
Мы постоянно сталкиваемся с системами, созданными другими людьми. Будь то UI приложений в смартфоне или облачные инфраструктуры современного Интернета — именно процесс взаимодействия определяет наши ощущения, впечатления, и в конечном счёте — отношение к технологии. Мы можем быть в роли инженеров, разработчиков или простых пользователей — user experience важен везде. Вокруг систем с хорошим UX образуется общество счастливых, довольных и продуктивных людей; плохой UX приводит только к боли и страданиям.
Даже если специально не отдаешь себе отчёт, то создавая новый софт, обязательно создаешь user experience. Когда код уже написан, с ним начинают взаимодействовать люди. Может быть, это разработчики из твоей команды. Может, это мобильные разработчики, пытающиеся использовать твой API, или сисадмины, на ночном держурстве пытающиеся разобраться, почему всё сломалось. Сами примеры могут быть совершенно различными по сути, но к ним применимы общие принципы. В этом хабропосте мы поговорим об идеях по поводу UX, дизайна API, психологии обучения, и других связанных областей. Рассмотрим применение хороших практик на самых разных уровнях разработки приложений. Что бы ты ни делал — писал базы данных, библиотеки, hypermedia API или мобильные приложения — рано или поздно кто-то прикоснется к твоему коду — и пусть уж он получит от этого удовольствие, верно?
В качестве прототипа хабропоста использован доклад Дилана Битти на DotNext 2017 Moscow, вошедший в тройку лучших докладов (по отзывам участников). Дилан занимается созданием веб-сайтов, начиная с далекого 1992 года. Девяносто второй год, с точки зрения разработки веб-приложений — времена действительно древние. Он является обладателем Microsoft MVP в категории Visual Studio and Developer Technologies. В родном городе Лондоне организует мероприятия .NET User Group. Дилан всегда раз общению и обмену идеями, поэтому можно писать ему на вот этот имейл: dylan@dylanbeattie.net, заходить на веб-сайт: www.dylanbeattie.net или комментить в твиттере: @dylanbeattie.
Счастье

Сегодня я бы хотел поговорить с вами об идее «счастливого» кода. Компания Spotlight, в которой я работаю уже 15 лет, занимается шоу-бизнесом, что включает в себя актерское искусство, телевидение, кино и т. п. В этой среде есть один общепринятый клип-арт, изображающий две греческие театральные маски — комедию и трагедию (или радость и грусть). За время своей профессиональной деятельности я становился свидетелем разных проектов. Были такие, которые, вроде бы, по всем параметрам заслуживали успеха. У них было прямо-таки всё: отличная команда, интересная задача, хорошая технология и т. д. Но этих ребят, как ни странно, ждал провал. Через каких-нибудь три месяца они приходили в свой офис и там их не ждало ничего кроме огромного моря проблем. А другие проекты, напротив, на старте казались безумными. У них не было даже денег — только два человека и одна неподъемная задача. И совершенно невероятным образом эти проекты удавались. Спустя три месяца команда располагала шикарнейшим продуктом, при этом их дух был на высоте, дело горело в руках, задачи решались оперативно одна за другой. Здесь есть о чём задуматься. На мой взгляд, те команды, которым вечно плохо, которые не любят приходить на работу, которым тяжело и они только и делают, что изнашивают себя дальше, — эти команды производят плохой софт. И наоборот, те команды, которые держатся на позитиве, — поставляют хорошие продукты. На протяжении всей своей карьеры я не наблюдал ни одной такой команды, в которой люди тяготились бы своей работой, все еще производя на свет отличные IT-системы. Я решил исследовать этот вопрос и попробовать понять, как же делать команды счастливыми. Ведь речь не о том, чтобы, скажем, закупить в офис настольный футбол. Поймите, что большинству программистов нравится кодить. Эти люди пришли в программирование не просто так, а потому что однажды они сели за комп и осознали, что им это очень интересно. И тот факт, что они могут зарабатывать этим занятием себе на хлеб, — большая удача для них. Но опыт накладывает свой отпечаток. И то, каким бывает этот отпечаток и как он сказывается на счастье программиста, мы с вами сегодня и обсудим.
Обнаруживаемость и дофамин
Обнаруживаемая система — это такая система, изучать работу которой вы можете свободно и самостоятельно. С такой системой не страшно взаимодействовать: она не даст вам сделать что-то непоправимое, потому что сконфигурирована безопасно, по принципу песочницы. Более того, такая система обычно активно предлагает вам способы осваивать ее — и не скучные, а увлекательные, такие, как будто у вас в руках игрушка или головоломка. Один из плюсов такой системы в том, что она действительно не требует ни обучающих руководств, ни документации. Но есть и другая особенность. Представьте такую ситуацию. Вы сидите на работе и принимаетесь за исправление багов. Один фикс, другой, третий. Вы чувствуете, что работа пошла, и вот вам уже не остановиться, как с Super Mario — пробуете ещё и ещё. Времени уже 3 часа ночи, а вы всё дерзаете. Было проведено исследование, показавшее, что в момент, когда человеку удаётся решить задачу, в его мозгу наблюдается прилив дофамина. Известно, что то же самое вещество отвечает за ощущения, испытываемые игроманом, когда он в очередной раз выигрывает, а также наркоманом, готовящимся принять дозу. Благодаря дофамину, человек усваивает вещи быстрее и качественнее, знания остаются на более долгий срок и легче применяются им на практике.

Получается, если мы создадим систему, работая с которой программист будет ощущать себя так, как будто щелкает одну за другой интересные задачки и головоломки, то он будет испытывать эти маленькие выбросы дофамина — станет работать продуктивнее и профессиональнее.
Кривая обучаемости
В психологии есть такое понятие как кривая обучаемости. Она показывает зависимость между количеством времени, затраченным человеком на изучение той или иной вещи, и той степенью компетентности, которую он приобрёл.

Перед вами две кривые: синяя — с крутым подъемом и красная — более пологая. Какая из них лучше? Мнения обычно разделяются пополам. Кто-то предпочитает идти по «крутому» пути: совершать трудный рывок, но достигать результата быстрее. Такие люди изучают язык Хаскель за 24 часа. Другие выступают за более медленный, но «ровный» процесс обучения. Это те, кто всю жизнь пользуются Microsoft Word, но пока что не знают как сделать разрыв страницы. Оба метода неплохие и имеют право на существование.
Табу №1: участки спада
Распространенной проблемой является кривая такого вида:
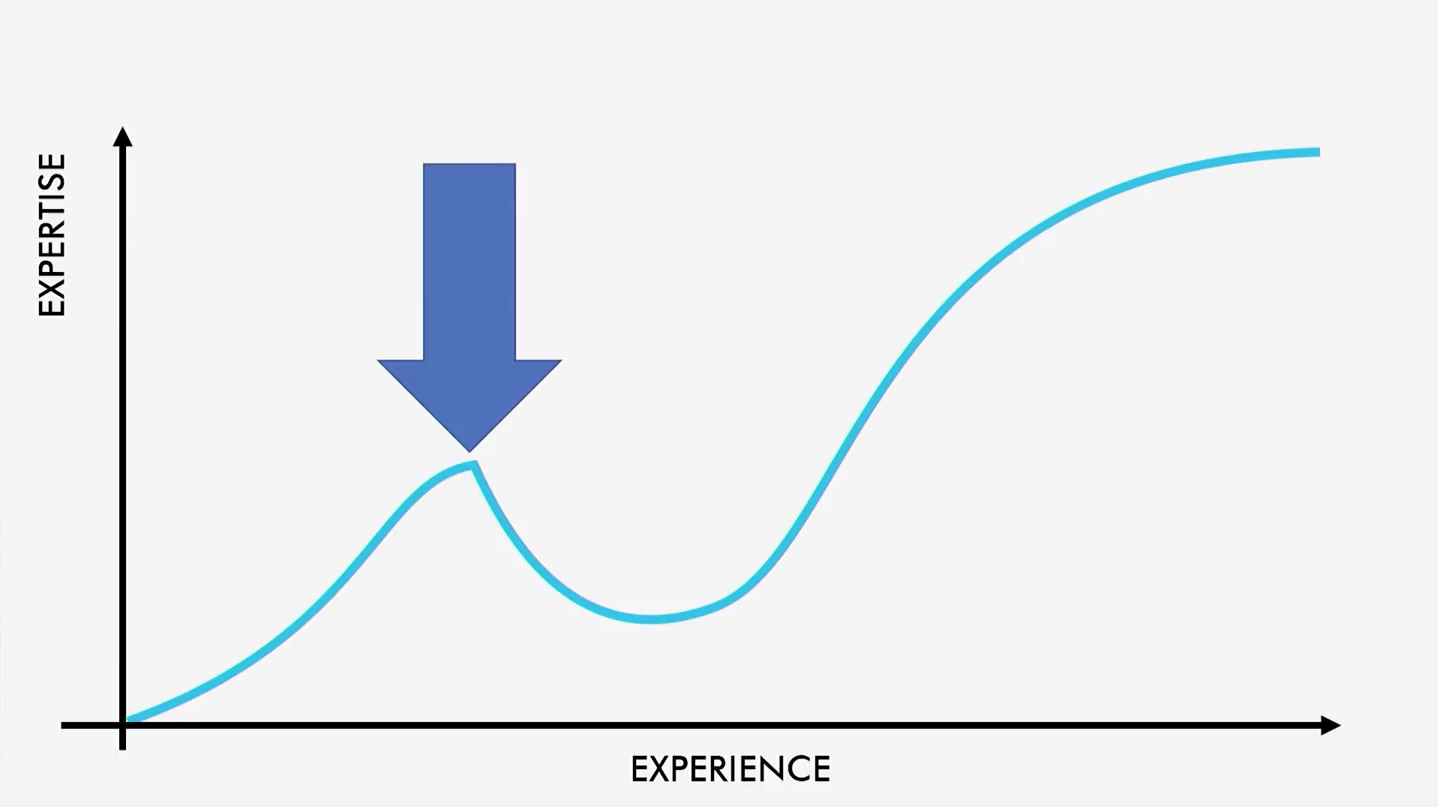
Участок спада графика, следующий сразу за локальным пиком, отражает ту ситуацию, когда пользователь вынужден сделать откат назад, потому что в ходе изучения материала понял что-то неверно и теперь вынужден переучиваться. Тот, кто занимался ASP.NET WebForms вероятно помнит, как легко осваиваются один за другим OnClick, OnItemDataBound и т. д. И вот вы уже чувствуете, что научились делать сайты. Но потом босс говорит вам, чтобы вы подключили систему потокового мультимедиа и настроили видео-трансляции. Вы заходите в Visual Studio, ищете здесь контроль потокового мультимедиа, но не находите его. ASP.NET WebForms сформировал у вас узкое, специфическое представление о вебе. Вероятно, заложенная в него абстракция была рассчитана на то, чтобы заманить в веб-программирование разработчиков VB. Потому что всё, чем оперирует ASP.NET WebForms, это кнопки, события, клики, привязка данных. А оказывается, что нужно понимать HTTP и HTML, запросы, ответы, stateless протоколы и прочее. Так вы и оказываетесь на том самом пике кривой. И скорей всего, в этот день вы уйдете с работы в плохом настроении, понимая, что потратили свои силы зря и теперь вам придется начинать заново. Так работать не нравится никому.
Табу №2: скачок кривой
Другой сценарий, которого желательно избежать, выглядит так:
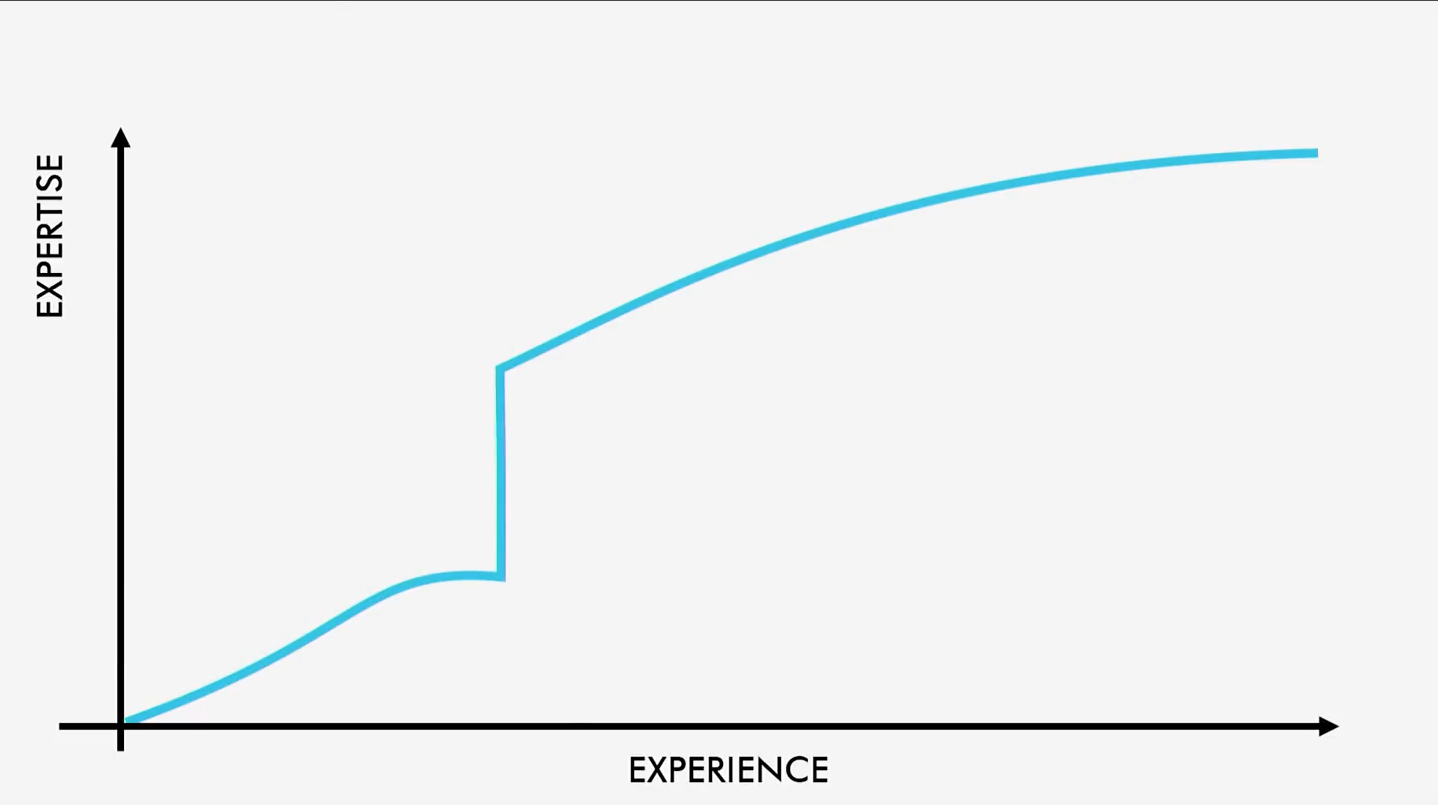
Это своего рода столкновение с кирпичной стеной. Вы уже начали понемногу осваиваться и вдруг на вашем пути возникает что-то неимоверно сложное, не поддающееся вашему пониманию, и вы благополучно застреваете. Я помню, как мне впервые объяснили понятие рекурсии в функциональном программировании. Я совершенно ничего не понял. Мне советовали просто тренироваться — применять её ещё и ещё. Но это сомнительный подход. По идее, это даже не скачок, а разрыв кривой:
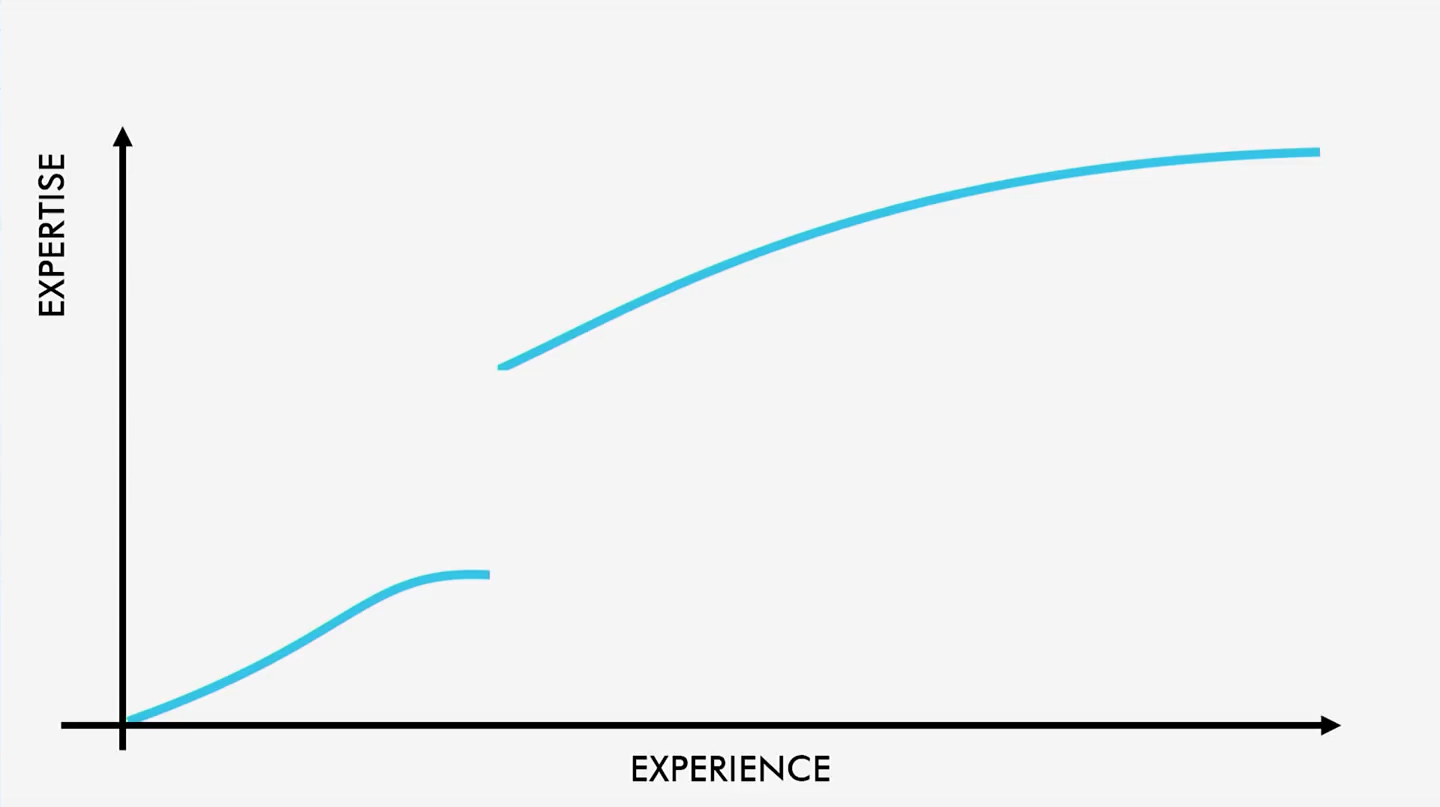
На самом деле здесь не одна, а две кривые. Попасть с одной на другую представляет для вас ощутимую сложность. А преодолев эту пропасть вы обнаруживаете, что вам так же сложно помочь в этом кому-то другому. Любое понятие реально раскусить. Рекурсия это или Y-комбинатор — вас рано или поздно «озарит». Я лично, на сегодняшний день не понимаю монады, хотя ясно, что однажды это преодолею. Человек может многое. И тем не менее, мы должны стараться разрабатывать наши системы так, чтобы изучающий ее пользователь по возможности не сталкивался особо сложными препятствиями.
User Experience
О UX я впервые задумался, работая с продуктом Castle Windsor. Скачав и установив его, я вставил в поле код, взятый с какого-то обучающего блога, нажал F5 и увидел такую ошибку:
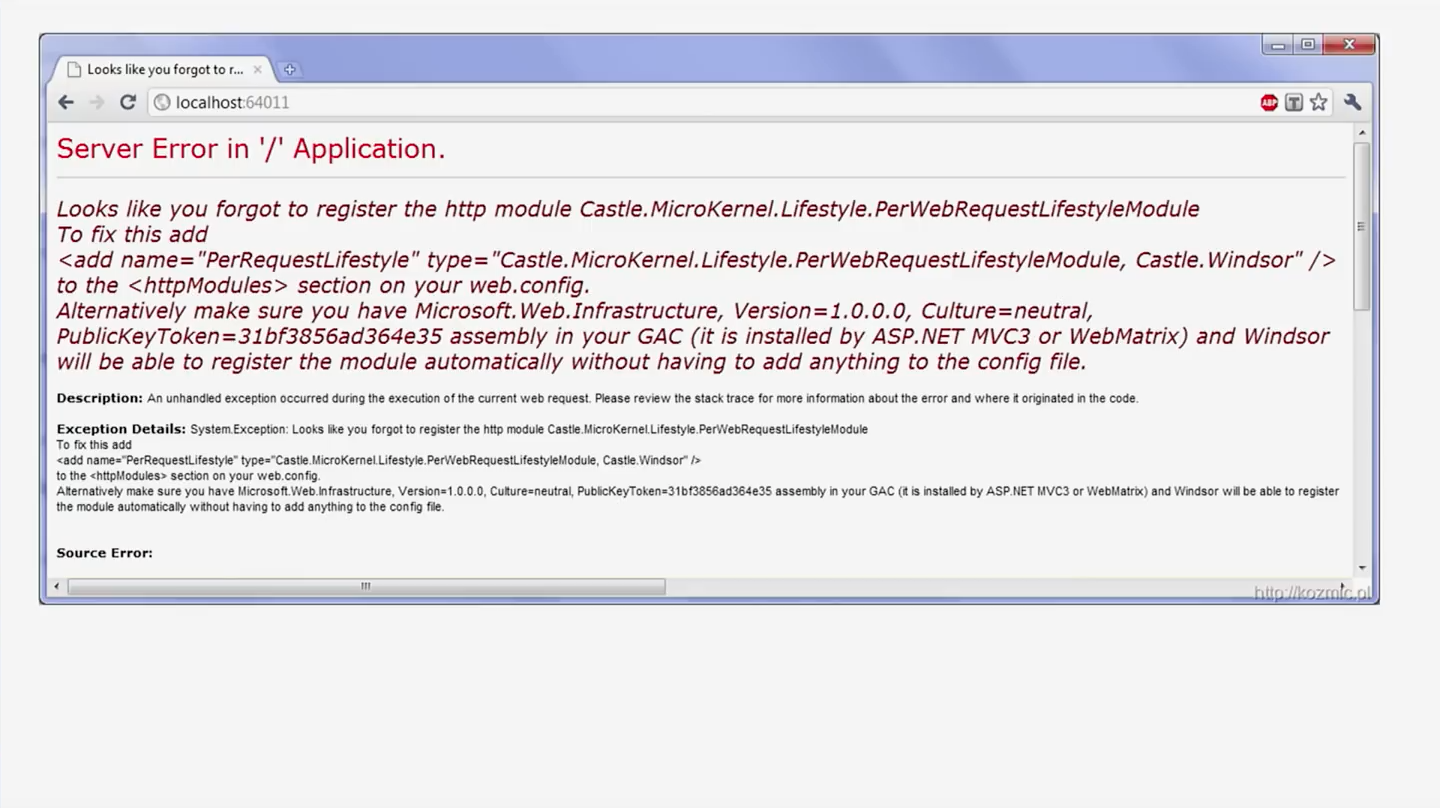
Я прочел текст целиком. «Похоже, что вы забыли зарегистрировать ваш модуль HTTP…». Обратите внимание на то, как по-дружески к вам обращаются. Разработчики не просто кинули вам ошибку. Они словно знали, что, вероятно, вы будете слабо понимать то, с чем работаете, и поэтому в комментарии привели кусок XML-кода и сказали вам скопировать его в свой конфиг-файл. После того, как я выполнил их указания, у меня действительно все запустилось. Человек, который писал обработку этого исключения, мог бы запросто оставить вам NullReferenceException или ConfigurationException, но он так не сделал. Он знал, что большое количество пользователей столкнётся с этой проблемой и знал причину. А причина, условно говоря, в том, что эти пользователи не выполнили некоторого действия, потому что для них оно не было очевидным, ведь никакого обучающего руководства они не открывали — просто нашли готовый код и запустили его. Разработчики же позаботились о том, чтобы ровно в момент запуска подоспеть с помощью. Среди девелоперов есть интересное поверье, будто UX — не их забота, что их дело заниматься бэкэндом, базами данных, API и прочим. Я не согласен с этим. С любым вашим кодом, так или иначе, будут взаимодействовать. Если вы создаете схему базы данных — знайте, что кто-то будет пытаться извлекать оттуда данные. Пишете API — кто-то будет использовать его для приложения. Разрабатываете приложение — кто-то будет отвечать за его поддержку, пока вы в отпуске.

Когда мы пишем код, мы определяем то, как будет происходить взаимодействие с различными группами наших пользователей (с коллегами-разработчиками, с покупателями, с партнерами). Очень важно рассматривать опыт и паттерны их работы: то, что вы почерпнете, поможет вам разумнее разрабатывать свои системы в дальнейшем. Итак, будем рассматривать примеры.

Первый день на работе, компания X
Представьте, что вы веб-разработчик и вас только что приняли на работу в новую команду. И вот вы приходите в офис в понедельник утром. Вам показывают, где кофемашина, где пожарный выход, затем наконец усаживают за рабочий стол и говорят, чтобы вы, для начала, ознакомились с сайтом и запустили его у себя локально. Итак, сперва вам нужен код сайта. Вы заходите в GitHub. Открываете репозиторий под названием «website», но он оказывается пуст. Видите другой репозиторий «website2», открываете его, но здесь тоже пусто. Потом находите «website2015», думаете, что наверное всё тут — но нет. Находите ещё какой-то «website», но здесь только несколько Perl-скриптов. Тогда вы вежливо обращаетесь к коллеге рядом с вопросом, где же вам найти код сайта. Оказывается, что всё хранится в репозитории «finance» Почему в «finance»? Потому что, как вам объяснили, разработчик сайта работал в команде финансистов… Окей, вы двигаетесь дальше. Находите код, запускаете его, но увы, ничего не работает: отсутствует куча требуемых dll-файлов. Вы снова вынуждены обратиться к коллеге рядом — теперь по поводу dll-файлов. Он быстро понимает о чём вы, говорит, что всё окей, сейчас он подключит вас к своему диску C и вы скопируете себе все нужные файлы. Сложная схема, думаете вы… Но так или иначе, вы получаете на руки все нужные файлы. Жмёте запуск. Но снова проблема: отсутствует подключение к базе данных. В лучшем случае, вы просто продолжите весь день дергать вашего коллегу и тогда к вечеру вы всё же запустите сайт на своей машине. Если же вам не повезло, то вас будет ждать такая ошибка:

В действительности, за этот эксепшн и за тот текст, который вы видите, кому-то были заплачены деньги. Этот кто-то знал о природе ошибки больше, но решил, что сообщать вам ничего не будет (ему вроде бы всё равно), а вы как-нибудь разберетесь и сами. Прямо скажем, опыт не из лучших. Обычно хорошие разработчики, пройдя через такие мучения, сразу берутся задокументировать процесс. Они составляют небольшое руководство, в котором описывают всю последовательность шагов, прикрепляют необходимые файлы, объясняют, что нужно сделать для подключения к базе данных и т. д. Но такого рода документация, как правило, очень быстро устаревает: буквально через неделю кто-нибудь обновит один из dll-файлов и ваше заботливое руководство моментально потеряет в цене.
Первый день на работе, компания Y
Вас точно так же наняли веб-разработчиком. В понедельник утром вы впервые являетесь в офис. Первое, что вам поручают: локально запустить сайт, код которого вы найдете в репозитории «Applejack». Вы заходите в GitHub, клонируете репозиторий, нажимаете F5 и видите: «Восстанавливаю пакеты NuGet». Берёте на заметку: у компании настроен сервер NuGet; здесь они хранят в общем доступе все dll-файлы, чтобы никому не нужно было просить их у коллеги рядом. Восстановление завершается, но запуск не удаётся: «Ошибка соединения с базой данных». Вы заходите в тот же самый репозиторий и в папке под названием «SQL» находите все скрипты базы. Сделаем остановку и проанализируем. Однозначно имеет место прилив дофамина. Ведь вы только что справились с поставленной задачей. При этом вам не пришлось просить никого о помощи — вы сами подняли систему и запустили её. Легко решив задачу, вы попутно ещё и запомнили, как всё устроено. Вы без труда зафиксировали, например, то, что в репозитории есть отдельная папка по базе данных и что там лежит описание схемы. И когда через несколько дней вам понадобится разобраться в том, как устроена та или иная таблица базы, вы, легко восстановив логику, найдёте файл со схемой — вам не придётся никого расспрашивать. Вся процедура запуска сайта занимает у вас не более пары часов. После этого ваш коллега предлагает вам пойти на ланч. Вы отправляетесь вместе с ним за гамбургером и по дороге спрашиваете, почему репозиторий с сайтом называется «Applejack». Он вам объясняет, что все репозитории здесь называют именами героев «My Little Pony». Ведь неважно то, как называть код, — важно наличие названия. Поэтому они распечатали список имен всех пони из мультика и каждый раз, создавая новый проект, просто выбирают какое-нибудь новое. Покажется, что это глупость. Но оказывается, что такой подход невероятно удобен. Когда система мониторинга присылает вам уведомление, говоря о том, что найдена проблема в работе «Applejack» — будьте уверены, вы сразу же поймете, о каком коде идет речь. Пользоваться именами также очень удобно тогда, когда вы проводите, скажем, финансовый анализ и вам нужно получить картину распределения ресурсов по различным проектам. У программистов есть понятие ограниченного контекста, идея разбиения системы на домены. Имена помогают вам получать подобные структуры. «Applejack», «Brandy Snap», «Cherry Jubilee» — каждый из них апеллирует к своей системе, охватывает всё, что с ней связано. Уже через день вас перестанут забавлять эти имена и вы ощутите, насколько система удобна.

UX: немного истории
Так выглядел мой первый компьютер:

Это был Intel 286, на котором был запущен знаменитый своими дискетами MS DOS. Когда вы включали его, он сначала издавал целую серию звуков, после чего на экране появлялось:

У вас в руках был работающий компьютер. Но дальше, чтобы вы не пробовали сделать, чаще всего он отвечал вам одинаково:
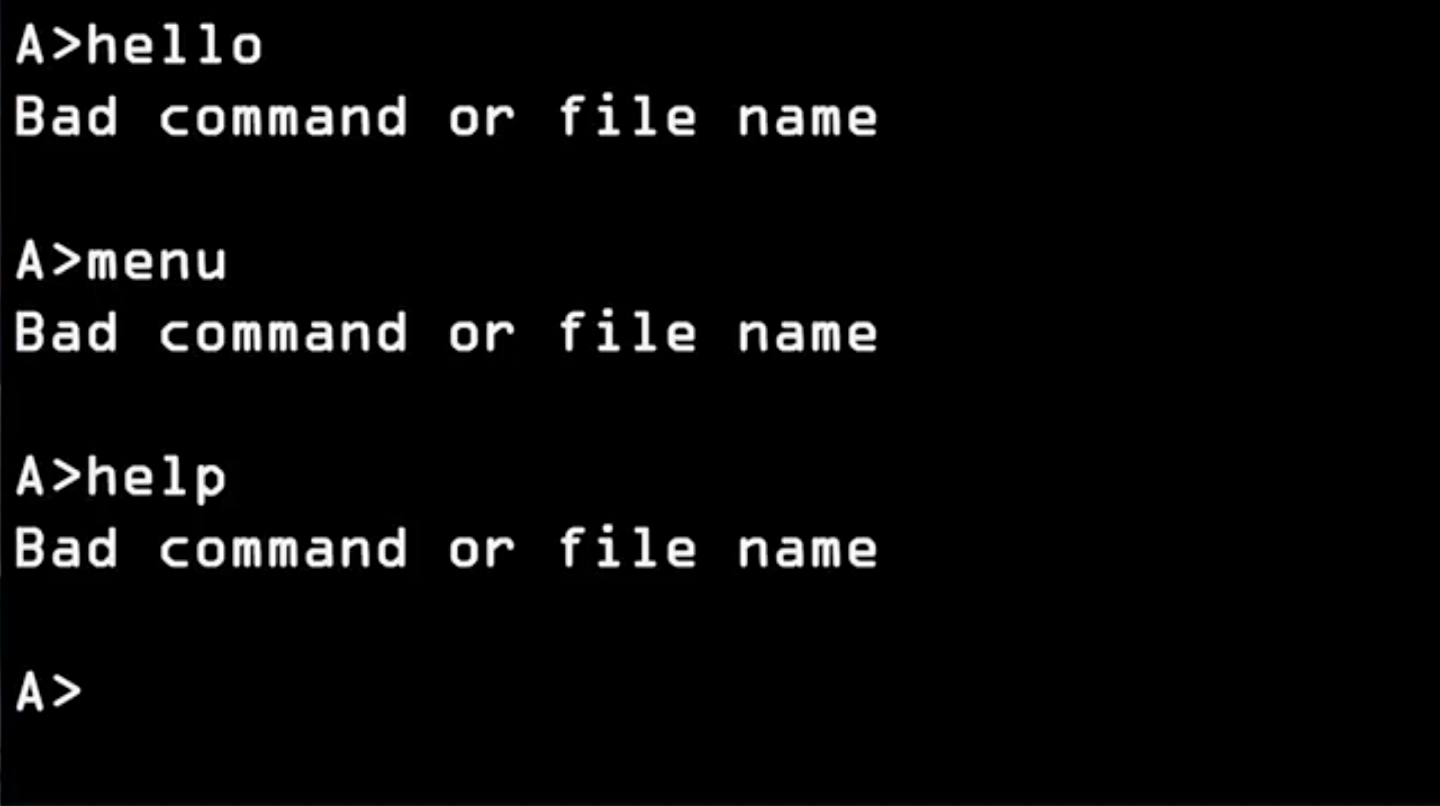
Это был дорогой компьютер и при том — непробиваемая бетонная стена. С ним невозможно было работать: вы без конца видели «A>», он ругался на каждую введенную вами команду. Поэтому вы приобретали толстенный справочник и там выискивали точный синтаксис команды. Другим популярным в то время ПК был Macintosh, работающий под Mac OS 7. Когда вы включали его, сначала появлялась маленькая иконка улыбающегося компьютера:

Затем загоралась надпись «Добро пожаловать в Macintosh»:

Какое-то время компьютер щелкал и выл, после чего загрузка завершалась и на экране появлялся интерактивный десктоп с множеством всего кликабельного:
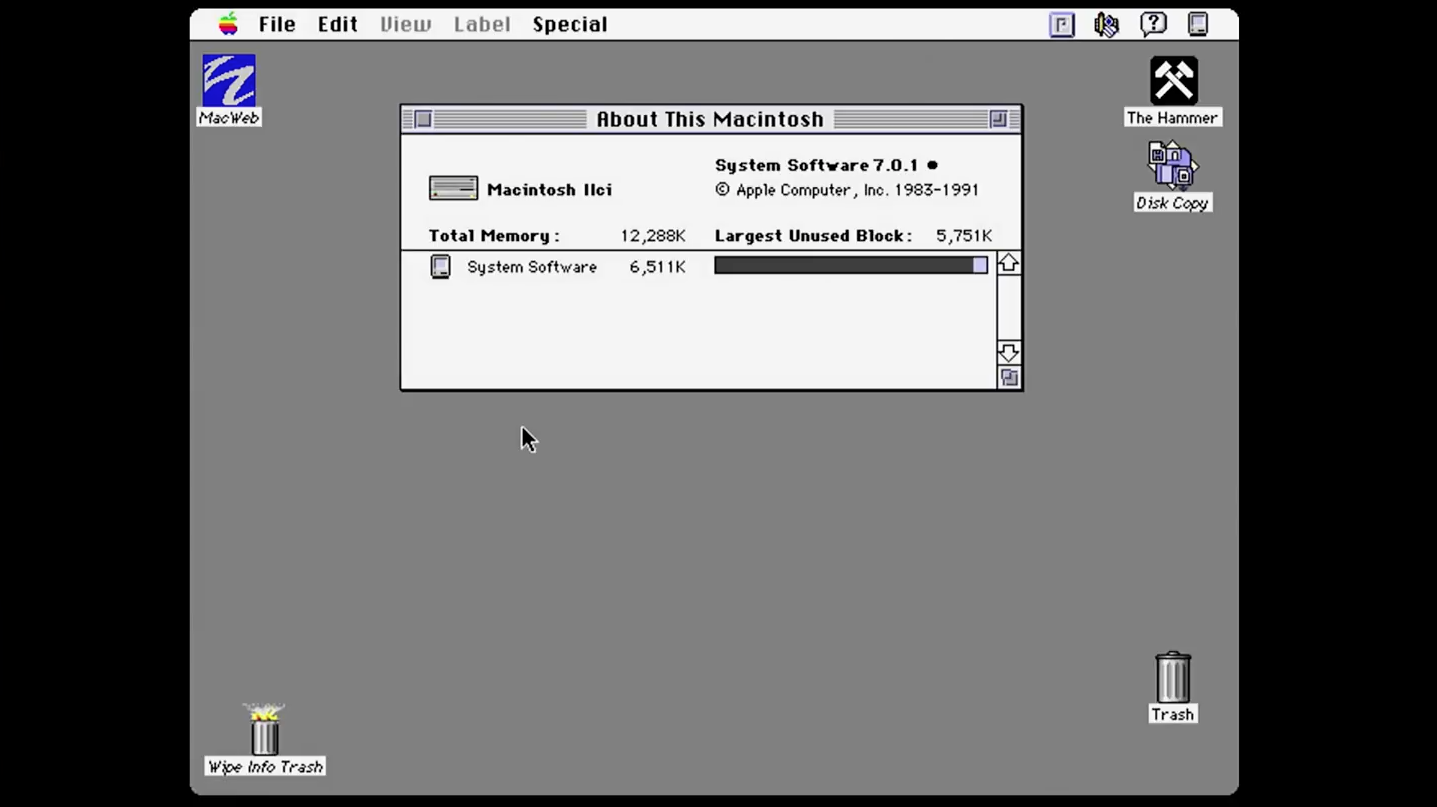
Под рукой у вас была мышка. Вы быстро ее осваивали и могли без труда управлять курсором на экране. Вы понемногу исследовали десктоп: «File» — очевидно здесь можно управлять хранящимися файлами, «Edit» — редактирование, «View» — просмотр. Мак воплощает идею аффордансов (идею возможностей) — когда система демонстрирует то, что умеет. И вместо того, чтобы лазить в справочник, вы можете наслаждаться исследованием системы: выбирать из предложенного, пробовать возможности. Иногда люди злоупотребляют таким подходом. У нас есть фичи, говорят они, так давайте для каждой из них добавим в интерфейсе свою кнопку — будет удобно. Они получают что-то такое:

Как видите, бессчетное число кнопок и маленькое окошко в середине, в котором пользователь будет писать код. Суть в том, что такой интерфейс ничем не лучше DOS-овского с его извечным «A>». Потому что это безумие — вынести всю имеющуюся функциональность в кнопки. Пользователь не будет знать ни то, с чего начать, ни то, за что отвечает та или иная кнопка, ни то как с этим всем работать.
UX: лучшее
Говоря о UX, я всегда очень рекомендую к просмотру этот ролик:
Думаю, что многие узнали первый уровень игры Portal 2. Мало того, что это смешно и затягивает — авторы в течение минуты обучили вас тому, как двигаться, как взаимодействовать со средой, какие клавиши для чего использовать. Вот таким должно быть ваше движение по кривой обучения!
Настраиваемость функциональности
Другой пример, который я приведу, касается MS Edge — альтернативы платформы для веб-браузера от Microsoft. Предположим, что вы программист и вы только что установили себе MS Edge. Вы открываете какую-нибудь страницу, щелкаете по ней правой кнопкой мыши и видите почему-то всего две опции: «Выделить всё» и «Печать». Как так, думаете вы, я же инженер-программист, где все мои инструменты для работы? Вы заходите в обозначенное тремя точками меню и находите здесь «Средства разработчика F12». В следующий раз вы уже быстро найдете эту опцию в списке: она очень примечательно отмечена горячей комбинацией «F12». Вы включаете эту опцию и Edge пишет вам: «Теперь в контекстном меню будут показаны пункты "Проверить элемент" и "Просмотреть источник"». Настройка Edge была прекрасно продумана разработчиками. Что касается кода источника, то, как вы понимаете, 99% всех людей, использующих веб-браузеры, никогда в жизни не открывают его. Сложно представить, что вам звонит мама, говорит, что у неё сломался интернет, что она открыла код источника, но забыла, что делать дальше. Первое, что вы ей посоветуете — закрыть код источника. Для разработчика же данное средство очень удобно: оно позволяет решать некоторые проблемы за время порядка 10-15 секунд. Таким образом, Edge настроенный по умолчанию, не грузит вас всем множеством своей функциональности. Если же эта функциональность вам необходима — вы без проблем её включите.
Поговорим теперь о том, что же мы можем привнести в наш собственный код для того, чтобы улучшить опыт и паттерны тех, кто им пользуется. Я так полагаю, что все вы знакомы с идеей автодополнения кода: вы пишете название объекта, ставите точку — и видите список всего, что доступно для использования.
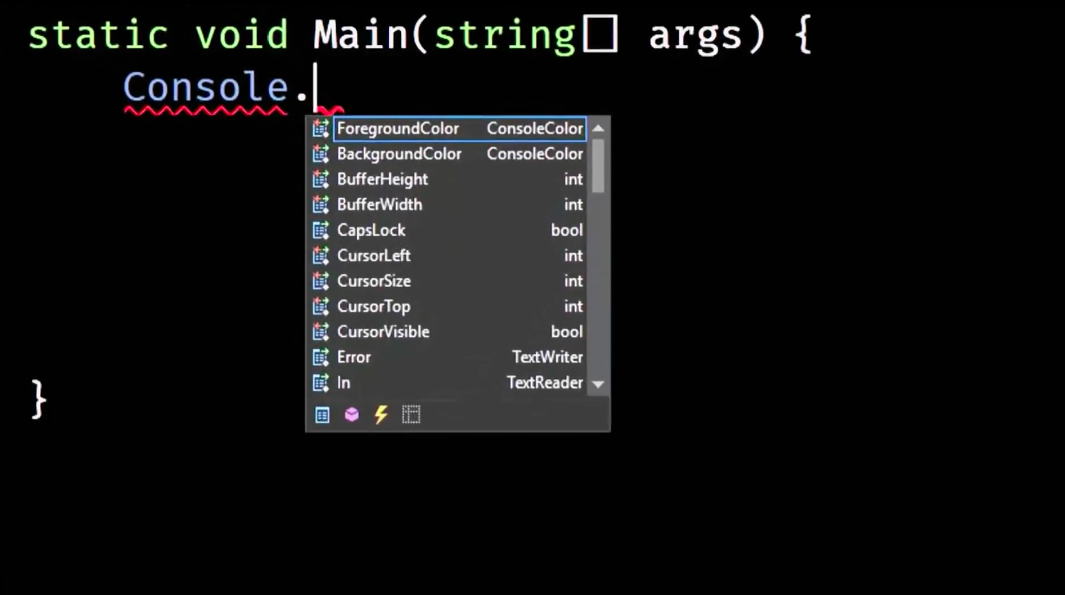
Вы пишете Console.ForegroundColor, ставите знак равно и система, понимая, что вы обратились к перечисляемому типу, предлагает вам доступные опции:
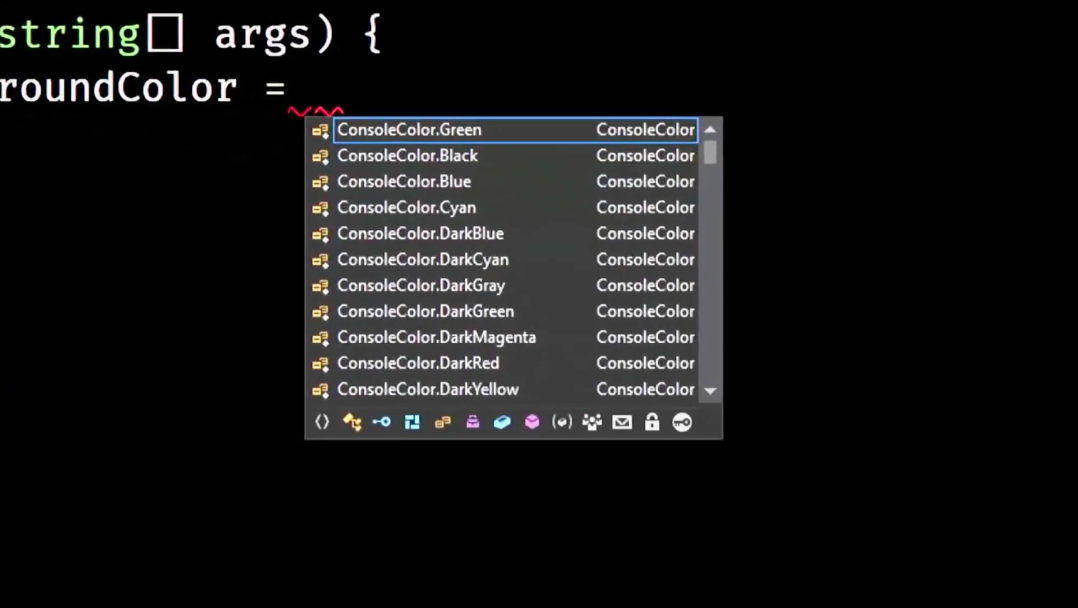
Технология носит название IntelliSense и значительно облегчает работу программиста. Вам не нужно обращаться к справочнику — просто ставите точку и выбираете из имеющегося. Все мы пользуемся этой функцией, но многие ли пробовали внедрить ее в свой собственный код, чтобы помочь тем людям, которые будут им пользоваться? Недавно я осознал, что, несмотря на 15 лет работы с .NET, я всё равно не умею составлять строки SQL подключения: я просто не помню их синтаксиса. При объявлении нового SQLConnection, мне подсказывают, что нужно вставить строку, но ничего не говорят о том, как ее сконструировать.

Мне приходится заходить на ConnectionString.com и искать информацию там. В качестве решения, я создал свою небольшую библиотеку SQL.Connect. В нее я поместил один единственный класс, в нём определил статический метод, а в комментарий к методу поместил кусок из документации. Теперь, в момент, когда требуется указать строку подключения, мне выскакивает подсказка с синтаксисом. Проблема решена. Реализовать такое решение очень просто: вам буквально понадобится вставить кусок данных XML в документацию к методу (специальный вид комментария).
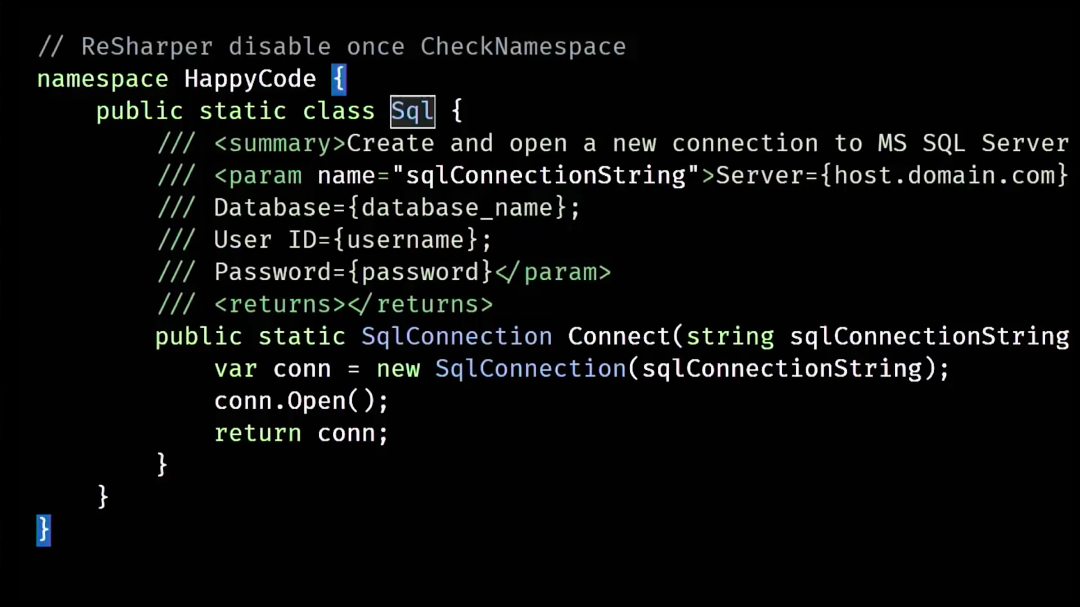
Если вы пользуетесь при этом Visual Studio, Visual Studio Mac, Code Writer или любой другой средой, поддерживающей пользовательскую документацию — ваш комментарий будет распознан и появится во всплывающем окне в качестве подсказки, как только вы откроете скобку.

При этом вам не придется останавливаться, переключаться к окну браузера, гуглить синтаксис. Писать код станет гораздо удобнее. Но важно отметить, что такие решения работают хорошо только тогда, когда вы знаете в точности, что и как будет делать пользователь. Иногда сценарий работы целевого пользователя с вашей библиотекой классов является строгим, без ветвлений. Но если не всё так однозначно, то мы должны позаботиться о том, чтобы помочь пользователю, подсказать какие опции ему в данный момент доступны, предложить удобный интерфейс для выбора.
Signposting

В UX есть паттерн, называемый «signposting» (буквально: «дорожные указатели»). Предположим, вы знаете, что в рамках работы с вашим приложением пользователь находится на некотором распутье, меняет какой-то код и т. п. Что мы можем сделать, чтобы подсказать ему доступные варианты и ресурсы? Поговорим об HTTP API, который является одной из лучших реализаций идеи «signposting» на сегодняшний день. Почему нам так легко пользоваться веб-страницами? Потому что они полны ссылок, которые являются мощнейшими инструментами навигации. Ссылки, которые вы видите на странице, показывают вам то, куда вы можете переместиться. Нажимаете на ссылку — попадаете на другую страницу; страница не понравилась — жмёте «назад», находите другую ссылку, нажимаете на неё — попадаете на новую страницу. Сеть является настолько удобно исследуемой системой именно благодаря грамотному «signposting». Эти паттерны вполне можно позаимствовать и для наших API. В течение последнего года я и моя команда работали над проектом, изначально задуманным как REST API с встроенной в ресурсы Hypermedia. Мы получали некоторый код JSON и, используя HAL (Hypermedia Application Language), вставляли в него ссылки, которые бы указывали на доступные со страницы ресурсы. В какой-то момент нам понадобилось создать несколько инструментов, которые бы помогали нам исследовать и дебажить написанный код, что мы и сделали. Впоследствии мы решили, что опубликуем эти инструменты вместе с документацией по нашему API, чтобы наши пользователи тоже могли при необходимости ими воспользоваться. Одно из этих приложений выглядит так:
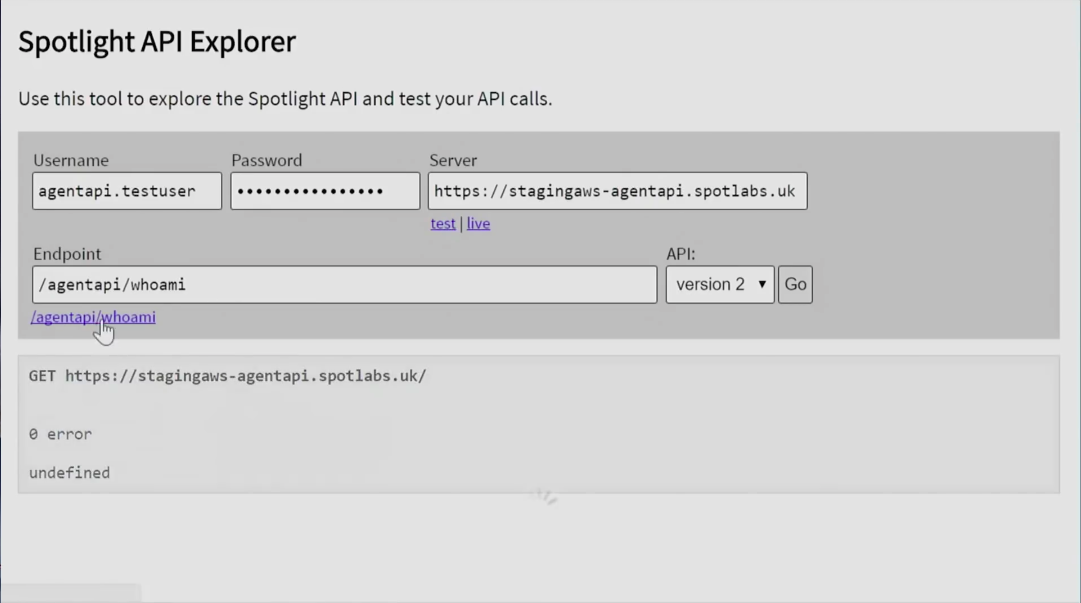
По идее, любой, обладающий необходимыми правами, сможет зайти в него, переключиться в режим песочницы и далее увидеть исполняющийся код основного приложения. По ссылкам внутри JSON-кода можно будет кликать и таким образом перемещаться по разным страницам.
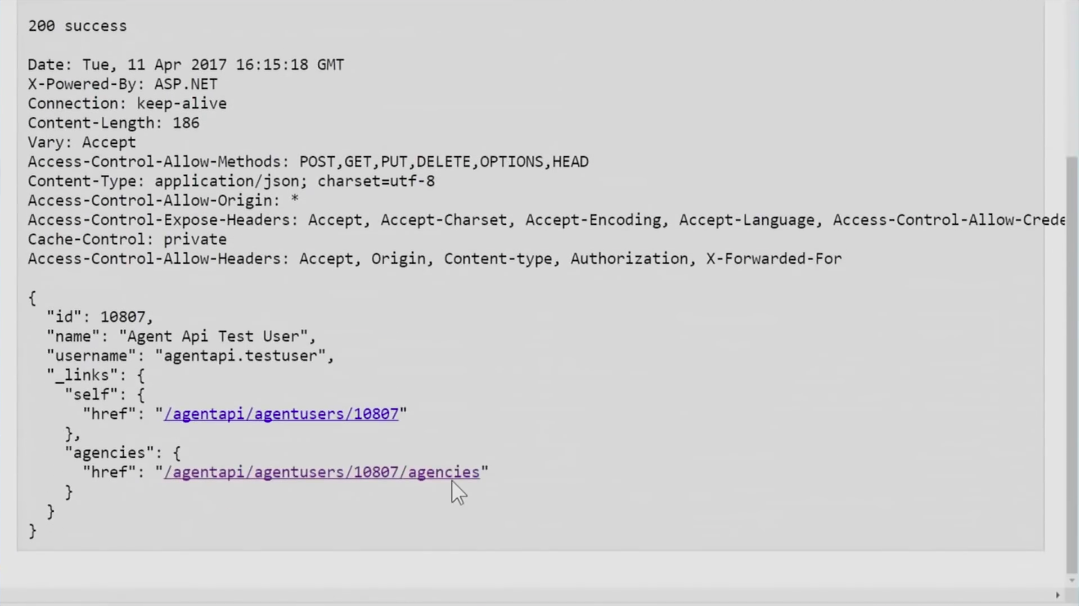
Таким образом, для того, чтобы исследовать наш API, разработчикам не понадобится писать свои программы, просматривать документацию — они смогут исследовать систему, рассматривая ее и взаимодействуя с ней. Начали мы именно с того, что создали поддержку кликов, навигации, перемещения от одного ресурса к другому. Позднее мы добавили сюда инструменты для взаимодействия с Hypermedia. Теперь вы можете выбрать ресурс, отобразить его в браузере и прямо оттуда выполнить запрос PATCH, POST, PUT, DELETE. Такие решения, опять-таки, избавляют от необходимости использования документации. Вы будете обращаться к ней скорей как к инженерной спецификации (тогда, когда вам понадобится информация об таблице кодировок, используемой для того или иного поля и т. д.). Если же вы просто исследуете систему, хотите получить представление о том, как она работает, чтобы суметь реализовать поверх неё своё собственное решение, — тут мне нравится идея просто выложить это в открытый интернет, чтобы люди могли играть этим как им заблагорассудится.
По большей части, мы говорили с вами о нашем взаимодействии с другими разработчиками. Но есть и другая многочисленная категория людей, которая будет работать с нашим кодом — это те, кто занимаются поддержкой системы. Это инженеры, консультирующие клиентов по телефону, команда вашего бэк-офиса, операционные команды компаний, которым вы поставляете свой продукт и т. д… Поэтому оставшуюся часть разговора я посвящу мониторингу и логированию.
Мониторинг
Сценарий первый
Утро, вы сидите на работе. Раздается звонок. Человек на том конце трубки сразу же заявляет: "у вас проблема с системой!". Ничего себе обвинение! Вы слушаете, делаете несколько в меру бесполезных заметок, спрашиваете контакты и кладёте трубку. И вы такой: "Проблема с системой? Что он имеет в виду вообще?" Раздается следующий звонок, и там тоже: "у вас проблема с системой". Вы такой: "С какой системой хотя бы?", клиент: "С той что в интернете! Она не работает!". Люди продолжают и продолжают звонить, но не могут объяснить ничего полезного.

Проходит время, и наконец-то кто-то обещает выслать вам скриншот. Вы приободрились, скрин должен облегчить вам работу! Но то, что вам присылают, выглядит так:

Каковы ваши шансы на устранение этой проблемы? Кодовая база приложения насчитывает примерно 60 000 строк кода и, вероятно, около 5000 HTTP-запросов. На проверку каждого запроса уйдёт по 20 минут — что ж вам, потратить на одну ошибку 6 недель? Всё, что вам известно: «Время ожидания запроса истекло». Вы не знаете ни то, какая из систем дала сбой, ни то, какой причиной он был вызван. Возможно, сеть клиента не в порядке. Видимо вам всё же придется проработать все 5000 запросов. Перспектива шестинедельного квеста не радует ни вас, ни вашего босса. Но другого выхода нет: от клиентов продолжают поступать жалобы.
Сценарий второй
Вы приходите на работу утром. Звонки, еще не начались. Вы подходите к большому экрану, висящему на стене.

Здесь отображается статус мониторинга различных частей системы, запущенной в продакшн. Обычно поля окрашены в зелёный. Сегодня же три из них светятся красным.
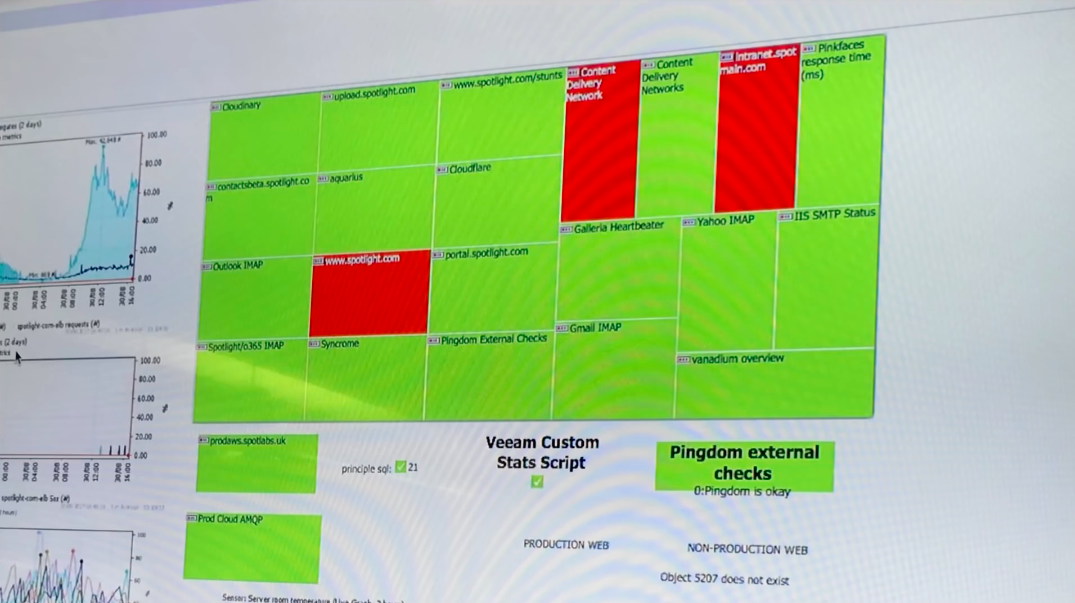
Вы видите, что проблемы возникли с основным сайтом, с Intranet и с CDN. Звонков пока не было, злых постов на твиттере — тоже. Это хорошо: пользователи еще не успели столкнуться с возникшими проблемами. Вы срочно беретесь траблшутить. Очевидно, что основной сайт и Intranet не могут работать, пока есть сбой с CDN. Поэтому в первую очередь вы будете чинить CDN. Вы заходите в нужную подсистему, начинаете искать здесь причину сбоя. Вскоре вы находите её: один из сертификатов то ли был отозван, то ли просрочился. Всё, основная работа вами сделана. Дальнейшие действия ясны. Таким образом, вам удалось идентифицировать, диагностировать и устранить проблему раньше, чем с ней столкнулся пользователь. При этом ваша команда тоже была в курсе происходящего и могла контролировать ситуацию. На самом деле фото с монитором было снято в моем лондонском офисе. Мы сделали такую систему исключительно из соображений удобства — чтобы команда в ходе работы могла видеть текущее состояние системы. И знаете какой дополнительный эффект мы заметили? Бывает, что коллега из другой команды заходит к вам в комнату с каким-нибудь ерундовым вопросом, вроде того, выбрали ли вы себе блюдо на предстоящий рождественский ланч. Теперь, если человек заходит к нам по такому делу и видит на экране красные поля, то сразу же без вопросов удалялся, понимая, что для его ерунды сейчас не время. А иногда нам даже предлагали занести кофе и сэндвичи. Этот экран неожиданным образом поднял наш командный дух. А бороться со сбоями, исключениями и прочими проблемами продакшна стало теперь намного проще.
Необходимый баланс
Точно так же, как и с интерфейсами, ваши экраны мониторинга ни в коем случае не должны быть перегружены информацией. С одной стороны, эта система не должна быть лампочкой, которая просто загорается красным при появлении где-либо в системе проблемы — такой мониторинг практически бесполезен. С другой стороны, нельзя отображать всё или почти всё — это точно так же неудобно.

Вы должны понимать, что какая-то небольшая часть вашей живой системы всегда будет работать не так, как было вами запланировано. По словам людей из NASA, при запуске Сатурна-5, системы, насчитывающей около 6 000 000 подвижных частей, исправно отработали 99.9% из них. Это означает, что около 6000 деталей дали сбой. Однако полет считается успешным. В любой системе, которая в достаточной мере сложна с инженерной точки зрения, в любой момент времени всегда будет что-то, что работает медленно либо неверно. Какой-нибудь узел одного из ваших кластеров обязательно будет тормозить, потому что одна из его баз данных решила провести переиндексацию. Выбирая то, какие данные о состоянии системы отображать, вы должны найти некий баланс: показать не слишком мало, но и не слишком много.

Автомобили снабжены отличной системой мониторинга. При нехватке бензина загорается одна лампочка, при проблемах с тормозами — другая. Всего вам нужно контролировать около 6 штук, каждая из которых отвечает за свою подсистему. А получив сигнал, вы уже разберетесь, какие вам предпринять действия. А теперь отвлекитесь на минуту и вспомните старые серии «Стартрека».

Двигатель для звездолета «Энтерпрайз», над которым они вели работу, был установлен в самом центре помещения и, таким образом, был обозреваем для всех. При этом корпус двигателя сделан прозрачным; всё, что обычно скрыто от нас за приборной панелью, здесь, напротив, — хорошо просматривается. Создатели шоу сделали это не просто так: двигатель должен был стать частью обстановки и, а некотором смысле, и частью нарратива. Постарайтесь сделать таким и ваше приложение. Вы можете создавать дашборды, которые будут приоткрывать завесу для ваших пользователей, давать им возможность обозревать систему и то, что в ней происходит.
Nancy
То средство для исследования API, которое я продемонстрировал вам ранее, со стороны бэкенда обеспечено системой Nancy — специальным фреймворком для создания HTTP API на .NET.

Если у вас есть продакшн-система, то вы просто добавляете на конец URI «/_Nancy/» и, получив реквизиты, попадаете в личный дашборд.
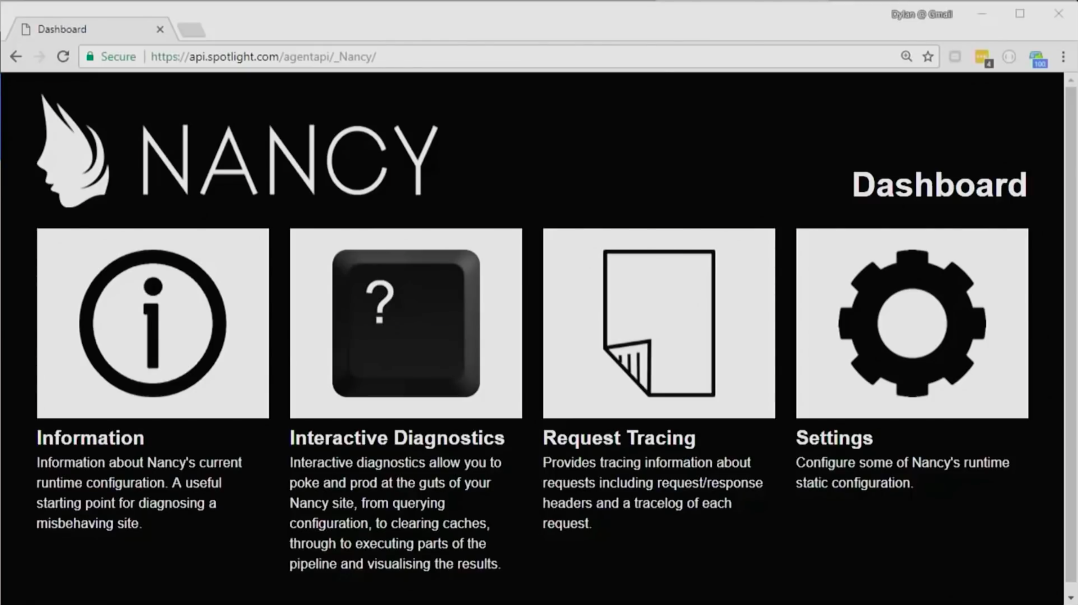
Перед вами отображается текущее состояние вашего живого приложения. Это уже не сайт, запущенный вами локально через Visual Studio — здесь вы наблюдаете за работой приложения в реальных условиях, можете следить за любыми конфигурациями, компонентами, зарегистрированными сервисами. И этот инструмент особенно пригодится вам в том случае, если понадобится срочно диагностировать проблему. С помощью Nancy вы сможете видеть все корни, скомпилированные в приложении. В коде вы могли дать программе вполне определенные указания, но всегда остаётся шанс, что что-нибудь пошло не так. Возможно, где-то возникла проблема чувствительности к регистру, где-то был пропущен кусок кода и т. д. Можно включить специальный трейсинг и следить за всеми запросами (в том числе и за успешными). К примеру, попросите ее отобразить все запросы, которые поступят в продакшн-систему в течение следующих 30 секунд — и вы сможете просмотреть любой из этих запросов в деталях (заголовки, данные о согласовании, об аутентификации и т. д.). Это очень мощное и удобное средство. Правильная организация мониторинга очень важна. С некоторых пор мы постоянно думаем о том, как нам лучше дать доступ до состояния приложения тем, кто с ним работает, что именно о его текущей работе важно показать и т. д. Но отображение текущего состояния системы — это только одна сторона медали. Есть и другая — логирование.
Логирование
Вы приходите на работу и видите на вашем большом экране красное поле. Как выясняется, процессор сервера базы данных загружен до 100%.

Но это не более чем точка на графике. Она не выявляет причину. Я знаю как минимум три сценария того, как может произойти загрузка процессора сервера БД до 100%:
1? Нагрузка росла постепенно и планомерно и только спустя долгое время она достигла максимума и спровоцировала отказы.
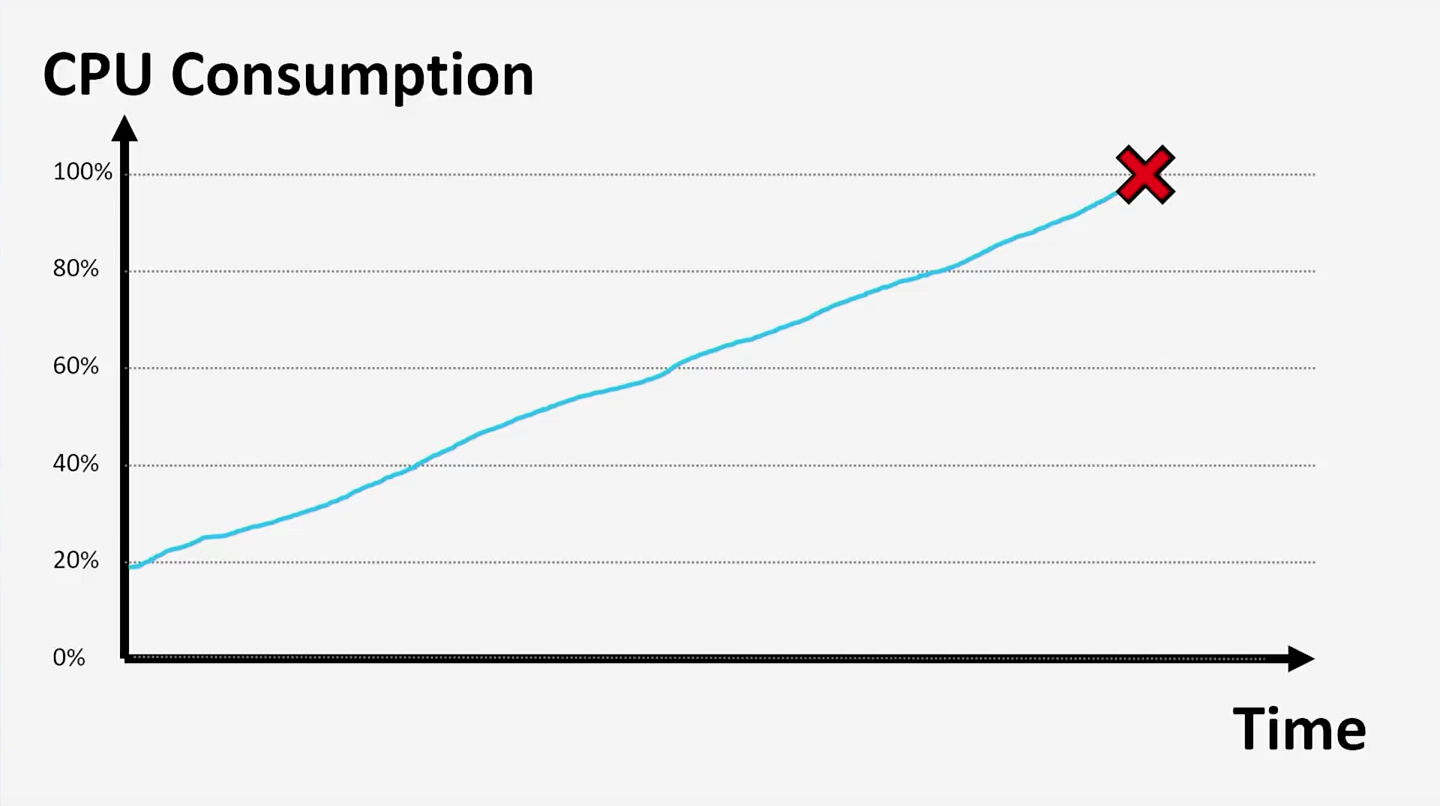
2? Другой сценарий выглядит так:
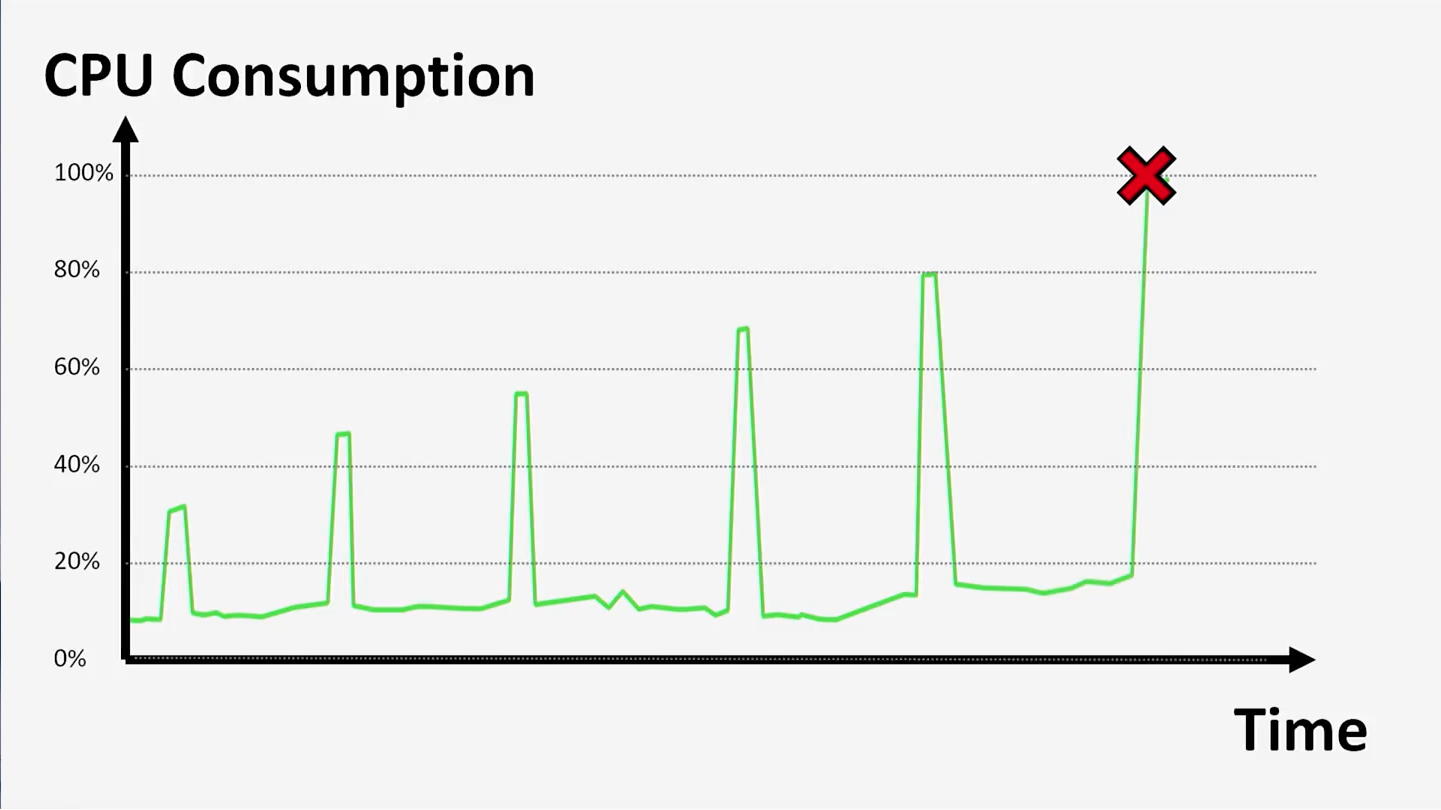
Такая картина потребления ресурсов очень характерна для систем, регулярно выполняющих крупные бэкапы. Подобный случай был и на нашей практике. Наш сервер должен был выполнять по бэкапу каждую ночь. Количество данных в базе с каждым днем увеличивалось. Пропорционально возрастал и объем каждого следующего бэкапа, и, однажды, достигнув критической цифры, он занял весь ресурс процессора — даунтайм сервера произошел прямо посреди ночи.
3? Ещё один вариант работы сервера:
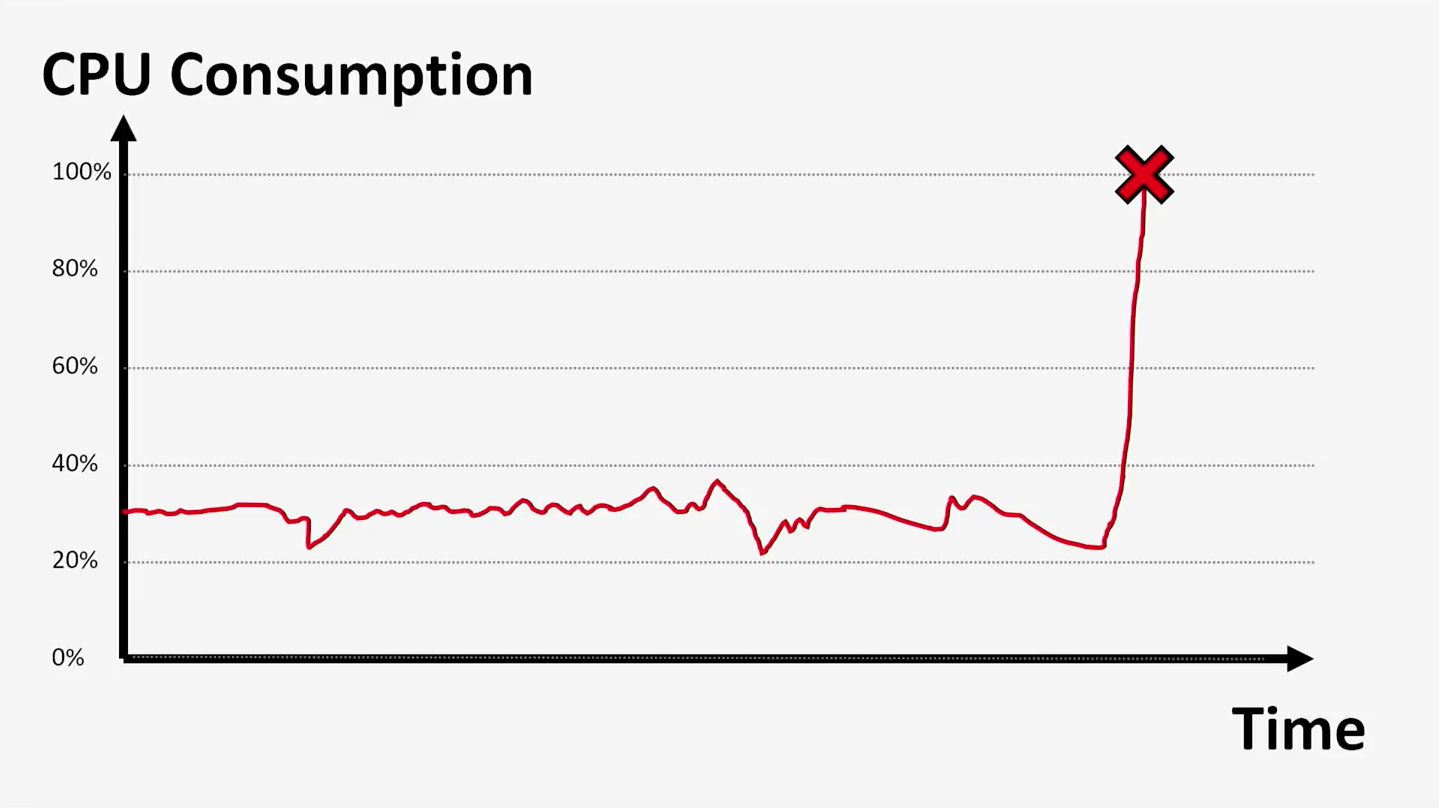
Такой сценарий мы наблюдали чаще других. В ходе разработки всё идет неплохо, а подскакивает загрузка процессора тогда, когда вы разворачиваете проект на продакшн. Как видите, самого по себе факта перегрузки процессора мало. Чтобы предпринять какие-либо действия, вам понадобится, для начала, увидеть некоторую картину произошедшего. Для начала нужно понять, какой период времени отображен на графике — последние 5 часов работы или последние полгода?
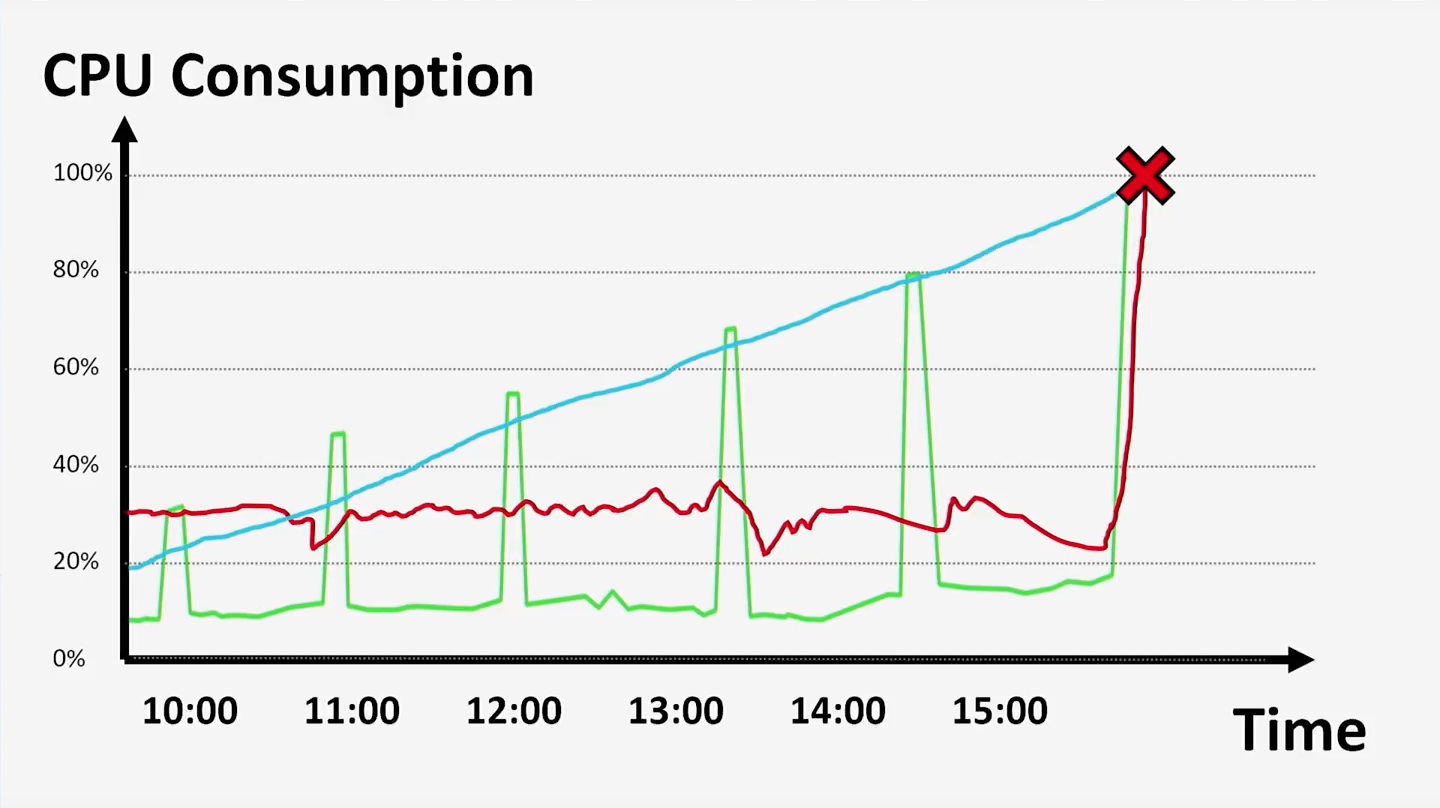
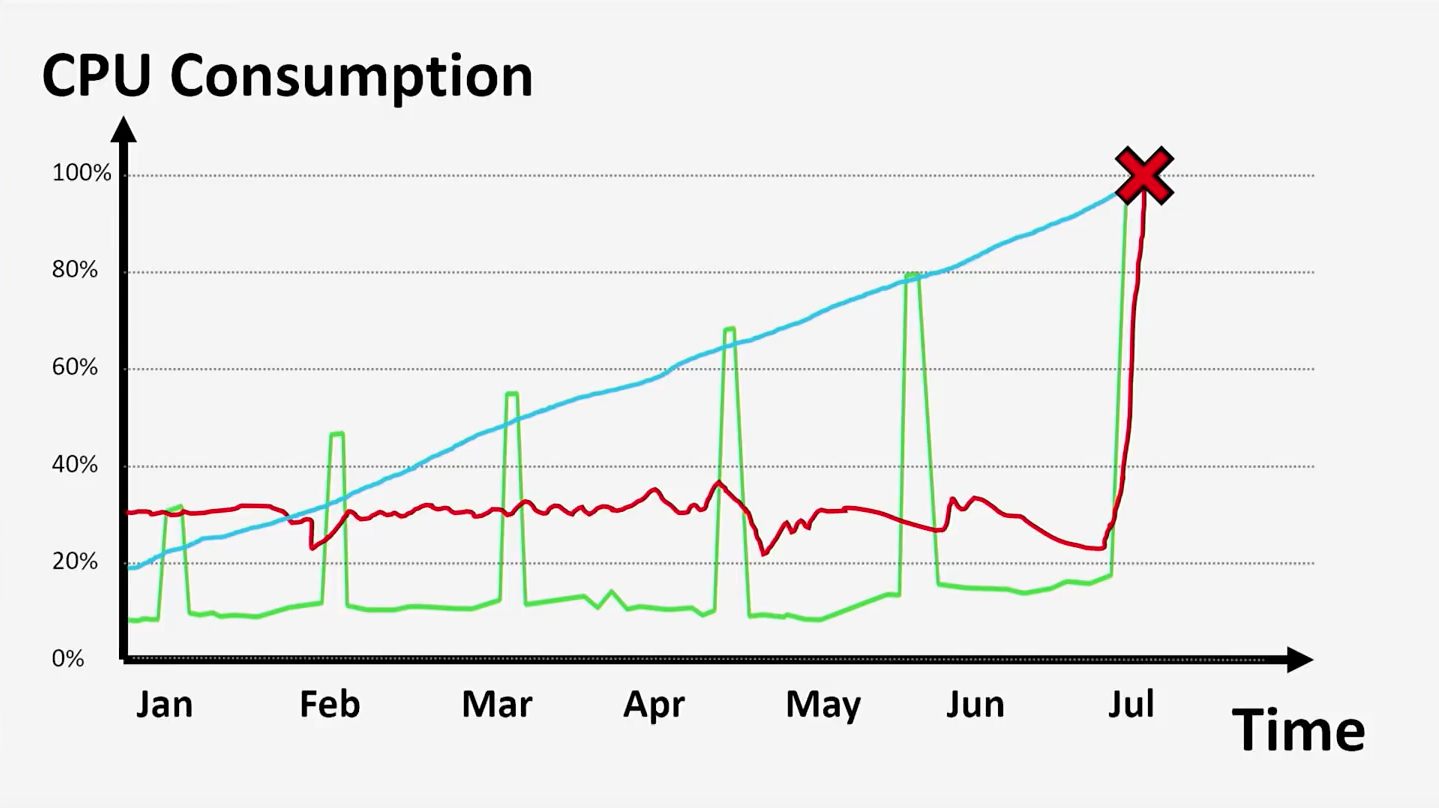
Если вы не знаете, что происходило с вами на прошлой неделе, вам будет сложно оценить то, насколько нормальны вещи, происходящие с вами сегодня. Ваше приложение, его инфраструктура и условия функционирования уникальны. Единственное, от чего вы можете попробовать оттолкнуться при сравнении, — это картина системы до критичных событий.
Redgate
Перед вами график состояния одной из наших продакшн систем, отображаемый системой SQL-мониторинга Redgate.
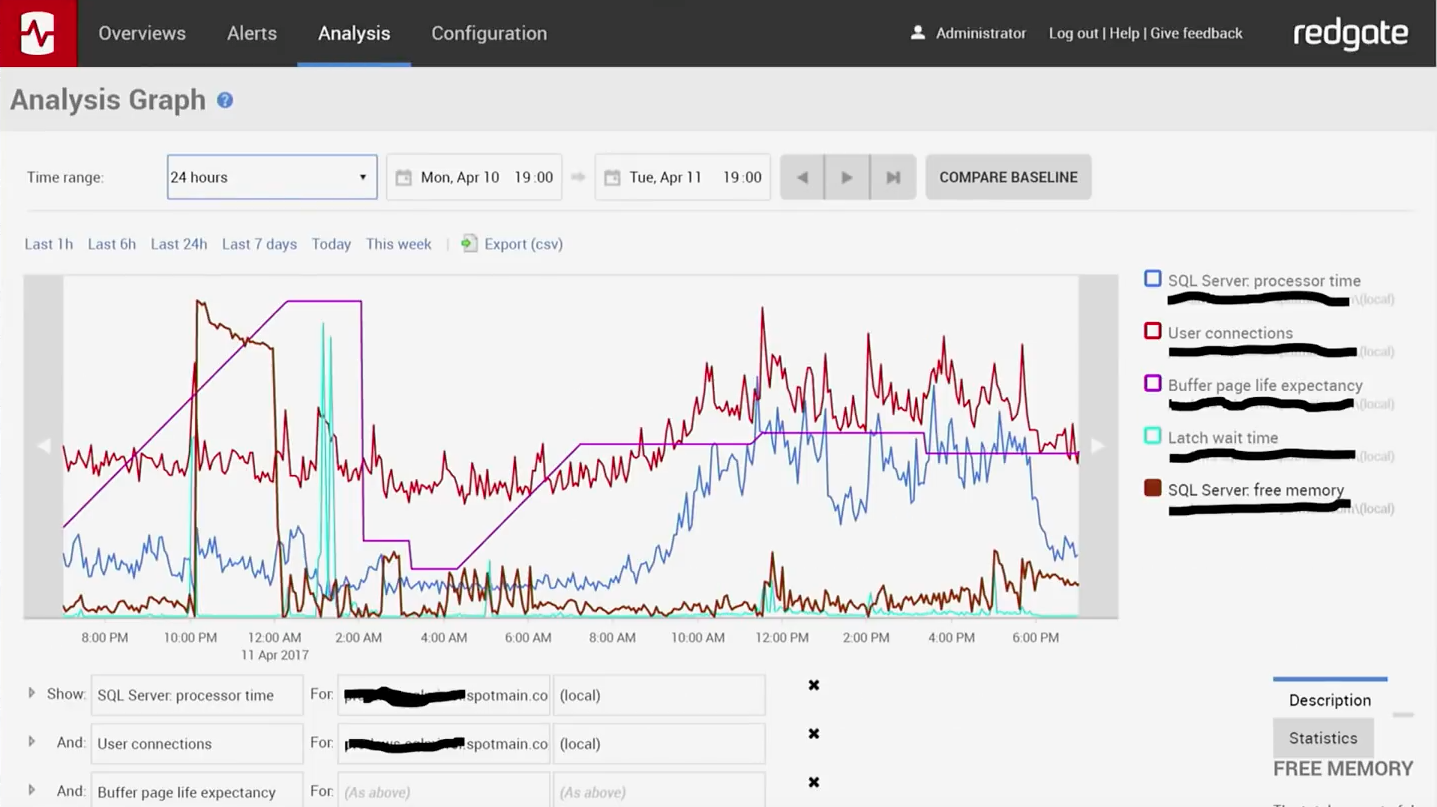
Здесь показана активность наших клиентов в системе за 24 часа. Отсюда видно, что большинство пользователей заходят в систему примерно в 10 утра, активно используют ее в течение нескольких часов, потом делают перерыв на ланч, и далее продолжают работу вплоть до 6 вечера. Если мы обнаруживаем в нашей системе проблему, то в первую очередь смотрим на этот график: отличается ли он от того, который был неделю назад, две недели назад? Возможности Redgate позволяют накладывать друг на друга графики за разные временные периоды. Это дает нам удобнейший инструмент диагностики. С помощью него мы обнаруживаем наличие проблемы, ее временные рамки, то, с чем одна может быть связана (с очередным деплойментом, с нагрузками и т. д.). Кроме того, графики позволяют нам видеть тенденции. Глядя на них, мы можем спрогнозировать, например, то, когда понадобится увеличить объем базы данных. Гораздо лучше, если вы будете иметь возможность предсказывать и планировать такого рода траты. О том, что понадобятся деньги на дополнительное железо или на облако Amazon, приятней узнавать заранее, а не когда гром грянет.
Логирование приложения
Поговорим теперь о логировании вашего приложения — о том, как писать код так, чтобы тем, кто его используют, было бы легче разобраться в произошедшем. Общепринятыми для .NET являются 5 уровней логирования: FATAL, ERROR, WARN, INFO и DEBUG. Первое и самое главное правило: не допускайте выполнения логирования в рамках основной системы. Логи не должны сохраняться на диск С, иначе он будет моментально забит. Вынесите систему логирования наружу. Вложиться в систему логирования достаточно важно, тем более если работа над проектами ведется несколькими командами. Вы можете использовать готовые системы: Graphite, Splunk, Logstash и пр.; есть решения SaaS, такие как Graylog, Logit.io. Система также может быть вашей собственной разработкой. Но как только у команды появляется общая система логирования, обнаруживается, что все пишут в логи по-своему: кто-то добавляет сообщение INFO каждые 10 секунд, другой пишет FATAL каждый раз, когда пользователь забывает пароль. Для того, чтобы объединение логов давало что-то вразумительное, нужно установить некоторые, правила, а именно, разработать четкую запоминающуюся логику того, в какой ситуации используется каждый из уровней. Далее я предлагаю вам свою версию.
FATAL
Фатальный уровень: приложение не отвечает, при этом затронуто множество пользователей, требуется немедленное внимание. Возможно, не все части вашей системы будут иметь возможность прописывать сообщения этого уровня. Если приложение изначально отвечает за низкоприоритетную задачу, то его ошибки уже не могут считаться фатальными. Приложение, которое включается ночью, чтобы сгенерировать рассадку акционеров на предстоящем ужине, даже при полном отказе не должно добавлять в лог сообщения с меткой FATAL. FATAL подразумевает повод разбудить команду ночью. Всё то, что может подождать до утра, сюда вряд ли относится.
ERROR и WARN
Ошибки и предупреждения: превышение времени ожидания ответа по API, дедлок в операции над базой данных и пр. ERROR — то, что кто-нибудь из вас всё же заметил, но в принципе, может попытаться устранить и сам (например, попробовать перезапустить). WARN — то, чего не заметил никто. Если вы запрашиваете через API данные о курсе обмена валют, но по некоторой причине, запрос превысил допустимое время ожидания, то в течение 10 минут и даже часа вы вполне можете воспользоваться кэшированным значением. Конечно, если API не работает продолжительное время, то статус лог-сообщения вы повысите.
INFO
Информационные сообщения: делаются для отчетности, при этом в системе всё в порядке. Если вы вернулись с четырехдневных праздничных выходных и не видите в логах ни одной записи, то версии у вас будет две: либо система действительно отработала идеально, без единой ошибки и предупреждения, либо ваша система логирования дала сбой на самом старте выходных. В данном случае, конечно же, вероятнее второе. Сообщения INFO обязательно должны быть в логе. Они сообщают об очистке кэша приложения, о включении и выключении серверов, о проведении эластичного масштабирования или балансировки нагрузки и т. д. Эти сообщения нужны для того, чтобы вы видели, что система работает, ощущали ее пульс. Не нужно генерировать их тысячами — достаточно одного сообщения в минуту.
DEBUG
Я бы очень хотел, чтобы вы вынесли с этой лекции одну практическую вещь: когда вы в следующий раз будете отлаживать код и соберетесь написать Console.WriteLine — приостановитесь, установите себе Log4net, NLog или Serilog и отныне пишите отладку в лог. При запуске системы в продакшн вы просто отключите логирование этих сообщений (для этого достаточно прописать один дополнительный флаг в вашем файле конфигураций). Важно то, все эти отладочные сообщения всегда можно будет вернуть, если кому-то понадобится заново работать с вашим кодом.



В DEBUG можно и нужно записывать все: факты запуска методов, время их отработки, возвращаемые значения, колбеки рекурсивных функций и пр. Все эти вещи важны для отладки сложных алгоритмов. Есть такой тип ошибок, который возникает не раньше, чем вы запускаете свой продукт в продакшн — притом внезапно и в 3 часа ночи. Если это случится, то для тех людей, которые будут срочно поднимать систему, возможность включить ваш отладочный код будет, если не спасительной, то уж точно не менее полезной, чем тогда — для вас. Люди смогут видеть вашу логику и это поможет им быстрее разобраться.
Другие названия?
На мой взгляд, причина, по которой разработчики путают уровни логирования, — в их плохих, ни о чём не говорящих названиях. Мне очень понравился вариант, предложенный взамен Дэниэлом Лебреро в своем блоге. В слегка адаптированном мной виде он выглядит так:

В заключение: правила «счастливого» кода
- Имена. Помните про «Applejack», про имена из «My Little Pony». Если вам не нравятся пони, то пусть это будут марки солодового виски, названия городов — что хотите. Придумайте свой способ и начните использовать имена, они очень помогут вам и вашей команде во всём что касается разграничения контекста и границ интерфейсов.
- Кривые обучаемости. Старайтесь делать их плавными. Кривая может быть крутой (рассчитанной на тех, кто готов обучиться вашей системе за ночь) и может быть более пологой (для тех, кто не готов перетруждаться). Избегайте участков спада (рецессии). Не создавайте свою версию ASP.NET WebForms: люди не должны обучаться и потом переучиваться. По-возможности не допускайте скачков кривой — чересчур сложных вещей, на которых пользователь застрянет. Для этого учитывайте все те моменты, когда пользователь может потерпеть неудачу, продумывайте текст ошибок — обеспечьте пользователю максимальную поддержку.
- «Signposting». Проанализируйте: какие действия предлагает пользователю ваше приложение, какой выбор у него есть на каждом шаге работы. Если, например, нужно что-то сконфигурировать — обеспечьте реализацию fluent interface, который будет визуально показывать доступные опции. Пусть, введя «Database» и поставив точку он видит список: «Encryption», «Credentials», «Timeout» и т. д. Продемонстрируйте пользователю, что ваша система умеет делать.
- Прозрачность. Покажите людям, что находится под капотом. Дайте доступ до дашбордов, до логов, выставите наружу метрики. Собирайте и распространяйте всю ту информацию, которая использовалась вами на этапе разработки. Раз уж она пригодилась вам при создании системы, то может оказаться полезной и позднее.
И главное, помните: занимаясь разработкой, вы в значительной степени определяете user experience. Какие бы средства для разработки вы не создавали — кто-то будет ими пользоваться. И только от вас зависит, уйдет ли ваш пользователь домой в этот день уставшим и расстроенным, или же довольным и энергичным, готовым с удовольствием вернуться и продолжить работу завтра. Сделайте что можете для их счастья и передайте эстафетную палочку. Ваши счастливые пользователи начнут и сами создавать хорошие продукты.
Комментарии (4)

Mikluho
16.03.2018 08:11+1В общем и целом — прописные истины… Хотя… К сожалению, не для всех :(
Логи, дэшборды, подсказки с коде — как по мне, так это индустриальный стандарт. Для всех, кто умеет думать наперёд, т.е. в курсе, что shit happens и всяко приятнее, когда разобраться, что к чему, можно быстро и безболезненно.
Вот только про пони всё-же перебор. Пот понадобится тебе сайт внутреннего мониторинга поднять, глядь в гит, а там Apple Dazzle погоняет Plumsweet и т.д… Мне всё же ближе нормальная доменная структура. Вариантов масса, но при единстве структуры, ориентироваться в Company/Infrastructure/Monitoring/Site сильно проще.
olegchir Автор
16.03.2018 12:39Вопрос в том, что будет, когда у тебя десять команд, и они не придерживаются чёткой доменной структуры, а пилят ad-hoc микросервисы с не совсем ясной областью применения. Сегодня что-то было системой логирования, а завтра стало уже мониторингом (почему бы кроме логов еще и метрики не собирать), послезавтра оттуда выбросили всю бизнес-логику (использовали другую систему сбора метрик) и оставили одни дашборды, и система стала чисто UI для дашбордов. Если изначально она называлась «LoggingSubsystem», через полгда люди будут ходить и офигевать от того, что UI дашбордов почему-то называется логером.
Mikluho
16.03.2018 15:14Я тут вижу три проблемы.
десять команд, и они не придерживаются чёткой доменной структуры
- это говорит об отсутствии единства и контроля в подходах к именованиям. Суть то же, что у автора "Site, Site1, Site2015" и т.д.
пилят ad-hoc микросервисы с не совсем ясной областью применения
- тут кто-то яростно забывает про разделение ответственностей, и наверняка пилит велосипеды. Часто это последствие п.1.
UI дашбордов почему-то называется логером
- а тут кто-то забыл вовремя
переименовать продуктсоздать новый продукт, когда старый перерос свои рамки.
Т.е. всё решаемо, если решать и не ждать, пока наступит попаболь :)
ps. не в ту кнопочку ткнул, это был ответ olegchir
dmitry_dvm
Отличная статья, срасибоц за перевод. Задумался о более подробном логировании.