
Привет! Меня зовут Макс Матюхин, я работаю в SRV-команде Badoo. Мы в Badoo не только активно пишем посты в свой блог, но и внимательно читаем блоги наших коллег из других компаний. Недавно ребята из Dropbox опубликовали шикарный пост о различных способах оптимизации серверных приложений: начиная с железа и заканчивая уровнем приложения. Его автор – Алексей Иванов – дал огромное количество советов и ссылок на дополнительные источники информации. К сожалению, у Dropbox нет блога на Хабре, поэтому я решил перевести этот пост для наших читателей.
Это расширенная версия моего выступления на nginx.conf 2017 в сентябре этого года. В качестве старшего инженера по контролю качества (SRE) в команде Dropbox Traffic я отвечаю за нашу сеть Edge: её надёжность, производительность и эффективность. Это proxy-tier-сеть, построенная на базе nginx и предназначенная как для обработки чувствительных к задержке метаданных, так и для передачи данных с высокой пропускной способностью. В системе, обрабатывающей десятки гигабитов в секунду и одновременно – десятки тысяч транзакций, чувствительных к задержкам, используются различные оптимизации эффективности и производительности: начиная с драйверов и прерываний, сквозь ядро и TCP/ IP-стек, и заканчивая библиотеками и настройками уровня приложения.
Пояснения
В этом посте мы рассмотрим многочисленные способы настройки веб-серверов и прокси. Пожалуйста, не занимайтесь карго-культом. Подходите к этому с позиции науки, применяйте оптимизации по одной, измеряйте эффект и принимайте решение, действительно ли они полезны для вашей работы.
Это не пост о производительности Linux (хотя я и буду часто ссылаться на bcc, eBPF и perf) и не исчерпывающее руководство по использованию инструментов профилирования производительности (если вы хотите узнать о них больше, почитайте блог Брендана Грегга).
Это также не пост о производительности браузеров. Я буду упоминать о клиентской производительности применительно к оптимизациям задержек, но очень коротко. Хотите узнать больше – прочитайте статью High Performance Browser Networking Ильи Григорика.
И это не компиляция на тему лучших методик TLS. Хотя я и буду упоминать TLS-библиотеки и их настройки, вы и ваша команда обеспечения безопасности должны самостоятельно оценивать их производительность и влияние на безопасность. Чтобы узнать, насколько ваши серверы отвечают набору лучших методик, можете воспользоваться Qualys SSL Test. Если хотите узнать больше о TLS в целом, подпишитесь на рассылку Feisty Duck Bulletproof TLS Newsletter.
Структура поста
Мы рассмотрим оптимизации эффективности/ производительности на разных уровнях системы. Начнём с самого нижнего, аппаратно-драйверного, уровня: эти настройки можно применить практически к любому высоконагруженному серверу. Затем я перейду к ядру Linux и его TCP/IP-стеку: можете покрутить эти ручки на своих ящиках, активно использующих TCP. Наконец, мы обсудим настройки на уровне библиотек и приложений, которые по большей части применимы ко многим веб-серверам и в частности к nginx.
По каждой области оптимизаций я постараюсь дать пояснения касательно компромиссов в отношении задержки/ пропускной способности (если они будут), а также дам советы по мониторингу и предложения по настройкам для разных уровней рабочей нагрузки.
Оборудование
Процессор
Для хорошей производительности асимметричного RSA/EC выбирайте процессоры как минимум с поддержкой AVX2 (avx2 в /proc/cpuinfo) и желательно подходящие для вычислений с большими целыми числами (bmi и adx). Для симметричного шифрования выбирайте AES-NI для AES-шифров и AVX-512 – для ChaCha+Poly. У Intel есть сравнение производительности разных поколений процессоров с OpenSSL 1.0.2, где рассматривается влияние этих аппаратных оптимизаций.
Для задач, где важен уровень задержки, вроде роутинга рекомендуется уменьшить количество NUMA-узлов и отключить Hyper-Threading. Задачи, требующие высокой пропускной способности, эффективнее выполняются при большем количестве ядер с использованием Hyper-Threading (если только нет привязки к кэшу), и в целом NUMA не играет для них особой роли.
Если выбираете среди продукции Intel, то смотрите на процессоры с архитектурой Haswell/ Broadwell, а лучше Skylake. У AMD впечатляющую производительность демонстрируют EPYC-модели.
Сетевая карта
Вам нужно как минимум 10 Гбит, а лучше – 25 Гбит. Если хотите передавать через один сервер с TLS ещё больше, то описанных здесь настроек может быть недостаточно – возможно, придётся сдвинуть TLS-фрейминг на уровень ядра (FreeBSD, Linux).
Что касается программного уровня, поищите open-source-драйверы с активными списками рассылки и сообществами. Это будет очень важным фактором, если (скорее «когда») вы будете заниматься решением проблем, связанных с драйверами.
Память
Эмпирическое правило: задачи, чувствительные к задержке, требуют более быстрой памяти; задачи, чувствительные к пропускной способности, требуют больше памяти.
Диски
Всё зависит от ваших требований к буферизации/кэшированию. Если вам нужно много буферизировать или кэшировать, то лучше выбрать SSD-диски. Некоторые даже устанавливают заточенные под флеш файловые системы (обычно log-structured), но они не всегда показывают более высокую производительность по сравнению с обычными ext4/ xfs.
В любом случае не сгубите свои флеш-накопители, забыв включить TRIM или обновить прошивку.
Операционные системы: низкий уровень
Прошивка
Используйте свежие прошивки, чтобы избежать долгого и болезненного выявления сбоев. Старайтесь поддерживать актуальные прошивки для процессора, материнской платы, сетевых карт и SSD-накопителей. Это не значит, что нужно всегда использовать самые последние версии — рекомендуется брать предпоследние, если в них нет критически важных багов, которые устранены в последних версиях.
Драйверы
Здесь можно дать тот же совет, что и в отношении прошивки: по возможности используйте свежие версии, но не последние. Старайтесь разделить апгрейды ядра и обновления драйверов. Например, можете упаковать драйверы с помощью DKMS или предварительно скомпилировать их для всех версий ядра, которые вы используете. Благодаря этому, если после обновления ядра что-то пойдёт не так, вы быстрее поймёте, в чём проблема.
Процессор
Ваш лучший друг — репозиторий ядра (и инструменты, поставляемые с ним). В Ubuntu/ Debian вы можете установить пакет linux-tools с набором утилит, но в этом посте мы будем использовать только cpupower, turbostat и x86_energy_perf_policy. Для проверки связанных с процессором оптимизаций вы можете провести стресс-тестирование своего ПО с помощью любимого генератора нагрузки (например, Yandex.Tank). Вот презентация о лучших методиках нагрузочного тестирования от разработчиков nginx: NGINX Performance testing.
cpupower
$ cpupower frequency-info
...
driver: intel_pstate
...
available cpufreq governors: performance powersave
...
The governor "performance" may decide which speed to use
...
boost state support:
Supported: yes
Active: yesПроверьте, включён ли Turbo Boost, а если у вас процессор Intel, удостоверьтесь, что система работает с intel_pstate, а не с acpi-cpufreq или pcc-cpufreq. Если вы всё ещё используете acpi-cpufreq, обновите ядро. Если это невозможно, используйте режим performance. При работе с intel_pstate даже режим powersave должен выполняться с хорошей производительностью, но вам придётся проверить это самостоятельно.
Что касается простоя, чтобы посмотреть, что реально происходит с вашим процессором, вы можете с помощью turbostat напрямую заглянуть в процессорные MSR и извлечь информацию о питании, частоте и так называемых Idle States:
# turbostat --debug -P
... Avg_MHz Busy% ... CPU%c1 CPU%c3 CPU%c6 ... Pkg%pc2 Pkg%pc3 Pkg%pc6 ...Здесь вы видите реальную частоту процессора (да, /proc/cpuinfo вам врёт), а также текущее состояние ядра/набора ядер.
Если даже с драйвером intel_pstate процессор тратит на простой больше времени, чем вы думали, вы можете:
- переключить регулятор на performance;
- для повышения производительности настроить
x86_energy_perf_policy.
А для очень чувствительных к задержке задач можно:
- использовать интерфейс
/dev/cpu_dma_latency; - для UDP-трафика использовать busy-polling.
Узнать больше об управлении питанием процессора в целом и P-состояниями в частности можно из презентации Balancing Power and Performance in the Linux Kernel с LinuxCon Europe 2015.
Привязка к процессору
Можно ещё больше уменьшить задержку, привязав поток или процесс к CPU. Например, в nginx есть директива worker_cpu_affinity, которая автоматически привязывает каждый процесс веб-сервера к конкретному ядру. Это позволяет исключить миграцию процесса / потока на другое ядро, уменьшить количество промахов кэша и ошибок страниц памяти, а также слегка увеличить количество инструкций в цикле. Всё это можно проверить через perf stat.
Но процессорная привязка негативно влияет на производительность, поскольку процессам дольше приходится ждать освобождения процессора. Это можно отслеживать с помощь запуска runqlat на одном из ваших PID nginx-воркера:
usecs : count distribution
0 -> 1 : 819 | |
2 -> 3 : 58888 |****************************** |
4 -> 7 : 77984 |****************************************|
8 -> 15 : 10529 |***** |
16 -> 31 : 4853 |** |
...
4096 -> 8191 : 34 | |
8192 -> 16383 : 39 | |
16384 -> 32767 : 17 | |Если заметите длинные хвосты на много миллисекунд, то, вероятно, на серверах выполняется слишком много всего, помимо nginx, и привязка увеличит задержку, а не уменьшит её.
Память
Все настройки Memory Management обычно сильно зависят от рабочего процесса, так что могу дать лишь такие рекомендации:
- настройте Transparent Huge Pages на
madviseи включайте их, только когда уверены в их пользе, иначе можете сильно замедлить работу, стремясь к 20%-ному уменьшению задержки; - если вы используете только один узел NUMA, то установите
vm.zone_reclaim_mode в 0.
Современные процессоры представляют собой несколько отдельных процессоров, связанных очень быстрой шиной и совместно использующих различные ресурсы, начиная с кэша L1 на HT-ядрах и заканчивая кэшем L3 применительно к пакетам, памятью и PCIe-соединениями в рамках сокетов. Это и есть NUMA: многочисленные модули исполнения и хранения с быстрой шиной обмена данными.
Исчерпывающее описание NUMA и её применения содержится в статье Фрэнка Деннемана NUMA Deep Dive Series.
Короче, вы можете:
- игнорировать её, отключив в BIOS или выполняя своё ПО под
numactl --interleave=all(так вы получите посредственную, но достаточно стабильную производительность); - отказаться от неё, используя одноузловые серверы, как это делает Facebook с платформой OCP Yosemite;
- принять её, оптимизируя размещение процессора/ памяти в пространствах ядра и пользователя.
Давайте рассмотрим третий вариант, поскольку в двух остальных не требуется много оптимизировать.
Для правильного использования NUMA вам нужно рассматривать каждый её узел в качестве отдельного сервера. Проверьте топологию с помощью numactl --hardware:
$ numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 16 17 18 19
node 0 size: 32149 MB
node 1 cpus: 4 5 6 7 20 21 22 23
node 1 size: 32213 MB
node 2 cpus: 8 9 10 11 24 25 26 27
node 2 size: 0 MB
node 3 cpus: 12 13 14 15 28 29 30 31
node 3 size: 0 MB
node distances:
node 0 1 2 3
0: 10 16 16 16
1: 16 10 16 16
2: 16 16 10 16
3: 16 16 16 10Что нужно проверять:
- количество узлов;
- объём памяти для каждого узла;
- количество процессоров для каждого узла;
- расстояние между узлами.
Это очень плохой пример, поскольку здесь четыре узла, и к тому же прикреплены узлы без памяти. Здесь нельзя использовать каждый узел как отдельный сервер без потери половины ядер.
Это можно проверить с помощью numastat:
$ numastat -n -c
Node 0 Node 1 Node 2 Node 3 Total
-------- -------- ------ ------ --------
Numa_Hit 26833500 11885723 0 0 38719223
Numa_Miss 18672 8561876 0 0 8580548
Numa_Foreign 8561876 18672 0 0 8580548
Interleave_Hit 392066 553771 0 0 945836
Local_Node 8222745 11507968 0 0 19730712
Other_Node 18629427 8939632 0 0 27569060Также с помощью numastat можно получить статистику использования памяти по каждому узлу в формате /proc/meminfo:
$ numastat -m -c
Node 0 Node 1 Node 2 Node 3 Total
------ ------ ------ ------ -----
MemTotal 32150 32214 0 0 64363
MemFree 462 5793 0 0 6255
MemUsed 31688 26421 0 0 58109
Active 16021 8588 0 0 24608
Inactive 13436 16121 0 0 29557
Active(anon) 1193 970 0 0 2163
Inactive(anon) 121 108 0 0 229
Active(file) 14828 7618 0 0 22446
Inactive(file) 13315 16013 0 0 29327
...
FilePages 28498 23957 0 0 52454
Mapped 131 130 0 0 261
AnonPages 962 757 0 0 1718
Shmem 355 323 0 0 678
KernelStack 10 5 0 0 16Теперь рассмотрим пример более простой топологии.
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 46967 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 48355 MBПоскольку узлы по большей части симметричны, мы можем привязать экземпляр нашего приложения к каждому NUMA-узлу с помощью numactl --cpunodebind=X --membind=X, а затем открыть его на другом порте. Пропускная способность увеличится благодаря использованию обоих узлов и уменьшению задержки за счёт сохранения локальности памяти.
Проверить эффективность размещения NUMA можно по задержке операций в памяти. Например, с помощью funclatency в BCC измерьте задержку операции, активно использующей память, допустим, memmove.
Наблюдать за эффективностью на стороне ядра можно с помощью perf stat, отслеживая соответствующие события памяти и планировщика:
# perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p PID
...
1 sched:sched_stick_numa
3 sched:sched_move_numa
41 sched:sched_swap_numa
5,239 migrate:mm_migrate_pages
50,161 minor-faultsПоследняя порция связанных с NUMA оптимизаций для сетевых нагрузок с активным использованием сети продиктована тем фактом, что сетевая карта — это PCIe-устройство, а каждое устройство привязано к своему NUMA-узлу; следовательно, у каких-то процессоров задержка при обращении к сети будет меньше. Возможные оптимизации мы обсудим в главе, где будет рассматриваться привязка сетевая карта > процессор, а пока перейдём к PCI Express.
PCIe
Обычно нет нужды углубляться в решение проблем с PCIe, если только не возникает какой-то аппаратный сбой. Однако стоит хотя бы просто создать для своих PCIe-устройств «ширину шины», «скорость шины» и предупреждения RxErr/BadTLP. Это должно сэкономить вам часы на отладку из повреждённого железа или сбойного PCIe-согласования. Для этого можете воспользоваться lspci:
# lspci -s 0a:00.0 -vvv
...
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM L1, Exit Latency L0s <2us, L1 <16us
LnkSta: Speed 8GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
...
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- ...
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+PCIe может стать узким местом, если у вас несколько высокоскоростных устройств, конкурирующих за ширину канала (например, при комбинации быстрой сети с быстрым хранилищем), так что вам может понадобиться физически шардить свои PCIe-устройства среди процессоров, чтобы получить максимальную пропускную способность.

Также советую прочитть статью Understanding PCIe Configuration for Maximum Performance, в ней подробнее рассматривается конфигурация PCIe, что может быть полезно при высоких скоростях, когда происходит потеря пакетов между картой и ОС.
Intel предполагает, что иногда управление питанием PCIe (ASPM) может приводить к большим задержкам, а значит, и к потере большего количества пакетов. Эту функцию можно отключить, введя pcie_aspm=off в командной строке ядра.
Сетевая карта
Прежде чем мы начнём, стоит упомянуть, что Intel и Mellanox предлагают собственные руководства по настройке производительности, и вне зависимости от выбранного вами вендора стоит прочитать оба материала. Кроме того, драйверы обычно идут с собственными README и наборами полезных утилит.
Также можете поискать руководства для вашей ОС. Например, в руководстве по настройке сетевой производительности в Linux от Red Hat Enterprise объясняются многие из упомянутых выше оптимизаций. У Cloudflare тоже есть хорошая статья о настройке этой части сетевого стека, хотя по большей части она посвящена ситуациям, когда нужна низкая задержка.
В ходе оптимизации вашим лучшим другом будет ethtool.
Примечание: если вы используете достаточно свежее ядро (а вам следует это сделать!), то вы также столкнётесь с некоторыми аспектами вашего пользовательского пространства. Например, для сетевых операций вы, вероятно, захотите использовать более свежие версии пакетов ethtool, iproute2 и, быть может, iptables/nftables.
Получить ценные сведения о том, что происходит с вашей сетевой картой, можно с помощью ethtool -S:
$ ethtool -S eth0 | egrep 'miss|over|drop|lost|fifo'
rx_dropped: 0
tx_dropped: 0
port.rx_dropped: 0
port.tx_dropped_link_down: 0
port.rx_oversize: 0
port.arq_overflows: 0Проконсультируйтесь с производителем вашей сетевой карты относительно подробного описания статистики. Например, у Mellanox есть отдельная Wiki-статья об этом.
Что касается ядра, то нужно смотреть /proc/interrupts, /proc/softirqs и /proc/net/softnet_stat. Здесь есть два полезных BCC-инструмента: hardirqs и softirqs. Цель вашей оптимизации сети заключается в такой настройке системы, чтобы процессор использовался минимально, а пакеты не терялись.
Привязка прерываний
Обычно настройки здесь начинаются с распределения прерываний по процессорам. Как именно это делать, зависит от вашей рабочей нагрузки:
- для максимальной пропускной способности можно распределить прерывания по всем NUMA-узлам;
- для минимизации задержки можно ограничить прерывания одним NUMA-узлом (для этого вам может понадобиться уменьшить количество очередей, чтобы не превысить возможности одного узла (обычно приходится уменьшать вдвое с помощью
ethtool -L).
Как правило, для этого вендоры предоставляют скрипты. Например, у Intel это set_irq_affinity.
Размеры кольцевого буфера
Сетевым картам нужно обмениваться информацией с ядром. Обычно это делается через структуру данных, называющуюся «кольцо». Текущий/ максимальный размер этого кольца можно посмотреть с помощью ethtool -g:
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
TX: 4096
Current hardware settings:
RX: 4096
TX: 4096С помощью -G можно настраивать значения в рамках предварительно заданных экстремумов. Обычно чем больше, тем лучше (особенно если вы используете объединение прерываний), поскольку это даёт вам лучшую защиту от пиков и каких-то проблем в ядре, а значит, уменьшает количество дропнутых пакетов из-за нехватки места в буфере или пропущенного прерывания. Но есть пара предостережений:
в более старых ядрах или драйверах без поддержки BQL высокие значения могут относиться к более высокому bufferbloat на TX-стороне;
- буферы большего размера увеличивают давление кэша, так что, если вы с этим столкнётесь, постарайтесь уменьшить буферы.
Объединение прерываний
Этот механизм обеспечивает задержку уведомления ядра о новых событиях за счёт объединения нескольких сообщений в одно прерывание. Текущие настройки можно посмотреть с помощью ethtool -c:
$ ethtool -c eth0
Coalesce parameters for eth0:
...
rx-usecs: 50
tx-usecs: 50Также вы можете придерживаться статичных пределов (static limits), жёстко ограничив максимальное количество прерываний в секунду на одно ядро, или положиться на автоматическую аппаратную подстройку частоты прерываний в зависимости от пропускной способности.
Включение объединения (-C) увеличит задержку и, вероятно, приведёт к потере пакетов, так что эту функцию не рекомендуется использовать для задач, чувствительных к уровню задержки. Но с другой стороны, её полное отключение может привести к троттлингу прерываний, а следовательно, ограничению производительности.
Разгрузки
Современные сетевые карты довольно умны и могут разгружать немалую часть работы посредством железа либо эмулировать разгрузку в самих драйверах.
Все возможные разгрузки можно просмотреть с помощью ethtool -k:
$ ethtool -k eth0
Features for eth0:
...
tcp-segmentation-offload: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]Все ненастраиваемые разгрузки помечены суффиксом [fixed]. О них можно долго рассказывать, но я только приведу несколько эмпирических правил:
- не включайте LRO – вместо этого используйте GRO;
- будьте осторожны с TSO, поскольку это сильно зависит от качества ваших драйверов/ прошивки;
- не включайте TSO/ GSO на старых ядрах, потому что это может привести к чрезмерному bufferbloat.
Регулирование пакетов
Все современные сетевые карты оптимизированы под многопроцессорные системы, поэтому они распределяют пакеты по виртуальным очередям (обычно по одной на процессор). Когда это выполняется аппаратно, то называется RSS; когда за балансировку пакетов между процессорами отвечает ОС, это называется RPS (TX-эквивалент называется XPS). Если ОС пытается регулировать потоки к процессорам, которые в данный момент обрабатывают этот сокет, это называется RFS. А когда этим занимается железо, это называется «ускоренный RFS» или aRFS.
Вот несколько хороших методик:
- если вы используете новое оборудование 25 Гбит+, то в нём, вероятно, есть достаточно очередей и огромная таблица косвенной переадресации (indirection table), чтобы можно было применять RSS между всеми ядрами (некоторые более старые карты могут использовать только первые 16 процессоров);
- можете попробовать включить RPS, если:
1) у вас больше процессоров, чем аппаратных очередей, и вы хотите пожертвовать задержкой в пользу пропускной способности;
2) вы используете внутреннее туннелирование (например, GRE/ IPinIP), при котором сетевая карта не может применять RSS;
- не включайте RPS, если у вас достаточно старый процессор, не имеющий x2APIC;
- привязка каждого процессора к собственной TX-очереди посредством XPS – в целом хорошая идея;
- эффективность RFS во многом зависит от вашей рабочей нагрузки, а также от того, примените ли вы процессорную привязку.
Flow Director и ATR
Включённый Flow Director (или fdir в терминологии Intel) по умолчанию оперирует в режиме Application Targeting Routing, при котором реализуется aRFS посредством семплирования пакетов и регулирования потоков в процессорное ядро, где они, по-видимому, обрабатываются. Статистику можно посмотреть с помощью ethtool -S:$ ethtool -S eth0 | egrep ‘fdir’ port.fdir_flush_cnt: 0 …
Хотя Intel заявляет, что fdir в некоторых случаях увеличивает производительность, результаты одного исследования говорят о том, что это может также привести к переупорядочиванию 1% пакетов, что может довольно негативно сказаться на производительности TCP. Поэтому протестируйте самостоятельно и посмотрите, будет ли Flow Director полезен при вашей рабочей нагрузке, проверяя счётчик TCPOFOQueue.
Операционные системы: сетевой стек
Существует огромное количество книг, видео и руководств по настройке сетевого стека Linux, в которых растиражирован «карго-культ sysctl.conf». И хотя свежие версии ядра уже не требуют такого объёма настройки, как десять лет назад, а большинство новых TCP/ IP-свойств по умолчанию включены и хорошо настроены, люди продолжают копипастить свои старые sysctls.conf, которые они использовали для настройки ядер версий 2.6.18/ 2.6.32.
Для проверки эффективности сетевых оптимизаций сделайте следующее:
- с помощью
/proc/net/snmp and /proc/net/netstatсоберите TCP-метрики в рамках системы; - добавьте метрики подключения, собранные с помощью
ss -n --extended --infoили при вызове внутри сервераgetsockopt(``[TCP_INFO]``)/getsockopt(``[TCP_CC_INFO]``); - соберите tcptrace(1)`ы образцов TCP-потоков;
- проанализируйте RUM-метрики приложения/ браузера.
В качестве источников информации о сетевых оптимизациях я обычно использую выступления специалистов по CDN, потому что, как правило, они знают, что делают. Например, Fastly on LinuxCon Australia. Полезно также послушать, что говорят разработчики ядра Linux, к примеру, на NetDevConf и Netconf.
Также стоит упомянуть про подробные материалы от PackageCloud по сетевому стеку Linux, особенно в свете того, что они сделали акцент на мониторинг, а не на «слепую» настройку:
- Monitoring and Tuning the Linux Networking Stack: Receiving Data;
- Monitoring and Tuning the Linux Networking Stack: Sending Data.
И позвольте дать совет напоследок: обновите ядро ОС! Существует множество новых сетевых улучшений, и я говорю даже не об IW10 (который 2010) – я говорю о таких новинках, как автоматический выбор размера TSO, FQ, pacing, TLP и RACK. В качестве бонуса от апгрейда вы получите ряд улучшений масштабируемости, например, убранный кэш рутинга, неблокирующие сокеты прослушивания, SO_REUSEPORT и многое другое.
Обзор
Из недавних документов по работе с сетью в Linux особенно выделяется Making Linux TCP Fast. В нём на четырёх страницах собраны улучшения в ядре ОС за много лет. TCP-стек на стороне отправителя разбит на функциональные части:

Fair queueing и pacing
Fair queueing отвечает за соблюдение «справедливости» и уменьшает блокировку очереди между TCP-потоками, что положительно сказывается на частоте отбрасывания пакетов. Pacing, в свою очередь, равномерно распределяет пакеты во времени с частотой, определяемой Congestion Control, что ещё больше уменьшает долю потерянных пакетов, тем самым увеличивая пропускную способность.
Попутно хочу заметить, что fair queueing и pacing доступны в Linux посредством fq qdisc. Обе фичи требуются для BBR (впрочем, уже нет), но их можно использовать и с CUBIC, добиваясь 15–20%-ного снижения потери пакетов, а значит, и повышения пропускной способности в алгоритмах управления перегрузками (loss-based CCs). Только не используйте их на старых ядрах (<3.19), поскольку вы станете регулировать обычные ACKs и сломаете аплоад/ RPCs.
Автоматический выбор размера TSO и TSQ
Обе функции отвечают за ограничение буферизации внутри TCP-стека, а следовательно, и за уменьшение задержки без ухудшения пропускной способности.
Управление перегрузками
CC-алгоритмы сами по себе – объёмная тема, и в последние годы о них было много разговоров. Что-то из этого вылилось в код: tcp_cdg (CAIA), tcp_nv (Facebook) и tcp_bbr (Google). Мы не будем углубляться в их устройство, скажу лишь, что индикация о перегрузке во всех них основана больше на увеличении отсрочки (delay), чем на отбрасывании пакетов.
BBR – один из наиболее задокументированных, протестированных и практичных из всех новых алгоритмов управления перегрузками. На основании доли доставленных пакетов создаётся модель сетевого пути, а затем для увеличения ширины пропускания и минимизации RTT выполняются управляющие циклы. Это именно то, что мы ищем в нашем прокси-стеке.
Предварительные результаты экспериментов с BBR на наших Edge PoP показали увеличение скорости скачивания файлов:

Шестичасовой эксперимент с TCP BBR в Tokyo PoP: ось x — время, ось y — скорость скачивания на клиенте
Увеличение скорости наблюдалось по всем перцентилям. При изменениях бэкенда такого не происходит — обычно положительный результат наблюдается только p90+ пользователей (у которых самое быстрое интернет-подключение), поскольку мы считаем, что у всех остальных уже ограничена полоса пропускания. Настройки на сетевом уровне вроде изменения управления перегрузками или включения FQ/ pacing демонстрируют, что у пользователей ограничена не полоса пропускания, а, я бы сказал, присутствует «ограниченность TCP».
Если вы хотите больше узнать о BBR, то у APNIC есть хороший обзор для новичков (и сравнение с loss-based-управлением перегрузками). Более глубокую информацию можно извлечь из архивов почтовой рассылки bbr-dev (там сверху закреплено множество полезных ссылок). Если вас в целом интересует тема управления перегрузками, то можете понаблюдать за активностью Internet Congestion Control Research Group.
ACK-обработка и обнаружение пропадания пакетов
Теперь поговорим об обнаружении пропадания пакетов (loss detection). Снова упомяну про важность использования свежей версии ядра ОС. В TCP постоянно добавляются новые эвристики вроде TLP и RACK, а старые (наподобие FACK и ER) убираются. Нововведения работают по умолчанию, так что вам не придётся настраивать систему после апгрейда.
Приоритизация пользовательского пространства и HOL
API сокета пользовательского пространства (userspace socket API) предоставляют механизм явной буферизации, и после отправки чанков их уже невозможно перегруппировать. Поэтому при использовании мультиплексирования (например, в HTTP/2) это может привести к Head-of-Line блокировке и инверсии h2-приоритетов. Для решения этой проблемы были разработаны опция сокета и соответствующая опция sysctl net.ipv4.tcp_notsent_lowat. Они позволяют настраивать границы, в пределах которых сокет считает себя доступным для записи (то есть epoll в вашем приложении будет врать). Это может решить проблемы с HTTP/2-приоритизацией, но при этом плохо повлиять на пропускную способность, так что рекомендую проверить самостоятельно.
Sysctls
Непросто говорить об оптимизации работы с сетью, не упомянув про необходимость настройки sysctls. Но сначала рассмотрим, что вам трогать точно не следует:
net.ipv4.tcp_tw_recycle=1: не используйте это — для пользователей за NAT это всё уже сломано, а если вы обновите ядро, то сломаете у всех;net.ipv4.tcp_timestamps=0: не отключайте как минимум до тех пор, пока не будете знать обо всех побочных эффектах. Например, одним из неочевидных последствия является то, что вы лишитесь оконного масштабирования и SACK-опций в syncookie.
Лучше сделайте вот что:
net.ipv4.tcp_slow_start_after_idle=0: главная проблема с медленным стартом (slow start) после простоя заключается в том, что «простой» определяется как один RTO, а этого слишком мало;net.ipv4.tcp_mtu_probing=1: полезно при наличии ICMP-«чёрных дыр» между вами и клиентами (наверняка они есть );net.ipv4.tcp_rmem, net.ipv4.tcp_wmem: нужно настроить так, чтобы подходило к BDP; только не забудьте, что больше – не значит лучше;echo 2 > /sys/module/tcp_cubic/parameters/hystart_detect: если вы используете FQ+CUBIC, то это может помочь решить проблему слишком раннего выхода tcp_cubic из медленного старта.
Стоит упомянуть, что существует RFC-черновик (хотя и подзаброшенный) от Дэниела Штенберга, автора curl, под названием TCP Tuning for HTTP, в котором сделана попытка собрать все системные настройки, которые могут быть полезны для HTTP.
Уровень приложения: средний уровень
Инструментарий
Как и в случае с ядром ОС, пользовательское пространство крайне важно актуализировать. Начните с обновления своего инструментария, например, можете упаковать более свежие версии perf, bcc и так далее.
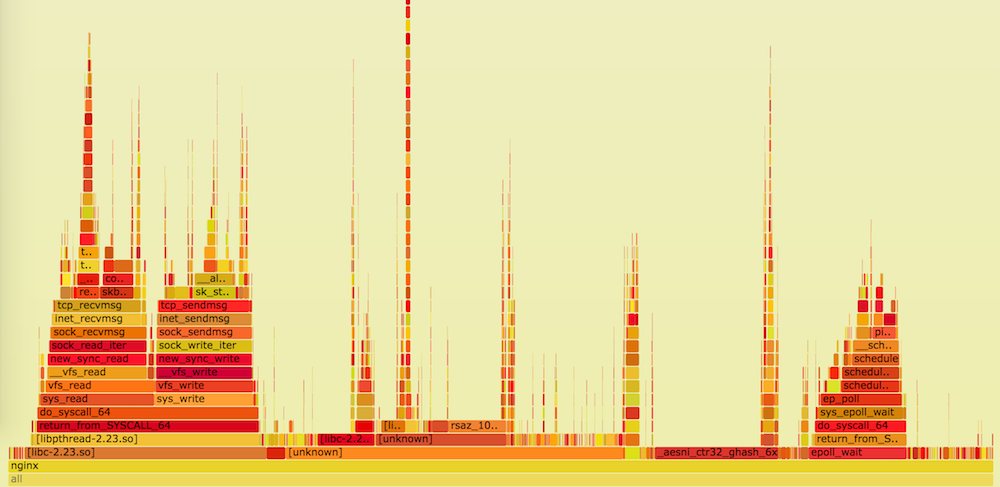
После этого можно приступать к настройке и отслеживанию поведения системы. В этой части поста мы будем по большей части опираться на профилирование процессора с помощью perf top, on-CPU flame-графики и ad hoc-гистрограммы из funclatency в bcc.
Инструментарий для компилирования
Если вы хотите сделать аппаратно-оптимизированную сборку, то необходимо обзавестись современными инструментами для компилирования, представленных во многих библиотеках, широко используемых в веб-серверах.
Помимо производительности, новые компиляторы могут похвастаться и новыми свойствами обеспечения безопасности (например, -fstack-protector-strong или SafeStack). Также современный инструментарий будет полезен, если вы хотите прогонять тесты через бинарные файлы, скомпилированные с использованием санитайзеров (например, AddressSanitizer и других).
Системные библиотеки
Рекомендую обновить системные библиотеки вроде glibc, иначе вы можете не получить свежих оптимизаций низкоуровневых функций из -lc, -lm, -lrt и так далее. Стандартное предупреждение: тестируйте самостоятельно, поскольку могут встречаться неожиданные регрессии.
zlib
Обычно за компрессию отвечает веб-сервер. В зависимости от объёма данных, проходящих через прокси, вы можете встретить упоминание zlib в perf top, например:
# perf top
...
8.88% nginx [.] longest_match
8.29% nginx [.] deflate_slow
1.90% nginx [.] compress_blockЭто можно оптимизировать на самом низком уровне: Intel и Cloudflare, как и отдельный проект zlib-ng, имеют собственные zlib-форки, обеспечивающие более высокую производительность за счёт использования новых наборов инструкций.
malloc
При обсуждении оптимизаций до этого момента мы по большей части ориентировались на процессор. Теперь же поговорим о памяти. Если вы активно используете Lua с FFI или тяжёлые сторонние модули, которые самостоятельно управляют памятью, то могли заметить рост потребления памяти из-за фрагментации. Эту проблему можно попытаться решить переключением на jemalloc или tcmalloc.
Использование кастомного malloc даёт следующие преимущества:
- ваши бинарные файлы nginx отделяются от окружения, так что на него меньше повлияют обновление версии glibc и миграция ОС;
- улучшаются самоанализ, профилирование и сбор статистики.
Если в конфигурации nginx вы используете многочисленные сложные регулярные выражения или активно применяете Lua, то могли встретить в perf top упоминание PCRE. Это можно оптимизировать, скомпилировав PCRE с JIT, а также включив её в nginx посредством pcre_jit on;.
Результат оптимизации можно проверить на flame-графиках или с помощью funclatency:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_http_regex_exec -u
...
usecs : count distribution
0 -> 1 : 1159 |********** |
2 -> 3 : 4468 |****************************************|
4 -> 7 : 622 |***** |
8 -> 15 : 610 |***** |
16 -> 31 : 209 |* |
32 -> 63 : 91 | |TLS
Если вы прерываете TLS не на границе с CDN, то TLS-оптимизации могут сыграть важную роль. При обсуждении настроек мы будем по большей части говорить об их эффективности на стороне сервера.
Сегодня первое, что вам нужно решить, — какую TLS-библиотеку вы будете использовать: Vanilla OpenSSL, OpenBSD’s LibreSSL или BoringSSL от Google. Определившись, вам нужно правильно её собрать: к примеру, у OpenSSL есть куча сборочных эвристик, позволяющих использовать оптимизации на базе сборочного окружения; у BoringSSL есть детерминистские сборки, но они более консервативны и по умолчанию просто отключают некоторые оптимизации. В любом случае, здесь вы наконец-то ощутите выгоду от выбора современного процессора: большинство TLS-библиотек могут использовать всё, от AES-NI и SSE до ADX и AVX-512. Можете воспользоваться встроенными тестами производительности. Например, в случае с BoringSSL это bssl speed.
Производительность по большей части зависит не от вашего железа, а от наборов шифров, которые вы собираетесь использовать, так что оптимизируйте их с осторожностью. Также знайте, что изменения в данном случае повлияют на безопасность вашего веб-сервера — самые быстрые наборы не обязательно лучшие. Если не знаете, какое шифрование использовать, можете начать с Mozilla SSL Configuration Generator.
Асимметричное шифрование
Если у вас “front”-сервис (сервис к которому пользователи подключаются напрямую), то вы могли столкнуться со значительным количеством TLS-«рукопожатий», а значит, немалая доля ресурсов вашего процессора тратится на асимметричное шифрование, которое необходимо оптимизировать.
Для оптимизации использования серверного процессора можете переключиться на сертификаты ECDSA, которые в десять раз быстрее, чем RSA. К тому же они значительно меньше, что может ускорить «рукопожатия» при наличии потерь пакетов. Но ECDSA сильно зависят от качества генератора случайных чисел в вашей системе, так что если вы используете OpenSSL, то удостоверьтесь, что у вас достаточно энтропии (в случае с BoringSSL об этом можно не волноваться).
И ещё раз напоминаю, что больше – не значит лучше, то есть использование сертификатов 4096 RSA ухудшит производительность в десять раз:
$ bssl speed
Did 1517 RSA 2048 signing ... (1507.3 ops/sec)
Did 160 RSA 4096 signing ... (153.4 ops/sec)Но меньше тоже не значит лучше: при использовании малораспространённого поля p-224 для ECDSA вы получите 60%-ное снижение производительности по сравнению с обычным p-256:
$ bssl speed
Did 7056 ECDSA P-224 signing ... (6831.1 ops/sec)
Did 17000 ECDSA P-256 signing ... (16885.3 ops/sec)Эмпирическое правило: самое распространённое шифрование обычно самое оптимизированное.
При запуске правильно оптимизированной библиотеки на основе OpenTLS, использующей сертификаты RSA, в своём perf top вы должны увидеть следующие трейсы: процессоры, использующие AVX2, а не ADX (например, с архитектурой Haswell), должны использовать кодовый путь AVX2:
6.42% nginx [.] rsaz_1024_sqr_avx2
1.61% nginx [.] rsaz_1024_mul_avx2Более новые модели должны использовать обычный алгоритм Монтгомери с кодовым путём ADX:
7.08% nginx [.] sqrx8x_internal
2.30% nginx [.] mulx4x_internalСимметричное шифрование
Если у вас много массовых передач данных вроде видео, фото и прочих файлов, то можете начать отслеживать в данных профилировщика упоминания о симметричном шифровании. Тогда просто удостоверьтесь, что ваш процессор поддерживает AES-NI и что вы настроили на сервере применение шифров AES-GCM. При правильно настроенном оборудовании в perf top должно выдаваться:
8.47% nginx [.] aesni_ctr32_ghash_6xНо заниматься шифрованием/ дешифрованием будут не только ваши серверы, но и клиенты, причём у них априори гораздо более слабые процессоры. Без аппаратного ускорения это может быть достаточно сложной операцией, поэтому позаботьтесь о выборе алгоритма, который работает быстро без аппаратных технологий ускорения работы с шифрованием, например, ChaCha20-Poly1305. Это снизит TTLB для части мобильных клиентов.
В BoringSSL из коробки поддерживается ChaCha20-Poly1305, а в OpenSSL 1.0.2 можете использовать патчи Cloudflare. BoringSSL также поддерживает «шифрогруппы равного предпочтения», так что можете использовать следующую конфигурацию, которая позволит клиентам решать, какие шифры использовать, отталкиваясь от своих аппаратных возможностей (бесстыдно украдено из cloudflare/sslconfig):
ssl_ciphers '[ECDHE-ECDSA-AES128-GCM-SHA256|ECDHE-ECDSA-CHACHA20-POLY1305|ECDHE-RSA-AES128-GCM-SHA256|ECDHE-RSA-CHACHA20-POLY1305]:ECDHE+AES128:RSA+AES128:ECDHE+AES256:RSA+AES256:ECDHE+3DES:RSA+3DES';
ssl_prefer_server_ciphers on;Уровень приложения: высокоуровневые оптимизации
Для анализа эффективности ваших оптимизаций на этом уровне вам нужно собирать RUM-данные. В браузерах можно применять API Navigation Timing и Resource Timing. Ваши главные метрики — TTFB и TTV/ TTI. Вам сильно упростит итерирование, если эти данные будут представлены в форматах, удобных для составления запросов и графиков.
Компрессия
В nginx компрессия начинается с файла mime.types, определяющего соответствие между расширением файла и MIME-типом. Затем вам нужно определить, какой тип вы хотите передавать компрессору, с, например, gzip_types. Если хотите завершить этот список, то для автоматического генерирования mime.types с добавлением compressible == true to gzip_types можете воспользоваться mime-db.
Включая gzip, имейте в виду:
- это увеличивает потребление памяти (проблема решается путём ограничения
gzip_buffers); - вследствие буферизации это увеличивает TTFB (проблема решается с помощью
gzip_no_buffer).
Отмечу, что HTTP-компрессия не ограничивается одним gzip: в nginx есть сторонний модуль ngx_brotli, который способен сжимать на 30% лучше, чем gzip.
Что касается настроек сжатия, давайте рассмотрим два отдельных случая: статичные и динамические данные.
В случае со статичными данными можно архивировать коэффициенты сжатия с помощью предварительной компрессии статичных ресурсов, сделав эту процедуру частью процесса сборки. Для gzip и brotli это подробно рассмотрено в посте Deploying Brotli for static content.
В случае с динамическими данными вам нужно выполнять осторожную балансировку полного цикла: время на сжатие данных + время на их передачу + время на распаковку. Поэтому может быть нецелесообразно устанавливать самую высокую степень сжатия не только с точки зрения потребления ресурсов процессора, но и с точки зрения TTFB.
Буферизация внутри прокси может сильно влиять на производительность веб-сервера, особенно с учётом задержки. В прокси-модуле nginx есть разные настройки буферизации, которые можно регулировать в зависимости от местонахождения буферов и каждая из которых полезна в определённых случаях. С помощью proxy_request_buffering и proxy_buffering можно отдельно управлять буферизацией в обоих направлениях. Если включена буферизация, то верхняя граница потребления памяти определяется с помощью client_body_buffer_size и proxy_buffers, и по достижении этой границы запрос/ ответ будут буферизоваться на диске. Для ответов это можно отключить, присвоив proxy_max_temp_file_size значение 0.
Наиболее распространённые примеры использования:
- буферизация запроса/ ответа до определённого предела — в памяти, а затем сбрасывание на диск. Если включена буферизация запросов, вы можете отправить запрос на бэкенд только после его полного получения. А если включена буферизация ответов, вы можете мгновенно освободить поток выполнения бэкенда, как только тот будет готов ответить. При таком подходе улучшаются пропускная способность и защита бэкенда, но при этом растут задержка, потребление памяти и количество операций ввода/ вывода (хотя, если вы используете SSD, это не будет особой проблемой);
- буферизация отключена. Это делается при наличии маршрутов, чувствительных к уровню задержки, особенно в случае со стримингом. Но если вы отключите буферизацию, то вашему бэкенду придётся как-то работать с медленными клиентами (включая обработку атак Slow POST/ Slow Read);
- также посредством заголовка
X-Accel-Bufferingможно реализовать управляемую приложением буферизацию ответов.
Что бы вы ни выбрали, не забудьте протестировать это на TTFB и TTLB. Как уже упоминалось, буферизация может повлиять на количество операций ввода/ вывода и даже использование бэкенда, так что отслеживайте и эти моменты.
TLS
Теперь поговорим о высокоуровневых аспектах TLS и уменьшения задержки, которые можно реализовать с помощью правильной конфигурации nginx. Большинство оптимизаций, которые я буду упоминать, описаны в разделе Optimizing for TLS High Performance Browser Networking и в выступлении Making HTTPS Fast(er) на nginx.conf 2014. Настройки, описываемые в этой части поста, повлияют на производительность и безопасность вашего веб-сервера, так что, если вы в них не уверены, обратитесь к руководству Mozilla’s Server Side TLS Guide и/ или проконсультируйтесь со своими коллегами, отвечающими за безопасность.
Для проверки результатов оптимизаций можно использовать:
- WebPagetest — влияние на производительность;
- SSL Server Test или Mozilla TLS Observatory — влияние на безопасность.
Возобновление сессии
Как любят говорить DBA, «самый быстрый запрос – тот, который вы не делали». Это касается и TLS: можно уменьшить задержку с помощью одного RTT, если вы кэшируете результаты «рукопожатия». Это можно сделать двумя способами:
- попросить клиент хранить все параметры сессии (в подписанном и зашифрованном виде) и отправлять их вам во время следующего «рукопожатия» (как и куки). На стороне nginx это конфигурируется посредством директивы
ssl_session_tickets. Это не приводит к потреблению памяти на сервере, но имеет ряд недостатков:
1) понадобится инфраструктура для создания, ротации и распределения случайных ключей шифрования/ подписи для TLS-сессий. Помните, что не следует: 1) использовать управление ресурсами для хранения тикет-ключей; 2) генерировать эти ключи на основе каких-то неэфемерных вещей вроде даты или сертификата;
2) PFS будет зависеть не от конкретной сессии, а от TLS-тикет-ключа, так что если злоумышленник завладеет тикет-ключом, то сможет расшифровать любой перехваченный трафик в течение всего действия тикета;
3) ваше шифрование будет ограничено размером тикет-ключа. Не имеет смысла использовать AES-256, если вы применяете 128-битный тикет-ключ. Nginx поддерживает 128-битные и 256-битные ключи;
4) не все клиенты поддерживают тикет-ключи (хотя они поддерживаются всеми современными браузерами);
- хранить параметры TLS-сессии на сервере и отдавать клиенту только ссылку (ID). Это делается посредством директивы ssl_session_cache. Преимущество подхода в том, что PFS сохраняется между сессиями, а видов возможных атак становится гораздо меньше. Хотя у тикет-ключей тоже есть недостатки:
1) они потребляют на сервере ~256 байтов памяти на каждую сессию, так что вы не сможете хранить слишком много ключей слишком долго;
2) нет простого способа использовать их одновременно несколькими серверами. Так что вам понадобится ещё и балансировщик нагрузки, который будет отправлять тот же клиент на тот же сервер, чтобы сохранить локальность кэша, либо писать распределённое хранилище TLS-сессий поверх чего-то вроде ngx_http_lua_module.
Отмечу, что если вы остановитесь на варианте с сессионными тикетами, то лучше использовать три ключа вместо одного. Например:
ssl_session_tickets on;
ssl_session_timeout 1h;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_curr;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_prev;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_next;В этом случае вы всегда будете шифровать с текущим ключом, но придётся принимать и сессии, зашифрованные следующим и предыдущим ключами.
«Скрепление» OCSP
«Скрепляйте» свои OCSP-ответы, иначе:
- TLS-«рукопожатие» может занять больше времени, потому что клиенту понадобится связаться с сертификационной компанией для подтверждения статуса OCSP;
- при сбое подтверждения OCSP ваш ресурс может оказаться недоступен;
- вы можете скомпрометировать данные пользователей, потому что их браузеры будут вынуждены связываться со сторонним сервисом, тем самым показывая, что они хотят подключиться к вашему сайту.
Для «скрепления» OCSP-ответов вы можете периодически получать их от сертификационной компании, раздавать результаты по своим веб-серверам и использовать с директивой ssl_stapling_file:
ssl_stapling_file /var/cache/nginx/ocsp/www.der;Размер TLS-записи
TLS разбивает данные на чанки (записи), которые вы не можете проверить и расшифровать, пока не получите всё целиком. Эту задержку можно измерять как разницу между TTFB из сетевого стека и точкой зрения приложения.
По умолчанию nginx использует 16-тикилобайтные чанки, которые не влезают даже в окно перегрузки IW10, поэтому требуется дополнительный roundtrip. Из коробки nginx предоставляет способ настройки размеров записей посредством директивы ssl_buffer_size:
- для уменьшения задержки задайте меньший размер, например, 4 КБ (дальнейшее уменьшение приведёт к повышению потребления процессора);
- для повышения пропускной способности оставьте 16 КБ.
Со статичной настройкой есть две проблемы:
- придётся делать её вручную;
- вы можете задать
ssl_buffer_sizeлибо для всей конфигурации nginx, либо для блока серверов, и если у вас появится сервер со смешанными рабочими нагрузками, когда требуются и высокая пропускная способность, и низкая задержка, то придётся идти на компромисс.
Альтернативный подход — настройка динамического размера записи. Для nginx есть патч от Cloudflare, добавляющий поддержку динамического размера. Он может оказаться сложен в начальном конфигурировании, но, когда сделаете, всё будет работать хорошо.
TLS 1.3
Возможности TLS 1.3 выглядят очень привлекательно, но если у вас нет возможности всё время решать связанные с TLS проблемы, то не рекомендую включать, потому что:
- это ещё черновик;
- «рукопожатие» 0-RTT подразумевает ряд вещей, относящихся к безопасности, и ваше приложение должно быть к этому готово;
- есть ещё промежуточные вещи (антивирусы, DPI и так далее), блокирующие неизвестные версии TLS.
nginx — веб-сервер на основе циклов событий. Это означает, что он может делать только что-то одно. Даже если выглядит так, будто он всё делает одновременно, как при мультиплексировании с разделением по времени, на самом деле nginx просто быстро переключается между событиями, обрабатывая одно за другим.
Обработка каждого события занимает всего пару микросекунд. Но если время обработки значительно увеличивается, например, потому что нужно раскрутить диск, то уровень задержки может взлететь до небес.
Если вы заметили, что nginx начал тратить слишком много времени на функцию ngx_process_events_and_timers, и распределение – бимодальное, то вы наверняка столкнулись с явлением eventloop stall.
# funclatency '/srv/nginx-bazel/sbin/nginx:ngx_process_events_and_timers' -m
msecs : count distribution
0 -> 1 : 3799 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 409 |**** |
32 -> 63 : 313 |*** |
64 -> 127 : 128 |* |AIO и пулы потоков выполнения
Поскольку основной причиной eventloop stall, особенно на обычных жёстких дисках, является ввод/ вывод, на это нужно обратить внимание в первую очередь. Влияние ввода/ вывода можно измерить с помощью fileslower:
# fileslower 10
Tracing sync read/writes slower than 10 ms
TIME(s) COMM TID D BYTES LAT(ms) FILENAME
2.642 nginx 69097 R 5242880 12.18 0002121812
4.760 nginx 69754 W 8192 42.08 0002121598
4.760 nginx 69435 W 2852 42.39 0002121845
4.760 nginx 69088 W 2852 41.83 0002121854В качестве решения этой проблемы nginx поддерживает разгрузку ввода/ вывода в пул потоков выполнения (также он поддерживает AIO, но в нативном AIO в Unix много выкрутасов, так что его лучше избегать, если вы точно не знаете, что делаете). Базовая настройка крайне проста:
aio threads;
aio_write on;В более сложных случаях можете настроить кастомные thread_pool, например, по одному на диск, чтобы, если один винчестер начнёт работать плохо, это не повлияло на остальные запросы. Пулы потоков выполнения могут заметно уменьшить количество nginx-процессов, застрявших в состоянии D, а также уменьшить задержку и увеличить пропускную способность. Но они не избавят вас целиком от eventloop stall, поскольку на данный момент не все операции ввода/ вывода могут быть разгружены таким образом.
Журналирование
Запись логов может занимать немало времени, поскольку она осуществляется на диски. Проверить, так ли это у вас, можно, запустив ext4slower и посмотрев ссылки на логи доступа/ ошибок:
# ext4slower 10
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
06:26:03 nginx 69094 W 163070 634126 18.78 access.log
06:26:08 nginx 69094 W 151 126029 37.35 error.log
06:26:13 nginx 69082 W 153168 638728 159.96 access.logЭто можно обойти с помощью параметра buffer для директивы access_log, записывая логи доступа в память перед скидыванием на диск. А с помощью параметра gzip можно ещё и сжимать логи перед записью, ещё больше уменьшая количество операций ввода/ вывода.
Но чтобы полностью избавиться от тормозов ввода/ вывода при записи логов, пишите их через syslog. Тогда логи будут полностью интегрированы в цикл событий nginx.
Кэш открытых файлов
Поскольку вызовы open(2) априори являются блокирующими, а веб-серверы буднично открывают/ считывают/ закрывают файлы, то может оказаться полезным иметь кэш открытых файлов. Проверить эффективность этой меры можно, посмотрев на задержку функции ngx_open_cached_file:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_open_cached_file -u
usecs : count distribution
0 -> 1 : 10219 |****************************************|
2 -> 3 : 21 | |
4 -> 7 : 3 | |
8 -> 15 : 1 | |Если увидите, что у вас было слишком много вызовов открытия или что их выполнение занимает слишком много времени, можете включить кэш открытых файлов:
open_file_cache max=10000;
open_file_cache_min_uses 2;
open_file_cache_errors on;После включения open_file_cache понаблюдайте за opensnoop, чтобы отследить все промахи кэша, и решите, нужно ли настраивать ограничения кэша:
# opensnoop -n nginx
PID COMM FD ERR PATH
69435 nginx 311 0 /srv/site/assets/serviceworker.js
69086 nginx 158 0 /srv/site/error/404.html
...Заключительное слово
Все описанные в этом посте оптимизации предназначены для одиночного веб-сервера. Одни улучшают масштабируемость и производительность, другие полезны для обслуживания запросов с минимальной задержкой или если нужно максимально быстро доставлять байты клиентам. Но, по нашему опыту, большинство улучшений производительности, заметных для пользователя, связаны с более высокоуровневыми оптимизациями, влияющими на поведение Dropbox Edge Network в целом, вроде инжиниринга выходного/ выходного трафика и продвинутой внутренней балансировки нагрузки. Сегодня решение этих проблем требует передовых решений, и индустрия лишь начинает нащупывать возможные пути.
Комментарии (7)

SaveTheRbtz
19.09.2017 17:37+3Спасибо, что проделали столь масштабную работу!
ПС. Забавно, что статья думалась на русском, писалась на английском, потом американский редаткор страдал, правя сложносочинённые конструкции, а теперь результат опять на "великом и могучем".
ППС. Вы пропустили последний абзац, но я так понимаю, это плата за перевод =)
max_m Автор
19.09.2017 17:51+1Спасибо тебе за такую полезную статью! Мы ломали голову – стоит ли писать последний абзац, но не решились :)

dmitrysamsonov
20.09.2017 00:04Ещё когда читал статью, мне это напомнило один чудесный комментарий. Оказалось, не случайно.
Статья огонь, а обилие ссылок делают её просто бесценной!

galdias
Спасибо что поделились и перевели столь прикладную информацию :)