

Пример работы AttnGAN. В верхнем ряду несколько изображений разного разрешения, сгенерированные нейросетью. Во втором и третьем рядах показана обработка пяти наиболее подходящих слов двумя моделями внимания нейросети для отрисовки наиболее релевантных участков
Автоматическое создание изображений по текстовым описаниям на естественном языке — фундаментальная проблема для многих приложений, таких как генерация произведений искусства и компьютерный дизайн. Эта проблема также стимулирует прогресс в области мультимодального обучения ИИ со взаимосвязью зрения и языка.
Последние разработки исследователей в этой области основаны на генеративно-состязательных сетях (GAN). Общим подходом является перевод всего текстового описания в глобальное векторное пространство предложений (global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие чёткой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Группа разработчиков из Лихайского университета, Ратгерского университета, Университета Дьюка (все — США) и компании Microsoft предложили своё решение проблемы: новая нейросеть Attentional Generative Adversarial Network (AttnGAN) представляет собой улучшение традиционного подхода и позволяет многоступенчато изменять сгенерированное изображение, меняя отдельные слова в текстовом описании.
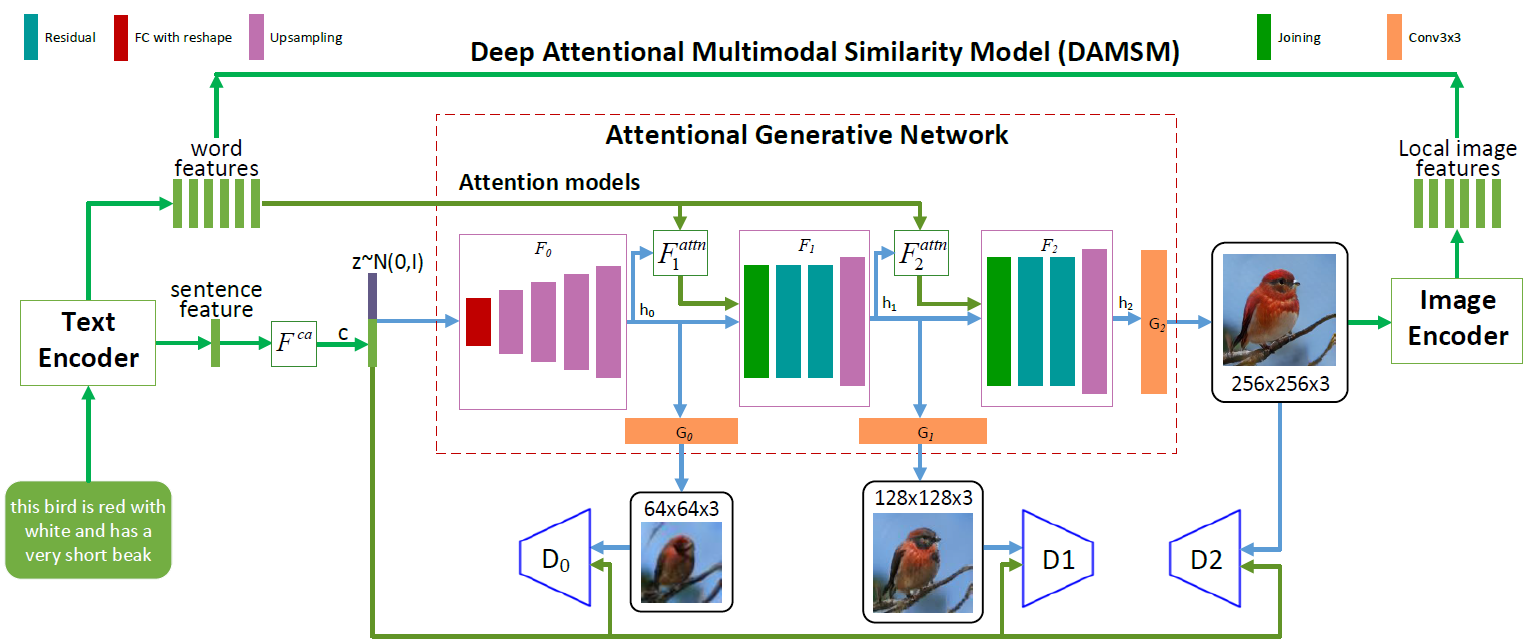
Архитектура нейросети AttnGAN. Каждая модель внимания автоматически получает условия (то есть соответствующие словарные векторы) для генерации разных областей изображения. Модуль DAMSM обеспечивает дополнительную детализацию для функции потерь соответствия на переводе из изображения в текст в генеративной сети
Как видно на иллюстрации с изображением архитектуры нейросети, в модели AttnGAN есть две инновации по сравнению с традиционными подходами.
Во-первых, это генеративно-состязательная сеть, которая относится к вниманию как к фактору обучения (Attentional Generative Adversarial Network). То есть в ней реализован механизм внимания, который определяет слова, наиболее подходящие для генерации соответствующих частей картинки. Другими словами, кроме кодирования всего текстового описания в глобальном векторном пространстве предложений, каждое отдельное слово тоже кодируется в виде текстового вектора. На первом этапе генеративная нейросеть использует глобальное векторное пространство предложений для отрисовки изображения низкого разрешения. На следующих этапах она использует вектор изображения в каждом регионе для запроса словарных векторов, используя слой внимания для формирования словоконтекстного вектора. Затем региональный вектор изображения комбинируется с соответствующим словоконтекстным вектором для формирования мультимодального контекстного вектора, на основании которого модель генерирует новые признаки изображения в соответствующих регионах. Это позволяет эффективно повысить разрешение всего изображения в целом, поскольку на каждом этапе появляется всё бoльшая детализация.
Вторая инновация нейросети от Microsoft — это модуль Deep Attentional Multimodal Similarity Model (DAMSM). Используя механизм внимания, этот модуль вычисляет степень похожести сгенерированного изображения и текстового предложения, используя одновременно и информацию с уровня векторного пространства предложений, и с хорошо детализированного уровня словарных векторов. Таким образом, DAMSM обеспечивает дополнительную детализацию для функции потерь соответствия на переводе из изображения в текст при обучении генератора.
Благодаря этим двум инновациям нейросеть AttnGAN показывает значительно лучшие результаты, чем самые лучшие из традиционных систем GAN, пишут разработчики. В частности, максимальный из известных показателей inception score для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89) на более сложном наборе данных COCO.
Важность этой разработки трудно переоценить. Нейросеть AttnGAN впервые показала, что многослойная генеративно-состязательная сеть, которая относится к вниманию как к фактору обучения, способна автоматически определять условия на уровне слов для генерации отдельных частей изображения.
Научная статья опубликована 28 ноября 2017 года на сайте препринтов arXiv.org (arXiv:1711.10485v1).
Комментарии (15)

Konachan700
19.01.2018 20:49Вот давно уже интересно такое дело… Берем исходники ядра. Там есть возможность рандомного конфига. Собираем рандомный бинарь. Дизасмим. И этим учим нейросеть. Исходный код < — > дизасм. Дальше скармливаем любой бинарь ядра и… у нас есть качественный декомпилятор. Да, собрать полученное может и не выйдет без серьезного чекинга на ошибки, но понять, что к чему вполне себе можно.
Интересно, это возможно вообще?
perfect_genius
19.01.2018 21:27Между исходным кодом и бинарником шаманит компилятор так, что нейросеть связь может и не обнаружить в некоторых местах.
«Качественным декомпилятором» вы хотите заглядывать под капот любых программ, так? Зачем вам это?

jex
20.01.2018 00:06Проблема в том, что семантика всё равно потеряется. Т.е. названия функций, переменых, коменты. Ну а если всё это не учитывать — существующие методы дизасма итак неплохо работают.
ankh1989
20.01.2018 08:58Это уже больше на маленький ИИ тянет. Нейросети в их нынешнем состоянии это по сути интерполяция больших чисел: бинарники это значения по оси x, исходники это значения по оси y, нейросеть пытается найти кривую которая как можно точнее проходит возле этих пар (x, y).
Alexey2005
19.01.2018 20:56Проблема подобных сетей в том, что им нужно просто сумасшедшее количество данных для обучения. Как-то игрался с сеткой, генерирующей портреты (иконки) 16x16 пикселей, так чтобы получить более-менее приличное качество, требовалось подборка из по меньшей мере 30 000 изображений, а лучше ещё раза в два больше.
Но если у меня есть столько изображений, то смысл в генеративной нейросети в значительной мере теряется — гораздо рациональнее обучить классификатор, который просто расставит теги на этих изображениях, чтобы по запросу выводить нужное, при таком объёме материала оно наверняка найдётся.
Ну и в конечном итоге такие сети — игрушка для больших корпораций, которые способны собрать обучающую выборку в десятки, а то и сотни тысяч изображений.
Вот если бы сетка могла обучиться на 400-700 изображениях и уже показывать приемлемые результаты, это был бы совсем другой разговор. Но до этого ещё ох как далеко, если вообще возможно.Hardcoin
19.01.2018 21:56А зачем с нуля? Берете обученную большими корпорациями сеть, сбрасываете пару слоев и дообучаете на своих 400-700 изображениях. Получите вполне приемлемый результат уже сейчас.
velovich
Каждый раз, когда я читаю про нейросети, я восхищаюсь, насколько мощная система тотального контроля из всех этих инструментов будет собрана в будущем.
G1lgamesh
Кто о чём, а лысый-о расчёске. Читателям гиктаймса явно следует поменьше читать Оруэла. Того глядишь, начнём восхищаться, как в будущем можно будет по нажатию одной кнопки оживлять книги.
dimkss
А с чем именно вы несогласны?
Нейросети мощный инструмент? — TRUE.
Нейросети используются в системах слежки за подозреваемыми? — TRUE.
Если нейросети будут развиваться (а они будут), то будут ли системы слежки развиваться? — TRUE.
Статья о нейросетях? — TRUE.
Комментарий тоже :)
vassabi
может он не «несогласен», а наоборот — что это очевидные вещи, какой смысл каждый раз писать про чудо «нажал кнопку — свет появился»?
dimkss
Ну… меня все еще удивляют возможности нейросетей. На реддите вон кто то забацал программу которая заменяет лица в роликах (*всяких) на лица знаменитостей, например. Меня именно удивило, то что автор не писал ничего с нуля, а просто скомпоновал уже существующие блоки алгоритмов и данных, и все.
G1lgamesh
Вот я и говорю, «кто о чём». Проблема во второй связке. Восприятие любой достаточно мощной технологии через призму своих страхов (ведь в статье нет ничего про слежку)-имхо, несколько странно. И интересной дискуссии про генерацию изображений явно не способствует.
velovich
Странно это в отрыве от реальности
vassabi
а я радуюсь, что только отсутствие бюджета и мотивации мешает сделать такую систему уже сейчас.
А вот была бы не вялотекущая холодная война с терроризмом, а самая настоящая горячая — уже бы давно нашлись и деньги, и мощности и всенародная поддержка ново-манхэттенского проекта. Ведь спецы и теоретические наработки — давно с нами.
quantum
А кто сказал, что мешает?
tjournal.ru/63638-zhurnalist-bi-bi-si-ispytal-kitayskuyu-sistemu-gorodskogo-nablyudeniya-ego-nashli-za-7-minut