

Распределение IP-адресов в 185/8, последнем свободном блоке RIPE, в 2012 году (слева) и 2018 году (справа), источник
17 апреля 2018 года Сетевой координационный центр RIPE — одна из пяти Региональных регистратур — распределил последние 1024 адресов IPv4 из последнего блока /8, полученного от IANA в 2011 году. Хотя последний блок 185/8 полностью распределён между европейскими компаниями, но в пуле RIPE NCC осталось 9 млн «восстановленных» адресов (то есть адресов, изъятых у бывших владельцев). По расчётам Координационного центра, этого хватит ещё примерно на два года, если выдавать по заявкам локальных регистраторов по /22 каждому.
На данный момент каждый адрес IPv4 — исключительно дефицитный товар, а последние выделенные IP-адреса используются очень интенсивно. Поэтому особенно неприятны ситуации вроде нынешней массовой блокировки IP-адресов в России. На пике блокировки 18 млн заблокированных Роскомнадзором IP-адресов соответствовали 5,5 млн заблокированных доменов — это около 2,45% из 223 млн известных доменов в интернете.
К счастью, сейчас российский регулятор постепенно снимает блокаду. Сейчас в блокировке осталось лишь 14,6 млн адресов по статистике бота RKNSHOWTIME или 14,7 млн по статистике другого сервиса RKN block digest. Разница связана с тем, в первом случае считаются только явно указанные IP-адреса, а во втором — и IP-адреса, и домены (некоторые записи в выгрузке Роскомнадзора содержат только название домена).
Как распределялся последний блок /8
Когда RIPE NCC получил последний /8 (блок 185/8, 16 777 216 адресов), в пуле RIPE оставалось около 75 млн адресов, так что они продолжали свободно распределяться по заявкам локальных регистраторов (LIR). Но в сентябре 2012 года единственным свободным блоком остался 185/8 — и тогда вступил в действие раздел 5.6 Политики распределения адресов IPv4 в европейском регионе. Эти правила специально приняли, когда стало понятно, что дефицита адресов не избежать.
Правила распределяют дефицитный ресурс в ограниченных количествах (по одному блоку каждому локальному регистратору). По итогу можно сказать, что правила очень помогли. Последний блок /8 растянули на 5,5 лет, в то время как предыдущий блок /8 по старым правилам раздали за пять месяцев.
Ниже приводим раздел 5.6 из новых правил в некотором сокращении. В частности, мы сократили часть по выделению адресов точкам обмена трафиком, для которых зарезервировали один диапазон /16 (65 536 адресов). Он распределяется блоками от /24 до /22, то есть от 256 до 1024 адресов.
5.6 Использование последнего блока /8 (Use of last /8 for PA Allocations)
Когда RIPE NCC начнёт выделять блоки адресов IPv4 из последнего блока /8, полученного от IANA, будет применяться политика, изложенная ниже.
- Выделение блоков для LIR из последнего /8.
Порядок удовлетворения заявок LIR на адреса IPv4 следующий:
- LIR может получить только один блок из последнего блока /8. Размер блока — /22.
- LIR получит только один блок /22, даже если потребность в адресах намного выше.
- LIR может запросить этот блок и получить его в соответствии с политикой распределения адресного пространства, которая действовала на момент запроса.
- Блоки IPv4 будет выданы только тем LIR'ам, которые получили адреса IPv6 от вышестоящего локального регистратора (upstream LIR) или от RIPE NCC.
- Выделение точкам обмена трафиком (Internet Exchange Point).
- Непредвиденные обстоятельства (Unforeseen circumstances).
- Блок /16 будет зарезервирован для будущих непредвиденных целей. Если таковых не окажется, то к моменту, когда последний /8 будет израсходован, этот блок будет распределен в соответствии с п. 1.
- Повторное использование адресов (Post-depletion Address Recycling)
Данные положения касаются только адресного пространства, возвращённого в RIPE NCC и не подлежащего возврату в IANA.
- Любое адресное пространство, возвращённое в RIPE NCC, будет распределяться по правилам, описанным в части 1.
- Минимальный размер блока, выделяемого из последнего /8, может быть при необходимости изменён.
- Если адресов для выделения блока /22 будет недостаточно, адреса будут выделены несколькими блоками (multiple allocations), но в количестве, эквивалентном /22.
Итак, в течение пяти с половиной лет RIPE NCC выделял блоки /22 из последнего /8 по этим правилам, за исключением двух блоков /16, зарезервированных для непредвиденных обстоятельств и для точек обмена трафиком.
Суть новых правил в том, что независимо от потребностей локальных регистраторов им выдавали только по 1024 адреса, то есть только по одному блоку /22 — и только когда они уже получили блок IPv6. Тем не менее, по статистике за 2012?2018 годы, скорость выделения адресов IPv4 в Европе росла в соответствии с квадратичной функцией. RIPE NCC объясняет это тем, что регистрировалось всё больше и больше локальных регистраторов.
{kind=link}

Этот рост регистраций RIPE NCC использует для прогноза по распределению остатков адресов IPv4
Сетевой координационный центр отметил увеличение количества регистраций в качестве членов RIPE NCC организаций, которые сами не распределяют адреса, а обслуживают конечных пользователей. По мнению специалистов, для организаций членство в RIPE NCC оказалось наиболее дешёвым способом раздобыть дополнительные адреса IPv4 для собственной инфраструктуры.
Оказалось также, что стимулы к переходу на IPv6 тоже не работают. Большинство организаций, которые зарегистрировали диапазоны IPv6-адресов перед получением блока IPv4, никак их не использовали. Более того, чтобы избежать бесполезной траты адресного пространства IPv6, в марте 2015 года RIPE вообще убрал требование об обязательной регистрации блока IPv6.
В ноябре 2015 года RIPE запретил регистрацию дополнительных локальных регистраторов членами RIPE NCC, но это тоже не помогло, так что в мае 2016 года ограничение сняли. К этому моменту организации начали регистрировать новые юридические лица, чтобы получить дефицитные блоки /22. Как сообщается, некий член RIPE NCC сумел получить 66 блоков /22, хотя выдавали только по одному на каждого локального регистритора. Ограничение сняли, потому что решили, что лучше пусть организации воспользуются легальной лазейкой в действующие процедуре, а не будут искать обходные пути.
Вот как распределились дефицитные ресурсы по странам (файл статистики). Для упрощения цифры на карте округлены до /22, хотя многие блоки разбивались на /23 и /24.
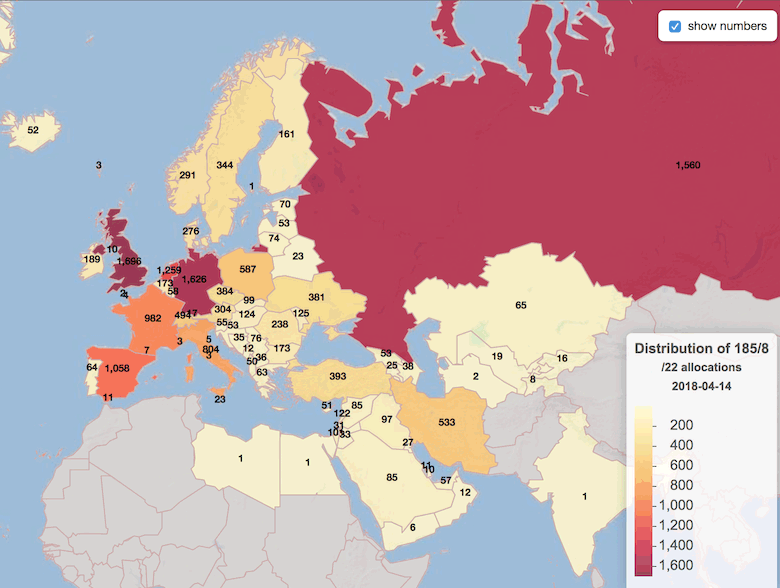
На карте можно заметить некоторые аномалии: например, необычно мало блоков выделено организациям из Бельгии, Португалии и Беларуси, по сравнению с их более «предприимчивыми» соседями.
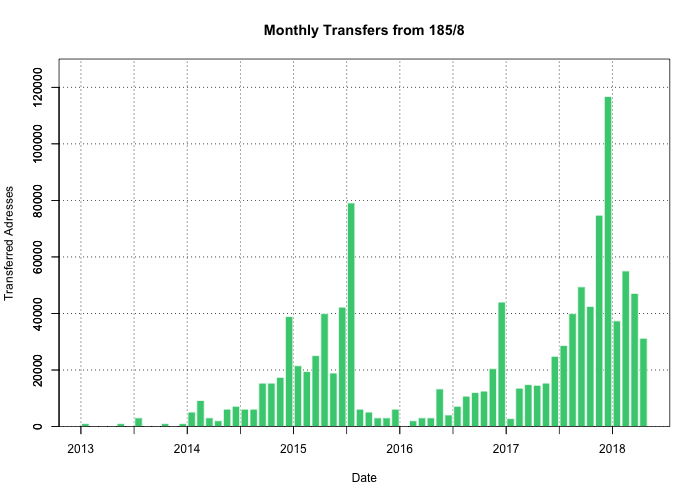
Только к 2015 году специалисты RIPE NCC осознали, что большое количество блоков /22 сразу после выделения меняют своего владельца и в течение нескольких дней или недель переходят к другому регистратору (transfer). Тогда регулятор запретил трансферы для адресов IPv4 до истечения 24 месяцев после выделения. Но судя по графику ежемесячных трансферов, это тоже не помогло, просто на два года заморозило трансферы свежих диапазонов.
{kind=link}
Когда закончатся последние адреса IPv4?
Как уже упоминалось, в пуле RIPE NCC осталось около 9,03 млн адресов IPv4, которых хватит ещё примерно на два года. Из них четыре миллиона — это 1/5 от 20 млн адресов, которые восстановила IANA (Администрация адресного пространства Интернет) и раздала пяти региональным регистратурам в течение последних четырёх лет. Ещё 5 млн адресов RIPE забрал самостоятельно, проведя «перекличку» организаций. По условиям процедуры, если отклика от владельца не было получено, то IP-адреса у него изымались.
В то же время провайдеры научились справляться с дефицитом адресного пространства. Многие освоили технику трансляции адресов (NAT), когда пользователям выделяются частные адреса IPv4 или IPv6, при этом используется меньшее количество глобальных адресов IPv4.
Если экстраполировать график, то нынешнего пула хватит примерно до мая 2020 года.
Предложения по купле-продаже или аренде IPv4 обсуждаются на форумах провайдеров и на Хабре. Судя по всему, сдача в аренду адресов IPv4 превратилась в неплохой бизнес.
Утилизация IPv4 и IPv6
Очень многие организации зарегистрировали на себя огромные по нынешним временам диапазоны IPv4, которые практически не используют и не собираются отдавать (например, 16,8 млн адресов в блоке 44.0.0.0/8, зарегистрированных якобы для любительского радио, или 218 млн IP-адресов у Министерства обороны США: 11.0.0.0/8, 22.0.0.0/8, 26.0.0.0/8, 28.0.0.0/8, 29.0.0.0/8, 30.0.0.0/8 и 33.0.0.0/8 ).
Другие блоки используются очень интенсивно. Например, визуализация кривыми Гильберта хорошо показывает, как распределено адресное пространство из примерно 4,2 млрд (2??) адресов.
Распределение адресного пространства IPv4, апрель 2018 года (кликабельна)
{kind=link}
Для сравнения, вот как выглядит на сегодняшний день распределение адресного пространства IPv6.

Распределение адресного пространства IPv6, апрель 2018 года
Комментарии (86)

mspain
07.05.2018 12:08-1Напоминает ситуацию с биткоинами. Ну намайнили все 21 млн. Разве это конец жизни? Адреса же никуда не исчезают. Просто надо чуть более честно перераспределить. А IPv6 так и не нужен, как был не нужен 10 лет назад.
Gansterito
07.05.2018 12:22+2А сейчас они не честно распределены? И кто будет определять как должно быть?
Hardcoin
07.05.2018 13:09+1Цена. Если, предположим, за адрес потребуется платить десять центов в год, министерство обороны дважды подумает, на самом ли деле им нужно 200 млн адресов или может им хватит 100 млн? А этих лишних 100 млн хватило бы на 20 лет при текущей скорости распределения.
Вопрос, кто и куда будет собирать деньги, опущу, просто отмечу, что распределение точно станет более равномерным — адреса будут попадать тем, кому они реально нужны и кто их использует.
Marwin
07.05.2018 13:24тем более за индивидуальную внешку оконечные абоненты и так платят почти всегда. Вот, кстати, да, почему такая несправедливость… мы платим, а всякие Ксероксы, владеющие миллионами адресов, не платят никому эти самые миллионы баксов в месяц
achekalin
08.05.2018 00:44Подумает… Ну да, мы с вами заплатим на 1% налога больше, чтобы они не думали.
А кому пойдут деньги? Райпу? Он работу будто бы и не делал лет 10 последние. Ну, кроме криков «все пропало, все кончается!»Hardcoin
08.05.2018 09:07+1Мы с вами? Во-первых, не знаю, почему вы решили, что я живу в США, но это не так. Во-вторых, бюджет согласуется через конгресс, министерство обороны напрямую налоги не собирает и не повышает. Хотят — покупают патроны. Хотят — платят за адреса. И не факт, что конгресс выделит им вообще на всё, что им хочется.
И есть другие организации — они тоже сами пусть решают, хотят платить за адреса или нет.
А деньги могут пойти, например, на внедрение IPv6, раз уж без него никак.
KivApple
07.05.2018 17:40Откуда такая нелюбовь к ipv6? Оборудование один фиг обновляется не реже, чем раз в несколько лет. Все ОС уже давно его поддерживают. Вопрос сугубо в том, чтобы однажды всем заморочиться и всё настроить.
firk
07.05.2018 17:58-2Уже писал где-то, повторю тут — он плохо спроектирован, избыточен, неудобен. Начиная с того что надо было додуматься выделить 128 бит под адрес, из которых 64 сразу выкинув в помойку, но свои лишние 16 байт в каждом пакете они будут занимать, и не только там. Есть и много других дефектов. В конце концов, он просто эстетически некрасив.
Что касается оборудования, то сейчас может работать (а где-то, уверен, и работает) в инете оборудование/софт, которому 25 лет. И, думаю, очень много где работает оборудование возраста 10-15 лет (закупленное во время активного проникновения интернета в массы). И очень плохо из-за выдуманной проблемы (нехватка адресов — именно такая, потому как их раздавали всем подряд бесплатно) взять и всё испортить.Aelliari
07.05.2018 19:12ipv6 уже больше 20 лет, его поддержка в ОС появилась далеко не вчера. Для приложений не умеющих в ipv6 вы всегда можете оставить немного оборудования в дуалстеке/ipv4 only на местах локально, и внутри туннелей, более-менее новое клиентское оборудование точно вытянет, это провайдерам придётся заморачиватся с обновлением своего железа. А 64 бита не улетают в трубу, это всего лишь часть механизма автоконфигурации, да, возможно кто то считает что это избыточный объём.
А по поводу плохой архитектуры — это спорно, спроектирован он лучше чем ipv4, роутить это добро проще, кое что надстроенное для ipv4 имеется в нём из коробки. Единственное что изначально механизма NAT не предусмотрено ввиду его архитектуры, но при желании и его можно выстроить для каких то своих специфических целей.
Соглашусь, правда, с тем, что для привыкшего работать с ipv4 адресами адреса 6й версии выглядят не оченьachekalin
08.05.2018 00:40Только одна переменная — приоритет протоколов — оказался заныкан далеко и глубоко. Я про то, что в dual stack варианте, если у хоста есть и A, и AAAA запись, на какой адрес сначала клиент пойдет — зависит от ОС клиента, а в ней зависит от настроек, и от версии к версии меняется дефолт.
На фоне ситуации, когда клиент просто не умеет проверить, напр., что ipv4 или ipv6, даже если имеется, но не работает (связности нет), имеем глюки вроде таймаутов и прочего — комп ждёт таймаута, а клиент-человек переживает паузу. В результате внедрять ipv6 в обычной жизни опасно, т.к. в случае проблем с ним часть клиентов будет все равно первым делом ломится на него, и будут испытывать паузы в работе.ivlad
08.05.2018 09:55На фоне ситуации, когда клиент просто не умеет проверить, напр., что ipv4 или ipv6, даже если имеется, но не работает (связности нет), имеем глюки вроде таймаутов и прочего
Вы посмотрели, какие таймауты у happy eyeballs, правда?
achekalin
08.05.2018 10:04Нет. Я про другое: хотим внедрить IPv6. Провайдер говорит «у меня ipv6 есть, но в тесте» (и он прав, он сам предвидит грабли). Хорошо, настроили, работаем. При этом в сети, например, Windows 7, Windows 10, Mac-и, может, еще что-то, плюс смартфоны. Если начинаем проверять, каждый из клиентов в dual stack сети исповедует разный приоритет протоколов, и начинают стучаться кто на A, а кто на AAAA записи ресурсов, с которыми работают.
Но вот IPv6 почему-то глюканул, и трафик посредством его стал ходить медленно либо вообще не стал ходить. Или ресурс, куда заходили, временно поломался по IPv6. Идеально бы было, чтобы клиенты, которые сначала идут на IPv6, а потом, как fallback, на ipv4, постучались по «шестерке», не дождались, и начали работать в режиме IPv4 first в течении какого-то времени. Но нет, при каждом обращении в мир к хостам, которые имеют A и AAAA записи, соединение сначала будет пробовать устанавливаться по IPv6, а только по таймауту — по IPv4.
Это неприятно, а для пользователей выглядит и вовсе глупо: у части компов все работает (да-да, в ОС, где IPv4 first, согласно настрокам ОС), у части же — работает с дикими тормозами.ivlad
08.05.2018 10:08Идеально бы было, чтобы клиенты, которые сначала идут на IPv6, а потом, как fallback, на ipv4, постучались по «шестерке», не дождались, и начали работать в режиме IPv4 first в течении какого-то времени.
Возможно. А возможно, это способ заставить сетевых инженеров провайдеров быстрее чинить IPv6 связанность.
firk
08.05.2018 14:13Приложения не умеющие ipv6 требуют не только ipv4 стека в ос, но и ipv4 связности с интернетом для компа, на котором они запущены. А таких приложений много, в том числе таких, которые по разным причинам (правовым, бюрократическим, экономическим) нельзя обновить, а иногда можно, но никто не знает как.
А 64 бита не улетают в трубу, это всего лишь часть механизма автоконфигурации, да, возможно кто то считает что это избыточный объём.
80% оверхед в ip-заголовке ради автоконфигурации?
механизма NAT не предусмотрено
А если и не надо предусматривать (в IPv4 тоже никто специально не предусматривал вроде), он просто возможен.
Соглашусь, правда, с тем, что для привыкшего работать с ipv4 адресами адреса 6й версии выглядят не очень
А ещё они не влезают в машинное слово, в отличие от первых. Очень хорошо, когда избавились от legacy-протоколов типа IPX, можно делать IP4-only софт, и адреса хранить и обрабатывать как uint32 без каких-либо спец. обёрток. Кстати, про обёртки. Это не то что бы строгий огрех, но ipv6 адреса ещё не влезают в абстрактную struct sockaddr. Были бы 64-битными — влезали бы. А так получается что sizeof(struct sockaddr)==sizeof(struct sockaddr_in) — в обеих есть паддинг до нужного размера, а вот sizeof(sockaddr_in6)>sizeof(struct sockaddr). Выглядит тоже некрасиво.
ipv6 уже больше 20 лет, его поддержка в ОС появилась далеко не вчера.
И как итог: был бы он продуманный и удобный, его бы уже 10-15 лет назад везде внедрили и никому бы не создалось проблем. Но видимо что-то не так.
Alexeyslav
08.05.2018 15:1180% от чего, от заголовка? А если посчитать процент от полезных данных? Не одни же заголовки передаём. Капля в море…
Зачем IP-адресу влезать в машинное слово? Проблема встанет разве что на программном роутинге и т.п. нынче типичный размер кеш-линии процессора 64 байта, поэтому проблема производительности не очень актуальна в этом плане — процессор успеет обработать 4 адреса за одно чтение из памяти. Немного усложнится работа с адресами на низком уровне — но это лишь один раз написать библиотеку и проблемы больше нет. Это не постоянные грабли на которые надо будет наступать.
Marwin
07.05.2018 12:19всё таки есть в ipv4 что-то тёплое, ламповое… поднял натик, одних в одну сеточку, других в другую, чувствуешь себя как в домике (да, да, я знаю, что домик дырявый, но мы же про психологию), всё своё, родное, просто и понятно (бывают исключения, но я про средние массы). А снаружи да хоть ipv666 — как-то там работает и ладно. Поэтому долго еще оно заходить в народ будет.
PS ярый сторонник ipv6, юзаю где только можно и нельзя, даже с туннелями в ущерб пингу… но давайте будем реалистами ))Meklon
07.05.2018 12:32Для меня ipv6 жутко неинтуитивен. Я никак не могу на глаз опередить принадлежность адреса к конкретному диапазону и тому подобное. Теперь ещё и проблема firewall. Я, кажется, накриворучил. Deny all после разрешающих правил отрубает к чертям Google с его сервисами. Медитативно ковыряюсь пока.
Wexter
07.05.2018 14:20А чего не так с файрволом то? всё настраивается аналогично ipv4, разрешить форвард всех/определённых соединений на нужные сервера/роутеры напрямую и разрешить форвард для established,related соединений в «локальную» сеть, остальное deny.
Meklon
07.05.2018 15:23У меня сейчас как-то так выглядит кусок с ipv6 firewall:
/ipv6 firewall filter
add action=drop chain=input connection-state=invalid
add action=accept chain=input connection-state=established,related in-interface=ISP_pppoe
add action=accept chain=input protocol=icmpv6
add action=accept chain=input dst-port=546 in-interface=ISP_pppoe protocol=udp
add action=drop chain=input
add action=accept chain=forward connection-state=established,related in-interface=ISP_pppoe out-interface=bridge-local
add action=accept chain=forward protocol=icmpv6
add action=accept chain=forward in-interface=!ISP_pppoe out-interface=ISP_pppoe
add action=drop chain=forward in-interface=!bridge-local
Wexter
07.05.2018 15:30У меня попроще, долго мучался с выбором схемы, ибо помимо домашней /64 есть ещё /48 для подключения других точек при необходимости и в двух прошлых конфигах случалось так что 3 сети прекрасно ходят в глобальный ipv6, а вот друг к другу не очень, либо городил ещё с десяток лишних правил, в итоге остановился на такой конфигурации:
/ipv6 firewall filter add action=accept chain=forward comment="allow all to 2001:470:1f0b:1658::2 from all" dst-address=2001:470:1f0b:1658::2/128 in-interface=sit1 add action=accept chain=forward comment="allow all to 2001:470:1f0b:1658::3 from all" dst-address=2001:470:1f0b:1658::3/128 in-interface=sit1 add action=accept chain=forward dst-address=2001:470:98fc:6::/64 add action=accept chain=forward dst-address=2001:470:98fc:6000::/52 add action=accept chain=forward comment="allow established/related" connection-state=established,related dst-address=2001:470:1f0b:1658::/64 in-interface=sit1 add action=drop chain=forward comment="drop all to local /64" dst-address=2001:470:1f0b:1658::/64 in-interface=sit1 add action=accept chain=forward comment="allow established/related" connection-state=established,related dst-address=2001:470:98fc::/48 in-interface=sit1 add action=drop chain=forward comment="drop all to local /64" dst-address=2001:470:98fc::/48 in-interface=sit1
В итоге под файрвол попадает только трафик приходящий из туннеля 6to4 (native не завезли к сожалению). Трафик с остальных подключений не попадает под него и маршрутизация между «локальными» сетями работает свободно. Единственное не проходит тест скорости на yandex.ru/internet на upload, но как оказалось то-же самое происходит при отключенном файрволе, видимо что-то сломалось на их сторонеMeklon
07.05.2018 15:33У меня тоже не нативный, а от Hurricane Electric. sit1 — это что за интерфейс?
Wexter
07.05.2018 15:346to4 к Hurricane Electric, поднимал просто скопировав из их шаблона
UPD: не из их, до этого был sit0 который 6to4 через 192.88.99.1, отказался из-за нестабильной работы, а HE остался sit1Meklon
07.05.2018 15:37Блин, твой конфиг весьма сложно понять. Ты по факту и так разрешаешь коннектиться извне кому угодно внутрь.
Wexter
07.05.2018 15:46Просто у меня порезано на несколько сетей, основная домашняя 2001:470:1f0b:1658::/64, там только разрешён весь трафик на два сервера (::2/::3) и established/related.
Потом разрешено всё к 2001:470:98fc:6::/64 (сеть на даче) и разрешено всё к 2001:470:98fc:6000::/52 (пул для VPN подключений), там у меня как правило разруливает локальный роутер.
Ну и на последок accept established/related & drop для всей сети /48, мало-ли куда ещё выделю — чтобы не лезло ничего.
В интерфейсе WinBox оно как-то проще выглядит

P.S: да, забыл изначально для 6::/64 и 6000::/52 указать in-interface, да не особо важно
Cayp
08.05.2018 11:33Возможно, вам стоит обратить внимание на стандартный набор правил для ipv6 firewall в свежих версиях RouterOs. Они не появляются сами по себе при активации ipv6.
/system default-configuration print
Они вполне себе вменяемы и откомментированны.
equand
07.05.2018 12:24-1IPv6 не решает проблему, а просто ее откладывает. Особенно с раздачей в /32 каждому провайдеру.
Есть у меня в голове альтернативы ему, которые будут быстрее и лучше работать, нежели текущая макулатура.
Можно сразу было бы срезать тонну обрубков с сетей как VLAN и другая адаптивность к реалиям. Интернет создавался эволюционно, но IPv6 это не переработка и планирование, а просто говно какое-то.
Ответ давно дан Bitcoin. Вместо IPv6 нужно использовать криптографические ключи. В замену соединений ip-port — уникальный канал, который является хешем других каналов и дополнительного nonce который постоянно обновляется с каждым пакетом (mitm защита). Транзакция на локе.
В замену всей лабуды с аукс системами, вроде dns, bgp, ospf — федеративный блокчейн, где токены являются разными сервисами.
По сути ответ у нас уже 10 лет перед глазами, но все ждут какого-то internet2.
Такой системой мы сразу убиваем возможность ddos (токенодаватель может выдавать конкретное количество пакетов и каналов для своей системы полностью нивелируя возможность ddos атаки, т.к. доступ будет съедать средства ддосера и передавать их токенодавателю), arp/mac/bgp poisoning (а нет больше мака — это теперь ключ, арпа (который заменен на прямую делегацию через ключи), бгп вообще по сути арп для l3 на уровне верхних подсетей со свистелками и перделками, которые приводят к bgp poisoning и другим проблемам).3al
07.05.2018 12:40+4Даже с /32, он откладывает проблему пусть и не до тепловой смерти Вселенной, но явно как минимум до расширения Солнца до орбиты Земли.
Блокчейн — это лишь медленная база данных, для адресации в интернете не подходит никак.equand
07.05.2018 12:53Блокчейн — это лишь медленная база данных, для адресации в интернете не подходит никак.
Ethereum блоки каждые 15 секунд кидает, есть вообще сабсекундные блокчейны, для адресации проблем с 15 секунд нет, тем более что с нашей системой мы можем поддерживать нативно мультиканалы с разным приоритетом полностью нивелируя переключения между провайдерами и рутерами.
Даже с /32, он откладывает проблему пусть и не до тепловой смерти Вселенной, но явно как минимум до расширения Солнца до орбиты Земли.
Ни черта он не откладывает, когда спамеры начнут забирать по тонне /32 каждый год
rednectar.net/2012/05/24/just-how-many-ipv6-addresses-are-there-really
К тому же у всего рутинга проблемы IPv6 не решает. Никто не знает, что будет когда будет 5 триллионов /64 (минимальный размер) делегирований в сети. Как рутеры с full bgp будут с этим дружить?3al
08.05.2018 07:22+1А блокчейн без гарантированного времени (точного) ответа — решает? Сабсекундные — это в идеальных условиях, интернет не всегда такой. Ну и выбирать между «спросить у всего блокчейна, куда роутить, и потерять секунды пинга» и «держать внутри каждого маломощного раутера все хэши» выглядит… странно.
> 5 триллионов /64
И когда они будут?
> спамеры начнут забирать по тонне /32 каждый год
Их 4 миллиарда. Если спаммеров будет сильно много — можно это регулировать централизованно.equand
08.05.2018 13:15Блокчейн решает, нам не надо все транзакции гнать через один единый блокчейн аля биткоин.
Я насколько вижу здесь нет специалистов по блокчейну. Открою Вам секрет. Блокчейн это не только классический лог Биткоина.
Вот например федеративный блокчейн — что это за зверь (ведь кто читал слово федеративный в моем тексте ни разу не задал вопрос)? У нас есть много малодецентрализованных нод, которые оперируют связностью между друг другом (пиры и их коннективити). Смысла каждому такому соединению писать в один единый блокчейн между миллионом нод не имеет смысла. Для этого мы разделяем state (channel — наш канал) и разбиваем блокчейн на смысловые блоки между каждыми L2 пирами, т.к. в нашем случае у нас авторитет вышестоящих провайдеров по распределению ресурсов, но нет авторитета на контент этих ресурсов! Для этого поднимается «мини»-блокчейн (т.к. абсолютного доверия рутинга у нас нет ни в локальном уровне ни в глобальном), где мы покупаем токены (неважно как, можно и через смарт контракт, можно в магазине, эмитент — апстрим), а наша сеть жгет их с каждым пакетом. Т.к. токены всего лишь запись в таблице, а не физически передаются с каждым пакетом — это никак не влияет на производительность.
Их 4 миллиарда. Если спаммеров будет сильно много — можно это регулировать централизованно.
Ага, столько же ipv4 было. И где мы теперь? Нарегулировались? Зарегал 100 фирм и получил 100 /32, тут же их закрыл, 1000 спаммеров так сделала и мы уже минус 100к подсетей, загадили подсети, пошли регать дальше. Особенно в странах где это бесплатно. Или в странах с коррумпированным устройством.3al
08.05.2018 14:51Если честно, то я совсем запутался. Допустим, есть умеющий в федеративные блокчейны роутер, есть пакет, в заголовке которого — один (1) хэш непонятно кого. Что роутер должен сделать, чтобы определить, что:
* этот пакет вообще валиден для конкретно него и его нужно роутить
* куда именно его роутить
* кого спросить, куда роутить, если сам роутер об этом не может быть в курсе по определению (он же не хранит 100% адресов внутри себя?!)
Какой безумный оверхэд появляется из-за того, что роутер даже в теории не может определить ничего полезного для своей основной задачи из заголовка пакета самостоятельно и вынужден каким-то образом консультироваться с распределённой (!!!) базой данных каждый раз, когда пропускает через себя пакет?
> Зарегал 100 фирм
Это не так дёшево и даёт не так много IPv6-адресов.equand
08.05.2018 16:19этот пакет вообще валиден для конкретно него и его нужно роутить
Это не его задача, а ендпоинтов (как впрочем и с v6).
* куда именно его роутить
Роутить куда он будет знать из блокчейна. Блокчейн будет работать не только по принципу PoW (не хрен жарить впустую), а по гибридному принципу PoS и PoW. Токены выпускаются на конкретный канал за счет «предпокупки» этих токенов апстримом у ендпоинта создателя канала, покупка производится инициализацией канала, когда сетевые интерфейсы обмениваются пакетами на максимальной скорости без ограничений не замедляя другие каналы.
Токены генерируются по принципу channel-packet/sec (дебаты, возможно что-то лучше? я это называю proof-of-bandwidth).
* кого спросить, куда роутить, если сам роутер об этом не может быть в курсе по определению (он же не хранит 100% адресов внутри себя?!)
Так что роутер знает только если у него есть доступ к ендпоинту и ресурсы для проведения операции.
Засчет этого канал прописывается далее в сети через каждый федеративный блокчейн в один глобальный (аналог bgp propagation, который может доходить до 30 минут, только в отличие от него, у нас есть конкретные каналы с конкретными ресурсами доступными внутри них). Федеративные блокчейны это локальный мемпул аналог local-bgp, глобальный блокчейн это лог каналов со снапшотами (чтобы не хранить гигабайты данных, мы храним только актуальные обновляющиеся каналы за время T -30сек, для сохранения чейна использовать снапшоты).
Соответственно оверхед — только хеши в памяти, ресурсы между пирами и хеши в памяти пиров. Все это минус сами знаете что и с большей безопасностью. Токены еще могут делиться по цвету согласно потерям пакетов и количеству хопов до ендпоинта (токен лучшего качества означает что ендпоинт рядом). Соответственно лучшие сети с высшим качеством каналов будут иметь больший приоритет автомагически.
Это не так дёшево и даёт не так много IPv6-адресов.
Зарегать 100 фирм стоит 0 например у нас в стране. После этого получить одну площадку по знакомству на 100 фирм и два анонса проще пареной репы. Ждать пару дней после каждого запроса и получать себе 100 подсетей в течение года. Вполне реально. Сделать им налоговые потери и банкротить после этого. Вуаля — 100 подсетей.
equand
08.05.2018 13:23И когда они будут?
FIB у большинства рутеров нашего времени рассчитан на 1млн в4 и 500-700к в6, не суммарно!
В 2019-2020 году многие рутеры уже будут плакать и требовать замены.
bgphelp.com/2017/01/01/bgpsize
Если рост продолжиться, то к 2030 году мы опять столкнемся с проблемой рут таблиц, только уже более тяжелого v6
achekalin
07.05.2018 19:27+2Кажется, вы ни в том, ни в том не разобрались.
equand
08.05.2018 00:16-2Прекрасно разбираюсь и в том и в другом. Есть аргументы? Вперед!
achekalin
08.05.2018 00:30+2Давайте не будем, чтобы вам и мне не было стыдно перечитывать этот тред год спустя. Вы смешиваете теплое и мягкое, это никогда к добру не вело.
Судя по минусам вашему комменту выше, идея блокчейна (бд, где элементы подтверждают истинность предыдущих) вам полностью затмила простой вопрос: как передать данные от точки А в Америке в точку Б в Европе через промежуточные хопы, в мире, где число хостов растет, и где все ежесекундно меняется. Хоть токены, хоть что вы в блокчейна положите — на роутинг это не может повлиять в лучшую сторону. Не говоря, что для передачи нужны пары адресов: от кого и кому, а где они в вашей идее?
Либо, если вы прямо видите гениальность вашей идеи, напишите пост. Лично обещаю поставить плюс, если будет понятно и по делу. А если придумаете, как на существующей инфраструктуре интернета разом ввести ваше новое, то цены посту вообще не будет.equand
08.05.2018 01:48-1Либо, если вы прямо видите гениальность вашей идеи, напишите пост. Лично обещаю поставить плюс, если будет понятно и по делу. А если придумаете, как на существующей инфраструктуре интернета разом ввести ваше новое, то цены посту вообще не будет.
Я пытаюсь подбросить идею, а не описать ее. К сожалению, с семьей тяжело сконцентрироваться на хобби. Писать то пишу, но идет медленно.
Судя по минусам вашему комменту выше, идея блокчейна (бд, где элементы подтверждают истинность предыдущих) вам полностью затмила простой вопрос: как передать данные от точки А в Америке в точку Б в Европе через промежуточные хопы, в мире, где число хостов растет, и где все ежесекундно меняется. Хоть токены, хоть что вы в блокчейна положите — на роутинг это не может повлиять в лучшую сторону. Не говоря, что для передачи нужны пары адресов: от кого и кому, а где они в вашей идее?
Ок попробую разъяснить для чего федеративный блокчейн и токены. Я не предлагаю использовать текущую сеть например перегруженного этереума или же перегруженного биткоина или даже свободного биткоин кеша. Эти сети предназначены для другого.
У нас не свободная сеть, у нас сеть с единым авторитетом, т.к. мы соединены с реальным миром напрямую (интерфейсы и кабели).
В локальной сети сохранить безопасность сети и упростить пакеты в старые времена было сложно. Именно поэтому мы используем названия с повторениями в реальной жизни и используем тонну сопутствующей информации для адресации и все равно допускаем ошибки (почта). Интернет (арпанет) писался по принципу и подобию. Соответственно сначала была сделан статическая связность с единым авторитетом рутинга. Как выяснилось с множеством агентов (разворот на интернет) это не было скалируемым решением. Началась работа над CIDR и сопутствующим протоколом BGP.
Факт есть факт, никто не думал в то время об адресации через криптографические хеши и ключи.
Решение выдалось временно безграничным (4.3 миллиарда адресов хватит всем). К сожалению, как любой ресурс он был высосан практически полностью в очень короткий срок. Результатом этого стала работа на костылями. NAT, CNAT, ограничения, запрет PI и т.п. и т.д. и в конце концов IPv6.
IPv6 является хорошим изменением по сути, но это изменение, а не пересмотр всей системы. Очень уменьшили пакет. Перекинули фрагментирование и чексамминг на endpointы. Но опять же source и destination адресы.
Распределение IPv6 осталось в прошлом и по сути повторяет IPv4, только теперь вместо одного IP мы даем подсеть, пущай все будет в WAN!
NDP запутанный протокол, который посути не решает проблем, которые должен был решить (и не надо мне про экспериментальщины с костылями из крипты поверх NDP).
Короче говоря имхо — полный провал.
Начнем с L2. Что нам нужно? Безопасность локальной сети. Она должна быть доступна только администратору и никому другому. У нас нет доверия endpointам.
Решение очевидно!
Вот этот унитаз: en.wikipedia.org/wiki/File:Ipv6_header.svg
выбрасываем.
Уменьшаем хедеры с 320 бит до 160бит (да да, до длины одного хеша)
Хешируем мы ident (зашифрованный публичным ключом рутера уникальный код системы, например MAC (но его желательно расширить с 48бит, он более не используется нигде у нас)), нонс. Т.к. рутер должен знать о новом ендпоинте, то вопрос идентификации и гашения канала решается легко и быстро: Не понял? Выключил.
Это замена статической аутентификации ендпоинта. Можно еще и шифрование данных добавить.
Не обязательно использовать RSA, Ed25519 и другую ассиметрячину, можно использовать и HMAC и другие симметричные алгоритмы шифрования, но в принципе это можно модулировать и изменять программированием типов шифрования до подключения (аля выбор сейчас статика, слаак, дхцп6 и т.п.) в соответствии с настройками рутера. Чем меньше знаний о рутере у конечной точки, тем меньше вероятность взлома.
Наш хедер стал «каналом» подключения к рутеру.
Такой схемой безопасность LAN становиться полноценной. В такой конфигурации нам не надо прятаться за VLAN, т.к. каждая система является ограниченной шифрованием данных внутри пакетов после хедера. Это не отбирает у нас возможность отобрать или дать L2 соседство у хостов, LAN определяется доступом к каналу, только главный рутер знает какие ноды общаются с кем, к нему обращаются за доступом к сети и ендпоинты и все посередные рутеры и свитчи. Но самое интересное, что главный рутер не может расшифровать траффик если это необходимо, т.к. рутеры оперируют только каналами и ключами теперь.
Это только L2. Статья с картинками будет позже.
Как Вы понимаете L3 намного сложнее, нам нужно заменить легко обнаружаемые порты на директ каналы и разработать протокол обмена токенов для поддержания обмена данными в пределах выставленных лимитов ендпоинтом, а не промежуточными системами, для этого и нужен федеративный блокчейн (федеративный, потому что между двумя или несколькими нодами как в текущей системе AS, блокчейн, т.к. больше нет портов и ACL, т.к. мы не знаем конечный пункт и начальный, мы оперируем каналами, может ли канал пропустить 500гб в течение 1 секунды или нет знает только ендпоинт, к которому отослан запрос и от которого отправлен). Главной проблемой я вижу бутстраппинг безопасности, ибо нам нужно получить честный первоначальный блок. В текущей схеме этим занимается ОС и браузеры, которые получают корневые сертификаты при установке. В нашей схеме генезис блок должен идти в поставке с ОС.
P.S.:
бд, где элементы подтверждают истинность предыдущих
Это не БД! А лог.
immaculate
07.05.2018 12:30+3Я за последние 1.5 месяца побывал в 3-х странах: Вьетнам, Камбоджа, Лаос. Это не самые экономически развитые и сильные в IT страны. Тем не менее, едва ли не в каждой забегаловке мой ноутбук и телефон получают IPv6 адрес, и обращаются к сайтам по IPv6.
Что мешает всем остальным наконец перейти, если даже в Камбодже и Лаосе уже перешли на IPv6?..
SirEdvin
07.05.2018 12:32+4Великая сила легаси. Чем раньше у вас появляется интернет, тем он у вас хуже, потому что никто не может или не хочет вкладывать там много денег с интернет-коммуникации.
navion
07.05.2018 13:50Скорее дело в ARPU и росте мобильных пользователей.
США всегда были королями legacy, однако по внедрение IPv6 они на первых местах.
semmaxim
07.05.2018 13:57+1В Камбодже и Лаосе не переходили на ipv6. Там не с чего было переходить. Они просто так с самого начала поставили.
immaculate
08.05.2018 04:49В России, например, инфраструктура с момента появления IPv6 менялась несколько раз, уверен в этом (IPv6 появился 22 года назад, черновики на несколько лет раньше, сомневаюсь, что где-то до сих пор работают роутеры, свитчи, и прочее оборудование, сделанное 22 года назад). Тем не менее, до сих пор с IPv6 в России не сталкивался ни разу.
zikasak
08.05.2018 08:54Ну, если быть честным, внедрение идёт. Но очень-очень медленно. Например, московский Ростелеком в некоторых районах уже даёт ipv6 подсеть /56. Но не гарантирует работу, выделенная подсеть может измениться в любой момент.
semmaxim
08.05.2018 12:53Инфраструктура обычно не меняется сразу вся. Она меняется по отдельным частям. И каждая новая часть должна быть совместима со всеми остальными. Даже по глюкам.
pda0
07.05.2018 12:53Карта распределения ipv6 порадовала. Посмотрел на неё — заметил одинокую белую точку. На всякий случай потёр экран в этом месте — оказалась пылинка прилипла.
u007
07.05.2018 13:56GlobalSign_admin, предлагаю в конец статьи дописать:
Я знаю, что ты сейчас сделал, хабраюзер
Заголовок спойлераПротёр монитор?Serge78rus
07.05.2018 15:47Лайфхак для ленивых: чтобы понять, является ли точка грязью на экране и не тянуться тереть экран, достаточно немного покрутить колесо скроллинга мыши.
staticlab
07.05.2018 13:20+3Ещё можно раскулачить Ford, Daimler, Apple и HP.
achekalin
07.05.2018 16:24+1Вспомнилось:
— Вот этого, этого и этого расстрелять! Запиши их в список!
— Я не хочу!
— Ну, раз не хочет, вычеркивай этого из списка расстреливаемых!
Мне кажется, что никто особо мнения райпа не спросит, скажут, что все адреса прям очень нужны — а райпу и крыть-то будет нечем.
И будет, как в известном кино:
— Вы арестованы!
— А пистолетик-то есть?
— Тогда — задержаны!
achekalin
07.05.2018 15:08+1Да неужели они хоть слово скажут хоть кому-то, кто уже владеет сетью? Особенно — крупной.
У RIPE вообще есть процедура отзыва адресов, которые не используются по назначению (или вообще не используются)?
Что характерно, норма, что BGP «маленькие» (меньше /24, а иные одаренные и крупнее размер «мелким» называет) сети фильтрует, создала такой вот геморой. Когда компании нужно было, скажем, десяток PI адресов, приходилось покупать /24, а то и /23, анонсируя их как две /24, чтобы разные сервисы на разные каналы приорететно развесить. И мы все дружно писали райпу в анкетах про сотни рабочих станций и сотни же VPN-юзеров, а они так же серьезно это глотали, помните?
С такой раздачей об экономии можно было не заикаться. Сегодня принять правила, обязывающие не фильтровать до /29 (например), и методы решения для тех, у кого BGP поднят на устройствах с небольшим числом ресурсов — и можно было бы тогда попробовать выкупать или как-то выманивать назад адреса, только пряник должен быть продуманным…firk
07.05.2018 15:54Это ещё раз подтверждает ненужность IPv6. Если кому-то памяти не хватает на приём /29 аноносов (а кто-то и /24 не принимал, пока это не стало критичным), то от включения IPv6 её количество не увеличится само собой. А если её увеличить (всем) и принимать тот же /29, то адресов вдруг станет надолго хватать и без IPv6.
achekalin
07.05.2018 16:08Не хватит: никто из владельцев не отдаст даже /29.
Я видел провайдеров, у которых даже откровенные точка-точка сети были сделаны на публичных адресах, и с приличным запасом — им, может, можно было бы дизайн сети сменить и отдать часть освободившегося, но кто же это сделает?!
Другой пример: есть офис, в котором 20 ПК и 2 сервера. На них всех /24 сеть. Зато в правилах брандмауэра прописали /24 — и все. А можно было бы сделать красиво, выделить на 22 хоста сеть /27, остальное под другие цели направить… Ага, ищите дураков, ломать то, что уже настроено!
RIPE не имеет процедуры отнимания адресов даже у тех, кто за них годами не платит (может, уже и придумали, но было так), а уж как они у компании размером с AT&T или MS (понятно, что это не в епархии райпа, но я про размер) попросят добровольно отдать ненужные адреса — хочется посмотреть.
Я бы раз был увидеть IPv6 в работе, но их и правда широко раздают, так что хватит (если и когда начнут серьезно использовать) не факт что на десятилетия.Wexter
07.05.2018 16:57Мегафон/РТК по всей россии на точки выдаёт по /30 (в паре регионов выдавал /29 или /28, но это прям редкость), точек порядка 200+, что выходит в 800 белых адресов на 200 точек… и это при том что в одном регионе около 30 сетей идут друг за другом, видимо им проще выдать 30 сетей /30, чем отдать одну /26 с запасом
navion
07.05.2018 16:07Сегодня принять правила, обязывающие не фильтровать до /29
Тогда ляжет половина интернета.
И мы все дружно писали райпу в анкетах про сотни рабочих станций и сотни же VPN-юзеров, а они так же серьезно это глотали, помните?
По-моему это давно прикрыли, но сейчас можно выдумать приватное облако.achekalin
07.05.2018 16:14Так вопрос не в том, что писать, а в том, что райп прямо подводит к мысли писать чушь, если написать правду: «мне нужна сеть /23, чтобы по-разному анонситься на двух моих аплинков, имея в сети 20 хостов и 2 сервера», ответят «мало оснований выдать /23», при этом кто там рекомендовал фильтровать сети короче /24?
А писать про облако — та же чушь, как про 200 VPN-юзеров: зачем серверам в приватном облаке вообще белые адреса? Адреса нужны на балансировщике, а облачные сервера лучше спрятать в приватную сетку. Но — прокатывает же!
Райп вообще любит отписываться по формальным причинам (читай «у вас помарка в анкете»), т.к. типа они чем-то заняты, а как они могут диктовать схему сети, которую строит конечник?ivlad
08.05.2018 10:18А писать про облако — та же чушь, как про 200 VPN-юзеров: зачем серверам в приватном облаке вообще белые адреса?
Для end-to-end связанности. Интернет вообще был придуман, как сеть с end-to-end связанностью.
SLB — это стейт. Стейт — это дорого. Tomahawk II сейчас даёт 64 * 100 Gbps. SLB делают на 40Gbps — 50Gbps при немалых ухищрениях, довольно длинных сессиях и т.п. Быстрые штуки делают без стейта. Если делать их без стейта, тогда всё равно придётся делать 1-to-1 маппинг адресов. Зачем тогда серые адреса?
ivlad
08.05.2018 10:05Сегодня принять правила, обязывающие не фильтровать до /29 (например), и методы решения для тех, у кого BGP поднят на устройствах с небольшим числом ресурсов
… И помрут TCAM по всему миру. Серьезно, всю эту энергию по гальванизации трупа IPv4 уже можно потратить с куда большей пользой на современный протокол.
achekalin
08.05.2018 10:21Для начала, мне идея сделать все на новом протоколе нравится.
Но вот сейчас точка такова, что и вперед тяжело, и назад сложно. И так, и так придется менять кучу железок. Только вера в то, что «мы заменим не старой циске софт, и она будет уметь IPv6» — это тоже неправда, т.к. «железно» она его не будет уметь, а что такое гонять все это на процах — мы все знаем. Будем объективны, вложений в приход IPv6 предстоит ещё много.
Но вот разумная мысль: если мы «настрогали» в нем адресов аж /128, но решили, что мы режем их по /64, то все равно менее, чем /64, но все же много префиксов нам надо как-то в голове устройств уложить. Если старые циски стонут от числа просто даже всех /24 префиксов (от того и фильтровали менее /23, а особо ограниченные ресурсами — и того меньше), то от «меньше, чем /64» префиксов нового протокола они никак не обрадуются.
А с v6 все плохо еще и потому, что его никто не просит у провайдеров, провайдеры его не внедряют (а зачем?), сайтам он не так и нужен. И все кивают на остальные части этой формулы: сайты говорят, что зачем им лишние сложности с безопасностью, если все равно протокол не массовый, юзерам по больше части пофиг, а провайдеры откровенно даже боятся внедрять: лишний геморой, проблемы с биллингом, шейпингом, непонятно, как клиенты будут его настраивать, и как им помогать при проблемах с IPv6.
Да вы и сами знаете.ivlad
08.05.2018 12:16Но вот сейчас точка такова, что и вперед тяжело, и назад сложно.
Есть мнение, что в среднем по миру мы сейчас находимся в точке между early adopters и early majority на кривой распространения технологий. Если верить книге "Crossing the chasm", этот разрыв имеет свои сложности и проблемы, но для России это нерелевантно.

Россия, если посмотреть на проникновение IPv6, находится в области innovators, даже не early adopters. Иначе говоря, в настоящий момент внедрение IPv6 не гарантирует никакого возврата инвестиций, формирования нового "голубого океана", ключевого дифферциатора, ничего. Таким образом, для принятия решения о внедрении IPv6 сейчас, техническому руководителю необходимо иметь глубокое понимание технологии, видеть (или верить в) её потенциал, а ещё — иметь волю (и яйца) для принятия этого решения и горизонт планирования больше 12 месяцев. Почему тогда Яндекс запустил IPv6 (как я рассказывал аж в 2012 году) и даже имеет IPv6-only датацентры? На мой взгляд, дело в том, что люди в Яндексе видят себя не в России (есть даже внутренняя шутка на этот счёт) и в своих суждениях и технологических решениях ориентируются не на, скажем, Ростелеком (смешно же), а на то, что делают в Google, Facebook или, на крайняк, в Amazon. Иначе говоря, Яндекс в 2012 году уже жил в мире 0.5% проникновения и экспоненциального роста (я хорошо помню, что я смотрел на график Google и, когда он достиг 2%, обсуждал с менеджером Главной страницы вопрос поддержки IPv6 аргументируя именно внутренним правилом про 2%), а типовой российский провайдер этого момента ещё не достиг.
Но мировой интернет пока не отрубили, а там проникновение растёт. ЦК КПК принял решение ускорить проникновение в Китае и поставил местной индустрии задачу достичь проникновения 20% к концу года. Я буквально сегодня был на совещании по этому поводу и практически уверен, что 20% проникновения, все федеральные и top 50 коммерческих сайтов Китая будут на IPv6 в срок — в тюрьму никто не хочет. Это означает, что к концу года мир будет находиться в области early majority (Китай даст +7 — +10 процентных пунктов), а там заработают другие механизмы. Будущее наступило, просто оно неравномерно распределено.
Россия, очевидно, в этой области отстала, я не знаю, сможет ли она догнать, но это уже не моя проблема. :) Я поймал себя на мысли, что мне любопытно наблюдать за этим со стороны, оттуда, где область early majority уже достигнута.
Такие дела. :)
achekalin
08.05.2018 12:25Вне тему ipv6, ваша фраза про (сокращаю):
люди в Яндексе… ориентируются… на то, что делают в Google
вообще хорошо описывает мое личное восприятие того, что делает Я. На самом деле, наверное, и не так, но — «выглядит-то оно именно таким образом».
Другими словами, если бы не Г, Я бы про шестерку не думал бы?ivlad
08.05.2018 14:08Я полагаю, думал бы.
Например, насколько я знаю, когда у Яндекса уже был IPv6-only датацентр, про такие у Google ещё не было слышно. Я сказал, что Яндекс ориентируется на мировые компании, но не в том смысле, что он всё за гуглом повторяет, а в том, что он ощущает себя в этой лиге (обосновано или нет, другой вопрос).
achekalin
08.05.2018 14:17Да, именно так. Хотя ipv6-only ДЦ — он того стоил, или это просто "because we can"?
Я под ДЦ рисую себе большое здание с серверами, но это может быть и неправдой, конечно.
А с v6 — в той же Америке провайдеры исповедуют раздачу клиентам только ipv6, и строят nat на пути трафика в мир ipv4, гемора масса, но у них зато процент проникновения высок.
ivlad
08.05.2018 15:08Мне кажется, вы просто не понимаете мою точку зрения. Для меня этот вопрос звучит, как «а вот переход с паровых машин на двигатели внутреннего сгорания — он того стоил или это because we can». :)
Американские провайдеры едут на v6 потому, что адреса кончились и NAT придётся делать в любом случае. Но если внедрить v6, то доля трафика в NAT64 будет постепенно уменьшаться, при этом главные поставщики трафика, типа YouTube и Facebook уже с v6 и NAT не требуют. Это — естественное бизнес-решение в ситуации early majority.
ivlad
08.05.2018 12:17Только вера в то, что «мы заменим не старой циске софт, и она будет уметь IPv6» — это тоже неправда, т.к. «железно» она его не будет уметь, а что такое гонять все это на процах — мы все знаем.
да, я как раз в 2012 году про это рассказывал :)
Да вы и сами знаете.
да. :)
yetanotherman
07.05.2018 18:06Вы будете удивлены, но 44.0.0.0/8 по факту используется. Роутится в интернет правда весьма ограничено.
DarkByte
07.05.2018 21:13В данной сети почти нет живых адресов. Большая часть сайтов из данной сети лежит по адресу 44.0.0.1. Недавно пробовал получить у них адрес, в ответ получил отказ под предлогом того, что в России запрещён VPN, а с настройкой ip-тоннелей они разобраться не смогли, говорят что работают не стабильно у них.
yetanotherman
07.05.2018 22:08Свяжитесь с админами dstar.su — они вполне успешно использовали эти адреса для нескольких радиолюбительских проектов, сейчас оно вроде работает на них же.
grey_rat
07.05.2018 22:49В Беларуси тотальный NAT к которому все привыкли. Собственно, оно видно по IPv6 распространению и приобретению IPv4 (зачем распылять силы и средства на IPv4 или IPv6, когда есть резиновый NAT).
Aelliari
07.05.2018 23:12-1У моего провайдера в РБ 2 варианта подключения, ipoe и l2tp туннель. Так вот, на ipoe белый ip придётся покупать, на l2tp — он белый всегда. А если подключатся не по доменному имени к l2tp серверу а по ip к конкретному (там штук 16 серверов в локальной сети) — так у тебя ещё будет псевдо статический, теоретически сменится может в любой момент — но если промежутки короткие (только переподключение когда оборвался l2tp туннель) почти без шансов его упустить:)
grey_rat
07.05.2018 23:37Это всё танцы с бубном. По факту, самые крупные провайдеры что МТС, что Velcom-Атлант, что Белтелеком как сидели так и будут сидеть со своим NAT пока это будет возможно.
achekalin
07.05.2018 23:56Правила по сути сказали: просто так не даём, но если вы фиктивно себя запишите LIR-ом...
Несколько лет назад (давно, до дефицита ещё) в поисках того, у кого купить pi подсеть, я обзвонил и обписал половину российских lir-ов. Все ответили: да, мы lir-ы, но адреса продавать не умеем/не хотим, так что звоните другим. А это, на минутку, была их обязанность. Райпу тогда было удобно на это закрывать глаза, и сегодня закрывают. Разница для них — больше lir-ом и больше отчислений, но и всё, всем понятно, что речь о фикции.
Сколько там сегодня стоит lir-а завести себе?
qwertyqwerty
08.05.2018 22:46Почему айпишек не 999.999.999.999 или больше?
Aelliari
09.05.2018 00:28связано с тем, что ipv4 адрес — 32 бита информации
11111111.11111111.11111111.11111111 = 255.255.255.255
ipv6 — 128 бит, адресов соответственно больше
reversecode
Страшный сон РКН блокировки ipv6…
SergeyMax
ipv6 access-list 1 deny ipv6 0000:: /0… oh, shi~
gx2
Надо 2000::/3
Wexter
так там ещё штук 13 сетей /3
gx2
Они все reserved, использоваться вряд ли когда-либо будут, так же как в ipv4.