

Красота, как известно, требует жертв, но и мир обещает спасти. Достаточно свежий (2015г) визуализатор от Google призван помочь разобраться с процессами, происходящими в сетях глубокого обучения. Звучит заманчиво.
Красочный интерфейс и громкие обещания затянули на разбор этого дизайнерского шайтана, с неинтуитивно отлаживающимися глюками. API непривычно скудный и часто обновляющийся, примеры в сети однотипны (глаза уже не могут смотреть на заезженный MNIST).
Чтобы опыт не прошел зря, решила поделиться максимально простым описанием инсайтов с хабравчанами, ибо рускоязычных гайдов мало, а англоязычные все как на одно лицо. Может, такое введение поможет вам сократить время на знакомство с Tensorboard и количество ругательных слов на старте. Также буду рада узнать, какие результаты он дал в вашем проекте и помог ли в реальной задаче.
Дабы не повторяться лиший раз, поднимать тему работы с Tensorflow как таковым не буду, об этом можно почитать например тут, а здесь в конце даже посмотреть на пример использования Tensorboard. Повествование будет вестись с предположением, что концепция графа операций, используемого в Tensorflow, вам уже знакома.
Официальный Guide Tensorboard содержит, на самом деле, все, что требуется, так что если вы привыкли работать с кратким описанием и подхватываете идеи на лету — можете переходить по ссылке и использовать инструкции разработчиков. Мне с наскока их осознать и применить не удалось.
Общий принцип записи логов
Вытащить параметры работы сети, выстроенной в TensorFlow(TF), очень непросто. TensorBoard(TB) выступает как инструмент в этой задаче.
TF умеет собирать, можно сказать, в «коробки» — summary, данные, которые нам и отображает TB. Причем, существует несколько видов этих «коробок» для разных типов данных.
— tf.summary.scalar Сюда можно класть любые числовые значения, например, функции потерь на каждой (или не каждой) эпохе обучения. Отображение в TB будет в виде привычного графика x(n).
— tf.summary.image Собирает изображения.
— tf.summary.audio Собирает любые аудиофайлы.
— tf.summary.text Собирает текстовые данные.
— tf.summary.histogram Собирает набор значений и в TB отображает «слоистые» гистограммы распределения этих значений, по каждому шагу записи. Хорошо для хранения данных весов, можно отслеживать изменения их величин на каждой эпохе обучения.
В качестве аргумента задается название «коробки» и переменная, из которой будет забираться значение. Например:
tf.summary.scalar('loss_op', loss_op)В моей задаче были актуальны типы scalar и histogram.
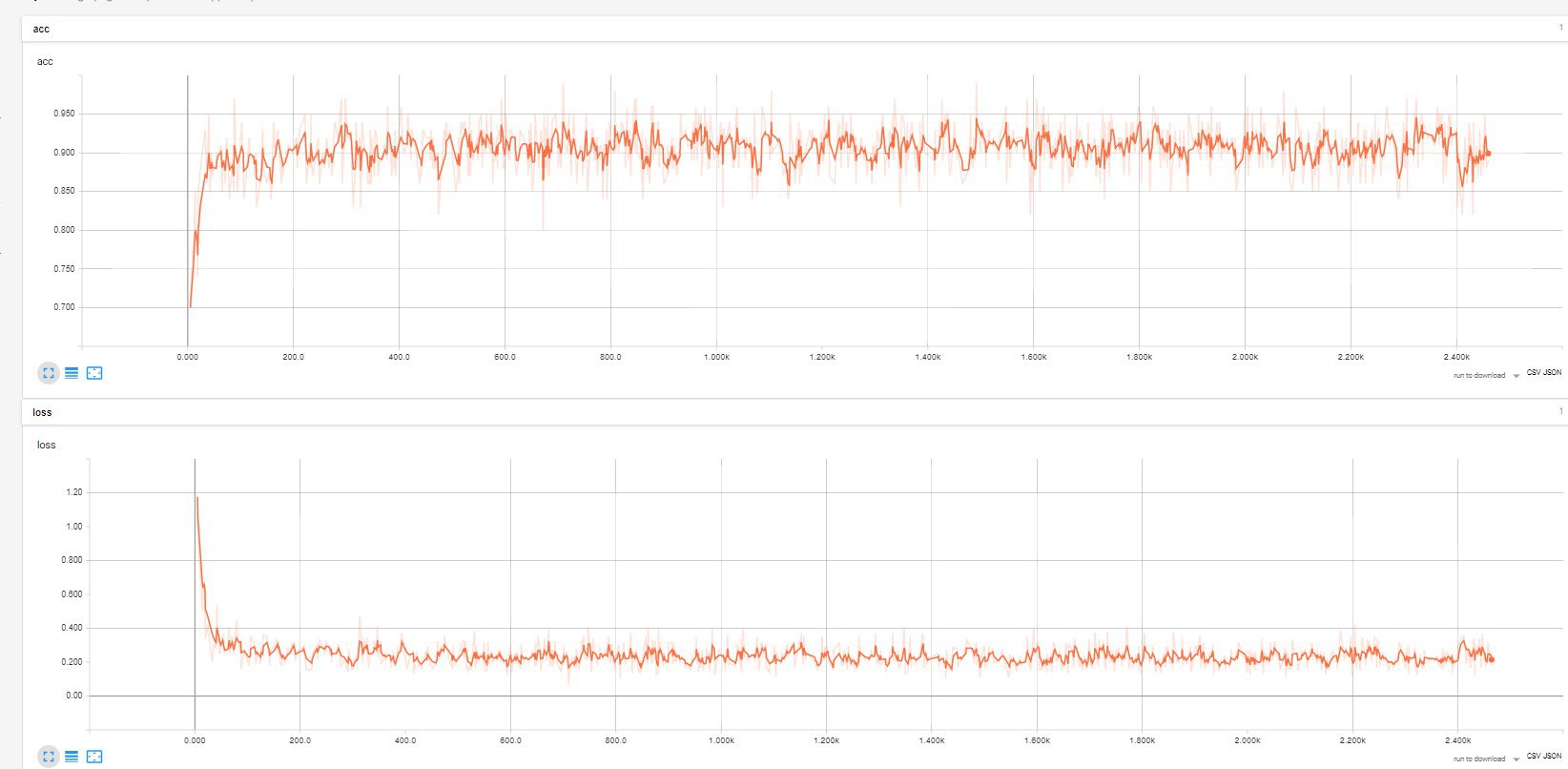
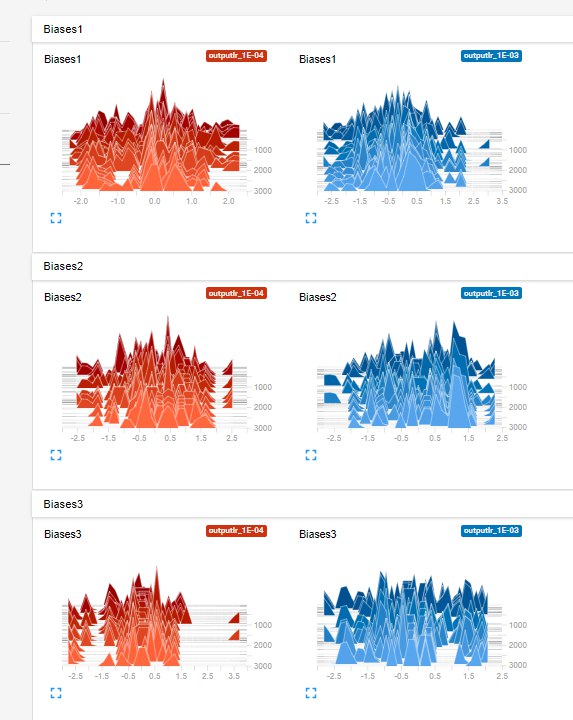
Гистограммы весов трех слоев, для двух величин Learning rate (0.001 и 0.0001).
Чтобы не пополнять по отдельности каждую «коробку» в явном виде, используйте merge_all() , собирав их таким образом в одну кучу и получая нужные данные по всем «коробкам» за раз.
tf.summary.scalar('loss_op', loss_op) #делаем "коробку" под функцию потерь.
tf.summary.scalar('accuracy', accuracy) #под точность
tf.summary.histogram('Biases1',biases['h1']) #под смещения первого слоя(они берутся из словаря по ключу h1)
tf.summary.histogram('Weights1',weights['h1']) #под веса первого слоя
"""
...
в общем,задаем все необходимые summaries
...
"""
merged_summary_op = tf.summary.merge_all() #и сливаем в единый набор "коробок" Естественно, упомянутые accuracy, loss_op, biases и weights объявляются отдельно как участники текущего графа операций.
Далее merged_summary_op просто активизируется в нужные моменты во время исполнения сессии. Например, при запуске обучения:
[_, _, sum_result] = sess.run([train_op, loss_op,merged_summary_op], feed_dict={X: batch_x_norm, Y: batch_y}) #запускаем обучение, на выходе нас ничего не интересует, кроме содержимого для "коробок", которое отдается в sum_result
summary_writer.add_summary(sum_result, i) #записываем результат в логи, i-номер степа обучения Как вы заметили, запись результата в файл происходит с помощью (простите за уменьшительно-ласкательное, но альтернативы я не смогла придумать) «записывалки» summary_writer и ее функции add_summary. «Записывалка» объявляется заранее, в аргументах указывается путь к папке с логами. Создание нескольких writer-ов удобно использовать для разнесения результатов на тестовой и тренинговой выборках, об этом подробнее расскажу в следующей статье. Плюс ко всему можно добавлять в логи значения используемых гиперпараметров (типа learning rate, вид функции активации, количесто слоев и тд. Боле подробно про то, как задавать гиперпараметры и можно посмотреть тут ), коротые будут также отображаться в TB.
Log_Dir="logs/outputNew/myNet" #директория к логам в рабочей папке
hparam= "LR_%s,h1_%s,h2_%s,h3_%s" % (learning_rate,n_hidden_1,n_hidden_2,n_hidden_3) #при отображение графика будет выведено название с указанными гиперпараметрами
summary_writer= tf.summary.FileWriter(Log_Dir+hparam)
summary_writer_train.add_graph(sess.graph)#и обязательно добавляем в наш writer граф операций текущей сессии для отображения в TB структуры графа Запуск визуализатора TB производится с помощью команды (конечно, через консоль):
tensorboard --logdir='Log_Dir'Так что прогнав сессию, обучив сеть и собрав все нужные данные в логи, можно наконец посмотреть их в браузере, зайдя на localhost:6006. Думаю, вы и сами разберетесь с разными форматами отображения: хотя бы это у TB действительно интуитивно понятно. А о том, как удобно выводить графики по группам (гиперпараметров, например), использовать теги, расскажу в следующей статье.
Итак, в целом процесс подготовки почвы для TB (опуская особенности построения графа операций с TF, конечно, сейчас не об этом) выглядит примерно так:
- Формируем граф операций, следуя принципам работы с TF
- Создаем «коробки»-summary под данные, которые хотим собирать в логи
- Сливаем все «коробки» с помощью merge_all()
- Задаем «записывалку» summary_writer, в которой указываем путь для логов и сразу добавляем наш граф
- Во время сессии вызываем смёрженные коробочки в run-e и пишем результат с помощью summary_writer
- Смотрим результат в TB, скрестив пальцы
Три проблемы, которые могут всплыть
TB не видит логи
Проверьте указанный к ним путь! Если не видит снова, еще раз перепроверьте! И так пока не заработает. Если в папке логов лежат файлы, то TB их не может увидеть лишь в случае неверной директории.
Сильно заторможенное обновление графиков
Для того, чтобы график отобразился в TB, приходится ждать до 15 минут. По началу я думала, что это какие-то проблемы с записью логов, но даже перезапуск TB не помогал решить проблему запоздалой подгрузки новых данных. Приходилось работать в режиме «пишем логи — ждем 10 минут — смотрим, что подгрузил TB». Винить в тормозах компьютор никогда не приходилось, так что корень проблемы где-то в другом месте. Интересно будет услышать, встретил ли кто-то еще этот глюк.
Дублирование имен и данных
Периодически у меня вылезало дублирование данных. Например могло возникнуть несколько видов точности или весов. Или что-то типа такого , причем эту проблему разрешить не удалось, так как неясно происхождение дубликатов. Призываю быть аккуратнее с присвоением имен — это иногда помогает (в графе операций и в summary) и анализом итоговых графиков. Иногда там оказывается не то, что хотелось бы.
Далее планирую осветить вопрос разделения writer-ов для тестовой и тренинговой выборок, а также какие есть варианты режимов отображения нагенерированой кучи логов.
В рабочем проекте по классификации участков временного ряда результата лучше, чем простая лог.регресия, нейронки не дали, как я ни пыталась пробовать разные конфигурации. Но инструмент освоен, а значит может принести плоды в дальнейшем.
Stay tuned!
P.S. В нашей компании «Инкарт» есть открытые вакансии для мозговитых программистов и электронщиков, а еще есть свой повар, классные корпоративы и офис на берегу озера. Мы разрабатываем и производим кардиореспираторные мониторы, которыми пользуются большинство кардиологов России. Постоянно совершенствуем алгоритмы обработки и железную часть дела. Свободные умы из Петербурга — пишите в личные сообщения за подробностями.
Комментарии (9)

lgorSL
25.03.2018 00:53Ещё c помощью
summary_writer.add_run_metadata(...)можно записать информацию о выполнении. Для каждой вершины графа — потребление памяти и затрачиваемое на вычисление время.
Для того, чтобы график отобразился в TB, приходится ждать до 15 минут.
Странно. У меня график обновляется с интервалом в 1-2 минуты.
yzoz
26.03.2018 22:32Я запускал .add_summary в цикле с .sess.run. Скажем, можно каждую итерацию, а можно i % step == 0. Тогда Tensorboard будет обновляться так, как указано в его интерфейсе, ведь данные будут поступать real-time.
Если абстрактно, то:
for i in range(train_batch): x, y = prepare(train_x, train_y, i * batch) dic={X: x, Y: y} _, summary = sess.run([train, merged], feed_dict=dic) writer.add_summary(summary, i)
Если детальней, то (: github.com/yzoz/rnn-market-predictionYuliyaCl Автор
27.03.2018 00:20Да, можно и так тоже делать. Видимо, с обновлением это у меня какой-то странный косяк на машине)
yzoz
27.03.2018 01:03У меня просто сейчас не установлен… но там вот та шестерёнка в правом верхнем углу — вроде там и была одна единственная настройка «update interval» или что-то типа того.
konar
27.03.2018 00:10Не вижу смысла еще раз описывать то, как рисовать скаляры и гистограммы. Примеров и так хватает. Другое дело, что в этих примерах практически нигде (как и в данной статье) не описано, как правильно читать эти гистограммы и распределения. В свое время не сразу смог понять, что они значат.
Гораздо реже встречаются примеры того, как удобно отображать изображения, аудио и текст. С аудио и текстом работал поменьше, а вот с изображениями в TB пришлось много поработать. И создалось впечатление, что какого-то общепринятого приема скармливания картинок нет.
В последних версиях TB появились какие-то дополнительные вкладки. Сам с ними еще не разбирался, хотелось бы и о них узнать…YuliyaCl Автор
27.03.2018 00:16Больше новых версий!)
Про анализ не стала даже трогать тему, не об этом хотелось говорить) Профитом от визуализации у нас было решение об изменении принципа генерации весов. Визуально они не должны быть сильно кучкообразны около нуля, тогда выходит, что часть нейронов почти неактивна. Основные вещи о настройке доступно описали тут . Нам они дали прирост на процентов 5, что было очень неплохо.
Скармливать картинки не пришлось, так что не подскажу, но да, общепринятых вещей тут впринципе мало…
terixoid
27.03.2018 00:10Достаточно интересно было бы услышать про projector в tb.
Какие решения принимать на основе гистограмм весов и градиентов? как я понимаю, если веса распрелены в области высоких значений, то можно подкрутить регуляризацию у слоёв (был бы признателен, если бы кто-нибудь подтвердил или опроверг моё предположение).
YuliyaCl Автор
27.03.2018 00:19Мы с ним «игрались», выходил космос) Но как использовать на практике так и не поняли)) Вещь заманчивая, хотим идею projector-а все же раскрыть и тогда напишу, что выйдет.
Да, если уходят в большие значения — то регуляризация, если у нуля торчат все почти — то потоньше настроить их начальную генерацию и регуляризацию попробовать «смягчить».
QtRoS
Хочется добавить, что в Keras (официальный фронтенд для TensorFlow) есть удобный коллбэк для записи логов для TensorBoard.