
Такой подход хорош тем, что он не требует сложных предварительных обработок и минимизирует риски «выплеснуть с водой ребенка» – пропустить документ, из которого потенциально может быть заимствован текст. С другой стороны, в результате мы мало знаем, какие именно документы находятся в итоге в индексе.
По мере роста интернет-индекса – а сейчас, на секундочку, это уже более 300 млн документов только лишь на русском языке – возникает вполне естественный вопрос: а много ли в этой свалке действительно полезных документов.
И раз уж мы (yury_chekhovich и Andrey_Khazov) занялись такой рефлексией, то почему бы нам заодно не ответить еще на несколько вопросов. Сколько проиндексировано научных документов, а сколько ненаучных? Какую долю среди научных статей занимают дипломы, статьи, авторефераты? Каково распределение документов по тематикам?

Так как речь идет о сотнях миллионов документов, то необходимо использовать средства автоматического анализа данных, в частности, технологии машинного обучения. Конечно, в большинстве случаев качество экспертной оценки превосходит машинные методы, но привлекать человеческие ресурсы для решения столь обширной задачи оказалось бы слишком дорогим удовольствием.
Итак, нам необходимо решить две задачи:
- Создать фильтр «научности», который, с одной стороны, позволяет отбрасывать в автоматическом режиме не подпадающие по структуре и содержанию документы, а с другой стороны определяет тип научного документа. Сразу оговоримся, что под «научностью» ни в коей мере не понимается научная значимость или достоверность полученных результатов. Задача фильтра – отделять документы, имеющие вид научной статьи, диссертации, диплома и т.п. от других видов текстов, а именно художественной литературы, публицистических статей, новостных заметок и т.п.;
- Реализовать средство рубрикации научных документов, относящее документ к одной из научных специальностей (например, Физико-математические науки, Экономические науки, Архитектура, Культурология и т.д.).
При этом решать эти задачи нам необходимо, работая исключительно с текстовой подложкой документов, никак не используя их метаданные, информацию о расположении текстовых блоков и изображений внутри документов.
Поясним на примере. Даже беглого взгляда хватает, чтобы отличить научную статью

от, например, детской сказки.

А вот при наличии только текстового слоя (для тех же самых примеров) приходится вчитываться в содержание.
Фильтр «научности» и сортировка по типам
Решаем задачи последовательно:
- На первом этапе отфильтровываем ненаучные документы;
- На втором этапе все документы, которые были определены как научные, классифицируем по типу: статья, кандидатская диссертация, докторский автореферат, диплом и т.д.
Выглядит это примерно так:
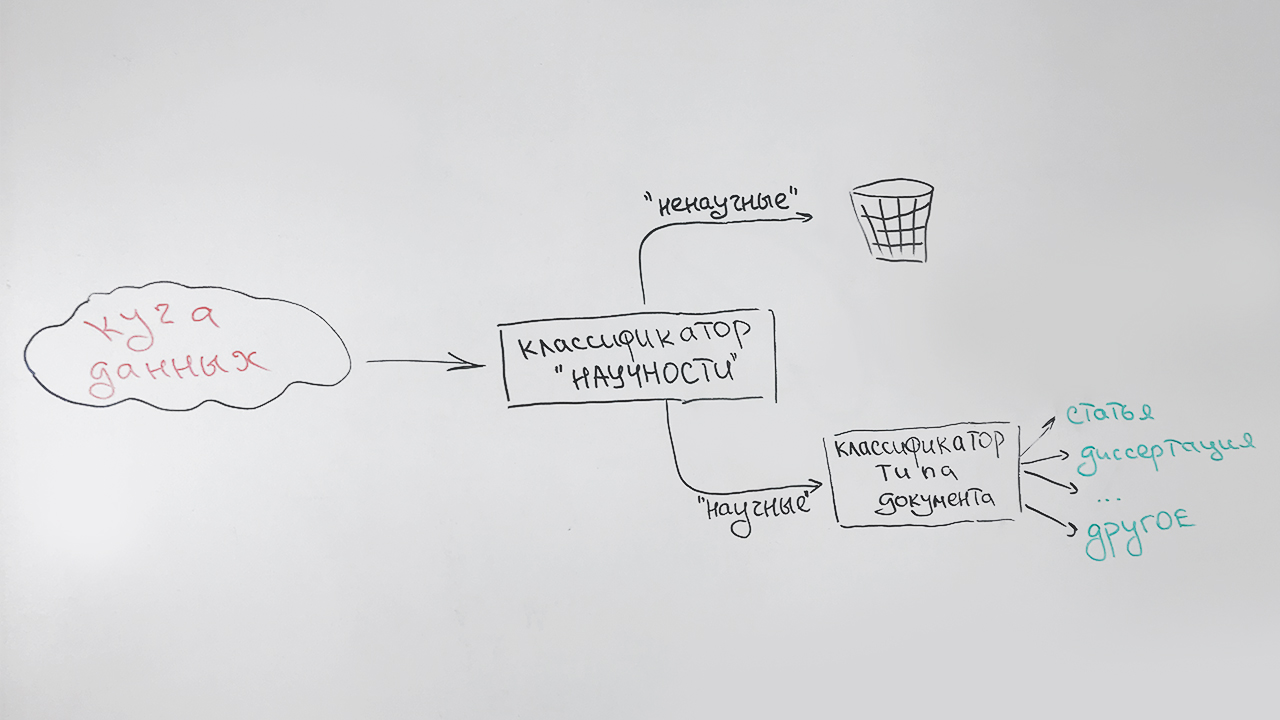
Особый тип (неопределенный) присваивается документам, которые нельзя с большой долей уверенности отнести к какому-либо одному типу (в основном это короткие документы – страницы научных сайтов, аннотации рефератов). К такому типу будет отнесена, например, эта публикация, которая имеет некоторые признаки научности, но не похожа ни на что из вышеперечисленного.
Есть еще одно обстоятельство, которое нужно принимать во внимание. Это высокая скорость работы алгоритма и нетребовательность к ресурсам – все-таки наша задача носит вспомогательный характер. Поэтому используем очень небольшое признаковое описание документов:
- средняя длина предложения в тексте;
- доля стоп-слов по отношению ко всем словам текста;
- индекс удобочитаемости;
- доля знаков препинания по отношению ко всем символам текста;
- количество слов из списка («автореферат», «диссертация», «дипломный», «аттестационный», «специальность», «монография» и т.п.) в начальной части текста (признак отвечает за титульный лист);
- количество слов из списка («список», «литература», «библиографический» и т.п.) в последних части текста (признак отвечает за список литературы);
- доля букв в тексте;
- средняя длина слова;
- количество уникальных слов в тексте.
Все эти признаки хороши тем, что они быстро вычисляются. В качестве классификатора используем алгоритм случайного леса (Random forest) — популярный в машинном обучении метод классификации.
С оценками качества при отсутствии размеченной экспертами выборки трудновато, потому напускаем классификатор на коллекцию статей научной электронной библиотекой Elibrary.ru. Предполагаем, что все статьи будут определены как научные.
Результат 100%? Ничего подобного – всего 70%. Может быть, мы создали плохой алгоритм? Просматриваем отфильтрованные статьи. Выясняется, что в научных журналах печатают много ненаучных текстов: редакционные статьи, поздравления с юбилеями, некрологи, кулинарные рецепты и даже гороскопы. Выборочный просмотр статей, которые классификатор посчитал научными, ошибок не выявляет, поэтому признаем классификатор годным.
Теперь беремся за вторую задачу. Здесь без качественного материала для обучения не обойтись. Просим асессоров подготовить выборку. Получаем чуть больше 3,5 тысяч документов с таким распределением:
| Тип документа | Количество документов в выборке |
|---|---|
| Статьи | 679 |
| Кандидатские диссертации | 250 |
| Авторефераты кандидатских диссертаций | 714 |
| Сборники научных конференций | 75 |
| Докторские диссертации | 159 |
| Авторефераты докторских диссертаций | 189 |
| Монографии | 107 |
| Учебные пособия | 403 |
| Дипломные работы | 664 |
| Неопределенный тип | 514 |
Для решения задачи многоклассовой классификации используем тот же Random forest и те же признаки, чтобы не рассчитывать что-то специальное.
Получаем следующее качество классификации:
| Точность | Полнота | F-мера |
|---|---|---|
| 81% | 76% | 79% |
Результаты применения обученного алгоритма к проиндексированным данным видны на диаграммах ниже. На рисунке 1 видно, что более половины коллекции составляют научные документы, а среди них, в свою очередь, больше половины документов — статьи.

Рис. 1. Распределение документов по «научности»
На рисунке 2 – распределение научных документов по типам, за исключением типа «статья». Видно, что второй по популярности тип научного документа — учебное пособие, а самый редкий тип — докторская диссертация.

Рис. 2. Распределение других научных документов по типам
В целом результаты соответствуют ожиданиям. От быстрого «грубого» классификатора нам больше и не нужно.
Определение тематики документа
Так получилось, что пока не создан единый общепризнанный классификатор научных работ. Наиболее популярными на сегодняшний день являются рубрикаторы ВАК, ГРНТИ, УДК. Мы решили на всякий случай тематически классифицировать документы под каждый из этих рубрикаторов.
Для построения тематического классификатора используем подход, основанный на тематическом моделировании (topic modeling) — статистическом способе построения модели коллекции текстовых документов, при котором для каждого документа определяется его вероятность принадлежности к определенным темам. В качестве инструмента для построения тематической модели используем открытую библиотеку BigARTM. Мы уже использовали эту библиотеку раньше и знаем, что она отлично подходит для тематического моделирования больших коллекций текстовых документов.
Однако есть одна сложность. В тематическом моделировании определение состава и структуры тем – это результат решения оптимизационной задачи по отношению к конкретной коллекции документов. Мы не можем повлиять на них напрямую. Естественно, что получившиеся при настройке на нашу коллекцию темы не будут соответствовать ни одному из целевых классификаторов.
Поэтому, чтобы получить итоговое неизвестное значение рубрикатора конкретного документа-запроса, нам нужно выполнить еще одно преобразование. Для этого в пространстве тем BigARTM мы с помощью алгоритма ближайших соседей (k-NN) ищем несколько наиболее похожих на запрос документов с известными значениями рубрикаторов, и, исходя из этого, присваиваем документу-запросу наиболее релевантный класс.
В упрощенном виде алгоритм изображен на рисунке:

Для обучения модели мы используем документы из открытых источников, а также данные, предоставленные Elibrary.ru с известными специальностями ВАК, ГРНТИ, УДК. Удаляем из коллекции документы, которые привязаны к очень общим позициям рубрикаторов, например, Общие и комплексные проблемы естественных и точных наук, так как такие документы будут сильно зашумлять итоговую классификацию.
Итоговая коллекция содержала порядка 280 тысяч документов для обучения и 6 тысяч документов для тестирования для каждого из рубрикаторов.
Для наших целей нам достаточно предсказывать значения рубрикаторов первого уровня. Например, для текста со значением ГРНТИ 27.27.24: Гармонические функции и их обобщения верным является предсказание рубрики 27: Математика.
Для улучшения качества разработанного алгоритма мы добавляем к нему в пару подход, в основе которого лежит старый добрый наивный байесовский (Naive Bayes) классификатор. В качестве признаков в нем используются частоты слов, наиболее характерных для каждого из документов с конкретным значением рубрикатора ВАК.
Зачем так сложно? В результате мы берем предсказания обоих алгоритмов, взвешиваем их и выдаем усредненное предсказание для каждого запроса. Этот прием в машинном обучении называется ансамблированием (Ensembling). Подобный подход в итоге дает нам заметный прирост качества. Например, для спецификации ГРНТИ точность исходного алгоритма составила 73%, точность наивного байесовского классификатора — 65%, а их объединения — 77%.
В итоге получается вот такая схема работы нашего классификатора:
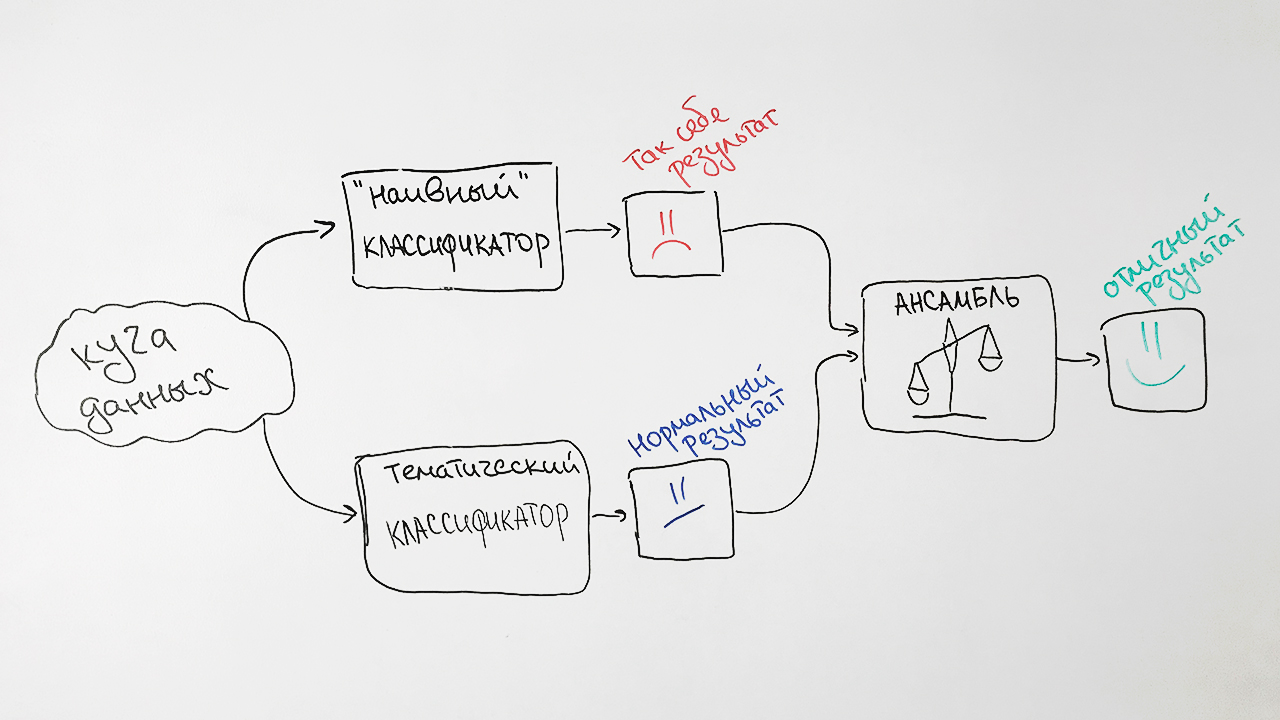
Отметим два фактора, влияющих на результаты классификатора. Во-первых, любому документу может быть одновременно присвоено более одного значения рубрикатора. Например, значения рубрикатора ВАК 25.00.24 и 08.00.14 (Экономическая, социальная и политическая география и Мировая экономика). И это не будет ошибкой.
Во-вторых, на практике значения рубрикаторов расставляются экспертно, то есть субъективно. Яркий пример — такие, казалось бы, непохожие темы, как Машиностроение и Сельское и лесное хозяйство. Наш алгоритм отнес статьи с названиями «Машины для рубок ухода за лесом» и «Предпосылки к разработке типоразмерного ряда тракторов для условий северо-западной зоны» к машиностроению, а по оригинальной разметке они относились как раз к сельскому хозяйству.
Поэтому мы приняли решение выводить топ-3 наиболее вероятных значения каждого из рубрикаторов. К примеру, для статьи «Профессиональная толерантность учителя (на примере деятельности учителя русского языка полиэтнической школы)» вероятности значений рубрикатора ВАК распределились следующим образом:
| Значение рубрикатора | Вероятность |
|---|---|
| Педагогические науки | 47% |
| Психологические науки | 33% |
| Культурология | 20% |
Точность итоговых алгоритмов составила:
| Рубрикатор | Точность на топ-3 |
|---|---|
| ГРНТИ | 93% |
| ВАК | 92% |
| УДК | 94% |
На диаграммах представлены результаты исследования по распределению тематик документов в индексе русскоязычного интернета для всех (рисунок 3) и только для научных (рисунок 4) документов. Видно, что большая часть документов относится к гуманитарным наукам: самые частые спецификации — экономика, юриспруденция и педагогика. При этом среди только научных документов их доля еще больше.
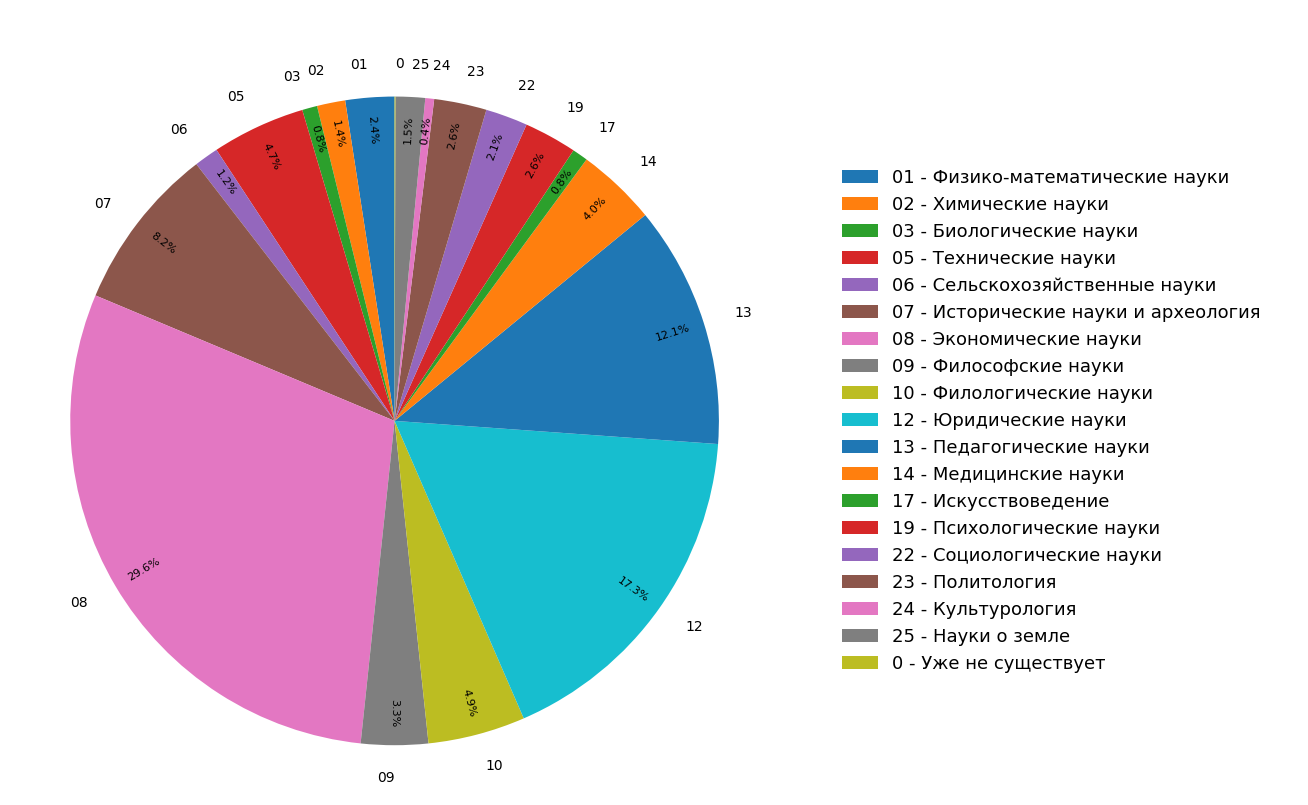
Рис. 3. Распределение тематик по всему модулю поиска
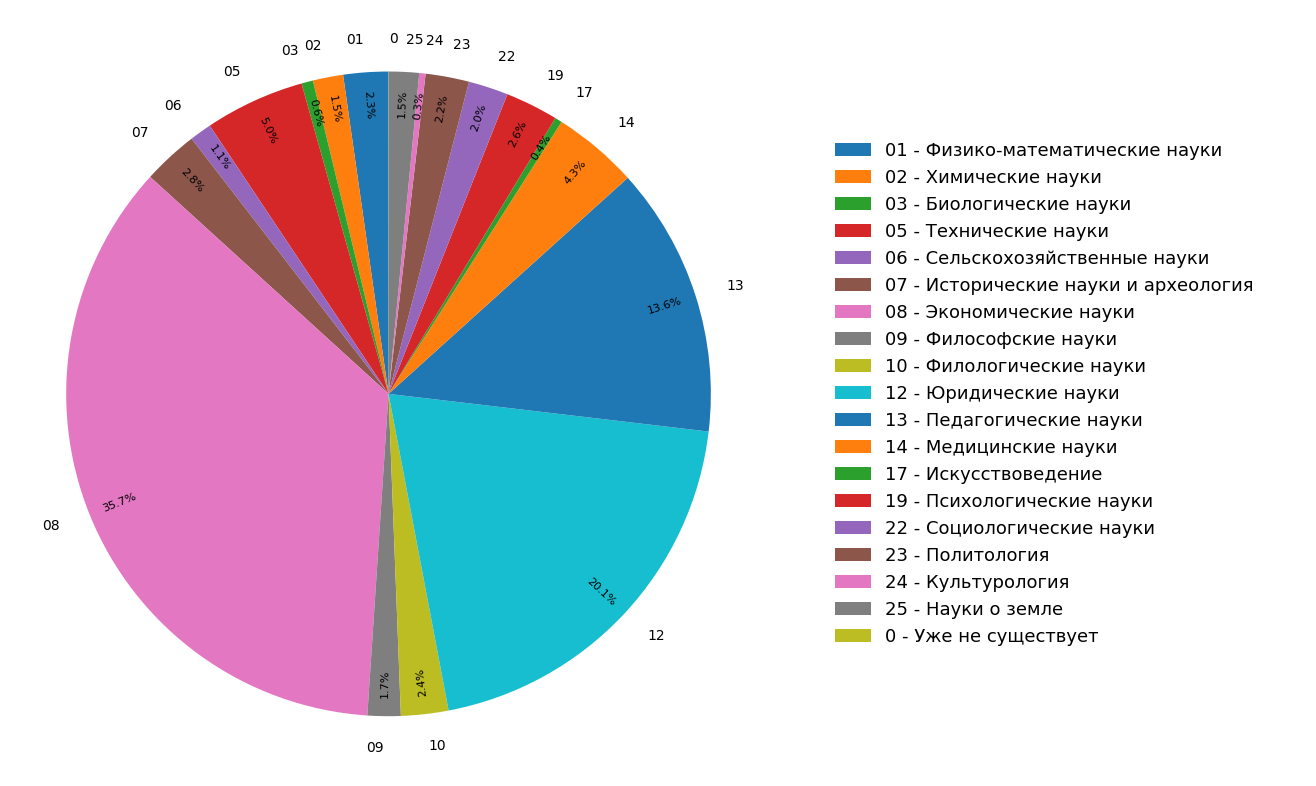
Рис. 4. Распределение тематик научных документов.
В результате мы буквально из подручных материалов не только узнали тематическую структуру проиндексированного интернета, но и сделали дополнительную функциональность, с помощью которой можно «одним движением» классифицировать статью или другой научный документ сразу по трем тематическим рубрикаторам.

Описанная выше функциональность сейчас активно внедряется в систему «Антиплагиат» и скоро будет доступна пользователям.
Комментарии (8)

Zmiy666
06.06.2018 20:52+2А можно ли как-то запретить вносить например мою дипломную работу в реестр антиплагиата?
Может я наоборот, чтоб ее активно плагиатили как только можно. У подавляющего большинства студентов сейчас большие проблемы в написании различных макулатурных работ (тех что нужны чисто для галочки и потом уйдут в макулатуру, всякие эссе, рефераты, практики и тд) Людям приходится платить деньги, чтоб за них написали работу, которую можно пропихнуть через антиплагиат. И проблема совсем не в том, что люди не хотят думать а хотят на халяву скопировать с интернета. Проблема в том, что темы для работ не меняются десятилетиями и если первые 5-6 лет все было нормально, то потом антиплагиат накопил критическую массу и большинству людей просто нет ни сил ни желания пытаться превзойти всю ту кучу работ, что были написаны до него. Ведь им надо не просто выполнить работу, а выполнить ее так, как никто до них не выполнял и с каждым годом рожать ежа все сложнее. Дошло до того, что даже за деньги на некоторые темы работы писать отказываются — тупо не пропускает антиплагиат.ads83
06.06.2018 21:26Я не в теме, поэтому мне не понятно, почему нельзя выбрать другую тему для реферата? И неужели кто-то требует уникального отчета по производственной практике?
Zmiy666
06.06.2018 21:40+2в разных вузах по разному… но например там где я учился — давали 30 тем на выбор и все. Сменить нельзя, они у них забиты в учебную программу аж с 97 года. Конечно многое зависит от преподавателя, которому ты будешь сдавать свое творение — нормальный закроет глаза на антиплагиат, потому как прекрасно понимает проблемы и прочитал 100500 таких же за свою жизнь. Но в последнее время прохождение антиплагиата стало обязательным, теперь от преподавателя уже ничего не зависит и результаты проверок уходят из вуза куда-то дальше. Вобщем все печально. Отчет о производственной практике… подавляющее большинство студентов просто не имеют возможности пройти производственную практику, а вузы не обязаны предоставлять им такую возможность, поэтому отчет о практике заменяется рефератом с фиксированной темой и опять таки требует прохождения антиплагиата. Более того у меня знакомый жаловался, что даже ЛАБЫ через антиплагиат прогоняют… вот уж действительно бред.
yury_chekhovich Автор
06.06.2018 22:07Ваши комментарии не совсем по теме статьи, а скорее по теме нашей деятельности. Тем не менее, вопросы важные.
1. Ваша работа может попасть Антиплагиат двумя разными путями: (1) она окажется среди общедоступных источников в интернете, где мы ее и проиндексируем, (2) вуз, в который вы эту работу сдали, добавит ее в свой индекс. Соответственно, единственное, что вы сможете сделать, это отследить, чтобы работа от вас не попала тем или иным образом в сеть. Кстати, если работу заказывали, то попадет в сеть почти наверняка — вопрос времени.
2. Вопрос тем работ. Здесь мы понимаем, что приходится «лечить» проблемы российского высшего профессионального образования. И получается, что лечить приходится большей частью за счет студентов. Как сделать по-другому, пока не знаем.
Gryphon88
07.06.2018 01:40Можете рассказать, откуда берёте материалы для проверки на плагиат? Elibrary, Истина, Киберленинка, диссеркат… Какие ещё?
yury_chekhovich Автор
07.06.2018 07:19Конечно. Elibrary — да. Истина — подписали соглашение, но пока индексирование не проводилось, Киберленинка — в режиме обычного сайта. Диссеркат — нет. Что касается диссертаций, то наиболее полная коллекция — у РГБ, с которой мы сотрудничаем.
В статье речь идет про открытые сайты, то есть из перечисленного только статьи из Киберленинки проходили через классификатор.
synedra
О, это вы круто придумали. Я правильно понимаю, что это скорее про генерацию датасета для каких-то дальнейших работ, чем про исследование статистики русскоязычной науки в целом? С удовольствием почитал бы про распределение межотраслевых заимствований, например, если есть такие.
И ещё (возможно, дилетантский) технический вопрос: при ассемблировании тематических классификаторов откуда брались веса? Какая-нибудь функция точности на тренировочной выборке?
yury_chekhovich Автор
Генерация датасета — это возможное использование в будущем, но основные мотивы, все-таки, это категоризация по жанрам и по темам. Нам действительно стало важно узнать по какой теме сколько у нас проиндексировано документов.
Вы правы, веса в ансамблировании настраивались на тот же самый материал обучения. Единственное, старались контролировать степень переобученности.