
В этой статье мы попробуем набросать boilerplate простейшего веб-приложения со следующей архитектурой:
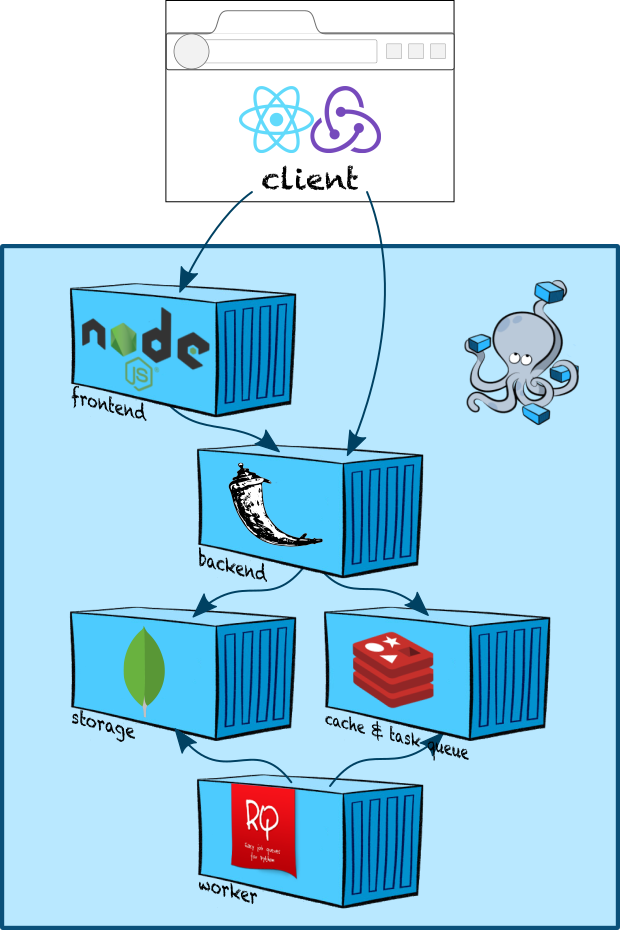
Что мы покроем:
- настройка dev-окружения в docker-compose.
- создание бэкенда на Flask.
- создание фронтенда на Express.
- сборка JS с помощью Webpack.
- React, Redux и server side rendering.
- очереди задач с RQ.
Введение
Перед разработкой, конечно, сперва нужно определиться, что мы разрабатываем! В качестве модельного приложения для этой статьи я решил сделать примитивный wiki-движок. У нас будут карточки, оформленные в Markdown; их можно будет смотреть и (когда-нибудь в будущем) предлагать правки. Всё это мы оформим в виде одностраничного приложения с server-side rendering (что совершенно необходимо для индексации наших будущих терабайт контента).
Давайте чуть подробнее пройдёмся по компонентам, которые нам для этого понадобятся:
- Клиент. Сделаем одностраничное приложение (т.е. с переходами между страницами посредством AJAX) на весьма распространённой в мире фронтенда связке React+Redux.
- Фронтенд. Сделаем простенький сервер на Express, который будет рендерить наше React-приложение (запрашивая все необходимые данные в бэкенде асинхронно) и выдавать пользователю.
- Бэкенд. Повелитель бизнес-логики, наш бэкенд будет небольшим Flask-приложением. Данные (наши карточки) будем хранить в популярном key-value хранилище MongoDB, а для очереди задач и, возможно, в будущем — кэширования будем использовать Redis.
- Воркер. Отдельный контейнер для тяжёлых задач у нас будет запускаться библиотечкой RQ.
Инфраструктура: git
Наверное, про это можно было и не говорить, но, конечно, мы будем вести разработку в git-репозитории.
git init
git remote add origin git@github.com:Saluev/habr-app-demo.git
git commit --allow-empty -m "Initial commit"
git push
(Здесь же стоит сразу наполнить
.gitignore.)Итоговый проект можно посмотреть на Github. Каждой секции статьи соответствует один коммит (я немало ребейзил, чтобы добиться этого!).
Инфраструктура: docker-compose
Начнём с настройки окружения. При том изобилии компонент, которое у нас имеется, весьма логичным решением для разработки будет использование docker-compose.
Добавим в репозиторий файл
docker-compose.yml следующего содержания:version: '3'
services:
mongo:
image: "mongo:latest"
redis:
image: "redis:alpine"
backend:
build:
context: .
dockerfile: ./docker/backend/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
ports:
- "40001:40001"
volumes:
- .:/code
frontend:
build:
context: .
dockerfile: ./docker/frontend/Dockerfile
environment:
- APP_ENV=dev
- APP_BACKEND_URL=backend:40001
- APP_FRONTEND_PORT=40002
depends_on:
- backend
ports:
- "40002:40002"
volumes:
- ./frontend:/app/src
worker:
build:
context: .
dockerfile: ./docker/worker/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
volumes:
- .:/code
Давайте разберём вкратце, что тут происходит.
- Создаётся контейнер MongoDB и контейнер Redis.
- Создаётся контейнер нашего бэкенда (который мы опишем чуть ниже). В него передаётся переменная окружения APP_ENV=dev (мы будем смотреть на неё, чтобы понять, какие настройки Flask загружать), и открывается наружу его порт 40001 (через него в API будет ходить наш браузерный клиент).
- Создаётся контейнер нашего фронтенда. В него тоже прокидываются разнообразные переменные окружения, которые нам потом пригодятся, и открывается порт 40002. Это основной порт нашего веб-приложения: в браузере мы будем заходить на http://localhost:40002.
- Создаётся контейнер нашего воркера. Ему внешние порты не нужны, а нужен только доступ в MongoDB и Redis.
Теперь давайте создадим докерфайлы. Прямо сейчас на Хабре выходит серия переводов прекрасных статей про Docker — за всеми подробностями можно смело обращаться туда.
Начнём с бэкенда.
# docker/backend/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD gunicorn -w 1 -b 0.0.0.0:40001 --worker-class gevent backend.server:app
Подразумевается, что мы запускаем через gunicorn Flask-приложение, скрывающееся под именем
app в модуле backend.server.Не менее важный
docker/backend/.dockerignore:.git
.idea
.logs
.pytest_cache
frontend
tests
venv
*.pyc
*.pyo
Воркер в целом аналогичен бэкенду, только вместо gunicorn у нас обычный запуск питонячьего модуля:
# docker/worker/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD python -m worker
Мы сделаем всю работу в
worker/__main__.py..dockerignore воркера полностью аналогичен .dockerignore бэкенда.Наконец, фронтенд. Про него на Хабре есть целая отдельная статья, но, судя по развернутой дискуссии на StackOverflow и комментариям в духе «Ребят, уже 2018, нормального решения всё ещё нет?» там всё не так просто. Я остановился на таком варианте докерфайла.
# docker/frontend/Dockerfile
FROM node:carbon
WORKDIR /app
# Копируем package.json и package-lock.json и делаем npm install, чтобы зависимости закешировались.
COPY frontend/package*.json ./
RUN npm install
# Наши исходники мы примонтируем в другую папку,
# так что надо задать PATH.
ENV PATH /app/node_modules/.bin:$PATH
# Финальный слой содержит билд нашего приложения.
ADD frontend /app/src
WORKDIR /app/src
RUN npm run build
CMD npm run start
Плюсы:
- всё кешируется как ожидается (на нижнем слое — зависимости, на верхнем — билд нашего приложения);
docker-compose exec frontend npm install --save newDependencyотрабатывает как надо и модифицируетpackage.jsonв нашем репозитории (что было бы не так, если бы мы использовали COPY, как многие предлагают). Запускать простоnpm install --save newDependencyвне контейнера в любом случае было бы нежелательно, потому что некоторые зависимости нового пакета могут уже присутствовать и при этом быть собраны под другую платформу (под ту, которая внутри докера, а не под наш рабочий макбук, например), а ещё мы вообще не хотим требовать присутствия Node на разработческой машине. Один Docker, чтобы править ими всеми!
Ну и, конечно,
docker/frontend/.dockerignore:.git
.idea
.logs
.pytest_cache
backend
worker
tools
node_modules
npm-debug
tests
venv
Итак, наш каркас из контейнеров готов и можно наполнять его содержимым!
Бэкенд: каркас на Flask
Добавим
flask, flask-cors, gevent и gunicorn в requirements.txt и создадим в backend/server.py простенький Flask application.# backend/server.py
import os.path
import flask
import flask_cors
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# CORS позволит нашему фронтенду делать запросы к нашему
# бэкенду несмотря на то, что они на разных хостах
# (добавит заголовок Access-Control-Origin в респонсы).
# Подтюним его когда-нибудь потом.
flask_cors.CORS(self)
app = HabrAppDemo("habr-app-demo")
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
app.config.from_object(f"backend.{env}_settings")
Мы указали Flask подтягивать настройки из файла
backend.{env}_settings, а значит, нам также потребуется создать (хотя бы пустой) файл backend/dev_settings.py, чтобы всё взлетело.Теперь наш бэкенд мы можем официально ПОДНЯТЬ!
habr-app-demo$ docker-compose up backend
...
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Starting gunicorn 19.9.0
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Listening at: http://0.0.0.0:40001 (6)
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Using worker: gevent
backend_1 | [2019-02-23 10:09:03 +0000] [9] [INFO] Booting worker with pid: 9
Двигаемся дальше.
Фронтенд: каркас на Express
Начнём с создания пакета. Создав папку frontend и запустив в ней
npm init, после нескольких бесхитростных вопросов мы получим готовый package.json в духе{
"name": "habr-app-demo",
"version": "0.0.1",
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/Saluev/habr-app-demo.git"
},
"author": "Tigran Saluev <tigran@saluev.com>",
"license": "MIT",
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
"homepage": "https://github.com/Saluev/habr-app-demo#readme"
}
В дальнейшем нам вообще не потребуется Node.js на машине разработчика (хотя мы могли и сейчас извернуться и запустить
npm init через Docker, ну да ладно).В
Dockerfile мы упомянули npm run build и npm run start — нужно добавить в package.json соответствующие команды:--- a/frontend/package.json
+++ b/frontend/package.json
@@ -4,6 +4,8 @@
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
+ "build": "echo 'build'",
+ "start": "node index.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
Команда
build пока ничего не делает, но она нам ещё пригодится.Добавим в зависимости Express и создадим в
index.js простое приложение:--- a/frontend/package.json
+++ b/frontend/package.json
@@ -17,5 +17,8 @@
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
- "homepage": "https://github.com/Saluev/habr-app-demo#readme"
+ "homepage": "https://github.com/Saluev/habr-app-demo#readme",
+ "dependencies": {
+ "express": "^4.16.3"
+ }
}
// frontend/index.js
const express = require("express");
app = express();
app.listen(process.env.APP_FRONTEND_PORT);
app.get("*", (req, res) => {
res.send("Hello, world!")
});
Теперь
docker-compose up frontend поднимает наш фронтенд! Более того, на http://localhost:40002 уже должно красоваться классическое “Hello, world”.Фронтенд: сборка с webpack и React-приложение
Пришло время изобразить в нашем приложении нечто больше, чем plain text. В этой секции мы добавим простейший React-компонент
App и настроим сборку.При программировании на React очень удобно использовать JSX — диалект JavaScript, расширенный синтаксическими конструкциями вида
render() {
return <MyButton color="blue">{this.props.caption}</MyButton>;
}
Однако, JavaScript-движки не понимают его, поэтому обычно во фронтенд добавляется этап сборки. Специальные компиляторы JavaScript (ага-ага) превращают синтаксический сахар в
2014 год. apt-cache search java
Итак, простейший React-компонент выглядит очень просто.
// frontend/src/components/app.js
import React, {Component} from 'react'
class App extends Component {
render() {
return <h1>Hello, world!</h1>
}
}
export default App
Он просто выведет на экран наше приветствие более убедительным кеглем.
Добавим файл
frontend/src/template.js, содержащий минимальный HTML-каркас нашего будущего приложения:// frontend/src/template.js
export default function template(title) {
let page = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>${title}</title>
</head>
<body>
<div id="app"></div>
<script src="/dist/client.js"></script>
</body>
</html>
`;
return page;
}
Добавим и клиентскую точку входа:
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import App from './components/app'
render(
<App/>,
document.querySelector('#app')
);
Для сборки всей этой красоты нам потребуются:
webpack — модный молодёжный сборщик для JS (хотя я уже три часа не читал статей по фронтенду, так что насчёт моды не уверен);
babel — компилятор для всевозможных примочек вроде JSX, а заодно поставщик полифиллов на все случаи IE.
Если предыдущая итерация фронтенда у вас всё ещё запущена, вам достаточно сделать
docker-compose exec frontend npm install --save react react-dom
docker-compose exec frontend npm install --save-dev webpack webpack-cli babel-loader @babel/core @babel/polyfill @babel/preset-env @babel/preset-react
для установки новых зависимостей. Теперь настроим webpack:
// frontend/webpack.config.js
const path = require("path");
// Конфиг клиента.
clientConfig = {
mode: "development",
entry: {
client: ["./src/client.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, "../dist"),
filename: "[name].js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
// Конфиг сервера. Обратите внимание на две вещи:
// 1. target: "node" - без этого упадёт уже на import path.
// 2. складываем в .., а не в ../dist -- нечего пользователям
// видеть код нашего сервера, пусть и скомпилированный!
serverConfig = {
mode: "development",
target: "node",
entry: {
server: ["./index.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, ".."),
filename: "[name].js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
module.exports = [clientConfig, serverConfig];
Чтобы заработал babel, нужно сконфигурировать
frontend/.babelrc:{
"presets": ["@babel/env", "@babel/react"]
}
Наконец, сделаем осмысленной нашу команду
npm run build:// frontend/package.json
...
"scripts": {
"build": "webpack",
"start": "node /app/server.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
...
Теперь наш клиент вкупе с пачкой полифиллов и всеми своими зависимостями прогоняется через babel, компилируется и складывается в монолитный минифицированный файлик
../dist/client.js. Добавим возможность загрузить его как статический файл в наше Express-приложение, а в дефолтном роуте начнём возвращать наш HTML:// frontend/index.js
// Теперь, когда мы настроили сборку,
// можно по-человечески импортировать.
import express from 'express'
import template from './src/template'
let app = express();
app.use('/dist', express.static('../dist'));
app.get("*", (req, res) => {
res.send(template("Habr demo app"));
});
app.listen(process.env.APP_FRONTEND_PORT);
Успех! Теперь, если мы запустим
docker-compose up --build frontend, мы увидим “Hello, world!” в новой, блестящей обёртке, а если у вас установлено расширение React Developer Tools (Chrome, Firefox) — то ещё и дерево React-компонент в инструментах разработчика: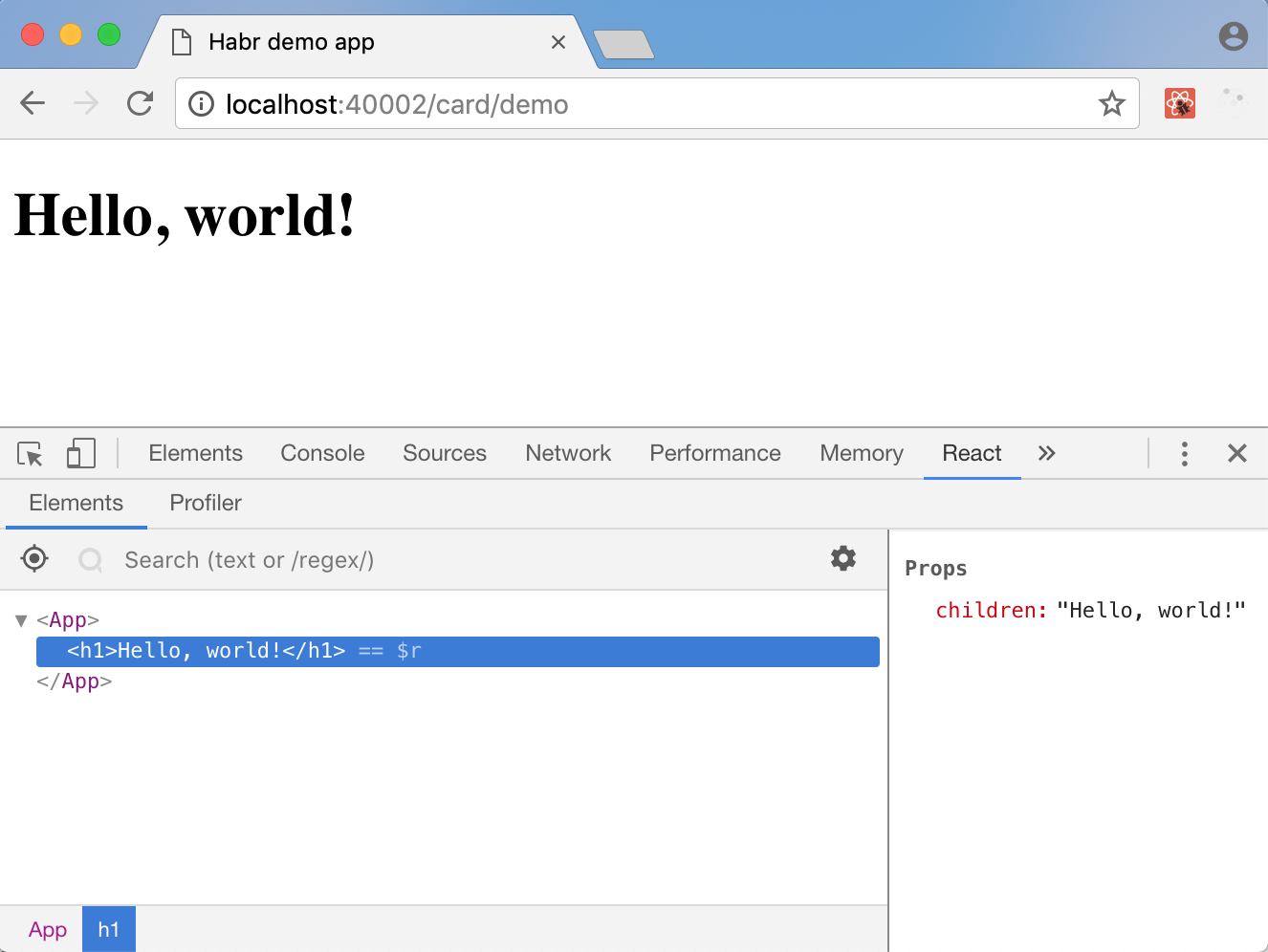
Бэкенд: данные в MongoDB
Прежде, чем двигаться дальше и вдыхать в наше приложение жизнь, надо сперва её вдохнуть в бэкенд. Кажется, мы собирались хранить размеченные в Markdown карточки — пора это сделать.
В то время, как существуют ORM для MongoDB на питоне, я считаю использование ORM практикой порочной и оставляю изучение соответствующих решений на ваше усмотрение. Вместо этого сделаем простенький класс для карточки и сопутствующий DAO:
# backend/storage/card.py
import abc
from typing import Iterable
class Card(object):
def __init__(self, id: str = None, slug: str = None, name: str = None, markdown: str = None, html: str = None):
self.id = id
self.slug = slug # человекочитаемый идентификатор карточки
self.name = name
self.markdown = markdown
self.html = html
class CardDAO(object, metaclass=abc.ABCMeta):
@abc.abstractmethod
def create(self, card: Card) -> Card:
pass
@abc.abstractmethod
def update(self, card: Card) -> Card:
pass
@abc.abstractmethod
def get_all(self) -> Iterable[Card]:
pass
@abc.abstractmethod
def get_by_id(self, card_id: str) -> Card:
pass
@abc.abstractmethod
def get_by_slug(self, slug: str) -> Card:
pass
class CardNotFound(Exception):
pass
(Если вы до сих пор не используете аннотации типов в Python, обязательно гляньте эти статьи!)
Теперь создадим реализацию интерфейса
CardDAO, принимающую на вход объект Database из pymongo (да-да, время добавить pymongo в requirements.txt):# backend/storage/card_impl.py
from typing import Iterable
import bson
import bson.errors
from pymongo.collection import Collection
from pymongo.database import Database
from backend.storage.card import Card, CardDAO, CardNotFound
class MongoCardDAO(CardDAO):
def __init__(self, mongo_database: Database):
self.mongo_database = mongo_database
# Очевидно, slug должны быть уникальны.
self.collection.create_index("slug", unique=True)
@property
def collection(self) -> Collection:
return self.mongo_database["cards"]
@classmethod
def to_bson(cls, card: Card):
# MongoDB хранит документы в формате BSON. Здесь
# мы должны сконвертировать нашу карточку в BSON-
# сериализуемый объект, что бы в ней ни хранилось.
result = {
k: v
for k, v in card.__dict__.items()
if v is not None
}
if "id" in result:
result["_id"] = bson.ObjectId(result.pop("id"))
return result
@classmethod
def from_bson(cls, document) -> Card:
# С другой стороны, мы хотим абстрагировать весь
# остальной код от того факта, что мы храним карточки
# в монге. Но при этом id будет неизбежно везде
# использоваться, так что сконвертируем-ка его в строку.
document["id"] = str(document.pop("_id"))
return Card(**document)
def create(self, card: Card) -> Card:
card.id = str(self.collection.insert_one(self.to_bson(card)).inserted_id)
return card
def update(self, card: Card) -> Card:
card_id = bson.ObjectId(card.id)
self.collection.update_one({"_id": card_id}, {"$set": self.to_bson(card)})
return card
def get_all(self) -> Iterable[Card]:
for document in self.collection.find():
yield self.from_bson(document)
def get_by_id(self, card_id: str) -> Card:
return self._get_by_query({"_id": bson.ObjectId(card_id)})
def get_by_slug(self, slug: str) -> Card:
return self._get_by_query({"slug": slug})
def _get_by_query(self, query) -> Card:
document = self.collection.find_one(query)
if document is None:
raise CardNotFound()
return self.from_bson(document)
Время прописать конфигурацию монги в настройки бэкенда. Мы незамысловато назвали наш контейнер с монгой
mongo, так что MONGO_HOST = "mongo": --- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -0,0 +1,3 @@
+MONGO_HOST = "mongo"
+MONGO_PORT = 27017
+MONGO_DATABASE = "core"
Теперь надо создать
MongoCardDAO и дать Flask-приложению к нему доступ. Хотя сейчас у нас очень простая иерархия объектов (настройки > клиент pymongo > база данных pymongo > MongoCardDAO), давайте сразу создадим централизованный царь-компонент, делающий dependency injection (он пригодится нам снова, когда мы будем делать воркер и tools).# backend/wiring.py
import os
from pymongo import MongoClient
from pymongo.database import Database
import backend.dev_settings
from backend.storage.card import CardDAO
from backend.storage.card_impl import MongoCardDAO
class Wiring(object):
def __init__(self, env=None):
if env is None:
env = os.environ.get("APP_ENV", "dev")
self.settings = {
"dev": backend.dev_settings,
# (добавьте сюда настройки других
# окружений, когда они появятся!)
}[env]
# С ростом числа компонент этот код будет усложняться.
# В будущем вы можете сделать тут такой DI, какой захотите.
self.mongo_client: MongoClient = MongoClient(
host=self.settings.MONGO_HOST,
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
Время добавить новый роут в Flask-приложение и наслаждаться видом!
# backend/server.py
import os.path
import flask
import flask_cors
from backend.storage.card import CardNotFound
from backend.wiring import Wiring
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
flask_cors.CORS(self)
self.wiring = Wiring(env)
self.route("/api/v1/card/<card_id_or_slug>")(self.card)
def card(self, card_id_or_slug):
try:
card = self.wiring.card_dao.get_by_slug(card_id_or_slug)
except CardNotFound:
try:
card = self.wiring.card_dao.get_by_id(card_id_or_slug)
except (CardNotFound, ValueError):
return flask.abort(404)
return flask.jsonify({
k: v
for k, v in card.__dict__.items()
if v is not None
})
app = HabrAppDemo("habr-app-demo")
app.config.from_object(f"backend.{env}_settings")
Перезапускаем командой
docker-compose up --build backend: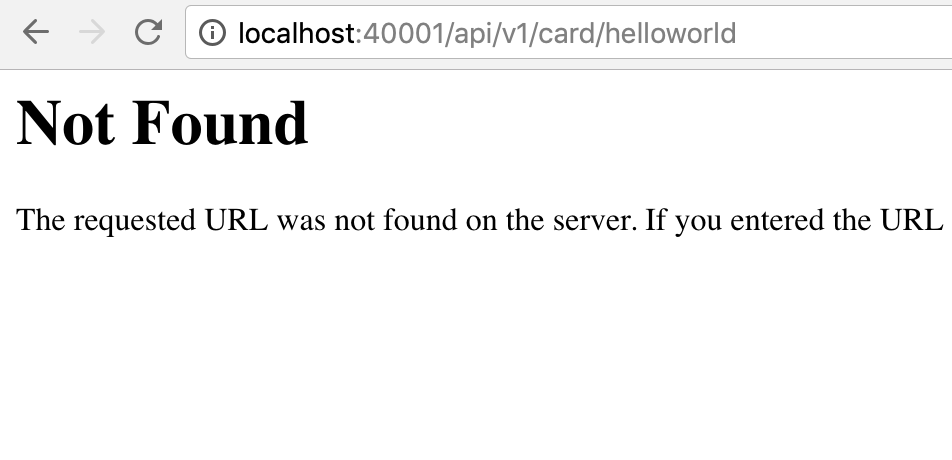
Упс… ох, точно. Нам же нужно добавить контент! Заведём папку tools и сложим в неё скриптик, добавляющий одну тестовую карточку:
# tools/add_test_content.py
from backend.storage.card import Card
from backend.wiring import Wiring
wiring = Wiring()
wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
Команда
docker-compose exec backend python -m tools.add_test_content наполнит нашу монгу контентом изнутри контейнера с бэкендом.
Успех! Теперь время поддержать это на фронтенде.
Фронтенд: Redux
Теперь мы хотим сделать роут
/card/:id_or_slug, по которому будет открываться наше React-приложение, подгружать данные карточки из API и как-нибудь её нам показывать. И здесь начинается, пожалуй, самое сложное, ведь мы хотим, чтобы сервер сразу отдавал нам HTML с содержимым карточки, пригодным для индексации, но при этом чтобы приложение при навигации между карточками получало все данные в виде JSON из API, а страничка не перегружалась. И чтобы всё это — без копипасты!Начнём с добавления Redux. Redux — JavaScript-библиотека для хранения состояния. Идея в том, чтобы вместо тысячи неявных состояний, изменяемых вашими компонентами при пользовательских действиях и других интересных событиях, иметь одно централизованное состояние, а любое изменение его производить через централизованный механизм действий. Так, если раньше для навигации мы сперва включали гифку загрузки, потом делали запрос через AJAX и, наконец, в success-коллбеке прописывали обновление нужных частей страницы, то в Redux-парадигме нам предлагается отправить действие “изменить контент на гифку с анимацией”, которое изменит глобальное состояние так, что одна из ваших компонент выкинет прежний контент и поставит анимацию, потом сделать запрос, а в его success-коллбеке отправить ещё одно действие, “изменить контент на подгруженный”. В общем, сейчас мы это сами увидим.
Начнём с установки новых зависимостей в наш контейнер.
docker-compose exec frontend npm install --save redux react-redux redux-thunk redux-devtools-extension
Первое — собственно, Redux, второе — специальная библиотека для скрещивания React и Redux (written by mating experts), третье — очень нужная штука, необходимость который неплохо обоснована в её же README, и, наконец, четвёртое — библиотечка, необходимая для работы Redux DevTools Extension.
Начнём с бойлерплейтного Redux-кода: создания редьюсера, который ничего не делает, и инициализации состояния.
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
return state;
}
// frontend/src/redux/configureStore.js
import {createStore, applyMiddleware} from "redux";
import thunkMiddleware from "redux-thunk";
import {composeWithDevTools} from "redux-devtools-extension";
import rootReducer from "./reducers";
export default function configureStore(initialState) {
return createStore(
rootReducer,
initialState,
composeWithDevTools(applyMiddleware(thunkMiddleware)),
);
}
Наш клиент немного видоизменяется, морально готовясь к работе с Redux:
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
// Нужно создать то самое централизованное хранилище...
const store = configureStore();
render(
// ... и завернуть приложение в специальный компонент,
// умеющий с ним работать
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Теперь мы можем запустить docker-compose up --build frontend, чтобы убедиться, что ничего не сломалось, а в Redux DevTools появилось наше примитивное состояние:

Фронтенд: страница карточки
Прежде, чем сделать страницы с SSR, надо сделать страницы без SSR! Давайте наконец воспользуемся нашим гениальным API для доступа к карточкам и сверстаем страницу карточки на фронтенде.
Время воспользоваться интеллектом и задизайнить структуру нашего состояния. Материалов на эту тему довольно много, так что предлагаю интеллектом не злоупотреблять и остановится на простом. Например, таком:
{
"page": {
"type": "card", // что за страница открыта
// следующие свойства должны быть только при type=card:
"cardSlug": "...", // что за карточка открыта
"isFetching": false, // происходит ли сейчас запрос к API
"cardData": {...}, // данные карточки (если уже получены)
// ...
},
// ...
}
Заведём компонент «карточка», принимающий в качестве props содержимое cardData (оно же — фактически содержимое нашей карточки в mongo):
// frontend/src/components/card.js
import React, {Component} from 'react';
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
render() {
const {name, html} = this.props;
return (
<div>
<h1>{name}</h1>
<!--Да-да, добавить HTML в React не так-то просто!-->
<div dangerouslySetInnerHTML={{__html: html}}/>
</div>
);
}
}
export default Card;
Теперь заведём компонент для всей страницы с карточкой. Он будет ответственен за то, чтобы достать нужные данные из API и передать их в Card. А фетчинг данных мы сделаем React-Redux way.
Для начала создадим файлик
frontend/src/redux/actions.js и создадим действие, которые достаёт из API содержимое карточки, если ещё не:export function fetchCardIfNeeded() {
return (dispatch, getState) => {
let state = getState().page;
if (state.cardData === undefined || state.cardData.slug !== state.cardSlug) {
return dispatch(fetchCard());
}
};
}
Действие
fetchCard, которое, собственно, делает фетч, чуть-чуть посложнее:function fetchCard() {
return (dispatch, getState) => {
// Сперва даём состоянию понять, что мы ждём карточку.
// Наши компоненты после этого могут, например,
// включить характерную анимацию загрузки.
dispatch(startFetchingCard());
// Формируем запрос к API.
let url = apiPath() + "/card/" + getState().page.cardSlug;
// Фетчим, обрабатываем, даём состоянию понять, что
// данные карточки уже доступны. Здесь, конечно, хорошо
// бы добавить обработку ошибок.
return fetch(url)
.then(response => response.json())
.then(json => dispatch(finishFetchingCard(json)));
};
// Кстати, именно redux-thunk позволяет нам
// использовать в качестве действий лямбды.
}
function startFetchingCard() {
return {
type: START_FETCHING_CARD
};
}
function finishFetchingCard(json) {
return {
type: FINISH_FETCHING_CARD,
cardData: json
};
}
function apiPath() {
// Эта функция здесь неспроста. Когда мы сделаем server-side
// rendering, путь к API будет зависеть от окружения - из
// контейнера с фронтендом надо будет стучать не в localhost,
// а в backend.
return "http://localhost:40001/api/v1";
}
Ох, у нас появилось действие, которое ЧТО-ТО ДЕЛАЕТ! Это надо поддержать в редьюсере:
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD
} from "./actions";
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
}
}
return state;
}
(Обратите внимание на сверхмодный синтаксис для клонирования объекта с изменением отдельных полей.)
Теперь, когда вся логика унесена в Redux actions, сама компонента
CardPage будет выглядеть сравнительно просто:// frontend/src/components/cardPage.js
import React, {Component} from 'react';
import {connect} from 'react-redux'
import {fetchCardIfNeeded} from '../redux/actions'
import Card from './card'
class CardPage extends Component {
componentWillMount() {
// Это событие вызывается, когда React собирается
// отрендерить наш компонент. К моменту рендеринга нам уже
// уже желательно знать, показывать ли заглушку "данные
// загружаются" или рисовать карточку, поэтому мы вызываем
// наше царь-действие здесь. Ещё одна причина - этот метод
// вызывается также при рендеринге компонент в HTML функцией
// renderToString, которую мы будем использовать для SSR.
this.props.dispatch(fetchCardIfNeeded())
}
render() {
const {isFetching, cardData} = this.props;
return (
<div>
{isFetching && <h2>Loading...</h2>}
{cardData && <Card {...cardData}/>}
</div>
);
}
}
// Поскольку этой компоненте нужен доступ к состоянию, ей нужно
// его обеспечить. Именно для этого мы подключили в зависимости
// пакет react-redux. Помимо содержимого page ей будет передана
// функция dispatch, позволяющая выполнять действия.
function mapStateToProps(state) {
const {page} = state;
return page;
}
export default connect(mapStateToProps)(CardPage);
Добавим простенькую обработку page.type в наш корневой компонент App:
// frontend/src/components/app.js
import React, {Component} from 'react'
import {connect} from "react-redux";
import CardPage from "./cardPage"
class App extends Component {
render() {
const {pageType} = this.props;
return (
<div>
{pageType === "card" && <CardPage/>}
</div>
);
}
}
function mapStateToProps(state) {
const {page} = state;
const {type} = page;
return {
pageType: type
};
}
export default connect(mapStateToProps)(App);
И теперь остался последний момент — надо как-то инициализировать
page.type и page.cardSlug в зависимости от URL страницы.Но в этой статье ещё много разделов, мы же не можем сделать качественное решение прямо сейчас. Давайте пока что сделаем это как-нибудь глупо. Вот прям совсем глупо. Например, регуляркой при инициализации приложения!
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
let initialState = {
page: {
type: "home"
}
};
const m = /^\/card\/([^\/]+)$/.exec(location.pathname);
if (m !== null) {
initialState = {
page: {
type: "card",
cardSlug: m[1]
},
}
}
const store = configureStore(initialState);
render(
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Теперь мы можем пересобрать фронтенд с помощью
docker-compose up --build frontend, чтобы насладиться нашей карточкой helloworld…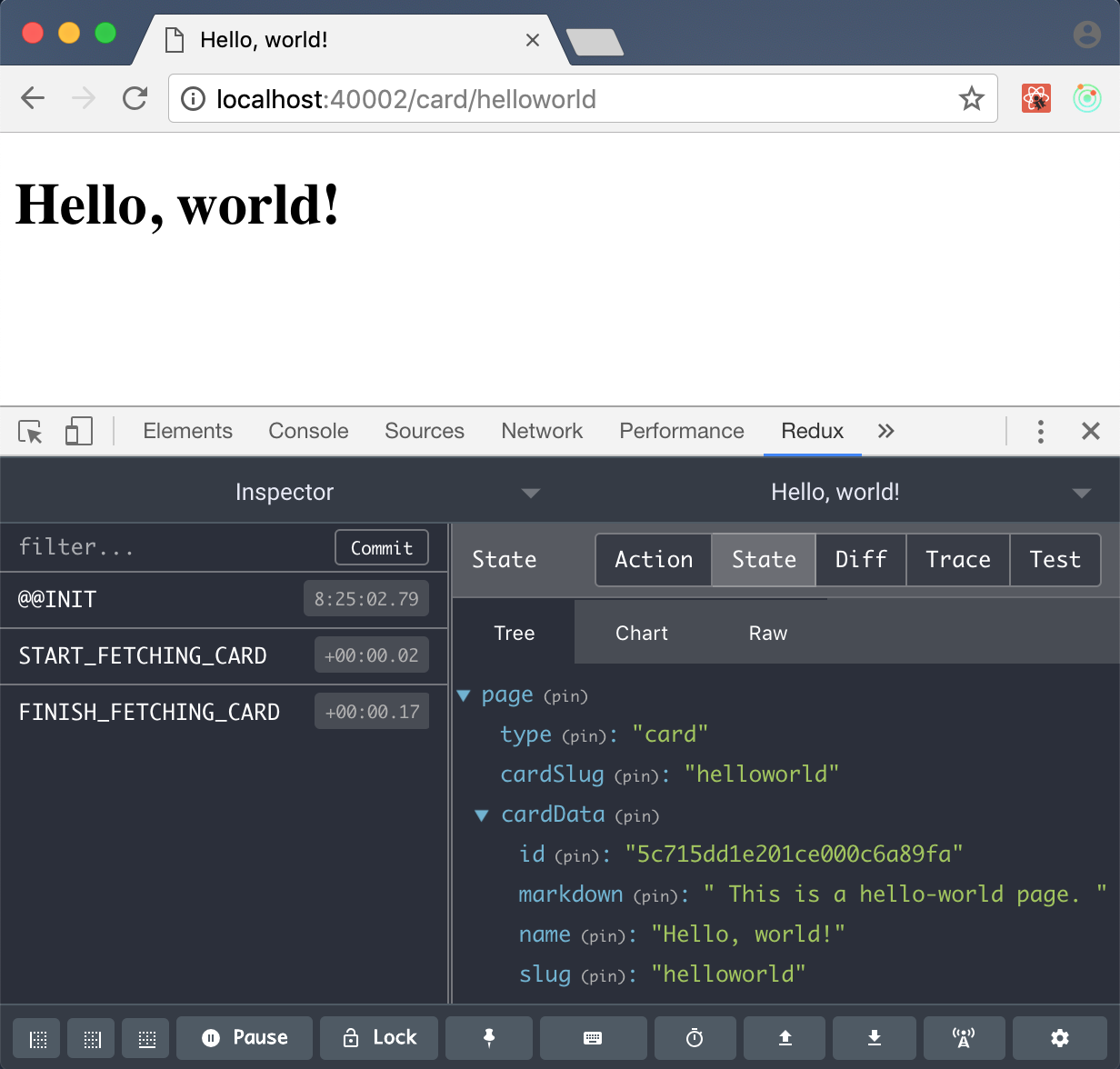
Так, секундочку… а где же наш контент? Ох, да мы ведь забыли распарсить Markdown!
Воркер: RQ
Парсинг Markdown и генерация HTML для карточки потенциально неограниченного размера — типичная «тяжёлая» задача, которую вместо того, чтобы решать прямо на бэкенде при сохранении изменений, обычно ставят в очередь и исполняют на отдельных машинах — воркерах.
Есть много опенсорсных реализаций очередей задач; мы возьмём Redis и простенькую библиотечку RQ (Redis Queue), которая передаёт параметры задач в формате pickle и сама организует нам спаунинг процессов для их обработки.
Время добавить редис в зависимости, настройки и вайринг!
--- a/requirements.txt
+++ b/requirements.txt
@@ -3,3 +3,5 @@ flask-cors
gevent
gunicorn
pymongo
+redis
+rq
--- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -1,3 +1,7 @@
MONGO_HOST = "mongo"
MONGO_PORT = 27017
MONGO_DATABASE = "core"
+REDIS_HOST = "redis"
+REDIS_PORT = 6379
+REDIS_DB = 0
+TASK_QUEUE_NAME = "tasks"
--- a/backend/wiring.py
+++ b/backend/wiring.py
@@ -2,6 +2,8 @@ import os
from pymongo import MongoClient
from pymongo.database import Database
+import redis
+import rq
import backend.dev_settings
from backend.storage.card import CardDAO
@@ -21,3 +23,11 @@ class Wiring(object):
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
+
+ self.redis: redis.Redis = redis.StrictRedis(
+ host=self.settings.REDIS_HOST,
+ port=self.settings.REDIS_PORT,
+ db=self.settings.REDIS_DB)
+ self.task_queue: rq.Queue = rq.Queue(
+ name=self.settings.TASK_QUEUE_NAME,
+ connection=self.redis)
Немного бойлерплейтного кода для воркера.
# worker/__main__.py
import argparse
import uuid
import rq
import backend.wiring
parser = argparse.ArgumentParser(description="Run worker.")
# Удобно иметь флаг, заставляющий воркер обработать все задачи
# и выключиться. Вдвойне удобно, что такой режим уже есть в rq.
parser.add_argument(
"--burst",
action="store_const",
const=True,
default=False,
help="enable burst mode")
args = parser.parse_args()
# Нам нужны настройки и подключение к Redis.
wiring = backend.wiring.Wiring()
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
# Если мы захотим запускать несколько воркеров в разных
# контейнерах, им потребуются уникальные имена.
name=uuid.uuid4().hex)
w.work(burst=args.burst)
Для самого парсинга подключим библиотечку mistune и напишем простенькую функцию:
# backend/tasks/parse.py
import mistune
from backend.storage.card import CardDAO
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
Логично: нам нужен
CardDAO, чтобы получить исходники карточки и чтобы сохранить результат. Но объект, содержащий подключение к внешнему хранилищу, нельзя сериализовать через pickle — а значит, эту таску нельзя сразу взять и поставить в очередь RQ. По-хорошему нам нужно создать Wiring на стороне воркера и прокидывать его во все таски… Давайте сделаем это:--- a/worker/__main__.py
+++ b/worker/__main__.py
@@ -2,6 +2,7 @@ import argparse
import uuid
import rq
+from rq.job import Job
import backend.wiring
@@ -16,8 +17,23 @@ args = parser.parse_args()
wiring = backend.wiring.Wiring()
+
+class JobWithWiring(Job):
+
+ @property
+ def kwargs(self):
+ result = dict(super().kwargs)
+ result["wiring"] = backend.wiring.Wiring()
+ return result
+
+ @kwargs.setter
+ def kwargs(self, value):
+ super().kwargs = value
+
+
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
- name=uuid.uuid4().hex)
+ name=uuid.uuid4().hex,
+ job_class=JobWithWiring)
w.work(burst=args.burst)
Мы объявили свой класс джобы, прокидывающий вайринг в качестве дополнительного kwargs-аргумента во все таски. (Обратите внимание, что он создаёт каждый раз НОВЫЙ вайринг, потому что некоторые клиенты нельзя создавать перед форком, который происходит внутри RQ перед началом обработки задачи.) Чтобы все наши таски не стали зависеть от вайринга — то есть от ВСЕХ наших объектов, — давайте сделаем декоратор, который будет доставать из вайринга только нужное:
# backend/tasks/task.py
import functools
from typing import Callable
from backend.wiring import Wiring
def task(func: Callable):
# Достаём имена аргументов функции:
varnames = func.__code__.co_varnames
@functools.wraps(func)
def result(*args, **kwargs):
# Достаём вайринг. Используем .pop(), потому что мы не
# хотим, чтобы у тасок был доступ ко всему вайрингу.
wiring: Wiring = kwargs.pop("wiring")
wired_objects_by_name = wiring.__dict__
for arg_name in varnames:
if arg_name in wired_objects_by_name:
kwargs[arg_name] = wired_objects_by_name[arg_name]
# Здесь могло бы быть получение объекта из вайринга по
# аннотации типа аргумента, но как-нибудь в другой раз.
return func(*args, **kwargs)
return result
Добавляем декоратор к нашей таске и радуемся жизни:
import mistune
from backend.storage.card import CardDAO
from backend.tasks.task import task
@task
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
Радуемся жизни? Тьфу, я хотел сказать, запускаем воркер:
$ docker-compose up worker
...
Creating habr-app-demo_worker_1 ... done
Attaching to habr-app-demo_worker_1
worker_1 | 17:21:03 RQ worker 'rq:worker:49a25686acc34cdfa322feb88a780f00' started, version 0.13.0
worker_1 | 17:21:03 *** Listening on tasks...
worker_1 | 17:21:03 Cleaning registries for queue: tasks
Ииии… он ничего не делает! Конечно, ведь мы не ставили ни одной таски!
Давайте перепишем нашу тулзу, которая создаёт тестовую карточку, чтобы она: а) не падала, если карточка уже создана (как в нашем случае); б) ставила таску на парсинг маркдауна.
# tools/add_test_content.py
from backend.storage.card import Card, CardNotFound
from backend.tasks.parse import parse_card_markup
from backend.wiring import Wiring
wiring = Wiring()
try:
card = wiring.card_dao.get_by_slug("helloworld")
except CardNotFound:
card = wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
# Да, тут нужен card_dao.get_or_create, но
# эта статья и так слишком длинная!
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
Тулзу теперь можно запускать не только на backend, но и на worker. В принципе, сейчас нам нет разницы. Запускаем
docker-compose exec worker python -m tools.add_test_content и в соседней вкладке терминала видим чудо — воркер ЧТО-ТО СДЕЛАЛ!worker_1 | 17:34:26 tasks: backend.tasks.parse.parse_card_markup(card_id='5c715dd1e201ce000c6a89fa') (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 tasks: Job OK (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 Result is kept for 500 seconds
Пересобрав контейнер с бэкендом, мы наконец можем увидеть контент нашей карточки в браузере:
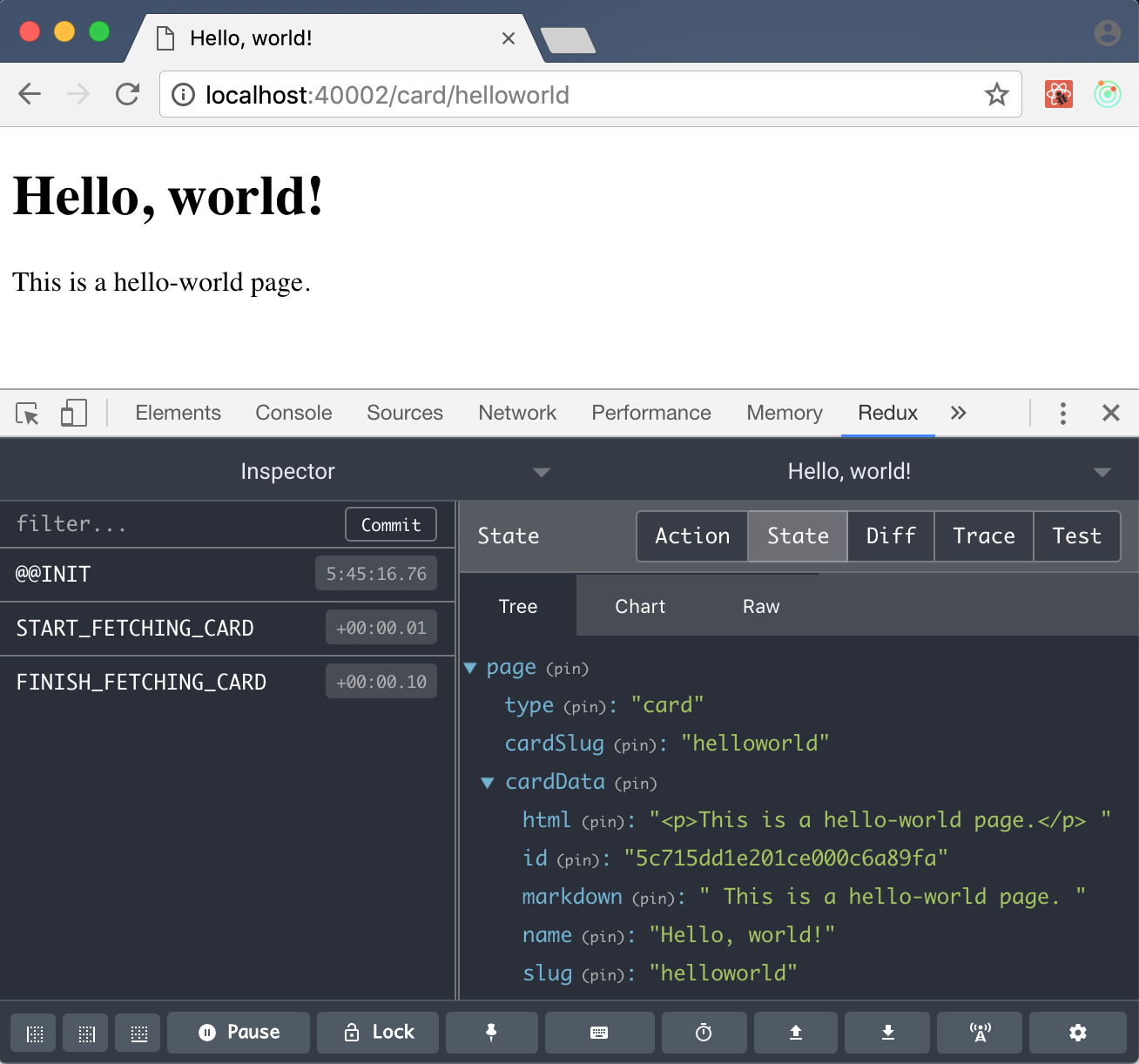
Фронтенд: навигация
Прежде, чем мы перейдём к SSR, нам нужно сделать всю нашу возню с React хоть сколько-то осмысленной и сделать наше single page application действительно single page. Давайте обновим нашу тулзу, чтобы создавалось две (НЕ ОДНА, А ДВЕ! МАМА, Я ТЕПЕРЬ БИГ ДАТА ДЕВЕЛОПЕР!) карточки, ссылающиеся друг на друга, и потом займёмся навигацией между ними.
# tools/add_test_content.py
def create_or_update(card):
try:
card.id = wiring.card_dao.get_by_slug(card.slug).id
card = wiring.card_dao.update(card)
except CardNotFound:
card = wiring.card_dao.create(card)
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
create_or_update(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page. It can't really compete with the [demo page](demo).
"""))
create_or_update(Card(
slug="demo",
name="Demo Card!",
markdown="""
Hi there, habrovchanin. You've probably got here from the awkward ["Hello, world" card](helloworld).
Well, **good news**! Finally you are looking at a **really cool card**!
"""
))
Теперь мы можем ходить по ссылкам и созерцать, как каждый раз наше чудесное приложение перезагружается. Хватит это терпеть!
Сперва навесим свой обработчик на клики по ссылкам. Поскольку HTML со ссылками у нас приходит с бэкенда, а приложение у нас на React, потребуется небольшой React-специфический фокус.
// frontend/src/components/card.js
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
navigate(event) {
// Это обработчик клика по всему нашему контенту. Поэтому
// на каждый клик надо сперва проверить, по ссылке ли он.
if (event.target.tagName === 'A'
&& event.target.hostname === window.location.hostname) {
// Отменяем стандартное поведение браузера
event.preventDefault();
// Запускаем своё действие для навигации
this.props.dispatch(navigate(event.target));
}
}
render() {
const {name, html} = this.props;
return (
<div>
<h1>{name}</h1>
<div
dangerouslySetInnerHTML={{__html: html}}
onClick={event => this.navigate(event)}
/>
</div>
);
}
}
Поскольку вся логика с подгрузкой карточки у нас в компоненте
CardPage, в самом действии (изумительно!) не нужно предпринимать никаких действий:export function navigate(link) {
return {
type: NAVIGATE,
path: link.pathname
}
}
Добавляем глупенький редьюсер под это дело:
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD,
NAVIGATE
} from "./actions";
function navigate(state, path) {
// Здесь мог бы быть react-router, но он больно сложный!
// (И ещё его очень трудно скрестить с SSR.)
let m = /^\/card\/([^/]+)$/.exec(path);
if (m !== null) {
return {
...state,
page: {
type: "card",
cardSlug: m[1],
isFetching: true
}
};
}
return state
}
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
};
case NAVIGATE:
return navigate(state, action.path)
}
return state;
}
Поскольку теперь состояние нашего приложения может изменяться, в
CardPage нужно добавить метод componentDidUpdate, идентичный уже добавленному нами componentWillMount. Теперь после обновления свойств CardPage (например, свойства cardSlug при навигации) тоже будет запрашиваться контент карточки с бэкенда (componentWillMount делал это только при инициализации компоненты).Вжух,
docker-compose up --build frontend и у нас рабочая навигация! 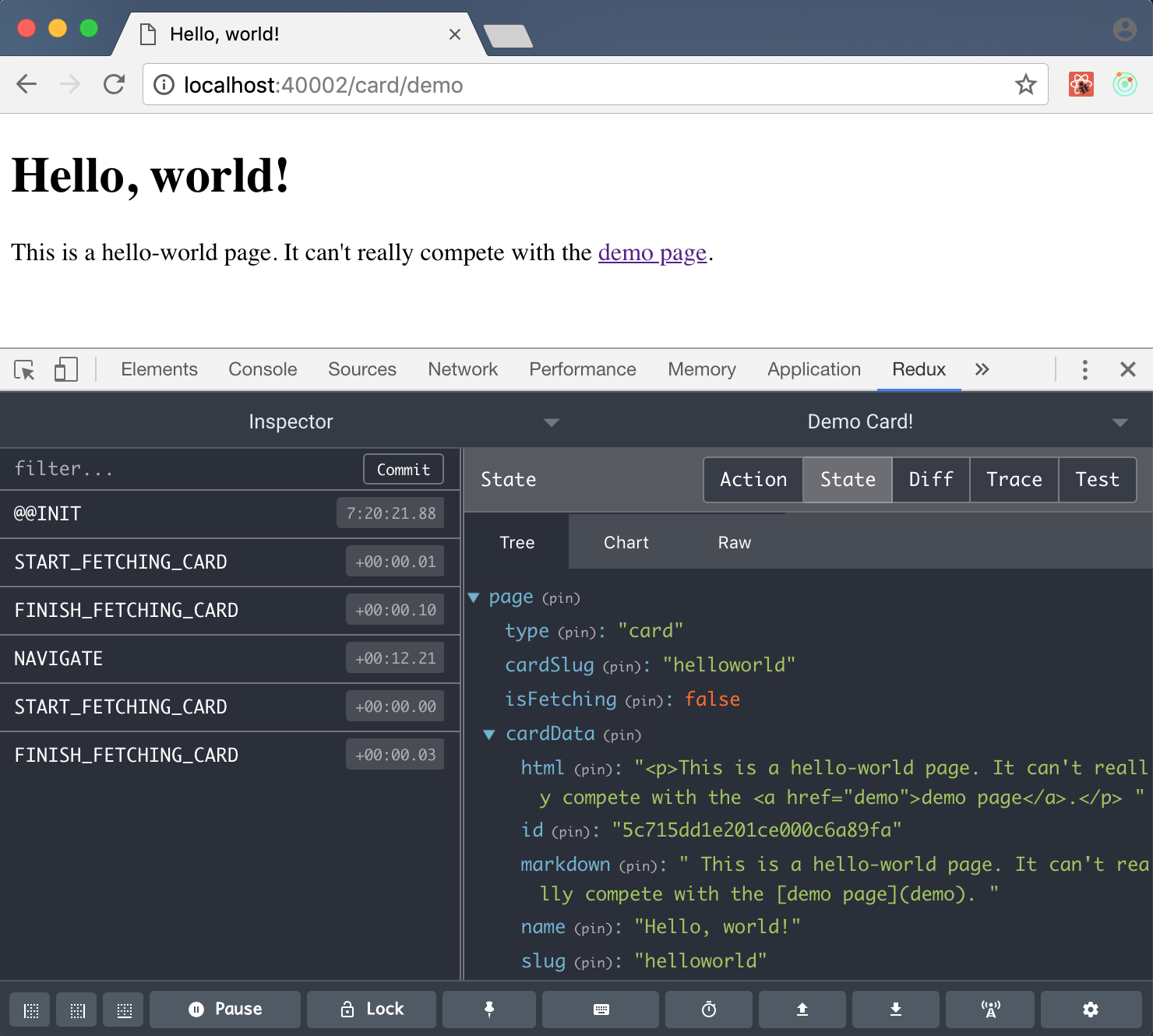
Внимательный читатель обратит внимание, что URL страницы не будет изменяться при навигации между карточками — даже на скриншоте мы видим Hello, world-карточку по адресу demo-карточки. Соответственно, навигация вперёд-назад тоже отвалилась. Давайте сразу добавим немного чёрной магии с history, чтобы починить это!
Самое простое, что можно сделать — добавить в действие
navigate вызов history.pushState.export function navigate(link) {
history.pushState(null, "", link.href);
return {
type: NAVIGATE,
path: link.pathname
}
}
Теперь при переходах по ссылкам URL в адресной строке браузера будет реально меняться. Однако, кнопка «Назад» сломается!
Чтобы всё заработало, нам надо слушать событие
popstate объекта window. Причём, если мы захотим при этом событии делать навигацию назад так же, как и вперёд (то есть через dispatch(navigate(...))), то придётся в функцию navigate добавить специальный флаг «не делай pushState» (иначе всё разломается ещё сильнее!). Кроме того, чтобы различать «наши» состояния, нам стоит воспользоваться способностью pushState сохранять метаданные. Тут много магии и дебага, поэтому перейдём сразу к коду! Вот как станет выглядеть App:// frontend/src/components/app.js
class App extends Component {
componentDidMount() {
// Наше приложение только загрузилось -- надо сразу
// пометить текущее состояние истории как "наше".
history.replaceState({
pathname: location.pathname,
href: location.href
}, "");
// Добавляем обработчик того самого события.
window.addEventListener("popstate", event => this.navigate(event));
}
navigate(event) {
// Триггеримся только на "наше" состояние, иначе пользователь
// не сможет вернуться по истории на тот сайт, с которого к
// нам пришёл (or is it a good thing?..)
if (event.state && event.state.pathname) {
event.preventDefault();
event.stopPropagation();
// Диспатчим наше действие в режиме "не делай pushState".
this.props.dispatch(navigate(event.state, true));
}
}
render() {
// ...
}
}
А вот как — действие navigate:
// frontend/src/redux/actions.js
export function navigate(link, dontPushState) {
if (!dontPushState) {
history.pushState({
pathname: link.pathname,
href: link.href
}, "", link.href);
}
return {
type: NAVIGATE,
path: link.pathname
}
}
Вот теперь история заработает.
Ну и последний штрих: раз уж у нас теперь есть действие
navigate, почему бы нам не отказаться от лишнего кода в клиенте, вычисляющего начальное состояние? Мы ведь можем просто вызвать navigate в текущий location:--- a/frontend/src/client.js
+++ b/frontend/src/client.js
@@ -3,23 +3,16 @@ import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
+import {navigate} from "./redux/actions";
let initialState = {
page: {
type: "home"
}
};
-const m = /^\/card\/([^\/]+)$/.exec(location.pathname);
-if (m !== null) {
- initialState = {
- page: {
- type: "card",
- cardSlug: m[1]
- },
- }
-}
const store = configureStore(initialState);
+store.dispatch(navigate(location));
Копипаста уничтожена!
Фронтенд: server-side rendering
Пришло время для нашей главной (на мой взгляд) фишечки — SEO-дружелюбия. Чтобы поисковики могли индексировать наш контент, полностью создаваемый динамически в React-компонентах, нам нужно уметь выдавать им результат рендеринга React, и ещё и научиться потом делать этот результат снова интерактивным.
Общая схема простая. Первое: в наш HTML-шаблон нам надо воткнуть HTML, сгенерированный нашим React-компонентом
App. Этот HTML будут видеть поисковые движки (и браузеры с выключенным JS, хе-хе). Второе: в шаблон надо добавить тег <script>, сохраняющий куда-нибудь (например, в объект window) дамп состояния, из которого отрендерился этот HTML. Тогда мы сможем сразу инициализировать наше приложение на стороне клиента этим состоянием и показывать что надо (мы даже можем применить hydrate к сгенерированному HTML, чтобы не создавать DOM tree приложения заново). Начнём с написания функции, возвращающей отрендеренный HTML и итоговое состояние.
// frontend/src/server.js
import "@babel/polyfill"
import React from 'react'
import {renderToString} from 'react-dom/server'
import {Provider} from 'react-redux'
import App from './components/app'
import {navigate} from "./redux/actions";
import configureStore from "./redux/configureStore";
export default function render(initialState, url) {
// Создаём store, как и на клиенте.
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
<Provider store={store}>
<App/>
</Provider>
);
// Оказывается, в реакте уже есть функция рендеринга в строку!
// Автор, ну и зачем ты десять разделов пудрил мне мозги?
let content = renderToString(app);
let preloadedState = store.getState();
return {content, preloadedState};
};
Добавим в наш шаблон новые аргументы и логику, о которой мы говорили выше:
// frontend/src/template.js
function template(title, initialState, content) {
let page = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>${title}</title>
</head>
<body>
<div id="app">${content}</div>
<script>
window.__STATE__ = ${JSON.stringify(initialState)}
</script>
<script src="/dist/client.js"></script>
</body>
</html>
`;
return page;
}
module.exports = template;
Немного сложнее становится наш Express-сервер:
// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
}
};
const {content, preloadedState} = render(initialState, {pathname: req.url});
res.send(template("Habr demo app", preloadedState, content));
});
Зато клиент — проще:
// frontend/src/client.js
import React from 'react'
import {hydrate} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
import {navigate} from "./redux/actions";
// Больше не надо задавать начальное состояние и дёргать навигацию!
const store = configureStore(window.__STATE__);
// render сменился на hydrate. hydrate возьмёт уже существующее
// DOM tree, провалидирует и навесит где надо ивент хендлеры.
hydrate(
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Дальше нужно вычистить ошибки кроссплатформенности вроде «history is not defined». Для этого добавим простую (пока что) фунцию куда-нибудь в
utility.js.// frontend/src/utility.js
export function isServerSide() {
// Вы можете возмутиться, что в браузере не будет process,
// но компиляция с полифиллами как-то разруливает этот вопрос.
return process.env.APP_ENV !== undefined;
}
Дальше будет какое-то количество рутинных изменений, которые я не буду тут приводить (но их можно посмотреть в соответствующем коммите). В итоге наше React-приложение сможет рендериться и в браузере, и на сервере.
Работает! Но есть, как говорится, один нюанс…

LOADING? Всё, что увидит Google на моём супер-крутом модном сервисе — это LOADING?!
Что ж, кажется, вся наша асинхронщина сыграла против нас. Теперь нам нужен способ дать серверу понять, что ответа от бэкенда с контентом карточки нужно дождаться, прежде чем рендерить React-приложение в строку и отправлять клиенту. И желательно, чтобы способ этот был достаточно общий.
Здесь может быть много решений. Один из подходов — описать в отдельном файле, для каких путей какие данные нужно зафетчить, и сделать это перед тем, как рендерить приложение (статья). У этого решения много плюсов. Оно простое, оно явное и оно работает.
В качестве эксперимента (должен же быть в статье хоть где-то ориджинал контент!) я предлагаю другую схему. Давайте каждый раз, когда мы запускаем что-то асинхронное, чего надо дожидаться, добавлять соответствующий промис (например, тот, который возвращает fetch) куда-нибудь в наше состояние. Так у нас будет место, где всегда можно проверить, всё ли скачалось.
Добавим два новых действия.
// frontend/src/redux/actions.js
function addPromise(promise) {
return {
type: ADD_PROMISE,
promise: promise
};
}
function removePromise(promise) {
return {
type: REMOVE_PROMISE,
promise: promise,
};
}
Первое будем вызывать, когда запустили фетч, второе — в конце его
.then().Теперь добавим их обработку в редьюсер:
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
switch (action.type) {
case ADD_PROMISE:
return {
...state,
promises: [...state.promises, action.promise]
};
case REMOVE_PROMISE:
return {
...state,
promises: state.promises.filter(p => p !== action.promise)
};
...
Теперь усовершенствуем действие
fetchCard:// frontend/src/redux/actions.js
function fetchCard() {
return (dispatch, getState) => {
dispatch(startFetchingCard());
let url = apiPath() + "/card/" + getState().page.cardSlug;
let promise = fetch(url)
.then(response => response.json())
.then(json => {
dispatch(finishFetchingCard(json));
// "Я закончил, можете рендерить"
dispatch(removePromise(promise));
});
// "Я запустил промис, дождитесь его"
return dispatch(addPromise(promise));
};
}
Осталось добавить в
initialState пустой массив промисов и заставить сервер дождаться их всех! Функция render становится асинхронной и принимает такой вид:// frontend/src/server.js
function hasPromises(state) {
return state.promises.length > 0
}
export default async function render(initialState, url) {
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
<Provider store={store}>
<App/>
</Provider>
);
// Вызов renderToString запускает жизненный цикл компонент
// (пусть и ограниченный). CardPage запускает фетч и так далее.
renderToString(app);
// Ждём, пока промисы закончатся! Если мы захотим когда-нибудь
// делать регулярные запросы (логировать пользовательское
// поведение, например), соответствующие промисы не надо
// добавлять в этот список.
let preloadedState = store.getState();
while (hasPromises(preloadedState)) {
await preloadedState.promises[0];
preloadedState = store.getState()
}
// Финальный renderToString. Теперь уже ради HTML.
let content = renderToString(app);
return {content, preloadedState};
};
Ввиду обретённой
render асинхронности обработчик запроса тоже слегка усложняется:// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
},
promises: []
};
render(initialState, {pathname: req.url}).then(result => {
const {content, preloadedState} = result;
const response = template("Habr demo app", preloadedState, content);
res.send(response);
}, (reason) => {
console.log(reason);
res.status(500).send("Server side rendering failed!");
});
});
Et voila!
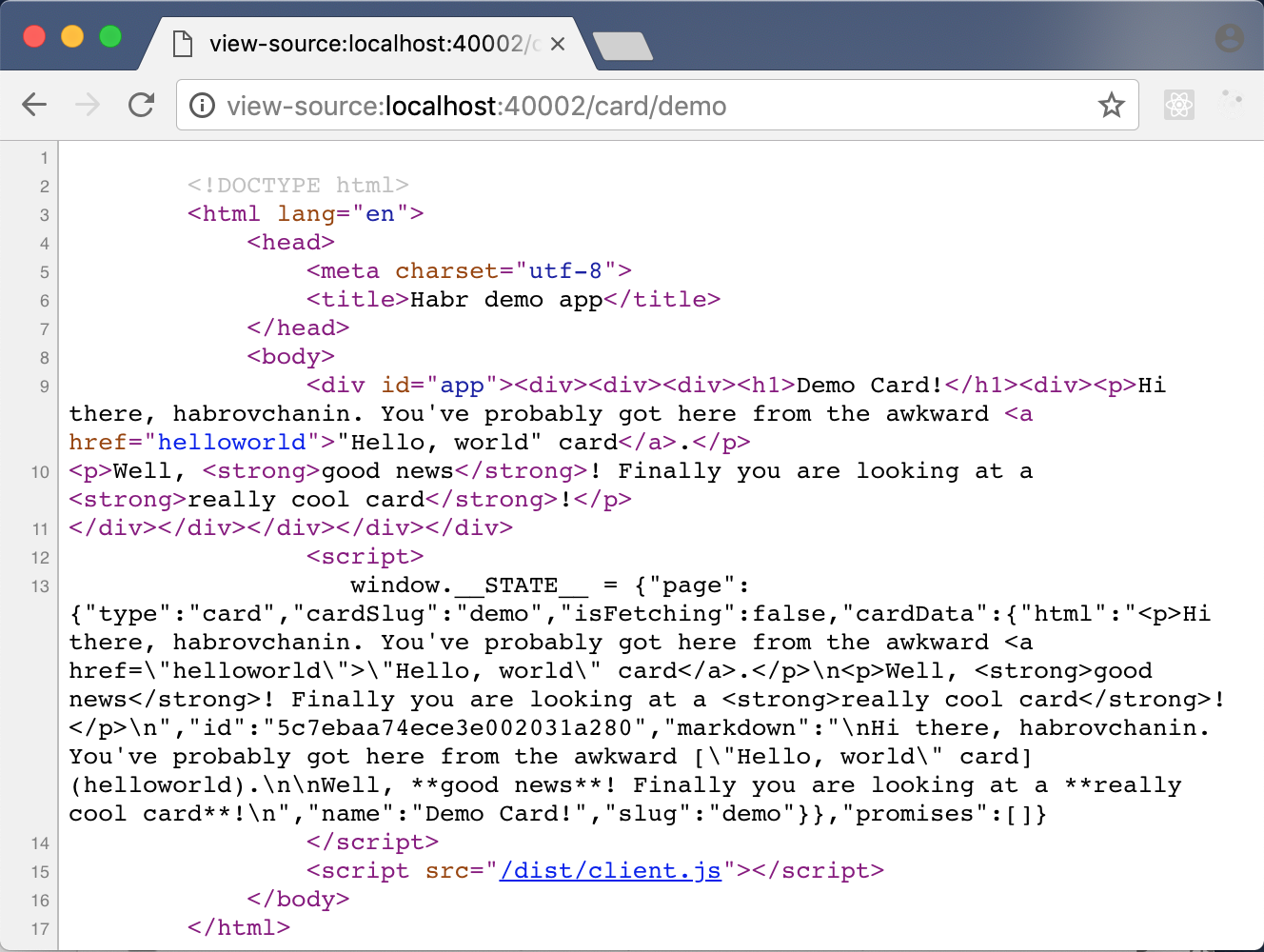
Заключение
Как вы видите, сделать высокотехнологичное приложение не так уж и просто. Но не так уж и сложно! Итоговое приложение лежит в репозитории на Github и, теоретически, вам достаточно одного только Docker, чтобы запустить его.
Если статья окажется востребованной, репозиторий этот даже не будет заброшен! Мы сможем на нём же рассмотреть что-нибудь из других знаний, обязательно нужных:
- логирование, мониторинг, нагрузочное тестирование.
- тестирование, CI, CD.
- более крутые фичи вроде авторизации или полнотекстового поиска.
- настройка и развёртка продакшн-окружения.
Спасибо за внимание!
Комментарии (107)

janvarev
20.03.2019 12:18Мне одному кажется, что тут не хватает хаба «Ненормальное программирование» или хотя бы тега /sarcasm в конце статьи?

saluev Автор
20.03.2019 12:25А расскажите конструктивно, что вас натолкнуло на такую мысль, пожалуйста.
janvarev
20.03.2019 12:43М-м. Ну, несоответствие используемых инструментов задаче (использование крупнокалиберных орудий против малых летающих целей)
Вообще оно больше всего мне напомнило вот эту статью про то, как люди пытаются выучить современный JavaScript: habr.com/ru/post/312022saluev Автор
20.03.2019 12:46Это странный аргумент. Каждый пет-прожект мечтает стать инстаграмом. Всем известны ведь графики типа такого:
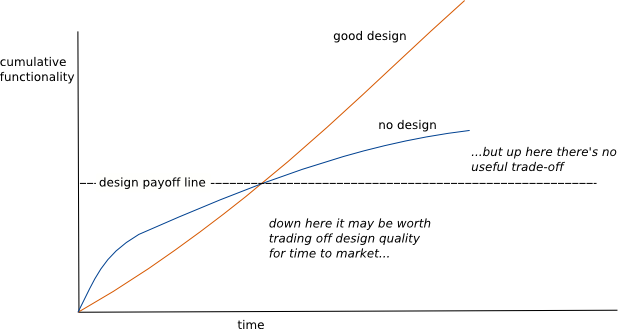
У меня была цель написать статью именно про подготовку проекта with good design.janvarev
20.03.2019 12:58Тем не менее, есть проблема избыточной оптимизации (усложнения) на старте проекта.
Из того, что быстро нашлось на Хабре:
«До микросервисов нужно дорасти, а не начинать с них» habr.com/ru/post/427215
«Преступный переинженеринг» habr.com/ru/post/99889saluev Автор
20.03.2019 13:03+4Тут элементарная архитектура, о каком переусложнении речь?
Как вы смогли применить слова «оптимизация» и «усложнение» как синонимы, я тоже не понимаю, ну да ладно.

a-tk
20.03.2019 13:46+3Если учиться строить только на примерах сараев, то небоскрёбы строить будет некому.
(Не помню из чьего доклада и на какой конференции)

movl
20.03.2019 13:52+1Я не увидел, что автор пытался донести мысль о необходимости или «правильности» описанной структуры приложения. Скорее был рассмотрен вопрос, что если вы уже пришли к выводу о том, что такая архитектура необходима, а она достаточно тривиальна, то как ее воплотить в жизнь на определенном стеке технологий. Рассматривались только технические вопросы. Ваши тезисы мной воспринимаются как спекуляция смыслами: увидели то, чего нет, и заявили о реальности увиденного.

denaspireone
20.03.2019 14:19Имхо, я бы назвал статью — «пишем $something с использованем трендов из мира DevOps»
Но опять же, это имхо.


Andrew_Pinkerton
20.03.2019 13:44+1Статья годная, не слушайте тех кто говорит что вы переусложнили.
saluev, небольшое уточнение:
В requirements.txt не указаны версии пакетов, это так и задумано?

dimuska139
20.03.2019 14:23Правильно ли я понимаю, что если по такому принципу делать блог, то для рендеринга на сервере текста статей (для того, чтобы поисковые системы видели не пустые страницы без текста статей), нужно в window.__STATE__ тексты вообще всех статей блога запихать?
saluev Автор
20.03.2019 14:25Зачем всех? На странице статьи — текст одной статьи, на ленте — тексты стольких статей, сколько у вас вмещает одна страница ленты (а лучше их первые N символов или часть текста до ката).
hardex
20.03.2019 14:59Хороший пример того, сколько бойлерплейта нужно писать на Redux для простейших вещей
ngalayko
20.03.2019 15:39"Фронтенд" кажется лишнем местом. Зачем тут разделять "фронтенд" и "бекенд"? или "фронтенд" и "клиент"?
saluev Автор
20.03.2019 15:55Это три разные компоненты, исполняющиеся в трёх разных местах. Слить бэкенд и фронтенд можно было бы, сделав весь бэкенд на Node.js, но как-то не хочется. И на самом деле практика с отдельным фронтендом, собирающим и выдающим HTML, довольно распространённая.
ngalayko
20.03.2019 15:59Я понимаю, что распространенная, не понимаю до конца почему.
Кажется, что клиент не особо усложнится, если будет в бекенд напрямую ходить. При этом архитектура станет на порядок проще, а фронтендерам не надо будет в два места изменения комититьsaluev Автор
20.03.2019 16:08Бэкенд усложнится. В нём появится тысяча новых роутов. Ему придётся, помимо бизнес-логики, заниматься ещё маппингом этой логики на урлы, что уже в значительной мере про репрезентацию, а не про логику. А если он обслуживает, например, ещё Android-приложение и iOS-приложение, ему не хочется брать на себя эту странную ответственность.
BTW, в статье изменения коммитятся в одно место, не понимаю, о каких двух местах речь.
serf
20.03.2019 23:03Слить бэкенд и фронтенд можно было бы, сделав весь бэкенд на Node.js, но как-то не хочется.
Возможно бэкенде совсем не нужен с этой штукой www.prisma.io? Особенно если сапописанный бэкенд это мерзкий питон и под реакт (который самый первый потребитель graphql)? Идеальный код это ведь ненаписанный код.
saluev Автор
20.03.2019 23:13+1А я люблю питон :(
Ненаписанный код — это, конечно, хорошо, но едва ли реализуемо в хоть сколько-то нетривиальном приложении.
fukkit
21.03.2019 12:03-1Особенно если сапописанный бэкенд это мерзкий питон
При живом Go, Nodejs, и даже, прости господи, PHP делать web на питоне, по крайней мере, странно.
Эти отступы, двойные подчеркивания, явный self и document[«id»] вместо document.id сделаны как-будто специально, чтобы вывести из равновесия даже самого флегматичного кодера.
Сам по себе язык не хуже других, но эстетические чувства раз от разу страдают.

ivymike
20.03.2019 17:18хотя я уже три часа не читал статей по фронтенду, так что насчёт моды не уверен
вот тут вы правы 100%! :)

eggstream
20.03.2019 18:19+1Смешались в кучу кони, люди,
И залпы тысячи орудий
Слились в протяжный вой…
О том, что здесь использована стрельба из крупнокалиберных орудий по малым целям, уже написано.
Я же со своей стороны хочу отметить, что
- называть любой кусок серверного кода «фронтэндом» — плохая практика, большинство разработчиков резервирует это слово для кода, выполняемого исключительно на клиенте, вместо вашего «frontend» стоит употреблять router, а вместо «backend» — API-server
- при наличии живого роутера, делать прямой доступ с клиента аджаксом на апи-сервер — нарушение инкапсуляции и создание проблем с CORS на ровном месте

Loxmatiymamont
20.03.2019 20:04+5В начале у меня было ощущение, что это просто очень хорошая, но очень злая ирония. Но потом зашёл в комментарии, и нет, всё серьёзно и на самом деле достаточно грустно.
dikkini
20.03.2019 20:48+2А мне статья понравилась и автор большой молодец. С несколькими но:
Решение явно не для продакшена.
Решение показывает как можно делать, если вам нужен реакт, как можно делать если нужно при на флажке и так далее, охватывая все аспекты.
Решение не должно носить характер how-to, так как тут предлагается на завтрак зажарить целого кабана, сделать карпачо и фуагру, после чего приготовить ещё и пиццу.
saluev Автор
20.03.2019 20:51Конфигурацию под продакшн я не стал описывать. Но разве есть какие-то концептуальные проблемы с этим? Я знаю пока что только, что стоило взять более надёжную очередь задач.

Megadeth77
20.03.2019 21:25+1Интересно когда запилят какую-нибудь абстракцию, чтобы весь этот бойлерплейт в 5 строчек умещался, а потом уже наконец можно было бизнес логику кодить.


skovpen
20.03.2019 21:37зачем во фронтенде express? по сути там статичный контент — на nginx не лучше заменить?
saluev Автор
20.03.2019 21:38Там не статичный контент, там делается server side rendering.
skovpen
20.03.2019 21:49+2зачем в 2019 году это лишнее звено?
btw, гугл сейчас отлично и client side rendering понимает.saluev Автор
20.03.2019 22:13+1Есть пруфы к «отлично»? Моё гугление этого вопроса показывало, что там до сих пор не всё так однозначно. Кроме того,
- Google — не единственный поисковый движок;
- сокращение времени до первого информативного рендера положительно сказывается на user experience.


Fen1kz
21.03.2019 00:27+1Замечательная статья, спасибо большое. Не слушайте всех кто говорит про переусложнение, это очень полезный материал для тех кому нужен хороший дизайн.
я считаю использование ORM практикой порочной и оставляю изучение соответствующих решений на ваше усмотрение
Почему?
frontend / backend
Может лучше SSR-server / API-server ?
Жду следующую статью с "логирование, мониторинг, нагрузочное тестирование.".
KirEv
21.03.2019 03:14+5Спасибо за проделанную работу…
но извините за оффтоп, наболело...Пожалуйста, не читайте: люди с хрупкой психикой, предпочитатели новых технологий, хипстеры.
Извините, много сумбурного текста…
Сегодня, практически часа 3 назад, обратился давний знакомый, много проектов разных вместе сделали за овер 10 лет… Попросил внести мелкие изменения для сайта
Два слова о проекте: сайт подобие соц.сети для публикации проблем\вопросов\етс. граждан и специальная команда (юристы, представители депутатов и т.п.) рассматривают вопрос… тоесть там и блог, и админка, и кабинет пользователя и разные сущности записей… крч. куча разных функций с множеством разграничений доступа…
Сайт был сделан лет 5 назад, если не 6ть…
И знаете что? Я был в шоке… в положительном смысле… крутиться это чудо на самом дешевом vps, но сам сайт летает… там нет космических технологий и т.п., делалось тупо в лоб и по простому…
Начинаю вспоминать последние 2-3 года и разные компании в которых доводилось работать.
Любой сайт\ресурс, это как минимум: прожект.менеджер, программисты бекэнд (а может и не один), фронтенд (а может и два), дев.опс, какой нибуть админ, дизайнер (а может и два), и еще разные лица вовлеченные по дороге реализации проекта… И огромный стек технологий… начиная c ангуляроа (к примеру), заканчивая CI/CD, TDD, разными менеджерами очередей, и все это, конечно, в облаке…
И самое страшное: клиенты платят за весь этот шабаш…
Причем вся эта куча и весь кипиш с техно-хайпом неоправданое усложнение относительно простого проэкта.
Смотрю на свой код 5ти летней давности… из технологий php5, mysql5, jquery, html,css… все… просто, тупо, плоско, понятно… очень легко разобраться спустя столько времени… без сервисов, промежуточных окружений и т.п., простые sql-запросы без orm-генераций…
Посмотрел и сравниваю сделанные проекты лет 5 назад, и то что делаю последнее время. И знаете что? Проекты по сути похожи своими функциями, лишь разница в стеке технологий и числе вовлеченного персонала. Но есть существенное отличие в методике реализации «современных» проектов: сложность реализации (из-за тех.стека и лиц которыми нужно управлять), и далее пошло-поехало: слабая оптимизация из-за фреймворков для нетривиальных задач, отсюда трафик, вдс принято считать слабым звеном — значит проект в облаке, может быть в aws, авс для абы-как сделанных проектов (пусть сервисов) не такое дешевое удовольствие… и т.д. и т.п. (грусть печаль)…
Раньше то что делалось 1-3 месяца до полного адекватного безбажного релиза, сейчас в год не укладывается… (пример последних 2х компаний над проектами которых трудился)…
Не знаю точно в чем дело, но я убежден, множество элементов (технологий) необходимых для современного проекта лишь вредит, особенно запуску первого релиза, не говоря о дальнейшем сопровождении, к небесам возвышает стоимость рабработки, усложняет сам процес, и т.д. и т.п., похоже, разучились искать простые решения сложных задач.
И самое страшное, многое из того то что пытаются применять — ни к месту, в предпоследней конторе заявили: нам нужен rabbitQL потому что не хотим казаться лохами в глазах заказчика (а задача, на самом деле, решалась в 3 функции и 1 map)
Потому, меня тошнит от нашей современности… npm, typescript, react, angular, docker, docker-compose, k8s, mongodb, mysql, golang, aws, ci\cd — это не полный список того из последнего проекта… А проект — цмс-каталог для управления разными сущностями, грубо говоря, у тебя 10 таблиц в бд, и каждому из пользователей настраивается право доступа к данным + разрграничения прав в пределах таблицы… абсолютная тривиальщина… но делается больше 1.5 года, только за 1й год разработки страшные счета за авс… сейчас оно запущено, работает, но частенько появляются новые узкие места…
Вот такие дела…

epishman
21.03.2019 08:59Дорога в ад лежит через
кредиты технологиисооблазны. Мне повезло, что я тупой, и неспособен освоить много фреймворков, и с удивлением обнаруживаю, что на чистой яве или там на го с жаваскриптом можно много чего написать. На работу только стало трудно устроиться без ангуляра последней версии :)
saluev Автор
21.03.2019 09:14Вы ведь понимаете, что все технологии, фреймворки — они не для сайта на одной vpsке с одним разработчиком? Одни для сайтов с огромной нагрузкой и для координации усилий сотен разработчиков. Конечно, для личного блога вам не нужен докер. Он нужен для зоопарка машин и сервисов, нескольких окружений (dev/stage/prod), быстрого добрасывания машин в кластер. CI/CD не нужно для личного блога — оно нужно для стартапа, который собирается пилить новые фичи каждый день. И так далее.
epishman
21.03.2019 09:37+1> для сайтов с огромной нагрузкой и для координации усилий сотен разработчиков
======================
Кстати, это противоположные требования. Если нужна огромная нагрузка — чистый HTML+JS+CSS и никаких фреймворков, если сотни разработчиков — ровно наоборот. И черт его знает, где лежит та самая серебряная пуля, которой к тому же нет.
janvarev
21.03.2019 10:17Знаете, данный подход и статья, скорее всего неплохо работают в определенной ситуации (когда надо делать «небоскреб»)
Но тут, наверное, мы попадаем на типовую «боль» современных разработчиков — а именно, что слишком часто идет переусложнение типовых вещей.
Аналогично — занимаюсь веб-разработкой уже 15 лет. Работаю в малых проектах, пишу архитектуру, код (LAMP, на клиенте в очень небольших местах JS/JQuery). Недавно решил прогнать нагрузочное тестирование, просто для оценки, сколько может выдержать небольшой VDS.
Оказалось — 10-20 тысяч клиентов в сутки (которые активно взаимодействуют с сервисом, а не просто посмотрели пару страничек)! Пиковая нагрузка до начала «подтормаживания» — что-то около 300 запросов в секунду. Это без специальных оптимизаций и докупки железа (очевидно, что железа на 1-2 машины всегда легче докупить, чем оплатить работу программиста).
Естественно, этого будет мало для любой бесплатной соцсети/инстаграмма/мессенджера и пр. Но для абсолютного большинства малых и средних платных сервисов (и магазинов) такого хватает с головой.
Как был приведен пример — просто слишком часто бывает ситуация, когда в проекте нужно администрировать 10-20 табличек в БД, и под него начинает наворачиваться докер, SPA, микросервисы… И чем думают техдиректора в таком проекте, мне прям сложно сказать.KirEv
21.03.2019 14:31-2я знаю о чем они думаю, цепочка связи примерно такая: проект — больше технологий больше времени больше бабок — чем больше зоопарк тем больше сотрудников вовлечены отсюда каждый вовремя получает зп — больше технологий шире спектр дальнейшей поддержки… и клиент попадает в кабалу…
похоже ноги растут не от желания решать бизнес задачи клиента, а от желания развивать свой ИТ-бизнес.
как писал в одном из комменте не так давно: я программирую после работы. =)movl
21.03.2019 15:21+1я знаю о чем они думаю
В действительности, Вы просто экстраполируете свой опыт на всех. Вы говорите, что технологии используются в угоду "техно-хайпу" и в угоду спекулятивного роста компании. Печально, если Вам приходилось сталкиваться с подобной практикой, но это не отменяет того, что технологии могут использоваться по назначению, и что это может происходить осознанно. Поэтому Ваша патетика в начале треда выглядит не очень уместной.
KirEv
21.03.2019 14:18+1здесь есть 2 вещи:
1. — весь этот зоопарк технологий сегодня превратился в мейнстрим, его использует только не ленивый, все проекты за посл.время перегружены всем этим, вот правда, не встретил по настоящему высоконагруженный проект…
2. — перегрузка проекта метриками, фреймворками и т.п. сами по себе неоправданно увеличивают расходы проекта (трафик\запросы), основная моя компания в которой работаю уже более 7ми лет с самого начала ее основания не использует не то что облачные сервисы и чудовищной инфраструктуры, а и в кластере не было и нет необходимости, все по тому, что ядро и код писался нативно, и проблемы с всплесками трафика и дикой нагрузкой решались на уровне оптимизаций кода и алгоритмов, до сих пор все крутиться на 1 железном серваке… за все время озу лишь добавили и 4тб места…
PS: простой пример, паралельно занимались разработкой микросервисов для 2х разных проектов в одной компании, я один над одним, команда разработчиков-подрядчиков над другим… у них сервис авторизации стал узким горлышком (все сервисы валидировали запросы и авторизировались через сервис авторизации), я же сервис авторизацию построил только для изменения пользователей, и каждый из десятка других сервисом содержат в своей БД таблицы сервиса авторизации и на основе репликации изменения в пользователях попадают на слейвы (сервисы отличны от auth)… это не только сократило чудовищный трафик и rps между сервисами, но и положительно повлияло на отклик целевого сервиса…
Я старый программист, 15лет практики в ИТ — целая эпоха, строго не судите.
aPiks
21.03.2019 18:20-1Все технологии и фреймворки, которые вы перечислили — это результат того, что в бэкенд засунули технологии, которые для него изначально не предназначались. А теперь, когда поняли, что вся эта борода не работает нормально, начали латать дыры с помощью фреймворков и библиотек. Docker, CI, CD — полезные вещи, бесспорно. Но вот этот весь зоопарк технологий, которые вы перечислили — это просто мусор. Стартап, которому надо постоянно делать новые Фичи, должен делать фичи, а не разбираться с кучей фреймворков и багами, которые там есть.
Вы привели в пример Facebook, но во первых, у Facebook достаточно специфичные задачи, а во вторых я не считаю, что это хороший пример производительности и безпроблемной работы. К тому же, смотреть как сделано у больших дядей и повторять за ними — глупо. У вас нет ни таких ресурсов, ни таких требований. Ваша архитектура избыточно сложна и зависит от стольких технологий, что будет сложно подобрать команду, чтоб человек пришел, сел и начать работать. Для стартапа — это минус. У них нет времени на обучение.
Всё, что вы сделали в половине статьи, можно сделать, подняв Контейнер со Spring Boot на Back'end за 10 минут. И разработчиков проще найти и комплексность в разы меньше.

Arris
21.03.2019 22:50Вы ведь понимаете, что все технологии, фреймворки — они не для сайта на одной vpsке с одним разработчиком?
Нет.
Все эти технологии, фреймворки и так далее — это инструменты упрощения разработки. Ну, в теории, должны быть.
На практике каша разных технологий дико повышает порог вхождения и дает огромные накладные расходы.
И в этом проблема вашей статьи.
Она не учит писать проекты с нуля и не объясняет как их нужно разрабатывать.
Она приучает к определенному узкому стеку инструментов. Без которых, якобы, ничего сделать нельзя.saluev Автор
21.03.2019 22:54Я нигде не писал, что без них ничего сделать нельзя. Я лишь показал, как сделать можно.
Arris
22.03.2019 01:13Но зачем так сложно?
Картинку про троллейбус из буханки хлеба знаете?saluev Автор
22.03.2019 09:53-1Если для вас элементарная архитектура, без которой даже design interview нельзя пройти, это сложно — я ничем не могу помочь. Я вроде бы обосновал необходимость всех компонент и даже ссылался на опыт крупных сервисов (в комментах).

epsonic
21.03.2019 13:46Прочел, вспомнил свои проекты, прослезился. У меня в течение чтения всей статьи были вооот такие глаза. Воооот такие, клянусь. Конечно, это не просто сайт, а веб-приложение, но от обилия новых (для меня лично) имен технологий рябит в глазах…
a-tk
21.03.2019 14:30Или даже вО_От такие?..
epsonic
21.03.2019 14:34Конечно, сказывается нехватка опыта создания приложений с таким уровнем абстракции. Ну вы знаете, старики — мы же упрямые. Нам подавай проверенные временем технологии, а не это ваше новомодное когда оно появилось и что оно вообще делает почему я о нем не знаю и знать не хочу напридумывали названий для усложнения простых вещей.
user9000
21.03.2019 08:02-1В JS низкий порог входа. Никто не хочет изучать теорию, все сразу практикуются. И в итоге выдумывают все паттерны проектирования заново, только на свой лад.
И есть ошибка в в основной архитектуре на которой все строится: фронтенд, который берет на себя слишком много функций и реализует все это на ЯП, в котором, из-за отсутсвия полноценного ООП, очень сложно организовать код без доп. фреймворков. И из-за этого и требуется писать столько лишних костылей.
Я с интересом наблюдаю, как фрондендщики изобретают бэкэнд заново: сервер-роутер, рендер сервер. И спрашиваю себя: а у JS-way подхода точно больше плюсов? Или новые фишки придумываются чтоб подпереть старые костыли?epishman
21.03.2019 08:48Это почему в JS нет полноценного ООП? Там только инкапсуляция хромает, нет приватных членов класса, а наследование на клиенте я очень активно применяю, особенно в сочетании с модулями.
Что касается толстого фронтенда — тоже вопрос религиозный, PWA вообще предлагают с сервера только JSON брать, есть куча приложений на чистом JS, выполняющимися локально с локальной же браузерной СУБД, которая даже индексировать атрибуты умеет.user9000
21.03.2019 08:53Ну вот и получается: инкапсуляция хромает, приватных членов класса нет, интерфейсов тоже.
epishman
21.03.2019 09:29Я делаю инкапсуляцию так — класс помещаю внутрь модуля и дефолтно экспортирую (один класс === один модуль === один файл), и тогда в замыкании можно инкапсулировать что угодно. Множественного наследования нет, согласен, плохо, но поскольку JS динамически выводит типы — полиморфизма можно добиться методом композиции, если уж очень надо. Теоретически можно на тайскрипте или дарте писать, без ангуляра в нагрузку, но мне пока и так хватает.
epishman
21.03.2019 08:39Господи, как сложно-то все, ради простого приложения с парой форм. Мама, верни мне Дельфи и Фокспро…
youyou2020
21.03.2019 09:08Питоном уже никто не пользуется.

Soo
21.03.2019 10:55Я то же постоянно про PHP слышу) А раз так — на чём лучше серверную часть писать?
aPiks
21.03.2019 19:23Для простого — PHP 7
Для сложного — JAVA, C#
3 года назад мне один сказал, что нет ничего лучше NodeJS, только он то боролся с утечками памяти, то переписывал под TypeScript, потому что устал бороться с проверками на тип, то еще что-то…
А приложение на PHP как работало тогда без проблем, так и сейчас работает. Может не так быстро, то полусекундная разница в загрузке страницы — не так уж решает.saluev Автор
21.03.2019 20:01Полусекундная разница в загрузке страницы иногда прокрашивается красным в A/B-экспериментах на крупных сервисах, так что я бы не был так уверен.

ideological
21.03.2019 11:47И чем же в вашей школе тогда пользуются?
youyou2020
21.03.2019 22:56-1Нормальными языками программирования такими как JS
ideological
21.03.2019 23:17И давно это JS стал нормальным языком?
По-моему, ему однажды повезло быть встроенным в браузеры и теперь от этого legacy-говнища хрен избавишься.
Но конечно каждому своё.
fukkit
22.03.2019 12:07Вы правы по поводу причин распространения и развития JS.
Но от стадии 'legacy-говнища' шагнул он знатно и теперь шикарно смотрится на фоне отстающих собратьев, не говоря уже о шизофреническом питоне.
ideological
21.03.2019 11:37Это всё конечно круто, спасибо за статью.
Но почему бы не отдавать сформированный динамически при каждом запросе готовый html контент прям на Python, а на JS если нужно сделать какой-то интерактив? Для чего нужен React+Redux?
Есть разные штуки вроде гуглокарт и гуглопочт, где нужно делать на стороне браузера именно приложение. Но подавляющее большинство остальных случае, это именно сайт, со страницами и контентом. Нафига делать простой сайт как сложное одностраничное приложение?
Вместо простой и быстрой отдачи html и удобного бекенда на любом языке, выбирать всякие заморочки на фронте. Не слишком ли усложнился фронтенд на пустом месте и без необходимости?
saluev Автор
21.03.2019 11:45Конечно, для простенького сайта это не нужно. Возможно, я выбрал не самый подходящий пример (хотя будь он сложнее, статья затянулась бы ещё сильнее). Но я всё-таки хотел написать именно про нетривиальный случай.
alex_mayak
21.03.2019 11:43Автору СПАСИБО!
жду продолжения с юнит тестами, selenium и регрессивными тыстами =)
dimuska139
21.03.2019 13:24+1Глянул комментарии еще раз — аж бомбить начало :)
Вот вы говорите, что этот подход — из пушки по воробьям. Ну ок, но ведь не все ограничивается блогами и досками объявлений. Вам не кажется, что автор в статье просто хотел показать разработку сайта «от и до»? Или он должен был все это показать на примере разработки аналога фейсбук? Это ж просто пример, вовсе не означающий, что блогоподобные сайты надо делать именно так.
По поводу того, что ssr не нужен, и это лишнее звено. Это достаточно спорное утверждение. Я считаю, что SSR в 2019 до сих пор нужен, даже несмотря на то, что гугл умеет сайты на js индексировать. Во-первых, кроме гугла есть еще и другие поисковые системы, а, во-вторых, насколько я знаю, он до сих пор такие сайты индексирует хуже обычных.0ther
21.03.2019 21:13Если уж на то пошло, то и показан был только hello world, рождённый в очень лишних муках.
А показать зачем надо было их потерпеть и какой пряник мы получаем из-за этого — нет, без этого смысл расчехлять BFG?dimuska139
22.03.2019 15:20+1Тут в статье автору довольно запарно было бы расписывать преимущества такого усложнения, потому что надо попробовать самому.
О Docker-контейнеризации. Можно все разворачивать и без контейнеров, но так ли уж проще без докера будет следить за тем, чтобы тестовое окружение не отличалось от локального разработчиков и продового? На такие вещи закрывать глаза нельзя, а ставить все везде в нужных версиях на голое железо вряд ли будет проще.
Рендеринг на сервере. Да, можно было не заморачиваться, отказавшись от него и оставив фронт на реакте, который дергает апи (бэкенд). Это было бы проще, но статьи с такого блога видел бы только гугл (и то плохо), а для остальных поисковиков ваш сайт бы состоял из пустых страниц.
Если делать сайт, рендеря по-старинке html на сервере средствами пхп/питона, то сделать нормально сложный качественный поддерживаемый фронтенд для этого всего достаточно сложно. А уж про отзывчивость такого интерфейса говорить, думаю, не надо, потому что сайты в виде SPA работают при переходе по страницам плавно и приятно — никакой полной перезагрузки страницы. Тут спорить можно долго: надо просто попробовать и сравнить. Можно то же самое сделать руками на jQuery, загружая аяксом контент статей блога, но тут опять упираемся в сложности с рендерингом на сервере. А, кстати, вручную настраивать системы сборки js и css для задач типа обфускации js-кода, объединения в один файл и т.п. для самописного фронта — так ли уж это проще разве?
Так что в итоге два варианта: либо так, заморочившись с инфраструктурой (хотя лично я тут не вижу сложностей вообще), либо ваять сайты по-старинке с бэком, где рендерятся шаблоны, а на фронте jquery-лапша. Учитывая мой опыт поддержки легаси-проектов, написанных с использованием второго подхода: нахрен оно надо вообще. И не проще это ни разу, особенно когда проект растет, а его фронтенд становится сложнее и сложнее.
minalexpro
21.03.2019 13:33А существует подобная статья для PHP вместо Python и всё что с ним связано или для LAMP?
dimuska139
21.03.2019 13:59+1Так просто замените ту часть, что написана на питоне, на код на пхп — и все. Это ж просто API — их можно писать на чем угодно. Остальные-то части проекта не затрагиваются. В этом один из плюсов такой архитектуры: любая часть такого проекта может независимо переписана, не затрагивая другие части.
a-tk
21.03.2019 14:31Осталось только оценить вероятность переписывания и сопоставить риски необходимости переписывания с затратами на подготовку инфраструктуры к переписыванию со старта.
dimuska139
21.03.2019 14:42Так эта инфраструктура вовсе не так сложна, как может показаться изначально. По сути — это просто разделение бэкенда и фронтенда, ну и ssr. Ssr вообще не особо нужен, если для сайта не важно, насколько хорошо его будут индексировать поисковые системы. То есть по сути эта инфраструктура состоит из двух частей — фронт, взаимодействующий с бэком по апи. Разве тут могут быть какие-то сложности? Это ж стандартный современный сайт. Сайты, сделанные в виде SPA работают быстро, плавно, при переключении по страницам не происходит полной перезагрузки — это выглядит приятно и современно.
Бэкенд-разработчики разрабатывают API, отдают фронтенд-разработчикам файл swagger.yml, по которому фронтенд-разработчики независимо делают фронтенд. Каждый занят своим делом.
На мой взгляд, такая инфраструктура явно выглядит лучше, чем рендеринг шаблонов на сервере с какими-то шаблонными тегами, завязанными на особенности фреймворка, обучение фронтенд-разработчиков конструкциям шаблонизатора и последующие прикручивание, как почему-то до сих пор модно, jQuery, потому что React/Angular/Vue — это сложно, а потому не нужно.
А что касается вероятности переписывания, то сайт, у которого фронт сделан в виде jQuery-лапши, а шаблоны рендерятся на сервере, намертво вколоченные в какой-то фреймворк и его особенности, может быть потому и не переписывают, потому что переписать такое без боли просто невозможно?Soo
21.03.2019 15:13У меня был проект, который был написан на чистом РНР без фреймворков и без API, но по факту, сделанный в виде SPA. Модули были написаны с помощью шаблонизатора SMARTY и просто при AJAX-запросе подгружались как странички в определённую область. Не сказал бы, что это работало медленно (там тормозила СУБД, так как бизнес-логика почему-то была вся там), но было модно и молодёжно на тот момент). И почти без боли)
dimuska139
21.03.2019 15:22Гонять html-куски через апи — это так себе решение. Про то, что такой проект при усложнении логики и расширении функциональности поддерживать во вменяемом в плане качества состоянии сложно — это отдельная тема. Также при таком подходе нередко приходится фронтенд-разработчиков посвящать во внутреннее устройство серверной части проекта: где какие шаблоны, как используются и т.п. Практически любые изменения в дизайне страниц не могут проходить без участия бэкенд-разраюотчиков. Со временем это превращается в лютое легаси без какой-либо возможности что-то с этим сделать. Имел дело с такими проектами не раз — везде одни и те же проблемы.
a-tk
22.03.2019 09:58Я подобное в далёком 2006 делал на своей первой работе…
Только там на входе была модель в XML, которая рендерилась на сервере с помощью XSLT и отдавалась целиком, а потом отдельные куски приезжали клиенту через AJAX в XML и там уже преобразовывались через XSLT в XHMLT и вставлялось в нужные места.
Но я давно ушёл из веба в профессиональном плане, хотя немного общие тенденции стараюсь отслеживать.
ideological
21.03.2019 23:39> «На мой взгляд, такая инфраструктура явно выглядит лучше, чем рендеринг шаблонов на сервере с какими-то шаблонными тегами, завязанными на особенности фреймворка, обучение фронтенд-разработчиков конструкциям шаблонизатора и последующие прикручивание, как почему-то до сих пор модно, jQuery, потому что React/Angular/Vue — это сложно, а потому не нужно.»
Ну по сути оба подхода одинаковы (в случае простого сайта конечно, а не чего-то вроде клиента телеги).
- Либо на сервере вся логика и генерация_html, а на фронте чуток JS/jQuery.
- Либо наоборот на сервере только API, а уже на фронте вся логика/ маршрутизация/генерация_html.
Одинокиеволкивебмастера обычно выбирают первый.
Во втором случае существует профессия фронтендер :). Конечно этот вариант может быть более оправдан в ряде случаев, особенно при постоянных сменах дизайна и когда бекендеры испытывают отвращение к JS и всему моднобраузерохипстерскому.
0ther
21.03.2019 21:22Оккам порезал себе вены бритвой, глядя на ничуть не лишний ворох всего.
А достаточно же просто файла.html,
и браузера для того, чтобы им открыть и увидеть результат.<h1>Hello, word!</h1>
Хотя и интересно.
Понятно что имелось ввиду «Так делают крутые дяди из гугла/фейсбука/вставь_своё, ибо куча плюшек!», но без показа этих самых плюшек, BFG тут выглядит прям очень лишним.
Довольно печально что в наше время уклон идёт в инструменты, а не решение задач.
Как посмотрю сколько модулей, так вспоминаю KISS и плакать хочется =)saluev Автор
21.03.2019 21:31Если бы я ушёл в плюшки, статья (и без того не маленькая) стала бы ещё больше в десять раз. Но про плюшки тоже когда-нибудь напишу.
0ther
21.03.2019 21:53Так без плюшек и статья теряет смысл ИМХО.
Плюшки обязательно показать надо. Тесты там, расширения и отличия от обычного апача с пэхапе, например.
Ждём следующей статьи.
a-tk
22.03.2019 10:02Есть ещё один момент: много инструментов стали опенсорсными и разработка часто напоминает сборку из готовых компонентов своего решения. Побочный эффект — паника при встрече с чем-то неизведанным (чаще — давно забытым).

divanus
21.03.2019 21:34Горите в аду кожаные ублюдки!
format MZ
heap 0
stack 100h
entry main:start
segment main use16
start: push 0
pop fs ; vector table
mov ax,data_segment
mov ds,ax
mov es,ax
mov ax, 13h ; modeX Graphics 320x200x256, 40x25, 8x8
int 10h
mov eax, dword [fs:43h*4]
mov dword [int43], eax ; Get 8x8 chargen ptr
mov si, hello
next: call gotoxy
lodsb
or al,al
jz exit
cmp al,20h ; ?
jnz @1
add byte [Y], 11
mov byte [X], 0
jmp next
@1: movzx ax,al
shl ax, 3 ; ax*8
push si
push ds
lds si, [int43]
add si, ax
; Вывод на экран
mov cx, 8
loo0: lodsb
mov bl, al
push cx
mov cx, 8
loo1: mov al, 20h
rcl bl, 1
jnc @@1
mov al, 0DBh
@@1: int 29h
loop loo1
pop cx
inc byte [es:Y]
call gotoxy
loop loo0
pop ds
pop si
add byte [X], 8
sub byte [Y], 8
jmp next
; выход
exit: xor ah, ah
int 16h
mov ax, 03h
int 10h
mov ah, 4Ch
int 21h
gotoxy: pusha
mov ah,2
xor bx,bx
mov dx, word [es:XY]
int 10h
popa
ret
segment data_segment use16
int43: dd ?
XY:
X: db 0
Y: db 3
hello: db 'Hello world',0
Xtray
Очень интересно, почему выбран именно такой стек.
Duffo
Более любопытно, почему автор, для полноты картины не добавил личный кабинет на друпале, django/django-orm для работы с базой