
Предисловие
Не так давно пришлось поработать с упрощением полигональной цепи (процесс, позволяющий уменьшить число точек полилинии). В целом, данный тип задач очень распространен при обработке векторной графики и при построении карт. В качестве примера можно взять цепь, несколько точек которой попадают в один и тот же пиксель – очевидно, что все эти точки можно упростить в одну. Некоторое время назад я практически ничего не знал об этом от слова «совсем», в связи с чем, пришлось в быстром темпе восполнять необходимый багаж знаний по этой теме. Но каково было мое удивление, когда в интернете я не нашел достаточно полных руководств по этому вопросу… Мне приходилось отрывками искать информацию с совершенно разных источников и, после проведенного анализа, выстраивать все в общую картину. Занятие не из самых приятных, если честно. Поэтому мне хотелось бы написать цикл статей, посвященных алгоритмам упрощения полигональной цепи. Как раз-таки начать я решил с наиболее популярного алгоритма Дугласа-Пекера.
Описание
Алгоритму задается исходная полилиния и максимальное расстояние (?), которое может быть между исходной и упрощенной полилиниями (то есть, максимальное расстояние от точек исходной к ближайшему участку полученной полилинии). Алгоритм рекурсивно делит полилинию. Входом алгоритма служат координаты всех точек между первой и последней, включая их, а также значение ?. Первая и последняя точка сохраняются неизменными. После чего алгоритм находит точку, наиболее удаленную от отрезка, состоящего из первой и последней (алгоритм поиска расстояние от точки до отрезка). Если точка находится на расстоянии меньшем, чем ?, то все точки, которые еще не были отмечены к сохранению, могут быть выброшены из набора, и получившаяся прямая сглаживает кривую с точностью не ниже ?. Если же это расстояние больше ?, то алгоритм рекурсивно вызывает себя на наборе от начальной точки до данной и от данной до конечных точек. Стоит отметить, что алгоритм Дугласа-Пекера в ходе своей работы не сохраняет топологию. Это означает, что в результате мы можем получить линию с самопересечениями. В качестве наглядного примера возьмем полилинию со следующим набором точек: [ { 1; 5 }, { 2; 3 }, { 5; 1 }, { 6; 4 }, { 9; 6 }, { 11; 4 }, { 13; 3 }, { 14; 2 }, { 18; 5 } ] и посмотрим на процесс упрощения при разных значениях ?:
Исходная полилиния из представленного набора точек:

Полилиния с ? равной 0.5:
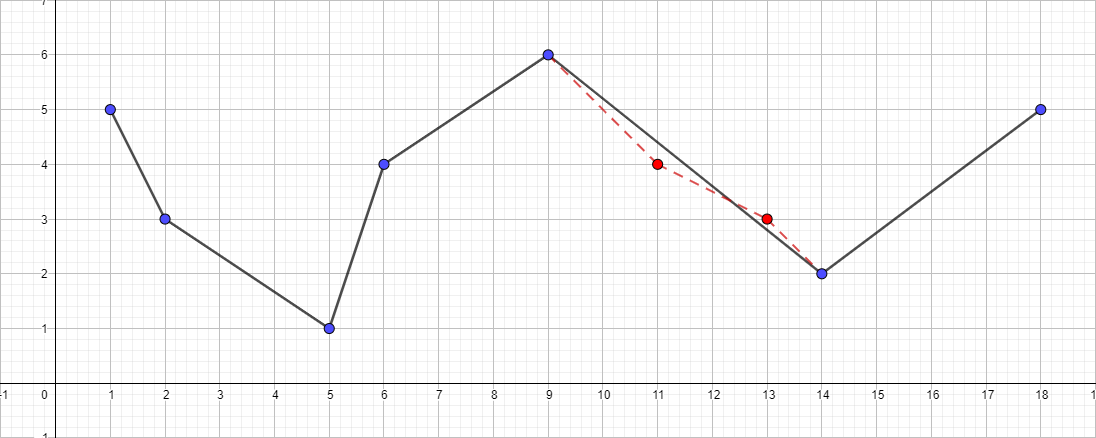
Полилиния с ? равной 1:

Полилиния с ? равной 1.5:
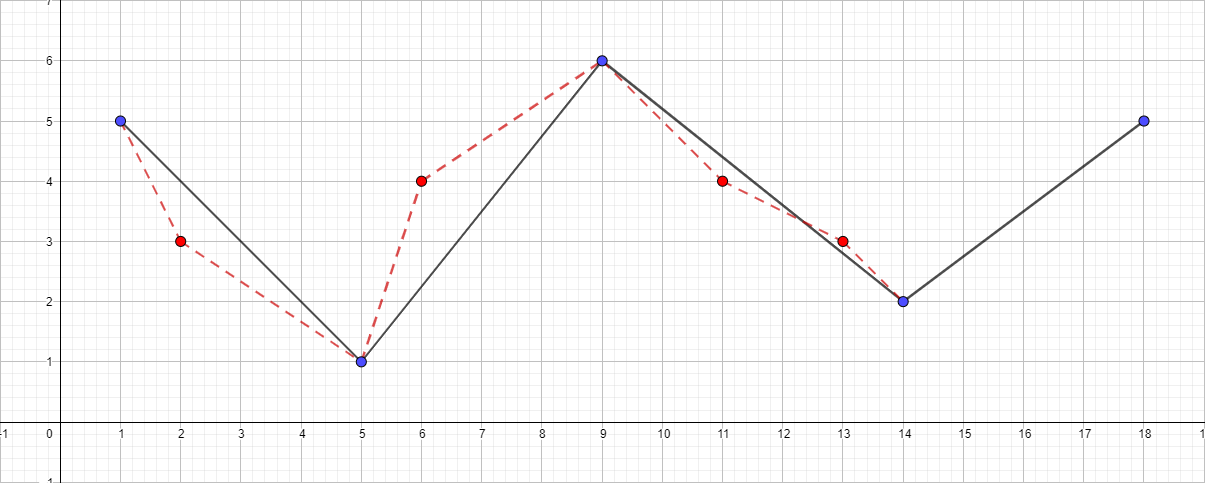
Можно и дальше продолжить увеличение максимального расстояния и визуализацию алгоритма, но, думаю, основная суть после этих примеров стала понятной.
Реализация
В качестве языка программирования для реализации алгоритма был выбран С++, полный исходный код алгоритма вы можете увидеть здесь. А теперь непосредственно к самой реализации:
#define X_COORDINATE 0
#define Y_COORDINATE 1
template<typename T>
using point_t = std::pair<T, T>;
template<typename T>
using line_segment_t = std::pair<point_t<T>, point_t<T>>;
template<typename T>
using points_t = std::vector<point_t<T>>;
template<typename CoordinateType>
double get_distance_between_point_and_line_segment(const line_segment_t<CoordinateType>& line_segment, const point_t<CoordinateType>& point) noexcept
{
const CoordinateType x = std::get<X_COORDINATE>(point);
const CoordinateType y = std::get<Y_COORDINATE>(point);
const CoordinateType x1 = std::get<X_COORDINATE>(line_segment.first);
const CoordinateType y1 = std::get<Y_COORDINATE>(line_segment.first);
const CoordinateType x2 = std::get<X_COORDINATE>(line_segment.second);
const CoordinateType y2 = std::get<Y_COORDINATE>(line_segment.second);
const double double_area = abs((y2-y1)*x - (x2-x1)*y + x2*y1 - y2*x1);
const double line_segment_length = sqrt(pow((x2-x1), 2) + pow((y2-y1), 2));
if (line_segment_length != 0.0)
return double_area / line_segment_length;
else
return 0.0;
}
template<typename CoordinateType>
void simplify_points(const points_t<CoordinateType>& src_points, points_t<CoordinateType>& dest_points, double tolerance, std::size_t begin, std::size_t end)
{
if (begin + 1 == end)
return;
double max_distance = -1.0;
std::size_t max_index = 0;
for (std::size_t i = begin + 1; i < end; i++)
{
const point_t<CoordinateType>& cur_point = src_points.at(i);
const point_t<CoordinateType>& start_point = src_points.at(begin);
const point_t<CoordinateType>& end_point = src_points.at(end);
const double distance = get_distance_between_point_and_line_segment({ start_point, end_point }, cur_point);
if (distance > max_distance)
{
max_distance = distance;
max_index = i;
}
}
if (max_distance > tolerance)
{
simplify_points(src_points, dest_points, tolerance, begin, max_index);
dest_points.push_back(src_points.at(max_index));
simplify_points(src_points, dest_points, tolerance, max_index, end);
}
}
template<
typename CoordinateType,
typename = std::enable_if<std::is_integral<CoordinateType>::value || std::is_floating_point<CoordinateType>::value>::type>
points_t<CoordinateType> duglas_peucker(const points_t<CoordinateType>& src_points, double tolerance) noexcept
{
if (tolerance <= 0)
return src_points;
points_t<CoordinateType> dest_points{};
dest_points.push_back(src_points.front());
simplify_points(src_points, dest_points, tolerance, 0, src_points.size() - 1);
dest_points.push_back(src_points.back());
return dest_points;
}
Ну и собственно само использование алгоритма:
int main()
{
points_t<int> source_points{ { 1, 5 }, { 2, 3 }, { 5, 1 }, { 6, 4 }, { 9, 6 }, { 11, 4 }, { 13, 3 }, { 14, 2 }, { 18, 5 } };
points_t<int> simplify_points = duglas_peucker(source_points, 1);
return EXIT_SUCCESS;
}
Пример выполнения алгоритма
В качестве входных данных возьмем раннее известный нам набор точек [ { 1; 5 }, { 2; 3 }, { 5; 1 }, { 6; 4 }, { 9; 6 }, { 11; 4 }, { 13; 3 }, { 14; 2 }, { 18; 5 } ] и ? равной 1:
- Найдем наиболее удаленную точку от отрезка { 1; 5 } — { 18; 5 }, данной точкой окажется точка { 5; 1 }.
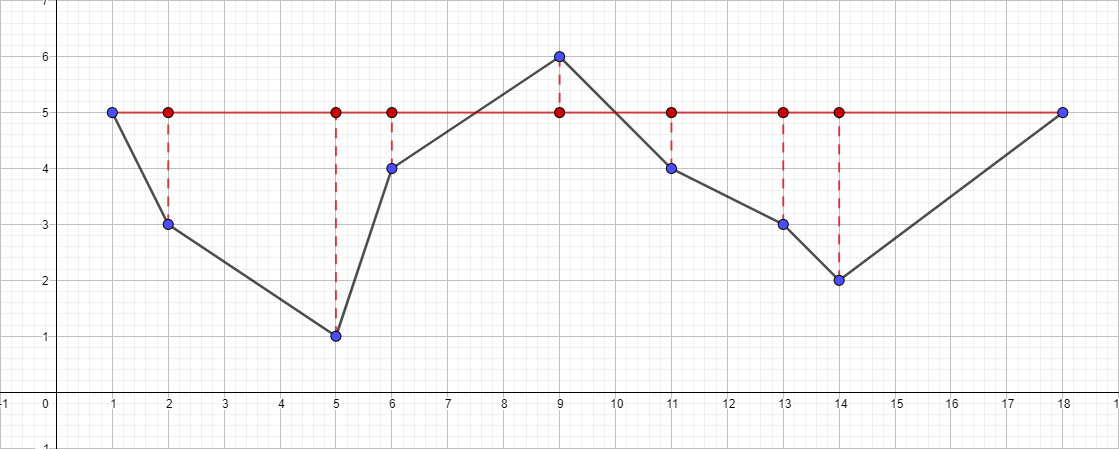
- Проверяем ее расстояние до отрезка { 1; 5 } — { 18; 5 }. Оно оказывается больше 1, значит добавляем ее в результирующую полилинию.
- Запускаем рекурсивно алгоритм для отрезка { 1; 5 } — { 5; 1 } и находим наиболее удаленную точку для этого отрезка. Данная точка — это { 2; 3 }.
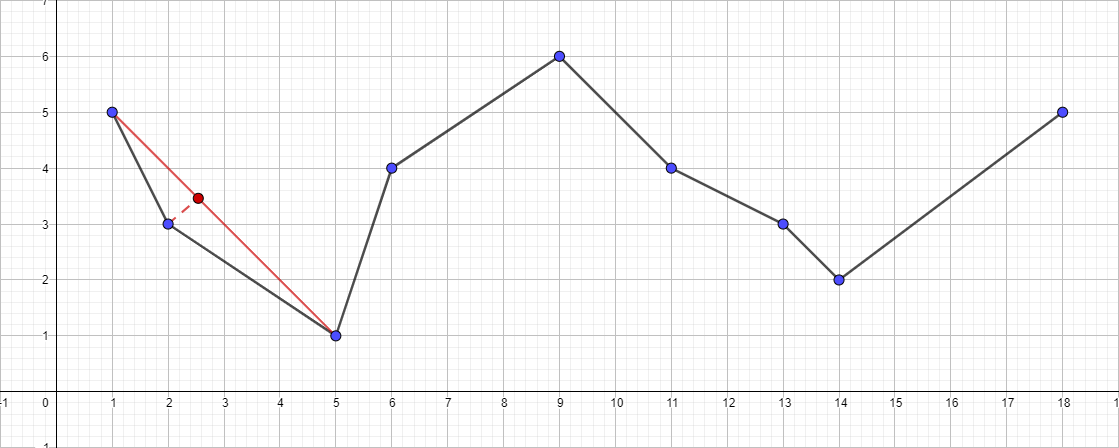
- Проверяем ее расстояние до отрезка { 1; 5 } — { 5; 1 }. В данном случае оно меньше 1, значит мы можем спокойно отбросить эту точку.
- Запускаем рекурсивно алгоритм для отрезка { 5; 1 } — { 18; 5 } и находим наиболее удаленную точку для этого отрезка…
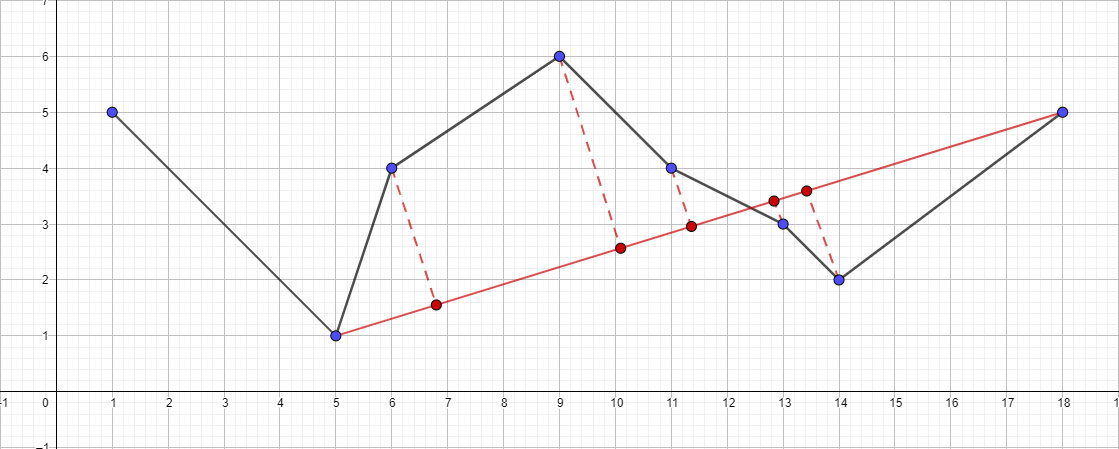
- И так далее по такому же плану...
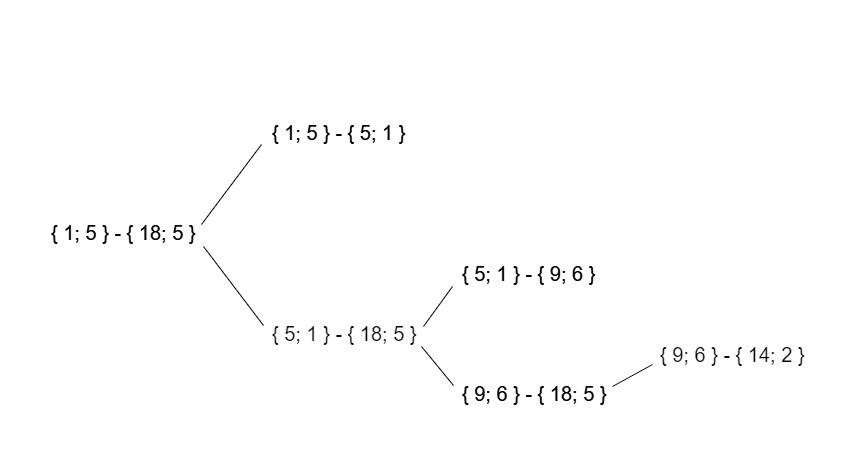
В результате дерево рекурсивных вызовов для этих тестовых данных будет выглядеть следующим образом:
Время работы
Ожидаемая сложность алгоритма в лучшем случае составляет О(nlogn), это когда номер наиболее удаленной точки всегда оказывается лексикографически центральным. Однако, в худшем случае сложность алгоритма составляет O(n^2). Это достигается, например, в случае, если номер наиболее удаленной точки всегда соседний к номеру граничной точки.
Надеюсь что моя статья окажется кому то полезной, также хотел бы заострить внимание на том, что если статья проявит достаточный интерес среди читателей, то в скором времени буду готов рассмотреть алгоритмы упрощения полигональной цепи Реуммана-Виткама, Опхейма и Ланга. Спасибо за внимание!
Комментарии (10)

little-brother
18.04.2019 18:45+1Конкретно для графиков неплох Largest Triangle Three Buckets от Sveinn Steinarsson. К тому же для популярных языков уже имеется реализация.
SaNNy32
18.04.2019 21:04Было бы неплохо описать работу алгоритма при задании ограничения по количеству оставшихся точек после упрощения
VladimirBalun Автор
19.04.2019 07:57Да, что-то я об этом совсем не подумал…
Постараюсь добавить это в статью в скором времени.

Alexufo
19.04.2019 03:58Тут выше уже упомянули Largest Triangle Three Buckets
Здесь я писал о варианте для одномерного массива.
habr.com/en/post/412629

freeExec
19.04.2019 09:05+1А можно пример где нарушается топология и происходит пересечение.
VladimirBalun Автор
19.04.2019 09:24+1Когда буду добавлять в статью правки по комментарию SaNNy32:
Было бы неплохо описать работу алгоритма при задании ограничения по количеству оставшихся точек после упрощения
Тогда заодно сделаю пример и визуализацию, где нарушается топология и происходят пересечения.
pallada92
Спасибо за статью! Периодически приходится решать подобные задачи отбражении карт в d3.js или WebGL, когда topoJSON файл границ регионов нужно сконверировать в набор полигонов с разумным числом точек и заанимировать. Мне было достаточно простого алгоритма, который пропускает точки, которые находятся слишком близко друг другу и дробит длинные отрезки. Не думал, что существует семейство алгоритмов для решения этой задачи с более точными гарантиями.
Если не секрет, для какой именно задачи вам потребовалась упрощать цепи?
VladimirBalun Автор
Стояла задача для написания программы, на вход которой поступал лист раскроя определенных размеров и набор различных фигур, целью которой было расположение этих фигур на листе так, чтобы расход материала был минимальным.