Первое, что пришло в голову, это
activation: 'relu'
заменить на
activation: 'sigmoid'
И сработало!
И далее можно добавить скрытых слоёв, просто копируя этот блок
layer_defs.push({
type: 'fc',
num_neurons: 5,
activation: 'sigmoid'
});erwins22
22.01.2017 11:26попробывал, 55 получается
пока лучшая идея из простых это убрать активацию на скрытом слое и увеличить его до 5Alex20129
25.01.2017 05:49«убрать» не получится. Активационная функция у нейрона есть всегда, без неё он просто не будет работать. В данном случае по умолчанию используется ReLU, если не указано другое.
erwins22
25.01.2017 09:50точно нет
слой функции активации не отображается и поведение принципиально разное.
тут просто получается линейный классификатор.Sadler
25.01.2017 18:04Вот только в Вашей конфигурации нет никакого смысла в линейном слое длины выходного слоя, ибо в результате получается всё та же линейная комбинация входных векторов. С тем же успехом этот слой можете просто убрать.
erwins22
26.01.2017 10:16Если там 5 и больше, то да, но если там 3 или 2 то происходит сжатие пространства.
Sadler
27.01.2017 13:02Которое затем просто заново расширяется на выходе. Если бы речь шла о модели энкодера-декодера, это могло бы иметь смысл, а так всё равно бесполезно.
erwins22
27.01.2017 13:33это работает
10 впереди 2 по бокам, 5 сзади промежуточный слой 3 без функции
72
временныхсрезов =0Sadler
27.01.2017 15:17Нет, это не работает. Вы вводите в модель абсолютно нефункциональный элемент. Ничего, кроме замедления расчёта, он не даёт.
erwins22
27.01.2017 15:42попробуйте.
с ним обучение идет быстро и эффективно.
без него сходимость идет медленно.Sadler
27.01.2017 15:44Давайте не будем заниматься здесь алхимией. Если этот слой даёт Вам какие-то преимущества, то у Вас где-то неэффективно работает trainer, возможно, один из других параметров неверен. Другой причины нет.
erwins22
27.01.2017 15:57Согласен, я написал, что я поменял, можете проверить. причем тут результат достигается очень быстро, так как фактически есть только 2 решения — дернуться вправо или влево.
худший вариант это relu (relu6 был бы в тему, но его нет) так как приходиться делать или большой слой, что бы избежать вырождения или отказаться от него.
tanh ведет себя хорошо и позволяет получить лучшие результаты при долгом обучении.
Линейный вариант при увеличении числа слоев ведет себя также (или немного хуже).
хорошо было бы сделать веток.
простую линейную и нелинейную
erwins22
22.01.2017 12:01А можно объединять в слой несколько разных функций активации.
Мне такое на тензорфлоу давала лучшие результаты.

newis
Антон, обгоняй уже Лекса.
artoym
На данный момент с 75,04 вышел на первое место.