

В приложениях, работающих с базами данных, естественным образом возникает потребность в тестах, которые проверяют корректность результатов выполнения запросов. На помощь приходят различные встроенные (embedded) базы данных. В этой статье я расскажу о том, как мы перевели unit-тесты с HSQLDB на PostgreSQL: зачем это затеяли, с какими трудностями столкнулись и что нам это дало.
Если в тестах нужно проверить работоспособность sql-запросов, удобно использовать так называемые встроенные базы данных. База создается при запуске теста и удаляется при завершении — таким образом, ее жизненный цикл ограничен процессом, в котором она была запущена (оттого они и называются embedded — то есть встроенные в процесс тестирования). Преимущество таких баз данных в том, что они позволяют работать с ограниченным набором тестовых данных, который, как правило, значительно меньше объема данных даже на тестовом сервере. Кроме того, создание базы, наполнение таблиц и последующее удаление всей инфраструктуры совершенно прозрачно для программиста: нет необходимости поднимать и настраивать тестовый сервер, а также заботиться об актуальности данных, что также положительно сказывается на скорости разработки.
В нашей компании для unit-тестирования исторически использовалась HSQLDB. И все бы ничего, но на продакшене стоит PostgreSQL, и получалось, что тесты не полностью отражают то, что происходит на проде. Некоторые фичи приходилось оставлять без тестирования: например, запросы, использующие window functions, протестировать не удавалось. Для некоторых тестов приходилось делать достаточно навороченные костыли: яркий тому пример — разная реализация мэппинга пользовательского типа массива на SQL в PostgreSQL и HSQLDB (ниже я расскажу об этом подробнее). Также мы столкнулись с проблемной реализацией exists — были случаи, когда ни с того ни с сего тест падал с NPE где-то в недрах HSQLDB.
Всех этих проблем можно было избежать, если бы в качестве СУБД для тестов мы использовали PostgreSQL. На данный момент существует две реализации embedded PostgreSQL: библиотека postgresql-embedded из yandex-qatools и otj-pg-embedded, представленная компанией OpenTable. Оба проекта достаточно активно развиваются, о чем свидетельствуют регулярные коммиты в репозитории, а также удобны в использовании: библиотеки можно загрузить из maven-репозитория, в обеих поддерживается работа под Windows, что немаловажно в компании, где часть разработчиков выбрали для работы именно эту ОС. В итоге мы решили остановиться на otj-pg-embedded по нескольким причинам:
- Во-первых, библиотека OpenTable оказалась значительно быстрее: время запуска при скачанном дистрибутиве составляет около 2 секунд, при этом yandex-qatools запускается в течение 7,5 секунды — практически в 4 раза медленнее! Выяснилось, что основное время идет на разархивацию дистрибутива при каждом запуске, при этом на машинах с Windows время старта возрастало до нескольких минут.
- Во-вторых, достаточно просто подменить версию PostgreSQL, если понадобится использовать более старую версию или кастомную сборку с расширениями. По умолчанию otj-pg-embedded 0.7.1 идет с PostgreSQL 9.5 (в версии 0.8.0, актуальной на сегодняшний день, — PostgreSQL 9.6). При этом не совсем ясно, каким образом можно подложить кастомную сборку в yandex-qatools.
- otj-pg-embedded — достаточно старый проект (первый коммит был в феврале 2012 года), на запросы в github мейнтейнеры отвечают оперативно.
- В yandex-qatools больше возможностей для конфигурации, в то же время otj-pg-embedded — небольшая библиотека, в которой легко разобраться, при этом она предоставляет достаточно возможностей для конфигурирования.
- В библиотеке OpenTable запускать экземпляр БД можно “одной строкой”, что очень удобно и интуитивно понятно. Кроме того, в версии 0.8.0 при запуске выводится достаточно информативный лог с указанием настроек, с которыми запущен PostgreSQL.
Итак, определившись с библиотекой и решительным жестом заменив все зависимости от hsql на otj-pg-embedded, мы радостно запустили тесты и…
Первые грабли
По-разному обрабатывается sql-тип DATE
Первым делом выяснилось, что упали тесты, которые работали с sql-типом Date (не Timestamp, а именно Date). Например, при поиске резюме по определенному критерию запрос возвращает все резюме, у которых дата изменения позже указанной даты:
return sessionFactory.getCurrentSession().createQuery(
"FROM ResumeViewHistory " +
"WHERE resumeId=:resumeId AND date IN " +
" (SELECT max(date) FROM ResumeViewHistory " +
" WHERE resumeId=:resumeId AND date>:date)")
.setInteger("resumeId", resumeId)
.setDate("date", from)
.list();В тесте создавалось резюме с текущей датой и затем проверялось, что не существует резюме с датой немного старше, чем в только что созданном:
assertTrue(resumeViewHistoryDao.findByResumeLastView(
resume.getResumeId(), new DateTime().plusMinutes(1).toDate())
.isEmpty());Этот тест, как и все остальные тесты с аналогичной проверкой, в PostgreSQL упал с AssertionError. Все дело в том, что в HSQLDB производилось сравнение даты и времени, поэтому разница в одну минуту считалась существенной. А в PostgreSQL время обнулялось, превращаясь просто в дату, и запрос вполне себе находил резюме, ведь оно было создано в этот же день!
Таким образом, мы практически на первых порах столкнулись с ситуацией, когда тест проверял sql-запрос, предполагая определенное поведение при заданных условиях, и это поведение отрабатывало на HSQLDB и не работало на PostgreSQL. То есть фактически этот тест был не только бесполезен, поскольку не давал никакой информации о работе запроса на продуктивной базе, но и даже вреден: разработчик, читая код теста и увидев, что есть проверка на пустой результат для объекта, созданного минуту спустя, мог бы подумать, что на уровне DAO используется метод setTimestamp(), и весьма бы удивился, увидев там setDate().
LIKE + CTE
Следующую проблему подкинул оператор LIKE в связке с общими табличными выражениями. CTE (Common Table Expressions) — это выражения, определяющие временные таблицы для использования в более сложном запросе. Эти временные таблицы создаются только для текущего запроса, что удобно для краткосрочного представления данных в том или ином виде. Например, Employer (работодатель, он же — клиент) — одна из центральных сущностей — с помощью CTE может быть представлена как более специализированный объект с сокращенным набором полей.
Допустим, нам нужно найти дубликаты клиентов — то есть компании, у которых есть совпадения по нескольким параметрам, например, адрес регистрации или url сайта. Среди прочего есть проверка на совпадение имени компании (или ее части), тут как раз в дело вступает оператор LIKE:
WITH clients(name) AS (VALUES …)
SELECT
employer.employer_id AS employerId,
employer.name AS employerName
FROM employer AS employer
JOIN clients AS clients ON employer.name LIKE '%' || clients.name || '%'Итак, для следующего списка клиентов:
- Alice
- Bob
- Хэдхантер
- Клиент
- Alice Cooper
- Bob Marley
результат запроса сильно отличался в зависимости от того, что подставлялось в оператор WITH (см. таблицу).
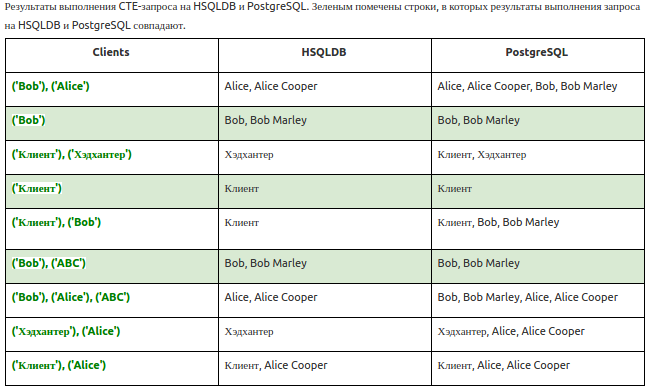
Похоже, что PostgreSQL всегда дает предсказуемый результат, а у HSQLDB проблемы во всех случаях, когда во временную таблицу попадает более одного значения, которое должно смаппиться join’ом. В результате пришлось поправить исходные данные в тесте, поскольку, как видно из таблицы, PostgreSQL и HSQLDB по-разному реагируют на множественные значения во временной таблице, а в тесте проверялось как раз несколько клиентов.
Разная реакция на некорректный SQL
В нашей модели данных есть объекты, которые хранят sql-код, который выполняется для того, чтобы выяснить, подходит ли объект под определенные условия. Естественно, появляется желание проверять поведение системы, когда она сталкивается с некорректным sql-кодом, поэтому у нас есть соответствующий тест: в объект передается некорректный sql, и затем вызывается метод, который этот sql выполняет.
SELECT user_id FROM user111 WHERE employer_id = :employerIdКонечно, таблицы user111 не существует — это ошибочное написание таблицы user. При попытке выполнения некорректного sql обрабатывается RuntimeException, исключая объект из дальнейшего процесса; именно это поведение и проверялось тестом. Действительно, при выполнении на HSQLDB код падал с ошибкой SQLException (наследуется от Exception), которая затем конвертировалась в JDBCException (наследуется от RuntimeException), это исключение в свою очередь обрабатывалось в методе сервиса, убирая проверяемый объект из результатов, затем выполнялись дополнительные операции для успешно обработанных объектов — и тест корректно завершался.
При запуске теста на PostgreSQL ошибка по-прежнему перехватывалась, преобразовывалась в JDBCException и отправлялась дальше, некорректный объект исключался из обработки, и все бы хорошо, но следующие действия прерывались из-за того, что при возникновении ошибки подобного рода в запросе — а именно, при попытке доступа к несуществующей таблице — PostgreSQL прерывает транзакцию, и остальные запросы уже не обрабатываются, что в итоге приводило к некорректному завершению теста.
Проблемы с сортировкой
Здесь можно выделить два класса проблем. Первый — это несоответствие порядка сущностей в коде тестов и в результате запроса. Например, в тесте есть список из нескольких экземпляров, которые затем создаются в базе и выгружаются из нее также в виде списка. Так вот, в HSQLDB порядок, в котором объекты загружались из базы, всегда совпадал с порядком в исходном списке. В PostgreSQL порядок не совпадал чуть менее, чем во всех тестах, где использовалась подобная конструкция, что привело к необходимости либо использовать явную сортировку исходного и результирующего списков, либо сравнивать списки без учета порядка элементов (кстати, для этих целей достаточно удобно использовать метод arrayContainingInAnyOrder из матчер-фреймворка Hamcrest).
Вторая проблема оказалась серьезнее: перестали работать некоторые тесты, в которых использовалась сортировка на уровне БД (ORDER BY). Причем сортировка вела себя по-разному при запуске на разных окружениях: после замены названий у пары вакансий тест стал корректно отрабатывать на Linux, но по-прежнему не работал при запуске на MacOS и Windows.
Естественно, подозрение пало на настройки локали в PostgreSQL — а именно на ту из них, которая отвечает за порядок сортировки строк в базе, — LC_COLLATE. Эта настройка не зависит от кодировки, указанной при создании базы: если не указать этот параметр в явном виде при инициализации базы в createdb или initdb, PostgreSQL возьмет значение из операционной системы (кстати, поменять его после инициализации базы нельзя). Правила сортировки могут быть самыми разными: например, учитывать или не учитывать пробелы, а также определение приоритета строчных или прописных букв.
Таким образом, мы получили тесты, результаты которых зависят от операционной системы, — то есть достаточно паршивую ситуацию. Можно было бы использовать настройку, которая позволяет выполнять сортировку по правилам, не зависящим от ОС, воспользовавшись поставляемой с PostgreSQL стандартной сортировкой, LC_COLLATE=C, но этот вариант не подошел, поскольку в реализации embedded-pg от OpenTable нет возможности передавать параметры в initdb. В текущей реализации можно изменять конфигурацию сервера при старте базы, но задавать настройки collate там нельзя, поэтому проблемные тесты временно отправились в @Ignore. Кстати, мейнтейнер OpenTable признал необходимость данной фичи, поэтому после краткого обсуждения мы создали PR, в котором добавили возможность инициализировать базу с разными настройками локали. Релизы происходят нечасто, но, надеемся, что уже в следующей версии embedded-pg эта проблема будет решена.
Проблема мэппинга пользовательских типов
Как известно, в Hibernate для хранения в базе поля типа “массив” необходимо написать пользовательский тип, реализующий интерфейс UserType. Достаточно лишь реализовать необходимые методы, в том числе sqlTypes(), определяющий SQL-тип столбца в базе, а также nullSafeSet() и nullSafeGet(), и добавить аннотацию @Type с указанием пользовательского типа к объявлению поля в классе сущности (или указав этот тип в файле мэппинга).
В наших проектах для чтения и записи объектов типа массива изначально использовался java.sql.Array, который отлично работает в связке с PostgreSQL на продакшене. Но, поскольку в HSQLDB мэппинг таким образом не работал, а тестировать сущности, которые в своем составе имеют массивы, было необходимо, мы немного поменяли реализацию пользовательских типов. Непосредственной имплементацией nullSafeSet() и nullSafeGet() теперь управляли стратегии: по умолчанию использовался код PostgreSQLArrayStrategy, работающий с java.sql.Array, а во время выполнения тестов в пользовательские типы передавалась специальная стратегия HsqldbArrayStrategy, которая для чтения и записи массивов использовала java.sql.Blob.
После перевода тестов на PostgreSQL мы наивно надеялись, что стоит просто убрать все связанное с HSQLDB и мэппинг заработает сам собой, но, конечно же, все было не так просто. На продакшене для получения соответствующего java-типу sql-типа используется класс AbstractJdbcConnection, который корректно резолвит типы массивов без всяких дополнительных настроек. К сожалению, в случае с тестами такой подход работал лишь наполовину: connection использовался только при непосредственном выполнении тестов. В то же время при создании тестовой базы работает другой механизм определения типов, а именно — их мэппинг происходит во время создания SessionFactory, когда инициализируются метаданные, представляющие собой ORM-модель. Этому механизму по-прежнему требовалось явно указывать тип массивов в описании диалекта, иначе Hibernate просто не удавалось создать таблицу с полем типа “массив”:
org.hibernate.MappingException: No Dialect mapping for JDBC type: 2003
Проблема заключалась в том, что мы не могли указать sql-тип для массивов в файле диалекта, потому что у нас их было два (String и Integer), а связать таким образом можно только один тип, например:
registerColumnType(Types.ARRAY, "integer[$l]");Пришлось искать обходной путь: для каждого пользовательского типа был создан свой идентификатор типа массива, например, строковые массивы были связаны с типом 200301, а массивы целых чисел — с типом 200302. Этот идентификатор возвращался в методе sqlTypes():
public class EnumArrayUserTypeString extends EnumArrayUserType {
public static final int VARCHAR_ARRAY_SQL_TYPE = 200301;
@Override
public int[] sqlTypes() {
return new int[] {VARCHAR_ARRAY_SQL_TYPE};
}
//...
}Затем типы были зарегистрированы в диалекте:
public class HHPostgreSQLDialect extends PostgreSQL9Dialect {
public HHPostgreSQLDialect() {
registerColumnType(EnumArrayUserTypeString.VARCHAR_ARRAY_SQL_TYPE, "varchar[$l]");
registerColumnType(EnumArrayUserTypeInteger.INT_ARRAY_SQL_TYPE, "integer[$l]");
}
// ...
}После этих манипуляций Hibernate наконец-то остался доволен и без проблем создал нужные таблицы.
Проблемы с производительностью
На закуску — самый животрепещущий вопрос: а что же стало с производительностью тестов? Ведь HSQLDB размещалась непосредственно в памяти, а embedded-pg — хоть и встроенная, но фактически полноценная база данных, при старте создающая целую кучу файлов!
Первые результаты были довольно удручающие: на машинах с SSD при прогоне всех тестов в модуле скорость упала на 25–30%, на более старых машинах с SATA все было еще хуже (замедление до 40%). Ситуация становилась заметно лучше, если тесты запускались в несколько потоков:
mvn clean test -T C1
— но все равно не вызывала восторга, особенно у тех, кто и раньше прогонял тесты в многопоточном режиме.
Мы обратили внимание на подозрительные логи при тестировании проекта, состоящего из нескольких модулей: как только surefire приступал к тестированию очередного модуля, запускался новый инстанс базы данных, со всеми вытекающими: создание схемы данных, заполнение таблиц тестовыми данными, — в общем, множество дорогостоящих I/O-операций. Это показалось странным, потому что за создание инстанса базы отвечал холдер синглтона, который был написан по всем правилам, включая volatile-поле для хранения инстанса и double-check locking в методе получения. Каково же было наше удивление, когда выяснилось, что этот синглтон оказался не совсем синглтоном, когда в дело вступал maven-surefire-plugin!
По умолчанию при тестировании очередного модуля surefire создает новый процесс JVM. В этом процессе выполняются все тесты, относящиеся к модулю; когда тестирование завершено, surefire переходит к следующему модулю, который будет выполняться в новой JVM. Настройкой этого поведения управляет параметр forkCount, который по умолчанию равен 1 (одна новая JVM на каждый модуль). Если этот параметр выставить в 0, то все модули будут выполняться в одной и той же JVM.
Стало ясно, что при использовании forkCount=1 мы получали новый инстанс PostgreSQL при старте каждого модуля. Тогда было решено попробовать использовать одну JVM для всех тестов, но и в этом случае оказалось, что инстанс создается каждый раз при старте очередного модуля! Причиной тому служил так называемый Isolated Classloader, который использовался surefire в случае forkCount=0. Несмотря на явное указание использовать системный класслоадер (useSystemClassloader=true), в данном случае surefire переключается на изолированный (кстати, сообщая об этом в логах, да и в документации на этом поведении сделан акцент — см. Class Loading and Forking in Maven Surefire). Итак, для каждого модуля создается отдельный класслоадер, который загружает все классы заново и, соответственно, вновь создает инстанс нашего синглтона со ссылкой на инстанс базы. Таким образом, проблема была обусловлена внутренним механизмом работы surefire, и мы решили сосредоточиться на тех аспектах производительности, которые можно было поправить.
Временные файлы в RAM
Сначала мы решили перенести временные файлы, которые embedded-pg создает во время своей работы, с дисков в память, то есть размещать их в разделе, смонтированном как RAM FS. Такой подход должен был улучшить ситуацию как минимум на машинах с медленными дисками, тем более что к тому времени он уже использовался в тестах для ускорения работы еще одной СУБД, Apache Cassandra — так что изобретать велосипед не пришлось, нужно было только немного расширить и унифицировать код. Единственное “но”: старый код ориентировался только на Linux, в котором поддерживается файловая система tmpfs. На “маках” также есть аналог tmpfs, но, в отличие от Linux, в MacOS нет раздела, который создается с такой файловой системой по умолчанию, наподобие /dev/shm или /run в Linux. Его довольно просто создать, но это требовало действий разработчиков, а хотелось, чтобы все работало прозрачно. С Windows все было еще хуже: помимо того, что тесты сами по себе работали медленно (скорости им не добавлял антивирус, который проверял каждый вновь создаваемый файл), никакой поддержки RAM FS “из коробки” там нет и в помине, поэтому единственным вариантом было установить стороннее ПО, например, RamDisk, и настраивать его для работы с папкой PostgreSQL. Естественно, перспектива ручной настройки не вызывала энтузиазма у разработчиков, кроме того, как оказалось, прирост скорости был совсем незначительный (менее 5%), поэтому пришлось искать другие пути.
Пул соединений
Решение, как это часто бывает, оказалось на поверхности: в отличие от HSQLDB, которая работала в режиме in-memory database — то есть, полностью размещалась в оперативной памяти, PostgreSQL создает соединения к базе — ведь в настройках соединения в jdbc url появился порт! Так почему бы не создать пул соединений, тем самым сокращая затраты на постоянное создание новых Connection, что, как известно, весьма затратная операция? В качестве реализации был выбран c3p0 — и это было самое заметное улучшение, поскольку скорость выполнения тестов фактически вернулась к прежнему уровню HSQLDB. Добавление пула не вызвало никаких проблем, и при запуске в многопоточном режиме все по прежнему работало, и работало быстро.
Настройки PostgreSQL
Наконец мы посмотрели в сторону настроек PostgreSQL:
- Отключение
autovacuumпривело к небольшому увеличению производительности; - Использование кэширования запросов (
preparedThreshold=X) не дало заметного увеличения производительности — пробовали на значениях от 1 до 4; - Попытки установки разных значений для настроек памяти, например,
shared_buffersиeffective_cache_sizeтакже не дали никакого прироста (то есть наблюдался либо негативный эффект, либо вообще никакого). Кроме того, эффект от этих настроек слишком сильно зависит от характеристик машины, на которой поднимается база — а тесты в конечном счете запускаются на разных окружениях, отличающихся друг от друга количеством установленной и доступной RAM, поэтому мы решили оставить значения по умолчанию.
Что в итоге?
Перейдя с HSQLDB на PostgreSQL, мы не только привели тесты в соответствие с поведением, которое имеет место на продакшене. Мы также улучшили качество самих тестов, отрефакторили большинство из них, избавившись от использования захардкоженных идентификаторов сущностей, а самое главное — исправили ошибки, которые делали некоторые тесты неактуальными и даже вредными, поскольку их поведение совершенно не отражало логику кода, который используется на проде.
Как это зачастую бывает, переход был не совсем гладким: где-то мы словили очевидные баги, как в случае с порядком сортировки исходного списка и списка, получаемого из базы в результате выполнения запроса. Где-то проблемы были посерьезнее — например, пришлось покопаться в документации maven-surefire-plugin и настройках локали PostgreSQL. Но в итоге результат оправдал все затраченные усилия: теперь можно смело тестировать любой запрос, не опасаясь, что в тесте он поведет себя как-то по-особенному или не сработает вообще.
UPD: в комментариях уточнили, что yandex-qatools не является "детищем «Яндекса»" — Яндекс просто обладает правами на код — в связи с чем в статью внесены соответствующие поправки. Спасибо Lanwen за пояснение!
Комментарии (48)

kullfar
19.07.2017 14:46+1Автор забыл про ещё один очень приятный бонус у otj-pg-embedded против yandex-qatools.
У otj-pg-embedded постгрес идет внутри джарки, а у яндекса при запуске тестов постгрес качается с интернета.
Если в компании такая ситуация, что есть много разработчиков и, главное, автоматизированных стендов, всяких CI и аналогичных, которые на чистой среде постоянно запускают сборку, то внешнему интернет-каналу быстро станет грустно и время сборки сильно увеличится на ожидание скачивания постгреса с сети, дополнительно добавляя новую точку отказа для сборки новой ветки. Нужно будет думать о кешировании-проксировании. А в случае с otj-pg-embedded, все быстро решается проксирующим мавен-репозиторием, который, как мне кажется, стоит в большинстве компаний с собстенной разработкой на java.
Borz
19.07.2017 15:02+1говорят, что если в
~/.embedpostgresqlподсунуть нужный архив, то из интернета ничего скачиваться не будет.
А ещё можно при запуске передать runtimeConfig, в котором переопределить под свои потребности PostgresDownloadConfigBuilder и указать свой источник дистрибутивов
Borz
19.07.2017 15:13+1да, ещё про кеширование. в том же README.md есть секция "Known issues" — там как раз пример с использованием кеша
kullfar
19.07.2017 15:17Выглядит, что такое сложнее настроить. Придется на каждом «голом» образе, где планируется сборка ветки, предсоздавать директорию с постгресом и именно тем, что нужен для конкретной ветки.
Borz
19.07.2017 15:26эм. а как доставка в образ дистрибутива происходит в otj-pg-embedded? разве не так же?
т.е. есть "голый" образ, в который доставляется архив дистрибутива сервера, либо есть "неголый" образ с уже залитым дистрибутивомkullfar
19.07.2017 15:41ну грубо говоря, CI видит новый коммит-ветку, берёт голый образ/виртуалку/chroot. в нём
1.git clone…
2.cd…
3.mvn clean installBorz
19.07.2017 15:50повторю вопрос — откуда otj-pg-embedded в этом образе получает дистрибутив PostgreSQL? и как выглядит у вас запуск сервера БД? не "EmbeddedPostgresRules.singleInstance();" же используете?
kullfar
19.07.2017 16:14внутри мавен-артифакта лежит. т.е. из класспаса получает.
А запуск сервера БД идет в коде тестового класса:
final EmbeddedPostgres pg = EmbeddedPostgres.builder().start();
jdbcUrl = pg.getJdbcUrl(PG_USERNAME, PG_PASSWORD);
и дальше этот jdbcUrl используется для создания датасурсов всевозможныхBorz
19.07.2017 16:19ну, т.е. по сути, вы всё равно делаете доставку артефакта дистрибутива сервера в образ, просто средствами Maven.
kullfar
19.07.2017 16:26да. именно так и написал в первом комментарии. и кешируется внутри локальной сети средствами локально запущенного мавен-репозитария (на 99% уже установленного).

kemenov
19.07.2017 15:49+1А есть возможность подключать extensions например postgis, и как много с этим проблем?
deebun
19.07.2017 15:58В данный момент такой возможности нет, но в проекте otj-pg-embedded на github этот вопрос уже поднимался (в том числе, каким образом это можно было бы реализовать)
kullfar
19.07.2017 16:18ну вообще, в opentable можно подсунуть свой архив с постгрес. не совсем тривиально, но вполне реально, с яндексом проблематичнее вышло. У яндекса только выбрать из их predefined набора версий можно. Что-то кастомное выглядит сложнее, чем в opentable подсунуть.
Borz
19.07.2017 16:22а разве
postgres.start(cachedRuntimeConfig("/path/to/my/extracted/postgres"));это не то самое "кастомное"?kullfar
19.07.2017 16:29Ну опять же — думать про доставку в среду.
и даже без CI.
Пришёл новый разработчик в компанию. И вместо git clone && mvn clean install, еще придётся постгрес качать, разворачивать.Borz
19.07.2017 16:35+1я для Gradle плагин сделал, который можно использовать и тогда разработчику не придётся заморачиваться. Так же под Maven можно сделать.
Это не предложение поменять библиотеку, а озвучивание того, что проблемы как бы и нет в qatools о которых писалосьHonoured_Nihilist
21.07.2017 10:43Говорят, хорошая примета сперва искать готовые решения :)
https://github.com/honourednihilist/gradle-postgresql-embedded
https://github.com/honourednihilist/gradle-postgresql-embedded-exampleBorz
21.07.2017 10:50наверное стоит дописать в readme почему я не стал его использовать и контрибьютить туда, да? :)
Или сами сравните текущие readme и код там и у меня? ну, чтобы разницу в подходах увидеть...
Lanwen
19.07.2017 16:24+4Про «Детище Яндекса» смешно :) На самом деле просто так случилось, что правами на код обладает Яндекс, так как он был написан частично в рабочее время для тестирования в том числе и рабочих проектов. А сейчас вообще меинтейнится человеком, не работающим в Яндексе.
Сейчас это выражение выглядит мягко говоря разжигающим, поэтому просьба подкорректировать.
smecsia
19.07.2017 17:23+3postgresql-embedded maintainer here.
Спасибо за статью, кто-то давно должен был написать что-то подобное, поскольку изложенная проблема актуальна долгое время, но при этом ни одной внятной статьи на данную тему я пока не видел.
Когда создавался проект postgresql-embedded, я к сожалению, не нашёл otj-pg-embedded и поэтому на коленке собрал своё решение, которое постепенно приобрело некоторую популярность. Основано оно было на библиотеке, которую использует embed.mongo, а в ней было обнаружилось немало архитектурных проблем, что в итоге сказалось на удобности API… Но история долгая, с тех пор API попричесался, а некоторые изложенные в статье проблемы на текущий момент решены.
Присоединяюсь к предыдущему комментарию — большая просьба подредактировать текст и убрать слова про «Детище Яндекса», поскольку они довольно далеки от реальности.
Хочу также слегка оправдаться за доставку артефакта из внешней сети. Данный вопрос поднимался в issues. На текщий момент это не совсем тривиально, но тем не менее довольно легко сконфигурировать с помощью PostgresDownloadConfigBuilder, который передаётся в RuntimeConfigBuilder. Там можно задать любой источник архивов, в том числе и локальный maven репозиторий.

Envek
19.07.2017 21:06+1А не проще ли использовать обычный отдельный PostgreSQL в Docker-контейнере? Нужен постгрес с кастомными расширениями и конфигами? Написал Dockerfile с этим всем и дальше уже проблемы докера — он и установит и соберёт и образ полученный закэширует.
Borz
19.07.2017 21:31+1нет, не проще.
тут сейчас как? есть Maven/Gradle и JDK. Запустил и понеслось хоть прям из IDE.
А вы как предлагаете? Отдельно поставить ещё и Docker и потом уже запускаться, да?
Здесь же говорится про запуски со стороны разработчика, а не серверного стенда.
Например у нас применяется гибридная модел — Embedded & Docker

relgames
20.07.2017 17:00+1Можно запускать Docker контейнеры прямо из тестов.
Мы используем свой велосипед, но я хочу перейти на TestContainersBorz
20.07.2017 17:07-1которые под капотом используют com.github.docker-java, который под капотом использует установленный в ОС Docker клиент. Вернулись к "поставить ещё и Docker" и к проблеме мультиОС поддержки
VolCh
19.07.2017 21:25+2По статье и комментам сложилось впечатление, что всё это актуально только для экосистемы Java. Правильно?

k_ram_s
20.07.2017 10:47+1А в сторону использования контейнеров не смотрели, тот же Docker? Почему вы используете такой вариант, нежели, к примеру, поднимать контейнер с postgresql при тестировании?
Интересно ваше мнение на этот счёт. Спасибо.deebun
20.07.2017 10:53Для прогона тестов на машине разработчика хотелось бы ограничиться Maven'ом, зачем городить дополнительную инфраструктуру?
AlexWinner
20.07.2017 11:47В докере можно поднимать и остальные сервисы, к которым может ходить сервис разработчика. Раз уже вопрос вышел за рамки юнит тестирования, которое по идее базу не должно трогать.

Nikita
20.07.2017 11:54+1Такая тестовая инфраструктура в hh тоже есть, но здесь же речь шла о запуске unittest'ов, немного другой уровень проблемы.
VolCh
20.07.2017 12:18Юнит-тестирование SQL-кода должно не трогать не базу, а остальной код, в данном случае Java похоже. Судя по всему возможностей Hibernate оказалось недостаточно и ребята стали писать SQL-запросы руками. А их надо как-то тестировать.
viartemev
20.07.2017 12:49У нас есть опыт использования embedded Postgre от Яндекса, из-за этого чуда все работает адски медленно, чем не угодил вариант работы с Docker?
deebun
20.07.2017 13:00+1Не хотелось усложнять инфраструктуру для запуска тестов на машинах разработчиков (выше в комментариях уже про это говорили). По поводу скорости — после некоторых оптимизаций, описанных в последней части статьи, в особенности после того, как задействовали пул соединений — тесты стали проходить так же быстро, как и при использовании in-memory базы.
k_ram_s
20.07.2017 17:01Т.е юнит тесты у вас прогоняются непосредственно на машинах разработчиков, не на CI сервере?
Borz
20.07.2017 17:11+2вполне нормально, когда часть или все Unit-тесты прогонятся у разработчика "здесь и сейчас", а не ожидая своей очереди на CI сервере.
С другой стороны, та же связка IDEA+TeamCity позволяет отправлять на CI патчи без коммита в VCS с целью протестировать. Хотя это тоже поставит их в очередь.k_ram_s
20.07.2017 20:00спасибо за ответы!
Еще такой нескромный вопрос — почему в качестве пула выбрали c3p0, а не, к примеру, hikaricp? hikaricp вроде как активно развивается по сравнение с теми же c3p0,bonecp… Или вам было достаточно c3p0 и вы с ним уже работали, поэтому не стали использовать что-то другое?Borz
20.07.2017 22:38эм, а вопрос точно мне предназначается?
k_ram_s
20.07.2017 23:17Borz простите.
конечно вопрос был адресован автору статьи — deebun, забыл упомянуть его в предыдущем комментарии…
deebun ответьте, пожалуйста, на этот вопрос, если вам будет не сложно:
Еще такой нескромный вопрос — почему в качестве пула выбрали c3p0, а не, к примеру, hikaricp? hikaricp вроде как активно развивается по сравнение с теми же c3p0,bonecp… Или вам было достаточно c3p0 и вы с ним уже работали, поэтому не стали использовать что-то другое?
deebun
21.07.2017 10:24Да, все верно. У нас есть опыт использования c3p0 в проектах, поэтому выбрали именно его.
Borz
21.07.2017 10:37а перейти на HikariCP думаете? он пошустрее будет. Или ваши тесты показали иное? Или "работает и ладно"?
deebun
21.07.2017 17:31Пробовали HikariCP, кстати, этот пул сейчас используется в продакшене в одном из проектов. C3P0 пока устраивает по скорости, поэтому нет смысла все переводить на Hikari (тем более, был эксперимент еще с одним репозиторием, ощутимого выигрыша в скорости не заметили). Юнит-тесты выполняются одинаково быстро, что с тем, что с другим.
VolCh
20.07.2017 18:20+3Там где практикуется TDD часто просто нельзя отправлять коммиты в репу без всех зеленых тестов.
rraderio
28.07.2017 14:59А где хранятся данные, на диске или в оперативной памяти?
Можно сделать Speedup unit tests by moving MySql data to memory,
Borz
используя Embedded PostgreSQL server, surefire пробовали использовать PostgresEmbeddedService?
kullfar
так в первых абзацах про сравнение yandex-qatools и otj-pg-embedded написано.
Borz
из того абзаца по пунктам.
1) то же самое можно сделать и в yandex-qatools, хотя да, "из коробки" это сразу не работает
2) версия подменяется при создании экземпляра класса EmbeddedPostgres, о чём в README.md в секции "How to use your custom version of PostgreSQL" написано
3) в qatools пока больших лагов в общении не заметил
4) для "разобраться" в кишках в том, как работает qatools чтобы сделать парочку исправлений мне хватило пары. дней. Для базовых настроек даже не помню сколько потратил времени, но очень мало
5) про логирование в том же README.md написано, а про "запуск одной строкой" — тоже вроде как работает "из коробки" — EmbeddedPostgres().start(_набор_параметров_длязапуска)