
После прочтения статьи "Нейронный машинный перевод Google" вспомнился курсирующий последнее время в интернет очередной epic-fail машинного перевода от Google. Кому сильно не терпится сразу мотаем в низ статьи.
GNMT есть система нейронного машинного перевода (NMT) компании Google, которая использует нейросеть (ANN) для повышения точности и скорости перевода, и в частности для создания лучших, более естественных вариантов перевода текста в Google Translate.
В случае GNMT речь идет о так называемом методе перевода на основе примеров (EBMT), т.е. ANN, лежащая в основе метода, обучается на миллионах примеров перевода, причем в отличии от других систем этот метод позволяет выполнять так называемый zero-shot перевод, т. е. переводить с одного языка на другой, не имея явные примеры для этой пары конкретных языков в процессе обучения (в обучающей выборке).
Рис. 1. Zero-Shot Translation
Причем GNMT разработан в первую очередь для улучшения перевода фраз и предложений, т.к. как раз при контекстном переводе нельзя использовать дословный вариант перевода и нередко предложение переводится совершенно по другому.
Кроме того, возвращаясь к zero-shot translation, Google стараются при этом выделить некоторую общую составляющую, действительную сразу для нескольких языков (как при поиске зависимостей, так и при построении связей для предложений и фраз).
Например на рисунке 2, показана такая interlingua «общность» среди всех возможных пар для японского, корейского и английского языков.

Рис. 2. Interlingua. 3-мерное представление данных сети для японского, корейского и английского языков.
Часть (а) показывает общую «геометрию» таких переводов, где точки окрашены по смыслу (и одинаковым цветом для одного и того же смысла у нескольких пар языков).
Часть (b) показывает увеличение одной из групп, часть © в цветах исходного языка.
GNMT использует большую ANN глубокого обучения (DNN), которая, выученная на миллионах примеров, должна улучшать качество перевода, применяя контекстное абстрактное приближение для наиболее подходящего варианта перевода. Грубо говоря выбирает лучший, в смысле наиболее соответствующего грамматике человеческого языка, результат, при этом учитывая общности построения связей, фраз и предложений для нескольких языков (т.е. отдельно выделяя и обучая interlingua модель или слои).
Однако DNN как в процессе обучения так и в процессе работы как правило полагается на статистический (вероятностный) вывод и редко обвязывается дополнительными не вероятностными алгоритмами. Т.е. для оценки лучшего из возможных результатов, вышедших из вариатора, будет выбран статистически наиболее лучший (вероятный) вариант.
Всё это, естественным образом, дополнительно зависит от качества обучающей выборки (и/или качества алгоритмов в случае самообучающейся модели).
Учитывая сквозной (zero-shot) метод перевода и помня о некой общей (interlingua) составляющей, при наличии некоторой позитивной логической глубокой связи для одного языка, и отсутствии негативных составляющих для других языков, некоторая абстрактная ошибка, вылезшая в процессе обучения и соответственно в результате перевода некоторой фразы для одного языка, с большой долей вероятности повторится и для других языков или даже языковых пар.
Все картинки кликабельны (в качестве пруфа на соответствующую страницу Google Translate).
Немецкий:
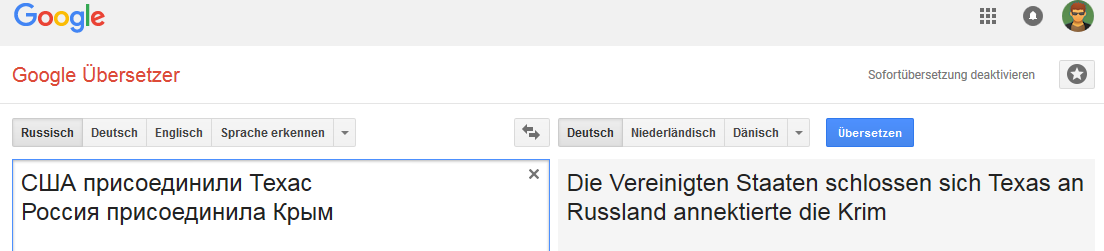
Английский:
Нидерландский:

Датский:

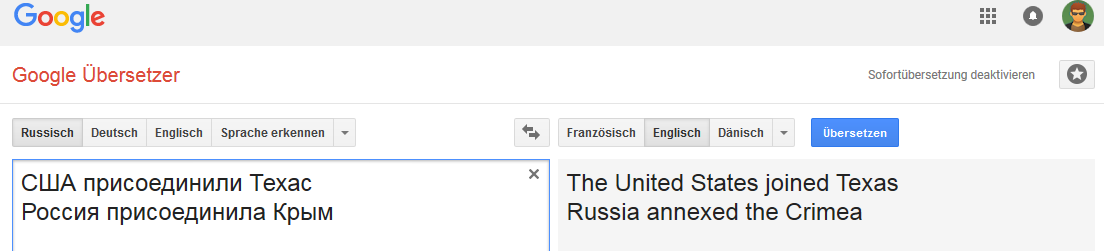
Французский:

И т.д.
Связь устойчивая для слова Россия (в том смысле что при замене России, например на Российскую империю, вариант «перевода» меняется).
И не очень устойчива при некоторых изменениях фразы, не типичных для перевода на английский язык, но общих например для русского, немецкого и нидерландского языков.
Это к сожалению далеко не единственный случай и интернет пестрит всевозможными ошибками Google Translate.
И думается мне, что немалая часть существующих ошибок проявляется из-за совокупности нескольких факторов, начиная от собственно качества обучающей выборки и заканчивая качеством алгоритмов семантического и морфологического разбора для конкретного языка (и модели обучения в частности).
Как-то раз, один коллега предложил поучаствовать в Text Normalization Challenge (для русского и английского языков) от Google на kaggle…
Перед тем как согласиться, я сделал тогда небольшой анализ качества обучающей тестовой выборки для всех классов токенов для обоих языков… и в результате отказался участвовать вовсе, ибо чем больше я копал, тем сильнее было чувство что конкурс будет похож на лотерею или выиграет тот, кто наиболее максимально точно сможет повторить все ошибки, допущенные при полу-ручном создании Google обучающей выборки.
Даже хотел написать статью на тему «Как запросто выбросить 50К...», да время — будь оно не ладно.
Если кому вдруг интересно — попробую выкроить чуть-чуть.
[UPD] Почему собственно это — фэйл. Не отвлекаясь на лирику, «политический» подтекст и всяческие попытки оправдать «так перевел бы человек» и т. п. тематику.
1. Это неправильный перевод. Точка.
2. На этом показательном случае видно полное отсутствие у GNMT какой-либо классификационной модели (в смысле CADM, в которой как раз Google должен блистать, ибо у них полно данных ото всюду). Просто постольку поскольку подлежащие в обоих случаях являются странами/государствами, а дополнения являются географическими субъектами (территорией).
Даже тупейшее plausibility-правило какой-нибудь fuzzy K-nn classification никогда не допустило бы такую ошибку. Умолчим уже про современные алгоритмы классификации и построения (семантических) связей.
Как говорится ничего личного, простая математика… Ну а если Google таки в лоб без разбора решил кормить свою сеть вырезками из бульварной прессы, то у меня для него плохие новости.
P. S. Однако, как сказал мне однажды один многоуважаемый мною профессор — «Очень трудно порой доказать дятлу, что он дятел, особенно если он уверен что умнее профессора».
Ну а для начала немного теории:
GNMT есть система нейронного машинного перевода (NMT) компании Google, которая использует нейросеть (ANN) для повышения точности и скорости перевода, и в частности для создания лучших, более естественных вариантов перевода текста в Google Translate.
В случае GNMT речь идет о так называемом методе перевода на основе примеров (EBMT), т.е. ANN, лежащая в основе метода, обучается на миллионах примеров перевода, причем в отличии от других систем этот метод позволяет выполнять так называемый zero-shot перевод, т. е. переводить с одного языка на другой, не имея явные примеры для этой пары конкретных языков в процессе обучения (в обучающей выборке).
Рис. 1. Zero-Shot Translation
Причем GNMT разработан в первую очередь для улучшения перевода фраз и предложений, т.к. как раз при контекстном переводе нельзя использовать дословный вариант перевода и нередко предложение переводится совершенно по другому.
Кроме того, возвращаясь к zero-shot translation, Google стараются при этом выделить некоторую общую составляющую, действительную сразу для нескольких языков (как при поиске зависимостей, так и при построении связей для предложений и фраз).
Например на рисунке 2, показана такая interlingua «общность» среди всех возможных пар для японского, корейского и английского языков.
Рис. 2. Interlingua. 3-мерное представление данных сети для японского, корейского и английского языков.
Часть (а) показывает общую «геометрию» таких переводов, где точки окрашены по смыслу (и одинаковым цветом для одного и того же смысла у нескольких пар языков).
Часть (b) показывает увеличение одной из групп, часть © в цветах исходного языка.
GNMT использует большую ANN глубокого обучения (DNN), которая, выученная на миллионах примеров, должна улучшать качество перевода, применяя контекстное абстрактное приближение для наиболее подходящего варианта перевода. Грубо говоря выбирает лучший, в смысле наиболее соответствующего грамматике человеческого языка, результат, при этом учитывая общности построения связей, фраз и предложений для нескольких языков (т.е. отдельно выделяя и обучая interlingua модель или слои).
Однако DNN как в процессе обучения так и в процессе работы как правило полагается на статистический (вероятностный) вывод и редко обвязывается дополнительными не вероятностными алгоритмами. Т.е. для оценки лучшего из возможных результатов, вышедших из вариатора, будет выбран статистически наиболее лучший (вероятный) вариант.
Всё это, естественным образом, дополнительно зависит от качества обучающей выборки (и/или качества алгоритмов в случае самообучающейся модели).
Учитывая сквозной (zero-shot) метод перевода и помня о некой общей (interlingua) составляющей, при наличии некоторой позитивной логической глубокой связи для одного языка, и отсутствии негативных составляющих для других языков, некоторая абстрактная ошибка, вылезшая в процессе обучения и соответственно в результате перевода некоторой фразы для одного языка, с большой долей вероятности повторится и для других языков или даже языковых пар.
Собственно свежий epic fail
Все картинки кликабельны (в качестве пруфа на соответствующую страницу Google Translate).
Немецкий:
Английский:
Нидерландский:
Датский:
Французский:
И т.д.
Вместо заключения
Связь устойчивая для слова Россия (в том смысле что при замене России, например на Российскую империю, вариант «перевода» меняется).
И не очень устойчива при некоторых изменениях фразы, не типичных для перевода на английский язык, но общих например для русского, немецкого и нидерландского языков.
Это к сожалению далеко не единственный случай и интернет пестрит всевозможными ошибками Google Translate.
И думается мне, что немалая часть существующих ошибок проявляется из-за совокупности нескольких факторов, начиная от собственно качества обучающей выборки и заканчивая качеством алгоритмов семантического и морфологического разбора для конкретного языка (и модели обучения в частности).
Как-то раз, один коллега предложил поучаствовать в Text Normalization Challenge (для русского и английского языков) от Google на kaggle…
Перед тем как согласиться, я сделал тогда небольшой анализ качества обучающей тестовой выборки для всех классов токенов для обоих языков… и в результате отказался участвовать вовсе, ибо чем больше я копал, тем сильнее было чувство что конкурс будет похож на лотерею или выиграет тот, кто наиболее максимально точно сможет повторить все ошибки, допущенные при полу-ручном создании Google обучающей выборки.
Даже хотел написать статью на тему «Как запросто выбросить 50К...», да время — будь оно не ладно.
Если кому вдруг интересно — попробую выкроить чуть-чуть.
[UPD] Почему собственно это — фэйл. Не отвлекаясь на лирику, «политический» подтекст и всяческие попытки оправдать «так перевел бы человек» и т. п. тематику.
1. Это неправильный перевод. Точка.
2. На этом показательном случае видно полное отсутствие у GNMT какой-либо классификационной модели (в смысле CADM, в которой как раз Google должен блистать, ибо у них полно данных ото всюду). Просто постольку поскольку подлежащие в обоих случаях являются странами/государствами, а дополнения являются географическими субъектами (территорией).
Даже тупейшее plausibility-правило какой-нибудь fuzzy K-nn classification никогда не допустило бы такую ошибку. Умолчим уже про современные алгоритмы классификации и построения (семантических) связей.
Как говорится ничего личного, простая математика… Ну а если Google таки в лоб без разбора решил кормить свою сеть вырезками из бульварной прессы, то у меня для него плохие новости.
P. S. Однако, как сказал мне однажды один многоуважаемый мною профессор — «Очень трудно порой доказать дятлу, что он дятел, особенно если он уверен что умнее профессора».
vassabi
… интересно, автор хотел потроллить на тему аннексии или таки тема про переводы.
sebres Автор
… можно почитать комментарии и статьи автора, чтобы проверить а) на предмет троллинга б) на предмет отношения к "политическим" дебатам в общем и оффтопу в частности...
Относительно статьи, и конкретного перевода конкретной фразы, хоть мне по множеству причин
(в том числе и потому что я — русский, и как ни странно, любящий родину патриот, хоть и живущий не в России)не нравится подобный вариант перевода… Но:vassabi
как раз наоборот — нейронная сетка гугла адекватно переводит смысл (т.н. «читаем между строк»), так что пока «пошлите реквизиты на мыло» не стало устойчивым, она будет переводить его буквально (попробуйте «США присоединили территорию» — будет тоже annexed)
sebres Автор
У нас с вами разные понятия слова «адекватно». Добавьте для примера в конце в русский вариант «в 1783 году»… Что-то поменялось?
Про территории же — это мимо, ибо вы пытаетесь той же «ошибкой» перевода оправдать предыдущую. В русском языке к счастью есть как слово «аннексировать», так и словосочетание «осуществлять аннексию» и т.д.
Если человек написал «присоединила», то я для этого слова и в английском и в немецком кучу устоявшихся выражений могу подобрать, и среди них ну никак не будет «политически» корректного по вашему мнению слова.
vassabi
то есть, когда вы видите в официальных новостях «уничтожили террористов» рядом с «убийство борцов за независимость», то это вас не удивляет, а когда то же самое умеет делать нейронная сетка, то «epic fail»?
sebres Автор
То не «умеет делать нейронная сетка», а делает сервис, претендующий на (дословно) «повышение точности перевода».
Если для вас это более точно, флаг вам в руки…
khim
В данном случае «более точно» == «ближе к тому, как перевёл бы человек».
И тут я бы скорее поаплодировал успехам Гугла, чем огорчился им.
А Doublespeak, как вам уже сказали — это не проблема Гугла, Гугл в данном случае — всего лишь зеркало того, как люди переводят и думают…
sebres Автор
По поводу «более точно» == «ближе к тому, как перевёл бы человек», улыбнуло, спасибо… Я «поаплодировал» вашим успехам в словоблудии.
Про остальное же..., по моему скромному мнению double standards занимаетесь как раз вы, т.к. пытаетесь одно и тоже действие называть разными словами… Я не против, но… или трусы, или крестик.
BigBeaver
Переводчик не должен делать правки. Если фраза не имеет контекста, то должна переводиться буквально. Переводчик не знает, откуда взята фраза — относится ли она вообще к реальному миру или вымышленному.
idiv
Буквально же не всегда выйдет, есть ведь частота смыслов слов и какой-то контекст на основе стоящих рядом слов чаще бывает. И живой переводчик чаще понимает, какое слово подойдет лучше.
Мое впечатление — последнее время Гугл стал хуже переводить, он выискивает какие-то одному ему известные варианты перевода и зачастую перевод вообще не имеет смысла. Конечно для уверенного заявления нужно иметь один и тот же текст и проверять его раз в пару месяцев, потому это только впечатление.
Тот же пример выше, если его сделать неграмотно, выдаст:
США присоединили Техас — The United States joined Texas
США присоединил Техас — The United States has annexed Texas
Гугл бы лучше занялся проверкой грамматики хотя бы на уровне согласования слов, тогда и переводы будут лучше выходить.
vassabi
BigBeaver
Про качество гуглопереводов согласен. Пользуюсь reverso, если нужно что-то контекстнозависимое.
sebres Автор
На самом деле — нет, даже если нет контекста, предложение редко можно перевести дословно… Просто поверьте (я очень долго занимаюсь этой темой, причём на хорошем уровне для многих языков, особенно германской группы).
Например, «Das Leben ist keine Einbahnstrasse» переводится с немецкого не как «жизнь — не улица с односторонним движением», а «жизнь бывает трудна» и т.п.
Но… Перевод одного и того же с подлежащим и дополнением одного класса, причем однозначно (государство/страна и территория/гео-субъект) с одинаковым сказуемым — по разному — это нонсенс… Даже если вся пресса мира (а это не так, поверьте) вам говорит об обратном… И даже какая никакая устойчивость выражения (с точки зрения той же прессы) не даёт ни в коем случае никакого основания заменять слова таким не равнозначным «алиасом», от слова СОВСЕМ. Просто потому, что железка, на основании такого текста, не может и не имеет права делать самостоятельный вывод, что говорящий имел ввиду.
Sdima1357
Тут надо объявить бойкот американской компании Гугл переводящей на американский английский как нравится американцам. Однозначно. Ну и заодно английскому. И написать жалобу в ООН. Ну а если не отзовутся то
в спортлотона хабрBigBeaver
Про дословно вообще речи не было. Речь про неискажение смысла.
Первый вариант немного режет слух в русском языке, но он все равно правильный и означает «сделанного не вернешь». Ваш вараинт искажает немного смысл в пользу нормального (для русских) звучания (кстати, спорно, мне вполне нравится, если заменить «улица» на «дорога»), но все еще сохраняет смысл, в целом. В обсуждаемом же примере смысл полностью меняется.Переводчик должен работать так, как будто бы у него кроме толкового словаря и сборника фразеологизмов больше ничего нет, оставляя свою личность за кадром.
sebres Автор
Дак то не мне нужно доказывать… и я ничего другого в статье и не написал.
lostmsu
Хм, а почему перевод не корректный?
Как раз нормальный перевод с пост-правды на нормальную речь с учётом контекста.
sebres Автор
Наверно постольку у некоторых, мигрировавших за лужу, мозг отключается напрочь, и они начинают огульно верить тому что им «правдивая» американская газета расскажет… Или сразу так в школе преподают?
А по теме контекста — он то как раз у обеих фраз один… Только перевод, внезапно, разный…
Но кому-то видимо всё то — Божья роса…
Достаточно развёрнуто, небрат?
lostmsu
Очень много персональных атак, но ничего, кроме теории заговоров в пояснении.
А логика проста:
Во времена присоединения Техаса (это когда вообще?) ещё не существовало никаких ООН, глобальных договоров. Поэтому говоря о нём, нет нужды упоминать о том, что это — аннексия. Т.к. все или почти все изменения границ в то время были аннексиями (покупки территорий, наверное, — редкое исключение).
Сейчас же все значимые игроки обычно оперируют территориями в рамках законов. Поэтому для того же события имеет смысл уточнять, что оно является аннексией, а не просто присоединением.
Конечно же, алгоритм гугла про всё это не знает, а только «догадывается», основываясь на содержании Интернета. И тут как раз логично, что в стране-агрессоре называние вещей своими именами избегается, пресловутая «пост-правда» в действии.
sebres Автор
Ну-ну… А кто сказал, что действие происходит в наше время, а небрат? А вдруг я исторический трактат перевожу? И Россия в этом случае много-много раньше США чего-то там наприсоединяла?
Как тут с логикой-то?.. Догадывается он, ага…
lostmsu
Ну так и попробуйте перевести исторический трактат. Этот пример-то тут при чём?
Найдите пример, где перевод будет некорректным с точки зрения фактов, тогда и жалуйтесь.
sebres Автор
Объясняю
для дятловдля тех кто в танке.Ещё вопросы есть?
lostmsu
Этот пример, даже если переводится так же, всё равно не искажает фактов, т.к. в 1783 тоже была аннексия.
На всякий случай напомню, что это не место для персональных атак.
BigBeaver
Искажается эмоциональный окрас фразы.
Androniy
Тут все сложнее. Слово «annexed» появляется при использовании слова «Крым», но только в сочетании с некоторыми странами. При этом с США и Россией появляется, с некоторыми — нет.
Россия присоединила Литву — Russia joined Lithuania
Россия присоединила Крым — Russia annexed the Crimea
США присоединила Крым — The United States annexed Crimea
Украина присоединила Крым — Ukraine joined the Crimea
Androniy
Вова присоединил Крым к связи — Vova joined the Crimea to the connection
Вова и Дима присоединили Крым к связи — Vova and Dima annexed the Crimea to the connection
Вова и Дима присоединили Крым к конференции — Vova and Dima joined the Crimea to the conference
В общем, человеческой логике не подчиняется в каком случае «annexed», а в каком «joined».
vassabi
разница в «присоединить территорию А к стране Б» и «присоединить какой-то В к какому-то Г»
Androniy
Нет, я специально привел примеры. Как с применением имен собственных, так и названий стран возможен и такой и такой варианты. Более того, влияют и добавочные слова. «присоединил к связи» будет «annexed», а «присоединил к конференции» будет «joined».
С первого взгляда, простой логики, объясняющей применение «annexed» или «joined» — нет. Объединяет все варианты только слово «Крым».
vassabi
для разнообразия можете попробовать «США присоединили территорию Техаса» — и будет тоже annexed (у которого тоже есть много своих смыслов кроме «присоединение территории»)
igrig
Да тут даже далеко ходить не надо.
Вова и Дима присоединили Крым — будет «Vova and Dima annexed the Crimea», но если
заменить Диму на условного Сережу, то будет все лояльнее — «Vova and Sergei joined the Crimea». Причем, заметьте, гугл прекрасно понимает имена собственные — он заменил Сережа на Sergei.
Справедливости ради, если поиграться именами, то начинается рандом.
Geenwor
Мне кажется, гуглопереводчик научился такому переводу по новостям. Он же давно уже стал показывать примеры употребления переводимого в новостях.
gridem
США присоединила территорию техаса
США присоединила территорию Техаса
США присоединили территорию техаса
США присоединили территорию Техаса
— результат
The United States joined the territory of Texas
The United States annexed the territory of Texas
The United States annexed the territory of Texas
The United States annexed the territory of Texas
gridem
The United States joined the territory of Texas
The United States annexed the territory of Texas
The United States annexed the territory of Texas\
— результат
Соединенные Штаты присоединились к территории Техаса
Соединенные Штаты присоединили территорию Техаса
Соединенные Штаты аннексировали территорию Техаса \
fedorro
Несколько лет назад пытался перевести гулом текст с китайского на русский — мало что понял. Но на английский перевелось очень даже хорошо. Это заметка про One Shot, возможно уже что-то поменялось. А по поводу epic fail — переводит лучше чем некоторые профессиональные переводчики. Но если кто подскажет переводчик получше (и ещё бы оффлайновый)- буду благодарен.
fedorro
Сам-себе отвечу. Наткнулся на статью, которая подтверждает мои слова, за что минус — не понятно.
Arris
Блеск и нищета электронных переводчиков.
Гугл транслейт не может мне перевести «Императорский аэрокосмический концерн» на немецкий.
Зато может на монгольский. Это звучит мощно!
Эзэн хааны сансар огторгуй анхаарал хандуулах
Но это не то, что мне нужно.
sebres Автор
Der keiserliche Luft- und Raumfahrt-Konzern…
Это не гугль, это как было бы правильно.
Arris
Благодарю.