
Несколько месяцев назад вышла первая версия Kepler.gl — нового Open Source инструмента для визуализации и анализа больших наборов гео-данных.
В этой статье я предлагаю вам познакомится с основными возможностями приложения и создать с его помощью две картографические визуализации, которые позволят нам узнать несколько интересных фактов о платных парковках Москвы.
Но сперва несколько слов о том, кто и зачем создал Kepler.gl
Изначально Kepler.Gl создавался командой Uber Engineering для аналитиков компании, которые хотели лучше понимать «как движется город», используя для этого огромное количество геоинформационных данных о дорожном движении, ежедневно собираемых тысячами «уберов» в различных городах по всему миру.
Однако в мае этого года компания сообщила об открытом доступе к данному приложению и выложила весь исходный код Kepler.gl на GitHub
Основные возможности Kepler.gl
Независимо от выбранных инструментов анализа данных, применяемых картографических сервисов или фреймворков, а также библиотек для создания различных визуализаций, сам процесс работы над ними сводится к 4 основным этапам:
- сбор информации
- обработка данных
- исследование и анализ подготовленных данных (для выявления зависимостей, поиска аномалий и т.д.)
- создание визуализаций
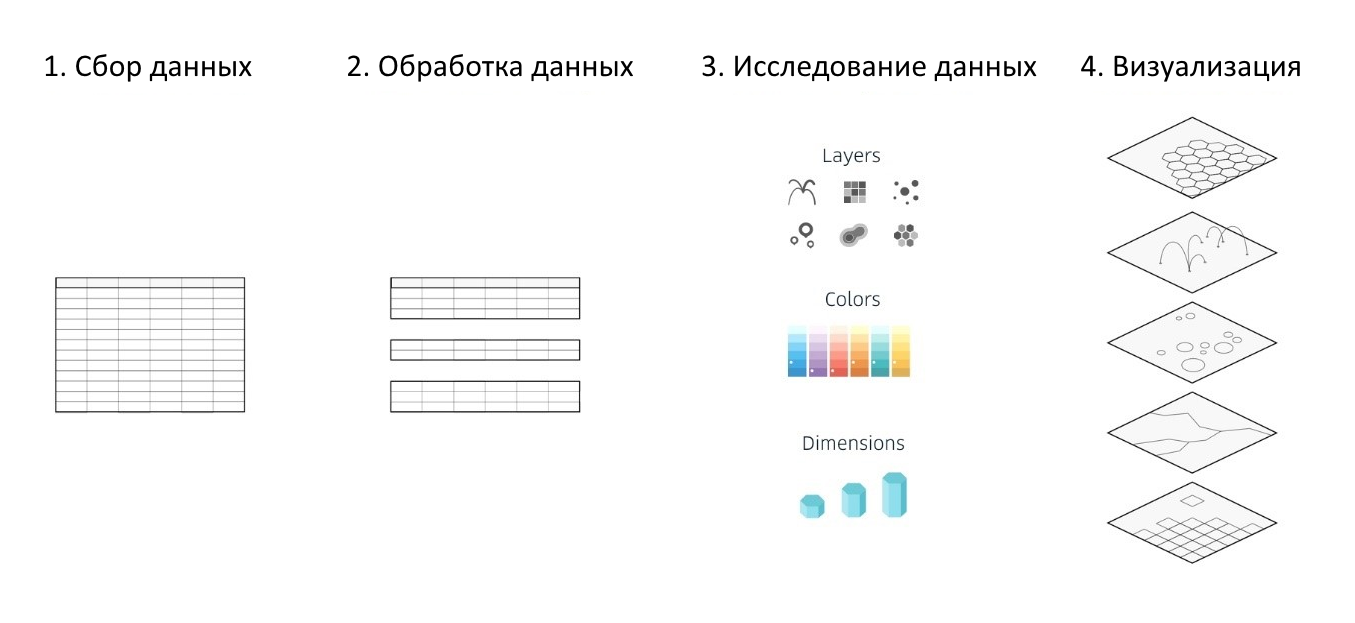
Рисунок 1. Базовые этапы создания визуализации
Kepler.gl частично автоматизирует и упрощает 3 из 4 перечесленных этапов, что заметно упрощает весь процесс анализа и визуализации больших наборов данных и помогает буквально за полчаса создать информативную, и что немаловажно, красочную интерактивную карту на основе собственных наборов гео-данных.
При этом, опыта программирования или дизайна абсолютно не требуется, ведь фильтрация и агрегация данных, выбор способа отображения данных в зависимости от различных параметров исследуемых объектов, наложение сведений из различных источников, переключение между 2D и 3D режимами и многое другое настраивается с помощью UI панели.
Как использовать Kepler.gl для анализа данных
Проще всего начать свое знакомство с Kepler.gl используя его онлайн-версию, доступную по адресу kepler.gl или, если вы не доверяете сторонних серверам, можно развернуть у себя локальную версию, следуя инструкциям на GitHub.
Здесь и далее я буду использовать данные о «Платных парковках Москвы», предоставляемые «Порталом открытых данных» правительства Москвы. Этот набор содержит сведения о более чем 9 тысячах объектов, расположенных на уличной сети, включая сведения о стоимости и количестве парковочных мест.
Этап 1. Загрузка данных
На сегодняшний день Kepler.gl поддерживает 3 формата исходных данных: geojson, json и csv. Сохранив данные в одном указанных форматов (в данном примере использую .csv) просто загружаем их в приложение. Кстати, здесь же, в диалоговом окне загрузки, для знакомства с приложением вы так же можете воспользоваться один из десятка предустановленных тестовых наборов данных.
Примечание. Для Chrome максимальный размер загружаемого файла не должен превышать 250Mb. Создатели Kepler.gl предлагают использовать Safari, если вам требуется загрузить файл большего объема. Однако, в любом случае нужно помнить, что производительность приложения зависит от устройства, на котором оно запущено. Ведь все манипуляции, связанные с агрегацией, фильтрацией и отображением данных происходят на клиенте.
Этап 2. Отображение данных на карте
Приложение поддерживает 9 типов слоев визуализации (layer of data visualization), отличающихся друг от друга набором настраиваемых параметров:
- точечный слой (Point)
- слой дуг (Arc)
- слой линий (Line)
- сетка (Grid)
- гексагональная сетка (Hexbin)
- слой полигоны (Poligon)
- слой кластеров (Claster)
- слой иконок (Icon)
- тепловая карта (Heatmap)
При этом даже слои одинакового типа, отображающие один и тот же набор данных, могут разительно отличаться в зависимости от выбранной конфигурации.

Рисунок 2. Карты созданные в kepler.gl с помощью различных типов слоев
Kepler.gl не ограничивает число слоев, используемых при отображении исследуемого набора данных. Слои отрисовываются на карте в том же порядке, в каком они расположены в списке слоев на боковой панели. Эту очередность легко изменить простым перетягиванием соответствующих слоев друг относительно друга на вкладке Layers.
При использовании нескольких слоев стоит обратить внимание на параметр “Layer Blending”, отвечающий за то, как слои накладываются друг на друга. Он является единым в рамках всей визуализации, что не дает возможности использовать различные типы смешивания для различных слоев.
В настоящее время доступны три значения этого параметра:
- Normal
В этом случае нижние слои никак не влияют на цвет точек(или иных элементов) верхних слоев.
- Additive
При этом типе наложения, значения цвета совпадающих элементов складываются. Он удобен для выявления областей высокой плотности, которые в данном случае будут более светлыми. - Subtractive
В отличае от additive, не складывает, а вычитает значение цветов в пересекающихся областях. Удобен при использования не темной, а светлой карты.
Таким образом, чтобы увидеть наши данные на карте, необходимо создать хотя бы один слой, использующий их. Стоит отметить, что после загрузки файла, Kepler.gl попытается определить поля, содержащие геолокационную информацию и мгновенно отобразить их, автоматически создав слои соответствующих типов (обычно point или polygon).
Однако, в нашем случае из-за различия в ожидаемом и используемом форматах данных, прийдется указывать источник координат самостоятельно. Для этого сначала удалим созданные Kepler.gl слои полигонов, а затем добавим новый слой типа Point вручную. В качестве источника координат используем поля «Latitude_WGS84» и «Longitude_WGS84» вместо поля «Coordinates», автоматически выбранного приложением для рендеринга данных на карте.
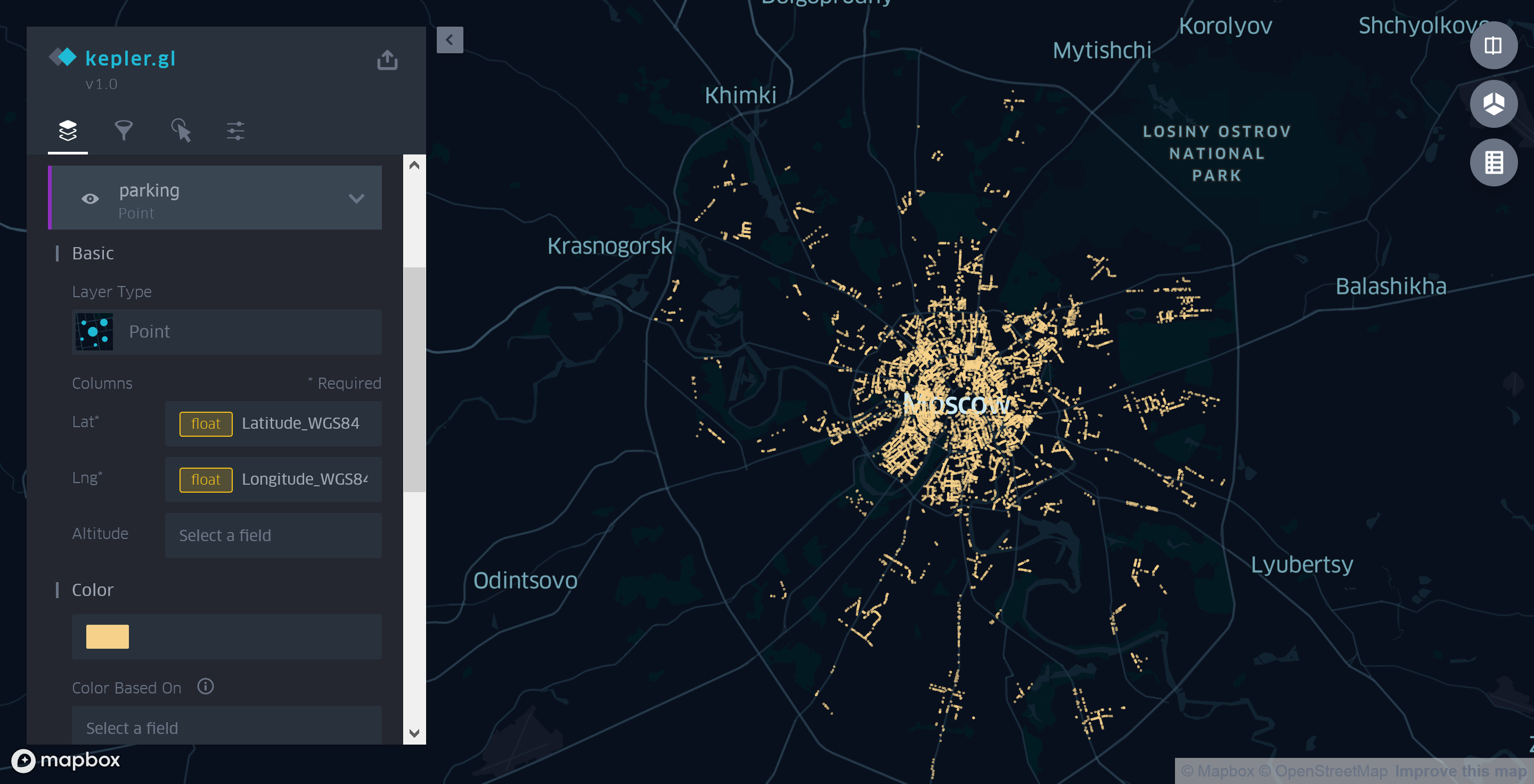
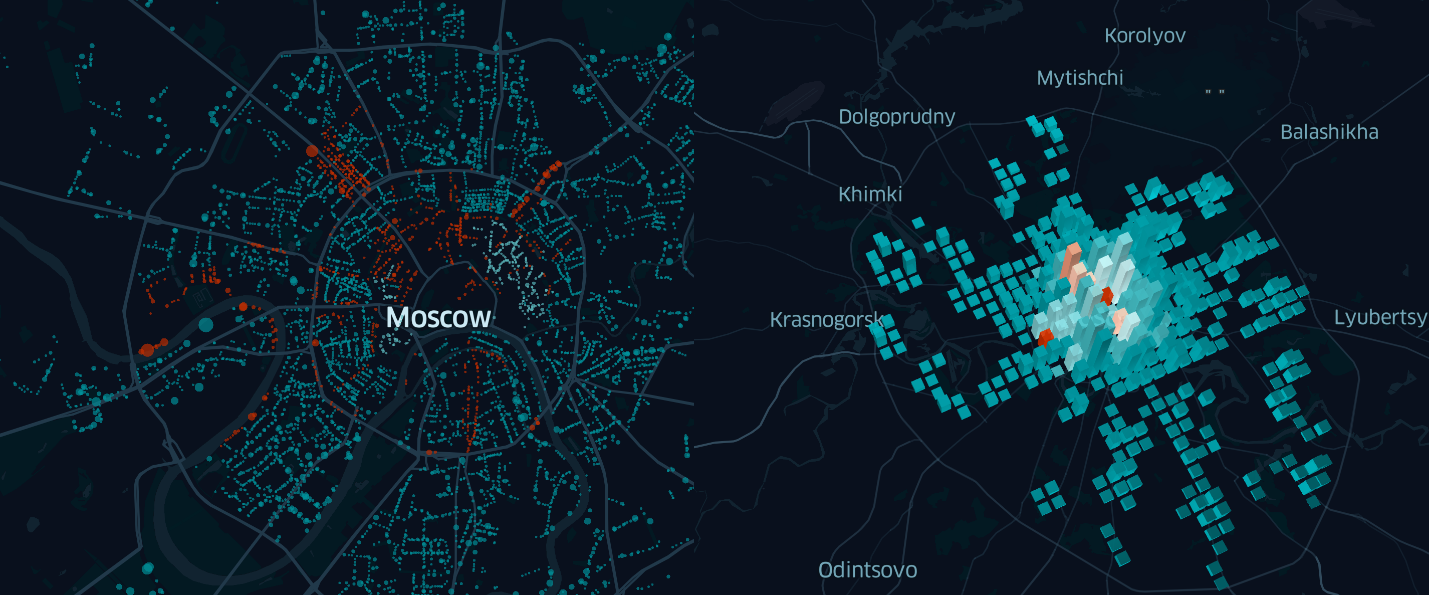
Рисунок 3. Использование точечного слоя Kepler.gl для отображения парковок Москвы
В таком варианте карта еще не очень информативна. Единственное, что можно сказать, глядя на нее, что в центре парковок больше, чем на окраинах.
А значит, пришло время воспользоваться и другими сведениями об изучаемых объектах для более детального анализа и поиска интересных фактов и/или закономерностей.
Этап 3. Модификация внешнего вида карты на основе сопутствующих данных об отображаемых объектах
В скаченном с Портала открытых данных наборе содержится достаточно много сведений о каждой из парковок, однако, наиболее интересными мне показались два параметра – стоимость часа парковки и число доступных мест.
Где в Москве самые дорогие парковки? Есть ли зависимость между размером парковки и ее удаленности от цента? На сколько сильно отличается стоимость часа парковки внутри и за пределами Садового кольца? Чтобы ответить на эти вопросы нам достаточно немного изменить настройки отображения ранее созданного точечного слоя и снова взглянуть на карту.
Для начала изменим цвет точек в зависимости от стоимости часа парковки в этом месте. Для этого в выпадающем списке «Color based on» в качестве основы для выбора цвета укажем параметр «Price» исходного набора данных.

Рисунок 4. Использование цвета для отображения сведений о стоимости часа парковки
Уже на этом этапе можно сделать несколько интересных наблюдений. Например, что не весь центр одинаково дорог для автомобилистов, но на Тверской лучше быть пешеходом
Теперь посмотрим на вместимость парковок. Для этого в качестве базового параметра для определения радиуса точки (атрибут «Radius Based On» точечного слоя) будем использовать поле «CarCapacity». Диапазон радиуса установим равным от 0 до 30px.

Рисунок 5. Кастомизация размера точек в зависимости от числа парковочных мест
Таким образом, наша карта парковок буквально за несколько минут стала заметно информативнее. Теперь даже беглый взгляд на нее позволяет не только сравнить ценовую политику различных районов города, но и примерно оценить свои шансы найти свободное место учитывая не только число парковок в окрестности, но и их вместительность.
Этап 4. Агрегация данных с помощью Kepler.gl
Использование точечного слоя для отображения каждой из более чем 9000 парковок уже позволило нам сделать несколько интересных наблюдений, однако полученная карта не дает нам возможности легко ответить на такие вопросы, как «Где больше всего парковочных мест на единицу площади?». Для ответа на него нам нужно воспользоваться одним из агрегирующих слоев.
На текущий момент, Kepler.Gl поддерживает 4 типа таких слоев: сетка (Grid), гексагональная сетка (Hexbin), тепловая карта (Heatmap) и кластер (Cluster). Последние два типа (Cluster и Heatmap) удобны в случае, когда требуется агрегировать данные только по одному параметру. Сетка и гексагональная сетка же позволяют проанализировать агрегированные значения по нескольким параметрам одновременно.
Для ответа на поставленный ранее вопрос мы изменим тип ранее созданного нами точечного слоя на «сетку» (Grid), это позволит не только оценить общее количество парковочных мест на единицу площади, но и сохранить информацию о средней стоимости часа стоянки в этом месте.
Зададим размер сетки 1км2 (минимально доступный в Kepler.gl). Значение параметра Покрытие (Coverage) уменьшим с 1 до 0.7 для того, чтобы между ячейками появилось небольшое пространство, улучшающее читаемость финальной карты.
Примечание. Список доступных для кастомизации параметров меняется в зависимости от выбранного типа слоя. Более подробно с атрибутами, поддерживаемыми каждым из них, вы можете познакомится в официальной документации Kepler.gl.
Цвет каждой ячейки в новой визуализации как и раньше будет зависеть от стоимости часа парковки. Однако теперь, кроме названия поля в используемом наборе данных, нам требуется еще указать каким образом Kepler.gl будет агрегировать эти сведения. Методы агрегации зависят от типа выбранного поля. В нашем случае «Price»– числовой тип(int) и приложение предлагает один из 5 вариантов:
- наибольшее значение (minimum)
- наименьшее значение (maximum)
- сумма (sum)
- среднее значение (average)
- медиана (median)
Высота же каждого из столбцов сетки будет отражать общее число парковочных мест на данном участке. Для этого перейдем в 3D-режим просмотра карты. Затем на вкладке «Слои» боковой панели укажем «Enable height» для нашего агрегирующего слоя, а в качестве базового параметра выберем поле «CarCapacity».
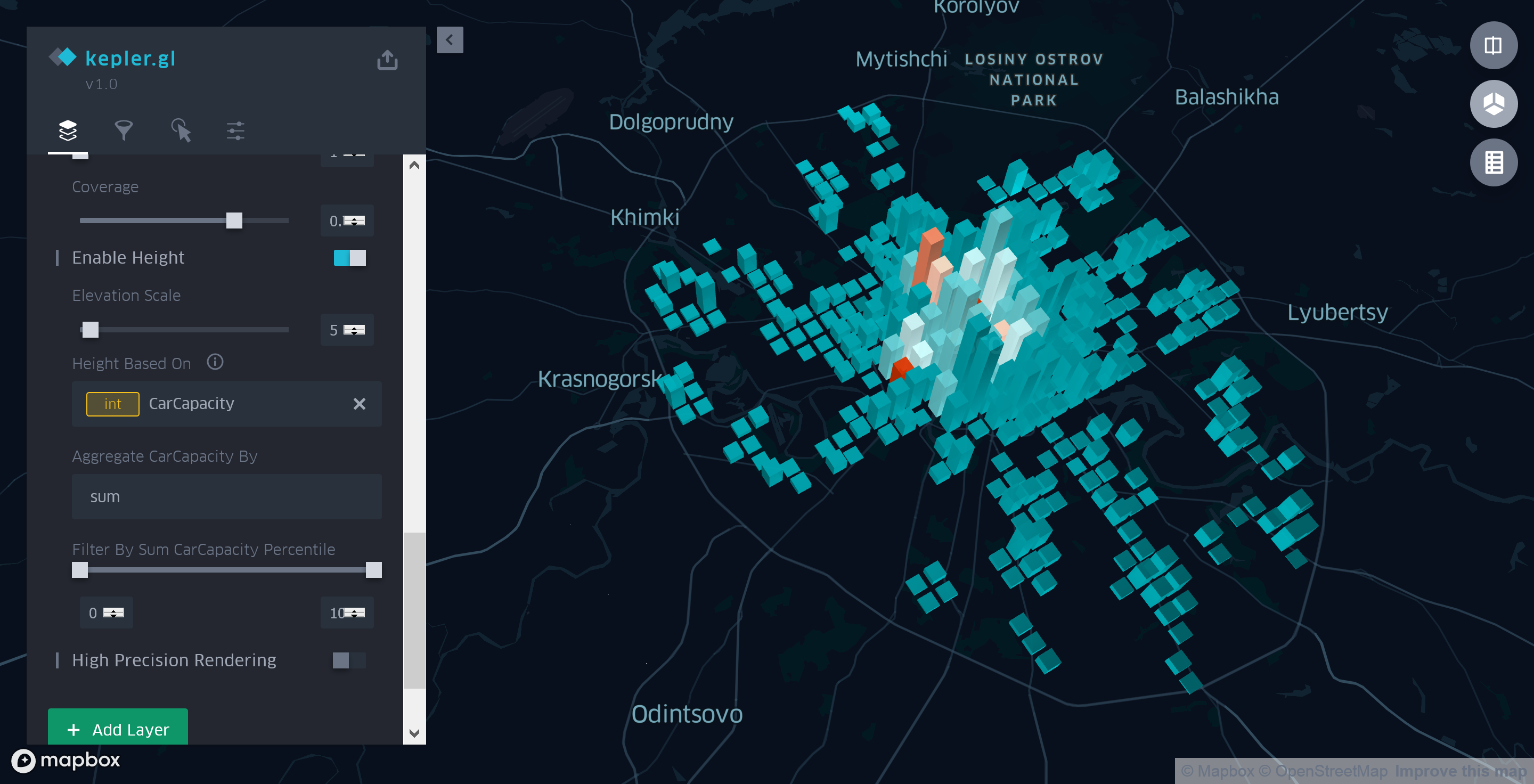
Рисунок 6. Обобщенные сведения о стоимосте и вместительности парковок
Таким образом, потратив еще несколько минут на настройку агрегирующего слоя, мы можем с уверенностью утверждать, что внутри Садового кольца не только число парковок, но и фактическое количество парковочных мест значительно больше, чем за его пределами.
Заключение
В этой статье на конкретном примере была рассмотрена лишь часть возможностей Kepler.gl как современного инструмента для визуализации и базового анализа различных гео-данных. Если вас заинтересовало это приложение, я рекомендую вам так же ознакомится с приведенными ниже статьями и туториалами, а также самостоятельно поэкспериментировать с фильтрацией данных, настройкой всплывающих подсказок и стилей карты и другими фичами этого приложения.
А в следующей статье я расскажу вам о способах поделится созданными вами визуализациями и картами, а так же об использовании Kepler.gl как React компонента для вашего веб-приложения.
Полезные ссылки
- Репозиторий Kepler.Gl на GitHub
- Подробная информация о Kepler.gl от его создателя на сайте Uber: «From Beautiful Maps to Actionable Insights: Introducing kepler.gl, Uber’s Open Source Geospatial Toolbox»
- Интервью с разработчиком Kepler.Gl Шен Хи
Комментарии (7)

lokks
31.07.2018 20:32Сервис действительно очень хорош для визуализации данных!
Понравилась поддержка отображения тысяч точек прямо на клиенте — спасибо работе с видеокартой — всё работает реально быстро.
Ещё хорошо сделана работа «из коробки», а точнее прямо из csv по отображению временно составляющей. Буквально за 10 минут можно записать такое видео
youtu.be/5XjJD29ot3U
В общем продукт получается годным, но были вопросы по поддержке кириллицы во всех его разделах, и кастомизации цветов в легенде — стандартные не всегда хорошо ложатся.maryzam Автор
31.07.2018 20:51Да, у Kepler впечатляющая способность работать с действительно большими объемами гео-информации. Мой пример с 9 тысячами точек «простоват» и не показывает всей мощи приложения (при учете, что ваш девайс достаточно мощен для подобных вычислений).
Kepler.gl построен на основе другого Open Source проекта Uber под названием desk.gl, которая собственно и является ключом к его производительности.
На счет поддержки кирилицы действительно есть ньюансы с кодировкой.
По поводу же собстенных наборов цветов для визуализации — это доступная опция, пусть и не через UI (по крайней мере в данной версии). Для этого нужно сначала экспортировать конфигурационный файл карты, для которой вы планируете задать собстенную цветовую палитру. Затем заменить массив цветов в «ColorRange» для соответствующих слоев и загрузить обновленный файл в приложение через окно загрузки файлов. Все.
vics001
31.07.2018 20:45Есть инструкция как из OSM данных получить такую визуализацию?
maryzam Автор
31.07.2018 20:56+1Текущая версия Kepler.gl не поддерживает OSM формат данных. Самое простое, что мне приходит на ум, это переконверировать OSM в geojson формат и использовать его для работы с приложением.
TimsTims
PS: за Kepler спасибо!
maryzam Автор
Да, конечно вы правы, в статье идет речь только о платных парковках на улично-дорожной сети. Я ограничилась лишь одним набором данных для того, чтобы познакомить всех заинтересовавшихся с базовыми фичами Kepler.
Но, возможно, стоило бы привести пример с использованием нескольких источников данных (что, кстати, Kepler отлично умеет), и добавить сведения о других типах парковки и иные сопутствующие данные. Но это само по себе уже отдельная тема.
Пожалуйста! Это действительно стоящий сервис.