
Мы уже рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа и три метода: хеш-индекс, B-дерево и GiST. В этой части речь пойдет о SP-GiST.
SP-GiST
Вначале немного о названии. Слово «GiST» намекает на определенную схожесть с одноименным методом. Схожесть действительно есть: и тот, и другой — generalized search trees, обобщенные деревья поиска, предоставляющие каркас для построения разных методов доступа.
«SP» расшифровывается как space partitioning, разбиение пространства. В роли пространства часто выступает именно то, что мы и привыкли называть пространством — например, двумерная плоскость. Но, как мы увидим, имеется в виду любое пространство поиска, по сути произвольная область значений.
SP-GiST подходит для структур, в которых пространство рекурсивно разбивается на непересекающиеся области. В этот класс входят деревья квадрантов (quadtree), k-мерные деревья (k-D tree), префиксные деревья (trie).
Устройство
Итак, идея индексного метода SP-GiST состоит в разбиении области значений на неперекрывающиеся подобласти, каждая из которых, в свою очередь, также может быть разбита. Такое разбиение порождает несбалансированные деревья (в отличие от B-деревьев и обычного GiST).
Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты. Например, узел дерева квадрантов обычно имеет четыре дочерних узла (в отличие от B-деревьев, где они измеряются сотнями) и большую глубину. Такие деревья хорошо подходят для работы в оперативной памяти, но индекс хранится на диске, и поэтому для сокращения числа операций ввода-вывода узлы приходится паковать в страницы — а это непросто сделать эффективно. Кроме того, время поиска разных значений в индексе может отличаться из-за разной глубины ветвей.
Так же, как и GiST, этот метод доступа берет на себя заботу о низкоуровневых задачах (одновременный доступ и блокировки, журналирование, собственно алгоритм поиска) и позволяет добавлять поддержку новых типов данных и алгоритмов разбиения, предоставляя для этого специальный упрощенный интерфейс.
Внутренний узел дерева SP-GiST хранит ссылки на дочерние узлы; для каждой ссылки может быть задана метка. Кроме того, внутренний узел может хранить значение, называемое префиксом. На самом деле это значение не обязано быть именно префиксом; его можно рассматривать как произвольный предикат, выполняющийся для всех дочерних узлов.
Листовые узлы SP-GiST содержат значение индексированного типа и ссылку на строку таблицы (TID). В качестве значения могут использоваться сами индексированные данные (ключ поиска), но не обязательно: может храниться и сокращенное значение.
Кроме того, листовые узлы могут собираться в списки. Таким образом, внутренний узел может ссылаться не на одно единственное значение, а на целый список.
Заметим, что префиксы, метки и значения в листовых узлах все могут быть совершенно разных типов данных.
Как и в GiST, основной функцией, которую надо определить для поиска, является функция согласованности. Эта функция вызывается для узла дерева и возвращает набор дочерних узлов, значения которых «согласуются» с поисковым предикатом (как обычно, вида «индексированное-поле оператор выражение»). Для листового узла функция согласованности определяет, удовлетворяет ли индексированное значение в этом узле поисковому предикату.
Поиск начинается с корневого узла. С помощью функции согласованности выясняется, в какие дочерние узлы имеет смысл заходить; алгоритм повторяется для каждого из найденных узлов. Поиск производится в глубину.
На физическом уровне узлы индекса упакованы в страницы, чтобы с ними можно было эффективно работать с точки зрения операций ввода-вывода. При этом на одной странице оказываются либо внутренние узлы, либо листовые, но не те и другие одновременно.
Пример: дерево квадрантов
Дерево квадрантов (quadtree) используется для индексирования точек на плоскости. Идея состоит в рекурсивном разбиении области на четыре части (квадранта) по отношению к центральной точке. Глубина ветвей такого дерева может различаться и зависит от плотности точек в соответствующих квадрантах.
Вот как это выглядит на картинках на примере демо-базы, дополненной аэропортами с сайта openflights.org. Кстати, недавно мы выпустили новую версию базы, в которой, помимо прочего, заменили долготу и широту одним полем типа point.

Сначала делим плоскость на четыре квадранта...
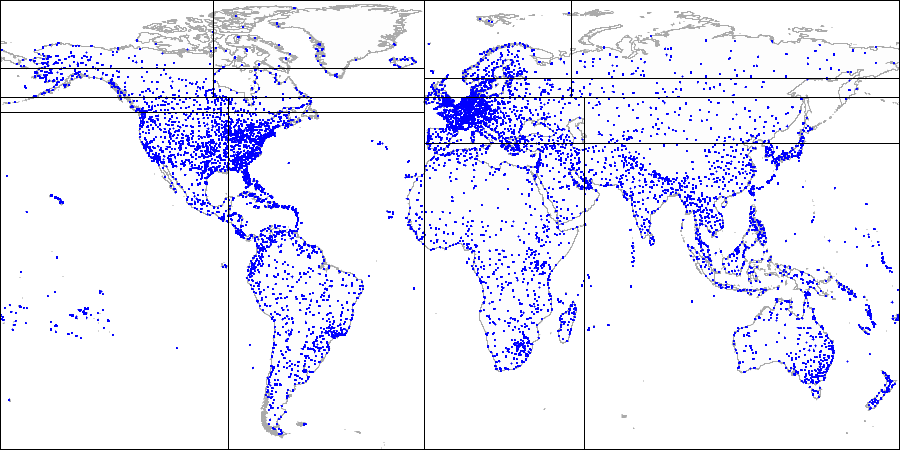
Затем делим каждый из квадрантов...
И так далее, пока не получим итоговое разбиение.
Рассмотрим теперь подробнее простой пример, который нам уже встречался в части про GiST. Вот как может выглядеть разбиение плоскости в этом случае:
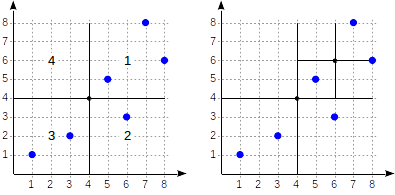
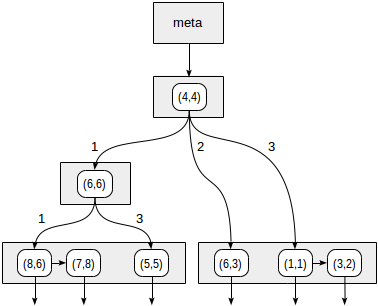
Квадранты нумеруются так, как показано на первом рисунке; для определенности будем располагать дочерние узлы слева направо именно в такой последовательности. Возможная структура индекса в этом случае показана на рисунке ниже. Каждый внутренний узел ссылается максимум на четыре дочерних узла. Каждую ссылку можно пометить номером квадранта, как на рисунке. Но в реализации метки нет; удобнее хранить фиксированный массив из четырех ссылок, некоторые из которых могут быть пустыми.
Точки, лежащие на границах, относятся к квадранту с меньшим номером.
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
В данном случае по умолчанию используется класс операторов quad_point_ops, в который входят следующие операторы:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 строго слева
>>(point,point) | 5 строго справа
~=(point,point) | 6 совпадает
<^(point,point) | 10 строго снизу
>^(point,point) | 11 строго сверху
<@(point,box) | 8 содержится в прямоугольнике
(6 rows)
Рассмотрим, например, как будет выполняться запрос
select * from points where p >^ point '(2,7)' (найти все точки, лежащие выше заданной).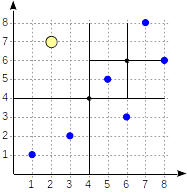
Начинаем с корневого узла и выбираем, в какие дочерние узлы надо спускаться с помощью функции согласованности. Для оператора
>^ эта функция сравнивает точку (2,7) с центральной точкой узла (4,4) и выбирает квадранты, в которых могут находиться искомые точки — в данном случае первый и четвертый.В узле, соответствующем первому квадранту, снова определяем дочерние узлы с помощью функции согласованности. Центральная точка (6,6), и нам снова требуется просмотреть первый и четвертый квадранты.
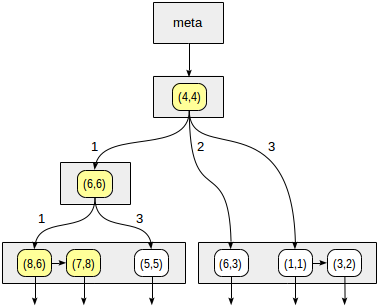
Первому квадранту соответствует список листовых узлов (8,6) и (7,8), из которых под условие запроса подходит только точка (7,8). Ссылка на четвертый квадрант пуста.
У внутреннего узла (4,4) ссылка на четвертый квадрант также пуста, и на этом поиск завершен.
postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
Внутри
Внутреннее устройство индексов SP-GiST можно изучать с помощью расширения gevel, про которое мы уже говорили ранее. Плохая новость: из-за ошибки расширение некорректно работает на современных версиях PostgreSQL. Хорошая новость: мы планируем перенести функциональность gevel в pageinspect (обсуждение). И ошибка там уже исправлена.
Для примера возьмем расширенную демо-базу, которая использовалась для рисования картинок с картой мира.
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
Об индексе можно, во-первых, узнать некоторую статистическую информацию:
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
И во-вторых, вывести само дерево индекса:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
Но имейте в виде. что функция spgist_print выводит не все листовые значения, а только первое из списка, и поэтому показывает структуру индекса, а не полное его содержимое.
Пример: k-мерные деревья
Для тех же точек на плоскости можно предложить и другой способ разбиения пространства.
Проведем через первую индексируемую точку горизонтальную линию. Она разбивает плоскость на две части: верхнюю и нижнюю. Вторая индексируемая точка попадает в одну из этих частей. Через нее проведем вертикальную линию, которая разбивает эту часть на две: правую и левую. Через следующую точку снова проводим горизонтальную линию, через следующую — вертикальную и так далее.
У всех внутренних узлов дерева, построенного таким образом, будет всего два дочерних узла. Каждая из двух ссылок может вести либо на следующий в иерархии внутренний узел, либо на список листовых узлов.
Метод легко обобщается на k-мерные пространства, поэтому и деревья в литературе называются k-мерным (k-D tree).
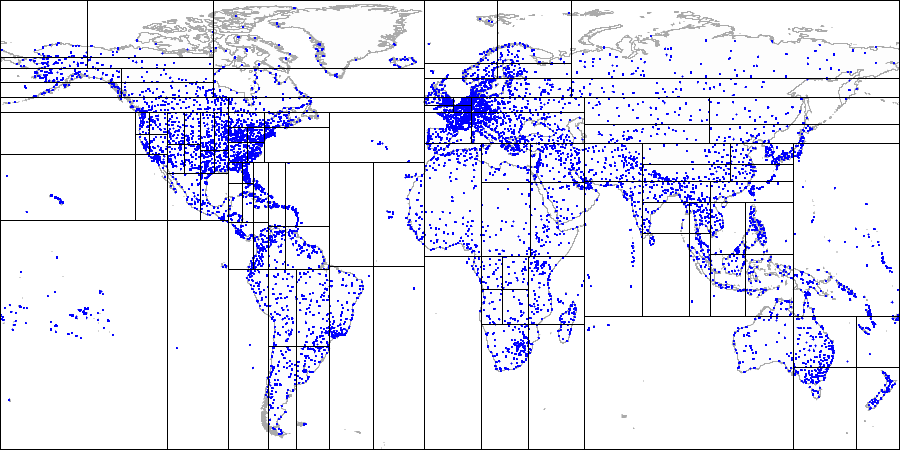
На примере аэропортов:
Сначала делим плоскость на верх и низ...
Затем каждую часть на лево и право...

И так далее, пока не получим итоговое разбиение.
Чтобы использовать именно такое разбиение, нужно при создании индекса явно указать класс операторов kd_point_ops:
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
CREATE INDEX
В этот класс входят ровно те же операторы, что и в «умолчательный» quad_point_ops.
Внутри
При просмотре структуры дерева надо учесть, что префиксом в данном случае является не точка, а всего одна координата:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
Пример: префиксное дерево
С помощью SP-GiST можно реализовать и префиксное дерево (radix tree) для строк. Идея префиксного дерева в том, что индексируемая строка не хранится целиком в листовом узле, а получается конкатенацией значений, хранящихся в узлах вверх от данного до корня.
Допустим, надо проиндексировать адреса сайтов: «postgrespro.ru», «postgrespro.com», «postgresql.org» и «planet.postgresql.org».
postgres=# create table sites(url text);
CREATE TABLE
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
Дерево будет иметь следующий вид:
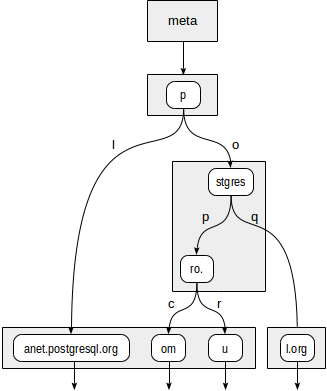
Во внутренних узлах дерева хранятся префиксы, общие для всех дочерних узлов. Например, в дочках узла «stgres» значения начинаются на «p» + «o» + «stgres».
Каждый указатель на дочерний узел, в отличие от дерева квадрантов, дополнительно помечен одним символом (на самом деле двумя байтами, но это не так важно).
Класс операторов text_ops поддерживает операторы, традиционные для b-tree: «равно», «больше», «меньше»:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
Операторы с тильдами отличаются тем, что работают не с символами, а с байтами.
В ряде случаев представление в виде префиксного дерева может оказаться существенно компактнее B-дерева за счет того, что значения не хранятся целиком, а реконструируются по мере необходимости при движении по дереву.
Рассмотрим запрос:
select * from sites where url like 'postgresp%ru'. Он может быть выполнен с помощью индекса:postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
Фактически по индексу находятся значения, большие или равные «postgresp» и в то же время меньшие «postgresq» (Index Cond), а затем из результата отбираются подходящие значения (Filter).
Сначала функция согласованности должна решить, в какие дочерние узлы корня «p» нужно спуститься. Есть два варианта: «p» + «l» (не подходит, даже не заглядывая дальше) и «p» + «o» + «stgres» (подходит).
Для узла «stgres» снова требуется обращение к функции согласованности, чтобы проверить «postgres» + «p» + «ro.» (подходит) и «postgres» + «q» (не подходит).
Для узла «ro.» и всех его дочерних листовых узлов функции согласованности ответит «подходит», так что индексный метод вернет два значения: «postgrespro.com» и «postgrespro.ru». Из них — уже на этапе фильтрации — будет выбрано одно подходящее значение.
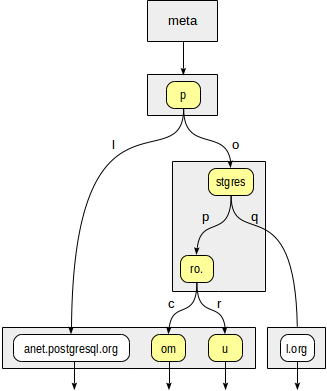
Внутри
При просмотре структуры дерева надо учесть типы данных:
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- тип префикса
node_label smallint, -- тип метки
leaf_value text -- тип листового значения
)
order by tid, n;
Свойства
Посмотрим на свойства метода доступа spgist (запросы приводились ранее):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
Индксы SP-GiST не могут использоваться для сортировки и поддержки уникальности. Кроме того, такие индексы нельзя строить по нескольким столбцам (в отличие от GiST). Использование для поддержки ограничений исключения допускается.
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
Здесь отличие от GiST состоит в отсутствии возможности кластеризации.
И, наконец, свойства уровня столбца:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
Поддержки сортировки нет, что понятно. Операторы расстояния для поиска ближайших соседей в SP-GiST пока не доступны; скорее всего такая поддержка появится в будущем.
SP-GiST может использоваться для исключительно индексного сканирования, по крайней мере для рассмотренных классов операторов. Как мы видели, в каких-то случаях индексированные значения непосредственно хранятся в листовых узлах, а в каких-то — восстанавливаются по частям при спуске по дереву.
Неопределенные значения
До сих пор мы ничего не говорили про неопределенные значения, чтобы не усложнять картину. Как видно из свойств индекса, NULL поддерживается. И действительно:
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
Однако неопределенное значение для SP-GiST — нечто чужеродное. Все операторы, входящие в класс операторов метода spgist, должны быть строгими: для неопределенных параметров они должны возвращать неопределенный результат. Это обеспечивает сам метод; неопределенные значения просто не передаются операторам.
Но, чтобы метод доступа мог использоваться для исключительно индексного сканирования, неопределенные значения все-таки нужно хранить в индексе. Они и хранятся, но в отдельном дереве со своим собственным корнем.
Другие типы данных
Помимо точек и префиксных деревьев для строк, в PostgreSQL реализованы и другие методы на основе SP-GiST:
- Дерево квадрантов для прямоугольников обеспечивает класс операторов box_ops.
Каждый прямоугольник представляется точкой в четырехмерном пространстве, так что число квадрантов равно 16. Такой индекс может выиграть у GiST по производительности, когда среди прямоугольников много пересечений: в GiST невозможно провести границы так, чтобы отделить пересекающиеся объекты друг от друга, а вот с точками (пусть и четырехмерными) таких проблем нет.
- Дерево квадрантов для диапазонов предоставляет класс операторов range_ops.
Интервал представляется двумерной точкой: нижняя граница становится абсциссой, а верхняя — ординатой.
Продолжение следует.
Комментарии (18)

SXN
18.09.2017 12:07-3Доброго времени суток, хотел спросить как заменить в запросе IN и NOT IN там проста данные много (около миллиона) и будет расти. Поля индексированное но все равно запросы работают дольше и дольше
Заранее спасибо!
erogov Автор
18.09.2017 12:47+2Хм, и какие выводы можно делать, не видя хотя бы
EXPLAIN ANALYZEзапроса?
Из самых общих соображений могу сказать, что если данных много, то индексы будут скорее мешать, чем помогать. Возможно, вам надо добиться такого плана, чтобы таблицы соединялись с помощью HASH JOIN.
Но это все лечение по фотографии. Покажите план запроса, тогда и подумаем. Только в личку, потому что SP-GiST тут явно ни при чем.

Komzpa
18.09.2017 14:45+1А что нужно, чтобы Postgres научился для SP-GiST делать compress и recheck, такой же, как и для GiST? Без этого его поддержку никак не могут запилить в PostGIS — он же не может сохранить в себе геометрию длиннее 8 килобайт, что в общем-то частое явление.
erogov Автор
18.09.2017 14:56+1Ну, общий алгоритм состоит в том, чтобы капать на мозги нашим разработчикам (:
Но я что-то не могу сообразить, как использовать SP-GiST для произвольной хитроизогнутой геометрии. Как эти фигуры непересекающимся образом развести по квадрантам?Komzpa
18.09.2017 14:59+2GiST делает compress из фигуры в её box, а потом box можно паковать уже как многомерную точку. На этапе выборки — быстро достать бокс, а потом сделать recheck по полной геометрии.
erogov Автор
18.09.2017 15:06+2В принципе да, на мой взгляд выглядит вполне себе реализуемо. Будем капать.
Komzpa
18.09.2017 15:23+1Я вам даже ссылками помогу:
trac.osgeo.org/postgis/ticket/1847
github.com/pramsey/postgres/tree/spgistcompress
github.com/postgis/postgis/compare/svn-trunk...mohitkharb:spgist
github.com/postgis/postgis/compare/svn-trunk...pramsey:spgist
Это дело начинали на Google Summer of Code в 2014, но задача повисла, так как больше на стороне Postgres, чем на стороне PostGIS.
smagen
18.09.2017 17:12+1Recheck в SP-GiST уже есть и кажется всегда был. См. структуру данных, которую возвращает leaf_consistent.
typedef struct spgLeafConsistentOut { Datum leafValue; /* reconstructed original data, if any */ bool recheck; /* set true if operator must be rechecked */ } spgLeafConsistentOut;
Патч о добавлении метода compress был на commitfest, но он как-то заглох. Будем его возобновлять.
www.postgresql.org/message-id/flat/54907069.1030506@sigaev.ru#54907069.1030506@sigaev.ru
Насколько я понял отсюда, пока реализован opclass только для точек. Точки имеют ограниченный размер, поэтому для них compress не так чтобы прямо жизненно необходим. Но, конечно, с compress'ом намного лучше, мы будем им заниматься.Komzpa
18.09.2017 17:42+1Проблема в том, что в PostGIS не отдельного типа для точки — они все по сути своей geometry. В рамках GSoC сделали скоростную кластеризацию для точек, тикет про неё — это уже навороты.
Опкласс для произвольной геометрии, похоже, есть у Пола в github.com/postgis/postgis/compare/svn-trunk...pramsey:spgist.smagen
18.09.2017 18:13+1Да, но насколько я понял, производительность у этого opclass'а не очень, если верить самому Полу.
www.postgresql.org/message-id/CACowWR2LhVi4JHEVV=PYzLSyBfnpMd5+bhr2R8t5vzs0o79Ndw@mail.gmail.com
Скорее стоит смотеть в сторону отображения 2-мерное прямоугольника в 4-мерную точку, по аналогии с acdf2a8b372aec1da09370fca77ff7dccac7646d.

vvmtutby
19.09.2017 10:58Вопрос несколько «приземлённый», зато важный на практике:
Postgres поддерживает VSS ( API позволяющее получить консистентность / целостность резервных копий)?erogov Автор
19.09.2017 11:06Это который микрософтовский Volume Shadow? Нет, его не поддерживает, конечно.
Но, разумеется, есть собственные средства, которые позволяют делать горячие резервные копии. Все это описано в документации в разделе Создание базовой резервной копии через низкоуровневый API.
vvmtutby
19.09.2017 11:19Хорошо, переходим к примерам:
делаем бэкап VM «целиком»
Если внутри виртуальной машины OS Windows + MS SQL ( или Oracle), то резервная копия гарантирована целостна
(
Для конкретики возьмём Hyper-V, Windows внутри VM для «честного» VSS,
а не для псевдо-VSS сброса буферов файловой системы на диск, как в варианте H-V VM с Linux + СУБД
просьба учитывать, что вопрос не про плюсы/минусы ESX/H-V и(или) *nix/Win и(или) т.п.
)
Если внутри Postgres, то?...erogov Автор
19.09.2017 12:14+3Я не очень представляю себе, как выполняется "бэкап VM целиком". Если для этого используется механизм снимков (snapshot) Hyper-V, то да, резервная копия должна быть годной (файлы данных будут рассогласованны, но в копии будут все необходимые журнальные файлы, чтобы Постгрес при старте автоматически восстановил целостность).
P. S. Казалось бы, при чем тут индексы?
JeStoneDev
Как происходит процесс вычисления центральной точки в дереве квадрантов? Медианы по обеим осям? Половина разности максимального и минимального значений x и y? Или какой-то более сложный алгоритм? Как вычисляется центральная точка, если построить индекс по пустой таблице? Может ли получиться, что после заполнения таблицы, в которой уже присутствует sp-gist индекс, все точки будут в одном квадранте верхнего уровня, а 3 других будут пустыми?
erogov Автор
Используются средние значения по осям. Забавно, что есть код и для медианы, но чтобы его включить, надо пересобрать Постгрес с
#define USE_MEDIAN. Если интересно, загляните в src/backend/access/spgist/spgistquadtreeproc.c.Центроид вычисляется, когда в дерево добавляется новый внутренний узел. Так что имеющиеся точки, которых уходят в новый узел, распределяются по квадрантам условно равномерно. Так что такой ситуации возникнуть не должно.