
Вкратце, микросервисы – это сервис-ориентированная архитектура программного обеспечения, в которой приложения на стороне сервера строятся путем объединения множества однозадачных, минимальных сетевых сервисов. К преимуществам относятся улучшенная модульность, упрощение тестирования, лучшая функциональная композиция, изоляция окружения и автономность команд разработки. Противоположность – монолитная архитектура, где большой объем функциональности расположен в одном сервисе, в котором тестирование, развертывание и масштабирование происходит как единое целое.
В начале 2017 года мы достигли переломной точки с основной частью нашего продукта Segment. Это выглядело так, как будто мы падали с дерева микросервисов, ударяясь о каждую ветку по пути вниз. Вместо того, чтобы разрабатывать быстрее, небольшая команда погрязла в возрастающей сложности. Существенные преимущества этой архитектуры стали тяжестью. По мере того, как падала наша скорость, возрастало число дефектов.
В итоге команда оказалась не в состоянии добиться успеха с тремя штатными инженерами, тратящими основную часть своего времени просто поддерживая систему. Что-то должно было измениться. Этот пост – история о том, как мы сделали шаг назад и приняли подход, который хорошо соответствовал нашим требованиям и потребностям команды.
Почему микросервисы работают работали
Инфраструктура данных клиентов Segment принимает сотни тысяч событий в секунду и перенаправляет их партнерским API, что мы называем направлениями на стороне сервера (server-side destinations). Существует более ста видов этих направлений, таких как Google Analytics, Optimizely или пользовательские веб-хуки.
Годы назад, когда продукт изначально был запущен, архитектура была простой. Был API, который принимал события и отправлял их в очередь распределенных сообщений. Событием в этом случае был JSON-объект сгенерированный веб- или мобильным приложением, содержащий информацию о пользователях и их действиях. Пример полезной нагрузки выглядел следующим образом:
{
"type": "identify",
"traits": {
"name": "Alex Noonan",
"email": "anoonan@segment.com",
"company": "Segment",
"title": "Software Engineer"
},
"userId": "97980cfea0067"
}Когда событие было получено из очереди, проверялась управляемая клиентом настройка, которая определяла каким направлениям оно предназначалось. Затем событие отправлялось каждому API получателей, один за одним, что было удобно, поскольку разработчикам нужно было отправлять их событие на единственную конечную точку – Segment API, вместо того, чтобы создавать потенциально десятки интеграций. Segment обрабатывал запрос для каждой конечной точки назначения.
Если один из запросов к получателю не удался, иногда мы пытаемся отправить это событие позже. Некоторые отказы безопасны для повторной отправки, некоторые нет. Ошибки, которые можно отправить позже, это те, которые потенциально могут быть приняты точкой назначения без изменений. Например, HTTP 500, лимиты и тайм-ауты. Ошибки, которые не отправляются повторно, это те, в которых мы уверены, что они не будут приняты точками назначения. Например, запрос содержит недопустимые данные или отсутствуют обязательные поля.
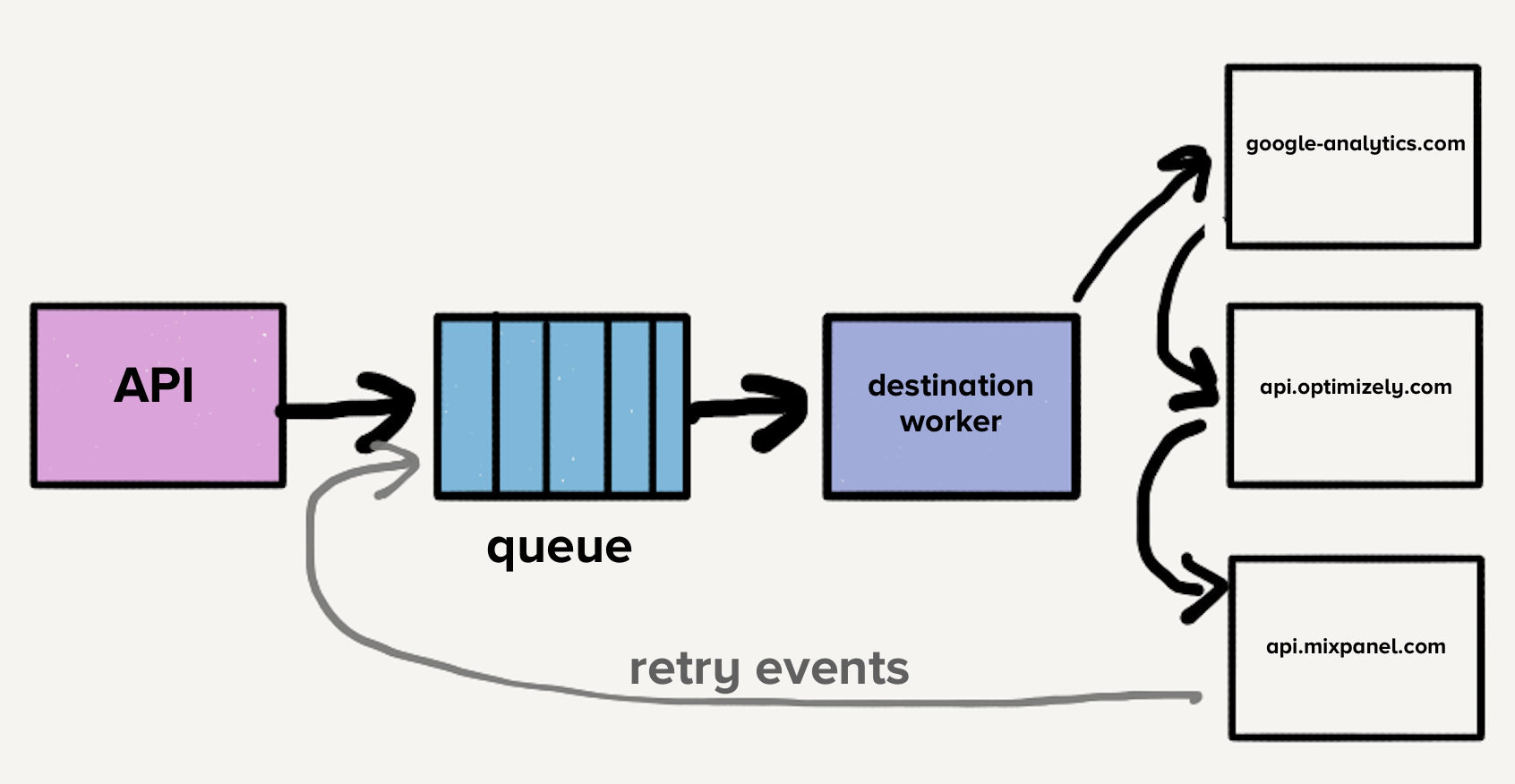
На этом этапе единственная очередь содержала как новые события, так и те, которые возможно имели несколько попыток повтора, по всем направлениям, что приводило к блокировке в начале очереди. В этом случае, если один пункт назначения замедлился или упал, очередь заполнится повторными попытками, что приведет к задержкам по всем направлениям.
Представьте, что направление X испытывает временные проблемы и каждый запрос оканчивается ошибкой тайм-аута. Теперь, это не только создает большое отставание запросов, которые еще не достигли X, но и каждое неудачное событие возвращается для повторной отправки в очередь. Хотя наши системы автоматически масштабируются в ответ на увеличение нагрузки, внезапное увеличение глубины очереди опережает нашу способность масштабирования, что приводит к задержкам для новых событий. Время доставки для всех направлений будет увеличиваться, поскольку на направлении X произошел кратковременный сбой. Клиенты полагаются на своевременность доставки, поэтому мы не можем позволить себе увеличивать время ожидания в любом месте нашего конвейера.

Для решения проблемы с блокировкой начала очереди, команда создала отдельные сервисы и очереди для каждого направления. Новая архитектура содержала дополнительный процесс-роутер, который принимает входящее событие и распределяет его копию для каждого выбранного назначения. Теперь, если у одного направления возникли проблемы, только его очередь будет остановлена, и никакие другие адресаты не будут затронуты. Эта архитектура в стиле микросервисов изолировала одни направления от других, что важно, когда один пункт назначения испытывает проблемы, как это часто бывает.
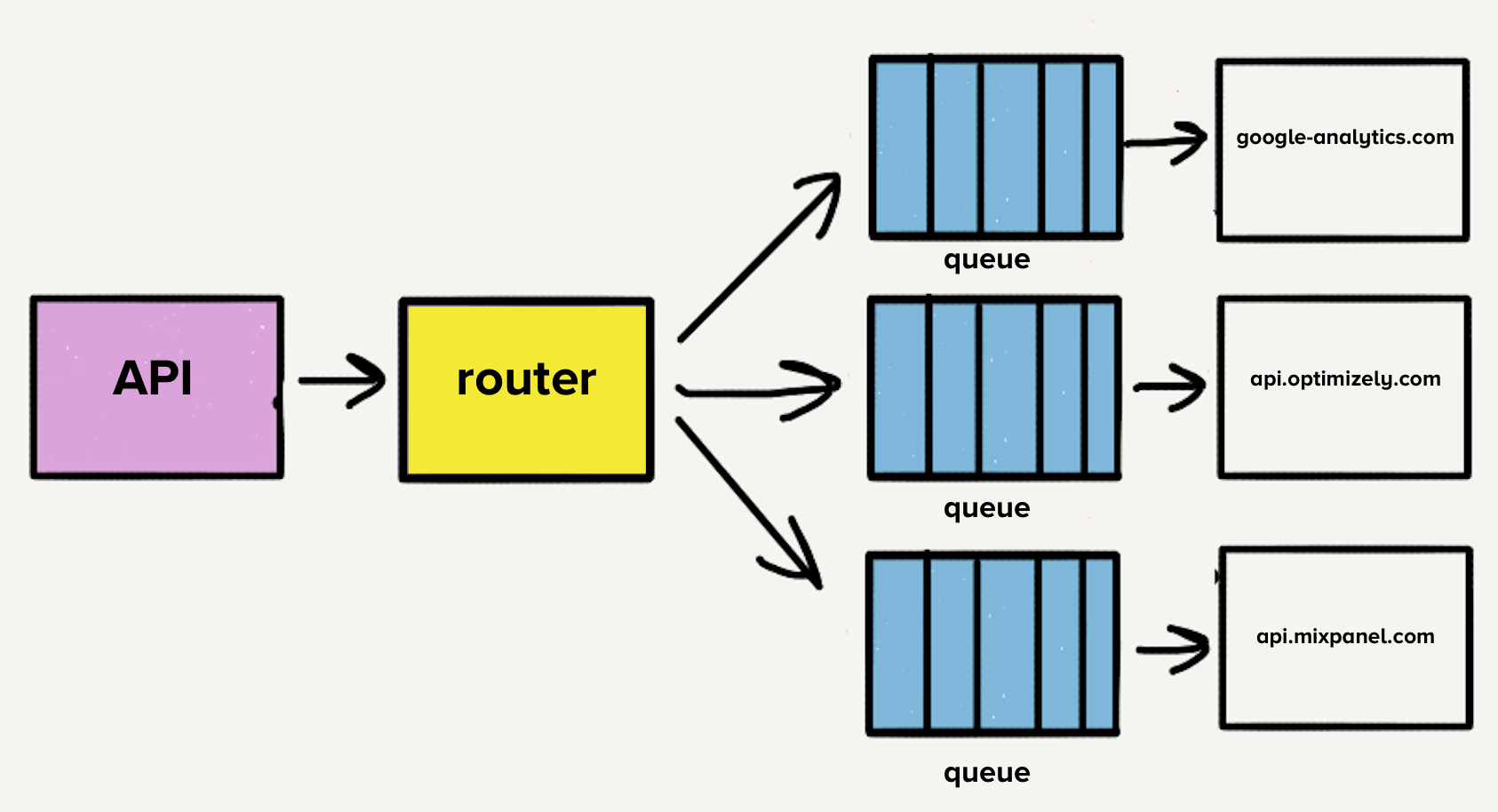
Случай индивидуальных репозиториев
Каждый API направлений использует разный формат запросов, требуя дополнительный код для перевода события в соответствии с этим форматом. Простой пример – назначение X требует отправки даты рождения как
traits.dob, в то время как наш API принимает traits.birthday. Код преобразования для назначения X будет выглядеть примерно так:const traits = {}
traits.dob = segmentEvent.birthdayМногие современные конечные точки назначений приняли формат запросов Segment, что делает некоторые преобразования относительно простыми. Однако, эти преобразования могут быть очень сложными в зависимости от структуры API назначения. Например, для некоторых из старых и самых размашистых точек назначения, мы вручную формируем XML со значениями.
Первоначально, когда назначения были разделены на сервисы, весь код жил в одном репозитории. Огромным разочарованием было то, что один сломанный тест, вызывал падение тестов по всем направлениям. Когда мы хотели развернуть изменение, требовалось время чтобы исправить сломанный тест даже если изменения не имели ничего общего с первоначальным состоянием. В ответ на эту проблему было решено разбить код для каждого назначения в свои собственные репозитории. Все пункты назначения были уже разбиты на их собственные сервисы, поэтому переход был естественным.
Разделение на отдельные репозитории позволило нам легко изолировать тесты направлений. Эта изоляция позволила команде разработчиков быстро переключаться во время поддержки.
Масштабирование микросервисов и репозиториев
Со временем мы добавили более 50 новых направлений и это означало 50 новых репозиториев. Чтобы облегчить бремя разработки и поддержки этих кодовых баз, мы создали библиотеки чтобы делать общие преобразования и функциональность, такую как обработка HTTP запросов, более единообразно в наших направлениях.
Например, если нам необходимо имя пользователя из события,
event.name() может быть вызвано из кода любого направления. Общая библиотека проверяет событие на наличие свойств name и Name. Если они не существуют, она проверяет свойства firstName, first_name, и FirstName. Тоже самое делает для фамилии, проверяя случаи и комбинируя их чтобы сформировать полное имя.Identify.prototype.name = function() {
var name = this.proxy('traits.name');
if (typeof name === 'string') {
return trim(name)
}
var firstName = this.firstName();
var lastName = this.lastName();
if (firstName && lastName) {
return trim(firstName + ' ' + lastName)
}
}Общие библиотеки позволяют быстро создавать новые направления. Знакомство с единой формой общей функциональности делало поддержку менее болезненной.
Однако возникла новая проблема. Тестирование и развертывание изменений в этих общих библиотеках повлияло на все наши направления. Это начало требовать значительного времени и усилий для поддержки. Внесение изменений для улучшения наших библиотек, зная что нам придется тестировать и разворачивать десятки сервисов, было рискованным предложением. При сжатых сроках инженеры должны были включать обновленные версии этих библиотек в кодовую базу одного направления.
Со временем, версии этих общих библиотек стали разниться в кодах направлений. Большое преимущество, которое мы когда то имели от уменьшения настроек каждого назначения повернулось в обратную сторону. В итоге каждое из них имело свои версии общих библиотек. Мы могли бы создать инструменты для автоматизации развертывания изменений, но на данном этапе страдала не только производительность разработчиков, но и мы начали сталкиваться с другими проблемами связанными с микросервисной архитектурой.
Дополнительная проблема заключается в том, что каждый сервис испытывает разную нагрузку. Некоторые сервисы обрабатывали несколько событий в день, а другие – тысячи в секунду. Для направлений, которые обрабатывали небольшое количество событий оператору пришлось бы вручную масштабировать сервис в случае внезапного всплеска нагрузки.
Хотя у нас и было автоматическое масштабирование, каждый сервис имел четкое сочетание требований ресурсов памяти и процессора, что сделало настойку авто-масштабирования больше искусством, чем наукой.
Число направлений продолжало быстро расти, при том что команда в среднем добавляла три в месяц, что значило больше репозиториев, больше очередей и больше сервисов. Благодаря микросервисной архитектуре, наши операционные расходы линейно увеличивались с каждым добавленным направлением. Поэтому мы решили сделать шаг назад и переосмыслить весь наш процесс разработки.
Избавление от микросервисов и очередей
Первым пунктом в списке было объединение более 140 сервисов в один. Управление этими сервисами создавало огромные накладные расходы на нашу команду. Мы буквально теряли сон, когда для инженера поддержки стало нормой получать уведомления о пиках нагрузки.
Однако, архитектура в то время сделала бы перенос в единый сервис целым испытанием. С отдельными очередями для назначений каждый обработчик должен был бы проверять все очереди на наличие работы, что добавило бы сложности сервисам назначений, с которыми нам было неудобно. Это было главным вдохновением для Centrifuge. Centrifuge заменит все наши отдельные очереди и будет отвечать за отправку событий в единый монолитный сервис.
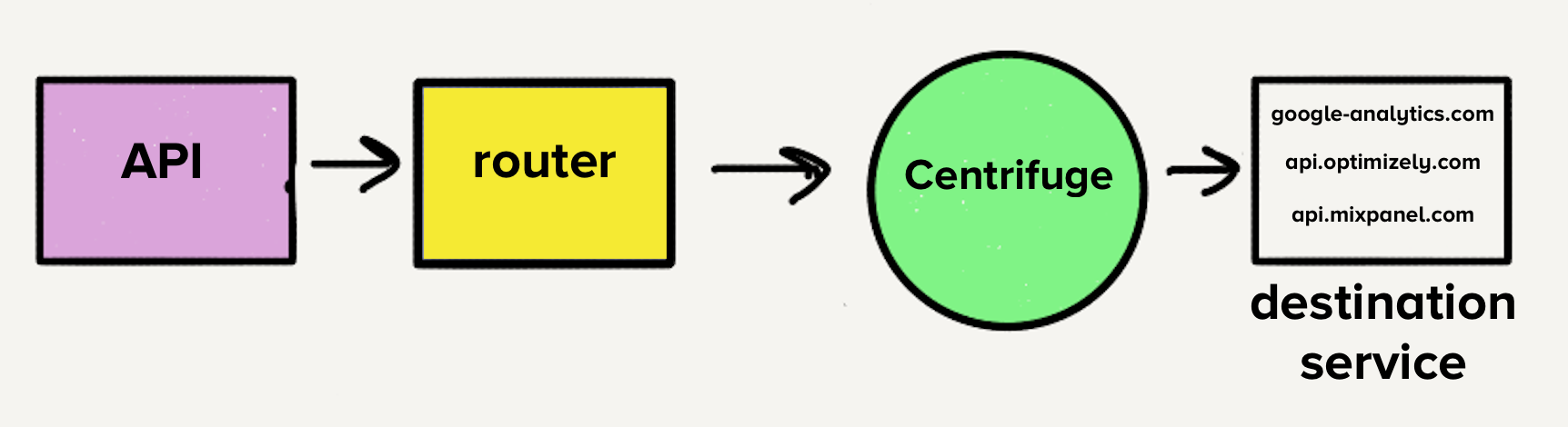
Перемещение в монорепозиторий
С учетом того, что будет только один сервис, имеет смысл переместить код всех направлений в один репозиторий, что означает слияние всех различных зависимостей и тестов в одном репозитории. Мы знали, что будет беспорядок.
Для каждой из 120 уникальных зависимостей мы решили взять одну версию для всех наших направлений. Когда мы переносили направления мы проверили их зависимости и обновили до последних версий. Также мы исправили все, что в них сломалось после обновления на новые версии.
При таком переходе, больше не нужно отслеживать различия между версиями зависимостей. Все наши направления использовали одну версию, что значительно уменьшило сложность всей кодовой базы. Поддержка направлений теперь стала менее трудоемкой и менее рискованной.
Нам также нужен был набор тестов, который позволял бы быстро и легко запускать сразу все тесты направлений. Запуск всех тестов был одним из главных блокирующих факторов при создании обновлений для библиотек, которые мы обсуждали ранее.
К счастью, все тесты направлений имели похожую структуру. В них были базовые модульные тесты для проверки корректности нашей логики преобразований и выполнение HTTP запросов на конечные точки партнеров, для проверки того, что все события появляются в местах назначения, как ожидается.
Напомним, что первоначальной мотивацией для разделения кодовой базы каждого направления на отдельные репозитории были сбои тестов. Однако оказалось, что это ложное преимущество. Тесты, которые делали HTTP запросы, все еще падали с некоторой частотой. Когда направления были разделены на собственные репозитории, было мало мотивации для чистки от падающих тестов. Эта плохая гигиена привела к постоянному источнику разочарования и техническому долгу. Часто небольшое изменение, которое должно было занять час или два, требовало от нескольких дней до недели для завершения.
Создание устойчивых наборов тестов
Исходящие HTTP запросы к конечным точкам направлений во время прогона тестов были основным источником падения. По опыту мы также знали, что некоторые конечные точки были гораздо медленнее других. Некоторые направления требовали до 5 минут для запуска их тестов. С более чем 140 направлениями время выполнения нашего тестового набора могло занять до часа.
Для решения этих проблем мы создали Traffic Recorder. Traffic Recorder собран на основе yakbak, и отвечает за запись и сохранение тестового трафика получателей. Всякий раз, когда тест выполняется в первый раз, любые запросы и их соответствующие ответы записываются в файл. При последующих тестовых запусках запрос и ответ воспроизводятся из файла вместо выполнения запроса по назначению. Эти файлы добавляются в репозиторий, чтобы тесты были согласованны при каждом изменении. Теперь, когда тестовый набор больше не зависит от HTTP запросов через Интернет, наши тесты стали существенно устойчивей и обязательными для миграции в единый репозиторий.
Я помню, как проходили тесты для каждого пункта назначения в первый раз после того, как мы интегрировали Traffic Recorder. Потребовались миллисекунды, чтобы завершить тесты для всех 140+ наших направлений. Раньше всего один пункт мог занять пару минут. Это было похоже на магию.
Почему монолит работает
Когда код для всех направлений находится в одном репозитории, они могут быть объединены в один сервис. Благодаря тому, что каждое направление находится в одном сервисе продуктивность наших разработчиков значительно улучшилась. Нам больше не нужно разворачивать 140+ сервисов при изменении одной из общих библиотек. Один инженер может развернуть сервис за считанные минуты.
Доказательством стало увеличение скорости. В 2016, когда наша микросервисная архитектура еще существовала, мы сделали 32 улучшения общих библиотек. Только в этом году мы сделали 46. Мы сделали больше улучшений библиотек за последние 6 месяцев, чем за весь 2016 год.
Это изменение также принесло пользу нашей операционной истории. Со всеми направлениями располагающимися в одном сервисе мы имеем хороший микс использования памяти и процессора, что значительно облегчает масштабирование. Большой пул обработчиков может сглаживать пики нагрузки, потому, что у нас больше нет направлений которые обрабатывают небольшие объемы.
Компромиссы
Перенос нашей микросервисной архитектуры в монолит в целом было огромным улучшением, однако пришлой пойти на компромиссы:
- Отказоустойчивость затруднена. Когда все работает в монолите, если появляется баг в одном направлении, который приводит к падению сервиса, сервис упадет для всех направлений. У нас есть всестороннее автоматическое тестирование, но тесты все равно могут подвести. В настоящее время мы работаем над гораздо более надежным способом не допустить того, чтобы один пункт назначения ломал весь сервис, сохраняя работоспособность остальных направлений в монолите.
- Кэширование в памяти менее эффективно. Раньше, с одним сервисом на направление у маршрутов с низким трафиком было всего несколько процессов, что означало, что их кэш в памяти оставался горячим. Теперь кэш тонко распределяется между 3000+ процессов, поэтому шансов попасть в него гораздо меньше. Мы могли бы использовать что-то вроде Redis чтобы решить эту проблему, но это добавило бы еще одну точку масштабирования. В конце концов, мы приняли эту потерю эффективности с учетом существенных эксплуатационных преимуществ.
Заключение
Наша первоначальная микросервисная архитектура работала некоторое время, решая прямые задачи производительности нашего рабочего процесса путем изоляции направлений друг от друга. Однако, мы не были настроены на масштабирование. Нам не хватало правильных инструментов для тестирования и развертывания микросервисов, когда было нужно массовое обновление. В результате, продуктивность наших разработчиков резко снизилась.
Переход к монолиту позволил нам избавить процесс разработки от эксплуатационных проблем, значительно повысив производительность разработчиков. Мы не сделали этот переход легкомысленно, хоть и знали, что есть вещи которые необходимо рассмотреть, если это сработает.
- Нам понадобился комплексный тестовый пакет для помещения всего в один репозиторий. Без этого, мы были бы в той же ситуации, когда мы изначально хотели их разбить. Постоянные неудачные тесты вредили нашей продуктивности в прошлом, и мы не хотели, чтобы это происходило снова.
- Мы приняли компромиссы, присущие монолитной архитектуре, и убедились, что у нас была хорошие основания связанные с каждым. Нам пришлось пойти на некоторые жертвы, в связи с этими изменениями.
При выборе между микросервисами или монолитом следует учитывать различные факторы. В некоторых частях нашей инфраструктуры микросервисы работают хорошо, но наши серверные направления являются прекрасным примером того, как популярная тенденция может навредить продуктивности и производительности. Получается решением для нас стал монолит.
Комментарии (83)

turbotankist
11.07.2018 18:26+1Хм, у нас в команде есть похожая проблема, но там причина не в микросервисах
А в том, что очень многиепрограммистыкодеры не понимают микросервисы, не представляют, что значит распределённая система. У каждого второго что-то «подключиться к localhost:8080» захардкожено. Потом он запускает нативно приложение — всё работает, а в контейнере не работает, и онемучается с этим несколько часов.
Statyan
11.07.2018 18:30+5Спасибо что подделились, но, по факту, у вас не было микросервисной архитектуры. Вы ее неправильно поняли. Делить нужно было по ролям, сделать возможность масштабирования конретной роли и вся ваша боль ушла бы. Вы же раскидали по разным воркерам код и назвали это микросервисной архитектурой. От неправильного ее формирования вы и получили проблемы и с саппортом и вот эти
Дополнительная проблема заключается в том, что каждый сервис испытывает разную нагрузку. Некоторые сервисы обрабатывали несколько событий в день, а другие – тысячи в секунду.
andreyverbin
12.07.2018 03:08Обожаю эти комментарии в стиле «вы просто не умеете их готовить» :) Раз говорим про роли, то давайте критерий (желательно универсальный), по которому эти роли выделять.
SchmeL
11.07.2018 19:11+1Был монолит, худо бедно справлялся с нагрузкой, потом клиентов стало больше, офисы стали расти как грибы и отдельные операции вешали систему. Хотели переписать, но не срослось. В итоге поделили на микросервисы на основе docker. Нагрузку размазали по серверам, стало гораздо лучше.
По началу на каждый чих создавался микросервис, печать документов — сервис, внешние заявки — сервис, плохие клиенты — сервис. Сейчас их большое количество, не 140 конечно, но около 25, хорошо они хоть друг от друга не так часто зависят.
В общем если сервисов около 20, то админить и тестировать их не сложно, развернуть весь стек приложений тоже, масштабировать и тп., но вот если их больше — то начинается боль, особенно если новый человек хочет разобраться в этом.
— А какой уж там сервис отвечает за X функционал? и какой — за Y?
— Я не мог пол дня настроить окружение, блин они еще друг от друга зависят.
В общем мой совет — не перебарщивать с количеством и делить сервисы на роли.mad_nazgul
12.07.2018 05:19+1А как же инфраструктура как программа?! :-)
Т.е. настройка и конфигурация должны настраиваться не в ручную, а быть в виде программного кода. С обязательным покрытием тестами.
Со всеми плюшками DI, тогда зависимости для развертывания dev-окружения можно mock-ировать
А так. Какая разница, что монолит, что микросеврисы.
В микросерисы хотя бы можно «есть по частям», т.е. в начале понять как работает один микросервис и поправить его (при этом вероятность что-то сломать минимальна), а потом все остальное.
А в монолите у вас есть куча говнокода, в темные уголки которого не заглядывают годами.
И при любом изменении нужно молиться, что есть тест, который может проверить, что что-то сломалось.mayorovp
12.07.2018 07:53Как будто в микросервисах говнокода не бывает...
В монолите у меня есть хоткей чтобы увидеть кто еще этот код использует.
mad_nazgul
12.07.2018 09:56Бывает. Но сам по себе микросервис настолько маленький, что переписать его легче. При этом можно быть точно уверенным, что все остальное не упадет. ;-)
mayorovp
12.07.2018 10:04А вот это не факт. Может, все остальное и не упадет — но работать в случае ошибки точно не будет, ведь микросервис был для чего-то нужен!
А при хорошей архитектуре можно и в монолите кусочек спокойно переписать.mad_nazgul
12.07.2018 12:56-1Работать будет но не правильно.
И опять же переписать легче, а значит быстрее.
А вот хорошая архитектура и монолит, это из области фантастики. :-)
jehy
11.07.2018 19:41+2Прекрасная история про то, как чуваки вместо пачки одинаковых библиотек сделали пачку одинаковых микросервисов, закономерно на этом огребли, и говорят про то, как хорошо быть в монолите…
Delphinum
11.07.2018 20:41+1Очередная команда, решившая заюзать архитектуру потому, что она модная, и разочаровавшаяся в ней потому, что не подошла под задачу/кривые руки/не осилили? Ох уж эта хайп-полезнь (
C4ET4uK
11.07.2018 23:48-1Не надо пожалуйста переводить термины, не сразу понял, что
Полезная нагрузка = payload
Конечная точка = endpointsaterenko
12.07.2018 09:43Наоборот, везде, где есть адекватный аналог в русском языке, надо использовать русский, а английский оставлять только для плохо переводимых терминов… Вымораживают тексты с постоянными «эндпоинтами» и «пейлоадами»…
ElectroGuard
12.07.2018 01:58Всё от хайпа, согласен. Решили хайпануть и напоролись. В программировании, увы, это сплошь и рядом. У нас сервис пока монилит, до тысячи задач одновременно, насколько я видел. Пока справляется как есть. Изоляция — отдельная проблема, но решаемая. Подумываю насчет разделения на несколько (не микро) сервисов. Инструмент — Delphi, проект порядка миллиона строк почти в одно лицо. Веб (без апача и аналогов), некоторые специфические протоколы, терабайты прокачиваемой через сервис информации.
mad_nazgul
12.07.2018 05:21Вообще странно что ТС напоролись на проблему изменений.
Такое ощущение, что DI к в команде не практикуется. :-)
Tiendil
12.07.2018 07:56Заголовок спойлераРассказ неосиляторов :-)iPilot
12.07.2018 09:42+1То есть у них по сути были некие модули, выполнявшие одинаковые операции: получить данные от клиента, замапить на новую структуру и отправить другому API. Они каждую отдельно реализовывали, огребая на тестировании всего этого? Вместо того, чтобы создать что-то типа базового сервиса с зависимостями от маппера и способом общения с получателем, развернув в итоге просто несколько копий этого базового сервиса: Мапперы и пересыльщиков можно тестировать отдельно, а DI-контейнеры решат проблему компоновки сервиса для каждого из направлений. Что не так в этой логике?
saterenko
12.07.2018 10:09Думаю, дело в том, что любой серьёзный, динамически развивающийся проект постоянно меняется и может меняться очень сильно. В начале делается прототип для одной концепции, потом концепция меняется, прототип дорабатывается с минимальными затратами по времени, потом ещё, ещё и ещё. В какой-то момент получается «некоторое дерьмо», которое сложно поддерживать и развивать, напрашивается рефакторинг. Это нормальный процесс жизни проекта без чёткого понимания конечной цели.
А самая большая проблема в таких проектах, по моему опыту — это донести до менеджера, что не бывает гибкой разработки проектов (agile) без рефаторинга. Иногда надо остановиться и существенно перетряхнуть внутренности проекта, что может занимать немало времени.mad_nazgul
12.07.2018 12:57Согласен.
Микросеврисная архитектура и предполагает, что проще переписать, чем изменять. :-)
saterenko
12.07.2018 09:58Я не любитель микросервисной архитектуры, так что люто плюсую автора.
Был опыт развития проекта, построенного на микросервисной архитектуре. Окончательно меня бомбануло, когда разработчик несколько дней дорабатывал API сервиса для того, чтобы сделать подобие LEFT JOIN между двумя сервисами. И работало это на 2-3 порядка медленнее, чем запрос в базу. После было принято решение объдинить сервисы в монолит. Жалею только о том, что не сделал это сразу, как пришёл в проект, много времени было потеряно зря. Но, безусловно, это не проблема концепции, это проблема архитектуры проекта и изменчивость требований заказчика.
Сама по себе микросервисная архитектура не плохая и не хорошая, просто на хайпе её суют куда попало, в каждый «утюг», это же, блин, модно… А каждый инструмент надо использовать с умом, там где он реально помогает решать задачу.
Спасибо автору за то, что поделился опытом. Здорово, что не упёрлись рогом в концепцию, а стали искать другие решения. Может они ещё и вернутся к микросервисной архитектуре, но в другом виде…sotnikdv
12.07.2018 10:43Я не любитель микросервисной архитектуры, так что люто плюсую автора.
Был опыт развития проекта, построенного на микросервисной архитектуре. Окончательно меня бомбануло, когда разработчик несколько дней дорабатывал API сервиса для того, чтобы сделать подобие LEFT JOIN между двумя сервисами. И работало это на 2-3 порядка медленнее, чем запрос в базу. После было принято решение объдинить сервисы в монолит. Жалею только о том, что не сделал это сразу, как пришёл в проект, много времени было потеряно зря. Но, безусловно, это не проблема концепции, это проблема архитектуры проекта и изменчивость требований заказчика.
Во-первых, просто не любить микросервисы или любить микросервисы, это непрофессионально.
Во-вторых, нужно понимать когда ее применяют, как условия так и место в жизненном цикле продукта. Какие проблемы она решает. Какие у нее антипаттерны и ограничения.saterenko
12.07.2018 10:51Во-первых, просто не любить микросервисы или любить микросервисы, это непрофессионально.
Почему?
Во-вторых, нужно понимать когда ее применяют, как условия так и место в жизненном цикле продукта. Какие проблемы она решает. Какие у нее антипаттерны и ограничения.
Об этом у меня написано:
Сама по себе микросервисная архитектура не плохая и не хорошая, просто на хайпе её суют куда попало, в каждый «утюг», это же, блин, модно… А каждый инструмент надо использовать с умом, там где он реально помогает решать задачу.
sotnikdv
12.07.2018 11:03Почему?
Потому-что это инструментарий. Это не вопрос личных симпатий и антипатий.
В процессе обучения любой технологии первое время всегда тратим на:
— зачем эту технологию изобрели, какую проблему решали? «вот жили люди спокойно 10 лет, а потом придумали это. зачем? думаете правда им было нечего делать?»
— границы ее применимости
— когда ее стоит применять
— любое решение — это tradeoff. Чего на что? Сюда-же плюсы и минусы технологии в общем.
Сама по себе микросервисная архитектура не плохая и не хорошая, просто на хайпе её суют куда попало, в каждый «утюг», это же, блин, модно… А каждый инструмент надо использовать с умом, там где он реально помогает решать задачу.
А вот с этим соглашусь. Беда в том, что автор оригинальной статьи не только не понимает когда использовать технологию, но и не понимает ее вообще.saterenko
12.07.2018 11:12Потому-что это инструментарий. Это не вопрос личных симпатий и антипатий.
Но почему у меня не может быть любимой лопаты? ))))
Беда в том, что автор оригинальной статьи не только не понимает когда использовать технологию, но и не понимает ее вообще.
Мне кажется, это проблема людей вообще, мы не можем всё знать и совершаем ошибки… Автор поделился своим опытом, сообщество обсудило, а автор, думаю, вынесет из обсуждения что-то полезное для себя.powerman
12.07.2018 11:31+1Вопрос не в том, может ли лопата быть любимой, а в том, что это не должно влиять на определение того, насколько лопата подходит для решения определённой задачи. Не нравятся микросервисы — просто не участвуйте в проектах, для которых микросервисная архитектура подходит лучше других. А вот навязывать этим проектам другую архитектуру из соображений личных симпатий — как раз непрофессионально. Впрочем, лично Вы в изначальном комментарии таких утверждений явно не делали, так что возможно sotnikdv немного поспешил с выводами.
ElectroGuard
12.07.2018 11:58Думается, что чаще бывает наоборот — как раз таки из-за хайпа чаще тянут микросервисы туда, куда не нужно.
rustler2000
12.07.2018 23:04+1Беда в том, что автор оригинальной статьи не только не понимает когда использовать технологию, но и не понимает ее вообще.
Это случайно не вы Джессике Фразелли недавно объясняли как контейнеры работают?
mad_nazgul
12.07.2018 13:03Э-э-э???
Если нужен был LEFT JOIN и была база, то почему бы не написать микросервис, который это делает?!
Т.е. если можно (и это проще) использовать готовые микросервисы, то надо ими пользоваться.
Если проще написать «с нуля», то почему бы и не написать «с нуля»?!
Тут вопрос к «архитектору», ну или кто отвечал за общую структуру проекта.
Почему он решил, что надо делать так?!saterenko
12.07.2018 13:12Я так и написал, что это проблема архитектуры:
Но, безусловно, это не проблема концепции, это проблема архитектуры проекта и изменчивость требований заказчика.
mad_nazgul
12.07.2018 13:34При чем тут архитектура.
Как реализовать микросервис, это задача программиста.
Если проще/удобнее напрямую обратиться к БД, то почему бы и да.
Просто «архитектор» мог поставит жесткие условия, что сделать надо так и никак иначе.
ИМХО, «архитектор» должен говорить, «что» будет делать микросервис, а «как» пусть программист сам решит.
Благо микросервис должен быть таким, чтобы он был понятен любому программисту.
Соответственно переписать его может любой программист.
Если, например, вы считаете, что проще/быстрее/удобнее использовать 1 один запрос к БД. То микросервисная архитектура никоим образом это не запрещает :-)JediPhilosopher
12.07.2018 17:07Вполне себе запрещает. Есть микросервис, у него есть своя приватная БД. По идее никто кроме него в эту БД лазать не должен, а все остальные должны обращаться к его публичному апи. Потому что если это разрешить — начнется совсем адский ад, который обычно ставят как пример недостатков монолитов — нарушается изоляция и модульность, и все летит кувырком как только кто-то начинает менять структуру этой бд. Причем если в случае монолита можно хотя бы более-менее просто обнаружить, что в бд лазает какой-то другой участок кода, и поправить его, то в случае микросервисов этот участок кода может лежать в другом репозитории и даже на другом языке программирования.
mad_nazgul
13.07.2018 05:31-1Честно говоря, еще на заре хайпа по микросервисам, я еще слышал максиму, что каждый микросервис должен работать только с приватной БД.
Но потом, практика показала, что это не максима и вообще хранилище данных это отдельная тема.
Т.к. желательно чтобы микросеврисы были без состояние, то это стоточение где-то должно быть.
Одно из хранилищ состояния может быть, например, БД.
Куда микросервисы обращаются за данными.
Поэтому в публичном АПИ, просто создается микросервис с JOIN-ом, к которому обращаются при надобности :-)
VolCh
12.07.2018 17:46Суть микросервисов именно в «как», в максимальной изоляции их друг от друга, в единственной задаче которые они решают.
Если нужно делать «джойн» данных нескольких микросервисов на уровне запросов к БД, то это, в общем случае, нарушение принципов MSA.mad_nazgul
13.07.2018 05:36-1Суть микросервисов в максимальной изоляции бизнес-логики, но не данных!
Т.е. разделения то что не должно меняться (данные) и то что может быть изменено со временем (логика работы с данными).
Почему данные не должны меняться — потому что история. Мы должны знать что у нас было в определенный момент времени.
Поэтому данные не меняются, а добавляются.
Так что общее хранилище данных для микросервисов — это норма.
При чем это может быть не только БД, но например kafka :-)powerman
13.07.2018 07:55+1Проблема общего доступа к данным в БД как раз в том, что из-за требований бизнеса и добавления новых фич схема данных меняется, и если несколько микросервисов работают с одной БД то изменение схемы требует одновременного обновления всех этих микросервисов — т.е. между ними создаётся жёсткая связь на данных. Ну и помимо очевидной проблемы при изменении схемы данных есть ещё проблема что БД — это одна большая глобальная переменная, так что когда разный код начинает по-разному с ней работать то изменения в том, как один микросервис читает/пишет данные в БД внезапно могут повлиять на другой микросервис.
Эта проблема не распространяется на кафку и аналогичные сервисы очередей потому, что данные в них изначально описываются как API — какие у нас топики, какие бывают типы событий, какие по ним даются гарантии, etc. ну и плюс там всё-таки нет свободного RW доступа к этим данным как в обычной БД.
Таким образом, максима про приватную БД у микросервисов это не какая-то глупость времён "зари микросервисного хайпа", а суровая реальность. Конечно, если у Вас данные с БД по своей природе иммутабельные (append-only), плюс формат схемы БД описан и не меняется, то по факту такая БД ничем не отличается от любого другого API — микросервисам доступны только операции которые не могут "сломать" данные в БД (кстати, чтобы это гарантировать, крайне желательно ограничить разрешённые операции для тех аккаунтов, под которыми микросервисы подключаются к БД, исключительно SELECT и INSERT, если речь об SQL) и сохраняется обратная совместимость. В этом случае никакой проблемы чтобы с этой БД работало несколько микросервисов нет. Но, мягко говоря, это не самый типичный сценарий использования БД, поэтому ту "максиму" он никак не отменяет.
mad_nazgul
13.07.2018 13:40Вы приводите в пример, только БД.
При изменении схемы данных, все равно будут меняться микросервисы, которые обращаются к микросервису работающему с БД.
Т.к. контракт скорее всего поменяется.
Если он не поменялся… То зачем изменение :-)
VolCh
13.07.2018 08:00Норма для микросервисов не общее хранилище операционных данных, а отдельный сервис или сервисы агрегации операционных данных основных сервисов по типу DWH. А история не является обязательным требованием и в целом к SOA или MSA ортогональна.
sotnikdv
12.07.2018 10:38+1Господа, у вас
волчанкаклассическая проблема с архитектурой:
— Вы очень странно понимаете концепцию микросервисов и принципы деления на микросервисы и ударились в классический антипаттерн, наносервисы. Хорошо описанный, кстати.
— Архитекторы явно бросились использовать концепцию, не читая вполне доступных материалов и без понимания, что такое микросервисная архитектура, какие задачи она решает, ее ограничений и когда ее применять. Решили, что это стильно-модно-молодежно.
— Еще в начале статьи становилось понятно, что архитектора не потянули задачу и не взлетит, независимо от наличия или отсутствия микросервисов.
А вот что меня действительно беспокоит, это то, что вместо того, что бы сесть и начать разбираться, дочитывать книги и улучшать свое понимание предметной области, вы тиснули статью на хабр.marsdenden
12.07.2018 10:54Это же перевод, так что всё Ваше беспокойство/негодование не к тем обращено
GreedyIvan
12.07.2018 10:48+1От статьи создается впечатление, что проблема там была не с микросервисами, а как поддерживать 100500 версий сервиса. Для поддержки — это, конечно, ад. Решение было в области отказа от старых версий.
Можно ли было это сделать, оставаясь в микросервисах? Наверное, да. Вопрос только в том, какую логику обновления сервисов задействовать после изменения в общих зависимостях? Автосборка всех зависимых сервисов? Отказ от деплоя или частичный деплой только прошедших тесты, сервисов? И т.д.
vedenin1980
12.07.2018 10:54-1Основаная проблема в этом:
Тестирование и развертывание изменений в этих общих библиотеках повлияло на все наши направления. Это начало требовать значительного времени и усилий для поддержки. Внесение изменений для улучшения наших библиотек, зная что нам придется тестировать и разворачивать десятки сервисов, было рискованным предложением.
ИМХО, в случае, такого большого кол-ва микросервисов лучше не иметь общих библиотек вообще (малейшая ошибка в общей библиотеке и лягут все микросервисы сразу).
Или они должны быть сильно ограничены и сигментированы (грубо говоря, на rest клиента одна библиотека, на работу с xml другая, не обязательно в разных репозиториях, но в разных jar'никах или в чем они делают выдачу).
К своим общим библиотекам лучше относится как к любой другой opensource библиотеки — если она не нужна, не включать, если есть opensource библиотека более подходящая — брать ее, а не свою общую библиотеку.
Эта обшая библиотека по сути делала все микросервисы Монолитом, который слегка кастомизируется и копируется в 120 инстансов. В результате логично, что оказалось, что Монолит для реализации Монолита лучше.
sotnikdv
12.07.2018 10:58А самая большая проблема в таких проектах, по моему опыту — это донести до менеджера, что не бывает гибкой разработки проектов (agile) без рефаторинга.
Никакого развивающегося проекта не бывает без рефакторинга. И, кстати, 90% встретившихся мне менеджеров не понимают, что такое Agile/SCRUM и как он работает.
Профнепригодные архитекторы, профнепригодные менеджеры, профнепригодные девелоперы. Куда деваются люди, со знанием — загадка.
В долине, кажется, многих поглощают крупные конторы типа гугл-амазон-нетфликс-фейсбук. Часть людей там. И потом они там сидят и делают совершенно левую фигню, для которой они реально overskilled. Три толковых моих коллеги — в гугле, делают какую-то фигню. Куда подевались толковые менеджеры — загадка, вроде и в нормальных компаниях, но они там стали просто винтиками и следуют общим трендам.
Где остальные — неясно, похищают и топят ли их что-ли?hamsterball
12.07.2018 15:38Возможно сидят и тихо работают, не пишут подобные статьи :-)
По моим наблюдениям мотивация рассказать о неудачном опыте сильно превышает таковую в случае успеха.
staticY
12.07.2018 17:02Профнепригодные архитекторы, профнепригодные менеджеры, профнепригодные девелоперы. Куда деваются люди, со знанием — загадка.
Про менежеров у меня есть теория: хорошо менеджерить IT-проект может только хороший программист, который потрогал всю подноготную ремесла. Который понял, зачем тесты, понял, что такое рефакторинг, деплой, архитектура. В общем, понял это непростое ремесло. После этого, человек имеет возможность менеджерить такие проекты хорошо. Но если он хороший программист — зачем ему менеджерить? Я думаю, что большинство хороших прогеров не хотят перерастать в менеджеров.
Если же менеджер не был программистом, то программистам придется выпрашивать (в буквальном смысле) время на рефакторинг/тесты/песочницы.pansa
12.07.2018 21:42А я не соглашусь с вами, менеджер и программист- очень разные активности. Безусловно, менеджер должен понимать тех детали, но это верно для любых профессий.
Судя по зарубежной литературе, хороший менеджер — это мировая проблема :) Вон, старик Брукс аж бестселлер написал про пули и… про то, как он развалил проект ОС/360 :)
А вообще я думаю, что хорошего менеджера практически не должно быть заметно. И это его основная цель: команда должна работать эффективно что с ним, что без. Но чтобы этого достич, нужен хороший менеджер, такая фигня :)staticY
13.07.2018 11:37Я немного криво выразился, с моей точки зрения — хороший менеджер получается из хорошего программиста. Но это не означает, что хороший программист станет хорошим менеджером. Быть хорошим прогером — это необходимое условие, но точно, абсолютно точно — не достаточное.
Уверен, что есть исключения, представляющие из собой просто отличных менеджеров, которые ничерта не смыслят в низкоуровневых слоях.
exmachine
13.07.2018 16:49Я думаю, что большинство хороших прогеров не хотят перерастать в менеджеров.
Если же менеджер не был программистом, то программистам придется выпрашивать (в буквальном смысле) время на рефакторинг/тесты/песочницы.
Когда программист идет в менеджеры, это не профессиональный рост, это просто человек уперся в пололок в своей области.
Хорошему менеджеру проекта не необходим опыт разработки, он оперирует другими категориями. Это план выпуска фич, список срочных фиксов, зависимости между задачами, возможность замены разработчика на задаче и т.д.
Вы как программист, можете обосновать необходимость юнит-тестов или рефакторинга? Но так, чтобы было понятно, почему это будет полезно проекту?
Например, юнит-тесты конечному продукту не нужны. Но при последующей разработке пригодятся. Это фиксация функционала и другой разработчик (низко квалифицированный или не погруженный в задачу) не сломает бизнес логику выпустив фикс. Это максимально ранее обнаружение ошибок, т.е. экономит время разработчика.
К конечном итоге это выбор руководства проекта: выпустить фичу позже без технического долга или выпустить фичу быстрее и замедлить дальнейшее развитие.
Попробуйте обосновать рефакторинг. Например, отделение в бэкенде слоя доступа к данным (DAL)
acsent1
12.07.2018 11:19А почему типовое решение для очереди не взяли, какую-нибудь Кафку, например?
mad_nazgul
12.07.2018 13:05Кафка это не совсем очередь, даже совсем не очередь.
Но продукт почти гениальный в простоте своей концепции :-)
x67
12.07.2018 14:48Не понятны два момента:
- Чего плохого в общих библиотеках? Они остаются общими, пока могут такими быть. Требования меняются — меняется и код. И не надо пытаться сохранить его, закостылив в "общей" библиотеке ради общности
- Вы сначала перешли на отдельные очереди с раздельным управлением, испытывая проблемы с отказоустойчивостью, а потом психанули и перешли на centrifuge, опять создав проблемы с отказоустойчовостью?
Если я правильно понял, то проблемы у вас были две — микросервисы ради микросервисов и общие библиотеки ради общих библиотек
VolCh
12.07.2018 15:48Общие библиотеки, насколько я понимаю, ради DRY и единообразности, уменьшения порога входа в микросервис.
mayorovp
12.07.2018 15:50Они бы создали проблемы с отказоустойчивостью если бы перешли на общую очередь. Но centrifuge, судя по описанию, такой общей очередью не является.
powerman
12.07.2018 17:54Выше VolCh ответил зачем им понадобились общие библиотеки. Но суровая правда в том, что общих библиотек, действительно, быть не должно.
Звучит как бред, да, я знаю. Но причина такого жёсткого требования в том, что "библиотеки проекта" (а речь именно о них) обычно не являются "настоящими" библиотеками — такими, как сторонние библиотеки, которыми без проблем пользуется любой проект. Выше уже упоминали, что проблема в том, что нужно было эти общие библиотеки писать как отдельное опенсорсное решение, и это правда — при таком подходе ими можно было бы пользоваться.
Проблема с общими библиотеками возникает из-за того, что, поскольку это "библиотеки проекта", они не пишутся настолько аккуратно, как опенсорсные, в них нет такого тщательного соблюдения semver и обратной совместимости API, они не являются настолько библиотеками общего назначения и в них проникает бизнес-логика этого проекта, и в следствие всего этого к ним предъявляется нетипичное требование "все микросервисы обязаны использовать последнюю версию этих библиотек". В результате общие библиотеки создают жёсткую связь между всеми микросервисами и появляется точка, в которой можно все микросервисы поломать, точка, обновление которой вызывает лавину перевыкатов всех микросервисов, точка, которая создаёт больше проблем, чем решает. Вот поэтому общих библиотек проекта у микросервисов быть не должно. А общие опенсорсные — без проблем, причём одна и та же библиотека может в разных микросервисах использоваться разной версии.
VolCh
12.07.2018 19:15+1Вот поэтому общих библиотек проекта у микросервисов быть не должно.
Как минимум, имеют право на жизнь, библиотеки проекта/продукта, инкапсулирующие конкретный способ использование других микросервисов, например икапсулирующие HTTP-проткол.
powerman
12.07.2018 19:54-1Либо эти библиотеки получаются достаточно "общего назначения", и тогда проще писать их как опенсорсные и не выдвигать жёсткого требования что все микросервисы обязаны ими пользоваться, либо этот код получается достаточно специфичным для проекта, и в этом случае я предпочитаю держать его в отдельном репо-шаблоне для создания новых микросервисов.
В случае с шаблоном мы получаем возможность быстро создать типичный микросервис с типичными реализациями всякой сетевой фигни вроде работы с реестром сервисов, поддержкой контекста запросов, логирования, etc. — но поскольку после момента создания нового микросервиса он никак не привязан к этому шаблону и все, условно, "общие библиотеки проекта" он получает в виде копии в момент создания из шаблона, то у него нет никаких общих зависимостей с другими микросервисами, что снимает проблему.
VolCh
13.07.2018 08:17Я кажется понимаю о чём вы, но я о другом. Я о библиотеках, реализующих клиентов к микросервису. Есть, например, сервис работы с пользователями, предоставляющий REST API, которым пользуются все остальные сервисы. Вместе с сервисом разрабытываем библиотеку, которая будет экспортировать классы User и UserRepository и прятать от остальных сервисов факт наличия REST API и вообще факт межпроцессного взаимодействия. Клиентский сервис работает с сервисом пользователей через эту библиотеку даже не подозревая о том, что там идут вызовы по сети. Цикл мажорных и минорных релизов библиотеки совпадает с циклом релизов сервиса пользователей.
powerman
13.07.2018 08:45Пока использование всеми сервисами этой библиотеки вообще, и только её последней версии в частности, не является обязательным — никаких проблем. Если сервисы предоставляют стабильное и документированное API, а библиотека существует исключительно для удобства разработчиков тех сервисов, которым лень напрямую вызывать REST API — всё в порядке. Как только библиотека начинает использоваться для сокрытия факта нестабильности и/или недокументированности API, что и приводит к требованию её обязательного использования причём только последней версии, вот тогда возникает та проблема, из-за которой "общих библиотек проекта быть не должно".
VolCh
13.07.2018 11:25Версия библиотеки определяется используемой версией API сервиса. Если есть требования использования только последней версии API сервиса, если он не поддерживает обратную совместимость, например в целях сокращения расходов на поддержку, то хочешь-не хочешь, нужно использовать последнюю версию библиотеки. И это гораздо меньшее зло, чем «самодельные» адаптеры в каждом клиентском сервисе, делающие в целом одно и то же, но немного по разному. А, главное, требующие индвидуального переписывания при обновлении API.
Цель подобных библиотек как раз уменьшения количества зависимого от API сервиса кода, чтобы при изменении API сервиса достаточно было обновить только библиотеку на клиентах (естественно, если API библиотеки не изменился), а не переписывать код самих клиентов. Ну и в целом она сама может являться документацией к сервису.mayorovp
13.07.2018 13:04+1Вот именно от обратно несовместимого API сервисов и проблемы. Иногда это нужно, но если такое постоянно — значит, микросервисы используются как-то неправильно.
mad_nazgul
13.07.2018 05:38Общие библиотеки у проекта могут быть, но это не должно быть догмой.
Т.е. их использование не должно быть обязательным.
В противном случае — да получаем монолит в библиотеках.
alec_kalinin
Спасибо за статью! Я буду благодарен, если вы поделитесь своим мнением по следующему вопросу.
Еще начиная с известного спора Линуса с Таненбаумом о микросервисной архитектуре, я не понимал почему их так сильно противопоставляют. Даже если мы имеем монолитный сервис, все равно у нас есть такое же разделение на микросервисы, только выполненное на уровне исходного кода. Это декомпозиция кода на модули, методы и определение четких интерфейсов взаимодействия между разными вызовами.
Так ли это важно, на каком уровне выполнена декомпозиция на отдельные независимо работающие части кода?
onyxmaster
Я отмечу, что это перевод, может быть вы не там спрашиваете.
Я не автор, но отмечу, что на мой взгляд микросервисная архитектура в первую очередь решает кадрово-организационный вопрос быстрого роста команды, всё остальное вторично.
zelenin
микросервисы — это про горизонтальное масштабирование. Монолит плохо и нерационально масштабируется.
andreylartsev
То что описано в статье по вашему монолит?
zelenin
я лишь ответил на коммент — где происходит декомпозиция важно, т.к. цель микросервисов — достичь хорошего масштабирования. Декомпозиция внутри приложения на это никак не влияет.
А в статье что-то странное, оценивать не буду.
powerman
В большинстве случаев декомпозиция в монолите выполнена намного хуже, чем в микросервисах. Типичный пример — у каждого stateful микросервиса обязательно собственная БД. В монолитах использование десятка разных БД (хотя бы на уровне разных логинов и database в одном MySQL) практикуется… практически никогда. Помимо изоляции данных, далеко не каждый язык программирования позволяет действительно надёжно изолировать разные части монолита друг от друга, не на уровне соглашений между разработчиками, а с жёстким контролем средствами языка (напр. в Go поддержка internal пакетов появилась всего 3 года назад).
В результате контроль изоляции разных частей монолита остаётся на ответственности и внимательности самих разработчиков, что, очевидно, не работает и не может работать с достаточно большими приложениями, командами, и дедлайнами.
Так что в теории да, можно делать микросервисы внутри монолита (встроенные микросервисы), но на практике это пока редко встречается.
igor_suhorukov
OSGI как раз мотивирует создавать такие приложения и в случае необходимости можно разнести сервисы из одного процесса в несколько на разных узлах используя DOSGI.
DeusModus
Разве декомпозиция напрямую зависит от выбора архитектурного паттерна монолит/SOA?
Значит ли это, что мир монолитных приложений погряз в проблемах композиции?
На какие практики или исследования вы опираетесь?
Исходя из моего опыта продуктовой разработки ваше утверждение ложно.
Поясните, пожалуйста, почему SOLID и GRASP не подходят, а требуются какие-то жесткие средства языка.
Обладают ли этими жесткими средствами C++/C/C#/JAVA?
Можете пояснить ваш use-case использования internal packages в контексте замены SOA на монолит?
Есть какие-то исследования, что все ПО написанное до второго бума SOA «не работает»?
Chromium/V8 тоже не работают?
powerman
Ну что Вам сказать… В теории Вы правы, это может работать так, как Вы описываете. Но, хотя в теории теория и практика различаться не должны, на практике они различаются.
В теории — нет. Но на практике эта зависимость однозначно наблюдается. Проблема в том, что если у разработчиков есть возможность (а в монолите — она обычно есть) нарушить архитектуру и сделать что-то неправильно, создать какие-то связи между компонентами, которых быть не должно — они сделают это, причём скорее рано, нежели поздно. Из-за отсутствия квалификации, понимания, или просто времени на то, чтобы сделать "правильно". В SOA намного сложнее и дольше создать такие некорректные связи, потому что для того, чтобы добраться до недоступного через API функционала стороннего сервиса из другого сервиса сначала надо изменить и выкатить первый сервис, добавив в него дополнительное API. Эта дополнительная сложность создаёт препятствие, которое довольно эффективно мешает портить текущую архитектуру. Конечно, при наличии должной степени упёртости можно и это преодолеть, но обычно архитектуру портят не из желания сделать гадость, а из желания сделать проще/быстрее — и вот в SOA делать такие вещи уже ни разу не проще и не быстрее, что очень помогает.
Не то, чтобы буквально погряз… но да, архитектурный паттерн big ball of mud определённо появился в монолитах, и, насколько мне известно, в микросервисах пока не встречался.
Лично я прямо сейчас пишу что-то вроде монолита/встроенных микросервисов, и у меня в одном приложении несколько изолированных логинов и database в MySQL. Тем не менее, где либо кроме своих собственных проектов я этого подхода не видел, ни в компаниях, ни в опенсорс-проектах. Так что хотелось бы узнать про Ваш опыт подробнее — где (кроме собственных проектов) Вы такое видели, и как часто это встречается.
Потому, что наличие в монолите какой-то библиотеки/класса с публичным интерфейсом ещё не означает, что ими можно пользоваться из любой части монолита.
Я не эксперт в этих языках, так что с гарантией не скажу. Насколько мне известно — скорее нет.
Пакеты в подкаталоге internal/ в Go не доступны никому в родительских/соседних каталогах, что позволяет гарантировать что вызывать эти библиотеки/классы из другой части монолита не получится, если только не открыть к ним явно доступ через API пакета находящегося в том же каталоге, что и internal. Этот подход вполне соответствует стилю работы с микросервисами — не важно, какой код доступен внутри микросервиса, снаружи есть доступ только к тому, к чему явно предоставили API.
Не надо передёргивать, я лично таких утверждений не делал. Если хотите услышать утверждения, с которым можно всласть поспорить — пожалуйста:
По моим наблюдениям, микросервисы требуют заметно большей квалификации от архитектора и меньшей квалификации от разработчиков, чем небольшие монолиты… но большие качественные монолиты, которые не тонут в растущей сложности и не превращаются в большой комок грязи, требуют такой же (а может и большей) квалификации архитектора как микросервисы плюс намного большей квалификации разработчиков, чем микросервисы. Иными словами, без хорошего архитектора к микросервисам подступаться бессмысленно. А с хорошим архитектором и средней командой разработчиков можно осилить микросервисы, но не большой и сложный монолит. Ещё иными словами: нормально написать большой монолит тупо дороже, чем то же самое на микросервисах. Идея со встроенными микросервисами в том, что они должны оказаться заметно дешевле обычных микросервисов, ценой потери незначительных для большинства проектов возможностей (разные ЯП в одном проекте, запуск разных частей проекта на разных серверах).
Tiendil
В микросервисах он мигрировал на следующий уровень абстракции :-) и может быть найден в скриптах деплоя и конфигах.
powerman
Есть такое. Но там small ball of mud :) — сколько там тех конфигов и скриптов, по сравнению с общим объёмом проекта.
stychos
Прошу прощения, вопрос Вы не мне адресовали, но моё личное мнение такое: когда разделение идёт на высоких уровнях, то возникают дополнительные накладные расходы на взаимодействие, в случае с контейнерами это вообще происходит по сети, что очень медленно. Даже если в исходном коде все данные будут передаваться по значениям а не ссылкам (через копирование), это всё равно получится быстрее в разы.
qw1
Производительность складывается из latency + throughput.
Какой-бы не был супер-монолит, с передачей всего по ссылкам и прочими ультра-оптимизациями, настанет момент, когда одного сервера перестанет хватать. Но всегда есть функциональность, которую нельзя просто накопипастить по серверам без взаимодействия между ними (например, регистрация аккаунта с проверкой уже занятых логинов), или ведение сессий пользователя. Появится необходимость специализации серверов, и это ведёт к сервисам.
VolCh
Ну, по сути, более-менее серьёзное веб-приложение состоит по умолчанию в наше время из двух-трёх сервисов типа веб-сервер, апп-сервер (может быть реализован как модуль веб-сервера), сервер СУБД. Причём первые два обычно легко горизонтально масштабируются.
demimurych
В случае Таненбаума и Линуса речь шла совсем не о том же самом что в статье. Точнее эти два спора нельзя сравнивать в принципе из за совершенно разных задач и рисков проектов. То есть риски Ядра операционной системы не всегда и не везде можно сравнивать с рисками веб проекта. Иначе говоря всему свое место.
mad_nazgul
Спор Линуса и Таненбаума, о том, что Линус говорил, что «сложность» никуда не девается.
Просто «сложность» ядра, переносится в «сложность» взаимодействия между микроядрами.
И он прав.
В микросервисной архитектуре сложность «монолита» переносится на «сложность» взаимодействия между микросервисами.