
Несколько лет назад рекомендательные системы только начинали завоевывать своего потребителя. Интернет-магазины активно используют алгоритмы рекомендаций, предлагая своим клиентам все новые и новые товары на основе их покупательской истории.
В клиентском сервисе рекомендательные системы стали актуальными не так давно. В связи с увеличением предлагаемого контента клиенты стали теряться в информационных потоках что, где и когда им нужно посмотреть. Головную боль любителей видео контента взялись лечить операторы платного ТВ и онлайн кинотеатры.

В качестве действенного способа решить извечную проблему «что посмотреть?» появились рекомендательные системы, работающие на базе той или иной математической модели.
Два года назад мы внедрили систему рекомендаций, позже дополнили ее редакторскими подборками и ощутили заметный эффект как в продажах, так и в продолжительности пользования нашим сервисом.
Рекомендательная система — это когда вы хотите что-то посмотреть, но не знаете, что именно, а телевизор очень удачно угадывает ваши предпочтения. Это фильтрация контента, которая подбирает фильмы и сериалы на основе преференций и анализе поведения пользователя. Используемая оператором система должна спрогнозировать реакцию телезрителя на тот или иной элемент и предложить контент, которые может ему понравиться.
При программировании рекомендательных систем применяется три основных метода: коллаборативная фильтрация (collaborative filtering), контентная фильтрация (content-based filtering) и экспертные системы (knowledge-based systems).
Коллаборативная фильтрация основана на трех этапах: сбор пользовательской информации, выстраивание матрицы для расчета ассоциаций и выдача достоверной рекомендации.
Хороший пример использования коллаборативной фильтрации — система Cinematch, которую использует компания Netflix. Пользователи явно или неявно выставляют оценки просмотренным фильмам, а рекомендации формируются с учетом как своих оценок пользователя, так и оценок других зрителей. Для этого система подбирает пользователей со схожими предпочтениями, чьи оценки близки к их собственным. На основании мнения этого круга людей зрителю автоматически выдается рекомендация: посмотреть тот или иной фильм.
Для максимально корректной работы рекомендательной системы, безусловно, основополагающую роль играют накопленные и собираемые данные. Чем больше данных накапливается о профиле потребления того или иного абонента, тем точнее рекомендации ему выдаются.
Контентная рекомендательная система формулируются на основе атрибутов, присваиваемых каждому элементу. Если вы смотрите фильмы определенного жанра, то система будет вам автоматически предлагать контент, который близок к вашему жанру по определенным позициям. Именно на основе такой рекомендательной системы работает сайт Pandora.
Экспертные рекомендательные системы предлагают рекомендации не на основе рейтингов, а на базе сходства между пользовательскими требованиями и описанием продукта, либо в зависимости от ограничений, выставляемых пользователем при конкретизации желаемого продукта. Поэтому система такого типа получается уникальной, ведь она позволяет клиенту явно указать, чего он хочет.
Экспертные системы наиболее эффективны в контекстах, где количество доступных данных ограничено, а коллаборативная фильтрация лучше всего работает в средах, где имеются большие массивы данных. Но когда данные диверсифицированы, можно решать одну и ту же задачу разными методами. А значит, оптимально будет комбинировать рекомендации, полученные несколькими способами, тем самым повысив качество системы в целом.
Именно подобная гибридная система от компании E-Contenta работает в нашем сервисе WiFire TV. Она была запущена в эксплуатацию и отладку в декабре 2016 года и работает по следующему принципу: если система знает о пользователе или о контенте достаточно много, то превалируют алгоритмы коллаборативной фильтрации. Если же контент новый, либо собрано недостаточно информации о взаимодействии с ним пользователей, то применяются контентные алгоритмы, оценивающие схожесть контента на основе имеющихся метаданных.
Для построения персонализированной подборки в E-Contenta было необходимо провести ранжирование всего доступного контента по вероятности того, что конкретный пользователь этим контентом заинтересуется.
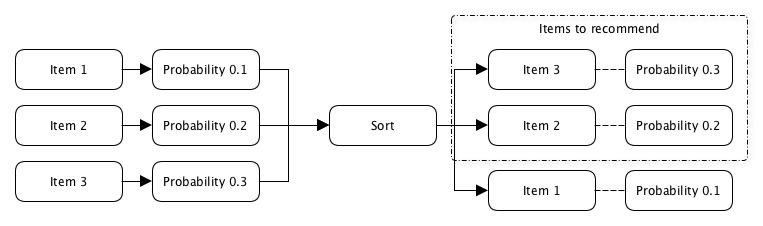
Интерес пользователя в первую очередь определяется в момент, когда он кликает на рекомендованный ему контент, а вероятность определяется как отношение числа кликов к числу раз, когда этот контент этому пользователю был рекомендован.
p(клика) = Nкликов / Nпоказов
Сложность заключается в том, что рекомендовать пользователю надо то, что он ни разу не видел, а значит данных о количестве кликов или показов для вычисления этой вероятности просто нет.
Поэтому, вместо фактической вероятности, было решено использовать оценку этой вероятности, другими словами, предсказанное значение.
Идея коллаборативного фильтра проста:
Таким образом пользователи совместно участвуют в процессе подбора контента.
Существует много разных вариантов реализации этого подхода:
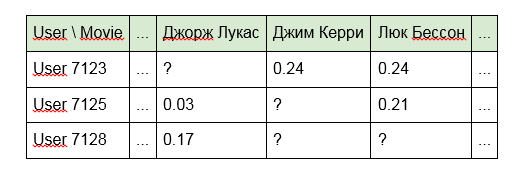
1. Построить модель, используя непосредственно идентификаторы единиц контента:
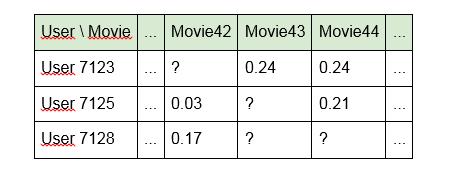
Минусом такого подхода является то, что модель «не видит» никаких связей между единицами контента. Например, «Терминатор» и «Терминатор 2» для нее будут так же далеки друг от друга как «Чужой» и «Спокойной ночи, Малыши!». К тому же сама матрица получается очень разреженной (много пустых ячеек и мало заполненных).
2. Вместо идентификаторов использовать слова, входящие в название статей, передач или фильмов:
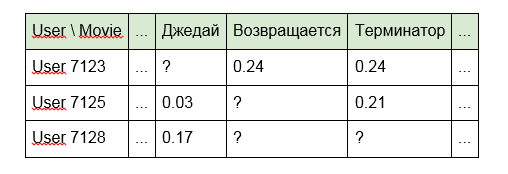
3. Для фильмов имена актеров, режиссеров или данные из IMDb:
Второй и третий варианты частично устраняют минусы первого подхода, учитывая связи контента, имеющего общие признаки (одного и того же режиссера или те же слова в названии). Однако разреженность (sparsity) матрицы так же снижается, но, как говорится, нет предела совершенству.
Хранение полного набора пользовательских рейтингов в памяти весьма накладно. Взяв грубые оценки количества пользователей рунета в 80 миллионов человек и размер базы IMDb в 370 тысяч фильмов, мы получаем необходимый размер в 27 Терабайт Сингулярное разложение — это метод снижения размерности матрицы.
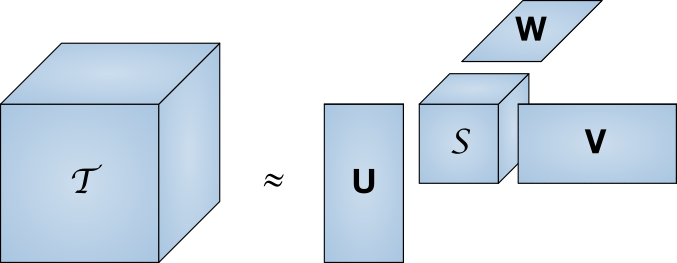
Матрица большого размера T представляется в виде произведения набора матриц меньшего размера
Другими словами, поиск «ядра» матрицы, которое обладает теми же свойствами, что и полная матрица, но значительно меньшего размера. Вместе со снижением размерности снижается и разряженность. В этой статье мы не будем вдаваться в тонкости реализации, тем более, что для ряда языков программирования уже существуют готовые библиотеки.
Холодный старт
Ситуация, когда отсутствие данных для нового контента или пользователя не позволяет выдать качественные рекомендации, также известная как «Холодный старт» — типичная проблема для коллаборативной фильтрации.
Одним из вариантов решения является подмешивание в выдачу рекомендаций нескольких единиц контента, по которым не собрано достаточное количество данных. Новому пользователю при этом будет рекомендован наиболее популярный контент.
Наиболее популярные
Используя вышеописанный подход, важно не забывать, что его следствием будет системное увеличение частоты появления «наиболее популярных» в списке рекомендованных. Обучаясь на поведении пользователей, которым часто предлагаются «наиболее популярные», рекомендательная система рискует обучиться рекомендовать исключительно наиболее популярный контент.
Главным отличием персональных рекомендаций от банальной рекомендации наиболее популярного контента является то, что они учитывают индивидуальные вкусы, которые могут значительно отличаться от «средних».
Таким образом, выборка реакций пользователя на контент используемая для обучения рекомендательной модели должна быть нормализована.
Доступность, отказоустойчивость и масштабируемость
Количество пользователей ресурса может создать нагрузку в сотни и тысячи запросов к рекомендательной системе в секунду. При этом выход одного или нескольких серверов из строя не должен приводить к отказу в обслуживании.
Классическим решением в данном случае будет использование балансировщика нагрузки, передающего запрос одному из серверов кластера. При этом каждый из серверов способен обработать входящий запрос. В случае выхода из строя любого из серверов в кластере балансировщик автоматически переключает нагрузку на сервера оставшиеся в строю. Выбрав в качестве транспортного протокола HTTP, мы можем использовать Nginx как балансировщик нагрузки.
По мере роста аудитории ресурса количество серверов в кластере может расти. В этом случае важно минимизировать затраты на подготовку нового сервера.
Рекомендательная система требует установки ряда компонентов, на которые она функционально опирается. Для автоматизации развертывания рекомендательной системы со всеми её зависимостями используется Docker.
Docker позволяет собрать все необходимые компоненты, «упаковать» их в образ и положить такой образ в хранилище (реестр), а затем скачать и развернуть его на новом сервере в считанные минуты. Важным преимуществом Docker является то, что «накладные расходы» при его использовании минимальны: время вызова приложения в docker-контейнере увеличивается на считанные наносекунды в сравнении с приложением, запущенном в обычной операционной системе.
Другим немаловажным достоинством является возможность быстро вернуться к предыдущей стабильной версии приложения в случае сбоя новой (достаточно просто взять старую версию из реестра).
Второй тип запросов к системе, об обслуживании которого необходимо заботиться — это запросы, отслеживающие действия пользователя. Чтобы пользователю не пришлось дожидаться пока система полностью обработает совершенное им действие, процесс обработки выполняется независимо от процесса записи действий.
В качестве платформы, обеспечивающей передачу данных о действиях пользователя обработчикам, в E-Contenta выбрали Apache Kafka. Kafka реализует архитектурный паттерн Message-Oriented Middleware), который способен обеспечить гарантированную доставку десятков и сотен тысяч сообщений в секунду и выступить буфером, защищающим обработчики от чрезмерного объема данных в моменты пиковой нагрузки.
Полная автономность самообучения
Регулярно появляется новый контент и новые пользователи — без регулярного обучения качество модели деградирует. Обучение должно выполняться на отдельных серверах, чтобы процесс обучения, требующий значительных вычислительных ресурсов, не влиял на работоспособность боевых серверов.
Классическим решением, обеспечивающим оркестрацию регулярных распределенных задач, является Jenkins. Сервис по расписанию запускает получение и нормализацию новых обучающих выборок, обучение рекомендательной модели, доставку новых моделей и обновление всех серверов кластера, что позволяет поддерживать качество рекомендаций без дополнительных усилий. В случае сбоя на любом из шагов Jenkins самостоятельно возвращает систему в предыдущее стабильное состояние и уведомляет администратора о сбое.
Дополнительно, чтобы система работала правильно, мы пригласили независимого телеизмерителя и предложили ему измерить телесмотрение абонентов. Полученные уникальные данные оживляются при помощи алгоритмов data science. Непрерывно работающая обратная связь от абонентов, взаимодействующих с рекомендациями, наполняет базу прецедентов алгоритмов машинного обучения и позволяет рекомендациям изменяться в зависимости от неявных признаков смены предпочтений абонентов, таких как время года, приближение праздников или изменение состава семьи.
В процессе тестирования нам пришлось решить задачу, связанную с рекомендацией телевизионного контента — как помочь своим абонентам разобраться в потоках трансляций. Задача усложняется еще и сервисами отложенного просмотра. Мы встроили систему, которая вместо бесконечного циклического переключения каналов помогает найти интересную передачу уже за 2–3 нажатия кнопки. Для этого рекомендательная система следит за выпуском новых серий передач и предсказывает интерес зрителей к нерегулярным передачам и трансляциям фильмов. Фактически, машинные алгоритмы заменяют работу ответственного редактора.
Работа с потоковым телевидением имеет свою специфику. К примеру, часто одни и те же популярные телешоу идут по разным каналам. В этом случае рекомендательной системе приходится понимать дублирование информации и выбирать рекомендацию на основе предпочтений абонента относительно каналов, времени начала передачи и т.п. Подобное дублирование информации также возникает при наличии у абонента подписки на SD и HD версии каналов.
Все эти два года мы экспериментировали с разными вариантами рекомендательных систем и нашли золотую середину, которая позволяет улучшать показатели вовлеченности зрителей и эффективнее монетизировать имеющийся контент. Мы используем автоматический подбор рекомендаций, описанный выше вместе с ручной настройкой — редакторские подборки.
Такой подход позволил значительно (в 10 раз) увеличить монетизацию VOD и SVOD сервисов.
Редакторские рекомендации — это подборки тематических фильмов и сериалов, завязанных на громких премьерах, праздниках, памятных датах. Это очень удобно – оповещать абонентов и давать им возможность посмотреть новинки кино, старые хиты или непопулярные, но на наш взгляд очень интересные фильмы с точки зрения содержания и сюжета. Мы тесно общаемся с нашими поставщиками (онлайн-кинотеатрами и дополнительными видео-сервисами, такими как ivi, megogo, amediateka) и лично подбираем каждый фильм, который будет интересно посмотреть нашему абоненту.
По праздникам мы делаем специальные подборки на определенную тематику. Например, ко Дню победы – это фильмы военной тематики. На Первое сентября — подборка контента для детей, которая состоит из познавательных передач, мультфильмов, и документальных фильмов.
Ручная подборка отлично повышает лояльность наших абонентов. По нашим самым скромным подсчетам, примерно около 10% нашей абонентской базы ежемесячно смотрят фильмы, которые мы рекомендуем и этот показатель постоянно растет.
В настоящее время на Wifire ТV работает интеллектуальная рекомендательная система от компании E-Contenta. В её основе data science и метаданных 90% абонентов оператора. Алгоритм учитывает сотни данных: что смотрит абонент, какие фильмы и передачи популярны, когда он пользуется сервисом и кто сейчас перед экраном. Мы хотим донести до наших абонентов ценность подписки на премиальные пакеты каналов, подмешивая из них релевантные пользователю передачи в рекомендации. Также мы хотим показать, что приобретать и смотреть легальный видеоконтент — это нормально, удобно и просто.
Рекомендательная система подскажет абоненту интересные фильмы, даже если они уже давно вышли из разряда новинок: таким образом обширный видеокаталог перестает быть пыльной библиотекой, а становится интерактивной витриной, гибко подстраивающейся под вкусы и настроения абонентов.
В клиентском сервисе рекомендательные системы стали актуальными не так давно. В связи с увеличением предлагаемого контента клиенты стали теряться в информационных потоках что, где и когда им нужно посмотреть. Головную боль любителей видео контента взялись лечить операторы платного ТВ и онлайн кинотеатры.
В качестве действенного способа решить извечную проблему «что посмотреть?» появились рекомендательные системы, работающие на базе той или иной математической модели.
Два года назад мы внедрили систему рекомендаций, позже дополнили ее редакторскими подборками и ощутили заметный эффект как в продажах, так и в продолжительности пользования нашим сервисом.
Что такое рекомендательные системы
Рекомендательная система — это когда вы хотите что-то посмотреть, но не знаете, что именно, а телевизор очень удачно угадывает ваши предпочтения. Это фильтрация контента, которая подбирает фильмы и сериалы на основе преференций и анализе поведения пользователя. Используемая оператором система должна спрогнозировать реакцию телезрителя на тот или иной элемент и предложить контент, которые может ему понравиться.
При программировании рекомендательных систем применяется три основных метода: коллаборативная фильтрация (collaborative filtering), контентная фильтрация (content-based filtering) и экспертные системы (knowledge-based systems).
Коллаборативная фильтрация основана на трех этапах: сбор пользовательской информации, выстраивание матрицы для расчета ассоциаций и выдача достоверной рекомендации.
Хороший пример использования коллаборативной фильтрации — система Cinematch, которую использует компания Netflix. Пользователи явно или неявно выставляют оценки просмотренным фильмам, а рекомендации формируются с учетом как своих оценок пользователя, так и оценок других зрителей. Для этого система подбирает пользователей со схожими предпочтениями, чьи оценки близки к их собственным. На основании мнения этого круга людей зрителю автоматически выдается рекомендация: посмотреть тот или иной фильм.
Для максимально корректной работы рекомендательной системы, безусловно, основополагающую роль играют накопленные и собираемые данные. Чем больше данных накапливается о профиле потребления того или иного абонента, тем точнее рекомендации ему выдаются.
Контентная рекомендательная система формулируются на основе атрибутов, присваиваемых каждому элементу. Если вы смотрите фильмы определенного жанра, то система будет вам автоматически предлагать контент, который близок к вашему жанру по определенным позициям. Именно на основе такой рекомендательной системы работает сайт Pandora.
Экспертные рекомендательные системы предлагают рекомендации не на основе рейтингов, а на базе сходства между пользовательскими требованиями и описанием продукта, либо в зависимости от ограничений, выставляемых пользователем при конкретизации желаемого продукта. Поэтому система такого типа получается уникальной, ведь она позволяет клиенту явно указать, чего он хочет.
Экспертные системы наиболее эффективны в контекстах, где количество доступных данных ограничено, а коллаборативная фильтрация лучше всего работает в средах, где имеются большие массивы данных. Но когда данные диверсифицированы, можно решать одну и ту же задачу разными методами. А значит, оптимально будет комбинировать рекомендации, полученные несколькими способами, тем самым повысив качество системы в целом.
Именно подобная гибридная система от компании E-Contenta работает в нашем сервисе WiFire TV. Она была запущена в эксплуатацию и отладку в декабре 2016 года и работает по следующему принципу: если система знает о пользователе или о контенте достаточно много, то превалируют алгоритмы коллаборативной фильтрации. Если же контент новый, либо собрано недостаточно информации о взаимодействии с ним пользователей, то применяются контентные алгоритмы, оценивающие схожесть контента на основе имеющихся метаданных.
Как выстраивались алгоритмы рекомендаций
Для построения персонализированной подборки в E-Contenta было необходимо провести ранжирование всего доступного контента по вероятности того, что конкретный пользователь этим контентом заинтересуется.
Интерес пользователя в первую очередь определяется в момент, когда он кликает на рекомендованный ему контент, а вероятность определяется как отношение числа кликов к числу раз, когда этот контент этому пользователю был рекомендован.
p(клика) = Nкликов / Nпоказов
Сложность заключается в том, что рекомендовать пользователю надо то, что он ни разу не видел, а значит данных о количестве кликов или показов для вычисления этой вероятности просто нет.
Поэтому, вместо фактической вероятности, было решено использовать оценку этой вероятности, другими словами, предсказанное значение.
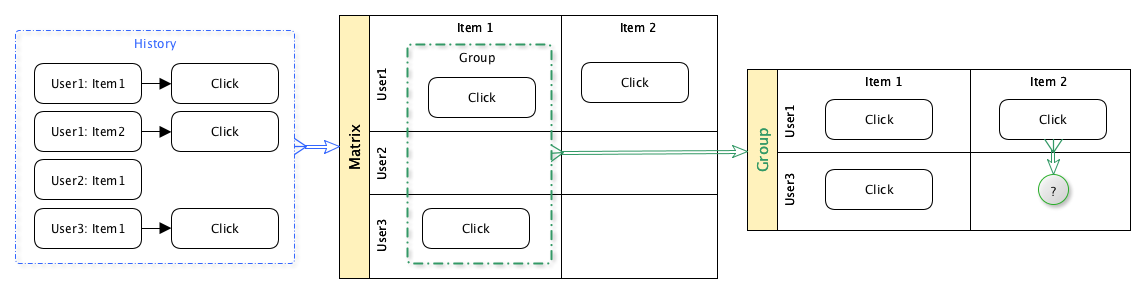
Идея коллаборативного фильтра проста:
- Взять исторические данные о просмотре пользователями контента
- На основе этих данных сгруппировать пользователей по контенту, который они смотрели
- Для заданного пользователя предсказывать вероятность его интереса к конкретной единице контента, исходя из исторических данных других пользователей, входящих в эту же группу.
Таким образом пользователи совместно участвуют в процессе подбора контента.
Существует много разных вариантов реализации этого подхода:
1. Построить модель, используя непосредственно идентификаторы единиц контента:
Минусом такого подхода является то, что модель «не видит» никаких связей между единицами контента. Например, «Терминатор» и «Терминатор 2» для нее будут так же далеки друг от друга как «Чужой» и «Спокойной ночи, Малыши!». К тому же сама матрица получается очень разреженной (много пустых ячеек и мало заполненных).
2. Вместо идентификаторов использовать слова, входящие в название статей, передач или фильмов:
3. Для фильмов имена актеров, режиссеров или данные из IMDb:
Второй и третий варианты частично устраняют минусы первого подхода, учитывая связи контента, имеющего общие признаки (одного и того же режиссера или те же слова в названии). Однако разреженность (sparsity) матрицы так же снижается, но, как говорится, нет предела совершенству.
Хранение полного набора пользовательских рейтингов в памяти весьма накладно. Взяв грубые оценки количества пользователей рунета в 80 миллионов человек и размер базы IMDb в 370 тысяч фильмов, мы получаем необходимый размер в 27 Терабайт Сингулярное разложение — это метод снижения размерности матрицы.
Матрица большого размера T представляется в виде произведения набора матриц меньшего размера
Другими словами, поиск «ядра» матрицы, которое обладает теми же свойствами, что и полная матрица, но значительно меньшего размера. Вместе со снижением размерности снижается и разряженность. В этой статье мы не будем вдаваться в тонкости реализации, тем более, что для ряда языков программирования уже существуют готовые библиотеки.
Технические сложности
Холодный старт
Ситуация, когда отсутствие данных для нового контента или пользователя не позволяет выдать качественные рекомендации, также известная как «Холодный старт» — типичная проблема для коллаборативной фильтрации.
Одним из вариантов решения является подмешивание в выдачу рекомендаций нескольких единиц контента, по которым не собрано достаточное количество данных. Новому пользователю при этом будет рекомендован наиболее популярный контент.
Наиболее популярные
Используя вышеописанный подход, важно не забывать, что его следствием будет системное увеличение частоты появления «наиболее популярных» в списке рекомендованных. Обучаясь на поведении пользователей, которым часто предлагаются «наиболее популярные», рекомендательная система рискует обучиться рекомендовать исключительно наиболее популярный контент.
Главным отличием персональных рекомендаций от банальной рекомендации наиболее популярного контента является то, что они учитывают индивидуальные вкусы, которые могут значительно отличаться от «средних».
Таким образом, выборка реакций пользователя на контент используемая для обучения рекомендательной модели должна быть нормализована.
Доступность, отказоустойчивость и масштабируемость
Количество пользователей ресурса может создать нагрузку в сотни и тысячи запросов к рекомендательной системе в секунду. При этом выход одного или нескольких серверов из строя не должен приводить к отказу в обслуживании.
Классическим решением в данном случае будет использование балансировщика нагрузки, передающего запрос одному из серверов кластера. При этом каждый из серверов способен обработать входящий запрос. В случае выхода из строя любого из серверов в кластере балансировщик автоматически переключает нагрузку на сервера оставшиеся в строю. Выбрав в качестве транспортного протокола HTTP, мы можем использовать Nginx как балансировщик нагрузки.
По мере роста аудитории ресурса количество серверов в кластере может расти. В этом случае важно минимизировать затраты на подготовку нового сервера.
Рекомендательная система требует установки ряда компонентов, на которые она функционально опирается. Для автоматизации развертывания рекомендательной системы со всеми её зависимостями используется Docker.
Docker позволяет собрать все необходимые компоненты, «упаковать» их в образ и положить такой образ в хранилище (реестр), а затем скачать и развернуть его на новом сервере в считанные минуты. Важным преимуществом Docker является то, что «накладные расходы» при его использовании минимальны: время вызова приложения в docker-контейнере увеличивается на считанные наносекунды в сравнении с приложением, запущенном в обычной операционной системе.
Другим немаловажным достоинством является возможность быстро вернуться к предыдущей стабильной версии приложения в случае сбоя новой (достаточно просто взять старую версию из реестра).
Второй тип запросов к системе, об обслуживании которого необходимо заботиться — это запросы, отслеживающие действия пользователя. Чтобы пользователю не пришлось дожидаться пока система полностью обработает совершенное им действие, процесс обработки выполняется независимо от процесса записи действий.
В качестве платформы, обеспечивающей передачу данных о действиях пользователя обработчикам, в E-Contenta выбрали Apache Kafka. Kafka реализует архитектурный паттерн Message-Oriented Middleware), который способен обеспечить гарантированную доставку десятков и сотен тысяч сообщений в секунду и выступить буфером, защищающим обработчики от чрезмерного объема данных в моменты пиковой нагрузки.
Полная автономность самообучения
Регулярно появляется новый контент и новые пользователи — без регулярного обучения качество модели деградирует. Обучение должно выполняться на отдельных серверах, чтобы процесс обучения, требующий значительных вычислительных ресурсов, не влиял на работоспособность боевых серверов.
Классическим решением, обеспечивающим оркестрацию регулярных распределенных задач, является Jenkins. Сервис по расписанию запускает получение и нормализацию новых обучающих выборок, обучение рекомендательной модели, доставку новых моделей и обновление всех серверов кластера, что позволяет поддерживать качество рекомендаций без дополнительных усилий. В случае сбоя на любом из шагов Jenkins самостоятельно возвращает систему в предыдущее стабильное состояние и уведомляет администратора о сбое.
О том, как мы осуществили это на WifireTV
Дополнительно, чтобы система работала правильно, мы пригласили независимого телеизмерителя и предложили ему измерить телесмотрение абонентов. Полученные уникальные данные оживляются при помощи алгоритмов data science. Непрерывно работающая обратная связь от абонентов, взаимодействующих с рекомендациями, наполняет базу прецедентов алгоритмов машинного обучения и позволяет рекомендациям изменяться в зависимости от неявных признаков смены предпочтений абонентов, таких как время года, приближение праздников или изменение состава семьи.
В процессе тестирования нам пришлось решить задачу, связанную с рекомендацией телевизионного контента — как помочь своим абонентам разобраться в потоках трансляций. Задача усложняется еще и сервисами отложенного просмотра. Мы встроили систему, которая вместо бесконечного циклического переключения каналов помогает найти интересную передачу уже за 2–3 нажатия кнопки. Для этого рекомендательная система следит за выпуском новых серий передач и предсказывает интерес зрителей к нерегулярным передачам и трансляциям фильмов. Фактически, машинные алгоритмы заменяют работу ответственного редактора.
Работа с потоковым телевидением имеет свою специфику. К примеру, часто одни и те же популярные телешоу идут по разным каналам. В этом случае рекомендательной системе приходится понимать дублирование информации и выбирать рекомендацию на основе предпочтений абонента относительно каналов, времени начала передачи и т.п. Подобное дублирование информации также возникает при наличии у абонента подписки на SD и HD версии каналов.
Все эти два года мы экспериментировали с разными вариантами рекомендательных систем и нашли золотую середину, которая позволяет улучшать показатели вовлеченности зрителей и эффективнее монетизировать имеющийся контент. Мы используем автоматический подбор рекомендаций, описанный выше вместе с ручной настройкой — редакторские подборки.
Такой подход позволил значительно (в 10 раз) увеличить монетизацию VOD и SVOD сервисов.
Редакторские рекомендации — это подборки тематических фильмов и сериалов, завязанных на громких премьерах, праздниках, памятных датах. Это очень удобно – оповещать абонентов и давать им возможность посмотреть новинки кино, старые хиты или непопулярные, но на наш взгляд очень интересные фильмы с точки зрения содержания и сюжета. Мы тесно общаемся с нашими поставщиками (онлайн-кинотеатрами и дополнительными видео-сервисами, такими как ivi, megogo, amediateka) и лично подбираем каждый фильм, который будет интересно посмотреть нашему абоненту.
По праздникам мы делаем специальные подборки на определенную тематику. Например, ко Дню победы – это фильмы военной тематики. На Первое сентября — подборка контента для детей, которая состоит из познавательных передач, мультфильмов, и документальных фильмов.
Ручная подборка отлично повышает лояльность наших абонентов. По нашим самым скромным подсчетам, примерно около 10% нашей абонентской базы ежемесячно смотрят фильмы, которые мы рекомендуем и этот показатель постоянно растет.
Что в итоге?
В настоящее время на Wifire ТV работает интеллектуальная рекомендательная система от компании E-Contenta. В её основе data science и метаданных 90% абонентов оператора. Алгоритм учитывает сотни данных: что смотрит абонент, какие фильмы и передачи популярны, когда он пользуется сервисом и кто сейчас перед экраном. Мы хотим донести до наших абонентов ценность подписки на премиальные пакеты каналов, подмешивая из них релевантные пользователю передачи в рекомендации. Также мы хотим показать, что приобретать и смотреть легальный видеоконтент — это нормально, удобно и просто.
Рекомендательная система подскажет абоненту интересные фильмы, даже если они уже давно вышли из разряда новинок: таким образом обширный видеокаталог перестает быть пыльной библиотекой, а становится интерактивной витриной, гибко подстраивающейся под вкусы и настроения абонентов.
Neusser
10% это не так уж и много. Если делать рекомендации случайным образом, без использования всяких хитрых алгоритмов и технологий, то может оказаться, что тоже окажется 10%. Сколько абонентов ежемесячно смотрело рекомендуемые фильмы до введения такой системы?
А можно сказать и по-другому: 90% абонентов не смотрят фильмы, которые вы им рекомендуете.
Netbynet Автор
Добрый день! Wifire TV — это прежде всего телевидение и недорогие пакеты каналов, VOD и SVOD контент оплачивается отдельно и востребован не у всех. Цифра в 10% — это примерная доля уникальных пользователей, которые приходит смотреть только фильмы/сериалы по подписке.
До введения рекомендательной системы вовлеченность в просмотр дополнительных сервисов составляла менее 1%, монетизация такого контента также была ниже — в 10 раз.