

Современные системы безопасности ОЧЕНЬ прожорливы до ресурсов. Почему? Потому что они считают больше, чем многие продакшн-сервера и системы бизнес-аналитики.
Что они считают? Сейчас объясню. Начнём с простого: условно первое поколение защитных устройств было очень простым — на уровне «пускать» и «не пускать». Например, файерволл пускал трафик по определённым правилам и не пускал трафик по другим. Естественно, для этого особая вычислительная мощность не нужна.
Следующее поколение обзавелось более сложными правилами. Так, появились репутационные системы, которые в зависимости от странных действий пользователей и изменений в бизнес-процессах присваивали им рейтинг надёжности по заранее заданным шаблонам и выставленным вручную порогам срабатывания.
Сейчас системы UBA (User Behavior Analytics) анализируют поведение пользователей, сравнивая их с другими сотрудниками компании, и оценивают логичность и правильность каждого действия сотрудника. Делается это за счёт Data Lake-методов и довольно ресурсоемкой, но автоматизированной обработки алгоритмами машинного обучения — в первую очередь потому, что прописывать все возможные сценарии руками занимает несколько тысяч человеко-дней.
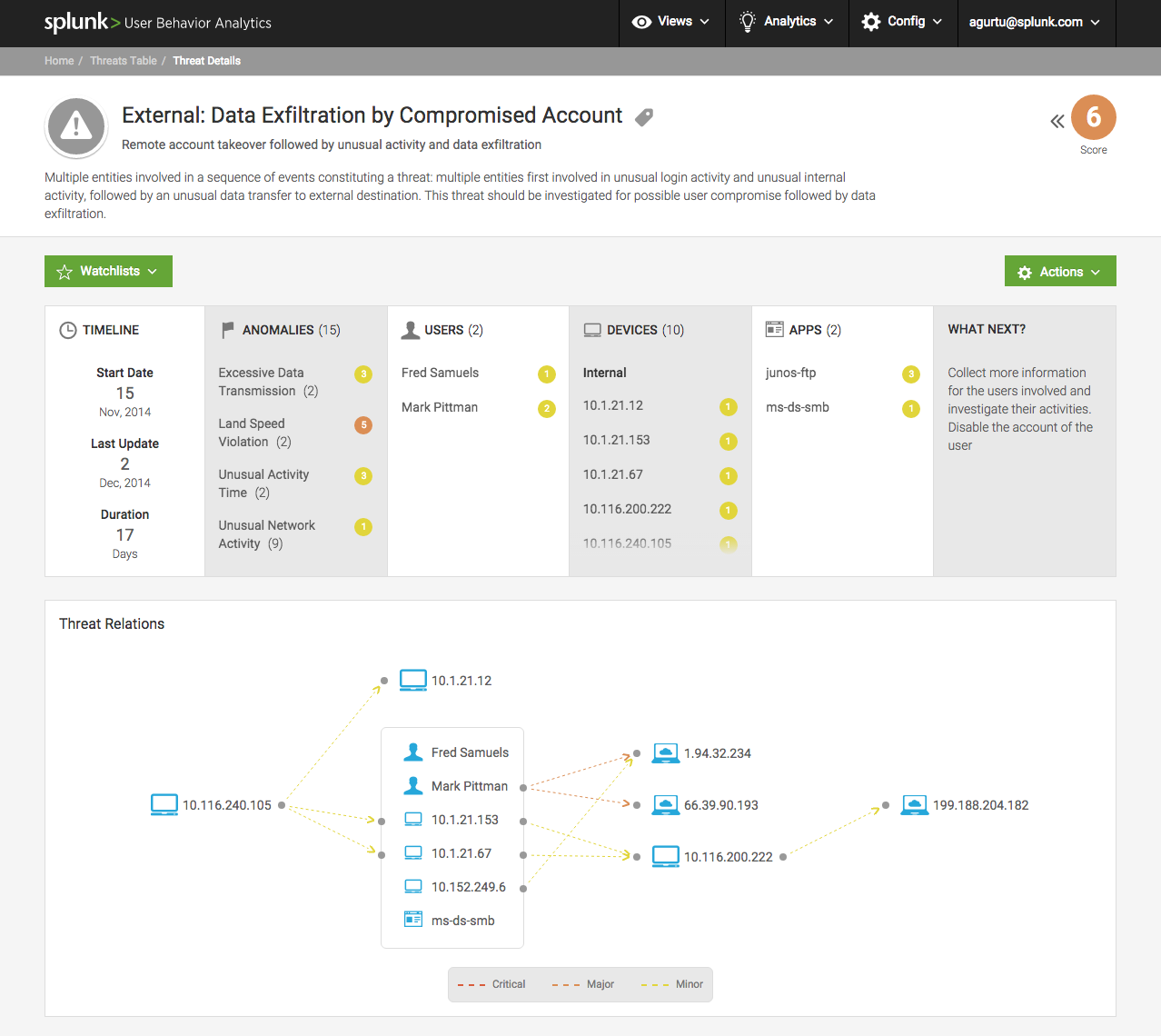
Классический SIEM
Примерно до 2016 года прогрессивным считался подход, когда все события со всех сетевых узлов собираются в какое-то одно место, где стоит сервер аналитики. Сервер аналитики умеет собирать, фильтровать события и мапить их на корреляционные правила. Например, если вдруг начинается массовая запись файлов на какой-то рабочей станции, то это может быть признак вируса-шифровальщика, а может и не быть. Но уведомление админу система на всякий случай отправит. Если станций несколько, вероятность развёртывания зловреда повышается. Надо поднять тревогу.
Если пользователь постучался в какой-то странный домен, зареганный пару недель назад, а через пару минут пошла вся эта цветомузыка, то это почти точно вирус-шифровальщик. Надо тушить АРМ и изолировать сегмент сети, параллельно оповещая админов.
SIEM сопоставлял данные от DLP, файерволла, антиспама и так далее, и это позволяло очень хорошо реагировать на разные угрозы. Слабым местом были вот эти шаблоны и триггеры — что считать опасной ситуацией, а что нет. Дальше — как в случае с вирусами и разными хитрыми DDoS — специалисты SOC-центров стали формировать свои базы признаков атак. Для каждого типа атаки рассматривался сценарий, выделялись симптомы, к ним назначались дополнительные действия. Всё это требовало непрерывной доработки и донастройки системы в режиме 24 на7.
Работает — не трогай, хорошо же всё работает!
То есть почему нельзя обойтись без UBA? Первая проблема в том, что прописать руками всё невозможно. Потому что разные сервисы ведут себя по-разному — и разные пользователи тоже. Если прописать события для среднестатистического пользователя внутри компании, поддержка, бухгалтерия, тендерный отдел и админы будут очень выделяться. Админ с точки зрения такой системы — явно злонамеренный пользователь, потому что творит много и активно лезет в неё. Поддержка злонамеренна, потому что подключается ко всем подряд. Бухгалтерия передаёт данные по шифрованным тоннелям. А тендерный отдел постоянно сливает наружу данные компании при публикации документации.
Вывод — надо прописывать сценарии использования ресурсов для каждого. Потом глубже. Потом ещё глубже. Потом что-то меняется в процессах (а такое случается каждый день) и прописывать надо заново.
Было бы логично использовать что-то вроде «скользящего среднего», когда норма для пользователя определяется автоматически. К этому мы ещё вернёмся.
Второй проблемой стало то, что злоумышленники стали в разы аккуратнее. Раньше слив данных, даже если вы пропустили сам момент взлома, было довольно легко поймать — например, хакеры могли закинуть интересующий файл себе на почту или на файлообменник и в лучшем случае шифровали в архив, чтобы избежать обнаружения DLP-системой.
Сейчас всё интереснее. Вот что мы встречали в своих SOC-центрах за последний год.
- Стеганография через отправку фотографий в Facebook. Зловред регистрировался в FB и подписывался на группу. Каждая публикуемая в группе фотография снабжалась встроенным чанком данных, содержащим указания для вредоноса. С учётом потерь при JPEG-сжатии получалось передавать около 100 байт на картинку. Также и сам вредонос выкладывал в день по 2-3 фотографии в соцсеть, чего было достаточно для передачи логинов/паролей, слитых через mimikatz.
- Заполнение форм на сайтах. Зловред запускал симулятор действий пользователя, шёл на определённые сайты, находил там формы «обратной связи» и отправлял данные через них, кодируя бинарные данные в BASE64. Это мы поймали уже на системе нового поколения. На классическом SIEM, не зная про такой способ отправки, скорее всего, ничего бы даже не заметили.
- Стандартным — увы, уже стандартным — образом подмешивали данные в DNS-трафик. Технологий стеганографии в DNS и вообще построения тоннелей через DNS довольно много, здесь акцент был не на опросе определённых доменов, а на типах запроса. Система подняла минорную тревогу по росту DNS-трафика для пользователя. Данные отправлялись медленно и через разные промежутки времени, чтобы затруднить анализ средствами защиты.
Для проникновения обычно используют строго кастомную вирусню, сделанную прямо под юзеров компании-цели. Причём атаки часто идут через промежуточное звено. Например, сначала компрометируется подрядчик, а потом уже через него зловред заносится в основную компанию.
Вирусы последних лет почти всегда сидят строго в оперативке и удаляются при первом же шухере — акцент на отсутствие следов. Форензика в таких условиях очень затруднена.
Общий результат — SIEM плохо справляется. Много что уходит из поля зрения. Примерно так на рынке возникло пустое место: чтобы систему не надо было настраивать на тип атаки, а она сама понимала, что не так.
Как это «сама понимала»?
Первыми репутационными системами безопасности были модули антифрода для защиты от отмывания денег в банках. Для банка главное — выявить все мошеннические транзакции. То есть и немного перебдеть не жалко, главное, чтобы оператор-человек понимал, к чему нужно присмотреться в первую очередь. И не был перегружен совсем мелкими тревогами.
Работают системы так:
- Они строят профиль пользователя по множеству параметров. Например, как он обычно тратит деньги: что покупает, как покупает, как быстро вводит код подтверждения, с каких устройств это делает и т. п.
- Cлой логики проверяет, можно ли успеть добраться от той точки, где была оплата, до другой точки на транспорте за срок между транзакциями. Если покупка в другом городе, проверяют, часто ли пользователь ездит в другие города, если в другой стране — часто ли пользователь бывает в других странах, а недавно купленный авиабилет добавляет шансов на то, что тревога не нужна.
- Репутационный модуль — если пользователь делает всё в рамках своего нормального поведения, то за его действия начисляются положительные баллы (очень медленно), а если в рамках нетипичного — отрицательные.
Про последнее поговорим подробнее.
Пример 1. Вы всю жизнь покупали себе пирожок и колу в Макдональдсе по пятницам, а потом внезапно купили на 500 рублей во вторник утром. Минус 2 балла за нестандартное время, минус 3 балла за нестандартную покупку. Порог срабатывания тревоги для вас установлен на –20. Ничего не происходит.
Примерно за 5-6 таких покупок вы эти баллы выведете в ноль, потому что система запомнит, что для вас зайти в Макдональдс во вторник утром — это нормально. Разумеется, я очень сильно упрощаю, но логика работы примерно такая.
Пример 2. Вы всю жизнь покупали себе разные мелкие штуки как обычный пользователь. То в продуктовом расплатитесь (система уже «знает», на какую сумму вы обычно едите и где чаще всего покупаете, — точнее, не знает, а просто пишет в профиль), то билет в метро купите на месяц, то закажете что-то небольшое через интернет-магазин. И вот вы покупаете рояль в Гонконге за 8 тысяч долларов. Могли? Могли. Давайте посмотрим на баллы: –15 за то, что это похоже на стандартный фрод, –10 за нестандартную сумму, –5 за нестандартное место и время, –5 за другую страну без покупки авиабилета, –7 за то, что вы раньше ничего не брали за рубежом, +5 за своё стандартное устройство, +5 за то, что другие пользователи банка там покупали.
Порог срабатывания тревоги для вас установлен на –20. Транзакция «подвешивается», в ситуации начинает разбираться сотрудник ИБ банка. Это очень простой случай. Скорее всего, минут через 5 он вам позвонит и скажет: «Вы правда решили купить в 4 утра что-то в музыкальном магазине в Гонконге за 8 тысяч долларов?» Если вы ответите утвердительно, вам пропустят транзакцию. Данные лягут в профиль как однажды совершённое действие, дальше за похожие действия будет даваться меньше отрицательных баллов, пока они вообще не станут нормой.
Как я уже говорил, я очень-очень упрощаю. Банки вкладывались в репутационные системы годами и годами же их оттачивали. Иначе куча мулов выводила бы деньги реально быстро.
Как это перекладывается на ИБ предприятия?
На базе алгоритмов антифрода и защиты от отмывания денег появляются системы поведенческого анализа. Собирается полный профиль пользователя: как быстро печатает, к каким ресурсам обращается, с кем взаимодействует, какой софт запускает — в общем, всё то, чем пользователь занимается каждый день.
Пример. Пользователь часто взаимодействует с 1С и часто вносит туда данные, а потом вдруг начинает выгружать всю базу в десятках мелких отчётов. Его поведение выбивается за рамки стандартного поведения для такого пользователя, но его можно сравнить с поведением похожих профилей по типу (скорее всего, это будут другие бухгалтеры) — там видно, что у них в определённые числа наступает неделя отчётов и они все так делают. Числа совпадают, никаких других отличий нет, тревога не поднимается.
Ещё пример. Пользователь всю жизнь работал с файловой шарой, записывая пару десятков документов в день, а потом вдруг начал забирать с неё сотни и тысячи файлов. И ещё DLP говорит, что он отправляет что-то важное наружу. Может, тендерный отдел начал подготовку к конкурсу, может, «крыса» сливает данные конкурентам. Система этого, естественно, не знает, но просто описывает его поведение и подаёт тревогу безопасникам. Принципиально поведение нового сотрудника, техподдержки или гендиректора, может мало отличаться от поведения «засланного казачка», и задача безопасников сказать системе, что это нормальное поведение. Профиль всё равно приложится, и, если учётку гендиректора скомпрометируют и репутация попрыгает по баллам вниз, тревога поднимется.
Профили пользователей порождают правила для UBA-системы. Точнее, тысячи эвристик, которые регулярно меняются. Для каждой группы пользователей есть свои принципы. Например, пользователи этого типа отправляют 100 Мб в день, пользователи другого — 1 Гб в день, если это не выходные. И так далее. Если первый отправит 5 Гб, это подозрительно. А если второй — то будут отрицательные баллы, но порог тревоги они не пробьют. А вот если рядом он обращался по DNS к подозрительным новым доменам, то будет ещё пара отрицательных баллов и тревога уже случится.
Подход в том, что это не правило «если были странные DNS-запросы и потом подскочил трафик, то…», а правило «если репутация дошла до –20, то…» — каждый отдельный источник баллов для репутации пользователя или процесса независим и определяется исключительно нормой его поведения. Автоматически.
При этом на первых порах отдел ИБ помогает обучить систему и определить, что есть норма, а что нет, а потом система адаптируется, дообучается сама на реальном трафике и логах пользовательской активности.
Что мы ставим
Как системный интегратор мы предоставляем нашим заказчикам услугу по оперативному управлению информационной безопасностью (управляемый сервис SOC КРОК). Ключевым компонентом наряду с такими системами, как Asset Management, Vulnerability Management, Security Testing и Threat Intelligence, доступными из нашей облачной инфраструктуры, является связка между классическим SIEM и проактивным UBA. При этом, в зависимости от пожеланий заказчика, для UBA мы можем использовать как промышленные решения крупных вендоров, так и нашу собственную аналитическую систему, основанную на связке Hadoop + Hive + Redis + Splunk Analytics for Hadoop (Hunk).
Для поведенческого анализа из нашего облачного SOC КРОК или по модели on premise доступны такие решения:
- Exabeam: пожалуй, самая удобная в использовании UBA-система, позволяющая проводить быстрое расследование инцидента за счёт технологии User Tracking, которая связывает активность в ИТ-инфраструктуре (например, локальный вход в БД под учёткой SA) с реальным пользователем. Включает в себя порядка 400 риск-скоринговых моделей, добавляющих пользователю штрафные баллы за каждое странное или подозрительное действие;
- Securonix: весьма прожорливая до ресурсов, но крайне эффективная система поведенческого анализа. Система ставится поверх Big Data платформы, из коробки доступно почти 1000 моделей. Большая часть из них использует проприетарную технологию кластеризации пользовательской активности. Движок очень гибкий, можно трекить и кластеризовать любое поле CEF-формата, начиная с отклонения от среднего количества запросов за сутки по логам веб-сервера и заканчивая выявлением новых сетевых взаимодействий по пользовательскому трафику;
- Splunk UBA: хорошее дополнение к Splunk ES. База правил из коробки небольшая, но с привязкой к Kill Chain, что позволяет не отвлекаться на мелкие инциденты и сконцентрировать своё внимание на реальном хакере. И конечно же, в нашем распоряжении вся мощь статистической обработки данных на Splunk Machine Learning Toolkit и ретроспективный анализ по всему объёму накопленных данных.
А для критичных сегментов, будь то АСУ ТП или ключевой бизнес-приклад, мы расставляем дополнительные сенсоры для сбора расширенной форензики и ханитопы для отвлечения внимания хакера от продуктивных систем.
Почему море ресурсов?
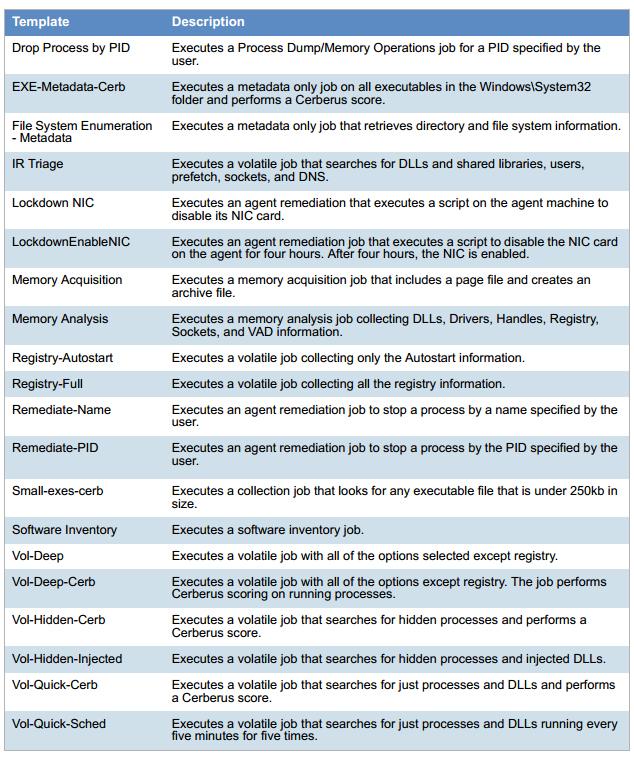
Потому что пишутся все события. Это как Гугл Аналитика, только на локальном АРМ. В локальной сети события отправляются в Data Lake все, через интернет — метаданными о статистике и ключевыми событиями, но если оператор SOC хочет расследовать инцидент, записанный полный лог тоже есть. Собирается всё: временные файлы, ключи реестра, все запущенные процессы и их контрольные суммы, что прописано в автозагрузке, действия, скринкаст — что угодно. Ниже пример собираемых данных.
Список параметров с рабочей станции:


Системы по объёму хранилища и оперативке становятся на порядок сложнее. Классическая SIEM начинается с 64 ГБ оперативы, пары процессоров и хранилища на полтерабайта. UBA — это от терабайта оперативки и выше. Например, наше последнее внедрение было на 33 физических сервера (28 вычислительных нод для обработки данных + 5 управляющих нод для распределения нагрузки), озера на 150 ТБ (600 ТБ в железе, включая быстрый кэш на инстансах) и по 384 ГБ оперативной памяти.
Кому это нужно?
В первую очередь тем, кто находится в «зоне риска» и постоянно подвергается атакам, — это банки, финансовые организации, нефтегазовый сектор, крупный ретейл и многие другие.
Для таких компаний стоимость утечки или потери данных может исчисляться десятками, а то и сотнями миллионов долларов. А вот установить у себя UBA-систему обойдётся куда дешевле. И конечно же, государственные компании и телеком, ведь никто не хочет, чтобы в какой-то момент данные миллионов пациентов или переписка десятков миллионов человек уплыла в открытый доступ.
Ссылки
- SOC-центры
- Большая компания, которая 5 лет не занималась ИБ и выжила
- Сайт проприетарных UBA-систем
- Моя почта для вопросов — dberezin@croc.ru
Комментарии (16)

Tortortor
16.08.2018 16:30я надеялся до такой слежки за юзерами/гражданами ещё далеко. А оно вот уже тут.
D_Berezin Автор
16.08.2018 17:24Речь про защиту корпоративной ИТ-инфраструктуры, Большой брат ни при чём. Я постарался раскрыть направление защиты от самого опасного мошенника – инсайдера.
opetrenko
18.08.2018 09:02А разве Большой Брат — тот же АНБ например, не более опасных пытается отлавливать? Но политиканы не дают нормально работать. В других странах на благо общества работается проще ;)
Если серьезно, пром шпионаж на западе кажется неактуальным. И экономически невыгодным, и морально недопустимым для подавляющего большинства. Не думаю, что за ваш секрет заплатят — скорее всего вас сдадут в полицию и вы отсидите немалый срок. Это лишь мое наивное имхо с позиции работы в большой аэрокосмической компании, и далеко не над ф35. Может, есть смысл отлавливать какие-то процессы-черви которые грепят терробайты файлопомойки. ( надо бы себе такого найти, что бы в своих авгеевых конюшнях «гуглить». Извините, напопаболело ). Ключевая инфа, скажем миссия самолета — совсем небольшой файл. Вряд-ли его отправка среди мегабайтов обычной шелухи снимет хотя-бы один балл в вашей системе. Имхо, надо самим быть себе шпионами и грепить всё, что из компании выходит. Такой вот вам ценный совет от «эксперта», который больше grep, похоже ничего и не знает )
А вообще, хотите и себе, например, построить самолет — просто наймите специалистов. И чем раньше -тем больше денег себе сэкономите. www.flightglobal.com/news/articles/mitsubishi-banks-on-foreign-experts-for-mrj-develo-436609
port443
16.08.2018 18:32Тут всё же следят за действиями сотрудников на рабочих местах.
А вот за гражданами в широком смысле подобными системами следят банки и платёжные системы, типа Мастер-карда.
Foggy4
16.08.2018 19:16Любопытно, как у этих новых систем обстоит ситуация с ложнопозитивными алертами? Насколько они снижают нагрузку на отдел ИБ? Испытывали в нашей среде OSSIM в свое время и пришли к выводу, что как вы и пишете — система требует непрерывной донастройки в режиме 24/7, в противном случае риск либо все равно не заметить взлом, либо закопаться в ручной проверке сотен поступающих алертов.
D_Berezin Автор
16.08.2018 21:53Действительно, проблема ложноположительных срабатываний, а также большое кол-во минорных инцидентов — это «бич» классических систем ИБ. К примеру, IPS, стоящая перед веб-сервером, за сутки даёт десятки тысяч срабатываний от сотен одинаковых автоматических сканеров, которые непрерывно шерстят Интернет в поиске незащищенных систем. Новые системы, в том числе UBA, используют несколько техник, которые позволяют сфокусироваться только на важных событиях. Во-первых, это динамическое профилирование минорных событий — правильно настроенный UBA вообще не будет уведомлять админа об «обычных» срабатываниях IPS, DLP и других систем, а сгенерирует инцидент только по новым векторам атак и нестандартным алертам. Во-вторых — привязка всех событий и потенциальных инцидентов к модели Kill Chain, позволяющей повысить приоритет минорного события при срабатывании эвристики.
Ogoun
16.08.2018 22:35А как поймали со стеганографией? Только засчет подозрительной активности на фейсбуке которой не было раньше?
D_Berezin Автор
16.08.2018 23:02Данную активность выявили за счет модуля Beaconing от Securonix. Он анализирует IP-адреса, DNS-запросы и объемы передаваемого трафика. Если модуль обнаруживает, что пользователь регулярно (например, каждые 5 минут) обращается к одному и тому же ресурсу, данная сессия помечается как подозрительная. Если есть и другие подозрительные действия, связанные с данным пользователем, система их связывает и генерирует инцидент. Чтобы снизить число ложных срабатываний, используются алгоритмы кластеризации: большая часть сессий будет связана с процессами обновления ОС\ПО, и только малая часть будет «выбиваться» из общей статистики и передаваться на анализ админу системы.
zugzwang
16.08.2018 23:46пишутся все события
записанный полный лог тоже есть
600ТБЛюбопытно. Каков поток событий? Срок хранения "полного лога"?
D_Berezin Автор
17.08.2018 11:23Расчет проводился для потока событий с пиками до 29000 EPS с длительностью хранения около 1 года. Потом логи архивируются и выгружаются в «холодное» хранилище.
perlestius
19.08.2018 00:07ханитопы для отвлечения внимания хакера от продуктивных систем
ханипоты, наверно?
По теме статьи вспомнил 3 случая с моим банком.
1. Однажды купил в МТС пять симок с красивыми номерами для одного проекта. Расплачивался пластиковой картой. Минут через 5 позвонили из банка и поинтересовались, действительно ли я совершал покупку.
2. Поздно ночью в банкомате другого банка в чужом районе пытался снять нужную сумму частями, т.к. за одну транзакцию можно было не больше 7 тыр. получить. На 4й или 5й транзакции карту заблокировали. На следующий день разблокировали по моему звонку на горячую линию.
3. Однажды пришло смс, что карта, возможно, была скомпрометирована, в связи с чем ее заблокировали. Попробовал дозвониться в колл-центр, но автоответчик обозначил 2 с лишним часа ожидания. Как оказалось, я был тогда не одинок. Когда пришел в отделение менять карту, была большая очередь, несмотря на вечер. БОльшая часть пришедших, как и я, пришли менять заблокированные карты. Наверно, было подозрение на утечку базы.
Последние два случая, конечно, вызвали неудобство, но лично мне было приятно знать, что безопасность для этого банка — не пустой звук.
WanGoff
Хорошая статья.
Название только не очень. А статья — очень.
D_Berezin Автор
спасибо
alan008
Собственно, плохоя идея была в использовании узкоспециплизированной аббревиатуры UBA, о которой я, например, впервые слышу. Хотя если её хотя бы раскрыть, то становится понятно, о чем в целом речь.