
Визуальное программирование позволяет описывать процессы в графическом виде, в отличии от текстового представления, где нужно приложить дополнительные усилия, чтобы мыслить так, как это должен выполнять компьютер. Звучит многообещающе, но попробуем разобраться в сути и выяснить, почему Вам стоит это попробовать.
Само по себе программирование подразумевает не только процесс написания кода, но зачастую на это тратится большая часть времени при разработке. Только представьте, сколько усилий приходится тратить на то, чтобы держать в голове множество правил и спецификаций к конкретному языку программирования, вместо того, чтобы сосредоточиться на решаемой проблеме. Особенно может раздражать разнообразие синтаксиса в языках: где-то нужна точка с запятой, где-то не нужны фигурные скобки, где-то вообще ни одно выражение не обходится без скобок. Что уж и говорить о холиварах, напоминающие религиозные споры.
 Кадр из сериала "Кремниевая долина"
Кадр из сериала "Кремниевая долина"
Часто советуют начать разработку ПО с графического описания будущей системы, ее компонентов и связей между ними, чтобы на ранних стадиях определить более выгодную структуру системы и минимизировать возможные проблемы в будущем. Графическое представление легче для понимания, чем текстовый вариант, но может иметь свои ограничения, к тому же это все равно придется переводить в понятный компилятору код. Конечно, на маленькие приложения (какими они могут казаться вначале) это не распространяется, можно сразу приступить к написанию кода, но проблема все равно остается — нужно думать в рамках определенного языка программирования. Тем более, когда вы это делаете в давно приевшемся вам императивном стиле.
Программисты по своей сути должны быть ленивыми, чтобы находить выгодные способы решения задач и не тратить силы на рутину, тем более, глядя на тенденции увеличения сложности ПО. Именно это стимулирует рождение парадигм, языков программирования и абсолютно новых, казалось бы, и малоизвестных инструментов визуального программирования.
Зачем и где применяют визуальное программирование
Одним из первых инструментов, более известных и дружелюбных для рядового гражданина, можно считать Scratch. Он предназначен исключительно для образовательных целей, так как представляет собой те же блоки кода, только обернутые в разноцветные пазлы. Практической пользы нет никакой, если вы уже умеете писать код.

Похожий инструмент от Google под название Blocky
Существует другой вид визуального программирования, более полезный на мой взгляд, это Data-flow programming. Он не такой гибкий как предыдущий и служит некоторой надстройкой для программирования процессов определенной тематики. Его суть состоит в манипуляции данными, передаваемыми между блоками (узлами).
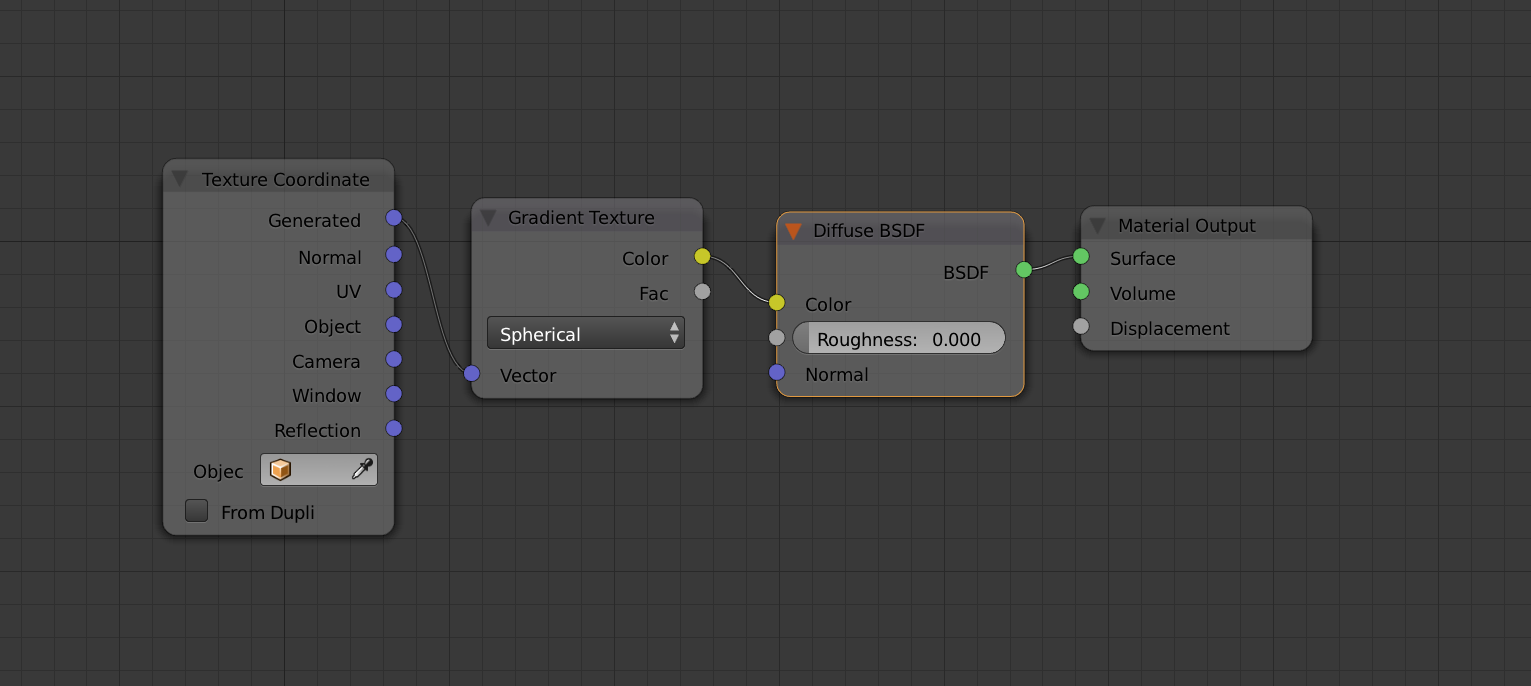
Пример редактора узлов из Blender
Преимущество такого подхода в следующем: не нужно думать о том, что происходит с данными в узлах, а лишь знать, что они делают, получают на вход и отдают на выходе. Остается лишь выбрать нужные узлы и соединить их между собой линиями, по которым без особого затруднения можно понять, что и с чем связано.
Редактор узлов в Blender — именно тот случай, когда используется программирование потоков данных для управления рендерингом, создания шейдеров и текстур. Такой подход в 3D моделировании и рендеринге достаточно популярен, так как никому не хочется писать код, а создавать инструкции для нелинейного управления данными необходимо.
Также известный всем в сообществе 3D моделлеров это Substance Designer, который позволяет создавать 3D материалы по принципу, описанному выше.

Редактор для создания материала в Substance Designer
Хотя в официальных источниках упоминания о программировании нету, в нем используется самый настоящий data-flow. Наверное, это такой маркетинговый ход — не говорить о том, что может отпугнуть.
Итак, разобрались в том, почему визуальное программирование используется в 3D моделировании, но как насчет тех сфер деятельности, где без умения писать код не получится сделать достаточно функциональный продукт? Казалось бы, если умеешь писать код, то просто нужно развивать этот навык, но нет — именно в геймдеве одними из первых стали применяться инструменты для программирования без кодинга. С одной стороны, это было выгодно для популяризации геймдева среди тех, кого отпугивает код лишь одним видом, с другой — прогресс не стоит на месте и даже гуру программирования надоело ставить пробелы вместо табов чтение тысяч строк кода и его поддержка, и они решили попробовать новые методики описания логики и процессов.
Многие знают UE4 с его Blueprint'ом. Это уже не просто data-flow, а что-то большее, так как позволяет формировать инструкции, которые будут выполняться не за один проход, а в течении всего жизненного цикла.

Пример вывода строки по событию
Например, в нем есть узлы для отправки событий. Подключенные к ним узлы выполняются только в тот момент, когда срабатывает событие. Получается очень удобно, не нужно оперировать какими-то объектами и методами, а просто провести соединение от выхода к входу.
Существует еще много отдельных инструментов для визуального программирования (чаще их позиционируют как среда графического программирования), но они не так привлекательны, имеют узкую направленность или вовсе более похожи на конструкторы, чем на инструменты программирования.
Общие аспекты разработки редакторов узлов
Допустим, однажды вы увидели как делают магию программируют с использованием какого-то редактора с блоками и линиями. К вашему удивлению это оказалось именно тем, что позволит воплотить вашу идею (скажем, какой-то продвинутый генератор диалогов, которые представить в виде обычного графа не получится).
Главное, от чего будет зависеть процесс разработки — платформа и технологии. В последнее время много чего можно сделать прямо в браузере, пусть даже пожертвовав производительностью, что в большинстве случаев никак не отразится на качестве приложения (в ином случае asm.js/wasm в помощь). Одна из особенностей таких приложений — они могут быть встроены в другие нативные приложения. Выбор инструментов и языков программирования должен быть в интересах разработчика, чтобы сделать процесс разработки более комфортным и эффективным и снизить вероятность выстрелить себе в ногу появления проблем.
Определившись с платформой и языком, было бы хорошо использовать готовые решения (в нашем случае речь идет о редакторе узлов), но и здесь не все гладко.
Есть несколько вариантов:
- вы используете готовое решение, которое вскоре окажется не таким подходящим и удобным, в придачу к этому вам
леньне под силу подправлять его под себя - написать свою реализацию, заодно изучив как это все работает изнутри и куда прикручивать колеса.
- использовать готовое решение, которое достаточно гибкое и позволяет без проблем настроить его под себя, не жертвуя при этом выгодными фичами для вашего продукта.
Проблема последнего в том, что это достаточно редкое явление, возникающее в последствии немалых усилий. Собственно, суть этой статьи и является в стимулирование достижения такого результата на примере представленной далее библиотеки.
Что такое D3NE
D3 Node editor (D3NE) — это JS библиотека для создания редакторов узлов для решения задач визуального программирования. Библиотека полностью берет на себя работу по отображению и обработке узлов. Использует D3.js и Angular Light

На GitHub Wiki доступен туториал, а также подробное описание всех компонентов и терминологии, используемой в библиотеке (вики на англ. и возможны грамматические ошибки, поэтому буду рад помощи в их исправлении)
Все началось с одного проекта (так он и лежит в draft'ах), в котором появилась идея применить что-то похожее на UE4 Blueprint, только с поправкой на то, что нужен просто data-flow. Среди готовых open source решений на JS не оказалось подходящих: критериями были внешний вид и необходимые возможности (например, разные типы сокетов, чтобы ограничить подключение несовместимых выходов и входов). Если первое еще можно было как-то подправить извне, то добавление второго могло бы вызвать проблемы, тем более если структура и исходный код оставляют желать лучшего.
Так и началось написание кода и формировании этого как отдельной библиотеки. Да, да, именно написание кода, без планирования и проектирования, хотя заранее было неизвестно что в итоге это будет из себя представлять (из-за чего не раз приходилось исправлять свои же ошибки).
К счастью, спустя несколько месяцев после начала разработки удалось дойти до полностью работоспособной версии с необходимыми компонентами для обеспечения гибкости при создании редакторов. Но это не значит, что это финал. Скорее, контрольная точка, после которой нужно стремиться к улучшению того, что уже имеется, и внедрению необходимых возможностей.
Как применить в своем проекте
Для начала нужно выяснить, необходимо ли это вам. Конечно, попробовать для себя кое-что новое никогда не помешает (если это не навредит здоровью :) ), но при решении реальных проблем стоит подумать.
Лучше один раз увидеть, чем… в общем посмотрите примеры:
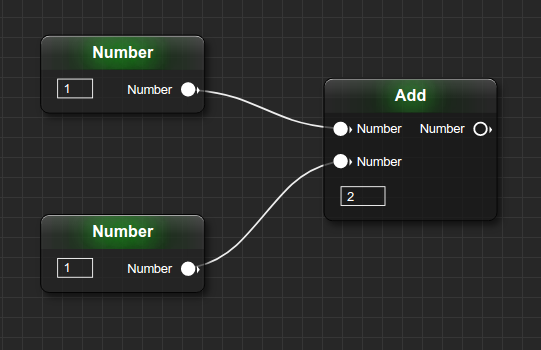
- Data-flow programming — пример сложения чисел
- События и условное управление данными — примерно так это делается в UE4
- Кастомизация — возможность изменять не только стили, но и структуру узлов и способ соединений
- Allmatter — проект, основанный на этой библиотеке
Пример кастомизации в стиле UE4
Рассмотрим основные компоненты, которые нужны для создания минимально работоспособного редактора
Это такие разъемы, которые могут представлять собой входы или выходы и необходимы для соблюдения правильности их подключения между собой. Назначив входам и выходам этот сокет, можно быть уверенными, что пользователь не сможет передать туда не те данные (вернее, он только назначает связи). Также есть возможность совместить сокеты для подключения между входами и выходами разного типа.
Узлы обычно представляют прямоугольниками (но можно это изменить в пределах вашей фантазии и возможностей CSS и HTML). Они могут иметь входы, выходы и контролы. Входы и выходы представляют сокеты и расположены в левой и правой части узла соответственно (опять таки вы можете их расположить как угодно, используя шаблоны).
Контролы нужны для того, чтобы добавлять в узлы произвольные элементы, а из них можно назначать данные к узлу на момент работы в редакторе (не при обработке данных). Например, с помощью простого поля ввода можно положить значение в узел, которое потом использовать при обработке.
Компоненты нужны для того, чтобы редактор знал какие в нем можно добавлять узлы и как их обрабатывать, а именно необходимы для поддержки импорта/экспорта. Используются так называемые билдеры и воркеры, обычный функции с соответствующим ключем, которые задаются при создании компонента (и должны находиться в одном месте).
Билдер отвечает за создание экземпляра узла — в функции вы создаете экземпляр, добавляете к нему нужные входи, выходы и контролы. Создается это именно программным путем, а не через конфиги (обычно такие реализации находил), чтобы позволить повторное использование, к примеру, контролов, а то и наследование узлов.
Воркер в качестве параметров дает вам входы, выходы и объект с данными узла (не экземпляр, который создается в билдере, а то, что из него достали через toJSON). Входной массив содержит данные, которые пришли на вход из другого узла и массив с выходными данными, в который вы должны положить данные, зависимо от того, что должен делать узел)
Один из основных объектов, который управляет всем вышеперечисленным с целью отображения и взаимодействия с пользователем. Ему передаются идентификатор, компоненты, контекстное меню.
Служит для обработки данных в узлах. Особенность в том, что ему нужны только данные, экспортированные из редактора, таким образом можно выполнять обработку узлов вовсе без наличия редактора (например, есть его реализация на С++). Именно этот компонент библиотеки отвечает за обход узлов, определяя с какого нужно начать обработку, вызывает ваши воркеры, передавая в них входные данные, полученные от предыдущих узлов. Может работать с асинхронными функциями, что не может не радовать на фоне поддержки браузерами async/await. Более того, за счет асинхронной обработки может параллельно выполнять несколько узлов.
Заключение
Как видим, визуальное программирование хоть и призвано заменить написание кода, но довольно редко используется в настоящий момент. Наверное потому, что многие скептически относятся к идее программирования мышкой. Это отчасти справедливо, так как большинство задач в разработке ПО привычнее будет решить на каком-либо языке программирования, чем использовать недостаточно проверенный инструмент.
Суть прогресса состоит в том, чтобы находить более выгодные пути в решении каких-либо задач. Так и в случае с визуальным программированием предоставляется возможность описывать процессы в легком для понимания представлении и достаточном уровне абстракции. Но в это же время нельзя избавиться от исходного кода, так как он является основой для всего этого.
Чтобы убедиться в этом и проверить, как говорится, на себе все описанные возможности, вы можете построить на основе D3NE свой редактор визуального программирования.
Комментарии (61)
Carburn
05.11.2017 00:18Я знаю о LabVIEW.
ZyXI
05.11.2017 00:55А я на нём «пишу» (на версии 2015). Нет практически никаких средств улучшения представления кода, даже аналогов команд из Altium Designer «выровнять по левому/правому/верхнему/нижнему» краю, из?за чего бо?льшая часть времени тратится на то, чтобы «код» был поддерживаемым. Нет масштабирования! Проблема с «цикломатической сложностью на пиксель» элегантно «решается» блоками вроде «case structure», которые в принципе не позволяют увидеть весь код сразу.
nerudo
05.11.2017 09:54Расскажите, а вы как-то документируете внутреннее содержимое? Ну кроме как «диаграмма — лучший документ сам себе».
ZyXI
05.11.2017 15:44LabVIEW позволяет размещать комментарии в произвольном месте, что даёт возможность подписывать длинные провода и неочевидные моменты. Плюс названия циклов и фреймов, если они не очевидны или если мне захотелось их назвать. Ну и необходимые вещи вроде названий VI’ек и их иконки.
Вообще?то у LabVIEW есть какая?то система документирования, но т.к. я, во?первых, не знаю, как посмотреть документацию из свойств VI методом, отличным от «открыть VI и пойти смотреть свойства», и, во?вторых, такая документация относится только к VI целиком и частично закрывается нормальным названием файла и иконкой, то мною эта функциональность как раз?таки не используется.
pudovMaxim
06.11.2017 09:45Выравнивание? Точно знаю, что там есть 2 кнопки для выравнивания и распределения элементов. И это было еще в ~2012 году.
А для упрощения, вроде бы хорошо подходит объединение элементов в блоки («виртуальные устройства»).ZyXI
06.11.2017 13:41Про кнопку не знал, но проблемы она не снимает: клавиатурное сочетание на все действия по выравниванию одно. Буду на работе, посмотрю, нельзя ли назначить разные на разные действия, а не одно на повторение последнего действия.
Блоки не всегда подходят: в хосте можно что?то сообразить на куче различных видов ссылок или с глобальными переменными, но на FPGA первого нет, а второе жрёт ресурсы, из?за чего такое объединение получается менее оптимальным, чем хотелось бы (в смысле, либо жрёт ресурсы, либо требует выноса в основную VI того, что я на хосте выносить не стал бы). (Впрочем здесь есть возможность задействовать VHDL, только пока руки не дошли.)

nckma
05.11.2017 08:17Эта тема (графическое представление или текстовое описание) очень обсуждаема в при проектировании электронных схем.
Можно писать текст Verilog или VHDL, а можно рисовать схемы в CAD типа Quartus II.
И вот несколько причин, почему текст лучше:
marsohod.org/11-blog/251-sch-or-txt

sshikov
05.11.2017 10:25Стандартный вопрос номер 1: как предлагается хранить графические схемы в системе версионирования, и как предлагается сравнивать две их версии между собой? Без истории кода ни один серьезный проект не выживает.
Что характерно — все подобные системы, что я видел (это конечно не все существующие в мире, но их было довольно много) сильно страдали от этой проблемы. Причем настолько сильно… приходишь на работу после недели отпуска, смотришь на схему — и не понимаешь, что именно там за неделю поменяли. И нет никаких вменяемых средств, чтобы это понять. А те что есть — уступают любому diff и текстовому представлению настолько, что даже и обсуждать тут нечего.

napa3um
05.11.2017 12:51Если говорить «о том, что есть», то да, вы правы, системы визуального программирования на текущий момент значительно отстают по удобству и выразительности от современных текстовых ЯП и IDE с их поддержкой. Ежели говорить о потенциальных возможностях графического программирования («о том, что будет»), то это просто некий умозрительный предел (до которого ещё идти и идти, конечно) закономерного и неотвратимого сращивания средств анализа/исследования кода, менеджмента изменений, зависимостей и авторства и, собственно, самого представления разрабатываемой логики. Итого: графическое представление не хуже текстового, а прост ещё в процессе поиска эффективных форм.
sshikov
05.11.2017 13:33Да дело не в IDE даже. Меня лично отталкивает то, что не видно никаких особых попыток решить фундаментальные проблемы этих систем. Та же проблема с diff — она повсеместная, и при этом она ломает всю коллективную разработку напрочь. Ну т.е. понятно, что тут нужны какие-то другие средства, включая и IDE — но не очень пока понятно, какие. В визуальном представлении имеется куча семантического "мусора", т.е. не обязательных, или дополнительных свойств этого вида кода, который очень трудно фильтровать от свойств, нужных в первую очередь.
Ну т.е. например, диаграмма может скажем иметь разные цвета стрелок, и это хорошо. Это должно помогать в понимании назначения и логики — но это же одновременно мешает понимать другие свойства, зачастую более нужные. Мы в последней версии вот этот квадратик переставили влево на 10 пикселей, соединили с другим входом стрелкой, и перекрасили в другой цвет — что из этого важно? Почему оно не работает, что мы тут сломали, кто, когда, и какую задачу при этом решали?
napa3um
05.11.2017 13:45> Та же проблема с diff — она повсеместная
Не очень понимаю эту проблему. У вас проблема в представлении дельт между графическими схемами? Ну, например, любую схему можно сериализовать в иерархический список (hello, LISP, ну или чуть более близкий современному разработчику XML), а построить дельту можно и в текстовом виде (хуже, все те же издержки потери структуры изменений в диффе, что и с текстовыми ЯП), и в графическом (лучше, потенциально граф может показать изменения во всех срезах представления).
> В визуальном представлении имеется куча семантического «мусора»
А я бы сказал наоборот, в текстовом представлении получается полно дублей имён объектов только лишь для показания связи между двумя сущностями или кусками логики. Там, где в графическом представлении было бы одно безымянное ребро графа, в текстовом возникает одно объявление переменной и два места её использования. (Это лишь один пример.)
> Мы в последней версии вот этот квадратик переставили влево на 10 пикселей, соединили с другим входом стрелкой, и перекрасили в другой цвет — что из этого важно?
Очевидно, что вы в графическом представлении объявили важным абсолютные координаты блоков, а теперь боретесь с этим чучелом графических ЯП. Посмотрите хотя бы пример из статьи — Blocky, графическое представление вовсе не обязано превращаться в векторный редактор, на котором можно рисовать картинки на абсолютно свободные сюжеты.
> соединили с другим входом стрелкой, и перекрасили в другой цвет — что из этого важно?
Очевидно, что это зависит от ЯП, и какие-то изменения в системе контроля версий отметятся как важные, какие-то как декоративные (и вообще не попадут в контроль версий, оставшись личной схемой раскраски на машине разработчика), а какие-то система просто не позволит сделать изначально, на уровне ограничений редактора.sshikov
05.11.2017 13:55Вот-вот. У вас схемы — а дельты вы мне предлагаете смотреть в XML? Скажем так — я практически три года занимался тем, что смотрел подобные вещи для BPMN, и это ужасно. Просто ужасно. Проблема тут простая — нет визуального представления именно дельты для схем. А когда мы переходим на другое представление — мы теряем всю визуальность. Я не говорю, что это понетциально не решаемая проблема, просто хороших решений, увы, не видать.
Насчет того, что в тексте свой мусор — соглашусь. Да, он есть — но его как-то научились фильтровать IDE и прочий инструмент. Ну и опять же… вы видели что-нибудь типа graphvizard? Вот вам вполне текстовый инструмент, который на выходе дает вполне красивые графы. И без лишнего мусора. Я это к чему — в тексте тоже можно без своего мусора, надо только язык придумать соответствующий задаче.
Ну и по последнему абзацу — я верю, что возможно есть такие системы, где все так хорошо, как вы рассказываете. И уж точно допускаю, что их можно сделать.
Мне просто их видеть пока ни разу не приходилось.
napa3um
05.11.2017 13:59> а дельты вы мне предлагаете смотреть в XML
Нет, я вам предлагаю таким образом понять, как могут строиться графические дельты.
> смотрел подобные вещи для BPMN, и это ужасно
> но его как-то научились фильтровать IDE и прочий инструмент
> я верю, что возможно есть такие системы, где все так хорошо, как вы рассказываете.
> Мне просто их видеть пока ни разу не приходилось.
Если говорить «о том, что есть», то да, вы правы, системы визуального программирования на текущий момент значительно отстают по удобству и выразительности от современных текстовых ЯП и IDE с их поддержкой. Ежели говорить о потенциальных возможностях графического программирования («о том, что будет»), то это просто некий умозрительный предел (до которого ещё идти и идти, конечно) закономерного и неотвратимого сращивания средств анализа/исследования кода, менеджмента изменений, зависимостей и авторства и, собственно, самого представления разрабатываемой логики. Итого: графическое представление не хуже текстового, а прост ещё в процессе поиска эффективных форм.
Tallefer
05.11.2017 15:03Решение простое — дудлы с полупрозрачным предыдущим/следующим слоем. :) Но да, никто еще не сделал такое, просто ну как бы объемы интересов разрабов интерфейсов ИДЕ находятся в области текстовых языков, просто работает статистика…
Ni55aN Автор
05.11.2017 19:58-2данные о схеме экспортируются в JSON формат. Далее можно работать с ним в любой системе контроля версий, может даже через какие-то специально предназначенные для JSON файлов.
По факту, все подобные вопросы могут быть решены в виде надстроек над библиотекой. Так как это не конечный продукт, то и нет смысла говорить об отсутствии чего-то «из коробки»Aquahawk
07.11.2017 15:14+1Ок, если у меня есть json. То есть два варианта:
1. я умею его быстро читать, тогда дифф смотреть удобно, но тогда зачем мне схема?
2. читать его сложно, тогда какой смысл от диффа?Ni55aN Автор
07.11.2017 16:121. json для хранения, схема для всего остального
2. сам json читать не нужно. Повторюсь, он нужен только для хранения, а функционал diff'а и подобное любой может сделать так, как пожелаетAquahawk
07.11.2017 17:18+1я к тому что аргумент с чтением диффа в json неприменим если формат нечитаем. А сделать грамотный вьювер изменений в граф формате я вообще не представляю как.
Ni55aN Автор
07.11.2017 17:44чей аргумент «с чтением»? Мною было предложено только использование vcs, чтобы хотя бы коммитить изменения. Если построчно сравнивать, то это вполне реально, но не думаю что в перспективе будет полезно. Так выглядят данные
Вьювера я пока не находил удобного. Вопрос с этим буду решать, может что подскажутZyXI
08.11.2017 02:23Я как?то думал, как выглядело бы представление LabVIEW’шных виртуальных инструментов в формате, который производил бы относительно читаемые diff’ы. Основная суть идеи в том, что метаданные отдельно, логика отдельно, представление отдельно. Если правильно выбрать способ сортировки данных одного уровня иерархии и разбивки на строки, то можно получить относительно читаемые diff’ы. Правда, в моём примере ниже нужно больше внимания уделить алгоритму генерации имени проводов.
Если что, получилось что?то вроде (мысленно удалите комментарии)
%YAML 1.2 --- description: Wait for delay milliseconds. # … # Other metadata from VI properties # … icon: palette: a: {A: 0x00, R: 0x00, G: 0xff, B: 0x00} b: {A: 0x00, R: 0x00, G: 0xff, B: 0x00} # “Image” key uses single-character ARGB colors from palette. # UTF-8 in case ASCII is not enough. image: | bbbbbbbbbb baaaaaaaab bbbbbbbbbb baaaaaaaab baaaaaaaab baaaaaaaab bbbbbbbbbb terminals: pattern: left: 3 top: 0 bottom: 0 right: 3 list: - name: delay caption: "delay (default 5000 ms)" location: left 0 direction: input type: I32 - name: error in caption: "error in (no error)" location: left 2 direction: output type: error cluster - name: error out caption: error out location: right 2 direction: output type: error cluster code: # Code: contains all used nodes and their relations, but not their positions # or positions of the wires. # # The code is created as following: first all node names are determined. # Then AST is sorted so that if node B has inputs wired to outputs of node A # then node A appears first. Should that not allow determining the order # then nodes are sorted alphabetically. # # After sorting is complete all nodes are appended indexes to make them # unique. Indexes are tracked in runtime and preserved so the below index # order only keeps being perfect on the first save. # # Note: if node was replaced via “Replace” context menu it still keeps its # index: this is one of the main points in having global incrementing indexes. # # Inputs/outputs are named after their nodes with terminal names appended. # Should terminal name be not unique its position is appended. # # Only inputs/outputs which have wires receive their names: names in # node dictionaries define connections. - control/delay 0: {output: control/delay 0/output} - control/error in 1: {output: control/error in 1/output} - case structure 2: selector: control/error in 1/output # Terminal properties which do affect logic are defined here use default if unwired: - indicator/error out 5/input cases: Error: # In some cases there is nothing, but wire; and it is significant # for the logic. - wire: !!set {control/error in 1/output, indicator/error out 5/input} No Error: # User VI: same as default ms waiter, just to show how it would look. # # Dictionary near the node maps terminals to connections. - My Wait.vi 4: {wait: control/delay 0/output} - indicator/error out 5: {input: indicator/error out 5/input} # Define wire positions in a form [anchor (output terminal), relative # x/y offset, anchor (input terminal)]. Wires without sources or with structure # terminals as sources are listed from sink. Wires without sources or sinks just # use [anchor, node name] with nearest anchor. No absolute positions used ever. # # Note: determining exact anchors still needs code above, pairs in wire # position only reference nodes. # # Since wire may have more then one sink this is a list of lists of lists, # innermost list is a 2-tuple (type, data). # # Structure terminal positions are also defined here. wires: control/delay 0/output: - [[source, control/delay 0], [structure terminal, [case structure 2, +1, 0]], [case, No Error], [sink, MyWait.vi]] control/error in 1/output: - [[source, control/error in 1], [structure terminal, [case structure 2, +1, 0]], [case, Error], [structure terminal, [case structure 2, +5, 0]]] indicator/error out 5/input: - [[sink, indicator/error out 5], [structure terminal, [case structure 2, -1, 0]]] # Node positions and properties that do not affect logic. nodes: control/delay 0: type: control terminal: delay # Position is absolute position: [0, 1] label: # label position relative to position position: [-1, -1] visible: true view: icon control/error in 1: type: control terminal: error in position: [0, 0] label: position: [-1, -1] visible: true view: icon case structure 2: type: case structure position: [1, 2] size: [5, 2] label: text: Case Structure visible: false position: [0, 0] # Case visible by default selected case: No Error MyWait.vi 4: type: VI # Logical location (which structure, which case) is defined by logic. position: [2, 1] label: position: [-1, -1] visible: false view: icon indicator/error out 5: type: indicator position: [6, 0] label: position: [-1, -1] visible: true view: icon

Idot
05.11.2017 13:01Практической пользы нет никакой, если вы уже умеете писать код.
Почему же никакой?
Конец и начало каждого логического блока становится очень легко найти.

Причём, цвет здорово помогает не запутаться, что случается в коде со множеством вложенных блоков с отступами без какого-либо цветного выделения.Ni55aN Автор
05.11.2017 13:43лично я больше времени потратил на поиск и перетаскивание блоков, чем просто на написание кода. Большая вложенность это плохо, что говорит о необходимости рефакторинга кода


vintage
05.11.2017 13:13Позиционировать блоки лучше через свойство transform — меньше тормозить будет.

{kind=link}
mouze1976
05.11.2017 13:29Спасибо за статью! Подскажите как запустить D3NE с примером на Ubuntu 16.04
Ni55aN Автор
05.11.2017 13:31все запускается в браузере, независимо от ОС
mouze1976
05.11.2017 13:59Я прошу прощенья если совсем глупый вопрос, но я в этом новичок.
Уточню вопрос как все это установить
Отсюда github.com/Ni55aN/D3-Node-Editor/wiki понял что установка делается так
npm install d3-node-editor
А дальше что?Ni55aN Автор
05.11.2017 14:05это в случае, если работать через сборщик (подключать из npm удобнее). А для начала олдскульным <script src… можно. Создаете .html, прописываете в нем зависимости и дальше ваш скрипт для работы с библиотекой (пример на Codepen)

DexterHD
05.11.2017 14:27Странно что не упомянули промышленную автоматизацию, там визуальное программирование достаточно частое явление и оно туда очень хорошо вписалось и применяется повсеместно.
Например CFC в ПЛК Siemens

Или же в контроллерах Metso

К тому же там достаточно простая «Бизнес-логика» и схемы как правило не перегружены (но конечно исключения бывают)
Oegir
05.11.2017 15:00Чисто как курьез: Как-то решил запрограммировать форму в 1С, но в конец запутался в обработчиках. Думал, что разрисовать схему их взаимодействий во FreeMind поможет. Вот что получилось
Обработчики не сложного документа
FadeToBlack
05.11.2017 21:02Однажды я создал графический язык программирования AnandamideAPI.

Мне удалось внедрить его в рамках одного проекта, и в некотором смысле, это было удачным внедрением. Но проблема в том, что нужно понимать, как извлечь пользу из использования таких языков. Время обучения разработчиков на этом языке — от двух дней (при условии, если человек делал лабы по программированию в универе). Если взять того же человека и начать учить его программированию с помощью текста — на это уйдут как минимум месяцы. Проблема лишь в том, что такие люди быстро скатываются к обычному текстовому программированию и теряют интерес к диаграммам. Выгода состоит в том, что затраты на такого программиста сравнительно низкие, при результате, который работает, и с которым смогут разобраться другие визуальные разработчики

realbtr
05.11.2017 23:03Как все печально. Сколько лет уже придумывают графическую метафору программирования и до сих пор это что-то на уровне детских кубиков. Наглядным делается то, что и так просто до примитивности. Но то, что действительно требует улучшение наглядности превращается в квест из разряда пиксель-хантинга. Сплошной визуальный мусор. Отвратительный UX
На практике, облегчить необходимо нечто, называемое «коннектинг». Но не формально, ради красивых «блокки». А инструментально. Для того, чтобы быстро заполнять сложные структуры соответствий. Это то, что создает много нудной рутины разработчику- сопоставление между собой сложных структур. Вот где хороша визуализация.
Там где форматированный текст прост и нагляден нужно совсем немного визуализации и она не должна быть излишне плотной или излишне рыхлой. Манипуляции с простыми данными легко читаются и простым текстом, его можно лишь оформить в легко декомпозируемые структуры.
Нужен гений высокого уровня, чтобы исправить этот UX и сделать визуализацию удобнее, чем привычный структурированный текстFadeToBlack
06.11.2017 12:39Да, тут я соглашусь, нужна хорошая визуализация сложных вещей. Но тут проблему не решить на стороне только одного UX, всегда найдется способ использовать это для создания монстров. Тут опять все будет зависеть от культуры разработчика.

maxminimus
06.11.2017 13:07Вот «совсем немного визуализации» для JS:

Подробнее: habrahabr.ru/post/332574
Для всех трех языков веб-программирования я сделал «визуальные» версии.
Начальная задача простая — адаптировать классический текстовый редактор кода для работы на сенсорном экране.mayorovp
07.11.2017 09:05Это генератор головоломок а не визуальный язык программирования. Все сделано точно так же как в текстовой версии, только менее удобно. Ну и зачем?
maxminimus
07.11.2017 13:32-2Ты генератор глупых комментариев ))
Ты если такой самый умный — сделай свой язык и редактор.
А тупо всё критиковать и обсирать как ты может любой дурак.
Наверняка ты сам в жизни ничего нового не придумал.Zenitchik
07.11.2017 14:04+1Думай что говоришь. На хабре не тусуются те, кто "ничего нового не придумал". Тут в основном те, для кого придумывать новое — работа.
А указанный редактор не имеет целевой аудитории, на что Вам неоднократно указывали.

babylon
07.11.2017 02:18На практике, облегчить необходимо нечто, называемое «коннектинг». Но не формально, ради красивых
Чтобы облегчить коннектинг нужно инкапсулировать код и оставить только интерфейсную часть, которая должна представлять собой торчащий наружу набор ключей, который, в свою очередь, будет самонаходить себе пару и самоорганизовывться ("бандлироваться") по предопределенным правилам, подобно тому как это происходит с белковыми структурами. Обмениваться данными — нейромедиаторами и также просто разбираться (деструктироваться) в случае необходимости. И эти процессы должны быть зациклены по времени и работать как живой организм. А графы это позапозавчерашний дней.
Zet_Roy
06.11.2017 13:27Вы забил дописать что blueprint ue4 в 250 раз медленнее чем на писаный вручную код. Это значит что любые блок схемы это высокоуровневая надстройка над обычным кодом, которая будет очень не оптимизированная.
Ni55aN Автор
06.11.2017 13:37С++ это тоже высокоуровневая надстройка над ассемблером, но это не значит, что он не поддается оптимизациям. Чисто теоретически: можно же преобразовать графы в исходный код (просто связать между собой воркеры, так называемый тот же написанный код для обработки внутри узлов), к тому же обход узлов и передача данных между ними — не затратная операция.
Попробую сделать сравнение производительности прямой обработки и через движок
FadeToBlack
06.11.2017 18:41было бы что там оптимизировать. никто не заставляет на нем писать тяжелые и сложные алгоритмы.
Cadog
06.11.2017 13:45В своё время мне очень понравился hiasm. Что-то сложное на нем нарисовать проблематично, но для обучения программированию просто супер. Люди, ранее не знакомые с программированием, быстро разбирались. Понимали логику. А когда возможностей становилось мало, с большим пониманием и с меньшими сложностями начинали изучать какой-нибудь язык программирования. Для него есть и web версия.
Ni55aN Автор
07.11.2017 19:31Первые попытки реализации модульности
Живой пример: codepen.io/Ni55aN/pen/QOEbEW
Aquahawk
Основная проблема в том, что часто в продакшн проектах пишется невероятно сложная бизнес логика, которая в посредством функций легко декомпозируется. Ну и текст плотнее. То, что человек много времени тратит на написание кода — миф, даже исследований приводить не буду. И пока представление в виде картинки увеличивает площадь на единицу цикломатической сложности, ничего хорошего для профессионального поведения не получится. Вот тут написано почему это не работает habrahabr.ru/company/everydaytools/blog/340410

Картинка оттуда для привлечения внимания.
Схемы просты, пока они маленькие. Я сам проектировал некоторые штуки в виде майндмапов, и они пригодны к работе только пока маленькие. Как только мапа становится большой, её становится сложнее применять. На самом деле читаемость больших схем ужасна.
Ni55aN Автор
Подобный вид (как на картинке) имеют исходники, называемые спагетти-кодом. Собственно, чем легко чтение большого количества исходного кода? Если он грамотно разбит на модули/файлы, тогда проще, но почему это не может быть применимо к другим видам инструкций, отличных от исходного кода?
Aquahawk
а что так с плотностью? Та же цикломатическая сложность имеет таки большую площадь в пикселях или нет?
sshikov
Текстовый вид удобен тем, что для него выработаны некоторые приемы декомпозиции. Ну например, можно легко назвать две парадигмы — ООП и функциональное программирование. И мы знаем, на какие части надо разбивать, и как их компоновать друг с другом (шаблоны проектирования, или скажем монады).
В случае диаграмм почти ничего из этого нет.
aamonster
Напомню, что прежде, чем императивный код стало проще писать/читать в виде текста, нежели в виде блок-схем — прошло довольно много времени и пришлось изрядно ограничить допустимые варианты кода (структурное программирование, ооп и т.п. — это именно ограничения, которые мы добровольно приняли, чтобы иметь возможность разбираться в своих программах). Так что в других областях (типа того же dataflow) графическое программирование может протянуть ещё долго, а то и остаться одним из самых удобных инструментов. С ограничением на размер одного модуля, естественно.
Carburn
Как зависит цикломатическая сложность от способа предоставления? Цикломатическая сложность зависит от топологии (структуры).
Aquahawk
О том и речь, что цикломатическая сложность от представления не зависит. А площадь зависит. И в отношении сложность/площадь два параметра. И площадь зависит как раз от представления. Вопрос о площади занимаемой каким-то куском логики. Код — нехилый концентрат логики. А графические представления часто обладают гораздо меньшей концентрированностью.
midday
А декомпозировать такие огромные схемы никак?
Ведь можно разделить на много частей. Один блок — внутри еще куча блоков и так далее.
Sdima1357
Можно. Simulink так например делает. Но проблема в другом, посмотрите этот комментарий чуть ниже habrahabr.ru/post/341690/#comment_10506578
Впрочем иногда графическое представление удобно.