
Применяем Deep Watershed Transform в соревновании Kaggle Data Science Bowl 2018
Представляем вам перевод статьи по ссылке и оригинальный докеризированный код. Данное решение позволяет попасть примерно в топ-100 на приватном лидерборде на втором этапе конкурса среди общего числа участников в районе нескольких тысяч, используя только одну модель на одном фолде без ансамблей и без дополнительного пост-процессинга. С учетом нестабильности целевой метрики на соревновании, я полагаю, что добавление нескольких описанных ниже фишек в принципе может также сильно улучшить и этот результат, если вы захотите использовать подобное решение для своих задач.
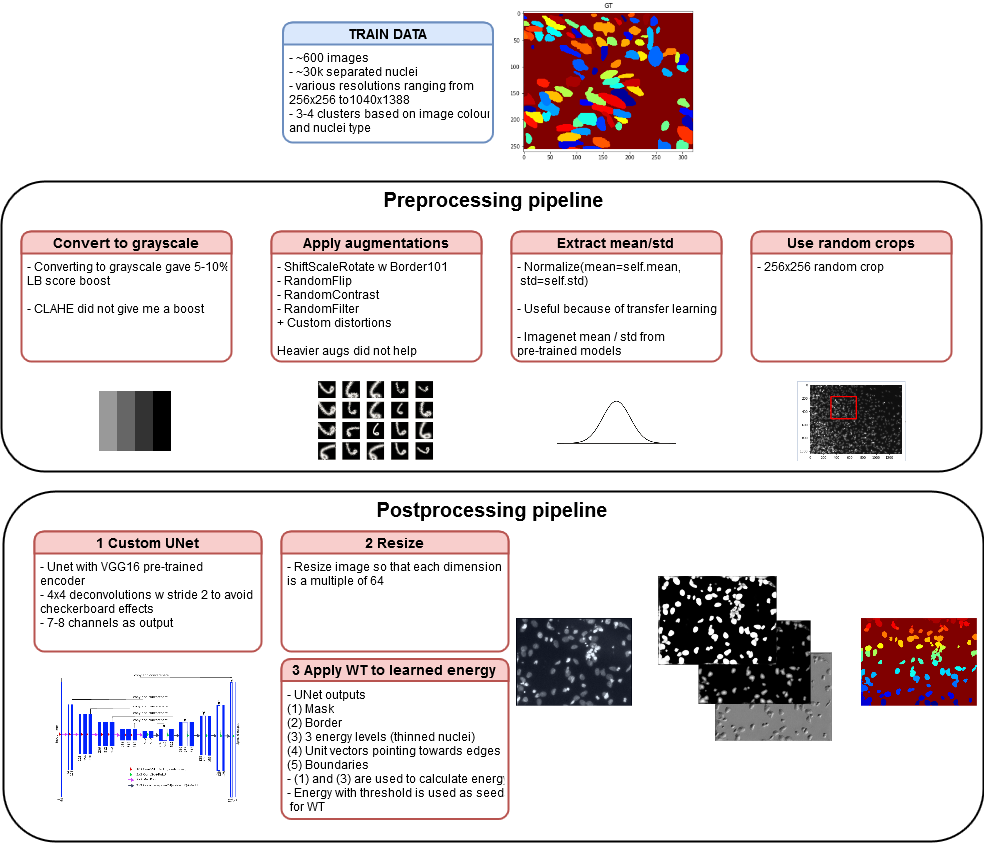
описание пайплайна решения
TLDR
(Заметка переводчика — некоторые термины оставлены как есть, т.е. я вообще не уверен, что на русском языке есть адекватные аналоги. Если вы знаете о таковых — пишите в комментарии — внесем правки).
Каждый год каггл запускает соревнование Data Science Bowl. В прошлом году это было довольно круто:
- Новая интересная тема в виде 3D-изображений
- Достойное задача — рак легких;
- Большой датасет — 50+ГБ;
- Соблазнительный приз;
К сожалению, когда в прошлом году соревнование запустилось, я еще не был готов принять в нем участие. В этом году, после того как Гугл купил Каггл, я начал замечать некоторые первые "тревожные звоночки" (парочка "заметок на полях" — вот и вот). Кратко — раньше соревнования по машинному обучению мне казались взаимовыгодными как для сообщества, так и организаторов соревнований, но сейчас я наблюдаю какой-то непонятный тренд в худшую сторону — такое ощущение, что соревнования превращаются в упражнения по коллективной разметке данных и / или награды становятся непривлекательными относительно количества усилий, которое надо приложить, чтобы нормально поучаствовать (разобраться / попасть в топ или призы / прокачаться).
Почему мне не понравилась организация этого соревнования:
- Маленький датасет (600 изображений для тренировки и 65 для валидации) на первом этапе конкурса вместе с в разы большим датасетом на втором этапе конкурса (3000 картинок только для теста);
- Распределение данных на второй стадии не имело ничего общего с первой (поставил тут жирный восклицательный знак);
- Также Каггл печально известен тем, что не особо пресекает читерство — в этом конкретном соревновании например, можно было заново обучать модель после релиза данных второй стадии;
- Если не верите мне — поспрашивайте членов комьюнити, которые принимали участие;
- (Дабы не быть голословным ближе к концу будет описано, как избежать таких проблем);
- Также целевая метрика — средняя mAP на нескольких уровнях точности (от 0.5 до 0.95) — ведет себя очень нестабильно. Судя по выбору такой метрики, организаторы были явно уверены в "идеальности" своей разметки, но на практике это было конечно же не так. Например если взять разметку, сместить ее на 1 пиксель в сторону, то скор падает с 1 до 0.6;
Сначала, когда я открыл данные, я вообще хотел не участвовать, т.к. их объем в мегабайтах вообще не внушал доверия. Но потом я рассмотрел их повнимательнее и понял, что задача тут состоит в instance segmentation, что было для меня новинкой. Сама задача — instance segmentation — очень интересная, несмотря на маленький размер датасета. Ожидается, что вы не только создадите точную бинарную маску клеток, а также разделите слипшиеся клетки (пардон, может там ядра, а не клетки, но судя по разметке, сами организаторы в этом тоже не уверены). С другой стороны размер датасета и качество разметки показались немного неадекватными, особенно с учетом того, что в том числе организаторы соревнования сообщали, что некоторые компании обладают аналогичными датасетами с терабайтами данных.

Базовые задачи компьютерного зрения. Тут в списке по идее также должна быть классификация объектов (классическая задача — найти кошек и собак на фото)
В этом посте дальше я объясню свой подход к решению этой задачки. Также я поделюсь своим пайплайном вдохновленным статьей Deep Watershed Transform for Instance Segmentation и расскажу про другие походы и решения, а также поделюсь своим мнением как такие соревнования должны в идеале быть организованы.
EDA или почему ML это не магия
Тренировочный датасет содержал примерно 600 изображений и валидационный датасет — 65. Отложенный тестовый датасет из второй стадии содержал ~3000 изображений.
Изображения из первой стадии имели разные разрешения — что само по себе было некоторым вызовом — как вы бы построили универсальный пайплайн для всех них?
256x256 358
256x320 112
520x696 96
360x360 91
512x640 21
1024x1024 16
260x347 9
512x680 8
603x1272 6
524x348 4
519x253 4
520x348 4
519x162 2
519x161 2
1040x1388 1
390x239 1Среди тренировочных данных было примерно три кластера, которые легко найти с помощью K-means:
- Изображения с черным фоном;
- Изображения с красителем;
- Изображения с белым фоном;
Это было главной причиной почему конвертирование RGB изображений в черно-белые помогало на публичном лидерборде.
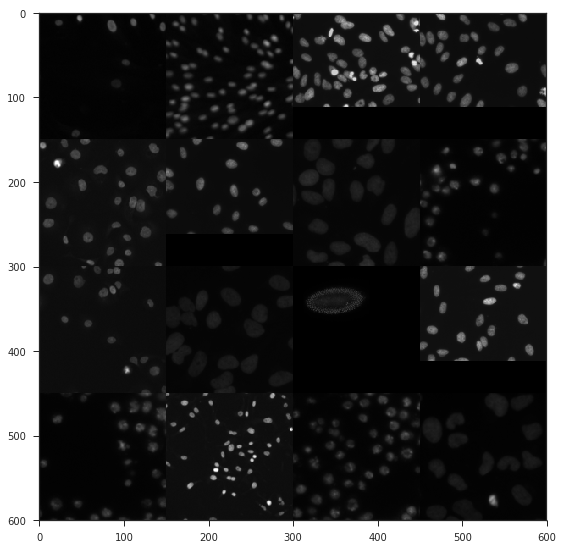
Черные изображения

Разные вариации ядер по форме, цвету, размеру
Визуальный просмотр тестового датасета с тремя тысячами картинок показал, что 50+% этих картинок не имеют ничего общего с тренировочным датасетом, что вызвало много споров и негодования со стороны комьюнити. Так что вы участвуете в соревновании за "спасибо", тратите время, оптимизируете модель, и бац и получаете 3000 картинок, которые никак не похожи на тренировочные данные? Понятно, что цели могут быть разные (в том числе предотвратить ручную разметку на между этапами соревнования) — но это можно сделать гораздо менее топорно.
Некоторые примечательные файлы из тестового датасета:
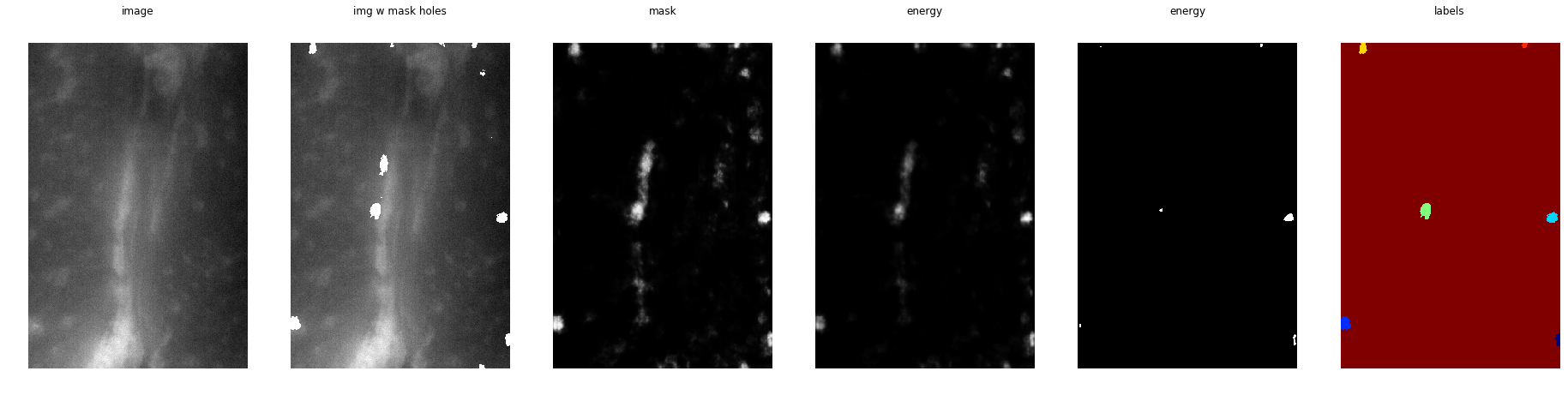
Я бы предположил, что маленькая штука на фоне это ядро

Честно, без понятия, что это

Выглядит как мышцы. Еще раз, эти белые штуки это ядра или что вообще?
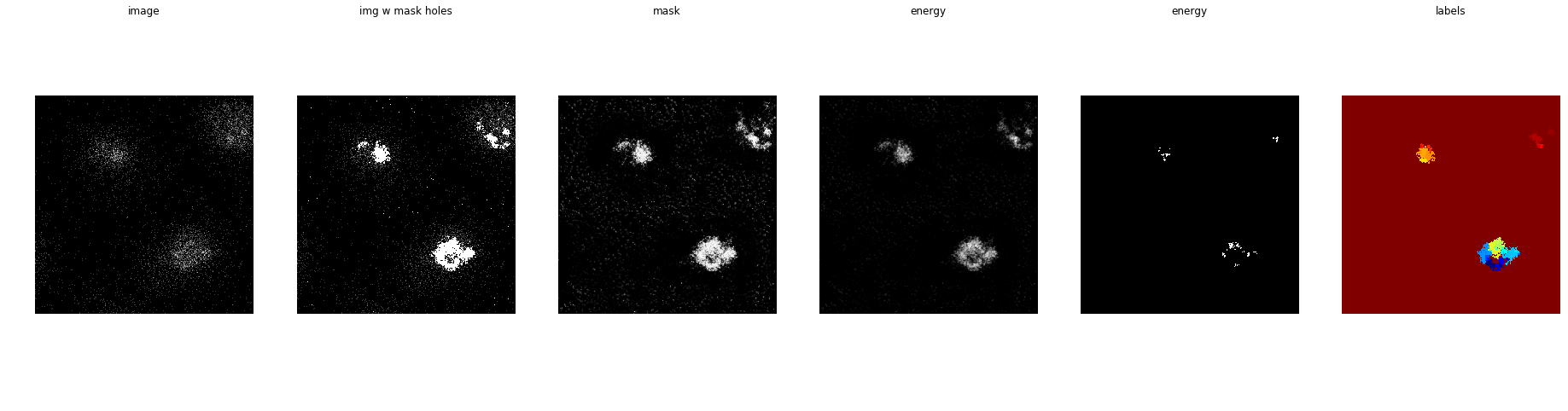
Ночное небо… Это ядра или просто шум?
Deep Watershed Transform
Если вы не знаете что это, то сходите вот сюда. Интуитивно, метод водораздела довольно простой — он превращает ваше изображение в отрицательный "горный ландшафт" (высота = интенсивность пикселей/маски) и заполняет бассейны из выбранных вами маркеров водой, пока бассейны не соединятся. Вы можете найти кучу туториалов с OpenCV или skimage, но все из них обычно задают такие вопросы:
- Как мы должны выбрать метки, откуда будет "вытекать вода"?
- Как мы должны определять границы водораздела?
- Как мы должны определять высоту ландшафта?
Deep Watershed Transform (DWT) поможет нам решить некоторые из этих проблем.
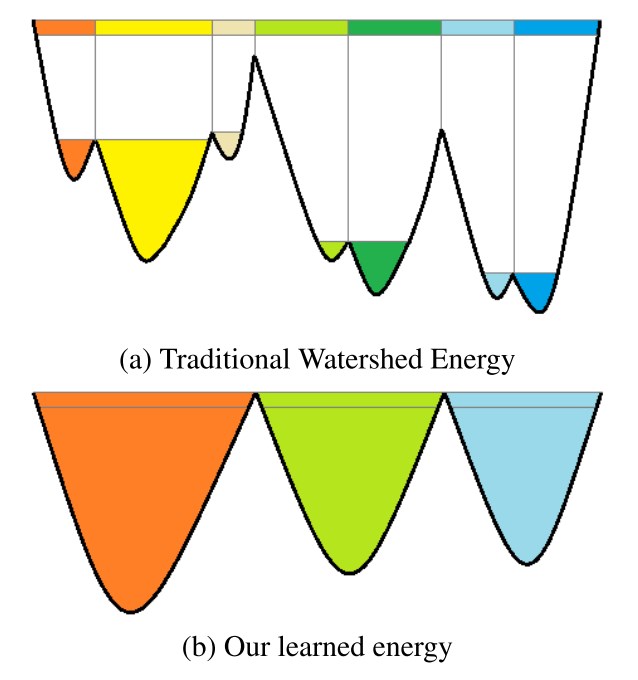
Главная мотивация из оригинальной работы
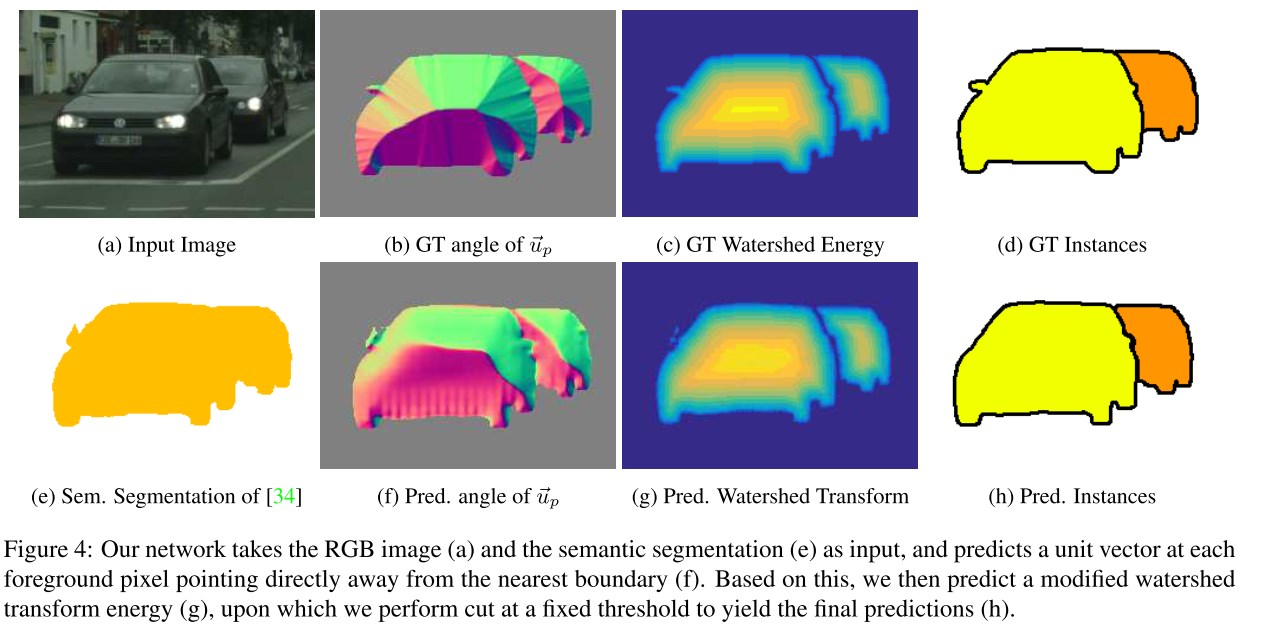
Идея в том, чтобы CNN учила две вещи — единичные вектора указывающие на границы и уровень энергии (высота гор)
На практике, если вы просто примените WT (Watershed Transform), скорее всего у вас получится слишком парцеллярная сегментация. Интуиция, лежащая за DWT, такая — надо научить CNN находить "горный ландшафт" за нас.
Авторы оригинальной статьи использовали 2 раздельные CNN VGG-типа для получения:
- Энергии (или высоты ландшафта);
- Единичных векторов, направленных к границам объектов или от границ, чтобы потом помочь CNN выучить энергию и границы объектов;
На практике можно использовать одну сеть или просто обучить несколько более мелких end-to-end сетей. В моем случае я игрался с сетями, которые выдавали:
- Бинарную маску клеток;
- Несколько масок с разными уровнями эрозии (1,5,7 пикселей);
- Центры ядер (не особо помогли в моем случае);
- Единичные вектора (слегка помогли, локально);
- Границы (слегка помогли, локально);
Потом вам нужно немного магии для того, чтобы скомбинировать это все и вуаля, у вас есть "энергия". Я не очень много экспериментировал с архитектурой, но Дмитро (автор решения выше) потом подсказал мне, что у него не получались более качественные результаты при добавлении второй CNN.
Для меня лучшим пост процессингом (функция energy_baseline по ссылке) был такой алгоритм действий:
- Суммируем предсказанную маску и три уровня предсказанных масок с эрозией;
- Применяем порог в 0.4, чтобы разделить центры клеток;
- Используем найденные центры в качестве маркеров для заливки;
- Используем расстояние до границы масок в качестве меры "высоты ландшафта";

Один из лучших примеров — сетка смогла четко разделить слипшиеся ядра
Выученные градиенты не подходят для использования в качестве водоразделов
Иногда прямой поиск центров ядер тоже работал, но в целом, это не помогло улучшить скор.
Другие подходы
Лично я бы разделил возможные подходы этой задачи на 4 категории:
- Подходы в стиле UNet архитектуры (UNet + предобученная Resnet34, UNet + предобученная VGG16, и тд) + Deep Watershed Transform пост-процессинг. UNet (его кузен, LinkNet) известны как универсальные и простые инструменты, когда нужно решать задачи семантической сегментации;
- Рекуррентные архитектуры. Я нашел только эту более менее релевантную работу (даже с учетом наличия готового кода на PyTorch я не успел ее попробовать);
- Proposal based модели типа Mask-RCNN. Хотя их довольно трудно использовать (и нет подходящей реализации на PyTorch), сообщалось, что подход первоначально дает более высокие результаты, но почти без вариантов их потом улучшить;
- Другие немного "авантюристические" (читай — сам автор пишет, что они вроде не особо работают) подходы, описанные здесь;
Для меня в пользу выбора DWT + UNet сыграло то, что это решение, где не надо особо возиться, потому что оно простое (можно просто подавать слои энергии как дополнительные каналы для маски) и потом наработки легко переложить на други задачи. Мне также очень нравится рекуррентное расширение UNet, но у меня не хватило времени попробовать.
В случае рекуррентного UNet, там есть три новых компонента по сути по сравнению с обычными UNet:
- ConvLSTM слой;
- Компонент функции потерь, который штрафует CNN за то, что она выучила слишком много ядер;
- Использование Венгерского алгоритма оптимального совмещения предсказанных объектов с разметкой;
Все это кажется ошеломляющим поначалу, но я точно буду пробовать это в будущем. Хотя, этот метод комбинирует две прожорливых по памяти архитектуры — RNN и encoder-decoder сеть, что может быть непрактично в реальном использовании за пределами маленьких датасетов и разрешений.

Описание ConvLSTM слоя

Рекуррентная Unet архитектура
Мой пайплайн
Вы можете найти детали здесь, но мой подход состоит в следующем:
- Unet с VGG16 энкодером (в репозитории есть много разных энкодеров);
- Deep Watershed;
- Множество мелких хаков, включая конвертацию в черно-белые картинки и
transfer learning; - Тренировка модели на 256x256 случайных кропах;
- Предсказание на ресайзах изображений (чтобы размеры картинок делились на 64) (возможно это плохой выбор);
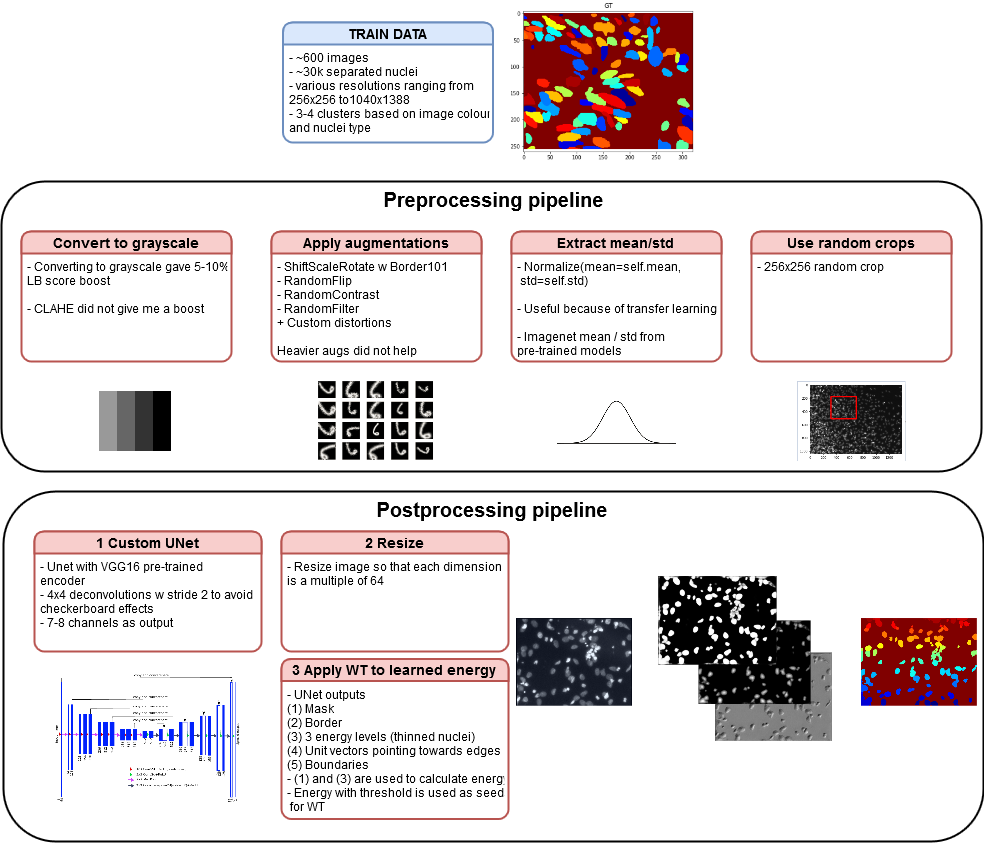
Весь пайплайн
Если вы хотите сильно улучшить результат этого пайплайна, то нужно заменить VGG-16 энкодер на Resnet152 — по словам участников соревнования этот энкодер вел себя намного стабильнее на отложенной валидации. Также замена softmax на sigmoid в качестве последней функции активации дает менее размытые границы.
А теперь про то, как надо по идее такие соревнования организовывать
Если вкратце, то SpaceNet с этой точки зрения был почти идеален, если продисконтировать раздражающие моменты платформы TopCoder:
- Большой датасет со сбалансированной тренировочной выборкой и тестовой выборкой;
- Четкие ограничения на внешние данные;
- Докеризация и заморозка кода для проверки организаторами;
- Никакой дополнительной тренировки моделей между первым и вторым этапом;
- Воспроизводимые результаты;
Благодарности
Как всегда большое спасибо Dmytro за плодотворные беседы и подсказки!
Ссылки:
- Страничка соревнования на Каггле
- Код решения на гитхабе
- Deep Watershed Transform for Instance Segmentation
- IMAGE SEGMENTATION AND MATHEMATICAL MORPHOLOGY
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Feature Forwarding: Exploiting Encoder Representations for Efficient Semantic Segmentation
- From Pixels to Object Sequences: Recurrent Semantic Instance Segmentation и страничка проекта
- Mask R-CNN
- Instance Embedding: Segmentation Without Proposals
- Recurrent Instance Segmentation (СonvLSTM)
- TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
- Nuclei mosaic