

В начале XX века Вильгельм фон Остин, немецкий тренер лошадей и математик, объявил миру, что научил лошадь считать. Годами фон Остин путешествовал по Германии с демонстрацией этого феномена. Он просил свою лошадь по кличке Умный Ганс (породы орловский рысак), подсчитывать результаты простых уравнений. Ганс давал ответ, топая копытом. Два плюс два? Четыре удара.
Но учёные не верили в то, что Ганс был таким умным, как заявлял фон Остин. Психолог Карл Штумпф провёл тщательное расследование, которое окрестили «Гансовским комитетом». Он обнаружил, что Умный Ганс не решает уравнения, а реагирует на визуальные сигналы. Ганс выстукивал копытом, пока не добирался до правильного ответа, после чего его тренер и восторженная толпа разражались криками. А затем он просто останавливался. Когда он не видел этих реакций, он так и продолжал стучать.
Информатика может многому научиться у Ганса. Ускоряющийся темп разработки в этой области говорит о том, что большая часть созданного нами ИИ обучилась достаточно для того, чтобы выдавать правильные ответы, но при этом не понимает информацию по-настоящему. И его легко обмануть.
Алгоритмы машинного обучения быстро превратились во всевидящих пастухов людского стада. ПО соединяет нас с интернетом, отслеживает в нашей почте спам и вредоносный контент, а вскоре будет водить наши машины. Их обман сдвигает тектонический фундамент интернета, и угрожает нашей безопасности в будущем.
Небольшие исследовательские группы – из Пенсильванского государственного университета, из Google, из военного ведомства США – разрабатывают планы защиты от потенциальных атак на ИИ. Теории, выдвинутые в исследовании, говорят, что атакующий может изменить то, что «видит» робомобиль. Или активировать распознавание голоса на телефоне и заставить его зайти на вредоносный сайт при помощи звуков, которые будут для человека только шумом. Или позволить вирусу просочиться через сетевой файервол.

Слева – изображение здания, справа – изменённое изображение, которое глубинная нейросеть относит к страусам. В середине показаны все изменения, применённые к первичному изображению.
Вместо перехвата контроля над управлением робомобилем, этот метод демонстрирует ему что-то вроде галлюцинации – изображение, которого на самом деле нет.
Такие атаки используют изображения с подвохом [adversarial examples – устоявшегося русского термина нет, дословно получается нечто вроде «примеры с противопоставлением» или «соперничающие примеры» – прим. перев.]: изображения, звуки, текст, выглядящие нормальными для людей, но воспринимаемые совершенно по-другому машинами. Небольшие изменения, сделанные атакующими, могут заставить глубинную нейросеть сделать неправильные выводы о том, что ей демонстрируют.
«Любая система, использующая машинное обучение для вынесения решений, критичных для безопасности, потенциально уязвима для такого рода атак», – говорит Алекс Канчельян, исследователь из Университета Беркли, изучающий атаки на машинное обучение при помощи обманных изображений.
Знание этих нюансов на ранних этапах разработки ИИ даёт исследователям инструмент к пониманию методов исправления этих недостатков. Некоторые уже занялись этим, и говорят, что их алгоритмы из-за этого стали ещё и эффективнее работать.
Большая часть основного потока исследований ИИ зиждется на глубинных нейросетях, в свою очередь основывающихся на более обширной области машинного обучения. Технологии МО используют дифференциальное и интегральное исчисление и статистику для создания используемого большинством из нас софта, вроде спам-фильтров в почте или поиска в интернете. За последние 20 лет исследователи начали применять эти техники к новой идее, нейросетям – программным структурам, имитирующим работу мозга. Идея в том, чтобы децентрализовать вычисления по тысячам небольших уравнений («нейронов»), принимающих данные, обрабатывающих и передающих их далее, на следующий слой из тысяч небольших уравнений.
Эти ИИ-алгоритмы обучаются так же, как и в случае с МО, которое, в свою очередь, копирует процесс обучения человека. Им демонстрируют примеры разных вещей и связанные с ними метки. Покажите компьютеру (или ребёнку) изображение кота, скажите, что кот выглядит вот так, и алгоритм научится распознавать котов. Но для этого компьютеру придётся просмотреть тысячи и миллионы изображений котов и кошек.
Исследователи обнаружили, что эти системы можно атаковать при помощи особым образом подобранных обманных данных, которые они назвали «adversarial examples».
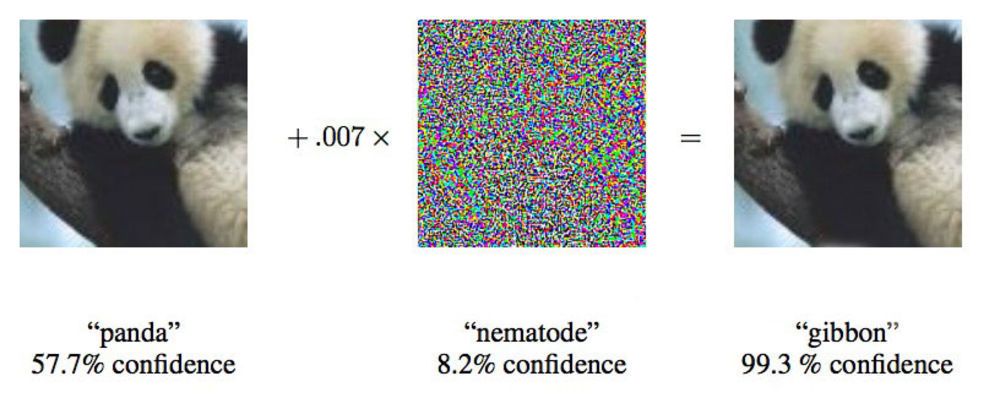
В работе от 2015 года исследователи из Google показали, что глубинные нейросети можно заставить отнести это изображение панды к гиббонам.
«Мы показываем вам фото, на котором явно видно школьный автобус, и заставляем думать, что это страус», – говорит Йэн Гудфелло [Ian Goodfellow], исследователь из Google, активно работающий в области подобных атак на нейросети.
Изменяя предоставляемые нейросетям изображения всего на 4%, исследователи смогли обмануть их, заставив ошибиться с классификацией, в 97% случаев. Даже если им не было известно, как именно нейросеть обрабатывает изображения, они могли обмануть её в 85% случаев. Последний вариант обмана без данных об архитектуре сети называется «атакой на чёрный ящик». Это первый документированный случай функциональной атаки подобного рода на глубинную нейросеть, и его важность заключается в том, что примерно по такому сценарию и могут проходить атаки в реальном мире.
В работе исследователи из Пенсильванского государственного университета, компании Google и Исследовательской лаборатории при ВМФ США провели атаку на нейросеть, классифицирующую изображения, поддерживаемую проектом MetaMind и служащую онлайн-инструментом для разработчиков. Команда построила и натренировала атакуемую сеть, но их алгоритм атаки работал независимо от архитектуры. С таким алгоритмом они смогли обмануть нейросеть-«чёрный ящик» с точностью до 84,24%.

Верхний ряд фото и знаков – правильное распознавание знаков.
Нижний ряд – сеть заставили распознавать знаки совершенно неправильно.
Скармливание машинам некорректных данных – идея не новая, но Даг Тайгар [Doug Tygar], профессор из Университета в Беркли, изучавший машинное обучение с противопоставлением в течение 10 лет, говорит, что эта технология атак превратилась из простого МО в сложные глубинные нейросети. Злонамеренные хакеры применяли эту технику на спам-фильтрах годами.
Исследование Тайгера берёт начало из работы 2006 года по атакам подобного рода на сети с МО, которую в 2011 году он расширил при помощи исследователей из Калифорнийского университета в Беркли и Microsoft Research. Команда Google, первой начавшая применять глубинные нейросети, опубликовала свою первую работу в 2014 году, через два года после обнаружения возможности таких атак. Они хотели убедиться в том, что это не какая-то аномалия, а реальная возможность. В 2015 они опубликовали ещё одну работу, в которой описали способ защиты сетей и повышения их эффективности, и Йэн Гудфелло с тех пор давал консультации и по другим научным работам в этой области, включая и атаку на чёрный ящик.
Исследователи называют более общую идею о ненадёжной информацией «византийскими данными», и благодаря ходу исследований они пришли к глубинному обучению. Термин происходит от известной "задачи византийских генералов", мысленном эксперименте из области информатики, в котором группа генералов должна координировать свои действия при помощи посыльных, не обладая при этом уверенностью в том, кто из них – предатель. Они не могут доверять информации, полученной от своих коллег.
«Эти алгоритмы разработаны так, чтобы справляться со случайным шумом, но не с византийскими данными», – говорит Тайгар. Чтобы понять, как такие атаки работают, Гудфелло предлагает представить себе нейросеть в виде диаграммы рассеивания.
Каждая точка диаграммы представляет один пиксель изображения, обрабатываемый нейросетью. Обычно сеть пытается провести линию через данные, наилучшим образом соответствующую совокупности всех точек. На практике это немного сложнее, поскольку у разных пикселей разная ценность для сети. В реальности это сложный многомерный график, обрабатываемый компьютером.
Но в нашей простой аналогии диаграммы рассеивания форма линии, проводимой через данные, определяет то, что, как думает сеть, она видит. Для успешной атаки на такие системы исследователям нужно поменять лишь небольшую часть этих точек, и заставить сеть вынести решение, которого на самом деле нет. В примере с автобусом, выглядящим, как страус, фото школьного автобуса испещрено пикселями, расположенными по схеме, связанной с уникальными характеристиками фотографий страусов, знакомыми сети. Это невидимый глазом контур, но когда алгоритм обрабатывает и упрощает данные, экстремальные точки данных для страуса кажутся ей подходящим вариантом классификации. В варианте с чёрным ящиком исследователи проверяли работу с разными входными данными, чтобы определить, как алгоритм видит определённые объекты.
Давая классификатору объектов подложные входные данные и изучая решения, принятые машиной, исследователи смогли восстановить работу алгоритма так, чтобы обмануть систему распознавания изображений. Потенциально такая система в робомобилях в подобном случае может вместо знака «стоп» увидеть знак «уступи дорогу». Когда они поняли, как работает сеть, они смогли заставить машину увидеть всё, что угодно.
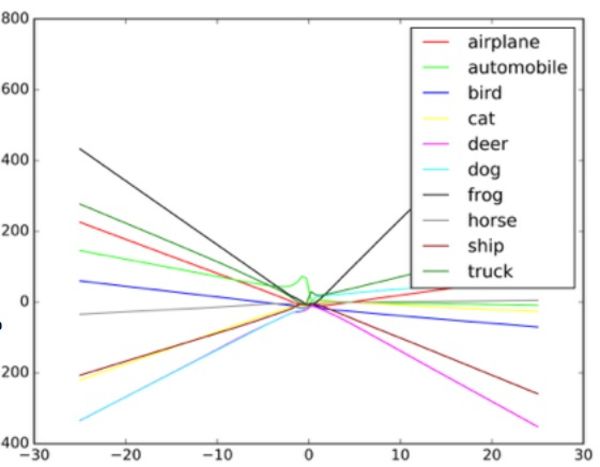
Пример того, как классификатор изображений проводит разные линии в зависимости от различных объектов на изображении. Примеры-обманки можно рассматривать как экстремальные величины на графике.
Исследователи говорят, что такую атаку можно ввести непосредственно в систему обработки изображений, минуя камеру, или эти манипуляции можно провести с реальным знаком.
Но специалист по безопасности из Колумбийского университета Элисон Бишоп говорит, что такой прогноз нереалистичен, и зависит от системы, используемой в робомобиле. Если у атакующих уже есть доступ к потоку данных с камеры, они и так могут выдать её любые входные данные.
«Если они могут добраться до входа камеры, такие сложности не нужны, – говорит она. – Вы можете просто показать ей знак 'стоп'».
Другие методы атаки, кроме обхода камеры – например, нанесение визуальных меток на реальный знак, кажутся Бишоп слабо вероятными. Она сомневается, что камеры с низким разрешением, используемые на робомобилях, вообще смогут различить небольшие изменения на знаке.

Нетронутое изображение слева классифицируется, как школьный автобус. Исправленное справа – как страус. В середине – изменения картинки.
Две группы, одна – в Университете в Беркли, другая – в Университете Джорджтауна, успешно разработали алгоритмы, способные выдавать речевые команды цифровым ассистентам вроде Siri and Google Now, звучащие как неразборчивый шум. Для человека такие команды покажутся случайным шумом, но при этом они могут давать команды устройствам вроде Alexa, непредусмотренные их владельцем.
Николас Карлини, один из исследователей византийских аудио-атак, говорит, что они в своих тестах смогли активировать распознающие аудио программы с открытым кодом, Siri и Google Now, с точностью более 90%.
Шум похож на какие-нибудь переговоры инопланетян из научной фантастики. Это смесь из белого шума и человеческого голоса, но она совсем не похожа на голосовую команду.
По словам Карлини, при такой атаке любой услышавший шум телефон (при этом необходимо раздельно планировать атаки на iOS и Android) можно заставить зайти на веб-страницу, также проигрывающую шум, что заразит и находящиеся рядом телефоны. Или же эта страница может по-тихому скачать вредоносную программу. Также есть возможность, что такие шумы проиграют по радио, и они будут запрятаны в белом шуме или параллельно с другой аудиоинформацией.
Такие атаки могут происходить, поскольку машину тренируют на то, что практически в любых данных содержатся важные данные, а также, что один вещи встречаются чаще других, как объясняет Гудфелло.
Обмануть сеть, заставив её поверить в то, что она видит распространённый объект, легче, поскольку она считает, что должна видеть такие объекты чаще всего. Поэтому Гудфелло и ещё одна группа из Университета Вайоминга смогли заставить сеть классифицировать изображения, которых вообще не было – она идентифицировала объекты в белом шуме, случайно созданных чёрных и белых пикселах.
В исследовании Гудфелло случайный белый шум, пропускаемый через сеть, классифицировался ею как лошадь. Это, по совпадению, возвращает нас к истории Умного Ганса, не очень сильно математически одарённой лошади.
Гудфелло говорит, что нейросети, как и Умный Ганс, на самом деле не выучивают какие-то идеи, а лишь учатся узнавать, когда находят нужную идею. Разница небольшая, но важная. Отсутствие фундаментальных знаний облегчает злонамеренные попытки воссоздавать видимость нахождения «правильных» результатов алгоритма, которые на поверку оказываются ложными. Чтобы понимать, чем нечто является, машине нужно также понять, чем оно не является.
Гудфелло, натренировав сортирующие изображения сеть как на естественных изображениях, так и на обработанных (поддельных), обнаружил, что смог не только уменьшить эффективность таких атак на 90%, но и заставить сеть лучше справляться с первоначальной задачей.
«Заставляя объяснять реально необычные поддельные изображения, можно добиться ещё более надёжного объяснения лежащих в основе концепций», – говорит Гудфелло.
Две группы исследователей аудио использовали подход, похожий на подход команды Google, защищая свои нейросети от своих же атак путём перетренировки. Они тоже добились сходных успехов, более чем на 90% уменьшив эффективность атаки.
Неудивительно, что эта область исследований заинтересовала военное ведомство США. Армейская исследовательская лаборатория даже спонсировала две самых новых работы на эту тему, включая атаку на чёрный ящик. И хотя ведомство финансирует исследования, это не означает, что технологию собираются использовать в войне. Согласно представителю ведомства, от исследований до пригодных для использования солдатом технологий может пройти до 10 лет.
Анантрам Свами [Ananthram Swami], исследователь из армейской лаборатории США принимал участие в создании нескольких недавних работ, посвящённых обману ИИ. Армия интересуется вопросом обнаружения и остановки обманных данных в нашем мире, где не все источники информации можно тщательно проверить. Свами указывает на набор данных, полученных с публичных датчиков, расположенных в университетах и работающих в проектах с открытым кодом.
«Мы не всегда контролируем все данные. Нашему противнику довольно легко обмануть нас, – говорит Свами. – В некоторых случаях последствия такого обмана могут быть несерьёзными, в некоторых – наоборот».
Также он говорит, что армия интересуется автономными роботами, танками и другими средствами передвижения, поэтому цель таких исследований очевидна. Изучая эти вопросы, армия сможет выиграть себе фору в разработке систем, неподверженных атакам подобного рода.
Но у любой использующей нейросети группы должны возникать опасения по поводу потенциальной возможности атак с обманом ИИ. Машинное обучение и ИИ находятся в зачаточном состоянии, и в это время промашки с безопасностью могут иметь ужасные последствия. Многие компании доверяют весьма чувствительную информацию системам ИИ, не прошедшим проверку временем. Наши нейросети ещё слишком молоды, чтобы мы могли знать про них всё, что нужно.
Похожий недосмотр привёл к тому, что бот для твиттера от Microsoft, Tay, быстро превратился в расиста со склонностью к геноциду. Поток вредоносных данных и функция «повторяй за мной» привели к тому, что Tay сильно отклонился от намеченного пути. Бот был обманут некачественными входными данными, и это служит удобным примером плохой реализации машинного обучения.
Канчельян говорит, что не считает, будто возможности подобных атак исчерпаны после успешных исследований команды из Google.
«В области компьютерной безопасности атакующие нас всегда опережают, – говорит Канчельян. – Довольно опасно будет заявлять, будто мы решили все проблемы с обманом нейросетей при помощи их повторной тренировки».
Комментарии (34)

FuzzyWorm
03.08.2017 19:02+1Что-то мне Пелевинские «Зенитные кодексы Аль-Эфесби» вспомнились. Там слегка другая атака была, но похоже…


kraidiky
03.08.2017 19:56+3Разводка ради бюджетов. Неустойчивость одной переобученой сети к максимизации ошибки давно известный феномен, тем более простой чем больше входных фич. Абсолютно бесполезно если вы не контроллируете сеть полностью. Абсолютно бесполезно если решение сети стакается из нескольких, из которых хотя бы одну вы не знаете. Абсолютно бесполезно если сеть сама стакается с собой добавляя к сети рандомизированные дисплейсменты и так далее.
Зато круто для статьи и гики ведутся. :\
BelerafonL
03.08.2017 22:10+1Судя по всему Вы не правы. Посмотрите оригинальную статью — https://arxiv.org/pdf/1602.02697v2.pdf
Adversarial examples are known to transfer from one model to another, even if the second model has a
different architecture or was trained on a different set. We introduce the first practical demonstration that this
cross-model transfer phenomenon enables attackers to control a remotely hosted DNN with no access to the model, its parameters, or its training data.
Так что хоть несколько сетей вместе в виде «черного ящика», хоть шум на вход сети добавлять, все равно атака работает.
andrey_gavrilov
04.08.2017 10:53в цитате нет того, что вы ей приписываете, а именно, рассказа о ансамбле моделей, вашего «Так что хоть несколько сетей вместе в виде «черного ящика»», ни о «хоть шум на вход сети добавлять, все равно атака работает».

SADKO
04.08.2017 20:55-1А это не важно, ибо даже самые упёртые заводчики чёрных ящиков, стекают их отнюдь не просто так, от балды.
И самым опофигеем ИМХО является натаскивание одного чёрного ящика, на ошибки другого, это тупо, но при правильной размерности это работает…
… и вообще, у ансамблей есть вполне конкретные математические смыслы если их по искать, но не мне палить контору, разумеющий да уразумеет…
kraidiky
04.08.2017 23:01Мне трудно поверить, что это не очень частные случаи, потому что это очень-очень сильно противоречит моим представлениям о том, каков математический смысл ошибок на линии максимальной произовдной по ошибке в очень многомерном пространстве фич. Если они правы, их искажение заставит картинку неправильно детектироваться даже если её повернуть, например, на 5 градусов по часовой стрелке (паралельные преобразования не в счёт), тогда я полагаю очень скоро мы услышим подтверждения других авторов, которые повторили эти результаты.
И если такие подтверждения будут мне потребуется серьёзно переучиваться.cepera_ang
05.08.2017 17:13+1Типа такого?
DiaG
06.08.2017 02:59Более того, не обязательно иметь возможность попиксельной модификации изображения (на стадии после захвата изображения). Ссылка на публикацию.
Т.е. можно добавлять модификацию к физическому объекту, и они также будут приводить к ложной классификации. Учитывая факт, что разные модели имеют общие adversarial expamples ничто не мешает обучить свои модели, подобрать эти примеры для дорожных знаков/дорожной разметки и нанести их на объекты. Вполне реальная атака.BelerafonL
06.08.2017 10:12+1Ну, конечно, при условии доступа либо к обучающему набору данных, либо к «игре» с атакуемой моделью как с черным ящиком.
cepera_ang
05.08.2017 17:21Есть universal adversarial examples:
[1] https://arxiv.org/abs/1610.08401
[2] https://arxiv.org/abs/1704.05712
[3] https://arxiv.org/abs/1705.09554
lash05
03.08.2017 21:04-1Сама идея «решения без понимания» ущербна, а нейросети как раз эту идею и воплощают.

Elegar
03.08.2017 23:15+2Вообще-то большинство решений люди тоже принимают без понимания. И я даже не про рефлекторные действия говорю. Например, для 99.9% пользователей компьютер является чёрным ящиком
ZiingRR
04.08.2017 09:56Странно сравнивать в этой ситуации людей и нейросети. Отсутствие прозрачности процесса принятия решений создаёт определённые проблемы даже с нынешними алгоритмами. Чего уж говорить о будущих системах ИИ, превосходящих людей во всех областях знаний и умений.
tarasale
03.08.2017 22:50+1С каких это пор машины не могут наезжать на панд, но могут на гиббонов? А если не могут и на тех и на других то не пофиг ли как именно воспринимается препятствие, в которое врезаться нельзя?
При этом большая часть подобных проблем в корне устраняется включением машин в самоорганизующуюся децентрализованную сеть, в которой автомобили будут рассказывать друг другу про каждую колдобину и за считанные секунды сдавать ГАИ каждого нарушающего правила-кем бы он ни был.
TheShock
04.08.2017 02:18Когда у машины есть выбор — наехать или на гиббона или на панду — она должна выбрать гиббона, потому что панды — миленькие и их все любят
tarasale
04.08.2017 10:50Вспоминается старый анекдот
«На экзамене в грузинской автошколе инструктор спрашивает курсанта:
— Вот вы едете по узкой горной дороге. Слева стоит старуха, справа — красивая девушка. Кого давить будешь?
— Конечно, бабушку!
— Дурак! Тормоз давить будешь! „
И это верный вариант, единственно разрешенный ПДД.
kxx
03.08.2017 23:44+1Проблема актуальная — на kaggle сейчас аж три соревнования по атакам и защитам есть.
Tachyon
04.08.2017 07:52разрабатывают планы защиты от потенциальных атак на ИИ.
То-есть, если чисто теоретически, ИИ может стать опасным для человечества, то оно само уже и защиту от себя придумывает… В общем глобальная Премия Дарвина.
Ну а если серьёзно, то люди давно делают то, что потенциально может их убить: от химико-биологического и ядерного оружия, до просто автомобилей. Но раз этого не произошло всё ещё, то думаю и с ИИ, когда создадут, справятся.ZiingRR
04.08.2017 09:36Но раз этого не произошло всё ещё, то думаю и с ИИ, когда создадут, справятся.
Ошибка выжившего ведь

Alexsandr_SE
04.08.2017 10:24Походу глазом заметно картинку фоновую которую добавляют. Значить нейросеть переводит для изучения оригинал фотографии в подобный вид и работает уже с ним. Отсюда возможность подать более яркие сигнальные (ключевые) моменты в исходную фотографию. Все же нейросеть не умеет видать обрабатываь картинки по другому. Она аоходу вычисляет в начале ключевые контуры и только потом пытается сообразить на что это похоже.
ainoneko
04.08.2017 19:21Какому-то глазастому Походу может и быть заметно, а для людей и роботов добавляемая картинка (для «панда в гиббон») умножена на 0.007 (меньше процента).
SADKO
04.08.2017 20:35В том то и дело, что глубокая-свёрточная, она по принципу сетчатки, устроена и на такой развод не поведётся…
… а вот какой-нибудь натасканный на обучающее множество, пусть глубокий, но тупой персептрон, из которого можно тупо взять веса, и малыми изменениями исходного изображения получить его «ошибочное» срабатывание…
… весь смысл выявления фичь вообще, и глубоких-свёрточных сетей в частности, в том что бы такой шляпы не было, и если сети предъявляют треугольник, то хоть его размой, хоть искази в пределах разумного, он остаётся треугольником, а не квадратом, жирафом или пандой, по чисто человеческим критериям…
equand
04.08.2017 15:56Я давно писал о том, что обработка векторного изображения в битах и подача на нейронку не верный подход!
Необходимо чтобы нейросеть преобразовывала двухмерную картинку в трехмерные векторные объекты без опоры на битовые данные растра и их сочетания. Именно поэтому нейросети не «видят», а только номера складывают.erwins22
04.08.2017 19:17А преобразование в трехмерное вы как будете делать?
SADKO
04.08.2017 21:12Например так-же как это делает человеческий глаз, там правда смысл этого мероприятия несколько иной, поднять разрешение, у свёрточных сетей его с избытком, но можно например не только таскать но и крутить и\или масштабировать, вот и получается инвариантность к повороту\масштабу\положению из говна и палок :-)
SADKO
04.08.2017 20:17Не ребята, это немного из разряда «учёный изнасиловал журналиста». Глубокими, свёрточными сетями тут и не пахнет, тк они в первых же слоях, превращают изображение в набор весьма тупых фич, а тут искажения не заметны на глаз, так-что по всей видимости учёные надругались над вызубрившим примеры песептроном, который и от элементарного шума такими глюками разойдётся, что и Путин и Трамп ему вполне сойдут за жирафа, хотя в этом наверное есть смысл ибо как сказал поэт Жираф большой, Ему видней :-)

SpiridonovAA
06.08.2017 02:59Люди тоже подвержены таким атакам. Многим мерещится знаменитое «лицо на Марсе»

Marble13
06.08.2017 15:27+1Какие-то гипнотические методики тут замешаны. Смотрела-смотрела, но никак мне автобус страуса не напомнил))
seminole
Вау, сила! Одел очки с хитрым узором и стал страусом.
p_fox
Надел.
nkie
«Надел пиджак, набул ботинки»… извините не удержался