
Кроме это, я постараюсь вскользь рассмотреть общие правила оптимизации кода и некоторые ошибки на которые стоит обратить внимание. Ещё расскажу про инструмент, который помогает не только в профилировании, но и «из коробки» собирает кучу базовых метрик о производительности вашего приложения (и надеюсь, вы дочитаете этот пост до конца).
Первым делом определим, что же такое производительность фронтенда, а затем уже перейдем к тому, как её измерять. Итак, как я уже сказал, мы не будет мерять некие ops/sec, нам нужны реальные данные, которые бы могли ответить на вопрос, что именно происходит с нашим проектом на каждой стадии его работы. Для этого нам понадобиться следующий набор метрик:
- скорость загрузки;
- время первой отрисовки и интерактивности (Time To Interactive);
- скорость реакции на действия пользователя;
- FPS при прокрутке и анимациях;
- инициализация приложения;
- если у вас SPA, то надо мерить время, которое тратится на переход между маршрутами;
- потребление памяти и трафика;
- и… пока хватит.
Всё это базовые метрики, без которых невозможно понять, что именно происходит на фронтенде. И не просто на фронтенде, а в реальности, у конечного пользователя. Но чтобы начать собирать эти метрики, для начала нужно научиться их измерять, поэтому давайте вспомним, какие способы есть для аналитики производительности.
Первое, с чего стоит начать, — это конечно Performance API. А именно performance.timing, через который вы можете узнать, сколько время заняло у пользователя открытие вашего проекта. Но Performance API покрывает только часть метрики, остальные нужно будет измерять самому, и для этого у нас есть следующие инструменты:
| Плюсы | Минусы | |
|---|---|---|
| console.time('label') | Работает из коробки. Выводится в консоль. Отображается в DevTools -> Performance -> User Timing. |
Вывод только в DevTools, на сервер никак не отправить (т.е. нет возможности получить значение для последующей аналитики). Требует console.timeEnd c изначальным label.Нет цветового кодирования. Нет группировки (что-то типа console.group / groupEnd). |
| performance.now() | Полный контроль над началом и концом. Можно отправить на сервер. |
Нет отображения в консоли. Нет отображения в DevTools -> Performance -> User Timing. Нужно таскать переменную «начала». Нет группировки. |
| performance.mark / measure | Полный контроль над началом и концом. Можно отправить на сервер. Отображается в DevTools -> Performance -> User Timing. |
Нет отображения в консоли. Чтобы что-то померить, надо задать три уникальные метки и вызвать два метода, а по-хорошему нужно ещё performance.clearMarks и performance.clearMeasures, что делает использование крайне неудобным.Нет группировки. |
PerfKeeper
- Полный контроль над началом и концом.
- Можно отправить на сервер.
- Выводится в консоли.
- Поддерживает DevTools -> Performance -> User Timing.
- Есть группировка.
- Есть цветовое кодирование (а также единицы измерения, т.е. измерять можно не только время).
- Поддерживает расширения.
Сейчас я не буду расписывать тут API, не для этого писал документацию, да и статья не об этом, а продолжу про то, как собирать метрики.
Скорость загрузки страницы
Как я уже говорил, скорость загрузки вы можете узнать из performance.timing, который позволит узнать полный цикл от начала загрузки страницы (время на резолв DNS, установку HTTP Handshake, обработку запроса) и до полной загрузки страницы (DomReady и OnLoad):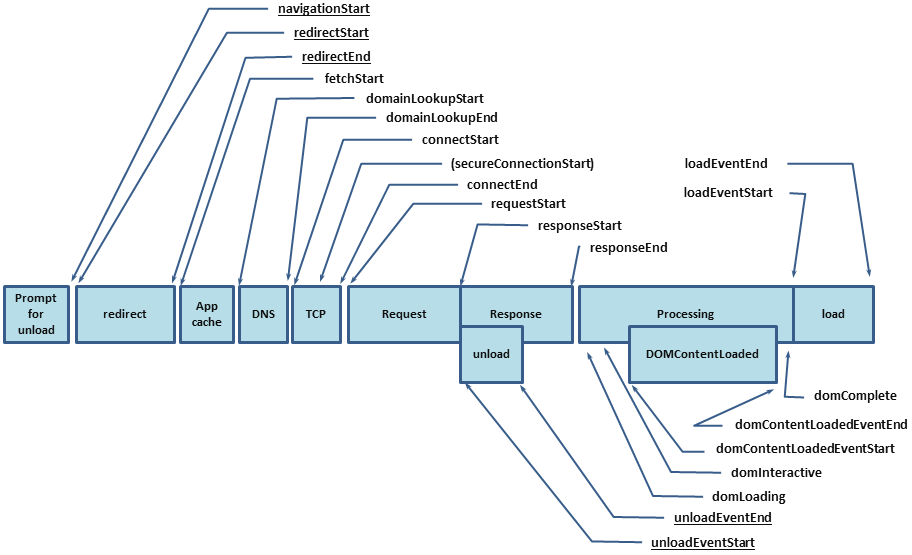
В итоге должен получиться следующий набор метрик:
 |
 |
 |
Но этого недостаточно, мы получили только базовые значения и до сих пор не знаем, что же именно заняло столько времени. А чтобы это узнать, надо нашпиговать и HTML метриками.
Как я уже говорил, примеры я буду показывать с использование PerfKeeper, поэтому первым делом инлайним в
<heаd/> сам PerfKeeper (2,5 Кб) и дальше:
В результате в консоли вы увидите вот такую красоту:
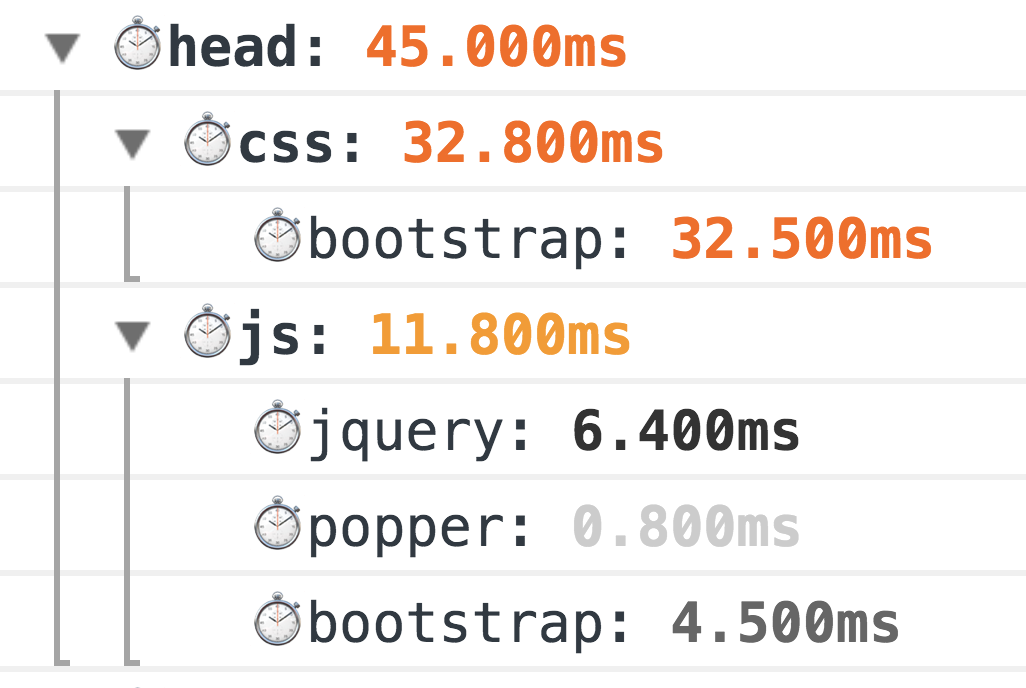
Это классический дедовский способ замера, 100 % работает. Но мир не стоит на месте, и для более точных измерений у нас теперь есть Resource Timing API (а если ресурсы находятся на отдельном домене Timing-Allow-Origin вам в помощь).
И тут стоит поговорить о классических ошибках при первоначальной загрузке страницы, а именно:
- отсутствие GZip и HTTP/2 (да-да, такое до сих пор встречается);
- необоснованное использование шрифтов (бывает шрифт подключают только ради одного заголовка или даже номера телефона в футере 0_o);
- слишком общие/большие бандлы CSS/JS.
Способы оптимизации загрузки страницы:
- используйте Brotli (или даже SDCH) вместо GZip, включайте HTTP/2;
- собирайте только необходимый CSS (сritical) и не забывайте про CSSO;
- минимизируйте размер JS-бандла, отделив минимальный CORE-бандл, а остальное грузите по требованию, т.е. ассинхронно;
- грузите JS и CSS в не блокирующем режиме, динамически создавая
/> и <sсript src="..."/>, в идеале грузите JS уже после основного контента; - используйте SVG вместо PNG, а если совместить с JS, то это позволит избавиться от избыточного XML (например как у font-awesome);
- применяйте lazy loading как для изображений, так и iframe (кроме этого, в ближайшем будущем появится нативная поддержка).
Время первой отрисовки и интерактивности (TTI)
Следующий этап после загрузки — это момент, когда пользователь увидел результат, и интерфейс перешел в интерактивный режим. Для этого нам понадобится Performance Paint Timing и PerformanceObserver.С первым всё просто, вызываем
performance.getEntriesByType('paint') и получаем две метрики:- first-paint — первая отрисовка;
- first-contentful-paint — и полная первая отрисовка.

Пример работы расширения paint для @perf-tools/keeper.
А вот со следующей метрикой, Time To Interactive, всё немного интереснее. Нет точного способа определить, когда ваше приложение стало интерактивным, т.е. доступным для пользователя, но это можно косвенно понять по отсутствию longtasks:
// TTI
let ttiLastEntry: PerformanceEntry | undefined;
let ttiPerfObserver: PerformanceObserver;
try {
ttiPerfObserver = new PerformanceObserver((list) => {
ttiLastEntry = list.getEntries().pop();
});
ttiPerfObserver.observe({
entryTypes: ['longtask'],
});
} catch (_) {}
domReady(() => {
// TTI Check
if (ttiPerfObserver) {
let tti: number;
const check = () => {
if (ttiLastEntry) {
tti = ttiLastEntry.startTime + ttiLastEntry.duration;
if (now() - tti >= options.ttiDelay) {
// Последний logntask был давно, будем считать,
// что эра интерактивности настала ;]
send('tti', 'value', 0, tti);
ttiPerfObserver.disconnect();
} else {
setTimeout(check, options.ttiDelay);
}
} else if (tti) {
send('tti', 'value', 0, tti);
ttiPerfObserver.disconnect();
} else {
// Не было logntask, поэтому делаем паузу и если их опять не будет,
// то считает, что приложение уже готово на момент DOMReady!
tti = now();
setTimeout(check, 500);
}
}
// Запускаем проверку
check();
}
});

Пример работы расширения performance для @perf-tools/keeper.
Кроме этих базовым метрик ещё нужна именно ваша метрика готовности приложения, т.е. где-то в вашем коде должно быть подобное:
Import { system } from '@perf-tools/keeper';
export function applicationBoot(el, data) {
const app = new Application(el, data);
// Подписываемся на готовность приложения
app.ready(() => {
system.add('application-ready', 0, system.perf.now());
// ?application-ready: 3074.000ms
});
return app;
}Скорость реакции на действия пользователя
Тут огромное поле для метрик и они очень индивидуальны, поэтому расскажу о двух базовых, которые подходят любому проекту, а именно:first-event — время первого события, например первый click (с делением куда пользователь ткнул), такая метрика особенно актуальна для разного рода поисковых выдачей, списка товаров, новостных лент и т.п. С помощью неё вы сможете контролировать, как меняется время реакции и флоу пользователя от ваших действий (изменений в: дизайн/новые фичи/оптимизации и т.п.)

Пример работы расширения performance для @perf-tools/keeper.
latency — задержка при обработке некоторых событий, например:
click, input, submit, scroll и т.д.Чтобы измерить задержку, достаточно повесить обработчик события на
window с capture = true и через requestAnimationFrame посчитать разницу, это и будет задержка:window.addEventListener(eventType, ({target}) => {
const start = now();
requestAnimationFrame(() => {
const latency = now() - start;
if (latency >= minLatency) {
// ….
}
});
}, true);

Пример работы расширения performance для @perf-tools/keeper когда на клик вычисляется Число Фибонначи.
FPS при прокрутке и анимациях
Это самая интересная метрика, обычно её измеряют черезrequestAnimationFrame, и если вам нужно делать постоянный замер FPS, то классический FPSMeter подойдет (хоть он излишне оптимистичен). Но он совсем не годится, если нужно измерить плавность прокрутки страницы, т.к. ему нужен «прогрев». И тут я наткнулся на очень интересный способ.Гениально, на самом деле, просто создаём прозрачный div (1x1px), добавляем ему
transition: left 300ms linear и запускаем его из одного угла в другой, а пока он анимируется, через requestAnimationFrame проверяем его реальный left, и если новая длина отличается от предыдущей, то увеличиваем количество отрисованных кадров (иначе имеем просадку FPS).И это ещё не всё, если вы пользуетесь FF, то там просто есть mozPaintCount, который отвечает за количество отрисованных кадров, т.е. запоминаем «ДО», а на
transitionend вычисляем разницу.Итого, без какого-либо прогрева мы точно знаем, перерисовал ли браузер кадр или нет.
Ещё в скором времени обещают нормальное API: http://wicg.github.io/frame-timing/
 |
 |
Оптимизация скрола:
- самое простое — это ничего не делать на scroll, либо откладывать выполнение через
requestAnimationFrame, либо дажеrequestIdleCallback; - очень осторожно используйте
pointer-events: none, включение и отключение его может дать обратный эффект, поэтому лучше провести A/B-эксперимент с использованиемpointer-eventsи без; - не забывайте про виртуализированные списки, практически все View-движки сейчас имеют такие компоненты, но опять же будьте аккуратнее, элементы такого списка должны быть максимально простыми, либо используйте «пустышки», которые будут заменены на реальные элементы после завершения прокрутки. Если вы сами пишите виртуализированный список, то никакого inner HTML и не забывайте про DOM Recycling (это когда вы не создаете DOM-элементы на каждый чих, а переиспользуете их).
Инициализация приложения
Тут есть только одно правило: детализируйте так, чтобы вы точно могли ответить, что именно съело время от инициализации приложения до финального запуска. В итоге должно получиться как минимум следующие метрики:- сколько времени ушло на резолв каждой зависимости;
- время на получение и подготовку данных для приложения;
- рендер приложения с детализацией по блокам.
Т.е. на выходе у вас должны получиться такие метрики, по которым вы точно сможете отследить, на какой именно фазе у вас идет просадка.
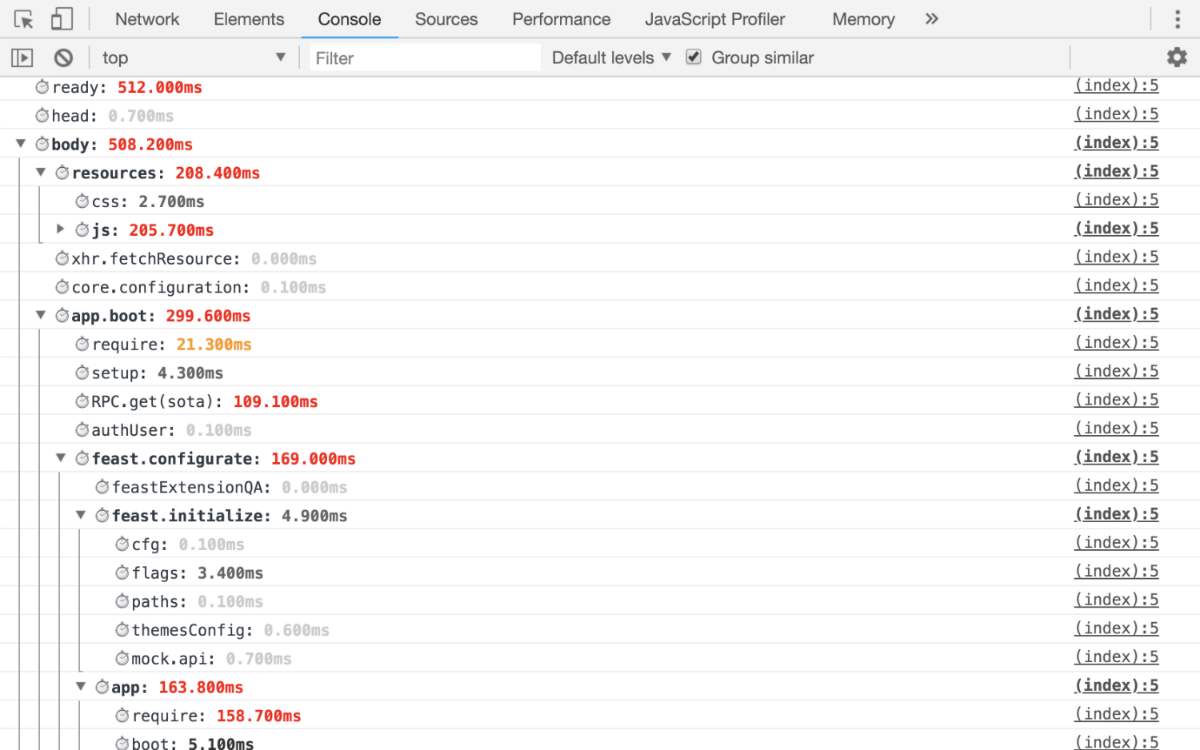
User Timing

Если у вас SPA, то надо измерять время маршрутизации
Во-первых, должна быть общая метрика для оценки производительности (время перехода по маршруту) в целом, но также обязательно нужно иметь метрику по каждому маршруту (например у нас это «Список тредов», «Чтение треда», «Поиск» и т.д.), сама метрика должна быть разбита на подметрики:- Получение данных (с разбиением, каких именно)
- Обработка
- Обновление
- Рендер
- Всего приложения
- Блоков (например у нас, это будет: «Левая колонка» (она же «Список папок»), «Умная строка поиска», «Список писем» и в том же духе)
Без всего этого невозможно понять, в каком месте начинаются проблемы, поэтому у нас многие модули из коробки имеют тайминги (например тот же модуль для XHR имеет
startTime и endTime, которые автоматически журналируются).Но и этих метрик недостаточно, чтобы адекватно оценить, что же происходит. Они слишком общие, т.к. мы говорим про SPA, то у вас точно имеется какой-либо Runtime Cache (чтобы не ходить на сервер лишний раз, если вы уже там были), поэтому наши метрики дополнительно разделены на маршрутизацию с cache и без. Ещё, конкретно в нашем случае, мы делим метрику по количеству сущностей в ней. Иначе говоря, нельзя складывать в одну метрику просмотр «Треда» с 1, 5, 10 или 100+ письмами, поэтому если у вас есть вывод какого-либо списка, надо выбрать контрольные точки и дополнительно разделить метрику.
Потребление памяти и трафика
Начнем с памяти. И тут нас ждет большое разочарование. На данный момент есть только нестандартизированный (Chrome only) performance.memory, который выдает до смешного низкие числа. Но всё же их нужно измерять и смотреть, как «течет» приложение со временем: |
 |
 |
Трафик. Чтобы считать трафик, вам понадобится Timing-Allow-Origin (если ресурсы находятся отдельном домене) и Resource Timing API, это поможет не просто посчитать трафик, но и детализировать его:
- какой протокол используется (HTTP/1, HTTP/2 и т.п.);
- типы загружаемых ресурсов;
- сколько времени потребовалось на их загрузку;
- размер, притом ещё можно понять, загружен ли ресурс по сети или взят из кеша.
 |
 |
 |
Что даёт подсчет трафика?
- Самое главное — это позволяет увидеть реальную картину, а не как обычно CSS + JS и кроме этого, как эта «картина» изменяется по времени.
- Далее вы можете проанализировать, что именно грузится, разделить ресурсы на группы и т.п.
- Насколько хорошо у вас работает кеширование.
- Нет ли аномалий, например через 15 минут работы, например код вошел в рекурсию и бесконечно грузит какой-нибудь ресурс, мониторинг трафика поможет и в этом.
Ну в догонку доклад от моего коллеги Игоря Дружинина на эту тему: Оценка качества работы приложения – мониторинг потребления трафика
Аналитика
Метрики мы расставили, а что дальше? А дальше их нужно куда-то отправить. И тут либо вы поднимаете у себя какой-нибудь Graphite, либо, для начала, можно использовать в корыстных целях Google Analytics или подобные для агрегации данных.И не забывайте, недостаточно просто получить график, по всем важным метрикам должны быть процентили, которые позволят понять, например, у какого процента аудитории проект загружается за <1s, <2s, <3s, <5s, 5s+ и т.п.
Пишем высокопроизводительный код
Сначала я хотел, написать тут что-то осмысленное, мол используйте WebWorker, не забывайтеrequestIdleCallback или что-то из экзотики, например сквозной Runtime Cache сквозь вкладки браузера при помощи SharedWorker или ServiceWorker (который не только про кеширование, если что). Но это всё очень абстрактно, да и многие темы избиты до невозможности, поэтому просто напишу следующее:- Изначально покрывайте ваш код метриками, которые позволят измерять его производительность.
- Не верьте бенчмаркам с jsperf. Подавляющее большинство из них написаны плохо, да и просто вырваны из контекста. Лучший бенчмарк — это реальная метрика на проекте, по которой вы увидите эффект от ваших действий.
- Помните про восприятие производительности, а точнее Закон Вебера — Фехнера. А именно, если вы начали оптимизацию, то не выкатывайте изменения, пока лучше не станет хотя бы на 20 %, иначе пользователи просто не заметят. Так же закон работает и в обратную сторону.
- Бойтесь регулярок, особенно генерируемых. Ими не только можно подвесить браузер, но и получить XSS, именно поэтому у нас в Почте запрещен разбор HTML с помощью них, только через обход DOM’а.
- Не нужно использовать массивы для вхождения значения в ту или иную группу, для этого есть
objectилиSet(например вместоsuccessSteps.includes(currentStep)нужноsuccessSteps.hasOwnProperty(currentStep)), O(1) наше всё. - Выражение «Преждевременная оптимизация — корень всех зол» — это не про то, что пишите как хотите. Если вы знаете, как оптимальнее, пишите оптимально.
Но если говорить про DOM, то например вместо удаления фрагмента из DOM, лучше его скрыть или deattach-нуть. Если всё же нужно удалить, то вынесите эту операцию в
requestIdleCallback (если возможно), или разделить процесс уничтожения на две фазы: синхронную и асинхронную.Сразу оговорюсь, используйте с умом такой подход, а то можно и колено прострелить.
Ещё одну интересную технику мы используем на списках, например «Списке Тредов». Суть техники в том, что вместо одного глобального «Списка» и обновления его данных, мы генерируем «Список Тредов» под каждую «Папку». В итоге когда пользователь переходит между «Папками», один список вынимается из DOM (не удаляется), а другой обновляется либо частично, либо не обновляется вовсе. А не весь, как в случае с «Единым Списком».
Всё это даёт мгновенный отклик на действия пользователя.
Математика. Всю математику с легкостью убираем либо в Worker, либо в WebAssembly, это давно уже работает.
Транспиллеры. Ох, многие даже не задумываются о том, что код, который они пишут, проходит через транспиллер. Да, они знают про него, но на этом всё. А вот что же он превратится их уже не волнует. Ведь в DevTools они видят результат source map.
Поэтому изучайте инструменты, которые вы используете, например у того же babel в playground есть возможность посмотреть, во что он генерирует код в зависимости от выбранных пресетов, просто гляньте на тот же
yeild, await или for of.Тонкости языка. Ещё меньше людей знает про мономорфность кода, или банально почему bind медленный и… используйте вы наконец
handleEvent!Данные и прекеширование. Меньше запросов, больше кеширования. Кроме этого, очень часто мы используем технику «предвидения», это когда в фоне мы подгружаем данные. Например, мы после рендера «Списка тредов» начинаем подгрузку N-непрочитанных тредов в текущей «Папке», чтобы при клике на них пользователь сразу перешел на «Чтение», а не очередной «лоудер». Подобную технику мы используем не только для Данных, но и JS. Например, «Написание Письма» — это огромный бандл (из-за редактора), а пишут письма не все и не сразу, поэтому грузим его в фоне, после инициализации приложения.
Лоудеры. Не знаю почему, но я не видел статей, в которых бы учили, как не делать лоудер, а наоборот, взять хоть презентацию «будущего» React, в которой этой проблеме в рамках Suspense уделено очень много времени. Но ведь идеальное приложение именно без лоудеров, мы в Почте уже очень давно стараемся показывать его только в экстренных ситуациях.
В целом политика у нас такая, нет данных, нет view, нечего рисовать полу-интерфейс, сначала загружаем данные и только потом «рисуем». Именно поэтому мы используем «предвидение» того, куда пользователь собирается пойти и подгружаем эти данные, чтоб юзер не увидел лоудер. Кроме этого, очень сильно в этой задаче помогает наш дата-слой, который обладает персистентностью, т.е. если вы где-то в одном месте запросили «Тред», то при следующем запросе из другого или того же места, запроса не будет, мы возьмем данные из Runtime Cache (точнее ссылку на данные). И так во всем, коллекции тредов тоже всего лишь ссылки на данные.
Но если вы всё же решили делать лоудер, то не забывайте основные правила, которые сделают ваш лоудер менее раздражающим:
- не нужно показывать лоудер сразу, в момент отправки запроса, перед показом должна быть задержка как минимум 300-500 мс;
- после получения данных не нужно резко убирать лоудер, тут опять же должна быть задержка.
Эти нехитрые правила нужны, чтобы лоудер появлялся только на тяжелых запросах и не «мигал» по завершению. Ну а главное, лучший лоудер — это лоудер, который не появился.
Спасибо за внимание, на это всё, измеряйте, анализируйте и используйте PerfKeeper (Live example), а так же вот мой github и twitter, на случай вопросов!
Комментарии (22)

Sergey-Pimenov
06.06.2019 17:48+1Хороший инструмент вы сделали, спасибо за него. Но вот столкнулся с очень критичной для меня особенностью — у меня на всём проекте кастомный скрол (дизайн такой, ничего не поделаешь) и pk-fps-page просто не показывается, если делать всё как в примере на гитхабе, оно и понятно — не возникает самого события скрола. Есть ли какой-то обходной путь, чтобы таки получить fps при не-нативном скроле?
RubaXa Автор
06.06.2019 17:54Хороший вопрос, сделайте пример на каком-нибудь jsfiddle/jsbin, подумаю как это решить. Но на первый взгляд, можно добавить методы для ручного делегирования событий
scrollи/илиscrollStart/scrollEnd.Sergey-Pimenov
06.06.2019 20:28+1Набросал — jsfiddle.net/0c2vtnb5/61. Я использую конкретно idiotwu.github.io/smooth-scrollbar. Добавил сразу 'плагин' для событий scrollStart/scrollEnd, вдруг вам нужно будет. Если как-то заставите работать всё это дело с кастомным скролом, то напишите, пожалуйста, я очень заинтересован.
RubaXa Автор
06.06.2019 22:28Sergey-Pimenov
06.06.2019 23:05Фидл вот такую ошибку выдаёт — ReferenceError: perfKeeperExtFps is not defined
at new FPSMeterPugin. Я попытался исправить своими силами, однако не вышло.RubaXa Автор
06.06.2019 23:08+1Упс, это я случайно, вот правильная ссылка https://jsfiddle.net/RubaXa/uhtecoas/3/

vladbarcelo
06.06.2019 18:08+1Спасибо, было интересно.
Можно ещё добавить что-нибудь про lazy hydration, метрики TTI этот приём улучшает на порядок.RubaXa Автор
06.06.2019 19:10Хм, звучит интересно. Но, у нас нет SSR (почти нет), а в тех местах где есть наоборот хотим провести обратный эксперимент с его отключением, чтобы мгновенно отдавать крохотный HTML и потом быстро рендерить приложение.
TTI интересная метрика, но я больше доверяю когда само приложение говорит Ready и обычно оно это делает заметно раньше ;], а лонг таски, лонг тасками, это ещё не значит, что интерфейс залип.
Поэтому в планах сделать непрерывный мониторинг интерактивности, но пока не очень вижу, как именно снимать сконструировать такую метрика (одно понятно, что она точно должна быть комплексной).
vladbarcelo
06.06.2019 22:24А почему SSR не используете? Быстрее работает же, апишка дёргается на сервере, первичный html отдаётся гидрированным, ну и для ботов хорошо. Вообще, по-моему круто для более-менее статичных страниц (типа лендинга) использовать пререндеринг на уровне CI/CD, для динамических — первые несколько блоков кидать на SSR, а дальнейшие блоки внизу страницы грузить и гидрировать лениво и асинхронно, отдавая скелетоны на время загрузки чанка с ними. Ну и выбросить все блоки, которые доступны после логина в отдельный чанк, который тоже загрузится после логина. Можно ещё обмазать это каким-нибудь smart prefetch-ингом, чтобы совсем всё отлично было.
RubaXa Автор
06.06.2019 22:41У нас нет задачи угодить ботам, а поддержка SSR это время, кроме этого, мы же Приложение (с большой буквы), тут SSR полноценный не выйдет, не всеми данными обладает сервер. Если брать туже Главную, то там и гидриротировать нечего, там вся страница отдаётся маленькими независимыми блоками (html + js + css).
kislovm
07.06.2019 03:06Привет! Классная статья, у вас все очень круто устроено. Если не сложно, то ответьте на пару вопрос:
- http2/brotli вы используете их везде и всегда? Проводили ли вы сравнение по скорости загрузки и использованию cpu? Можно где-нибудь почитать про это, если да?
- Вы вручную разбиваете по бандлам? Используете ли three-shaking? Как решаете проблему дублирования модулей?
RubaXa Автор
07.06.2019 09:04HTTP/2 везде, но опять же, есть мониторинг трафика, поэтому если откуда-то выползает HTTP/1, разбираемся.
Brotli стоит в планах, готовить его будем при сборке, а то никакого железа не хватит, но это только после запуска так называемых HTTP2-бадлов, на которые у нас большие надежды.
Смысл в том, что в HTTP2-бандл, это не сборка исходников в один файл, а только файл декларация, в которой объявлены все зависимости в порядке их использования, т.е.
В итоге при загрузке такого бандла сразу запрашиваются все файлы из него и т.к. у нас HTTP/2 всё должно пройти как нельзя лучше ;] Но самый профит, что при изменении любого файла сборки, юзеру не нужно будет выкачивать весь мегабайтный бандл (что сейчас происходит абсолютно у всех), а только обновленную декларацию и низменные файлы у которого изменился checksum (такой подход называется дедубликация).
Про бандлы. Где webpack, там кто-во что горазд, но больше руками, на Почте своя система сборки на основе r.js и там тоже руками, но c с хитростью, бандлы объявляются в виде массива и каждый следующим бандл становиться зависимым от предыдущего, поэтому и не включает в себя его зависимости, даже если из явно указать. В самом конце этого массива есть
rest-bundle, в который попадают все файлы, которые не вошли ни в одну из сборок.kislovm
07.06.2019 13:00+1Надеюсь вы поделитесь результатами после запуска HTTP2-бандлов. Интересно как себя поведет подобная структура на реальных каналах с потерями и большим пингом.
Насчет brotli — у нас получилось так, что дополнительное время на декомпрессию клиентом примерно равнялось разнице в скорости загрузки. В итоге не выйграли ничего.RubaXa Автор
07.06.2019 13:04+1Конечно, в независимости от результата напишем.
А вот про brotli интересно (все же пишут только про размер, а не реальный профит ;]), вы это по каким метрикам увидели?
kislovm
07.06.2019 13:25+1Важная ремарка: brotli мы запускали для мобильных телефонов и с CPU там гораздо хуже.
Мы измеряем примерно те же метрики что и вы. После запуска brotli не увидели значительного профита на метриках usable (когда мы считаем, что страница готова к использованию), но время загрузки бандлов упало. Стали профилировать, обнаружили, что CPU гораздо сильнее нагружается и решили не углубляться дальше. Возможно закопавшись в это можно было бы подобрать наиболее оптимальный brotli_comp_level и получить значимый профит.RubaXa Автор
07.06.2019 13:27+1Ясно, просто Brotli, по идее, должен разжимается быстрее GZip, возможно пережали ;]
alxgutnikov
Привет Кость! Классный пост, давно ждал когда вы про это напишите. Есть пара вопросов:
1) Есть ли у вас какой-то бюджет на загрузку страниц. Ну например вы такие собрались подумали и решили что главная страница почты должна открываться за 2 секунды по 75-ой перцентили. И если есть то как и исходя из чего вы его определяете?
2) Мериете ли вы отдельно кешированный/некешированный флоу ( ну типа пользователь зашел первый раз/ и последующие )?
3) Что таки используется для подсчета перцентилей ( я думаю что вряд ли гугл аналитика )? есть ли оно в опенсорсе?
4) Мониторите ли вы что-то постоянно? или просто после релизов смотрите не просели ли где-то?
5) Есть ли аномали детекшн может какой
khinartur
Привет! На половину из этих вопросов ответ есть в моем докладе про особенности мониторинга нашей Почты — qualityconf.ru/2019/abstracts/5284. Доклад был недавно в рамках РИТ 2019, буквально в течение недели должно появиться видео — советую посмотреть, хорошее дополнение к данной статье.
alxgutnikov
Спасибо! Обязательно гляну
RubaXa Автор
Бюджет понятие очень размытое, у каждого проекта он свой, конечно мы стремимся к максимальной скорости, например Главная не просто быстро должна быстро отдаётся, она изначально сконструирована особым способом, чтобы по мере загрузки пользователь увидел сначала самые важные блоки, а потом уже остальные. В то же время для Почты, первая загрузка важна, но всё же это тяжелый SPA, тут другие правила.
Кроме этого, проекту много лет, поэтому нам немного проще, запуская новую Главную или Почту, нам однозначно нельзя сделать хуже ;] Кроме этого, периодически мы запускаем хакатон по оптимизации первой загрузки Почты.
Ну и на остальные вопрос:
alxgutnikov
Спасибо!