
Достоинства, проблемы и ограничения сверточных нейронных сетей (CNN) в настоящее время достаточно неплохо изучены. Прошло уже около 5 лет после признания их сообществом инженеров и первое впечатление «вот теперь решим все задачи», хочется верить, уже прошло. А значит, пришло время искать идеи, которые позволят сделать следующий шаг в области ИИ. Хинтон, например, предложил CapsuleNet.
Вместе с Алексеем Редозубовым, опираясь на его идеи об устройстве мозга, мы тоже решили отступить от мейнстрима. И сейчас у меня есть что показать: архитектуру (идёт заглавной картинкой для привлечения внимания) и исходники на Tensorflow для MNIST.
Более формально, результат описан в статье на arxiv.
Зачем?
Всегда и во всём мы имеем дело с неоднозначностью. Чем дальше информация уходит от органов чувств, тем больше вариантов ее трактовки становится. Кажется, зрение нас не подводит. Но нет, есть ряд иллюзий, которые демонстрируют, что это не так: иллюзия вогнутой маски (нужно очень постараться, чтобы осознать ее вогнутой в глубину), известное бело-сине-коричневое платье. Со слухом та же история, что поражает даже больше, чем зрительные иллюзии: хочу вас поздравить с этим. А когда вопрос восприятия информации касается абстрактных понятий, то нельзя не вспомнить бесконечные споры о политике.
Этот принцип изменения смысла наблюдаемого в зависимости от контекста универсален, тем или иным образом реализуется для любой информации, с которой мы имеем дело. И, одновременно с этим, плохо или не явно отражен в большинстве подходов в машинном обучении. Зачастую, формулировка задач машинного обучения исключает саму возможность различных трактовок. Хотя, если присмотреться к идее сверточных сетей с другого ракурса, то получается, что постановка задачи для одного сверточного слоя формулируется следующим образом: необходимо выделить K фич размером MxM, вне зависимости от того, в какой позиции (пространственном контексте) они представлены. Если при этом допустить, что операция переноса по X,Y, не запрограммирована заранее, то задача становится весьма нетривиальной. Аналогично и с рекуррентными сетями: необходимо выделить последовательности во времени, вне зависимости от того, в какой момент времени T (контексте времени) она появлялась.
Кроме того, после обучения мы можем пользоваться представлениями о том, как данные изменяются из-за изменения контекста. Покажите человеку новую модель автомобиля с 4х сторон, он легко её узнает потом в перспективе со случайного угла. Ребёнок увидит мультик, где некоторая социальная модель взаимодействия продемонстрирована зверями, ему не сложно узнать эту же ситуацию во взаимоотношении с людьми. Это настолько мощный и универсальный принцип, что лично меня очень удивляет, почему ему уделяется так мало внимания.
Я убежден, что Сильный Искусственный Интеллект и будет отличаться именно способностью любую информацию на любом уровне обработки представлять в различных контекстах, выбирать наиболее подходящий контекст наблюдаемой ситуации и опыту, полученному в результате обучения.
Источником вдохновения для сверточных сетей (а точнее неокогнитрона) были исследования Хьюбеля и Визела, которые в своё время провели очень эффектные исследования визуальной коры V1 и функции миниколонок в ней, за что были удостоены Нобелевской премии. Но результаты их экспериментов можно интерпретировать и иначе. Подробнее здесь.
Капсульные сети Хинтона — это тоже способ переосмысления функции миниколонок.
Предположим функцию миниколонок
Кора головного мозга структурно состоит из зон с различными функциями, но при этом, вне зависимости от зоны, структурно выделяются миниколонки — столбики из нейронов, вертикальные связи между которыми плотнее, чем горизонтальные.
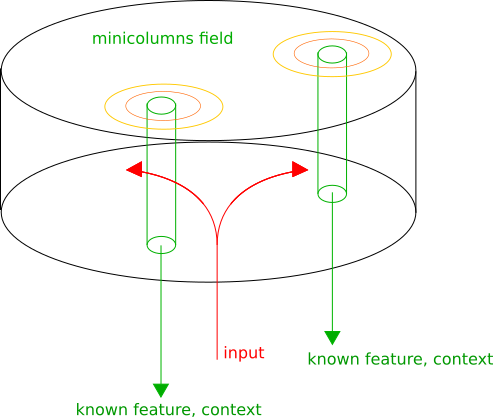
Мы предполагаем, что миниколонка представляет входную информацию в собственном контексте. Затем в каждой миниколонке узнаются известные паттерны, её активность пропорциональна степени достоверности узнавания. Соседние миниколонки представляют похожие преобразования, за счет этого мы можем выбрать локальные максимумы активности на коре, которые и будут соответствовать наилучшим контекстам, в которых трактуется входная информация. Выходом области коры будет перечень: (узнанные паттерны, контекст).
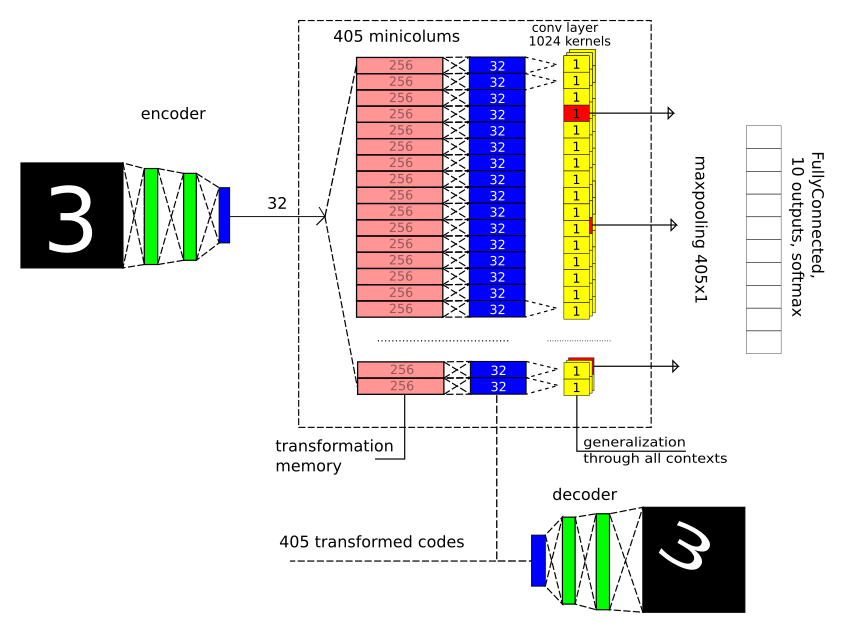
Модель для MNIST
Моделировался лишь один уровень анализа информации (одна зона), несколько зон будет следующим этапом.
Принципиально важно, что здесь мы отказались от пространственных сверток по изображению (Conv2D) и max-pooling 2х2, которые прощают небольшие геометрические искажения, за счет чего точность на MNIST заметно улучшается.
Повторю картинку, чтобы не пришлось далеко отматывать назад при чтении текста:
Тут есть 3 важные части:
1) В зону попадает лишь вектор длиною 32 — результат сжатия классическим автоэнкодером с 2мя полносвязными слоями для декодирования и кодирования.
2) Задаем 405 геометрических контекстов-преобразований: 5 поворотов Х 9 смещений Х 9 масштабов. Смотрим, как изменяется код (32 компоненты) после преобразования входных изображений, обучаем для каждого контекстного преобразования 2 полносвязных слоя (32->256->32), т.е. один скрытый и один выходной. По сути, конечно, просто запоминаем.
3) Ищем устойчивые паттерны, вне зависимости от того, в каком контексте они появились, для каждого паттерна выбираем один наилучший контекст (слой max-pooling).
Затем выход зоны отправляем в небольшую полносвязную сеть, которая принимает решение, что за цифра перед нами.
Тренировка
Да, тут везде использовался принцип обратного распространения ошибок. Единственное, что его «дальнодействие» было весьма ограничено. Т.е. обучалось поэтапно, реально «глубокого обучения» почти и не было. Есть ощущение, что всё должно работать на иных подходах, но пока алгоритмы не написаны будем пользоваться проверенными инструментами.
Сначала отдельно тренируем автоэнкодер:

И фиксируем веса слоев энкодера и декодера.
На самом деле, это совершенно не обязательный шаг. Более того, за счет не идеального представления данных, точность немного ухудшится. Но на этапе 3 за счет этого уменьшается количество вычислений.
Затем обучаем все 405 преобразований. Т.е. как меняется код изображения после этих преобразований. Протестируем, что получилось. Восстановим из преобразованных кодов исходные изображения:

Кажется, что банально (а так и есть)! Но здесь есть пара очень важных моментов:
1) С точки зрения модели, преобразование не запрограммировано, а получено тренировкой. Т.е. абсолютно никаких ограничений на то, с какими данными мы имеем дело и с какими контекстными преобразованиями. А что еще круче, можно даже преобразовывать не в то же самое пространство. Но об этом позже.
2) Можно взять и подать на вход знак, который никогда ранее не показывали, и мы будем знать, как он меняется в зависимости от контекста.
Подадим на вход перевёрнутый треугольник и получим:

Выглядит, конечно, не так чтобы впечатляюще. Но идейно это очень здорово! За счёт предыдущего опыта вы знаете, как объект, который вы ранее никогда в жизни не видели, будет выглядеть во всех возможных контекстах. А это открывает возможность для one-shoot learning. Увидели объект в одном представлении, а узнаете затем совершенно в другом! Это круто уменьшает необходимую обучающую выборку. И если говорить про компьютерное зрение, то ведь речь не только про геометрические преобразования, а также и про цвет, яркость и др.
А потом нужны общие для всех контекстов детекторы. Реализовано это было с помощью сверточного слоя с размером ядра 1х1 и слоем max-pooling, который выбирал победителя для каждого ядра. Сверточный слой здесь — лишь способ использовать одинаковые веса для разных контекстов, он не выполняет свою обычную функцию (как и max-pooling с ядром необычного размера 405х1).
Результаты
В первую очередь, было важно проверить, как обстоят дела с уменьшением размера обучающей выборки. Возьмем первую 1000 изображений и натренируем только на них.
Кривая обучения получилась такой:

Точность 96%.
Надо сравнить со сверточной сетью, например, такой архитектуры:

Точность после тренировки CNN составила 95.3%.
Внимательный читатель заметит, что сравнение нечестное, т.к. я использовал неявную аугментацию (геометрические искажения входных изображений). Так что введем аналогичную аугментацию и для сверточной сети. Получим уже 96.2%.
Неплохо, результат сравним со сверточной сетью.
Обучение по полной базе дало точность 99.1%. Что заметно хуже сверточной сети, но и лучше полносвязной сети из нескольких уровней.
Отказ от использования сверточных слоев, предположительно, уменьшил точность. Но, в любом случае, удалось отладить архитектуру и получить адекватную точность.
Что-то же это всё напоминает?
Да, во-первых, конечно, неожиданно похоже на CapsuleNet Хинтона. Он также предлагает свою трактовку функциональности миниколонок. Основное отличие — в CapsuleNet не содержится идеи представления информации в различных контекстах. Но то, что архитектуры получились похожи, наводит на очень интересные размышления. В его реализации активность миниколонки соответствует узнаванию одной из цифр, а в нашей концепции выходит, что цифра — это контекст. А что значит данная картинка в контексте того, что это семёрка? А в контексте того, что это единица? И этот вопрос действительно не лишён смысла. Контекстом может быть геометрическое преобразование, и контекстом может быть тип узнаваемого объекта. Об этом дальше.
Ещё идея преобразований содержится в Spartial Transformation Networks. В разрыв слоёв включается слой геометрического преобразования и еще небольшая сеточка, которая оценивает наиболее подходящее преобразование с помощью регрессии. При этом не допускается разрывов в дифференцируемости и всё это можно тренировать с помощью метода обратного распространения ошибок. Здесь есть 2 отличия: не формулируется, что же делать с дискретными преобразованиями (а, например, в грамматике речи они дискретные), и, кажется, небольшая сеть с регрессией для оценки оптимального преобразования — это лишнее. Наилучший контекст стоит выбирать на основании того, в каком из контекстов данные формируют известный паттерн, и нет иного оптимального способа, кроме анализа каждого из преобразований.
И еще мысль, которая никак не отпускает
Существует так называемая «Two-stream hypothesis» в визуальном тракте (да и в слуховом/речевом). С одной стороны мозга (ventral stream) миниколонки откликаются преимущественно на характеристики объектов и сами типы объектов, а с другой стороны мозга (dorsal stream) преимущественно на пространственные характеристики.
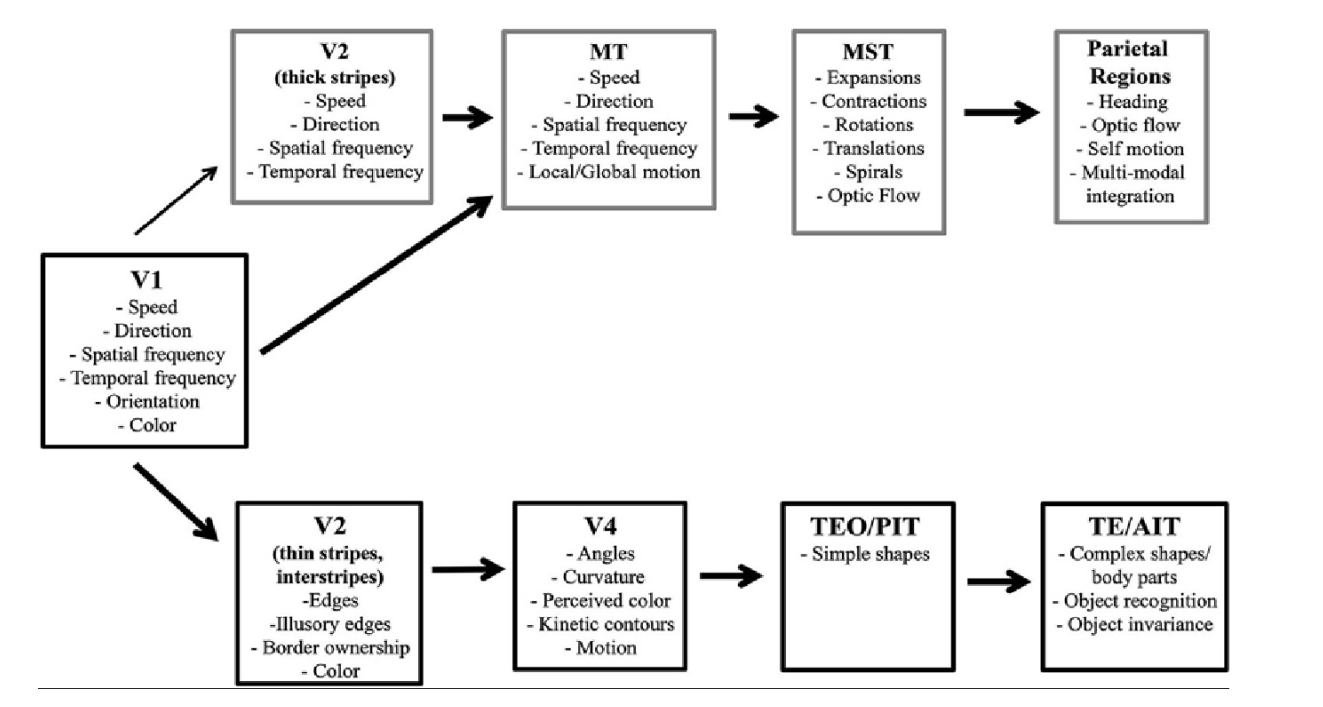
В нашей интерпретации dorsal stream как раз про пространственные и временные преобразования. Взглянем на V2 и V3: Speed X Direction — переход в систему отсчета, движущуюся с заданной скоростью с заданными направлением, Spartical Frequency — попросту преобразование масштаба, Temporal Frequency — изменение масштаба во времени.
Но совершенно контринтуитивно выглядит Ventral Stream. Что значит перейти в контекст «Simple shapes» (контекст формы), или контекст кривизны? В контекст цвета, кстати, не составляет проблем. Или в TE/AIT «в контекст объекта»? Эту проблему можно преодолеть если допустить, что код миниколонки характеризует свойства и характеристики объекта. Например, кривизна границы на изображении характеризуется контрастом, размытием, цветом и др. И эти характеристики будут общими для каждой из миниколонок, ответственными за кривизну.
Очень близко к CapsuleNet, но стили или характеристики внутри миниколонок должны быть общими для некоторой окрестности. Остается открытым лишь вопрос, как обучать такой тип контекстных преобразований.
Так же тут замечательно то, что результат узнавания, полученный в одном из Stream-ов, может быть использован в другом. Узнав форму в контексте определённой позиции в dorsal stream, ориентации и масштабе, можно повысить вероятность активации соответствующих миниколонок в ventral stream. И наоборот.
Выводы
Впереди еще полно работы.
П.С.: название ContextNet, которое я использовал в исходниках, на самом деле уже занято, но уж больно хорошо оно подходит.
Комментарии (11)
Vasyutka Автор
25.12.2017 21:19Она объясняет механизм памяти в минколонках, которая необходима для запоминания контекстных преобразований. Да и механизмы обобщения, но их всех программировать надо

perfect_genius
25.12.2017 21:31любую информацию на любом уровне обработки представлять в различных контекстах, выбирать наиболее подходящий контекст наблюдаемой ситуации и опыту
А если сигналы равносильны, не удаётся выбрать один, то получается удивление и смех, да? Юмор — абсурдность того, что полученную информацию можно равнозначно интерпретировать и так и по другому.
А если знать заранее, что сейчас этот комик будет постоянно сыпать вас такими неоднозначностями, то удивление значительно снижается и остаётся только получать удовольствие.Vasyutka Автор
25.12.2017 23:48Юмор определенно связан с неожиданным (замаскированным) изменением контекста. Это в сторону сильного ИИ же. Как понимать суть шутки и генерировать их в диалоге. Кстати, именно по-этому так ржачно иногда отвечает чат-бот от Яндекса — мимо ожидаемого контекста.

Ermit
25.12.2017 21:510.95 в MNIST'е получается при применении kNN с одним соседом, без какого-либо обучения чего-либо и представлении о «волновых моделях» и кортикальных колонках.

napa3um
25.12.2017 22:59Модель, описанная в статье, скорее всего (как минимум на этой задаче) и является сильно избыточной версией «обычной» сети. Типа как вместо 2 + 2 получили (2*100500 + 2*100500) / 100500, а в колонках заметили отпечаток этого 100500, что навело авторов на мысль об осмысленности этих колонок (в данной задаче). Думаю, чтобы действительно их наделить смыслом в архитектуре, придётся моделировать задачу посложнее (с сильно большей обучающей выборкой), а пока эти колонки — что-то типа аудиофильских проводов для более мягкого и лампового результата (пусть и с меньшим рейтингом, чем у других решений).
Vasyutka Автор
25.12.2017 23:33нет, смысл каждой миниколонки легко проверяется декодером, что и было продемонстрировано. Так что не «случайно обучилось». Но да, безусловно, избыточно
napa3um
26.12.2017 01:38Больше похоже не на проверку, а на confirmation bias (не сформулирован фальсифицируемо эксперимент). Ваши «контексты» с неясной сутью, для которых вы сочиняете объяснения, — всего лишь отдельные выученные признаки данных из обучающей выборки, и их совместимость между образцами данных говорит лишь о малом количестве этих образцов, а не универсальности найденного признака «для всего». Вы построили избыточную версию DCIGN, в которой вся суть заключается в разрежении пространства признаков, что достигается сочетанием конволюции и деконволюции сигнала, а миниколонки служат лишь бесполезным утолщением глубинного слоя сети. (Во всяком случае так всё выглядит на мой поверхностный и непрофессиональный взгляд.)
erwins22
26.12.2017 12:200.983 дает
1x1................3x3................1x1
1 -16..............16-16............16-10
.....................20 раз
итого 16+16*16*3*3+16*10=2480
после каждого шага relu6

Arseny_Info
29.12.2017 13:14Сколько параметров в вашей сети и сколько в референсной CNN? Не переобучается ли CNN — на первый взгляд как-то многовато фильтров для мниста.

VDG
29.12.2017 19:05Интересно, но настоящая колонка имеет доступ только к небольшой локальной области, а не ко всему зрительному полю.
Anc
Так, я не понял, а где вся та волновая магия от Редозубова?
Неужели скатились в обычное машинное обучение?