

Добрый день, коллеги.
В сегодняшней статье речь пойдет о российском вендоре Aerodisk – разработчике и производителе решений в области хранения данных (аппаратные СХД) и виртуализвации, о трудностях, с которыми сталкивается вендор на рынке. И, более подробно, о линейке СХД Aerodisk Engine (железо + софт).
Сразу отмечу, что 9 октября (вторник) с 11:00 до 12:30 (МСК) пройдёт бесплатный
технический вебинар, где мы покажем на живой системе, как все работает.
Начать статью хочу с одной из моих любимых притч:
Однажды странник попал в город, где шло грандиозное строительство. Мужчины ворочали большие камни под палящим солнцем. «Что ты делаешь?» — спросил наш герой у одного из рабочих, который медленно тащил булыжник. «Ты что, не видишь — камни таскаю!» — зло ответил тот. Тут странник заметил другого рабочего, который волок телегу с большими камнями, и спросил: «Что ты делаешь?» «Я зарабатываю на еду для своей семьи», — получил он ответ. Странник подошел к третьему рабочему, который занимался тем же, но работал энергичнее и быстрее. «Что делаешь ты?» «Я строю храм», — улыбнулся тот.
О чем эта притча?
О том, что если веришь в большую идею, видишь большую цель, то для тебя нет ничего невозможного, все достижимо. И каждый шаг, который приближает тебя к большой цели, удваивает твои силы. Мы в свое время большую цель увидели и в большую идею поверили.
Это первая статья нашей компании AERODISK, и в ней я расскажу о тех решениях, которые мы выпускаем. Кроме того, один из продуктов опишу более подробно.
Наша команда находится в Москве, и мы с 2011 года разрабатываем системы хранения данных (СХД). Мы не изобретаем велосипед, а всего лишь стараемся сделать его лучше и доступней. Мы не новомодная стораджовая компания, созданная под выполнение закона Яровой и прочих правительственных указов по импортозамещению. Поэтому разрабатываем системы нацеленные на бизнес-задачи. Идея создать свою СХД родилась из многочисленного глубокого общения с СХД мировых лидеров EMC, NetApp, HDS, IBM/Lenovo и прочих, и четкого понимания, что это не rocket science и что результаты их работы, как минимум, вполне по силам повторить команде заинтересованных инженеров и разработчиков.
Действительно, существует устоявшийся миф о том, что разработка СХД (как и любого серьезного продукта), по силам только транснациональной корпорации, у которой обязательно сотни или тысячи программистов по всему миру. В жизни это совсем не так. Практически всегда (за редким исключением), новый серьезный продукт создается небольшим коллективом до 10 человек (а обычно 2-3). При этом на этапе создания закладывается 80% всего функционала продукта. Далее продукт либо силами этого маленького коллектива выходит на рынок (или как-то еще громко заявляет о себе), и там его уже подхватывают инвесторы (фонды, холдинги или крупные производители), либо он умирает, что, как вы поняли, не про нас. В первом, успешном, случае только после вхождения этого небольшого коллектива в ряды крупной корпорации появляются те самые 100500 программистов и инженеров, которые по сути уже наводят лоск на продукт и занимаются его поддержкой. Примеров масса: 3par сначала сделал свою СХД и начал вполне успешно продавать ее в Штатах, и только потом был куплен HP. Та же история была с Compellent и Dell. Riverbed (это уже, как вы поняли, не про СХД, но тоже про серьезную технику) изначально был написан двумя разработчиками года за полтора и только потом привлек инвесторов. Смысл в том, что не боги, на самом деле, горшки обжигают, и мы это четко понимали.
За время, прошедшее с момента зарождения идеи, было много чего. Как и положено нормальному стартапу, первые несколько лет мы (в количестве трех с половиной человек) сидели в офисе, который из-за отсутствия денег находился на территории одного из околоМКАД-ных заводов.
Вот так мы каждое утро ходили на работу. Для попадания в офис нам нужно было пройти через гламурный коридор брошенного заводского цеха.

Но это совсем не мешало продуктивной работе, и в 2013 году мы смогли сделать прототип первой своей СХД AERODISK ENGINE, которая хоть и была
А вот так выглядела первая консоль управления нашей СХД, которую один из наших заказчиков мило обозвал GreenDOS.
Веб-интерфейс и прочие плюшки, само собой, появились намного позже.
Сейчас, например, он выглядит так.
Хотя, конечно, от консоли мы не отказываемся, она есть, она удобна и функциональна и позволяет скриптами автоматизировать многие операции.
К 2014-ому году мы смогли отполировать систему до стабильной (ну, точнее так мы считали сами) и начали ее аккуратно тестировать у заказчиков и продавать. В целом, первые внешние тесты были успешны (само собой, не без напильника) и мы получили первые продажи. Продаж было не много, за полтора года мы продали чуть больше десятка систем. Связано это было с
С начала 2017-ого года мы начали жить по-новому. Расширили штат, переехали с завода в человеческий офис, сделали нормальную тестовую лабу и демо-зону, запустили разработку vAIR и RAILGUN и начали активно продавать ENGINE. И тут мы столкнулись с первым сюрпризом.
Поскольку вендор мы новый, то почти в ста процентах случаев перед покупкой заказчики тестировали нашу СХД с пристрастием и примерно 80% тестов завершалась эпическим фэйлом. Один раз нам даже пришлось сделать заказчику скидку в 100% (т.е. отдать систему бесплатно), т.к. тестировал её он уже после покупки в бою (так получилось), и результат его не удовлетворил (мягко говоря). Конечно были 20%, которые завершились успешными продажами, и заказчики эти остались довольны, но было понятно, что продукт в текущем его состоянии
Не менее радостно мы начали 2018 год, продажи шли хорошо, ENGINE получал лестные отзывы от заказчиков. Окрылённые успехом, мы выпустили следующую версию ПО ENGINE, в которой появилась куча новых полезных функций, и которая, соответственно, пошла в новые тесты у заказчиков. И тут нас ждал второй сюрприз.
Несмотря на то, что новая версия ENGINE проходила все необходимые внутренние тесты (те, что позволили нам выпустить стабильную версию осенью 2017-ого), этих тестов было уже недостаточно для более сложной новой версии ПО. Новый функционал принес с собой новые задачи и, соответственно, новые типы внешних тестов у заказчиков. В итоге мы опять получили снижение результативности внешних тестов (не так страшно, как в первый раз, но ощутимо) и начали искать причину. Тут до нас дошло, что усложнение продукта условно в 2 раза, требует усложнения его внутреннего тестирования в 4. Но т.к. калачи мы уже были тёртые, нам не составило труда быстро адаптировать наши тесты под новую реальность. Мы расширили тестовую лабу и автоматизировали многие тесты, которые раньше делали руками. Тем самым достаточно быстро смогли вернуть новой версии должную стабильность. Позже опыт, полученный в ходе ранее набитых шишек и пройденных граблей, мы использовали при выпуске второго нашего продукта vAIR, который уже не совсем СХД, а, скорее, гиперконвегентная система (хотя vAIR тоже может прикинуться СХД, если его хорошо попросить). С ним сюрпризов не было, первые тесты у заказчиков дали результат сразу, и продажи пошли.
Оглядываясь назад, можно сказать, что был проделан большой путь и как оказалось, самое главное — это не то, какой ты есть сейчас, а то, каким ты хочешь стать, что ты считаешь правильным и как быстро ты готов адаптироваться к меняющимся внешним условиям. При этом важно четкое понимание, что сделать можно и нужно намного больше. Главное — много работать и не унывать, если результат приходит не сразу.
Теперь о самих продуктах AERODISK
На текущий момент мы работаем над четырьмя продуктами, два из которых уже продаются, а третий и четвертый на подходе.
- AERODISK ENGINE – это классическая унифицированная СХД для корпоративных задач среднего и начального уровня (Mid-range и Low-end). ENGINE имеет практически весь функционал современной СХД, включая отказоустойчивость в режиме Active-Active (ALUA), блочный и файловый доступ, различные варианты SSD и RAM кэширования, дедупликация, возможность хранить данные на нескольких уровнях (Tiering), All-Flash режим и т.д. Именно про этот продукт пойдет речь в этой статье.
- AERODISK vAIR – гиперконвергентная система, которая позволяет в рамках одной коробки запускать серверную виртуализацию, программную сеть и горизонтально масштабируемую СХД. vAIR может работать как со своим родным гипервизором (KVM), так и с внешним гипервизором VMware. Кроме того, в отличие от других наших продуктов, vAIR поддерживает установку на стороннее железо, в полной мере реализуя концепцию SDDC (Software-Defined-Datacenter).
- AERODISK RAILGUN (это рабочее название, окончательное еще не выбрано). Изначально у нас был свой, написанный с нуля виртуальный RAID, который мы решили обозвать первой буквой алфавита и, заодно, названия нашей компании, т.е. RAID-A. Но в итоге, все пришло к тому, что это стало отдельным продуктом, в частности, СХД Hi-End-класса. Как отдельный продукт, он находится в стадии бета-теста и все идет к тому, что в начале следующего года будет релиз первой версии. Данная СХД предназначена для самых критичных задач и самых экстремальных нагрузок. Отличительными особенностями Рэйлгана являются отказоустойчивый симметричный ввод-вывод (одновременная утилизация всех контроллеров сразу), многоконтроллерность (до 16 в SAN-режиме) и полностью автоматизированный тиринг в реальном времени с любым количеством уровней хранения.
- Адаптивная дедупликация (дедупликация с блоком переменной длины), у которой нет пока даже рабочего названия, но есть уже работающая боевая версия (что важнее). Изначально, также, как и с RAID-A, эта была (и остается) одна из опций к ENGINE. Но по ходу пьесы оказалось, что оно прекрасно работает не только с ENGINE, а с любым блочным устройством. В итоге мы получили отдельное ПО, которое позволяет выполнять дедупликацию данных на блочном уровне, автоматически подбирая размер блока, что в разы увеличивает эффективность дедупликации (экономим много места на дисках) и при этом увеличивает производительность ввода-вывода и снижает задержки (за счет того, что транзакций записи тупо меньше, т.к. большая их часть дедуплицируется). Данное ПО доступно либо как доп. лицензия к любой нашей СХД, либо (будет доступно после НГ) как отдельный продукт (аппаратный или программный), который может дедуплицировать любой внешний блочный сторадж.
Теперь перейдем к конкретике. Как я писал выше, эта статья про ENGINE. Другие продукты мы обязательно подробно распишем в наших следующих статьях.
В этой статье я опишу железо, архитектуру хранения и принципы отказоустойчивости СХД ENGINE. В рамках следующей статьи про ENGINE будет приведено описание расширенного функционала, а также развернутые тесты производительности (с детальными методиками, различными профилями нагрузки, графиками и прочим блэкджеком). Тут же мы сосредоточимся на аппаратке и архитектуре.
Железо
На самом деле изначально я не хотел сильно расписывать аппаратную составляющую, т.к. в СХД самое ценное — это интеллект, т.е. софт, который установлен на железе, а железо у нас, хоть и с особенностями, но примерно такое же, как и у 99% СХД всех (и западных, и восточных) вендоров. Иногда даже с одних и тех же заводов.
Но т.к. в отличие от, например, нашего SDDC-продукта (т.е. vAIR) система хранения ENGINE является все-таки аппаратной СХД и поставляется как полноценный ПАК (т.е. железо+софт+сервис) и, соответственно, не является классическим SDS-ом (т.е. ПО ENGINE крайне сложно поставить на обычные x86 серверы, т.к. есть куча аппаратных особенностей). Поэтому описание железа в случае с ENGINE является крайне важным и поэтому, как вы поняли, описанию железа быть.
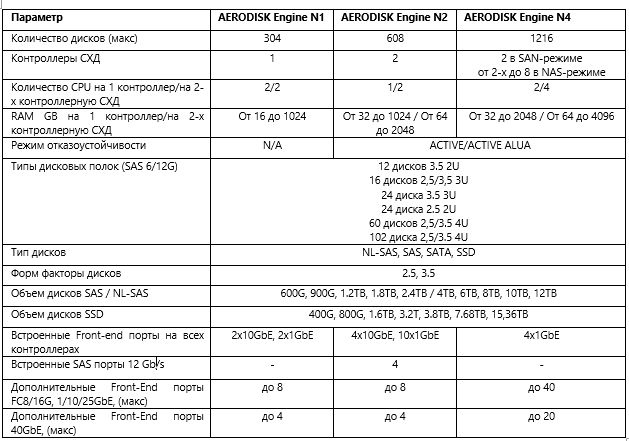
Итак, железо. В модельном ряде AERODISK ENGINE есть 3 модульные платформы.
- ENGINE N1 — одноконтроллерная СХД для некритичных задач и хранения архивов/бэкапов
- ENGINE N2 – отказоустойчивая СХД для критичных задач и средней нагрузки до 150 000 IOPS
- ENGINE N4 – отказоустойчивая СХД для критичных задач и высокой нагрузки до 300 000 IOPS
Все платформы отличает следующая аппаратная особенность — платформы состоят из динамично заменяемых модулей, которые можно легко заменить в любой момент, что сильно упрощает эксплуатацию СХД и замену комплектующих. Это относится не только к HA-платформам (т.е. отказоустойчивым N2 и N4), но и к одноконтроллерной N1.
Для отказоустойчивых конфигураций (N2 и N4) мы используем шасси с двумя контроллерами (они же «головы», они же ноды) с общим backplane-ом. Спереди в шасси устанавливаются диски (12 штук, 24 штуки 2,5 или 3,5 дюйма). Диски через backplane, в свою очередь, смотрят одновременно на две головы СХД по SAS-интерфейсу. Дополнительные диски подключаются с помощью дисковых полок (24, 60, 102 диска) в каждой полке через SAS 48G (4x12 Gb), которые установлены в контроллерах-головах. Поддерживается каскадное подключение.
В SAN-режиме (scale-up) количество контроллеров не может превышать двух (если нужно для SAN больше, то это уже будет RAILGUN), при этом в NAS-режиме количество контроллеров может масштабироваться до 8 (N4).
Теперь картинки
AERODISK ENGINE N1


AERODISK ENGINE N2


AERODISK ENGINE N4


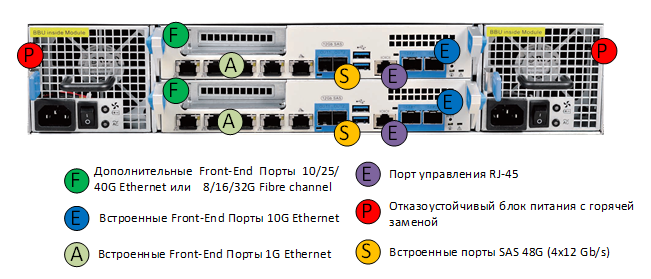
Сами головы установлены сзади и поддерживают возможность замены на горячую. Сзади также устанавливаются два блока питания, которые обеспечивают отказоустойчивость электропитания СХД. Внутри корпуса (N2 и N4) контроллеры соединены двумя интерконнектами.
- PCI-bridge, который обеспечивает минимальные задержки и высочайшую производительность, что позволяет синхронизировать оперативную память между головами СХД.
- 1 Gb Ethernet, который используется в качестве кластерного heartbeat-а.
Внутри головы установлены материнские платы, процессоры Intel Xeon, модель и количество которых меняется в зависимости от конкретной модели СХД, оперативная память (объем также варьируется от 32-х ГБ до 2 ТБ на контроллер), а также внутренние загрузчики (M2 SATA SSD), на которые устанавливается наше ПО.
Защита оперативной памяти от потери питания выполнена с помощью дополнительной батареи (BBU), которая обеспечивает до 10 минут автономной работы материнской платы, оперативной памяти, процессора и загрузчика. За это время, в случае аварийного отказа питания, система автоматически сбросит незаписанные данные из RAM-кэша на внутренний загрузчик, не допуская тем самым потерю данных. После возобновления питания данные с загрузчика автоматически сбросятся на диски СХД и, соответственно, с ними будет все ОК. В зависимости от модели в контроллерах СХД устанавливаются порты ввода-вывода: Ethernet 1/10/25/40Gb и/или FC 8/16/32Gb. Отдельным бонусом является возможность установки и FC, и Ethernet в одну коробку, без дополнительных шлюзов и серверов, что позволяет получить и файловый, и блочный доступ в одной коробке.
ENGINE N2 – вид сзади
Ниже приведены основные аппаратные характеристики модельного ряда ENGINE.
Софт
А теперь интересное. Программная составляющая выполнена, само собой, на базе ядра православного Линукса. Есть 2 дистрибутива, один на базе Astra, второй на базе Debian, по функционалу они не отличаются ничем, данное разделение нужно скорее для правильной сертификации, поэтому в дальнейшем на него не стоит обращать внимания. Поверх ядра Линукса установлены наши собственноручно написанные модули, а также доработанные нами open source решения.
Особенностью и одной из главных плюшек является то, что независимо от аппаратной платформы (N1, N2, N4) софт всегда ставится один. Т.е. даже на самой младшей модели ENGINE можно получить все преимущества старших моделей, что позволяет получить Enterprise-ные функции в моделях самого начального уровня, а также легко и бесшовно проводить апгрейд.
Архитектура хранения
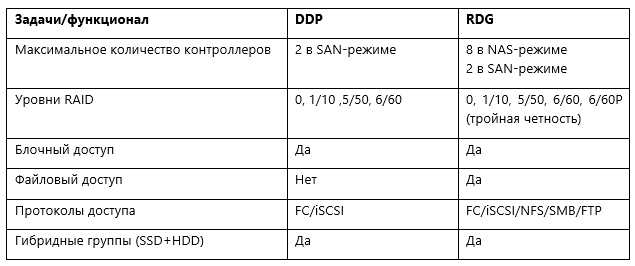
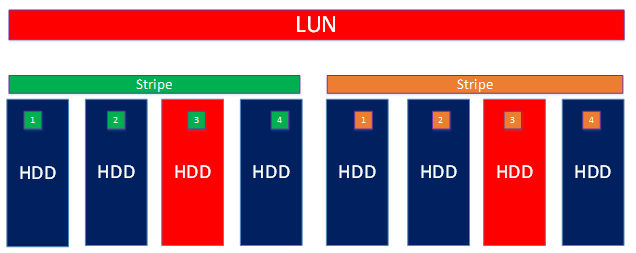
Самое главное в системах хранения — это принципы организации хранения данных или архитектура хранения. В случае ENGINE в одной системе мы объединили два подхода и, соответственно, две архитектуры хранения, которые, в свою очередь, реализованы в виде двух типов виртуального RAID.
- Dynamic Disk Pool (DDP) – для высокопроизводительного блочного доступа, а также случайной и смешанной нагрузки (в первую очередь all-flash)
- RAID Distributed Group (RDG) – для интеллектуального файлового доступа, больших объемов данных и последовательной нагрузки
Естественно возникает вопрос, зачем такое деление? Что, RDG, что DDP – это группы хранения (или пулы хранения), каждая из которых имеет свои плюсы и минусы. Некоторые вендоры не парятся и поступают проще (для себя, конечно же) и выпускают 2 линейки СХД, никак не связанные между собой, для разных задач. Мы же стараемся сделать наши системы как можно более универсальными, чтобы в рамках одной СХД можно было смешивать различные типы задач и нагрузок.
Ниже приведена таблица сравнения DDP и RDG.
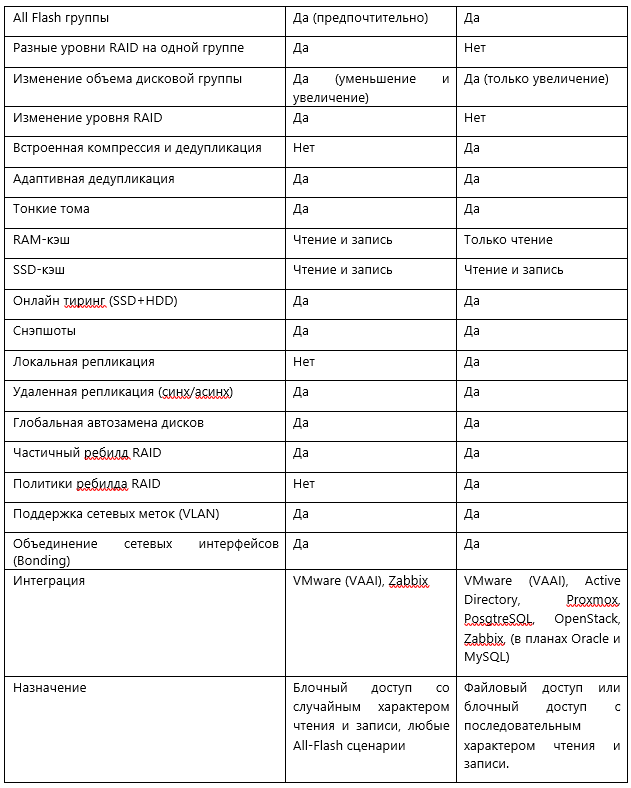
Теперь перехожу к внутренностям каждой из групп.
Dynamic Disk Pool (DDP)
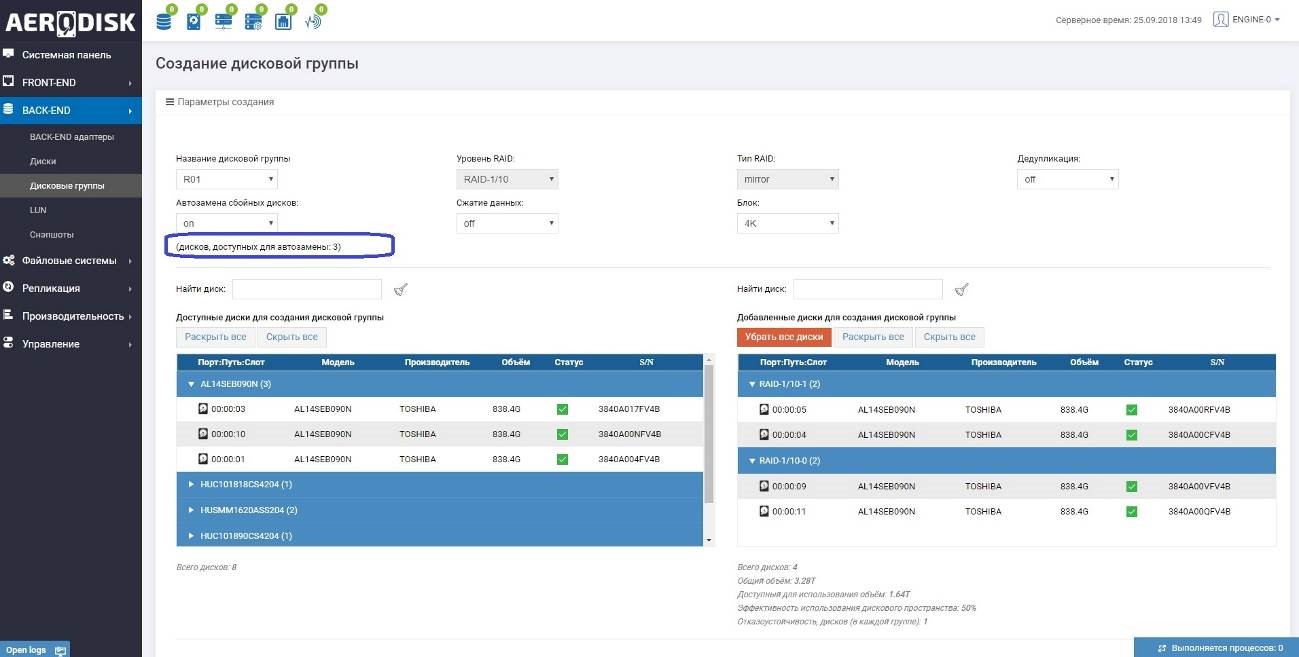
В DDP физические диски (одного или двух типов) объединяются в дисковый пул, при этом первоначально не форматируются, а лишь помечаются меткой о том, что принадлежат к тому или иному пулу. Пул состоит из виртуальных блоков (чанков). При создании пула администратор может указать размер чанка 4 или 16 МБ, по умолчанию используется 4. Также автоматически при создании пула диски, идентичные тем что в пуле, но не добавленные туда, помечаются как диски горячей замены. Соответственно, если в ходе работы диск из пула выйдет из строя, то при наличии hot spare диска, сбойный диск будет выведен из пула, а вместо него будет добавлен hot spare, а потом начнется копирование чанков с других дисков, которые были на сбойном диске (процесс частичного перестроения).
При создании пула система автоматически показывает сколько дисков горячей замены доступно.
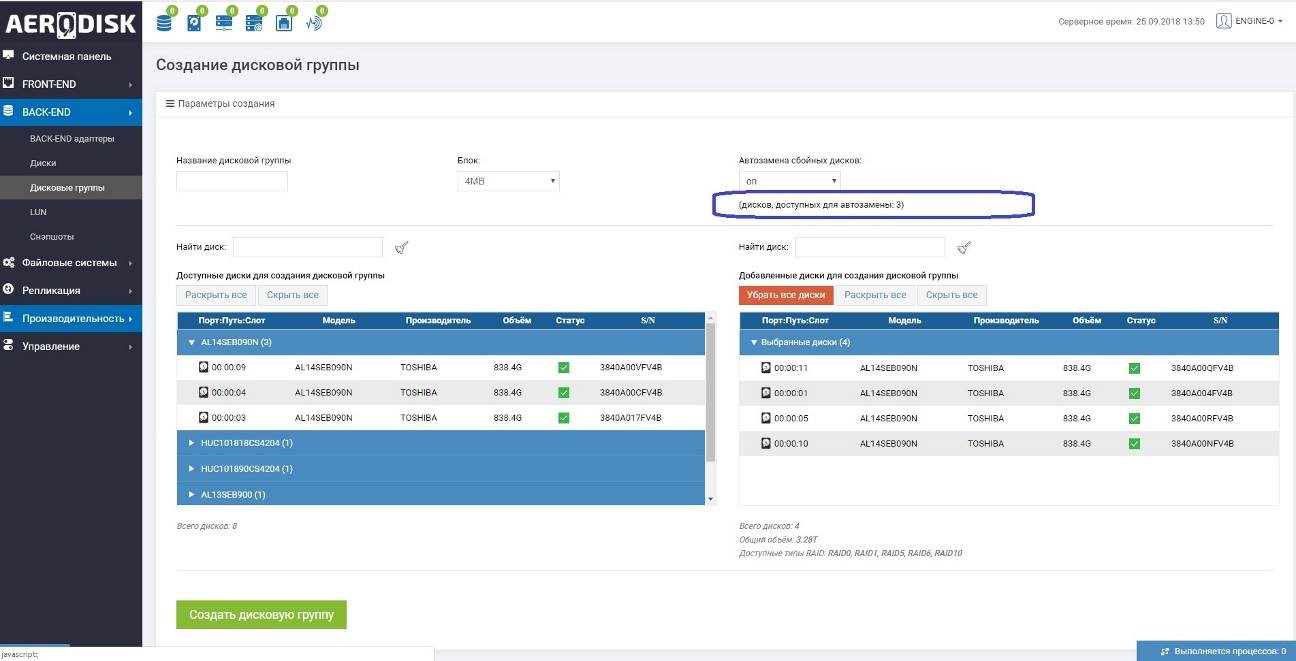
Один диск горячей замены по умолчанию может использоваться для любого количества групп DDP и RDG, где есть аналогичные диски. Специально назначать диски для горячей замены не нужно. Важно обращать внимание на их количество при создании DDP.
Важной особенностью DDP является то, что уровень RAID задается на уровне LUN, а не пула/группы (в RDG наоборот). Таким образом, в одном пуле можно получить LUN-ы с разным уровнем RAID, кроме того уровень RAID на LUN-е можно в любой можно изменить без прерывания доступа к данным.
После создания пул также можно увеличивать или уменьшать путем добавления или исключения физических дисков (в RDG диски можно только добавлять). Если в пуле уже есть созданные LUN-ы, то после добавления новых дисков есть возможность сделать перераспределение чанков LUN-а на новые диски, для получения большей производительности и объема.
В DDP пуле есть 3 опции многоуровневого хранения данных, которые назначаются на LUN администратором СХД
- RAM-кэш на чтение и запись
- SSD-кэш на чтение и запись
- SSD-tier (Online-tiering)
Во всех трех случая назначение опций происходит на конкретный LUN. Можно назначить опции и на все LUN-ы в пуле, но следует учитывать конкуренцию LUN-ов за более быстрый ресурс SSD или RAM. Механизма приоритетов в многоуровневом хранении в DDP на текущий момент нет (при этом есть в RAILGUN, но это уже отдельная система).
Схематично организация хранения в DDP выглядит следующим образом.
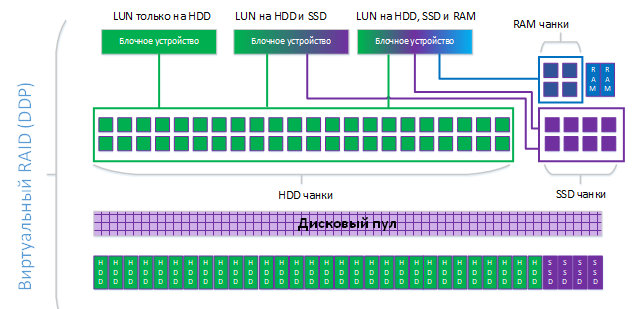
В нашем примере в дисковом пуле создано три LUN-а, один хранит данные только на HDD, второй на HDD+SSD-tier, третий на HDD+SSD-tier+RAM-кэш.
В DDP поддерживаются RAID уровней 0, 1/10, 5/50, 6/60 (см. таблицу ниже)
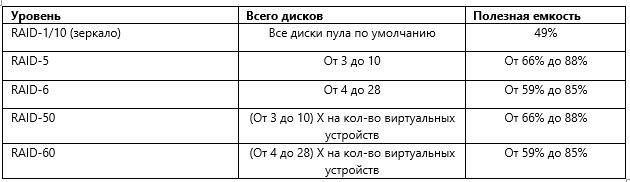
В отличие от RDG DDP поддерживает только стандартные уровни RAID (0, 1/10, 5/50, 6/60). При этом чанки LUN-ов равномерно могут быть распределены между всеми дисками в пуле, если выбран RAID уровня 1/10. Если выбраны RAID-ы уровней 5 или 6, то при создании группы администратор выбирает максимальное количество дисков для конкретного LUN-а (лимиты выставлены в силу особенностей RAID 5 и 6). Но задействовать все диски пула для пятерки и шестерки возможно, для этого нужно использовать уровни 50 или 60, которые, по сути, являются объединениями виртуальных устройств на базе пятерки или шестерки.
Основными преимуществами использования всех дисков пула сразу являются:
- Повышенная надежность: чем больше дисков используется для LUN-а, тем ниже шанс потерять данные (см. примеры в сценариях отказов)
- Линейный рост производительности: чем больше дисков используется для хранения данных LUN-а, тем выше производительность (особенно для all-flash сценариев)
Сценарии отказов
Возьмем простой пример LUN-а, который расположен только на HDD c RAID-ом уровня 10. Пул организован изначально на четырех дисках. LUN в 10-ом рэйде, это значит что все чанки равномерно распределены по всем дискам пула и формируют зеркало из двух страйпов. Для простоты примера представим, что дисков горячей замены нет (в продуктиве
Схематично хранение данных такого LUN-а выглядит так.
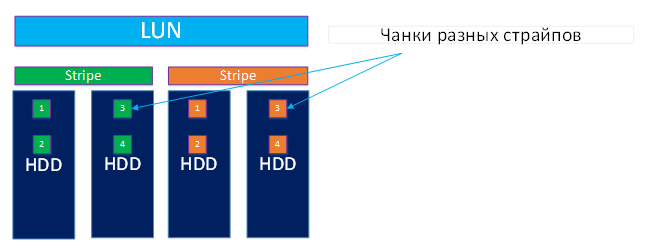
Чтобы потерять данные в такой конструкции, достаточно выхода из строя:
• любого из страйпов полностью (2 диска) + 1 диск другого страйпа (3 диска из 4-х);
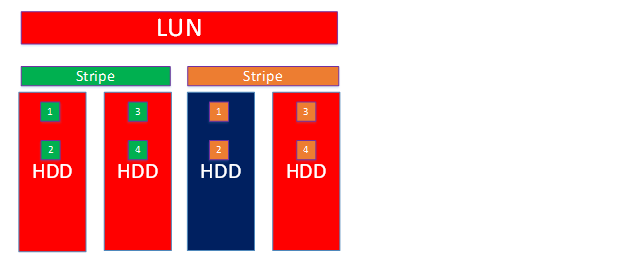
• по одному диску в каждом страйпе с зеркальными чанками (в нашем случае чанки 3 и 4) – 2 диска из 4-х
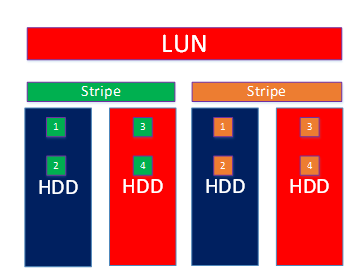
При этом, в случае выхода из строя диска с чанками 1 и 2 в одном страйпе и чанками 3 и 4 в другом страйпе, данные потеряны не будут. Ввод-вывод будет продолжаться, но нужны hot spare диски, чтобы исправить ситуацию.
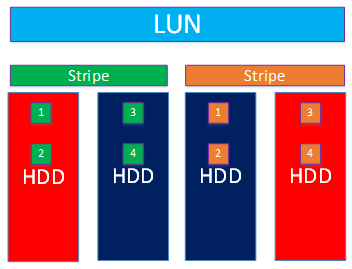
Если нам нужно повысить надежность и заодно производительность, мы можем добавить дисков в пул и растянуть LUN на новые диски.
Масштабирование пула может выполняться любым количеством дисков (можно по одному добавлять, например). LUN будет растягиваться переносом чанков на новые диски в фоновом режиме (после подтверждения от администратора).
У администратора также есть выбор, как использовать новые диски в пуле:
- просто перераспределить чанки, добавив производительности и надежности
- увеличить объем LUN-а с помощью новых дисков, добавив емкости, а также производительности и надежности.
Увеличим пул ещё на 4 диска и перераспределим чанки без увеличения объема.
Чанки равномерно перераспределились на все диски пула.
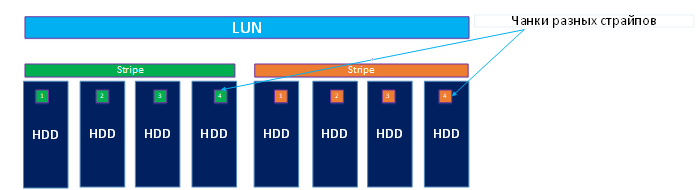
Теперь, чтобы уничтожить данные, должны выйти из строя:
• также любой из страйпов (4 диска) + 1 диск другого страйпа (уже 5 дисков из 8);
• по одному диску в каждом страйпе с зеркальными чанками (берем случай с чанком 3), также 2 диска из 4-х, как и в первом примере
При этом, чем большее количество дисков в пуле, тем ниже шанс что выйдут дублируемые чанки. Соответственно, если в пуле дисков 100+, шанс, что выйдут из строя 2 диска в разных страйпах с идентичными чанками крайне низок. Таким образом, в больших пулах надежность DDP крайне высокая, а если использовать hot spare диски, то еще выше.
RAID Distributed Group (RDG)
В RDG физические диски первоначально объединяются в виртуальные устройства согласно четности уровня RAID, который указывается при создании группы. Далее эти виртуальные устройства объединяются в длинный страйп, который уже и представляет из себя RDG.
У RDG несколько закономерностей.
- Чем больше в RDG виртуальных устройств, тем выше её производительность и надежность;
- Чем выше уровень RAID единичного виртуального устройства, тем выше надежность группы, но при этом полезный объем снижается;
- Чем больше дисков в единичном виртуальном устройстве, тем выше надежность, больше полезный объем, но тем выше шаг увеличения группы (см. пример ниже).
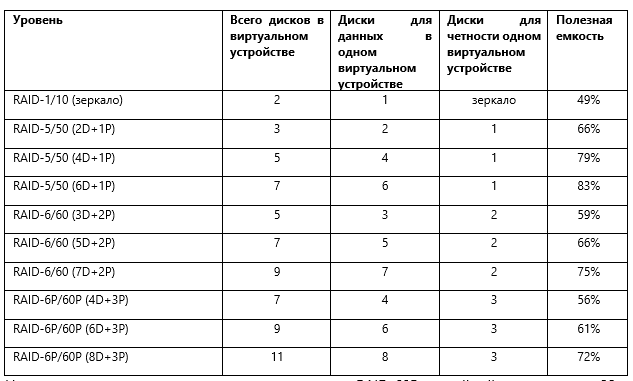
В таблице ниже приведены поддерживаемые уровни RDG с указанием четности для одного виртуального устройства и процента полезной емкости. Это не все возможные комбинации, при необходимости можно сделать шаблон виртуального устройства самостоятельно.
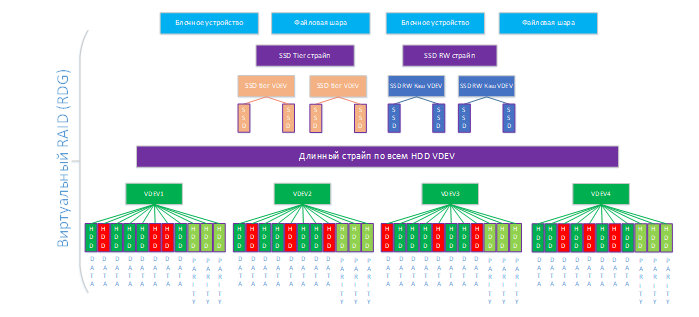
На схеме ниже приведен пример группы уровня RAID-60P с тройной четностью из 33-х дисков. Кэш в оперативной памяти тут не показан, т.к. в случае RDG он работает только на чтение и включен всегда.
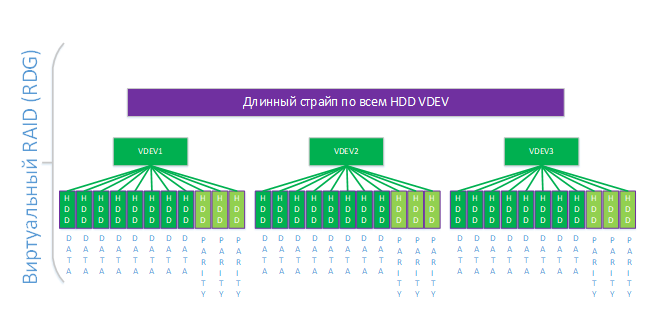
Отдельной полезной плюшкой является то, что количество дисков (и виртуальных устройств) в RDG логически никак не ограничено, что позволяет создавать действительно огромные группы.
Логика работы дисков автозамены в RDG аналогична DDP. При создании группы система автоматически показывает, сколько дисков горячей замены (hot spare) будет доступно. Один диск горячей замены по умолчанию может использоваться для любого количества групп, где есть аналогичные диски. Специально назначать hot spare диск не требуется, следует просто обращать внимание на их количество при создании RDG. Hot spare диски для RDG могут одновременно быть hot spare дисками для DDP и наоборот.
Сам процесс перестроения диска при автозамене в RDG является частичным т.е. перезаписывается не диск целиком, а только те части данных, которые были повреждены, что серьезно ускоряет процесс перестроения. Также данный процесс поддается предварительной настройке политиками. На уровне СХД можно заранее задать политику:
- Скорость восстановления. Политика предназначена для случаев, когда нужно быстрее выполнить ребилд. При этом во время ребилда будет снижена производительность ввода-вывода (20-30%)
- Производительность ввода-вывода. Политика предназначена для случаев, когда нужно при ребилде не терять производительность, а скорость ребилда не так важна. В этом режиме во время ребилда не будет существенно снижена производительность ввода-вывода (не более 10%), при этом ребилд будет происходить в 1,5-2 раза дольше.
Далее опционально к RDG можно добавить SSD-кэш и дополнительный уровень хранения на SSD (Online-tiering). Минимальное количество дисков в обоих случаях равно двум. SSD-кэш и SSD-tier всегда добавляется виртуальными устройствами уровня RAID-10, независимо от уровня RDG. На схеме ниже к нашей группе мы добавили SSD-кэш и SSD-tier. В отличие от DDP в RDG уровни SSD добавляются не к LUN-ам, а на группу в целом, т.е. все объекты группы (LUN-ы и шары) используют SSD-уровни, если они добавлены.
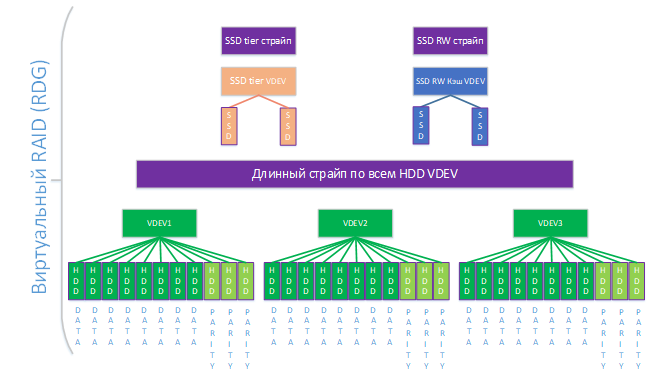
Созданную RDG, а также SSD уровни, всегда можно расширить дополнительными дисками на горячую (но нельзя уменьшить в отличие от DDP). При добавлении дисков следует учитывать четность RDG и SSD-уровней. В нашем примере:
- минимальный шаг добавления дисков для нижнего уровня – 11, т.к. размер виртуального устройства — 11 дисков. Если бы мы сделали этот размер меньше изначально, то, соответственно, и шаг добавления был бы меньше (например, для RAID-10 он, очевидно, равен двум дискам)
- для уровня кэша и тиринга, этот шаг всегда два диска, т.к. SSD-уровни — это всегда RAID уровня 10 и всегда добавлять надо минимум по два диска.
На схеме ниже мы увеличили каждый из уровней хранения на одно виртуальное устройство. Теперь у нас на нижнем уровне 4 виртуальных устройства по 11 дисков (44) и на уровнях SSD по 2 виртуальных устройства в каждом страйпе
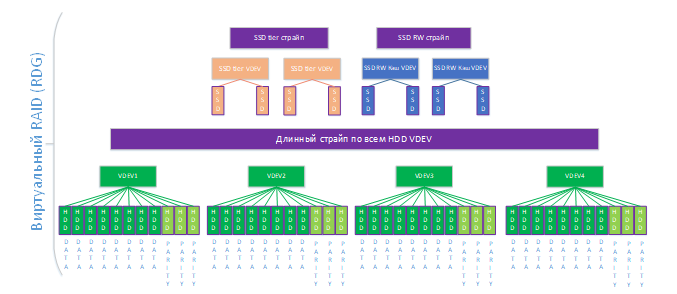
После добавления новых виртуальных устройств система автоматически распределит рабочие нагрузки по ним, дополнительных действий администратору выполнять не требуется.
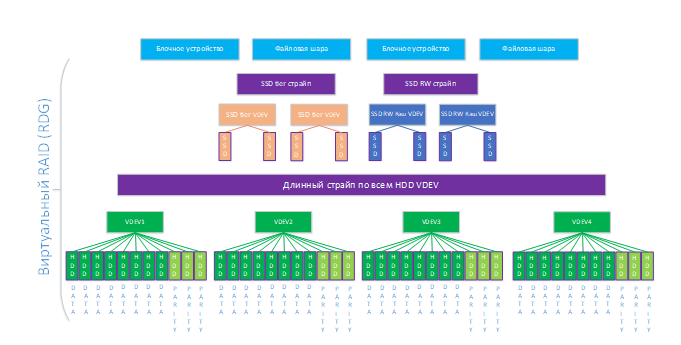
После создания группы (или в процессе создания) к ней можно прикрутить такие полезные вещи как компрессия и дедупликация. Эти обе опции можно включать как на уровне RDG (тогда они работают на всю группу и блочные устройства, и на файловые шары), так и на уровне отдельного объекта хранения.
Далее в RDG создаются объекты, в которых непосредственно можно хранить данные. Это могут быть блочные устройства (доступ по iSCSI/FC) или файловые шары (доступ NFS/SMB/FTP). В одной группе можно одновременно создавать и LUN-ы, и шары.
Теперь рассмотрим сценарии отказа нашей группы
Чтобы потерять данные любое из виртуальных устройств должно быть уничтожено.
Из схемы мы видим, что у нас на нижнем уровне есть четыре виртуальных устройства, в каждом по три диска для четности. Соответственно, чтобы убить виртуальное устройство, в нем одном должны выйти из строя четыре диска (при потере трех дисков устройство будет работать нормально). Если смотреть на нижний уровень RDG в целом, то мы можем потерять до двенадцати дисков (по три в каждом виртуальном устройстве). Вся эта математика не учитывает hot spare диски. Т.е., если они будут, то количество дисков для отказа можно увеличивать на количество свободных дисков из hot spare. В данном примере, также, как и в примере с DPP, для простоты мы представим, что hot spare диска нет (повторюсь, в продуктиве так делать нельзя).
Сценарий 1
Отказ 12-ти дисков из 44 (по 3 в каждом виртуальном устройстве)
В каждом виртуальном устройстве вышло из строя максимально допустимое для данной конфигурации число дисков (SSD не трогаем, там логика идентичная, но только для RAID10). Ввод-вывод продолжается, но ситуация критическая, нужно срочно добавлять/менять диски. В каждом виртуальном устройстве вышло из строя максимально допустимое для данной конфигурации число дисков (SSD не трогаем, там логика идентичная, но только для RAID10). Ввод-вывод продолжается, но ситуация критическая, нужно срочно добавлять/менять диски.
Сценарий 2
Отказ 13-ти дисков из 44 (в одном из устройств вышло из строя 4 диска)
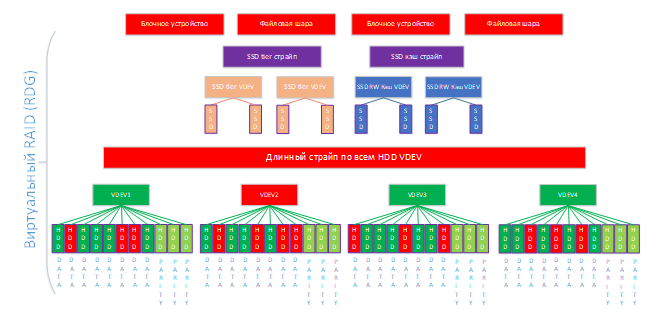
Тут уже ничего не поделаешь, одно из виртуальных устройств умерло, поэтому ввод-вывод остановлен и данные следует восстанавливать из резервных копий (есть, конечно, наши средства восстановления, но это тема отдельной статьи). Очевидно, что такую ситуацию допускать нельзя, поэтому надо использовать hot spare и следить за оповещениями в СХД или в системе мониторинга, которая к ней подключена (SNMP поддерживается).
DDP vs RDG
Если сравнивать два типа групп, то проще всего сказать следующее.
Если вам нужна высокая производительность на блочном доступе при случайном или смешанном характере нагрузки и динамичный RAID, то однозначно нужно использовать DDP. Если же вам нужен файловый доступ или последовательный характер нагрузки, а также возможность создавать огромные RAID-группы (петабайты), то вам однозначно в RDG.
При этом если в ходе работы нужно поменять тип группы, то миграция данных между RDG и DDP поддерживается, процесс этот, конечно, нетривиальный, но выполнимый.
Отказоустойчивость
Далее про высокую доступность в ENGINE. Ранее я писал, что используется схема ассиметричного Active/Active (ALUA — Asymmetric Logical Unit Access ).
Кластерное ПО ENGINE работает как с блочным, так и с файловым доступом. Heartbeat между нодами выполняется с помощью интерконнекта. Кластер автоматически переключает оптимальные и неоптимальные пути, а также автоматически меняет владельца групп хранения в следующих случаях:
- Отказ контроллера (смена владельца)
- Отказ задействованных в воде-выводе портов СХД (смена владельца)
- Отказ порта на хосте (смена путей оптимальный-неоптимальный
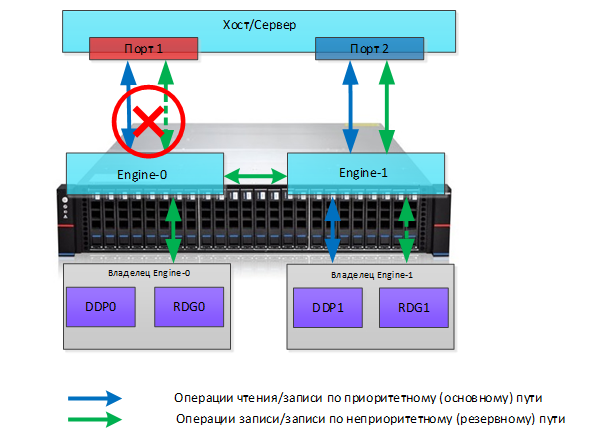
Для наглядного примера изобразим на схеме 2-х контроллерную конфигурацию, которая подключена к 2-м портам хоста, для которых средствами ОС настроен multipath. На СХД созданы 4 группы хранения, для 2-х из них назначен владельцем первый контроллер (Engine-0), для 2-х других владельцем назначен Engine-1. Оба контроллера (и 4 группы) видны обоим портам хоста.
Для DDP0 и RDG0 владельцем назначен Engine 0, пути через этот контроллер для данной группы являются оптимальными. При этом существует неоптимальный путь (через интерконнект и Engine-1), который задействуется в случае отказа основного порта на хосте. Для DDP1 и RDG1 обратная ситуация: владельцем является Engine-1, через него лежит оптимальный путь, а через интерконнект и Engine-0 – неоптимальный.

В любой момент администратор СХД может сменить владельца каждой из групп. Процесс смены владельца занимает примерно 5-10 секунд и происходит без прерывания ввода-вывода. Эта же операция выполняется администратором для перевода контроллера в режим обслуживания, например, когда требуется аппаратное или программное обновление СХД.
Отказ порта
Представим, что произошёл отказ порта на хосте, который был оптимальным для групп DDP0 и RDG0 (через Engine-0). В этом случае СХД автоматически задействует неоптимальный путь через Engine-1 и интерконнект, что сохранит доступ к данным, но с дополнительной задержкой.
Когда порт на хосте будет восстановлен, данные автоматически пойдут по оптимальному пути.
Отказ контроллера
Более сложный сценарий – это отказ контроллера. В этом случае неоптимальные пути нас уже не спасут, и в случае физической потери контроллера (или 2-х портов ввода-вывода на контроллере) система выполнит принудительную смену владельца всех групп хранения на отказавшем контроллере. Соответственно, далее произойдёт смена владельца, что происходит без прерывания ввода вывода.

Когда контроллер Engine-0 снова вернется в строй, администратору нужно будет вручную сменить владельца на Engine-0 обратно.
Заключение
Как видно из примеров, на текущий момент AERODISK ENGINE имеет довольно гибкую архитектуру хранения, применимую для самых разных задач и высокую степень надежности, что позволяет использовать систему в критичных для бизнеса задачах.
На текущий момент в разных регионах России установлены около ста систем хранения ENGINE и это количество неуклонно растет. Большинство этих инсталляций проходили через долгие тесты на площадках наших партнеров и заказчиков, и большинство завершалось успешно. Конечно, это не десятки тысяч инсталляций, как у транснациональных топ-вендоров, но Москва не сразу строилась, и все ещё впереди.
В следующих статях про ENGINE я подробно распишу дополнительные функциональные плюшки, такие как дедупликация, компрессия, снэпшоты и репликация, а потом будет отдельная статья по тестам производительности RDG и DDP групп. После этого вас ждет разбор других наших продуктов.
Кроме того, 9 октября (вторник) с 11:00 до 12:30 (МСК) пройдёт бесплатный
технический вебинар, где мы с TS Solution расскажем и главное покажем на
живой системе, как все работает.
Комментарии (10)

Antilles7227
04.10.2018 16:47Есть ли у вас варианты взять хранилки в демо? Было бы интересно покрутить, выглядит здорово.

amarao
04.10.2018 17:35+3Скажите, а вы её сами писали? Я вот вижу enp5s15 и почему-то чудятся мне коммиты в linux-stable. А если не сами, то как насчёт исполнения лицензии GPL? Сырцы там, например?
Второе. Т.к. снизу там linux, то разумно предположить, что и сверху там насыпано опенсорсным софтом. ceph? drbd? gluster? Стикеры поверх acer'овских мониторов?
ximik13
05.10.2018 13:02Что касается ALUA, я правильно понимаю, что на контроллер мапятся целиком дисковые пулы? Т.е. что бы оба контроллера работали одновременно с вводом\выводом нужно создавать как минимум два дисковых пула? Если же берем небольшую конфигурацию и для увеличения производительности пула добавляем в него все диски контроллерной полки, то второй контролер будет "тихо курить в сторонке" до события, вызывающего смену владельца? Т.е. фактически мы не можем задействовать больше чем 50% производительности системы? Так как узким местом в таких системах чаще всего являются именно контроллеры.
А в случае создания двух пулов, по одному на контроллер, нужно будет думать как распределить по ним в ручном режиме луны и файловые системы, что бы сбалансировать нагрузку на оба контроллера?
Еще вопрос, когда создаются снэпшоты, то начинают отслеживаться изменения для конкретного луна и FS или для всего дискового пула, где они расположены. Т.е. на каком уровне делается снэпшот на уровне LUN/FS или на уровне пула дисков?
vtolstov
А можно рассказать немного про софт, написан ли с нуля, на чем? Что легло в основу?..
Как будет работать в режиме трех нод, как будете выбирать лидера группы и тп?
bawler
Софт написан с использованием C, ASM, python, php, js, HTML5.
В основе ядро Линукс (Astra или Debian) + свои модули, написанные с нуля (кластер, репликация, мониторинг, виртуальный RAID, volume manager, CLI, веб + скриптовая обвязка) + опенсорс (scst, lio, cassandra, timer, zfs, ext4,lvm,drdb).
Что касается 3-х нод, то такого режима нет, СХД работает HA-парами (2 ноды для SAN и до 8-и для NAS).
По лидеру (видимо речь идет о владельце DDP\RDG), он назначается руками администратором и автоматически переключается на соседа в случае сбоя.
Также поддерживаются стандартные механизмы мультипасинга в Windows, Linux, VMware.
Произвольное количество нод — это vAIR (SDDC-продукт), о котором позднее напишем.
vtolstov
Планируется ли какие-то части открыть в opensource или пока нет таких планов?
Darka
Вангую, что нет, они похоже и на GPL положили.
vtolstov
Вы зря так категоричны.
Во первых по-началу почти все делают закрытый продукт. Построить бизнес на полностью опенсорсе тяжело и удается не многим.
Во вторых, чтобы что-то выложить в опенсорс и было как минимум не стыдно — надо тоже постараться и достаточно времени потратить.
В третьих отделить свою поделку (если ее не хочется открывать) от опенсорс куска, сформировав поделку как самодостаточный модуль тоже стоит времени-денег.
Но конечно же, хочется, чтобы все не просто высасывали все из опенсорса и ничего не привносили своего.