
Эта статья посвящена эволюции разработки и администрирования, и определению собственной позиции во всеобщей картине всего. Статья вдохновлена слайдами Marc Hornbeek, но имеет к ним опосредованное отношение. Для широкого круга хаброжителей (опсов, девов и девопсов).
Сначала небольшая предыстория, чтобы познакомиться. Я знаю, что предыстории обычно очень скучные, с другой стороны — как вы иначе поверите, что автор вообще имеет право говорить на эту тему?
Году этак в 2003 я впервые устроился на работу админом. На некоторое время, вопросы типа ручного патчинга и переборок ядра для VPN и ночных бдений за установкой postfix-dovecot-spamassassin-итп поглотило с головой. Где-то в 2011 году оторвался от запинывания очередного баш-скрипта размером с комментарии под постом Ализара, посмотрел вокруг, и с удивлением заметил, что у всех все и так работает. Без этих вот титанических усилий. «Раз-раз и в продакшен» к нам приходит, и разве теперь на этом заработаешь?
Сейчас, в случае подобной проблемы, я бы просто пошел на конференцию типа DevOops, и мгновенно разобрался бы: и что сейчас в тренде, и как вытащить свою команду. Сейчас есть связи, и Фейсбук с пятью тысячью друзей-айтишников. Тогда ничего этого не было: пришлось уйти с текущей работы (чтобы не стать в конце концов специалистом по раскладыванию пасьянса), начать отчаянно изучать Java, и стать в конце концов законченным джавистом.
К чему это? Хочется ясно показать, что наша зависимость от конкретной культуры администрирования, культуры программирования и разработки вообще, набора инструментов — это не шутка. Это вопрос выживания.
Все знакомые чуваки, которые не успели адаптироваться — сейчас либо стали крутыми профессионалами в узких областях администрирования, либо про них вообще ничего незвестно. Может, они и не живые уже.
Как сказал когда-то астрофизик Карл Саган,
Вымирание — это правило, а выживание — это исключение.

В нашем, вполне себе цивилизованном мире, в есть особые джунгли администрирования и разработки, со своей собственной эволюцией.
Как мы помним из школы, естественная эволюция движется вдоль процессов адаптации (естественного набора), плюс есть еще и некоторые дополнительные причины: дрейф генов, поток генов, мутации.
Наша админская эволюция движется вдоль вполне конкретных интересов бизнеса. Когда ты не можешь приспособиться ко вполне конкретному набору изменений, твой шеф тебя съедает.
Вот к чему нужно адаптироваться сразу же:
- Гибкость
- Эффективность
- Стабильность
- Безопасность
(Это только начало длинного списка. Для начала хватит и этого).
Бей, беги, замри
По каждому из этих параметров можно сделать какие-то вполне конкретные процессные (внутри компании), или как минимум — карьерные изменения.
Сейчас мы поиграем в некое bullshit bingo, попытавшись человеческими словами описать, что же хочет от нас шеф, прежде чем съесть.
Будем бить и замирать, а вариант с убеганием (на последнюю зарплату купить коробку от холодильника и жить у теплотрассы) — не рассматриваем.
Гибкость
Что такое гибкость — сказать сложно, но её отсутствие очевидно. Это когда в компании исчезают инновации, люди начинают загнивать на месте (постепенно превращаясь из админов в специалистов по игре в пасьянс), а продукты компании релизятся ну хорошо если раз в три месяца.
Что хочет увидеть от нас шеф? Например, что продукты начали выкатываться каждый день ровно в 15.00. Или что клиенты начали использовать сервис чаще (потому что его тупо быстрее устанавливать, настраивать и развертывать).
Замри: кстати, вы понимаете, что такое — выкатить продукт? Нужно выполнить 100500 команд в консоли, прочитать тонну обновившейся документации, итп. Мы можем просто работать больше. Очень сильно больше! У админа всегда есть какой-то кусок личных ресурсов, который еще остался на черный день (если такого нет — это плохой админ), и вот этот кусок и пойдет в топку революции.
Бей: существуют вполне конкретные способы и инструменты, которые помогают выкладывать новые сборки быстрее. Самое простое и логичное — это полностью воспроизводимые сборки, которые до этого уже много раз были обкатаны самими разработчиками, и поэтому для выпуска новой версии достаточно повторить все то же самое. А раз оно «все то же самое» — это можно автоматизировать. Скрипты и докеры в руки — и пошел :-)
Адаптация по стратегии «бей» — это изучение, использование и участие в разработке современных CI/CD систем и других devops инструментов.
Эффективность
Когда вы выкатили продукт, и он тут же развалился (возможно, даже не запустившись), и приходится раз за разом его чинить и запинывать — это крайне низкая эффективность.
Шеф хотел бы увидеть, что сделанное однажды — не нужно каждый раз заново переделывать. Что написание какого-то определенного действия занимает интуитивно понятные сроки, например, скрипт-запускалка пишется за 5 минут, а не за 5 часов.
Замри: у нас есть стандартные, проверенные годами инструменты типа Bash, знания которых можно полировать до зеркального блеска. Для любой стандартной задачи есть сниппет либо инструкция на Конфлюенсе. Нужно продолжать делать всё то же самое, что и раньше — повышать свою квалификацию в этих инструментах.
Бей: а можно напротив взять инструменты, в которых все эти проблемы решены. Например, для запускалок можно использовать Systemd, и вся ваша лапша на 20 страниц баша может внезапно свернуться до нескольких строчек. И да, выкинуть уже RHEL6. Если обязательно нужен скрипт, его можно написать на Python, благо наличие Dive into Python, PyCharm и Ansible делает управление кластерами на Python доступным даже для школьников. Впрочем, Bash все еще нужен, но по-другому.
Адаптация по стратегии «бей» — это изучение программирования и максимальная автоматизация повседневного труда. Вещи, которые можно не программировать — лучше не программировать и взять готовые решения, при условии что внедрение этого решения обходится почти бесплатно (как в случае с Systemd).
Стабильность
В нашей стране ценится стабильность, если вы понимаете, о чем я :-) Для нас важна как стабильность самого админа, так и сервиса, который он обслуживает.
Например, мы работаем на фрилансе. Шеф хочет, чтобы мы каждый раз брали задачу, и каждый раз ее выполняли. То есть, нельзя сегодня настроить суперважный сервер и получить премию, а завтра не сделать ничего и уйти в горизонт. Такое могут позволить себе только программисты :-)
Я специально опрашивал руководителей, и большинство из них считают стабильность высшим приоритетом: лучше постоянно иметь стабильно плохой результат, чем временами получать чудеса, а временами — ничего.
То же касается и автоматизированных сервисов, которые мы обслуживаем. Сервис должен падать с примерно понятной частотой по понятным проблемам. Например, если Джава сожрала всю RAM, и регулярно делает это раз в день в 00:00 — это ОК, это же Java, все привыкли. А вот если в идеально работающем сервисе раз в месяц случается неразрешимая проблема — это катастрофа.
Замри: мы можем надеяться на долгое время жизни наших инструментов. Вряд ли с BIND9 произойдет что-то, что уже не происходило. Все уже придумано, все уже есть где-то в интернете, или в этом разбирается ближайший знакомый. Ну и в конце концов, у нас за эти годы было достаточно времени, чтобы прочитать и разобраться в исходнике BIND.
Бей: современное айти постоянно придумывает что-то новое. Например, микросервисы. Микросервисы как источники данных в сложных топологиях. Нереляционные базы данных с хитрыми архитектурами. Как мы будем это разруливать, как будем отлаживать? Где взять готовые технологии? Все это совершенно неясно. Вместо этого можно рвануться и начать создавать технологии самостоятельно! Например, для service discovery в микросервисах можно взять стек Netflix Open Source. Не хватает возможностей Netflix Eureka? Нашли баги? Да не беда. Все это написано на джаве с современным спрингом, всегда можно взять исходники Эврики и похачить их ровно так, как нужно твоей компании для конкретной ситуации. (Да, для этого нужно знать Java в достаточной мере, но это уже совсем другая история — история о том, как админу научиться программировать).
Адаптация по стратегии «бей» — это изучение средств автоматизированного и полуавтоматического реагирования, а также средств автоматической диагностики и мониторинга. Стабильно не то что не ломается вообще, а то, что постоянно ломается и чинится с известной скоростью.
Безопасность
Тут все понятно, учитывая что обычно мы и есть те люди, которые либо помогают безопасникам, либо вообще являются ими. Люди просто хотят безопасности.

Замри: использовать существующие, проверенные годами решения. Весь процесс поставки продукта проверять руками и глазами. В процессе поставки использовать как можно больше секретности и security through obscurity, чтобы злоумышленнику было невероятно трудно понять даже векторы атаки.
Бей: Что касается низкого уровня, то к сожалению, вот именно здесь с новыми технологиями все очень печально. Ты не можешь взять и написать хорошую криптографию на коленке. Возможно, комментаторы расскажут, какие современные технологии безопасности сейчас нужно использовать.
Что касается высокого уровня, полезно использовать полную автоматизацию и прозрачность всех процессов. Администраторы должны вмешиваться в процесс автоматической поставки только в самых критических ситуациях. В норме, поставка должна полностью управляться кодом на Python, Ansible и тому подобных вещах. Администраторы должны писать код, либо регулировать параметры существующего кода. Заметьте, что даже мелочи типа ввода паролей нужно уменьшить либо убрать вообще.
Адаптация по стратегии «бей» — это внедрение полностью автоматического CI/CD, включая безболезненное внедрение обновлений безопасности
Качество жизни
Можно долго рассуждать на тему, что новые технологии это хорошо, просто потому что они новые. Лично мне интересно, как заработать на этом побольше денег, и не дать себя съесть.
Из этого, главный эволюционный вопрос: какую стратегию выбрать, замереть или бить?
Представьте человека, который всегда выбирает старые стабильные решения. Скорей всего, это какой-то человек с невообразимым стажем и опытом, наделенный столь большим интеллектом, что он позволяет выкрутиться небольшим готовым набором средств из любой новой ситуации. Это должно быть какое-то богоподобное существо вроде Ричарда Столлмана, который с помощью Емакса управляет движением звезд.

Но вот в чем дело, не каждый может стать Столлманом.
Много вы видели таких людей? Точно ли вам хочется проводить на работе все свободное время, изучая сетевые технологии с самого начала веков?
Ну и главный вопрос всех времен и народов. Деньги. Деньги платят за то, что сейчас в тренде. Если посмотреть на отчет товарищей из Puppet, оказывается, что в тренде сейчас…
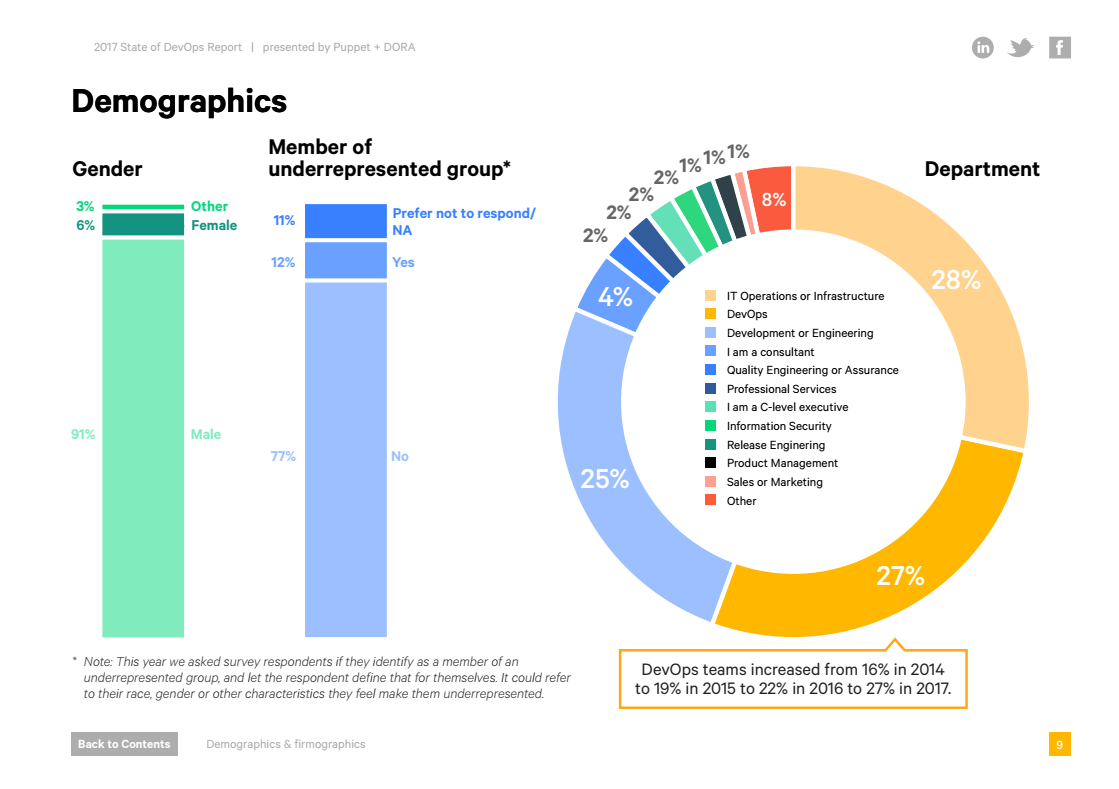
Внезапно, в тренде сейчас DevOps. Хорошие новости, нам не придется жить в коробке у теплотрассы. 10% рост за три года — это очень круто.
Проще говоря. Простое изучение Python уже дает нефиговый бонус к твоей зарплате. Если же есть силы, чтобы оторвать задницу и включиться в построение полноценного девопс-процесса в своей компании, можно начинать мазать бутеры икрой. Вот это — бизнес!
Модель развития
Чтобы более ясно наблюдать, как двигаются к тебе бутеры, нужно иметь какую-то более ясную модель, чем просто изучение слов из буллшит бинго. Без модели можно и не дожить, съедят-с.
В качестве каркаса можно взять Capability Maturity Model (CMM), и слегка адаптировать под наши реалии. По модели предполагается несколько уровней развития, по которым проект превращается из обезьяны в человека.
В оригинале это выглядит вот так (описания взяты из Википедии, русские переводы названия этапов мне тоже не очень нравятся):
- Начальный. Самый примитивный статус организации. Организация способна разрабатывать ПО. Организация не имеет явно осознанного процесса, и качество продукта целиком определяется индивидуальными способностями разработчиков. Один проявляет инициативу, и команда следует его указаниям. Успех одного проекта не гарантирует успех другого. При завершении проекта не фиксируются данные о трудозатратах, расписании и качестве.
- Повторяемый. В некоторой степени отслеживается процесс. Делаются записи о трудозатратах и планах. Функциональность каждого проекта описана в письменной форме. В середине 1999 года лишь 20 % организаций имели 2-й уровень или выше.
- Установленный. Имеют определённый, документированный и установленный процесс работы, не зависящий от отдельных личностей. То есть вводятся согласованные профессиональные стандарты, а разработчики их выполняют. Такие организации в состоянии достаточно надёжно предсказывать затраты на проекты, аналогичные выполненным ранее.
- Управляемый. Могут точно предсказать сроки и стоимость работ. Есть база данных накопленных измерений. Но нет изменений при появления новых технологий и парадигм.
- Оптимизированный. Есть постоянно действующая процедура поиска и освоения новых и улучшенных методов и инструментов.
Давайте переколбасим этот список под наши реалии.
1. Начальный уровень, Хаос и Превозмогание
Все начинается с какого-нибудь клевого стартапа.
В нашем случае стартапом было само создание компьютеров.
Переносная немецкая шифровальная машинка Энигма

1939 год — в тред врывается Алан Тьюринг со взломом кодов Энигмы, «Bombe»

Другая немецкая шифровальная машинка — Лоренц

1943 год — всего за 9 месяцев Томми Флауэрс с товарищами делает «Colossus» для работы с кодами Лоренца

1946 год — баллистические таблицы и «ENIAC» — один из первых вычислителей общего назначения

1954 год — наконец, первый компьютер, ушедший в массовое производство, IBM 650

Великолепные годы, наполненные великими открытиями и выдающимися хакерами типа Алана Тьюринга.
С другой стороны, с точки зрения современного devops, эта стадия — отличный пример того, как не следует делать.
- Все роли существовали де-факто, но не были выражены в конкретные технические дисциплины, не было внятных критериев и механизмов роста и развития этих дисциплин.
- Разработка обычно велась по модели водопада, которая еще подходила тому технологическому укладу в общем по миру, но уже не сильно вписывалась в компьютерные реалии
- Ничего похожего на современные CI/CD тулчейны не было. Существующие тулчейны так разительно друг от друга отличались, что состыковать их между собой требовало невероятных усилий. По сути, универсальный интерфейс между системами имелся, и этот интерфейс — человек.
- Большинство действий внутри водопада производилось вручную (ну да, тогда у людей еще не было суперкомпьютера в мобильном телефоне)
2. Механизация

На картинке — Маргарет Гамильтон, ведущий разработчик Apollo Project. Она стоит рядом с исходными текстами программ, которые_ написала вручную._ А в результате, люди побывали на Луне.
Начиная с 60х годов в дело вступают процессы автоматизации ручного труда, начавшиеся с попыток формально записать и объяснить широкой массе тайные ad-hoc знания. Формализованные знания превращаются в стандарты, разработка по стандартам позволяет создавать проекты с миллионами строк кода.
Большое внимание уделяется не просто стандартизации а тестированию относительно этих стандартов (по возможности, автоматическому).
- 1961 — Leeds и Weinberg пишут «Computer Programming Fundamentals»
- 1963 — стандарт на блок-схемы (Rossheim)
- 1964 — первая программа на языке Basic (Dartmouth College)
- 1965 — создание небезызвестной IBM 360 (1 миллион строк программного кода!)
- 1967 — формальное функциональное тестирование (IBM)
- 1967 — термин «Software Engineering» (НАТО)
- 1968 — термин «QA» (НАТО)
- 1971 — создание сообщества IEEE
- 1972 — язык программирования Си. Керниган и Ричи.
- 1974 — MIL-S-52779 SW, требования к качеству софта
- 1975 — создание Microsoft
- 1976 — создание Apple
- 1976 — «Software Reliability: Principles and Practices», написанная Glenford Myers
- 1976— «Design and Code Inspections» (ссылка ведет на pdf), Michael Fagan
- 1976— понятие цикломатической сложности, Tom McCabe
- 1979 — «The Art of Software Testing», Glenford Myers
- 1983 — IEEE 829 Standard for Software Test
3. Вариация инструментов и культур
Пропуская девяностые годы с их бурными экспериментами, прыгаем сразу же почти в современность — и видим вершину инженерной мысли этого времени, гибкие методологии.
- 1986 — «The New Product Development Game» — Хиротака Такэути и Икудзиро Нонака. Статья в Harvard Business Review, первое упоминание scrum-подобного подхода к организации разработки.
- 1991 — «Wicked Problems, Righteous Solutions: A Catalog of Modern Engineering Paradigms», Leslie Hulet Stahl. Первое упоминание Scrum как названия инженерной практики.
- 1995 — Sutherland и Schwaber вместе презентуют методологию Scrum на воркшопе в рамках OOPSLA (ежегодной конференции ACM).
- 2001 — Agile Manifesto, 4 ценности и 12 принципов Аджайла
- 2002— Экстремальное программирование, Кент Бек
- 2003— Test-Driven Development (разработка через тестирование), Кент Бек, Мартин Фаулер
В ходе бурного развития стало совершенно понятно, что просто внедрять новый софт недостаточно, нужно апгрейдить еще и процесс производства.
Что касается инструментов, то у нас случился некий бульон из огромного количества инструментов. Самый верный способ тронуться крышей — попробовать изучить и применить все эти инструменты.
Чтобы понизить сложность задачи, инструменты можно условно разделить на группы:
- Репозитории — Git, Mercurial, Perforce, Github, Bitbucket, Nexus, Artifactory …
- Сборщики — Maven, Gradle, Jenkins, Bamboo, TeamCity…
- Тестирование кода — SonarQube, Coverity, klocwork, Parasoft…
- Инструменты тестирования — Selenium, Ranorex, ixia, TestPlant…
- Автоматизация тестирования — Jenkins, Cucumber, ixia, BlazeMeter, XebiaLabs…
- Инфраструктура — Azuer, AWS, VMWare, OpenStack, …
- Развертывание — Ansible, Puppet, Chef, Docker, Kubernetes, Jenkins…
- Аналитика — Splunk, New Relic, JIRA, Zephyr…
Зачастую, внедрение «девопса» на протяжении этого периода заключалось в том, чтобы собрать как можно больше новых методологий разработки, популярных утилит, запустить внутри одного проекта, хорошенько обмазать смузи, и как-то попытаться с этим жить. Такой подход мог бы привести к хаосу в любом другом производстве, но нам повезло — все используемые инструменты предназначены для увеличения порядка и работают с минимальными человеческими усилиями, так что при наличии прямых рук все это можно держать под контролем.
4. Стандартизация
/МЫ НАХОДИМСЯ ЗДЕСЬ/
В 2017 году «девопс» стал мейнстримом. Как показывают исследования Puppet, количество и качество внедрения девопса растет как на дрожжах.
В условиях тотальной коммодизации, нам необходимо придерживаться нескольких проверенных стратегий. Например, вырисовывающиеся стеки технологий и направления деятельности нужно оформлять в виде вполне конкретных линеек, и давать этим стекам имена.
Какие направления сразу приходят в голову?
Во-первых, это имеется некий «тулчейн DevOps», который включает в себя стандартные элементы: начинается DEV-средой (репозиторий кода, его проверка тип), продолжается централизованной сборкой и хранением в репозитории (Jenkins, Artifactory), продолжается конфигурацией (Ansible, Chef, Puppet) и конечным развертыванием (Docker, облачные платформы).
Если вы берете на работу нового сотрудника (или проверяете, что нужно подтянуть в собственных знаниях), там обязательно должны быть все эти стандартные классы инструментов, и умение выстраивать их в четкую непрерывную цепь полностью автоматической поставки. Инструменты могут отличаться от команды к команде, но блоки в основном неизменны.
Во-вторых, обучение. Это может быть все что угодно, начиная с планового переноса знаний внутри команд или внешних конференций типа DevOops, и заканчивая жестко стандартизованными сертификационными тренингами. Организации, работающие в этой сфере уже существуют, к ним можно обратиться прямо сейчас. Например, глобально представлены компании типа DevOps Institute или DASA (Devops Agile Skills Association). Если же вам хочется посетить конференцию (или даже организовать её под ключ) — в России для этого существует команда JUG.ru.
В-третьих, это формальные стандарты. Прямо сейчас уже существует «P2675 — DevOps — Standard for Building Reliable and Secure Systems Including Application Build, Package and Deployment». Общее понимание можно сравнить с ETSI TST006 Report on CI/CD and Devops. Даже если заморачиваться с международными инициативами не хочется, стоит создать собственный стандарт для команд внутри своей организации и опубликовать ясным и легко доступным способом (например, на Конфлюенсе).
Заметка. Зачем нам нужно такое четкое деление и имена? Например, существует чисто психологический феномен, что если какому-то продукту или принципу дать четкое название, то человек вначале верит в это название, и потом уже ищет логические объяснения этой веры. Например, многих бесит, что общее понятие «девопс» намертво приклеился к Jenkins, бесит своей нерациональностью. С другой стороны, «Jenkins как основа для девопса» — это хорошая стартовая площадка для построения доверия к тому, чем мы занимаемся. Дженкинс — это нечто конкретное, вещественное, и сто раз оправдал доверие к себе. Даже несмотря на то, что в 2017 году для многих он не выглядит как топовое техническое решение, но является топовым психологическим решением для продавливания своих интересов. Важно тут концентрироваться не на конкретных именах продуктов или компаний (типа Jenkins и Ansible), а на потребностях наших команд (например, возможности быстрой интеграции изменений), чтобы развивать доверие к самому девопсу в целом. Это же относится не только к инструментам, но и к программам обучения, или стандартным элементам культуры разработки.
Построив хорошую стандартную платформу, можно отправляться в светлое будущее.
5. Оптимизация
Оптимизация — это наше будущее. То, благодаря чему мы будем в самое ближайшее время мазать бутерброды маслом. Говорить о будущем сложно, поэтому намечу самые общие тенденции.
На предыдущем этапе стандартизации, разработчики стремились к полностью автоматическому CI/CD, но все риски все равно отрабатывали вручную. Грубо говоря, если поставка разваливается или сервис падает — это скорей всего SMS или письмо администратору соответствующего сервиса, подъем SRE и девопса, и так далее.
Скорей всего, в самом ближайшем будущем, такие работы будут сильно оптимизированы интеллектуальными системами, отрабатывающими большинство проблемных ситуаций. Человек вручную будет разруливать только самые сложные 10% ошибок. Это стало возможным благодаря повсеместному внедрению Docker, микросервисов, конфигурации как кода и других хорошо автоматически управляемых технологий. Человек в этой модели будет описывать (в виде программного кода, или конфигурации как кода) конкретные способы решения проблем, а интеллектуальные системы будут автоматически применять эти решения при необходимости.
Совершенно все системы станут continuous-*. Continuous integration, continuous testing, continuous monitoring, continuous delivery и deployment. Разворачивание будет идти в основном, на всевозможные эластичные платформы, и создание серверов-снежинок окончательно отойдет на второй план даже в наиболее классических компаниях типа банков.
Соответствующим образом будет изменяться и общая культура разработки и управления ей. Менеджмент учится любить и применять метрики типа количества релизов в день, стабильности (MTR), качества (MBTF), и так далее.
Изменяются принципы проектирования программного обеспечения, удобство для использования в стандартизованных (на предыдущем этапе!) технологических и процессиях стеках становится обязательной основой в архитектуре и дизайне программного обеспечения. Например, для современных продуктов всегда следует явно продумать инфтерфейсы для проведения полностью автоматического или полуавтоматического администрирования, и если в выбранной архитектурной концепции это невозможно — значит архитектурная концепция отправляется в мусорку.
И если когда-то существовали должности типа «девопс» или «разработчик с навыками девопса», или «администратор с навыками девопса», то по сумме факторов можно считать о появлении более общей и конкретной специальности типа «process automation scientist».
Все это — слишком большой груз, чтобы замереть на месте и пытаться решить проблемы в рамках технологий начала 90х годов. Мы можем только храбро сражаться, учиться администрировать (в смысле — программировать) все эти новые системы, адаптировать свое поведение под изменяющиеся правила игры. Надеюсь, все читатели этого поста доживут до утра, до нашего большого светлого будущего, и мы еще обсудим будущие этапы эволюции.
Комментарии (15)

powerman
28.08.2017 23:02+2Изменяются принципы проектирования программного обеспечения, удобство для использования в стандартизованных (на предыдущем этапе!) технологических и процессиях стеках становится обязательной основой в архитектуре и дизайне программного обеспечения.
К сожалению, пока что разработка stateful микросервиса, не рассчитанного на запуск в облаке в более чем одном экземпляре, обходится в разы дешевле (и для многих проектов реальной необходимости в поддержке HA и/или масштабирования для этого сервиса просто нет). Что сильно осложняет автоматическое управление этим сервисом в стиле AWS ECS.
Я к тому, что необходимые принципы проектирования уже есть, и давно (напр. https://12factor.net/ru/), но пока они не станут выгодны экономически описанного будущего нам не видать.

olegchir Автор
29.08.2017 09:06+1Какие факторы наиболее сильно влияют на экономическую составляющую вопроса? Скорость разработки? Оверхед гиперконвергентной среды? Еще что-то?
powerman
29.08.2017 17:29+2Сложность реализации. Скорость и стоимость разработки страдают как следствие увеличившейся сложности.
Когда у сервиса собственная БД под боком и он запущен в единственном экземпляре — открывается масса возможностей как написать его проще, быстрее и эффективнее:
- сервис может использовать любой подходящий под его данные формат БД (от подключения к сторонней SQL/NoSQL СУБД до бинарных или json-файликов у себя на диске), что упрощает реализацию сервиса и позволяет сделать его более производительным
- сервис может работать со своими данными не беспокоясь о блокировках, а транзакции используя только там, где это необходимо для сохранения целостности БД (напр. подменяя изменённые json-файлы атомарной операцией перемещения файла)
- сервис может кешировать в памяти всё, что хочет, включая держать вообще всю БД в памяти если влазит (а она часто влазит — у "микро"сервисов зачастую и данных тоже "микро") и в этом есть смысл (a-la "memcached inside") и этот кеш очень легко поддерживать в актуальном состоянии
- нет необходимости реализовывать одновременную поддержку двух версий структуры БД в одной версии сервиса — ведь миграцию БД можно делать между отключением старой версии сервиса и запуском новой
- etc.
А как только таких запущенных сервисов становится больше одного — всё резко усложняется. Приходится учитывать в коде необходимость синхронизации и координации между сервисами, приходится использовать менее удобные БД, распределённые/удалённые кеши и инвалидация устаревших данных в них это отдельная проблема, приходится поддерживать возможность одновременной работы двух разных версий сервиса и изменения формата БД в процессе работы сервиса, etc.
Учитывая, что обычно микросервисы достаточно мелкие, объёмной и сложной бизнес-логики в них обычно нет, то основное время на их реализацию тратится именно на такого рода "служебные" задачи. И когда сложность этих служебных задач настолько увеличивается — скорость и стоимость разработки и тестирования сервиса ухудшаются в разы.

shuron
30.08.2017 00:22Совершенно верно "стейт" — это сложно и затратно. Но набив руку вы не сядите в лужу…
Если вы строите чтп-то новое, то все карты в руки.
Задача сводится к отдалению "стейта" например туда где эго мэнджмент уже решон, например нормально настроеная NoSQL.
Есть мног итнересных паттернов… и возможностей избежать сейта или жить с его не синхроными копийми или или или..
П.С. за последний год переписал часть одной легаси системы. Около 10 новых микросервисов, пока только один со стейтом и не скалируется, то такой мощный что его хватит на 100% рот нашего лоада…
а главнео мы когда этотот 100% лоад достигнем и стнем лиллионерами :) просто заменим этот сервис за пру спринтов.powerman
30.08.2017 00:39+2Если данные тупо оторвать от сервиса переместив их в СУБД — stateless сервис мы не получим. Мы получим сервис, состоящий из двух сильно связанных частей, одна в виде как-бэ stateless сервиса, вторая в виде данных в БД.
Это жизнь никоим образом не упростит, и возможность запускать более одного экземпляра этого сервиса не даст (в общем случае). Наоборот, всё станет только сложнее, и в реализации и в эксплуатации. Единственная причина делать такую фигню — необходимость формально отчитаться перед технически не разбирающимся начальством, что "у нас все сервисы — stateless", если вдруг оное начальство где-то прочитало про то, что stateless сервисы это дико круто, и потребовало немедленно внедрить ради галочки в отчётах.
P.S. Что касается "набивания руки" и "луж" — я микросервисы пишу примерно с 2009 (да, этого термина тогда ещё не было). Так что рука уже давно отбита напрочь. Но описанную проблему это не решило.
shuron
30.08.2017 11:34+1Вы поняли как вам это хотелось…
Да синхронизация через базу даных это самообман и антипэттерн.
Я поясню и так. Мы написали олколо 10 новых сервисов, делающих тоже самое что старый монолит, но посколько мы изначально думали о том что такое "shared state".
Все они имеют кой-то стейт и это не проблема. Проблема возникает если вы вдруг водите "shared state" и считаете что именно так и никак иначе в вашей архитектуре быть не может.
Конечно это зависит от задачь, но я в работл во многих индустриях и проблемы на самом деле обысчно очень похоже… И я почти уверен что распределенный стейт можно локализировать и особо к нему подойти. В этом то и ошибка многих команд, что к нему не достаточно внимания.
Давайте конкретенее… Вот раньше сесси на стороне сервиса/сервера были проблемой, сечас сессионый статус держит клиент — и это очень элегантный выход из моних ситуаций…
Мы используем еще внешние системы которы звонятнаам по колбэкам. В одном случае мы встроили наш ключ в callback url в данном случает хэто позволяет полностью избежать знание о друг други или общис стейт между звонящим и принимающим звонок сервис.
Хорошо вы скажете а как же вы будете скалировать ваш User data сервис… ну очень надо 10 инстанций… Тут вот и есть вопрос загнанного в угл "shared state".
И тут вы может епринять решения.
Ответьте себе на впрос вам дейтвительно нужно ACID или вполне достачно BASE.
Вообще-то в реальная жизнь тоже поххоже на BASE и на событийную архитектуру…
Если каждая инстанция сервиса имеет свою наиболее актуальную версию стейта, но без гарантии — это BASE и это отлично скалиерует. С паттернами Event Sourcing и CQRS вообще открываются очень интересные возможности.
А если вы уверены что вам нуже только ACID и только он — ну да это не скалирует…
Но может вы говорите о кластере сервисов которы в волатильной памяти должны держать "shared state", бывает и такие задачи, но тут возникаакуут вопрос, что именно это за стейт? Может это просто кэш? возмите что-то готовое, есть кучу решений…
Я вот очень сильно хотел бы прочитать о вашем примере…
Но и на это случай полно очень продуманых штук от навароченых библиотек Apache Ignite до простых распределенных примитивом или реализаций протоколов выбора лидера… — Но оно вам надо? моя практика показвыет что обычно это идет в бой когда девелоперы хотят поробовать новые штуки а не когда это действительно нужно и без это-го никак.powerman
30.08.2017 16:26Если я правильно понимаю, то Вы говорите о том, что всё это — решаемая проблема, есть много разных подходов к её решению, что нужно задуматься о природе данных, присмотреться к тому, как они на самом деле используются, etc.
Я же говорю о том, что всё это усложняет реализацию и в 2-3 раза увеличивает время (и, соответственно, стоимость) разработки среднего микросервиса. И поэтому в проектах, в которых нет необходимости масштабирования и/или HA для этого stateful сервиса — бизнесу не выгодно тратить в разы больше ресурсов на то, чтобы сделать этот сервис stateless.
Вы поняли как вам это хотелось…
Да синхронизация через базу даных это самообман и антипэттерн.Нет, я понял в контексте исходного обсуждения — т.е. как можно вынести данные из сервиса не увеличивая стоимость его разработки в разы.

Merkat0r
29.08.2017 00:54+2Внезапно, в тренде сейчас DevOps. 10% рост за три года — это очень круто
Не-а, это просто мышкофтыкатели не спят — как было с админами в свое время, но теперь они пишут(на том же hh тонны их), что они таки уже не просто админы, а девопсы и точно также утягивают на дно теперь и это понятие :)
Так, что я просто вангую через годикна самом деле уже естьбудет куча вакансий типа *нужен инженер девопс с навыками замены печек в принтерах и протяжкой видеонаблюдения*Merkat0r
29.08.2017 01:04+4даже далеко ходить не надо — третьим в поиске же выскочило — убить, самка собаки, мало
olegchir Автор
29.08.2017 09:11судя по описанию, к работе SRE или process automation scientist aka «человек-девопс» это вакансия вообще никакого отношения не имеет
либо имеет, но они не смогли выразить свои желания в тексте
может, стоит оказать им платную консультацию, и объяснить суть проблемы? :)madesst
29.08.2017 10:46+3Рискну предположить, что суть комментария была в том, что пункт «10% за три года — это очень круто» некорректен из-за большого количества мусорных вакансий, не имеющих никакого отношения к этой теме.
varnav
29.08.2017 12:25+2Ну так хрюши начали вставлять модные слова в вакансии — и соискатели подтягиваются.
Nikita_Danilov
02.09.2017 15:21Важно тут концентрироваться не на конкретных именах продуктов или компаний (типа Jenkins и Ansible), а на потребностях наших команд (например, возможности быстрой интеграции изменений), чтобы развивать доверие к самому девопсу в целом.
Вот. Потребности команд. «Золотые слова Юрий Венедиктович» ©
Решать проблему, а не стремиться вкрутить еще больше сложновыдуманных нетривиальных инструментов.
Лучи ненависти в сторону PowerShell и DSC, которые, на мой взгляд, созданы без оглядки на прошлый опыт и скорее с желанием придумать нечто новое прикольное, чем решить досадные ограничения bat-скриптов.
menstenebris
После прочтения первой части статьи осталась одна мысль. Это не ты такой умный и сам изучаешь новые технологии в ИТ. А это объективные экономические законы ведения бизнеса и накопления капитала вынуждают тебя это делать. Просеивают через сито. Тех, кто не прошел отбор, просто съедают.
Вторая часть сильно напомнила прохождение этапов становления производства. И описанный сейчас этап и правда сильно напоминает переход от мануфактуры к фабрике и замену человеческого труда машинами.