
*Все верно! Быть компилятором — это здорово!
Дело было одним замечательным воскресеным днем в Бушвике, Бруклин. В моем местном книжном магазине я наткнулась на книгу Джона Маэда “Design by Numbers”. Это была пошаговая инструкция по изучению DBN — языка программирования, созданного в конце 90-х в MIT Media Lab для визуального представления концепций компьютерного программирования.
Приведенные на первом рисунке три строки кода рисуют черную линию на белой бумаге (пример взят отсюда). Для отрисовки более сложных фигур, таких как, например, квадрат, требуется нарисовать просто больше линий (второй рисунок).

Я сразу подумала, что в 2016 году, это могло бы стать интересным проектом — создавать SVG из DBN без установки Java для выполнения исходного DBN кода.
Я решила, что для этого мне нужно написать компилятор из DBN в SVG, таким образом мой квест написания компилятора начался. Создание компилятора звучит как довольно сложный научный процесс, но я даже никогда не писала обход графа на интервью… Смогу ли я написать компилятор?

Попробуем сначала сами стать компилятором
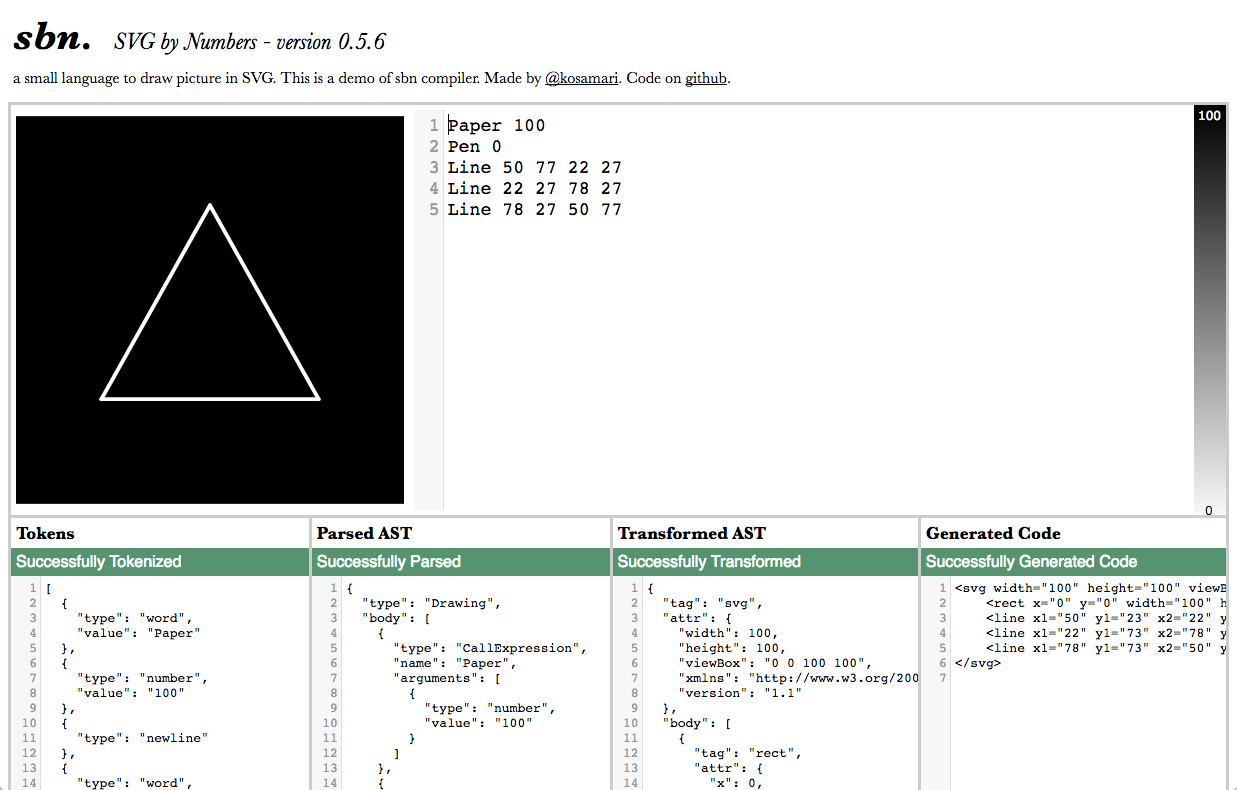
Компилятор — это механизм, который берет кусок кода и преобразует его во что-то другое. Давайте скомпилируем простой DBN код в физический рисунок.
Возьмем три DBN команды: Paper задает цвет бумаги, Pen задает цвет кисти и Line рисует линию. Цвет 100 равнозначен 100%-ному черному цвету, что есть rgb(0%, 0%, 0%) в CSS. Изображения созданные в DBN всегда находятся в градации серого. В DBN бумага всегда 100?100, ширина линии всегда 1, а сама линия задается (x, y) координатами, отсчет ведется от нижнего левого угла изображения.
Давайте остановимся на этом и попробуем сами побыть компилятором. Возьмите бумагу, ручку и попробуйте скомпилировать следующий код в рисунок.
Paper 0
Pen 100
Line 0 50 100 50
Вы нарисовали горизонтальную линию от левого края листа до правого, и она находится в центре по вертикали? Поздравляю! Вы только что стали компилятором.

Как же работает компилятор?
Давайте разберемся, что происходило в нашей голове, пока мы были компилятором.
1. Лексический анализ (Tokenization)
Первое, что мы сделали, разбили исходный код на слова по пробелам. В процессе мы условно определили примитивные типы для каждого токена, такие как “слово” или “число”.

2. Синтаксический анализ (Parsing)
Как только мы разбили фрагмент текста на токены, мы прошли по каждому из них и попытались найти взаимосвязь между ними.
В данном случае мы сгруппировали вместе набор чисел и относящееся к ним слово. Сделав это, мы стали различать определенные структуры кода.

3. Трансформация (Transformation)
После синтаксического анализа, мы трансформировали полученные структуры во что-то более подходящее под конечный результат. В нашем случае мы собираемся нарисовать изображение, значит нам нужно преобразовать наши структуры в пошаговую инструкцию, понятную человеку.

4. Генерация кода (Code Generation)
На этом этапе мы просто следуем инструкциям, которые мы сделали на предыдущем шаге подготовки к рисованию.

Именно этим занимается компилятор!
Рисунок, который мы сделали, это и есть скомпилированный результат (аналогично .exe файлу, который создается в процессе компиляции программы на C). Мы можем отправить этот рисунок любому человеку или на любое устройство (сканер, камера и т.п.) и все распознают черную линию в центре листа.
Давайте напишем компилятор
Теперь, когда мы знаем, как работает компилятор, давайте напишем еще один, но уже с использованием JavaScript. Этот компилятор будет брать DBN код и преобразовывать его в SVG.
1. Lexer function
Точно так же, как мы можем разделить предложение “У меня есть ручка” на слова [У, меня, есть, ручка], лексический анализатор может разбить представленный в виде строки код на определенные осмысленные части (токены). В DBN все токены разделены пробелами и классифицируются как “слово” или “число”.
function lexer (code) {
return code.split(/\s+/)
.filter(function (t) { return t.length > 0 })
.map(function (t) {
return isNaN(t)
? {type: 'word', value: t}
: {type: 'number', value: t}
})
}
input: "Paper 100"
output:[
{ type: "word", value: "Paper" }, { type: "number", value: 100 }
]
2. Parser function
Парсер проходит по каждому токену, собирает синтаксическую информацию и строит так называемое абстрактное синтаксическое дерево (Abstract Syntax Tree). Вы можете рассматривать AST как карту нашего кода — способ увидеть как он структурирован.
В нашем коде два синтаксических типа “NumberLiteral” и “CallExpression”. NumberLiteral означает, что значение — это число. Это число используется в качестве аргумента для CallExpression.
function parser (tokens) {
var AST = {
type: 'Drawing',
body: []
}
// Циклический перебор токенов
while (tokens.length > 0){
var current_token = tokens.shift()
// Так как числовой токен сам по себе ничего не делает,
// мы анализируем синтаксис только тогда, когда находим слово
if (current_token.type === 'word') {
switch (current_token.value) {
case 'Paper' :
var expression = {
type: 'CallExpression',
name: 'Paper',
arguments: []
}
// Если текущим токеном является CallExpression типа Paper,
// следующий токен должен быть аргументом цвета
var argument = tokens.shift()
if(argument.type === 'number') {
expression.arguments.push({ // Добавить информацию об аргументе в объект выражения
type: 'NumberLiteral',
value: argument.value
})
AST.body.push(expression) // Добавить наше выражение в АСТ
} else {
throw 'Paper command must be followed by a number.'
}
break
case 'Pen' :
...
case 'Line':
...
}
}
}
return AST
}
input: [
{ type: "word", value: "Paper" }, { type: "number", value: 100 }
]
output: {
"type": "Drawing",
"body": [{
"type": "CallExpression",
"name": "Paper",
"arguments": [{ "type": "NumberLiteral", "value": "100" }]
}]
}
3. Transformer function
Абстрактное синтаксическое дерево (AST), что мы создали на предыдущем шаге, хорошо описывает, что происходит в коде, но мы все еще не можем создать из этого SVG.
Например, команда “Paper” понятна только коду, написанному на DBN. В SVG для представления бумаги мы бы хотели использовать <rect> элемент, поэтому нам нужна функция, которая сконвертировала бы наше AST в другое AST, более подходящее для SVG.
function transformer (ast) {
var svg_ast = {
tag : 'svg',
attr: {
width: 100, height: 100, viewBox: '0 0 100 100',
xmlns: 'http://www.w3.org/2000/svg', version: '1.1'
},
body:[]
}
var pen_color = 100 // Цвет по умолчанию - черный
// Циклический перебор выражений
while (ast.body.length > 0) {
var node = ast.body.shift()
switch (node.name) {
case 'Paper' :
var paper_color = 100 - node.arguments[0].value
svg_ast.body.push({ // Добавить информацию о rect элементе в тело svg_ast
tag : 'rect',
attr : {
x: 0, y: 0,
width: 100, height:100,
fill: 'rgb(' + paper_color + '%,' + paper_color + '%,' + paper_color + '%)'
}
})
break
case 'Pen':
pen_color = 100 - node.arguments[0].value // Сохранить текущий цвет кисти в переменную `pen_color`
break
case 'Line':
...
}
}
return svg_ast
}
input: {
"type": "Drawing",
"body": [{
"type": "CallExpression",
"name": "Paper",
"arguments": [{ "type": "NumberLiteral", "value": "100" }]
}]
}
output: {
"tag": "svg",
"attr": {
"width": 100,
"height": 100,
"viewBox": "0 0 100 100",
"xmlns": "http://www.w3.org/2000/svg",
"version": "1.1"
},
"body": [{
"tag": "rect",
"attr": {
"x": 0,
"y": 0,
"width": 100,
"height": 100,
"fill": "rgb(0%, 0%, 0%)"
}
}]
}
4. Generator function
На последнем шаге компилятора вызывается функция, которая строит SVG код на основе нового AST, которое мы создали на предыдущем шаге.
function generator (svg_ast) {
// Преобразовать объкет атрибутов в строку
// { "width": 100, "height": 100 } преобразуется в 'width="100" height="100"'
function createAttrString (attr) {
return Object.keys(attr).map(function (key){
return key + '="' + attr[key] + '"'
}).join(' ')
}
// Верхним узлом всегда является <svg>. Создать строку с атрибутами для svg тэга
var svg_attr = createAttrString(svg_ast.attr)
// Для каждого элемента из тела svg_ast сгенерировать svg тэг
var elements = svg_ast.body.map(function (node) {
return '<' + node.tag + ' ' + createAttrString(node.attr) + '></' + node.tag + '>'
}).join('\n\t')
// Обернуть в открывающийся и закрывающийся svg тэг для завершения SVG кода
return '<svg '+ svg_attr +'>\n' + elements + '\n</svg>'
}
input: {
"tag": "svg",
"attr": {
"width": 100,
"height": 100,
"viewBox": "0 0 100 100",
"xmlns": "http://www.w3.org/2000/svg",
"version": "1.1"
},
"body": [{
"tag": "rect",
"attr": {
"x": 0,
"y": 0,
"width": 100,
"height": 100,
"fill": "rgb(0%, 0%, 0%)"
}
}]
}
output:
<svg width="100" height="100" viewBox="0 0 100 100" version="1.1" xmlns="http://www.w3.org/2000/svg">
<rect x="0" y="0" width="100" height="100" fill="rgb(0%, 0%, 0%)">
</rect>
</svg>
5. Соберем все вышесказанное вместе
Давайте назовем наш компилятор “sbn compiler”. Создадим sbn объект с нашими лексером, парсером, трансформатором и генератором. Добавим “compile” метод, который будет вызывать цепочку из 4 этих методов.
Теперь мы можем передать строку кода методу компиляции и получить SVG.
var sbn = {}
sbn.VERSION = '0.0.1'
sbn.lexer = lexer
sbn.parser = parser
sbn.transformer = transformer
sbn.generator = generator
sbn.compile = function (code) {
return this.generator(this.transformer(this.parser(this.lexer(code))))
}
// Вызвать sbn компилятор
var code = 'Paper 0 Pen 100 Line 0 50 100 50'
var svg = sbn.compile(code)
document.body.innerHTML = svg
Я сделала интерактивное демо, в котором можно посмотреть результат работы компилятора на каждом их шагов. Код для sbn компилятора можно скачать на github. На данный момент я работаю над расширением функционала компилятора. Если вы хотите увидеть только базовый компилятор, собственно тот, что создавался в этой статье, вы можете найти его здесь.
Должен ли компилятор использовать рекурсию, обход и т.д.?
Да, все эти техники безусловно прекрасно подходят для создания компилятора, но это совершенно не значит, что вы сразу должны применить их в своем компиляторе.
Я начала писать свой компилятор, используя лишь небольшой набор команд DBN. Постепенно я стала усложнять функциональность, и сейчас собираюсь добавить в компилятор использование переменных, блоков и циклов. Это конечно хорошо иметь все эти конструкции, но не обязательно применять их с самого начала.
Писать компиляторы это здорово
Что вы можете делать, если вы умеете писать компилятор? Быть может, вам захочется написать свою новую версию JavaScript на испанском… Как насчет EspanolScript?
// ES (espanol script)
funcion () {
si (verdadero) {
return «?Hola!»
}
}
Уже есть те, кто написали свой язык, используя Emoji (Emojicode) или цветные изображения (Piet). Возможности безграничны!
Обучение в процессе создания компилятора
Создавать компилятор было весело, и я многому научилась, касаемо разработки ПО. Перечислю всего несколько вещей, которым я научилась в процессе написания компилятора.

1. Вполне нормально чего-то не знать
Как и нашему лексическому анализатору, вам не нужно все знать с самого начала. Если вы не совсем понимаете часть какого-то кода или технологии, это нормально перенести работу с этим на следующий шаг. Не стоит нервничать, рано или поздно вы разберетесь в этом!
2. Уделите внимание тексту ваших сообщений об ошибках
Роль парсера — четко следовать инструкциям и проверять, написано ли все так, как сказано в правилах. Да, ошибки случаются часто. Когда это происходит, попробуйте отправлять информативное, дружеское сообщение об ошибке. Легко сказать — “Так оно не работает” (“ILLEGAL Token” или “undefined is not a function” в JavaScript), но вместо этого попробуйте предоставить пользователю как можно больше полезной информации.
Это также относится к командной коммуникации. Когда кто-то застрял со своим таском, вместо того, чтобы сказать ”Да это не работает”, можно начать говорить “Я бы поискал информацию в google по таким ключевым словам как…” или “Я рекомендую почитать такую-то документацию”. Вам не нужно брать на себя работу другого человека, но вы определенно можете помочь ему сделать его работу лучше и быстрее всего лишь подкинув ему свежую идею.
Язык программирования Elm использует этот подход в выводе сообщений об ошибках, где пользователю предлагаются варианты решения его проблемы (“Maybe you want to try this?”).
3. Контекст наше все
И наконец, точно так же, как наш трансформатор превратил один тип AST в другой, более подходящий для конечного результата, все в программировании зависит от контекста.
Нет ни одного совершенно идеального решения. Не делайте что-то, только потому, что сейчас это модно, или потому, что вы уже делали это раньше, подумайте сначала о контексте задачи. Вещи, которые работают для одного пользователя, могут быть совершенно ужасны для другого.
Поэтому цените работу “трансформаторов”, вы вполне возможно знаете такого в своей команде, человека, который хорошо завершает, начатую кем-то работу, или делает рефакторинг. Он по сути не создает новый код, но ведь результат его работы чертовски важен для конечного качественного продукта.
Надеюсь, вам понравилась эта статья и что я убедила вас, как это здорово писать компиляторы и самому быть компилятором!
Это перевод статьи Mariko Kosaka, которая является частью ее выступления на JSConf Colombia 2016 в Медельине, Колумбия. Если вы хотите узнать больше об этом, вы можете найти слайды здесь и оригинал статьи здесь.
Комментарии (18)

vlreshet
07.03.2018 00:35Кто нибудь может «на пальцах» объяснить как происходит токенизация в языках где пробелы не обязательны? (x = 7 и x=7 это одно и то же почти во всех языках). В своё время пытался написать свой язык (чисто интереса ради), и сильно споткнулся как раз таки на этом моменте. А когда пытался реализовать строки, да при этом не сломаться на коде вроде «var x = „var “;» — то вообще засыпался. Пытался сделать что-то вроде автомата состояний, но не получилось. А как правильно?

1vanK
07.03.2018 01:07Я только слегка этой темы касался, поэтому могу фигню сморозить. Но я так понимаю — сперва исходник делится на лексемы, а потом токенизация на основе этого (хотя часто лекса и токен одно и тоже). Т.е. просматривается строка посимвольно: видим символ '=' или пробел, значит предыдущая лексема кончилась (так как проблел или = не может быть частью имени переменной), и начинаем собирать символы следующей лексемы.
github.com/1vanK/RecursiveDescentParser
А вообще перерывами читаю книгу linux-doc.ru/programming/assembler/book/compilers.pdf. Кажется достойной.
AxisPod
07.03.2018 08:08Аааа, почему же просто не сказать Dragon Book 2? Книга действительно достойная, главное не пытаться читать русский перевод первого издания, оно ужасно. 2я уже хороша.
alenakhineika Автор
07.03.2018 01:17Могу предположить, что для такой задачи придется сканировать код не один раз. Исходная строка должна анализироваться символ за символом и сравниваться с ключевыми словами (такими как например var, function), специальными символами (+, =, ;) и т.д., это поможет выявить структуры кода. Причем если мы обнаружили функцию, например, мы можем уже предположить что где-то далее по коду могут идти параметры и тело функции. В конечном счете, то, что останется, можно будет рассматривать как литералы.
vepanimas
07.03.2018 01:38Предположим, что мы разбираем
myVar=7. На каждой итерации лексера читаем один текущий символ, разбор реализуем самым простым образом с помощью switch'а по нему. Лексер умеет делать Read(), читая следующий символ из ввода и изменяя свое состояние, и Peek(), «подглядывая» следующий символ за текущим.
На первом шаге увидели, что текущий символ —m. Попадаем в default ветку switch'a. Вызываем соответствующий метод, например,ReadIdentifier, который читает символы до тех пор, пока они являются допустимыми для идентификатора. Как только встретили=, проверяем, что уже прочитанные символы не являются ключевым словом и возвращаем новый токен{ type: IDENT, literal: 'myVar' }. Переходим на следующую итерацию лексера, которая вновь читает текущий символ, получим{ type: EQ, literal: '=' }и т.д.
Это достаточно упрощенный пример, тем не менее отражающий суть.
Стоит заметить, что в лексерах можно встретить метод SkipWhitespaces, который вообще все пробелы до первого значащего символа опускает, как видно из названия. Если это не какой-нибудь абстрактный Python, то для разбора они не имеют значения. Думаю, что Вас смутило наличие split'a по пробелам в самом начале статьи, но это встречается, скорее, в таких школьных примерах для изучения, чем в реальных компиляторах.

zirix
07.03.2018 02:34Посимвольно пройдитесь по тексту и разбейте его на «слова». Слово может состоять только из букв+цифр ([a-zA-Z0-9]+) или только из спец символов (=,.\). Если встретился недопустимый для текущего слова символ ("=" после X или пробел), то считайте, что началось новое слово. Пробелы пропускайте.
Если встречаете символ ", то отключайте разбивку до следующего символа ".
В результате var x !=«var »; будет разбит на:
var
x
!=
«var »
;
Лексический анализ
Абстрактное синтаксическое дерево
AxisPod
07.03.2018 08:13+1Машина состояний. делал, работает отлично, главное правильно расписать все возможные переходы по состояниям правильно. В вашем случае без проблем всё обработается. Изначальное состояние — ожидание ключевого слова, далее соответственно будет ожидание имени переменной, далее спец-символа — знака равно, далее ожидание литерала. по знаку кавычки определяем, что это строковой литерал и идём далее до следующего знака кавычки.
Естественно переходов будем много, рисовал здоровенную диаграмму до того как начать прям вот реализовывать.

ammaaim
07.03.2018 15:13Там все очень просто — вы смотрите начальный символ токена и для него вызываете соответствующее правило — так для токена начинающегося с цифры вызывается правило обработки чисел, для токена начинающегося с буквы или прочерка вызывается правило считывания имени. Как только правило встретит неподходящий символ (например пробел или, в вашем случае — знак равенства) оно свернет все что успело выбрать из текста в соответствующий ему (правилу) нетерминал и завершится. Далее лексер исходя из того какой следующий символ (например мы встретили знак равенства) будет искать подходящее правило для него. И это будет правило «оператор». Оно проверит просто ли там равно или == или => итд — то есть все варианты оператора начинающегося с =. И свернет уже его)

domix32
07.03.2018 10:36+4Жаль Марико не различает интерпретацию и компиляцию

tyomitch
07.03.2018 11:21Это в том числе потому, что различие между ними в реальной жизни стирается.
Вот V8 — компилятор или интерпретатор?Zenitchik
07.03.2018 15:30«Интерпретатор компилирующего типа» — так подобное называли в книгах 80-х. Это когда код компилируется, но результат компиляции не сохраняется для повторного использования и удаляется после завершения работы.
domix32
07.03.2018 20:18На выходе в исполнение уходит некоторый байткот с оптимизациями, поэтому JIT-компиляция. В данном случае преобразования кода во что-то совсем низкоуровневое и более близкое к железу не происходит.

koldoon
Спасибо за перевод! В дополнение к статье разрешите я оставлю здесь еще вот этот супермаленький проектик, где аналогичным образом на js очень хорошо «на пальцах» объясняется разбор lisp-подобного синтаксиса.
alenakhineika Автор
да, отличный ресурс! именно с него начинала изучать принципы работы компиляторов.