
Хранимые объекты без головной боли: простой пример работы с объектами Cache на языках ObjectScript и Python

Замок Нойшванштайн
В июне 2020 года ровно 50 лет табличным хранилищам данных или говоря формально — реляционной модели данных. Вот официальный документ – та самая знаменитая статья. За что говорим огромное спасибо доктору Эдгару Фрэнку Кодду. И, между прочим, реляционная модель данных входит в список важнейших мировых инноваций последних 100 лет по версии Форбса.
С другой стороны, как ни странно, Кодд считал реляционные базы данных и язык SQL искаженной реализацией своей теории. В качестве ориентира, он даже разработал 12 правил, которым должна удовлетворять каждая система управления реляционными базами данных (на самом деле это 13 правил). И, по правде говоря, на сегодня, в мире не найти СУБД удовлетворяющих хотя бы «Правилу 0» Кодда и, следовательно, никто не может называть свою СУБД на 100% реляционной :) Может есть исключения, подскажите?
Реляционная модель не очень сложна и изучена вдоль и поперёк. Может быть даже слишком глубоко изучена. А между тем, в этом 2019 году году отметим ещё и другой юбилей – ровно 10 лет назад хештег #NoSQL он же впоследствии «not only SQL» появился в твиттере и начал своё стремительное проникновение в практики разработки моделей баз данных.
К чему такое долгое предисловие? К тому, что вселенная программирования состоит из данных (и алгоритмов конечно), а монопольное положение реляционной модели приводит к, как это повежливее сказать, раздвоению сознания программиста. Потому что рабочие объекты в голове разработчика (ООП тоже тотально, правда?), все эти списки, очереди, деревья, кучи, словари, потоки и так до бесконечности, далеко не таблицы.
А если продолжить и вспомнить про архитектуру хранения в современных СУБД? Давайте говорить прямо, никто в здравом уме данные в виде таблиц не хранит. Разработчики СУБД, чаще всего используют разновидности B-дерева (в PostrgeSQL например) или, что происходит гораздо реже, хранилище на основе словаря. С другой стороны баррикад, разработчики, использующие для хранения СУБД, оперируют тоже не таблицами. И это вынуждает программистов постоянно ликвидировать семантический разрыв с помощью неуклюжего промежуточного слоя данных. И, тем самым, вызывать у себя внутреннее дихотомическое напряжение, системный дискомфорт и отладочную бессонницу.
То есть, если коротко, налицо противоречие – данные пакуем в подходящие под задачу объекты, а при сохранении должны заботится о каких-то таблицах.
Безнадёга? Нет :) А как же объектно-реляционное отображение, оно же в простонародье ORM? Оставим эту священную войну Егору Бугаенко со товарищи. Да и вся эта история из прошлого века, как по версии дядюшки Боба, не должна нас волновать.
Безусловно стоит упомянуть, что «мешок с байтами» ( Роберт Мартин «Чистая Архитектура») можно сериализовать и скинуть в файл или толкнуть в какой-нибудь другой подходящий поток. Но, во-первых, это нас сразу ограничит в языке, а во-вторых, мы сейчас будем волноваться только о хранении в СУБД.
В этих перипетиях с «мешками с байтами» есть приятное исключение – СУБД Intersystems Cache (а ныне и платформа данных InterSystems IRIS). Это, возможно, единственная в мире СУБД, которая не скрывает от разработчика очевидное и даже идёт дальше — освобождает от мыслей «как это всё правильно хранить». Достаточно сказать, что класс продолжает род Persistent и дело в шляпе, то есть в глобалах (не путать с глобальными переменными!).
Хранить можно все типы данных, включая символьные и бинарные потоки. Вот простейший пример:
// класс для сохраняемого объекта с одним свойством-строкой
// сюрприз: именовать свойства можно любой строкой и, в этом примере потребовались кавычки, для идентификаторов без пробелов они, конечно, не требуются
Class FW.Events Extends %Persistent {
Property "My name" As %String;
}
// пробуем в работе через терминал
// создаём новый «чистый» объект
set haJS = ##class(FW.Events).%New()
// сохраняем его
write haJS.%Id()
Причём, и это замечательно, с хранимыми объектами можно общаться не только на ObjectScript, родном для Cache, а получая и сохраняя их непосредственно в программах на Python, Java, JavaScript, C++, C#, Perl. И даже, о ужас :). черпать информацию из этих же объектов напрямую через SQL запросы, да и вызывать собственные методы объектов тоже возможно. Точнее, методы в этом случае сами собой (и волшебного слова SqlProc) превращаются в хранимые процедуры. Вся магия уже есть под капотом СУБД Cache.
Как получить бесплатный тестовый доступ к СУБД Intersystems Cache?Удобнее всего работать с кодом на ObjectScript и прямым доступом непосредственно к серверу СУБД Cache (и платформе InterSystems IRIS тоже) используя IDE Atelier, которая основана на Eclipse. Все инструкции по загрузке и установке здесь.
Это абсолютно реально, что бы не утверждали злые языки! :) Скачать и установить однопользовательскую полнофункциональную версию Cache можно здесь (потребуется пройти бесплатную регистрацию). Доступны сборки для MacOS, Windows и Linux.
Кому удобнее и привычнее, можно использовать комфортный и простой Visual Studio Code, дополнив его разрабатываемым сообществом плагином ObjectScript.
А теперь несколько практических примеров. Попробуем создать пару из связанных объектов и поработать с ними на ObjectScript и на Python. Интеграция с другими языками реализована очень похоже. Python выбран из соображений «максимального родства» с ObjectScript – оба языка скриптовые, поддерживают ООП и не имеют строгой типизации :)
За идеями для примеров обращаемся к бодрым хабаровским (не путать с хабровскими!) проектам «Фреймворк-посиделок». Идейный исходный код лежит на github.com/Hajsru/framework-weekend А наш исходный код ниже по тексту.
Важный нюанс для пользователей macOS. При запуске модулей поддержки для Python необходимо помнить, что требуется указать путь DYLD_LIBRARY_PATH к каталогу, где у вас установлены Cache. Например так:
export DYLD_LIBRARY_PATH=/application/Cache/bin:$DYLD_LIBRARY_PATH
В документации это указано особо.
Создаём хранимые классы на ObjectScript
Итак поехали. Классы в Cache у нас будут очень простые. Можно обойтись и без IDE – скопировать код классов прямо через портал вашего экземпляра платформы Cache (да, СУБД Cache далеко не только СУБД): Обозреватель системы > Классы > Импорт (Namespace USER).
Объекты после сохранения появятся в глобалах с именами совпадающими с названиями соответствующих классов. Искать так же в портале управления Cache: Обозреватель системы > Глобалы (Namespace USER).
// объект событие включает название, описание, дату проведения и список участников
Class FW.Event Extends %Persistent
{
Property title as %String;
Property description as %String;
Property date as %Date;
Property visitors as list of FW.Attendee;
}
// объект участник имеет имя/ник
Class FW.Attendee Extends %Persistent
{
Property name As %String;
}
Получаем доступ к объектам в Cache из Питона
Вначале подключаемся к базе данных СУБД Cache. Повторяем так, как и в документации.
Просто полезный факт для работы. Бесплатная, она же учебная, версия СУБД Cache позволят делать всё что доступно в полнофункциональной версии, но разрешает только два активных подключения. Поэтому одновременно держать соединение из IDE и пытаться запустить другой код для взаимодействия с сервером не удастся. Самое простое найденное решение – закрывайте IDE на время запуска Python кода.
# импорт модуля Cache для интеграции с Python3
import intersys.pythonbind3
# соединение с сервером
conn = intersys.pythonbind3.connection()
conn.connect_now("localhost[1972]:USER","_SYSTEM","SYS", None)
# проверка дескриптора подключения
print ("conn = %d " % conn.handle)
# подключение к базе данных
database = intersys.pythonbind3.database(conn)А сейчас мы сделаем объектную базу данных об ИТ-мероприятиях и их участниках. Очень-очень простую. Первым создадим класс для регистрации и хранения информации об участнике мероприятия. Для простоты к классе только имя участника.
# класс для объектов с информацией о зарегистрированных участниках
class Attendee:
# инициализация нового пустого объекта в оперативной памяти
def __init__ (self):
self.att = database.create_new("FW.Attendee", None)
# запись имени участника и сохранение объекта в базе данных с присвоением уникального id
def new (self, name):
self.att.set("name", name)
self.att.run_obj_method("%Save",[])
# загрузка объекта по id из базы данных участников
def use (self, id):
self.att = database.openid("FW.Attendee",str(id),-1,-1)
# удаление объект из базы данных участников
def clean (self):
id = self.att.run_obj_method("%Id",[])
self.att.run_obj_method("%DeleteId", [id])
Как можете заметить, используем готовые функции-обёртки для методов доступа к полям объектов в Cache: set и в параметрах передаём имя свойства в кавычках и openid с именем пакета и класса. Про аналогичную функцию get есть примеры ниже. Для доступа в любым другим методам, включая унаследованные классом от предков используется функция run_obj_method() с именем метода и параметрами вызова, если они необходимы.
Самая важная магия в строчке: self.att.run_obj_method("%Save",[])
Именно так мы имеем возможность сохранять объекты прямым указанием и без необходимости применять дополнительные библиотеки и каркасы/фреймворки, вроде вездесущих и неприглядных ORM.
Кроме того, учитывая объектно-ориентированную природу ObjectScript вместе с методами своего класса (в нашем примере мы их не делали) бонусом получаем доступ из Python ко всему набору методов унаследованных от класса Persistent и его предков. Вот полный список, если что.
Создадим первого участника:
att = Attendee()
att.new("Аким")
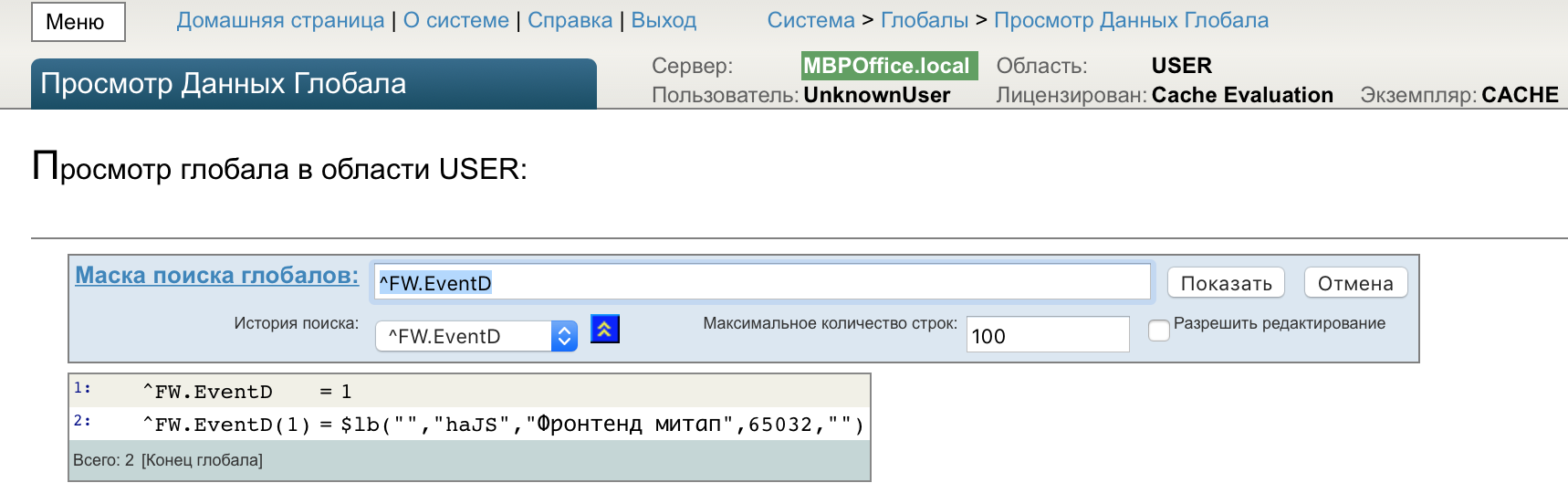
После запуска этого кода в базе данных появится глобал с именем FW.AttendeeD и содержимым только что сохранённого объекта как на скриншоте:

У этого объекта после сохранения появился собственный id (с номером 1). Поэтому можно загружать его в нашу программу по этому id:
att = Attendee()
att.use(1)
print (att.att.get("name"))
И теперь, опять же зная id, при необходимости можно удалить объект из базы данных участников:
att = Attendee()
att.use(1)
att.clean()
Проверьте, после запуска этого примера, запись об объекте должна исчезнуть в глобале. Хотя загруженные данные всё ещё остаются «в памяти» вашего объекта до завершения работы программы.
Сделаем следующий шаг. Создадим собственно записи о мероприятиях.
# класс для объектов с информацией о мероприятиях
class Event:
# инициализация нового пустого объекта в оперативной памяти
def __init__ (self):
self.event = database.create_new("FW.Event", None)
# наполнение объекта информацией и сохранение в базе данных с присвоением уникального id
def new (self, title, desc, date):
self.event.set("title", title)
self.event.set("description", desc)
self.event.set("date", date)
self.event.run_obj_method("%Save",[])
# загрузка объекта по id из базы данных
def use (self, id):
self.event = database.openid("FW.Event",str(id),-1,-1)
# добавление участника в список участников мероприятия
def addAttendee (self, att):
eventAtt = self.event.get("visitors")
eventAtt.run_obj_method("Insert", [att])
self.event.set("visitors", eventAtt)
self.event.run_obj_method("%Save",[])
# удаление объекта из базы данных
def clean (self):
id = self.event.run_obj_method("%Id",[])
self.event.run_obj_method("%DeleteId", [id])
Структура класса почти такая же как было выше у класса для участника. Самое главное, появился метод добавления участников в список участников этого мероприятия addAttendee(att).
Пробуем создать объект-запись о новом мероприятии и сохранить его в базе данных:
haJS = Event()
haJS.new("haJS", "Фронтенд митап", "2019-01-19")
Должно получится примерно так (заметьте, что дата автоматически конвертирована в формат ObjectScript и при загрузке обратно в объект Python вернётся в исходно заданном формате):
Осталось добавить участника в мероприятие:
# загружаем ранее сохранённое мероприятие
haJS = Event()
haJS.use(1)
# создаём нового участника
att = Attendee()
att.new("Марк")
# добавляем участника в наше мероприятие
haJS.addAttendee(att.att)
Итак, на этих примерах видно, что не обязательно думать одновременно о своей модели данных и её табличной схеме хранения. Можно применять более очевидные инструменты для своих задач.
Подробные инструкции по подключению и использованию Cache с Python и другими языками всегда доступны вам в документации и на портале сообщества разработчиков InterSystems – это ни много не мало, а 5000 участников community.intersystems.com
Справка: мультимодельная СУБД InterSystems Cache остаётся бессменным мировым лидером объектных баз данных

Комментарии (76)

VMichael
10.01.2019 13:25Еще было бы неплохо указать какой % среди СУБД вообще занимает Caсhe и какое количество вакансий на Cache существует (на HH бегло поискав, я нашел 3! вакансии в России, в медицинской сфере, с ЗП 30-50 тыс. рублей).
Т.е. мне кажется, потратив время на хорошее изучение продукта, станешь специалистом одного продукта.
В то время, как изучив «классический» SQL и любую другую реляционную БД, получишь уже широкий навык, который можно применять в любой реляционной СУБД.vasyan
10.01.2019 13:35Вообще, в России проекте на Cache даже были. Общался минимум с двумя разработчиками. Вторая начала свою речь примерно так: «Я работаю с СУБД, вы её, конечно, не знаете».

torgeek Автор
10.01.2019 13:58Именно так учат почти во всех российский вузах — есть SQL и что-то ещё, о чём знать не стоит. Оракул и Микрософт немалые деньги в это вложили :)
torgeek Автор
10.01.2019 13:56-1Изучив Cache или IRIS одновременно получаешь опыт работы с SQL и объектным подходом к хранению. На других, чисто реляционных СУБД будет узкий однобокий опыт.
VMichael
10.01.2019 15:56+1Времени на все не хватит.
Ко мне периодически обращаются разные молодые люди, спрашивают, что изучить полезно, мне не приходит в голову отправить их изучать Cache. Настолько узкая ниша у этих товарищей, что очень низкий КПД затрат времени, в нашей быстротекущей жизни, по величине затраты/отдача.
Вообще, одна из опасностей, которая подстерегает — это трата времени на изучение какого то очень узкого, нишевого продукта. Проходит время и вот ты уже мало кому нужен. От этого я предостерегаю молодых людей, если ко мне обращаются за советом. Речь, конечно о востребованности на рынке как специалиста.
Если только из любви к искусству, типа посмотреть на досуге, как оно устроено. Но это нужно иметь хобби такое.
Все на мой субъективный взгляд, конечно.torgeek Автор
10.01.2019 17:59Те, кто из любви к искусству, сами активно ищут и находят. А вашем случае, скорее всего, работает подход изучения State of the art. Это уже не про искусство, а про передовой уровень достигнутый на сегодня. И тут всё в порядке. Не представляю, где ещё можно подсмотреть эффективную реализацию объектного подхода к хранению данных, кроме как в продуктах Intersystems.
По этой же причине, например, стоит изучить язык Rust. Практической пользы прямо сейчас мало, а концепты, которые реализованы в языке – пустые типы, типажи, владение и так далее, самый передовой уровень.
torgeek Автор
10.01.2019 14:28Про общий % с ходу не скажу, нет у меня такой статистики. У Интерсистемс есть ниши, где применение её продуктов наиболее востребовано. Вот цитата хорошо отражает этот момент: «Little known outside the niche its technology dominates, InterSystems underpins health-related information for the national health services of England, Scotland and Wales and the U.S. Defense Department, as well as trading systems at Credit Suisse and the efforts of the European Space Agency to map the Milky Way.»
epishman
10.01.2019 13:49ИМХО, проблема РСУБД не в нормализации, а в чисто-технических ограничениях — невозможности на лету добавить атрибут для конкретного факта. Обычно нужно выгнать пользователей и ждать десятки минут. А если пытаться реализовать гибкую схему — сразу упираемся в производительность и множественные джойны к самому себе. Сам думаю свалить на NoSQL.
flancer
10.01.2019 13:58+2невозможности на лету добавить атрибут для конкретного факта.
Я правильно понимаю, что вы пытаетесь добавить колонку в таблицу в реляционной СУБД? А почему эта операция занимает столько времени и с такими сложностями (нужно выгнать пользователей и ждать десятки минут)? Или "атрибут" и "факт" имеют какие-то другие смыслы в данном контексте?
epishman
10.01.2019 18:02-1В системах NoSQL я могу к одному конкретному объекту добавить атрибут, не затронув остальные, и это очень круто, а в РСУБД нужно добавлять колонку в таблицу. Теоретически alter table неблокирующая операция, но практически все коммерческие системы ее не используют, а создают пустую правильную таблицу, переносят данные, затем переименовывают таблицы, а это блокировка базы. В системах 24x8 даже ночью выкроить окно в полчаса бывает проблематично.
flancer
10.01.2019 19:46А при каких размерах таблиц (кол-во записей, размер в байтах) данный эффект (ждать десятки минут) возникает?
epishman
11.01.2019 08:59Миллиард записей, 100 полей (запись пару мегабайт), да дело не во времени, а в реализации обновления структуры в коммерческих ERP, где требуется блокировка базы. Почему так — нужно у них спросить, предполагаю что в монопольном режиме дешевле строить индексы (новое поле может туда входить например).
flancer
11.01.2019 09:39А при чём тут ERP? Вернее, при чём тут таблицы и колонки RDBMS, если некая коммерческая ERP добавляет новый атрибут к объекту? Это вопросы к авторам "коммерческой ERP" — что за логику они реализовали на десятки минут и почему нужно выгонять пользователей. Уверяю вас, такого же эффекта разрабы ERP могли добиться и на NoSQL-базах, и на файловой системе, и, если постараются, в оперативной памяти и при гораздо меньших объёмах данных. Вы как-то слишком широко обобщили свой негативный опыт с ERP сразу на все РСУБД.
epishman
11.01.2019 11:221) Я работал с многими коммерческими ERP, да и с множеством других крупных продуктов, все делают так. РСУБД не подвешена в воздухе, она существует в окружении, которое, да, неидеально.
2) В NoSQL такой эффект невозможен, или возможно я просто не знаю, как его создать. Там все объекты независимы, и только индекс их может связывать, который не требует блокировки корня.flancer
11.01.2019 12:15Стесняюсь спросить, но не могу не уточнить, а вы с какой конкретно RDBMS имели дело и каким образом добавляли
атрибут к объектуколонку к таблице? Очень хочется узнать всё-таки, какая из RDBMS так тормозит наALTER TABLE.epishman
11.01.2019 12:20+1Да никакая не тормозит! Я же писал — в больших системах применяют другой подход — с промежуточной таблицей. Oracle EBS, DAX, SAP, 1C, Navision. СУБД Oracle, MSSQL. Да в любом бизнес-приложении мне известном обновление метаданнх — это блокировка базы. Я бы так не писал, но все так пишут — видимо не без причины.
flancer
11.01.2019 13:25Посмотрел на MySQL (10.1.34-MariaDB) — действительно, есть ощутимые задержки при изменении структуры таблицы (взял навскидку таблицу с самым большим кол-вом строк и самую большую по объёму данных из имеющихся на локалке):
table: report_viewed_product_index rows: 1,384,812 size: 57,245,696 bytes ALTER TABLE report_viewed_product_index ADD habrotest varchar(100) NULL; time: 18.177s table: sales_order_item rows: 185,011 size: 118,161,408 bytes ALTER TABLE sales_order_item ADD habrotest varchar(100) NULL; time: 9.271s
Полагаю, что вам ещё повезло, что при миллиарде записей по паре мегабайт на каждую ваш процесс уложился в полчаса. Сочувствую, что вам приходится иметь дело с такими приложениями.
epishman
11.01.2019 13:37На миллионе записей 18 секунд это очень много, возможно там индексов куча, и оно начинает какую-то реорганизацию блоков, не знаю. У нас конечно кластеры, быстрые SSD и хранилища, но все равно полчаса минимум получается.
Yo1
12.01.2019 12:37В системах NoSQL я могу к одному конкретному объекту добавить атрибут, не затронув остальные, и это очень круто, а в РСУБД нужно добавлять колонку в таблицу.
вам нужно на курсы какие-то сходить, начальные. не надо так делать, за такое и побить могутepishman
12.01.2019 12:49Бывают разные приложения, с разной архитектурой. А побить я и сам могу :)
Yo1
12.01.2019 13:06да, бывают разные приложения. бывают люди не имеющие базовых знаний лабают код, но это не оправдание так делать. не надо в рсубд на каждый чих колонку добавлять, даже если глупые люди где то так делают.
структуры таблиц крупнейших ERP наверно с 80х не менялись.torgeek Автор
12.01.2019 13:46То что за 40 лет могла не меняться модель данных, вполне поверю. Есть такие динозавры. Но это очень редкие особые случаи. Там и компьютеры могли не меняться с тех пор.
Yo1
12.01.2019 16:44-1боюсь особый случай это вы. по факту все эти ERP из 80х вполне сегодня справляются абсолютно с любыми отраслями, от финансов и телекома, до медицины. и ведь получается все эти годы добавлять атрибут объекту пользуя все те же структуры таблиц, что и в 80х.
epishman
12.01.2019 17:45+1Надеюсь, Вы в курсе что DAX начиная с 2012 версии поддерживает наследование таблиц, и это реально используется в дизайне?
epishman
12.01.2019 17:44Господи, да Вы хоть просветите всех, как правильно с NoSQL работать, а то все одни общие фразы. Ждем.
Yo1
12.01.2019 20:00как работать наверняка не знаю, знаю как не надо. вот например каша — пример как не надо, причем то что иерархические субд проиграли было известно еще в 80х.
если так хочется конкретики, ну есть она у меня. конкретно сейчас работаю со spark на датафреймах. как и каша можно использовать обычный sql, есть обычный жава/скала синтаксис. в отличие от каши там полноценный оптимизатор и относительно декларативная работа с датафреймами. т.е. фреймворк и его оптимизатор решает как и в какой последовательности полезть к данным. там все кластерные прибабахи сразу из коробки. причем датафреймы не лезут за данными сразу, т.е. если в каше код выполняется как написано, датафреймы в спарке не тянут данные пока клиент не потребовал нечто, что требует результат. т.е. я могу задефайнить датафрейм, отправить в «процессор», который задефайнит фильтры, агрегаты, потом отправить в другой «процессор», который с чем-то заджоинит, но за данными оно полезет только когда я попрошу первые строки. и оптимизатор будет оптимизировать итоговый датафрейм, со всеми фильтрами, джоинами и прочей логикой разбросанной по разным классам. при этом это все в jvm — запросто прилаживается любые жава либы, начиная с ML. при этом это фреймвок, ему относительно пофигу как данные хранятся. оно работает и на файликах хадуп и на монге, игнайт, kudu.
вообщем совершенно иной уровень, чем каша. и этот уровень все равно не дотягивает до того что у меня было в оракле. побеждает лишь ценой.epishman
13.01.2019 10:03Согласен, это Ваш опыт. Но Гугл например не использует РСУБД, а запилил свою NoSQL, на серверах Амазон успешно продается MongoDB. Это как с языками — есть жестко-типизированные Go/Java, но если ваша задача — обрабатывать произвольные объекты, прилетающие по сети от неизвестного пользователя — на порядок проще использовать динамический язык типа Javascript. Документные базы данных (я не беру Cache, потому что ее не знаю) — это динамический язык в мире СУБД, а реляционка — аналог статического языка, где все типы нужно описать заранее.
torgeek Автор
10.01.2019 14:04+1У РСУБД нетпроблем. Это практика доказавшая свою прагматичность и полезность. Cache и IRIS поддерживают реляционное отображение и SQL на 100%. Но дают гораздо больший горизонт возможностей, не только объектные решения, но и варианты в NoSQL. Про GraphQL например habr.com/company/intersystems/blog/413717
maslyaev
10.01.2019 15:27+2Технические ограничения не при чём. Добавление колонки с NULLом по умолчанию не стоит ничего.
Проблема скорее в том, что хранение и обработка — это действительно, совсем два разных мира, два разных детства. Факты мы храним или неструктурировано (тексты, картинки, видео и т.п.), или структурировано, и тогда здраствуй, дедушка Кодд с исчислением предикатов, сущностями, связями и всем тем, что мы называем РБД. А в обработке мы вынуждены так либо иначе жить в объектной парадигме (даже если не применяем ООП, всё равно по факту даже ячейка памяти — это тоже объект).
Задача ORM выглядит как пустяк, но в настоящий момент, насколько мне известно, её никто и нигде целиком нормально не решает. Сделать вид и показать на игрушечных примерах, что она решена — легко, но что нам в кровавом энтерпрайзе с этого вида?epishman
10.01.2019 18:11По первому вопросу ответил выше habr.com/post/435612/#comment_19599588
По второму — если вы пишете действительно высоккопроизводительную систему, то функции нужно не разделять а сливать. Была красивая идея MVC, давайте хранить данные как попало, на среднем слое мы их превратим в объекты, допишем CRUD-методы, и в интерфейс отдадим в третьем виде. Все эти трансформации данных — чудовищные торомза, в итоге простейшая задача — по миллиону строчек расчеты провести — превращается с сложную. Поэтому и вернулись все промышленные ERP фактически к двузвенке, разрешив голый SQL выводить на форму, и фактически отказавшись от объектного представления — хоть DAX возьмите, хоть 1C, где все теперь на SQL пишут.
eefadeev
10.01.2019 16:09В чём практический смысл «добавления атрибута к факту на лету»?
epishman
10.01.2019 18:04+1Дописываю статью как раз с примерами, если кратко — приблизить объекты системы к объектам реального мира, где бывает медведь без хвоста и медведь с прыщом, и это не разные реализации абстрактного медведя, а просто разные экземпляры одного класса, но… с немного разным набором атрибутов.
maslyaev
10.01.2019 14:02на лицо противоречие
Налицо.
Извините.
Cache — безусловно достойная и интересная тема. Но я как-то услышал и перенял полезную привычку называть эту штуку фразой «мифическая СУБД Кашe».
Было бы любопытно услышать от народа соображения, почему эта, как декларируется, фантастически прекрасная вещь всё никак по-настоящему не взлетает.
… это вынуждает программистов постоянно ликвидировать семантический разрыв с помощью неуклюжего промежуточного слоя данных. И, тем самым, вызывать у себя внутреннее дихотомическое напряжение, системный дискомфорт и отладочную бессонницу.
Кашe тоже, похоже, не убирает неуклюжий промежуточный слой, а лишь маскирует его синтаксическим сахаром. На детских примерах всё получается красиво (на Джанге, кстати, даже ещё красивее), а на взрослых эти самые упомянутые дихотомическое напряжение и системный дискомфорт должны приходить с той же силой и в том же объёме.
Переубедите меня, пожалуйста, если я не прав.torgeek Автор
10.01.2019 14:15За народ не скажу. Сам хочу услышать свежие соображения) Тем более за последние 5 лет столько нового было влито в Cache (контроль версий, новая мультиплатформенная IDE, автоматический CI и т.д.), что теперь это даже не СУБД, а полноценная облачная платформа данных и среда быстрой разработки приложений Intersystems IRIS.
maslyaev
10.01.2019 14:58Вот!!! В этом, собственно, и вопрос.
То ли затея страдает от ошибок в маркетинге, то ли есть какой-то врождённый порок реализации, то ли оно всё есть один большой хитро спрятанный концептуальный просчёт.
Проще всего свалить всё на маркетинг/продвижение, но есть смысл подумать и над последними двумя пунктами.torgeek Автор
10.01.2019 15:38Так это не затея и не стартап)) Не молодая MemSQL, не RethinkDB и не свежая FoundationDB (уже Apple). А стабильно и плодотворно работающая компания. С доходом, соответствующим капитализации примерно 15 млрд. долларов. На полтора Яндекса или два EPAM хватит. Лидер своей ниши рынка. Прямой конкурент Оракл и Микрософт (так в wiki записано). Всё ок ;)
torgeek Автор
10.01.2019 16:03Насчёт синтаксического сахара не могу согласиться. Внутри InterSystems Cache и InterSystems IRIS полноценный объектно-ориентированный язык ObjectScript. Да, есть встроенная 100% поддержка унаследованного процедурного языка М-систем, который используется, например, в YottaDB, MiniM, GT.M. Для сравнения в СУБД Oracle и PosgreSQL используется чисто процедурная Ада — PL/SQL и PL/pgSQL соответственно.
Это как TypeScript называть синтаксическим сахаром для JavaScript или Kotlin – сахарком для Java ;)
transcengopher
11.01.2019 16:17Typescript, в целом, и есть синтаксическая надстройка над JavaScript — потому что компилируется и исполняется через JavaScript в итоге.
А вот Kotlin — это не суперсет от Java, а самостоятельный язык, потому что компилируется в JVM-байткод, а не в Java (или и вовсе в какой-нибудь Javascript, кстати; как я понимаю, там и Kotlin-native где-то в работе).torgeek Автор
11.01.2019 21:05А что с этим делать: how Kotlin compiles to JavaScript? :)
transcengopher
11.01.2019 22:01+1Именно из-за этой возможности Kotlin является самостоятельным языком, а TypeScript — синтаксической надстройкой над JavaScript. Потому что у Kotlin определяет независимую семантику текста, которую возможно перекладывать на почти любую платформу, а семантика TypeScript находится в строгой привязке к семантике ECMAScript.
eefadeev
10.01.2019 15:06+1Не очень понятен ответ на основной вопрос при работе с нереляционными БД: «Что делать, если мне нужно обращаться не к отдельному экземпляру (по ключу), а к множеству для массовой обработки (группировки, агрегаты, вот это вот всё)?»
torgeek Автор
10.01.2019 15:48Самое очевидное — загружать, искать, сортировать и т.д. Можно встроенными методами ObjectScript или SQL запросами и, соответственно через встроенные биндинги на Python, Java и так далее. Ссылка на доступные языковые привязки есть в статье. Можно дополнить своими объектными методами на ObjectScript, Python, Java и далее по той же схеме.
Как только чувствуем ограничения в производительности (в Cache есть встроенные средства профилирования), дополняем объектными индексами и прочими инструментами расшивки узких мест.eefadeev
10.01.2019 16:39И чем это принципиально отличается от нормально спроектированной реляционной БД?
torgeek Автор
10.01.2019 18:14Точкой зрения и моделями отличается. Если решили, что модель данных вашего приложения наилучшим образом передаётся «табличным» представлением. И все объекты в вашем приложении — только таблицы и связи. То разницы никакой не будет. За это табличные процессоры и любят. В Экселе, например, при должном старании, можно создать любое приложение :)
eefadeev
11.01.2019 10:14Я лет 20 уже работаю с реляционными БД мысля (при проектировании) в категориях объектов.
При этом модель, предложенная Коддом имеет строгие математические основы и в состоянии описать любые данные.torgeek Автор
11.01.2019 15:29-1Продолжу эту мысль. Некоторые 40 лет работают с Паскалем и Фортраном в категориях процедурного программирования, которое имеет строгие математические основы. И в состоянии описать любые данные ;)
Прикрываясь «строгой математической основой», необходимо её использовать. А что-то примеров строго соответствия реляционной модели по Кодду среди РСУБД не видно. Как-то все своими «граблями» обходятся.
Я говорю о сравнении «мёртвых данных» в таблицах с живыми объектами в программах. И хочется про это поговорить.eefadeev
11.01.2019 16:31Принципиальная разница между «мёртвыми данными» в таблицах и «живыми объектами» в программах состоит только в том, что в таблицах экземпляры адресуются ключами, а в программах — адресами в памяти. И если хорошенько подумать, то можно понять что разница эта не так уж принципиальна.
torgeek Автор
11.01.2019 19:31Что-то не едут мои лыжи))
Я говорю о разнице между манипуляцией данными и общением объектов между собой. Как хранятся данные физически — это из другой оперы.
То есть self.att.run_obj_method("%DeleteId", [id]) читаем как «эй дружок тебя не взяли в космонавты». И он что-то там делает по самоудалению из хранилища. Может метку поставит "«здесь был Вася» или «отправит сообщение другому объекту — регистратору несостоявшихся космонавтов: внеси меня в свой список». Это уже неважно. Структуры данных так не делают – они же записи в таблице, а не объекты.
michael_vostrikov
10.01.2019 18:42+1А если продолжить и вспомнить про архитектуру хранения в современных СУБД?
Разработчики СУБД, чаще всего используют разновидности B-дерева
В этих перипетиях с «мешками с байтами» есть приятное исключение – СУБД Intersystems Cache
Хранить можно все типы данных, включая символьные и бинарные потоки.Так каким образом она это все хранит-то?
Самая важная магия в строчке: self.att.run_obj_method("%Save",[])
Именно так мы имеем возможность сохранять объекты прямым указанием и без необходимости применять дополнительные библиотеки и каркасы/фреймворки, вроде вездесущих и неприглядных ORM.Чем это отличается от ORM? Я бы даже сказал, чем это отличается от ActiveRecord?
Итак, на этих примерах видно, что не обязательно думать одновременно о своей модели данных и её табличной схеме хранения.
Эти примеры ничем не отличаются от кода, использующего ORM. С ORM, пожалуй, код выглядит даже чище и понятнее.
Осталось добавить участника в мероприятие
haJS.addAttendee(att.att)Список участников хранится в самом объекте Event? Как получить информацию, в каких мероприятиях участвует участник?
torgeek Автор
10.01.2019 19:19-1Так каким образом она это все хранит-то?
Как и всё мейнстимовые СУБД — разновидность B-деревьев. Только не прячет этот факт за фасадом SQL, а активно использует на благо разработчиков.
Чем это отличается от ORM? Я бы даже сказал, чем это отличается от ActiveRecord?
Фасадом. Фактически ORM отсутствует для разработчика приложения. Я люблю Ruby, но это было так давно… А сегодня только так.
Список участников хранится в самом объекте Event? Как получить информацию, в каких мероприятиях участвует участник?
Участников этого мероприятия — да, в Event. Ссылкой на Attendee. Этот кусочек кода для примера и взят приложения, где один и то же участник посещает разные Event. Этой части в примерах нет, а там объект-участник знает в каких он мероприятиях участвовал. А внутри Event может быть в разных ролях: слушателем, докладчиком и комментатором.michael_vostrikov
10.01.2019 20:00Только не прячет этот факт за фасадом SQL, а активно использует на благо разработчиков.
В чем это выражается? В коде примеров нет никаких отличий от кода с SQL ORM.
Фактически ORM отсутствует для разработчика приложения.
Вот код с ActiveRecord:
class User extends ActiveRecord { ... } function createUser() { $user = new User(); $user->login = 'TestUser'; $user->save(); }
Логически ничем не отличается от примеров из статьи. Но используются средства языка программирования, а не магические константы.
Этой части в примерах нет, а там объект-участник знает в каких он мероприятиях участвовал.
То есть в Event хранится список Attendee, а в Attendee список Event, и это 2 разных массива, которые можно менять независимо?
torgeek Автор
10.01.2019 21:21В чем это выражается? В коде примеров нет никаких отличий от кода с SQL ORM.
Сознательно отказался от примеров с SQL. Если интересно, посмотрите примеры в большом обзоре про глобалы 1, 2, 3.
Если будет много вопросов, подумаю над дополнительным материалом для публикации.
torgeek Автор
10.01.2019 21:38Вот код с ActiveRecord
Отличается. Если я правильно пониманию, ActiveRecord работает только с кортежами.
Магических констант что-то не припомню :) Два языка и привязки между ними. При использовании только ObjectScript всё ещё проще.
torgeek Автор
10.01.2019 21:44То есть в Event хранится список Attendee, а в Attendee список Event, и это 2 разных массива, которые можно менять независимо?
Да, два разных «массива» (это не массивы). Дальше как разработчику заблагорассудится. У меня зависимые объекты (в примере этой части нет).
И спасибо за вопросы! Хорошая мне тренировка для изучения новых тем и хабр-разметки :)michael_vostrikov
10.01.2019 22:38Если интересно, посмотрите примеры в большом обзоре про глобалы
Там это точно так же спрятано за специальным языком.
Отличается. Если я правильно пониманию, ActiveRecord работает только с кортежами.
ActiveRecord работает с объектами языка программирования, с обычным ООП. В моем примере
Userэто класс, как и в вашем.
Магических констант что-то не припомню
att.run_obj_method('какая-то строка')— "какая-то строка" это и есть магическая константа. С точки зрения языка это константы, а на самом деле запускают разную логику.
Да, два разных «массива»
То есть технически возможна ситуация, когда Attendee находится в списке участников объекта Event, но этого объекта Event нет в списке событий объекта Attendee. Ну тогда получается это обычная NoSQL со всеми их недостатками.
Реляционные базы выбирают в том числе и из-за контроля целостности данных. Даже если не поставить внешние ключи для промежуточной таблицы
attendee-event(что иногда делают по техническим причинам), база все равно не даст создать запись без указанияattendee_idилиevent_id.torgeek Автор
11.01.2019 13:05Там это точно так же спрятано за специальным языком.
ActiveRecord работает с объектами языка программирования, с обычным ООП. В моем примере User это класс, как и в вашем.
Это про одно и тоже. Поэтому будем есть этого слона по частям.
ActiveRecord основан на соглашениях и специальном языке. Он вводит свой DSL. Как минимум для миграций это нужно.
Примеров объектов на ActiveRecord, окромя кортежей, не обнаруживаю. Скажите где посмотреть?
torgeek Автор
11.01.2019 13:10att.run_obj_method('какая-то строка') — «какая-то строка» это и есть магическая константа. С точки зрения языка это константы, а на самом деле запускают разную логику.
По мне странно называть всё 'что в кавычках' константами. Обоснуете?flancer
11.01.2019 13:35IMHO, вполне обосновано — inline константа. Как анонимные функции, только анонимные константы. Я в Magento с этой бедой постоянно сталкиваюсь. Написано 'status' и пойди пойми, этот 'status' в этом месте то же самое, что 'status' в другом методе другого класса или только названия одинаковы. А если написано:
namespace Vendor\Project\Module\Path\To\Class; class Order { const STATUS='status'; }
то и вопросов возникает гораздо меньше.
torgeek Автор
11.01.2019 13:16Реляционные базы выбирают в том числе и из-за контроля целостности данных. Даже если не поставить внешние ключи для промежуточной таблицы attendee-event (что иногда делают по техническим причинам), база все равно не даст создать запись без указания attendee_id или event_id.
Именно так и написал. Хотите целостности — получите хоть в объектном, хоть в реляционном виде. Нет такой потребности — на здоровье.michael_vostrikov
11.01.2019 15:48ActiveRecord основан на соглашениях и специальном языке. Он вводит свой DSL.
Не знаю, что вы под этим подразумеваете, ничего он такого не вводит. Если он что-то и вводит, то только то же самое, что и Cache.
Примеров объектов на ActiveRecord, окромя кортежей, не обнаруживаю. Скажите где посмотреть?
Я привел пример с созданием пользователя. Где там кортежи?
Вы уходите от ответа на вопрос. Чем конкретно ваш код отличается от моего кода с ActiveRecord? По-моему, кроме названий он не отличается ничем.
По мне странно называть всё 'что в кавычках' константами. Обоснуете?
Всё, что в кавычках — это по определению "строковая константа", другое название "строковый литерал".
Именно так и написал. Хотите целостности — получите хоть в объектном, хоть в реляционном виде.
Вы написали, что там 2 разных массива. Как гарантируется целостность? Конкретно для этого примера, как гарантируется отсутствие ситуации, когда в event.visitors пользователь есть, а в его свойстве attendee.events такого события нет?
torgeek Автор
11.01.2019 19:38Так в примере про целостность ничего не сказано. Вы спрашиваете о том, чего нет в статье. В комментариях выше написал какие есть варианты развития событий.
michael_vostrikov
11.01.2019 21:01В статье вы говорите, что Cache лучше подходит для разработки, чем реляционные БД. Ссылочная целостность это одно из качеств реляционной БД. Сравнивать их без учета этого нет смысла.
В комментариях вы высказываете необоснованные утверждения и уходите от ответов на вопросы. Складывается впечатление, что вы не разбираетесь в теме. Статья конечно рекламная, но техническим моментам можно было больше внимания уделить.
torgeek Автор
11.01.2019 21:28Согласен, наверное стоило добавить ещё пример. Решил не перегружать. Про связывание и целостность хранимых объектов в документации Defining and Using Relationships
Обманное впечатление :) Верно другое – разбираюсь в теме. ObjectScript для меня новый язык.
Maksim87
10.01.2019 18:57+1Я год проработал разработчиком на Cache и это был просто ад с ежедневным баттхёром. Ужасная IDE, кривой псевдоязык, отсутствие внятной документации, отсутствие сообщества, отсутствие сторонних библиотек: все приходится писать с нуля! Баттхёрт начался с первого же проекта, когда потребовалось написать код для кодировки кириллических доменных имён. Баттхёрт при отладке, когда выясняется что отладчик понимает и подсвечивает не то что ты видешь в IDE, а псевдокод в который транслируется твоя программа. Баттхёрт при неожиданном поведении БД, например, индексы надо было перестраивать вручную после измененияе класса. На вопрос «почему» наш гуру отвечал «потому что это Cache». В 2013 году плюнул и уволился из этой конторы. Недавно бывший коллега сообщил что Cache очень сильно улучшили и добавили даже Json-сериализацию «из коробки». Прогресс, блин, когда на дворе 2018 год
torgeek Автор
10.01.2019 19:15Eclipse ужасная IDE? Редко такое слышу :) VS Code тоже вполне ничего так. Говорят, в древние времена, была другая IDE и из той галактики доносятся возгласы, как непривычно работать в Atelier ;) Видимо за 6 пропущенных лет много утекло. Моя б воля, остался бы в борландовском Turbo Pascal или, что ещё лучше, в ОС Оберон-2
Про отличную документацию и сообщество написал выше. Если приглядеться к фамилиям, то каждый 10 будет нашим соотечественником (но это не точно).
Про REST «из коробки» напишу как-нибудь поподробнее и с примерами.
И на дворе уже 2019 год наступил ;)
Yo1
12.01.2019 12:30cache вобрал все недостатки объектных и реляционных субд, потому проиграл еще в 90х. врядли в наше время можно найти проект на cache не из 90х.
суть современных реляционных субд — оптимизатор. т.е. сегодня план один, завтра таблички подросли и оптимизатор перестроит план. у cache же код не декларативный, доступ к данным зашивается насмерть. никакого смысла возвращаться в 90е с такой технологией нет.torgeek Автор
12.01.2019 13:52oracle/microsoft/ibm вобрал в себя все недостатки реляционных субд (Кодд аж возмущался по этому поводу и уволился из ibm), поэтому проиграл ещё в 90-х. врядил в наше время можно найти проект на oracle/microsoft/ibm не из 90х (ibm с горяча запилила noSQL lotus/domino и расстроившись сбросила его на индийцев)
никакого смысла возвращаться в 90е с такой технологией нет.
подставь свой вариант :)Yo1
12.01.2019 14:10вы выбираю вариант с психологической травмой, нанесенной кашей. новые проекты, особливо в энтерпрайзе так и делают на тройке лидеров рсубд.
torgeek Автор
12.01.2019 14:32Что тут сказать, сочувствую((
Сегодня всё сильно другое. Если включить свежий незамутненный прошлым взгляд, а себя переступить/обновить очень боязно, наверное, то можно увидеть прогресс. Я, например люблю среду Оберона, но обжёгся на Дельфи. С++ меня долго ломал и, наверное к нему не вернусь. А у сегодняшнего Каше, по сравнению даже с тем что было 7-10 лет назад, резкий прогресс. И любовь его настоящих разработчиков, как бы пафосно это не звучало. Я вот и решил разобраться сам, отчего такие полярные мнения.
Пока вывод такой, кто не работал вплотную с Cache последние 5 лет, ничего по делу сказать не могут. А резкий рост новых разработчиков и успех на рынке говорят сами за себя.
torgeek Автор
12.01.2019 14:18А если серьёзно, напишите в чём ваш профессиональный взгляд видит примеры «недостатков», как с монстрами РСУБД типа Оракл/Микрософт, так и новичками, типа Апачевских HBase/Kudu или вполне отечественных ClickHouse и Postres Pro?
Чуть выше Михаил michael_vostrikov устроил мне вполне качественный детальный допрос/разнос с примерами живого кода. :)michael_vostrikov
12.01.2019 21:13Ну что же вы сразу "разнос") Ничего такого не хотел, просто поинтересовался. Может слишком настойчиво, так как не было тех ответов, которые я ожидал.
torgeek Автор
12.01.2019 21:47Так очень хорошие вопросы получились. У меня есть ответы, но я в них засомневался и появились новые. Например, где граница между просто данными и уже объектами? Вроде бы просто – у объектов есть собственное поведение, а у данных нет. В реляционной модели есть только данные и нет объектов. Это граница между процедурным и объектными подходами. То есть любой ORM ликвидирует объект, превращая его в набор данных. И ActiveRecord не исключение.
А дальше? В первом приближении разница в именовании. Объект оживает сам. А в $user->login = 'TestUser' что-то странное. У меня по объектно-православному att.new(«Аким»). Но после вопроса уверенность пропала))
vasyan
Интересно было бы почитать батхёрты от Cache. Мне кажется, первый батхёрт был бы от называния, которое замучаешься гуглить.
torgeek Автор
это правда :) поэтому всегда работает хак с добавлением InterSystems в поиске.