
В этой части статьи я расскажу о новом способе раскладки кода, который мы придумали, пытаясь решить наши проблемы, и о том, как с ним преобразилась наша система патчей.

Изображение: источник
Универсальное решение — Multiversional Deployment Kit
После очередного пересмотра нашей системы Юра youROCK Насретдинов заявил, что у него есть идея, как решить все наши проблемы. Всё, что он просил, — кучу времени, чтобы переделать систему раскладки. Так появилась концепция Multiversional Deployment Kit, или, в простонародье, MDK (Юра сравнивал ее с другими способами раскладки кода в своем докладе на HighLoad++).
Новая система была призвана изменить нашу процедуру раскладки. Тем, кто не читал мою первую часть статьи, вкратце расскажу, как у нас выглядит процесс деплоя: сначала мы собираем все нужные файлы в одной директории, потом сохраняем и доставляем состояние директории до серверов.
До эпохи MDK для сохранения и доставки мы использовали блочные устройства (то есть образы файловой системы), которые называли лупами. Директория копировалась в пустой луп, он архивировался и отправлялся на серверы.
В новой системе мы версионируем не директорию целиком, а каждый файл по отдельности так, чтобы версия файла однозначно коррелировала с его содержимым. Для директорий существуют карты (maps) — специальные файлы, в которых записаны версии всех файлов в директории. Эти карты тоже версионируются, и выглядит всё это приблизительно так:
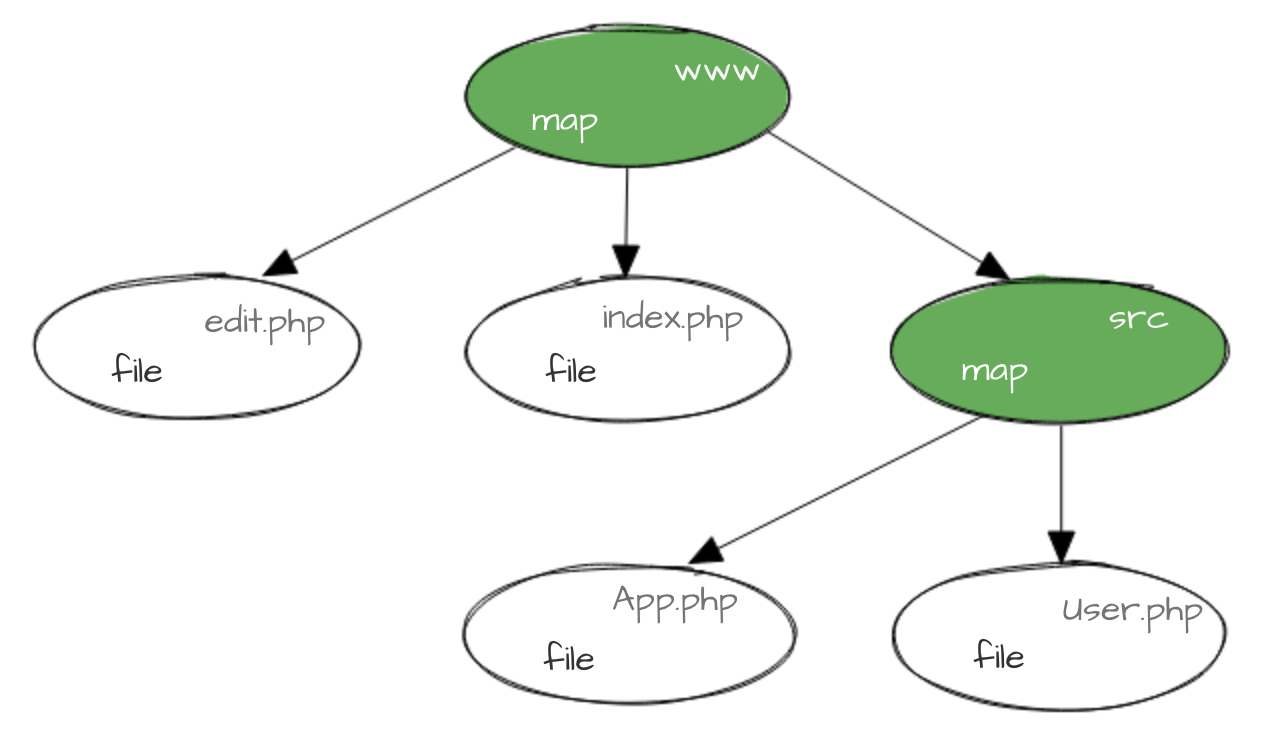
Выглядит знакомо? Именно так устроены объекты в Git (можете почитать об этом здесь, но для понимания статьи это не обязательно).
Для версионирования мы используем первые восемь символов от MD5-хеша (от его шестнадцатиричного представления, если быть точным), взятого от содержимого файла. Эта версия записывается в конец имени файла или в начало имени карты (чтобы можно было отличить файл map от сгенерированной карты версий):

Версия кода — это версия карты корневой директории www. Для того чтобы найти текущую карту, у нас есть символическая ссылка (symlink) current.map.
Сборка с MDK
MDK нужен, чтобы сохранить состояние директории в конце сборки. Для этого у нас есть специальное место, которое мы назвали репозиторием, — хранилище всех версий файлов, которые представляют для нас ценность (то есть которые мы можем захотеть разложить). Когда новое содержимое директории готово, мы вычисляем версии всех файлов в ней и докладываем в репозиторий недостающие.
Раскладка с MDK
Во время раскладки на каждом из принимающих серверов мы запускаем скрипт, который проверяет, все ли необходимые файлы есть на сервере, и запрашивает из репозитория те, которых не хватает. Нам остаётся только переключить версию на новую, поменяв симлинк current.map.
Как это должно решить наши проблемы
Предполагалось, что, если в новой версии изменилось всего несколько файлов, её сборка и раскладка с помощью новой системы должна быть как минимум сравнима по времени с раскладкой патча отдельными файлами. Если это так, то для каждого патча мы просто будем генерировать новую версию.
Внедрение MDK
У MDK был один недостаток: на конечных машинах в названии каждого файла должна быть его версия. Именно это позволяет хранить в директории сразу очень много версий одного файла, но это же не позволяет сделать include user.php из кода — обязательно нужно указать конкретную версию. Добавьте к этому различные баги, которые вполне могли остаться в коде системы раскладки, новый алгоритм раскладки, который был сложнее старого, — и станет ясно, почему мы решили внедрять новую систему небольшими шагами. Мы начали буквально с одного-двух серверов и постепенно расширяли их список, попутно исправляя возникающие проблемы.
Учитывая, что переключение на новую систему должно было занять много времени, нам пришлось подумать о том, как будут работать наши патчи во время переходного периода. В то время для раскладки патчей мы использовали самописную утилиту mscp, которой раскладывали файлы по одному. Мы заранее научили её подменять текущие файлы на серверах с MDK, но вот добавить новый файл на такие серверы не получалось (потому что нужно было менять карту файлов). Внедрять какое-то очень сложное промежуточное решение не хотелось — ведь мы шли в светлое будущее, где mscp не нужен. В итоге пришлось мириться с этой проблемой. Вообще за время переходного периода разработчики успели настрадаться, но сейчас нам кажется, что оно того стоило.
Не верь никому

Изображение: источник
Наверное, закономерным будет вопрос, а не случится ли коллизия версий в MDK (т.е. ситуация, когда двум файлам с разным содержимым присвоится одна версия)?
На самом деле, мы достаточно хорошо защищены от такого рода ошибок. Мы именуем файлы так:
{оригинальное имя}.{версия}, а значит, должно совпасть гораздо больше, чем восемь символов, чтобы произошла ошибка.Но однажды что-то всё же пошло не так. После очередной выкладки мы обратили внимание на рост числа ошибок с HTTP-кодом 404 (файл не найден). Небольшое расследование показало, что не хватает части файлов статики. Выяснилось, что мы разложили очень старую карту статики и даём ссылки на файлы, которых уже и не должно быть на серверах. Но откуда эта карта взялась? В первой части статьи я отмечал, что статика раскладывается отдельным процессом, и с PHP-кодом уезжает только карта версий. Когда мы генерируем новую версию MDK, мы докладываем недостающие версии файлов в репозиторий, из которого ничего не удаляется (места много, нам не жалко). А ещё мы достаточно часто выкладываемся на стейджинг, и поэтому карта версий статики — один из тех файлов, которые изменяются чаще других. Всё это привело к тому, что мы столкнулись с коллизией. Проверив версию, MDK решил, что всё хорошо, потому что файл такой версии уже есть, и разложил его на серверы. Хорошо, что ошибку мы обнаружили быстро.
Теперь, помимо версии, мы проверяем размер файла: если в репозитории он такой же, то, скорее всего, это один и тот же файл. В худшем случае у нас будет история для новой статьи.
MDK — похититель Рождества

Изображение: источник
И ещё об одной ошибке мне хочется рассказать, потому что она как минимум забавная. Нетрудно догадаться, что у нас был процесс очистки старых версий файлов на конечных серверах. В попытке быстро решить одну из проблем мы приняли судьбоносное решение: выставили период очистки в одни сутки (вместо семи, как было раньше). Это сработало — и проблема ушла. Мы даже прожили так какое-то время.
Где-то в пять часов утра в воскресенье у меня в спальне зазвонил телефон, звонил дежурный мониторщик: «У нас не работают скрипты. Говорят, что ты знаешь, в чём дело». Для меня это прозвучало примерно как «В офисе соковыжималка сгорела. Говорят, ты знаешь, в чём дело». Про принципы работы нашего скриптового фреймворка я знал только по статьям и рассказам, никаких «личных отношений» у меня с ним не было, и уж тем более я его никогда не чинил. Но я полез на серверы, чтобы выяснить, что происходит, и обнаружил, что проблема действительно «на нашей стороне»: на серверах просто не было кода.
Я выложил код заново — и всё заработало. Ошибка, кстати, оказалась примитивной: в субботу не было разложено ни одной новой версии MDK, а скрипт очистки, как оказалось, не делал никаких проверок, чтобы не удалить текущую версию. В итоге в пять утра он (по расписанию) удалил со всех серверов код. Уже после этой истории мы поняли, что со старыми настройками это всплыло бы на праздниках длиной в 7 дней, например в новогодние каникулы, как раз в канун Рождества. «Христос родился — код удалился» — ещё долго у нас можно было услышать эту шутку.
Новая система патчей
В конечном итоге мы внедрили новую систему раскладки — и пришло время переделывать систему патчей. Больше не было нужды в mscp и не нужно было избегать генерации новых версий. Для начала мы изменили цикл жизни патча. Теперь после подтверждения изменений он попадает обратно к разработчику, который принимает решение, когда патч готов к выкладке. Он нажимает на кнопку Deploy, после чего мы добавляем патч в master, генерируем и раскладываем новую версию MDK. Участие разработчика на этом этапе больше не требуется.
Мы добились очень хорошей скорости раскладки: изменения попадают на серверы буквально в течение минуты. Для этого, правда, нам пришлось прибегнуть к паре хитростей: например, мы всё ещё не генерируем статику или переводы — вместо этого мы берём версию из последнего разложенного билда. Из-за этого мы сохраняем ограничение на патчи для JS- и CSS-файлов.
Эксперименты
Нам действительно удалось решить все проблемы, которые у нас были раньше. Больше не нужно думать о том, как правильно сформировать изменения, которые не вызовут сложностей при пофайловой раскладке, — достаточно просто не трогать статику, и всё будет работать.
Зато появилась новая трудность. Раньше мы разрешали разработчикам раскладывать свои изменения на один или несколько серверов, чтобы просто убедиться в том, что с ними всё будет работать. С новой системой эта возможность пропала, ведь master теперь стала актуальной версией для всех серверов без исключения.

Изображение: источник
Из-за этого появилось новое требование к системе патчей: нужна возможность проверить свои изменения на небольшом количестве серверов без добавления изменений в master. Новую функциональность мы назвали экспериментами.
Для разработчика процесс выглядит приблизительно так: после получения апрува в интерфейсе системы патчей становится доступна новая страница, где можно выбрать серверы, на которых хочется поэкспериментировать. Это может быть группа серверов, один сервер или любая комбинация, которую поймёт наша система. Система раскладывает патч и уведомляет об этом разработчика. В этот же момент на странице появляется лог последних ошибок с затронутых серверов.
Мы никак не ограничиваем разработчиков, они могут создавать эксперименты на одних и тех же серверах. Один может экспериментировать на 10% кластера, другой — на всём кластере.
Это стало возможным благодаря тому, что у нас появилась та самая «версия патчей», которой нам так не хватало. Это версия, которая в теории может быть уникальна для каждого сервера. Она выглядит как строка из идентификаторов, разделённых запятыми, например, «32,45,79». Это значит, что на сервере должны быть все изменения из мастера и патчи под номерами 32, 45 и 79. Для каждой такой версии мы генерируем собственную версию MDK. Мы берём свежие изменения из основной ветки, а затем последовательно накладываем каждый из патчей. Если во время генерации какой-то из версий возникает конфликт, мы просто отменяем эксперимент для самого свежего патча и уведомляем об этом разработчика.
Генерируемые файлы
С первого дня существования системы патчей мы пошли на хитрость: отказались от генерации статики, чтобы изменения попадали на серверы как можно быстрее. Конечно, нам очень хотелось заполучить возможность менять JS-код так же, как мы меняем PHP-код, но все попытки построить этот процесс не увенчивались успехом.
Около полугода назад мы снова вернулись к этому вопросу. Цель: нужно менять статику, но нельзя жертвовать скоростью раскладки PHP-кода. Основная проблема: полная сборка занимает восемь минут. Что делать?
Нужно идти на компромиссы. Начали с того, что JS-код нельзя будет раскладывать в рамках экспериментов. Это должно заметно сэкономить время: достаточно поддерживать одну версию статики в актуальном состоянии вместо генерации десятков разных версий для разных групп машин. Но это всё ещё долго. На чём ещё можно сэкономить? Мы не придумали, как сократить время, но решили, что проблемы не будет, если сборка не будет блокировать раскладку PHP-кода.
Мы начали генерировать статику асинхронно. С изменениями JS- или CSS-файлов мы запускаем отдельный процесс, который создаёт новую карту версий статики. Процесс сборки PHP-кода в начале работы проверяет, нет ли новой карты статики, и, если она есть, забирает и раскладывает её на все серверы. Решили проблему? Практически. С таким подходом мы пошли на новое ограничение: нельзя поменять JS- и PHP-код в одном патче, потому что мы раскладываем эти изменения асинхронно и не можем гарантировать, что они окажутся на машинах одновременно.
Итог
Мы очень довольны обновлением. Оно далось нам нелегко, но сделало нашу систему намного надёжнее. Экспериментам разработчики нашли альтернативное применение: с ними можно легко собрать специфические логи с пары серверов, не добавляя свои изменения в master.
У нас все еще есть идеи по улучшению системы, на реализацию которых пока не хватило времени. Например, мы хотим переделать процесс создания патча и добавить возможность изменения JS-файлов одновременно с основным кодом, чтобы избавиться от последних ограничений.
Ежедневно мы выкладываем примерно 60 патчей, иногда их бывает в несколько раз больше, например, во время разработки какого-то функционала, доступного пока только тестировщикам. Около трети патчей проходит через эксперименты до того, как будут выложены. Всего за время существования системы у нас было порядка 46 000 патчей для мастера.
Комментарии (29)

slonopotamus
14.06.2018 00:16первые восемь символов от MD5-хеша
Что это значит? MD5 128-битный. Кто такие "символы"?
ShaggyRatte Автор
14.06.2018 00:30Как правило, эти 128 бит представляют в виде последовательности из 32 шестнадцатиричных цифр, например так делает стандартная утилита md5sum:
$ echo 1 | md5sum b026324c6904b2a9cb4b88d6d61c81d1 -
Мы берем первые 8 из этих чисел, которые, по сути, просто символы из набора [0-9a-f]. Немного удивлен вопросу, потому что думал что неподготовленному человеку это должно быть более понятно. Постараюсь с утра придумать альтернативный, лаконичный вариант, спасибо!
slonopotamus
14.06.2018 01:038/32*128=32(бит). Теперь вопрос, почему 8? Почему не 7 или не 9? Не 4 или не 16? А вы уверены что если вот так брать и откусывать кусок байт от хэша, то оно хоть сколько-то адекватно будет работать? А чего сразу не взять 32-битный хэш-алгоритм?
alexkrash
14.06.2018 03:36Есть такое понятие как common sense. Я полагаю что тестирования на возникновение колллизий не производилось, но выбранной (с запасом) точности хватает для решения поставленной задачи. Риск (вероятность возникновения ошибки, помноженная на стоимость её устранения) присутствует при разработке любого ПО. Как мне кажется, в данном случае риск не стоит того чтобы применять алгоритмы хеширования, отличные от повсеместно распространённых.
slonopotamus
14.06.2018 08:42Взятие первых 32 бит от MD5 является типичным алгоритмом хэширования? И там ведь сверху ещё велосипедик навёрнут:
Теперь, помимо версии, мы проверяем размер файла: если в репозитории он такой же, то, скорее всего, это один и тот же файл.
ShaggyRatte Автор
14.06.2018 09:49А вы уверены что если вот так брать и откусывать кусок байт от хэша, то оно хоть сколько-то адекватно будет работать?
Лавинный эффект позволяет так думать. Если лень читать, то это свойства, при котором выход функции будет сильно, "лавинно", меняться при небольшом изменении входа.
Взятие первых 32 бит от MD5 является типичным алгоритмом хэширования?
Я знаю, что так часто делают — берут кусок хэша. Наверное, это не очень оптимально, но я описал выше, почему, как мне кажется, это должно давать более-менее приличный результат.
И там ведь сверху ещё велосипедик навёрнут
Я думаю, что стоило "подстелить" этот велосипед еще в самом начале, потому что даже полный md5 хэш не гарантирует, что коллизии не будет. Этот шаг — скорее попытка разрешить коллизию, когда она появится, чем полностью предотвратить ее.
youROCK
14.06.2018 23:43Для криптографических хешей любая его часть тоже является криптографической хэш функцией. Тот же crc32, к примеру, не криптографический хэш, и его качество в качестве алгоритма хеширования будет хуже куска md5. Ну а 8 символов было выбрано, чтобы имена файлов были не слишком длинные :). Лучше было сделать побольше, по всей видимости :).
immaculate
14.06.2018 03:43Несмотря на то, что MDK частично заимствует идеи у Git, у них есть и несколько отличий. Самое главное — то, как хранятся файлы в рабочей директории (т.е. на машинах). Если Git хранит там только одну, текущую, версию, то MDK держит там все доступные версии файлов. При этом на текущую версию кода указывает только один симлинк current.map, который использует в своей работе autoload и который можно атомарно поменять. Для сравнения, Git для изменения версии использует git-checkout, который меняет файлы по очереди и не атомарен.
В git еще есть worktree, позволяющий одновременно иметь несколько открытых веток:
https://git-scm.com/docs/git-worktree
Просто для информации — вдруг кто-то прочитает, и решит, что в Git нет такой функциональности.
ShaggyRatte Автор
14.06.2018 10:00Кстати, отличная штука для некоторых задач автоматизации процессов, был очень рад, когда они добавили эту функциональность.
DarkWanderer
14.06.2018 09:40+1Того же самого можно было достичь, используя "double buffer" из двух рабочих директорий Git и одного симлинка — вот вам и версионирование и атомарность
ShaggyRatte Автор
14.06.2018 09:58Если рассматривать только эти два требования — да, это сработает. Но в таком варианте вам нужно следить за тем, чтобы выкладывать код не чаще, чем max_execution_time скрптов или запросов, которые этот код используют.
В нашем случае, это плохо работает потому, что у нас есть скрипты, которые работают часами. Если я ничего не путаю, то мы договаривались что версия кода должна оставаться «рабочей» на машине в течение 2 часов. Не могу сказать, что мне нравится это требование, но с ним приходится жить. Для статистики могу добавить, что за 2 последних часа вчерашнего дня мы выложили 28 версий кода, т.е. нам понадобилось бы 28 рабочих директорий. Это все еще можно использовать, но с Git и доставлять не так удобно, особенно, сгенерированные файлы.GreedyIvan
14.06.2018 12:11Это все еще можно использовать, но с Git и доставлять не так удобно, особенно, сгенерированные файлы.
С гитом доставлять как раз очень удобно. Схема очень проста.
Артефакт любой сборки версионируется с помощью гита, что позволяется иметь версионность прокадшен кода. На сервере, на который нужно выложить данный код, запускается git pull. Всё. Выкладка кода на сервер на этом заканчивается.
Если нужно использовать данный код, то используем rsync в соседнюю директорию.
Докер позволяет всё это красиво упаковать по самостоятельным контейнерами:
— git-pull контейнер, который деплоит код в отдельный том.
— php-fpm (или что угодно) контейнер, который делает rsync кода в другой том (если нужно делить код между несколькими контейнерами) или в локальную систему (например, для cli-контейнера).
Протокол обновления:
— стартуем git-pull контейнер, который деплоит код на сервер;
— как он отработал, запускаем rsync-контейнер, который подготовит текущую версию к использованию (если этот этап нужен);
— как он отработал, запускаем новые upstream контейнеры с приложением, а старые постепенно глушим;
— если нужен скрипт, то запускаем cli-контейнер, который сам себе делает rsync, работает сколько ему нужно, после чего удаляется.
Статика деплоится по такой же схеме:
— git-pull контейнер на базовых серверах деплоит текущую версию статики.
— rsync-контейнеры (или любой другой способ) на cdn-нодах.
Статика собирается с хешом в именах файлов, так что на cdn спокойно живут версии разных файлов.
Для статистики могу добавить, что за 2 последних часа вчерашнего дня мы выложили 28 версий кода, т.е. нам понадобилось бы 28 рабочих директорий.
Версия с докером подразумевает, что может быть до 28 дополнительных директорий с кодом, если на сервере будет крутиться до 28 версий апстримов приложения.
Неиспользуемые тома от уже заглушенных версий можно использовать при инициализации новых версий, чтобы копировать только изменения, а не весь объем кода.uyga
14.06.2018 13:19Красиво расписали. А теперь представьте что серверов не 3 и не 5, а несколько тысяч. И что выкладка делается без остановки всего и вся, «наживую». И подумайте еще раз.

DenKoren
14.06.2018 14:22По сути, MDK очень похож на git в смысле «git pull и всё». Так что с этой точки зрения — мы ровно так и деплоимся. К сожалению git — инструмент не для деплоя. Он прост и удобен и хорошо работает на малых масштабах, но pull — достаточно прожорливая операция. 100-200 параллельных git pull и сервер задыхается. Да, можно заткнуть эту проблему железом — поставить сервер «пожирнее», потом, когда его не станет хватать — сделать несколько «реплик» git-репозиториев на разных серверах и выкладывать кластерами, каждый из которых будет смотреть в свою реплику. Но этим тоже нужно управлять: следить за тем, что свежая версия выехала на все реплики, что кластер ходит в свою реплику и может сходить в соседнюю при недоступности своей и т.п.
Касаемо поддержки множества версий готовых к быстрому включению в работу: да, можно хранить 28 дополнительных директорий, но если считать, что одна версия весит 1ГБ и код этот лежит на 1000 серверов, получается 28ТБ места. Да, тут тоже можно оптимизировать: можно разворачивать директорию с нужной версией только непосредственно перед использованием, но тогда время переключения версии «везде» будет занимать не 2-3 секунды, а несколько минут. Можно использовать хардлинки или специфические свойства ФС (снепшоты и т.п.), но в этом случае сложность системы всё растет и добавляются всё новые проблемы.
В зависимости от ваших собственных потребностей, как компании, в зависимости от вашего флоу разработки и графика выкладок вы будете отдавать разные приоритеты разным проблемам. Если у вас выкладка всегда на весь продакшн и она происходит раз в неделю — хранение всего 4 версий-директорий закрывает целый месяц жизни компании.
В общем, решений для любой задачи существует масса и недостатки какой-то одной системы или подхода всегда можно заткнуть применением чего-то дополнительного. И одни и те же недостатки вообще не заметны в одних процессах и очень больно бьют в других.
MDK в данном случае — это ещё один инструмент со своим набором плюсов и минусов.
Он прост и один решает из коробки комплекс задач: атомарность переключения (symlink current.map), быстрое и почти синхронное переключение версии на большом количестве машин, экономия трафика при выкладке (за счет доставки только недостающих изменений), высокая стойкость к нагрузкам (у нас каждый ДЦ сейчас обслуживается всего одним сервером и он не умирает, когда тысяча машин с производства внезапно хотят сразу все получить свежие данные), отсутствие необходимости держать несколько PHP-FPM во время переключения (и тратить на них драгоценную память), возможность автоматически обнаруживать неконсистентность кода (если кто-то пришёл и руками поправил на машине файлик).
Благодаря его использованию у нас получилась _простая_ система: в ней нет большого количества узлов и механизмов, она даёт нам много свободы, за ней просто следить и её просто эксплуатировать, она хорошо вписалась в нашу инфраструктуру.GreedyIvan
14.06.2018 15:22да, можно хранить 28 дополнительных директорий, но если считать, что одна версия весит 1ГБ и код этот лежит на 1000 серверов, получается 28ТБ места.
Такая ситуация возможна, только если реально кто-то держит старые процессы, не давая им умереть. Если контейнеры со старыми версиями глушаться, то мы получим одновременно на сервере не более чем количество коммитов за max_execution_time + 1.
100-200 параллельных git pull и сервер задыхается
Тут честно скажу, что не представляю, какая будет нагрузка от git pull, который получает изменения от небольшого коммита, помноженная на сотни серверов. Возможно, что без кластеризации репозитория не обойтись в этом случае.
Сам же идея MDK мне понравилась. Элегантное решение, позволяющее заставить работать разные версии кода в рамках одного мастер-процесса. Докер-вей в этом плане проще, так как просто запусти контейнер с нужным кодом. И гит или не гит, с кластером или без, где и что кешировать, чтобы нужные версии кода быстро подсунуть новому контейнеру на конкретном сервере — это вопрос транспортной инфраструктуры, а не продакшен среды. Здесь «гит пул и всё» — это только вариант доставки кода приложения туда, где он будет использоваться контейнером.DenKoren
14.06.2018 17:12И гит или не гит, с кластером или без, где и что кешировать, чтобы нужные версии кода быстро подсунуть новому контейнеру на конкретном сервере — это вопрос транспортной инфраструктуры, а не продакшен среды.
Так MDK — это как раз про решение задачи доставки данных и есть.
Докер-вей в этом плане проще, так как просто запусти контейнер с нужным кодом.
Да, но у него есть свои недостатки: вам, например, приходится выбрасывать все ресурсы, которыми обладал контейнер с предыдущей версией. И если между версиями поменялась буквально пара файлов — все кеши, память, подгруженные классы и пр. способы ускорения работы кода это не спасет. У вас новые процессы, соответственно новая память, новые autoload'ы классов и пр.
Если данные (код) не пихать в docker, то по сути нет большой разницы: с доставкой кода средствами MDK, FPM не будет нужды перезапускать ни в виде контейнера, ни в виде сервиса напрямую в системе. Если код пихать в контейнер — то опять вылезает задача эффективной доставки всего этого добра с новой версией на производство: вам либо надо тащить из-за пары файлов всё, либо как-то выкручиваться.GreedyIvan
14.06.2018 20:04Далее всё сферическо-вакуумное.
В принципе, контейнеры можно и не убивать. Нужна система изоляции, позволяющая исключать апстримы. После чего на том контейнера накатывается rsync и он возвращается в строй. С одним сервисом на машину нам бы пришлось изолировать её целиком. Контейнерами мы же можем упаковать железку каким угодно способом.
Но преимущество докера не в максимальном использовании машины, а в снятии с разработки инфраструктурных ограничений в виде языков, версий, библиотек.
MDK реально хорош для натива. Но, в том числе из-за того что это всё-таки фреймворк исполнения, мне ближе и интереснее докер-вей, как не вводящий очередные «рамки» в разработку.
datacompboy
15.06.2018 00:48Очень важные требования к системе, упущенные в статье :) стоит добавить
ShaggyRatte Автор
15.06.2018 10:36Вообще я не очень хотел останавливаться на выборе способа раскладки. От части, оно было бы здесь уместно, но мне было интереснее рассказать о том, чего мы добились именно с патчами. В конце концов, о процессе раскладки не плохо рассказывает Юра в своем докладе (хотя я понимаю, что не все его посмотрят — я сам люблю статьи больше, чем видео), а еще немного о требованиях может стать понятно из прочтения первой части статьи.
В целом я немного удивлен, что именно эта часть статьи такая комментируемая, думал что люди чаще будут писать о своем опыте "багфиксинга", это было бы интересно (по крайней мере мне) почитать.
GreedyIvan
14.06.2018 14:08А теперь представьте что серверов не 3 и не 5, а несколько тысяч.
Что именно тут не масштабируется?ShaggyRatte Автор
14.06.2018 15:21Все в этой жизни масштабируется, вопрос в трудозатратах. Но мне хочется другую сторону вопрос обсудить: а вы решаете вопрос доставки? Зачем в этой задач git-pull- и rsync- контейнеры, почему не сделать это просто на системе? Мне правда интересно, что с этого можно получить.
Статика собирается с хешом в именах файлов, так что на cdn спокойно живут версии разных файлов.
Т.е. статика у вас будет выглядеть как у нас код, только без карт содержимого?
GreedyIvan
14.06.2018 15:48Т.е. статика у вас будет выглядеть как у нас код, только без карт содержимого?
Вебпак и ко по сути ввели стандарт, что вся сборная статика выглядит в виде [name].[hash].[ext].
git-pull- и rsync- контейнеры
Это и есть способ доставки.
Гит-пулл — чтобы доставить до сервера код, который на нем будет крутится.
Rsync — чтобы снять слепок этого кода, таким образом сняв «блокировку» с гит-пулл-тома. php-fpm будет использовать тот же том, что и rsync-контейнер, в том время как гит-пулл контейнер спокойно может обновлять у себя код до новой версии, ни о чем более не думая.
Простой кейс, когда приходит новый коммит.
— гит-пулл-контейнер обновляет свой том до этого коммита;
— rsync-контейнер ищет неиспользуемый rsync-том (чтобы не с нуля) и синхронизирует в нем код с гит-пулл-тома;
— поднимается php-fpm-контейнер с этим синхронизированным томом;
— старый php-fpm-контейнер глушится, освобождая для повторного использования свой rsync-том.ShaggyRatte Автор
15.06.2018 10:30Кажется, разобрался. Не сразу сообразил, что под томами вы имеете ввиду volume, не был знаком с этим термином в русскоязычном варианте.
Не могу сказать, что это выглядит просто, если честно. Иногда кажется, что докер все-таки не так удобен для скриптовых языков программирования — теряется часть их (языков) преимуществ в виде простой замены части файлов с кодом (именно простой, придумать вариант всегда можно). С другой стороны, не человеку из компании, придумавшей целую систему для замены файликов, говорить о простоте :)
GreedyIvan
15.06.2018 10:46В другом комментарии уже написал, что контейнер со старым кодом можно и не глушить. Изолировать его каким-нибудь образом, чтобы новые запросы на него не шли, спокойно синхронизировать его том и вернуть в пул.
Либо пойти ещё дальше и делать сине-зеленый деплой.
GreedyIvan
15.06.2018 11:11Если же говорить о чисто «багфиксинге», то все сводится к попаданию кода в продакшен-ветку. После чего она собирается, артефакт кладется в деплой-репу. Все, кто мониторят деплой-репу, обновляются. Продакшен, стейдж, что угодно — просто разные ветки.
Peter1010
а как же вариант?
Делаем багфикс релиз с частичным циклом тестирования?
ShaggyRatte Автор
Упустили, когда делал опрос и я думаю что сейчас уже совсем не круто менять варианты, но это здорово, что вы отписались тут. А не расскажите, чем у вас отличается цикл тестирования багфикса от полного и почему? Не гоняете автотесты или только автотестами и обходитесь? Может, какой-то промежуточный вариант?
И прям очень интересно было бы узнать, насколько автоматизирован процесс, если не хотите описывать, то может хотя бы оцените по шкале 0-10 баллов?
Peter1010
Прогоняем регрессионные автотесты для области в которую делался фикс. И ещё проверяется непосредственно сам фикс, что он действительно исправил проблему. У нас к счастью проект разбит по областям, а фиксы в ядро не так часто делаются :)
А полный цикл содержит в себе ещё множество кейсов которые проверяются руками, из-за невозможности их автоматизировать (требуется взаимодействие со сторонними системами), но более я не знаю, этим рулит уже qa отдел.
ShaggyRatte Автор
Спасибо!