

Процессор Intel Itanium — микропроцессор на архитектуре IA-64 (EPIC), разработанный совместно компаниями Intel и Hewlett-Packard и представленный 29 мая 2001 года, то есть почти 16 лет назад. Из-за неудачного маркетинга и низких продаж этот процессор с огромными амбициями иронично называли Itanic, созвучно известному трансатлантическому лайнеру.
В своё время архитектуру IA-64 называли революционной. Она должна была заменить x86 в 64-битных серверах и настольных компьютерах. Но что-то пошло не так. Годы разработки и продвижения стоили компаниям Intel и Hewlett-Packard миллиарды долларов, но теперь их мучения подошли к концу. В четверг 11 мая 2017 года компания Intel начала поставки микросхемы Itanium 9700 (кодовое название Kittson) — это официально и окончательно последний чип семейства Itanium, подтвердили представители компании Intel.
Поддержка Intel сокращалась в последнее десятилетия, так что постепенно эти процессоры уходили со сцены. Производители серверов прекратили выпуск новых моделей на Itanium, обновление программного обеспечения тоже остановилась, а сама компания Intel открыто рекомендовала клиентам
переходить на процессоры Xeon с архитектурой x86, так что окончательное прощание с линейкой Itanium не стало чем-то удивительным. Ну а Intel теперь может полностью сфокусироваться на Xeon — успешном семействе, которое бурно развивается.
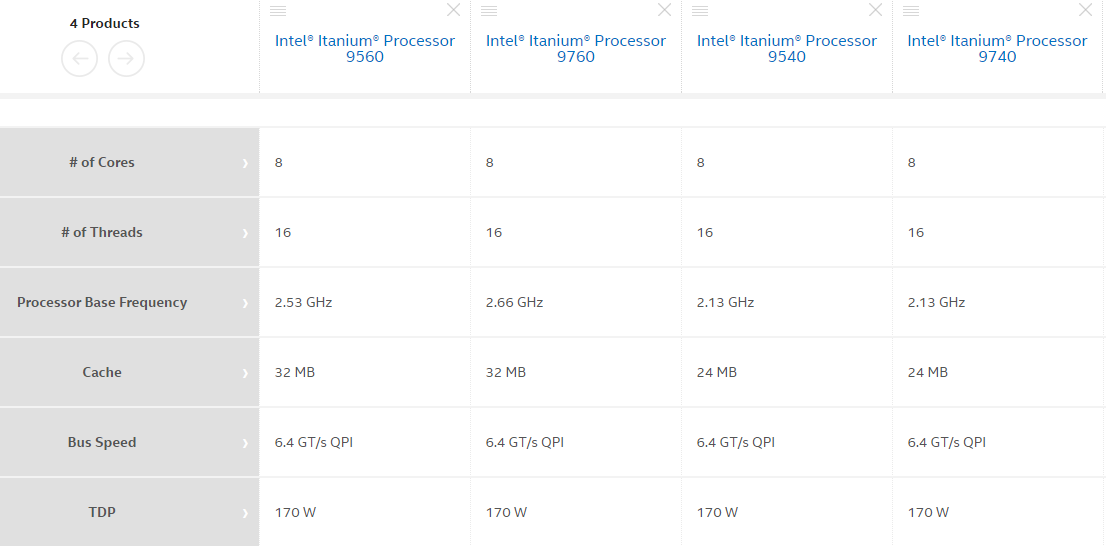
Модель Itanium 9700, выполненная по 32 нм техпроцессу, — это небольшое обновление предыдущей модели с кодовым названием Poulson, которая предназначалась для высокопроизводительных серверов под Unix и вышла в 2012 году. Как видно из таблицы, разница между Poulson и Kittson действительно невелика.
Единственным крупным покупателем этих процессоров остаётся компания Hewlett Packard Enterprise, которая сделает апгрейд своих серверов Integrity i6. Эти серверы работают под операционной системой HP-UX. Модель Itanium 9700 совместима по разъёму с Poulson, так что апгрейд произвести легко. Серверы Integrity i6 с новыми процессорами продаются по цене от $14 500.
В 90-е годы процессор Itanium был разработан Intel совместно с Hewlett-Packard. Последняя искала способ, как обновить свою стареющую архитектуру PA-RISC и приспособить её для современных 64-битных серверных чипов, на которых можно запускать традиционные старые ОС вроде Unix. В то время Intel как раз искала способ выйти на рынок высокопроизводительных серверов — и партнёры нашли друг друга. Вместе они предложили альтернативу на этом рынке существующим архитектурам мейнфреймов вроде Oracle/Sun SPARC и IBM Power. В первое время казалось, что это инновационная технология, которая может добиться успеха.
Инженеры HP и Intel предполагали, что архитектура микропроцессора EPIC (Explicitly Parallel Instruction Computing) («вычисление с явным параллелизмом машинных команд») на основе VLIW способна преодолеть врождённые ограничения RISC и поможет увеличивать производительность процессоров без увеличения тактовой частоты, выполняя всё больше и больше команд за такт, при этом планировщик инструкций, предсказание ветвлений и прочее удалялись из процессора и переносились в компилятор. В теории, это должно было освободить на микросхеме место для дополнительных модулей выполнения и увеличить параллельную производительность. Но на практике это не сработало. По-настоящему эффективных компиляторов не было создано. К тому же EPIC настолько радикально отличалась от других архитектур, что ARM и x86 можно считать братьями-близнецами по сравнению с ней.
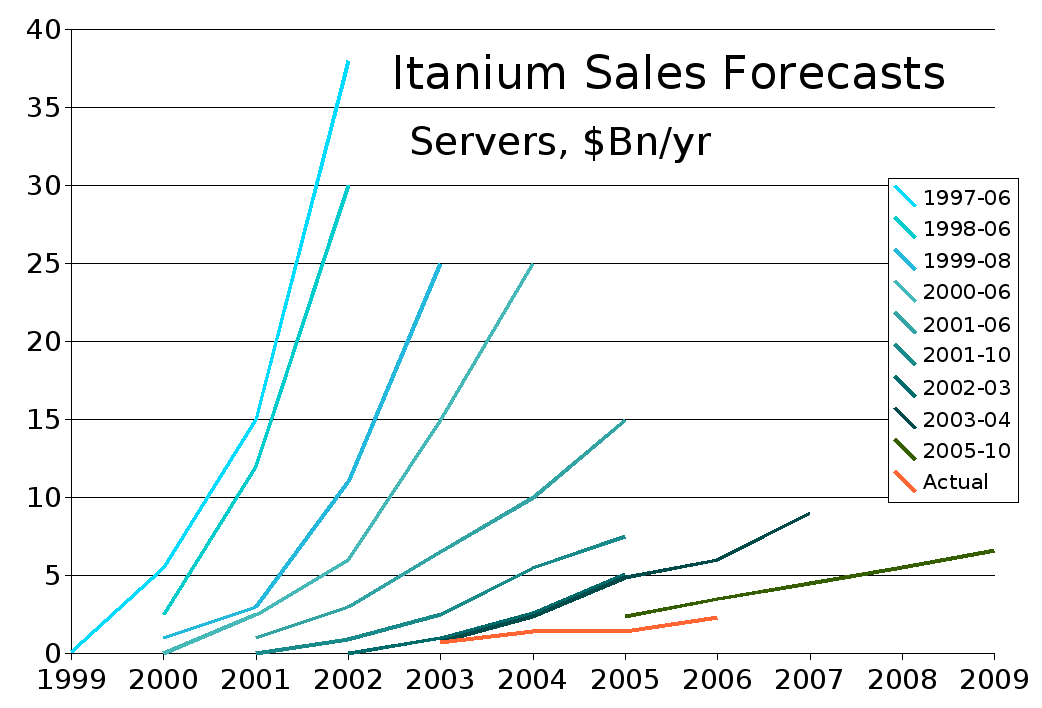
До выхода в 2001 году архитектуру IA-64 преподносили как революционную. На иллюстрации показано, какие прогнозы по продажам Itanium делались в разные годы, а оранжевым цветом показан реальный объём продаж постфактум.
Первые процессоры семейства Itanium оказались невероятно прожорливыми по энергопитанию. Им требовалось мощное охлаждение. Процессоры были дорогими и сложными в производстве. И они вышли на рынок на много лет позже запланированного.
Intel изначально хотела выпустить потребительскую версию IA-64 для настольных компьютеров, но этого так никогда и не случилось, а рынок быстро видоизменился, когда в 2003 году AMD выпустила первые 64-битные процессоры на архитектуре x86 (Opteron на архитектуре AMD K8 с набором инструкций AMD64), в то время как у Intel тогда были только 32-битные. Intel пришлось догонять со своей 64-битной версией x86 (Intel даже реализовала набор инструкций от AMD, который теперь известен как x86-64), а развитие Itanium тогда отошло на второй план. Вместо этого, наоборот, 64-битные процессоры на архитектуре x86 стали завоёвывать рынок высокопроизводительных серверов.
Самый мощный удар под дых Itanium получил в 2010 году от корпорации Microsoft. Она тогда объявила, что Windows Server 2008 R2 станет последней серверной ОС с поддержкой Itanium. В марте 2011 года Oracle тоже объявила о прекращении любой софтверной разработки под Itanium. Причём в заявлении Oracle была прямая претензия к менеджменту Intel, который «дал понять, что их стратегической целью является микропроцессор x86, и что Itanium находится у окончания своего жизненного цикла». После этого HP подала в суд на Oracle, требуя продолжения поддержки программного обеспечения Oracle для пользователей своих серверов под HP-UX.
В конце концов, процессоры Xeon даже по функциональности догнали Itanium. Так, в 15-ядерном Xeon E7 v2 (2012 год) Intel реализовала некоторые уникальные функции Itanium. К тому времени и компания HP облегчила клиентам миграцию с серверов Itanium на серверы Xeon x86. Стало понятно, что сворачивание производства Itanium не за горами. Но это было не так просто, потому что многие клиенты, закупившие эту технику, требовали поддержки и не хотели отказываться от Itanium. Так что HP продолжила выпускать серверы, а семейство процессоров Itanium прожило чуть дольше, чем планировалось.
HPE заявляет, что поддержка серверов Itanium сохранится до 2025 года, а последнее обновление HP-UX 11i v3 2017 выйдет в июне.
Подводя итог, Itanium был одним из интересных экспериментов с архитектурой микропроцессоров, и он продолжался намного дольше, чем удалось другим. Многие говорят, что архитектура x86 устарела. И сама Intel неоднократно пыталась заменить её. Itanium — это очередная такая попытка, но x86 по прежнему на коне.
Комментарии (48)

hdfan2
12.05.2017 20:26+1В своё время в широко известном в узких кругах ограниченных людей блоге «The old new thing» был цикл из 10 статей по архитектуре этого монстра (можно гуглить по «old new thing itanium processor part»). Я добрался до середины второй и там сломался. Неудивительно, что под него не появилось нормального оптимизирующего компилятора.

beeruser
12.05.2017 22:59+1>> Я добрался до середины второй и там сломался
Вообще она и разрабатывалась чтобы удобно было компиляторы писать.
Экс-Эльбрусовцы его (компилятор) и писали.
pohab
13.05.2017 10:34Экс-Эльбрусовцы его (компилятор) и писали.
Что вы хотели сказать этой фразой? Я бы не стал смешивать «эльбрусовцев» и тех, кто писали/пишут компилятор для Эльбруса с теми, кто делал тоже самое для Итаниума, хотя бы из уважения к этим самым эльбрусовцам.
На мой взгляд, Итаниум так и не получил нормального компилятора по той причине, что способных это сделать людей у Интела просто не было (да, представьте себе). А вот у МЦСТ такие люди есть, и компилятор Эльбруса — это, без преувеличений, произведение искусства. Никакой LLVM, над которым кстати работает весь мир, еще даже близко не способен на то, на что способен компилятор эльбруса, который тоже не стоит на месте и постоянно развивается, с каждым годом становясь все лучше и лучше.
Бабаян, про которого вы скорее всего говорите, далеко не компиляторщик, а железячник, при этом далеко не самый лучший.
Dreablin
13.05.2017 11:41Примерно в годы создания Itanium некоторое количество разработчиков Эльбрус были раханчены Intel'ом. Думаю они внесли большой вклад в ход работы по всем аспектам Itanium. Кстати, некоторые потом вернулись.
Это инсайд :)Dioxin
15.05.2017 10:07ЦРУ смогло украсть наработки Эльбруса, но не смогли украсть программистов :)
Dreablin
15.05.2017 16:08ЦРУ то тут при чем?) Понимаю, что это сарказм, но мой коммент не имел конспирологического подтекста)
Программистов украсть как раз смогли (RTLщиков как минимум).
История давно была, еще до меня, нет точной информации, но слухи ходят разные и если хотя бы половина из них правда, то Интел:
1) Очень хотела этих разработчиков
2) Не принимает отказы :)

asm0dey
13.05.2017 20:54Ну что, я тогда буду ждать когда этим компилятором OpenJDK построят. Чтобы посмотреть как оно зааутперформит i386 железки обычные.
pohab
13.05.2017 21:48+1Ждите конечно :) Но вы наверное не вкурсе про следующие вещи
Во-первых, производительность OpenJDK слабо зависит от того, каким компилятором ее строят, поскольку весь горячий код генерируется налету, а поэтому не важно, какой был компилятор. От этого больше зависит то, как быстро этот код будет генерироваться, и как быстро будет собираться мусор. Впрочем GC упирается больше в шину памяти, поэтому вклад компилятора не стоит преувеличивать. Я предлагаю вам самим в этом убедиться, построив OpenJDK с разными опциями gcc (-O1, -O2, -O3). Хочу подчеркнуть, что я говорю именно об уровнях оптимизации, а не режимах Debug/Release.
Во-вторых, производительность OpenJDK зависит, о сюрприз, от железа. Эльбрусы пока проигрывают интеловским камням в этом аспекте.
В-третьих, а чем вас, собственно, не устраивает производительность OpenJDK на Эльбрусе? Как показывает практика, то основная причина низкой производительности лежит не в рантайме или железе, а в коде, который исполняется.
И на последок, смеяться и критиковать конечно прикольно, но вы должны понимать, что над x86/x64 трудится весь мир последние 30 лет, а над Эльбрусом 100 человек в РФ (это скорее верхняя оценка). Ресурсы, затраченные на Intel и на Эльбрус, просто несопоставимы. В подобных условиях довольно странно требовать от Эльбруса таких же результатов, что и от Intel.
beeruser
14.05.2017 09:28>> Бабаян, про которого вы скорее всего говорите, далеко не компиляторщик, а железячник, при этом далеко не самый лучший.
Нет, я имел в виду Андрея Боханко и других бывших сотрудников МЦСТ
Randl
15.05.2017 00:54А вот у МЦСТ такие люди есть, и компилятор Эльбруса — это, без преувеличений, произведение искусства. Никакой LLVM, над которым кстати работает весь мир, еще даже близко не способен на то, на что способен компилятор эльбруса, который тоже не стоит на месте и постоянно развивается, с каждым годом становясь все лучше и лучше.
Тем обиднее, что эти люди работают над Эльбрусом, а не над LLVM...
И, кстати на что способен компилятор Эльбруса, с чем LLVM рядом не стоял?
pohab
15.05.2017 02:26Почему обиднее? Как только мировое собщество начнет контрибьютить в Эльбрус, эльбрусовцы начнут контрибьютить в мировое сообщество, в т.ч. в LLVM.
И, кстати на что способен компилятор Эльбруса, с чем LLVM рядом не стоял?
1. Планировщик инструкций. В LLVM он тоже есть, но такого качества, что по сравнению с эльбрусовским можно считать, что в LLVM его нет.
2. Регаллокатор. Тоже самое, что и с планировщиком. Качетсво распределения регистров в эльбрусовском компиляторе существенно выше.
3. Преобразование свитчей в линейный код. LLVM даже понятия не имеет, что так можно.
4. Конвейеризация циклов, в т.ч. достаточно сложных. В LLVM такой оптимизации нет в принципе.
5. Оптимизация работы с кешами процессора. Если в LLVM и есть нечто подобное, то очень низкого качества.
Список можно продолжать долго, но суть в том, какую бы оптимизацию не взять, то с высокой долей вероятности в эльбрусовском компиляторе она будет сделана качественне и работать эффективнее по сравнению с LLVM, а некоторых оптимизаций в LLVM попросту нет. Все выше сказанное взято из собственного опыта.Randl
15.05.2017 09:02Почему обиднее? Как только мировое собщество начнет контрибьютить в Эльбрус, эльбрусовцы начнут контрибьютить в мировое сообщество, в т.ч. в LLVM.
Потому что Эльбрусом пользуются 2.5 человека, а LLVM — миллионы

ACPrikh
15.05.2017 10:04С такой логикой до сих пор бухгалтерскими счётами бы пользовались.

MTyrz
15.05.2017 10:59Как только мировое собщество начнет контрибьютить в Эльбрус
Открывать свои собственные разработки, такие как компилятор LCC, фирма не планирует
Ну и о чем это вы?pohab
17.05.2017 08:02+1Фраза «контрибьютить в Эльбрус» означает не только учавстовавать в разработке компилятора (что на мой взгляд не имеет смысла, т.к. необходимо знать архитектуру), но еще и помогать портировать софт. Благо, работы в этой области хоть отбавляй. Кроме того, как оказывается, нужно еще оптимизировать этот самый софт под эту архитектуру. Много ли желающих, особенно со стороны софтверных гигантов? Вот и я о том же. Им это не надо, ровно как и многим здесь присутствующим, поэтому ситуация именно такая, какая есть.
MTyrz
17.05.2017 12:13+1Мне в этом контексте интереснее, что означает фраза «эльбрусовцы начнут контрибьютить в мировое сообщество».
pohab
18.05.2017 00:25Можете заменить «мировое сообщество» на «опенсурс» или «ЛЛВМ». Должно стать понятнее.
MTyrz
19.05.2017 00:25+2Не, не стало.
Я понимаю, чего хотелось бы МЦСТ (или как правильнее назвать — сообщество разработчиков Эльбруса?) от мирового сообщества.
Я понимаю, что такое вклад в опенсурс.
Я не понимаю, каков будет этот вклад от МЦСТ, если открытия их разработок не планируется. МЦСТ выделит оплачиваемые часы для работы над LLVM? Или разработчики Эльбруса начнут это делать частным порядком (а сейчас что мешает?)?
Я не в порядке наезда, я действительно не понимаю. Можете описать подробнее: что именно, по вашему мнению, может законтрибьютить фирма, если свои разработки она открывать не собирается?
При этом вроде бы понятно, что частная инициатива разработчика тут не очень причем (или я ошибаюсь?) — в свободное от работы время ему никто не мешает писать куда угодно, лишь бы NDA соблюдал.
Randl
15.05.2017 12:33Объективно, у Эльбруса шансов захватить рынок нет. У революционных идей, которые, по вашим словам, содержаться в его компиляторе — возможно, но их же практически никто не видел -_-
pohab
17.05.2017 08:07Объективно, на равне с Intel+AMD у Эльбруса шансов захватить рынок нет. Поэтому применяется политика протекционизма, в том числе на основе гос. контрактов и соответствующих законов. Нравится ли это общественности или нет — это уже другой вопрос, но опять же, объективно, другого варианта просто нет, иначе бы им уже давно воспользовались.
P.S. не видел тот, кто не искал :) Вот, пожалуйстаpohab
17.05.2017 08:34Прошу прощения, прочитал «идей» как «людей».
По поводу идей, можно поискать в интернете компиляторные статьи ученых МЦСТ. Не все, но какие-то идеи станут понятны.
Randl
17.05.2017 17:14Объективно, на равне с Intel+AMD у Эльбруса шансов захватить рынок нет.
То есть не делаем, чтобы покупали, а покупаем, чтобы делали?
Я считаю что рынок в искусственной регуляции не нуждается, и если продукт никто не покупает, то он никому не нужен. Если же он хорош с теоретической точки зрения, то и заниматься им надо в институтах, на гранты, с полной публикацией результатов.
pohab
17.05.2017 18:36+1Вы либо не читаете, то что я пишу, либо не понимаете.
Если бы мы жили в идеальном мире, вы бы с такими предствалениями были бы лучшим экономическим стратегом. Но как многие наверное заметили, реальный мир немного (совсем) не идеальный. Я полностью согласен с вами, что регуляция вредит рынку, ровно как и с любыми другими либеральными утверждениями. Но почему-то все подобные теоретики забывают, что эти правила работат только в том случае, когда участники находятся в равных условиях. Эльбрус, оставший от интела на 15 лет, явно не в таких условиях. И без помощи государства, без регуляции рынка, у него нет шансов. Поэтому все именно так, как есть.Randl
17.05.2017 18:56И без помощи государства, без регуляции рынка, у него нет шансов.
Я утверждаю, что и с помощью государства у него шансов нет, кроме как производиться для того, чтобы было чему помогать.
Эльбрус, оставший от интела на 15 лет, явно не в таких условиях.
Но ведь он никогда Intel не догонит? С этого я и начал. И потому, как в продукте, смысла в нем нет.
pohab
18.05.2017 00:24Я утверждаю, что и с помощью государства у него шансов нет, кроме как производиться для того, чтобы было чему помогать.
Отлично, ваша правда. В таком случае я предлагаю вам немедленно связаться с МЦСТ, а лучше лично прийти к ним в офис, и объяснить, что они все делают не так, как нужно. Уверен, им будет очень интересно взглянуть на неопровержимые доказательства вашей правоты, которые у вас безусловно имеются, ведь вы «утверждаете». Заодно откроете им глаза, что оказывается надо код для LLVM писать, а не свои технологии развивать (они то ведь не в курсе, правда :) ). Можете также предложить им план по распродаже компании Интелу и АМД.
Но ведь он никогда Intel не догонит? С этого я и начал. И потому, как в продукте, смысла в нем нет.
Если ничего не делать, ведь вы именно это предлагаете, то конечно не догонит. Как известно, дорогу осилит идущий. А есть ли в нем смысл или нет, это, к счастью, решать не вам.
После ваших комментариев мне очевидно, что вы не понимаете и не хотите меня понимать. Поэтому предлагаю закончить этот, теперь уже бессмысленный, разговор.Randl
18.05.2017 11:20+1После ваших комментариев мне очевидно, что вы не понимаете и не хотите меня понимать. Поэтому предлагаю закончить этот, теперь уже бессмысленный, разговор.
Я и правда не понимаю, что вы пытаетесь сказать, но и вы, как мне кажется, не совсем меня поняли.
Я хотел сказать, что с моей точки зрения, было бы гораздо круче, если бы крутые ребята из Эльбруса пилили что-то, чем пользуется весь мир, по сравнению с Эльбрусом, у которого, имхо, перспектив нет. Все это сугубо личное мнение, а не истина в последней инстанции.
Если ничего не делать, ведь вы именно это предлагаете, то конечно не догонит.
Я имел ввиду чисто физически, пока интел продолжает работать, отставание во времени не уменьшается -_-
Salabar
17.05.2017 18:571,2 и 5 обычные процессоры делают в динамике, когда у них заведомо больше информации. 3 не нужно благодаря предсказателям ветвлений, которые позволяют не выполнять лишней работы.
Не надо путать «не могут» и «не хотят париться бесполезной фигней».pohab
18.05.2017 00:31У вас наверное научная степень в проектировании процессоров, не так ли?
У обычных процессоров заведомо больше информации, и существенно меньше времени и ресурсов на ее обработку. Кроме того, обработка этой информации в рантайме требует существенно больших энергозатрат. Последнее, кстати, не очень вяжется с политикой борьбы с глобальным потеплением и прочими «зелеными» идеями.
У любого подхода есть сильные и слабые стороны, в том числе у ВЛИВ'ов и суперскаляровSalabar
20.05.2017 16:05Зачем мне научная степень, чтобы использовать логику?
float x = (cond()) ? f1(y) : f2(y);
VLIW компилятор переделывает под
float x' = f1(y), x'' = f2(y); float x = (cond()) ? x' : x'';
Даже если по факту cond() выполняется раз в год, процессор будет считать и f1, и f2, потому что VLIW не может в ветвления, а так код параллелится лучше. Откуда экономия энергии?
Или такой код:
float s = 0; for (int i = 0; i < 16; ++i) s += d[i];
Обычный ОоО сделает так:reg0 = 0;
[какой-то ассемблер для цикла for]
load(reg1, d[i])
add reg0, reg
In-Order процессору придется делать так:
reg0 = 0
load(reg1, d[0])
...
load(reg16, d[15])
add reg0, reg1
...
add reg0, reg16
При той же степени сокрытия задержек памяти, код на VLIW в пять-десять раз больше, значит при прочих равных потребует гораздо больше кеша инструкций, который самый дорогой кремний на чипе после регистрового файла и TLB-кеша. Причем, наращивать его бесконечно всё-равно нельзя, поэтому миссы в кеше инструкций заведомо будут чаще, чем у ОоО собрата, так что зачастую всё ядро будет крутить такты впустую. Такая-то экономия.
Ну и еще не получится выполнять сложения одновременно с загрузкой данных, но это уже ерунда относительно.pohab
21.05.2017 02:31+1Зачем мне научная степень, чтобы использовать логику?
После вашего комментария я читаю это как «зачем мне что-то знать, я и так самый умный».
Вы хотите использовать логику, чтож, давайте рассуждать логически.
Что мы имеем? На одном из самых авторитетных ресурсов в мире по полупроводниковой логике и процессоростроении выходит статья, что Тинел Титаник потанул из-за того, что разработчик не сумел одновременно усидеть на двух архитектурах (VLIW и Суперскаляр) и двух рынках (мобильный и десктоп/сервер). В комментарии к этой статье приходит эксперт и на пальцах объясняет всем, что VLIW — это смерть, кладбище, ..., а суперскаляр — это вершина человеческого развития и у первого нет никаких шансов победить по ряду простеших причин, понятных даже ребенку (почему вы еще не Intel fellow в таком случае?). Если бы это было в 1965 году, то все супер, но, доброе утро, сегодня уже 2017.
Вы что, в серьез думаете, что люди, защитившие докторские диссертации, посвятившие свои жизни разработке процессоров не знают об этих простейших вещах? И не понимают плюсов и минусов различных подходов? И ни разу не пытались решить эти проблемы? И не решили? Это звучит нелогично, нелепо и смешно, даже чтобы это комментировать, не говоря уже о том, чтобы быть правдой. Мне вообще не понятно, почему люди привыкли считать себя умнее других.
Но ладно, чтобы не быть голословным, я объясню вам, почему все ваши доводы не имеют смысла.
Даже если по факту cond() выполняется раз в год, процессор будет считать и f1, и f2, потому что VLIW не может в ветвления, а так код параллелится лучше. Откуда экономия энергии?
Это еще почему процессор будет считать это каждый раз? Как можно вызывать какие-то функции, не зная условия допустимости сделать это, но давайте опустим эту малозначительную деталь. Вы вообще понимаете, как комлюхтер работает? Зачем ему мочь в ветвления, если здесь ветвления просто не нужны? И кстати, а что в этом случае сделает суперскаляр?
Далее, здесь как минимум 3 независимых потока исполнения, которые могут быть распараллелены. В общем гуглите по словам «спекулятивное» и «условное» исполнение инструкций.
Или такой код: (какой-то цикл)
Это простейший пример конвейеризуемого цикла. Для оптимизации доступа в память используются наложенные итерации в паре с технологией индексной адресации регистров (google «вращаемая база»). В вашем примере суперскалярного ассемблера (неправильного кстати) тело цикла стоит минимум 3 такта (load + add + branch). Для Эльбруса этот цикл будет стоить 1 такт. На самом деле для суперскаляра тоже будет 1 такт.
Я бы для большей эффектности рассмотрел что-то вроде
for (int i = 0; i < n; ++i) r[i] += d[i] * (c[5*i - 2] % m == 2 ? a[i*2] : b[i] / k);
Как думаете, сколько надо ресурсов, памяти, кремния, времени и т.д., чтобы в рантайме заоптимизировать подобный цикл?
Далее, как вы наверное знаете, смысла оптимизировать линейный код нет, весь перфоманс находится в циклах, а значит нужно уметь обнаруживать эти самые циклы. Скажите пожалуйста, сколько подобных реалтаймовых, реализуемых в железе, алгоритмов вы знаете? Я тоже. Безусловно, такие алгоритмы существуют, скорее всего они являются комерческой тайной микропроцессорных компаний. Но совершенно очевидно, что они требуют гораздо больше памяти и все остального, чем просто большой кэш инструкций.
Вообще, если вы не в курсе, то в суперскалярном процесссоре работу компилятора выполняет железо, компилирующее x86 код в микрокод.
Далее, как вы сами сказали, железные ресурсы очень дорогие и ограниченные, а по времени жесткие рамки, поэтому возможности выполнять сложные оптимизирующие алгоритмы там нет. Совершенно иная ситуация обстоит с оптимизирующими компиляторами для VLIW'ов, у которых, фактически, бесконечное количество ресурсов и времени.
Проблема предсказания переходов решается с помощью статического предсказателя, профилировки, спекулятивного и условного исполнения, глобального планирования исполнения кода.Salabar
21.05.2017 17:33+1Это еще почему процессор будет считать это каждый раз? И кстати, а что в этом случае сделает суперскаляр?
Потому что в этом идея VLIW, мы фигачим обе ветки исполнения параллельно, а потом отбрасываем не оправдавшую себя и за счет этого выкидываем сложный предсказатель ветвлений, не ломая конвеер на каждом ифе. Если это не использовать, то в чем вообще смысл широкого слова?
Суперскаляр здесь запомнит, что cond() в 95% случаев возвращает true или false и даже не будет задумываться о более редкой ветке, таким образом не тратя регистры, место в кешах и не прогревая воздух бесполезной арифметикой. Даже если он будет ошибаться в 50% случаев, это всё еще лучше чем что бы там ни соорудил компилятор в статике.
Скажите пожалуйста, сколько подобных реалтаймовых, реализуемых в железе, алгоритмов вы знаете?
Но совершенно очевидно
Да он по факту один и есть. https://en.wikipedia.org/wiki/Tomasulo_algorithm За 60 лет к нему добавили возможность выполнять условные переходы до того, как стало известно, выполнилось ли условие (собственно, спекулятивное исполнение), убрали ложные зависимости, когда две инструкции пишут в разные половины одного регистра, да еще load после store по одному указателю ни в кеш, ни в память может не лезть. Сами же написали, ресурсы ограниченные, ничего реально сложного туда не запихнешь.
Ну, мне это не совершенно очевидно. Как минимум, кеш тупо занимает больше места на кристалле, чем N узко строго специализированных под нужны планировщика регистров. Но точных замеров у меня нет, может вам и очевидно.
выполняет железо, компилирующее x86 код в микрокод.
Это вообще вещь ортогональная, что x86, что ARM делают это из-за трейд-оффа между плотностью инструкций и сложностью вычислительных конвееров (ну и обратной совместимости, конечно). Не очень, знаете, приятно, когда код, в котором слишком много делений, превращается в томик Войны и мира на ассемблере.
компиляторами для VLIW'ов, у которых, фактически, бесконечное количество ресурсов и времени.
Проблема предсказания переходов решается с помощью статического предсказателя, профилировки, спекулятивного и условного исполнения, глобального планирования исполнения кода.
1) Половина задач, которые решает компилятор — вообще NP-полные. Любые «сложные» алгоритмы — это такой брутфорс с амбициями. Т.е., допустим, Skylake имеет reordering buffer на 211 микроопераций, а компилятор VLIW (очень условно) сможет что-то оптимайзить с окном 400 инструкций, но без рантаймовой информации. Попробуем взять больше — никаких бесконечных ресурсов не хватит, чтобы перемолоть что-то длиннее hello world. И компилятор не может предсказать, что переменная A будет находиться в L1, переменная B в L2, а переменной C даже в TLB-кеше не будет.
2) Профилирование — это всегда здорово, но только одно дело, когда мы переписываем на ассемблере всякую экзотику типа битового упаковщика для архиватора, потому что никакой компилятор не догадается использовать специальные инструкции для этого, а другое — вести проц за руку на любом нетривиальном участке кода. Причем, когда выйдет новое поколение, у которого регистров на 40% больше или там буфер для предзагрузки не два килобайта, а четыре, это придется проделывать заново, иначе новенький чип новообретенные ресурсы использовать никак не сможет и окажется быстрее старого процентов на 20, а это полнейшая ересь. И это еще если программа в исходниках доступна.
Я ничего не имею против существования Эльбруса, понимаю, почему он представляет собой то, что представляет, но VLIW — это вещь изученная и опробованная. Ничего кардинально нового тут не придумать.
DmitryBabokin
13.05.2017 05:41+2Проблема с компилятором там ровно одна. Машина очень чувствительна к качеству планирования кода, а код хорошо спланировать можно только зная его динамическое поведение (по каким путям ходили, где стояли и ждали загрузки из памяти и т.д.). В итоге получается, что если угадали, то всё хорошо, если не угадали, то всё плохо. И это достаточно фундаментальное ограничение архитектуры.
В остальном архитектура была очень красивая и приятная.
iChaos
13.05.2017 09:22+1У архитектур с сильным распараллеливанием (это касается и многоядерных процессоров), есть ещё одно фундаментальное ограничение, согласно которому, машина с одним исполнительным блоком, работающим на частоте v*N, будет всегда эффективнее машины, с числом N исполнительных блоков, работающих на частоте v.
DmitryBabokin
13.05.2017 10:56+2Итаниум не шире современных x86 архитектур. Так что это не совсем про него.
Просто в Итаниуме явно доступен параллелизм на уровне инструкций, а в x86 он неявный (за счёт out-of-order исполнения).
PerlPower
12.05.2017 21:36+1Как вообще выглядя серверы с RAM на десятки террабайт? Там какая-то хитрая кластеризация, и RAM — это просто абстракция, и все операции гоняются через сеть/специальыне кабели? Или есть хитрые материнские платы с сотнями распаянных чипов?

leocat33
12.05.2017 21:50+2В угоду титанику HP полностью свернули производство процессоров Alpha (не плохой камень был...). Перевели VMS на титаник (следует отметить: говно отменное получилось)
Что теперь с VMS? Хоронить с музыкой будут, или на х86 перетаскивать?
Thlan
13.05.2017 10:34+1Права и разработка VMS переехали к VMS Software Inc.
https://www.vmssoftware.com/
Обещают версию 9 на x86-x64 в 2018 году, но мы особо на это не рассчитываем :)

Goodkat
13.05.2017 12:38+12Ализар.
Заголовок: Процессор Intel Itanium официально умер
Текст статьи: Вчера начались поставки новой модели процессоров Intel Itanium.

NeoCode
13.05.2017 14:10Кстати, а с точки зрения системы команд Итаниум лучше других архитектур? Есть там какие-то интересные оригинальные решения?
Где бы почитать об этом?
Alaunquirie
14.05.2017 01:40https://ru.wikipedia.org/wiki/VLIW
Раздел «преимущества и недостатки»
https://ru.wikipedia.org/wiki/Itanium
Да и тут инфы хватает

Greendq
13.05.2017 16:53А хоть приблизительно известно, сколько стоит процессор? Т.е. тот же серверный Xeon/Opteron в среднем от 500 до 2к вечнозелёных. А Итаниум сколько стоит?

xxxgoes
13.05.2017 22:33Ну к примеру если взять ebay то серверы десятилетней давности на itanium'е в 4-5 раз дороже своих ровесников на xeon'ах.
Serge78rus
По Вашей ссылке на Википедию очень символично соседствуют изображения «умирающего» Itanium и «перспективного» Эльбрус-4С, построенных на схожей архитектуре.