
Введение
Очередной раз работая с компанией, делающей проект, связанный с машинным обучением (ML), я обратил внимание, что менеджеры используют термины из области ML, не понимая их сути. Хотя слова произносятся грамматически правильно и в нужных местах предложений, однако их смысл им не более ясен, чем назначение сепулек, которые, как известно, применяются в сепулькариях для сепуления. В тоже время тимлидам и простым разрабам кажется, что они говорят с менеджментом на одном языке, что и приводит к конфликтным ситуациям, так осложняющим работу над проектом. Итак, данная статья посвящена приемам фасилитации (с латинского: упрощение или облегчение) общения разработчиков с менеджментом или тому, как просто и доходчиво объяснить базовые термины ML, приведя тем самым ваш проект к успеху. Если вам близка эта тема — добро пожаловать под кат.
Эстету на заметку: Сепульки, сепулькарий и сепуление — термины, примененные гениальным Станиславом Лемом в 14 путешествии Ийона Тихого.
Начало проекта
Проект ML должен начаться с легитимации метрики валидизации. Звучит устрашающе, не правда ли? Давайте начнем объяснения. Легитимация (по-русски с латинского это узаконивание) — это просто приход к согласию сторон, зафиксированный письменно и завизированный — желательно, конечно, тоже письменно. Стороны — это как донор, так и менеджмент проекта, а также его исполнители.
Теперь перейдем к валидизации. Программист ML обычно имеет опыт написания кода валидизации и при трассировке видит возвращаемые ему true и false. Но как объяснить это понятие менеджеру, не имеющему дела с кодом? Давайте воспользуемся вот таким простым жизненным примером.
Представьте, что вы проходите мимо рынка и видите: продают персики. Продавец говорит вам: «Бэри! Хароший пэрсик, свэжий, сочный такой, нэ пожалэеш». Однако вы приглядываетесь и видите: в одном месте он испорчен. Вы говорите: «ну где же он хороший? вот — подгнивший». Продавец предлагает за полцены. Если вы думаете: «Испорченное можно и вырезать, это всего четверть, вроде и выгодно» — и покупаете его, то на языке ML происходит валидизация и персик (на сленге ML — sample) признается валидным. В случае же, если вы думаете, что можно в другом месте найти и лучший вместо порченного, то происходит инвалидизация, а персик признается вами не валидным.
Получается, в валидизации нет ничего сложно и все мы каждый день занимаемся валидизацией, признавая что-то одно хорошим, годным для себя или инвалидизацией, признавая что-то другое плохим, негодным.
Эстету на заметку: Неожиданно Журден с удивлением узнает, что всю жизнь выражался прозой (с). Мольер, Мещанин во дворянстве.
Наконец, осталось лишь объяснить, что такое метрика валидизации. Давайте задумаемся, почему мы решили купить персик из предыдущего примера?
- он достаточно дешевый (цена < порогового значения)
- он достаточно спелый (спелость > порогового значения), но не переспелый (спелость ниже 2-го порогового значения)
- он нормального размера, то есть его величина находится в категории «нормальный» (все категории: слишком маленький, маленький, нормальный, большой, огромный)
- он не достаточно порченый (площадь подгнивших и порченных областей меньше порогового значения)
Все это, перечисленное выше и есть пример метрики валидизации, состоящей в данном примере из 4 категорий. В самом простом случае, это когда персик удовлетворяет сразу всем критериям, то он будет признан валидным и куплен.
Теперь становится очевидным, почему так важно договориться с самого начала, как именно будет проходить валидизация, по какому числу параметров и какие пороговые значения будут устраивать все заинтересованные стороны. Особый раздел могут занимать описания действий в случае частичного соответствия условиям.
Естественно, каждый проект ML в зависимости от своей предметной сферы будет иметь свою собственную метрику валидизации. Документ, фиксирующий метрику валидизации, является таким же важным для проекта ML, как конституция для государства.
Только после того, как в проекте, наконец, появился зафиксированный документ, регламентирующий метрику валидизации и стал доступен всем участникам проекта, имеет смысл написать его код. Код валидизации — это сердце проекта и его качество должно быть безукоризненно, любая ошибка в этой части с большой долей вероятности может привести к краху всего проекта ML в целом.
Таинство вычисления accuracy
Важнейшим показателем текущего положения дел в проекте для менеджмента является accuracy. Как же по-простому объяснить менеджеру, что это такое и какие действия нужно выполнить, чтобы его вычислить?
Сначала нам нужно объяснить, что такое валидизированная выборка. В нашем примере — это когда мы купили не один персик, а тонну. Мы садимся сами или нанимаем работников и они перебирают персики в 2 контейнера. На контейнерах надписи: Х (хороший) и П (плохой). Работа, выполненная по переборке персиков, и есть создание валидизированной выборки.
Как объяснить, зачем нужна валидизированная выборка? Представьте, что у вас есть младшая сестра и вы хотите научить ее выбирать персики. Вы берете ее на рынок и говорите: «Учись, смотри, как делаю я». Когда вам кажется, что она уже научилась, вы хотите проверить ее умения. Как это сделать? Вы создаете контрольную выборку, т.е. берете из контейнеров, например, по 100 уже перебранных персиков из каждого контейнера и незаметно наклеиваете на них тайные наклейки, чтобы знать самому из какого контейнера они были взяты, но сестре это было бы неизвестно, и предлагаете ей самостоятельно разложить их в новые пустые контейнеры. Процент совпадений выборов вашей сестры с тайными наклейками и есть показатель accuracy. Другими словами, accuracy — это объективное значение того, насколько вашей сестре можно доверить выбор персиков вместо вас. 100% означает, что она — ваша вылитая копия и все делает ровно, как и вы. 0% — что ее мнение прямо противоположно вашему.
Эстету на заметку: Да, вы правы, со временем персики могут начать портиться и нужно учесть, что их годность придется время от времени пересматривать. И в компьютерных данных такое тоже бывает, например, с такой характеристикой, как «актуальность».
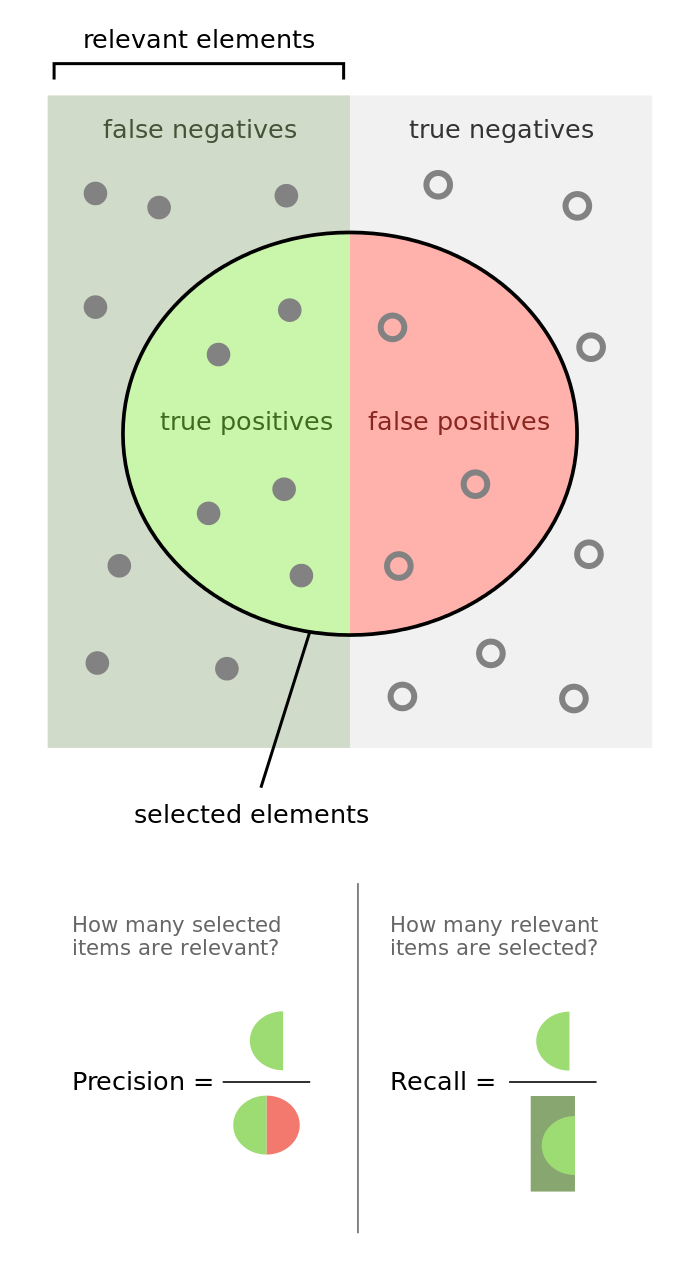
А теперь разберем 4 показателя эффективности ML, в которых бывает путаются. Это true-positive (TP), false-positive (FP), true-negative (TN) и false-negative(FN). Первая половина слова означает совпадение (true) или несовпадение (false) мнения вашей сестры с тайной наклейкой на персике. Вторая половина просто означает контейнер, в который ваша сестра бросила персик (X-хороший — positive, П-плохой — negative). А два слова вместе — это просто число персиков в такой категории.
Кроме accuracy еще используют 3 вспомогательных показателя, это precision (точность), recall (чувствительность) и f1_score.
Precision показывает % совпадений с вашим мнением персиков, брошенных в контейнер Х (хороший). 100% означает, что все персики, признанные вами годными, признаны таковыми и вашей сестрой. Меньшее значение означает, что в контейнер Х попались и те, что признаны вами негодными. Показатель важен тогда, когда для бизнеса критично, чтобы негодные персики не попадали в годные, но вот если годный будет признан ошибочно негодным — то ничего страшного.
Recall показывает соотношение между правильно отобранными годными персиками (TP) и к сумме этого значения с хорошими персиками, ошибочно признанными негодными (TP+FN). 100% означает, что ваша сестра никогда не кидает годные персики в корзину с плохими и является противоположностью Precision. Этот показатель важен, когда для бизнеса необходимо, чтобы годные персики как можно реже попадали в контейнер к негодным.
F1 score — это синтетический показатель, объединяющий пользу от precision и recall. Его большое значение свидетельствует о сбалансированности обучения и говорит о том, что как хорошие персики не попадают в корзину с плохими, так и плохие не бросаются к хорошим.
Эстету на заметку: Этот показатель является средним гармоническим между precisions и recall и считается по формуле:
f1_score = 2*(recall*precision) / (recall + precision)
Зачастую возникает вопрос: зачем менеджеру проекта ML так глубоко знать и понимать все эти показатели. Ответ: это важно для бизнеса. Как менеджеру молочной фермы нужно знать, что такое удои и по какой формуле они считаются, как менеджеру фермерского хозяйства нужно знать, что такое урожайность и как она вычисляется. Да, менеджер может не вникать, как именно доятся коровы, как они телятся и как их лечить, но понимать главные бизнес-показатели проекта — это залог успешности бизнеса.
Итоги
Все мы, участники проектов ML, делаем хорошее и нужное дело. Кто из нас, будучи студентом, не мечтал, перебирая картофель, помидоры и капусту в колхозе, чтобы за него это делали роботы, а не человек (с). Мы делаем сказку былью и пусть наши проекты будут успешными. Я буду рад, если эта статья поможет внести небольшой вклад в успешное начинание проектов ML.
Если эта статья покажется вам полезной, пишите в комментариях и я сделаю 2-ю статью о том, как объяснить менеджменту аддитивность и генерализацию, эти столпы правильного, годного проекта ML.
Комментарии (21)

masai
07.04.2019 20:28+1F1 score — это синтетический показатель объединяющий пользу от precisions и recall. Его самое хорошее значение вблизи 70%.
Почему 70 % лучше, чем, например, 95 %?

szobin Автор
07.04.2019 21:04-1Здесь все дело в математике ) Хорошее значение precision — как можно ближе к 1 (это максимальное совпадение хороших выборов обучаемого и обучающего). Затем recall — хорошее значение 0.5 (это значит что обучаемый в равной степени хорошо проверен на способность различать хороший и плохой вариант). Теперь считаем: 2*1*0.5/(1+0.5) = 0.6(6). Округляем для красоты и получаем 0,7. Теперь если мы хотим получить значение 0.95, то мы должны загнать recall аж в значение 0.91, а это в свою очередь значит, что в контрольной выборке появится значительное превышение TP над FN (например 100 и 9 дадут нам нужное значение recall). Для нашего примера такое, явно недостаточное число порченных персиков в контрольной выборке, может породить сомнение, а так ли все хорошо с обучением? Или все дело в том, что просто мало порченных персиков.

lair
07.04.2019 21:18+2Затем recall — хорошее значение 0.5
А, что? Хорошее значение recall — это единица, когда мы не даем false negative.
Для нашего примера такое, явно недостаточное число порченных персиков в контрольной выборке, может породить сомнение, а так ли все хорошо с обучением? Или все дело в том, что просто мало порченных персиков.
Извините, но порченные персики в контрольной выборке — это просто negative, не обязательно false negative.
szobin Автор
07.04.2019 21:23-1сами испорченные персики — это и вправду negative, а вот то, что они были определены обучаемым, как испорченные — это false-negative
А теперь разберем 4 показателя эффективности ML, в которых бывает путаются. Это true-positive (TP), false-positive (FP), true-negative (TN) и false-negative(FN). Первая половина слова означает совпадение (true) или несовпадение (false) мнения вашей сестры с тайной наклейкой на персике. Вторая половина просто означает контейнер, в который ваша сестра бросила персик (X-хороший — positive, П-плохой — negative). А два слова вместе — это просто число персиков в такой категории.
lair
07.04.2019 21:27+1Эм. Если у вас испорченные персики — это negative, то то, что они обучаемым определены, как испорченные (то, есть, определены правильно) — это заведомо true (потому что правильно) negative.
szobin Автор
07.04.2019 22:06+1Вы абсолютно правы, я внес изменения в статью. Очень признателен вам за своевременно обнаруженную неточность, действительно ранее был описан совсем другой показатель вместо recall.
masai
07.04.2019 21:32+1Затем recall — хорошее значение 0.5 (это значит что обучаемый в равной степени хорошо проверен на способность различать хороший и плохой вариант).
Это не так. У идеального классификатора значение recall = 1.
Если вы откроете хотя бы википедию, то увидите, что идеальное значение F1 также 1.
szobin Автор
07.04.2019 22:10+1поправка: благодаря очень своевременному комментарию пользователя lair была устранена неточность в статье насчет recall (вместо него был описан другой показатель, который действительно используется для балансирования позитивных и негативных образцов). еще раз выражаю мои благодарности пользователю lair
lair
07.04.2019 20:59+1Простите, а чем вот это всё, которое вы описали, отличается от совершенно не специфических для ML "приемочных критериев"?
Проект ML должен начаться с легитимации метрики валидизации.
Знаете, что занятно? Никогда, ни в какой литературе о ML-проектах я не видел этого термина. Можете дать ссылку на источник?
Важнейшим показателем текущего положения дел в проекте для менеджмента является accuracy.
А с чего бы вдруг? Люди копья ломают, подбирают метрику под конкретную бизнес-задачу — а вы так взяли, и легко выдали "важнейший показатель — accuracy".
szobin Автор
07.04.2019 21:09я вроде так и написал:
Естественно, каждый проект ML в зависимости от своей предметной сферы будет иметь свою собственную метрику валидизации
lair
07.04.2019 21:14+1Неа. Метрика валидизации — она до рассчета accuracy, потому что — ну, конечно, если вам верить — "валидизация" влияет на, собственно, обучающую и тестовую выборки, а accuracy считается по этим выборкам.
Ну либо вы так объяснили, что из вашего текста понятно совсем не то, что вы имели в виду.
szobin Автор
07.04.2019 21:17Вот этот видеокурс мне кажется весьма достойным по данной теме
ru.coursera.org/lecture/vvedenie-mashinnoe-obuchenie/otsienivaniie-kachiestva-xCdqNlair
07.04.2019 21:23+1Спасибо, я проходил курс МИФИ-Яндекса (в том числе и у Соколова), и то, что вы говорите, не совпадает с тем, что я там услышал. Как оно не совпадает и с тем, что говорит Эндрю Ын в "Structuring Machine Learning Projects".
sshmakov
08.04.2019 00:09+1Зачастую возникает вопрос: зачем менеджеру проекта ML так глубоко знать и понимать все эти показатели. Ответ: это важно для бизнеса. Как менеджеру молочной фермы нужно знать, что такое удои ...
Извините, нет. Современному менеджеру совершенно излишне знать смысл цифр, как они считаются и на что влияют, помимо его отчета. А если они не передаются «наверх» или клиенту, то и слышать об этих цифрах он не желает.
Если бы менеджер интересовался цифрами и формулами, то он не стал бы менеджером.
А за статью спасибоszobin Автор
08.04.2019 09:38Благодарю за чудесную формулировку проблемы, которую я, признаться, не решился вставить в тело статьи. Ведь вроде все правильно: современную цивилизацию сделало разделение труда и логично, когда программист пишет код, а менеджер организует рабочий процесс. На деле же уже давно прошли те благословенные времена, когда менеджер вмешивался в процесс разработки только, если проект выходил за рамки бюджета или срывал сроки. (народ: если есть еще те реликтовые места, где это так — я попрошусь к вам на работу:). Сейчас, даже делая внеплановую таску на 14 стори-поинтов, ее нужно обосновать менеджеру. А сделать это непросто и тимлиды бывает идут на хитрость: они делают в проекте эпик с эпичным названием «Онтология сепуления» на 120 стори-поинтов и все, что было не учтено сразу при планировании (а такое бывает часто) пишут на этот эпик, избегая тем самым непростых переговоров. Но у этого метода есть недостаток — нужно иметь дружную команду. Если туда затешется карьерист, он легко сдаст ТЛ и займет его место, и, кстати, сразу столкнется с той же проблемой, что и предшественник. Я же хочу предложить другой путь для ТЛ — фасилитацию, т.е. умение сложное объяснить простыми и ясными бытовыми примерами. И, если описанные в статье приемы пригодятся хоть одному человеку — напишите, я буду знать что это кому-то нужно, и продолжу серию.

Nick_Maverick
08.04.2019 11:54В общем то не все менеджеры с двухбуквенным тайтлом одинаковы. ПМ и пм но есть одно но. Проджект менеджеру в общем случае этого не надо, это больше про софт скиллы, там у разумного ПМ девиз «найти толкового тимлида», а вот продукт менеджер просто обязан понимать влияние сепуления на продукт.
papasha_mueller
08.04.2019 13:36Позвольте с вами не согласиться — ПМ — это всего лишь жалкая копия Walther PP.\
— С уважением,
Генрих Мюллер, группенфюрер.
rsashka
Спасибо за статью!
Действительно проблемы сепуления встречаются сплошь и рядом.
Да и относятся не только к ML, а практически к любому проекту.