
«Восьмерка» еще даже не вышла RTM а я уже пишу про нее пост. Зачем? Ну, основная идея что тот, кто предупрежден — вооружен. Так что в этом посте будет про то что известно на текущий момент, а если это все подстава, ну, поделом.
Nullable Reference Types
Я не знаю, в курсе вы или нет, но дизайнеры всех современных языков «продолбали» как минимум несколько важных аспектов. Один из основных продолбов — это неинициализированные объекты, указатель на которые имеет значение NULLnullptrnull
C# это конечно тоже зацепило в разных ипостасях, вот например:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string MiddleName { get; set; }
public Person(string first, string last, string middle) =>
(FirstName, LastName, MiddleName) = (first, last, middle);
public string FullName =>
$"{FirstName} {MiddleName[0]} {LastName}";
}
Пример выше очень хорошо иллюстрирует проблему. У человека может быть отчество но у меня, например, в паспорте его нет и следовательно непонятно что писать в это поле. Дефолтное значение строки в C# это null$string.Format()null
Кардинального решения этой проблемы нет, т.к. если внезапно запретить nullOptional
Системы статического анализа вроде Решарпера уже давно пытаются как-то облегчить участь разработчика, предупреждая о возможных косяках. Собственно для этого придумали аннотации (NuGet пакет JetBrains.Annotations
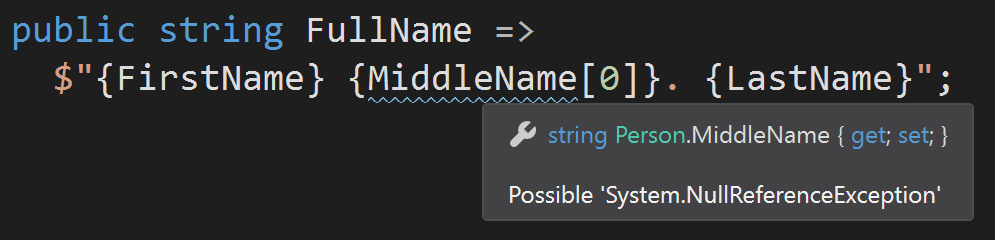
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
[CanBeNull] public string MiddleName { get; set; }
public Person(string first, string last, [CanBeNull] string middle) =>
(FirstName, LastName, MiddleName) = (first, last, middle);
public string FullName =>
$"{FirstName} {MiddleName[0]} {LastName}";
}
Код выше заставляет системы статического анализа ругаться на возможный NRE в точке MiddleName[0]
Но Microsoft… как всегда берет то, что делает другие и банально копирует. Вообще есть шутка, что в долгосрочной перспективе VS просто скопирует все фичи Решарпера. А потом запретит плагины. Поэтому хорошо что есть райдер.
Короче, МС естественно не стали менять язык. Точнее как не стали, они конечно его поменяли. Вместо решарперных аннотаций, в C#8 можно написать вот так:
#nullable enable
Просто написав от эту штуку наверху файла вы меняете поведения компилятора. Теперь, при написании чего-то вроде
var p = new Person("Dmitri", "Nesteruk", null);
вы получите следующий warning:
1>NullableReferenceTypes.cs(26,48,26,52): warning CS8625: Cannot convert null literal to non-nullable reference or unconstrained type parameter.
Да-да, просто предупреждение, а не ошибку (хотя treat warnings as errors никто не отменял).
Ну да ладно, а что дальше? А дальше нам хочется как-то все-таки сказать C#, что теоретически MiddleNamenull[0]
Для этого мы меняем поле на вот такое:
public string? MiddleName;
Хмм, что это? Кому-то может показаться что string?Nullable<T>T : structstring
Теперь компилятор выдаст вам еще один варнинг на доступ по индексу ноль. И чтобы оно заработало вам придется как-то перестраховаться, например написав:
public string FullName => $"{FirstName} {MiddleName?[0]} {LastName}";
Теперь самый важный вопрос: что же поменялось в IL? С точки зрения исполняемого кода — ничего! Но с точки зрения метаданных поменялось конечно: теперь в типе который использует nullable аннотации все типы которые являются nullable проаннотированы атрибутом [Nullable]
Чувствительность к проверкам
Аннотации в C#8 работают в какой-то мере как Котлиновские смарт-касты. Иначе говоря, если у меня есть апи который выдает nullable-тип
string? s = GetString();
То конечно при попытке достучаться до первой буквы я получу warning. Но если я напишу так:
if (s != null){ char c = s[0];}
то варнингов не будет! Компилятор понимает, что мы сами сделали проверку и поэтому не стоит лишний раз волноваться. Насколько глубоко компилятор копает подобные сценарии я не проверял.
Предотвращение лишних проверок
Есть два способа отключить проверки на null. Первый — это просто писать код без «вопросиков», тем самым констатировав тот факт что все твои поля, параметры и так далее вообще ни при каких условиях null-ами быть не могут.
Второй подход — это явно сказать компилятору что в этой точке проверка не нужна. Вот несколько примеров:
(null as Person).FullName(null as Person)!.FullName(null as Person)!!!!!!!!!!!!!.FullName(null as Person)!?.FullNamenull?!
Проверки в либах
Естественно, то вся эта кухня имеет хоть какой-то смысл только при условии что BCL и прочие популярные библиотеки проаннотированны этими аннотациями. Ведь сейчас я могу написать
Type t = Type.GetType("abracadabra");Console.WriteLine(t.Name);
и не получить никакого предупреждения. Я-то знаю что Type.GetType()nullnullable
И нет, мы не можем «форсировать» подобные проверки кодом вроде
Type t = Type.GetType("abracadabra");
Type? u = t;
Console.WriteLine(u.Name);
Код выше все равно не выдаст предупреждение. Очевидно, компилятор считает что t != nullunull
Итого
Nullable reference types — сомнительной полезности фича, которую еще рано использовать. Оригинальности в ней мало. В долгосрочной перспективе она, конечно, должна помочь нам как-то бороться с рисками nullability но глобально она проблему, как вы понимаете, не решает.
Индексы и Диапазоны
На матстатистке есть такое хороше упражнение: брать диапазон чисел, обладающих тем или иным распределением, преобразовывать его, и потом считать статистику по результату. Например, если X~N(0,1), чему равны E[X?] и V[X?]?
Диапазоны это очень хорошо, но дизайнерами сишарпа явно хотелось получить диапазоны в стиле Питона, а для этого пришлось ввести понятие «с конца».
Итак, у нас за кулисами появляются два новых типа: IndexRange
Index
Вы никогда не задумывались, почему это индекс в массив обязательно intuintx[-1]
Некоторые языки позволяют брать элементы массива с конца с помощью отрицательных индексов. Но это немного криво т.к. последний элемент получит индекс -1 в связи с тем, что у нас нет понятия положительного и отрицательного нуля, нуль один.
В C# пошли другим путем и ввели новый синтаксис. Но, все по порядку. Для начала, ввели новый тип под названием Index
Index i0 = 2; // implicit conversion
Индекс выше, как вы понимаете, будет ссылаться на третий элемент с начала той или иной коллекции.
У самого типа Index
ValueIsFromEnd
Структуру можно инициализировать просто вызвав конструктор:
Index i1 = new Index(0, false);
Код выше, как вы поняли, берет первый элемент с начала. А вот последний элемент (то есть нулевой, но с конца) можно взять вот так:
var i2 = ^0; // Index(0, true)
Опаньки! Многие из вас наверное хотели, чтобы оператор ^
Встроенные типы, такие как массивы или строки, конечно же поддерживают индексер (operator this[]Index
var items = new[] { 1, 2, 3, 4, 5 };
items[^2] = 33; // 1, 2, 33, 4, 5
Range
Следующий кусочек этого паззла — это тип Range
X..Y
Что означает «все элементы от X включительно до Y». При этом, включает ли диапазон значение с индексом YY
Итак, вот несколько примеров:
var a = i1..i2; // Range(i1, i2)var b = i1..; // Range(i1, new Index(0, true));i1var c = ..i2; // Range(new Index(0, false), i2)i2var e = ..;Range.ToEnd(2);
Включается ли конечный элемент?
Окей, знаете что в С++ толстым слоем разбросано неопределенное поведение (undefined behavior?). Ну так вот, в реализации Range
Представьте массив x = {1, 2, 3}x[0..2]{1, 2}x[..2]x[..]{1, 2, 3}
Это немного выносит мозг т.к. элементы x[2]x[^1]Range
Еще немного семантики
Во-первых, диапазон X..YX <= YArgumentOutOfRangeException
Во-вторых, «шаг» не включен в спеку, то есть нельзя написать 1..2..100
Range
В массивах, он дает копию подмассива, прям копируя каждый элемент
В строках происходит вызов
Substring()На коллекциях можно вызывать
AsSpan()RangeВ
SpanRangeSpan.Slice()
Конечно, вы можете также запилить поддержку Index/Rangeoperator this[]
Итого
Полезные в целом фичи, которые являются просто слоем синтаксического сахара который компилятор разворачивает в инициализацию разных struct
И да, решарпероводам будет много всяких веселых инспекций:
Default Interface Members
Никто не рискует породить столько ненависти сколько реализация дефолтных интерфейс мемберов, то есть бархатное преврашение интрефейсов в абстрактные классы. И первый вопрос, на который нужно ответить — зачем?
Ну типичная мотивация такая. Вот допустим вы хотите сделать Enumerable.Count()while (x.MoveNext())Count()
if (x is IList<T> list)
return list.Count;
Логично? А как насчет IReadOnlyList<T>
Ситуация, приведенная выше наводит нас на вынужденное, очень грубое нарушение open-closed principle да и других принципов SOLID, т.к. делать проверки на все возможные типы ради оптимизации — это провальная затея.
А что можно сделать? Ну, можно было бы, чисто теоретически, как-то взять и добавить реализацию Count()IReadOnlyList<T>IReadOnlyList<T>.Count()IEnumerable<T>.Count()
Именно этот подход и реализуют дефолтные методы интерфейсов. Они позволяют реализовать нечто, функционально-эквивалентное экстеншн-методам, но также поддающееся правилам наследования и виртуальных вызовов.
Тонкости использования
Но давайте для начала посмотрим на более приземленный пример:
public interface IHuman
{
string Name { get; set; }
public void SayHello()
{
Console.WriteLine($"Hello, I am {Name}");
}
}
public class Human : IHuman
{
public string Name { get;set; }
}
Пример выше искусственнен, но обязателен для понимания того, что вот так писать нельзя:
Human human = new Human() { Name = "John" };
human.SayHello(); // will not compile
Странно да? Вроде бы, валидный код. На самом деле нет — дело в том, что конкретный класс, хоть он и реализует тот или иной интерфейс, понятия не имеет о дефолтных методах этого интерфейса.
Почему, спросите вы? Потому, что вся соль этих методов в том, чтобы добавлять их пост фактум, когда вашим интерфейсом уже пользуются. А что если за это время класс HumanSayHello()
Поэтому дизайнеры приняли такое решение: дефолтные методы доступны только через сам интерфейс, то есть требуется явное или неявное приведение типа к интерфейсу:
IHuman human = new Human() { Name = "John" };
human.SayHello();
((IHuman)new Human { … }).SayHello();
Наследование интерфейсов
Все, что я описал выше, наводит нас на интересную мысль: если два интерфейса реализуют одинаковый метод Foo()Foo()
public interface IHuman
{
string Name { get; set; }
void SayHello()
{
Console.WriteLine($"Hello, I am {Name}");
}
}
public interface IFriendlyHuman : IHuman
{
void SayHello()
{
Console.WriteLine( $"Greeting, my name is {Name}");
}
}
((IHuman)new Human()).SayHello();
// Hello, I am John
((IFriendlyHuman)new Human()).SayHello();
// Greeting, my name is John
Заметьте, что в коде выше IFriendlyHuman.SayHello()IHuman.SayHello()SayHello()
public interface IFriendlyHuman : IHuman
{
void IHuman.SayHello()
// ^^^^^^
{
Console.WriteLine( $"Greeting, my name is {Name}");
}
}
Вот в этом случае вызов SayHello()IHumanIFriendlyHuman
((IHuman)new Human()).SayHello();
Greeting, my name is John
((IFriendlyHuman)new Human()).SayHello();
Greeting, my name is John
Diamond Inheritance
Естественно, в ситуации когда вы можете иметь два «честных override-а» в двух интерфейсах-наследниках породит конфликт в случае, если вы попытаетесь реализовать их оба:
interface ITalk { void Greet(); }
interface IAmBritish : ITalk
{
void ITalk.Greet() => WriteLine("Good day!");
}
interface IAmAmerican : ITalk
{
void ITalk.Greet() => WriteLine("Howdy!");
}
class DualNational : IAmBritish, IAmAmerican {}
// Error CS8705 Interface member 'ITalk.Greet()' does not have a most specific implementation. Neither 'IAmBritish.ITalk.Greet()', nor 'IAmAmerican.ITalk.Greet()' are most specific.
Проблема тут в том, что компилятор не может найти «более специфичный» (то есть, ниже в иерархии наследования) интерфейс для использования и, в результате равнозначности, не поймет что нужно делать если кто-то вызовет какой-нибудь IAmAmerican.Greet()
Итого
Фича для писателей АПИ. Обычным пользователям скорее всего не стоит беспокоиться, особенно если вы, как я, контролируете весь свой код и вам не страшно в любой момент менять его API. Единственный реальный кейс — это когда вот прям нужно оверрайдить экстеншн-методы. У вас есть подобные юз-кейсы?
Pattern Matching
Эту фичу нагло крадут из F# уже на протяжении нескольких минорных релизов. Конечно — в F# ведь эта фича очень удобна, но она идет рука об руку с теми фичами, которых в С# нет, а именно алгебраические типы и функциональные списки.
Но несмотря на это, аналогом F#ного matchswitch
Property Matching
Если у объекта есть поля или свойства, можно мэтчить по ним:
struct PhoneNumber{
public int Code, Number;
}
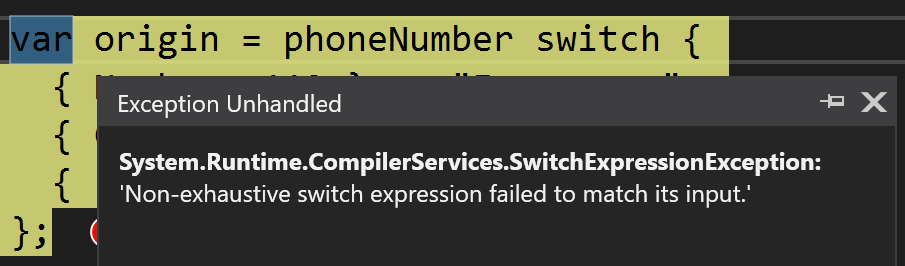
var phoneNumber = new PhoneNumber();
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK"
};
Код выше анализирует структуру объекта phoneNumber
Несмотря на всю лаконичность, код выше — бажный, так как не отлавливает все кейсы. У дизайнеров было два выбора: либо молча сглатывать неохват паттерна делая default-init (иначе говоря, возвращать default(T)
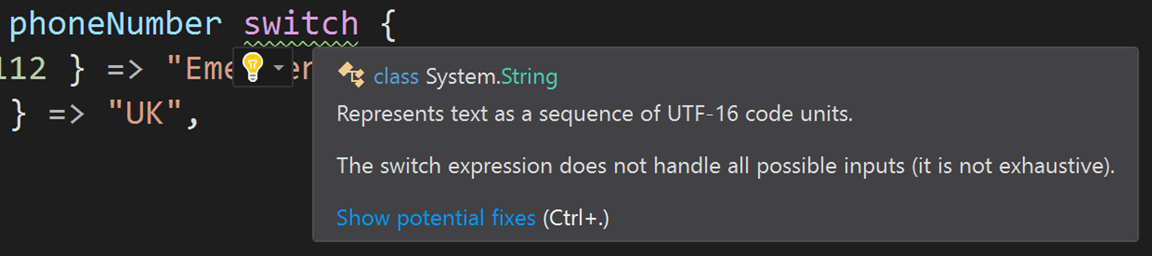
Ну и системы статического анализа кода тоже в долгу не останутся:
Загадка
Поскольку мы можем между фигурных скобок анализировать все что угодно, мы можем сделать и кейс, где фигурные скобки пустые:
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK",
{ } => "Indeterminate",
_ => "Missing"
};
Что это значит? Да то, что теперь есть 2 кейса: _{}null
Пример выше определенно покрывает все кейсы, так что исключение мы на нем не словим. А что насчет вот такого?
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK",
{ } => "Unknown"
};
Покрывает ли пример выше все варианты? Если phoneNumberstructclassnull
Вот и получается, что покрытие всех вариантов зависит не только от типа объекта но еще и от контекста компилятора.
Рекурсивные паттерны
Все-таки с неймингом у МС получается ооочень плохо, прям фееричный булшит. Сначала nullable reference types — масло масляное, ибо референсные типы являются nullable по определению, но термин recursive patterns — это еще на порядок хуже.
В F#, поскольку там есть функциональные списки, можно рекурсивно проверять подсписки списка на соответствие паттернам. В C# же, этот термин значит совсем другое, причем как я уже сказал, нейминг этой фичи в C# — просто шлак.
Если коротко, «рекурсивные паттерны» в C# это возможность углубиться внутри структуры того или иного объекта и проверить еще и поля-полей, если так можно выразиться:
var personsOrigin = person switch {
{ Name: "Dmitri" } => "Russia",
{ PhoneNumber: { Code: 46 } } => "Sweden",
{ Name: var name } => $"No idea where {name} lives"
};
В примере выше проиллюстрированы сразу две идеи. Первая — это то, что можно углубиться в объект person.PhoneNumberCode46
Валидация
Хорошее применение всей этой кухне: комплесная валидация разных аспектов одного сложного объекта в одном switch
var error = person switch {
null => "Object missing",
{ PhoneNumber: null } => "Phone number missing entirely",
{ PhoneNumber: { Number: 0 } } => "Actual number missing",
{ PhoneNumber: { Code: var code } } when code < 0 => "WTF?",
{ } => null // no error
};
if (error != null)
throw new ArgumentException(error);
Как видите, в коде выше идет несколько проверок: простые проверки с паттернами, плюс ключевое слово when
Интеграция с проверками на типы
Проперти-паттерны можно «поженить» с проверками на типы которые появились одним сишарпом ранее. Теперь можно проверить на тип, а потом еще и распаковать структуру:
IEnumerable<int> GetMainOfficeNumbers()
{
foreach (var pn in numbers)
{
if (pn is ExtendedPhoneNumber { Office: "main" })
yield return pn.Number;
}
}
В примере выше мы сначала проверяем тип номера телефона и, если он подходит, распаковываем его и проверяем что речь идет именно про главный офис. Очень удобно.
Деконструкция
Надеюсь вы не забыли про деконструкцию — фичу языка которая позволяет, по сути, распаковывать тип в кортеж. Для этого тип должен реализовывать метод Deconstruct()out
Так вот, эту фичу тоже можно поженить с паттерн-мэтчингом и получить следующее:
var type = shape switch
{
Rectangle((0, 0), 0, 0) => "Point at origin",
Circle((0, 0), _) => "Circle at origin",
Rectangle(_, var w, var h) when w == h => "Square",
Rectangle((var x, var y), var w, var h) =>
$"A {w}?{h} rectangle at ({x},{y})",
_ => "something else"
};
Код выше распаковывает содержимое прямоугольника или круга в кортежные структуры, при этом есть варианты: либо заниматься паттерн-мэтчингом, либо просто деструктурировать объекты в переменные, как показано в последнем примере. Заметьте что этот процесс тоже является «рекурсивным» — у прямоугольника есть точка начала, которая деструктурируется в круглых скобках. Прочерк (_
Итого
Нужные и полезные возможности, которые найдут свое применение. Валидация и похожий анализ типов становится очень лаконичным.
Заключение
Что, я не все фичи показал? Ну, я и не обещал, вообщем-то. Для начала хватит. Пока язык не релизнули я могу еще чуток поисследовать. А если и вы хотите поисследовать, вам потребуется VS 2019 Preview (да-да, preview версия а не RTM), .NET Core 3 (многое из описанного выше попросту не поддерживается в .NET Framework), ну и dotPeek тоже будет полезен чтобы понять, что же там за кулисами.
У меня пока все. Продолжение (возможно) следует. ¦
Комментарии (185)

mentin
02.06.2019 01:15+1По-моему либо тут, либо в предварительной документации Майкрософта что менее вероятно, некоторая путаница насчет индексов с конца. Сам не проверял, но вот что говорит Майкрософт, в предложении:
docs.microsoft.com/en-us/dotnet/csharp/language-reference/proposals/csharp-8.0/ranges
и в описании новых фич:
docs.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-8#indices-and-ranges
The ^0 index is the same as sequence[sequence.Length]. Note that sequence[^0] does throw an exception, just as sequence[sequence.Length] does.
То есть ^0 это не последний элемент, как написано в статье, а индекс за-последним. Индексировать по нему нельзя, выбросится исключение! Это то же самое, что collection::end() в С++.
В Майкрософтовском предложении для взятия последнего элемента есть пример
var lastItem = list[^1]; // list[Index.CreateFromEnd(1)]
Разобравшись с индексами, становится понятно, что никакой путаницы с тем, включается ли последний элемент диапазона, нет — он никогда не включается! Независимо от того, берется ли последний индекс в диапазоне с начала или с конца.
[0..^0] работает и описывает весь массив именно потому что второй индекс ^0 не включается, иначе бы бросалось исключение.Eldhenn
02.06.2019 07:06Получается какой-то substr. 0..4 тут 4 элемента от нулевого. Да нет, зреет получается. 4..5 выберет один элемент? Они упрлс?
mentin
02.06.2019 09:08Не, это как раз нормальное и ожидаемое поведение в С-подобных языках.
Вот если бы было как описал автор, то последнее значение в Range не включено, если индекс с начала, то включено, если индекс с конца — я бы решил что что-то не так.Eldhenn
02.06.2019 09:18-1Что нормального в том, что в 4..5 помещается один элемент? Как это читать тогда вообще?
mayorovp
02.06.2019 10:34+1Все нормально и очевидно: 5-4=1.

NeoCode
02.06.2019 11:08Это действительно так, и это действительно некрасиво с точки зрения математики. Но понятно откуда это пошло — с С++овских итераторов begin() и end(), а там end() указывает за конец коллекции, а не на последний элемент, потому что иначе не сделать итерацию коллекций нулевой длины. Вот в Swift сделали оба вида диапазонов — и закрытые, и полузакрытые. Вполне логично и удобно, наличие обоих вариантов подчеркивает разницу между ними и уменьшает путаницу. Две точки для полузакрытых, три точки для закрытых. Можно даже мнемонически запомнить — три точки больше, значит и диапазон больше (включает последний элемент).
khim
02.06.2019 12:57+1Да уж. Змея сожрала свой хвост. Вообще-то этот вопрос уже исследовался много десятилетий назад. Тем самым Дейсткрой, который, как известно, не программист, потому что свои статьи не на компьютере набирал.
Но, конечно, Apple не может же использовать опыт того самого Xerox PARC, с которого они слизали интерфейс MacOS (оригинальной версии, не MacOS X).
А так — полузакрытые интервалы и нумерация с нуля — это просто удобно. Может быть не слишком привычно для человека без опыта, но удобно.
AgentFire
02.06.2019 16:07интересно в каком языке все таки сделали полное математическое описание, с круглыми и квадратными скобками?
khim
02.06.2019 16:41Mesa. 1976й год. Собственно на опыт работы с Mesa обсуждение, ссылку на которое я давал выше, и ссылается.
Вот всё как вы хотели: и все четыре варианта предусмотрены и да — таки круглые и квардартные скобки. Но «новое поколение» хочет, видимо, лично понаступать на те же грабли. Языки, созданные до их рождения, видимо «неправильные» — наверное за полвека что-то кардинально новое в математике случилось…
Eldhenn
02.06.2019 16:59Нет, вы мне ответьте, как это читать? 2..7 — это «взять с третьего и не доходя до восьмого элемента»? В чём смысл такой записи? Ну то есть я вижу один смысл — когда у нас есть либо длина, либо «указатель на конец». Но мы берём срезы списков не только «до конца». Может быть, описание открытых интервалов само по себе и имеет смысл (хотя лично мне он неведом, это же целые числа в любом случае), но для срезов…
khim
02.06.2019 17:17+2В чём смысл такой записи?
Вы в каждой строчке программы хотите увидеть «смысл жизни»? Или как?
С полуинтервалами легко работать: их объединение — это тоже полуинтервал если они пересекаются — и это пересечение легко проверить, их разность — это один-два полуинтервала и там тоже всё легко считается. Самая важный прицип в программировании (разделяй и властвуй) с полуинтервалами делается тривиально, а с интервалами или отрезками — с трудом.
И это всё совершенно не зависит от того — рассматриваете ли вы вещественные числа или целые.
Может быть, описание открытых интервалов само по себе и имеет смысл (хотя лично мне он неведом, это же целые числа в любом случае), но для срезов…
Вот именно для срезов полуинтрвалы и лучше. Потому что вы их делаете не для того, чтобы на доску повесить, а для того, чтобы какой-то алгоритм реализовать. И вот там +1/-1 встречается реже, если использовать полуинтервалы.
Как уже упоминалось: попытки использовать другие варианты в истории были. Mesa вообще все четыре варианта поддерживала. Но оказалось, что это — хуже: если у вас в 70% случаев полуинтервалы, а в 30% случаев — что-то другое (да, иногда могут и отрезки и даже интервалы оказаться удобными), то в этих случаях возникает путаница уже из-за того, что человек забывает, что вот конкретно здесь у него не полуинтервал, а что-то другое. Лучше в этих [относительно редких] случаях +1/-1 написать…Eldhenn
02.06.2019 17:39Надо посмотреть завтра на свой код. Какие срезы и как я там использую. Пока что мне кажется, что я всегда знаю номер конечного элемента, а не следующего за ним.
Но вы так убедительно говорите, что может быть, я просто привык.

Bronx
02.06.2019 22:53+4В чём смысл такой записи?
- Попробуйте взять пустой интервал если запись
a..bэквивалентна отрезку[a,b], а не полуинтервалу[a,b). Отрезок[a,a]непустой, он состоит из 1 элементаa. Писатьa..a-1, что ли? Илиa+1..a? Для полуинтервалов же это не проблема,[a,a)— пустой. - Попробуйте взять два смежных отрезка.
[a,b]и[b,c]не подходят, так как элементbвходит в оба отрезка. Писатьa..b-1иb..c? Илиa..bиb+1..c? Для полуинтервалов же это не проблема,[a,b)и[b,c)— смежные и не пересекаются, их суммой самым натуральным образом оказывается[a,c).
khim
03.06.2019 00:55Я думаю что претензии к тому, что
a..bвыглядит симметричной при том, чтоaвходит в интервал, аb— не входит. Что, действительно, выглядит немного странно: конструкция вроде симметрична, а на самом деле — нет.
Но это уже чисто вопрос привычки: получинтервалы реально удобнее, а что немного непривычно выглядят — так тут уж «как получилось».Bronx
03.06.2019 03:10Возможно так. Хотя взять ту же пару
std::begin(), std::end()— вроде выглядит симметрично, на на деле нет. Тех, кто интервалов касался, эта кажущаяся симметрия вряд ли введёт в заблуждение.
DistortNeo
03.06.2019 09:16Как тут, симметрично?
for (int i = a; i < b; i++)khim
03.06.2019 15:05Так там и выглядит выражение несимметрично, почему должна быть симметрия в функциональности?
- Попробуйте взять пустой интервал если запись
hrenvam
02.06.2019 01:29Я думаю увидев такой код на продакшене:
var type = shape switch { Rectangle((0, 0), 0, 0) => "Point at origin", Circle((0, 0), _) => "Circle at origin", Rectangle(_, var w, var h) when w == h => "Square", Rectangle((var x, var y), var w, var h) => $"A {w}?{h} rectangle at ({x},{y})", _ => "something else" };
Я бы без зазрения совести мог бы его публиковть на говнокод ру
А вот дефолтную реализацию методов я поддерживаю. Мне подобные плюшки и в Java нравятся.math_coder
02.06.2019 02:40+2Нормальный функциональный код.
hrenvam
02.06.2019 13:49-1Да мне как бы все равно как вы его называете.
Вот только легко читаемым он от этого не становится!
И еще меня умиляют такие слова как «нормальный». Их как понимать?
Как нормальный для вас? Или среднестатистичекий по больнице?
И если второе, так я скажу, что в аутсорсе переодически и не такая дрянь встречается.
Но это же не означает, что подобный код перестает быть Г.
Отнюдь, просто г-код становится чем-то приемлимым в сфере программирования.
Вот, например, вы пишете, что для вас это «нормально».DistortNeo
02.06.2019 14:01Стареете, хуже воспринимаете нововведения — это нормально.
hrenvam
02.06.2019 23:35-3Почитайте мой пост на пару строчек ниже. Может что-нибудь и дойдет.
А вообще нужно быть очень самоувернным человеком, чтобы вот так как вы гадать.
И нет я не старею… И очень радостно отношусь к нововведениям, но это должно быть улучшением(!), а не деградацией в очередной манимирок вкайтившегося вайтишника.
И еще, наверное из-за отсутствия опыта или по какой-то другой неосмотрительности, до вас до сих пор еще не дошло, что ОСНОВУ ВСЕХ ИННОВАЦИЙ как раз и закладывают всякие СЕДОВЛАСЫЕ ДЯДЬКИ ЗА 50.
Именно они стоят у руля лабораторий, которые дают вам технологие, на которые вы молитесь. Например Реймонд Ваган Дамадьян, изобретатель МРТ, ему сейчас около 80 лет.
И нет я далеко не седовласый дядька. Но у меня хватает мозгов, чтобы хотя бы понимать как всё работает в реальности. И это конечно факт прискорбный, что «истина недоступна большинству», но ожидаемо — так что по барабану.
И, перефразировав Познера, скажу только — «Ну что же поделать… такие люди.»khim
03.06.2019 01:03Например Реймонд Ваган Дамадьян, изобретатель МРТ, ему сейчас около 80 лет.
И что он такого сделал «прорывного» в 5 лет? Когда он свою первую статью про МРТ публиковал — ему 35 было. А IT… В основном сейчас на Big Data молются и прочие всякие Map Reduce. Джеффу Дину, когда он это всё придумал — было 32. И это — в общем типичная история: случаи, когда «седовласые дядьки за 50» что-то реально изобретают (а не приписывают себе что-то, что сделали другие) — случаются, но их очень-очень мало.
Именно они стоят у руля лабораторий, которые дают вам технологие, на которые вы молитесь.
Стоять у руля != изобретать. Многие изобретения вообще случаются потому, что учёные, которые их делают всё проводят «мимо» руководителей.
И это конечно факт прискорбный, что «истина недоступна большинству», но ожидаемо — так что по барабану.
Как раз большинству она доступна. А вам — похоже, что нет.hrenvam
03.06.2019 03:05-1Проигнорировав откровенный бред, я отвечу по сути:
> Когда он свою первую статью про МРТ публиковал — ему 35 было
Это была отлаженная и реально работающая технология?
Это уже можно было называть словом «инновация»?
И не забываем (не забываем ведь?), что мы говорим о возрасте, в котором начинается «сопротивлению всему новому»!
Но даже, если опираться на ваши факты, то если мне 35 лет, то этого уже достаточно, чтобы формулировка: «Стареете, хуже воспринимаете нововведения — это нормально.», начала звучать по-идиотски? Т.е. 35 — это еще недостаточно «старый», чтобы уже противиться инновациям?
Так что да… автор сообщения очень далек от истины:
1) Потому что как правило именно за 50. Исключение составляют более «молодые» технические отрасли, и то срок снижается не сильно ну максимум лет на 10. Сколько было Маску когда тесла только вышла? 40?
А сколько Торвальдсу когда линукс стал мейнстримом и реально вошел в жизнь каждого? А сколько им сейчас? Около 50? И эти люди ПРОДОЛЖАЮТ СВОЕ ДЕЛО, и каждый день придумавают что-то новое!
Назовите юное 20-летнее дарование, затащившее инновацию?
BolgenOS не считается ))))))))
Я надеюсь не надо объяснять, что чтобы быть в 50 «Илоном», надо уже начать идти этой дорогой с юности?
Возможно когда-либо в будущем срок «становления юного инноватора» весьма сократится и вообще человечество поумнеет, но это уже другая история.
А на сегодняшний день в 20 лет — это не инновации, это ваши влажные фантазии. Так что да я считаю что ВОЗРАСТ — НЕ ПОКАЗАТЕЛЬ! И я привел парочку примеров в подтверждение (помните чего? именно неверности «Стареете, хуже воспринимаете нововведения»). И дело не в возрасте, а в человеке.
Если вы утверждаете обратное, то просто, избавьте меня, пожалуйста, от дальнейшего обсуждения этого пункта (в этом случае оно никому не нужно, по-крайней мере мне).
2) Потому что он утверждает, что знает, что именно определяет мое мнение. И это даже не зная моего возраста, а ведь именно на этом основаны его тезисы.
Я прекрасно понимаю, что его формулировка, это не что иное как обыкновенный популизм (я не завсегдатый хабра, просто проходил мимо, но приблизительно представляю как ваша г-карма или как там ее работатет). И пипл хавает… Так вот нет… она недоступна.
И Аристотель, и многие ученые мужи современности, и собственно лично я, считаем именно так. Вы конечно можете думать как вам вздумается. Но на этой двойственности мнений мы и закончим с этим пунктом.khim
03.06.2019 03:25А сколько Торвальдсу когда линукс стал мейнстримом и реально вошел в жизнь каждого?
А причём тут это вообще? Торвальдс уже давно код сам не пишет и, фактически, играет роль того самого «заведующего лабораторией». Под руководством которого другие люди занимаются инновациями. Последняя действительно прорывная вещь, которую он сделал — это был Git. Что случилось больше 10 лет назад и было ему тогда, оп-па, таки 36.
И я привел парочку примеров в подтверждение (помните чего? именно неверности «Стареете, хуже воспринимаете нововведения»).
Это где, извините? Всё что вы привели — несколько примеров того, как человек в 20-30-40 лет что-то сделал — что захватило мир гораздо позже. И те же самые люди, которые в молодости «переворачивали мир» — в старости начинают, зачастую, выглядеть чудаками. Как тот же Столлман, который реально очень сильно изменил путь всей индустрии когда-то… а сегодня отказывается пользоваться браузером, чем всех умиляет.
Потому что он утверждает, что знает, что именно определяет мое мнение.
Нет, он просто шутит. А вот уже то, что вы безобидные шутки воспринимаете «в штыки» — заставляет хлопнуть себя ладонью по лбу и громко расхохотаться.
И Аристотель, и многие ученые мужи современности, и собственно лично я, считаем именно так. Вы конечно можете думать как вам вздумается. Но на этой двойственности мнений мы и закончим с этим пунктом.
Ну, Аристотель — он, конечно, дядька умный, да. Но вот вы ответьте на один вопрос: если вам нужно будет количество лап у мухи узнать — вы просто возьмёте и посчитаете или будете тоже схоластику разводить?hrenvam
03.06.2019 04:06-1было ему тогда, оп-па, таки 36.
не полезем в историю комитов, не будем оценивать его вклад в «инновации» на сегодняшний день, а наконец ответим на мой вопрос
то если мне 35 лет, то этого уже достаточно, чтобы формулировка: «Стареете, хуже воспринимаете нововведения — это нормально.», начала звучать по-идиотски? Т.е. 35 — это еще недостаточно «старый», чтобы уже противиться инновациям?
как человек в 20-30-40 лет что-то сделал — что захватило мир гораздо позже.
в том виде в котором оно было 20 лет назад? конечно нет
но мы ведь не об этом да? зачем вы заставляете меня напоминать?
Нет, он просто шутит.
Точный текст:
«Стареете, хуже воспринимаете нововведения — это нормально.»
Где смеяться? Но допустим это просто неудачная шутка.
Но тогда спросим автора, а почему он хотя бы смайл какой-нибудь самый захудалый не вставил? Непогрешимая уверенность в собственном опезденительном чувстве юмора.
Да и не думаю что это шутка… но даже если…
А как насчет «в каждой шутке есть доля шутки»?
Или вы признаете, что пост автора исключительно «веселье», и не несет сколь-нибудь истинной и полезной информации?
заставляет хлопнуть себя ладонью по лбу и громко расхохотаться.
можете приступать, но хлопайте не сильно… пригодится ведь еще.
math_coder
03.06.2019 14:27Но это же не означает, что подобный код перестает быть Г.
Нет, не означает, но он и в самом деле перестаёт быть этим самым Г.
Я называю это "нулевой рефакторинг": нулевой рефакторинг — это частный случай рефакторинга кода, при котором код — как текст — не изменяется, но при этом (иногда кардинально) меняется его архитектура, архитектура программы. Нулевой рефакторинг может быть итоговым результатом настоящего сложного многостадийного рефакторинга когда в итоге неожиданно оказывается, что получился "полный круг", а может совершаться исключительно в голове программиста в результате повышения его кругозора и опыта работы.
Вот чтобы обсуждаемый код перестал быть "Г.", требуется именно нулевой рефакторинг, и большое количество людей в отрасли его уже проделали.
Karl_Marx
02.06.2019 17:25Дело не в том, функциональный он или нет, а в том, что он абсолютно нечитаем, его будет тяжело сопровождать.

ApeCoder
02.06.2019 18:22+7А как вы определили, что он "абсолютно не читаем", а не просто "непривычен"?
hrenvam
02.06.2019 23:14Нет он именно не читаем!
И именно это я и хотел сказать в своих постах.
А то, что мое мнение не разделяет большинство, то мне как бы все равно. НО! Это фактически подтверждение того, насколько некачественный код продуцирует большая часть разработчиков (причина? хз… вкатившиеся?).
Вот типичный пример кода из статьи:
var error = person switch { null => "Object missing", { PhoneNumber: null } => "Phone number missing entirely", { PhoneNumber: { Number: 0 } } => "Actual number missing", { PhoneNumber: { Code: var code } } when code < 0 => "WTF?", { } => null // no error }; if (error != null) throw new ArgumentException(error);
А написать его нужно было бы как-то так:
if (person == null) throw new ArgumentNullException(nameof(person), "Object missing"); if (person.PhoneNumber == null) throw new ArgumentException("Phone number missing entirely"); if (person.PhoneNumber.Number == 0) throw new ArgumentException("Actual number missing"); if (person.PhoneNumber.Code < 0) throw new ArgumentException("WTF?");
— этот код легко читается
— легко проверяется во время дебага (даже точки останова ставятся элементарно)
— не нужно набирать тонну говноскобок
— есть возможность использовать разные типы исключений
— модификация кода валидации на что-то более сложное не требует изменений всего куска кода
— и занимает места такой код приблизительно столько же
Так какая выгода от такого матчинга? Один вред.eabrega
03.06.2019 02:04— этот код легко читается
С чего вы взяли? Кто вам сказал что он легко понимается всей командой разработчиков?
Так какая выгода от такого матчинга? Один вред.
Реализация функционального подхода наверное.
— не нужно набирать тонну говноскобок
Нужно набирать тонну говно-if'ов
— есть возможность использовать разные типы исключений
Кто вам запрещает вместо строки возвращать разные исключения?
легко проверяется во время дебага (даже точки останова ставятся элементарно)
Unit test, не слышали?
Внезапно у вас поменялась структура объекта, который надо валидировать, и вы радостно переписываете все свои if'ы.hrenvam
03.06.2019 03:41-1> С чего вы взяли? Кто вам сказал что он легко понимается всей командой разработчиков?
может потому что она у меня есть?
> Реализация функционального подхода наверное.
если вам так будет легче, то в рассматрвиаемом примере кода, реализация функционального подхода — вред для читаемости и сопровождения.
> Нужно набирать тонну говно-if'ов
ответите? что прям г-ифов?
Я не знаю насколько часто вам приходилось работать с огромным количеством кода, но я вам точно скажу что для того изучить пару сотен тысяч строк кода за 1-2 дня нужно чтобы код был читаемым.
А что такое читаемость я сейчас расскажу:
Есть две строки…
"3f5efded87f3e54760f46bfd6444c4ec06659e970c9039f32f00bf6dc6d9d" "778959537cf5c516021f162723807928944a7dc54cc1b4ec06644c9cffb24"
В них нужно бегло глазами найти значение 4ec06.
Вот и попробуйте сделать это и заодно сказать есть ли такой текст в обеих этих строчках.
А теперь изменим эти строки на вот такие (можем менять — это эквивалент рефакторинга):
"4ec063f5efded87f3e54760f46bfd6444c659e970c9039f32f00bf6dc6d9d" "4ec06778959537cf5c516021f1627238074a7dc54cc1b92894644c9cffb24"
Ну что? Времени потребовалось в разы меньше?
Все что универсально — проще для восприятия и понимания.
Так вот if в данном случае совсем не Г, if задает легкочитаемую структуру кода, а Г — это ваш необдуманный комментарий.
> Кто вам запрещает вместо строки возвращать разные исключения?
Конечно можно (и это лучше чем текст), но обсуждаем то, что в статье, а не все возможные альтернативы. И даже если будет возвращаться исключение это ведь по-хорошему ничего не меняет.
Да и что вы будете делать, если в одном случае нужно исключение, а в другом просто выполнить какой-то алгоритм? Не надо пытаться натянуть ФП туда куда не нужно его натягивать.
P.S.
Последние два пункта даже не буду комментировать — там словесный понос.
eabrega
03.06.2019 09:53-2но обсуждаем то, что в статье,
Да и что вы будете делать, если...
Как мне кажется это взаимно исключающие вещи.
если вам так будет легче, то в рассматрвиаемом примере кода, реализация функционального подхода — вред для читаемости и сопровождения.
Не вы вызывает затруднений у меня. И как бы это же синтетический пример, вы помните?
А что такое читаемость я сейчас расскажу:
Серьезно?
В своей работе, разработка приборов учета и ПП безопасности, несколько лет успешно используем ДРАКОН. Для нас код вторичен.там словесный понос.
В вашей комнате разработчиков это допустимая словесная форма?

0xd34df00d
03.06.2019 19:06Все что универсально — проще для восприятия и понимания.
Чем меньше универсальности, тем проще понимать. Чем более ограниченным инструментом вы пользуетесь, тем меньше вариантов семантики кода.
Паттерны чуть более ограничены, чем ифы, поэтому то, что по смыслу является паттерн-матчингом, проще, лучше и понятнее делать на соответствующем синтаксисе.
ApeCoder
03.06.2019 09:58+2этот код легко читается
Почему вы считаете что он читатся легко? Рациональные аргументы?
if (person.PhoneNumber == null)
throw new ArgumentException("Phone number missing entirely");
if (person.PhoneNumber.Number == 0)
throw new ArgumentException("Actual number missing");
if (person.PhoneNumber.Code < 0)
throw new ArgumentException("WTF?");
Лично мне не очень нравится три раза писать и читать одно и то же.
— не нужно набирать тонну говноскобок
Круглые не считаются?
модификация кода валидации на что-то более сложное не требует изменений всего куска кода
Это также аргумент чтобы заменить a * 2 на switch(a){ case 1: return 2; case 2: return 4

Virviil
03.06.2019 11:47+1Расскажу как для меня видятся эти два кусочка кода, возможно проследив за моим ходом мыслей вы поймете, что бывают люди, думающие по другому, и это тоже правильно (а может быть и более правильно):
Код с матчингом читается легче, потому что все ветки находятся на соседних строчках, друг под другом, и их легко визуально сравнивать. Тот самый ваш пример про два хеша — тут то же самое. Код с if — разделен блоками кода — это в некоторой степени засоряет визуальное восприятие. Однако главное не это.
Код с шаблонов описывает сам себя — он декларативен, он как две картинки с отличиями, которые дети сравнивают в детском саду. Это просто как дышать. Код же с if — императивен. Мне надо загрузить строчку сравнения в "оперативную память", чтобы понять что именно там сравнивается. А чтобы сравнить два условия — мне вообще необходимо нагрузить свой мозг. Сравните это с "в верхней строчке после двоеточия null, а в нижних — что-то… все понятно".
При дебаге кода с сопоставлением шаблона, я ставлю одну точку останова — в месте инициализации person, затем вывожу его визуальное представление и визуально сравниваю с шаблоном. Один раз делаю операцию из детского сада. Я точно уверен, что внутри кейса person никак не изменится — мне вообще не нужно жать step forward, потому что это всего один шаг.
Сравните с кодом с if, где в принципе объект person может поменяться по дороге (по крайней мере теоретически). Кроме того, я скорее всего буду жать step forward 4 раза, и сравнивать конкретные вещи 4 раза — в первом случае это person с null, потом PhoneNumber с null и так далее. По-моему, когнитивная нагрузка и временные затраты в этом случае больше.
Набирать много скобок или много if — это в принципе дело вкуса, и врядли аргумент. Если бы это было важно для вас, вы бы программировали на Питоне. А тут всетки не Лисп, чтобы не это ругаться. Выглядит как обычный json.
Очевидно, что вместо строк объекту person можно было при присвоить эти самые разные исключения, чтобы потом их зарейзить:
{ PhoneNumber: null } => new ArgumentException("Phone number missing entirely"), ... throw error;
Вот только в этом коде и Вашем есть большая разница: Ваш код нарушает базовые принципы структурного программирования. Наличие более одной точки выхода из блока кода значительно увеличивает когнитивную нагрузку (надо держать в голове где там оно могло прервать поток исполнения) и приводит к багам при дальнейшем изменении этого участка кода. 4 throw это 4 goto по своей сути. Возможно, программисты C# привыкли к такому, и это наоборот best-practise, но я предпочитаю в этом вопросе следовать Дейкстре неукоснительно.
По-моему все ровно наоборот. Предлагаю вам не изменяя целиком ваш блок, добится того же, что и я, при добавлении одной строки:
var error = person switch { null => "Object missing", { PhoneNumber: null } => "Phone number missing entirely", + { PhoneNumber: { Number: 0, Code: var code} } when code < 0 => null, { PhoneNumber: { Number: 0 } } => "Actual number missing", { PhoneNumber: { Code: var code } } when code < 0 => "WTF?", { } => null // no error }; if (error != null) throw new ArgumentException(error);
Пример синтетический — однако можно представить появление валидации такого типа (когда по отдельности два условия — ошибка, а вместе — нет). Скорее всего в этом месте в вашем решение появится nested if, а это очевидно увеличивает сложность.
Место — по всей видимости так-же не аргумент.
Подводя итог, я ни в коем случае не собираюсь навязывать свою точку зрения, однако призываю вас взглянуть на вопрос пошире — в том числе с моей точки зрения, и не быть настолько категоричным.
Odrin
03.06.2019 13:10+2Нет он именно не читаем!
Нет, он прекрасно читаем. Ваша неспособность легко разобраться с этим кодом не означает, что «насколько некачественный код продуцирует большая часть разработчиков».
— не нужно набирать тонну говноскобок
В Вашем коде 18 скобок.math_coder
03.06.2019 14:35+1Я заметил на своём опыте, а также косвенно на опыте коллег, что любой непривычный стиль написания кода кажется объективно нечитаемым и вызывает отторжение. Такое когнитивное искажение. Если некоторое время попытаться им пользоваться, несмотря на негативное отношение, искажение пропадает и можно пытаться проводить более объективное сравнение.
0xd34df00d
03.06.2019 18:59Во-первых, pattern matching может проверяться тайпчекером на полноту, а последовательность
ifов проверять на полноту сложнее.
Во-вторых, пример из статьи скучноват. Давайте мы лучше возьмём, например, красно-чёрные деревья
data Tree a = Empty | Node { color :: Color , left :: Tree a , elt :: a , right :: Tree a }
и функцию балансировки для случая вставки в левую подветвь:
lbalance :: Color -> Tree a -> a -> Tree a -> Tree a lbalance B (Node R (Node R t1 e1 t2) e2 t3) e3 t4 = Node R (Node B t1 e1 t2) e2 (Node B t3 e3 t4) lbalance B (Node R t1 e1 (Node R t2 e2 t3)) e3 t4 = Node R (Node B t1 e1 t2) e2 (Node B t3 e3 t4) lbalance color left elt right = Node { .. }
Как будет выглядеть код без паттерн-матчинга, с ифами и прочим?
Ещё бы эффектнее это выглядело, если бы в х-ле был сахар для случая, когда правые части для разных паттернов выглядят синтаксически одинаково, но тут х-ль, увы, сливает некоторым ML'ам. Запилить, что ли...
Virviil
02.06.2019 09:06Скорее всего вам в качестве внеклассного чтения следует ознакомиться с понятиями функционального программирования.
Если у вас C# основной — тогда советую crash course F#.
Судя по тому, что в мире происходит, видны явные движения индустрии в этом направлении.

Nomad1
02.06.2019 09:25Не вижу почему такие тренды и «явные движения» должны приводить к смешению двух языков в один. Если у вас есть лучшие в мире пылесос и телевизор, разве это автоматом значит, что пылесосу к месту придется 40" экран, а телевизору — мешок с мусором?
Virviil
02.06.2019 09:35И ФП и ООП служат одной цели — управлению сложностью при написании программного кода, и они естественным образом могут сосуществовать, как это происходит в десятке современных языков. В отличие от вашей аналогии)
Сможет ли C# сообщество пойти по этому пути — я не знаю. Скорее всего сможет, потому что процесс начался ещё в .net 3.5 с появление linq, в отличие от Java мира, где было легче седлать Scala чем как-то трогать саму Java.
Так что теперь вопрос только за «программистами» — будут ли они достаточно гибкими.
Nomad1
02.06.2019 09:43В одном проекте отлично могут сосуществовать .cs, .fs и .il файлы и/или библиотеки. Лично мне кажется, что пытаться слепить их все в одну сущность — откровенно неудачная идея. Время покажет, конечно.
yarosroman
02.06.2019 11:41Вы сравниваете изначально разные вещи, с различным предназначением. Для ЯП нормально взаимствовать друг у друга.

0x1000000
02.06.2019 10:43+1Нормальный паттерн матчинг — это единственное нововведение, среди пречисленных в статье, которое у меня вызывает однозначно положительную реакцию.
0x1000000
02.06.2019 11:33Хотя есть один момент, что расстраивает:
У дизайнеров было два выбора: либо молча сглатывать неохват паттерна делая default-init (иначе говоря, возвращать default(T) из свича у которого не замэтчился ни один паттерн) или же бросать исключение. Микрософт выбрали второе...
Во многих ФП языках ветка по умолчанию обязательна, и это тот третий и самый, на мой взгляд, логичный вариант.
0xd34df00d
03.06.2019 19:15Это в каких?
В хаскеле не надо, там неплохой эвристический тоталити чекер. В идрисе и агде не надо, там по построению тотальность проверяется. В известных мне диалектах ML'а тоже не надо.
0x1000000
04.06.2019 12:11Вообще согласен — такого действительно нет. Хаскель, кстати, тоже ошибку кидает
Non-exhaustive patterns in case.
И в принципе понятно почему нет, если мы перебрали все возможные варианты (например, bool: true|false), то дефолтная ветка не нужна, соответственно нельзя ее сделать обязательной на уровне языка.
Но это проблему можно (и на мой взгляд нужно) решить через предупреждение компилятора.0xd34df00d
04.06.2019 16:59Но по очевидным причинам в том же хаскеле у вас всегда будут либо false positives, либо false negatives.
В Idris тоже, например, будут, для некоторого множества функций.
math_coder
04.06.2019 13:29там неплохой эвристический тоталити чекер
Он там был неплохой, а в какой-то версии его зачем-то переписали на прямой тупой перебор всех вариантов, и он стал очень тормозной.
AntonLozovskiy
02.06.2019 09:59+3чем выше версия C# тем ужаснее становится синтаксис… хорошо хоть даже сами microsoft большинство этого ужаса не используют в примерах
IvanNochnoy
02.06.2019 11:11Это ответ автору статьи
Все-таки с неймингом у МС получается ооочень плохо, прям фееричный булшит. Сначала nullable reference types — масло масляное, ибо референсные типы являются nullable по определению
Серьёзно? Проблемы у Вас. По какому такому «определению»? Вот определение ссылочного типа в C#
В C# существуют две разновидности типов: ссылочные типы и типы значений. В переменных ссылочных типов хранятся ссылки на их данные (объекты), а переменные типа значений содержат свои данные непосредственно. Две переменные ссылочного типа могут ссылаться на один и тот же объект, поэтому операции над одной переменной могут затрагивать объект, на который ссылается другая переменная.
Где здесь упоминание о том, ссылочные типы обязаны быть nullable? Какая вообще связь между размещением объекта в куче и (не)возможностью объвлять этот тип nullable?Got_Oxidus
02.06.2019 16:35+2Возможность размещать объекты в куче — означает nullable.
Создаем ссылочную переменую и забываем проинициализировать. Что там будет храниться? Т.к. это ссылка, значит null, потому что дефолтное значение ссылки — null.
Делаем вывод, что
референсные типы являются nullable по определению
khim
02.06.2019 16:46+1Создаем ссылочную переменую и забываем проинициализировать.
Хммм. Ok.
Что там будет храниться?
Ничего, потому что программа не скомрилируется и не запустится — чем такой ответ был бы плох?
Т.к. это ссылка, значит null, потому что дефолтное значение ссылки — null.
А можно «мусок», как в C оставить. Или ссылку на какой-нибудь специальный синглтон.
Делаем вывод, что
Witch-hunter
02.06.2019 17:12Создаем ссылочную переменую и забываем проинициализировать. Что там будет храниться?
Есть языки в которых Вы не сможете забыть проинициализировать переменную ссылочного типа, если она явно не обявлена как nullable: Scala, Kotlin, TypeScript и C# 8 как пример, ваш код просто не скомпилируется.
mayorovp
02.06.2019 17:54+4На самом деле в C# нельзя забыть проинициализировать переменную даже если она nullable.
Witch-hunter
03.06.2019 00:08Нельзя, но если прочитать C#-спецификацию, то можно.
C# defines seven categories of variables: static variables, instance variables, array elements, value parameters, reference parameters, output parameters, and local variables.
Пруфлинк
Вы же не станете возражать, что забыть проинициализировать, например, instance variable можно? И при этом она будет автоматичестки инициализирована default-значением?
0x1000000
02.06.2019 11:00Помню, в ранних черновиках для “Nullable Reference Types” было совершенно здравое предложение просто добавить символ “!” ко всем полям, переменным и тд. которые не могут быть null. По сути, это был бы аналог атрибута [NotNull]. Это решало бы проблему с null ref там, где ее надо решить и не ломало бы обратной совместимости.
Witch-hunter
02.06.2019 11:48+1Оно не совсем здравое
1. В подавляющем большинстве случаев (> 90%) nullabe типы не нужны. Это означет, что все было бы утыкано воклицателными знаками, как будто программа кричит на программиста.
2. Это привело бы к тому, что программисы просто ленились бы писать (!) и делали бы все типы nullable, что способствовало бы плохим практикам
Текущее решение было тщательно продумано и обсуждено с общественностью.0x1000000
02.06.2019 12:53Я согласен, что вариант с "!" не идеален как и любое компромиссное решение, но им хотя бы можно было безболезненно начать пользоваться постепенно обновляя существующую кодовую базу.
Сейчас же, многие просто не будут включать эту опцию в уже существующих проектах потому как понять, где нужно ставить “?”, а где не нужно, зачастую очень сложно.AgentFire
02.06.2019 18:56где нужно ставить “?”, а где не нужно, зачастую очень сложно.
как это так? объясните. имхо, это же очень просто
0x1000000
02.06.2019 20:44+1Вот у вас есть существующий класс
class MyClass { public string Id; public SomeType1 Property1; public SomeType2 Property2; ... public SomeTypeN PropertyN; }
Глядя на этот класс я с большой долей вероятности могу сказать какое поле, скорее всего является, обязательным.
Какие поля являются «не обязательными» нужно выяснять разбирая код программы.
Теперь я включаю эту новую опцию, и получаю кучу предупреждений при попытке собрать проект. Дальше есть 4 варианта:
1) Забить на предупреждения (тогда зачем это все?)
2) Пометить все поля как "?" (тогда зачем это все?)
3) Отключить эту опцию (тогда зачем это все?)
4) Потрать кучу времени на рефакторинг работающей и отлаженной программы (здорово конечно, но надолго ли вас хватит).AgentFire
02.06.2019 23:18это вопрос про настройку большого старого проекта. да, здесь единственный 100% точный вариант — это просмотреть код, чтобы знать, что nullable, а что нет. (хотя по хорошему уже бы иметь какие-то маркеры, комментарии там, или атрибуты, чтобы декоративно было все видно).
но если вы не хотите тратить время на подобную модернизацию большого и старого проекта, тогда зачем вы написали этот коммент?0x1000000
02.06.2019 23:50Эта ветка начиналась с напоминания о том, что были и другие варианты как реализовать nullable ref types.
Идея помечтать обязательные поля "!" имеет обратную совместимость и не требует костылей в виде опций компилятора.
Witch-hunter
02.06.2019 23:48«Детей, конечно, нельзя убивать. Но что-то с ними надо делать». Даниил Хармс.
Вы же понимаете, что «Ошибку на миллиард долларов» так просто не исправишь? Процесс будет долгим и сложным. Если включить nullable контекст во всем проекте, то программиста завалит предупреждениями, это уже обсуждалось неоднократно. К счастью, контекст можно включать для отдельных участков кода с помощью директив, это позволит постепенно перевести проект на новые рельсы, путем постепенного увеличения кода в non-nullable контексте. Всё учтено могучим ураганом.
ckaut
02.06.2019 21:47-1Здесь проблема, что теперь над каждым полем, свойством, параметром надо дополнительно думать, может ли оно потенциально быть null. Раньше мы думали только об Nullable значимых типах, а теперь нужно вообще обо всех типах. Причем, эта настройка только проверяет, что вы сами в вашем коде не можете присвоить null, но есть огромное число фреймворков (тот же MVC), где объекты создаются им самим из, например, http запроса. Что должно быть, если свойство не null, но в запросе его нет — exception или все-таки значение null? Сейчас это будет null. Т.е. потенциально возможно, что даже nonnullable reference type все равно будет равен null. И теперь в каждом месте программы я должен об этом думать…
AgentFire
02.06.2019 23:16+1но позвольте! а как вы раньше писали код, серьезно не задумываясь о том, что, в какой то конкретный момент, вот в этом вот месте, вы планируете возвращать null, и что вызывающий код должен сделать соответсвующую проверку? или вы просто по дефолту везде ThrowIfNull писали?
а что же касается "огромного количество фреймворков", то здесь ожидается полезность фунции только если конкретный фреймворк использовал это нововведение. скорее всего, MS введет атрибут [DontCheckForNullables] для референсов разных DLL.
ckaut
03.06.2019 12:47+2Задумываться над чем, простите? Может ли объект быть null? Может, т.к. это reference type. А вот сейчас мы будем смотреть, есть ли у него «знак вопроса» или нет. Но самое ужасное пока в этом новшестве то, что runtime не гарантирует, что если вы объявите свой тип без «знака вопроса», то в нем не будет null.
Т.е. вот у нас функция принимает строковый параметр (без ?). Нужно ли проверять его на null? В текущей парадигме — да, в новой — нет. Хотя null потенциально может быть и там и там.
Текущее решение — не доделано, это костыль, чтобы улучшить проверки кода на потенциальные NullReferenceException. Но оно может привести к тому, что многие начинающие или низкоквалифицированные разработчики (коих хватает) будут считать, что в таких типах null не может быть никогда и это может привести не к уменьшению, а к увеличению этих самых NullReferenceException-ов, которые как известно, мы получаем в самый неожиданный и непредсказуемый момент (иначе бы мы их выловили бы еще на стадии тестирования).
alex_zzzz
02.06.2019 17:34+1Плюс '?' и так уже используется для nullable value types: int vs int?
0x1000000
02.06.2019 22:05+1Для Value Types, "?" — это синтаксический сахар для структуры Nullable<>:
int? = Nullable<int>
Для Reference Types, "?" — это просто подсказка компилятору + добавляется [NullableAttribute] (подсказка компилятору при испльзовании кода из других сборок)
Разница ещё в том, что в Value Types "?" логически относится к типу, а в случае с Refernce Types к переменной, полю или методу, так, что с точки зрения логики, надо было бы писать:
string myVariable? = null
a не
string? myVariable = nullApeCoder
02.06.2019 22:28+1Он и относится к типу, просто это тип анонимный. То, что тип реализован атрибутом, это уже детали реализации.
0x1000000
02.06.2019 23:02+1Не совсем понял про анонимный тип: в примере тип переменной это string и он никакой не анонимный.
mayorovp
03.06.2019 00:50Нет, тип второй переменной —
string?0x1000000
03.06.2019 10:21-1string? это не анонимный тип, это обычный string.
Под анонимными типами в C# понимается совершенно другая вещь, например:
var myVariable = new {Field1 = "Field 1", Field2 = 2};
увидев такой код, компилятор создаст тип:
class ___AnonymusXXXX { public string Field1 {get; private set;} public int Field2 {get; private set;} }mayorovp
03.06.2019 10:31Тут произошел конфликт названий, речь шла о другом виде типов. Статические типы (т.е. типы, известные компилятору) вовсе не обязаны совпадать с рантайм-типами.
Некоторые типы существуют только в исходном коде, а в рантайме полностью заменяются другими. Их-то ApeCoder и не вполне корректно обозвал "анонимными".
В языке C# уже были примеры таких типов — это
dynamic, заменяемый наobject; и кортежи, заменяемые наValueTupleс потерей информации об именах свойств. Теперь появился ещё один класс таких типов, только и всего. Но типами они от этого быть не перестали.0x1000000
03.06.2019 11:23Вот оригинальный текст:
Теперь самый важный вопрос: что же поменялось в IL? С точки зрения исполняемого кода — ничего! Но с точки зрения метаданных поменялось конечно: теперь в типе который использует nullable аннотации все типы которые являются nullable проаннотированы атрибутом [Nullable]. Сделано это по понятным причинам: чтобы потребители вашего кода могли использовать ваши аннотации.
Этот string существует и в исходном коде и в рантайме.
По сути запись:
public string? MyProperty { get; set; } = null;
это синтаксический сахар для:
[System.Runtime.CompilerServices.NullableAttribute] public string MyProperty { get; set; } = null;
Кстати, по поводу:
… заменяемые на ValueTuple с потерей информации об именах свойств
имена свойств не теряются, они сохраняются в метаданных.mayorovp
03.06.2019 11:26Каким образом написанное вами опровергает тот факт, что
string?— тип?
имена свойств не теряются, они сохраняются в метаданных
Они пропадают из информации о типе. Был тип
(foo: int, bar: string), сталValueTuple<int, string>0x1000000
03.06.2019 11:45string? это тот же тип string, между ними нет разницы
но int? это действительно другой тип — Nullable.
Это как раз та путаница, о которой я говорил в предыдущих комментариях.mayorovp
03.06.2019 11:49-1string? это тот же тип string, между ними нет разницы
Вы ходите по кругу. Почему между ними нет разницы, если для них определены разные допустимые операции (второму нельзя присвоить null)?
0x1000000
03.06.2019 12:11второму нельзя присвоить null
Очень даже можно, просто компилятор выдаст предупреждение, что эта переменная помечена как «Not Null», а вы пытаетесь присвоить эй null.
Сам тип string символ "?" никак не меняет.
Более того, если я попытаюсь использовать сборки скомпилированные в C#8 из C#7, то все поля помеченные как «string?» будут видны как обычные «string» и накаких предупреждений (или ошибок компиляции) не будет, если я попытаюсь присвоить им null.
mayorovp
03.06.2019 12:27А всегда ли это будет предупреждением, или это просто текущее состояние компилятора?
Более того, если я попытаюсь использовать сборки скомпилированные в C#8 из C#7
Естественно, что в разных языках разные системы типов.
ApeCoder
03.06.2019 14:01Сам тип string символ "?" никак не меняет.
"Тип данных (тип) — множество значений и операций на этих значениях."
Так как набор операций изменяется, то это уже другой тип.
эта штука не меняет тип String, но она обозначает тип "nullable string" который может быть проассоциирован с переменной. Так же как и int[10] не меняет тип int, а делает новый тип по int и количеству элементов.
Предупреждения — это дань переходному периоду — фактически у этих конкретно типов пока более слабый контроль, но концептуально — это тип. Поэтому и синтаксис такой
0x1000000
03.06.2019 14:21Если бы «string?» был другим типом, то требовалось бы приведение типов, но код ниже будет скомпилирован без предупреждений:
string notNullable = "value1"; string? nullable = "value2"; if(nullable != null) { notNullable = nullable; }
но зато:
int? nullable = 1; int notNullable = 2; if (nullable != null) { notNullable = nullable; }
выдаст ошибку:
error CS0266: Cannot implicitly convert type 'int?' to 'int'. An explicit conversion exists (are you missing a cast?)Witch-hunter
03.06.2019 14:36Если бы «string?» был другим типом, то требовалось бы приведение типов
Ну, не факт, это зависит от языка, скажем, в F# нельзя неявно привести Int32 к Double, а в С# можно.
А что рефлекшн говорит по поводу «string?»?DistortNeo
03.06.2019 14:43+1А что рефлекшн говорит по поводу «string?»?
Что это обычный
string. А атрибут относится не к типу, а к переменной.
0x1000000
03.06.2019 14:44По поводу Int32 и Double — это честное неявное приведение типов, которое не зависит от каких-либо предварительных проверок.
Я такое приведение могу сделать и для других типов определяя оператор «implicit».
А что рефлекшн говорит по поводу «string?»?
Ответ в статье:
Теперь самый важный вопрос: что же поменялось в IL? С точки зрения исполняемого кода — ничего!
mayorovp
03.06.2019 20:11Статические типы (т.е. типы, известные компилятору) вовсе не обязаны совпадать с рантайм-типами.
alex_zzzz
03.06.2019 02:26Есть готовый синтаксис:
int i1 = 10; int? i2 = null;
ну и нечего изобретать велосипед:
string s1 = "10"; string? s2 = null;
Кто учит язык и пока не знает, как это реализовано, тому и так нормально: суть похожая и внешне выглядит одинаково.
Кто уже знает, что там под капотом, тому тоже нормально: суть похожая и внешне выглядит одинаково, а что под капотом, он и так знает.
anaym
02.06.2019 11:48+2Поэтому он теоретически может быть отрицательным, хотя конечно в C# запись x[-1] лишена всякого смысла.
Не лишена.
Во-первых — можно перегрузить индексатор в вашем классе и корректно обрабатывать в нем отрицательные индексы.
Во-вторых, в C# массивы могут индексироваться не только с 0:
var x = (int[,])Array.CreateInstance(typeof(int), new[] { 42, 42 }, new[] { -1, 2 }); x[-1,3] = 1234;

blaka
02.06.2019 11:48А будет ли в c# аналог lateinit того же Котлина?

mezastel Автор
02.06.2019 11:56Ну пока не планируется. По сути, если вы инжектите свойство через DI, вам придется приписать к типу вопросительный знак.
blaka
02.06.2019 12:10Другое. Запрос к api возвращает json, который десериализуем в граф объектов. И хоть мы знаем, что у нас после этого будут инициализированы все свойства, приходится определять все поля nullable и потом в тысяче мест добавлять!.. Или же инициализировать свойства значениями, что в случае вложенных классов может быть очень развесисто и попросту захламляют кучу, ведь сразу после создания объекта все эти свойства будут перезаписаны.
А хотелось бы сказать компилятору «да я уверен, что там null не будет, не заставляй меня их инициализировать»mayorovp
02.06.2019 17:56Для этого всего-то нужно инициализировать свойства в конструкторе...
blaka
02.06.2019 18:15А в чем отличие? Ну кроме места где будет инициализация? Результат тот же.
ApeCoder
02.06.2019 20:01Если инициализировать в конструкторе есть гарантия, что в уже созданном объекте не будет null, иначе состояние, когда есть объект и там null — допустимо (в процессе десериализации)
blaka
02.06.2019 21:26Вы не понимаете. Хватает ситуаций «я уверен, что на момент чтения оно не будет null, поэтому не заставляй меня делать его nullable, раз уж у компилятора не хватает ума самому это вычислить». В котлин для этого есть модификатор lateinit (по названию видно что он делает). Это и различные dto без конструкторов, методы вида Init, на границе с UI тоже пригождается и на границе с жавой (там ведь тоже никакого null safety). Вот прям такая же ситуация и с шарпом — множество обычного кода, который знать не знает про nullable
Инициализация в конструкторе это костыль
1. Я уже говорил, что эта инициализация просто нагружает GC лишний раз. Можно сказать что это короткоживущие объекты, но есть пункт 2
2. Может быть совсем не просто инициализировать свойство, которое суть сложный объект, да еще с приватным/интернал конструктором (сериализатору это без разницы, а вот вы будете в тупике)
3. И даже если можно, то в случае проблем с десериализацией вы можете получить неконсистентное состояние (новые данные + бесполезное дефолтные)
А теперь про гарантии. Вдруг десериализатор не заполнит некоторые свойства. Сравните:
а) В случае lateinit я просто сделаю проверку на null всех свойств 1 раз (и все) после десериализации. Я выполню гарантии в рантайме и у меня есть способ сказать компилятору «я сам».
б) в случае «дефолтные в конструкторе» я не смогу отличить что новое, а что старое. Мне придется делать полный валидатор, что уже перебор. Также он может быть невозможен, если значение свойства не отличить — и тогда придется все делать nullable. А это приведет к тому, что в 1000 мест мне придется проставлять!
Ожидалось, что шарп не будет изобретать свое, а возьмет удачные решения с других языков, но он взял только базовое и это явно недостаточно.ApeCoder
02.06.2019 22:33Возможно, он просто не успел. В Котлине это сразу было или потом добавили?
Логически правильно тогда либо не позволять создавать объекты такого типа никак кроме как десериализацией (и допустим вручную, но с заполнением всех полей). Либо десериализация возращает тип, который знает, что все поля заполнены. Хотя наверное, так все вообще сложно будет.
blaka
02.06.2019 23:41Возможно и не успел. Поэтому и спросил. На гитхабе сложно следить где что там решили, да и часто это просто болтовня, а не «решили».
Пример реальной попытки: сериализатор требует пустого конструктора и заполняет только те свойства, что может заполнить (причем через internal сеттеры). Если не заполнены, то это нештатная ситуация и простой валидатор проверяет на null зная, что ни одно поле не может быть null. Сложный валидатор невозможен — ему тут не место. И все работает, все хорошо, только фатальный недостаток — не использует новых фич
Пробую #nullable. Инициализация дефолтными значениями не прошла. Сразу поломался валидатор на незаполненность, а больше ничего и не проверить. Попытка обвесить модельки #nullable disable тоже ничего не дало. В итоге сделал свойства моделек nullable и начал массово (реально в сотнях мест) проставлять! но на полпути задался вопросом «а зачем?»
Код остался прежним, но я получил требование в клинтском коде писать! (и необходимость помнить, что! обязателен, ведь non-null гарантирован логикой, nullable из-за компилятора), а вот выгоду я увидеть не смог
и придумать как переделать, да чтобы не городить жуткие костыли из-за слабости поддержки nullable в языке, я тоже не смог, поэтому вернул все обратно.Bronx
03.06.2019 00:16По-идее, клиентский код (в смысле business logic) не должен видеть все эти DTO, т.е. по хорошему у вас в доменной модели должен быть тип (скажем,
class Person{}), который обеспечивает все гарантии nullability и прочего, и который конструируется из DTO (скажем,class PersonDTO{}) имеющий пустой конструктор, nullable поля и ноль гарантий, т.е. простой мешок пропертей. Валидация входных десериализованных данных происходит один раз в конструктореPerson(PersonDTO dto), а дальше гарантии распространяются через этотPerson.blaka
03.06.2019 04:13Все зависит от точки зрения. Ваша цепочка выглядит примерно так:
--> json --> десериализация в PersonDTO --> Person(PersonDTO dto) -->
«десериализация в PersonDTO» может быть библиотекой-клиентом к некому апи, которую клиентский код может использовать. Она, можно сказать, транспортный слой, который при этом ничего не знает про business logic. И нормально, что этот слой валидирует полное получение данных, хоть и не может валидировать их суть. Я получаю ошибку сразу «fail fast», и к тому же на уровне, где она произошла.
Если я получаю из api погоду в виде иммутабельного объекта Weather c 3мя свойствами «город, температура, влажность», то рассматривать Weather как dto и создать WeatherModel, или просто использовать как есть? — каждый решает сам, но в случае «использовать как есть» у нас все равно есть гарантия транспортного слоя, что «город не null» и «температура настоящая, а не дефолтная»
И если переделка под nullable привносит только необходимость прописывать восклицательные знаки (или же отказ от проверок транспортного слоя), то я лучше откажусь от nullableBronx
03.06.2019 08:38И нормально, что этот слой валидирует полное получение данных, хоть и не может валидировать их суть.
Ну вот я собственно и сомневаюсь в том что транспортный слой должен давать какие-то гарантии модели, помимо типа и формата данных (число, строка, дата, объект, массив и т.п.). Это как бы не его роль. Его роль — тупо сконвертировать данные из одного представления в другое "as is" и дальше дать решать бизнес-слою, полные это данные или нет. Может оказаться, что ему и не нужна абсолютная полнота, что он терпит частичные данные, и если у Weather не будет температуры, то и фиг с ней, он её не использует.
Тем более что частичные DTO — это распространённый метод обновления лишь некоторых выбранных значений вместо посылки полной модели..
blaka
03.06.2019 12:46Ну это мы в сторону ушли (моя вина). Не должен транспортный давать гарантии модели. Он должен давать гарантии получения данных «не потерялось и дошло как надо». Но мы ушли в обсуждение архитектуры, а ведь проблема куда проще.
Речь идет о сериализаторе. К нему есть требование дать гарантию, что он заполнит все поля в классе, тип которого ему передадут для материализации (и они не будут дефолтными). Это у него постусловия такие. И сериализатор достаточно глуп, чтобы отследить это прямо в процессе разбора данных. Приходится проверять постусловием
Эти постусловия четко отражены в спеке и следуя «концепции баррикады» можно не писать дополнительные проверки на это в клиентском коде и не получить NRE.
и с #nullable в их текущей реализации выбор очевиден
1 инициализировать дефолтные и поломать постусловия, от чего пострадает клиентский код (breaking change) — и все это с нулевой выгодой
2 заставить в клиентском коде проставить везде "!" и заставлять в новом коде это писать — и снова выгоды не вижу
3 оставить все как есть.
Bronx
03.06.2019 20:53Сериализатор говорит: у меня
Weather.Cityвсегда не null. И тут приходитHTTP PATCHс частично заполненным JSON, в котором нет поляcity(потому что на клиенте оно не менялось). Какова реакция сериализатора? Выкинуть исключение, потому что, по мнению сериализатора, безcityэтих данных недостаточно для работы? А с чего он взялся решать такие вопросы? А бизнес-слой считает, что ему данных хватает, но между клиентом и ним сидит чересчур умный сериализатор и не даёт данным дойти.
Это у него постусловия такие.
Постусловия можно поменять. Может вы имели в виду тех-задание, против которого нельзя возразить и ничего нельзя поменять? Ну да, с таким тех-заданием придётся выкручиваться.
blaka
03.06.2019 21:47+1А с чего он взялся решать такие вопросы
Именно так. Конечно можно сказать, что не дело сериализатора проверять заполненность и пусть проверяет уже на месте. Но если апи четко объявляет, что такого не будет (спека), то нарушение постусловия означает, что система работает неправильно.
Допустимо ли это и пропустить дальше или упасть «fail fast» зависит от приложения. Все эти «fail fast» обычно все исчезают в процессе разработки и тестирования. И если далее такое будет, то это ну совсем нештатная ситуация, которая требует немедленного внимания, потому что логике быть не должна ни в коем случае.
И да, поле с возможностью null будет nullable (или помечено аттрибутом, раз уж #nullable не зашел)
Постусловия можно поменять
Нельзя. Если имеется код, который завязан на контракт (спеку) кода сериализации, то ничего менять уже нельзя.
зы: конечно вы правы про то, что «каждый должен заниматься своим делом». Но подход fail-fast себя оправдывает, если ошибки, которые он ловит, можно починить до релиза. Если же это сервис, который должен быть устойчивый ко всем «а что если», то там предусматриваются все варианты, а не «зови программиста»Bronx
03.06.2019 22:22Так как у вас на выходе "сериализатора" не DTO, а фактически частично валидированные модели с частичными гарантиями (и у вас выходит уже не совсем сериализатор, а целый API), то если вам хочется донести эти гарантии до пользователя, вам придётся делать промежуточный слой из настоящих DTO, например:
JSON --> JObject --> new Weather(JObject dto)
И тогда Weather может спокойно сделать свои поля non-nullable, а все проверки держать в своём конструкторе (а если валидация сложная и в один конструктор не влазит, то в фабрике).
0xd34df00d
04.06.2019 01:30Я, наверное, упустил контекст, но зачем вся эта ерунда, если прямо сериализатору можно сказать об ограничениях на значения через типы? Если там поля может не быть, то, значит, тип поля —
Maybe a/std::optional<T>/etc.Bronx
04.06.2019 04:51В C# не завезли Optional/Maybe из коробки :(, поэтому популярные библиотеки сериализации работают либо со строго-типизированным POD через рефлексию, либо создают
dynamic(объект "динамического типа", который создаётся в рантайме — примерно какObjectв JavaScript), либо выдают значения через какую-нибудь кастомную обёртку вроде упомянутого NewtonSoftJObject. Последние два способа — это фактическиDictionary<string,object>под разными соусами, и наличие/отсутствие значения проверяется через наличие/отсутствие ключа. Первый способ — более строгий, но безOptionalв стандарте приходится извращаться либо со "специальным значением" (0, "", null, default(T)) в случае отсутствия поля, либо вводить дополнительное булево свойство вроде:
[XmlElement(IsNullable = false) public string City; [XmlIgnore] public bool CitySpecified;
Такая вот попоболь.
DistortNeo
04.06.2019 09:49Не очень понял, за что минус. Конечно, вы можете написать свой Optional и свой сериализатор (как я сделал для своих задач), но это уже велосипедостроительство. Будет сильно лучше, если эти типы будут присутствовать в стандартной библиотеке в пространстве имён System.
0xd34df00d
04.06.2019 17:00Я вообще не могу рассуждать о C# и .NET, но для своего ORM'а на плюсах я сделал обёртки типа
PKey,Unique,NotNullи подобные, которые движку сообщают всю нужную семантику.
Но за что минус, я тоже не понимаю.
ApeCoder
04.06.2019 22:20Чем именно вот это https://github.com/microsoft/referencesource/blob/master/mscorlib/system/nullable.cs отличается от option?
DistortNeo
04.06.2019 22:30Тем, что
where T : struct.ApeCoder
05.06.2019 07:15Ну, а для ссылочных типов null есть. Фактически для них только Option был до 8.0

ckaut
02.06.2019 12:18+1Появление var, lambda функций, linq, nullable VALUE types, tuples, nameof, async await, $"..." — как же это все было круто! Благодаря этим и многим другим фичам C# сегодня — это, на мой взгляд, лучший язык программирования.
Но Nullable Reference Types — это какой-то перебор и шаг не туда.
Это очень странное решение, которое выливается в множество неочевидных нюансов, включая обратную совместимость с существующим кодом, отсутствие поддержки в runtime (хоть это и обещают сделать в следующих версиях, интересно как?) и многое другое. Уже сейчас, когда новой версией языка по сути еще никто не пользовался, это нововведение уже вызвало некий раскол среди разработчиков, т.к. плюсов и минусов у этого решения хватает.
Интересно, что Nullable Value Types (int?) такой реакции не вызывали, они очень органично «зашли» в язык.
blaka
02.06.2019 12:30+1Nullable Reference Types — то, что должно быть изначально. В котлине он изначально и там с этим очень неплохо. А вот в c#… прямо сейчас я чиню очередной NRE, причем в библиотеке, а ведь его могло бы и не быть, будь от этого защита.
и «поддержка в runtime» не нужна. Ведь основная задача этой функциональности — позволить на этапе написания кода избегать NRE с нулевой стоимостью во время выполнения.
Просто «поздно решили внедрить» и поэтому приходится делать это костыльно
lorc
02.06.2019 13:14Undefined behavior в C — это совсем не то. Это когда are[-1] в коде может привести к чему угодно — от вычитывания любого элемента из массива, до восстания SkyNet.
У вас же — возможно surprising behavior, но ни как не undefined.
mezastel Автор
02.06.2019 16:38Строго говоря вы правы, не спорю. Но результат один: придется дебажить.

KvanTTT
02.06.2019 16:02+3После прочтения поста и комментов, создалось впечатление, что комментаторы — профессионалы, которые конечно же прочитали все треды по обсуждению новых фич на гитхабе и не хуже разработчиков знают какие новые фичи нужны в C# и какой синтаксис у них должен быть, который не повлияет на обратную совместимость.
vortupin
02.06.2019 18:13-3Это вполне нормальное явление на Хабре: люди, не имеющие возможности приобрести даже самый дешевый автомобиль от «Tesla», долго и со смаком рассуждают о преимуществах Model X, или«учат» Илона Маска, как нужно вести бизнес, или делать ракеты. А уж сколько появляется «экспертов» в комментариях любой «болтологической» статьи (будь-то про job interview, жизни за рубежом, seniors vs juniors etc.)…
mezastel Автор
02.06.2019 22:15+4Ну, люди пишут в соответствии с тем фактом, что им с этими фичами работать.
vortupin
03.06.2019 04:46-1Ой, я вас умоляю, «работать»… Если человек реально заинтересован в какой-то новой фиче, уверен в своей правоте, и может эту правоту доказать не «минусованием кармы» оппонента (на гитхабе анонимные пакостники не в почете), а аргументированным feature request-ом, а, еще лучше, pull request-ом, то он не будет «чесать» свое ЧСВ тут, в комментариях — что, по сути, занятие бессмысленное и полностью бесполезное. Но я глубоко сомневаюсь, что кто-то из здешних комментаторов выдал хоть один PR в "репу".
Xandrmoro
02.06.2019 16:20+1Дефолтные реализации интерфейсов — это, на самом деле, почти миксины. Именно для этого создавался пропоузал, и это абсолютно замечательная фича.
А вот, например, паттерматчингом я никогда не пользовался (разве что is null вместо == null) и вообще не вижу зачем он, но мб зачем-то и нужен.mezastel Автор
02.06.2019 16:39+1Поведенческие миксины уже существуют давно как методы-расширения-на-интерфейсах.
alex_zzzz
02.06.2019 16:30+1хотя конечно в C# запись x[-1] лишена всякого смысла
Если речь только только про массивы, то да. Если про C# вообще, то нет. Смысл зависит от того, что есть x. Самописный индексатор можно делать всё что хочет. Даже без самописных индексаторов я собственными руками писал x[-1], где x был указателем.
alex_zzzz
02.06.2019 16:35Встроенные типы, такие как массивы или строки, конечно же поддерживают индексер (operator this[]) для типа Index, так что смело можно писать
var items = new[] { 1, 2, 3, 4, 5 }; items[^2] = 33; // 1, 2, 33, 4, 5
Проверяю:
var items = new[] { 1, 2, 3, 4, 5 }; Print(items); items[^2] = 33; Print(items);
0) 1,2,3,4,5 1) 1,2,3,33,5mezastel Автор
02.06.2019 16:40Смею предположить, что вы проверяете на VS2019 RTM. А надо на Preview.
alex_zzzz
02.06.2019 16:48Microsoft Visual Studio Community 2019 Preview Version 16.2.0 Preview 1.0
NET Core 3.0.100 Preview 5
HavenDV
03.06.2019 10:52-1Есть статья на английском хабре, там сказано:
There is no compatibility guarantee from one C# 8.0 preview to another.
In short, if you use C# 8.0 preview in Visual Studio 2019, some features and behavior may change between now and when C# 8.0 fully releases.
Источник: habr.com/ru/company/microsoft/blog/443000
mentin
03.06.2019 08:33+2Это, кстати, соответствует майкрософтовской документации (см мой коммент выше), что ^0 это индекс за-концом массива (а не последний как в статье), ^1 это последний элемент, а ^2 предпоследний.
HavenDV
03.06.2019 18:39Эти результаты правильны согласно официальной документации:
Для любого числа n индекс ^n совпадает с sequence.Length — n
Возможно, в предыдущих Preview было иначе.
alex_zzzz
02.06.2019 16:43Представьте массив x = {1, 2, 3}. Если взять x[0..2] вы получите {1, 2}, а вот если взять x[..2] или например x[..], вы получите {1, 2, 3}.
Проверяю:
// Представьте массив x = {1, 2, 3}. var x = new[] { 1, 2, 3 }; // Если взять x[0..2] вы получите {1, 2} Print(x[0..2]); // а вот если взять x[..2] или например x[..], вы получите {1, 2, 3}. Print(x[..2]); Print(x[..]);
0) 1,2 1) 1,2 2) 1,2,3

danfe
02.06.2019 17:44+1дизайнеры всех современных языков «продолбали» как минимум несколько важных аспектов [...] zero-terminated strings, когда длина строки вычисляется за О(n).
Ну, не так уж и всех, а лишь тех, кто решил не заморачиваться с нормальным строковым типом и обойтисьchar[]. В любом приличном современном языке (да и не только современном, вспомните тот же Паскаль) строки — один из базовых типов, который неплохо оптимизирован (во всяком случае, для более-менее коротких строк никто длину не вычисляет).
Ascar
02.06.2019 17:50-2Норму по нововведениям выполнили. Мне кажется скоро весело придут к обертке над ссылочными типами которая не может быть null. CanNotBeNullable<>

mjr27
02.06.2019 21:44+1В принципе, попробовал все перечисленные фичи.
Мнение:
- nullable — сделано совсем через задний проход. Если по дефолту сделать nullable, в происходящем появится хоть какой-то смысл. Имхо сильно на любителя.
- Index & Range — звучит безумно, но пальцы привыкают быстро.
- Default interface members — минимум 90% разработчиков это не понадобится никогда. И слава богу.
- Pattern matching — ура. просто ура.
blaka
02.06.2019 22:00Если по дефолту сделать nullable
Ну так оно и так во всем существующем коде по дефолту nullable. И все эти годы так было. И именно это «по дефолту null и инициализации не было и никто не подсказал про забытую инцицализацию» и является основной причиной ошибок NRE.
Проблема NRE в том, что вроде есть стектрейс, но он бесполезен, потому что я не знаю через сколько уровней и откуда пришла переменная, а воспроизвести не получается. А так если бы каждое место не допускало null, то мне бы еще компилятор указал где это и это было бы далеко от места реального NRE
А так лучше бы они records сделали — крайне полезная вещь.mjr27
03.06.2019 09:42Лучше бы они records сделали
Это да. Я очень расстроился, когда понял, что все слухи о них оказались слухами.А по поводу nullable моя претензия заключается в том, что данные, приходящие из legacy (#nullable disable) кода, почему-то считаются non-nulable, хотя обычно это не так. И за счет этого мечта о "прощай, внезапный NRE" остается мечтой.
alex_zzzz
02.06.2019 23:06У меня реакция такая:
- Nullable ? Ура! Наконец. Теперь ещё период всеобщей адаптации пережить и будет счастье.
- Index & Range ? Кому-то реально не хватало? Ну ладно, пусть.
- Default interface members ? whatever
- Pattern matching ? За if (x is string s) большое спасибо, а для чего всё остальное?
- Switch expressions ? Спасибо.
- Async streams ? Может быть, когда-нибудь.
- Using declaration ? Кое-где бы пригодились, а то иначе некрасиво.
- Static local functions ? Предположим, кому-то это принципиально.
- Disposable ref structs ? Кому-то точно это принципиально.

IL_Agent
03.06.2019 00:42Как же жаль, что Котлин так и не запилили под дотнет (
alex_zzzz
03.06.2019 01:07Родному F# трудно играть на одном поле с C#. Всё взлетает, взлетает, никак не взлетит. Последний недостаточно плох, чтобы с него дёргаться. Котлин, на сколько я его себе представляю, это что-то а-ля C# или нечто среднее между C# и F#, лишь бы забыть про Яву.
Котлин под дотнет мог бы быть способом перетащить людей с платформы Java на Net. Кому-то это надо?
ApeCoder
03.06.2019 10:04Я думаю, также C# недостаточно плох по сравнению с Котлин тоже. Так что котлину придетбя бороться с C# для которого есть большая поддержка
mezastel Автор
05.06.2019 01:16И на другие языки, например Scala, тоже были надежды что сделают под CLR. Но если это делать, придется конкурировать с C#-ом, а это практически невозможно, т.к. по сути это конкуренция с МС со всеми вытекающими.

ad1Dima
03.06.2019 05:51Про индексы, и прочее. Там все немного поменялось же:
In the previous preview, the framework supported Index and Range by providing overloads of common operations, such as indexers and methods like Substring, that accepted Index and Range values. Based on feedback of early adopters, we decided to simplify this by letting the compiler call the existing indexers instead. The Index and Range Changes document has more details on how this works but the basic idea is that the compiler is able to call an int based indexer by extracting the offset from the given Index value. This means that indexing using Index will now work on all types that provide an indexer and have a Count or Length property. For Range, the compiler usually cannot use an existing indexer because those only return singular values. However, the compiler will now allow indexing using Range when the type either provides an indexer that accepts Range or if there is a method called Slice. This enables you to make indexing using Range also work on interfaces and types you don’t control by providing an extension method.

RomanPokrovskij
03.06.2019 16:11Знатоки, напишите статью, и поделитесь пожалуйста примерами до чего дошел Pattern Matching в F# или других языках развивающих эту концепцию? Хотелось бы понять «о чем мечтает команда разработчиков C#» и к чему стремится прогресс. И конкретно, а где нибудь уже дошли до разбора выражений языка средствами языка?
Отдал был часть кармы если бы Хабр позволял «краудфайндить» на статьи.ApeCoder
03.06.2019 16:20F#
RomanPokrovskij
03.06.2019 23:58Документация конкретной реализации не дает виденья. У меня остался возможно наивный вопрос, вот эта фича развивается от релиза к релизу, так что ее двигает и куда ее двигают? Как из заявленной решаемой задачи «разложения данных на составные части или извлечения информации из данных различными способами» — например пусть это будет конкретно Natural Language Processing — вырастает запрос на pattern-matching? Никак не вырастает потому что программеры работающие с этой задачей (NLP) работают с функциями своих NLP шных библиотек и мыслят в них. Зачем им новые statementы?
Если бы проще заявили «немного полезного синтаксиса над рефлекшном» я бы не мучился, а так остается недоумение — что я упускаю.
math_coder
04.06.2019 03:33При чём здесь рефлекшен?
RomanPokrovskij
05.06.2019 00:12Еще предстоит разобраться что было с головой, что так повело рассуждение. Ошибка. Спасибо что обратили внимание. Сейчас бы написал «немного полезного синтаксиса вокруг условных присваиваний».
0xd34df00d
04.06.2019 17:06Знатоки, напишите статью, и поделитесь пожалуйста примерами до чего дошел Pattern Matching в F# или других языках развивающих эту концепцию?
Хаскель — pattern guards (очень удобно, кстати, регулярно пользуюсь), view patterns (тоже очень удобно, но реже), pattern synonyms (удобно при написании eDSL'ей).
Idris — dependent pattern matching, или та же идея чуть более формально.
И конкретно, а где нибудь уже дошли до разбора выражений языка средствами языка?
Template Haskell?
Elaborator reflection (но это я пока ещё не осилил)?
mezastel Автор
05.06.2019 01:18У меня есть один продукт, написаный на F# с использованием активных рекурсивных паттернов. Посли полгода я не могу читать свой собственный код. И этим все сказано. Фичи действительно очень мощные, но им грош цена если они порождают write-only code.
IvanNochnoy
05.06.2019 14:34И этим все сказано
Что именно сказано? Что Вы пишете такой код, что не можете его прочитать?
Feihoa
Так и хочется сказать «астанавитесь». Я конечно люблю c#, но что-то становится уже страшновато)
Source
Да фичи то ещё ладно, а вот синтаксис для них они выбирают какой-то слишком странный.
В
MiddleName?[0]знак вопроса ни к селу, ни к городу, семантики никакой. Сделали бы просто, что для переменной Nullable-типа вызов любого метода возвращает null обёрнутый в Nullable-тип возврата, если в самой переменной был null.^0как автор в статье написал, лучше бы для возведения в степень использовали.А тут можно было бы
~0Зачем для этого вообще отдельный термин? Это же самый обычный паттерн-матчинг с нормальной деконструкцией и биндингом сматченных значений в переменные.
Можно было бы обозвать "Pattern matching restrictions have been eased."
mentin
Я думаю с операторами просто — унарный оператор
`~`уже есть. Так что использование ~0 создало бы неоднозначность в грамматике — то ли это индексирование с конца, то ли побитное инвертирование, как раньше. Поэтому добавили унарный оператор^. Он, кстати, никак не мешает добавить позже бинарный оператор^для возведения в степень.Знак вопроса уже используется в подобных местах, скажем
x ?? -1, возвращает х, если тот не пустой, или -1. Так же логично сделалиx?.foo, x?[0]. Менять поведение по умолчанию и семантику существующего кода не хотят, ввели новые операторы.v0s
Ну кстати
~0для интов как раз отлично бы работал %)Флип всех битов как раз даёт
~0 == -1,~1 == -2и т.д., можно было бы сделать отрицательные индексы для "с конца", таким образом сохранить соместимость с питонистами, а остальным объяснить что надо~0юзатьDistortNeo
Вы исходите из ложного предположения, что индексы начинаются с нуля.
А ещё возможны приколы, когда вместо оэтдаемого IndexOutOfRangeException будет какой-то другой функционал.
v0s
А когда они не с нуля? (в шарпах не шарю)
Jesting
Можно создать массив с ненулевым начальным индексом (например начинающийся с 1 и длиной в 2 элемента) Array.CreateInstance в помощь. Тогда Exception будет бросаться одинаково при доступе к 0 и к 3 элементам.
v0s
А что тогда будет делать ^0 ?
Source
Про унарный оператор
~v0s меня уже опередил. С этим как раз ничего менять не пришлось бы. Технически бинарный оператор^добавить то можно, но вряд ли одному символу станут придавать настолько разный смысл в зависимости от кол-ва операндов.А
x?.по мне всё равно дико смотрится, особенно для тех, у кого есть опыт работы с Ruby, где существует совершенно логичная конвенция, чтоx?всегда возвращает boolean, ну типаactive?вместоisActive. Думаю, всё равно в итоге нормальную Maybe монаду завезут и эти? после x станут deprecated.ad1Dima
?.. Присутствует и в других языках программирования и делает то же самое
yarosroman
В kotlin подобный же синтаксис. А больше всего раздражает там, когда вызов или свойство класса из java библиотеки идёт, везде эти вопросы тыкать надо. По мне, ну не вылетает исключение, но все равно, при необходимости выполнение идёт не в то русло и попробуй отловить. Спорная это вещь. И думаю они явно на kotlin смотрели.
Prototik
Вы давно не смотрели в kotlin. Давно же появились платформенные типы —
String!, которые могут использоваться как nullable, как и non-null.Acuna
Извиняюсь, а это зачем? Чтобы нельзя было засунуть null в non-null? Но если он «как nullable, как и non-null», значит в него в любом случае можно сунуть null? Или это у них такой аналог аннотации @NonNull? Не знаю, по мне дак аннотации намного нагляднее, чем вспоминать что означает тут восклицательный знак, то ли указатель какой, то ли факториал вообще.
Prototik
Не, этот тип применяется только когда nullability неизвестна (когда дёргаем java код, на котором нет никаких аннотаций). Тогда компилятор позволит работать с этим типом как с nonnull, но везде натыкает проверок на null для early null propagation. Т.е. когда есть аннотации — то в Kotlin всё будет хорошо и везде будет нужный тип. Если нет (старый код или просто не заморачивались) — то можно не писать портянки из всяких ?., ?:,!!! и прочего и просто писать код, не столь безопасный (хотя если где-то прилетит null, где вы его не ожидали — то вылетит как можно раньше, а не когда этот null расползётся по всем структурам), но без манускриптов из символов и просто красивый.
Acuna
Не понимаю, почему его все так любят? Прям реально в комментах пишут какой Котлин классный. Как будто-бы до этого они ни на чем не писали и это их первый язык.
Prototik
Как и со всеми языками — нужно пробовать, желательно не на хеллоуворлдах.
А вообще он решает много попоболи из Java, простой (относительно какой-нибудь Scala например), фичастый (корутины, инлайновые классы вон завозят потихоньку и т.п.), ну и с недавних пор мультиплатформенный (jvm, js, native).
Не помню кто сказал (кажется это был Андрей Бреслав), когда пишешь на Котлине — прям на душе приятно. Ты не пишешь очередные геттеры, а пишешь код.
ad1Dima
Потому что в андроиде ооочень старая Java. А Котлин — хороший современный язык.
Acuna
Ну я думаю язык надо выбирать в плане синтаксиса, а не новизны.
ad1Dima
и андроидовская джава очень многословна и не отвечает требованиям к современным языкам.
NeoCode
В D вроде бы используется arr[i] для индексирования с начала и arr[$-i] для индексирования с конца. То есть внутри контекста скобок доступна длина массива в виде символа $.
DistortNeo
~0вернёт обычныйint. Это будет являться проблемой, т.к. усложнит индекацию и поломает существующий код, где индекс не является неотрицательным и начинается с нуля. Должен возвращаться объект типаIndex, чтобы всё работало корректно.Оператор ^ уже используется для операции XOR. Его нельзя использовать для возведения в степень. Так как унарного ^ не было, его решили использовать таким образом — всё в порядке.
А для возведения в степень разумным выглядит такая конструкция:
a ** b.KvanTTT
С опретором
**тоже могут быть проблемы: Proposal: Exponentiation operator.DistortNeo
Ничего страшного. Указатели в C# — штука крайне редкоиспользуемая, чтобы отказываться от такого функционала.
alex_zzzz
Как минимум по бюрократическим причинам. В рамках C# 8.0 ведётся работа над некоторой подфичей Pattern Matching. Чтобы при разговорах о ней не размахивать руками в воздухе или не ссылаться на неё по номеру (Feature #5982), необходимо было придумать какое-то человеческое название. Конечному пользователю языка, если он на github.com/dotnet/csharplang не ходит и спецификации не читает, это название ненужно.
Source
Но название фичи ведь должно кратко описывать её суть, а не просто из случайных слов состоять? А тут в чём рекурсивность? Тут скорее "Nested deconstruction"
alex_zzzz
Можно написать паттерн внутри паттерна внутри паттерна внутри паттерна… Выглядит, правда, адски, как ни форматируй.
Можно назвать nested, можно назвать recursive ? примерно одинаково.
ApeCoder
Потому, что на вопрос "из чего может состоять паттерн?" среди можно ответить "паттерн" — т.е. он как бы определен через самого себя.
Source
Рекурсивность появится если паттерн будет состоять из самого себя, а не просто из набора других паттернов.
Если бы было так:
то можно было бы сказать, что есть рекурсивный паттерн, который соответственно запускает рекурсивный поиск совпадения на любую глубину вложенности.