

Доброго времени суток.
Сегодня расскажу вам о попытках осилить анализ учебных материалов, борьбе за качество этих документов и разочаровании, которое мы познали. «Мы» это пара студентов из МГТУ им. Н. Э. Баумана. Если вам интересно, добро пожаловать под кат!
Задача
Мы собирались оценивать качество учебных материалов (методических указаний, учебников и пр.) по статистическим показателям. Показателей таких было немало, вот некоторые из них: отклонение числа глав от «идеального» (равного пяти), среднее число символов на страницу, среднее число схем на страницу и так далее по списку. Не так уж и сложно, да? Но это было только начало, ведь дальше, в случае успеха, нас ждало построение онтологии и семантический анализ.
Инструменты и исходные данные
Проблема заключалась в исходных материалах, а ими были всевозможные методички/учебники в PDF. Вернее, проблема была даже не в самих материалах, а в PDF и качестве конвертации.
Для работы с PDF было решено использовать Python и какую-нибудь модную молодежную библиотеку на роль которой была выбрана pdfminer.six.
История
Вообще, сначала мы пробовали разные библиотеки для питона, но все они не очень дружили с кириллицей, а литература у нас написана на русском языке. К тому же, самые простые библиотеки умели только вытаскивать текст, чего нам было недостаточно. Остановившись на pdfminer.six, мы начали прототипировать, экспериментировать и развлекаться. К счастью, для начала примеров из документации нам хватило.
Мы создавали свои PDF-документы с текстом, изображениями, таблицами и прочим. Всё у нас шло хорошо, мы могли спокойно вытащить любой элемент из нашего документа.
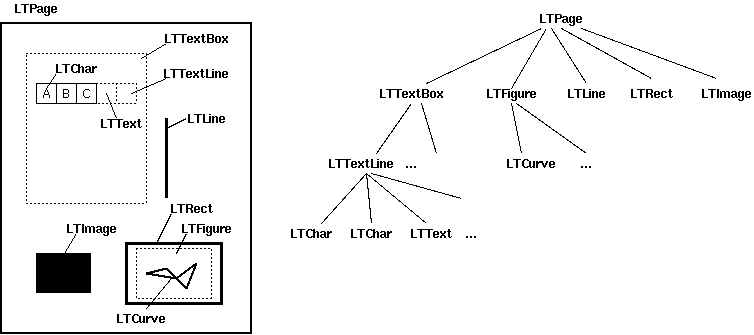
Вот как выглядит страница документа в нашем представлении
Приведу небольшой пример взаимодействия с документом: получение текста документа.
file = open(path, 'rb')
parser = PDFParser(file)
document = PDFDocument(parser)
output = StringIO()
manager = PDFResourceManager()
converter = TextConverter(manager, output, laparams=LAParams())
interpreter = PDFPageInterpreter(manager, converter)
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
converter.close()
text = output.getvalue()
output.close()
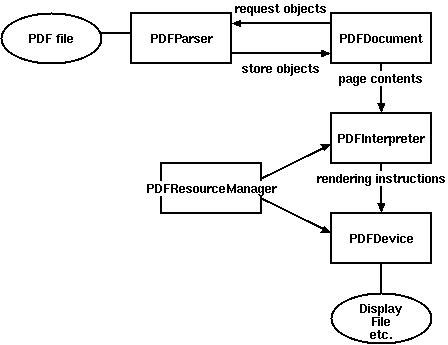
Как можно увидеть, получить текст из документа довольно просто. Всякое взаимодействие осуществляется согласно схеме ниже
Почему ничего не вышло?
Все эксперименты были удачными и на тестовых PDF-файлах всё было прекрасно. Как оказалось, сломать всё – задача тривиальная и идея разбилась о суровую действительность.
После экспериментов мы взяли несколько настоящих учебников и обнаружили, что всё что угодно может пойти не так.
Первое, что мы заметили: количество изображений, подсчитанных программой, не соответствует действительности, а части текста просто теряются.
Выяснилось, что некоторые (иногда даже многие) части текста в документе были представлены не в виде текста и неизвестно как так получилось. Этот факт сразу же отмел анализ частотного распределения символов/слов/словосочетаний, семантики, да и вообще любой другой вид анализа текста.
Возможно, что при конвертации или создании этих документов произошло что-то непредвиденное, а возможно, что никому и не было нужно, чтобы они были сформированы «правильно». К сожалению, таких материалов было большинство, что и привело к разочарованию в идее подобного анализа.
Литература
Раздел документации из репозитория pdfminer.six был использован для написания статьи и в качестве справочника.
Комментарии (12)

ximik666
09.10.2018 21:23У нас есть система электронных курсов(несколько тысяч), которым требуется проверка соответствия требованиям(например,5 лекций на 50 страниц, автоматизированный тест на 20 вопросов, допматериал в виде презентации и ссылки на видео). До этого все делалось в ручном режиме, теперь проводится анализ в автоматическом режиме. Но это оценка количества, а не качества. Вот теперь тоже думаем, как автоматически проверить качество курса?
zoonman
09.10.2018 22:54Я вам честно скажу — автоматически никак.
Среднюю температуру по больнице можно получить с помощью системы отзывов о курсе от людей, прошедших через него. И спрашивать их нужно примерно после полугода с момента того, как они прошли курс. Вопросы должны быть конкретными — понятно ли описание, хорошо ли проиллюстрировано, полно ли были раскрыты понятия, нужно ли видео, удобен ли интерфейс и т.д.
Если вы хотите полноценную проверку — заказывайте слепой независимый аудит от работающих в отрасли специалистов.
Exchan-ge
10.10.2018 13:37Выяснилось, что некоторые (иногда даже многие) части текста в документе были представлены не в виде текста и неизвестно как так получилось.
Учитывая, как именно создаются такие документы — этого следовало ожидать.
В большинстве случаев преподаватели создают эти документы в MS Word, добавляя в него текст и изображение из совершенно разных источников (я видел эти оригиналы в ворд — там бывает просто чудовищное форматирование).
Потом все это сохраняется как файл в формате pdf.
BigElectricCat
11.10.2018 18:25Учебники обычно верстают в соответствующих программах, Ворд не умеет CMYK на выходе, а без него не будет цветоделённых пластин.
Exchan-ge
12.10.2018 18:57Учебники обычно верстают в соответствующих программах
Насколько я понял — речь идет о вузовских учебниках.
А большинство вузовских учебников, учебно-методических пособий (не говоря уже простых «методичках») — верстают их авторы. Бо отдавать это дело в руки профессионалов достаточно накладно.
В издательство передается уже готовый макет, в который вносятся минимально необходимые исправления.
Так что «соответствующая программа» — это почти всегда MS Word.
без него не будет цветоделённых пластин
Цвет в вузовском учебнике — это очень дорогое удовольствие.
Hardcoin
10.10.2018 13:47У вас скорее жалоба, чем отчёт о попытке. "Никому не было нужно" — так это вам было нужно. Распознайте текст. Это в разы разумнее, чем каждый раз каждый файл делать "правильно", под машину. В конце концов преподаватель старается для студентов, а не для условной машины, которая потом будет что-то анализировать. Так что это задача машины — подстроиться, а не наоборот.
RVetas Автор
10.10.2018 18:20Конечно, все стараются для людей, с этим невозможно спорить. Но не могу согласиться с тем, что разумнее «не делать правильно» каждый документ: есть же стандарты, спецификации и здравый смысл в конце концов (это к тексту картинками). Как мне кажется, применение распознавания это не разумнее, а просто-напросто единственный возможный вариант в сложившейся ситуации.
scumware
11.10.2018 00:09Выглядит как «мы попробовали — у нас не получилось». Маловато для статьи.
Где подробности!!!?
Это проблемы PDF документов или библиотеки? Почему вы так думаете? Вы пробовали другие библиотеки? Какие именно проблемы в PDF документах? Как сделать так, чтобы получилось?
BigElectricCat
12.10.2018 09:34Очень печально когда «анализировать» пытаются те, у кого не специального образования по предмету. Это не значит, что надо 5 курсов отучится на дизайнера полиграфической продукции, но хотя бы стоит почитать про то, что должен смотреть в «белках» выпускающий редактор.
А вот это, с точки зрения полиграфиста:
отклонение числа глав от «идеального» (равного пяти), среднее число символов на страницу, среднее число схем на страницу и так далее по списку
вообще тянет на бред.
Число глав не должно быть ограничено 5, а выбирается редактором издания для удержания равномерной скорости подачи материала раздела.
Число символов на странице (а так же размеры схем, диаграмм и их число на странице) определяются СанПиН-ами, которые ограничивают размер кегля гарнитуры возрастом читателя этого текста (например вот ссылка для взрослых пункт 4.2. Для учебников точно так же есть нормы… что в гугле навскидку нашлось… вообще оно у заинтересованных в виде книжечки на полочке у дизайнера стоит).
части текста в документе были представлены не в виде текста и неизвестно как так получилось
Элементарно, верстальщик случайно нажал комбинацию клавиш для преобразования в кривые. Поскольку текст этот не правился, то его так и вывели в пдф-ку, основной текст нормально, а часть «случайных» блоков в кривых.
amaksr
Ожидал увидеть что вы ну хотя попытались отрендерить PDF-ы в изображения, которые потом прогнали через кастомизированный полусамописный OCR, который бы автоматически восстановил текст из картинок (и убрал бы картинки, которые текст). А так — очень мало для статьи на хабре.
RVetas Автор
Спасибо за ответ. Эта задача не была сильно востребована, поэтому использование OCR мы посчитали избыточным. К сожалению, распознавание текста не решает некоторых других проблем (возможно, стоило о них сказать). Например, OCR может распознать текст со схемы или изображения. Также невозможно отличить схему от простого изображения/примера. В общем, остановились мы не только из-за «невозможности» перегнать «текст-картинку» в текст, но и из-за других проблем. А количество учебных материалов на самые разные темы использует большое количество изображений, которые в наших метриках классифицировались по-разному, но программно – одинаково. Таких принципиальных трудностей, как оказалось, можно придумать большое множество.
gecube
Если текст все-таки преимущественно состоит из абзацев текста, выровненного по левой и правой границам страницы, то false на схемах и изображениях будут низковероятными.