
Пару недель назад в Яндексе прошла встреча PyData, посвящённая анализу больших данных с использованием Python. В том числе на этой встрече выступил Василий Агапитов — руководитель группы разработки инструментов аналитики Яндекса. Он рассказал о двух наших библиотеках: для описания и запуска расчетов на MapReduce и для извлечения информации из логов.
Под катом — расшифровка и часть слайдов.
Меня зовут Агапитов Василий, я представляю команду интеллектуального анализа данных.
В Яндексе мы выполняем расчеты по большим данным, в частности по данным, лежащим на кластерах MapReduce. В основном это анонимизированные логи сервисов и приложений. Кроме того, мы предоставляем наши инструменты по обработке больших данных другим командам. Наши основные потребители — команды аналитиков-разработчиков. Для простоты я буду называть их аналитиками.
Хочу рассказать о двух инструментах, библиотеках, истории их появления, и том, как мир Hadoop оказал влияние на их появление.

Давайте синхронизируем некоторое представление о терминах. Источники данных. Мы будем говорить исключительно о логах, поэтому для примера давайте рассмотрим какой-нибудь лог доступа к сервисам.

У нас по горизонтали располагаются записи этого лога, каждая запись имеет поля: vhost — идентификатор хоста, yandexuid — идентификатор посетителя, iso_eventtime — дата и время обращения, request — сам запрос и многие другие поля.
Данные из некоторых полей уже можно использовать в расчетах. Из других полей данные сначала надо извлечь и нормализовать. Например, в поле request содержатся параметры запроса. У каждого сервиса такие параметры свои. Для поиска наиболее используемым является параметр text. После того, как мы извлечем его из поля request, нам надо его нормализовать, поскольку он может быть очень большим или иметь какую-то странную кодировку.
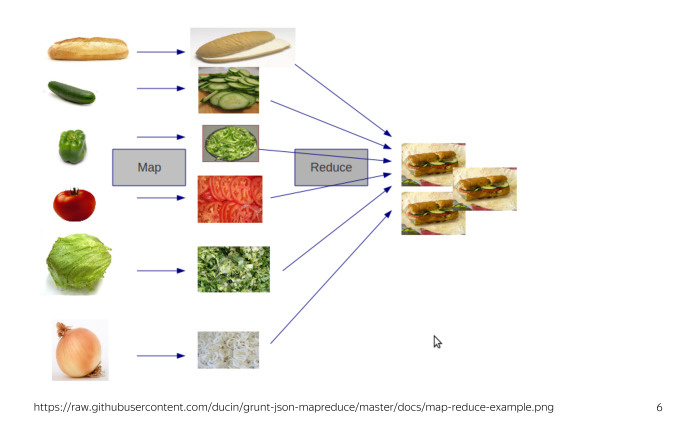
Во-вторых, мы будем рассматривать наши расчеты в части расчетов на кластерах MapReduсe. Как вы знаете, MapReduсe — технология изготовления сэндвичей. На самом деле нет, это технология обработки больших данных. Если вы с ней не знакомы, то для текущего доклада вам надо знать, что она предполагает обработку данных с использованием двух операций — Map и Reduce.
Задача аналитика в том, чтобы построить расчет по событиям лога с учетом некоторой бизнес-логики. С какими трудности может столкнуться аналитик, решая свою задачу на кластерах MapReduсe без использования каких-либо библиотек? Во-первых, ему придется реализовывать бизнес-логику на базе операций MapReduсe. Такой подход добавляет в расчет код, не относящийся к бизнес-логике этого расчета, что существенно ухудшает его читаемость и поддержку. Во-вторых, нам надо данные из логов сначала извлечь и нормализовать — например, параметр text из поля request.
Как принято решать первую проблему? Очевидно, нам нужна какая-то библиотека, которая упростит доступ пользователя к кластеру и взаимодействие с ним.
В мире Hadoop к таким библиотекам можно отнести Pig, Hive, Cascading и некоторые другие.
В Яндексе используется собственная реализация MapReduсe, называемая YT, о преимуществах которой вы можете почитать в статье на Хабре и которая предоставляет для обработки данных базовые операции MapReduсe. Но, к сожалению, YT не имела аналогов библиотек из мира Hadoop. Нам пришлось это исправить.
В самом начале, когда мы столкнулись с этой проблемой, мы действительно при каждом расчете отдельно описывали Map-стадии, отдельно — Reduce-стадии, и отдельно — связь между этими стадиями для запуска расчета на кластере.

Более того, у каждого был собственный запускатор. Поддерживать такой зоопарк очень дорого. Решением для нас стала библиотека Nile, библиотека для описания и запуска расчетов на кластере. При ее создании мы взяли идею Сascading из мира Hadoop и реализовали ее на языке Python — во многом потому, что Python использует аналитики для локальной обработки данных, а использовать один язык для расчетов на кластере и для локальной обработки данных очень удобно.
Если вы знаете Cascading, то процесс обработки данных на Nile вам также покажется знакомым. Мы создаем поток из таблиц на кластере, модифицируем его, группируем, например, считаем какие-то агрегаты, разбиваем поток на несколько потоков, объединяем несколько потоков в один поток, производим другие действия, после чего полученный поток с нужными данными сохраняем обратно в таблицу на кластер.
Какие у Nile есть операции модификации потока? Их очень много, здесь представлены наиболее часто используемые. Project, чтобы получить список нужных нам полей. Filter, чтобы отфильтровать, оставив только нужные нам записи. Groupby + aggregate, чтобы сгруппировать поток по заданному набору полей и посчитать некоторые агрегаты. Unique, random и take, чтобы построить выборки уникальную, случайную и с заданным числом записи. Join, чтобы объединить два потока по равенству заданного набора полей. Split, чтобы разбить поток на несколько потоков по некоторому правилу с дальнейшей индивидуальной обработкой каждого из них. Sort, чтобы отсортировать. Put, чтобы положить таблицу на кластер.
Операции Map и Reduce также доступны, но требуются крайне редко, когда нужно сделать что-то действительно нестандартное и сложное.

Давайте посмотрим на инициализацию Nile. Она довольно проста. После импорта мы создаем два объекта — cluster и job. Cluster требуется, чтобы указать, на каком кластере мы хотим запускаться и прочее примерное окружение. Job — чтобы описать процесс модификации потока.

Как создать поток? Поток можно создать двумя путями: из таблицы на кластере или из существующих потоков. Первые два примера показывают, как создать поток из таблицы на кластере. В качестве аргумента передан путь до таблицы на кластере. Последний пример показывает, как нам создать поток из двух существующих потоков путем их слияния.
Давайте рассмотрим какой-то пример реализации задачи на Nile.
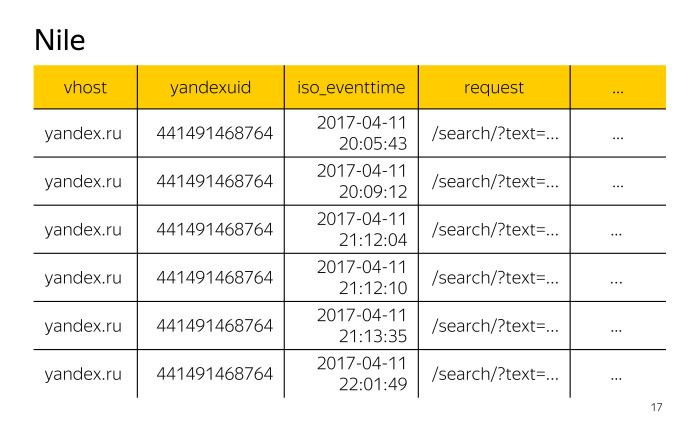
По логам доступа нужно посчитать число посетителей на хосте yandex.com.tr. Вспомним, как выглядят наш логи доступа. Из всего множества представленных полей нас будут интересовать поля vhost, чтобы отфильтровать и оставить только записи, относящиеся к хосту yandex.com.tr, и yandexuid, чтобы посчитать число посетителей.
Сам код на Nile для этой задачи будет иметь следующий вид.
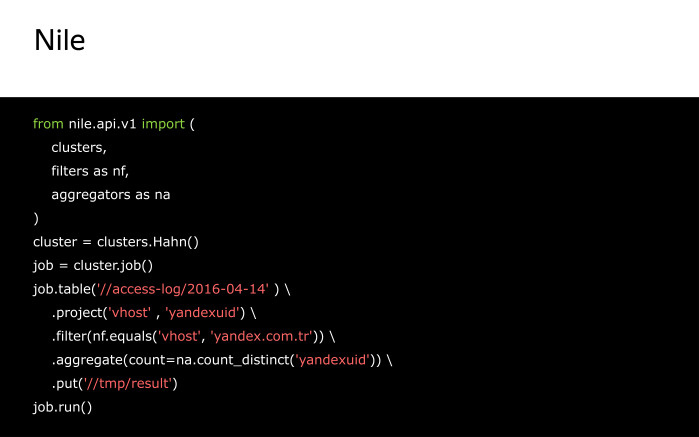
Тут мы создаем поток из таблицы на кластере, получаем поля vhost и yandexuid. Оставляем только записи со значением поля vhost, равным yandex.com.tr, и считаем число уникальных значений поля yandexuid, после чего сохраняем поток в таблицу на кластере. Job.run() запустит нас расчет.
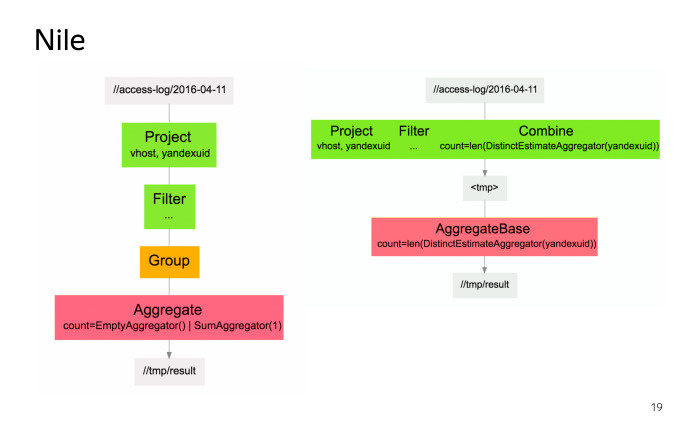
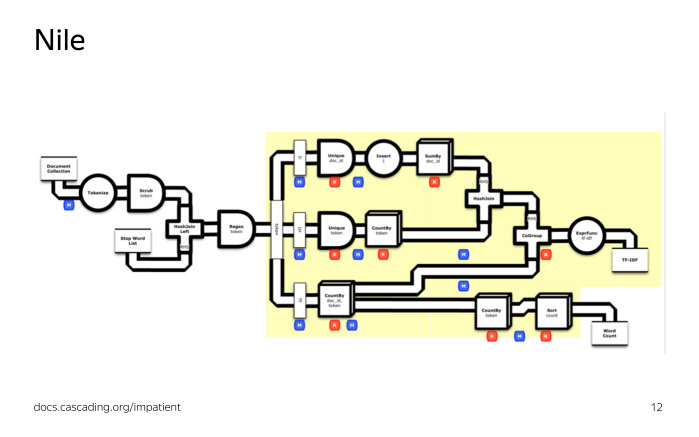
Перед запуском расчета на кластере Nile переведет наш расчет в набор MapReduсe-операций. Слева граф преобразования потока в терминах Nile, справа — в терминах MapReduсe-операций. Кроме того, Nile автоматически оптимизирует наш расчет, а именно, если у нас есть несколько Map-операций, идущих подряд, то Nile может их склеить в одну Map-операцию, выполняемую на кластере. Мы видим, что так и произошло. Это довольно простая задача, и код для нее будет сравнительно просто выглядеть на любом языке программирования.
Чтобы рассмотреть что-то более сложное, давайте вспомним о второй проблеме, с которой сталкиваются аналитики: данные из логов нужно извлечь и нормализовать.
Как принято решать эту проблему? Обычно для решения этой проблемы используют ETL. Кто знает, что это? Процентов 30 знает. Кто не знает или знал, но забыл: ETL предполагает, что у нас есть сырые необработанные данные, мы из них производим извлечение нужных нам записей, полей и прочего, модифицируем их с учетом некоторой бизнес-логики и загружаем в хранилище. В дальнейшем мы будем производить все расчеты по данным из хранилища, то есть по нормализованным данным.
Мы выбрали другой путь. Мы храним сырые данные и выполняем расчеты по ним, а процесс извлечения и нормализации данных происходит в каждом расчете.
Почему мы выбрали такой путь? Предположим, в процессе извлечения и нормализации полей используется внешняя библиотека, и в этой библиотеке была бага. После того, как мы багу исправим, нам надо будет пересчитать расчеты за прошлое. В нашем подходе мы просто запускаем расчеты за прошлое и получаем верные результаты. В случае ETL — если эта библиотека использовалась в процессе — нам придется сначала данные заново извлечь, обработать этой библиотекой, положить в хранилище и только потом выполнить расчеты.
Хороший вариант, если вы можете хранить как сырые данные, так и нормализованные. У нас, к сожалению, из-за большого объема данных такой возможности нет.
Вначале мы для каждого расчета выполняли извлечение и нормализацию данных индивидуально. Затем мы заметили, что для одних и тех же логов мы часто достаем похожие поля примерно одним и тем же образом, и мы объединили эти правила в одну библиотеку QB2. Сами правила назвали экстракторами, наборы таких правил для логов — деревьями разбора.

Итак, сейчас библиотека QB2 предоставляет абстрактный интерфейс к сырым логам и знает про деревья разбора.
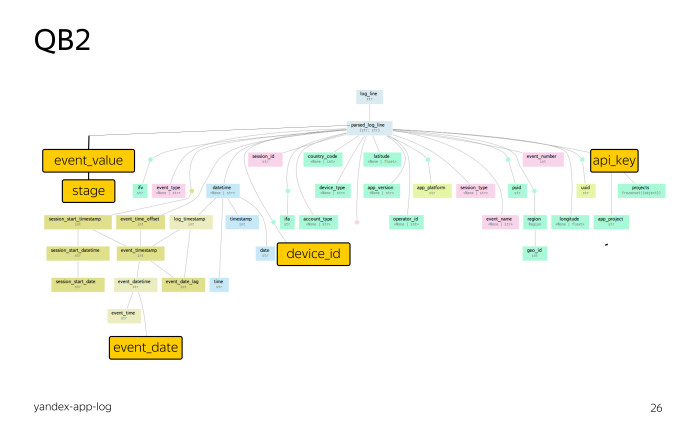
Давайте познакомимся с деревом разбора. Это дерево разбора для логов мобильных приложений Яндекса. Не присматривайтесь, это глобальная карта.
В самом верху запись лога. Все остальные цветные прямоугольники — это виртуальные поля. Связи — это экстракторы. Таким образом, пользователь без библиотеки QB2 может обращаться только к полям лога. Пользователь, использующий библиотеку QB2, может использовать как поля лога, так и поля, предоставляемые библиотекой QB2 для данного лога.
Давайте рассмотрим преимущества этой библиотеки на конкретном примере. Рассмотрим задачу. Пусть у нас есть некоторое мобильное приложение Яндекса, идентифицируемое значением поля API_key, равным 10321. Мы знаем, что оно пишет логи в поля, в частности в поле event_value, содержащее словарь в виде JSON-объекта. Нас будет интересовать значение ключа stage этого словаря.
Нам надо посчитать число посетителей для каждого stage в разбивке по дате события. Какие поля нам для этого предоставляет библиотека QB2? Во-первых, API_key, идентификатор приложения. Во-вторых, device_id, идентификатор пользователя. И наконец event_date, дата события, которая получена не непосредственно из записи лога, а путем довольно большого числа преобразований. Без использования библиотеки QB2 нам бы пришлось в каждом расчете, где требуется это поле, выполнять преобразования вручную. Согласитесь, это неудобно.
Кроме того, нам нужны поля event_value и значение stage. Их в нашем дереве разбора нет, и это логично, потому что они пишутся только для одного конкретного приложения.
Нам придется дополнить наше дерево разбора до следующего вида путем применения экстракторов. Как поменяется инициализация для данной задачи? Мы дополнительно импортируем экстракторы и фильтры. Экстракторы потребуются, чтобы получить значения полей event_value и stage. Фильтры — чтобы отфильтровать записи, оставив только нужные.
Вы можете задаться вопросом: почему в данном примере мы использовали фильтрацию из библиотеки QB2, хотя в предыдущем использовали фильтрацию из Nile? QB2, как и Nile, старается оптимизировать ваш расчет, а именно она пытается получить значения для полей, используемых в фильтрациях, как можно раньше. Раньше, чем значения для остальных виртуальных полей.
Зачем это сделано? Чтобы мы не получали значения для остальных виртуальных полей, если наша запись не проходит по каким-то условиям фильтрации. Тем самым мы сильно экономим вычислительные ресурсы и ускоряем расчет на кластере.

Сам код расчета будет иметь следующий вид. Мы тут точно так же создаем поток из таблицы на кластере и модифицируем его оператором QB2, который инициализируем следующими вещами: именем дерева разбора, которое в нашем случае совпадает с именем лога, а также набором полей и фильтров.
В полях мы перечисляем поля API_key, device_id и event_date по их именам, потому что библиотека QB2 уже знает, как доставать эти поля.
Для извлечения поля event_value воспользуемся стандартным экстрактором json_log_field. Что он делает? По переданному ему имени он получает значение из соответствующего поля лога и загружает его как JSON-объект. Это загруженное значение мы сохраняем в поле event_value.
Чтобы получить значение stage, мы используем другой стандартный экстрактор — dictItem. По переданному ему имени ключа и имени поля он извлекает соответствующее значение из этого поля для этого ключа.
Про фильтрации. Нас будут интересовать только записи, у которых определено значение поля device_id и которые относятся к нашему приложению, то есть значение поля api_key у них равно 10321. После применения оператора QB2 наш поток будет иметь следующие поля: api_key, device_id, event_date, event_value и stage.
Модифицируем полученный поток следующим образом. Сгруппируем по паре полей event_date и stage и посчитаем число уникальных значений device_id. Это значение мы положим в поле users, после чего полученный поток сохраним на кластер. Job.run() запустит расчет.
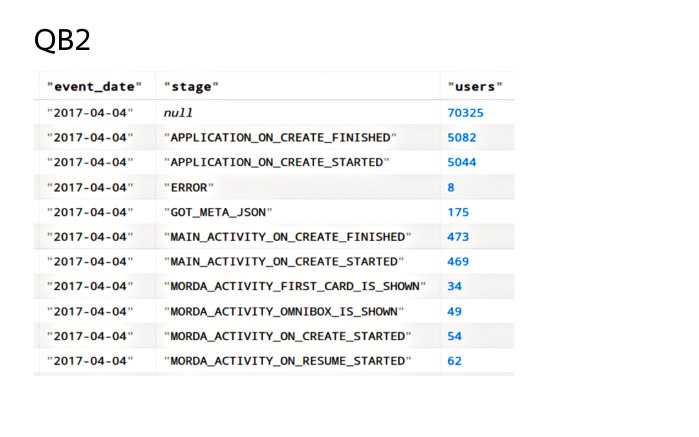
После окончания расчета на кластере будет таблица следующего вида: для каждой пары полей event_date и stage в поле users будет лежать число уникальных значений пользователей. Таким образом, интеграция библиотек QB2 и Nile решает обе проблемы, которые я озвучил. Спасибо за внимание.
Под катом — расшифровка и часть слайдов.
Меня зовут Агапитов Василий, я представляю команду интеллектуального анализа данных.
В Яндексе мы выполняем расчеты по большим данным, в частности по данным, лежащим на кластерах MapReduce. В основном это анонимизированные логи сервисов и приложений. Кроме того, мы предоставляем наши инструменты по обработке больших данных другим командам. Наши основные потребители — команды аналитиков-разработчиков. Для простоты я буду называть их аналитиками.
Хочу рассказать о двух инструментах, библиотеках, истории их появления, и том, как мир Hadoop оказал влияние на их появление.
Давайте синхронизируем некоторое представление о терминах. Источники данных. Мы будем говорить исключительно о логах, поэтому для примера давайте рассмотрим какой-нибудь лог доступа к сервисам.
У нас по горизонтали располагаются записи этого лога, каждая запись имеет поля: vhost — идентификатор хоста, yandexuid — идентификатор посетителя, iso_eventtime — дата и время обращения, request — сам запрос и многие другие поля.
Данные из некоторых полей уже можно использовать в расчетах. Из других полей данные сначала надо извлечь и нормализовать. Например, в поле request содержатся параметры запроса. У каждого сервиса такие параметры свои. Для поиска наиболее используемым является параметр text. После того, как мы извлечем его из поля request, нам надо его нормализовать, поскольку он может быть очень большим или иметь какую-то странную кодировку.
Во-вторых, мы будем рассматривать наши расчеты в части расчетов на кластерах MapReduсe. Как вы знаете, MapReduсe — технология изготовления сэндвичей. На самом деле нет, это технология обработки больших данных. Если вы с ней не знакомы, то для текущего доклада вам надо знать, что она предполагает обработку данных с использованием двух операций — Map и Reduce.
Задача аналитика в том, чтобы построить расчет по событиям лога с учетом некоторой бизнес-логики. С какими трудности может столкнуться аналитик, решая свою задачу на кластерах MapReduсe без использования каких-либо библиотек? Во-первых, ему придется реализовывать бизнес-логику на базе операций MapReduсe. Такой подход добавляет в расчет код, не относящийся к бизнес-логике этого расчета, что существенно ухудшает его читаемость и поддержку. Во-вторых, нам надо данные из логов сначала извлечь и нормализовать — например, параметр text из поля request.
Как принято решать первую проблему? Очевидно, нам нужна какая-то библиотека, которая упростит доступ пользователя к кластеру и взаимодействие с ним.
В мире Hadoop к таким библиотекам можно отнести Pig, Hive, Cascading и некоторые другие.
В Яндексе используется собственная реализация MapReduсe, называемая YT, о преимуществах которой вы можете почитать в статье на Хабре и которая предоставляет для обработки данных базовые операции MapReduсe. Но, к сожалению, YT не имела аналогов библиотек из мира Hadoop. Нам пришлось это исправить.
В самом начале, когда мы столкнулись с этой проблемой, мы действительно при каждом расчете отдельно описывали Map-стадии, отдельно — Reduce-стадии, и отдельно — связь между этими стадиями для запуска расчета на кластере.
Более того, у каждого был собственный запускатор. Поддерживать такой зоопарк очень дорого. Решением для нас стала библиотека Nile, библиотека для описания и запуска расчетов на кластере. При ее создании мы взяли идею Сascading из мира Hadoop и реализовали ее на языке Python — во многом потому, что Python использует аналитики для локальной обработки данных, а использовать один язык для расчетов на кластере и для локальной обработки данных очень удобно.
Если вы знаете Cascading, то процесс обработки данных на Nile вам также покажется знакомым. Мы создаем поток из таблиц на кластере, модифицируем его, группируем, например, считаем какие-то агрегаты, разбиваем поток на несколько потоков, объединяем несколько потоков в один поток, производим другие действия, после чего полученный поток с нужными данными сохраняем обратно в таблицу на кластер.
Какие у Nile есть операции модификации потока? Их очень много, здесь представлены наиболее часто используемые. Project, чтобы получить список нужных нам полей. Filter, чтобы отфильтровать, оставив только нужные нам записи. Groupby + aggregate, чтобы сгруппировать поток по заданному набору полей и посчитать некоторые агрегаты. Unique, random и take, чтобы построить выборки уникальную, случайную и с заданным числом записи. Join, чтобы объединить два потока по равенству заданного набора полей. Split, чтобы разбить поток на несколько потоков по некоторому правилу с дальнейшей индивидуальной обработкой каждого из них. Sort, чтобы отсортировать. Put, чтобы положить таблицу на кластер.
Операции Map и Reduce также доступны, но требуются крайне редко, когда нужно сделать что-то действительно нестандартное и сложное.
Давайте посмотрим на инициализацию Nile. Она довольно проста. После импорта мы создаем два объекта — cluster и job. Cluster требуется, чтобы указать, на каком кластере мы хотим запускаться и прочее примерное окружение. Job — чтобы описать процесс модификации потока.
Как создать поток? Поток можно создать двумя путями: из таблицы на кластере или из существующих потоков. Первые два примера показывают, как создать поток из таблицы на кластере. В качестве аргумента передан путь до таблицы на кластере. Последний пример показывает, как нам создать поток из двух существующих потоков путем их слияния.
Давайте рассмотрим какой-то пример реализации задачи на Nile.
По логам доступа нужно посчитать число посетителей на хосте yandex.com.tr. Вспомним, как выглядят наш логи доступа. Из всего множества представленных полей нас будут интересовать поля vhost, чтобы отфильтровать и оставить только записи, относящиеся к хосту yandex.com.tr, и yandexuid, чтобы посчитать число посетителей.
Сам код на Nile для этой задачи будет иметь следующий вид.
Тут мы создаем поток из таблицы на кластере, получаем поля vhost и yandexuid. Оставляем только записи со значением поля vhost, равным yandex.com.tr, и считаем число уникальных значений поля yandexuid, после чего сохраняем поток в таблицу на кластере. Job.run() запустит нас расчет.
Перед запуском расчета на кластере Nile переведет наш расчет в набор MapReduсe-операций. Слева граф преобразования потока в терминах Nile, справа — в терминах MapReduсe-операций. Кроме того, Nile автоматически оптимизирует наш расчет, а именно, если у нас есть несколько Map-операций, идущих подряд, то Nile может их склеить в одну Map-операцию, выполняемую на кластере. Мы видим, что так и произошло. Это довольно простая задача, и код для нее будет сравнительно просто выглядеть на любом языке программирования.
Чтобы рассмотреть что-то более сложное, давайте вспомним о второй проблеме, с которой сталкиваются аналитики: данные из логов нужно извлечь и нормализовать.
Как принято решать эту проблему? Обычно для решения этой проблемы используют ETL. Кто знает, что это? Процентов 30 знает. Кто не знает или знал, но забыл: ETL предполагает, что у нас есть сырые необработанные данные, мы из них производим извлечение нужных нам записей, полей и прочего, модифицируем их с учетом некоторой бизнес-логики и загружаем в хранилище. В дальнейшем мы будем производить все расчеты по данным из хранилища, то есть по нормализованным данным.
Мы выбрали другой путь. Мы храним сырые данные и выполняем расчеты по ним, а процесс извлечения и нормализации данных происходит в каждом расчете.
Почему мы выбрали такой путь? Предположим, в процессе извлечения и нормализации полей используется внешняя библиотека, и в этой библиотеке была бага. После того, как мы багу исправим, нам надо будет пересчитать расчеты за прошлое. В нашем подходе мы просто запускаем расчеты за прошлое и получаем верные результаты. В случае ETL — если эта библиотека использовалась в процессе — нам придется сначала данные заново извлечь, обработать этой библиотекой, положить в хранилище и только потом выполнить расчеты.
Хороший вариант, если вы можете хранить как сырые данные, так и нормализованные. У нас, к сожалению, из-за большого объема данных такой возможности нет.
Вначале мы для каждого расчета выполняли извлечение и нормализацию данных индивидуально. Затем мы заметили, что для одних и тех же логов мы часто достаем похожие поля примерно одним и тем же образом, и мы объединили эти правила в одну библиотеку QB2. Сами правила назвали экстракторами, наборы таких правил для логов — деревьями разбора.
Итак, сейчас библиотека QB2 предоставляет абстрактный интерфейс к сырым логам и знает про деревья разбора.
Давайте познакомимся с деревом разбора. Это дерево разбора для логов мобильных приложений Яндекса. Не присматривайтесь, это глобальная карта.
В самом верху запись лога. Все остальные цветные прямоугольники — это виртуальные поля. Связи — это экстракторы. Таким образом, пользователь без библиотеки QB2 может обращаться только к полям лога. Пользователь, использующий библиотеку QB2, может использовать как поля лога, так и поля, предоставляемые библиотекой QB2 для данного лога.
Давайте рассмотрим преимущества этой библиотеки на конкретном примере. Рассмотрим задачу. Пусть у нас есть некоторое мобильное приложение Яндекса, идентифицируемое значением поля API_key, равным 10321. Мы знаем, что оно пишет логи в поля, в частности в поле event_value, содержащее словарь в виде JSON-объекта. Нас будет интересовать значение ключа stage этого словаря.
Нам надо посчитать число посетителей для каждого stage в разбивке по дате события. Какие поля нам для этого предоставляет библиотека QB2? Во-первых, API_key, идентификатор приложения. Во-вторых, device_id, идентификатор пользователя. И наконец event_date, дата события, которая получена не непосредственно из записи лога, а путем довольно большого числа преобразований. Без использования библиотеки QB2 нам бы пришлось в каждом расчете, где требуется это поле, выполнять преобразования вручную. Согласитесь, это неудобно.
Кроме того, нам нужны поля event_value и значение stage. Их в нашем дереве разбора нет, и это логично, потому что они пишутся только для одного конкретного приложения.
Нам придется дополнить наше дерево разбора до следующего вида путем применения экстракторов. Как поменяется инициализация для данной задачи? Мы дополнительно импортируем экстракторы и фильтры. Экстракторы потребуются, чтобы получить значения полей event_value и stage. Фильтры — чтобы отфильтровать записи, оставив только нужные.
Вы можете задаться вопросом: почему в данном примере мы использовали фильтрацию из библиотеки QB2, хотя в предыдущем использовали фильтрацию из Nile? QB2, как и Nile, старается оптимизировать ваш расчет, а именно она пытается получить значения для полей, используемых в фильтрациях, как можно раньше. Раньше, чем значения для остальных виртуальных полей.
Зачем это сделано? Чтобы мы не получали значения для остальных виртуальных полей, если наша запись не проходит по каким-то условиям фильтрации. Тем самым мы сильно экономим вычислительные ресурсы и ускоряем расчет на кластере.
Сам код расчета будет иметь следующий вид. Мы тут точно так же создаем поток из таблицы на кластере и модифицируем его оператором QB2, который инициализируем следующими вещами: именем дерева разбора, которое в нашем случае совпадает с именем лога, а также набором полей и фильтров.
В полях мы перечисляем поля API_key, device_id и event_date по их именам, потому что библиотека QB2 уже знает, как доставать эти поля.
Для извлечения поля event_value воспользуемся стандартным экстрактором json_log_field. Что он делает? По переданному ему имени он получает значение из соответствующего поля лога и загружает его как JSON-объект. Это загруженное значение мы сохраняем в поле event_value.
Чтобы получить значение stage, мы используем другой стандартный экстрактор — dictItem. По переданному ему имени ключа и имени поля он извлекает соответствующее значение из этого поля для этого ключа.
Про фильтрации. Нас будут интересовать только записи, у которых определено значение поля device_id и которые относятся к нашему приложению, то есть значение поля api_key у них равно 10321. После применения оператора QB2 наш поток будет иметь следующие поля: api_key, device_id, event_date, event_value и stage.
Модифицируем полученный поток следующим образом. Сгруппируем по паре полей event_date и stage и посчитаем число уникальных значений device_id. Это значение мы положим в поле users, после чего полученный поток сохраним на кластер. Job.run() запустит расчет.
После окончания расчета на кластере будет таблица следующего вида: для каждой пары полей event_date и stage в поле users будет лежать число уникальных значений пользователей. Таким образом, интеграция библиотек QB2 и Nile решает обе проблемы, которые я озвучил. Спасибо за внимание.
Поделиться с друзьями
ASiD
Эти библиотеки доступны только сотрудникам Яндекса или есть где-то в открытом доступе?
ASiD
Вопрос снят. Доступ пока только для Яндекса, но планируют открыть. Ответ на 22 минуте видео