
Всем привет. Как вы, возможно, знаете, раньше я все больше писал и рассказывал про хранилища, Vertica, хранилища больших данных и прочие аналитические вещи. Сейчас в область моей ответственности упали и все остальные базы, не только аналитические, но и OLTP (PostgreSQL), и NOSQL (MongoDB, Redis, Tarantool).
Эта ситуация позволила мне взглянуть на организацию, имеющую несколько баз данных, как на организацию, имеющую одну распределенную гетерогенную (разнородную) базу. Единую распределенную гетерогенную базу, состоящую из кучи PostgreSQL, Redis-ов и Монг… И, возможно, из одной-двух баз Vertica.
Работа этой единой распределенной базы порождает кучу интересных задач. Прежде всего, с точки зрения бизнеса важно, чтобы с данными, движущимися по такой базе, все было нормально. Я специально не использую здесь термин целостность, consistency, т.к. термин это сложный, и в разных нюансах рассмотрения СУБД (ACID и CAP теорема) он имеет разный смысл.
Ситуация с распределенной базой обостряется, если компания пытается перейти на микросервисную архитектуру. Под катом я рассказываю, как обеспечить целостность данных в микросервисной архитектуре без распределенных транзакций и жесткой связности. (А в самом конце объясняю, почему выбрал для статьи такую иллюстрацию).

Согласно Крису Ричардсону (одному из известнейших евангелистов микросервисной архитектуры), в этой архитектуре есть два подхода к работе с базами данных: shared database и database-per-service.

Shared database — это неплохой первый шаг, отличное решение для небольшой компании без амбициозных планов роста. При этом сам по себе этот паттерн является анти-паттерном с точки зрения микросервисной архитектуры, т.к. два сервиса, делящих общую базу, нельзя независимо тестировать и масштабировать. Т.е. эти сервисы скорее — один сервис, тяготеющий к превращению в монолит.
Паттерн database-per-service предполагает, что у каждого сервиса своя база. Сервис может обращаться к данным другого сервиса только через API (в широком смысле), без прямого подключения к его базе.
Паттерн database-per-service позволяет командам соответствующих сервисов выбирать базы, как им нравится. Кто-то умеет в MongoDB, кто-то верит в PostgreSQL, кому-то достаточно Redis (риск потери данных при выключении для этого сервиса приемлем), а кто-то вообще хранит данные в CSV-файлах на диске (а почему бы, собственно, и нет?).
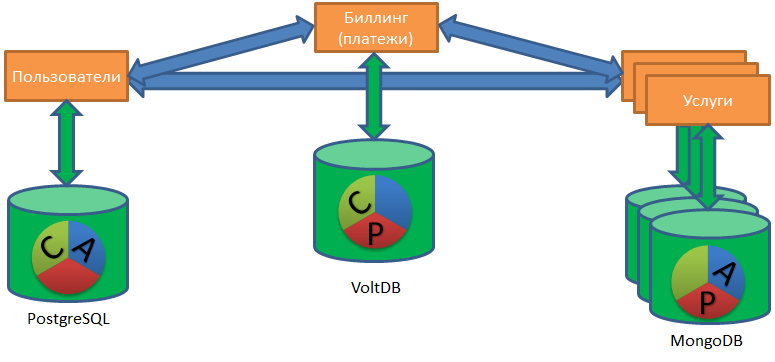
Работа с подобным «зоопарком» баз данных поднимает задачу наведения порядка в данных на абсолютно новый уровень сложности.
ACID и микросервисная архитектура
Давайте посмотрим на задачу наведения порядка через призму классического СУБД-шного набора требований ACID: развернем суть каждой буквы аббревиатуры, и проиллюстрируем сложности с этой буквой в микросервисной архитектуре.
(A) CID — Atomicity. Atomicity — все или ничего.
Согласно требованию Atomicity, нужно обязательно выполнить все шаги (с возможными повторами), при отказе важного шага — отменить выполнившиеся.
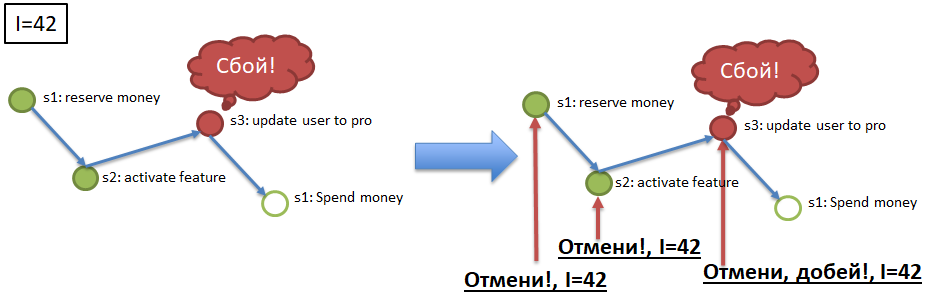
В приведенной иллюстрации демонстрируется тестовый процесс покупки услуги VIP: резервируются деньги в биллинге (1), для пользователя подключается бонусная услуга (2), тип пользователя меняется на Pro (3), зарезервированные деньги в биллинге списываются (4). Все четыре шага должны либо выполниться, либо не выполниться.
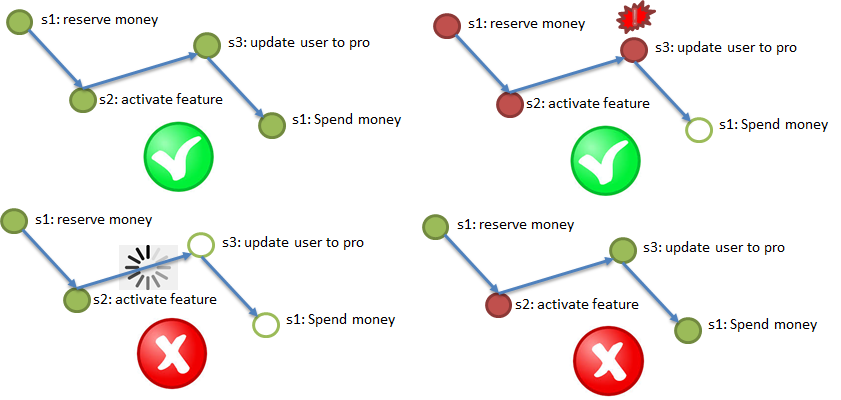
При этом нельзя зависнуть посередине процесса, поэтому предпочтительнее асинхронность, в крайнем случае — синхронность со встроенным таймаутом.
A(С)ID – Consistency. Consistency – каждый шаг не должен противоречить граничным условиям.
Классические примеры условий для, например, отправки денег от клиента А в сервисе 1 клиенту B в сервисе 2: в результате подобной отправки денег не должно стать меньше (деньги при пересылке не должны пропасть) или больше (недопустимо отправить одни и те же деньги двум пользователям одновременно). Для соблюдения этого требования нужно где-то кодировать условия и проверять данные для условий (в идеале — без дополнительных обращений).

ACI(D) — Durability. Требование Durability означает, что последствия операций не пропадают.
В условиях Polyglot persistence сервис может работать на базе данных, которая штатно может «потерять» записанные в нее данные. Подобный фокус можно получить даже от солидных баз наподобие PostgreSQL, если там включена асинхронная репликация. На иллюстрации демонстрируется, как изменения, записанные в Master, но не доехавшие в Slave по асинхронной репликации, могут быть уничтожены сгоранием сервера Master. Для обеспечения требования Durability требуется уметь штатно диагностировать и восстанавливать подобные потери.
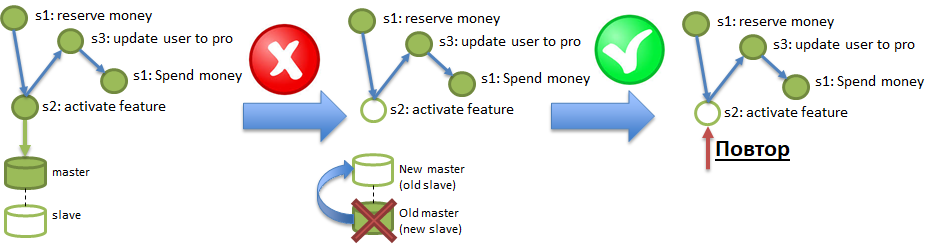
А где же I, спросите вы?
А нигде. Изоляция в среде нескольких независимых асинхронных сервисов — это техническое требование. Современные исследования показали, что реальные бизнес-процессы можно реализовывать без изоляции. Изоляция упрощает мышление тем, что минимизирует параллелизм (разработка параллельных вычислений сложнее для программиста), но микросервисная архитектура по своей сути массивно-параллельная, изоляция в такой среде избыточна.
Существует много подходов, позволяющих добиться соблюдения перечисленных выше требований. Наиболее широко известен алгоритм распределенных транзакций, обеспечиваемых так называемым двухфазным коммитом (2PC). К сожалению, реализация двухфазных коммитов требует переписывания всех вовлеченных сервисов. И самое серьезное: этот алгоритм не очень производителен. Приведенные иллюстрации из недавних исследований показывают, что этот алгоритм показывает определенную производительность на распределенной базе из двух серверов, но при росте количества серверов производительность растет не линейно… А точнее, практически совсем не растет.

Одно из главных достоинств микросервисной архитектуры — возможность около линейно наращивать производительность, просто добавляя больше и больше серверов. Получается, что если для обеспечения распределенной целостности использовать двухфазный коммит, то этот процесс станет узким местом, ограничителем для роста производительности, несмотря на наращивание количества серверов.
Как же можно обеспечить распределенную целостность (требования ACiD) без двухфазных коммитов, с возможностью линейно масштабироваться по производительности?
Современные исследования (например, An Evaluation of Distributed Concurrency Control. VLDB 2017) утверждают, что помочь может так называемый «оптимистический подход». Разницу между двухфазным коммитом и обобщенным «оптимистическим подходом» можно проиллюстрировать разницей между старым советским магазином (с прилавком), и современным супермаркетом, вроде Ашана. В магазине с прилавком каждый покупатель считается подозрительным, и обслуживается с максимальным контролем. Отсюда очереди и конфликты. А в супермаркете покупатель по умолчанию считается честным, ему дают возможность самому подходить к полкам и набивать тележки. Конечно, есть средства мониторинга для ловли жуликов (камеры, охрана), но большинству покупателей никогда не приходится с ними сталкиваться.
Поэтому супермаркет можно масштабировать, расширять, просто ставя больше касс. Аналогично и с микросервисной архитектурой: если распределенная целостность обеспечивается «оптимистическим подходом», когда дополнительно нагружаются проверками только процессы, где что-то пошло не так. А нормальные процессы идут без дополнительных проверок.
Важно. К «оптимистическому подходу» относится несколько алгоритмов. Я хотел бы рассказать вам про сагу — алгоритм поддержания распределенной целостности, рекомендуемый Крисом Ричардсоном.
Саги — элементы алгоритма
Алгоритм саг имеет два варианта. Поэтому сначала я хотел бы универсально описать требуемые элементы алгоритма, чтобы описание подходило для обоих вариантов.
Элемент 1. Надежный персистентный канал доставки событий между сервисами, гарантирующий «at least once delivery». Т.е. если шаг 2 процесса успешно завершился, то извещение (событие) об этом должно достигнуть шага 3 как минимум однажды, повторные доставки допустимы, но потеряться ничего не должно. «Персистентный» означает, что канал должен хранить извещения какое-то время (2-3 дня, неделю), чтобы сервис, потерявший последние изменения из-за потери базы (см. пример про Durability, на иллюстрации это шаг 2), мог восстановить эти изменения, «перепроиграв» события из канала.
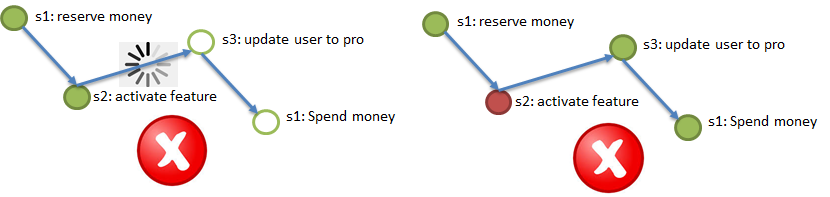
Элемент 2. Идемпотентность вызовов сервисов за счет использования уникального ключа идемпотентности. Представим, что я (пользователь) инициирую процесс покупки VIP-пакета (см. пример для Atomicity). В начале процесса мне выдается уникальный ключ, ключ идемпотентности, например, 42. Далее вызов каждого из шагов (1>2>3>4) должен выполняться с указанием ключа идемпотентности. В пункте выше упоминается возможность повторного прихода одинакового сообщения в сервис (в шаг). Сервис (шаг) должен автоматически уметь игнорировать повторный приход обработанного события, проверяя повторность по ключу идемпотентности. Т.е., если все сервисы (шаги процессов) идемпотентные, то для обеспечения требований Atomicity и Durability достаточно переотправить в шаги, соответствующие событиям из каналов. Шаги, пропустившие события, выполнят их, а шаги, уже выполнившие события, проигнорируют их из-за идемпотентности.

Элемент 3. Отменяемость вызовов сервисов (шагов) по ключу идемпотентности.
Для обеспечения Atomicity (см. пример), если процесс с ключем идемпотентности 42, например, остановился/упал на шаге 3, то необходимо отменить успешные выполнения шагов 1 и 2 для ключа 42. Для этого каждый обязательный шаг процесса должен обладать «компенсирующим» шагом, API-методом, отменяющим выполнение обязательного шага для указанного ключа идемпотентности (42). Реализация компенсирующих вызовов — это тяжелый, но необходимый элемент доработки сервисов в рамках внедрения алгоритма саг.
Перечисленные выше три элемента актуальны для обоих вариантов реализации «cаг»: оркестрируемых и хореографических.
Оркестрируемые саги
Более простой и очевидный алгоритм оркестрируемых саг проще для понимания и реализации. В своей отличной статье kevteev описал алгоритм и процесс реализации механизма оркестрируемых саг в Авито. Их алгоритм предполагает существование контролирующего сервиса, «оркестрирующего» вызовы сервисов в рамках обслуживаемых бизнес-процессов. Этот же контролирующий сервис может обладать собственной базой данных (например, PostgreSQL), выступающей в роли надежного персистентного канала доставки событий (элемент 1).
Хореографические саги
С хореографической сагой хитрее. Тут в качестве надежного персистентного канала должна выступать шина данных, реализующая следующие требования: fire-and-forget publishing, publish-subscribe event delivery, at least once delivery. Т.е. каждый шаг каждого процесса должен получать команду на срабатывание из шины, и кидать туда же сообщение об успешном выполнении, о старте следующего шага, чтобы тот тоже прочитал его из шины и продолжил выполнение процесса. При этом на каждое сообщение может быть несколько подписчиков.
В хореографической саге тоже должен быть контролирующий сервис, сервис саг, но существенно более «легковесный». Сервис должен знать о зарегистрированных в системе бизнес-процессах, о составе входящих в каждый процесс шагов. Также он должен слушать шину, мониторить выполнение каждого процесса (каждого ключа идемпотентности), и, только если что-то пошло не так, либо кидать «повторы» конкретных шагов, либо кидать «отмены», «компенсации» для выполнившихся шагов.
Нюансы
Один из самых важных нюансов саг, отличающих их от классических транзакций, является отход от линейности, последовательности, обязательности каждого шага. Сага — это не обязательно линейная цепочка событий, этом может быть направленный граф: событие регистрации нового пользователя может породить несколько шагов в параллель (отправка смс, регистрация логина, генерация пароля, отправка письма), часть из которых может являться необязательными. В первом приближении кажется, что в подобной «разветвленной» саге с необязательными шагами тяжело определить завершение саги (процесса), но, на самом деле, все просто: сага (процесс) завершена, когда завершены все обязательные шаги, в любом порядке.

Второй нюанс, характерный скорее для хореографических саг, но возможный и для оркестрируемых, заключается в выборе подхода к регистрации бизнес-процессов, типов саг в сервисе саг. В примере для Atomicity описан процесс из четырех последовательных обязательных шагов.
Кто зарегистрировал этот процесс, указал все шаги, расставил зависимости и обязательность шагов? Очевидный, но старомодный ответ заключается в том, что регистрация процесса должна выполняться централизованно, в сервисе саг. Но этот ответ не очень соответствует микросервисной архитектуре. В микросервисной архитектуре более перспективно, более производительно и более быстро регистрировать процессы «снизу вверх». Т.е. не прописывать все нюансы процесса в сервисе саг, а дать возможность отдельным сервисам самостоятельно «вписываться» в существующие процессы, указывая свою обязательность/необязательность и обязательных предшественников.
Т.е. процесс регистрации пользователя в сервисе саг может изначально состоять из трёх шагов, а потом, в ходе развития системы, туда впишутся еще семь шагов, а один шаг выпишется, и их станет девять. Подобная «анархическая» и «децентрализованная» схема сложна для тестирования, для реализации строгого согласованного процесса, но она намного удобнее для Agile команд, для непрерывной разнонаправленной эволюции продукта.
Собственно вот. С серьезным изложением, думаю, стоит закончить, а то статья получилась слишком большая.
Вот ссылка на презентацию этого материала, доклад на эту тему я делал на Highload Siberia 2018.
UPD — и видео с конференции:
Эпилог
Напоследок хотел бы попробовать объяснить все, перечисленное выше, более образным языком.
Ведь что такое сага изначально? Это сюжет, это приключение из средних веков… Или из Игры Престолов. Происходит событие (битва, свадьба, кто-то умирает), весть об этом летит по миру через гонцов, через почтовых голубей, через купцов. Когда весть доходит до заинтересованных (через неделю, через месяц, через год), они реагируют: отправляют армии, объявляют войну, кого-то казнят, и летят новые вести.
Нет контролирующего органа, следящего за последовательностью действий. Нет транзакций, нет rollback, в смысле отмены действия, как будто его никогда не было. Все по-взрослому, каждое действие происходит навсегда. Его можно компенсировать, но это именно действие (убийство) и компенсация (плата за голову, вира), а не отмена смерти.
События идут долго, доходят из разных источников, действия происходят параллельно, а не строго последовательно. И довольно часто в сюжете внезапно возникают новые участники, решившие поучаствовать (прилетают драконы ;))… а кое-кто из старых участников внезапно умирает.
Такие дела. Вроде бардак и хаос, но все работает, внутренняя согласованность мира не нарушается, сюжет развивается и непротиворечив… Хотя иногда и непредсказуем.
Комментарии (56)

azathot Автор
11.10.2018 19:26Как шина, да, Кафка выглядит наиболее многообещающей.
И NATS Streaming.
Обе шины в процессе нагрузочного тестирования сейчас.powerman
12.10.2018 06:51Я NATS Streaming тестировал пару месяцев назад — как по мне, он ещё сыроват. К самому NATS претензий нет, но вот Streaming под нагрузкой и с внезапными рестартами глючил странным образом, что-то терял, что-то присылал не в том порядке.
azathot Автор
12.10.2018 08:16Проверим :)… Кафку используют все, где тут инженерный челлендж? Про сбои — нарушение порядка на больших объемах это норм. А вот потеря — это будет приговор.
powerman
12.10.2018 15:44Вот что я им отрепортил за время тестирования. Помню, что было что-то ещё, но у меня тогда был дедлайн, и времени тщательно уточнять граничные условия всех проблем чтобы их отрепортить просто не было. Надо отметить, что поддержка там очень неплохая, вникают и фиксят очень быстро. В принципе, впечатления были положительные, просто в условиях дедлайна не было возможности писать тщательные тесты всех use case которые нам нужны, а без этого его использовать явно рановато.

vagon333
11.10.2018 21:02Распределенная транзакция может ссылаться на данные, измененные в предыдущих шагах.
Параллельное выполнение шагов распределенной транзакции может привести к нарушению целосности данных.
Вопросы:
1. каким образом определяются зависимости одного шага транзакции от другого?
2. не кажется-ли вам, что с ростром сложности транзакции отслеживать зависимости будет нелинейно сложнее?
Т.е. подход классный — масштабируемо, современно, но отлавливать data inconsistency у распределенных транзакций с параллельным выполнением, на мой взгляд, невероятно сложно особенно учитывая, что распределенные транзакции работают с базками разных отделов (или компаний), что еще больше усложняет troubleshooting.azathot Автор
11.10.2018 21:07Важное уточнение.
В тексте нет ни слова про распределенную транзакцию. Вообще не представляю, как возможны параллельные шаги распределенной транзакции.
Речь идет о подходе, альтернативном транзакциям. Соответственно, нельзя ссылаться на данные, измененные ранее. Т.к. в момент выполнения операции эти изменения уже могут быть отменены.
martin_wanderer
12.10.2018 11:05Получается, в такой архитектуре использование Shared database прямо-таки недопустимо: ведь нет никакой гарантии, что данные не были изменены другим вызовом хоть этой же хоть другой саги.
vagon333
11.10.2018 23:00Неясно выразился, моя ошибка.
Если речь об альтернативе распределенным транзакциям, то как реализовать в новом подходе требования, предъявляемые к распределенной транзакции. Есть ли опасения насчет сложности дальнейшей поддержки данного решения?azathot Автор
11.10.2018 23:12Какие именно требования, предъявляемые к распределенным транзакциям?
vagon333
12.10.2018 00:34При переходе от последовательной (распределенная транзакция) к параллельной обработке посредством саг, каким образом определяются зависимости между сагами для обеспечения целостности данных?
azathot Автор
12.10.2018 07:59Зависимости — никак. Зачем?
Параллелизм шагов не является сутью описанного подхода. Описанный подход с последовательными шагами не станет распределенной транзакцией, ни в каком виде.vagon333
12.10.2018 09:02Я не писал, что описанный вами подход — распределенная транзакция.
В названии вы декларируете альтернативу распределенной транзакции для микросервисной архитектуры. Однако, описанный вами подход не может быть альтернативой.
Это ввело в заблуждение и вызвало вопросы.
Комрад gridem, ниже, описал более целостно.
Николай, у меня желание найти решение, а не подловить.
Извините, но ваше решение не надежное.azathot Автор
12.10.2018 10:01Самое опасное последствие этой статьи — это представление, что с помощью саг можно дешево сделать распределенные транзакции. Это не так, логику основанную на распределенных транзакциях нельзя переносить на саги as is. Речь про другой подход к проектированию логики, БЕЗ распределенных транзакций.
GoodGod
11.10.2018 23:53Поэтому супермаркет можно масштабировать, расширять, просто ставя больше касс.
А другие магазины нельзя масштабировать просто ставя больше касс?azathot Автор
12.10.2018 07:56Да, «об опасности бытовых аналогий» :)))… Схему вида «продавщица пробивает на кассе товар, снятый с полки за спиной» нельзя масштабировать только кассами. Нужно масштабировать еще и продавщиц с полками и товаром. А ашан вполне масштабируется, в том числе, просто кассами, даже без продавщиц, это можно у них вживую наблюдать.
mwizard
12.10.2018 04:08-1Такая статья, а ни слова ни про CQRS, ни про ES, ни про DDD, а некое подобие process manager-ов вообще обозвали «хореографическими сагами».
gridem
12.10.2018 06:02Можете уточнить:
- Что такое CQRS, ES, DDD?
- Какое отношение они имеют к статье и почему о них обязательно нужно было написать?
- Почему нельзя вводить новые термины для обозначения конкретной реализации обработки данных?
azathot Автор
12.10.2018 08:20Как так ни слова? :))) Вот вы же их и написали. Я когда статью писал — обоими руками себя держал, чтобы уложиться во вменяемый объем и передать суть с определением минимума терминов.
gridem
12.10.2018 06:20Современные исследования (например, An Evaluation of Distributed Concurrency Control. VLDB 2017) утверждают, что помочь может так называемый «оптимистический подход».
Двухфазный коммит совместим с оптимистичным подходом. Более того, оптимистичность в контексте VLDB 2017 статьи имеет очень далекое отношение к тому, что здесь описано. Дело в том, что оптимистичность — это про блокировки во время выполнения пользовательских операций. Они берутся только в последней фазе — во время коммита.
В то же время в приведенной статье ни о каких транзакциях речь не идет. Речь идет про атомарное исполнение на каждом этапе с возможностью отката изменений в случае, если последующая операция не имеет возможности выполнится.
К недостаткам такого подхода, как и другие масштабируемые подходы, можно отнести:
- Отсутствии целостности данных. Т.е. в любой момент времени мы видим какое-то промежуточное состояние, причем не факт, что то, что мы видим, будет в реальности, из-за возможного отката действий. Т.е. тут налицо практически все нарушения консистентности, включая фантомные данные. Как правило, такое поведение усложняет пользовательский код, т.к. никакой инвариант не может быть гарантирован в любой момент времени.
- Подразумевается, что откат действия происходит без сбоев. В простейших случаях все просто, в сложных — как нетрудно догадаться, все сложно. Например: мы применили действие, другая сага поверх этого действия еще что-то сделала, а потом надо откатить первое. Далеко не всегда это представляется возможным в случае конкурентного взаимодействия. Необходимо знать все способы изменения данных, что, конечно же, никто не делает, т.к. проект развивается. Поэтому откат транзакции может завершиться неудачей и никогда не откатить исходную транзакцию. Нужно следить внимательно, что все действия являются откатываемыми при любых конкурентных взаимодействиях ВСЕХ других транзакций.
В целом, подход очень похож на то, что я описал с статье "Гетерогенная конкурентная обработка данных в реальном времени строго один раз": https://habr.com/post/413817/
azathot Автор
12.10.2018 08:07Статью почитаю, спасибо. Про оптимистичный подход — тут ключевая оптимистичность в полном отказе от коммита. Поэтому синхронизация не ситуативная, а вообще отсутствует.
Про целостность — тоже да, это в чистом виде eventual consistency.
Про риски откатов — есть такое. Мы внутри себя поняли, что эта схема будет работать, только если при разработке мы полностью уйдем от операций вида «обнови объявление и поставь статус X». Для отката таких штук очень важен порядок. Внутри саг безопасно использовать команды вида «произошло то-то и то-то», а сервис уже сам решает, какие поля ему обновлять, и что еще учесть. Никаких безусловных директив.gridem
12.10.2018 09:36тут ключевая оптимистичность в полном отказе от коммита
В моем понимании, если нет коммита, то говорить об оптимистичности не имеет смысла. Оптимистичность можно использовать в контексте транзакций.
Поэтому синхронизация не ситуативная, а вообще отсутствует.
Каждое действие является атомарным, а значит, синхронизация присутствует, но локально для этого действия. Т.е. разные саги над одним и тем же элементом будут синхронизированы.
сервис уже сам решает, какие поля ему обновлять, и что еще учесть. Никаких безусловных директив.
Ну тогда это не саги, а набор костылей, чтобы как-то работало. Саги имеют вполне понятную четкую и довольно жесткую семантику.
azathot Автор
12.10.2018 13:09+1Да, терминологически термин «оптимистичный» я использовал не совсем правильно. В статье 2017 он касается прежде всего OCC, алгоритма с оптимистичным коммитом. Тут возникла сложность из-за упаковки результатов из нескольких статей в один абзац. В том числе, многие идеи были взяты, например, из The Homeostasis Protocol: Avoiding Transaction Coordination Through Program Analysis, и упомянутых в статье 2017 года детерменистических алгоритмов, которые минимизируют постфактум координацию за счет анализа кода при выполнении. Я их всех скопом обозвал оптимистичными, в плане координации.
Кто касается синхронизации на атомарном действии — в целом это верно, с точки зрения невозможности выполнения одновременных изменений на, например, одном пользователе. Но даже порядок выполнения действий над одним пользователем в ходе работы разных саг, в общем случае, не гарантирован. Если саги стартуют одновременно, нельзя быть точно уверенным, какая первая доберется до пользователя.
Про набор костылей — возможно так и есть. Механически переложить старую монолитную логику, без переписывания сервисов согласно Domain Driven Desighn и Single Point of Responsibility, у нас не получается.
Возможно, у вас получится :)… Статью прочитал, было интересно. СРазу возник вопрос — как система обрабатывает ситуацию, когда одна полу-транзакция отработала, закоммитилась, передала управление на вторую, а потом отразившая первую полутранзакцию база была утерена и восстановлена без следов этой полутранзакции?
gridem
12.10.2018 19:17Детерминированные алгоритмы дают транзакционное поведение с высокими гарантиями по консистентности. В то время как здесь нет транзакций. Нельзя же сказать, что саги бывают пессимистичными или оптимистичными. Да, они выглядят как оптимистичные транзакции, но градаций у них нет.
как система обрабатывает ситуацию, когда одна полу-транзакция отработала, закоммитилась, передала управление на вторую, а потом отразившая первую полутранзакцию база была утерена и восстановлена без следов этой полутранзакции?
Передачи управления не происходит, каждый участник коммитит и работает со своими полутранзакциями. При этом если после выполнения полутранзакции участник сразу падает, то затем после восстановления он проверяет, не была ли выполнена полутранзакция. Таким образом достигается идемпотентность операции: см.
push_at_idempotentфункцию.azathot Автор
13.10.2018 11:48Я бы сказал, что сагу можно назвать супер-оптимистичной транзакцией. :) В ту сторону, где оптимизм уже граничит с идиотизмом.
Это сознательный отход от контроля И 100% детерминизма, т.к. та же квантовая физика учит нас, что реальность не детерминирована. No teleportation theorem и все такое.
Про подход к идемпотентному восстановлению полутранзакций по логу(шине) — да, понял, у нас это предусмотрено примерно также.gridem
13.10.2018 23:44+1Я бы сказал, что сагу можно назвать супер-оптимистичной транзакцией. :)
Настолько оптимистичной, что она перестает быть вообще транзакцией.
та же квантовая физика учит нас, что реальность не детерминирована.
Типичное заблуждение. Квантовое уравнение описывает эволюцию неклассического (квантового) состояния, которое по заданным начальным условиям точно определяет все события в будущем и прошлом.
Речь не про 100% детерминизм. Ведь в двухфазном коммите тоже нет детерминизма. Речь про консистентные переходы системы из одного состояния в другое. И саги тут решают проблему масштабируемости и переносят проблему консистентности на плечи пользовательского кода.
Вообще, это иллюзия, что двухфазный коммит тормозной. Я вот здесь как раз написал про это: "Достижимость нижней границы времени исполнения коммита распределенных отказоустойчивых транзакций" https://habr.com/post/353248/
Просто существует ряд иллюзий по поводу консистентности. Все возникает из-за недостаточной базы в распределенных системах.
kkirsanov2
12.10.2018 10:15Решая схожие проблемы (важное уточнение — первый раз) я остановился на таком решении: «Сага» — слишкмо сложно и нужно всячески избегать их появления. Для этого «микросеврисы» делаются чуть крупнее что бы не допустить появления распределенных транзакций.
azathot Автор
12.10.2018 16:20+1Мы 10 лет держались без распределенности, ростили монолит :)… Это не такое плохое решение, на самом
kkirsanov2
12.10.2018 17:58Кстати, а как вы рисуете то, что получается?
Если результат моих двухлетних усилий отобразить на графвиз то получается https://i.imgur.com/DPRTk63.png
Здесь прямоугольники — топики кафки, а овалы — сервисы, не всегда микро.
Если же рисовать без топиков — всё превращется в десяток ощетинившихся связями ёжиков.azathot Автор
13.10.2018 11:40Круто, спасибо :)… У нас топиков побольше будет, но это нюансы реализации (топик-на-тип события, типов сотни). У нас многие не рисуют, и так понятно. Те, кто рисует свой сложный кусочек, делает это примерно как и вы. Общая картинка в процессе, на ближайшем хайлоаде расскажу, как мы ее храним и визуализируем...
kkirsanov2
13.10.2018 22:33Под такое рисование (graphviz) возникла ещё одна идея: Т.к. один и тот же микросервис участвует в разных бизнес-процессах и хочется уметь на общей схеме (графе) всех микросервисов выделять путь конкретного бизнеспроцесса, то ребрыанужно раскрашивать. Математика для этого дела есть — en.wikipedia.org/wiki/Multigraph#Labeling только вот инструмента нет :(
Кстати, как на таком количесве топиков вы фиксируете формат данных в них и обеспечиваете версионирование? Мы гвоздями прпбиваем к названию топика AVRO-схему
{kind=link}
Kirill_Dan
12.10.2018 10:34Не буду тут «умничать», задам практические вопросы.
Т.е. процесс регистрации пользователя в сервисе саг может изначально состоять из трёх шагов, а потом, в ходе развития системы, туда впишутся еще семь шагов, а один шаг выпишется, и их станет девять.
Пока на проекте трудится команда программистов, которые все это планировали и реализовывали, то все хорошо. А что происходит с поддержкой и разработкой, когда на смену старым специалистам приходят новые. Как вообще с этим разобраться. И даже не в коде, а вообще в логике всех экшенов, событий и результате?
Подход очень хаотичный и сложный. На сколько часто появляются какие-то баги, и как сложно их отлавливать? Как вообще этот процесс выглядит? Ведь все процессы, на сколько я понял, асинхронные.
В первом приближении кажется, что в подобной «разветвленной» саге с необязательными шагами тяжело определить завершение саги (процесса), но, на самом деле, все просто: сага (процесс) завершена, когда завершены все обязательные шаги, в любом порядке.
Что происходит, если деньги со счета клиента уже списаны, а сообщение об этом ему не доставлено? Получается, что процесс не завершен и он будет торчать в подвешенном состоянии, пока не будет доставлено сообщение? Если это так, что как быстро клиент начнет нервничать, что деньги списали, а услугу не оказывают?azathot Автор
13.10.2018 11:27Про поддержку и развитие такой архитектуры: нелегко, как и с альтернативами :). На чем делается упор: единый реестр саг, где можно посмотреть текущие цепочки вызовов. При этом сами саги легкие, без сложной логики, без риска разрастания god object-ов. Сами сервисы, за счёт необходимости следовать общим правилам, тоже без избыточных зависимостей. Про команду, которая это делала: если команда одна, все это, возможно, вообще избыточно. Саги — это когда команд несколько, они независимо релизят, у них нет (обязательного ) общего планирования.
Про пример со снятием со счета и недоставленным сообщением — а что тут такого? Сбой на стороне смс- провайдера — не причина отменять отправку денег. Человек может сам глянуть свой баланс, можно отправить ему поясняющее письмо или push нотификацию. Смс может уйти через час. Это классический необязательный шаг, который никак не должен мешать завершению саги. Хорошая разница с транзакциями.Kirill_Dan
13.10.2018 12:54Спасибо за пояснение. А архитектура на сколько долго уже в бою крутится? Уже есть полное понимание очевидных преимуществ и слабых сторон?
azathot Автор
13.10.2018 17:09Отдельные саги в бою уже полгода. Их станет больше. И есть инсайт от других компаний, которые начали раньше и испытали больше.
Полного понимания нет :)… Понятно, что распределенные транзакции у нас не взлетят, как и микросервисы без саг. Но всех нюансов и опасностей мы ещё точно не испытали :)
arTk_ev
12.10.2018 15:44-4крайне неудачное название «микросервисная архитектура». К архитектуре она не имеет отношения.
borv
12.10.2018 16:41Вопрос про управление состоянием. Как вы относитесь к идее состояния в саге?
Т.е. несколько серверов хранят состояние саги, доступное сервисам по ключу идемпонентности. Элементы саги могут читать все состояние как документ, но писать могут только "свой" кусок. При этом состояние помнит все свои изменения, что можно использовать для компенсации.
Привлекательность тут в следующем:
- Во-первых операционно можно понять состояние транзакции просто поглядев в документ состояния в одном месте, что очень удобно.
- Сервисы для хранения состояния могут масштабироваться линейно и должны обеспечивать ACID состояния саги только на время ее жизни, которое относительно короткое (максимум в большинстве случаев — дни). Ключ идемпонентности это просто полный URL для документа состояния. На запуске саги мы выбираем один из инстансов, даже балансеров не нужно.
- Писать транзитивные данные в состояние предпочтительнее сохранению их в локальной базе сервиса и передаче их сообщениями, т.к. не надо заботиться о их компенсации и совместимости сервисов на уровне протокола. Грубо говоря если шаг 3 зависит от данных шага 1, а шаг 4 зависит от данных шага 2, цепочка 1-2-3-4 подразумевает либо публичное API чтобы 1-3 и 2-4 могли поговорить между собой, либо шаги 2 и 3 должны знать о данных которые нужны следующему по цепочке.
- Как уже отмечалось — компенсации делать проще, если иметь лог изменений. И хранить его в документе состояния — самое оно.
Затруднения же в том, что это выглядит больше как шаг назад от "трушной" распределенности в сторону DTC. Прям подмывает последним шагом в саге сделать "а теперь запишем изменения". Наличие сервера состояния ни как не отменяет наличия шины или оркестратора. Ну и соответственно "а что будет если состояние таки потерялось".
azathot Автор
13.10.2018 11:35Общую единую базу изменений иметь удобно :)… А потом в ней же ещё делать транзакции ;)… Кончится может монолитом.
В нашей реализации, в PG Saga ( оркестра цинния) единая база +лог состояний на PostgreSQL. В этой статье единый лог состояний на шине (Кафка?). Т.е. элементы вашего подхода есть.
В чем риск- как бы не перегрузить единую базу состояний. Какой-то шаг положил туда много и часто, второй — начал читать это без индекса. И все, единая точка отказа складывает всю систему.
Throwable
12.10.2018 20:57Под катом я рассказываю, как обеспечить целостность данных в микросервисной архитектуре без распределенных транзакций и жесткой связности. (
Да никак. Забудьте. И не вводите людей в заблуждение.
Изоляция в среде нескольких независимых асинхронных сервисов — это техническое требование. Современные исследования показали, что реальные бизнес-процессы можно реализовывать без изоляции.
На самом деле это не так. Изоляция как раз гарантирует, что другая транзакция не увидит изменения до тех пор, пока они не будут закоммичены. Если вашими измененными данными уже воспользовалась другая транзакция, вы данную транзакцию уже не сможете корректно откатить (или скомпенсировать).
Помимо технической стороны вопроса, такой как отказоустойчивость или гарантированная доставка, так или иначе все ваши бизнес-процессы должны удовлетворять условию линеаризуемости. Обеспечить линеаризуемость вне ACID возможно, но на порядки сложнее. И есть всего три способа:
- Либо мы вручную реализуем распределенный ACID в том или ином виде: это потребует введение аналога двухфазного коммита для ресурсов и дополнительных состояний ("заблокирован" или "в обработке"), а также для каждого действия процессов-"компенсаций", которые делают откат в изначальное состояние. И соответственно еще тонны геморроя.
- Либо все ваши бизнес-процессы можно представить ввиде линейной (или в общем случае древовидной) "потоковой" архитектуры взаимодействия, в которой каждая система может принимать сообщения только от единственной другой. Но далеко не все процессы можно уложить в данную архитектуру.
- Либо мы анализируем каждый кейс отдельно, все возможные конфликты и способы компенсации, и доказываем, что в каждом случае линеаризуемость не нарушается. С увеличением бизнес процессов сложность процедуры возрастает экспоненциально.
Однако, большинство использует четвертый вариант:
- Микросервисы — модно, стильно, молодежно. Ставим Монгу, Кафку, соединяем, пробуем — заработало. Ставим в продакшн. Линеаризуемость? Не, не слышали. Все и так норм.
azathot Автор
12.10.2018 21:11Никакой линеаризуемости тут не предполагается, совершенно верно. Я пытался на это указать, когда выкидывал I из ACID.
Предлагаю вам (и другим комментаторам выше предложу) простую игру: опишите бизнес сценарий в микросервисной архитектуре, где отсутствие линеаризуемости приводит к ошибкам. А я постараюсь его положить на саги. Не факт что получится, но вдруг :)… Гипотеза: линеаризуемость не нужна самому бизнес процессу, она нужна разработчику, т.к. нашему мозгу проще осознавать линеаризуемые процессы.Throwable
12.10.2018 22:21Навскидку. Микросервисы A, B, C, D, E. Две изменяющие транзакции: A->B->C, D->B->E. Последовательность выполнения изменений во времени: A, B, D, B, E, и первая транзакция на C отвалилась с валидацией, вторая транзакция закоммичена. В системе B обе изменили один и тот же регистр. Нет возможности откатить первую транзакцию, так как регистр уже был изменен второй (и мы не знаем как). Чтобы было совсем конкретно, в B лежит счет одного клиента. Две транзакции от разных источников A и D (оплата по карте, и ипотечный сбор). Любое решение, которое вы предложите будет сводиться к одному из трех вышеперечисленных мной сценариев:
- Заблокировать счет на время проведения любой транзакции, чтобы любое другое изменение на нем сразу отваливалось (типа ручной двухфазный коммит).
- Проводить все транзакции в B последовательно через одну и ту же очередь.
- Увеличение и уменьшение счета — коммутируемые операции и их очередность применительно к счету не имеет значения.
Все решения плохие в том или ином случае и уступают ACID. Поэтому если есть сделать систему монолитной, лучше делать так и не утруждать себя лишним геморроем.
P.S. Я знаю как работают некоторые банковские системы: у них есть дорогая и монолитная ACID-система, которая обслуживает счета и базу данных. И куча всяких микросервисных и любых других спутников вокруг, целостность которых уже никого сильно не волнует.
kkirsanov2
13.10.2018 07:24>> И куча всяких микросервисных и любых других спутников вокруг целостность которых уже никого сильно не волнует.
Не то что бы «целостность не волнует», просто там процессы не требующие полноценного ACID.
Скажем в интернет эквайренеге мы же будем откатывать транзакацию, если партнер при принял наше HTTP уведомление о успешном платеже. Так что можно смело сделать свервис уведомлений со тдельной БД и никак не подвязывать его к ACID в основной системе.
azathot Автор
13.10.2018 07:47Совершенно верно, необходимость целостности чаще все рождается там, где затрагиваются деньги. В нашем случае — когда в процессе хоть где-то есть биллинг (аренда, доставка, покупка услуг, покупка отчётов).
Паттерн с финансовым ACID монолитом в центре (кейс банков и, внезапно, убера) — это понятно, привычно… но немного старомодно и немасштабируемо. Старая проверенная временем классика, но не критерий оценки новых решений.
Про решения задачи: я, в контексте саг, строго за вариант 3. Чтобы в сервисы шли не не директивные апдейты "сумма на счету стала X (т.к. было Y а я вычел Z и налоги, но это мое дело)", а бизнесовые запросы "поступило X денег", "отправь Y денег"… В случае которых с линеаризуемостью проще
Komesk
12.10.2018 22:51В случае запуска многих копий одного сервиса при database-per-service, у них тоже должна быть своя копия БД?
azathot Автор
13.10.2018 07:51Тонкая тема :)… У копий сервиса должна быть общая база… Но масштабируемая, в идеале — шардируемая… Хотя довольно часто общего постгреса им всем хватает с 10 кратным
powerman
13.10.2018 16:16Не "должна быть", а "может быть", и обычно лучше если всё-таки у каждой копии своя база, но это зависит от природы сервиса.
azathot Автор
13.10.2018 17:13+2Вот тут не соглашусь. Своя база у каждой копии блокирует масштабирование вверх или вниз. Было 3 копии сервисов, в пике понадобилось 10, а потом 2… Как дробить/сливать отдельные базы, да ещё и быстро, по ?
powerman
13.10.2018 18:00Зависит от сервиса.
Если сервису нужно много CPU, и его нужно динамически масштабировать от нагрузки, и его база при этом не является узким местом — да, удобнее делать либо общую базу, либо сделать дополнительный прокси-сервис между этим и базой (чтобы было проще контролировать что и как делается с базой, особенно в ситуации когда идёт обновление первого сервиса и из 10 копий часть работает ещё на старой версии а часть на новой).
А вот если узкое место это база, и есть возможность её шардировать, то может быть разумнее сразу сделать 10 копий сервиса (с запасом), просто пока нет нагрузки несколько могут работать на одном сервере. Если запаса не хватит, и нужно будет шардировать дальше — будет небольшой даунтайм чтобы из 10-ти сделать 20-ть (если сервис внутренний, то юзеры этот даунтайм могут вообще не заметить).
Своя база даёт кучку дополнительных возможностей в связи с отсутствием необходимости в синхронизации: упрощается миграция схемы базы при обновлении/откате сервиса, можно делать меньше блокировок, проще писать код, и, главное, можно активно кешировать в памяти сервиса (вместо использования redis).azathot Автор
13.10.2018 21:23Вы описываете кейс предварительного избыточного шардирования. Мы его раньше часто применяли, например, в мессенджере. Это, по сути ручное шардирование единой базы, после которого решардировать уже нельзя, можно давать больше физических машин. 64 логических шардов базы, на 4 машинах (и 4 слева), а копий сервиса, внезапно… 7!… В кубе (Kubernetes). А вечером 9. А утром 3. При этом шаг с 64 логических шардов до 128 (у вас с 10 до 20) может быть адским.
Что касается копий сервиса, сейчас прогресс идёт в сторону гибкого решардировая. Предел этого процесса, уже достигнутый в облаке АлиЙунь — это функциональный подход, одноразовый микропод (копия сервиса) в облаке под каждый (!) вызов сервиса. Выделяется под вызов и потом гасится. Конечно, с базами так нельзя, база должна жить и шардироваться
kolesoffac
Для описанного выше идеально, как мне кажется, подходит kafka. Не думали в эту сторону?