
Введение
Когда мы думаем о биоинформатике, мы обычно представляем себе какие-нибудь сложные последовательности ДНК, фолдинг белка или, на худой конец, моделирование диффузии вируса.
В данной же статье речь пойдёт несколько о другой теме, куда более близкой, можно сказать, машинному зрению и анализу документов, или даже прикладной автоматизации, чем высокой науке. Но на самом деле, тема важна и актуальна, хотя бы уже потому, что существует в очень интересной экологической нише.
КДПВ:

Кого заинтересовал — прошу под кат.
TL;DR:
Презентация проекта по распознаванию карт, нарисованных от руки.
У проекта есть вебсайт: biorec.sourceforge.net
Код выложен в SVN: sourceforge.net/p/biorec/code/HEAD/tree
/TL;DR;
У этой истории есть несколько «корней» и я постараюсь, не слишком углубляясь в дебри, всё же кратко их описать, чтобы создать в голове у читателя более полную картину.
Для начала, что такое орнитология? Орнитология — это раздел экологии, наука о поведении птиц, о том, как они себя ведут и как выбирают стратегии для выживания в этом сложном мире.
Можно сказать, что главная фундаментальная задача экологии — это узнать, почему у нас существуют именно такие виды, а не какие-нибудь другие. Какие такие энергетические минимумы существуют в странном многомерном пространстве, которое представляет из себя наша жизнь, позволяющие некоторым видам выживать (например, домашние коровы очень хорошо приспособились, и вряд ли когда-нибудь вымрут), а некоторым вымирать (скажем, мамонтам).
Орнитология же решает эту задачу в применении к птицам.
Скажем, наверняка многие из читателей, на вопрос о том, чем занимаются орнитологи, скажут «вешают на птиц кольца и смотрят, куда те улетят».
И в самом деле, это один из методов, которым пользуются орнитологи. В частности, например, благодаря нему можно установить, по каким маршрутам перемещаются перелётные птицы из одного конца нашей обширно, но всё же такой маленькой Земли в другой.
Картинка:
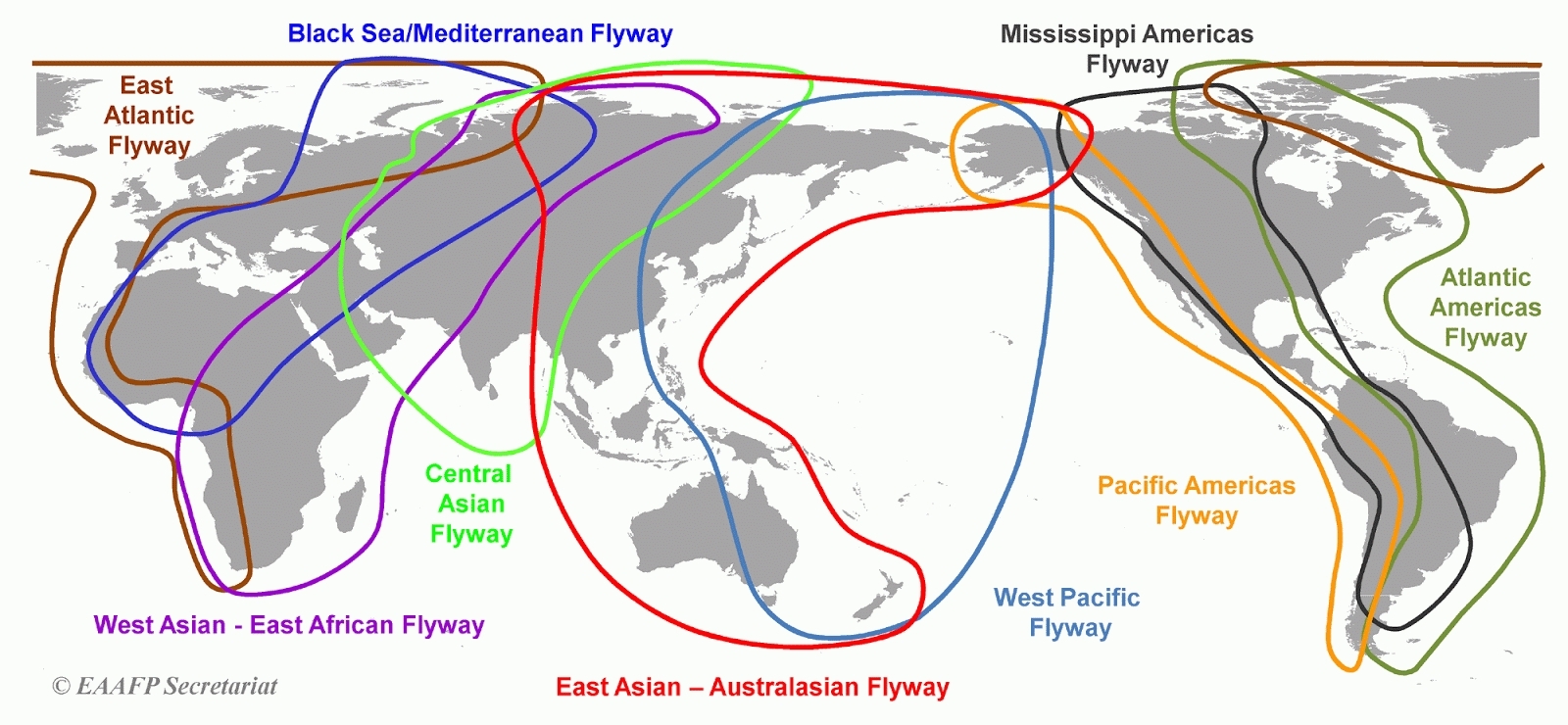
По вышеуказанной картинке можно понять, что России в некотором смысле повезло, потому что точка пересечения множества разных, непохожих друг на друга маршрутов, оказывается именно на территории России.
Собственно, именно в точке пересечения областей и находится одна из ведущих мировых лабораторий по изучению птиц — Енисейская биологическая станция ИПЭЭ РАН «Мирное».
Сбор данных
Однако в данной статье я хочу обратить ваше внимание на другой метод, использующийся в изучении птиц.
Можно сказать, что как микроскоп может иметь разную разрешающую способность, и бессмысленно пытаться рассмотреть нечёткий шрифт с помощью атомного силового микроскопа, так и орнитологические методы имеют разную разрешающую способность. Упомянутый выше метод кольцевания, имеет типичный радиус действия в тысячи километров. Тот же метод, о котором хочу поговорить я — всего десятки метров.
Этот метод называется Common Bird Census.
Его идея в том, что _каждый день_ специально обученные люди, умеющие определять вид птицы по внешнему виду, идут на исследуемый полигон, и отмечают разных замеченных птиц в свой рабочий блокнот.
Формат маркеров, отмечаемых специалистами, вы можете видеть на следующем слайде.
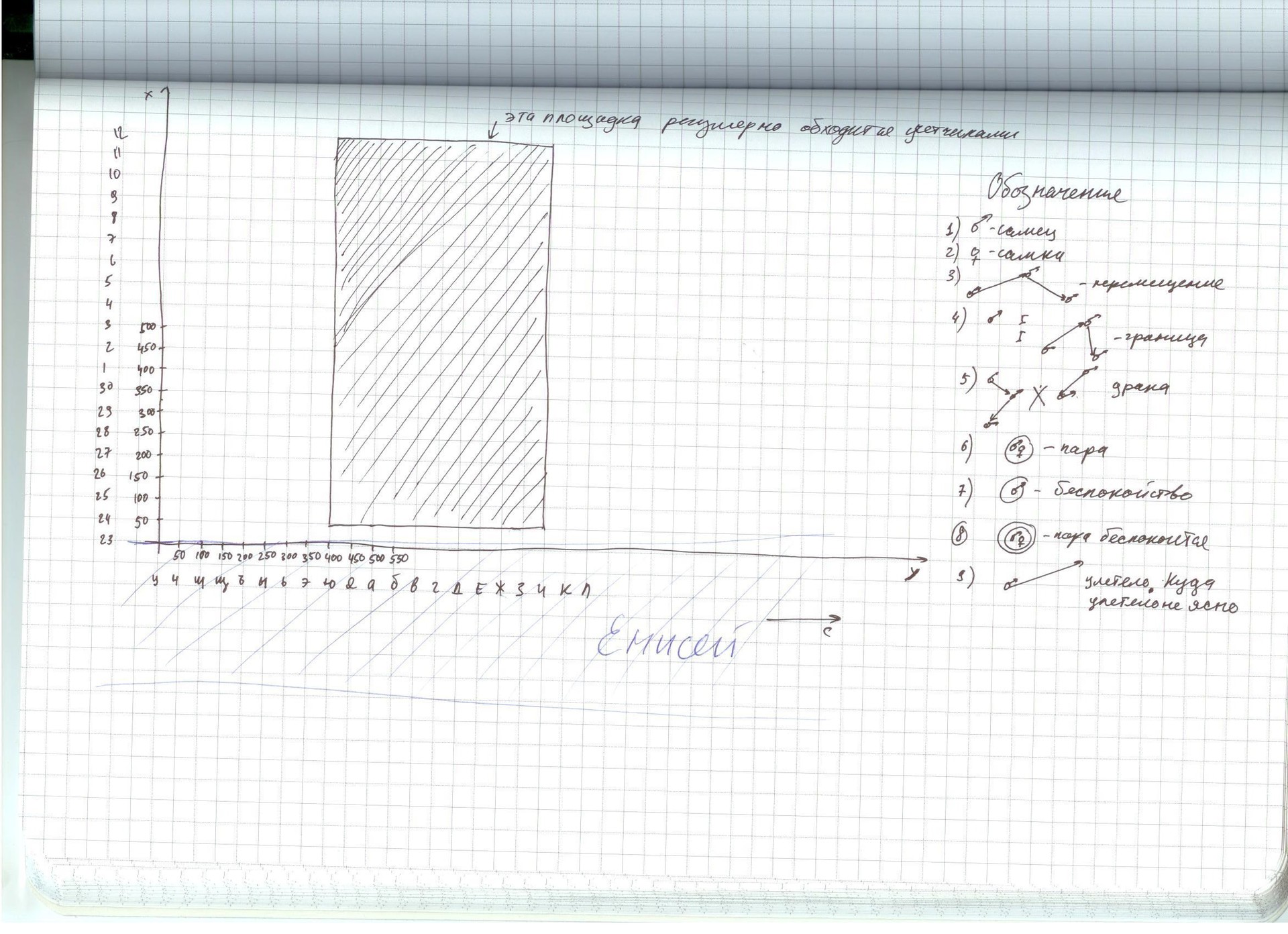
А вот так выглядит фрагмент данных, которые собираются на местности:

Ах, как было бы хорошо, если бы этой работой могли бы заниматься роботы! Можно было бы запустить на каждый участок своего робота, который облетал бы каждое дерево и докладывал обо всём увиденном.
Но увы и ах, до этого технология ещё не дошла (хотя, возможно, и дойдёт в обозримом будущем).
Пока же, для наблюдения требуются специально обученные люди, которым требуется впитать в себя огромный объём информации о поведении, внешнем виде, звуковом профиле и социальных навыках птиц. Причём эта информация, к сожалению ещё и слабо применима во обычной жизни человека. С другой стороны, трудно переоценить возможность читать лес как открытую книгу. Одно это уже может заставить человека пойти в орнитологи.
И тем более впечатляет, что_вся_ территория Великобритании, где данный метод был придуман (в 1962 году) покрыта квадратами, которые наблюдались подобным образом каждый год, целых 38 лет, до 2000 года, когда точность метода была признана излишней.
bto.org.uk

Кстати, метод был придумал J Dennis Summer-Smith, который, вообще говоря, удивительный человек. Ктобы ещё перевёл статью из Вики про него на английский?
Однако, внимательный читатель подскажет мне другое место, где можно было бы применить технологии, имеющиеся в данный момент.
Ну хорошо, пусть собирать данные автоматически невозможно. Но хотя бы сохранять их в каком-нибудь удобном формате-то должно быть возможно?
Увы, ответ и на этот вопрос — нет. К сожалению, в местах, наиболее удобных для наблюдения, существую большие проблемы с электричеством, водо и грязе-защитой, холодом и плохой связью с «большой землёй». Там же, где таковых проблем те, возникает задача выдать стандартизированное оборудование (в качестве которого можно было бы вообразить какой-нибудь industrial-grade планшет на Linux/Windows).
Что же у нас имеется, спросите вы!
А вот что:
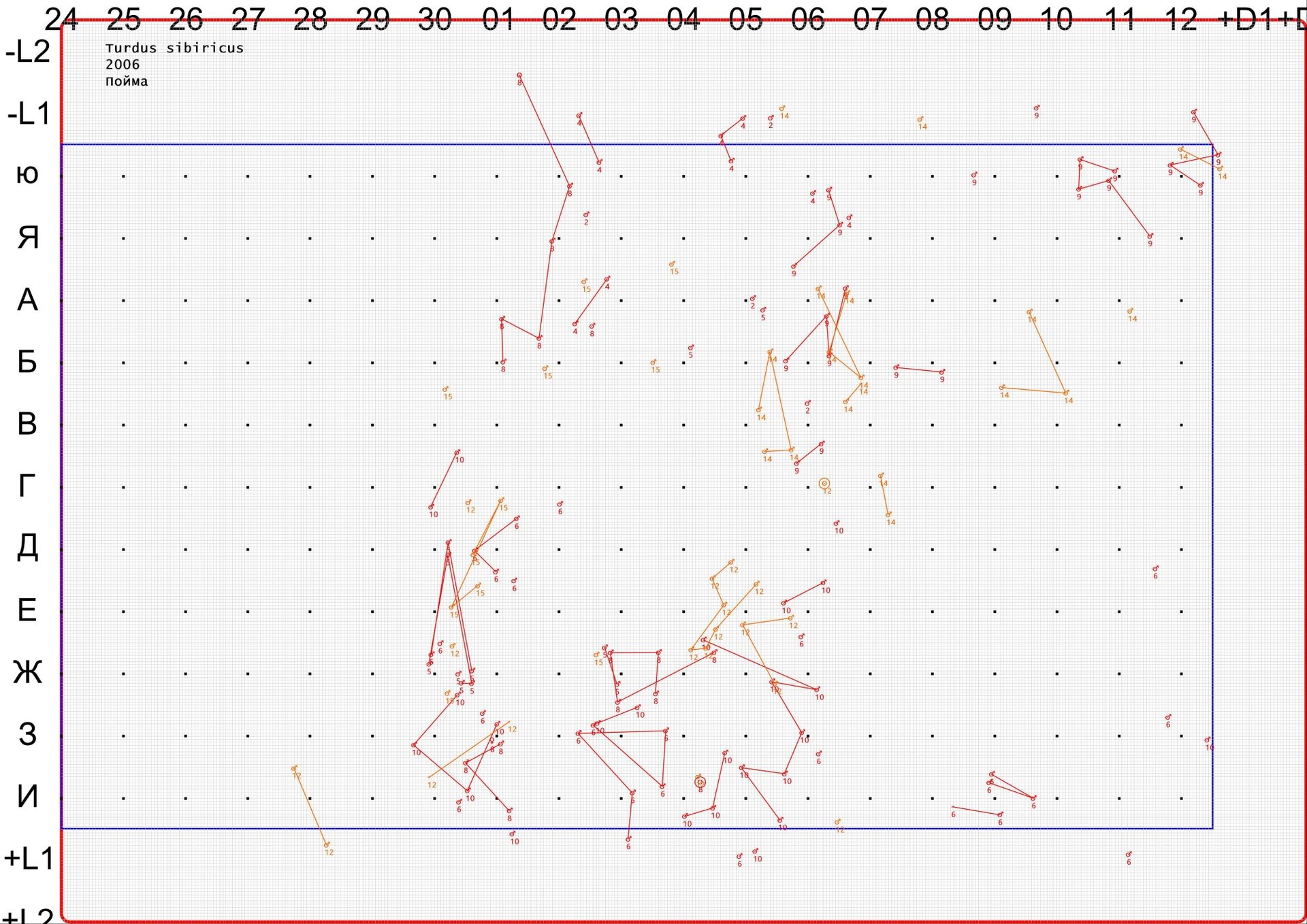
Тут я ещё раз покажу картинку с данными:

На изображении вы видите фрагмент карты, расчерченной на столбцы и строки буквами и числами (обратите внимание на «формат данных» на предыдущем слайде).
Вот это — та самая неприглядная, но такая дорогая и важная реальность.
Именно здесь мы видим, как птицы перемещаются из точки в точку, дерутся, женятся, ухаживают за потомством.
Каждый такой лист — это много часов трудной полевой работы, которая в итоге и должна дать нам ответ на самый трудный вопрос на свете: как жить правильно? Как жить так, чтобы прожить долго, не болеть, произвести потомство, вырастить, спеть самую лучшую (по каким параметрам?) песню и в ней реализовать себя.
Почему одни птицы большие, а другие маленькие? Почему у одних большой ареал, у других маленький? Почему у одних птиц много детей, а у других — мало?
Анализ данных
Хорошо, спросите меня вы. Но если данные как-то (пусть и аналоговым способом) собираются. Если они как-то (пусть на бумаге) хранятся.
Но ведь мы же с вами — Data Science-тисты. Ну уж обрабатываться-то эти данные-то как-нибудь да должны?
И ответ на этот вопрос имеется, хотя он далеко не так радостен, как нам хотелось бы.
Самая очевидная задача по препроцессингу — это разделить данные с листа на несколько слоёв, где каждому слою соответствовал бы всего один вид. Это логичная, осмысленная задача, потому что целесообразно изучать птиц разных видов вместе, как сэмплы из одного множества, и возможно, сравнивать их с другими видам по стратегиям адаптации.
И эта задача решается. Вот вам результат:

Но видите ли, какая загвоздка. Как и большинство техпроцессов в такой деликатной области, решается она аналогово.
В результате построение даже одной такой карты занимает много времени, а если учесть, что (как уже было написано выше), по крайней мере российский полигон для Common Bird Census находится в крайне удачной с точки зрения видового разнообразия точке, построение таковой карты по всем 200 видам — это очень трудоёмкая задача.
Однако, на карте есть ещё один элемент, которого не видно на дневных фрагментах: карандашные кружки.
А они-то что такое?
А они-то как раз и представляют из себя то самое, шажок к той самой альфе и омеге, к пониманию поведения вида. Они — индивидуальные территории. Можно сказать, зарождение частной собственности. Это те территории, которые птицы считают «своими», на которых активно кормятся, строят гнездо и которые готовы защищать, вплоть до самых страшных последствий.
Но как же они чертятся?
Вот тут возникает ещё один важный научный вопрос. Потому что ответов на этот вопрос два.
Один приводится, например, в руководстве по проведению CBC от Британского Орнитологического Траста (изобретателей этого метода)
www.bto.org/sites/default/files/u31/downloads/details/CBC-instructions-g100.pdf
Другой, например, чисто механический, в статье Филиппа Норта
www.jstor.org/stable/2347022?seq=1#page_scan_tab_contents
Какой из них лучше?
Очень интересный вопрос. В руководстве от BTO написано, что метод должен применяться одной и той же группой экспертов в течение многих лет, чтобы обеспечить консистентность результатов. Иными словами, они говорят «натренировать человека мы можем, а сформулировать закон природы — нет». В ИПЭЭ РАН делают то же самое.
Насколько метод Норта хорош? Отличный вопрос! Кто хочет заняться? Вызываю вас на слабо!
В принципе, очевидный подход — это как-то кластеризовать точки, с тем чтобы затем обвести кластеры… ну, например, слегка выйдя за их выпуклую оболочку. Но как их кластеризовать? Можно увидеть, что некоторые кластеры имеют солидного размера пустоты внутри. И какая именно степень гладкости границы должна наблюдаться?
Начала автоматизации
Когда ваш покорный слуга был моложе и смелее, и занимался вопросами машинного зрения, он представил себя белым рыцарем на коне, и решил, что настолько мощная задача заслуживает того, чтобы стать вызовом.
Я начал решать задачу методом машинного зрения, пытаясь выцепить и распознать буквы и цифры столбцов и строк. Под это дело я даже договорился с компанией Cognitive Technologies об использовании их промышленного движка (!) по распознаванию рукописного текста.
Вот некоторые следы этой работы:
Например, проектируя всё изображение на одну ось, можно сравнительно легко обрезать края:

При помощи комбинирования эрозии и дилатации, можно вычесть фон и сетку:

При помощи преобразования Хафа можно определить угол поворота изображения и пофиксить его:
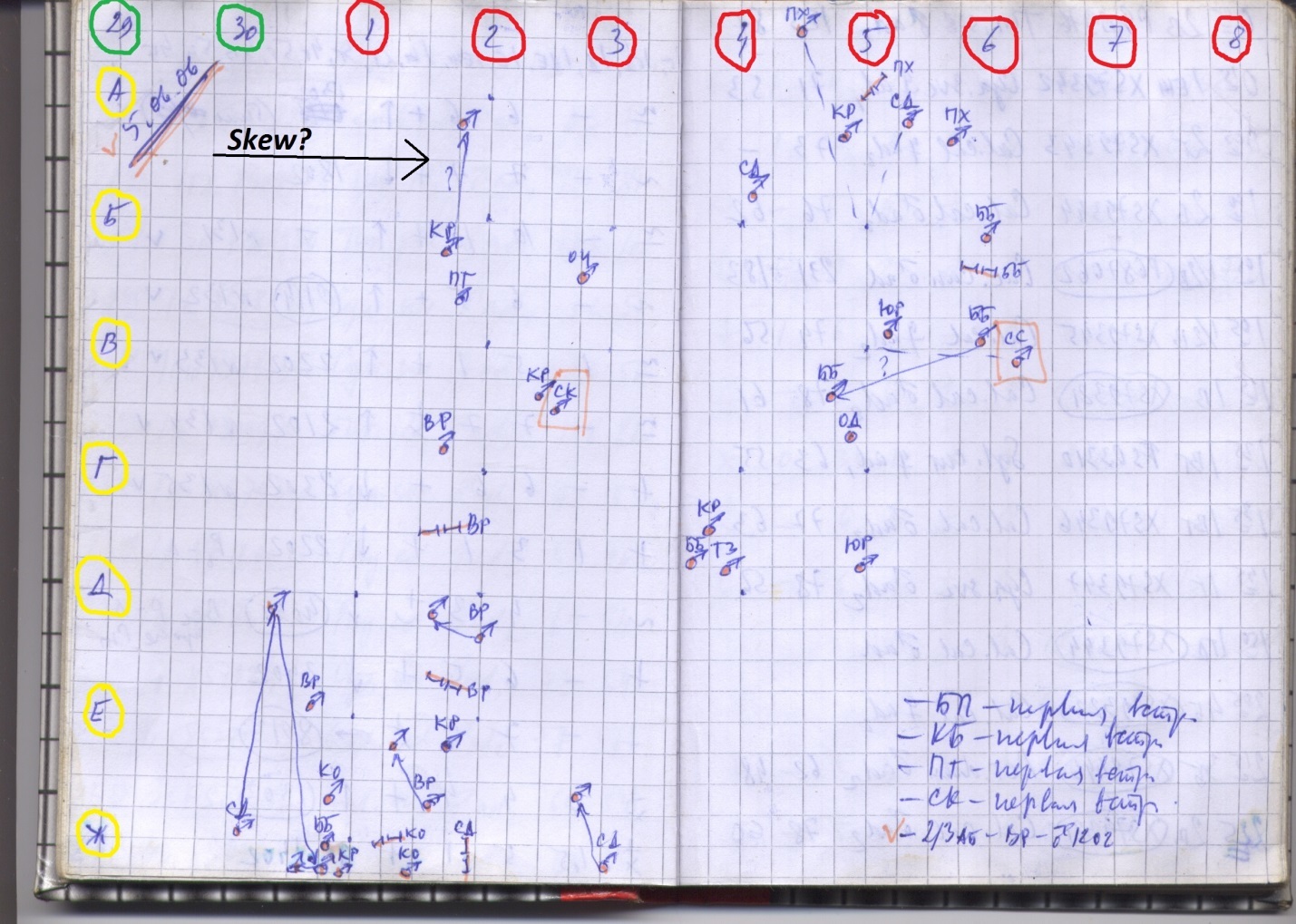
Той же самой проекцией картинки на одну ось, можно выцеплять отдельные буквы:

И в конце концов, даже найти их все на фрагменте:

А потом скормить распознающему движку:
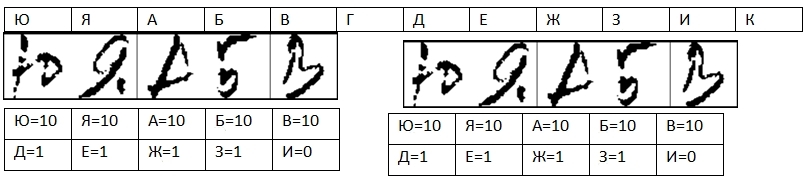
К сожалению, с некоторым цифрами приходилось работать вот так:



Результаты этой работы до сих пор лежат неопубликованные, потому что результат не впечатлил — точность распознавания 66%, хотя и позволил мне в своё время защитить диплом. Работу ещё можно было бы доделать, но к концу дипломного времени я понял, что без хорошей _ручной_ разметки делать мне нечего, потому что к тому моменту я собрал список из более чем пятидесяти разных возможных косяков в изображениях, каждый из которых надо было как-то отлавливать.
И тогда, уже закончив институт, я в свободное время, в качестве хобби, взялся написать ручной разметчик-аннотатор, который в итоге и дал побудил меня взяться за написание этой статьи.
На следующих слайдах вы можете увидеть элементы интерфейса этого разметчика.
Менеджер проекта:

Positioned означает разметку букв и цифр.
Но вообще говоря, я сделал больше — я сделал разметку ВСЕХ маркеров, которые бывают.
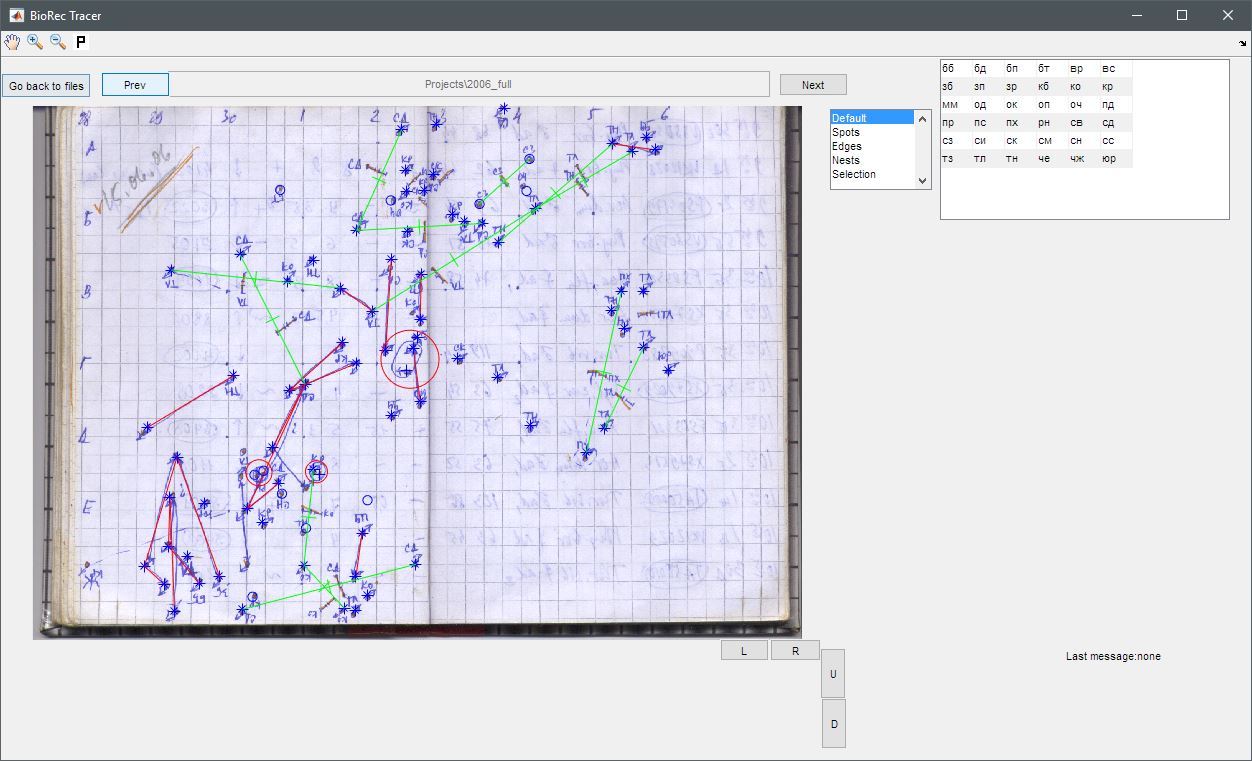
Разметчик оказался более осмысленный, чем я ожидал. Просто в какой-то момент я сообразил, что если всего-навсего запустить его на планшете, то можно же было бы собирать данные напрямую в него, минуя бумажный этап.
В итоге, вместо картинки вида
Можно было бы получать картинку вида:
И даже размечать территории. Вручную, разумеется.
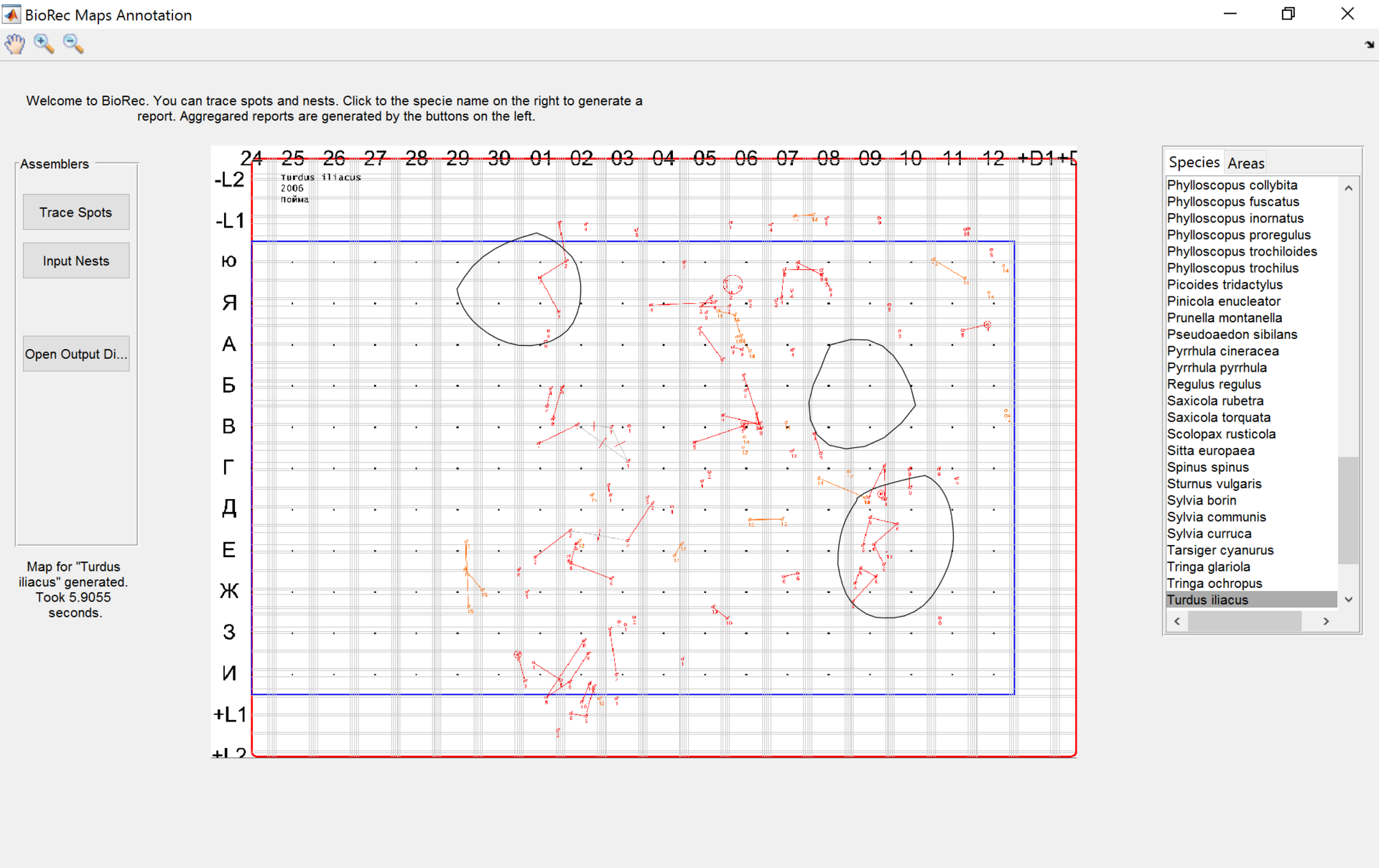
Разметив один год вручную, можно было бы уже запустить регулярные тесты автоматики, не говоря уже о том, что можно было бы браться и за содержательную аналитику (вроде вычисления территорий), а не только копаться в машинном зрении.
Результаты
Тут бы закончить эту статью каким-нибудь жизнерадостным финалом… Но увы, его нет.
В ИПЭЭ РАН лежит двадцать пять лет собранных данных, на бумаге.
Объём же данных, имеющихся в BTO в Великобритании, кажется, не поддаётся исчислению. _Вся_ территория Соединённого Королевства за 38 лет.
С другой стороны, к сожалению, я поссорился с людьми, которые помогали мне в работе над проектом, да и в целом перестал интересоваться областью.
Поэтому я ужасно хочу найти героя, который захотел бы унаследовать проект от меня, и довёл бы его до логического завершения. Слава и борьба ждут вас, а работа окажет неоценимую пользу человечеству.
В проекте практически готов разметчик и размечена примерно половина одного года наблюдений в ИПЭЭ. (То есть сделана базовая работа по очистке данных.)
Проект по обработке Common Birds Census называется BioRec, и написан он на MATLAB 2015b.
В проекте осмысленная модель данных, он готов к работе как с «Visit Maps», так и с «Species Maps».
У проекта есть вебсайт: biorec.sourceforge.net
Код выложен в SVN: sourceforge.net/p/biorec/code/HEAD/tree
У проекта есть мейлинг-лист, багтрекер, всё как у взрослых.
Есть алгоритм, который можно чуть-чуть доделать, чтобы часть данных распознавалась автоматом. Любителям машинного зрения — можно по уже размеченным данным попытаться сделать детектор маркеров и доавтоматизировать вторую половину.
Любителям геопространственного анализа — можно попробовать формализовать алгоритм BTO, реализовать алгоритм Норта, или попробовать написать свой, например на основе диаграммы Вороного.
Можно потом будет сравнить алгоритмически выделенные территории с экспертными.
Можно попробовать наложить территории на карту местности и посмотреть, как, например, связаны размеры территорий и ландшафт.
В общем, благородные воины, жаждущие крови и славы — это ваш шанс.
Пишите мне на lockywolf@gmail.com, или в скайп 'lockywolf'.
Форк, патчи, разговоры с описаниями непонятных кусков кода — всё к вашим услугам.
Комментарии (11)

Barafu
16.03.2017 17:43Точность распознавания указанных заметок и не будет выше 60-70% никогда. Потому что при написании загогулин на бегу 30% из них получаются равно похожими на 2-3 цифры. Когда человек вынужден прищуриваться, применять логику ("Дрозд умеет летать 110 км/ч? Нет? Значит, это не 11 а 4") — значит данные катастрофически зашумлены. Распознают и худшее, но в контексте. А без контекста — нет.
Я это к чему… Нужно создать контекст. Нужно переходить к следующему этапу с обратной связью. Обработанные данные нужно собрать, положить в базу, математически выявить аномальные и невозможные величины, отметить их на сканах. Далее распознать заново, с разными настройками. Если вновь не помогло, данные нужно оценить: на сколько именно эта запись полезна для науки. И самые ценные записи просмотреть вручную, остальные просто выбросить.
А на будущее выдать птичьим вуайеристам нормальные анкеты, чтобы такого не было. Клеточки для цифр радикально исправляют ситуацию.
lockywolf
16.03.2017 17:56Ну, на деле для машинной части можно сделать много лучше, чем 66%. Контекст-то имеется. Цифры всегда идут в одном порядке (пусть и не натуральном), и в целом распознаются хорошо. То есть, там где распознаётся А, там же и Д (с схожими вероятностями), но не Ю.
Тут вполне можно было бы сделать 95%.
С маркерами, естественно, так хорошо не выйдет.
Но вообще неплохо было эта хотя бы техпроцессу с ручной разметкой наладить.
Уже массу времени бы сэкономило, да новые возможности для аналитики дало.
lash05
Проект категорически не имеет прикладного значения? Наверное, стоит попробовать обсудить и этот вопрос…
lockywolf
Хороший вопрос.
Готовы ли учёные платить за оцифровку? Думаю, что нет.
Можно ли малой кровью адаптировать его для разметки чего-нибудь ещё? Ну, вероятно можно адаптировать для каких-нибудь похожих полевых исследований.
Более практические и прибыльные вещи? Без гадкой бумаги но с потребностью ручной разметки. Сходу не могу придумать. В городах обычно можно поставить камеру и обрабатывать видео.
Idot
Можно, при знании английского, попробовать получить какой-нибудь международный грант.
lockywolf
Хотите заняться?
Idot
Это получится у того кто в теме и знает как и у кого можно получать гранты. То есть Вам нужно найти биолога, который уже получал гранты, и знает как это делать.
lockywolf
Найдёте — киньте ему ссылку на эту статью :-). В целом, я её с таким прицелом и написал.
Idot
У меня знакомых учёных-биологов нет :(
Попробуйте спросить вот тут https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B0:%D0%91%D0%B8%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F (Проект Биология в Википедии) — там кто-нибудь должен знать.
lash05
Idot
Последователь Мао Цзэдуна?
О том что есть польза, Вам в голову не приходило?