
Прошлые посты в корпоративном блоге не содержали ни одной консольной команды, и мы решили наверстать упущенное.
В нашей компании есть метрика, созданная для предотвращения больших факапов на виртуальном хостинге. На каждом сервере виртуального хостинга расположен тестовый сайт на WordPress, к которому периодически идут обращения.
Так выглядит тестовый сайт на каждом сервере виртуального хостинга
Замеряется скорость и успешность ответа сайта. Любой сотрудник компании может посмотреть на общую статистику и увидеть, насколько хорошо идут у компании дела. Может увидеть процент успешных ответов тестового сайта по всему хостингу или по конкретному серверу. Не обязательно быть сотрудником компании – в панели управления клиенты тоже видят статистику по серверу, где размещён их аккаунт.
Мы назвали эту метрику uptime (процентное отношение успешных ответов от тестового сайта ко всем запросам к тестовому сайту). Не очень удачное название, легко перепутать с uptime-который-общее-время-после-последней-перезагрузки-сервера.
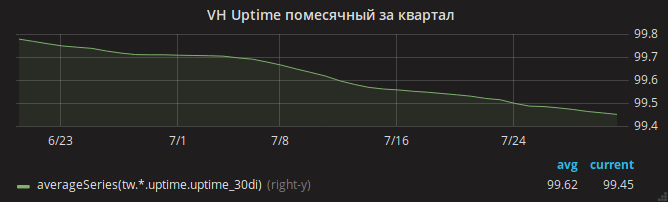
Лето прошло, и график uptime медленно ушёл вниз.
Администраторы сразу же определили причину – нехватка оперативной памяти. В логах легко было увидеть случаи OOM, когда на сервере кончалась память и ядро убивало nginx.
Руководитель отдела Андрей рукой мастера разбивает одну задачу на несколько и распараллеливает их на разных администраторов. Один идёт анализировать настройки Apache – возможно, настройки не оптимальные и при большой посещаемости Apache использует всю память? Другой анализирует потребление памяти mysqld – вдруг остались какие-либо устаревшие настройки с тех времён, когда виртуальный хостинг использовал ОС Gentoo? Третий смотрит на недавние изменения настроек nginx.
Один за другим администраторы возвращаются с результатами. Каждому удалось уменьшить потребление памяти в выделенной ему области. В случае nginx, например, был обнаружен включённый, но не используемый mod_security. OOM тем временем всё также часты.
Наконец, удаётся заметить, что потребление памяти ядром (в частности, SUnreclaim) страшно большое на некоторых серверах. Ни в выводе ps, ни в htop этот параметр не виден, поэтому мы не заметили его сразу! Пример сервера с адским SUnreclaim:
root@vh28.timeweb.ru:~# grep SU /proc/meminfo
SUnreclaim: 25842956 kB24 гигабайта оперативной памяти отдано ядру, и ядро тратит их неизвестно на что!
Администратор (назовём его Гавриил) бросается в бой. Пересобирает ядро с опциями KMEMLEAK для поиска утечек.
Для включения KMEMLEAK достаточно указать опции, указанные ниже, и загрузить ядро с параметром kmemleak=on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y
CONFIG_DEBUG_KMEMLEAK=y
CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y
CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000KMEMLEAK пишет (в /sys/kernel/debug/kmemleak) такие строки:
unreferenced object 0xffff88013a028228 (size 8):
comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s)
hex dump (first 8 bytes):
00 00 00 00 00 00 00 00 ........
backtrace:
[<ffffffff818570c8>] kmemleak_alloc+0x28/0x50
[<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0
[<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40
[<ffffffff81332d63>] security_file_alloc+0x33/0x50
[<ffffffff811f8013>] get_empty_filp+0x93/0x1c0
[<ffffffff811f815b>] alloc_file+0x1b/0xa0
[<ffffffff81728361>] sock_alloc_file+0x91/0x120
[<ffffffff8172b52e>] SyS_socket+0x7e/0xc0
[<ffffffff81003854>] do_syscall_64+0x54/0xc0
[<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a
[<ffffffffffffffff>] 0xffffffffffffffff
unreferenced object 0xffff880d67030280 (size 624):
comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s)
hex dump (first 32 bytes):
01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................
00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn....
backtrace:
[<ffffffff818570c8>] kmemleak_alloc+0x28/0x50
[<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0
[<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0
[<ffffffff8121082d>] alloc_inode+0x1d/0x90
[<ffffffff81212b01>] new_inode_pseudo+0x11/0x60
[<ffffffff8172952a>] sock_alloc+0x1a/0x80
[<ffffffff81729aef>] __sock_create+0x7f/0x220
[<ffffffff8172b502>] SyS_socket+0x52/0xc0
[<ffffffff81003854>] do_syscall_64+0x54/0xc0
[<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a
[<ffffffffffffffff>] 0xffffffffffffffffГавриил не раскрыл нам всех своих тайн и не рассказал, как он из вышеуказанных строк выяснил точную причину утечки памяти. Скорее всего, он использовал команду addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 для поиска точной строки. Или просто открыл файл net/socket.c и смотрел на него, пока файлу стало неуютно.
Проблема оказалась в патче на файл net/socket.c, который много лет назад был добавлен в наш репозиторий. Цель его в том, чтобы запретить клиентам использовать системный вызов bind(), это простая защита от запуска прокси-серверов клиентами. Патч свою цель выполнял, но не очищал после себя память.
Возможно, появились новые модные вредоносы на PHP, которые пробовали запустить в цикле прокси-сервер – что и привело к сотням тысяч заблокированных вызовов bind() и потерянным гигабайтам оперативной памяти.
Дальше было просто – Гавриил поправил патч и пересобрал ядро. Добавил мониторинг значения SUnreclaim на всех серверах под ОС Linux. Инженеры предупредили клиентов и перезагрузили хостинг в новое ядро.
OOM исчезли.
Но проблема с доступностью сайтов осталась
На всех серверах тестовый сайт несколько раз в день переставал отвечать.
Здесь автор начал бы рвать волосы на разных частях тела. Но Гавриил сохранял спокойствие и включил запись трафика на части хостинговых серверов.
В дампе трафика было видно, что чаще всего запрос к тестовому сайту падает после внезапного получения пакета TCP RST. Другими словами, запрос до сервера доходил, но соединение в итоге разрывалось со стороны nginx.
Дальше ещё интереснее! Запущенная Гавриилом утилита strace показывает, что демон nginx не отправляет этот пакет. Как такое может быть, ведь только nginx слушает 80-й порт?
Причиной оказалась совокупность нескольких факторов:
- в настройках nginx указана опция
reuseport(включающая опцию сокетаSO_REUSEPORT), позволяющая разным процессам принимать соединения на одинаковом адресе и порту - в (на тот момент, самой новой) версии nginx 1.13.0 есть баг, из-за которого при запуске теста конфигурации nginx через
nginx -tи использовании опцииSO_REUSEPORTэтот тестовый процесс nginx действительно начинал слушать 80-й порт и перехватывать запросы реальных клиентов. И при завершении процесса теста конфигурации клиенты получалиConnection reset by peer - наконец, в мониторинге заббикса был настроен мониторинг корректности конфигурации nginx на всех серверах с установленным nginx: команда
nginx -tвызывалась на них раз в минуту.
Только после обновления nginx можно было выдохнуть спокойно. График uptime сайтов пошёл вверх.
Какая мораль у всей этой истории? Сохраняйте оптимизм и избегайте использования самостоятельно собранных ядер.
Комментарии (17)

gecube
09.11.2018 13:20Хм. Имена героев заменены. Или Родина не должна их знать?
timeweb_team
09.11.2018 13:46+1Привет, Георг!
Верно, имена заменены. Но лишь по той причине, что некоторые сотрудники сейчас не работают в команде. Их достижения мы ценим и всегда ждём в гости.gecube
09.11.2018 21:48Спасибо на добром слове.
Желаю вам, чтобы ваши возможности и желания совпадали :-)
И побольше довольных клиентов ))))
SirEdvin
09.11.2018 15:45Наконец, в мониторинге заббикса был настроен мониторинг корректности конфигурации nginx на всех серверах с установленным nginx: команда nginx -t вызывалась на них раз в минуту.
А какой вообще в этом смысл?
gecube
09.11.2018 15:59я думаю, что в этой фразе из статьи потерялся некий великий смысл.
Например, «вызывалась на них всего лишь раз в минуту.». Или «был найден оптимальный интервал времени проверки». Или «были убраны дублирующиеся проверки». Или еще что-то. Надо спросить автора статьи :-)MrAloof
09.11.2018 19:47Нет. Смысл не потерян. Да и проверка думаю всё так же вызывается раз в минуту.
Написано же, проблему решили обновив nginx на версию без этого бага.gecube
09.11.2018 21:46А Вы, извините, — кто?
Уверен, что там под капотом хостинга еще куча скриптов, которые тоже делают «nginx -t» :-) и основная оптимизация была в чем-то другом ))))
timeweb_team
09.11.2018 16:53+1Спасибо за интересный вопрос. Основной смысл в том, что хостинг-провайдеру нужно мониторить корректность конфигурации nginx. Иначе он может столкнуться с ситуацией:
— из-за ошибки в коде или из-за ручного вмешательства создаётся невалидная конфигурация nginx;
— пользователи пытаются создать сайт / привязать новый домен к сайту / сменить версию PHP на сайте и у них ничего не получается. Потому что nginx не загружает новую конфигурацию;
— пользователи звонят / пишут в техподдержку;
— от техподдержки администраторы рано или поздно узнают о проблемах и исправляют их.
Наличие триггера в Zabbix всё упрощает — можно оперативно устранять такие проблемы.
o-pod
10.11.2018 17:24Администраторы сразу же определили причину – нехватка оперативной памяти. В логах легко было увидеть случаи OOM, когда на сервере кончалась память и ядро убивало nginx.
А настроить своп религия не позволяет?gecube
10.11.2018 23:59+1Я думаю, что
1. своп не помогает в абсолютно всех случаях ООМ
2. использование свопа — это зло. Поясню почему — если мы вылезли за объем ОЗУ, то у нас УЖЕ очень большие проблемы. Дальше система будет попросту тормозить и скидывать странички на диск. Зачем устраивать себе проблемы и потом продолжать агонию? Лучше сразу отстрелить процесс, который не нужен, перезапустиь его и продолжить ковылять дальше. Кстати, утечки, как показывает практика, есть везде. В любом коде. Поэтому не нужно гнаться за аптайм, который «uptime-который-общее-время-после-последней-перезагрузки-сервера.», а строить автоматически лечащую себя систему. И в новых проектах я стараюсь по максимум пользоваться опциями изоляции (docker/namespaces etc) и опциями ограничения ресурсов (cgroups etc).
Я более того скажу — мне известны случаи, когда ООМ Киллер работал некорректно, а именно была регрессия в ядре, которая делала его слишком агрессивным и он убивал процессы, хотя памяти было навалом. Потом это пофиксили. Повторюсь, что такое было в строго определенной версией ядра.o-pod
11.11.2018 01:40использование свопа — это зло
Я и НЕ ПИСАЛ, что использование свопа для штатных задач — это круто. Но своп позволяет избежать краха системы, если что-то пошло не так, и какой-нибудь процесс сожрал слишком много памяти. Своп — это как буфер, использование которого даёт админу запас времени, чтоб решить проблему.
Дальше система будет попросту тормозить и скидывать странички на диск.
Да, система будет тормозить, НО РАБОТАТЬ! Думаю, многие со мной согласятся, что это гораздо лучше для репутации, чем ошибки в браузерах клиентов.
Далее, настраиваете метрику для Заббикс, которая будет сообщать админу, что сервер залез в своп. А уже админ руками убъёт (или перезапустит) жадный процесс.
После этого останется всего лишь выполнить 2 команды, которые пренесут оставшиеся в свопе данные в оперативку:
sudo swapoff -a sudo swapon -a
gecube
11.11.2018 02:27Да, система будет тормозить, НО РАБОТАТЬ! Думаю, многие со мной согласятся, что это гораздо лучше для репутации, чем ошибки в браузерах клиентов.
в случае с каким-нибудь php, тормоза приведут либо к тому, что страничка у клиента будет грузиться сильно дольше обычного (что приведет к тому, что клиент закроет страницу и уйдет к конкурентам), либо к тому, что тот же php-бекенд будет очень долго рендерить, что приведет к 503 или аналогичной ошибке (опять же клиент потерян).
Тем более — в случае, когда проблемы начались, любой повтор запроса от клиента приводит только к каскадному нарастанию проблемы.
что сервер залез в своп.
Особенность работы линукса такова, что он все равно будет скидывать в своп, даже если оперативка полностью свободна. Т.е. правильная метрика — не то, что своп используется, а как активно он используется.o-pod
11.11.2018 04:44в случае с каким-нибудь php, тормоза приведут либо к тому, что страничка у клиента будет грузиться сильно дольше обычного (что приведет к тому, что клиент закроет страницу и уйдет к конкурентам), либо к тому, что тот же php-бекенд будет очень долго рендерить, что приведет к 503 или аналогичной ошибке (опять же клиент потерян).
Специально для вас сделал простое нагрузочное тестирование тестового виртуального сервера: 1 CPU / 1Gb Ram / 4 Gb swap SSD. Характеристики выбрал, чтоб максимально переложить нагрузку на своп. На сервере Ubuntu 18 LTS, Nginx, Php7.2-fpm, Mysql, в качестве приложения сайт на Wordpress с 50 страницами.
1. Останавливаем Nginx, Php-fpm:
sudo systemctl stop nginx sudo systemctl stop php7.2-fpm
2. Запускаем простой скрипт, чтоб забить память и уйти в своп:
i=0; while true; do a[${i}]=100000000000000000000000000000; i=$(($i+1)); done
Ждём, чтоб оперативка полностью забилась (к примеру, можно отследить в другом терминале через htop) и останавливаем скрипт Crtl+Z (скрипт нужно именно остановить, а не убить посредством Ctrl+C, чтоб данные остались в памяти).
3. Запускаем Nginx, Php-fpm:
sudo systemctl stop nginx sudo systemctl stop php7.2-fpm
Теоретически, система им должна выделить память в свопе.
4. Открываем локально 5 терминалов и в случайном порядке запрашиваем страницы в бесконечном цикле:
while true; do curl http://hostname/?p=$(echo $((RANDOM%50)) ); sleep 1; done
Как результат мы создали нагрузку примерно 5 запросов в секунду. Да, сервер тормозит, что в принципе логично. Но задержка не 30 секунд (необходимо для ошибки 503 при дефолтном max_execution_time), а всего 1-3 секунды. Как я и писал выше: да, сервер тормозит, но отвечает. Из-за пары секунд ожидания на интервале 5-10 минут (пока админ фиксит проблему) клиент точно не уйдет к конкурентам. А вот если в браузере ошибка 502, то у него не будет никаких оснований чего-то ждать.gecube
11.11.2018 08:00Теоретически, система им должна выделить память в свопе.
Теоретически — нет. Ядро должно быть достаточно умным, чтобы скинуть все башевские скрипты в своп, а nginx и php-fpm гонять в оперативе. К тому же, «горячие» данные у обоих сервисов не такие большие по объему.
Запускаем Nginx, Php-fpm:
sudo systemctl stop nginx
sudo systemctl stop php7.2-fpm
Неудачный копипаст? В 4 утра спать надо, а не комментарии писать :-)
Специально для вас сделал простое нагрузочное тестирование тестового виртуального сервера: 1 CPU / 1Gb Ram / 4 Gb swap SSD.
Насколько корректно экстраполировать результаты этого теста на услугу «виртуальный хостинг», которая обеспечивается мощным сервером, на котором «пасется» несколько десятков пользователей с несколькими сотнями сайтом?o-pod
11.11.2018 13:29Неудачный копипаст? В 4 утра спать надо, а не комментарии писать :-)
:)
Насколько корректно экстраполировать результаты этого теста на услугу «виртуальный хостинг», которая обеспечивается мощным сервером, на котором «пасется» несколько десятков пользователей с несколькими сотнями сайтом?
Как-то мне приходилось работать админом в компании, занимающейся хостингом. В большинстве случаев, количество сайтов на сервер колебалось от 20 до 100. А вот совокупная нагрузка как раз таки была не очень большой и колебалась в пределах 0...10 запросов в секунду (в зависимости от времени суток), что в принципе и логично: серьёзные высоконагруженные проекты обычно на виртуальном хостинге не размещают.gecube
11.11.2018 17:08Я вообще не склонен спорить, а скорее дружить со всеми.
Как-то мне приходилось работать админом в компании, занимающейся хостингом. В большинстве случаев, количество сайтов на сервер колебалось от 20 до 100. А вот совокупная нагрузка как раз таки была не очень большой и колебалась в пределах 0...10 запросов в секунду (в зависимости от времени суток), что в принципе и логично: серьёзные высоконагруженные проекты обычно на виртуальном хостинге не размещают.
Не знаю, что там в Таймвеб, но
- скорее всего количество пользователей на каждом сервере исчисляется десятками (вряд ли сотнями)
- у каждого пользователя от одного до десятка сайтов
Что и даёт оценку порядка 20-300 сайтов на типовой сервер.
Касательно высоконагруженных проектов — соглашусь, ставить их на ВХ чуть более, чем странно. Что для меня ещё более странно — почему услуга ВХ до сих пор жива, учитывая конкурентные ценники на VDS/VPS. В теории можно было сделать вообще прозрачное управление сайтами для пользователя, т.к. ему (пользователю) все равно, что там за технология под капотом. Ему лишь бы было дёшево, ну, и качество услуги было не очень плохим.
В этом аспекте очень интересно выглядят перспективы развития докер-хостинга. Такое реализовано у beget.ru и netangels («облачный хостинг»).
aol-nnov
Гаврила был не робкий малый.
Гаврила ядра собирал…
(с) (тм)