
Тестировать регресс верстки скриншотами модно, этим никого не удивишь. Мы давно хотели внедрить этот вид тестирования у себя. Всё время смущали вопросы простоты поддержки и применения, но в большей степени — пропускная способность решений. Хотелось, чтобы это было что-то простое в использовании и быстрое в работе. Готовые решения не подошли, и мы взялись делать свое.
Под катом расскажем, что из этого вышло, какие задачи решали, и как мы добились того, чтобы тестирование скриншотами практически не влияло на общее время прохождения тестов. Этот пост — расшифровка доклада, который прозвучал на HolyJS 2017 Moscow. Видео можно посмотреть по ссылке, а почитать и посмотреть слайды — далее.
Всем привет, меня зовут Роман. Я работаю в Avito. Занимаюсь многими вещами, в том числе open-source, автор нескольких проектов: CSSTree, basis.js, rempl, мейнтейнер CSSO и других.
Сегодня я расскажу про юнит-тестирование скриншотами. Этот доклад — история про поиск инженерных решений. Я не дам рецептов на все случаи жизни. Но поделюсь направлением мысли: куда пойти, чтобы сделать всё хорошо.
Велосипеды — это не всегда плохо. Те, кто меня знает, помнят, что я часто пытаюсь делать что-то новое, несмотря на то, что есть много готового. К чему это приводит? Если не сдаваться, то можно найти решения, причём совсем не там, где вы их искали.
Так как у нас сегодня заявлена тема про скриншоты, скажу, что ускорять тестирование можно не только оптимизируя код. Проблема может быть не только в нём. И экспериментируя, можно получить интересные ходы и решения.
Современные фронтендеры при возникновении какой-то проблемы обычно сразу идут на NPM, на StackOverflow и пытаются использовать готовые решения. Но не всегда npm install может помочь. «В нас пропал дух авантюризма»: мы редко пытаемся делать что-то самостоятельно, копать вглубь.

Будем это исправлять.
Unit-тестирование: инструменты
Тестирование бывает разным: юнит, функциональное, интеграционное… В этом докладе я расскажу про юнит-тестирование компонент или некоторых блоков, которые мы хотим тестировать на предмет регрессии верстки.
Мы хотели давно заняться этой темой, но всё не доходили руки. Нам нужно было такое решение, чтобы оно было простым, дешевым и быстрым.
Какие есть варианты?
- Готовые сервисы;
- Готовые инструменты, например Gemini;
- Можно написать свое.
Сервисы нам не подходят по определенным причинам: мы не хотим использовать внешние сервисы, хотим чтобы все было внутри.
Что насчёт готовых инструментов? Они есть, их несколько, но они обычно ориентированы на то, чтобы ходить по урлам и «щелкать» определенные блоки. Это не совсем подходило нам — мы хотели тестировать именно компоненты и блоки, их состояние, делая скриншоты.
Есть инструмент Gemini от Яндекса, хорошая штука, но она похожа на космический корабль. Сложно завести, настраивать, приходится писать много кода. Возможно, это не проблема. Но для меня проблемой стало то, что взяв простой тест из readme, скопировав его сто раз, я получил такую цифру: 100 изображений 282х200 проверяются примерно две минуты. Это очень долго.
В итоге стали делать своё. Про это и будет сегодняшний доклад. Забегу вперёд: покажу что у нас получилось.

Так, имея некий тест разметки компонента на React, мы добавляем одну строку, в которой делаем скриншот и вызываем «магический» метод toMatchSnapshotImage(). То есть одна дополнительная строчка в тесте — и мы помимо прочего проверяем состояние компонента скриншотом.
В цифрах: если сравниваются два одинаковых скриншота размером 800х600, то, в нашем решении, сравнение занимает примерно 0 мс. Если скриншоты немного отличаются, и надо посчитать пиксели, которые отличаются, это занимает примерно 100 мс. Обновление скриншотов, получение картинки, когда мы инициализируем «базу» эталонных скриншотов, занимает примерно 25 мс на скриншот. Много это или мало — увидим позже.
Если мы делаем своё решение, которое умеет брать скриншот от текущей разметки и сравнивать с эталоном, что нужно для этого сделать? Во-первых, получить статическую разметку компонента с необходимыми стилями и ресурсами, загрузить это всё в браузер, сделать скриншот и сравнить с эталонным скриншотом. Не так уж и сложно.

Генерация разметки
Начнём с генерации разметки. Она разбивается на несколько шагов. Сначала генерируем HTML компонента. Затем определяем, какие есть зависимые части: какие стили он использует, какие ему нужны изображения, и так далее. Пытаемся всё это собрать в единый HTML-документ, в котором нет ссылок на локальные ресурсы или файлы.
Генерация HTML
Генерация HTML сильно зависит от стека, который вы используете. В нашем случае это React. Берем готовую библиотеку react-dom/server, позволяющую генерировать статическую строку, тот самый HTML, который нам необходим.

То есть подключаем react-dom/server, вызываем метод renderToStaticMarkup() — получаем HTML.
Генерация CSS
Идём дальше: генерация CSS. У нас уже есть HTML, но к нему, скорей всего, еще относится множество стилей и других ресурсов. Всё это нужно собрать. Какой же здесь план действий? Во-первых, надо найти файлы, которые подключаются и используются в компонентах. И преобразовать CSS-файлы таким образом, чтобы они не содержали ссылки на ресурсы. То есть найти ссылки на ресурсы и заинлайнить их в сам CSS. Потом это всё склеить.
Решение, опять же, зависит от стека. В нашем случае мы используем Jest в качестве тест раннера, Babel для преобразования JavaScript и CSS Modules, чтобы описывать стили.
Для начала делаем поиск CSS-файлов.

CSS Modules подразумевает, что CSS подключается в JavaScript как обычный модуль, то есть используется либо import, либо require().
Технически, нужно перехватить все такие вызовы и преобразовать их так, чтобы сохранить пути, которые были запрошены.
Для этого мы написали плагин для Babel. У Jest есть возможность настраивать трансформацию JavaScript (возможно, вы уже это делаете, если используете Jest). С помощью настройки transform добавляются скрипты для трансформации ресурсов, которые соответствуют правилу. В нашем случае нужны JavaScript-файлы.

Скрипт создает трансформер, используя babel-jest. К прочим настройкам нам нужно добавить собственный плагин, который будет делать необходимое.

Задача плагина состоит из двух частей. Сначала делается поиск всех import, которые приводятся к require(), чтобы было проще потом искать подключения CSS. После этого все require() заменяются на специальную функцию:

Такая функция инициализирует глобальный массив для хранения путей, добавляет новые пути в этот массив и возвращает оригинальный экспорт, который был заменен. Код плагина составляет 52 строки. Решение можно упростить, но пока не было необходимости.
На момент генерации HTML-разметки компонента в массиве includedCssModules будут все пути, которые запрашивались через require(). Всё что нам остается — это преобразовать пути в контент этих файлов.
Обработка CSS
На данном этапе нам необходимо обойти все CSS-файлы, найти в них ссылки на ресурсы и заинлайнить их. А ещё нам нужно выключить динамику: если используется анимация или некоторые динамические части, то результат может оказаться разным, скриншот может быть сделан в непредсказуемый момент.
Инлайн ресурсов
Чтобы заинлайнить ресурсы, мы написали еще один плагин. (Можно использовать готовый, но в данном случае оказалось проще написать свой).

Как это всё выглядит? Помните, мы добавляли плагин в jest-transform? Здесь такая же история, только мы используем специальный плагин для CSS Modules, а именно css-modules-transform для babel-jest, у которого есть возможность настроить препроцессинг CSS: некий скрипт, который будет преобразовывать CSS перед тем, как он будет использоваться.
Итак, добавляем в processCss путь к нашему плагину и пишем сам плагин. Для него используется парсер CSSTree. Дело не только в том, что я его автор ;) — он быстрый, детальный и позволяет, например, искать пути и урлы без сложных RegExp'ов. Также он толерантен к ошибкам: если в CSS будут непонятные части, то ничего не сломается, просто эти части останутся не разобранными. Но такое случается редко.

Плагин ищет в CSS урлы и заменяет их на инлайн-ресурсы.
Что здесь происходит? В первой строке мы получаем AST, то есть разбираем CSS-строку в дерево. Дальше обходим это дерево, находим узлы типа Url, выбираем из них значение и используем как путь к файлу, который нужно заинлайнить. В конце просто вызываем translate, то есть преобразуем трансформированное дерево обратно в строку.

Реализация инлайн ресурсов не такая сложная, как может показаться:
- берем URI, разрешаем его относительно CSS-файла, в котором он используется (потому что пути относительные);
- читаем из файла бинарные данные;
- вычисляем по расширению mime-тип;
- генерируем Data URI ресурса.
Всё! Мы заинлайнили ресурсы. Описанные функции — это 26 строк кода, которые делают всё необходимое.
Чем еще может оказаться полезно написать собственное решение: мы можем его расширять, например, позже мы добавили конвертацию анимированных GIF в статичные изображения. Но об этом далее.
Избавляемся от динамики
Следующим шагом нам нужно избавиться от динамики. Как заморозить анимацию и где она бывает?
Динамика появляется в:
- CSS Transitions;
- CSS Animations;
- каретка в полях ввода, которая мигает и в любой момент может пропасть или появиться;
- анимированные GIF и ряд других моментов.
Давайте попытаемся все это «отключить», чтобы всегда получался один и тот же результат.
CSS Transition
Обнуляем все transitions-delay и transition-duration.

В этом случае все transition будут гарантированно находиться в конечном состоянии.
CSS Animation
Похожим образом поступаем с CSS анимациями.

Здесь можно увидеть такой хак:

Обратите внимание на значение animation-delay: –0.0001s. Дело в том, что без этого в Safari у анимаций не будет финального состояния.
И последнее: мы пригнали анимацию в конец (финальное состояние), но анимации отличаются от транзиций тем, что могут повторяться. Поэтому мы ставим состояние анимации в паузу, устанавливая animation-play-state в paused. Таким образом анимации ставятся на паузу, то есть перестают проигрываться.

Каретка
Следующий момент — каретка в полях. Проблема в том, что она мигает: в какой то момент мы видим вертикальную черту, в какой то момент — нет. Это может оказать влияние на результирующий скриншот.
В последние месяцы в браузерах появилось такое свойство как caret-color: сначала в Chrome, потом в Firefox и Safari (Technology Preview). Чтобы «выключить» каретку, мы можем сделать её прозрачной (задать в качестве цвета значение transparent). Таким образом каретка всегда будет невидимой и не будет влиять на результат.
Для других версий браузеров надо будет придумать что-то ещё, но это только тогда, когда мы будем их использовать для скриншотов.

GIF
С GIF ситуация немного сложнее. Задача сводится к тому, чтобы из анимированного GIF оставить один статичный кадр. Я пытался найти модуль для этого, поставить его и забыть о проблеме. В результате нашел множество библиотек, которые ресайзят картинки, меняют палитру, делают GIF из нескольких изображений, или, наоборот, делают из анимированного GIF набор изображений. Но не нашел такого пакета, который делает анимированный GIF статичным. Пришлось написать самому.
После двух часов поиска библиотеки, решил посмотреть, насколько сложный формат GIF. Почитал Вики, открыл спецификацию от 89-го года — оказалось достаточно понятно.

GIF состоит из нескольких блоков: в начале есть сигнатура описания размера изображения и таблица индексированных цветов. Затем идут последовательно блоки: Image Descriptor Block, который отвечает за графику, и Extension Block, в котором можно хранить палитру, некоторый текст, комментарии, копирайты и прочее. В конце файла идет Trailer, специальный блок, который говорит, что GIF закончился.
Таким образом, нужно пройти эти блоки и отфильтровать (удалить) все Image Descriptor Block, кроме первого. Вот ссылка на Gist с кодом, который делает необходимое. Я написал его за пару часов, отладил, пока работает отлично, проблем не нашли.
В итоге: GIF изображения статичны, анимации выключены, все пути к CSS есть. Осталось склеить. Что может быть проще, казалось бы?
Склейка CSS
Давайте посмотрим, как устроен Jest. Обычно он работает в параллель, запускает несколько потоков, которые выполняют тесты. Каждый файл с тестами запускается в один из потоков, и каждый файл — это отдельный контекст, который не шарит данные между другими контекстами. И проблема в том, что у нас трансформация CSS, где мы получали доступ к исходному коду CSS файлов, находится вне контекста теста, и мы не можем получить доступ к этому контенту. Читать CSS из файла мы тоже не можем, потому что CSS уже преобразован, хранится в самом JavaScript, в каком-то окружении, контексте, воркере.
Как пошарить CSS между тестами? Мы сделали небольшой хак. Каждый воркер создает временный файл в формате JSON, где ключ — путь к CSS, а само значение — уже преобразованный CSS. Каждый поток читает этот файл, берет оттуда нужное и делает конкатенацию внутри контекста теста.

Здесь мы читаем некоторый временный файл, парсим его в JSON, добавляем в него нужный контент. Filename — это ключ, CSS — преобразованное значение. И записываем обратно преобразованную карту.
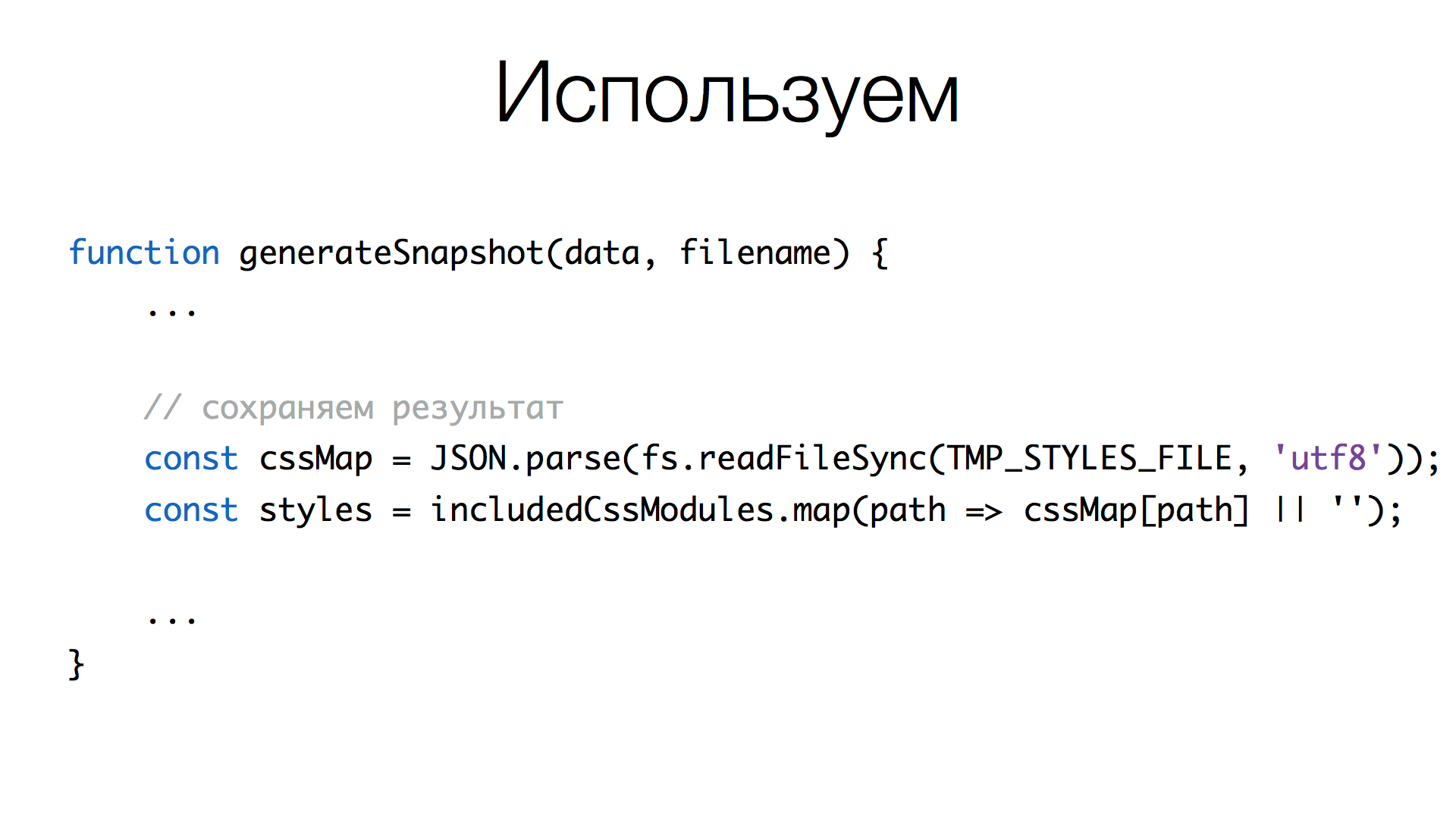
Когда мы генерируем CSS для скриншота, мы читаем из этого файла, используем includedCssModules (массив путей CSS), получаем контент нужных файлов и делаем join().
Осталось собрать всё вместе.
Финальная сборка

Генерируем финальный HTML. Сначала задаем стили, которые отключают динамику (анимации). Во втором style подключаются все склеенные CSS, которые мы нашли. У каждого теста будет свой набор этих стилей, потому что когда мы делаем require() компонента, он подтягивает свои зависимости, которые и будут в нашем списке. Как итог подключаются только используемые CSS файлы, а не весь CSS в проекте. HTML, соответственно, мы получали раньше — это код самого компонента.
В итоге мы добились своего. Мы можем генерировать HTML компонент в нужном состоянии плюс CSS, который ему необходим.
Итак, вся разметка собрана, анимация выключена – все готово, чтобы сделать скриншот. Решения не идеальны, можно сделать лучше, но для этого нужно дальше копаться внутри Jest, Babel, CSS Modules и так далее, чтобы получить более элегантные и стабильные решения. Но в целом нас это устраивает, и мы можем двигаться дальше.
Скриншоты
Сегодня делать скриншоты в браузере достаточно просто. Еще несколько лет назад это могло быть сложной задачей, нужно было использовать сложные решения. Сегодня же есть headless браузеры, которые запускаются без GUI, в которых можно загружать произвольный код и смотреть, как он работает, в том числе снимать скриншоты.
Также все современные браузеры поддерживают WebDriver. Если вы используете, например, Selenium, то все делается относительно несложно. Есть библиотеки, хелперы, которые упрощают написание тестов для таких сред.
В нашем случае мы делали простые сравнения с помощью одного браузера. Пока не было необходимости делать кроссбраузерное сравнение, поэтому мы использовали Puppeteer, специальную библиотеку, которая может запустить безголовый Chrome и предоставляет достаточно удобный интерфейс для работы с ним. Вот основной код, который делает скриншот.

Здесь подключается Puppeteer, запускается браузер, и когда необходимо сделать скриншот, мы вызываем функцию screenshot() с некоторым HTML. Эта функция создает новую страницу, вставляет в нее переданный HTML, делает скриншот, закрывает страницу и отдает нам результат скриншота. Работает. Несложно. Но оказалось, не все так просто.
Дело в том, что когда мы запускаемся код локально, у нас всё хорошо работает. У нас изображения эталонное и новое совпадает, потому что мы создаем новое изображение в той же версии браузера, той же системе, где мы делали эталон. Но когда мы начали запускать все это на CI, где у нас уже не Мас, не Windows, а Linux, своя версия Chrome, свои правила антиалиасинга, свои шрифты и прочее, изображения получились другие. То есть начали получать разный результат.
Что делать? Есть несколько решений. Некоторые решения пытаются эту разницу побороть с помощью математики. Они сравнивают не попиксельно, а пиксель и соседние пиксели – то есть нестрогое сравнение с определенным допуском. Это дорого и как-то странно, хотелось бы просто сравнить попиксельно.
Мы пошли в сторону другого решения: сделать внешний микросервис, куда можно отправить POST-запрос с HTML-кодом, а на выходе получить изображение, скриншот, который нам необходим.
Какие плюсы мы получили? Нет зависимости от машины, где запускаются тесты, можно обновляться, менять версию браузера — это не важно, на стороне микросервера всегда один и тот же браузер, который дает один и тот же результат.
Также не требуется локальных настроек для нового проекта. Не нужно запускать браузеры, настраивать Puppeteer и прочие вещи, мы просто делаем POST-запрос и получаем изображение. Получается даже быстрее, как ни странно, хотя есть сетевые издержки. Мы отправляем в сервис запрос, там есть и кэши, и разогретый браузер, который очень быстро отдает изображение. Плюс PNG достаточно маленькие, хорошо жмутся, сетевой трафик не очень большой.
Минусы тоже есть. Сервис может в любой момент упасть, нужно следить за его «здоровьем». Все знают, что браузер может «отъедать» много памяти, даже если посещаются простые страницы. На сервис может резко хлынуть нагрузка, он может не справиться, его ресурсы ограничены. И если сервис падает, он не может отдать изображения – наши тесты не проходят.
Соответственно, если все одновременно решат проверить скриншоты (запустить), то может получиться так, что либо придётся долго ждать, либо сервис перестанет отвечать, потому что большая нагрузка. Последнее решается более-менее: у нас есть локальное облако, где можно создать несколько инстансов сервиса и распределить нагрузку. Но тем не менее, такая проблема существует. Как выглядит смерть сервиса?
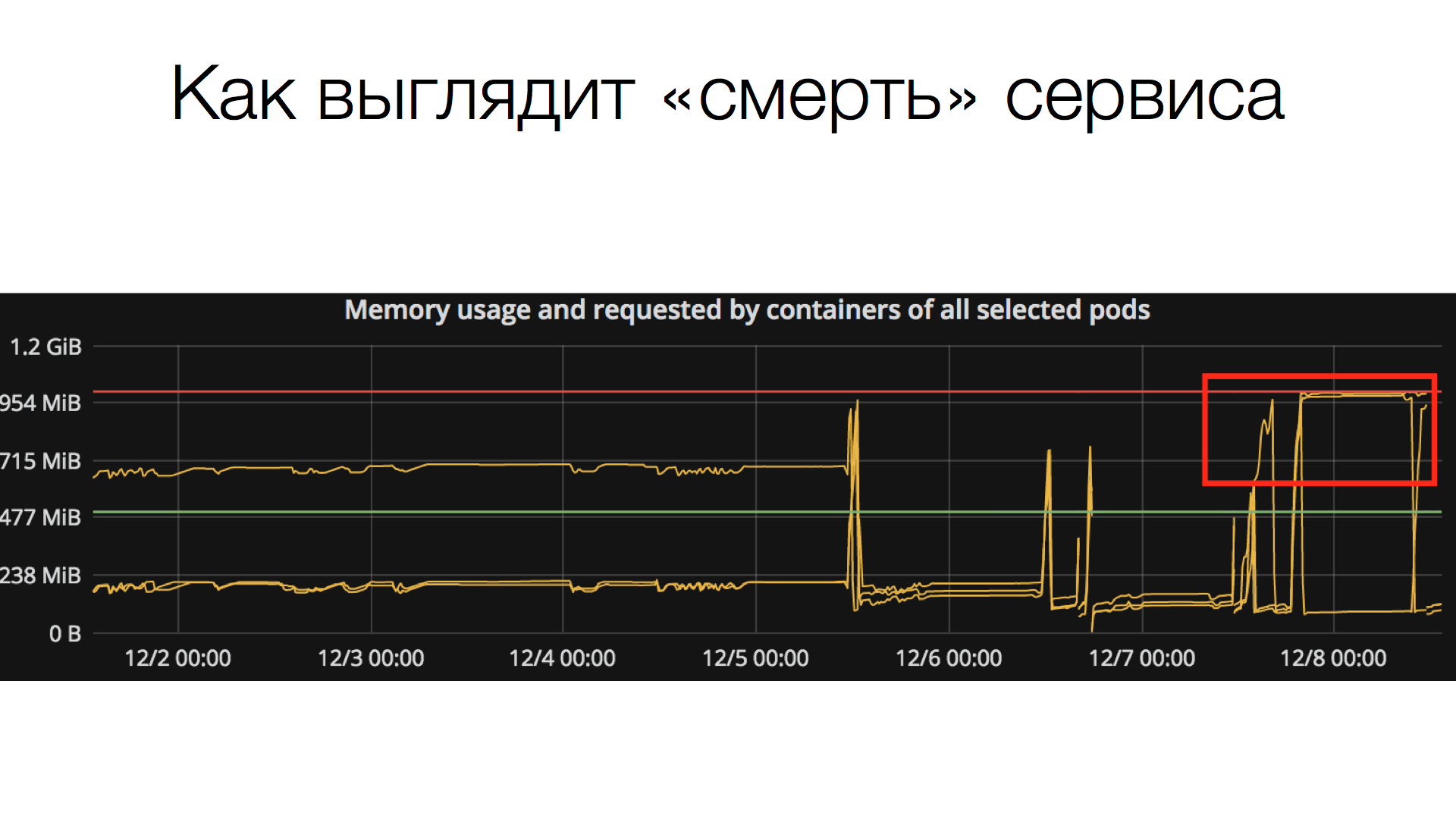
Есть определенный инстанс сервиса, который работает, у него ограниченное количество памяти (в данном случае 1 Гб), он может «съесть» всю доступную память и перестать отвечать. В таких случаях помогает только перезагрузка.
У решения с микросервисом есть и другая сторона. Когда мы сделали создание скриншотов по коду, появилась идея научить сервис отдавать скриншоты не только по коду, но и по URL плюс некий селектор. Что делает сервис в этом случае: заходит на страницу, и либо делает полный скриншот страницы, либо того блока, на который матчится переданный селектор. Это оказалось удобно и полезно для других задач, совсем не связанных с тестированием. Например, сейчас мы экспериментируем: вставляем в документацию, в нашу базу знаний скриншоты страниц, инструкции к нашим сервисам, частям сайта, используя для изображений (<img>) в качестве адреса URL к сервису. Получается, что когда мы заходим в документацию, у нас всегда актуальные скриншоты. И не нужно постоянно их обновлять. Это очень интересное решение, которое получилось само собой.
Применение метода, когда мы можем использовать в качестве изображения URL к сервису скриншотов, и таким образом получить скриншот страницы или блока, очень полезно и для других задач, не только для документации. Например, можно строить функциональные графы сайтов: в каждом блоке графа могут быть скриншоты страниц или блоков, которые будут обновляться с каждой выкаткой сайта.
Сравнение изображений
Итак, переходим непосредственно к тестированию скриншотами. Мы получили код, получили по этому коду скриншоты, осталось их сравнить.
Напомню, мы используем Jest для тестирования компонентов. Это важно.
В Jest есть «киллер-фича» — сравнение снэпшотов.

Мы делаем разметку объектов, какие-то данные, и можем вызвать метод toMatchSnapshot() для этих данных. Как работает метод:
- приводит проверяемое значение к строке, используя различные методы вроде
JSON.stringify(); - eсли тест новый, результат сохраняется в локальную базу результатов для последующего сравнения;
- если тест запускается повторно, то из базы достается предыдущий снэпшот и сравниваются две строки, равны они или нет. Если не равны, то будет ошибка, то есть тест не пройден. Если тест был удалён, Jest отмечает, что в базе есть неактуальный снэпшот, чтобы не было мусора.
Используя метод toMatchSnapshot() мы можем проверить изменилась ли у нас разметка (HTML) компонентов или нет, и нам не нужно писать код для того чтобы снепшоты сравнивать, обновлять, хранить и прочее. Магия!
Но вернёмся к сравнению изображений. Изображения у нас бинарные, это не строковое представление. Встроенных инструментов для сравнения изображений в Jest пока нет. На GitHub есть тикет на эту тему, они ждут pull request. Может, сами сделают со временем. Но на данный момент есть плагин от American Express — jest-image-snapshot. Он хорошо подойдет для старта, чтобы сразу начать сравнивать бинарные изображения. Выглядит это так:

Мы подключаем этот модуль и расширяем expect новым методом toMatchImageSnapshot(), который берется из jest-image-snapshot.

Теперь мы можем добавить в тест сравнение скриншотов. Получение скриншота — асинхронная операция, потому что нам нужно сделать запрос к серверу, дождаться ответа, и только тогда мы получим содержимое изображения.
Когда изображение получено, делаем вызов toMatchImageSnapshot(). Происходит примерно та же история, что и с toMatchSnapshot(). Если тест новый, то изображение сохраняется как есть в файл. Если не новый, то читаем файл, который у нас есть, смотрим, что пришло и сравниваем (об этом — чуть позже), равны они или нет.
Какие проблемы есть у этого плагина? Когда мы начинали его использовать, он был недостаточно быстрым. Недавно он стал быстрее, что уже хорошо. Также он не учитывает режимы Jest. (Тут интересно, что Jest работает в нескольких режимах: по умолчанию он просто дописывает новые снэпшоты в вашу базу или на диск, есть режим апдейта, когда снепшоты перезаписываются или удаляются более не актуальные. Есть режим CI, в котором файлы не создаются, не обновляются и не удаляются, сравнивается только то, что есть и что нам пришло). Так вот, плагин jest-image-snapshot это не учитывает, он всегда пишет файлы, независимо от того, какой режим у нас включен, что плохо для CI, потому что CI может ложно пройти тест, для которого просто нет снэпшота.
Также плагин плохо работает со счетчиками и не умеет удалять устаревшие изображения: со временем тесты меняются, меняется описание к ним, в кодовой базе могут оставаться изображения, которые не актуальны, просто лежат мертвым грузом.
Но ключевая проблема — производительность. Когда мы сравнивали изображения 800х600, мы получали 1,5-2 секунды на изображение. Насколько это плохо? Например, у нас сейчас больше 300 изображений. Мы ожидаем, что в скором времени счёт скриншотов будет идти на тысячи, время будет постоянно расти. А ведь 300 скриншотов — это уже пять минут.
Мы сделали форк jest-image-snapshot и начали чинить проблемы. В первую очередь — сравнение изображений. Мы начинали с того, что у нас было примерно 300 скриншотов и инициализация (когда мы говорим: «делай скриншоты для всех компонент и просто сохрани как эталон») происходила за 10-20 секунд, достаточно быстро. В то же время проверка делалась 4,5 минуты. Получается, что проверка занимает в несколько раз больше, чем сделать сам скриншот. И это при том, что время указано для трех потоков Jest, в одном потоке получается примерно 12-15 минут.
Почему так медленно? Каждый раз, когда jest-image-snapshot получает новое изображение, он сравнивает их попиксельно через blink-diff, специальную библиотеку, которая умеет сравнивать два PNG.
Посчитаем, что необходимо, чтобы сравнить два изображения 800х600. Одно такое изображение — это 480 тысяч пикселей. Два изображения — в два раза больше. Каждый пиксель — 4 байта (RGB и прозрачность). Получаем примерно 2 Мб на изображение. Чтобы получить ответ, равны изображения или нет, нам нужно выделить около 4 Мб памяти. 300 изображений — 300 раз выделяем по 4 Мб, а потом освобождаем.
Как вы понимаете, это удар по Garbage Collector и прочим вещам, то есть не очень хорошо. Помимо этого нам нужно пройтись по массивам, сравнить поэлементно. То есть здесь уже играет значение количество пикселей: нужно перебрать по полмиллиона элементов в двух массивах и сравнить.

Вот как работают библиотеки сравнения изображений. Например, blink-diff, с которого мы начинали, тратит примерно 1,5-2 сек при сравнении изображений (800x600). Есть более быстрая реализация сравнения — библиотека pixelmatch. Она работает втрое быстрее. Кстати, jest-image-snapshot уже перевели на неё (но после того, как мы форкнули). Есть looks-same от команды Gemini, которая умеет делать дополнительную магию, но использует тот же pixelmatch по капотом и скорость сравнения сопоставимая.
Как же сделать быстрее? Тут помогло важное наблюдение: при повторных прогонах тестов (а именно в этом случае необходимо сравнение) большая часть изображений совпадает. Поэтому можно начать сравнивать файлы без их декодирования. PNG хорошо сжимается, размер файлов не очень большой (например, для 800x600 это обычно несколько десятков килобайт, а не 2 мегабайта, как в разжатом виде). А если файлы побайтно не равны, тогда уже сравнивать попиксельно.
Как быстро сравнить два файла? Конечно, хеш!

Используем встроенный модуль node.js – crypto, который умеет делать хеши. Пишем небольшую функцию, которая делает md5 или sha1, неважно. Добавляем бинарные данные, и получаем хеши в hex, например.
Посмотрим на время. Для 4 Кб изображений получается примерно 58 тыс. операций сравнения в секунду, что неплохо. Для 137 Кб получается уже около 2 тысяч. Это, кажется, неплохие цифры.
Но это неправильно. Получение хеша — это overkill. Мы по сути делаем сравнение двух буферов, считая от них хеш. А что такое буфер? Это массив чисел, и чтобы их сравнить, нужно пройтись по этим массивам побайтно (или не побайтно) и сравнить равны они или не равны. Чтобы посчитать хеш, нужно также пройти оба массива и дополнительно выполнить множество операций для вычисления хеша. Более простое решение такое:

У экземпляров Buffer есть метод equals() (еще есть метод compare(), который возвращает –1, 1 и 0, что полезно для сортировки). Суть в том, что мы получаем два буфера, читая файлы, и вызываем метод equals(). Реализация этого метода очень быстрая: если у вас 4 Кб изображение — можно выполнить около 3 млн операций сравнения в секунду, а если изображение 137 Кб — 148 тысяч операций. Это в 50-70 раз быстрее, чем использовать хэш.
Попиксельное сравнение
Итак, мы ответили на вопрос, равны файлы или нет. И теперь умеем это делать очень быстро. А если они не равны, то нужно сравнивать попиксельно. Для этого есть библиотеки, но почему бы не сделать сравнение самостоятельно? Цифры библиотек мы видели, но хотелось попробовать самим, насколько это будет быстрее.

Можно заметить, что здесь делается много подготовительной работы: для того, чтобы сравнить два PNG, нужно сначала их декодировать, потому что они хранят информацию в сжатом виде. Для кодирования используется GZIP, который пакует данные, а перед этим применяются хитрые построчные алгоритмы, в зависимости от структуры изображения, которое кодируется.
Итак, функция сравнения получает два буфера (actualImage и expectedImage), и первым делом осуществляет декодирование с помощью библиотеки fast-png. Далее создает массивы Uint32Array для этих же буферов. Кажется, что делается дополнительное копирование памяти, но на самом деле нет. Дело в том, что когда типизированные массивы создаются с переданным им буфером, они не создают копию памяти. Они используют тот же фрагмент памяти, что и переданный буфер, но у них получается другой интерфейс доступа к данным. В данном случае в actual.data, например, будет храниться массив байт, а когда создается Uint32Array, то получается четырехбайтная адресация к тому же массиву. Таким образом, можно сравнивать гораздо быстрее, не по одному байту, а по четыре сразу. Это и будут наши пиксели: мы проходим по массиву, сравниваем, равны пиксели или нет, и сравниваем, сколько неравенств произошло.
Чтобы потом посчитать процент не совпавших пикселей, мы возвращаем высоту и ширину изображения, которое мы декодировали (считаем: count / (width * height)).
Посчитаем время сравнения двух изображений, когда нужно посчитать количество пикселей. Для 800х600 это ~100 мс, в несколько раз быстрее, чем дают библиотеки, которые мы могли бы использовать для этой операции.
Генерация diff-изображений
Следующий вопрос: как увидеть разницу невооруженным глазом? Как это вообще работает?
Для этого создается дополнительный буфер, который будет хранить эту разницу между двумя изображениями. Все совпадающие пиксели обесцвечиваем и засвечиваем, чтобы оставался намёк на оригинальное изображение, но это не сильно мешало для отображения разницы. А для несовпадающих пикселей пишем в diff-буфер красный пиксель.

Эта функция похожа на предыдущую, только здесь добавляется несколько новых строк. Сначала делается аллокация нового буфера, мы делаем alloc() того же размера, что и актуальное изображение (они равны по длине). Создаем для него Uint32Array. Помимо этого в цикле появилось две дополнительных секции. В случае, когда пиксели не равны, мы просто пишем туда красный пиксель. Это четыре байта. Самый левый — прозрачность, делаем его максимально непрозрачным. Потом синий, зеленый и в конце красный. Красный — полностью красный пиксель. Дальше мы обесцвечиваем и засвечиваем пиксели, и в конце дополнительно возвращаем все три буфера.
Как засветить пиксели?

Мы берем пиксель, берем три компонента — красный, зеленый, синий, — складываем вместе, делим на максимальную сумму — получается трижды по 255. Получается яркость серого. Дальше преобразуем эту яркость, чтобы она была в верхней четверти диапазона. В таком случае изображение получается менее контрастным и лучше видно разницу изображений. Финальным шагом берем gray (это та самая градация серого) и обратно складываем в пиксель. Помимо этого сохраняем прозрачность из оригинального пикселя.
Таким образом получаем три изображения: эталон, новый скриншот и разницу между ними. Теперь необходимо сделать композицию, чтобы увидеть, что было, что стало и какая между ними разница.

Склеиваем три буфера (actual, expected и diff) с помощью Buffer.concat(), метод который получает массив буферов и возвращает новый объединенный буфер. Далее используем ту же библиотеку fast-png, но уже для кодирования PNG. В нее передаем объединенный буфер, оригинальную ширину, а высоту в три раза больше, потому что будет три изображения подряд.
На выходе получаем сверху эталонное изображение, снизу новое (куда я добавил руку), а посередине — diff: обесцвеченные цвета, картинка серая. Что не совпадает? Красная рука.
Что в цифрах? Кодирование занимает несколько больше времени, чем декодирование, поэтому получается 250 мс для двух изображений (полное время, то есть сравнение и генерация diff-изображения). Приемлемо. Быстрее, чем у других библиотек.
Несколько мыслей по реализации. Описанное решение сделано на JS, в нем используется декодирование/кодирование PNG, распаковка/упаковка GZIP и другие операции. Это всё работа с буферами, работа с байтами. Сегодня есть WebAssembly и другие штуки, которые для этого хорошо подходят и позволяют ускорять подобные операции. По идее, вполне возможно сделать библиотеку, которая будет делать то же самое, но быстрее.
Еще одно наблюдение: мы создаем diff-изображение, чтобы разработчик увидел разницу. Но на самом деле diff нам не нужен! Многие инструменты имеют встроенное сравнение изображений, которые работают с Git. При этом они более функциональные, чем три подряд идущих изображения. Например, GitHub имеет такую функцию, и многие клиенты для него. Мы используем BitBucket (Stash), там это выглядит так:
С помощью таких инструментов можно увидеть, что изменилось в изображении. Зачем тогда делать diff? Поэтому его мы создаем только тогда, когда пользователь (разработчик) об этом попросил. А это случается редко.
У Jest, кстати, есть специальный режим expand. В этом режиме, когда мы ищем разницу между двумя не совпадающими значениями, нам должна предоставляться максимально полная информация о разнице. По дефолту Jest показывает минимум информации, чтобы получить базовое представление что не так с тестом. Если деталей не хватает — запускаем его с флагом --expand, и нам выдается больше информации. Наш форк так и делает: если expand не задан, просто сообщаем сколько пикселей не совпало, а если передан, то дополнительно генерируем diff-изображение.
Еще быстрее?
Можно ли еще сделать быстрее? Казалось бы, уже и так всё хорошо. Но мы постоянно получаем новый скриншот. Что это значит? Это значит, нужно сделать новый запрос к нашему сервису, или поднять браузер и там запустить код. Но в большинстве случаев, когда мы делаем скриншот, мы для одного и того же кода получаем тот же результат. Зачем же тогда генерировать новый скриншот, если код, из которого сгенерирован предыдущий скриншот, совпадает с тем, что мы получили сейчас? В этом случае, по идее, делать запросы к сервису скриншотов не нужно.
При тестировании скриншотами, мы первым делом генерируем HTML компонента со всеми стилями и зависимостями, то есть код по которому будет делаться скриншот. После этого мы располагаем:
- эталонным изображением (скриншот);
- кодом, из которого это эталонное изображение сгенерировано;
- новым кодом для тестирования.
Первым делом мы сравниваем старый и новый код. Если они совпадают, то нам не нужно делать запрос к сервису, чтобы получить скриншот. В этом случае мы используем эталонное изображение, как будто мы получили его от сервиса скриншотов. А если нет изображения или код отличается чем-то, только тогда выполняем запрос к сервису.
Каждый раз, когда мы прогоняем тесты, независимо от того, совпадают ли изображения (эталонное и новое), мы сохраняем актуальный код в некоторый файл (если не включен режим CI, конечно). То есть сохраняем тот код, из которого получено изображение. И этот код используется в следующем прогоне тестов, для определения, нужно ли отправлять запрос на сервису скриншотов или нет. Получается, мы разгружаем сервис, не делая к нему запросы без необходимости.
А вот вопрос: как же нам хранить этот код? Сначала у меня была безумная идея — в самом изображении. Почему нет? Я знал, что в PNG можно хранить произвольные данные, но хотел понять, насколько это просто. Ведь GIF удалось побороть, почему бы с PNG не «поиграть»?
Открываем Вики, читаем про формат PNG. Читаем, как работают с PNG несколько библиотек. Все оказывается проще, чем с GIF. Если в GIF секции и блоки разной длины с разным форматом, то в PNG все секции одинакового типа и состоят из 4х частей: длина блока, тип блока, контрольная сумма и сами данные.
Чтобы добавить код (текст) в PNG, нужно добавить новую секцию в файл. И мы можем как записать секцию, так и читать ее обратно. Вот решение. Что получается? Когда мы делаем новый скриншот, мы берем актуальный скриншот, читаем из него секцию с кодом и сравниваем с тем, что только что сгенерировали. Если совпали — значит, мы используем изображение как есть.
Заработало, очень круто работает. Но есть проблема – человеческий фактор. Так как мы храним код в самом изображении, то это влияет на его содержимое в плане байт. При этом эталонный код и новый могут генерировать одинаковое изображение в плане пикселей (например, когда изменения в коде не влияют на визуальную часть). И получается странная история, что файл изменился (по составу байт), но инструменты сравнения показывают, что визуальных различий нет – все пиксели одинаковые. Поэтому хранить код в самом файле можно (и это крутое решение на мой взгляд), но это не очень подходит с точки зрения восприятия человеком. В итоге мы храним код скриншота в отдельном файле, рядом с файлом изображения.
Когда мы добавили проверку подписей (кода для генерации скриншотов), чтобы избежать лишних запросов к сервису, время тестов упало значительно. Раньше мы ждали 45-50 секунд, чтобы все юнит-тесты прошли, теперь же тесты проходят за 12-15 секунд локально. Это время для полной проверки примерно 300 достаточно больших изображений (800x600). Бонусом получили снижение нагрузки на сервис скриншотов.
Представьте: раньше, когда кто-то запускал прохождение юнит-тестов, то сервису приходило около 300 запросов за несколько секунд. Если несколько коллег запускали тесты в один момент, то сервису становилось довольно грустно (генерация скриншота — не дешёвая операция). Теперь же все гораздо лучше в плане нагрузки на сервис.
Хранение изображений в GIT
Еще одна тема, про которую мало кто вспоминает, ведь она немного в стороне от фронтенда – это хранение изображения в Git. Мы должны хранить эталонные изображения в самом Git, чтобы было с чем сравнивать, рядом с тестами.
Проблема в том, что Git, как и многие VCS, в основном рассчитан на работу с текстовыми файлами. Так он не хранит целиком каждую версию текстовых файлов, вместо этого хранит список дельт изменений (патчи оригинального файла). Для бинарных данных эта история не работает, Git не умеет делать дельту для бинарных файлов, поэтому сохраняет каждую версию бинарных файлов целиком. Это сильно раздувает историю Git.
Решить проблему помогает плагин для Git — GIT LFS. Тема достаточно развита, ее поддерживает большинство инструментов для работы с Git. Вот как это работает:

При определенных настройках для бинарного файла в сам Git сохраняется текстовый файл, обычно состоящий из трех строк: версия GIT LFS, хеш файла и его размер. А сами изображения хранятся в специальном хранилище для бинарных данных. Когда вы локально делаете pull репозитория, то изображения скачиваются и сохраняются на диск как реальные файлы. Когда делаете push, то само изображение закачивается в хранилище, а в Git пишется его хеш и размер. То есть git push/pull работают как обычно и делают всю магию.
CI, или beyond the frontend
Еще неожиданный момент: когда мы разогнали все это до 12-15 секунд локально, я подумал, что и на CI все стало быстрее. Но это оказалось не так. На CI время упало, но незначительно: оно там занимало 14 секунд, стало 4 секунды. В целом круто: за это время проверено 700+ снэпшотов, из них 300+ изображений. Но если посмотреть на полное время выполнения задачи, все проверки — получалось 3,5 минуты. Вроде бы момент для грусти. Можно было бы подождать, пока кто-то другой сделает лучше, например, можно было бы найти доброго devops-инженера, который бы это починил и разобрался, но я решил, почему бы не попробовать самому? Уже столько всего пройдено, почему бы не залезть в TeamCity и не посмотреть, в чем проблема.
Внутри CI происходит много интересного: делается стейджинг, когда поднимается git, делается git checkout, ставятся зависимости, потом запускаются юнит-тесты, eslint-ы, stylelint-ы и прочее. Это всё отрабатывает каждый раз. Если запускать «на холодную», это занимало, в нашем случае, 3,5 минуты. Но если поковыряться в настройках, настроить галочки и кеши, которых там очень много, получается, можно сильно разогнать. За счет ряда настроек, время упало до 30 секунд и даже меньше.
Результаты
В итоге сейчас все юнит-тесты библиотеки компонент локально выполняются за 12-15 секунд. Это время включает проверку 300 достаточно больших скриншотов (800х600). Прохождение всех проверок на CI — 20-30 секунд. Время важно: когда мы коммитим в репозиторий, нужно дождаться прохождения всех проверок, чтобы замёрджить ветку. Если все проверки проходят 3,5 минуты, нам приходится ждать, нас это тормозит. 20-30 секунд вполне приемлемо.
Наш плагин для Jest. Получилось решить множество проблем, всё работает правильно: правильно считаются счетчики, учитываются режимы, поддерживается expand, работает быстро, поддерживаются подписи (код, из которого получен скриншот). Планы такие: будем пробовать, скорее всего, законтрибьютить это в Jest. План Б, если не получится, то либо смёрджить с jest-image-snapshot, либо опубликовать как самостоятельный пакет, смотря что будет проще.
Все остальное — «домашние решения», которые пока не знаем, публиковать или нет. Когда обкатаем и будем уверены, что всё работает правильно, хорошо и стабильно, подумаем про Open Source.
Итоги
В итоге мы написали несколько плагинов для Babel, CSS Modules, Jest. Получилось решение, которое полностью под нашим контролем, мы знаем, как это работает, можем тюнить и расширять как угодно под наши задачи и требования. И, главное, время юнит-тестов не пострадало от того, что мы добавили проверку скриншотами.

Две результирующие цифры: здесь слева 11 секунд без скриншотов, и справа вместе со скриншотами. Время в пределах погрешности. Проверялось 328 изображений: они актуальны и в них нет отличий.
Главный бонус для нас: работая над этой задачей, мы поняли, что скриншоты можно применять не только для тестирования. Есть интересные кейсы, которые мы будем в дальнейшем развивать: использование в документации, инструментах и так далее. Это другая история, если что-то получится — расскажем об этом.
Чему мы научились? Мы узнали, как работает Jest внутри, как устроены форматы GIF, PNG, что делать с этими изображениями. Стали лучше понимать Buffer API, как настраивается TeamCity, и как сделать юнит-тестирование скриншотами достаточно быстро.
Главный мой тезис: юнит-тестирование скриншотами может работать со скоростью пули. Нужно об этом задуматься и поискать варианты. И не бойтесь делать свои решения, они приводят к неожиданным результатам.
На этом всё. Спасибо!
Комментарии (10)

snowrain
14.03.2018 15:37Круто. Особенно понравилось про каретку. Я в свое время не додумался до такого. Только вот вопрос, это вообще правильно идеалогически тестировать что-то специально сгенерированное? Есть гарантия что это будет 100% то что надо? Про микросервис тоже странно мне показалось, проблема кросплатформенности и кроссбаузерности безспорно решена, а по-факту это тестирование в одном браузере.
сорри может я невнимательно прочитал, но тут был описан процесс обновления новых эталонных скриншотов?
lahmatiy Автор
15.03.2018 03:36это вообще правильно идеалогически тестировать что-то специально сгенерированное? Есть гарантия что это будет 100% то что надо?
100% гарантию сложно получить в чем бы то ни было. Мы стараемся получить максимально похожее на правду. Когда вносятся изменения или создаются новые тесты, то скриншоты проверяются как автором изменений, так и коллегами на code review. Если получаемые скриншоты похожи на "правду", то они становятся эталонными. Иначе исправляем проблему.
Про микросервис тоже странно мне показалось, проблема кросплатформенности и кроссбаузерности безспорно решена, а по-факту это тестирование в одном браузере.
Да, на данном этапе это было достаточно. То есть пока не ставилась задача кроссбраузерного тестирования. Если потребуются другие браузеры, мы их интегрируем в сервис и добавим параметр, для какого браузера необходимо получить скриншот. Для разработчика мало что поменяется: ему не нужно будет устанавливать локально необходимые браузеры, нужно будет лишь добавить параметр(ы) в настройки на стороне исполнения тестов.
сорри может я невнимательно прочитал, но тут был описан процесс обновления новых эталонных скриншотов?
Для обновления эталонный скриншотов используется тот же механизм, что и для обновления снепшотов в Jest (запускается с флагом
-uили--updateSnapshot)snowrain
15.03.2018 08:34Из ответа к комментарию выше стало понятно почему так сделано, я не понял вначале про компоненты.

Ivanq
14.03.2018 16:11Так он не хранит целиком каждую версию текстовых файлов, вместо этого хранит список дельт изменений (патчи оригинального файла).
Кстати, не факт. Писал как-то свою реализацию Git и Mercurial. Так вот, Git никакие дельты не хранит, только gzip-ом сжимает.
lahmatiy Автор
15.03.2018 03:18Возможно зависит от реализации, которая может не использовать дельты.
Но когда делается клонирование стандартным клиентом, то в выводе можно увидеть упоминание дельт, например:
> git clone ssh://git@host/path/to/repo.git Cloning into 'repo'... remote: Counting objects: 138271, done. remote: Compressing objects: 100% (47402/47402), done. remote: Total 138271 (delta 95998), reused 129451 (delta 88469) Receiving objects: 100% (138271/138271), 29.03 MiB | 6.84 MiB/s, done. Resolving deltas: 100% (95998/95998), done.
В Wikipedia в секции Design отмечено:
Periodic explicit object packing
Git stores each newly created object as a separate file. Although individually compressed, this takes a great deal of space and is inefficient. This is solved by the use of packs that store a large number of objects delta-compressed among themselves in one file (or network byte stream) called a packfile. Packs are compressed using the heuristic that files with the same name are probably similar, but do not depend on it for correctness. A corresponding index file is created for each packfile, telling the offset of each object in the packfile. Newly created objects (with newly added history) are still stored as single objects and periodic repacking is needed to maintain space efficiency. The process of packing the repository can be very computationally costly. By allowing objects to exist in the repository in a loose but quickly generated format, Git allows the costly pack operation to be deferred until later, when time matters less, e.g., the end of a work day. Git does periodic repacking automatically but manual repacking is also possible with the git gc command. ...В версии статьи на русском можно найти:
В репозитории иногда производится сборка мусора, во время которой устаревшие файлы заменяются на «дельты» между ними и актуальными файлами (именно так! актуальная версия файла хранится не-инкрементально, инкременты используются только для шагания назад), после чего данные «дельты» складываются в один большой файл, к которому строится индекс. Это снижает требования по месту на диске.

nizkopal
Привет. Спасибо за статью, интересно.
Раз уж речь зашла о Selenium, такой вопрос… А чем хуже в том же Selenium открывать необходимую страницу и получать HTML-source? Так будет честнее, чем собирать HTML «руками», как мне кажется.
Если необходимо сравнение не всей страницы, а только ее части, ее довольно легко вырезать уже на скриншоте, после выключения всей динамики.
lahmatiy Автор
В нашем случае, мы тестируем компоненты и блоки. Нас интересует множество возможных состояний, которых может быть очень много. Например, компонент Checkbox сейчас имеет 39 состояний (если не ошибаюсь) – нам бы хотелось понимать как он выглядит в каждом, что это каждый соответствует дизайну и не имеет дефектов. А так же иметь гарантию, что при последующих изменениях все останется под контролем.
Если мы используем компонент в рамках блока или страницы, нам не нужны все его состояния – необходимо проверять, что его вид соответствует текущему набору данных и бизнес логике. А если что-то не так, нужна уверенность, что проблема не в самом компоненте, а в контексте (где он используется).
Можно загружать компонент/блок в Selenium, но для этого тоже нужно сделать сборку (bundle). А это не меньшее время. Запустить Selenium, открыть в нем страницу, чтобы получить HTML (а ведь нужен еще и CSS), по которому потом делать скриншот – оверхед, дополнительные траты ресурсов и времени. В целом можно, но получится сложнее и вряд ли быстрее.
Тестирование страниц и их блоков – несколько другой вид тестирования, со своими особенностями. И если нам нужно перебрать все состояния конкретного блока, то загрузка страницы и выделение лишь необходимого будет очень значительным оверхедом.
nizkopal
Это почти наверняка дольше. Единственное, почему я решил спросить — на первый взгляд такая проверка выглядит надежнее. Мы будем «стопудово» проверять компонент в том виде, в котором он показывается пользователю на сайте.
Но в целом Вы правы, это будет уже не unit-тестирование. Если описаный Вами метод приносит пользу, значит все не зря. :)
Спасибо за Ваш ответ.