
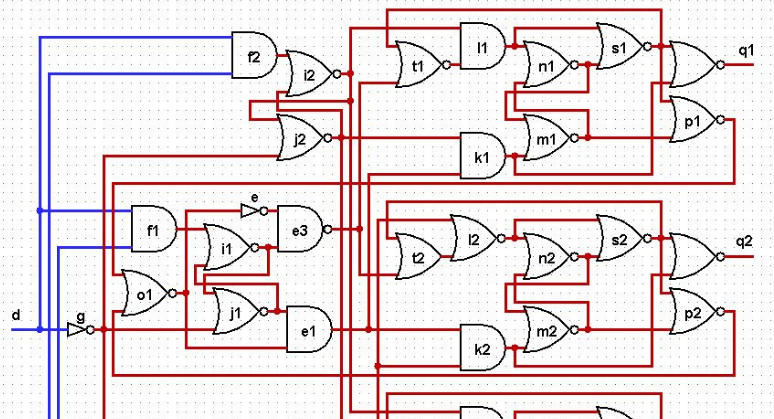
Прочитал статью FPGA/Асинхронный дешифратор от ajrec.
Я сперва прочитал и ничего не понял, а потом прочитал еще раз и опять ничего не понял. На самом деле я прочитал уже все статьи ajrec про асинхронные схемы и должен констатировать, что мало понимаю, что это вообще такое (хотя считаю, что опыт проектирования в FPGA у меня есть).
В комментариях к статьям автор в основном получает минусы, народ посмеивается и кажется так же не понимает, как и я.
Честно говоря, я всегда с любопытством смотрю на проекты, которые «не такие, как все». Я считаю, что только такие проекты имеют шанс либо глубоко провалиться, либо высоко взлететь. Если делаешь что-то так же, как и сотни других разработчиков, то идешь проторенной дорогой, здесь легко и комфортно. Сделать шаг в сторону и пойти своей тропой могут далеко не все.
Я попробовал разобраться в проекте асинхронного дешифратора и по крайней мере сделать временную симуляцию кода в ModelSim. Далее о том, что из этого получилось.
Честно говоря, изложенное в статье "Асинхронный дешифратор" и "Система синтеза самосинхронных схем Petrify: проблемы и их решение" плохо влазит в мою голову. Я основательно «испорчен методикой синхронного дизайна».
Кроме того, в статье есть странности, которые режут глаз. Вот, например, цитата:
Выходные сигналы:
q1 — переключается если r1=1 и r2=1;
q2 — переключается если r1=1 и r2=0;
q3 — переключается если r1=0 и r2=1;
q4 — переключается если r1=0 и r2=0.
Я наверное придираюсь, но с трудом представляю себе программиста, который пишет нумерацию сигналов начинающуюся с единицы и чтобы q4 переключается, когда r1=0 и r2=0. В моей голове все строго по шаблону: { 0, 0 } — соответствует сигналу q0. { 0, 1 } — соответствует сигналу q1. { 1, 0 } — соответствует сигналу q2 и { 1, 1 } — соответствует сигналу q3. Но это, конечно, мелочи, которые не относятся к делу.
Основная же претензия с моей стороны: автор не проверяет свои гипотезы/исследования/проекты в ПЛИС или любым другим способом. Он пишет: «У меня нет возможности проверить схему в реальном воплощении.» Ну как так то?
Собственно это и подтолкнуло меня к мысли попробовать просимулировать логику описанного ajrec дешифратора. Временная симуляция — это достаточно хорошая модель, которая будет показывать поведение схемы в реальной ПЛИС. Правда… тут есть нюанс — у меня нет полной уверенности, что ModelSim сможет достоверно симулировать асинхронные схемы: симулятор ModelSim предназначен прежде всего для «традиционного» синхронного дизайна.
Итак. Исходный код из статьи FPGA/Асинхронный дешифратор у нас не знаю на каком языке и выглядит следующим образом:
e=NOT(o1); e1=AND(o1,j1); e2=AND(o2,h1); e3=NAND(e,i1);
e4=OR(o2,h1); f1=AND(d,r1); f2=AND(d,r2); g=NOT(d);
h1=NOR(g,r1); h2=NOR(g,r2); i1=NOR(f1,j1); i2=NOR(f2,j2);
j1=NOR(g,i1); j2=NOR(g,i2); k1=AND(e1,j2); k2=AND(e1,h2);
k3=AND(e2,j2); k4=AND(e2,h2); l1=AND(t1,i2); l2=NOR(t2,h2);
l3=AND(t3,i2); l4=NOR(t4,h2); m1=NOR(k1,n1); m2=NOR(k2,n2);
m3=NOR(k3,n3); m4=NOR(k4,n4); n1=NOR(l1,m1); n2=NOR(l2,m2);
n3=NOR(l3,m3); n4=NOR(l4,m4); o1=NOR(p1,p2); o2=NOR(p3,p4);
p1=NOR(m1,s1); p2=NOR(m2,s2); p3=NOR(m3,s3); p4=NOR(m4,s4);
s1=NOR(n1,l1); s2=NOR(n2,l2); s3=NOR(n3,l3); s4=NOR(n4,l4);
t1=NOR(e3,s1); t2=OR(e3,s2); t3=NOR(e4,s3); t4=OR(e4,s4);
q1=NOR(s1,k1); q2=NOR(s2,k2); q3=NOR(s3,k3); q4=NOR(s4,k4).Далее в статье идет эквивалентная схема этой штуки и говорится о том, что вообще-то сигналы m1, m2, m3, m4 нужно еще сбрасывать в исходное состояние перед началом работы. Хорошо, перепишу все это на язык Verilog вот так:
module test(
input wire d,
input wire r1,
input wire r2,
input wire set0,
output wire q1,
output wire q2,
output wire q3,
output wire q4,
output wire [3:0]qq
);
wire e, e1, e2, e3, e4;
wire f1, f2;
wire g;
wire i1, i2;
wire j1, j2;
wire h1, h2;
wire k1, k2, k3, k4;
wire l1, l2, l3, l4;
wire m1, m2, m3, m4;
wire n1, n2, n3, n4;
wire o1, o2;
wire p1, p2, p3, p4;
wire s1, s2, s3, s4;
wire t1, t2, t3, t4;
function NOT;
input s;
begin
NOT=~s;
end
endfunction
function AND;
input s1,s2;
begin
AND=s1&s2;
end
endfunction
function NAND;
input s1,s2;
begin
NAND=~(s1&s2);
end
endfunction
function OR;
input s1,s2;
begin
OR=s1|s2;
end
endfunction
function NOR;
input s1,s2;
begin
NOR=~(s1|s2);
end
endfunction
assign e=NOT(o1); assign e1=AND(o1,j1); assign e2=AND(o2,h1); assign e3=NAND(e,i1);
assign e4=OR(o2,h1); assign f1=AND(d,r1); assign f2=AND(d,r2); assign g=NOT(d);
assign h1=NOR(g,r1); assign h2=NOR(g,r2); assign i1=NOR(f1,j1); assign i2=NOR(f2,j2);
assign j1=NOR(g,i1); assign j2=NOR(g,i2); assign k1=AND(e1,j2); assign k2=AND(e1,h2);
assign k3=AND(e2,j2); assign k4=AND(e2,h2); assign l1=AND(t1,i2); assign l2=NOR(t2,h2);
assign l3=AND(t3,i2); assign l4=NOR(t4,h2);
assign m1=NAND( set0, OR(k1,n1)); /* NOR(k1,n1); */
assign m2=NAND( set0, OR(k2,n2)); /* NOR(k2,n2); */
assign m3=NAND( set0, OR(k3,n3)); /* NOR(k3,n3); */
assign m4=NAND( set0, OR(k4,n4)); /* NOR(k4,n4); */
assign n1=NOR(l1,m1); assign n2=NOR(l2,m2);
assign n3=NOR(l3,m3); assign n4=NOR(l4,m4); assign o1=NOR(p1,p2); assign o2=NOR(p3,p4);
assign p1=NOR(m1,s1); assign p2=NOR(m2,s2); assign p3=NOR(m3,s3); assign p4=NOR(m4,s4);
assign s1=NOR(n1,l1); assign s2=NOR(n2,l2); assign s3=NOR(n3,l3); assign s4=NOR(n4,l4);
assign t1=NOR(e3,s1); assign t2=OR(e3,s2); assign t3=NOR(e4,s3); assign t4=OR(e4,s4);
assign q1=NOR(s1,k1); assign q2=NOR(s2,k2); assign q3=NOR(s3,k3); assign q4=NOR(s4,k4);
assign qq = 1 << {r2,r1};
endmodule
Я постарался в исходный код вносить минимальные изменения, чтобы случайно не нарушить логику, которую я не понимаю. Поэтому я определил Verilog функции AND, OR, NOR, NAND, чтобы они делали то, что должны делать. Присвоение значения сигнала в Verilog делается через assign. Если кому нужно, то вот Краткое описание языка Verilog.
Таким образом, в модуле test имеются входные сигналы декодируемого адреса r1 и r2, а так же сигнал сброса set0 и сигнал d — команда на операцию дешифрации адреса (в терминологии автора). Выходные сигналы q1, q2, q3 и q4.
Кроме этого, я добавил отсебятину, четырехбитный выходной сигнал qq, который вычисляется традиционным дешифратором, вот так: assign qq = 1 << {r2,r1};
Модуль test был вставлен в проект Intel Quartus Prime Lite Edition v16.1 для микросхемы ПЛИС Cyclone IV E.
Проект был скомпилирован. Предварительно в настройках проекта Assignments=> Settings => EDA Tools Settings => Simulation нужно выбрать Tool Name => ModelSim-Altera. Тогда, после компиляции будет создана папка simulation/modelsim в которой будут находиться модули *.sdo и *.vo, которые нужны для временной симуляции.
Теперь нужен testbench. Я написал его по простому:
`timescale 1ns / 1ns
module tb();
reg r1_;
reg r2_;
reg d_;
reg set_;
wire q1_,q2_,q3_,q4_;
wire [3:0]qq_;
test test_inst(
.d(d_),
.r1(r1_),
.r2(r2_),
.set0(set_),
.q1(q1_),
.q2(q2_),
.q3(q3_),
.q4(q4_),
.qq(qq_)
);
initial
begin
$dumpfile("out.vcd");
$dumpvars(0,tb);
//reset m1-m4 signals using "set_"
r1_=0;
r2_=0;
d_=0;
set_=0;
#100;
set_=1;
#100;
//check addr 00
r1_=0;
r2_=0;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 01
r1_=1;
r2_=0;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 10
r1_=0;
r2_=1;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 11
r1_=1;
r2_=1;
#100;
d_=1;
#100;
d_=0;
#200;
//--------------------
//check addr 00
r1_=0;
r2_=0;
d_=1;
#100;
d_=0;
#200;
//check addr 01
r1_=1;
r2_=0;
d_=1;
#100;
d_=0;
#200;
//check addr 10
r1_=0;
r2_=1;
d_=1;
#100;
d_=0;
#200;
//check addr 11
r1_=1;
r2_=1;
d_=1;
#100;
d_=0;
#200;
end
endmoduleЗдесь сигналы адресов r1 и r2 поочередно устанавливаются во все четыре возможные значения 2'b00, 2'b01, 2'b10 и 2'b11, при этом еще вырабатывается этот сигнал d, который активизирует декодирование.
Это все происходит два раза, причем первые четыре сигнала активации дешифрации d происходят при установившихся сигналах r1 и r2, а во второй группе сигналов d приходит одновременно с сигналами r1 и r2. Честно говоря я не знаю, как это на самом деле должно быть по замыслу автора. Именно по этому я рассматриваю вот такой крайний случай, приход сигнала активации d в момент установления сигналов r1 и r2.
Теперь запускаю ModelSim-Altera (или теперь уже Intel). Создаю проект и воркспейс. Добавляю в него два существующих файла: тестбенч tb.v и скомпилированный квартусом проект async_test.vo:
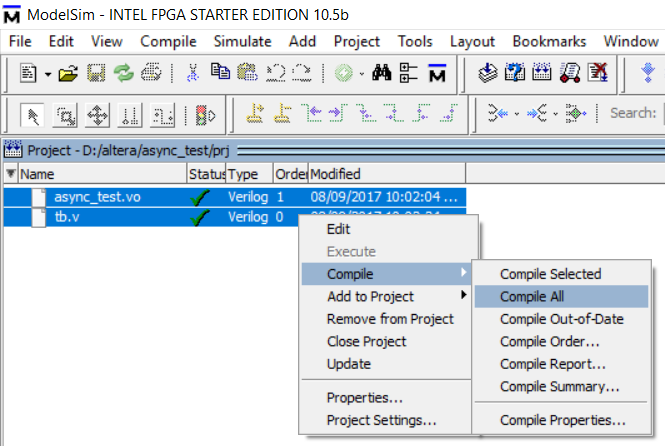
Их теперь еще нужно откомпилировать уже с помощью ModelSim. Правая кнопка мыши и выбираю из меню Compile All. Нужно чтобы появились зеленые чек-марки возле каждого файла. Иногда бывает странность и ModelSim находит синтаксические ошибки там, где их не видит квартус. Это так, к слову.
Теперь можно начинать симуляцию через меню ModelSim, Simulate-> Start Simulation…
Тут появляется диалоговое окно где нужно:
1) выбрать топ модуль и сейчас это тестбенч
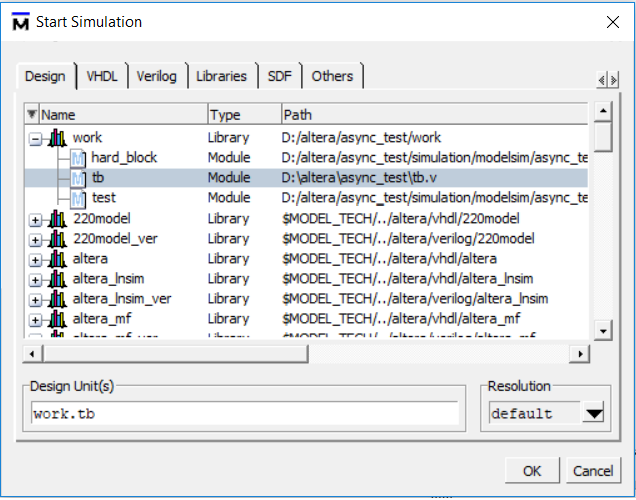
2) добавить библиотеки альтеры
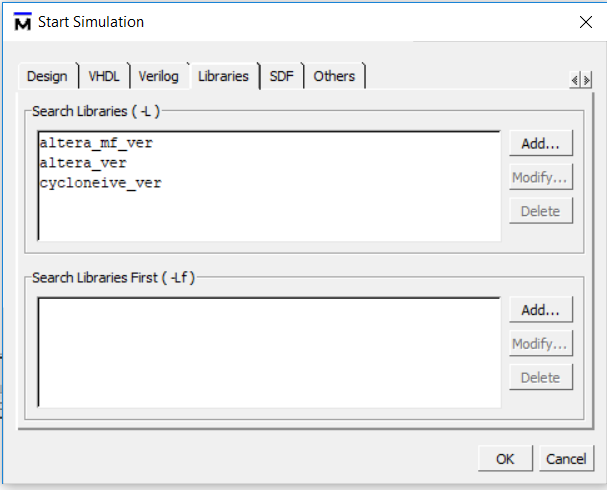
3) добавить скомпилированный SDF файл, из которого все временные параметры пойдут

После успешной подгрузки всех нужных для симуляции файлов и модулей нужно добавить интересующие нас сигналы в окно временных диаграммм.
Нажимаем OK и далее меню Simulate => Run => Run-all
Вот оно и получилось — заработало!
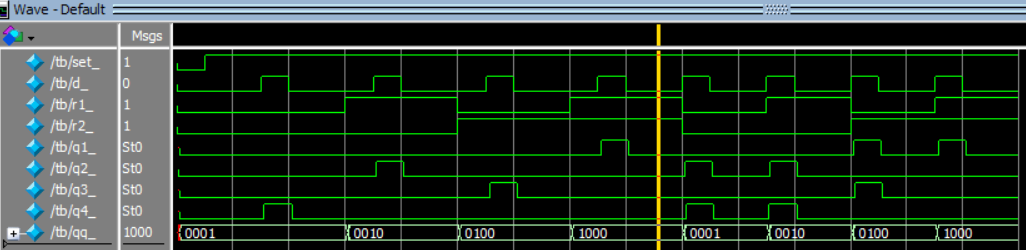
Что я вижу:
Во-первых, проект похоже почти работает и декодирует адреса, как и обещано — вот только для первой группы четырех импульсов d. Как-то перепутаны выходы дешифратора, при {r2,r1} = 2'b01 зажигается q2. Но я про эту странность выше уже говорил. Честно говоря, я был сильно удивлен, что это вообще работает при каких-то условиях.
Вторая группа из 4х импульсов d не работает правильно. Это тот момент когда сигнал d приходит одновременно с изменяющимися r1 и r2.
Здесь хотелось бы точнее понять роль сигнала d. В синхронной логике я знаю есть тактовая частота, которая защелкивает данные пришедшие от одного регистра к другому через комбинационные функции. При этом разработчик обязан обеспечить так называемые временные параметры tsu и thold. Вот первая попавшаяся картинка по теме из гугла:
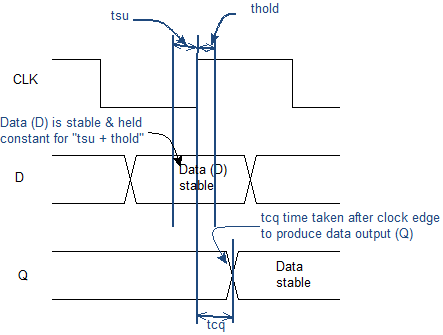
Защелкиваемый в регистре сигнал обязан быть стабильным некоторое время tsu (setup time) до фронта тактовой частоты и некоторое время после фронта тактовой частоты thold (hold time). Если это условие не выполняется, то синхронная схема не работает или работает не надежно (ну то есть фактически не работает).
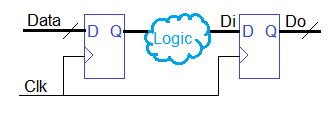
Что такое стабильный сигнал? Вот есть регистр, в котором запоминаются входные данные. Далее идет логическая функция, которая из входных данных (это может быть несколько разрядов) вычисляет следующее значение, которое запоминается в следующем регистре. Так вот логическая функция должна вычислить результат за время меньшее, чем длительность периода тактовой частоты. Не только успеть вычислить. Поскольку разрядов несколько, то результат еще должен успеть вовремя прибежать по проводникам каждый к своему защелкивающему регистру.
Теперь, возвращаясь к асинхронной схеме и сигналу d я понимаю, что вторая группа из четырех импульсов d в этой асинхронной схеме во время симуляции видимо не работает правильно точно по той же причине, по которой может не работать и синхронная схема. А именно, не выдержан tsu. Сигнал d приходит, когда сигналы r1 и r2 еще не пришли или не стабильны.
Мне кажется, что автору асинхронной схемы не удастся избежать временного анализа. Обязательно нужно позаботиться о стабильности сигналов r1 и r2 до прихода d. Это нужно как-то контролировать и учитывать. Честно говоря, сам импульс d чем-то напоминает синхроимпульс тактовой частоты. У сигнала d есть длительность, значит она, эта длительность чем-то обеспечена, каким-то генератором? Получается, что для работы асинхронной схемы все таки нужны времязадающие цепи, те которые определяют длительность и позицию сигала d? Вообще, происхождение этого сигнала d не очень понятно…
Хотел обратить внимание еще на несколько моментов в моей симуляции. Даже когда схема работает (первые 4 импульса d на симуляции) выходные сигналы q1, q2, q3, q4 сдвинуты относительно сигнала d и каждый сдвинут на разное время. Самое интересное, что ширина импульсов q1, q2, q3 и q4 всегда больше ширины импульса d и все они разные по ширине. Я не знаю, как автор собирается комбинировать такие схемы одну с другой. Если предположить, что выходной сигнал q1 для последующих схем становится сигналом d, то получится, что через цепочку схем сигнал d становится шире и шире — но это уже мои фантазии. Повторюсь, я не очень понимаю как такие схемы будут собираться в бОльшие.
Еще одна мысль не покидает меня.
Мне кажется, что традиционный дешифратор вроде такого, как у меня выше assign qq = 1 << {r2,r1}; займет в чипе гораздо меньше места по числу транзисторов, чем описанная автором асинхронная схема. А число транзисторов в ASIC напрямую влияет на производительность, ведь получается большая площадь чипа занята и более длинные трассы между элементами, большее энергопотребление. Об этом обязательно нужно подумать, как это оценить и как это посчитать.
У меня иногда у самого возникают странные «прорывные» идеи о том, как сделать электронику быстрее или задействовать «иной принцип» работы. Закон Мура уже как-то не очень работает и для увеличения быстродействия электроники требуются новые идеи. В случае с микропроцессорами это может быть некая принципиально иная архитектура (хм… она есть у меня). Или нужны свежие технологии и идеи об устройстве базовых элементов чипов.
Я как-то делал эксперименты по реализации схемы на Double-Edge-Trigger. Идея заключалась в том, чтобы использовать для обычной синхронной логики оба фронта тактовой частоты. Я думал, что использование DET триггера позволит в чипе для той же скорости вычислений иметь рабочую частоту в два раза меньше и значит как минимум снизится энергопотребление. Я просимулировал свой проект и даже запустил его в ПЛИС — он работал. Подробности об этом проекте здесь.
Далее я попытался оценить необходимое число транзисторов и пришел для себя к неутешительным выводам: похоже схема с DET триггерами потребует в чипе транзисторов гораздо больше, чем обычно.
Асинхронная логика, как идея, интересна. Но, к сожалению, требует глубокой проработки. До реального применения еще слишком далеко и неочевидно. И нужно обязательно проверять результат хоть в ПЛИС, хоть в симуляции — это не трудно и не дорого. Похоже ModelSim вполне справляется с симуляцией асинхронных схем.
Симуляция — бесплатна! Пробуйте господа!
32bit_me
Вот это правильный подход, в отличие от.