
Если есть время, и заказчик хочет чуть большего, то гуглят реализацию наиболее популярного алгоритма (коим является «расстояние Левенштейна») и вписывают его.
В данной статье, я опишу сильно доработанный алгоритм, основанный, правда, на расстояния Левенштейна, и приведу примеры кода на C# нечеткого поиска по названиям, например: кафе, ресторанов или неких сервисов… В общем всё, что можно перечислить и имеет от одного до нескольких слов в своем составе:
«Яндекс», «Mail», «ProjectArmata», «world of tanks», «world of warships», «world of warplanes» и т.д.
Тем, кто незнаком с алгоритмом, я рекомендую прочитать сначала статьи "Реализация нечеткого поиска", "Нечёткий поиск в тексте и словаре" или его описание в моем изложение под слайдером.
Таких действий всего три:
• Удаление
• Вставка
• Замена
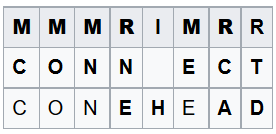
Например, для 2-х строк «CONNECT» и «CONEHEAD» можно построить следующую таблицу преобразований:
В теории, цены операций могут зависеть от вида операции (вставка, удаление, замена) и/или от участвующих в ней символов. Но в общем случае:
w(a, ?) — цена удаления символа «a», равняется 1
w(?, b) — цена вставки символа «b», равняется 1
w(a, b) — цена замены символа «a» на символ «b», равняется 1
Везде ставят единицы.
А с точки зрения математики расчёт выглядит так.
Пусть S1 и S2 — две строки (длиной M и N соответственно) над некоторым алфавитом, тогда редакционное расстояние (расстояние Левенштейна) d(S1, S2) можно подсчитать по следующей рекуррентной формуле:
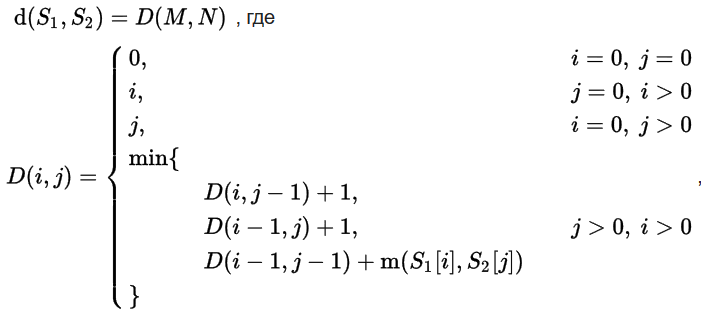
«Дефолтную реализацию» алгоритма Левенштейна сделали два математика Вангер и Фишер [не путать со шахматистом].
И выглядит это на С# так:
private Int32 levenshtein(String a, String b) {
if (string.IsNullOrEmpty(a))
{
if (!string.IsNullOrEmpty(b))
{
return b.Length;
}
return 0;
}
if (string.IsNullOrEmpty(b))
{
if (!string.IsNullOrEmpty(a))
{
return a.Length;
}
return 0;
}
Int32 cost;
Int32[,] d = new int[a.Length + 1, b.Length + 1];
Int32 min1;
Int32 min2;
Int32 min3;
for (Int32 i = 0; i <= d.GetUpperBound(0); i += 1)
{
d[i, 0] = i;
}
for (Int32 i = 0; i <= d.GetUpperBound(1); i += 1)
{
d[0, i] = i;
}
for (Int32 i = 1; i <= d.GetUpperBound(0); i += 1)
{
for (Int32 j = 1; j <= d.GetUpperBound(1); j += 1)
{
cost = Convert.ToInt32(!(a[i-1] == b[j - 1]));
min1 = d[i - 1, j] + 1;
min2 = d[i, j - 1] + 1;
min3 = d[i - 1, j - 1] + cost;
d[i, j] = Math.Min(Math.Min(min1, min2), min3);
}
}
return d[d.GetUpperBound(0), d.GetUpperBound(1)];
}Взято отсюда.
А визуально работа алгоритма для слов «Арестант» и «Дагестан» представляется так:
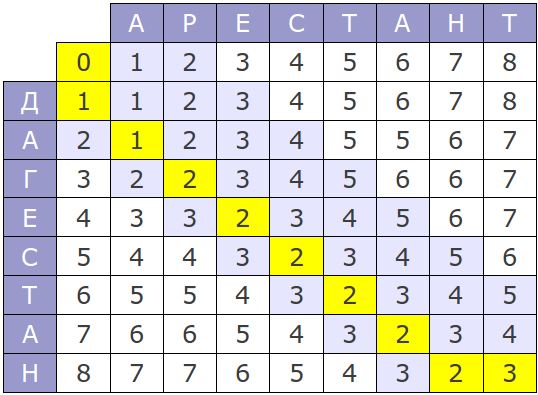
Крайний правый-нижний угол матрицы показывает, насколько сильно отличаются слова. Из матрицы, что в данном конкретном случае разница между словами составляет 3 условных попугая.
Если непонятно, то посмотрим на эти слова в другом представлении:
_ А Р Е С Т А Н Т
Д А Г Е С Т А Н _
Таким образом, получается, чтобы превратить слово «Арестант» и «Дагестан», нужно одну букву «Д» добавить, одну букву «Р» заменить на «Г» и букву «Т» удалить. Т.к. все действия имеют вес 1, то получается различие в словах составляет 3 попугая.
Если слова полностью совпадают, то расстояние будет 0. Вот и вся теория, всё гениальное просто.
И казалось бы — вот оно! Всё придумано за нас и делать вообще ничего не надо, но есть проблема…
1) Брать весовой коэффициент 1 всегда – не совсем правильно, ибо вероятность опечатки зависит от нескольких конкретных факторов: расстояния клавиш на клавиатуре, фонетические группы, да и даже банальной скорости набора символов.
2) Идея Левенштейна предназначена для «нахождения различий между словами», а не части слов, что для динамического выдаваемых результатов по мере ввода букв критично.
3) Названия сервисов имеют в своем составе более одного слова, то человек может просто не помнить, в каком именно порядке они идут.
Так же учтем еще несколько факторов, типа:
• раскладка клавиатуры на другом языке
• транслитерации символов
Именно эти проблемы мы постараемся решить в данной статье.
Для начала, давайте условимся, что все слова мы будем приводит к одному единому регистру. В своей версии кода я выбрал нижний регистр, это будет отражено в справочках, которые нам потребуются (данные справочники будут приведены по ходу описания). В самой статье я будут прибегать с различным стилям написания, например, к «CamelCase» — ProjectArmata, но это сделано исключительно для удобства восприятия человеком, с точки зрения анализа регистр один (нижний). И еще, за основу мы возьмем не классический, а оптимизированный вариант кода для нахождения расстояния Левенштейна отсюда:
Немного скорректируем его, убрав изменения порядка слов. Для алгоритма Левенштейна порядок слов не имеет значения, но для нас он будет важен по другим причинам. В итоге получили следующее:
public int LevenshteinDistance(string source, string target){
if(String.IsNullOrEmpty(source)){
if(String.IsNullOrEmpty(target)) return 0;
return target.Length;
}
if(String.IsNullOrEmpty(target)) return source.Length;
var m = target.Length;
var n = source.Length;
var distance = new int[2, m + 1];
// Initialize the distance 'matrix'
for(var j = 1; j <= m; j++) distance[0, j] = j;
var currentRow = 0;
for(var i = 1; i <= n; ++i){
currentRow = i & 1;
distance[currentRow, 0] = i;
var previousRow = currentRow ^ 1;
for(var j = 1; j <= m; j++){
var cost = (target[j - 1] == source[i - 1] ? 0 : 1);
distance[currentRow, j] = Math.Min(Math.Min(
distance[previousRow, j] + 1,
distance[currentRow, j - 1] + 1),
distance[previousRow, j - 1] + cost);
}
}
return distance[currentRow, m];
}Начнем улучшение алгоритма поиска с изменения весовых коэффициентов. Для начала сделаем, коэффициенты вставки и удаления равным 2.
Т.е. поменяются строки:
for(var j = 1; j <= m; j++) distance[0, j] = j * 2;
...
distance[currentRow, 0] = i * 2;
...
distance[previousRow, j] + 2
...
distance[currentRow, j - 1] + 2А вот строчку расчета коэффициента замены символов, мы, превратив в функцию CostDistanceSymbol:
var cost = (target[j - 1] == source[i - 1] ? 0 : 1);И будем учитывать два фактора:
1) Клавиатурное расстояние
2) Фонетические группы
В связи с этим, для более удобной работы с объектами source и target мы превратим их в объект:
class Word {
//Исходная поисковая строка
public string Text { get; set; }
//Коды клавиш клавиатуры
public List<int> Codes { get; set; } = new List<int>();
}
Для этого на потребуются следующие вспомогательные справочники:
Соотношение кодов клавиш русскоязычной клавиатуры:
private static SortedDictionary<char, int> CodeKeysRus = new SortedDictionary<char, int>
{
{ 'ё' , 192 },
{ '1' , 49 },
{ '2' , 50 },
...
{ '-' , 189 },
{ '=' , 187 },
{ 'й' , 81 },
{ 'ц' , 87 },
{ 'у' , 69 },
...
{ '_' , 189 },
{ '+' , 187 },
{ ',' , 191 },
}Соотношение кодов клавиш для англоязычной клавиатуры
private static SortedDictionary<char, int> CodeKeysEng = new SortedDictionary<char, int>
{
{ '`', 192 },
{ '1', 49 },
{ '2', 50 },
...
{ '-', 189 },
{ '=', 187 },
{ 'q', 81 },
{ 'w', 87 },
{ 'e', 69 },
{ 'r', 82 },
...
{ '<', 188 },
{ '>', 190 },
{ '?', 191 },
};Благодаря этим двум справочникам, говоря математическим языком, мы можем преобразовать два различных пространства символов в одно единое универсальное.
И на нем будут справедливы следующие соотношения:
private static SortedDictionary<int, List> DistanceCodeKey = new SortedDictionary<int,
List<int>>
{
/* '`' */ { 192, new List<int>(){ 49 }},
/* '1' */ { 49 , new List<int>(){ 50, 87, 81 }},
/* '2' */ { 50 , new List<int>(){ 49, 81, 87, 69, 51 }},
...
/* '-' */ { 189, new List<int>(){ 48, 80, 219, 221, 187 }},
/* '+' */ { 187, new List<int>(){ 189, 219, 221 }},
/* 'q' */ { 81 , new List<int>(){ 49, 50, 87, 83, 65 }},
/* 'w' */ { 87 , new List<int>(){ 49, 81, 65, 83, 68, 69, 51, 50 }},
...
/* '>' */ { 188, new List<int>(){ 77, 74, 75, 76, 190 }},
/* '<' */ { 190, new List<int>(){ 188, 75, 76, 186, 191 }},
/* '?' */ { 191, new List<int>(){ 190, 76, 186, 222 }},
};Т.е. мы берем клавиши стоящие вокруг другой клавиши. Убедиться в этом можно на примере рисунка:
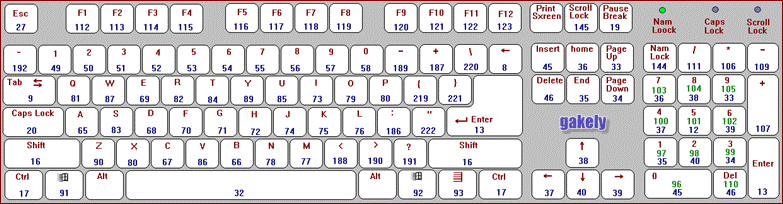
Да, я знаю, что помимо QWERTY клавиатуры есть и другие раскладки, и тогда таблица клавиатурных расстояний будет не совпадать, но мы берем наиболее распространённый вариант.
Если кто-то знает способ лучше – напишите, пожалуйста.
Теперь мы готовы к первому этапу — расчету веса ошибочного символа в функции CostDistanceSymbol:
Как и было ранее, если символы одинаковые, то расстояние 0:
if (source.Text[sourcePosition] == target.Text[targetPosition])
return 0;Если коды клавиш одинаковые, то расстояние тоже 0:
if (source.Codes[sourcePosition] != 0
&& target.Codes[targetPosition] == target.Codes[targetPosition])
return 0;Если у вас возник вопрос зачем мы сравниваем коды клавиш после того, как сравнили символы, то ответ прост – мы хотим, чтобы слово «Вода» и «Djlf» воспринимались одинаково. А символы, которые можно набрать на разных раскладках, например, «;» или «,» вне зависимости от раскладки тоже воспринимались одинаково.
Далее, мы уже смотрим только по кодам насколько близко стоят коды клавиш друг от друга. Если близко, то расстояние 1, а если нет, то 2 (точно такой же вес как при вставке или удалении):
int resultWeight = 0;
List<int> nearKeys;
if (!DistanceCodeKey.TryGetValue(source.Codes[sourcePosition], out nearKeys))
resultWeight = 2;
else
resultWeight = nearKeys.Contains(target.Codes[searchPosition]) ? 1 : 2;На самом деле такая небольшая доработка покрывает огромное число случайных ошибок начиная от неправильной раскладки, заканчивая промахом мимо клавиши.
Но корме ошибок при наборе, человек просто может не знать как слова пишутся. Например: щюка, пошол. тэст.
Такие слова есть не только в русском, но и на английском. Подобные случаи нам тоже нужно учесть. Для английских слов мы возьмем за основу работу Цобеля и Дарта о фонетических группах.
«aeiouy», «bp», «ckq», «dt», «lr», «mn», «gj», «fpv», «sxz», «csz»
А для русского я составлю сам по наитию:
«ыий», «эе», «ая», «оёе», «ую», «шщ», «оа», «йо»
Данные фонетические группы преобразуем в объект типа:
PhoneticGroupsEng = {
{ ‘a’, { ‘e’, ‘i’, ‘o’, ‘u’, ‘y’} },
{ ‘e’, { ‘a’, ‘i’, ‘o’, ‘u’, ‘y’} }
...
}
Это можно сделать руками или как я написать код, но результат будет одинаковым. И теперь после проверки кода клавиш, можно проверить буквы на вхождение в фонетическую группу с такой же логикой нахождения ошибок, как и на предыдущем шаге:
List<char> phoneticGroups;
if (PhoneticGroupsRus.TryGetValue(target.Text[targetPosition], out phoneticGroups))
resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2);
if (PhoneticGroupsEng.TryGetValue(target.Text[targetPosition], out phoneticGroups))
resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2);Кроме выше разобранных опечаток, есть опечатки «скорости набора» текста. Это когда две подряд идущие буквы люди, при наборе, путают местами. Причем это настолько распространённая ошибка, что некий математик Фредерик Дамерау доработал алгоритм Левенштейна добавив операцию транспозиции (перестановки) символов.
С программной точки зрения, мы в функцию LevenshteinDistance добавляем следующее:

if (i > 1 && j > 1
&& source.Text[i - 1] == target.Text[j - 2]
&& source.Text[i - 2] == target.Text[j - 1]) {
distance[currentRow, j] = Math.Min(distance[currentRow, j], distance[(i - 2) % 3, j - 2] + 2);
}
Поэтому вот этот участок кода «distance[(i — 2) % 3, …», работать в текущем виде не будет, правильный вариант функции я приведу в конце статьи.
Таким образом мы выполнили первый пункт по доработке кода. Переходим ко второму пункту. Напомним, что идея Левенштейна предназначена для «нахождения различий между словами», а не части слов, что для динамического выдаваемых результатов, по мере ввода букв, является критичным.
Например, в справочнике есть два слова:
• «ProjectArmata»
• «Як»
Введя в строку поиска запрос «Pro» мы получим на выходе «Як» как более приоритетное, по причине того, что замена двух символов и удаление одного составит всего 3 попугая (с учетом единичных коэффициентов и классического алгоритма Левенштейна, без наших доработок), а добавление части слова «jectArmata» 10 попугаев.
Самым логичным в этой ситуации является сравнение не всего слова, а только части искомого слова с веденной строкой.
Т.к. поисковый запрос состоит из трех символом «Pro», мы возьмем первые три символа от сверяемого слова «ProjectArmata», т.е. «Pro» и получим 100% совпадение. Для данного конкретного случая – идеально. Но давайте рассмотрим еще несколько вариантов. Допустим, у нас в базе, есть следующий набор слов:
• «Коммуналка»
• «Конвейер»
• «Колония»
• «Косметика»
Поисковый запрос будет выглядеть так «Ком». Как следствие слова будут иметь следующие коэффициенты совпадения:
Коммуналка — 0
Конвейер — 1
Колония – 1
Косметика — 1
Если со словом «Коммуналка» всё нормально, то остальные три слова выглядят как-то единообразно… Хотя видно, что, возможно, человек описался в одной букве и он ищет «Косметика», а не Конвейер или Колония. А наша задача состоит в том, чтобы выдавать ему максимально подходящий результат, а не просто всё подряд. Тем более, как сказал Дамерау – большинство ошибок — это перестановки букв.
Для устранения подобной оплошности, делаем небольшою доработку:
Возьмем не первые «n» букв, а «n+1» букв, где n – это количество букв в запросе. И тогда коэффициенты, при запросе «Ком» будут такими:
Коммуналка – 1
Косметика — 1
Конвейер — 2
Колония – 2
«Косметику» поправили, но «Коммуналка» уехала… Но этот вариант мне нравиться больше вот по каким причинам. Обычно, если требуется поиск, то первоначально информацию показывают пользователю в виде выпадающего списка, под поисковой строкой, по мере ввода букв. Длину этого выпадающего список ограничивают по размерам 3-7 записей. Как следствие, если записи всего три, то во втором варианте покажутся: «Коммуналка», «Косметика» и «Конвейер» [т.к. он тупа первый в выдаче из-за guid-а или просто из-за даты создания]. А в первом случае будет «Коммуналка», «Конвейер», «Колония» и никакой «Косметика», т.к. ей не повезло по другим причинам…
Конечно, у данной проблемы есть и другие пути решения. Например, сортировать сначала, по «n» буквам, а потом, взять те группы слов у кого совпали индексы и дополнительно пересортировать «n+1» букв и можно еще раз, и еще раз… Тут уже решается индивидуально в зависимости от данных в базе, решаемой задачи, вычислительной мощности.
Давайте не будем сейчас заострять внимание на решении вышеописанной проблемы… Мы только в середине пути и мне еще есть, что рассказать.
Следующий нюанс в правильной поисковой выдачи к нам приходит из времен СССР. Тогда любили делать названия, состоящие из нескольких слов объединённых в одно. Да и сейчас это актуально:
Потребсоюз
ГазПромБанк
Россельхозбанк
ProjectArmata
БанкУРАЛСИБ
И т.д.
[п.с. я знаю, что некоторые из названий пишутся через пробел, но мне нужно было подобрать яркие примеры]
Но, если следовать нашему алгоритму, то мы всегда берем первые «n+1» букв из слова. И если человек наберет слово «Банк» он не получит адекватной выдачи. Т.к. сравнивать мы будем строки:
«БанкУ»
«Потре»
«ГазПр»
«Россе»
«Proje»
Чтобы находить слово «банк» вне зависимости от позиции, нам нужно будет сделать плавающее окно по фразе и возвращать наименьший коэффициент:
double GetRangeWord(Word source, Word target) {
double rangeWord = double.MaxValue;
Word croppedSource = new Word();
int length = Math.Min(source.Text.Length, target.Text.Length + 1);
for (int i = 0; i <= source.Text.Length - length; i++) {
croppedSource.Text = target.Text.Substring(i, length);
croppedSource.Codes = target.Codes.Skip(i).Take(length).ToList();
rangeWord = Math.Min(LevenshteinDistance(croppedSource, target) + (i * 2 / 10.0), rangeWord);
}
return rangeWord;
}Как можно видеть, к ошибке, полученной после подсчёта расстояния Левенштейна, мы добавляем еще значение (i * 2 / 10.0). Если с «i * 2» — всё ясно, это ошибка вставки букв в начале слова, как и классическом алгоритме нахождения расстояния Левенштейна, но зачем мы её делим на 10? Суть в том, что если мы просто оставим «i * 2», то в по исковую выдачу попадут слова, которые тупа меньшие по длине и мы опять уйдем от названия банков. И поэтому коэффициент приходится делить на 10, что сократить это смещение. Почему именно на 10? Для нашей базы он подходил более-менее нормально, но я не исключаю, что можно делить и на большее. Всё зависти от длины слов и от того насколько слова схожи. Расчет наиболее подходящего коэффициента я приведу чуть позже.
Со словами, как и поисковой единицей, вроде разобрались, теперь переходим к фразам. И для начала опять несколько примеров:
• warface
• world of tanks
• world of warplanes
• world of ships
Давайте поймем, что нам в принципе нужно от поиска на фразе. Нам нужно чтобы недостающие слова добавлялись, лишние фразы удалялись, а также, что бы они менялись местами. Где-то я такое уже говорил… А, точно, вспомнил… В начале статьи, когда рассказывал о словах и функции расстояния Левенштейна. Чтобы не тратить ваше время, сразу скажу, что в чистом виде её использовать не получилось, но вдохновившись ей удалось написать код применимый к фразам.
Как и при реализации функции расстояния Левенштейна, если одна из фраз пуста, то мы возвращаем величину ошибки равное вставке или удалению [в зависимости от того, с какой стороны пришла пустая фраза] всех букв.
if (!source.Words.Any()) {
if (!search.Words.Any())
return 0;
return search.Words.Sum(w => w.Text.Length) * 2 * 100;
}
if (!search.Words.Any()) {
return source.Words.Sum(w => w.Text.Length) * 2 * 100;
}Т.е. мы суммируем количество букв в фразе помножаем на 2 (это коэффициент был выбран еще вначале статьи для букв) и еще множим на 100. Вот эти 100 — самый противоречивый коэффициент в всем алгоритме. Для чего он нужен будет более наглядно представлено чуть ниже, а после я поясню, что в теории его нужно высчитать, а не просто брать с потолка.
double result = 0;
for (int i = 0; i < search.Words.Count; i++) {
double minRangeWord = double.MaxValue;
int minIndex = 0;
for (int j = 0; j < source.Words.Count; j++) {
double currentRangeWord = GetRangeWord(source.Words[j], search.Words[i], translation);
if (currentRangeWord < minRangeWord) {
minRangeWord = currentRangeWord;
minIndex = j;
}
}
result += minRangeWord * 100 + (Math.Abs(i - minIndex) / 10.0);
}
return result;
}В этом коде мы сопоставляем каждое слово с из записи в базе с каждым из поискового запроса и берем наименьшие коэффициенты для каждого слова. Суммарным коэффициентом для фразы является следующее:
result += minRangeWord * 100 + (Math.Abs(i — minIndex) / 10.0);
Как можно видеть, вся логика та же самая, как и описанная ранее, минимальный коэффициент для слова minRangeWord помножаем на наши 100 и суммируем с коэффициентом, показывающим на сколько близко слово стоит к его наиболее подходящей позиции (Math.Abs(i — minIndex) / 10.0).
Домножение на 100 применяется для компенсации добавочного коэффициента, который может возникнуть при поиске наиболее подходящей позиции поискового слова на предыдущем шаге. Как следствие, данный коэффициент можно высчитать как наибольший между фразой в поисковой строке и всеми словами в базе. Не фразами, а именно словами. Но для этого придется в «пустую» измерить расстояние Левенштейна с нашими доработками, что очень расточительно по ресурсам.
Т.е. прогнать функцию GetRangeWord и взять максимальное значение отклонение фразы «i * 2» от наиболее подходящего места. И после взять набольший значение довести его до ближайшего большего десятикратного числа (10, 100, 1000, 10000, 100000 и т.д.). Таким образом мы получим два значения:
Первое, это значение на которое нужно делить смешенное слово в функции GetRangeWord. Второе, значение которое нужно умножить minRangeWord для компенсации предыдущего смещения. Таким образом мы получим точные показатели схожести фраз. Но на практике можно пренебречь большими отклонениями, и приблизительно прикинуть среднее… Что я собственно и сделал.
В принципе всё. Основные вопросы я разобрал осталось лишь небольшая доработка «транслитерации символов». Разница между выше описанным поиском и поиском в по транслитерации состоит в том, что в функции CostDistanceSymbol мы не будем корректировать значения ответа по расстояниям клавиш, т.к. выдача в данном случае будет не корректна.
Также можно отметить, что адекватная выдача результат начинается с 3 символов в поисковой строке, если символом меньше, лучше использовать более топорный метод с точным сопоставлением строк.
Далее я приведу наиболее полный код всего выше описанного, но сначала:
1) Данный код написан мной лично в свободное от работы время.
2) Алгоритм продуман мной лично в свободное от работы время.
Отдельно хочу сказать спасибо, за ссылки и вдохновение: Дмитрий Панюшкин, Павел Григоренко.
Названия, которые приведены в статье, взяты из отрытых источников и принадлежат их владельцам. Не является рекламой.
Спасибо всем, кто прочитал. Приветствуется критика и советы.
public class DistanceAlferov {
class Word {
public string Text { get; set; }
public List<int> Codes { get; set; } = new List<int>();
}
class AnalizeObject {
public string Origianl { get; set; }
public List<Word> Words { get; set; } = new List<Word>();
}
class LanguageSet {
public AnalizeObject Rus { get; set; } = new AnalizeObject();
public AnalizeObject Eng { get; set; } = new AnalizeObject();
}
List<LanguageSet> Samples { get; set; } = new List<LanguageSet>();
public void SetData(List<Tuple<string, string>> datas) {
List<KeyValuePair<char, int>> codeKeys = CodeKeysRus.Concat(CodeKeysEng).ToList();
foreach (var data in datas) {
LanguageSet languageSet = new LanguageSet();
languageSet.Rus.Origianl = data.Item1;
if (data.Item1.Length > 0) {
languageSet.Rus.Words = data.Item1.Split(' ').Select(w => new Word() {
Text = w.ToLower(),
Codes = GetKeyCodes(codeKeys, w)
}).ToList();
}
languageSet.Eng.Origianl = data.Item2;
if (data.Item2.Length > 0) {
languageSet.Eng.Words = data.Item2.Split(' ').Select(w => new Word() {
Text = w.ToLower(),
Codes = GetKeyCodes(codeKeys, w)
}).ToList();
}
this.Samples.Add(languageSet);
}
}
public List<Tuple<string, string, double, int>> Search(string targetStr) {
List<KeyValuePair<char, int>> codeKeys = CodeKeysRus.Concat(CodeKeysEng).ToList();
AnalizeObject originalSearchObj = new AnalizeObject();
if (targetStr.Length > 0) {
originalSearchObj.Words = targetStr.Split(' ').Select(w => new Word() {
Text = w.ToLower(),
Codes = GetKeyCodes(codeKeys, w)
}).ToList();
}
AnalizeObject translationSearchObj = new AnalizeObject();
if (targetStr.Length > 0) {
translationSearchObj.Words = targetStr.Split(' ').Select(w => {
string translateStr = Transliterate(w.ToLower(), Translit_Ru_En);
return new Word() {
Text = translateStr,
Codes = GetKeyCodes(codeKeys, translateStr)
};
}).ToList();
}
var result = new List<Tuple<string, string, double, int>>();
foreach (LanguageSet sampl in Samples) {
int languageType = 1;
double cost = GetRangePhrase(sampl.Rus, originalSearchObj, false);
double tempCost = GetRangePhrase(sampl.Eng, originalSearchObj, false);
if (cost > tempCost) {
cost = tempCost;
languageType = 3;
}
// Проверка транслетерационной строки
tempCost = GetRangePhrase(sampl.Rus, translationSearchObj, true);
if (cost > tempCost) {
cost = tempCost;
languageType = 2;
}
tempCost = GetRangePhrase(sampl.Eng, translationSearchObj, true);
if (cost > tempCost) {
cost = tempCost;
languageType = 3;
}
result.Add(new Tuple<string, string, double, int>(sampl.Rus.Origianl, sampl.Eng.Origianl, cost, languageType));
}
return result;
}
private double GetRangePhrase(AnalizeObject source, AnalizeObject search, bool translation) {
if (!source.Words.Any()) {
if (!search.Words.Any())
return 0;
return search.Words.Sum(w => w.Text.Length) * 2 * 100;
}
if (!search.Words.Any()) {
return source.Words.Sum(w => w.Text.Length) * 2 * 100;
}
double result = 0;
for (int i = 0; i < search.Words.Count; i++) {
double minRangeWord = double.MaxValue;
int minIndex = 0;
for (int j = 0; j < source.Words.Count; j++) {
double currentRangeWord = GetRangeWord(source.Words[j], search.Words[i], translation);
if (currentRangeWord < minRangeWord) {
minRangeWord = currentRangeWord;
minIndex = j;
}
}
result += minRangeWord * 100 + (Math.Abs(i - minIndex) / 10.0);
}
return result;
}
private double GetRangeWord(Word source, Word target, bool translation) {
double minDistance = double.MaxValue;
Word croppedSource = new Word();
int length = Math.Min(source.Text.Length, target.Text.Length + 1);
for (int i = 0; i <= source.Text.Length - length; i++) {
croppedSource.Text = source.Text.Substring(i, length);
croppedSource.Codes = source.Codes.Skip(i).Take(length).ToList();
minDistance = Math.Min(minDistance, LevenshteinDistance(croppedSource, target, croppedSource.Text.Length == source.Text.Length, translation) + (i * 2 / 10.0));
}
return minDistance;
}
private int LevenshteinDistance(Word source, Word target, bool fullWord, bool translation) {
if (String.IsNullOrEmpty(source.Text)) {
if (String.IsNullOrEmpty(target.Text))
return 0;
return target.Text.Length * 2;
}
if (String.IsNullOrEmpty(target.Text))
return source.Text.Length * 2;
int n = source.Text.Length;
int m = target.Text.Length;
//TODO Убрать в параметры (для оптимизации)
int[,] distance = new int[3, m + 1];
// Initialize the distance 'matrix'
for (var j = 1; j <= m; j++)
distance[0, j] = j * 2;
var currentRow = 0;
for (var i = 1; i <= n; ++i) {
currentRow = i % 3;
var previousRow = (i - 1) % 3;
distance[currentRow, 0] = i * 2;
for (var j = 1; j <= m; j++) {
distance[currentRow, j] = Math.Min(Math.Min(
distance[previousRow, j] + ((!fullWord && i == n) ? 2 - 1 : 2),
distance[currentRow, j - 1] + ((!fullWord && i == n) ? 2 - 1 : 2)),
distance[previousRow, j - 1] + CostDistanceSymbol(source, i - 1, target, j - 1, translation));
if (i > 1 && j > 1 && source.Text[i - 1] == target.Text[j - 2]
&& source.Text[i - 2] == target.Text[j - 1]) {
distance[currentRow, j] = Math.Min(distance[currentRow, j], distance[(i - 2) % 3, j - 2] + 2);
}
}
}
return distance[currentRow, m];
}
private int CostDistanceSymbol(Word source, int sourcePosition, Word search, int searchPosition, bool translation) {
if (source.Text[sourcePosition] == search.Text[searchPosition])
return 0;
if (translation)
return 2;
if (source.Codes[sourcePosition] != 0 && source.Codes[sourcePosition] == search.Codes[searchPosition])
return 0;
int resultWeight = 0;
List<int> nearKeys;
if (!DistanceCodeKey.TryGetValue(source.Codes[sourcePosition], out nearKeys))
resultWeight = 2;
else
resultWeight = nearKeys.Contains(search.Codes[searchPosition]) ? 1 : 2;
List<char> phoneticGroups;
if (PhoneticGroupsRus.TryGetValue(search.Text[searchPosition], out phoneticGroups))
resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2);
if (PhoneticGroupsEng.TryGetValue(search.Text[searchPosition], out phoneticGroups))
resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2);
return resultWeight;
}
private List<int> GetKeyCodes(List<KeyValuePair<char, int>> codeKeys, string word) {
return word.ToLower().Select(ch => codeKeys.FirstOrDefault(ck => ck.Key == ch).Value).ToList();
}
private string Transliterate(string text, Dictionary<char, string> cultureFrom) {
IEnumerable<char> translateText = text.SelectMany(t => {
string translateChar;
if (cultureFrom.TryGetValue(t, out translateChar))
return translateChar;
return t.ToString();
});
return string.Concat(translateText);
}
#region Блок Фонетических групп
static Dictionary<char, List<char>> PhoneticGroupsRus = new Dictionary<char, List<char>>();
static Dictionary<char, List<char>> PhoneticGroupsEng = new Dictionary<char, List<char>>();
#endregion
static DistanceAlferov() {
SetPhoneticGroups(PhoneticGroupsRus, new List<string>() { "ыий", "эе", "ая", "оёе", "ую", "шщ", "оа" });
SetPhoneticGroups(PhoneticGroupsEng, new List<string>() { "aeiouy", "bp", "ckq", "dt", "lr", "mn", "gj", "fpv", "sxz", "csz" });
}
private static void SetPhoneticGroups(Dictionary<char, List<char>> resultPhoneticGroups, List<string> phoneticGroups) {
foreach (string group in phoneticGroups)
foreach (char symbol in group)
if (!resultPhoneticGroups.ContainsKey(symbol))
resultPhoneticGroups.Add(symbol, phoneticGroups.Where(pg => pg.Contains(symbol)).SelectMany(pg => pg).Distinct().Where(ch => ch != symbol).ToList());
}
#region Блок для сопоставления клавиатуры
/// <summary>
/// Близость кнопок клавиатуры
/// </summary>
private static Dictionary<int, List<int>> DistanceCodeKey = new Dictionary<int, List<int>>
{
/* '`' */ { 192 , new List<int>(){ 49 }},
/* '1' */ { 49 , new List<int>(){ 50, 87, 81 }},
/* '2' */ { 50 , new List<int>(){ 49, 81, 87, 69, 51 }},
/* '3' */ { 51 , new List<int>(){ 50, 87, 69, 82, 52 }},
/* '4' */ { 52 , new List<int>(){ 51, 69, 82, 84, 53 }},
/* '5' */ { 53 , new List<int>(){ 52, 82, 84, 89, 54 }},
/* '6' */ { 54 , new List<int>(){ 53, 84, 89, 85, 55 }},
/* '7' */ { 55 , new List<int>(){ 54, 89, 85, 73, 56 }},
/* '8' */ { 56 , new List<int>(){ 55, 85, 73, 79, 57 }},
/* '9' */ { 57 , new List<int>(){ 56, 73, 79, 80, 48 }},
/* '0' */ { 48 , new List<int>(){ 57, 79, 80, 219, 189 }},
/* '-' */ { 189 , new List<int>(){ 48, 80, 219, 221, 187 }},
/* '+' */ { 187 , new List<int>(){ 189, 219, 221 }},
/* 'q' */ { 81 , new List<int>(){ 49, 50, 87, 83, 65 }},
/* 'w' */ { 87 , new List<int>(){ 49, 81, 65, 83, 68, 69, 51, 50 }},
/* 'e' */ { 69 , new List<int>(){ 50, 87, 83, 68, 70, 82, 52, 51 }},
/* 'r' */ { 82 , new List<int>(){ 51, 69, 68, 70, 71, 84, 53, 52 }},
/* 't' */ { 84 , new List<int>(){ 52, 82, 70, 71, 72, 89, 54, 53 }},
/* 'y' */ { 89 , new List<int>(){ 53, 84, 71, 72, 74, 85, 55, 54 }},
/* 'u' */ { 85 , new List<int>(){ 54, 89, 72, 74, 75, 73, 56, 55 }},
/* 'i' */ { 73 , new List<int>(){ 55, 85, 74, 75, 76, 79, 57, 56 }},
/* 'o' */ { 79 , new List<int>(){ 56, 73, 75, 76, 186, 80, 48, 57 }},
/* 'p' */ { 80 , new List<int>(){ 57, 79, 76, 186, 222, 219, 189, 48 }},
/* '[' */ { 219 , new List<int>(){ 48, 186, 222, 221, 187, 189 }},
/* ']' */ { 221 , new List<int>(){ 189, 219, 187 }},
/* 'a' */ { 65 , new List<int>(){ 81, 87, 83, 88, 90 }},
/* 's' */ { 83 , new List<int>(){ 81, 65, 90, 88, 67, 68, 69, 87, 81 }},
/* 'd' */ { 68 , new List<int>(){ 87, 83, 88, 67, 86, 70, 82, 69 }},
/* 'f' */ { 70 , new List<int>(){ 69, 68, 67, 86, 66, 71, 84, 82 }},
/* 'g' */ { 71 , new List<int>(){ 82, 70, 86, 66, 78, 72, 89, 84 }},
/* 'h' */ { 72 , new List<int>(){ 84, 71, 66, 78, 77, 74, 85, 89 }},
/* 'j' */ { 74 , new List<int>(){ 89, 72, 78, 77, 188, 75, 73, 85 }},
/* 'k' */ { 75 , new List<int>(){ 85, 74, 77, 188, 190, 76, 79, 73 }},
/* 'l' */ { 76 , new List<int>(){ 73, 75, 188, 190, 191, 186, 80, 79 }},
/* ';' */ { 186 , new List<int>(){ 79, 76, 190, 191, 222, 219, 80 }},
/* '\''*/ { 222 , new List<int>(){ 80, 186, 191, 221, 219 }},
/* 'z' */ { 90 , new List<int>(){ 65, 83, 88 }},
/* 'x' */ { 88 , new List<int>(){ 90, 65, 83, 68, 67 }},
/* 'c' */ { 67 , new List<int>(){ 88, 83, 68, 70, 86 }},
/* 'v' */ { 86 , new List<int>(){ 67, 68, 70, 71, 66 }},
/* 'b' */ { 66 , new List<int>(){ 86, 70, 71, 72, 78 }},
/* 'n' */ { 78 , new List<int>(){ 66, 71, 72, 74, 77 }},
/* 'm' */ { 77 , new List<int>(){ 78, 72, 74, 75, 188 }},
/* '<' */ { 188 , new List<int>(){ 77, 74, 75, 76, 190 }},
/* '>' */ { 190 , new List<int>(){ 188, 75, 76, 186, 191 }},
/* '?' */ { 191 , new List<int>(){ 190, 76, 186, 222 }},
};
/// <summary>
/// Коды клавиш русскоязычной клавиатуры
/// </summary>
private static Dictionary<char, int> CodeKeysRus = new Dictionary<char, int>
{
{ 'ё' , 192 },
{ '1' , 49 },
{ '2' , 50 },
{ '3' , 51 },
{ '4' , 52 },
{ '5' , 53 },
{ '6' , 54 },
{ '7' , 55 },
{ '8' , 56 },
{ '9' , 57 },
{ '0' , 48 },
{ '-' , 189 },
{ '=' , 187 },
{ 'й' , 81 },
{ 'ц' , 87 },
{ 'у' , 69 },
{ 'к' , 82 },
{ 'е' , 84 },
{ 'н' , 89 },
{ 'г' , 85 },
{ 'ш' , 73 },
{ 'щ' , 79 },
{ 'з' , 80 },
{ 'х' , 219 },
{ 'ъ' , 221 },
{ 'ф' , 65 },
{ 'ы' , 83 },
{ 'в' , 68 },
{ 'а' , 70 },
{ 'п' , 71 },
{ 'р' , 72 },
{ 'о' , 74 },
{ 'л' , 75 },
{ 'д' , 76 },
{ 'ж' , 186 },
{ 'э' , 222 },
{ 'я' , 90 },
{ 'ч' , 88 },
{ 'с' , 67 },
{ 'м' , 86 },
{ 'и' , 66 },
{ 'т' , 78 },
{ 'ь' , 77 },
{ 'б' , 188 },
{ 'ю' , 190 },
{ '.' , 191 },
{ '!' , 49 },
{ '"' , 50 },
{ '№' , 51 },
{ ';' , 52 },
{ '%' , 53 },
{ ':' , 54 },
{ '?' , 55 },
{ '*' , 56 },
{ '(' , 57 },
{ ')' , 48 },
{ '_' , 189 },
{ '+' , 187 },
{ ',' , 191 },
};
/// <summary>
/// Коды клавиш англиской клавиатуры
/// </summary>
private static Dictionary<char, int> CodeKeysEng = new Dictionary<char, int>
{
{ '`', 192 },
{ '1', 49 },
{ '2', 50 },
{ '3', 51 },
{ '4', 52 },
{ '5', 53 },
{ '6', 54 },
{ '7', 55 },
{ '8', 56 },
{ '9', 57 },
{ '0', 48 },
{ '-', 189 },
{ '=', 187 },
{ 'q', 81 },
{ 'w', 87 },
{ 'e', 69 },
{ 'r', 82 },
{ 't', 84 },
{ 'y', 89 },
{ 'u', 85 },
{ 'i', 73 },
{ 'o', 79 },
{ 'p', 80 },
{ '[', 219 },
{ ']', 221 },
{ 'a', 65 },
{ 's', 83 },
{ 'd', 68 },
{ 'f', 70 },
{ 'g', 71 },
{ 'h', 72 },
{ 'j', 74 },
{ 'k', 75 },
{ 'l', 76 },
{ ';', 186 },
{ '\'', 222 },
{ 'z', 90 },
{ 'x', 88 },
{ 'c', 67 },
{ 'v', 86 },
{ 'b', 66 },
{ 'n', 78 },
{ 'm', 77 },
{ ',', 188 },
{ '.', 190 },
{ '/', 191 },
{ '~' , 192 },
{ '!' , 49 },
{ '@' , 50 },
{ '#' , 51 },
{ '$' , 52 },
{ '%' , 53 },
{ '^' , 54 },
{ '&' , 55 },
{ '*' , 56 },
{ '(' , 57 },
{ ')' , 48 },
{ '_' , 189 },
{ '+' , 187 },
{ '{', 219 },
{ '}', 221 },
{ ':', 186 },
{ '"', 222 },
{ '<', 188 },
{ '>', 190 },
{ '?', 191 },
};
#endregion
#region Блок транслитерации
/// <summary>
/// Транслитерация Русский => ASCII (ISO 9-95)
/// </summary>
private static Dictionary<char, string> Translit_Ru_En = new Dictionary<char, string>
{
{ 'а', "a" },
{ 'б', "b" },
{ 'в', "v" },
{ 'г', "g" },
{ 'д', "d" },
{ 'е', "e" },
{ 'ё', "yo" },
{ 'ж', "zh" },
{ 'з', "z" },
{ 'и', "i" },
{ 'й', "i" },
{ 'к', "k" },
{ 'л', "l" },
{ 'м', "m" },
{ 'н', "n" },
{ 'о', "o" },
{ 'п', "p" },
{ 'р', "r" },
{ 'с', "s" },
{ 'т', "t" },
{ 'у', "u" },
{ 'ф', "f" },
{ 'х', "x" },
{ 'ц', "c" },
{ 'ч', "ch" },
{ 'ш', "sh" },
{ 'щ', "shh" },
{ 'ъ', "" },
{ 'ы', "y" },
{ 'ь', "'" },
{ 'э', "e" },
{ 'ю', "yu" },
{ 'я', "ya" },
};
#endregion
}Виталий Алферов, 2017
Комментарии (20)

aulitin
19.06.2017 13:39+1спасибо за стаью!
больше всего смущает ситуацию с производительностью. Вы ее не измеряли? ведь автодолнение должно быть отзывчивым, а Левенштейн достаточно сложен.
И из текста, не очень понятно, как в итоге была решена проблема: (и решена ли вообще)
3) Названия сервисов имеют в своем составе более одного слова, то человек может просто не помнить, в каком именно порядке они идут.
я всегда мечтал, чтобы на сайтах поиск работал по camelhumps, как в ReSharper-е и IntelliJ IDEA :)
RussianDragon
19.06.2017 14:18Пожалуйста :)
Производительность в консоле при 1000 наименований была в пределах 1 секунды, что меня вполне устроило, а на большее энтузиазма не хватило.
3 часть начинается со слов:
Со словами, как и поисковой единицей, вроде разобрались, теперь переходим к фразам.
aulitin
19.06.2017 15:18а если поисковый запрос будет выглядить как «а а а а а а » повторенное 100 раз?
RussianDragon
19.06.2017 15:39Не пробовал. Вечером ради интереса посмотрю. Но тут на первый план выходит адекватность данных.
Алгоритм предназначен для поиска по названиям, а не по текстам.
То такие поисковые запросы можно отсекать до попытки поиска на них.
Тут я еще не поднял вопрос о том как отсекать результаты при выводы на странице "со всеми совпадениями". И вот на эту тему можно похолеварить.:)

Pochemuk
19.06.2017 17:58Вот тут не понял:
А для русского я составлю сам по наитию:
«ыий», «эе», «ая», «оёе», «ую», «шщ», «оа», «йо»
Что за группа «йо»? Тем более, что и «й» и «о» уже входят в другие группы.RussianDragon
19.06.2017 20:27Группа "йо" взялась с транскрипций расскоязычных звуков. Буква ё разлогается на звук "йо". Но если подумать, то Вы правы. Перехода "й" в "о" я не смог придумаль или быстро нагуглить.
Одна буквы может входить в несколько груп например sxz и csz.
Просто так проще их обдумывать и править. И поэтому мы и преобразуем эти фонетические группы в новый справочник который и используем потом в коде
eugenebb
19.06.2017 22:55Если количество пользователей довольно большое, то можно воспользоваться методикой от гугла — смотрим что пользователи вводят, а потом смотрим что в конечном итоге выбрали.
Через некоторое время у нас будут пары из реальной жизни. Качество результата будет скорее всего выше чем у алгоритмов.RussianDragon
19.06.2017 22:58Почему именно google? Вон недавно Яндекс выступал о нейронных сетях, автоматизации и т.д. и т.п.
Всё бы здорово, но где взять данные в таком объеме? Это все не реально для обычных сайтов.eugenebb
19.06.2017 23:49поэтому я и уточнил что будет работать только в случае с большим количеством пользователей

sutasu
19.06.2017 23:48Lucene в качестве решения не рассматривали? У него и .NET обертка есть…
RussianDragon
20.06.2017 01:23Не-а. Сейчас попробовал про него поискать и воспользоваться для сравнения результатов выборки, но, в полусонном состоянии, особо ничего не вышло. :) Попробую, как время будет. Спасибо)
RussianDragon
24.06.2017 11:16Попробовал я поработать с Lucene.NET.
С одной стороны — да.
по слову «Кометика» удалось найти «Косметика». Но поиск упорно выдавал только одно слово и всё. Хотя я, по идее, просил не меньше 1000 результатов
indexSearcher.Search(query, 1000)
Дальше больше, когда я сократил слово до «Ком», результатов вообще не было.
Хотя по идее используется именно нечеткий поиск
Term term1 = new Term(«line», term);
Query query = new FuzzyQuery(term1);
Таким образом получается, что — да он позволяет находить слова с ошибками, но не делать поисковый запрос.
Да и те примеры которые я находил относят именно к поиску на тексте, а не по названиям.
В общем штука интересная, но настраивать и разбираться в документации дольше, чем сделать самому с нуля — это не удобно.
Как то так. Но спасибо за библиотеку.sutasu
24.06.2017 14:37По поводу сделать самому — без всякой иронии поддерживаю и желаю удачи, вдруг у вас выйдет свой продукт, который займет достойное место на рынке полнотекстового поиска ) Другое дело, что бывают такие задачи, когда пилить свой велосипед накладно или нецелесообразно. У меня в свое время была задача в «мешке» из 7 млн адресов — естественно, неструктурированных и со всеми возможными орфографическими ошибками, найти соответствия мешку из 8к адресов, так же в плачевном состоянии. Lucene отбирал подходяшие на первый взгляд варианты, а основная работа была в том, чтобы отбросить ложные срабатывания и просто похожие, но не одинаковые адреса.

dim2r
20.06.2017 14:03Постоянно пользуюсь такими алгоритмами.
В oracle например есть utl_match.jaro_winkler(s1,s2)
unsafePtr
Может я не доглядел, но в чём польза использования SortedDictionary заместо Dictionary в данном случае. Какую это может принести пользу?
RussianDragon
Все справочники мы заполняем единожды, а обращаемся мы к ним часто. Как следствие это сделано лишь для оптимизации доступа.:)
unsafePtr
Имплементация SortedDictionary базируется на бинарном дереве, Dictionary базируется на хеш-таблице. Скорость доступа Dictionary выше. Так что можно ускорить немного алгоритм, заменив структуру данных.:)
RussianDragon
Если посмотреть на графики из данной статьи, то можно увидеть, что скорость чтения из SortedDictionary выше
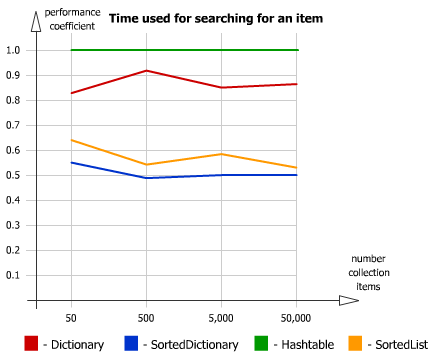
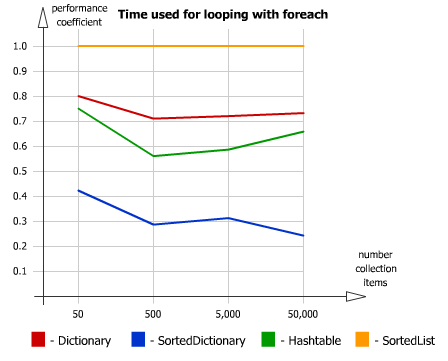
полная статья
В любом случае это нюансы. И, кстати, да, я не увидел большой разницы при использовании Dictionary и SortedDictionary. Но тут показалось мне более логичным использовать SortedDictionary.
sasha1024
Вы неправильно интерпретируете графики. Лучшие результаты — бо?льше (а не меньше).
Upd.: Упс, извиняюсь, не заметив Ваш комент ниже.
RussianDragon
Что-то я фигню сморозил. Перемудрил. Да, Dictionary, будет быстрее спасибо :)