
Разработчики из Google Brain доказали, что «противоречивые» изображения могут провести как человека, так и компьютер; и возможные последствия — пугающие.

На картинке выше — слева вне всякого сомнения кот. Но можете ли вы сказать однозначно, кот ли справа, или просто собака, которая выглядит похожей на него? Разница между ними в том, что правая сделана при помощи специального алгоритма, который не даёт компьютёрным моделям, называемым «сверточными нейросетями» (CNN, convolutional neural network, далее СНС) однозначно сделать вывод, что на картинке. В данном случае СНС считают, что это скорее пёс, нежели кот, но что самое интересное — большинство людей думают точно так же.
Это пример того, что называется «картинкой-противоречием» (далее КарП): она специально изменена так, чтобы обмануть СНС, не дать верно определить содержимое. Исследователи из Google Brain хотели понять, можно ли таким же способом заставить сбоить биологические нейросети в наших головах, и в итоге создали варианты, которые одинаково влияют и на машины, и на людей, заставляя их думать, что они смотрят на что-то, чего на самом деле нет.
Практически повсеместно для распознавания в СНС используются алгоритмы визуальной классификации. «Показывая» программе большое количество разных иллюстраций с пандами, можно натренировать её на узнавание панд, так как она учится путём сравнения с целью выделить общий признак для всего представленного множества. Как только СНС (также их называют «классификаторами») наберёт достаточный массив «панда-признаков» на обучающих данных, то сможет распознать панду на любых новых картинках, которые ей предоставят.
Мы же узнаём панд по абстрактным характеристикам: маленькие чёрные уши, большие белые головы, чёрные глаза, мех, и всякое такое прочее. СНС поступает иначе, что неудивительно, поскольку объём информации об окружающем, который люди интерпретируют каждую минуту, значительно больше. Поэтому, с учётом специфики моделей, возможно воздействовать на изображения таким образом, чтобы сделать их «противоречивыми» путем смешения с тщательно высчитанными данными, после чего результат для человека будет выглядеть почти как оригинал, но совершенно иным для классификатора, который начнёт ошибаться при попытке определить содержимое.
Вот пример с пандой:
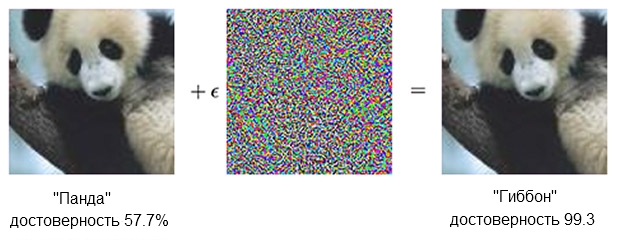
Изображение панды, скомбинированное с возмущением, может убедить классификатор, что на самом деле это гиббон.
Источник: OpenAI
Классификатор на базе СНС уверен, что слева панда, примерно на 60%. Но если слегка дополнить («создать возмущение») исходник добавлением того, что выглядит просто хаотичными шумом, тот же классификатор будет на 99.3 процента уверен, что теперь он смотрит на гиббона. Маленькие изменения, которые даже нельзя толком увидеть, порождают весьма успешную атаку, но сработает она только на конкретной компьютерной модели и не проведёт те, которые могли быть «научены» на чём-то другом.
Чтобы создать контент, вызывающий неверную реакцию у большого и разнородного количества искусственных аналитиков, следует действовать грубее — крошечные поправки не повлияют. То, что срабатывает надёжно, не получалось сделать «малыми средствами». Иными словами, если захочется получить работающее с любых ракурсов и дистанций наполнение, то придётся вмешаться существенней, или как сказал бы человек, очевидней.
Вот два примера грубоватых КарП, где человек легко обнаружит помеху.

Источник: Open AI слева, Google Brain справа
Картинка кота слева, которая СНС определяется как компьютер, сделана при помощи «ломаной геометрии». Если взглянуть поближе (или даже не слишком близко), то будет видно, что намечено несколько угловатых и коробкообразных конструкций, которые могут напоминать очертания системного блока. А изображение банана справа, которое распознаётся как тостер, устойчиво даёт ложное срабатывание с любой точки обзора. Люди в момент найдут здесь банан, однако странная штуковина рядышком имеет некоторые признаки тостера — и это дурит технику.
Когда ты делаешь гарантированно подходящее «противоречивое» изображение, которым нужно обыграть целую компанию распознающих моделей, то очень часто это приводит к появлению «человеческого фактора». Другими словами, то, что собьёт с толку одиночную нейросеть, может быть человеком и вовсе не воспринято за проблему, а когда пытаешься получить ребус, однозначно подходящий для обмана пяти или десяти сразу, то выходит, что он работает на основе механизмов, которые в случае людей совершенно бесполезны.
Как следствие, совершенно незачем пытаться заставить человека считать, что угловатый кот это корпус компьютера, а сумма банана и странной мазни смахивает на тостер. Гораздо лучше при создании КарП, предназначенных для нас с вами, сразу ориентироваться на использование моделей, воспринимающих мир так же, как и люди.
СНС с глубоким обучением и человеческое зрение чем-то схожи, но в основе своей нейросеть «смотрит» на вещи «по-компьютерному». Например, когда ей скармливают картинку, она «видит» статичную решётку из прямоугольных пикселей, одновременно. Глаз же работает по-другому, человек воспринимает высокую детализацию в секторе примерно пять градусов в каждую сторону от линии взгляда, но за пределами этой зоны внимание к деталям линейно снижается.
Таким образом, в отличие от машины, скажем, размывание краёв изображения не сработает с человеком и останется просто-напросто незамеченным. Исследователи смогли смоделировать эту особенность, добавив «слой сетчатки», который изменил данные, подаваемые СНС, так, как они выглядели бы для глаза, с целью ограничить нейросеть теми же рамками, в которых работает обычное зрение.
Следует отметить, что человек справляется со своими недостатками восприятия тем, что взгляд не направлен в одну точку, а постоянно перемещается, осматривая изображение целиком, но и это оказалось возможным скомпенсировать условиями постановки эксперимента, нивелирующими различия между СНС и людьми.
Примечание из самой работы:
Каждый опыт начинался с установочного перекрестия, показывавшегося в центре экрана в течение 500-1000 миллисекунд, и каждый субъект был проинструктирован зафиксировать взгляд на перекрестии.
Использование «сетчаточного слоя» стало последним шагом, который пришлось предпринять в рамках «тонкой подгонки» машинного обучения под «человеческие особенности». При генерации образцов их прогоняли через десять различных моделей, каждая из которых должна была однозначно назвать, скажем, кота, например, собакой. Если результат был «10 из 10 ошиблись», то материал передавался для тестирования на людях.
В эксперименте задействовались три группы картинок: «питомцы» (кошки и собаки), «овощи» (кабачки и брокколи) и «угрозы» (пауки и змеи, хотя как хозяин змеи я бы предложил другой термин для оценки). Для каждой группы, успех засчитывался, если тестируемый выбирал неправильно — называл собаку кошкой, и наоборот. Участники сидели перед монитором, на котором демонстрировалось изображение в течение примерно 60 или 70 миллисекунд, и они должны были нажать одну из двух кнопок, обозначающую объект. Поскольку изображение показывалось очень недолго, это сглаживало разницу между тем, как ощущают мир люди и нейросети; иллюстрация в заголовке, кстати, поразительна своей устойчивостью ошибки.
То, что показывали испытуемым, могло быть немодифицированным изображением (image), «обычная» КарП (adv), «перевёрнутая» (flip) КарП, на которой шум был перевёрнут вверх ногами перед наложением, или «ложная» КарП, на которой слой с шумом был применён к картинке, не относящейся ни к одному из типов в группе (false). Два последних варианта использовались для контроля характера возмущения (будет структура шума влиять иначе в перевёрнутом виде, или просто «есть-нет»?), плюс давали возможность понять, действительно ли помехи напрочь обманывают людей или просто немного снижают точность.
Примечание из самой работы:
«ложная»: условие было добавлено для того, чтобы принудить испытуемого ошибиться. Мы добавили его, поскольку если исходные изменения уменьшают точность работы наблюдателя, это может происходить по причине снижения непосредственного качества изображения. Чтобы показать, что КарП действительно срабатывают в каждом классе, мы внесли варианты, где ни один выбор не может быть правильным и соответственно их точность равна 0, и наблюдали за тем, какой именно «верный» ответ был в таком случае. Мы демонстрировали произвольные картинки из ImageNet, к которым было применено воздействие от одного или другого класса в группе, но не подходившие при этом ни к одному. Участник эксперимента должен был определить, что перед ним. Для примера, мы могли показать картинку самолёта, искажённую путём наложения «собачьего» шума, хотя в течение опыта субъект должен был узнать только кошку или собаку.
Вот пример, показывающий в процентном соотношении количество людей, которые смогли чётко определить картинку как собаку, в зависимости от того, как зашумление было использовано. Напомню, было всего 60-70 миллисекунд, чтобы взглянуть и принять решение.

Источник: Google Brain
Оригинальная картинка с собакой; КарП с собакой, принятая и человеком, и компьютером за кошку; контрольная картинка с перевёрнутым вверх ногами слоем шума.
А вот итоговые результаты:
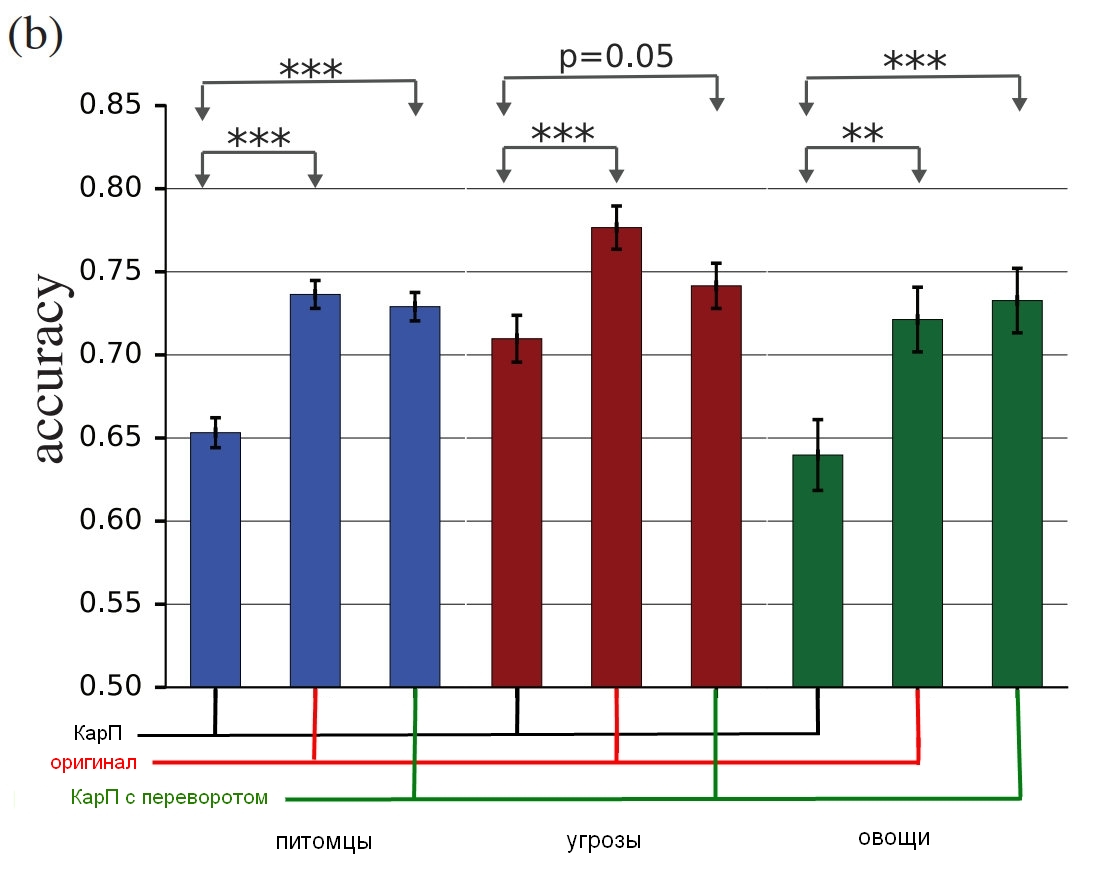
Источник: Google Brain
Результаты исследования, насколько верно люди идентифицируют настоящие картинки с сравнении с искажёнными.
Диаграмма показывает точность соответствия. Если вы выбираете кота и это действительно кот, точность растёт. Если вы выбираете кота, но это на самом деле собака, превращённая шумом в подобие кота, точность снижается.
Как можно видеть, люди гораздо более корректны в выборке нескорректированных изображений или с перевёрнутыми шумовыми слоями, чем в выборке «противоречивых». Это доказывает, что принцип атаки на восприятие может быть перенесён с компьютеров на нас.
Мало того, что воздействия бесспорно эффективны, они ещё и тоньше, чем ожидается — никаких коробкокотов или псевдотостеров, или чего-то такого плана. Поскольку мы видели и слои с шумом, и изображения до и после обработки, надо разобраться, что именно в этом сбивает нас с толку. Хотя исследователи осторожничают, заявляя что «наши примеры специально сделаны, чтобы дурить голову, поэтому стоит быть аккуратными, используя людей как подопытных для изучения эффекта».
Команда постарается в будущем вывести некоторые общие правила для определённых категорий модификации, включая "разрушение кромок объекта, в особенности путём воздействий средней степени, по перпендикуляру к линии кромки; коррекция граничащих областей путём путем увеличения контраста с одновременным текстурированием границы; изменение текстуры; использование тёмных частей изображения, на которых уровень воздействия на восприятие получается высоким даже несмотря на крохотные возмущения". Ниже показаны примеры, где красным обведены области, в которых описанные способы видны лучше всего.

Источник: Google Brain
Примеры картинок с разными принципами искажения
Суть в том, что это больше, значительно больше, чем просто ловкий трюк. Ребята из Google Brain подтвердили, что они могут создать эффективную технику обмана восприятия, но не до конца и сами понимают, почему она работает, с учётом уровня абстракции, и возможно, что это буквально базовый уровень действительности:
В завершение, если вы и правда хотите немножко запараноить, то исследователи с радостью сделают вам одолжение, указав на то, что «визуальное распознавание объектов… сложно дать объективную оценку. Правда ли „Рис.1“ объективно собака, или это объективно кошка, которая может заставить людей думать, что она собака?» Иначе говоря, превращается ли картинка действительно в предмет, или просто заставляет тебя думать иначе?
Жутковато здесь то (и я всерьёз говорю «жутковато»), что в итоге можно получить способы воздействия на любые факты, потому что дистанция между манипулированием СНС и манипулированием человеком, очевидно, не слишком большая. Соответственно, технологии машинного обучения потенциально могут быть использованы для искажения картинок или видео в нужном ключе, который подменит наше восприятие (и соответствующую реакцию), и мы даже не поймём, что произошло. Из доклада:
Разумеется, такие методы можно использовать и «во благо», и уже предложен ряд вариантов, вроде «обострить характерные особенности изображений, дабы повысить уровень сосредоточенности, например, при контроле за воздушной обстановкой или анализе рентгеновских снимков, поскольку этот труд является монотонным, а последствия невнимательности могут быть ужасными». Также, «дизайнеры пользовательских интерфейсов могут использовать возмущения, чтобы разработать более интуитивные интерфейсы». Хммм. Это безусловно здорово, но я как-то больше обеспокоен насчёт той штуки со взломом моего мозга и выставлением уровня доверия к людям, понимаете?
Некоторые из поставленных вопросов станут предметом будущих исследований — возможно, выяснится, что именно делает конкретные картинки более подходящими, чтобы передать ошибку к человеку, и это может дать новые зацепки для понимания принципов работы мозга. А это, в свою очередь, поможет создать более совершенные нейросети, которые станут учиться быстрее и лучше. Но нам стоит быть осторожными и помнить, что, как и компьютеры, нас порой не так-то и сложно обмануть.
Проект "Adversarial Examples that Fool both Human and Computer Vision, by Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, and Jascha Sohl-Dickstein, from Google Brain", можно скачать из arXiv. А если вам нужны ещё спорные картинки, которые работают на людях, то вспомогательный материал тут.
На картинке выше — слева вне всякого сомнения кот. Но можете ли вы сказать однозначно, кот ли справа, или просто собака, которая выглядит похожей на него? Разница между ними в том, что правая сделана при помощи специального алгоритма, который не даёт компьютёрным моделям, называемым «сверточными нейросетями» (CNN, convolutional neural network, далее СНС) однозначно сделать вывод, что на картинке. В данном случае СНС считают, что это скорее пёс, нежели кот, но что самое интересное — большинство людей думают точно так же.
Это пример того, что называется «картинкой-противоречием» (далее КарП): она специально изменена так, чтобы обмануть СНС, не дать верно определить содержимое. Исследователи из Google Brain хотели понять, можно ли таким же способом заставить сбоить биологические нейросети в наших головах, и в итоге создали варианты, которые одинаково влияют и на машины, и на людей, заставляя их думать, что они смотрят на что-то, чего на самом деле нет.
Что такое «противоречивые изображения»?
Практически повсеместно для распознавания в СНС используются алгоритмы визуальной классификации. «Показывая» программе большое количество разных иллюстраций с пандами, можно натренировать её на узнавание панд, так как она учится путём сравнения с целью выделить общий признак для всего представленного множества. Как только СНС (также их называют «классификаторами») наберёт достаточный массив «панда-признаков» на обучающих данных, то сможет распознать панду на любых новых картинках, которые ей предоставят.
Мы же узнаём панд по абстрактным характеристикам: маленькие чёрные уши, большие белые головы, чёрные глаза, мех, и всякое такое прочее. СНС поступает иначе, что неудивительно, поскольку объём информации об окружающем, который люди интерпретируют каждую минуту, значительно больше. Поэтому, с учётом специфики моделей, возможно воздействовать на изображения таким образом, чтобы сделать их «противоречивыми» путем смешения с тщательно высчитанными данными, после чего результат для человека будет выглядеть почти как оригинал, но совершенно иным для классификатора, который начнёт ошибаться при попытке определить содержимое.
Вот пример с пандой:
Изображение панды, скомбинированное с возмущением, может убедить классификатор, что на самом деле это гиббон.
Источник: OpenAI
Классификатор на базе СНС уверен, что слева панда, примерно на 60%. Но если слегка дополнить («создать возмущение») исходник добавлением того, что выглядит просто хаотичными шумом, тот же классификатор будет на 99.3 процента уверен, что теперь он смотрит на гиббона. Маленькие изменения, которые даже нельзя толком увидеть, порождают весьма успешную атаку, но сработает она только на конкретной компьютерной модели и не проведёт те, которые могли быть «научены» на чём-то другом.
Чтобы создать контент, вызывающий неверную реакцию у большого и разнородного количества искусственных аналитиков, следует действовать грубее — крошечные поправки не повлияют. То, что срабатывает надёжно, не получалось сделать «малыми средствами». Иными словами, если захочется получить работающее с любых ракурсов и дистанций наполнение, то придётся вмешаться существенней, или как сказал бы человек, очевидней.
В прицеле — человек
Вот два примера грубоватых КарП, где человек легко обнаружит помеху.
Источник: Open AI слева, Google Brain справа
Картинка кота слева, которая СНС определяется как компьютер, сделана при помощи «ломаной геометрии». Если взглянуть поближе (или даже не слишком близко), то будет видно, что намечено несколько угловатых и коробкообразных конструкций, которые могут напоминать очертания системного блока. А изображение банана справа, которое распознаётся как тостер, устойчиво даёт ложное срабатывание с любой точки обзора. Люди в момент найдут здесь банан, однако странная штуковина рядышком имеет некоторые признаки тостера — и это дурит технику.
Когда ты делаешь гарантированно подходящее «противоречивое» изображение, которым нужно обыграть целую компанию распознающих моделей, то очень часто это приводит к появлению «человеческого фактора». Другими словами, то, что собьёт с толку одиночную нейросеть, может быть человеком и вовсе не воспринято за проблему, а когда пытаешься получить ребус, однозначно подходящий для обмана пяти или десяти сразу, то выходит, что он работает на основе механизмов, которые в случае людей совершенно бесполезны.
Как следствие, совершенно незачем пытаться заставить человека считать, что угловатый кот это корпус компьютера, а сумма банана и странной мазни смахивает на тостер. Гораздо лучше при создании КарП, предназначенных для нас с вами, сразу ориентироваться на использование моделей, воспринимающих мир так же, как и люди.
Обманывая глаз (и мозг)
СНС с глубоким обучением и человеческое зрение чем-то схожи, но в основе своей нейросеть «смотрит» на вещи «по-компьютерному». Например, когда ей скармливают картинку, она «видит» статичную решётку из прямоугольных пикселей, одновременно. Глаз же работает по-другому, человек воспринимает высокую детализацию в секторе примерно пять градусов в каждую сторону от линии взгляда, но за пределами этой зоны внимание к деталям линейно снижается.
Таким образом, в отличие от машины, скажем, размывание краёв изображения не сработает с человеком и останется просто-напросто незамеченным. Исследователи смогли смоделировать эту особенность, добавив «слой сетчатки», который изменил данные, подаваемые СНС, так, как они выглядели бы для глаза, с целью ограничить нейросеть теми же рамками, в которых работает обычное зрение.
Следует отметить, что человек справляется со своими недостатками восприятия тем, что взгляд не направлен в одну точку, а постоянно перемещается, осматривая изображение целиком, но и это оказалось возможным скомпенсировать условиями постановки эксперимента, нивелирующими различия между СНС и людьми.
Примечание из самой работы:
Каждый опыт начинался с установочного перекрестия, показывавшегося в центре экрана в течение 500-1000 миллисекунд, и каждый субъект был проинструктирован зафиксировать взгляд на перекрестии.
Использование «сетчаточного слоя» стало последним шагом, который пришлось предпринять в рамках «тонкой подгонки» машинного обучения под «человеческие особенности». При генерации образцов их прогоняли через десять различных моделей, каждая из которых должна была однозначно назвать, скажем, кота, например, собакой. Если результат был «10 из 10 ошиблись», то материал передавался для тестирования на людях.
Работает ли это?
В эксперименте задействовались три группы картинок: «питомцы» (кошки и собаки), «овощи» (кабачки и брокколи) и «угрозы» (пауки и змеи, хотя как хозяин змеи я бы предложил другой термин для оценки). Для каждой группы, успех засчитывался, если тестируемый выбирал неправильно — называл собаку кошкой, и наоборот. Участники сидели перед монитором, на котором демонстрировалось изображение в течение примерно 60 или 70 миллисекунд, и они должны были нажать одну из двух кнопок, обозначающую объект. Поскольку изображение показывалось очень недолго, это сглаживало разницу между тем, как ощущают мир люди и нейросети; иллюстрация в заголовке, кстати, поразительна своей устойчивостью ошибки.
То, что показывали испытуемым, могло быть немодифицированным изображением (image), «обычная» КарП (adv), «перевёрнутая» (flip) КарП, на которой шум был перевёрнут вверх ногами перед наложением, или «ложная» КарП, на которой слой с шумом был применён к картинке, не относящейся ни к одному из типов в группе (false). Два последних варианта использовались для контроля характера возмущения (будет структура шума влиять иначе в перевёрнутом виде, или просто «есть-нет»?), плюс давали возможность понять, действительно ли помехи напрочь обманывают людей или просто немного снижают точность.
Примечание из самой работы:
«ложная»: условие было добавлено для того, чтобы принудить испытуемого ошибиться. Мы добавили его, поскольку если исходные изменения уменьшают точность работы наблюдателя, это может происходить по причине снижения непосредственного качества изображения. Чтобы показать, что КарП действительно срабатывают в каждом классе, мы внесли варианты, где ни один выбор не может быть правильным и соответственно их точность равна 0, и наблюдали за тем, какой именно «верный» ответ был в таком случае. Мы демонстрировали произвольные картинки из ImageNet, к которым было применено воздействие от одного или другого класса в группе, но не подходившие при этом ни к одному. Участник эксперимента должен был определить, что перед ним. Для примера, мы могли показать картинку самолёта, искажённую путём наложения «собачьего» шума, хотя в течение опыта субъект должен был узнать только кошку или собаку.
Вот пример, показывающий в процентном соотношении количество людей, которые смогли чётко определить картинку как собаку, в зависимости от того, как зашумление было использовано. Напомню, было всего 60-70 миллисекунд, чтобы взглянуть и принять решение.
Источник: Google Brain
Оригинальная картинка с собакой; КарП с собакой, принятая и человеком, и компьютером за кошку; контрольная картинка с перевёрнутым вверх ногами слоем шума.
А вот итоговые результаты:
Источник: Google Brain
Результаты исследования, насколько верно люди идентифицируют настоящие картинки с сравнении с искажёнными.
Диаграмма показывает точность соответствия. Если вы выбираете кота и это действительно кот, точность растёт. Если вы выбираете кота, но это на самом деле собака, превращённая шумом в подобие кота, точность снижается.
Как можно видеть, люди гораздо более корректны в выборке нескорректированных изображений или с перевёрнутыми шумовыми слоями, чем в выборке «противоречивых». Это доказывает, что принцип атаки на восприятие может быть перенесён с компьютеров на нас.
Мало того, что воздействия бесспорно эффективны, они ещё и тоньше, чем ожидается — никаких коробкокотов или псевдотостеров, или чего-то такого плана. Поскольку мы видели и слои с шумом, и изображения до и после обработки, надо разобраться, что именно в этом сбивает нас с толку. Хотя исследователи осторожничают, заявляя что «наши примеры специально сделаны, чтобы дурить голову, поэтому стоит быть аккуратными, используя людей как подопытных для изучения эффекта».
Команда постарается в будущем вывести некоторые общие правила для определённых категорий модификации, включая "разрушение кромок объекта, в особенности путём воздействий средней степени, по перпендикуляру к линии кромки; коррекция граничащих областей путём путем увеличения контраста с одновременным текстурированием границы; изменение текстуры; использование тёмных частей изображения, на которых уровень воздействия на восприятие получается высоким даже несмотря на крохотные возмущения". Ниже показаны примеры, где красным обведены области, в которых описанные способы видны лучше всего.
Источник: Google Brain
Примеры картинок с разными принципами искажения
А что в итоге?
Суть в том, что это больше, значительно больше, чем просто ловкий трюк. Ребята из Google Brain подтвердили, что они могут создать эффективную технику обмана восприятия, но не до конца и сами понимают, почему она работает, с учётом уровня абстракции, и возможно, что это буквально базовый уровень действительности:
Наш проект ставит фундаментальные вопросы о том, как воздействуют КарП, как работают нейросети и мозг. Удалось ли перенести атаки с СНС на мозг потому, что смысловые представления информации в них схожи? Или потому, что оба эти представления соответствуют некоей общей смысловой модели, которая естественным образом существует в окружающем мире?
В завершение, если вы и правда хотите немножко запараноить, то исследователи с радостью сделают вам одолжение, указав на то, что «визуальное распознавание объектов… сложно дать объективную оценку. Правда ли „Рис.1“ объективно собака, или это объективно кошка, которая может заставить людей думать, что она собака?» Иначе говоря, превращается ли картинка действительно в предмет, или просто заставляет тебя думать иначе?
Жутковато здесь то (и я всерьёз говорю «жутковато»), что в итоге можно получить способы воздействия на любые факты, потому что дистанция между манипулированием СНС и манипулированием человеком, очевидно, не слишком большая. Соответственно, технологии машинного обучения потенциально могут быть использованы для искажения картинок или видео в нужном ключе, который подменит наше восприятие (и соответствующую реакцию), и мы даже не поймём, что произошло. Из доклада:
Для примера, кластер моделей с глубинным обучением можно натренировать на оценках людьми уровня доверия к определённым типам лиц, чертам, выражениям. Станет возможным сгенерировать «противоречивые» возмущения, которые будут увеличивать или уменьшать ощущение «достоверности», и такие «подправленные» материалы могут быть использованы в новостных роликах или политической рекламе.
В перспективе теоретические риски включают в себя возможность создания сенсорных стимуляций, взламывающих мозг огромным множеством способов и с весьма высокой эффективностью. Как известно, многие животные замечены в уязвимости к сверхпороговым стимуляциям. Скажем, кукушата могут одновременно прикидываться беспомощными и издавать жалобный зов, что в сочетании заставляет птиц других пород кормить птенцов кукушки раньше собственного потомства. «Противоречивые» образцы можно рассматривать как такую своеобразную форму сверхпороговой стимуляции для нейросетей. И вызывает немалое беспокойство тот факт, что чрезмерные стимулы, которые в теории куда как сильнее повлияют на человека чем просто заставят повесить бирку «это кот» на картинку собаки, могут быть созданы с помощью машины, а потом перенесены на людей.
Разумеется, такие методы можно использовать и «во благо», и уже предложен ряд вариантов, вроде «обострить характерные особенности изображений, дабы повысить уровень сосредоточенности, например, при контроле за воздушной обстановкой или анализе рентгеновских снимков, поскольку этот труд является монотонным, а последствия невнимательности могут быть ужасными». Также, «дизайнеры пользовательских интерфейсов могут использовать возмущения, чтобы разработать более интуитивные интерфейсы». Хммм. Это безусловно здорово, но я как-то больше обеспокоен насчёт той штуки со взломом моего мозга и выставлением уровня доверия к людям, понимаете?
Некоторые из поставленных вопросов станут предметом будущих исследований — возможно, выяснится, что именно делает конкретные картинки более подходящими, чтобы передать ошибку к человеку, и это может дать новые зацепки для понимания принципов работы мозга. А это, в свою очередь, поможет создать более совершенные нейросети, которые станут учиться быстрее и лучше. Но нам стоит быть осторожными и помнить, что, как и компьютеры, нас порой не так-то и сложно обмануть.
Проект "Adversarial Examples that Fool both Human and Computer Vision, by Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, and Jascha Sohl-Dickstein, from Google Brain", можно скачать из arXiv. А если вам нужны ещё спорные картинки, которые работают на людях, то вспомогательный материал тут.
vassabi
оптические иллюзии?
обман биологических нейронных сетей?
Zet_Roy
Это немного не то, нейросеть не видит все изображение в контексте оно попиксельно анализирует.
saboteur_kiev
Есть оптические иллюзии не связанные с макияжем.
Hardcoin
Нейросети на вход подается, конечно, изображение целиком. И анализирует она изображение, конечно целиком. Вот отдельный нейрон, да, видит только свой кусок обычно.
OriSvet Автор
Думаю, материал исследования ближе не к макияжу (который суть нарисовать совсем другую картинку на исходнике), а к «деформирующей окраске», которая не прячет изначальный объект, а искажает пропорции и затрудняет точное определение параметров.
lavmax
Вы описали макияж.
LSDtrip
Забавно, но эти вносимые возмущения очень похожи на рисунки, возникающие в мозгу под ЛСД. По сути это один из способов искажения (улучшения) человеческого восприятия. Как макияж только на уровне нейронных связей. То есть по сути любая нейросеть и человеческий мозг довольно легко могут дать ответ не соответствующий реальности. Это как раз и отличает их от точных аналитических методов.
kvarkicn
Разве что участников группы Kiss.
Нормальный макияж должен подчеркивать, а не искажать картину. Губы/брови мы же видим именно как губы и брови. В случае окраски кораблей: был кораблик — стала скала. Или тучка. Или сон Дали.
P.S. варианты вида «была голая кожа — нарисовали бровь» не рассматриваю.
TheShock
Но ведь «был нос некрасивой формы/стал нос красивой формы», «были маленькие глаза, стали большие» — это не оно? Исказило пропорции — глаза стали больше относительно головы, затруднило определение параметров
kvarkicn
Как-то так.

Evengard
Вы б хоть в спойлер скрыли, картинка залипающая…
Jogger
Только это не на всех работает. Вот я, сколько не смотрел подобных подборок «до и после», результаты всегда примерно такие:
1) Примерно половина картинок — до макияжа хорошо, с макияжем плохо.
2) Примерно четверть — до макияжа хорошо, с макияжем тоже хорошо (но не лучше чем до)
3) Оставшаяся четверть — до макияжа плохо, с макияжем тоже плохо
То есть варианта «до плохо, после хорошо» — я не встречал никогда. Смею предположить, что я не уникален.
Exchan-ge
Как-то на людной улице я встретил с десяток девушек, что-то певших хором.
В их лицах было что-то очень необычное и настораживающее.
Через секунду выяснилось, что это хор баптисток, не пользующихся косметикой.
Ariez
Чуть оффтопом расскажу случай из жизни. Дежурил в травматологическом отделении, часов в 10 вечера привезли пациента с травмой, иду стучаться в сестринскую «выцепить» сестру в перевязочную на помощь. Открывается дверь, далее меня встречает наша медсестра с отекшими, покрасневшими глазами, с мешками под ними. При этом полчаса назад — красивая молодая медсестричка. И далее диалог:
— Насть, тебя обидел кто-то, ты плакала что ли? (пациенты были не из спокойных периодически)
— Нет, Саш, я просто умылась, ты без косметики меня не видел что ли?
Так что таки нет. Бывают случаи =)
TheShock
Это не более, чем самообман, увы (если быть точным, то это эффект послезнания). Просто лично вы судите о «без макияжа до» — «слишком много макияжа после». И у вас срабатывает внутреннее возмущение: «меня ведь стараются обдурить, конечно мне нравится без макияжа». Если бы вы оценивали не задумываясь, на подсознании, то на улице считали бы более красивыми тех девушек, которые удачно воспользовались макияжем, а не тех, кто не воспользовался
TheShock
Скажите, вот вы правда считаете, что не стало лучше на этой фото?
Carry
Можно было левую еще снизу фонариком подсветить.
И такое количество неравномерности цвета кожи вылазит от дурацкого серого светодиодного освещения.
Ну, а справа — фотошоп, и в реальности такой эффект будет только с расстояния 50 метров.
TheShock
Что вы понимаете под «фотошопом»? Вы делали вообще студийные портреты? Подобное достигается светом и макияжем и крайне мало влияния фотошопа.
ktod
Конечно, достигается. Только, это не отменяет того факта, что справа фотошоп.
TheShock
Я же спросил, что вы понимаете под фотошопом? У вас какое-то странное понятие этого термина. Учитывая, что влияния фотошопа на той фотке — минимум и настолько более приятный вид достигается именно макияжем и светом.
NINeOneone
Да у нее нос другой формы совсем, причем справа — он меньше.
lavmax
Грамотные тени на крыльях носа все решают безо всякого фотошопа.
Lenderdoc
Девушки с макияжем встреяются и распознаются легко, но вот отфотошопленных дувушен ниразу не встречал, только на картинках.
AllexIn
0xlevi
Не сказал бы, что это как-то связано с «обманом» — наша нейронная сеть понимает, что ресницы накрашены, есть пудра, накрашенные губы и т.д., а что до симпатичности, то это уже «выставление оценок за гармоничное соотношение параметров»
SlavaSA
название ролика забавляет, это не просто девушки, же.)
cyberly
Казалось бы, причем тут порно?
Хинт: это подборка не совсем обычных девушек.
DASM
Не понял. Автору все время жутковато, мне же, после фото собаки, определенной с 100% вероятностью как кот, кажется, что распознаем мы образы как-то иначе. «дистанция между манипулированием СНС и манипулированием человеком, очевидно, не слишком большая.» — совершенно неясно откуда такой вывод, все эти картинки распознаются человеком на 100%, без ошибок и трудностей, а СНС лажает по полной
scg
Шок, сенсация! Берем собаку, пересовываем ее как кошку и 99% людей воспринимают ее как кошку!
Sychuan
Если бы нейронные сети умели говорить, они бы сказали ровно то же самое про остальные картинки, я думаю.
Hikkomori
На КДПВ я справа вижу собаку, потому что это похоже на собаку (по форме морды, окраске). Что называется подставили условия, чтобы результат сошелся. IRL коты ну никак не похожи на собак по форме морды, в отличие от фото
port443
Вообще, если учесть всё многообразие пород собак и котов, определение собака-кот весьма непросто. Попробуйте словами описать, чем они отличаются. У меня получается только описанием поведения, которое на фото не видно.
Hikkomori
Ну навскидку глаза, морда у собаки более острая и вытянутая, расположение и форма ушей, да дохрена в общем то различий.
port443
Вы видели французского и английского бульдогов? А мопса? :)
Hikkomori
Видел. Ок, может некоторые собаки и похожи на кошек, но таких случаев не так много, чтобы можно было говорить, что непросто определить кошка на фото или собака. Даже в тех случаях похожести всё равно с вероятностью 99% легко определяется кошка это или собака.
А насчет мопса, вот например максимально похожая на мопса кошка, что я нашел, прям вообще одно лицо, отличить нереально, да?

port443
Да, отличить не сложно. Но теперь давайте вернёмся к вашему первому комментарию и моему вопросу: как описать отличительные признаки? :)
Hikkomori
Раз отличия есть, то и описать их способ найдётся.
Я не буду тут расписывать, ну разве что одно.
Допустим есть фото морды животного, очень мыльное, но точно кошки или собаки. На фото в фокусе лишь зрачки, и они вертикальные, кто на фото, кошка или собака ?
port443
Я вот и пытаюсь подвести к тому, что конкретная задача различения собака-кот при таком разнообразии пород весьма затруднительна, так как почти все характеристики пересекаются. Если добавить в задачу, что это дикие животные, всё сильно упрощается; селекционеры же всё запутывают.
Зрачки, кстати, хороший признак, но не стабильный: когда света мало, у кошек они не настолько явно выражены, да и качество фото должно быть приличным (кроме случаев «портрета»).
Hikkomori
Как раз таки в темноте глаза кошки ещё как выражены

port443
Возможно я вас удивлю, но у собак глаза тоже светятся. Хотя и не так сильно. Но я надеюсь, вы меня поняли. На фото из статьи никаких взарумительнях признаков из того, что мы в этой ветке напридумывали, не видно и по настоящему классифицировать там что-то можно только на основе опыта, который запросто даёт сбои.
OriSvet Автор
Ещё хочу отметить, что распределение по родам-видам-классам-отрядам и прочее в зоологии — это одно, а вот такое описательно-бытовое — другое. С точки зрения зоолога, лисы и собаки это почти одно и тоже, а с точки зрения обычного человека — «ну это же совершенно разные вещи, лисы рыженькие, а собаки лают!».
А с точки зрения компьютера, наверное, что-то третье.
Ezhyg
лисы тоже тявкают — «йиф-йиф», же :D
и лают (не тявкают) не все собаки
Meklon
«йиф-йиф»… Ну-ну)
igruh
Сосед говорит, что у него мопс. Он рыжий и не лает, а шипит что-то вроде вашего «йиф-йиф». Кажется я начинаю догадываться…
Evengard
Zenitchik
С точки зрения зоолога — тоже разные. ЕМНИП, разные подсемейства.
slonopotamus
Элементарно. Разница между кошками и собаками в том что первые умеют втягивать когти.
port443
Да, ближе. Хотя, например, гепард не умеет :) И у безшерстных кошек это не так явно видно. Ну и на фото это так же далеко не всегда видно.
port443
3aicheg
Попробовал перефотошопить мопса поверх кота частями, чтобы понять, что более всего, субъективно, делает кота похожим на кота, а собаку — на собаку:

По моим впечатлениям, всё решает форма рта. Уши вообще не дают заметных отличий, а глаза разве что меняют общее выражение лица с «жалобного» на «чумачечее».
zzzmmtt
Форма зрачков же решает
3aicheg
Не знаю, для меня — нет. Если присмотреться и вдуматься, конечно, различишь собачьи и кошачьи зрачки, но чисто на уровне восприятия мне одних зрачков совершенно недостаточно: справа сверху на картинке жывотне для меня выглядит, как кошка, несмотря на собачьи зрачки, а обе нижних картинки — скорее, как адская собака со странными злыми глазами.
Glays
горилла 80%
psinetron
Наверное стоит сделать изображение черно-белым.

Позвольте просто добавить яркости и убрать цвет с изображений:
По моему форма глаз «решает» гораздо меньше, чем форма лица, так как на мой взгляд похожее на кота только верхнее правое изображение и нижнее левое, т.к. воображение дорисовывает острые уши не присущие мопсам
3aicheg
Во! Чё я сам не догадался-то. Вообще ничего кошачьего не осталось.
Вообще, где-то читал, что у людей тоже больше нижняя часть лица позволяет отличить, кто есть кто. Поэтому, если хочешь скрыть собственную личность, надо не пижонить, как Зорро, а закрывать в первую очередь область вниз от уровня глаз. Возможно, тут ещё играет роль то, что хоть глаза и зеркало души, а мимическая мускулатура, в основном, расположена в области рта и нижней части носа — поэтому наши мозги и запрограммированы эволюцией придавать этой области лица большее значение.
fapsi
Наличием вибриссов (усов) у котов хотя бы
port443
О! Неплохой признак, хотя тоже не такой явный (у собак тоже усы есть, хоть и заметно меньше). Выше ещё форму зрачков и складные когти выделили. Вот по сумме этого всего можно пытаться что-то получить. По крайней мере на фото из статьи только усы на одной достаточно чётко видны. Хотя, даже там видна проблема: немного другой ракурс — и всё сольётся.
isden
У котов еще сами глаза крупнее при сопоставимом размере морды.
exehoo
Усы и вибриссы отсутствуют (породный стандарт), когти не втягиваются, а на этом фото еще и зрачки круглые.
Welran
Не факт что люди никогда не видевшие сфинксов опознают на этой фотке кота.
exehoo
В равной степени не факт, что люди, никогда не видевшие пекинеса, опознают в нем собаку
DASM
уверен что опознают. Есть более важные признаки, чем усы (форма черепа, строение глаза, форма носа). Кстати тут есть чему поучиться у погранконтроля. Их натаскивают на это дело, на что именно смотреть. Есть признаки, навроде соотношения межглазного расстояния к длине носа и тп, которые неизменны. На парики, макияж — они не смотрят
humanelement
Человек и не должен рационализировать для себя это в каких-то терминах. Он просто умеет это делать.
Просто пример. Миллиарды людей прекрасно отличают мужчин от женщин по лицам, но никогда не задумываются, как они это делают.
А теперь попробуйте обратить эти различия в список признаков, руководствуясь которыми можно делать это различение автоматически.
Rohan66
Несколько раз случалось, что отличить не мог. ))) Не трапы и на в Таиланде.
Ну и анекдот
Грузинская свадьба. Один мужик смотрит на невесту и говорит:
— Какой странный невеста.
Другой его спрашивает:
— А что такое?
— Да не пойму: дэвочка это или малчиг.
— Вах зарэжу, это мой дочь!
— Простите. очень красивый нэвеста. Я не знал что вы его атэц.
— Вах,! точно зарэжу! Я его мать.!
Idot
На правом рисунке глаза меньше. Если бы там были большие глаза, то сомнения в форме морды истолковывались бы в пользу кошки.
Zenitchik
Не только. Там ещё кончик морды искажён так, что морда кажется более длинной и острой.
agat000
Ну да, плюс окраска, редкая для кошек и распространенная у собак.
Lennonenko
мне кажется, что там ничего не искажено, кроме контрастов и шумов
Zenitchik
Вот именно из-за удачно совпавших шумов «нарисовался» новый кончик носа — более маленький примерно посередине настоящего, из-за чего морда стала вытянутой — собачьей.
Несовпади эта «раковина» на полсилуэта — картина была бы другая.
u010602
Нет не похоже на собаку, но и на кота не похоже. Похоже на какое-то искаженное уродливое животное. У собаки другие пропорции отношения размера черепа к длине носа, к ушам. Расстояние между ушами, положение глаз, длина шеи, и очертания корпуса. Собакой это быть не может ни как. Это скорее какая-то неведомая зверюшка из Австралии, Америки или Мадагаскара. Типа лемура.

Lennonenko
так сразу меняется же и оценка расстояния
на левой фотке виден кот и по пропорциям мы предполагаем небольшое расстояние (или большой зум)
на правой же общий размер тот же, но так как кажется, что это собака, объект начинает казаться более далёким от объектива, потому что немецкая овчарка значительно крупнее обычных котов
пропорции же объясняются положением головы относительно туловища, это ведь плоское изображение
распечатайте эти изображения на разных листах и посмотрите на них с разницей минут в 10-15
ну а также учитывайте, что изображения испытуемым показывали на довольно короткий промежуток времени
u010602
Ну не знаю… Как-то ваши объяснения не кажутся мне убедительными. Не уверен что искажением перспективы или любыми другими обычными искажениями обычных объективов, можно сделать голову немца меньше его ушей, шею укоротить, а туловище сделать рахитским. Я себе такие искажения представить не могу. Т.е. я понимаю что там можно увидеть нос немца и уши немца, но их взаимное расположение — очень сильно не соответствует. Ну примерно как если взять ноутбук, и выделить у него части: клавиатуру, тачпад, экран. Но скомбинировать их так, что тачпад будет по центру экрана, а клавиатуры слева от экрана. Для бушмена возможно это и будет похоже на ноутбук, но кто каждый день с ним работал — не ошибется. Я регулярно контактирую с кошками и собаками, для меня очевидно что собаки нет, прямо вот с первого взгляда не-собака там. Скинул другу, который рос с собакой, у него аналогично. Предлагаю автору сделать опрос на 4 варианта. Вижу собаку, живу без собаки. Вижу собаку, живу с собакой. И так далее. Скорее всего дело именно в натренированность мозга на образ собаки и кошки.
zzzmmtt
Выше уже писали, у собак очень различаются пропорции в зависимости от породы. Да у большинства морда вытянута, но есть мопсы, английский и французский бульдоги, гриффоны или чихуахуа. Уши (форма, расположение) тоже варьируется. А вот зрачок кота и собаки спутать гораздо сложнее.
psinetron
По мне, так второе изображение сильно похоже на собаку. И вот почему: (описываю правую картинку)

1 — изменен цвет макушки «кота». Она стала больше сливаться с фоном, и тут же, ниже добавлена горизонтальная черта, которая больше подходит под очертания головы собаки, так что уши визуально становятся длиннее и больше подходят немецкой овчарке
2 — цвет в наложенной форме собаки изменен на более рыжий, что опять таки приближает образ к овчарке
3 — Направленность разреза глаз направлена более к переносице (или, скажем более горизонтально) что опять таки делает изображение присущее собакам
4 — нос вынесен более низко, нежели у кота, что подсказывает что длина морды относительно глаз более длинная, что опять таки присуще собакам
Ну и наконец — возьмем просто две правые части изображений, без тела. Я думаю так сразу становится проще определить кто есть кто:
Хотя предполагаю все вышеописанное каждый воспринимает по своему, как пример с бело-желтым, черно-синим платьем
Допускаю такой момент, что я также, подсознательно, например по заголовку статьи готов увидеть в изображении собаку.
И еще — если приведенные мной «правые части» каждого изображения отзеркалить — сомнений не останется совсем
psinetron
Подкреплю свой комментарий «отзеркаленным изображением»

Я думаю тут даже компьютер не ошибится. Может стоит внести корректировки в метод распознавания?
zzzmmtt
1,2 — внесен цветовой шум + он добавлен неравномерно, где-то его больше.
3 — наложено тёмное пятно. Горизонтальное. Форма и направление разреза глаз не читаются из-за этого пятна + цветовой шум.
4. нос не вынесен ниже, опять же вас ввели в заблуждение пятнами и шумом, добавлен «блик» чуть ниже верхней «кромки» носа.
Ну и исходное изображение вытянуто по вертикали, попробуйте чуть сжать его.
exehoo
Оно не вытянуто, линейных искажений вообще нет, вас тоже ввели в заблуждение. Все манипуляции — исключительно тенями, бликами и шумами
zzzmmtt
Возможно, не спорю. Хотя…
zzzmmtt
Zenitchik
Так больше похоже на истину. Кот стал котом, а «собака» — странным размазанным зверем.
psinetron
Шум может сбить только в случае, если вам нужно исказить изображения для конкретного алгоритма. Это мы видим в примере с пандой, когда шум перестроил изображение так, что алгоритм видит что-то другое, чего не замечает человек.

А вот тени и блики это основа для построения объемного изображения и в зависимости от того, как они расположены — так и воспринимается объем и его форма.
Например вот такое изображение воспринимается как выпуклое, хотя на самом деле имеет совершенно другую форму — вогнутую.
amarao
У меня есть совершенно тупая идея: компьютер применяет КарП на все показываемые изображения с целью доказать, что эта картинка — именно то, что компьютер имел в виду. Сама КарП генерируется в соответствии с распознаванием оригинальной картинки роботом.
Получается обыкновенное человеческое «услышал — переврал».
BlessYourHeart
Учитывая тенденцию к внедрению распознавания образов в разные области жизни не мудрено, что будут разрабатываться способы взлома этих систем.
OriSvet Автор
У Филипа Дика в «Помутнении» был «костюм-болтунья» — комбинезон, который постоянно проецирует на поверхность микс из огромной библиотеки образов.
HueyOne
Вы думаете, что видите чиновника, а на самом деле преступника
urticazoku
agat000
Шикарное фото. Яркие ложные маркеры глаз сразу ломают автоматическую обработку мозгом, приходится подключать думалку. 20 секунд тупил.
Andy_Big
Там и глаза перерисованы, и нос с пастью искажены, и окрас, и общая пропорция — фото вытянуто по вертикали. Фото кошки целенаправленно переделано в фото собаки :)
TheShock
Всмысле? На этом фото, очевидно, ничего не искажено, вполне нормальное животное в странной позе
Welran
Почему странной? Собака на боку лежит, что тут странного :)? Просто ракурс необычный.
Andy_Big
Обе картинки вытянуты по вертикали раза в полтора если не больше.
По правой картинке: отдельные детали где-то выделены, где-то затемнены; глаза модифицированы либо затемнением либо геометрическим искажением; вся картинка сильно размыта и зашумлена.
Zenitchik
Там просто шумы в форме «ракушек» удачно легли на глаза и на морду. Если их сместить на «полракушки» — не факт, что останется похоже на собаку.
Andy_Big
Не удачно легли, а тщательно и целенаправленно подготовлены :)
thatsme
У меня переключение моментально произошло, возможно из за опыта общения с американскими стафордширами. А вот на КПДВ, я начал с поиска различий, поэтому не сразу понял, что слева искажённая картинка сиамского кота. При этом сомнений, что справа овчарка даже не возникло. Вопрос которая из картинок исходник? Что во что морфили?
Да эффект очень интересный. Теперь нужны нейросети которые будут проверять картинку на манипуляцию с ней. Как предварительный фильтр. А что делать с восприятием человека? Правая картинка не воспринимается как поддельная, она воспринимается как зашумлённая. Левая, воспринимается как искажённая.
zzzmmtt
«Исходник», наиболее вероятно, левый кадр, правда вытянут по вертикали, добавив на него шумов получаем правый кадр. Только вот у меня там всё равно скорее кот, чем собака, хотя коллеге там видится скорее что-то овчаркоподобное.
porn
grozaman
Искалеченную голову собаки.
Driver86
Zenitchik
Её правда кто-то видит?
mayorovp
Да.
Atractor
А, да, классная картинка. Полагаю, что проблемы с её правильным восприятием возникли по большей части из-за контекста. После прочтения статьи мозг уже настроен искать подвох, собственно и ищет. А подвоха как раз нет.
mayorovp
Забавно. Чуть-чуть наклонив голову направо я без малейших усилий вижу правильно, а вот без наклона головы я успешно обманываюсь даже зная правильный ответ.
killik
Боян лет триста как. Классический Wolpertinger.
ntfs1984
Ой вей.
Не вижу здесь никаких картинок-противоречий.
Это скорее неполная информация (кстати бага была пофиксена природой введением бинокулярного зрения). На первой картинке, добавочно к собственно плоскоте, еще и затемнили кусок морды, из-за чего труднее стало разобрать верные отличия кота от собаки: зрачок, нос и вибриссы.
С таким же успехом можно надеть на глаза (или объектив) матовую пленку и рассказывать как мы похачили мозг, потому что теперь х. от пальца почти не отличимы.
LightSUN
На 1-й фотографии справа однозначно собака — по вытянутой морде. Усов почти не видно. А если убрать изображение кошки слева, то скорее всего никто и вовсе не подумает, что на изображении справа кошка.
Alek_roebuck
Мне достаточно снять очки, чтобы и левую картинку распознать как собаку. Это не справа хитро искаженная картинка, а слева — специально подобранная. Чуть убрать детали (например, чтобы зрачок левого глаза зверя окончательно слился с веками) — и кот на левой картинке превращается в собаку.
Andy_Big
То есть берем картинку одного объекта, искажаем ее почти до неузнаваемости, дорисовываем признаки другого объекта, показываем ее в течении одного мгновенья и после ожидаемой ошибки в опознании говорим "мы взломали мозг"?
Ariez
В целом странно. Есть объективная реальность. Когда мы смотрим на эту самую реальность — мы всегда получаем субъективную интерпретацию этой реальности, которая зависит от большого количества факторов. В том числе и личный настрой человека (когда ты настороже — начинаешь от теней шарахаться). И естественно любые варианты нечеткости изображения будут участвовать в его интерпретации
SirAlex
Маленькая победа капчи над ботом — радоваться нужно)) Уж лучше угадать котика или собачку, чем 5 раз в плитке X на Y найти номер машины, знак итп
Zmiy666
А никто не пробовал тренировать сеть на поиск именно обработанных таким образом изображений? Чтоб она отсеивала их прежде чем скормить другой сети.
Да и вообще как-то натянуто… если поучить сеть не только на обычны картинках, но и на измененных думаю она и измененные начнет отсеивать весьма быстро и точно.
humanelement
Об этом речь и не шла. Только о том, что была готовая сеть, натренированная на обычных изображениях. И что её удалось обмануть.
Теперь вопрос. Откуда вы заранее будете знать вид «атаки», который будет когда-нибудь использован? Вы можете заранее обучать только на уже известных видах таких «атак».
С людьми же ровно точно так же. В куче областей простого человека легко обмануть, но трудно обмануть специалиста, который уже заранее специально натренирован на выявление «подозрительных» объектов.
KivApple
Мне почему-то пришла идея, что идея с наложениями невидимого для человека шума хороша для обхода автоматизированных фильтров контента (копирайт, порнография и т. д.) на каких-либо сервисах.
3aicheg
Не бойтесь, она не кусается?
mSnus
Скрестили кошку с собакой, и удивляются, что получился котопес?
Хакинг мозга в реальной жизни:
Берём мандариновое варенье и смешиваем с пихтовым. Получаем мандапихтовое, и мозг уже не в состоянии определить, какому из начальных компонентов более соответствует результат.
Берём мелодию из классики, накладываем немного барабанов — и получается уже современная попса.
Красим жирафа в черно-белые полоски — и получается зебра с длинной шеей.
Так в чем пугающий эффект?
Marsikus
Занятно, так ведь на вид немножко подпорченный нехорошими людьми дорожный знак может быть совершенно неправильно распознан автопилотом и спровоцировать аварию. При этом мало кто из людей, глядя на знак, поймет что с ним что-то не так.
GermanRLI
В дорожных знаках всё-таки достаточно простые примитивы и контрастные цвета. Так что наложением шума (особенно невоспринимаемого человеком шума) их испортить должно быть довольно сложно. Ну и в тесты систем распознавания образов для роботов водителей ИМХО должны входить мятые, грязные и простреленные дробью знаки видимые под разными углами, можно добавить и знаки с наложением шума.
humanelement
Кстати темой для подобной атаки чуть ранее как раз были дорожные знаки.
Вот топик: geektimes.ru/post/291847
Rohan66
Читал про «разрыв шаблона».
Просить закурить, а жестом показывать вопрос «Сколько времени?» (Постукивать по запястью).
Или наоборот.
Спрашивать время, а жестом показывать желание прикурить.
Народ, обычно, зависает слегка…
killik
Так нынче не курят, а парят, и просить прикурить это подзарядить аккумулятор.
lingvo
Еще лет двадцать назад ребенком я баловался морфингом, как в клипе Майкла Джексона — Black and White. Смешно было скрещивать фото одноклассников с одноклассницами и получать фото а-ля их детей. В итоге получался мальчикдевочка иногда симпатичный иногда нет, но похожий на оба исходника.
Так к чему это я? А к тому, что нет смысла морфить два изображения кошек и собак, а потом спрашивать, что нарисовано — кошка или собака? В большинстве случаев люди ответят, что видят и то и другое и неуверенны. Причем их восприятие будет смещено в ту или иную сторону в зависимости от предпочтений, настроения и жизненного опыта. И окажутся правы, так как картинка действительно искусственная. Так где тут обман мозга?
zzzmmtt
На КДПВ нет морфинга, там только шум, и отчетливо видно, что это не совсем рандомный шум, там видны структуры, «постморфингом» занимается в данном случае именно мозг.
Maslukhin
Мне интереснее другое. Человеческий мозг веками учился не тратить силы на решение автоматических задач. В результате он может легко лажать на картинках, где ИИ легко определит правду. К примеру, вот видео, где мозг пересчитывает размер детали в зависимости от того, видит ли он два радиуса дуги или один.
DASM
данный опыт некорректен. В 3Д надо и на 3Д мониторе. А иначе — мы лишаем мозг информации о дальности
Maslukhin
3d не поможет. Мозг обманывается в реальности, со всеми глубинами и прочим. Вопрос том, что мозг уменьшает объект из-за меньшей кривой. Глубина тут не причем.
u010602
Нет не обманывается, у меня дети и полно этих железных дорог. И на видео мне кажется что верхняя дальше, и от того меньше. Внутренняя дуга то действительно меньше внешней, а внешние практически равны, отличия в размере — четверть соеденителя, и это результат перспективы. Конечно из-за дуги кажется что отличия чуть больше, но все-же обмана нет.

Maslukhin
Ок, а вот так? :)
Проблеме не в дальности. Это баг мозга, вызванный алгоритмами быстрого принятие решений, работающими без нагрузки основного процессора.
u010602
Тут другая иллюзия, тут из-за малого изгиба кажется что изгиб равен, и потому угловой размер сектора разный. И приоритет идет именно на угловой размер, а не на линейный. А угловой ДЕЙСТВИТЕЛЬНО меньше, эти рельсы бывают с допуском, позволяющим собрать окружность разного радиуса за счет изгиба в соединителе. И если так сделать — то для большего круга нужно будет больше деталей. Т.е. угловой размер зависит от диаметра. И т.к. верхняя лежит дальше — то и соотв и радиус окружности, которую она описывает больше, а угловой размер меньше.
killik
Опыт красив и корректен вполне, информация о дальности не нужна и не является необходимой вообще.
DASM
То есть ваза на подоконнике и дом напротив — одного размера с точки зрения человека? Природа нас снабдила стереозрением, чтобы корейцы могли продавать 3Д телевизоры только?.. Ой, это собеседнику чуть выше по ветке
killik
Природа нас снабдила стереозрением не для того, чтобы мы друг другу подножки ставили. Чем мы занимаемся исключительно из-за отсутствия внешней угрозы, ибо все остальные виды разума этой планеты уже не смогут пробиться сквозь нас.
OlegZH
Ужас. Теперь понятно, к чему идёт дело и что на самом деле хотят сделать. Самопознание человечества —штука хорошая, но оно имеет и обратную сторону. К сожалению, за прорывными технологиями могут стоять люди, которые планируют не осчастливить человечество, а осчастливить только себя. В этом смысле, фраза
вызывает недоумение. Вопрос в том, что было с самого начала, какова была исходная постановка задачи. Печальный исторический опыт учит, что деструктивные постановки задач (почти) всегда предшествуют конструктивному «побочному» эффекту.Положительный результат, однако, заключается в том, что, скорее всего, имеется некая общность различных форм, некая «конформность» восприятия, которая позволяет параметризовать в едином пространстве буквально любую форму, которую можно помыслить. А это значит, что, в перспективе, теоретические исследования позволят связать воедино человеческое восприятие, человеческий язык (как таковой) и человеческую анатомию. Если лёгким поворотом «рычажка» можно получать практически любую форму, то устройство вселенной может оказаться большим голографическим калейдоскопом, все картинки которого получаются путём витиеватых проекций конечного набора элементов, а ощущение непрерывности создаётся для того, чтобы не «слышать» звуков поворота Всемирного Калейдоскопа. Вот.
killik
Через Тысячелетнюю Тьму пробились. Побьемся и через это.