
Привет, Хабр! Я работаю системным администратором, совмещая это дело с организацией и проведением нагрузочного тестирования для различных проектов (как игровых, так и не очень). Так уж получилось, что нагрузкой занимается только один человек (это я).
В моей компании одновременно работает несколько студий и чтобы сохранять качество каждого игрового проекта каждой из этих студий необходимо проводить нагрузочное тестирование независимо друг от друга, и это привело к тому, что стало необходимо автоматизировать это дело по-максимуму и свести ручное участие к минимуму.
Сам процесс нагрузочного тестирования в своём сознании я делю на несколько этапов:
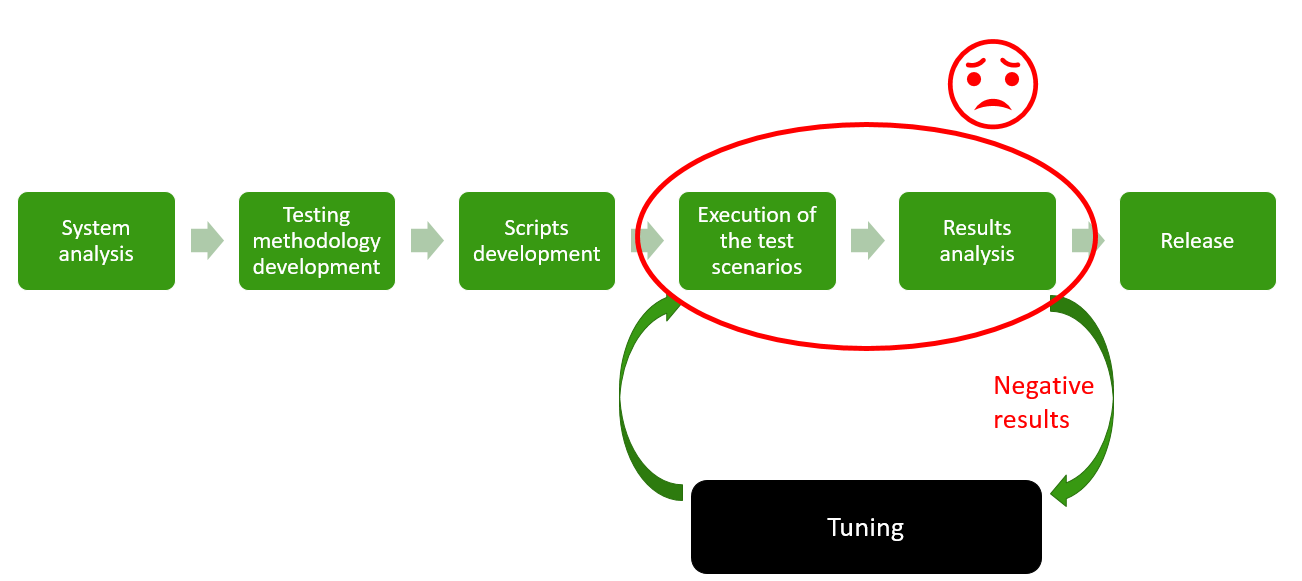
Первые три этапа это просто анализ системы и разработка скриптов. Дальше начинается самый скучный и долгий итеративный этап, а именно: само тестирование и анализ результатов, в результате которого мы, в зависимости от результатов, переходим к самому интересному — тюнингу.
Но этап тюнинга занимает несколько минут, а вот ожидание результатов несколько часов. Далее нужно провести сбор и анализ результатов, что совсем недавно требовало много ручной работы, от которой, собственно мне и предстояло избавиться, чтобы свести весь процесс к более интересным делам: разработке скриптов и тюнингу.
В качестве инструмента для нагрузочного тестирования мы (естественно) используем Apache Jmeter.
Проекты Innogames используют различные протоколы, которые можно легко эмулировать при помощи данного продукта (конечно зачастую используя дополнительные собственные плагины): http, websockets, protobuf, protobuf+STOMP и даже udp. Также благодаря неплохой системе распределения нагрузки мы можем легко эмулировать необходимое количество VUs (виртуальных пользователей) и трафика. Для примера на одном проекте необходимо было поднять 65k VUs и произвести 3000 запросов/с.
Естественно как и все модные конторы мы стали запускать тесты с использованием Jenkins CI. Но проблема с анализом результатов, а главное сравнение результатов с результатами предыдущих тестов была очень актуальна. Так же как и проблема онлайн-мониторинга: тесты, естественно, запускаются в консольном режиме мы имеем только консольный output от jmeter, а хочется графиков.
По началу, как решение неплохо работал Performance plugin для дженкинса. Но с ростом количества тестов на каждом проекте и с появлением реально больших файлов для анализа (3 часовой тест с 3000 запросов/с производит CSV-файл размером в 4Gb+), этот плагин начал работать часы и падать в OOM вместе с дженкинсом.
Количество проектов, данных, заинтересованных лиц росло, нужно было что-то делать.
Поискисмысла жизни какого-либо готового решения никакого результата не дало. Пока я не наткнулся на одну статью, где автор описывал как при помощи python и pandas (библиотека для анализа данных) анализировал csv файлы от Jmeter и строил графики. Прочитав это и осознав, что pandas может с легкостью пера работать с гигабайтными файлами и аггрегировать данные из них я написал простенький скрипт который генерировал HTML-репорты с результатами тестов и публиковал их в дженкинсе при помощи HTML Publisher plugin.
Вот ссылка на этот скрипт, не смотрите туда.
На время это решило проблему. Но это было очень плохое решение, с кучей подгружаемых картинок и Java-скриптов, которые читали локальные CSV файлы и строили таблички.
В какое-то время репорты стали также долго подгружаться (по несколько минут), это всех бесило и кое-кто предложил рассмотреть вариант с сотрудничеством с одним из известных SaaS — провайдеров нагрузочного тестирования, сервис которых построен на генерации нагрузки при помощи бесплатного Jmeter, но они это дело продают за немалые деньги, предлагая удобную среду для запуска тестов и анализа результатов. Я не очень люблю эти сервисы, хотя они делают много для того же Jmeter (например BlazeMeter).
Надо сказать, я не понял как они собирались эмулировать нестандартные протоколы и поднимать большое количество VUs, но идея их удобной среды для нагрузочного тестирования с этими всеми графиками и отчетами мне понравилась, как и то что этим могут пользоваться множество человек одновременно.
Держа в уме pandas я решил попытаться придумать своё решение.
Наконец-то мы подошли к главной теме. В течениие немалого времени проб и ошибок, а также изучения Django, HTML, java-скриптов и прочего, родилось следующее решение, названное мной Innogames Load Testing Center (далее LTC).
Скачать и поучаствовать в развитии проекта (благо делать там есть много чего) вы можете с официального гит-хаба компании: Jmeter Load Testing Center.
Это web-приложение на Django и использует Postgres для хранения данных. Для анализа файлов с данными используется вышеупомянутый модуль pandas.
Состоит из следующих основных компонентов (на языке Django — приложений):
На данный момент Jenkins пока никуда не делся, приложение Controller пока ещё находится в разработке. Но в скором времени возможно заместим и дженкинс.
Таким образом, если пользователь по имени Ганс захочет запустить тест он открывает Jenkins выбирает проект и нажимает пуск:

После этого Jenkins запускает главный инстанс Jmeter на основном сервере (назовем его admin.loadtest, там же находятся сам Jenkins и LTC), а также Jmeter-серверы на одной или нескольких удаленных виртуальных машинах в необходимом количестве (об этом позже) и начинается собственно сам процесс тестирования.
В процессе теста в папке $WORKSPACE проекта создается и пополняется данными CSV-файл с результатами JMeter, а также ещё один CSV-файл с данными мониторинга удаленных хостов.
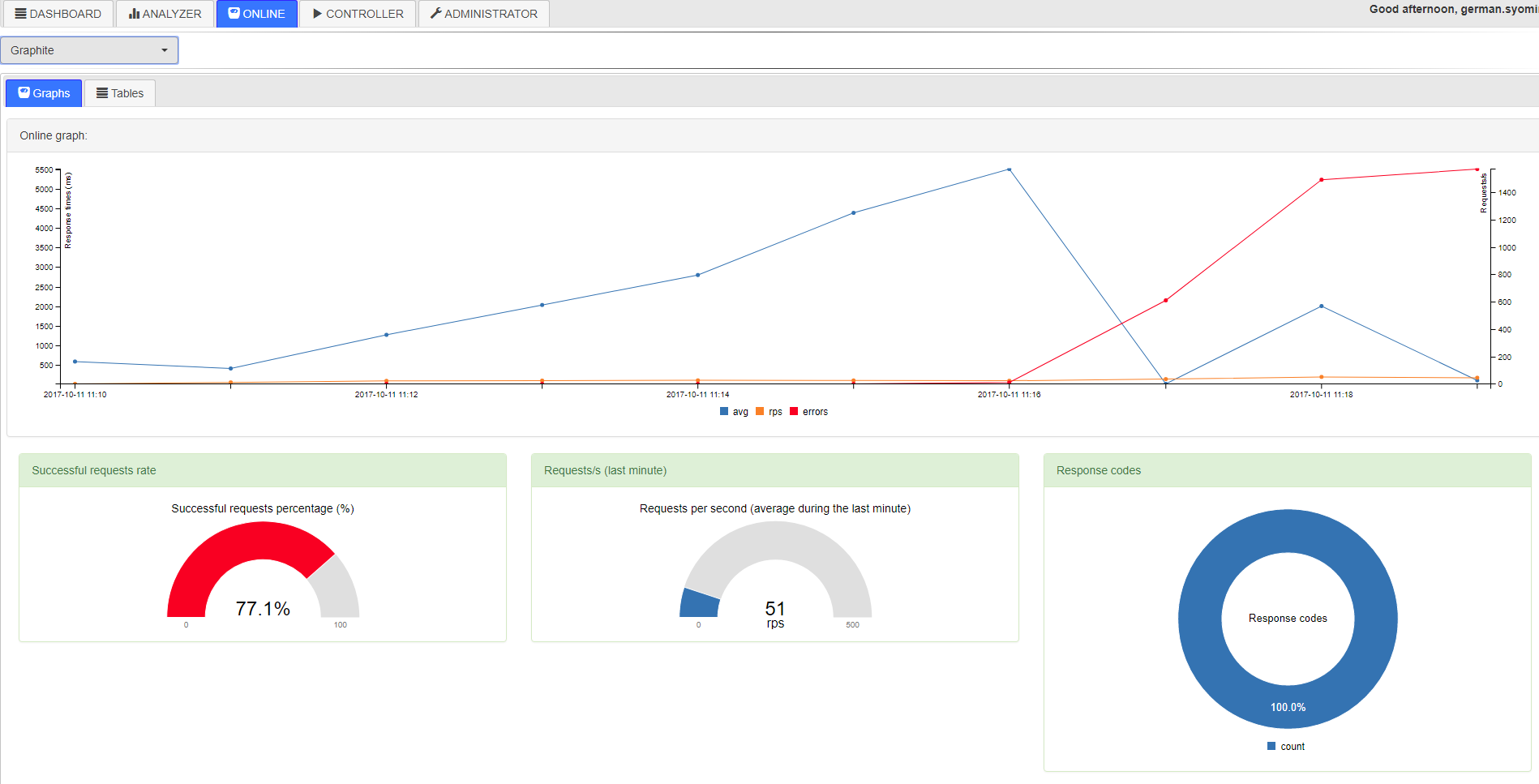
Далее Ганс может открыть LTC и наблюдать за прохождением теста в режиме онлайн. (в это время приложение будет парсить вышеупомянутые CSV файлы и класть их во временные таблицы в базу, из которой Online рисует графики:
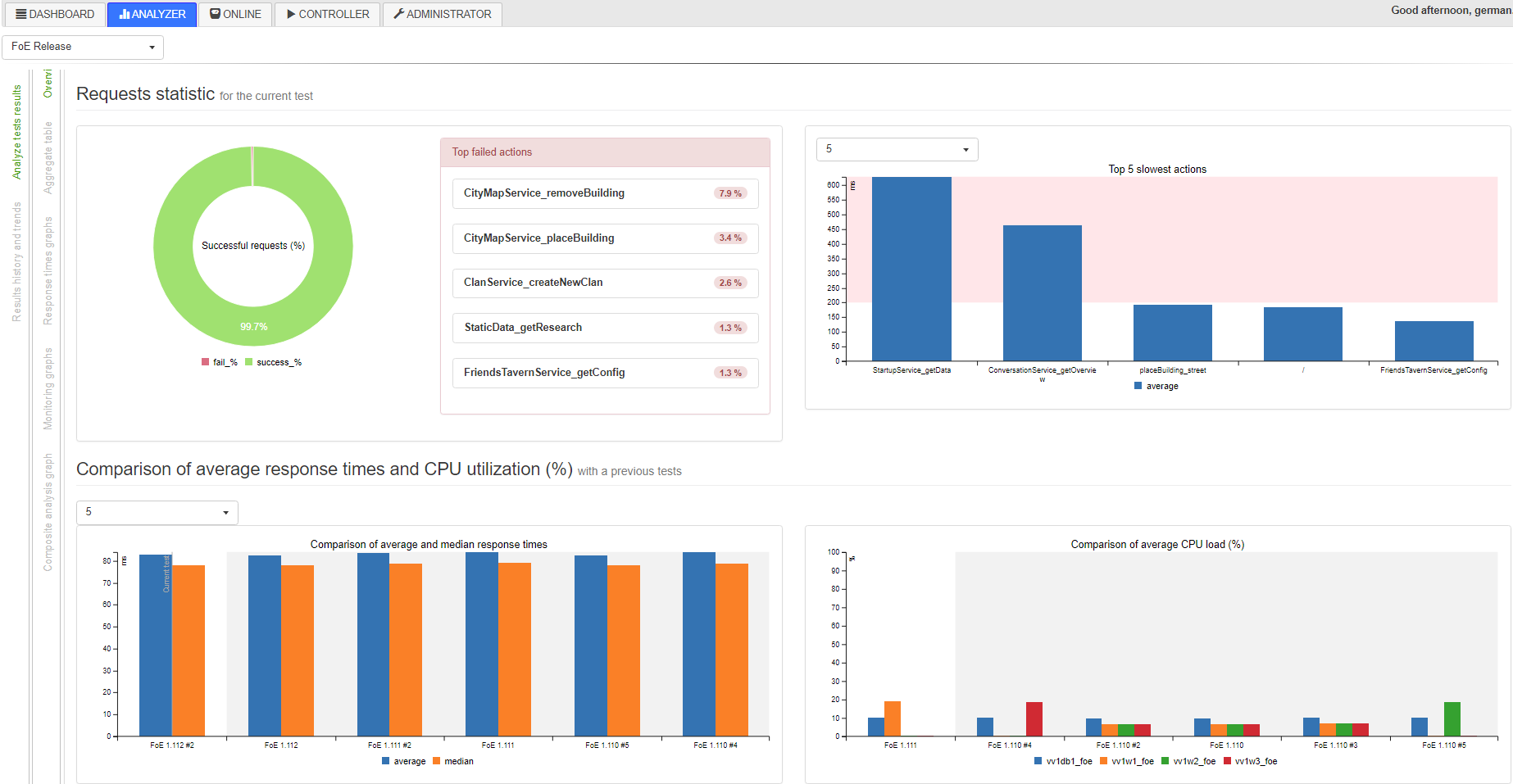
Или же этот же Ганс может подождать до конца теста, когда в конце специальный скрипт соберет все данные в базу и их можно будет использовать в Analyzer для анализа и сравнения с другими результатами:
Осталась последняя проблема: проектов несколько, проекты требуют разные мощности для проведения нагрузки (читай, эмулируют разное количество VUs), пользователи могут запускать их одновременно, а могут и нет. Как распределить имеющиеся допустим 10 виртуальных машин-генераторов на всех. Можно назначить каждый проект под определённые генераторы (в начале так и было), можно составить расписание или использовать блокирующий плагин для Jenkins, а можно сделать что-то умное интересное. Об этом ниже.
Как я уже сказал бекенд написан на фреймворке Django. В разработке фронтенда я использовал все стандартные библиотеки: jquery и bootstrap. В качестве графиков мне нужно было решение, которое легко нарисует данные полученные в формате JSON. Неплохо с этим справляются c3.js.
В таблицах в базе данных обычно присутствует пара ключей и одно поле с типом данных JSONField(). JSONField используется поскольку впоследствии можно легко добавлять новые метрики в эту таблицу, не меняя её структуру.
Таким образом типичная модель, которая хранит данные о временах отклика, количестве ошибок и прочего в течение одного теста выглядит очень просто:
Сами данные в поле data — это, соответственно, JSON`ы хранящие информацию, агрегированную за одну минуту:

Для извлечения данных из этой таблицы в файле urls.py присутствует один эндпоинт, который вызывает функцию, обрабатывающую эти данные и возвращающую удобно читаемый JSON:
Эндпоинт:
Функция:
На фронтенде мы имеет c3.js график которые обращается к этому эндпоинту:
В итоге мы имеем это:

Собственно, всё приложение и состоит из графиков, которые рисуют данные из соответствующих эндопоинтов на бэкенде.
Как работает вся система для анализа тестов вы можете увидеть из исходных кодов, далее я хочу рассказать процесс запуска нагрузочного теста в Innogames (и эта часть пока актуальна только для нашей компании).
Как я уже сказал вся среда нагрузочного тестирования состоит из одного главного сервера admin.loadtest, и нескольких generatorN.loadtest серверов.
admin.loadtest — виртуалка Debian Linux 9, 16 ядер/16 гигов, на нём работают Jenkins, LTC и другой дополнительный маловажный софт.
generatorN.loadtest — голые виртуалки Debian Linux 8, с установленной Java 8. мощность разная, но допустим 32 ядра/32 гига.
На admin.loadtest в качестве собранного заранее deb-дистрибутива установлен Jmeter (последняя версия с самыми основными плагинами) в папке /var/lib/apache-jmeter.
Тест-план для каждого проекта находится в отдельном проекте на нашем GitLab внутри InnoGames, соответственно разработчики или QA из каждой команды могут вносить свои поправки. И каждый проект сконфигурирован для работы с Git:

Каждый проект состоит из:
./jmeter_ext_libs/src/
./test-plan.jmx
./prepareAccouts.sh
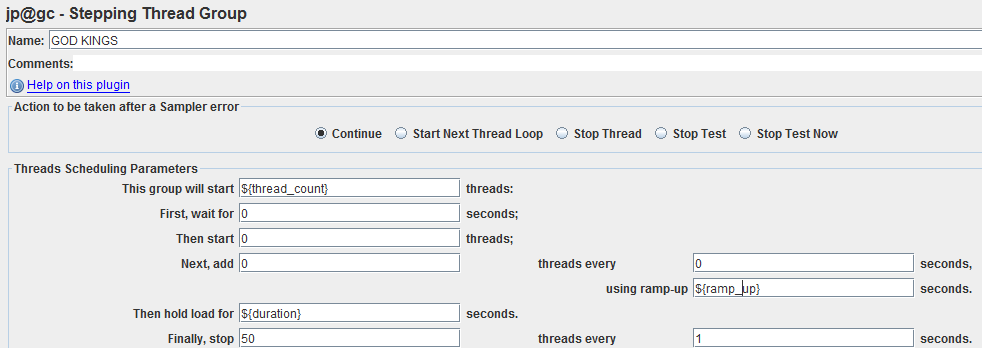
Каждый тест-план в качестве тред-группы использует Stepping Thread Group с тремя переменными: thread_count, ramp_up, duration:
Значения для данных переменных приходят из Jenkins при запуске теста, но для начала их надо соответствующим образом объявить в главном элементе тест-плана в User Defined Variables, как и все остальные параметризуемые переменные. Одна из важных, назовём её pool — в нее посылается последовательный номер для каждого запущенного Jmeter-сервера, чтобы впоследствии разграничить используемые пулы данных (например логины пользователей):

где в ${__P(THREAD_COUNT,1)}: THREAD_COUNT — имя переменной которая придет из Jenkins, 1 — дефолтное значение, если не придет.
Также в каждом тест-плане есть SimpleDataWriter который пишет результаты выполнения сэмплеров в CSV-файл. В нём активированы следующие опции:
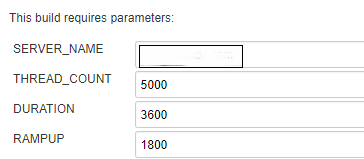
Перед запуском теста каждый пользователь может задать некоторые параметры которые передаются в вышеупомянутые переменные тест-плана Jmeter:
Теперь перейдём к скриптам. Для начала в pre-build скрипте подготавливаем дистрибутив Jmeter:
Далее возвращаемся к последней задаче: мы имеем 10 виртуальных машин предназначенных для генерации нагрузки (мы также не знаем запущены ли тесты от других проектов) и исходя из требуемого суммарного количества эмулируемых тредов THREAD_COUNT необходимо запустить на этих виртуальных машинах (разных) некоторое количество Jmeter-серверов, достаточных для эмуляции необходимой нагрузки.
В нашем скрипте это выполняется при помощи трех строк в bash-скрипте Jenkins, которые, естественно, ведут к более серьёзным вещам скриптах самого LTC.:
Итак, в первой строчке:
Вызываем prepare_load_generators функцию и передаем в нее название проекта, путь к директории workspace проекта, путь к временному дистрибутиву Jmeter (/tmp/jmeter-xvgenq/), созданному выше, длительность теста и самое главное — желаемое суммарное количество эмулируемых тредов $THREAD_COUNT.
Что происходит далее вы можете увидеть в репозитории, если в общем:
Собственно в данный момент все Jmeter-сервера запущены и ждут когда к ним подключатся и начнется сам тест. Таким образом, далее во второй и третьей строчки мы берем значения из этого JSON и передаем в главный инстанс Jmeter, изначальное значение THREAD_COUNT делится между удалёнными jmeter-серверами и на каждый приходится threads_per_host (обратите внимание, что в качестве THREAD_COUNT мы передаём вышеполученное значение threads_per_host):
где $JMETER_DIR — папка с временным дистрибутивом Jmeter (/tmp/jmeter-xvgenq/).
Для запущенных удалённых Jmeter-серверов, существует своя модель. Мы сохраняем данные о том какой тест запущен, на какой виртуальной машине, порт, id данного процесса и прочее. Всё это необходимо для дальнейшей остановки теста, когда эти же самые jmeter-сервера необходимо уничтожить:
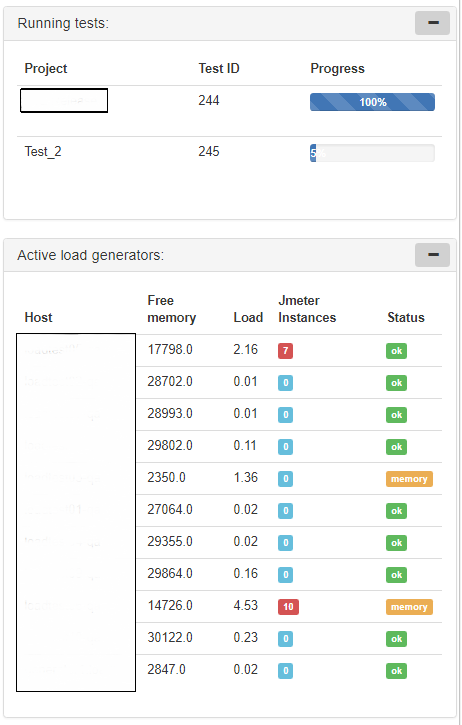
Также на фронтальной странице у нас есть специальные красивые таблички с информацией о запущенных тестах и статусе генераторов нагрузки:
После теста необходимо уничтожить все запущенные Jmeter-сервера, удалить временные Jmeter-дистрибутивы и собрать результаты.
В post-build скрипте добавляем:
В начале удаляем временный дистр с главного сервера, далее вызываем функцию stop_test_for_project, передавая в нее название проекта. Функция проходит по специальной таблице в БД, в которой хранится информация о запущенных Jmeter-инстансах и останавливает их.
И самый последний шаг, сбор результатов можно произвести двумя путями, запустить скрипт:
Или локально вызвать веб сервис:
На данный момент я использую скрипт, он пробегается по всем джобам в папке дженкиса и сравнивает с тем, что есть в базе, сохраняя консистентность.
В LTC я встроил парочку kronos — джобов которые каждые N минут собирают информацию о виртуальных машинах и запущенных java-процессах jmeter-инстансов, Например, собирая S0U, S1U, EU и OU для процесса jmeter-сервера и потом разделив сумму данных метрик на количество тредов, запущенных на нем — я получаю средний размер памяти, потребляемой одним тредом. Метрика довольно странная, а может и глупая, но помогает примерно рассчитать нужный размер памяти для java-процесса, требуемый для эмуляции определённого количества тредов.
Само собой многие используют встроенную систему репортинга Jmeter, которая также не стоит на месте и постоянно развивается. Если кому-то необходимо хранить данные и сравнивать результаты между различными тестами, то он может воспользоваться сервисами наподобие BlazeMeter.
В моих реалиях данные сервисы будут довольно дороги, да и у нас в наличии достаточное количество мощностей для генерации нагрузки, поэтому я попытался создать “инсайд”-решение.
Оно уже умеет многое, но далеко не идеально и дел не впроворот. Так что сейчас нахожусь в надежде, что есть ещё люди со схожими проблемами.
Всем спасибо и удачи.
В моей компании одновременно работает несколько студий и чтобы сохранять качество каждого игрового проекта каждой из этих студий необходимо проводить нагрузочное тестирование независимо друг от друга, и это привело к тому, что стало необходимо автоматизировать это дело по-максимуму и свести ручное участие к минимуму.
Сам процесс нагрузочного тестирования в своём сознании я делю на несколько этапов:
Первые три этапа это просто анализ системы и разработка скриптов. Дальше начинается самый скучный и долгий итеративный этап, а именно: само тестирование и анализ результатов, в результате которого мы, в зависимости от результатов, переходим к самому интересному — тюнингу.
Но этап тюнинга занимает несколько минут, а вот ожидание результатов несколько часов. Далее нужно провести сбор и анализ результатов, что совсем недавно требовало много ручной работы, от которой, собственно мне и предстояло избавиться, чтобы свести весь процесс к более интересным делам: разработке скриптов и тюнингу.
Исходные данные
В качестве инструмента для нагрузочного тестирования мы (естественно) используем Apache Jmeter.
Проекты Innogames используют различные протоколы, которые можно легко эмулировать при помощи данного продукта (конечно зачастую используя дополнительные собственные плагины): http, websockets, protobuf, protobuf+STOMP и даже udp. Также благодаря неплохой системе распределения нагрузки мы можем легко эмулировать необходимое количество VUs (виртуальных пользователей) и трафика. Для примера на одном проекте необходимо было поднять 65k VUs и произвести 3000 запросов/с.
Естественно как и все модные конторы мы стали запускать тесты с использованием Jenkins CI. Но проблема с анализом результатов, а главное сравнение результатов с результатами предыдущих тестов была очень актуальна. Так же как и проблема онлайн-мониторинга: тесты, естественно, запускаются в консольном режиме мы имеем только консольный output от jmeter, а хочется графиков.
По началу, как решение неплохо работал Performance plugin для дженкинса. Но с ростом количества тестов на каждом проекте и с появлением реально больших файлов для анализа (3 часовой тест с 3000 запросов/с производит CSV-файл размером в 4Gb+), этот плагин начал работать часы и падать в OOM вместе с дженкинсом.
Количество проектов, данных, заинтересованных лиц росло, нужно было что-то делать.
Первоначальное решение
Поиски
Вот ссылка на этот скрипт, не смотрите туда.
На время это решило проблему. Но это было очень плохое решение, с кучей подгружаемых картинок и Java-скриптов, которые читали локальные CSV файлы и строили таблички.
В какое-то время репорты стали также долго подгружаться (по несколько минут), это всех бесило и кое-кто предложил рассмотреть вариант с сотрудничеством с одним из известных SaaS — провайдеров нагрузочного тестирования, сервис которых построен на генерации нагрузки при помощи бесплатного Jmeter, но они это дело продают за немалые деньги, предлагая удобную среду для запуска тестов и анализа результатов. Я не очень люблю эти сервисы, хотя они делают много для того же Jmeter (например BlazeMeter).
Надо сказать, я не понял как они собирались эмулировать нестандартные протоколы и поднимать большое количество VUs, но идея их удобной среды для нагрузочного тестирования с этими всеми графиками и отчетами мне понравилась, как и то что этим могут пользоваться множество человек одновременно.
Держа в уме pandas я решил попытаться придумать своё решение.
Решение
Наконец-то мы подошли к главной теме. В течениие немалого времени проб и ошибок, а также изучения Django, HTML, java-скриптов и прочего, родилось следующее решение, названное мной Innogames Load Testing Center (далее LTC).
Скачать и поучаствовать в развитии проекта (благо делать там есть много чего) вы можете с официального гит-хаба компании: Jmeter Load Testing Center.
Это web-приложение на Django и использует Postgres для хранения данных. Для анализа файлов с данными используется вышеупомянутый модуль pandas.
Состоит из следующих основных компонентов (на языке Django — приложений):
- Dashboard — фронтальная страница с общей информацией о последних запущенных тестах.
- Analyzer — здесь строить репорты и анализировать результаты тестов
- Online — позволяет наблюдать за тестами в режиме онлайн
- Controller — здесь можно настраивать и запускать тесты (в процессе разработки)
- Administrator — для настройки разных параметров/переменных.
На данный момент Jenkins пока никуда не делся, приложение Controller пока ещё находится в разработке. Но в скором времени возможно заместим и дженкинс.
Таким образом, если пользователь по имени Ганс захочет запустить тест он открывает Jenkins выбирает проект и нажимает пуск:
После этого Jenkins запускает главный инстанс Jmeter на основном сервере (назовем его admin.loadtest, там же находятся сам Jenkins и LTC), а также Jmeter-серверы на одной или нескольких удаленных виртуальных машинах в необходимом количестве (об этом позже) и начинается собственно сам процесс тестирования.
В процессе теста в папке $WORKSPACE проекта создается и пополняется данными CSV-файл с результатами JMeter, а также ещё один CSV-файл с данными мониторинга удаленных хостов.
Далее Ганс может открыть LTC и наблюдать за прохождением теста в режиме онлайн. (в это время приложение будет парсить вышеупомянутые CSV файлы и класть их во временные таблицы в базу, из которой Online рисует графики:
Или же этот же Ганс может подождать до конца теста, когда в конце специальный скрипт соберет все данные в базу и их можно будет использовать в Analyzer для анализа и сравнения с другими результатами:
Осталась последняя проблема: проектов несколько, проекты требуют разные мощности для проведения нагрузки (читай, эмулируют разное количество VUs), пользователи могут запускать их одновременно, а могут и нет. Как распределить имеющиеся допустим 10 виртуальных машин-генераторов на всех. Можно назначить каждый проект под определённые генераторы (в начале так и было), можно составить расписание или использовать блокирующий плагин для Jenkins, а можно сделать что-то умное интересное. Об этом ниже.
Общее устройство
Как я уже сказал бекенд написан на фреймворке Django. В разработке фронтенда я использовал все стандартные библиотеки: jquery и bootstrap. В качестве графиков мне нужно было решение, которое легко нарисует данные полученные в формате JSON. Неплохо с этим справляются c3.js.
В таблицах в базе данных обычно присутствует пара ключей и одно поле с типом данных JSONField(). JSONField используется поскольку впоследствии можно легко добавлять новые метрики в эту таблицу, не меняя её структуру.
Таким образом типичная модель, которая хранит данные о временах отклика, количестве ошибок и прочего в течение одного теста выглядит очень просто:
class TestData(models.Model):
test = models.ForeignKey(Test)
data = JSONField()
class Meta:
db_table = 'test_data'
Сами данные в поле data — это, соответственно, JSON`ы хранящие информацию, агрегированную за одну минуту:
Для извлечения данных из этой таблицы в файле urls.py присутствует один эндпоинт, который вызывает функцию, обрабатывающую эти данные и возвращающую удобно читаемый JSON:
Эндпоинт:
url(r'^test/(?P<test_id>\d+)/rtot/$', views.test_rtot),Функция:
def test_rtot(request, test_id):
# Получаем timestamp начала теста
min_timestamp = TestData.objects. filter(test_id=test_id). values("test_id"). aggregate(min_timestamp=Min(
RawSQL("((data->>%s)::timestamp)", ('timestamp',))))['min_timestamp']
# Извлекаем данные из БД, отнимаем полученный выше min_timestamp, чтобы получить абсолютное время теста, сортируем по timestamp, кастим в JSON и возвращаем.
d = TestData.objects. filter(test_id=test_id). annotate(timestamp=(RawSQL("((data->>%s)::timestamp)", ('timestamp',)) - min_timestamp)). annotate(average=RawSQL("((data->>%s)::numeric)", ('avg',))). annotate(median=RawSQL("((data->>%s)::numeric)", ('median',))). annotate(rps=(RawSQL("((data->>%s)::numeric)", ('count',))) / 60). values('timestamp', "average", "median", "rps"). order_by('timestamp')
data = json.loads(
json.dumps(list(d), indent=4, sort_keys=True, default=str))
return JsonResponse(data, safe=False)На фронтенде мы имеет c3.js график которые обращается к этому эндпоинту:
var test_rtot_graph = c3.generate({
data: {
url: '/analyzer/test/' + test_id_1 + '/rtot/',
mimeType: 'json',
type: 'line',
keys: {
x: 'timestamp',
value: ['average', 'median', 'rps'],
},
xFormat: '%H:%M:%S',
axes: {
rps: 'y2'
},
},
zoom: {
enabled: true
},
axis: {
x: {
type: 'timeseries',
tick: {
format: '%H:%M:%S'
}
},
y: {
padding: {
top: 0,
bottom: 0
},
label: 'response times (ms)',
},
y2: {
min: 0,
show: true,
padding: {
top: 0,
bottom: 0
},
label: 'Requests/s',
}
},
bindto: '#test_rtot_graph'
});В итоге мы имеем это:
Собственно, всё приложение и состоит из графиков, которые рисуют данные из соответствующих эндопоинтов на бэкенде.
Как работает вся система для анализа тестов вы можете увидеть из исходных кодов, далее я хочу рассказать процесс запуска нагрузочного теста в Innogames (и эта часть пока актуальна только для нашей компании).
Fire!
Load testing environment
Как я уже сказал вся среда нагрузочного тестирования состоит из одного главного сервера admin.loadtest, и нескольких generatorN.loadtest серверов.
admin.loadtest — виртуалка Debian Linux 9, 16 ядер/16 гигов, на нём работают Jenkins, LTC и другой дополнительный маловажный софт.
generatorN.loadtest — голые виртуалки Debian Linux 8, с установленной Java 8. мощность разная, но допустим 32 ядра/32 гига.
На admin.loadtest в качестве собранного заранее deb-дистрибутива установлен Jmeter (последняя версия с самыми основными плагинами) в папке /var/lib/apache-jmeter.
GIT
Тест-план для каждого проекта находится в отдельном проекте на нашем GitLab внутри InnoGames, соответственно разработчики или QA из каждой команды могут вносить свои поправки. И каждый проект сконфигурирован для работы с Git:
Каждый проект состоит из:
./jmeter_ext_libs/src/
./test-plan.jmx
./prepareAccouts.sh
- jmeter_ext_libs — папка с исходными кодами дополнительных плагинов которые собираются при помощи Gradle и кладутся в /var/lib/apache-jmeter/lib/ext перед каждым тестом.
- test-plan.jmx — тест-план
- *.sh — дополнительные скрипты для подготовки пользовательских аккаунтов и прочего.
Test-plan
Каждый тест-план в качестве тред-группы использует Stepping Thread Group с тремя переменными: thread_count, ramp_up, duration:
Значения для данных переменных приходят из Jenkins при запуске теста, но для начала их надо соответствующим образом объявить в главном элементе тест-плана в User Defined Variables, как и все остальные параметризуемые переменные. Одна из важных, назовём её pool — в нее посылается последовательный номер для каждого запущенного Jmeter-сервера, чтобы впоследствии разграничить используемые пулы данных (например логины пользователей):
где в ${__P(THREAD_COUNT,1)}: THREAD_COUNT — имя переменной которая придет из Jenkins, 1 — дефолтное значение, если не придет.
Также в каждом тест-плане есть SimpleDataWriter который пишет результаты выполнения сэмплеров в CSV-файл. В нём активированы следующие опции:
<time>true</time>
<latency>true</latency>
<timestamp>true</timestamp>
<success>true</success>
<label>true</label>
<code>true</code>
<fieldNames>true</fieldNames>
<bytes>true</bytes>
<threadCounts> true</threadCounts>Jenkins
Перед запуском теста каждый пользователь может задать некоторые параметры которые передаются в вышеупомянутые переменные тест-плана Jmeter:
Запуск теста
Теперь перейдём к скриптам. Для начала в pre-build скрипте подготавливаем дистрибутив Jmeter:
- Создаём временную папку вида /tmp/jmeter-xvgenq/
- Копируем туда основной дистрибутив из /var/lib/apache-jmeter/
- Собираем дополнительные плагины из папки jmeter_ext_libs (если они есть).
- Копируем собранные *.jar в /tmp/jmeter-xvgenq/
- Готовый временный дистрибутив Jmeter далее мы распространим на генераторы нагрузки.
#!/bin/bash
export PATH=$PATH:/opt/gradle/gradle-4.2.1/bin
echo "JMeter home: $JMETER_HOME"
JMETER_INDEX=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 8 | head -n 1) # генерим рандомное имя
JMETER_DIR="/tmp/jmeter-$JMETER_INDEX"
echo "JMeter directory: $JMETER_DIR"
echo $JMETER_DIR > "/tmp/jmeter_dir$JOB_NAME"
mkdir $JMETER_DIR
cp -rp $JMETER_HOME* $JMETER_DIR
if [ -d "$WORKSPACE/jmeter_ext_libs" ]; then
echo "Building additional JMeter lib"
cd "$WORKSPACE/jmeter_ext_libs"
gradle jar
cp ./build/libs/* $JMETER_DIR/lib/ext/
ls $JMETER_DIR/lib/ext/
fi
cd $WORKSPACEДалее возвращаемся к последней задаче: мы имеем 10 виртуальных машин предназначенных для генерации нагрузки (мы также не знаем запущены ли тесты от других проектов) и исходя из требуемого суммарного количества эмулируемых тредов THREAD_COUNT необходимо запустить на этих виртуальных машинах (разных) некоторое количество Jmeter-серверов, достаточных для эмуляции необходимой нагрузки.
В нашем скрипте это выполняется при помощи трех строк в bash-скрипте Jenkins, которые, естественно, ведут к более серьёзным вещам скриптах самого LTC.:
REMOTE_HOSTS_DATA=`python /var/lib/jltc/manage.py shell -c "import controller.views as views; print(views.prepare_load_generators('"$JOB_NAME"','"$WORKSPACE"','"$JMETER_DIR"', '$THREAD_COUNT', '$duration'));"`
THREADS_PER_HOST=`python -c 'import json,sys;data=dict('"$REMOTE_HOSTS_DATA"');print data["threads_per_host"]'`
REMOTE_HOSTS_STRING=`python -c 'import json,sys;data=dict('"$REMOTE_HOSTS_DATA"');print data["remote_hosts_string"]'`
Итак, в первой строчке:
Вызываем prepare_load_generators функцию и передаем в нее название проекта, путь к директории workspace проекта, путь к временному дистрибутиву Jmeter (/tmp/jmeter-xvgenq/), созданному выше, длительность теста и самое главное — желаемое суммарное количество эмулируемых тредов $THREAD_COUNT.
Что происходит далее вы можете увидеть в репозитории, если в общем:
- Исходя из заданного thread_count по выдуманным мной формулам рассчитывается нужное количество Jmeter-серверов — X.
- Далее исходя из текущей нагрузки и доступной памяти на машинах generatorN.loadtest на каждой из этих машин запускается n-ое количество Jmeter-серверов пока общее их число не станет равным X.
- На каждый из отобранных generatorN.loadtest посредством rsync загружается тот временный дистрибутив Jmeter:
- На каждом генераторе запускается n-ое количество Jmeter-серверов (полученное на предыдущем шаге), каждому запущенному процессу мы передаем последовательный номер pool, для распределения пулов данных (как я писал ранее):
- Все данные о запущенных Jmeter-инстансах сохраняются в БД, после теста все они будут уничтожаться исходя из этих данных.
- В конце функция возвращает JSON вида:
{
“remote_hosts_string”: “generator1.loadtest:10000,generator2.loadtest:10000, generator2.loadtest:10001”,
"threads_per_host": 100
}Собственно в данный момент все Jmeter-сервера запущены и ждут когда к ним подключатся и начнется сам тест. Таким образом, далее во второй и третьей строчки мы берем значения из этого JSON и передаем в главный инстанс Jmeter, изначальное значение THREAD_COUNT делится между удалёнными jmeter-серверами и на каждый приходится threads_per_host (обратите внимание, что в качестве THREAD_COUNT мы передаём вышеполученное значение threads_per_host):
java -jar -server $JAVA_ARGS $JMETER_DIR/bin/ApacheJmeter.jar -n -t $WORKSPACE/test-plan.jmx -R $REMOTE_HOSTS_STRING -GTHREAD_COUNT=$threads_per_host -GDURATION=$DURATION -GRAMPUP=$RAMPUPгде $JMETER_DIR — папка с временным дистрибутивом Jmeter (/tmp/jmeter-xvgenq/).
Для запущенных удалённых Jmeter-серверов, существует своя модель. Мы сохраняем данные о том какой тест запущен, на какой виртуальной машине, порт, id данного процесса и прочее. Всё это необходимо для дальнейшей остановки теста, когда эти же самые jmeter-сервера необходимо уничтожить:
class JmeterInstance(models.Model):
test_running = models.ForeignKey(TestRunning, on_delete=models.CASCADE)
load_generator = models.ForeignKey(LoadGenerator)
pid = models.IntegerField(default=0)
port = models.IntegerField(default=0)
jmeter_dir = models.CharField(max_length=300, default="")
project = models.ForeignKey(Project, on_delete=models.CASCADE)
threads_number = models.IntegerField(default=0)
class Meta:
db_table = 'jmeter_instance'
Также на фронтальной странице у нас есть специальные красивые таблички с информацией о запущенных тестах и статусе генераторов нагрузки:
Остановка теста
После теста необходимо уничтожить все запущенные Jmeter-сервера, удалить временные Jmeter-дистрибутивы и собрать результаты.
В post-build скрипте добавляем:
JMETER_DIR=$(cat /tmp/jmeter_dir$JOB_NAME)
echo "Removing Jmeter dir from admin: $JMETER_DIR"
rm -rf $JMETER_DIR
python /var/lib/jltc/manage.py shell -c "import controller.views as views; print(views.stop_test_for_project('"$JOB_NAME"'))"В начале удаляем временный дистр с главного сервера, далее вызываем функцию stop_test_for_project, передавая в нее название проекта. Функция проходит по специальной таблице в БД, в которой хранится информация о запущенных Jmeter-инстансах и останавливает их.
И самый последний шаг, сбор результатов можно произвести двумя путями, запустить скрипт:
python /var/lib/jltc/datagenerator_linux.pyИли локально вызвать веб сервис:
curl --data "results_dir=$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_NUMBER/" http://localhost:8888/controller/parse_results На данный момент я использую скрипт, он пробегается по всем джобам в папке дженкиса и сравнивает с тем, что есть в базе, сохраняя консистентность.
Дополнительно
В LTC я встроил парочку kronos — джобов которые каждые N минут собирают информацию о виртуальных машинах и запущенных java-процессах jmeter-инстансов, Например, собирая S0U, S1U, EU и OU для процесса jmeter-сервера и потом разделив сумму данных метрик на количество тредов, запущенных на нем — я получаю средний размер памяти, потребляемой одним тредом. Метрика довольно странная, а может и глупая, но помогает примерно рассчитать нужный размер памяти для java-процесса, требуемый для эмуляции определённого количества тредов.
Заключение
Само собой многие используют встроенную систему репортинга Jmeter, которая также не стоит на месте и постоянно развивается. Если кому-то необходимо хранить данные и сравнивать результаты между различными тестами, то он может воспользоваться сервисами наподобие BlazeMeter.
В моих реалиях данные сервисы будут довольно дороги, да и у нас в наличии достаточное количество мощностей для генерации нагрузки, поэтому я попытался создать “инсайд”-решение.
Оно уже умеет многое, но далеко не идеально и дел не впроворот. Так что сейчас нахожусь в надежде, что есть ещё люди со схожими проблемами.
Всем спасибо и удачи.
atomheart
Удивительно, что до сих пор никто не прокомментировал. Очень большую работу вы проделали, и достигли уже хороших результатов. Вы же наверняка видели как устроен LoadRunner? Чем-то Ваше решение напоминает Performance Center.
Как минимум появился интерес снова "потыкать" JMeter.
Но т.к. опыта работы с JMeter у меня мало, интересует такой вопрос:
Вы как-то собираете метрики утилизации HW во время тестов? Какие-нибудь сборщики интегрированы у вас (PerfMon, sar/top через ssh, Zabbix...)?
Интересно было бы узнать, как вы решили или будете решать такую задачу.
v0devil Автор
Да конечно видел и много пользовался. Их идея разделения лоад раннера на несколько частей (VUgen, controller, analyzer) вдохновило меня поступить также. Это позволяет пилить отдельные части, не убивая другие.
Мониторинг у нас основан на Graphite, для которого мы собираем метрики при помощи набора скриптов из github.com/innogames/igcollect.
Для лоад тестов использовался долго Monitoring плагин из yandex-танка, который легко засылается на удалённую машину и собирает всё что нужно, собирая в удобночитаемый CSV (оч крутая штука).
Но сейчас всё равно ухожу в сторону парсинга данных из графита.
atomheart
Я так понимаю, что метрики собираются постоянно в Graphite, и потом Вы смотрите, какая утилизация была во время теста. Но не совсем понятно, у Вас в текущей реализации метрики утилизации HW, полученные из Graphite, как-то сливаются и отображаются в Analyzer? Можно ли получить среднюю утилизацию и утилизацию с шагом за период нагрузочного теста, чтобы можно было их так же сравнивать с прошлыми тестами, по аналогии с временами отклика?
v0devil Автор
Да, вместе с файлом результатов самого jmeter собирается также похожий CSV-файл с результатами мониторинга для каждого теста. И эти результаты хранятся в БД их можно отрисовать или сравнить с предыдущими тестами:


Простой график сравнения:
atomheart
Отлично, это очень здорово) В основном именно отсутствие возможности автоматической синхронизации данных теста с данными утилизации меня отпугивало от применения JMeter. Спасибо!
saw_tooth
А PerfMon Metrics Collection Вы не пробовали?
ТСу:
Я делал подобную штуку, правда не в таких масштабах (не нужно было огромных нагрузок, все куда проще). Крутилось все на flask/sqlite, морда на vue. Люблю минимализм и отсутствие зависимостей( никакого там планировщика, или очереди задач, ровно как и отведенного сервиса БД) В плане работы было все просто: добавляешь jmx на морде, выставляешь настройки (если они есть типа урл/кол. юзеров и т.п), запускаешь. Python запускает jmeter, и читает stdout, кладет все в базу, ну и там vue уже все рисует. Для каждого из jmx были конфигурации (проект с измененными параметрами), что бы можно было быстро там включить stage/dev сервера. База что бы не разбухала после месяца архивировалась и создавалась новая (в целом дольше хранить исходники результатов не имело смысла).В общем как то так.
atomheart
Еще вопрос — есть ли у Вас (или может планируется) какое-то API, чтобы можно было выполнять хотя бы часть простых действий (запуск теста, например) из вне?