
Примечание переводчика: Автор оригинального материала Эндрю Уорфилд работает в качестве CTO компании Coho Data, кроме того он является доцентом направления компьютерных наук в Университете Британской Колумбии. Это первый материал на тему облачной инфраструктуры и интеграции Big Data в традиционные ИТ-системы. Перевод второй заметки будет опубликован в нашем блоге на этой неделе.

Пару лет назад я начал общаться с представителями компаний из списка Fortune 500 и интересовался тем, как они используют инструменты вроде Apache Hadoop или Spark для работы с big data. Мне это было интересно, поскольку я предполагал услышать что-то о гигантских объёмах развертывания, сложных аналитических приложениях, и различных командах, чью работу облегчают все эти технологии.
Я работаю CTO стартапа, который занимается enterprise-инфраструктурой, и хотел понять, как большие компании интегрируют огромные массивы больших данных с уже существующей инфраструктурой, особенно с точки зрения хранилищ данных. В общем, хотел узнать о болевых точках.
Результаты подобных опросов были удивительными. За редкими исключениями использование больших данных в крупных организациях характеризуется несколькими общими чертами.
Очень часто на вопрос о «владельце больших данных» мне представляли целый ряд людей, каждый из которых отвечал за кластер из 8-12 узлов. ИТ-руководители компаний называли это «разрастанием аналитики», а некоторые даже шутили о том, что упаковка и развертывание Cloudera CDH с помощью Docker сделало создание и поддержку новых кластеров «слишком простым» делом.
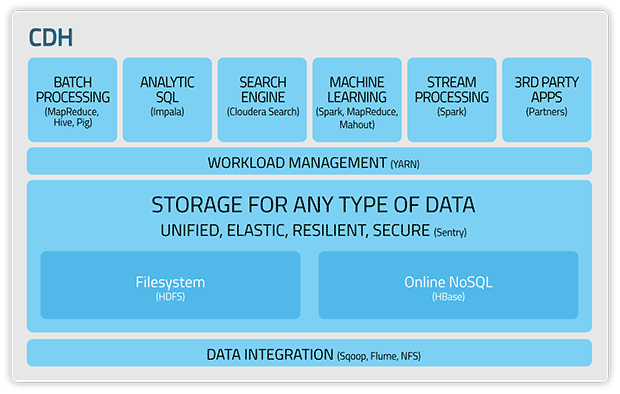
Схема работы Cloudera с официального сайта проекта
В этих упомянутых небольших кластерах как правило используются известные платформы для работы с большими данными вроде Cloudera или Hortonworks — они объединяют множество аналитических инструментов в одну хорошо документированную и легко управляемую среду. Интересно, что обычно эти платформы используются лишь как основа, в которую вручную добавляются другие полезные инструменты.
Пример — кастомизация ETL (extract, transform, load — извлечение, траспортировка, загрузка), то есть выгрузка данных из существующих ресурсов. Также часто добавляются новые аналитические инструменты (H2o, Naiad и другие). Экосистема вокруг Big Data развивается так быстро, что коробочные продукты не могут охватить все важные для инженеров аспекты, поэтому им приходится вручную расширять функциональность используемых систем.
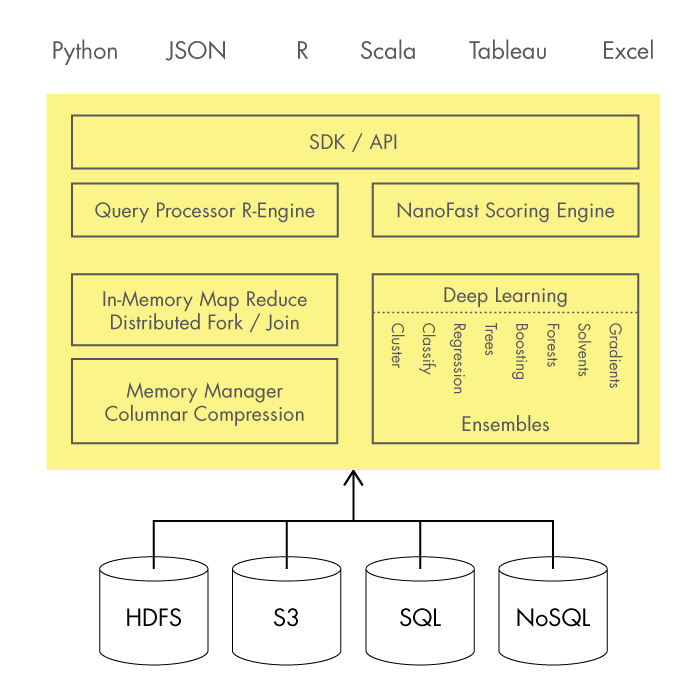
Схема работы H2O с официального сайта проекта
Как правило, аналитическая инфраструктура разворачивается отдельно от традиционных ИТ-систем, то есть в собственных стойках, со своими свитчами и так далее. Данные копируются из enterprise-систем хранения в HDFS, запускаются процессы обработки, а затем данные копируются из HDFS обратно в основную систему.
Разделение вычислительной инфраструктуры приводит к неэффективной трате ресурсов и увеличению операционных издержек бизнеса. Также бизнес сильно переживает о сохранности данных и решает эту проблему с помощью создания дублирующей инфраструктуры в разных физических локациях, и в каждом из этих мест выполняется одна и та же работа.
Важно отметить, что все вышеописанное не обязательно является чем-то неправильным. По большому счету компании только начинают всерьез работать с большими данными, что выливается в разнообразные эксперименты. Однако, когда подобные средства станут уже критически важными для бизнеса, операционные нужды резко изменятся.
В разговорах с инженерами Big Data и работниками, отвечающими за «обычную» ИТ-инфраструктуру, мне часто доводилось слышать, что все эти большие данные в компании воспринимаются как «экспериментальный научный проект». Это не негативное описание, но оно объясняет тенденции к созданию отдельных изолированных инфраструктурных кластеров для работы с большими данными.
Сейчас одной из главных задач ИТ-команд крупных компаний является вопрос о том, как сделать так, чтобы большие данные стали надежным и воспроизводимым «продуктом» (это не говоря об эффективности и стоимости), таким как хранилища, виртуальные машины, базы данных и другие инфраструктурные сервисы в наши дни.
Сложность заключается не в выборе облачной платформы для работы с Big Data. Текучесть стека связанных с ними технологий и преобладание «кустарного» подхода к разработке систем (с «допиливанием» готовых продуктов руками) в ближайшее время не изменятся.
Для того, чтобы «научный проект» трансформировался в жизнеспособное и эффективное решение для бизнеса, потребуется переосмысление многих вещей от вендоров и компаний, которые внедряют их решения в своей инфраструктуре. Эта эволюция происходит прямо на наших глазах, и очень скоро мы увидим, как компании разных размеров и форм, будут работать со своими большими данными для роста бизнеса и станут использовать их для лучшего обслуживания своих клиентов и понимания их нужд.
Пару лет назад я начал общаться с представителями компаний из списка Fortune 500 и интересовался тем, как они используют инструменты вроде Apache Hadoop или Spark для работы с big data. Мне это было интересно, поскольку я предполагал услышать что-то о гигантских объёмах развертывания, сложных аналитических приложениях, и различных командах, чью работу облегчают все эти технологии.
Я работаю CTO стартапа, который занимается enterprise-инфраструктурой, и хотел понять, как большие компании интегрируют огромные массивы больших данных с уже существующей инфраструктурой, особенно с точки зрения хранилищ данных. В общем, хотел узнать о болевых точках.
Результаты подобных опросов были удивительными. За редкими исключениями использование больших данных в крупных организациях характеризуется несколькими общими чертами.
Много небольших кластеров Big Data
Очень часто на вопрос о «владельце больших данных» мне представляли целый ряд людей, каждый из которых отвечал за кластер из 8-12 узлов. ИТ-руководители компаний называли это «разрастанием аналитики», а некоторые даже шутили о том, что упаковка и развертывание Cloudera CDH с помощью Docker сделало создание и поддержку новых кластеров «слишком простым» делом.
Схема работы Cloudera с официального сайта проекта
Нестандартные установки, даже на стандартных платформах
В этих упомянутых небольших кластерах как правило используются известные платформы для работы с большими данными вроде Cloudera или Hortonworks — они объединяют множество аналитических инструментов в одну хорошо документированную и легко управляемую среду. Интересно, что обычно эти платформы используются лишь как основа, в которую вручную добавляются другие полезные инструменты.
Пример — кастомизация ETL (extract, transform, load — извлечение, траспортировка, загрузка), то есть выгрузка данных из существующих ресурсов. Также часто добавляются новые аналитические инструменты (H2o, Naiad и другие). Экосистема вокруг Big Data развивается так быстро, что коробочные продукты не могут охватить все важные для инженеров аспекты, поэтому им приходится вручную расширять функциональность используемых систем.
Схема работы H2O с официального сайта проекта
Неэффективности
Как правило, аналитическая инфраструктура разворачивается отдельно от традиционных ИТ-систем, то есть в собственных стойках, со своими свитчами и так далее. Данные копируются из enterprise-систем хранения в HDFS, запускаются процессы обработки, а затем данные копируются из HDFS обратно в основную систему.
Разделение вычислительной инфраструктуры приводит к неэффективной трате ресурсов и увеличению операционных издержек бизнеса. Также бизнес сильно переживает о сохранности данных и решает эту проблему с помощью создания дублирующей инфраструктуры в разных физических локациях, и в каждом из этих мест выполняется одна и та же работа.
Больше одного способа построения больших данных
Важно отметить, что все вышеописанное не обязательно является чем-то неправильным. По большому счету компании только начинают всерьез работать с большими данными, что выливается в разнообразные эксперименты. Однако, когда подобные средства станут уже критически важными для бизнеса, операционные нужды резко изменятся.
В разговорах с инженерами Big Data и работниками, отвечающими за «обычную» ИТ-инфраструктуру, мне часто доводилось слышать, что все эти большие данные в компании воспринимаются как «экспериментальный научный проект». Это не негативное описание, но оно объясняет тенденции к созданию отдельных изолированных инфраструктурных кластеров для работы с большими данными.
Сейчас одной из главных задач ИТ-команд крупных компаний является вопрос о том, как сделать так, чтобы большие данные стали надежным и воспроизводимым «продуктом» (это не говоря об эффективности и стоимости), таким как хранилища, виртуальные машины, базы данных и другие инфраструктурные сервисы в наши дни.
От научного проекта к научному продукту
Сложность заключается не в выборе облачной платформы для работы с Big Data. Текучесть стека связанных с ними технологий и преобладание «кустарного» подхода к разработке систем (с «допиливанием» готовых продуктов руками) в ближайшее время не изменятся.
Для того, чтобы «научный проект» трансформировался в жизнеспособное и эффективное решение для бизнеса, потребуется переосмысление многих вещей от вендоров и компаний, которые внедряют их решения в своей инфраструктуре. Эта эволюция происходит прямо на наших глазах, и очень скоро мы увидим, как компании разных размеров и форм, будут работать со своими большими данными для роста бизнеса и станут использовать их для лучшего обслуживания своих клиентов и понимания их нужд.
unkinddragon
Поставил минус.
На западе все эти технологии уже вполне приносят конкретные выгоды и маленьким, и средним, и крупным. В оригинальном тексте написано «further use».У вас перевод получился в два раза короче оригинала. И не удалось понять мысль, её специфику в части «больших данных».
1cloud Автор
Если есть какие-то поправки, то в личных сообщениях они вполне принимаются. Конечно поставить минус и покрасоваться в комментариях — оно приятнее, это понятно. Ну и наш перевод не короче оригинала в два раза, не надо говорить неправду. Данный материал состоит из двух частей, вторая будет позднее на этой неделе.
alinatestova
Не совсем понятно, что вас тут не устроило. Тем более если речь идет о продолжении темы. И да, на западе подобные технологии далеко не большая часть бизнесов применяет. Там еще возможностей роста предостаточно. Хотели что-то умное сказать, но выглядите странно :)