
В предыдущей статье мы познакомились с понятием библиотеки SAS, научились назначать библиотеку для файла Excel, а также познакомились с процедурой, которая создает детализированные отчеты.
Напомню, что скачать ПО вы можете на сайте SAS, ссылка на документацию по установке SAS UE указана в статье №1.
В данной статье вы познакомитесь с несколькими способами чтения текстовых файлов.

Все примеры основаны на файлах, которые хранятся в директории c:\workshop\habrahabr и были созданы заранее в Notepad.
Для создания набора данных SAS из текстового файла, первый необходимо проанализировать, чтобы верно выбрать тип чтения текстового файла. Текстовый файл может содержать как стандартные, так и не страндартные данные.
Стандартные данные – это данные, которые SAS считает без каких-либо инструкций, например, значение переменной Salary в текстовом файле хранится как 12355.44 или дата уже записана как стандартная дата SAS (см. Урок 1). А если вам необходимо обработать значение, например, $12.355,44 или же 01JAN2018, то требуется указать правило чтения, инструкцию, в соответствии с которой данные значения преобразуются в формат SAS. В данной статье кратко описано применение оператора INPUT для преобразования необработанных данных в наборы данных SAS.
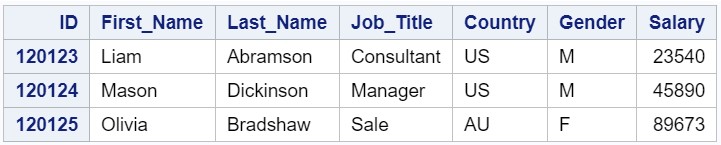
Рассмотрим простейший пример текстового файла. Файл managers1.dat является текстовым файлом с разделителем «запятая» и выглядит следующим образом:

Новый набор данных SAS должен содержать следующие переменные: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary. Вы можете заметить, что данные, хранящиеся в этом файле являются стандартными, и SAS считает их без проблем.
Чтение текстового файла реализуется с помощью операторов INFILE и INPUT на шаге DATA.
Подробно изучить оператор INFILE можно в справочнике SAS 9.4 DATA Step Statements: Reference.
Оператор INFILE задает внешний файл для чтения.
Общий синтаксис оператора:
file-specification – идентифицирует источник данных, он может быть внешним файлом или ссылкой на внешний файл.
device-type – метод доступа.
options – допустимые опции.
operating-environment-options – параметры рабочей среды.
В нашем конкретном случае оператор INFILE будет записан следующим образом:
DLM= (или delimiter=) — это опция оператора INFILE, которая задает альтернативный разделитель (пробел является разделителем по умолчанию), который будет использован для чтения внешнего файла. Список разделителей указывается в парных кавычках.
После того, как мы задали путь, необходимо задать имена переменных. В решении этой задачи нам поможет оператор INPUT .
Общий синтаксис оператора INPUT:
specification(s) – могут включать переменные, списки переменных, признак текстового типа ($), pointer-control, спецификацию столбцов, форматы для чтения и так далее (подробнее – в справочнике SAS 9.4 DATA Step Statements: Reference).
@ — спецификатор удержания строки.
Оператор INPUT в нашем случае будет записан следующим образом:
Повторюсь еще раз, что чтение текстового файла происходит на шаге DATA, поэтому требуемый для чтения текстового файла код будет выглядеть так:
Мы создаем временный набор данных SAS под названием managers, который будет храниться в библиотеке WORK до закрытия сеанса SAS (см. Урок 2)
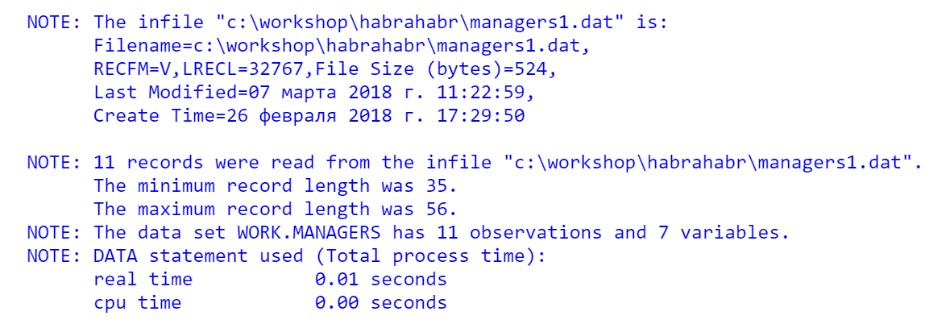
Проверим, корректно ли работает код. Запустим программу и проверим Log:
Распечатаем набор данных:
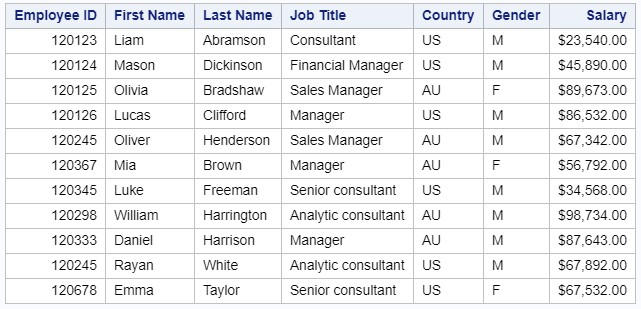
Результат выполнения шага PROC PRINT:

Обратите внимание, что текстовые значения в некоторых столбцах «обрезаны». Запустим процедуру PROC CONTENTS для опеределения длины созданных переменных:
Опция VARNUM выводит переменные в том порядке, в котором они хранятся в таблице
Фрагмент вывода процедуры:

По умолчанию SAS Base создает переменные любого типа с длиной 8 байт. Чтобы избежать «обрезанных» значений длину необходимо задавать явно. Данная проблема легко решается с помощью оператора LENGTH.
Важно знать, что данный оператор необходимо писать перед оператором INPUT, это связано с особенностями работы SAS Base.
Итак, наш программный код с использованием оператора LENGTH будет выглядеть следующим образом:
Принадлежность к типу переменных мы указали в операторе LENGTH, поэтому в INPUT просто перечислили названия переменных. Обратите внимание, что в операторе INPUT переменные перечисляются в том порядке, в каком они располагаются в источнике!
Запустим программу и изучим результаты:
Результат выполнения шага PROC PRINT:

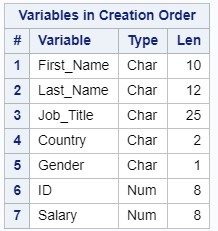
Результат выполнения PROC CONTENTS:
Переменные выведены в другом порядке. Это связано с тем, что SAS Base читает все последовательно: сначала внесены переменные из оператора LENGTH, а лишь потом проверен INPUT, и набор данных дополнен переменными ID и Salary.
Для того, чтобы вывести столбцы в первоначальном порядке, мы можем длину переменных ID и Salary задать явно в операторе LENGTH. Минимальная длина для числовых переменных – 3 байта, но не забывайте, что при изменении длины числовой переменной на меньшую можно потерять точность числовых значений.
Таким образом, программа приобретает следующий вид:
На шаге DATA зададим постоянные атрибуты переменным: формат и ярлык. В этом случае атрибуты будут записаны в дескриптор выходного набора данных и будут использоваться на каждом шаге PROC.
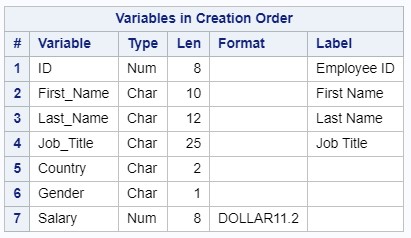
Атрибуты выходного набора данных записаны в дескриптор:
Создадим отчет из полученного набора данных SAS. Обратите внимание, что в опциях PROC PRINT мы указываем параметр label для того, чтобы данная процедура использовала заданные ярлыки в отчете.
Рассмотрим текстовый файл managers2.dat из директории c:\workshop\habrahabr.
По сравнению с предыдущим есть столбцы, которые содержат не стандартные для SAS данные.
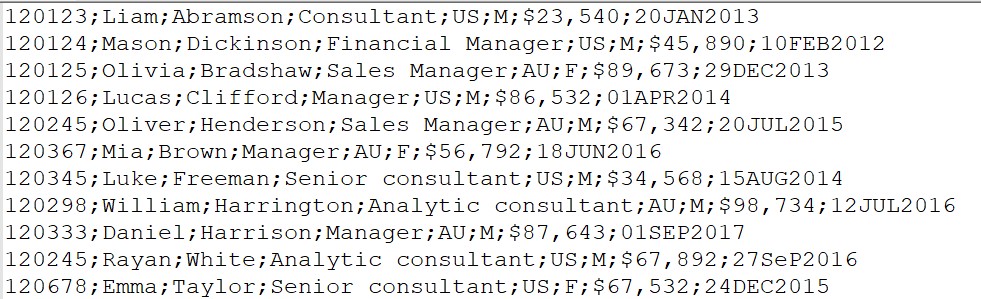
Новый набор данных должен содержать следующие переменные: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary, Hire_Date.
Переменная Salary содержит специальные символы, также дата в формате SAS — это число, представляющее количество дней, начиная с 1 января 1960 года, (см. Урок 1), а HireDate хранит другие значения. Для того, чтобы считать нестандартные данные необходимо использовать формат ввода – Informat. Важно помнить, что данные в столбце должны быть одного типа для применения формата ввода.
Всю информацию по форматам ввода можно посмотреть в справочнике SAS 9.4 Formats and Informats: Reference.
Infromat – это правило, которое применяется для чтения не стандартных для SAS входных данных. Тип формата для чтения соответствует типу данных SAS. Например, в источнике хранится значение $100,000. Чтобы удалить знак доллара и запятую перед преобразованием данного значения в число, необходимо применить INFORMAT comma8. или dollar8. В этом случае в итоговой таблице будет храниться значения 100000.
Общий синтаксис формата для чтения выглядит следующим образом:
$ — указатель текстового типа.
Informat — название формата для чтения.
w — ширина поля, включая все символы.
d — количество десятичных знаков.
Считаем текстовый файл managers2.dat
Результаты выполнения процедуры:
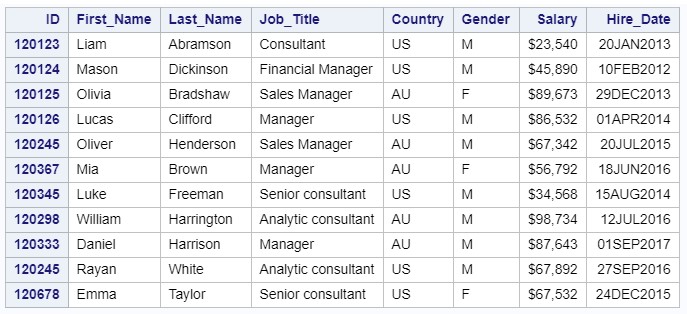
Если в данных есть пропущенные значения, то можно использовать 2 опции DSD и MISSOVER.
DSD ищет пропущенные значение внутри строки, а MISSOVER – в конце.
Таким образом, если мы хотим считать файл managers2a, в котором два подряд идущих разделителя кодируют пропущенное значение:

Используя указанные опции, мы сможем с легкостью считать данный текстовый файл:
Результат выполнения программы:
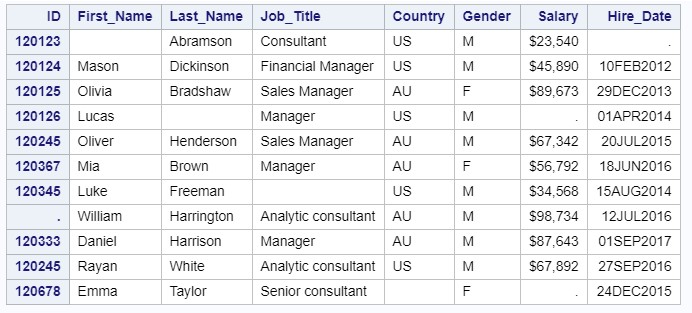
Если в столбце данные разных типов или форматов, рассмотрим следующий пример
В директории c:\workshop\habrahabr хранится файл bad_data.dat

Напишем DATA Step, который считает данный файл:
Запустим код и посмотрим Log:
В журнале указание на ошибку чтения данных:

Создаются две автоматические переменные:_N_ и _ERROR_.
_N_ — итерация шага.
_ERROR_ — значение 1 указывает на ошибку.
Результат выполнения программы:

Обратите внимание, что значение «44» в переменной Country считалась без ошибок чтения данных, а для переменных Salary и Hire_Date в Log появилось указание на ошибку чтения данных.
Если нам необходимо считать подобный текстовый файл info.dat из директории c:\workshop\habrahabr:

Еще один вариант считать внешний файл – использовать указатель позиции начального символа переменной.
Указывается позиция, имя переменной и формат ввода (informat).
Код для нашего случая будет выглядеть следующим образом:
Запустим код и проверим результат:
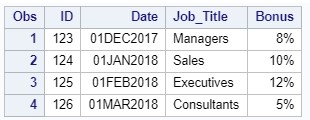
Если же нам необходимо считать текстовый файл, в котором одно наблюдение занимает несколько строк:

Решить данную задачу можно несколькими способами:
И в том и в другом случае создается набор данных managers6, который находится во временной библиотеке WORK (см. Урок 2)
Распечатаем полученный набор данных:
Результат выполнения процедуры:
Для чтения внешних файлов можно использовать процедуру PROC IMPORT.
Импортируем текстовый файл managers5.

Процедура PROC IMPORT в нашем случае выглядит следующим образом:
Запустим код и посмотрим Log:
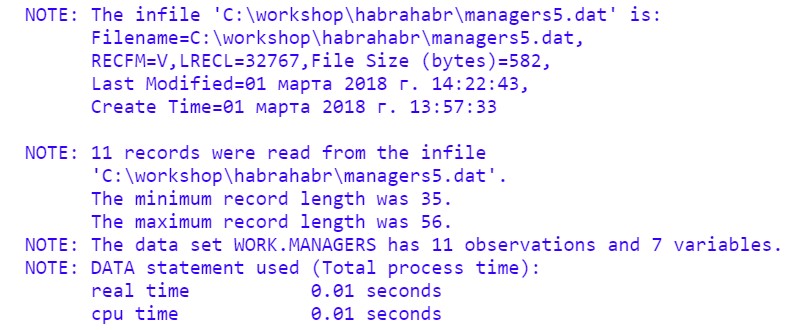
Результат выполнения программы:

Итак, это кратко о чтении текстовых файлов. Обратите внимание, что функционал у рассмотренных операторов и процедур намного обширнее, подробное описание представлено в документации.
В следующей статье рассмотрим создание наборов данных SAS. И, конечно, традиционно – Grow with SAS!
Напомню, что скачать ПО вы можете на сайте SAS, ссылка на документацию по установке SAS UE указана в статье №1.
В данной статье вы познакомитесь с несколькими способами чтения текстовых файлов.
Все примеры основаны на файлах, которые хранятся в директории c:\workshop\habrahabr и были созданы заранее в Notepad.
Для создания набора данных SAS из текстового файла, первый необходимо проанализировать, чтобы верно выбрать тип чтения текстового файла. Текстовый файл может содержать как стандартные, так и не страндартные данные.
Стандартные данные – это данные, которые SAS считает без каких-либо инструкций, например, значение переменной Salary в текстовом файле хранится как 12355.44 или дата уже записана как стандартная дата SAS (см. Урок 1). А если вам необходимо обработать значение, например, $12.355,44 или же 01JAN2018, то требуется указать правило чтения, инструкцию, в соответствии с которой данные значения преобразуются в формат SAS. В данной статье кратко описано применение оператора INPUT для преобразования необработанных данных в наборы данных SAS.
Чтение текстового файла со стандартными данными с разделителем.
Рассмотрим простейший пример текстового файла. Файл managers1.dat является текстовым файлом с разделителем «запятая» и выглядит следующим образом:
Новый набор данных SAS должен содержать следующие переменные: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary. Вы можете заметить, что данные, хранящиеся в этом файле являются стандартными, и SAS считает их без проблем.
Чтение текстового файла реализуется с помощью операторов INFILE и INPUT на шаге DATA.
Подробно изучить оператор INFILE можно в справочнике SAS 9.4 DATA Step Statements: Reference.
Оператор INFILE задает внешний файл для чтения.
Общий синтаксис оператора:
INFILE file-specification<device-type><options><operating-environment-options>;file-specification – идентифицирует источник данных, он может быть внешним файлом или ссылкой на внешний файл.
device-type – метод доступа.
options – допустимые опции.
operating-environment-options – параметры рабочей среды.
В нашем конкретном случае оператор INFILE будет записан следующим образом:
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';DLM= (или delimiter=) — это опция оператора INFILE, которая задает альтернативный разделитель (пробел является разделителем по умолчанию), который будет использован для чтения внешнего файла. Список разделителей указывается в парных кавычках.
После того, как мы задали путь, необходимо задать имена переменных. В решении этой задачи нам поможет оператор INPUT .
Общий синтаксис оператора INPUT:
INPUT <specification(s)> <@ | @@>;specification(s) – могут включать переменные, списки переменных, признак текстового типа ($), pointer-control, спецификацию столбцов, форматы для чтения и так далее (подробнее – в справочнике SAS 9.4 DATA Step Statements: Reference).
@ — спецификатор удержания строки.
Оператор INPUT в нашем случае будет записан следующим образом:
input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary;Повторюсь еще раз, что чтение текстового файла происходит на шаге DATA, поэтому требуемый для чтения текстового файла код будет выглядеть так:
data managers;
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';
input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary;
run;
Мы создаем временный набор данных SAS под названием managers, который будет храниться в библиотеке WORK до закрытия сеанса SAS (см. Урок 2)
Проверим, корректно ли работает код. Запустим программу и проверим Log:
Распечатаем набор данных:
proc print data=managers;
run;
Результат выполнения шага PROC PRINT:
Обратите внимание, что текстовые значения в некоторых столбцах «обрезаны». Запустим процедуру PROC CONTENTS для опеределения длины созданных переменных:
proc contents data=managers varnum;
run;
Опция VARNUM выводит переменные в том порядке, в котором они хранятся в таблице
Фрагмент вывода процедуры:
Длина переменных
По умолчанию SAS Base создает переменные любого типа с длиной 8 байт. Чтобы избежать «обрезанных» значений длину необходимо задавать явно. Данная проблема легко решается с помощью оператора LENGTH.
Важно знать, что данный оператор необходимо писать перед оператором INPUT, это связано с особенностями работы SAS Base.
Итак, наш программный код с использованием оператора LENGTH будет выглядеть следующим образом:
data managers;
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';
length First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1;
input ID First_Name Last_Name Job_Title Country Gender Salary;
run;
proc print data=managers;
run;
proc contents data=managers varnum;
run;
Принадлежность к типу переменных мы указали в операторе LENGTH, поэтому в INPUT просто перечислили названия переменных. Обратите внимание, что в операторе INPUT переменные перечисляются в том порядке, в каком они располагаются в источнике!
Запустим программу и изучим результаты:
Результат выполнения шага PROC PRINT:
Результат выполнения PROC CONTENTS:
Переменные выведены в другом порядке. Это связано с тем, что SAS Base читает все последовательно: сначала внесены переменные из оператора LENGTH, а лишь потом проверен INPUT, и набор данных дополнен переменными ID и Salary.
Для того, чтобы вывести столбцы в первоначальном порядке, мы можем длину переменных ID и Salary задать явно в операторе LENGTH. Минимальная длина для числовых переменных – 3 байта, но не забывайте, что при изменении длины числовой переменной на меньшую можно потерять точность числовых значений.
Таким образом, программа приобретает следующий вид:
data managers;
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';
length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8;
input ID First_Name Last_Name Job_Title Country Gender Salary;
run;
proc print data=managers;
run;
Постоянные атрибуты.
На шаге DATA зададим постоянные атрибуты переменным: формат и ярлык. В этом случае атрибуты будут записаны в дескриптор выходного набора данных и будут использоваться на каждом шаге PROC.
data managers;
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';
length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8;
input ID First_Name Last_Name Job_Title Country Gender Salary;
label ID = 'Employee ID'
First_Name = 'First Name'
Last_Name = 'Last Name'
Job_Title = 'Job Title';
format Salary dollar11.2;
run;
proc contents data=managers varnum;
run;
Атрибуты выходного набора данных записаны в дескриптор:
Создадим отчет из полученного набора данных SAS. Обратите внимание, что в опциях PROC PRINT мы указываем параметр label для того, чтобы данная процедура использовала заданные ярлыки в отчете.
proc print data=managers label noobs;
run;
Чтение текстового файла с нестандартными данными с разделителем.
Рассмотрим текстовый файл managers2.dat из директории c:\workshop\habrahabr.
По сравнению с предыдущим есть столбцы, которые содержат не стандартные для SAS данные.
Новый набор данных должен содержать следующие переменные: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary, Hire_Date.
Переменная Salary содержит специальные символы, также дата в формате SAS — это число, представляющее количество дней, начиная с 1 января 1960 года, (см. Урок 1), а HireDate хранит другие значения. Для того, чтобы считать нестандартные данные необходимо использовать формат ввода – Informat. Важно помнить, что данные в столбце должны быть одного типа для применения формата ввода.
Всю информацию по форматам ввода можно посмотреть в справочнике SAS 9.4 Formats and Informats: Reference.
Infromat – это правило, которое применяется для чтения не стандартных для SAS входных данных. Тип формата для чтения соответствует типу данных SAS. Например, в источнике хранится значение $100,000. Чтобы удалить знак доллара и запятую перед преобразованием данного значения в число, необходимо применить INFORMAT comma8. или dollar8. В этом случае в итоговой таблице будет храниться значения 100000.
Общий синтаксис формата для чтения выглядит следующим образом:
<$>informat<w>.<d>$ — указатель текстового типа.
Informat — название формата для чтения.
w — ширина поля, включая все символы.
d — количество десятичных знаков.
Считаем текстовый файл managers2.dat
data managers2;
infile "c:\workshop\habrahabr\managers2.dat" dlm=';';
input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25.
Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.;
label ID = 'Employee ID'
First_Name = 'First Name'
Last_Name = 'Last Name'
Job_Title = 'Job Title';
format Salary dollar10. Hire_Date date9.;
run;
proc print data=managers2 noobs;
ID ID;
run;
Результаты выполнения процедуры:
Обработка пропущенных значений.
Если в данных есть пропущенные значения, то можно использовать 2 опции DSD и MISSOVER.
DSD ищет пропущенные значение внутри строки, а MISSOVER – в конце.
Таким образом, если мы хотим считать файл managers2a, в котором два подряд идущих разделителя кодируют пропущенное значение:
Используя указанные опции, мы сможем с легкостью считать данный текстовый файл:
data managers2a;
infile "c:\workshop\habrahabr\managers2a.dat" dlm=';' dsd missover;
input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25.
Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.;
label ID = 'Employee ID'
First_Name = 'First Name'
Last_Name = 'Last Name'
Job_Title = 'Job Title';
format Salary dollar10. Hire_Date date9.;
run;
proc print data=managers2a;
ID ID;
run;
Результат выполнения программы:
Ошибка чтения данных.
Если в столбце данные разных типов или форматов, рассмотрим следующий пример
В директории c:\workshop\habrahabr хранится файл bad_data.dat
Напишем DATA Step, который считает данный файл:
data new;
infile "c:\workshop\habrahabr\bad_data.dat" dlm=',';
input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25.
Country :$2. Gender :$1. Salary :5. Hire_Date :date9.;
label ID = 'Employee ID'
First_Name = 'First Name'
Last_Name = 'Last Name'
Job_Title = 'Job Title';
format Salary dollar10. Hire_Date date9.;
run;
proc print data=new;
ID ID;
run;
Запустим код и посмотрим Log:
В журнале указание на ошибку чтения данных:
Создаются две автоматические переменные:_N_ и _ERROR_.
_N_ — итерация шага.
_ERROR_ — значение 1 указывает на ошибку.
Результат выполнения программы:
Обратите внимание, что значение «44» в переменной Country считалась без ошибок чтения данных, а для переменных Salary и Hire_Date в Log появилось указание на ошибку чтения данных.
Использование указателя позиции начального символа переменной при чтении текстового файла
Если нам необходимо считать подобный текстовый файл info.dat из директории c:\workshop\habrahabr:
Еще один вариант считать внешний файл – использовать указатель позиции начального символа переменной.
Указывается позиция, имя переменной и формат ввода (informat).
Код для нашего случая будет выглядеть следующим образом:
data info;
infile "c:\workshop\habrahabr\info.dat";
input @1 ID 3.
@4 Date mmddyy10.
@15 Job_Title $11.
@26 Bonus percent3.;
format Date date9. Bonus percent.;
run;
proc print data=info;
run;
Запустим код и проверим результат:
Чтение текстового файла с наблюдением в несколько строк.
Если же нам необходимо считать текстовый файл, в котором одно наблюдение занимает несколько строк:
Решить данную задачу можно несколькими способами:
- Использовать несколько операторов INPUT.
data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10.; input Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run;
- Использовать указатель.
SAS загружает следующую запись (строку) при обнаружении символа слэш (/) в операторе INPUT:
data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10./ Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run;
И в том и в другом случае создается набор данных managers6, который находится во временной библиотеке WORK (см. Урок 2)
Распечатаем полученный набор данных:
proc print data=managers6 noobs;
id id;
run;
Результат выполнения процедуры:
Импорт внешних файлов
Для чтения внешних файлов можно использовать процедуру PROC IMPORT.
Импортируем текстовый файл managers5.
Процедура PROC IMPORT в нашем случае выглядит следующим образом:
proc import datafile="C:\workshop\habrahabr\managers5.dat"
dbms=dlm
out=managers
replace;
delimiter=',';
getnames=yes;
run;
proc print data=managers;
run;
Запустим код и посмотрим Log:
Результат выполнения программы:
Итак, это кратко о чтении текстовых файлов. Обратите внимание, что функционал у рассмотренных операторов и процедур намного обширнее, подробное описание представлено в документации.
В следующей статье рассмотрим создание наборов данных SAS. И, конечно, традиционно – Grow with SAS!