
В нашей прошлой статье мы рассказали о том как строили централизованный конвейер, но описали его довольно поверхностно. Это породило массу вопросов, которые мы не можем оставить без ответа. Здесь мы попробуем максимально глубоко залезть «под капот» и рассказать, как работает наш централизованный конвейер.

Я думаю, что лучше всего описать весь процесс с момента начала работы над задачей и до запуска сделанных изменений в эксплуатацию. И по ходу повествования постараюсь ответить на все вопросы, оставшиеся без ответа в прошлой статье.
Сразу оговорюсь, что наши команды разработчиков пользуются полной свободой при построении процессов, поэтому нельзя сказать, что все команды работают в точном соответствии с приведенным ниже описанием. Хотя, конечно, набор инструментов накладывает определенные ограничения. Итак, к делу.
В банке основной системой отслеживания ошибок является JIRA. В ней регистрируются задачи на все доработки, изменения и прочее. Разработчики, приступая к задаче, «срезают» ветку с основного репозитория и дальше разрабатывают уже в ней. Ниже пример довольно типовой задачи.

Закончив с задачей, разработчик заводит в Bitbucket pull request на внесение своих изменений в основную ветку. И тут он впервые сталкивается с проявлением работы конвейера: pull request запускает процесс автоматической ревизии кода.
Ревизия у нас выполняется с помощью SonarQube, интегрированного в конвейер через плагины Sonar for Bamboo и Sonar for Bitbucket. При регистрации pull request’а в Bamboo автоматически запускается план сборки, анализирующий ветку, которую хотят добавить. Результат анализа выводится прямо в pull request вот в таком виде:
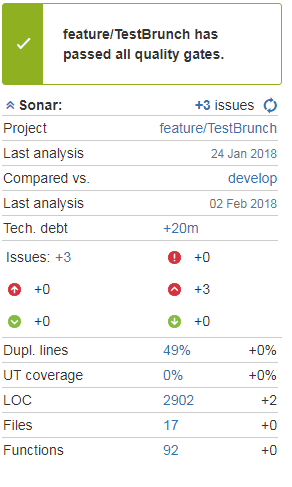
В форме pull request’а сразу видно, какие новые замечания содержит код, их критичность, категория и т.д. Сами замечания можно посмотреть непосредственно из формы pull request’а, достаточно перейти на вкладку Diff.
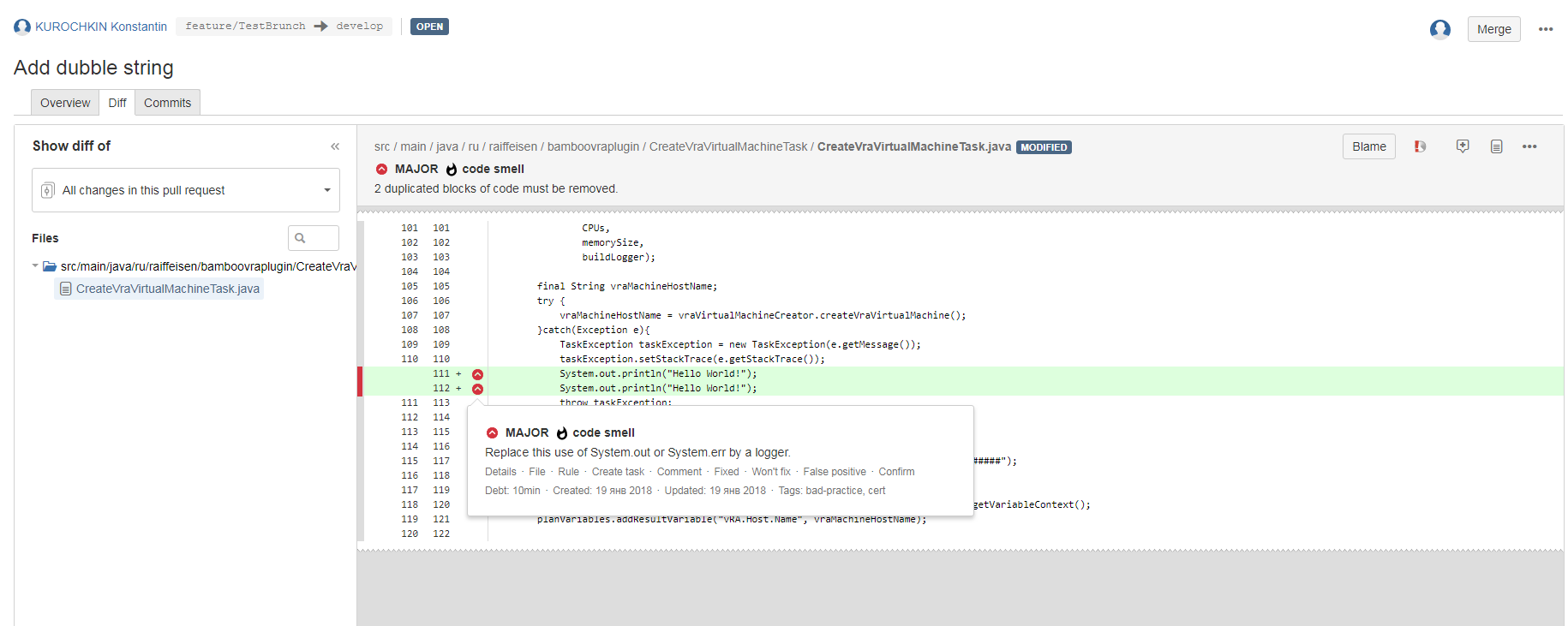
Таким образом, процесс ревизии кода существенно ускоряется и облегчается, плюс довольно большое количество настроек позволяет очень гибко регулировать поведение конвейера как при проведении ревизии, так и по её результатам. Допустим, ревизия завершилась успешно, и мы можем двигаться дальше.
Следующим этапом идет сборка из нашего кода чего-то нужного и полезного. Сборка запускается в Bamboo самыми разными способами. Можно вручную, можно автоматически по факту слияния или коммита в репозитории, по расписанию, или вообще через вызов Bamboo Rest API. Для простоты и наглядности рассмотрим самый банальный вариант — запуск сборки руками. Для этого надо зайти в Bamboo, выбрать нужный план и нажать старт.
После запуска по указанным в плане зависимостям подбирается подходящий агент, на котором будет выполняться сборка. На данный момент у нас есть 30 Windows-агентов, 20 Linux, 2 iOS-агента, и ещё 5 мы держим под эксперименты и пилоты. Половина агентов развернуты в нашем внутреннем облаке, но об этом чуть позже. Такое количество позволяет нам бесперебойно обслуживать более 500 активных сборочных планов и примерно пару сотен проектов развёртывания.
Но вернемся к нашему сборочному плану. Конвейер поддерживает все распространенные инструменты сборки, перечень которых может быть расширен с помощью плагинов.
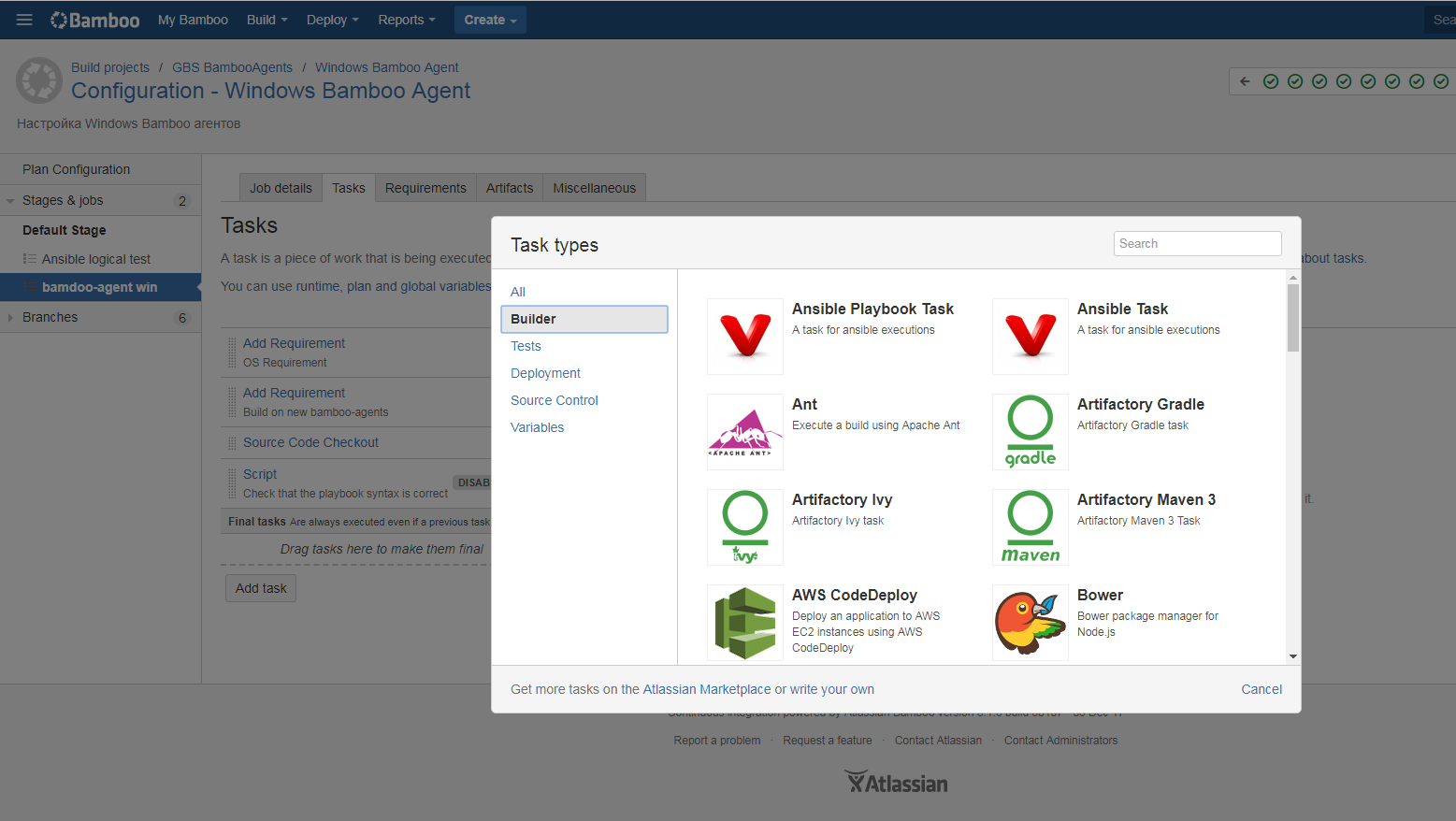
Сама сборка происходит стандартно: код сохраняется на агент, там же компилируется в бинарники и пакуется в соответствующие пакеты. Опционально подключается любое тестирование, вплоть до модульного и интеграционного. По окончании сборки мы получаем красивый отчет, содержащий массу полезной информации о том, какие коммиты вошли в сборку, какие тесты выполнялись и с каким результатом, какие задачи вошли в сборку, и т.д.
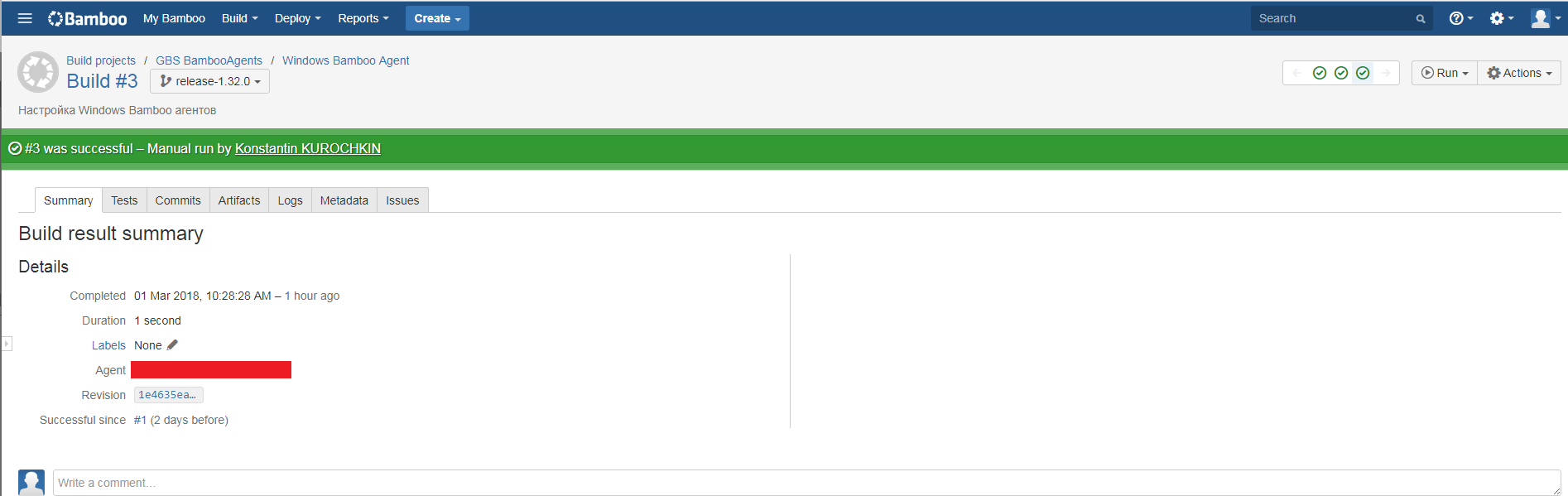
Сформированный в результате сборки артефакт автоматически размещается в Artifactory.

С одной стороны, эта система используется как централизованное хранилище собранных нами артефактов, а с другой — через Artifactory мы проксируем большинство внешних репозиториев, что существенно ускоряет процесс сборки и снижает нагрузку на сеть. При сборке мы за всеми зависимостями обращаемся к Artifactory, а не выкачиваем их из внешних репозиториев, что очень хорошо сказывается на скорости и стабильности работы сборочных планов.
Разместив пакет в Artifactory, мы можем делать с ним всё, что угодно, в том числе и устанавливать на нужную нам среду. Как правило, команды используют три среды для создания ПО. Dev-среда — среда разработки, используется для разработки и отладки. Test-среда — используется для функционального и интеграционного тестирования приложений. Preview-среда — используется для приемки функциональности заказчиком и нагрузочного тестирования; как правило, она ближе всего к условиям рабочей эксплуатации. У некоторых команд еще принято перед установкой в production проводить установку на вчерашнюю копию рабочей среды, что тоже помогает выявлять проблемы.
Команды совместно с поддержкой решают, кто и в какие среды устанавливает, и тут у нас используются практически все варианты. Есть команды, у которых за развёртывание отвечают только разработчики (привет, DevOps!); есть команды, где разработчики обновляют только dev и test, а поддержка — preview и prod. В некоторых командах вообще есть специально выделенные люди, занимающиеся установкой во все среды.
Развёртываемый проект представляет из себя набор сред, связанных с определенным планом сборки.
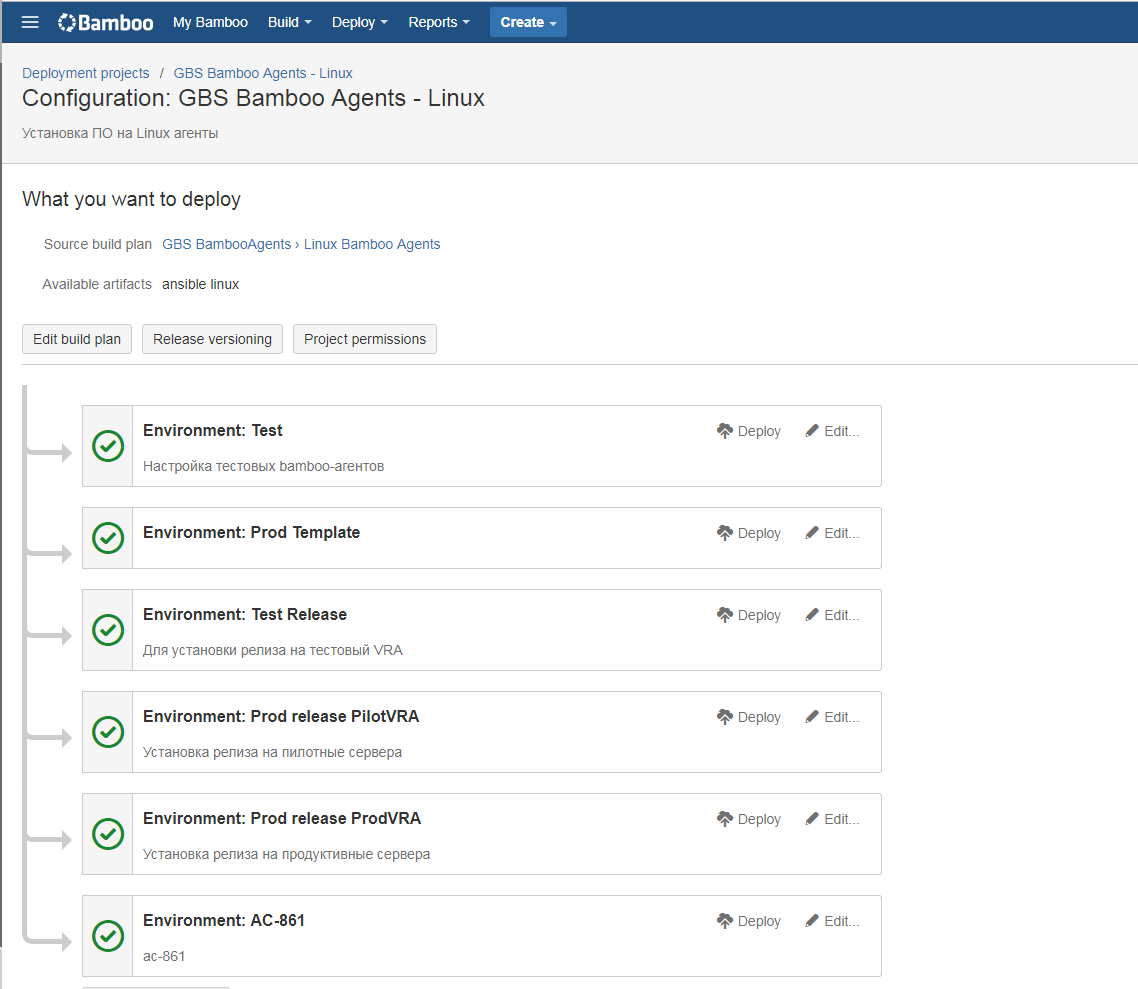
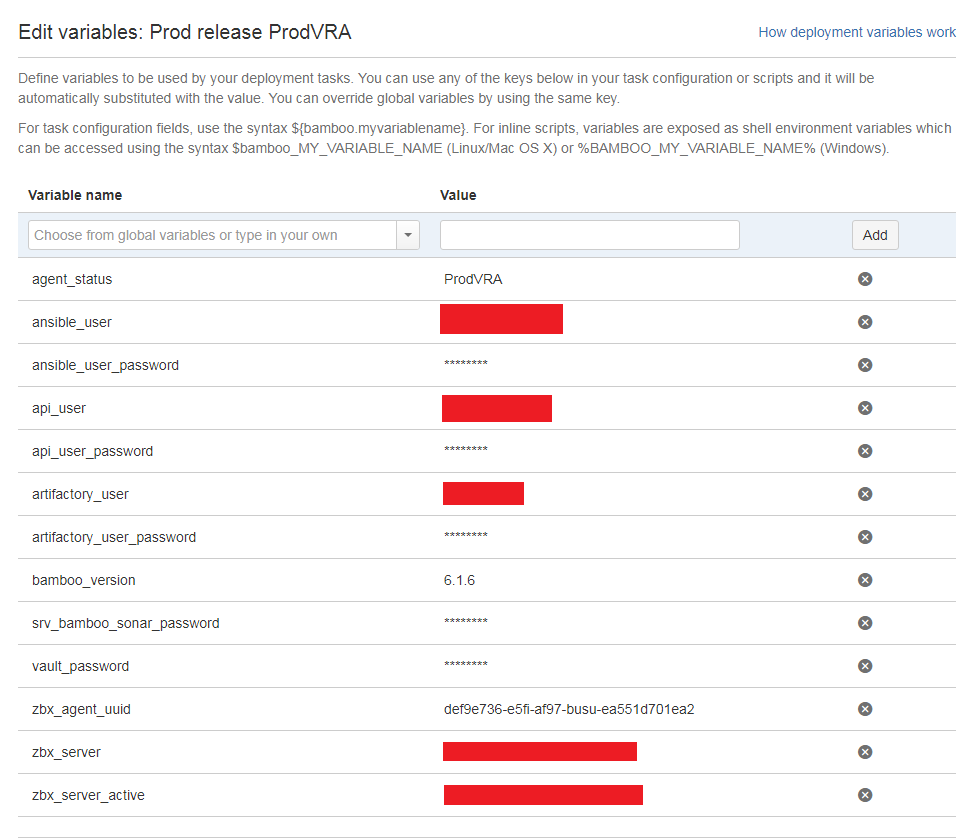
Среда содержит средозависимые переменные, настроенные для каждой среды отдельно. В комментариях к прошлой статье был вопрос о том, как мы храним пароли. Как видно на скриншоте, мы храним их в параметрах планов сборки и развёртывания. В Bamboo реализован механизм шифрования паролей: достаточно в имени переменной использовать слово password, и она будет зашифрована. После сохранения, значение такой переменной уже невозможно будет просмотреть через интерфейс или увидеть в логах выполнения, оно везде будет «замаскировано» звездочками.
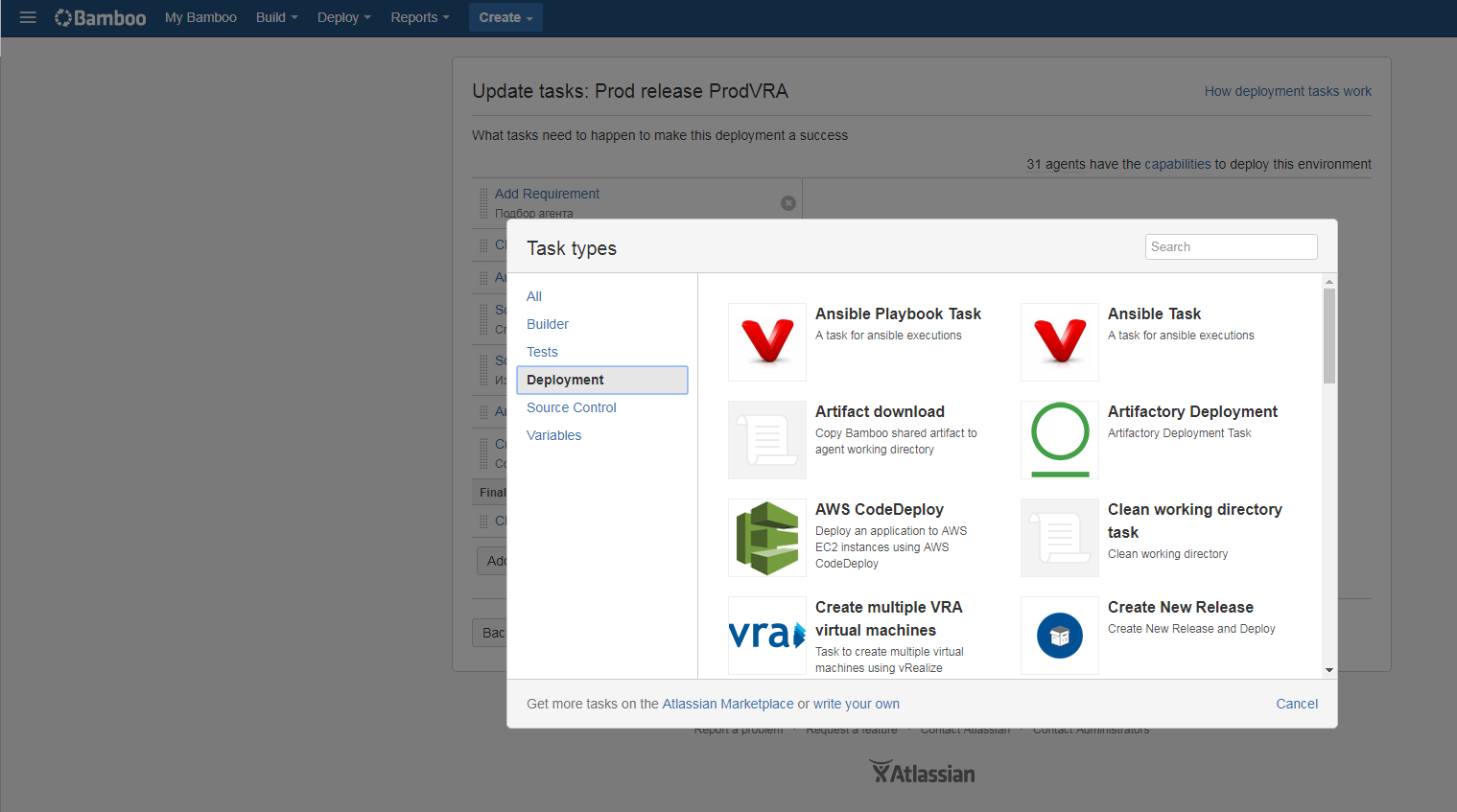
Помимо переменных, среда содержит исполняемую часть, реализованную в виде задач, которые описывают набор действий, необходимых для установки приложения на целевой хост или хосты. Список поддерживает все стандартные инструменты и может быть расширен с помощью плагинов.
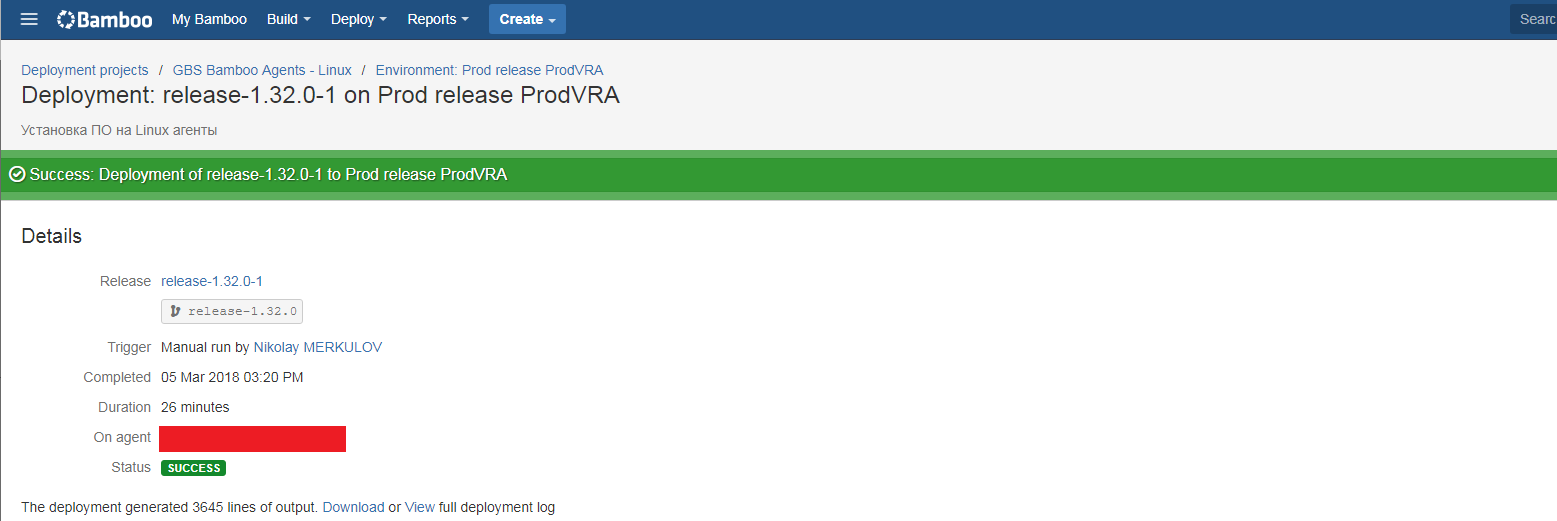
По результатам выполнения мы также получаем подробный лог выполнения, с уровнями вложенности и перекрестными ссылками на задачи, коммиты, сборки и т.д.
Про установки в production, наверное, стоит поговорить отдельно. В банке есть процесс регистрации изменений (CM), согласно которому все изменения в production должны быть заранее объявлены и согласованы. Для регистрации изменений команда заводит change management request (CRQ) не менее чем за три дня до установки. К этому CRQ прикладываются всевозможные отчеты по тестированию, формируется внушительный список согласующих. Процесс достаточно медленный и громоздкий… Но мы же развеиваем мифы об IT в банках
У нас есть команды, которые совместно с бизнесом и поддержкой решили, что делают всё настолько хорошо, что готовы вносить в production любые изменения и в любое время, и это не приведет к плачевным последствиям. Специально для таких команд был придуман процесс упрощенной регистрации и согласования изменений в production-системе, в рамках которого можно в любое время вносить изменения в production, а регистрировать CRQ уже по факту проведенных работ. Но какой же это CI/CD, если надо какие-то заявки заводить вручную… Поэтому мы написали собственный плагин для Bamboo, позволяющий автоматически регистрировать CRQ, который встраивается в план развёртывания.
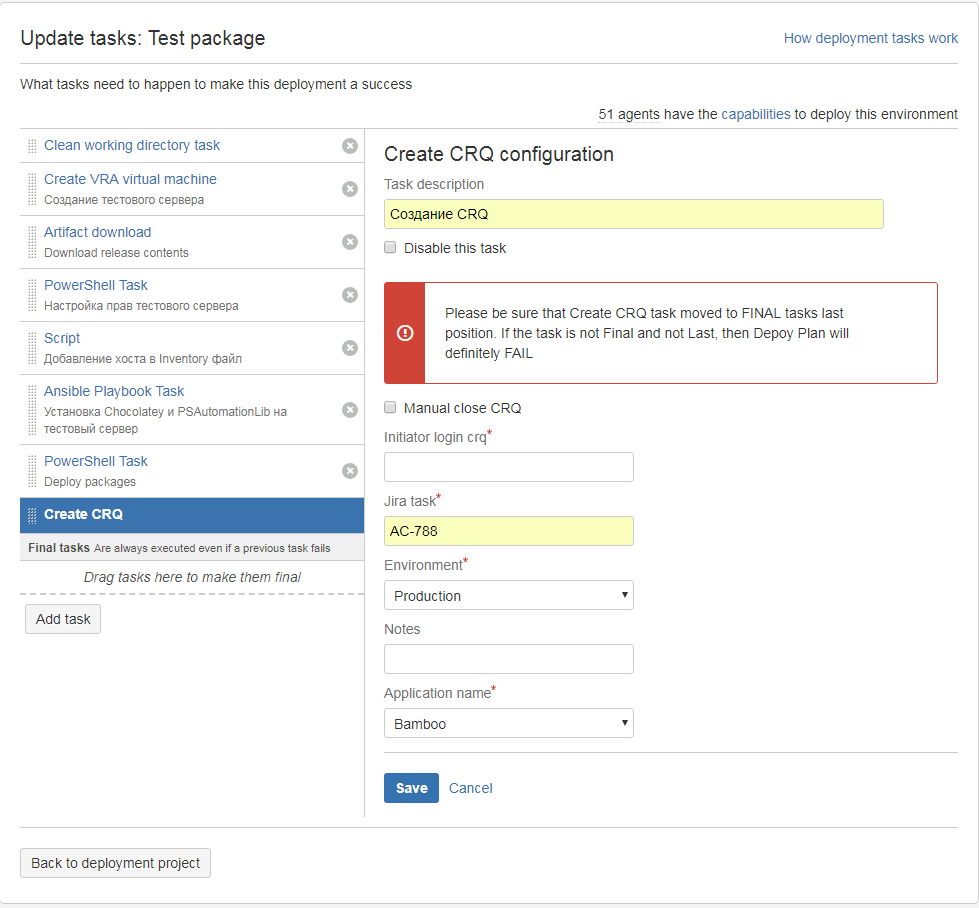
Теперь весь процесс регистрации и согласования изменений занимает несколько минут и не требует ручного вмешательства. К слову сказать, команд, работающих по этому новому процессу, у нас уже больше десятка, и их количество неуклонно растет. Так что и в таких громоздких, консервативных организациях, как банк, можно успешно внедрять передовые практики из IT-сферы.
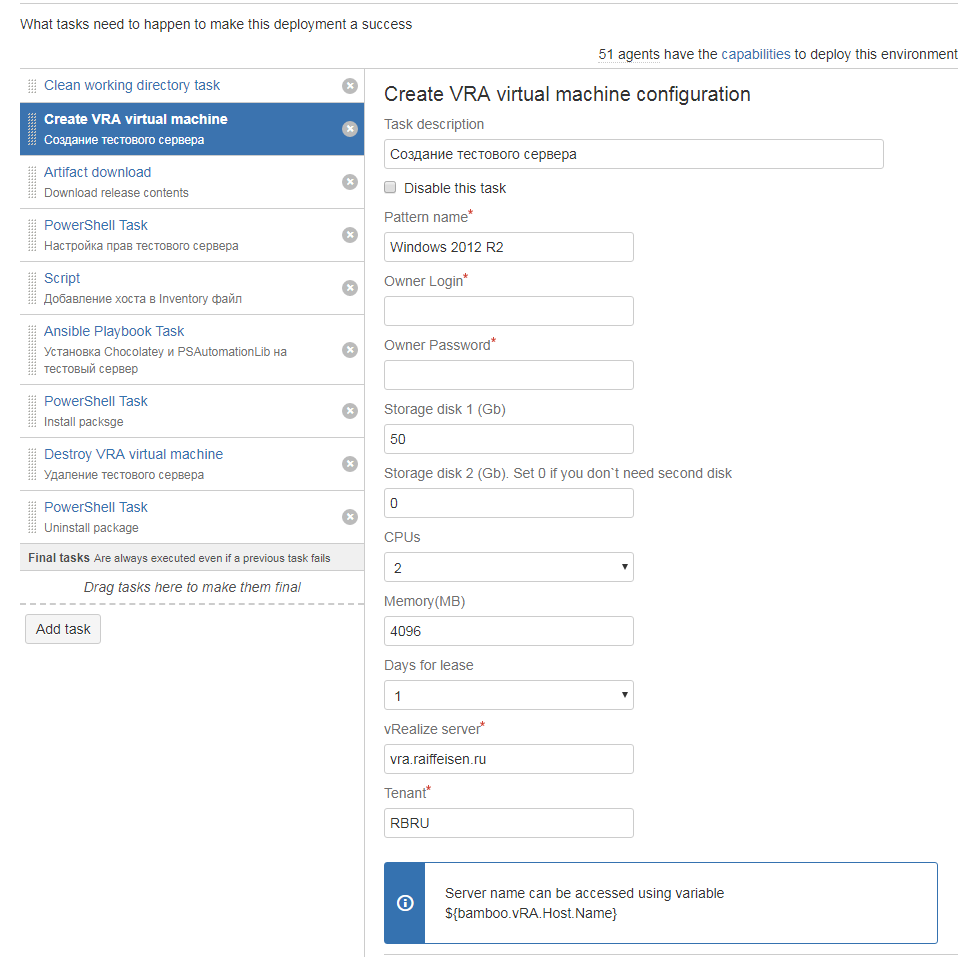
В современных реалиях, рассказывая о процессе развёртывания, нельзя обойти вниманием такую вещь, как облака. Как мы уже писали, что у нас есть внутреннее облако на базе VMWare vRealize. Оно используется как в непромышленных средах, так и в production. Облако мы тоже интегрировали в конвейер с помощью еще одного собственного плагина. Теперь через Bamboo мы можем создавать или удалять серверы в облаке.
Например, упомянутые выше серверы под Bamboo-агенты мы пересоздаем в облаке каждые две недели, просто запустив план развёртывания, который создает нужное количество серверов, устанавливает на них всё необходимое ПО, регистрирует в системе мониторинга и т.д. На эту операцию уходит порядка двух часов, да и то лишь потому, что устанавливается более сотни приложений.
Таким образом, благодаря коробочным интеграциям и небольшой кастомизации, мы смогли построить CI/CD-конвейер, способный решить все поставленные задачи. Но ничто не стоит на месте. Сейчас мы (как и всё прогрессивное человечество) активно движемся в сторону интеграции конвейера с инструментами chatops, использования контейнеров и автоматизации процессов, связанных с самим конвейером.
В комментариях к прошлой статье задали ещё ряд вопросов, на наш взгляд, не имеющих отношения ни к CI/CD, ни к конвейеру. Так что ответим на них в формате «вопрос-ответ». Вероятно, ответы покажутся вам однообразными. Но в банке более 700 приложений написанных в разное время, под разные ОС и с использованием разных технологий, поэтому дать однозначный ответ невозможно, в большинстве случаев всё определяется приложением и его командой.
Какие схемы развёртывания используются? (green/blue, rolling, canary и т.д.). А если надо откатиться?
Зависит от конкретного приложения. Насколько я знаю, точно есть green/blue и rolling, насчет остальных не уверен. Команды сами выбирают оптимальный вариант развёртывания. Если надо откатиться и это возможно, то откатываемся.
Как и кем принимается решение об успешном развёртывании? На основании каких параметров?
Не совсем понятно, о чем речь. Если о самом процессе развёртывания, то решение принимает Bamboo План отработал без ошибок — хорошо, не отработал — ошибка. Если же вопрос про функциональную составляющую устанавливаемых изменений, то решение принимают бизнес-заказчики в ходе smoke-тестирования после установки.
Что делать, если нагрузка увеличивается? Легко ли добавить больше серверов, чтобы удержать нагрузку? Если ли автомасштабирование?
Зависит от приложения и еще очень многих и многих факторов, как и всегда, когда дело касается нагрузки. Автомасштабирование не используется.
Каждое новое развёртывание выполняется на вновь созданные серверы или на те же самые?
Зависит от приложения. Наша команда пересоздает серверы каждые две недели, и развёртываем только на новые. Другие команды развёртывают всегда на одни и те же серверы. Команды сами выбирают подход.
Что с патчами на операционную систему?
Зависит от приложения, ОС и обновления. Но, в итоге, все критичные исправления у нас установлены и уязвимостей нет.
А что с мониторингом и метриками приложений и системы (OS)?
Тема мониторинга заслуживает отдельной большой статьи, которую, возможно, напишут наши специалисты, занимающиеся мониторингом. Я же могу сказать, что мониторинг есть, алерты работают, инциденты регистрируются и обрабатываются, часть обработки автоматизирована.
Что используете для балансировки нагрузки между копиями приложений? nginx/haproxy/etc?
Зависит от приложения Есть и nginx, и haproxy, и NLB, и железная Cisco.
Я думаю, что лучше всего описать весь процесс с момента начала работы над задачей и до запуска сделанных изменений в эксплуатацию. И по ходу повествования постараюсь ответить на все вопросы, оставшиеся без ответа в прошлой статье.
Сразу оговорюсь, что наши команды разработчиков пользуются полной свободой при построении процессов, поэтому нельзя сказать, что все команды работают в точном соответствии с приведенным ниже описанием. Хотя, конечно, набор инструментов накладывает определенные ограничения. Итак, к делу.
В банке основной системой отслеживания ошибок является JIRA. В ней регистрируются задачи на все доработки, изменения и прочее. Разработчики, приступая к задаче, «срезают» ветку с основного репозитория и дальше разрабатывают уже в ней. Ниже пример довольно типовой задачи.
Закончив с задачей, разработчик заводит в Bitbucket pull request на внесение своих изменений в основную ветку. И тут он впервые сталкивается с проявлением работы конвейера: pull request запускает процесс автоматической ревизии кода.
Ревизия у нас выполняется с помощью SonarQube, интегрированного в конвейер через плагины Sonar for Bamboo и Sonar for Bitbucket. При регистрации pull request’а в Bamboo автоматически запускается план сборки, анализирующий ветку, которую хотят добавить. Результат анализа выводится прямо в pull request вот в таком виде:
В форме pull request’а сразу видно, какие новые замечания содержит код, их критичность, категория и т.д. Сами замечания можно посмотреть непосредственно из формы pull request’а, достаточно перейти на вкладку Diff.
Таким образом, процесс ревизии кода существенно ускоряется и облегчается, плюс довольно большое количество настроек позволяет очень гибко регулировать поведение конвейера как при проведении ревизии, так и по её результатам. Допустим, ревизия завершилась успешно, и мы можем двигаться дальше.
Следующим этапом идет сборка из нашего кода чего-то нужного и полезного. Сборка запускается в Bamboo самыми разными способами. Можно вручную, можно автоматически по факту слияния или коммита в репозитории, по расписанию, или вообще через вызов Bamboo Rest API. Для простоты и наглядности рассмотрим самый банальный вариант — запуск сборки руками. Для этого надо зайти в Bamboo, выбрать нужный план и нажать старт.
После запуска по указанным в плане зависимостям подбирается подходящий агент, на котором будет выполняться сборка. На данный момент у нас есть 30 Windows-агентов, 20 Linux, 2 iOS-агента, и ещё 5 мы держим под эксперименты и пилоты. Половина агентов развернуты в нашем внутреннем облаке, но об этом чуть позже. Такое количество позволяет нам бесперебойно обслуживать более 500 активных сборочных планов и примерно пару сотен проектов развёртывания.
Но вернемся к нашему сборочному плану. Конвейер поддерживает все распространенные инструменты сборки, перечень которых может быть расширен с помощью плагинов.
Сама сборка происходит стандартно: код сохраняется на агент, там же компилируется в бинарники и пакуется в соответствующие пакеты. Опционально подключается любое тестирование, вплоть до модульного и интеграционного. По окончании сборки мы получаем красивый отчет, содержащий массу полезной информации о том, какие коммиты вошли в сборку, какие тесты выполнялись и с каким результатом, какие задачи вошли в сборку, и т.д.
Сформированный в результате сборки артефакт автоматически размещается в Artifactory.
С одной стороны, эта система используется как централизованное хранилище собранных нами артефактов, а с другой — через Artifactory мы проксируем большинство внешних репозиториев, что существенно ускоряет процесс сборки и снижает нагрузку на сеть. При сборке мы за всеми зависимостями обращаемся к Artifactory, а не выкачиваем их из внешних репозиториев, что очень хорошо сказывается на скорости и стабильности работы сборочных планов.
Разместив пакет в Artifactory, мы можем делать с ним всё, что угодно, в том числе и устанавливать на нужную нам среду. Как правило, команды используют три среды для создания ПО. Dev-среда — среда разработки, используется для разработки и отладки. Test-среда — используется для функционального и интеграционного тестирования приложений. Preview-среда — используется для приемки функциональности заказчиком и нагрузочного тестирования; как правило, она ближе всего к условиям рабочей эксплуатации. У некоторых команд еще принято перед установкой в production проводить установку на вчерашнюю копию рабочей среды, что тоже помогает выявлять проблемы.
Команды совместно с поддержкой решают, кто и в какие среды устанавливает, и тут у нас используются практически все варианты. Есть команды, у которых за развёртывание отвечают только разработчики (привет, DevOps!); есть команды, где разработчики обновляют только dev и test, а поддержка — preview и prod. В некоторых командах вообще есть специально выделенные люди, занимающиеся установкой во все среды.
Развёртываемый проект представляет из себя набор сред, связанных с определенным планом сборки.
Среда содержит средозависимые переменные, настроенные для каждой среды отдельно. В комментариях к прошлой статье был вопрос о том, как мы храним пароли. Как видно на скриншоте, мы храним их в параметрах планов сборки и развёртывания. В Bamboo реализован механизм шифрования паролей: достаточно в имени переменной использовать слово password, и она будет зашифрована. После сохранения, значение такой переменной уже невозможно будет просмотреть через интерфейс или увидеть в логах выполнения, оно везде будет «замаскировано» звездочками.
Помимо переменных, среда содержит исполняемую часть, реализованную в виде задач, которые описывают набор действий, необходимых для установки приложения на целевой хост или хосты. Список поддерживает все стандартные инструменты и может быть расширен с помощью плагинов.
По результатам выполнения мы также получаем подробный лог выполнения, с уровнями вложенности и перекрестными ссылками на задачи, коммиты, сборки и т.д.
Про установки в production, наверное, стоит поговорить отдельно. В банке есть процесс регистрации изменений (CM), согласно которому все изменения в production должны быть заранее объявлены и согласованы. Для регистрации изменений команда заводит change management request (CRQ) не менее чем за три дня до установки. К этому CRQ прикладываются всевозможные отчеты по тестированию, формируется внушительный список согласующих. Процесс достаточно медленный и громоздкий… Но мы же развеиваем мифы об IT в банках
У нас есть команды, которые совместно с бизнесом и поддержкой решили, что делают всё настолько хорошо, что готовы вносить в production любые изменения и в любое время, и это не приведет к плачевным последствиям. Специально для таких команд был придуман процесс упрощенной регистрации и согласования изменений в production-системе, в рамках которого можно в любое время вносить изменения в production, а регистрировать CRQ уже по факту проведенных работ. Но какой же это CI/CD, если надо какие-то заявки заводить вручную… Поэтому мы написали собственный плагин для Bamboo, позволяющий автоматически регистрировать CRQ, который встраивается в план развёртывания.
Теперь весь процесс регистрации и согласования изменений занимает несколько минут и не требует ручного вмешательства. К слову сказать, команд, работающих по этому новому процессу, у нас уже больше десятка, и их количество неуклонно растет. Так что и в таких громоздких, консервативных организациях, как банк, можно успешно внедрять передовые практики из IT-сферы.
В современных реалиях, рассказывая о процессе развёртывания, нельзя обойти вниманием такую вещь, как облака. Как мы уже писали, что у нас есть внутреннее облако на базе VMWare vRealize. Оно используется как в непромышленных средах, так и в production. Облако мы тоже интегрировали в конвейер с помощью еще одного собственного плагина. Теперь через Bamboo мы можем создавать или удалять серверы в облаке.
Например, упомянутые выше серверы под Bamboo-агенты мы пересоздаем в облаке каждые две недели, просто запустив план развёртывания, который создает нужное количество серверов, устанавливает на них всё необходимое ПО, регистрирует в системе мониторинга и т.д. На эту операцию уходит порядка двух часов, да и то лишь потому, что устанавливается более сотни приложений.
Таким образом, благодаря коробочным интеграциям и небольшой кастомизации, мы смогли построить CI/CD-конвейер, способный решить все поставленные задачи. Но ничто не стоит на месте. Сейчас мы (как и всё прогрессивное человечество) активно движемся в сторону интеграции конвейера с инструментами chatops, использования контейнеров и автоматизации процессов, связанных с самим конвейером.
В комментариях к прошлой статье задали ещё ряд вопросов, на наш взгляд, не имеющих отношения ни к CI/CD, ни к конвейеру. Так что ответим на них в формате «вопрос-ответ». Вероятно, ответы покажутся вам однообразными. Но в банке более 700 приложений написанных в разное время, под разные ОС и с использованием разных технологий, поэтому дать однозначный ответ невозможно, в большинстве случаев всё определяется приложением и его командой.
Какие схемы развёртывания используются? (green/blue, rolling, canary и т.д.). А если надо откатиться?
Зависит от конкретного приложения. Насколько я знаю, точно есть green/blue и rolling, насчет остальных не уверен. Команды сами выбирают оптимальный вариант развёртывания. Если надо откатиться и это возможно, то откатываемся.
Как и кем принимается решение об успешном развёртывании? На основании каких параметров?
Не совсем понятно, о чем речь. Если о самом процессе развёртывания, то решение принимает Bamboo План отработал без ошибок — хорошо, не отработал — ошибка. Если же вопрос про функциональную составляющую устанавливаемых изменений, то решение принимают бизнес-заказчики в ходе smoke-тестирования после установки.
Что делать, если нагрузка увеличивается? Легко ли добавить больше серверов, чтобы удержать нагрузку? Если ли автомасштабирование?
Зависит от приложения и еще очень многих и многих факторов, как и всегда, когда дело касается нагрузки. Автомасштабирование не используется.
Каждое новое развёртывание выполняется на вновь созданные серверы или на те же самые?
Зависит от приложения. Наша команда пересоздает серверы каждые две недели, и развёртываем только на новые. Другие команды развёртывают всегда на одни и те же серверы. Команды сами выбирают подход.
Что с патчами на операционную систему?
Зависит от приложения, ОС и обновления. Но, в итоге, все критичные исправления у нас установлены и уязвимостей нет.
А что с мониторингом и метриками приложений и системы (OS)?
Тема мониторинга заслуживает отдельной большой статьи, которую, возможно, напишут наши специалисты, занимающиеся мониторингом. Я же могу сказать, что мониторинг есть, алерты работают, инциденты регистрируются и обрабатываются, часть обработки автоматизирована.
Что используете для балансировки нагрузки между копиями приложений? nginx/haproxy/etc?
Зависит от приложения Есть и nginx, и haproxy, и NLB, и железная Cisco.
Комментарии (4)

merc
14.03.2018 15:23Интересно читать про изменения в крупных компаниях, а тем более — в банках.
Ответы на последние 7 вопросов не несут никакого смысла. Мне кажется, можно было вообще их не писать и закончить — coming soon.
Вы писали, что у вас было 120 компонентов для установки на агенты. Почему не использовать докер для победы над этой болью?
kkurochkin Автор
14.03.2018 15:42Как я уже писал в предыдущем комментарии, мы сейчас находимся в процессе выбора. Когда закончим выбирать и начнем использовать, думаю напишем еще один пост.
izzmajjra
А сколько команд из общего числа не использует построенный конвейер? Наверняка есть такие, кто не хочет (или это обязательное требование?) или не может. Какой-нибудь rocket-science на уникальных технологиях, к которому сложно прикрутить CI/CD. С продуктами SAS, в свое время, намучались и решили лучше не трогать, себе дороже делать CI оказалось.
Ну и мини-вопрос, какую технологию контейнеризации рассматриваете сейчас для внедрения?
kkurochkin Автор
Сейчас у нас примерно 90 % команд использует конвейер, для всех новых команд использование конвейера является требованием. Из оставшихся 10% часть команд это приложения под IOS +Android, для них мы сейчас создаем агенты, чтобы и их перевести на конвейер. Еще часть это команды в процессе перехода и совсем малая часть это приложения для которых использовать конвейер признали не целесообразным.
С SAS мы тоже помучились, но в итоге команде удалось реализовать и сборку и автодеплой через конвейер.
Технологии контейнеризации мы сейчас рассматриваем все основные, но пока ничего определенного сказать не могу. Процесс выбора только начался.