
Источники вдохновения
Этот пост возник благодаря недавней публикации Араса Пранцкевичуса о докладе, предназначенном для программистов-джуниоров. В нём рассказывается о том, как адаптироваться к новым ECS-архитектурам. Арас следует привычной схеме (объяснения ниже): показывает примеры ужасного ООП-кода, а затем демонстрирует, что отличным альтернативным решением является реляционная модель (но называет её «ECS», а не реляционной). Я ни в коем случае не критикую Араса — я большой фанат его работ и хвалю его за отличную презентацию! Я выбрал именно его презентацию вместо сотен других постов про ECS из Интернета потому, что он приложил дополнительные усилия и опубликовал git-репозиторий для изучения параллельно с презентацией. В нём содержится небольшая простая «игра», используемая в качестве примера выбора разных архитектурных решений. Этот небольшой проект позволил мне на конкретном материале продемонстрировать свои замечания, так что спасибо, Арас!
Слайды Араса выложены здесь: http://aras-p.info/texts/files/2018Academy — ECS-DoD.pdf, а код находится на github: https://github.com/aras-p/dod-playground.
Я не буду (пока?) анализировать получившуюся ECS-архитектуру из этого доклада, но сосредоточусь на коде «плохого ООП» (похожего на уловку «чучело») из его начала. Я покажу, как бы он выглядел на самом деле, если бы правильно исправили все нарушения принципов OOD (object-oriented design, объектно-ориентированного проектирования).
Спойлер: устранение всех нарушений OOD приводит к улучшениям производительности, аналогичным преобразованиям Араса в ECS, к тому же использует меньше ОЗУ и требует меньше строк кода, чем ECS-версия!
TL;DR: Прежде чем прийти к выводу, что ООП отстой, а ECS рулит, сделайте паузу и изучите OOD (чтобы знать, как правильно использовать ООП), а также разберитесь в реляционной модели (чтобы знать, как правильно применять ECS).
Я уже долгое время принимаю участие во множестве дискуссий про ECS на форуме, частично потому, что не думаю, что эта модель заслуживает существовать в качестве отдельного термина (спойлер: это просто ad-hoc-версия реляционной модели), но ещё и потому, что почти каждый пост, презентация или статья, рекламирующие паттерн ECS, повторяют следующую структуру:
- Показать пример ужасного ООП-кода, реализация которого имеет ужасные изъяны из-за излишнего использования наследования (а значит, эта реализация нарушает многие принципы OOD).
- Показать, что композиция — это лучшее решение, чем наследование (и не упоминать о том, что OOD на самом деле даёт нам тот же урок).
- Показать, что реляционная модель отлично подходит для игр (но назвать её «ECS»).
Такая структура бесит меня, потому что: (A) это уловка «чучело»… сравнивается мягкое с тёплым (плохой код и хороший код)… и это нечестно, даже если сделано ненамеренно и не требуется для демонстрации того, что новая архитектура хороша; и, что более важно: (B) это имеет побочный эффект — такой подход подавляет знания и непреднамеренно демотивирует читателей от знакомства с исследованиями, проводившимися в течение полувека. О реляционной модели впервые начали писать в 1960-х. На протяжении 70-х и 80-х эта модель значительно улучшалась. У новичков часто возникают вопросы типа "в какой класс нужно поместить эти данные?", и в ответ им часто говорят нечто расплывчатое, наподобие "вам просто нужно набраться опыта и тогда вы просто научитесь понимать нутром"… но в 70-х этот вопрос активно изучался и на него в общем случае был выведен формальный ответ; это называется нормализацией баз данных. Отбрасывая уже имеющиеся исследования и называя ECS совершенно новым и современным решением, вы скрываете это знание от новичков.
Основы объектно-ориентированного программирования были заложены столь же давно, если не раньше (этот стиль начал исследоваться в работе 1950-х годов)! Однако именно в 1990-х годах объектно-ориентированность стала модной, виральной и очень быстро превратилась в доминирующую парадигму программирования. Произошёл взрыв популярности многих новых ОО-языков, в том числе Java и (стандартизированной версии) C++. Однако так как это было связано с ажиотажем, то всем нужно было знать это громкое понятие, чтобы записать в своё резюме, но лишь немногие по-настоящему в него углублялись. Эти новые языки создали из многих особенностей ОО ключевые слова — class, virtual, extends, implements — и я считаю, что именно поэтому в тот момент ОО разделилась на две отдельные сущности, живущие собственными жизнями.
Я буду называть применение этих вдохновлённых ОО языковых особенностей "ООП", а применение вдохновлённых ОО техник создания дизайна/архитектур "OOD". Все очень быстро подхватили ООП. В учебных заведениях есть курсы ОО, выпекающие новых ООП-программистов… однако знание OOD плетётся позади.
Я считаю, что код, использующий языковые особенности ООП, но не следующий принципам проектирования OOD, не является ОО-кодом. В большинстве критических отзывов, направленных против ООП, используется для примера выпотрошенный код, на самом деле не являющийся ОО-кодом.
ООП-код имеет очень плохую репутацию, и в частности потому, что бОльшая часть ООП-кода не следует принципам OOD, а потому не является «истинным» ОО-кодом.
Предпосылки
Как сказано выше, 1990-е стали пиком «моды на ОО», и именно в то время «плохой ООП», вероятно, был хуже всего. Если вы изучали ООП в то время, то, скорее всего, узнали о «четырёх столпах ООП»:
- Абстрагирование
- Инкапсуляция
- Полиморфизм
- Наследование
Я предпочитаю называть их не четырьмя столпами, а «четырьмя инструментами ООП». Это инструменты, которые можно использовать для решения задач. Однако недостаточно просто узнать, как работает инструмент, необходимо знать, когда нужно его использовать… Со стороны преподавателей безответственно обучать людей новому инструменту, не говоря им, когда каждый из них стоит применять. В начале 2000-х оказывалось сопротивление активному неверному использованию этих инструментов, своего рода «вторая волна» OOD-мышления. Результатом этого стало появление мнемоники SOLID, предоставлявшей быстрый способ оценки сильных сторон архитектуры. Надо заметить, что эта мудрость на самом деле была широко распространена в 90-х, но не получила ещё крутого акронима, позволившего закрепить их в качестве пяти базовых принципов…
- Принцип единственной ответственности (Single responsibility principle). Каждый класс должен иметь только одну причину изменения. Если у класса «A» есть две обязанности, то нужно создать класс «B» и «C» для обработки каждой из них по отдельности, а затем создать «A» из «B» и «C».
- Принцип открытости/закрытости (Open/closed principle). ПО со временем изменяется (т.е. важна его поддержка). Стремитесь помещать части, которые скорее всего будут изменяться, в реализации (implementations) (т.е. в конкретные классы) и создавайте интерфейсы (interfaces) на основе тех частей, которые скорее всего не изменятся (например, абстрактные базовые классы).
- Принцип подстановки Барбары Лисков (Liskov substitution principle). Каждая реализация интерфейса должна на 100% соответствовать требованиям этого интерфейса, т.е. любой алгоритм, работающий с интерфейсом, должен работать с любой реализацией.
- Принцип разделения интерфейса (Interface segregation principle). Делайте интерфейсы как можно более малыми, чтобы каждая часть кода «знала» о наименьшем объёме кодовой базы, например, избегала ненужных зависимостей. Этот совет хорош и для C++, где время компиляции становится огромным, если ему не следовать.
- Принцип инверсии зависимостей (Dependency inversion principle). Вместо двух конкретных реализаций, обменивающихся данными напрямую (и зависящих друг от друга), их обычно можно разделить, формализовав их интерфейс связи в качестве третьего класса, используемого как интерфейс между ними. Это может быть абстрактный базовый класс, определяющий вызовы методов, используемых между ними, или даже просто структура ПСД (POD), определяющая передаваемые между ними данные.
- Ещё один принцип не включён в акроним SOLID, но я уверен, что он очень важен: «Предпочитать композицию наследованию» (Composite reuse principle). Композиция это правильный выбор по умолчанию. Наследование стоит оставить для случаев, когда она абсолютно необходима.
Так мы получаем SOLID-C(++)
Ниже я буду ссылаться на эти принципы, называя их по акронимам — SRP, OCP, LSP, ISP, DIP, CRP…
Ещё несколько замечаний:
- В OOD понятия интерфейсов и реализаций не возможно привязать к каким-то конкретным ключевым словам ООП. В C++ мы часто создаём интерфейсы с абстрактными базовыми классами и виртуальными функциями, а затем реализации наследуют от этих базовых классов… но это только один конкретный способ воплощения принципа интерфейса. В C++ мы также можем использовать PIMPL, непрозрачные указатели, утиную типизацию, typedef и т.д… Можно создать OOD-структуру, а затем реализовать её на C, в котором вообще нет ключевых слов ООП-языка! Поэтому когда я говорю об интерфейсах, я необязательно имею в виду виртуальные функции — я говорю о принципе сокрытия реализации. Интерфейсы могут быть полиморфными, но чаще всего такими не являются! Полиморфизм правильно используется очень редко, но интерфейсы — фундаментальное понятие для всего ПО.
- Как я дал понять выше, если вы создаёте POD-структуру, которая просто хранит какие-то данные для передачи от одного класса другому, тогда эта структура используется как интерфейс — это формальное описание данных.
- Даже если вы просто создаёте один отдельный класс с общей и частной частями, то всё что находится в общей части, является интерфейсом, а всё в частной части — реализацией.
- Как я дал понять выше, если вы создаёте POD-структуру, которая просто хранит какие-то данные для передачи от одного класса другому, тогда эта структура используется как интерфейс — это формальное описание данных.
- Наследование на самом деле имеет (по крайней мере) два типа — наследование интерфейсов и наследование реализаций.
- В C++ наследование интерфейсов включает в себя абстрактные базовые классы с чисто виртуальными функциями, PIMPL, условными typedef. В Java наследование интерфейсов выражается через ключевое слово implements.
- В C++ наследование реализаций происходит каждый раз, когда базовые классы содержат что-то, кроме чисто виртуальных функций. В Java наследование реализаций выражается с помощью ключевого слова extends.
- В OOD есть много правил наследования интерфейсов, но наследование реализаций обычно стоит рассматривать как «код с душком»!
И, наконец, мне стоит показать несколько примеров ужасного обучения ООП и того, как оно приводит к плохому коду в реальной жизни (и плохой репутации OOP).
- Когда вас учили иерархиям/наследованию, то, возможно, давали подобную задачу: Допустим, у вас есть приложение университета, в которой содержится каталог студентов и персонала. Можно создать базовый класс Person, а затем класс Student и класс Staff, наследуемые от Person.
Нет-нет-нет. Здесь я вас остановлю. Негласный подтекст принципа LSP гласит, что иерархии классов и алгоритмы, которые их обрабатывают, являются симбиотическими. Это две половины целой программы. ООП — это расширение процедурного программирования, и оно по-прежнему в основном связано с этими процедурами. Если мы не знаем, какие типы алгоритмов будут работать с Students и Staff (и какие алгоритмы будут упрощены благодаря полиморфизму), то будет полностью безответственно приступать к созданию структуры иерархий классов. Сначала вам нужно узнать алгоритмы и данные. - Когда вас обучали иерархиям/наследованию, то, вероятно, давали подобную задачу: Допустим, у вас есть класс фигур. Также у нас есть в качестве подклассов квадраты и прямоугольники. Квадрат должен быть прямоугольником, или прямоугольник квадратом?
На самом деле, это хороший пример для демонстрациии разницы между наследованием реализаций и наследованием интерфейсов.
- Если вы используете подход с наследованием реализаций, то совершенно не учитываете LSP и думаете с практической точки зрения о возможности многократного использования кода, пользуясь наследованием как инструментом.
С этой точки зрения совершенно логично следующее:
struct Square { int width; }; struct Rectangle : Square { int height; };
У квадрата есть только ширина, а у прямоугольника есть ширина + высота, то есть расширив квадрат компонентом высоты, мы получим прямоугольник!
- Как вы могли догадаться, OOD гласит, что делать так (вероятно) неправильно. Я сказал «вероятно», потому что здесь можно поспорить о подразумеваемых характеристиках интерфейса… ну да ладно.
Квадрат всегда имеет одинаковые высоту и ширину, поэтому из интерфейса квадрата совершенно верно предположить, что площадь равна «ширина * ширина».
Наследуясь от квадрата, класс прямоугольников (в соответствии с LSP) должен подчинятся правилам интерфейса квадрата. Любой алгоритм, правильно работающий для квадрата, должен также правильно работать и для прямоугольника. - Возьмём другой алгоритм:
std::vector<Square*> shapes; int area = 0; for(auto s : shapes) area += s->width * s->width;
Он корректно будет работать для квадратов (вычисляя сумму их площадей), но не сработает для прямоугольников.
Следовательно, прямоугольник нарушает принцип LSP.
- Как вы могли догадаться, OOD гласит, что делать так (вероятно) неправильно. Я сказал «вероятно», потому что здесь можно поспорить о подразумеваемых характеристиках интерфейса… ну да ладно.
- Если вы используете подход с наследованием интерфейсов, то ни Square, ни Rectangle не будут наследоваться друг от друга. Интерфейсы для квадрата и прямоугольника на самом деле отличаются, и один не является надмножеством другого.
- Поэтому OOD препятствует использованию наследования реализаций. Как сказано выше, если вы хотите многократно использовать код, то OOD говорит, что правильным выбором является композиция!
- Так что правильная версия приведённого выше (плохого) кода иерархии наследования реализаций на C++ выглядит так:
struct Shape { virtual int area() const = 0; }; struct Square : public virtual Shape { virtual int area() const { return width * width; }; int width; }; struct Rectangle : private Square, public virtual Shape { virtual int area() const { return width * height; }; int height; };
- «public virtual» в Java означает «implements». Используется при реализации интерфейса.
- «private» позволяет расширить базовый класс, не наследуя при этом его интерфейс — в этом случае прямоугольник не является квадратом, хотя и наследуется от него.
- «public virtual» в Java означает «implements». Используется при реализации интерфейса.
- Я не рекомендую писать подобный код, но если вам хочется использовать наследование реализаций, то это нужно делать именно так!
- Так что правильная версия приведённого выше (плохого) кода иерархии наследования реализаций на C++ выглядит так:
- Если вы используете подход с наследованием реализаций, то совершенно не учитываете LSP и думаете с практической точки зрения о возможности многократного использования кода, пользуясь наследованием как инструментом.
TL;DR — ваш ООП-класс говорил вам, каким было наследование. Ваш отсутствующий OOD-класс должен был сказать вам не использовать его 99% времени!
Концепции «сущность/компонент» (Entity / Component)
Разобравшись с предпосылками, давайте перейдём к тому, с чего начинал Арас — к так называемой начальной точке «типичного ООП».
Но для начала ещё одно дополнение — Арас называет этот код «традиционным ООП», и на это я хочу возразить. Этот код может быть типичным для ООП в реальном мире, но, как и приведённых выше примерах, он нарушает всевозможные базовые принципы ОО, поэтому его вообще не стоит рассматривать, как традиционный.
Я начну с первого коммита, прежде чем он начал переделывать структуру в сторону ECS: «Make it work on Windows again» 3529f232510c95f53112bbfff87df6bbc6aa1fae
// -------------------------------------------------------------------------------------------------
// super simple "component system"
class GameObject;
class Component;
typedef std::vector<Component*> ComponentVector;
typedef std::vector<GameObject*> GameObjectVector;
// Component base class. Knows about the parent game object, and has some virtual methods.
class Component
{
public:
Component() : m_GameObject(nullptr) {}
virtual ~Component() {}
virtual void Start() {}
virtual void Update(double time, float deltaTime) {}
const GameObject& GetGameObject() const { return *m_GameObject; }
GameObject& GetGameObject() { return *m_GameObject; }
void SetGameObject(GameObject& go) { m_GameObject = &go; }
bool HasGameObject() const { return m_GameObject != nullptr; }
private:
GameObject* m_GameObject;
};
// Game object class. Has an array of components.
class GameObject
{
public:
GameObject(const std::string&& name) : m_Name(name) { }
~GameObject()
{
// game object owns the components; destroy them when deleting the game object
for (auto c : m_Components) delete c;
}
// get a component of type T, or null if it does not exist on this game object
template<typename T>
T* GetComponent()
{
for (auto i : m_Components)
{
T* c = dynamic_cast<T*>(i);
if (c != nullptr)
return c;
}
return nullptr;
}
// add a new component to this game object
void AddComponent(Component* c)
{
assert(!c->HasGameObject());
c->SetGameObject(*this);
m_Components.emplace_back(c);
}
void Start() { for (auto c : m_Components) c->Start(); }
void Update(double time, float deltaTime) { for (auto c : m_Components) c->Update(time, deltaTime); }
private:
std::string m_Name;
ComponentVector m_Components;
};
// The "scene": array of game objects.
static GameObjectVector s_Objects;
// Finds all components of given type in the whole scene
template<typename T>
static ComponentVector FindAllComponentsOfType()
{
ComponentVector res;
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
res.emplace_back(c);
}
return res;
}
// Find one component of given type in the scene (returns first found one)
template<typename T>
static T* FindOfType()
{
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
return c;
}
return nullptr;
}Да, в ста строках кода сложно разобраться сразу, поэтому давайте начнём постепенно… Нам нужен ещё один аспект предпосылок — в играх 90-х популярно было использовать наследование для решения всех проблем многократного использования кода. У вас была Entity, расширяемая Character, расширяемая Player и Monster, и так далее… Это наследование реализаций, как мы описывали его ранее («код с душком»), и кажется, что правильно начинать с него, но в результате это приводит к очень негибкой кодовой базе. Потому что в OOD есть описанный выше принцип «composition over inheritance». Итак, в 2000-х стал популярным принцип «composition over inheritance», и разработчики игр начали писать подобный код.
Что делает этот код? Ну, ничего хорошего
Если говорить вкратце, то этот код заново реализует уже существующую особенность языка — композицию как библиотеку времени выполнения, а не как особенность языка. Можно представить это так, как будто код на самом деле создаёт новый метаязык поверх C++ и виртуальную машину (VM) для выполнения этого метаязыка. В демо-игре Араса этот код не требуется (скоро мы его полностью удалим!) и служит только для того, чтобы примерно в 10 раз снизить производительность игры.
Однако что же он на самом деле выполняет? Это концепция "Entity/Component" («сущность/компонент») (иногда по непонятной причине называемая "Entity/Component system" («система сущность/компонент»)), но она полностью отличается от концепции "Entity Component System" («сущность-компонент-система») (который по очевидным причинам никогда не называется "Entity Component System systems). Он формализует несколько принципов «EC»:
- игра будет строиться из не имеющих особенностей «сущностей» («Entity») (в этом примере называемых GameObjects), которые состоят из «компонентов» («Component»).
- GameObjects реализуют шаблон «локатор служб» — их дочерние компоненты будут запрашиваться по типу.
- Компоненты знают, каким GameObject они принадлежат — они могут находить компоненты, находящиеся с ними на одном уровне, с помощью запросов к родительскому GameObject.
- Композиция может быть глубиной только в один уровень (компоненты не могут иметь собственных дочерних компонентов, GameObjects не могут иметь дочерних GameObjects).
- GameObject может иметь только один компонент каждого типа (в некоторых фреймворках это обязательное требование, в других нет).
- Каждый компонент (вероятно) со временем изменяется неким неуказанным образом, поэтому интерфейс содержит «virtual void Update».
- GameObjects принадлежат сцене, которая может выполнять запросы ко всем GameObjects (а значит и ко всем компонентам).
Подобная концепция была очень популярна в 2000-х годах, и несмотря на свою ограничительность, оказалась достаточно гибкой для создания бесчисленного количества игр и тогда, и сегодня.
Однако это не требуется. В вашем языке программирования уже есть поддержка композиции как особенность языка — для доступа к ней нет необходимости в раздутой концепции… Зачем же тогда существуют эти концепции? Ну, если быть честным, то они позволяют выполнять динамическую композицию во время выполнения. Вместо жёсткого задания типов GameObject в коде их можно загружать из файлов данных. И это очень удобно, потому что позволяет дизайнерам игр/уровней создавать свои типы объектов… Однако в большинстве игровых проектов бывает очень мало дизайнеров и в буквальном смысле целая армия программистов, поэтому я бы поспорил, что это важная возможность. Хуже того — это ведь не единственный способ, которым можно реализовать композицию во время выполнения! Например, Unity использует в качестве «языка скриптов» C#, и во многих других играх используются его альтернативы, например Lua — удобный для дизайнеров инструмент может генерировать код C#/Lua для задания новых игровых объектов без необходимости использования подобного раздутой концепции! Мы заново добавить эту «функцию» в следующем посте, и сделаем это так, чтобы он не стоил нам десятикратного снижения производительности…
Давайте оценим этот код в соответствии с OOD:
- GameObject::GetComponent использует dynamic_cast. Большинство людей скажет вам, что dynamic_cast — это «код с душком», большой намёк на то, что где-то у вас ошибка. Я бы сказал так — это свидетельство того, что вы нарушили LSP — у вас есть какой-то алгоритм, работающий с базовым интерфейсом, но ему требуется знать разные подробности реализации. По конкретно этой причине код и «дурно пахнет».
- GameObject в принципе неплох, если представить, что он реализует шаблон «локатор служб»… но если пойти дальше, чем критика с точки зрения OOD, то этот шаблон создаёт неявные связи между частями проекта, а я считаю (без ссылки на Википедию, способной поддержать меня знаниями из computer science), что неявные каналы связи — это антипаттерн, и им следует предпочесть явные каналы связи. Тот же аргумент применим к раздутым «концепциям событий», которые иногда используются в играх…
- Я хочу заявить, что компонент — это нарушение SRP, потому что его интерфейс (virtual void Update(time)) слишком широкий. Использование «virtual void Update» в разработке игр распространено повсеместно, но я бы тоже сказал, что это антипаттерн. Хорошее ПО должно позволять вам легко размышлять о потоке управления и потоке данных. Размещение каждого элемента кода геймплея за вызовом «virtual void Update» полностью и совершенно обфусцирует поток управления и поток данных. IMHO, невидимые побочные эффекты, также называемые дальнодействием — одни из самых распространённых источников багов, а «virtual void Update» гарантирует, что почти всё будет являться невидимым побочным эффектом.
- Хотя цель класса Component — обеспечение возможности композиции, он выполняет её через наследование, что является нарушением CRP.
- Единственная хорошая сторона этого примера в том, что код игры лезет из кожи вон, лишь бы соблюсти принципы SRP и ISP — он разбит на множество простых компонентов с очень малыми обязанностями, что отлично подходит для многократного применения кода.
Однако он не так хорош в соблюдении DIP — многие компоненты имеют непосредственное знание друг о друге.
Итак, весь показанный выше код на самом деле можно удалить. Всю эту структуру. Удалить GameObject (в других фреймворках называемые также Entity), удалить Component, удалить FindOfType. Это часть бесполезной VM, нарушающая принципы OOD и ужасно замедляющая нашу игру.
Композиция без фреймворков (то есть использование особенностей самого языка программирования)
Если мы удалим фреймворк композиции, и у нас не будет базового класса Component, то как нашим GameObjects удастся использовать композицию и состоять из компонентов? Как сказано в заголовке, вместо написания этой раздутой VM и создания поверх неё GameObjects на странном метаязыке, давайте просто напишем их на C++, потому что мы программисты игр и это в буквальном смысле наша работа.
Вот коммит, в котором удалён фреймворк Entity/Component: https://github.com/hodgman/dod-playground/commit/f42290d0217d700dea2ed002f2f3b1dc45e8c27c
Вот первоначальная версия исходного кода: https://github.com/hodgman/dod-playground/blob/3529f232510c95f53112bbfff87df6bbc6aa1fae/source/game.cpp
Вот изменённая версия исходного кода: https://github.com/hodgman/dod-playground/blob/f42290d0217d700dea2ed002f2f3b1dc45e8c27c/source/game.cpp
Вкратце об изменениях:
- Удалили ": public Component" из каждого типа компонента.
- Добавили конструктор к каждому типу компонента.
- OOD — это в первую очередь про инкапсуляцию состояния класса, но поскольку эти классы так малы/просты, скрывать особо нечего: интерфейс — это описание данных. Однако одна из главных причин того, что инкапсуляция является основным столпом, заключается в том, что она позволяет нам гарантировать постоянную истинность инвариантов класса… или в случае, если инвариант нарушен, то вам достаточно исследовать инкапсулированный код реализации, чтобы найти ошибку. В этом примере кода стоит добавить конструкторы, чтобы воплотить простой инвариант — все значения должны быть инициализированы.
- Я переименовал слишком общие методы «Update», чтобы их названия отражали то, что делают на самом деле — UpdatePosition для MoveComponent и ResolveCollisions для AvoidComponent.
- Я удалил три жёстко заданных блока кода, напоминающие шаблон/префаб — код, который создаёт GameObject, содержащий конкретные типы Component, и заменил его тремя классами C++.
- Устранил антипаттерн «virtual void Update».
- Вместо того, чтобы компоненты искали друг друга через шаблон «локатор служб», игра явным образом связывает их вместе при конструировании.
Объекты
Поэтому вместо этого кода «виртуальной машины»:
// create regular objects that move
for (auto i = 0; i < kObjectCount; ++i)
{
GameObject* go = new GameObject("object");
// position it within world bounds
PositionComponent* pos = new PositionComponent();
pos->x = RandomFloat(bounds->xMin, bounds->xMax);
pos->y = RandomFloat(bounds->yMin, bounds->yMax);
go->AddComponent(pos);
// setup a sprite for it (random sprite index from first 5), and initial white color
SpriteComponent* sprite = new SpriteComponent();
sprite->colorR = 1.0f;
sprite->colorG = 1.0f;
sprite->colorB = 1.0f;
sprite->spriteIndex = rand() % 5;
sprite->scale = 1.0f;
go->AddComponent(sprite);
// make it move
MoveComponent* move = new MoveComponent(0.5f, 0.7f);
go->AddComponent(move);
// make it avoid the bubble things
AvoidComponent* avoid = new AvoidComponent();
go->AddComponent(avoid);
s_Objects.emplace_back(go);
}У нас теперь есть обычный код C++:
struct RegularObject
{
PositionComponent pos;
SpriteComponent sprite;
MoveComponent move;
AvoidComponent avoid;
RegularObject(const WorldBoundsComponent& bounds)
: move(0.5f, 0.7f)
// position it within world bounds
, pos(RandomFloat(bounds.xMin, bounds.xMax),
RandomFloat(bounds.yMin, bounds.yMax))
// setup a sprite for it (random sprite index from first 5), and initial white color
, sprite(1.0f,
1.0f,
1.0f,
rand() % 5,
1.0f)
{
}
};
...
// create regular objects that move
regularObject.reserve(kObjectCount);
for (auto i = 0; i < kObjectCount; ++i)
regularObject.emplace_back(bounds);Алгоритмы
Ещё одно серьёзное изменение внесено в алгоритмы. Помните, в начале я сказал, что интерфейсы и алгоритмы работают в симбиозе, и должны влиять на структуру друг друга? Так вот, антипаттерн "virtual void Update" стал врагом и здесь. Первоначальный код содержит алгоритм основного цикла, состоящий всего лишь из этого:
// go through all objects
for (auto go : s_Objects)
{
// Update all their components
go->Update(time, deltaTime);Вы можете возразить, что это красиво и просто, но ИМХО это очень, очень плохо. Это полностью обфусцирует и поток управления, и поток данных внутри игры. Если мы хотим иметь возможность понимать своё ПО, если мы хотим поддерживать его, если мы хотим добавлять в него новые вещи, оптимизировать его, выполнять его эффективно на нескольких процессорных ядрах, то нам нужно понимать и поток управления, и поток данных. Поэтому «virtual void Update» нужно предать огню.
Вместо него мы создали более явный основной цикл, который сильно упрощает понимание потока управления (поток данных в нём по-прежнему обфусцирован, но мы исправим это в следующих коммитах).
// Update all positions
for (auto& go : s_game->regularObject)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
for (auto& go : s_game->avoidThis)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
// Resolve all collisions
for (auto& go : s_game->regularObject)
{
ResolveCollisions(deltaTime, go, s_game->avoidThis);
}Недостаток такого стиля в том, что для каждого нового типа объекта, добавляемого в игру, нам придётся добавлять в основной цикл несколько строк. Я вернусь к этому в последующем посте из этой серии.
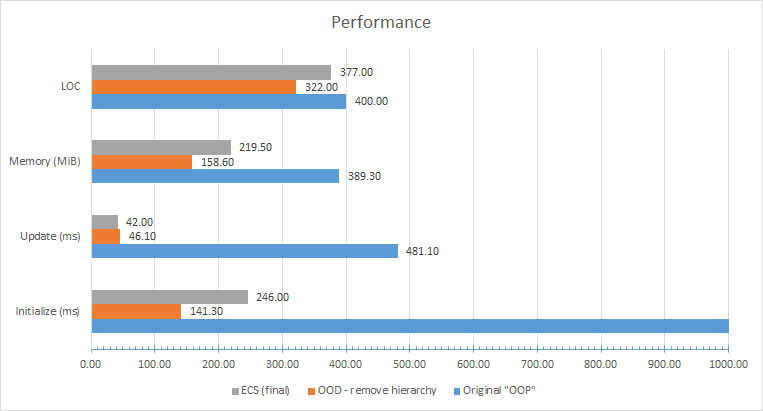
Производительность
Здесь множество огромных нарушений OOD, сделано несколько плохих решений при выборе структуры и остаётся много возможностей для оптимизации, но я доберусь до них в следующем посте серии. Однако на уже на этом этапе понятно, что версия с «исправленным OOD» почти полностью соответствует или побеждает финальный «ECS»-код из конца презентации… И всё, что мы сделали — просто взяли плохой код псевдо-ООП, и заставили его соблюдать принципы ООП (а также удалил сто строк кода)!
Следующие шаги
Здесь я хочу рассмотреть гораздо больший спектр вопросов, в том числе решение оставшихся проблем OOD, неизменяемые объекты (программирование в функциональном стиле) и преимущества, которые они могут привнести в рассуждениях о потоках данных, передачу сообщений, применение логики DOD к нашему OOD-коду, применение относящейся к делу мудрости в OOD-коде, удаление этих классов «сущностей», которые в результате у нас получились, и использование только чистых компонентов, использование разных стилей соединения компонентов (сравнение указателей и обработчиков), контейнеры компонентов из реального мира, доработку ECS-версии для улучшения оптимизации, а также дальнейшую оптимизацию, не упомянутую в докладе Араса (например многопоточность/SIMD). Порядок не обязательно будет таким, и, возможно, я рассмотрю не всё перечисленное…
Дополнение
Ссылки на статью распространились за пределы кругов разработчиков игр, поэтому добавлю: "ECS" (эта статья Википедии плоха, кстати, она объединяет концепции EC и ECS, а это не одно и то же...) — это фальшивый шаблон, циркулирующий внутри сообществ разработчиков игр. По сути, он является версией реляционной модели, в которой «сущности» — это просто ID, обозначающие бесформенный объект, «компоненты» — это строки в конкретных таблицах, ссылающиеся на ID, а «системы» — это процедурный код, который может модифицировать компоненты. Этот «шаблон» всегда позиционировался как решение проблемы избыточного применения наследования, но при этом не упоминается, что избыточное применение наследования на самом деле нарушает рекомендации ООП. Отсюда моё возмущение. Это не «единственно верный способ» написания ПО. Пост предназначен для того, чтобы люди на самом деле изучали существующие принципы проектирования.
Комментарии (41)

cosmrc
22.02.2019 14:24Джентльмены, а посоветуйте хорошую книгу по OOD, если такова имеется.

krokodily
22.02.2019 20:32Practical Object-Oriented Design, An Agile Primer Using Ruby (POODR). Понравилась эта книга, написана простым языком. Скорее для начинающих. Мне, например, трудно читать классические книги по ООП, а эта хорошо пошла. Возможно кому то не понравятся примеры на ruby.

PashaNedved
22.02.2019 15:56Если вы используете подход с наследованием реализаций, то совершенно не учитываете LSP и думаете с практической точки зрения о возможности многократного использования кода, пользуясь наследованием как инструментом.
Примеры иллюстрируют желании уменьшить количества кода, а не о его многократном использовании.
ByGandalf
22.02.2019 17:24+3(Liskov substitution principle). Каждая реализация интерфейса должна на 100% соответствовать требованиям этого интерфейса, т.е. любой алгоритм, работающий с интерфейсом, должен работать с любой реализацией.
В этой формулировке утрачена строгая определённость, что есть «требования интерфейса», и почему строгое им соответствие эквивалентно тому, что «любой алгоритм должен...» и почему просто «работать».
Самая большая проблема LSP — это его интерпритация. Вот что говорила Барбара Лисков (из книги Роберта Мартина «Принципы, паттерны...»):
Мы хотели бы иметь следующее свойство подстановки: если для
каждого объекта o 1 типа S существует объект o 2 типа T, такой, что
для любой программы P, определенной в терминах T, поведение P
не изменяется при замене o 1 на o 2, то S является подтипом T.
Очень важно понимать, что соответствие некой иерархии классов этому принципу совершенно невозможно оценить рассматривая эти классы в отрыве от программы, в которой они используются. Т.е. можно унаследовать квадрат от прямоугольника, или наоборот, и написать код, который использует эту иерархию таким образом, что LSP не будет нарушен.
Поясняю, т.к. вокруг меня множество людей, которые на словах понимают LSP, а ревью их кода показывает, что на самом деле не понимают.
0xd34df00d
22.02.2019 23:26Очень важно понимать, что соответствие некой иерархии классов этому принципу совершенно невозможно оценить рассматривая эти классы в отрыве от программы, в которой они используются.
Возможно, там же перед P квантор всеобщности.
ByGandalf
25.02.2019 13:15Квантор всеобщности в данном случае просто затем, чтобы ограничить все программы только теми, что определены в терминах Т:
… такой, что
для любой программы P, определенной в терминах T, ...
А затем говорится вот что:
… поведение P
не изменяется при замене o 1 на o 2, ...
Т.е. рассматривается поведение программы, которая использует рассматриваемые объекты о1 и о2.
Таким образом, именно поведение конкретной программы может говорить о том, нарушен принцип LSP или нет, а рассматривать классы отдельно от неё не приводит к верным выводам.
MacIn
22.02.2019 17:39+1Также у нас есть в качестве подклассов квадраты и прямоугольники. Квадрат должен быть прямоугольником, или прямоугольник квадратом?..
С этой точки зрения совершенно логично следующее:
struct Square { int width; }; struct Rectangle: Square { int height; };
У квадрата есть только ширина, а у прямоугольника есть ширина + высота, то есть расширив квадрат компонентом высоты, мы получим прямоугольник!
Мне кажется, что это как раз пример «чучела» с вашей стороны.
Здесь есть четкая однонаправленная импликация: любой квадрат — это прямоугольник, но не любой прямоугольник — квадрат.
Следовательно, логично, наоборот, сделать базовый класс более общим (прямоугольник), а при специализации установить связь между шириной и высотой. И это будет верное наследование.
Таким образом, обращаясь к квадрату, как к прямоугольнику, мы будем получать тот же, корректный, результат.Ddnn
22.02.2019 19:21+1Обращаться к квадрату, как к прямоугольнику можно только до тех пор, пока мы не захотим изменить параметры квадрата. Представьте, что у вас есть функция, которая в процессе работы сужает фигуру по высоте в два раза.
void complexFunction(Rectangle &r) { // ... r.setHeight(r.getHeight() / 2 ); // ... }
Очевидно, что любой прямоугольник останется валидным прямоугольником после такой операции. А вот квадрат уже не останется квадратом (нужно пропорционально изменить ширину) — нарушение LSP. И я не знаю, как эту ситуацию решить — далеко не все операции, которые оставят прямоугольник прямоугольником, оставят квадрат квадратом.MacIn
22.02.2019 20:39+1Не вижу проблем.
Я написал: «при специализации установить связь между шириной и высотой.»
Переопределенный сеттер для размеров оставит квадрат квадратом и при этом он по-прежнему будет прямоугольником.
Я не уверен, что здесь есть нарушение LSP, потому что для прямоугольника соблюдается консистентность всех операций: как установление размера, так и его получение. Т.е. мы будем обращаться с ним как с прямоугольником. А сохранение, скажем, ширины при изменении высоты не является элементом контракта прямоугольника как такового — нам не стоит ожидать этого и от объекта.
Сугубо ИМХО.lorc
22.02.2019 21:15+1Почему не является? Логично ожидать, что если я уменьшил высоту прямоугольная в два раза, то его площадь тоже уменьшиться в два раза. А вот площадь квадрата при пропорциональном уменьшении станет равна четверти начальной.
Правильное решение — превратить квадрат обратно в прямоугольник. Только это нельзя выразить средствами большинства языков.
Ddnn
22.02.2019 21:37+1Уменьшение площади прямоугольника в два раза при уменьшении высоты — это следствие контракта «высота не зависит от ширины». Если мы этот контракт отбрасываем — то можно без проблем наследовать квадрат от прямоугольника. Насколько это было бы удобное и правильное решение — зависит уже от контекста.
Danik-ik
23.02.2019 07:34Да, главная проблема данного классического примера — что в нём рассматриваются, простите за мой французский, сферический прямоугольник и сферический квадрат, бесцельно болтающиеся в вакууме. То есть нам сначала предлагают построить иерархию классов, а затем начинается рассуждение о том, можем ли мы использовать полученный класс неизвестным заранее образом. И похоже, что ищется
философский каменьуниверсальное решение на все случаи жизни.
Кажется, первый принцип, который можно из этого примера вывести: двигаться надо от целей к реализации, а не зная смысла задачи — не стоит приступать к проектированию.
netch80
23.02.2019 13:42+100.
Только ожидания свойств и поведения (обычно формулируемые как контракт) определяют, что можно и как менять в свойствах и реализации.
MacIn
22.02.2019 23:07+1Логично ожидать, что если я уменьшил высоту прямоугольная в два раза, то его площадь тоже уменьшиться в два раза.
Только если вы используете объект просто как запись для хранения данных и произвольным образом делаете предположения о внутреннем состоянии объекта.
В противном случае, в норме, вычисление площади — это его, объекта, задача.
Ddnn
22.02.2019 21:21Согласен, если независимость ширины от высоты не является контрактом прямоугольника — то никакого нарушения LSP здесь не будет. Автору оригинала стоило бы более четко сформулировать, какие именно объекты моделируются в его коде. Но если контракт на независимость высоты от ширины есть, то при любом из вариантов наследования(Square -> Rectange/Rectangle -> Square) LSP будет нарушаться.
geher
23.02.2019 00:06С точки зрения геометрии, квадрат — частный случай прямоугольника.
Но если рассматривать более сложное поведение, например, изменение размеров, то получается, что в нашей модели квадрат не совсем прямоугольник, поскольку отличается от него особенностями поведения (не позволяет независимо менять ширину и высоту).
Придется корректировать модель в соответствии с особенностями задачи.
Можно посчитать квадрат и прямоугольник разными сущностями.
Можно сделать базовый класс без метода изменения размера, реализовав его в наследниках "обычный прямоугольник" и "квадрат".
Можно придумать что-то еще.MacIn
23.02.2019 00:21+1поскольку отличается от него особенностями поведения (не позволяет независимо менять ширину и высоту).
Выше уже отмечено несколько раз, что это зависит от контракта. Вы считаете возможность менять ширину и высоту любого прямоугольника независимо друг от друга его, прямоугольника, неотъемлемым свойством — пожалуйста; с моей точки зрения это не так.
Это можно и повернуть вспять: если мы считаем квадрат частным случаем прямоугольника, при этом квадрат не позволяет изменять W и H независимо друг от друга, то и прямоугольник, как более общий случай, не может налагать таких ограничений. Иначе, если бы прямоугольник обязан был иметь независимые W и H (т.е. объект прямоугольник обязательно должен иметь возможность различных W и Н), то квадрат не мог бы быть частным случаем.

fzn7
22.02.2019 18:24В том и смысл ECS, что из него всегда можно вытащить все кишки наружу, когда продукт готов к поставке и необходимо добиться наивысшего качества и производительности. При обратном подходе практически невозможно заранее спроектировать систему, достаточно гибкую и масштабируемую, т.к. все требования заранее неизвестны. Как правило, спустя несколько месяцев разработке внезапно оказывается, что поток новых, ранее неописанных сущностей, ломает к чертям всю изначально красивую архитектуру и в релиз выпускается реальный франкенштейн
akurilov
22.02.2019 19:40Какие страсти бушуют на фронте геймдева.
https://youtu.be/mNmG6dmToEc
Смотреть с 4:45
truthfinder
22.02.2019 19:46+2Хоть статья и понравилась. То что нужно геймдеву не увидел ни у критикуемого, ни у критикующего. Во-первых наличие методов в компоненте это какой-то отдельный пример ECS паттерна. Корректный вариант всё-таки считаю Entity — id, Component — данные(и только данные), System — алгоритм. В этом плане метод Update в компоненте это уже изначально неверный посыл (как и в куче других примеров по ECS), который перетёк в другой неверный посыл. ECS для игр в корректном варианте реализует тот самый переход AoS -> SoA, который так любят современные процы, который cache-friendly и легко масштабируется по ядрам.
Автор так ругает неверное использование принципов ООП (согласен, ещё отмечу: канонично ООП пиарили в книгах в виде 3 основных принципов: инкапсуляция, наследование, полиморфизм). При этом в качестве базы для разбора, считаю, выбран пример с неверным в корне использованием паттерна ECS, который красивый, но ужасный с точки зрения геймдева. Например: методы в компонентах (ещё и виртуальные!), dynamic_cast где он не нужен и т.д.
То что геймдеву реализация не даёт и близко. Равно и новый вариант, который переделал кривой и неработающий SoA подход на красивый, но также не дающий требуемого, AoS формат. А в правильном ECS это одна из ключевых фишек. Которая обычно не работает без ручного аллокатора.
P.S. Мне так и не ясно, почему был выбран такой подход, ведь в репе Араса куда более корректный пример ECS, чем в том, который модифицирует автор статьи.

SH42913
23.02.2019 10:10Складывается ощущение, что автор так и не понял ECS, хоть и видит разницу между EC и ECS.
ИМХО, ECS позволяет куда более масштабируемый, простой и удобный подход к архитектуре, нежели ОО. В условиях вечно меняющихся идей у геймдизов и начальства, ECS — подходит куда лучше. Но понять ECS после ОО действительно крайне трудно.
dtho-dtho
23.02.2019 10:11А теперь главный вопрос. Мне как гейм-разработчику, как пользоваться ECS, которую предлагает автор статьи?
Я вот слабо представляю, как это должно работать…
Например у меня есть компонент Renderable (от которой наследуются Mesh, Material, Texture и т.д.). У меня есть компонент Transform.
Есть RenderSystem, который вызывеат Draw всех спрайтов сцены.
Если у сущности нету компонента Transform, то Renderable рисуется так как есть, в нулевой матрице трансформации. Но если у сущности есть компонент Transform, то с матрицей трансформации Renderable должна складываться матрица трансформации Transform.
В итоге, во круг Transform у нас завязаны все другие компоненты. BoundBox, CollisionBox, Renderable и т.д. Можно всем этим компоентам задать свои параметры позиционирования, сделать методы и удалить компонент Transform. Но не много ли кода получается, ради трансформации одной сущности?
Еще пример. Вот допустим, у меня есть сущность.
Мне нужно в эту сущность, в рантайме добавлять новые компоненты, в зависимости от того, что с сущнностью происходит во время процесса игры.
Например это сущность Mechanism.
Я добавляю в него компонент Wheel, MechBody, Engine — в итоге я имею автомобиль.
Но я добавляю во время игры в него компонент Cannon и Trailer — и машина становиться боевой фурой. Я удаляю Wheel и добавляю компонент MechLegs — и фура с пушкой превращается в мехо-дредноут.
Если делать как говорит автор статьи, то мне придется наплодить 100500 разных сущностей, разных типов в коде.
Ну вот зачем мне отдельный класс Ork, Demon, Human, Barrel и Dragon?
Так я добавлю пару компонентов и при взаимодействиях игрока с одной из этой сущностью, могу сделать проверку на наличие того или иного компонента. А так мне придется писать 100500 перегруженных функций на каждый тип Enemy, с которым игрок будет взаимодействовать. Да и в итоге без проверки на тип — не обойтись.
Вот допустим игрок кидает фаербол по области. Я получаю список всех HitBox компонентов, которые попали в зону действия фаербола. Что делать дальше? Если классический подход, я могу напрямую получить parent компонента и отправить туда ивент или напрямую вызвать метод нужного мне компонента, если он есть.
В случае если у нас архитектура как у автора статьи — то что тогда делать? Это может быть как и Barrel, который вообще статичен и просто коллизия в мире так и Demon, который должен лечиться от огня.
Нарушая принципы OOD, и теряя пару процентов производительности, я оставляю понятный код и легко смогу крутить компоентами как вздумается, прикрутить к ним любую систему и т.д.netch80
23.02.2019 13:48Автор же сказал, что исходит из того, что
>> Однако в большинстве игровых проектов бывает очень мало дизайнеров и в буквальном смысле целая армия программистов
Я не gamedev и никогда не был, но даже видя файловую структуру современных игр, предполагаю, что это очень рисковое утверждение, а в большинстве случаев ситуация обратная — особенно когда мы учитываем тысячи моддеров, которые не правят движок, но переделывают всё остальное до полной неузнаваемости.dtho-dtho
23.02.2019 15:34я хз, откуда взялась армия программистов… Но с какими студиями я не говорил, почти везде на одного программиста, 3-5 дизайнеров/художников приходится и зачастую все упирается как раз таки в художников.
Ну и как программист. Все таки писать тот подход, что предлагает автор, начнет рушиться, как только нужно будет создавать логику. На каждую новую сущность — писать логику взаимодействия между всеми остальными сущностями. Писать логику между компонентами не выйдет, т.к. компоненты не знаю об существовании сущности, т.к. у них нету общего базового класса. В итоге количество кода начнет расти в геометрической погрешности, с ростом разнообразных сущностей.
SH42913
23.02.2019 20:22Можешь посмотреть как работает и выглядит ECS на примере простенького PacMan с использованием LeopotamECS и Unity3D
github.com/SH42913/pacmanecs
Самый главный плюс ECS — его легкая расширяемость, взаимозаменяемость и слабосвязность систем, в некоторых случаях(LeoECS самый лучший пример такого случая) ECS дает еще и приличный буст к производительности, ибо обработка выходит гораздо легче. Единственная трудность ECS — его освоение на первых парах, очень сложно перестроить восприятие и построение архитектуры с ОО на ECS, у меня на это ушло пол года и весь этот опыт я постарался вложить в примере PacMan.
Быть может когда-нибудь я напишу статью о том как перестроить видение архитектуры с ОО на ECS.truthfinder
25.02.2019 09:11А ECS + UI есть опыт или какие-то мысли? Да, нет, вообще нет? Если да, то может есть пример. Возможно ECS + Events для UI?
FloorZ
25.02.2019 09:44-1А что не так с UI?
Для UI лучше пойдет граф, что бы каждый элемент UI рендерился в родительских координатах. Опять же, UI — это сущность. В котором есть компонент rect, event, transform и 9TextureRect. А там уже зависит от системы, как логика реализована
SH42913
25.02.2019 09:57Есть несколько вариантов как использовать ECS в UI.
В проекте, которым я сейчас занимаюсь на работе(тут свой закрытый ECS-фреймворк), например каждый UI элемент — сущность. То есть кнопка — сущность с компонентами ButtonComponent и MyMarkComponent, при нажатии она генерирует ивент по самой себе и его можно ловить в любой из систем.
Но я больше склоняюсь к варианту, который предлагает Leopotam, где UI элементы просто-напросто генерируют ивенты внутрь ECS.
github.com/Leopotam/ecs-uitruthfinder
25.02.2019 10:52Мне всё-таки не очень нравится решение с добавлением компоненты для reload и прочего. Почему бы это не делать через события? Просто это провоцирует более активную работу с динамическими компонентами, что имхо медленнее. Может есть опыт и так, и так? Чтобы прокомментировать в сравнении.
Ну и ещё OpenWorld с ECS тоже интересная тема.
FloorZ
25.02.2019 09:40+1Я знаю что такое ecs и давно им пользуюсь.
Ecs, ns(оно же Scene Graph) и их комбинации.
То что предлагает автор статьи — безумно не оптимально.
Можно с помощью шаблонов провести хитрую агрегацию компонентов в сущность, которую я делал для ECS в чужом движке. Но при росте проекта, мы заплатим временем компиляции.
LeoECS я изучал. Но все таки это с# а не плюсы. А у плюсов есть нюансы.
SH42913
25.02.2019 09:58Автор статьи все усложняет и, не до конца понимая ECS, немного передергивает.
Да, у плюсов слишком много нюансов :(
Alexey2005
24.02.2019 21:04Проблема ECS в том, что оно подходит только для достаточно простых систем. Как только вы попытаетесь реализовать мало-мальски сложную систему наподобие d20, у вас просто глаза на лоб полезут, потому что сущности начнут плодиться как тараканы, код дико дублироваться, и с этим мало что можно поделать.
Точно так же не завидую я тому, кто с помощью ECS попытается реализовать коллекционную карточную игру по типу Magic The Gathering.FloorZ
25.02.2019 09:54+1Не вижу проблем.
Сущность остается базовой.
Просто собираем сущности из компонентов.
У тебя наплодятся компоненты и системы.
При том, можно пойти по пути. Когда наличие компонента какого то типа — и есть индетификатор какой то логики.
А так, я не так давно д20 днд5 делал.
Сделал один компонент атрибутов.
Систему, которая обсчитывала атрибуты.
Ивенты, и систему ивентов, которая напрямую взаимодействовала с системой атрибутов.
Состояния — это были отдельные компоненты, с общей системой состояний. Я тут не гемороял, просто в каждый компонент эффектов передавал функцию-обработчик, которая определяла поведение эффектов.
SH42913
25.02.2019 10:00ECS никак не ограничивает разработчика. Можно сделать все, что угодно. Единственное, что ECS потребует немного больше времени на построение хорошей архитектуры проекта.
Ну а чтобы не дублировать код, в ECS тоже возможна абстракция, только выстраивается она совсем иначе, нежели в ОО.
geher
Отличная статья. Не соглашусь только с противопоставлением наследования и композиции.
Это все-таки разные вещи предназначенные для реализации разных деталей модели предметной области.
Наследование реализует классификацию сущностей одного порядка. Т.е. это про отношения "является подмножеством".
Композиция реализует внутреннее утройство сущностей. Т.е про отношения "состоит из"
И в наследовании реализации нет ничего особо страшного. Ведь если оно приводит к проблемам, это всего лишь означает ошибки в выстраивании иерархии наследования.
NightShad0w
Не только иерархии наследования, но и используемых алгоритмов.
В статье верно подмечено про квадрат и прямоугольник. Наследование не проблема, если интерфейс(который внешний контракт взаимодействия) не нарушен или изменен. В корректном коде метод вычисления площади успешно наследуется и алгоритм полагается на метод, и для раскрашеного квадрата наследование реализации не должно привести к проблемам. Но в случае внешних алгоритмов, полагающихся на интерфейс, унаследованная реализация зачастую проникает в интерфейсную часть и протекает в алгоритм, который самостоятельно использует поле ширины. И тут уже возникают проблемы нарушения SOLID.
Использование композии по умолчанию менее рискованно, и обращаться к наследованию стоит только в случае необходимости.
defuz
Цветные прямоугольники являются подмножеством прямоугольников. Наследуем ColoredRect от Rect? Квадраты являются подмножеством прямоугольников. Наследуем Square от Rect? Что делать если нас не устраивают возникшие накладные расходы на хранение размера квадрата (две величины – длина и ширина, вместо одной)? От кого будем теперь наследовать ColoredSquare, от ColoredRect или от Square?
То что что-то является подмножеством чего-то не является достаточным основанием для использования наследования. Многие множества одновременно могут выступать подмножествами разных множеств, а реализация некоторого интерфейса на определенном подмножестве может требовать специализации алгоритма и/или способа хранения состояния.
Mingun
Но хранение ширины и высоты в прямоугольнике — это особенность реализации, а не его интерфейс. В обсуждаемом примере интерфейсом является только метод вычисления площади. И он спокойно наследуется в квадрат. А чтобы накладных расходов не возникало, то
Rectпросто не должен содержать данных и превращается в интерфейс (по классификации Java). Теоретически,ColoredRectможет содержать данные о цвете, иColoredSquareбудет унаследован и отSquare, и отColoredRect. Но если у нас появитсяGradientRect(который по логике тоже цветной), то опять возникнут те же проблемы. Придется опять разделять хранение данных и интерфейс получения цвета. Если есть опасность, что это понадобиться то такое разделение следует сделать уже при проектировании. В противном случае не вижу ничего страшного, чтобы не разделять.Danik-ik
Постойте-постойте, откуда эта мысль — обсуждать иерархию в отрыве от назначения? Не стоит ли начать с целей и задач? Может, цветность вообще должна быть в отдельном объекте, чтобы скины на лету менять.
0xd34df00d
Должен ли у
Rectбыть методSetWidth(uint)? Должен ли дляRectпроходить тест?