
Автоматические системы модерации внедряются в веб-сервисы и приложения, где необходимо обрабатывать большое количество сообщений пользователей. Такие системы позволяют сократить издержки на ручную модерацию, ускорить её и обрабатывать все сообщения пользователей в real-time. В статье поговорим про построение автоматической системы модерации для обработки английского языка с использованием алгоритмов машинного обучения. Обсудим весь пайплайн работы от исследовательских задач и выбора ML алгоритмов до выкатки в продакшен. Посмотрим, где искать готовые датасеты и как собрать данные для задачи самостоятельно.
Подготовлено совместно с Ирой Степанюк (id_step), Data Scientist в Poteha Labs
Описание задачи
Мы работаем с многопользовательскими активными чатами, где каждую минуту в один чат могут приходить короткие сообщения от десятков пользователей. Задача состоит в выделении токсичных сообщений и сообщений с любыми нецензурными высказываниями в диалогах из таких чатов. С точки зрения машинного обучения — это задача бинарной классификации, где каждое сообщение нужно отнести к одному из классов.
Для решения такой задачи в первую очередь нужно было понять, что такое токсичные сообщения и что именно делает их токсичными. Для этого мы просмотрели большое количество типичных сообщений пользователей в интернете. Приведем несколько примеров, которые мы уже разделили на токсичные сообщения и нормальные.
| Токсичные | Нормальные |
|---|---|
| Your are a damn fag*ot | this book is so dummy |
| ur child is so ugly (1) | Winners win, losers make excuses |
| White people are owners of black (2) | black like my soul (2) |
Видно, что токсичные сообщения часто содержат нецензурные слова, но всё же это не обязательное условие. Сообщение может не содержать недопустимых слов, но быть оскорбительным для кого-либо (пример (1)). Кроме того, иногда токсичные и нормальные сообщения содержат одни и те же слова, которые употребляются в разном контексте — оскорбительном или нет (пример (2)). Такие сообщения тоже нужно уметь различать.
Изучив разные сообщения, для нашей системы модерации мы назвали токсичными такие сообщения, которые содержат высказывания с нецензурными, оскорбительными выражениями или проявлением ненависти к кому-либо.
Данные
Открытые данные
Одним из самых известных датасетов по задаче модерации является датасет с соревнования на Kaggle Toxic Comment Classification Challenge. Часть разметки в датасете некорректна: например, сообщения с нецензурными словами могут быть отмечены как нормальные. Из-за этого нельзя просто взять Kernel соревнования и получить хорошо работающий алгоритм классификации. Нужно больше работать с данными, смотреть, каких примеров недостаточно, и добавлять дополнительные данные с такими примерами.
Помимо соревнований есть несколько научных публикаций с ссылками на подходящие датасеты (пример), однако не все можно использовать в коммерческих проектах. В основном в таких датасетах собраны сообщения из социальной сети Twitter, где можно встретить много токсичных твитов. Кроме того, данные собирают из Twitter, так как можно использовать определенные хэштеги для поиска и разметки токсичных сообщений пользователей.
Данные, собранные вручную
После того, как мы собрали датасет из открытых источников и обучили на нем базовую модель, стало понятно, что открытых данных недостаточно: не устраивает качество модели. Помимо открытых данных для решения задачи нам была доступна неразмеченная выборка сообщений из игрового мессенджера с большим количеством токсичных сообщений.

Чтобы использовать эти данные для своей задачи, их нужно было как-то разметить. На тот момент уже был обученный бейзлайн классификатор, который мы решили использовать для полуавтоматической разметки. Прогнав все сообщения через модель, мы получили вероятности токсичности каждого сообщения и отсортировали по убыванию. В начале этого списка были собраны сообщения с нецензурными и оскорбительными словами. В конце наоборот находятся нормальные сообщения пользователей. Таким образом, большую часть данных (с очень большими и очень маленькими значениями вероятности) можно было не размечать, а сразу отнести к определенному классу. Осталось разметить сообщения, которые попали в середину списка, что было сделано вручную.
Аугментация данных
Часто в датасетах можно увидеть измененные сообщения, на которых классификатор ошибается, а человек правильно понимает их смысл.
Все потому, что пользователи подстраиваются и учатся обманывать системы модерации, чтобы алгоритмы ошибались на токсичных сообщениях, а человеку смысл оставался понятен. Что пользователи делают уже сейчас:
- генерируют опечатки: you are stupid asswhole, fack you,
- заменяют буквенные символы на цифры, похожие по описанию: n1gga, b0ll0cks,
- вставляют дополнительные пробелы: i d i o t,
- удаляют пробелы между словами: dieyoustupid.
Для того, чтобы обучить классификатор устойчивый к таким подменам, нужно поступить так, как поступают пользователи: сгенерировать такие же изменения в сообщениях и добавить их в обучающую выборку к основным данным.
В целом, эта борьба неизбежна: пользователи всегда будут пытаться находить уязвимости и хаки, а модераторы реализовывать новые алгоритмы.
Описание подзадач
Перед нами стояли подзадачи по анализу сообщения в двух разных режимах:
- онлайн режим — real-time анализ сообщений, с максимальной скоростью ответа;
- офлайн режим — анализ логов сообщений и выделение токсичных диалогов.
В онлайн режиме мы обрабатываем каждое сообщение пользователей и прогоняем его через модель. Если сообщения токсичное, то скрываем его в интерфейсе чата, а если нормальное, то выводим. В таком режиме все сообщения должны обрабатываться очень быстро: модель должна выдавать ответ настолько быстро, чтобы не нарушать структуру диалога между пользователями.
В офлайн режиме ограничений по времени работы нет, и поэтому хотелось реализовать модель с максимальным качеством.
Онлайн режим. Поиск слов по словарю
Вне зависимости от того, какая модель будет выбрана дальше, мы должны находить и фильтровать сообщения с нецензурными словами. Для решения этой подзадачи проще всего составить словарь недопустимых слов и выражений, которые точно нельзя пропускать, и делать поиск таких слов в каждом сообщении. Поиск должен происходить быстро, поэтому наивный алгоритм поиска подстрок за такое то время не подходит. Подходящим алгоритмом для поиска набора слов в строке является алгоритм Ахо-Корасик. За счет такого подхода удается быстро определять некоторые токсичные примеры и блокировать сообщения еще до их передачи в основной алгоритм. Использование ML алгоритма позволит «понимать смысл» сообщений и улучшить качество классификации.
Онлайн режим. Базовая модель машинного обучения
Для базовой модели решили использовать стандартный подход для классификации текстов: TF-IDF + классический алгоритм классификации. Опять же из соображений скорости и производительности.
TF-IDF — это статистическая мера, которая позволяет определить наиболее важные слова для текста в корпусе с помощью двух параметров: частот слов в каждом документе и количества документов, содержащих определенное слово (более подробно здесь). Рассчитав для каждого слова в сообщении TF-IDF, получаем векторное представление этого сообщения.
TF-IDF можно рассчитывать для слов в тексте, а также для n-грам слов и символов. Такое расширение будет работать лучше, так как сможет обрабатывать часто встречающиеся словосочетания и слова, которых не было в обучающей выборке (out-of-vocabulary).

Пример использования TF-IDF на n-грамах слов и символов
После преобразования сообщений в векторы можно использовать любой классический метод для классификации: логистическую регрессию, SVM, случайный лес, бустинг.
В нашей задаче решили использовать логистическую регрессию, так как эта модель дает прирост по скорости работы в сравнении с другими классическими ML классификаторами и предсказывает вероятности классов, что позволяет гибко подбирать порог классификации в продакшне.
Полученный с использованием TF-IDF и логистической регрессии алгоритм быстро работает и хорошо определяет сообщения с нецензурными словами и выражениями, но не всегда понимает смысл. Например, часто сообщения со словами ‘black’ и ‘feminizm’ попадали в токсичный класс. Хотелось исправить эту проблему и научиться лучше понимать смысл сообщений с помощью следующей версии классификатора.
Офлайн режим
Для того, чтобы лучше понимать смысл сообщений, можно использовать нейросетевые алгоритмы:
- Эмбеддинги (Word2Vec, FastText)
- Нейросети (CNN, RNN, LSTM)
- Новые предобученные модели (ELMo, ULMFiT, BERT)
Обсудим некоторые из таких алгоритмов и как их можно использовать подробнее.
Word2Vec и FastText
Модели эмбеддингов позволяют получать векторные представления слов из текстов. Существует два типа Word2Vec: Skip-gram и CBOW (Continuous Bag of Words). В Skip-gram по слову предсказывается контекст, а в CBOW наоборот: по контексту предсказывается слово.
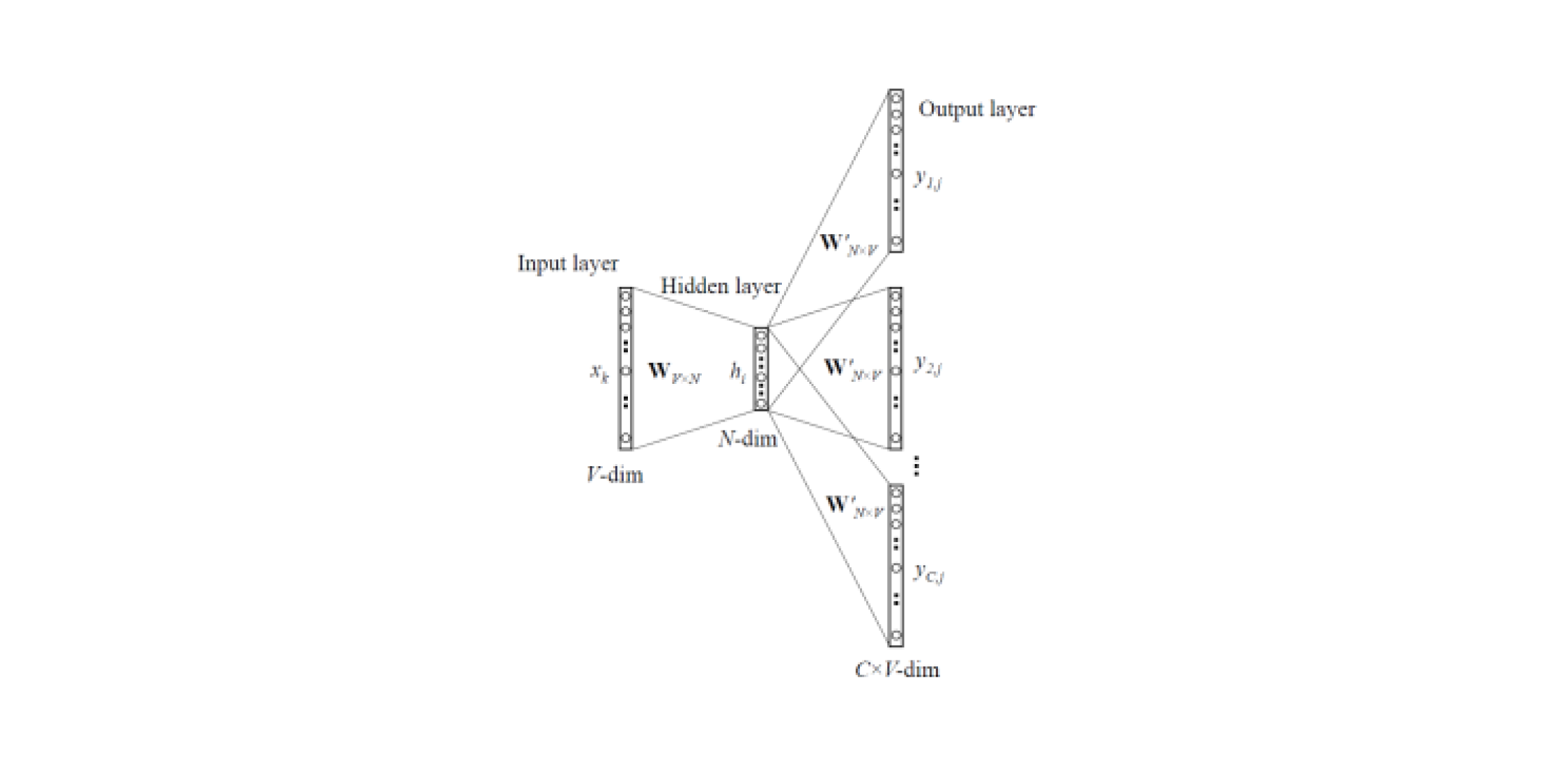
Такие модели обучаются на больших корпусах текстов и позволяют получить векторные представления слов из скрытого слоя обученной нейросети. Минус такой архитектуры в том, что модель обучается на ограниченном наборе слов, которые содержатся в корпусе. Это означает, что для всех слов, которых не было в корпусе текстов на этапе обучения, не будет эмбеддингов. А такая ситуация происходит часто, когда предобученные модели используются для своих задач: для части слов не будет эмбеддингов, соответственно большое количество полезной информации будет теряться.
Для решения проблемы со словами, которых нет в словаре, (OOV, out-of-vocabulary) есть улучшенная модель эмбеддингов — FastText. Вместо использования отдельных слов для обучения нейросети, FastText разбивает слова на n-грамы (подслова) и обучается на них. Для получения векторного представления слова нужно получить векторные представления n-грам этого слова и сложить их.
Таким образом, для получения векторов признаков из сообщений можно использовать предобученные модели Word2Vec и FastText. Полученные признаки можно классифицировать с помощью классических ML классификаторов или полносвязной нейросети.
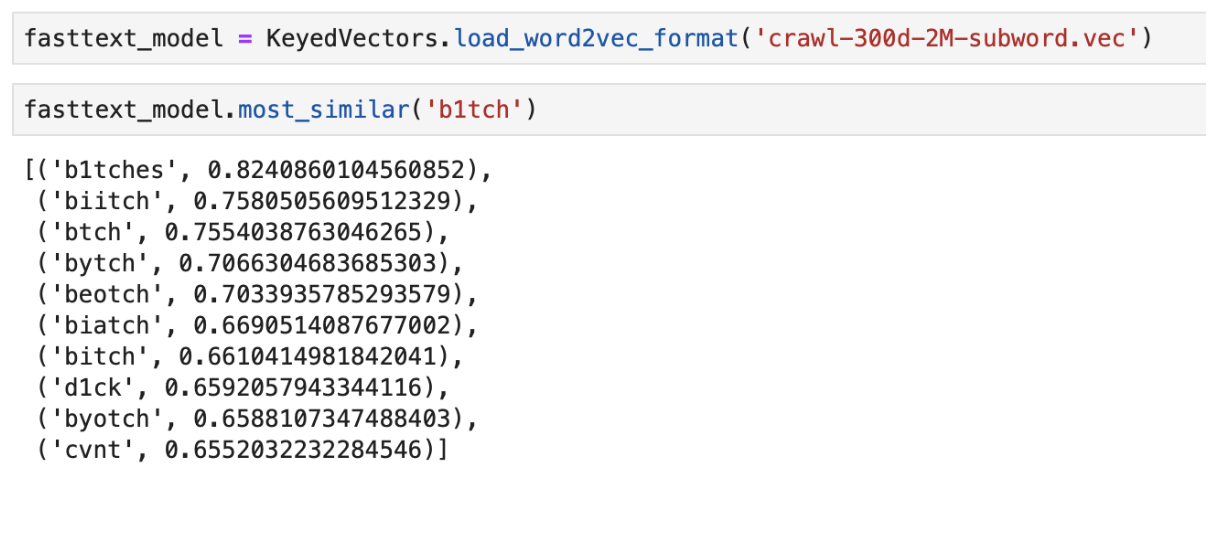
Пример вывода “ближайших” по смыслу слов с использованием предобученного FastText
Классификатор на CNN
Для обработки и классификации текстов из нейросетевых алгоритмов чаще используют рекуррентные сети (LSTM, GRU), так как они хорошо работают с последовательностями. Сверточные сети (CNN) чаще всего используют для обработки изображений, однако их также можно использовать в задаче классификации текстов. Рассмотрим, как это можно сделать.
Каждое сообщение представляет собой матрицу, в которой на каждой строке для токена (слова) записано его векторное представление. Свертка применяется к такой матрице определенным образом: фильтр свертки “скользит” по целым строкам матрицы (векторам слов), но при этом захватывает несколько слов за раз (обычно 2-5 слов), таким образом обрабатывая слова в контексте соседних слов. Подробно, как это происходит, можно посмотреть на картинке.
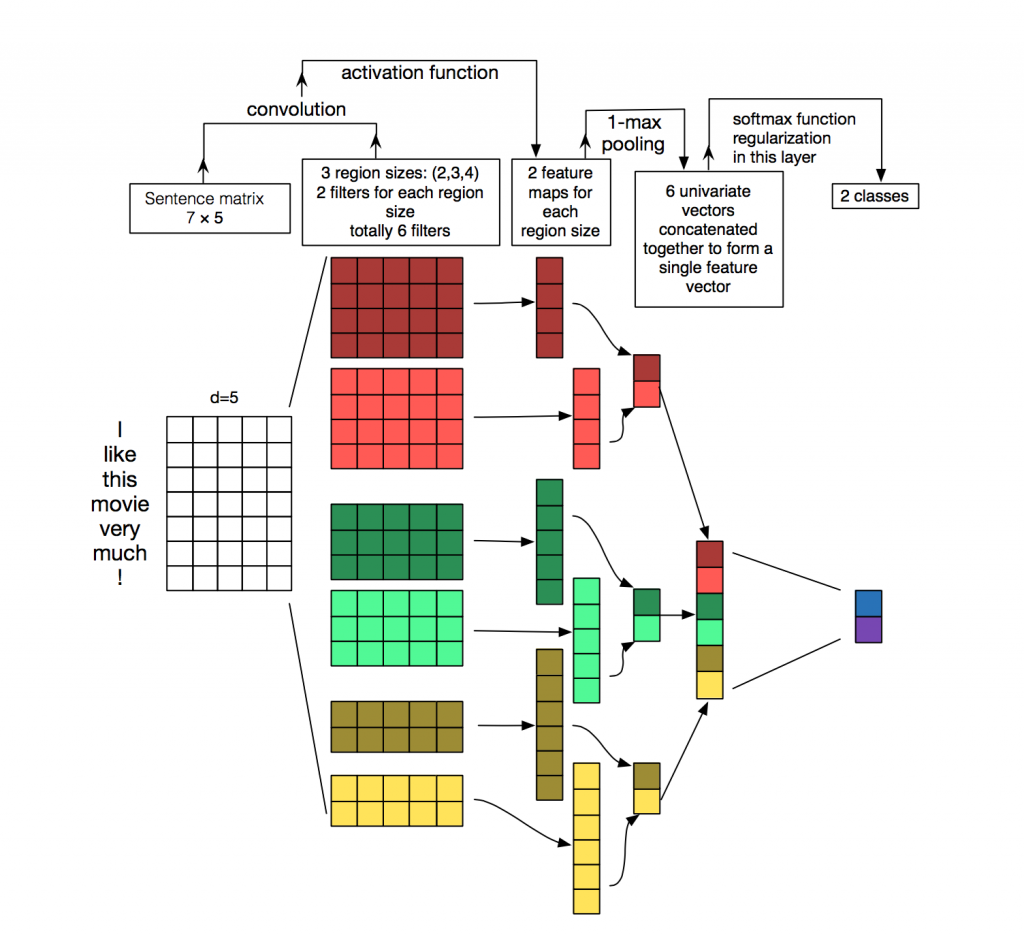
Зачем же применять сверточные сети для обработки текстов, когда можно использовать рекуррентные? Дело в том, что свертки работают сильно быстрее. Используя их для задачи классификации сообщений, можно сильно сэкономить время на обучении.
ELMo
ELMo (Embeddings from Language Models) — модель эмбеддингов на основе языковой модели, которая была недавно представлена. Новая модель эмбеддингов отличается от Word2Vec и FastText моделей. Вектора слов ELMo обладают определенными преимуществами:
- Представление каждого слова зависит от всего контекста, в котором оно используется.
- Представление основано на символах, что позволяет формировать надежные представления для OOV (out-of-vocabulary) слов.
ELMo можно использовать для разных задач в NLP. Например, для нашей задачи полученные с помощью ELMo вектора сообщений можно отправлять в классический ML классификатор или использовать сверточную или полносвязную сеть.
Предобученные эмбеддинги ELMo достаточно просто использовать для своей задачи, пример использования можно найти здесь.
Особенности реализации
API на Flask
Прототип API был написан на Flask, так как он прост в использовании.
Два Docker образа
Для деплоя использовали два докер образа: базовый, где устанавливались все зависимости, и основной для запуска приложения. Это сильно экономит время сборки, так как первый образ редко пересобирается и за счет этого экономится время при деплое. Довольно много времени тратится на сборку и скачивание библиотек машинного обучения, что не нужно при каждом коммите.
Тестирование
Особенность реализации довольно большого числа алгоритмов машинного обучения состоит в том, что даже при высоких значениях метрик на валидационном датасете реальное качество алгоритма в продакшне может быть низкое. Поэтому для тестирования работы алгоритма всей командой использовали бота в Slack. Это очень удобно, потому что любой член команды может проверить, какой ответ выдают алгоритмы на определенное сообщение. Такой способ тестирования позволяет сразу увидеть, как будут работать алгоритмы на живых данных.
Хорошей альтернативой является запуск решения на публичных площадках вроде Яндекс Толоки и AWS Mechanical Turk.
Заключение
Мы рассмотрели несколько подходов к решению задачи автоматической модерации сообщений и описали особенности нашей реализации.
Основные наблюдения, полученные в ходе работы:
- Поиск слов по словарю и алгоритм машинного обучения, основанный на TF-IDF и логистической регрессии, позволили классифицировать сообщения быстро, но не всегда корректно.
- Нейросетевые алгоритмы и предобученные модели эмбеддингов лучше справляются с такой задачей и могут определять токсичность по смыслу сообщения.
Конечно, мы выложили открытое демо Poteha Toxic Comment Detection в фейсбук боте. Помогите нам сделать бота лучше!
Буду рад ответить на вопросы в комментариях.
Комментарии (19)

A114n
06.06.2019 17:06Попробую дать вам совет, как сделать бота лучше, хоть и не связанный с работой нейросетей.
Поначалу я очень обрадовался этой статье — о, неужели наконец-то кто-то решил научить нейросеть бороться с настоящими токсичными высказываниями, а не тупо работать по словарю.
Читаю дальше — нет, всё то же самое:
нужно поступить так, как поступают пользователи: сгенерировать такие же изменения в сообщениях и добавить их в обучающую выборку к основным данным.
Таким образом, большую часть данных (с очень большими и очень маленькими значениями вероятности) можно было не размечать, а сразу отнести к определенному классу.
Лет эдак пятнадцать назад наш городской провайдер открыл на своём локальном сайте чат местных пользователей.
Безо всякого новомодного машинного обучения там успешно блокировались поклонники академической гребли и люди, к которым в гости приехал поп из деревни.
Прошли годы, а борцы против токсичности — какой-нибудь Steam или Livejournal — продолжают закрывать звёздочками слова типа «захлебнулись» или «хулить», вызывая смех и раздражение.
Это именно то, что порождает больше всего негатива, и, в общем-то, дискредитирует саму идею автомодерации.
Так вот, главная задача всех автоматических борцов с токсичными высказываниями — это не словарь «плохих» слов, а словарь «хороших слов, которые просто похожи на плохие». Добавьте в разметку эту категорию, скорее всего у вас там на вершине списка, где можно «не размечать, а сразу отнести к определённому классу» какая-нибудь «оглобля».
iwitaly Автор
06.06.2019 17:16Спасибо за совет! У нас бот работает только на английском (пока что), но основную проблему вы подметили верно. Мы решаем такую проблему тем, что ищем нетривиальные корпусы, как игровые чаты и используем сетки, они как раз и могут выучивать локальные зависимости. С точки бизнес логики, задача была сделать рейтинг сообщений 12+ (то есть уровень цензуры довольный высокий, а именно высокий recall), но при этом падает точность и решение может фолзить, что в нашем случае не так страшно.
Дальнейшие планы — собрать больше выборку и уменьшать ошибку первого рода (фолзы).
DrunkBear
06.06.2019 17:31дополнительная часть челленжа — если можно что-то вставлять в игровых чатах и использовать эти вставки как часть слов — это будет сделано.
Допустим, можно линковать внутриигровые вещи и есть вещь с названием [Ankh]
Линкуем, добавляем 'us' после линка — гыгыгы! (детский восторг, поход наперекор системы, баттхерт у собеседника).legolegs
06.06.2019 17:35Если собеседник оскорбительно тупой или вызывающе умный — никакие системы модерации не спасут.
A114n
06.06.2019 18:36Эзопов язык никто не отменял. Будут говорить иносказаниями, да.
Но цель-то убрать прямые оскорбления.
legolegs
06.06.2019 17:34-2С нетерпением жду такую же статью от автора антиольгинского скрипта для двача. Там, правда, без нейросетей, но переполох у фильтруемых был знатный.

vladbarcelo
06.06.2019 17:42Жаль что иногда банит слова в пользу "ругательного" значения. Например, рассказать как съел крекер с сыром не получится — забанят за расовые оскорбления, ууу.
Плюс, можно легчайшим образом обмануть:
console.log("fu\u202etahssa gnikc") // получаем (можете попробовать сами): fu?tahssa gnikc
И система это не детектит, для неё это выглядит как "fu\u202etahssa gnikc".
iwitaly Автор
06.06.2019 18:13Разумно, это же то, что вы ей отправили. Понятно, что в любой системе модерации можно найти уязвимость. Таких данных в нашем корпусе не было и такой метод аугментации я лично не встречал, сможете разъяснить? Это сложнее, чем русскую с на английскую c. vladbarcelo
vladbarcelo
06.06.2019 18:32+1По сути, просто используется RLO в середине словосочетания. Строка на входе получается мусором c юникодом, а при отображении юникод-символ не отображается, но переворачивает всё что идёт за ним справа на лево. Вы и сами можете это увидеть — попробуйте выделить ругательное словосочетание в комментарии и увидите как выделение "глючит" — сначала выделяет слева на право, о потом начинает идти в обратную сторону.
vladbarcelo
06.06.2019 18:46+1Вот, кстати, ещё один метод обхода, вдогонку: script capital letters. Например: https://pastebin.com/6jWMb15a
Ka_Wabanga
07.06.2019 14:43+1Не элегантно конечно, но обычно для всех символов, выходящих за рамки «белого списка» идет нормализация или другая обработка.
import unicodedata s = 'xxx' #ваша строка, хабр режет ее к сожалению s = ''.join([unicodedata.name(c).split()[-1:][0] if len(unicodedata.name(c).split()[-1:][0])==1 else c for c in s])
> s
'FUCK YOU'

vtrokhymenko
07.06.2019 13:39так в конечном итого сколько всего у Вас было наблюдений в датасете?
подскажите также плз что по времени обучению было для онлайн. также что по метрикам.
и какую Вы выбрали модельку для оффлайна все же? и что по метрикам тут тоже.
зы
нужное дело сделали. :fire:id_step
07.06.2019 13:55Всего в датасете 420к примеров, из которых примерно 20% токсичные.
Время обучения онлайн модели не больше часа, F-мера на тестовом наборе данных ~0.86. ?
Про модель для оффлайн: не можем раскрывать финальную архитектуру, но она посложнее, чем примеры архитектур в статье.
Ka_Wabanga
07.06.2019 14:08В новом «челледже» участвуете?
www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification
Там и «датасет» побольше))iwitaly Автор
07.06.2019 14:09Мы следим за ним, но пока думаем. Датасет больше, но он не совсем нам подходит, у нас таргет именно на сообщения, а там большие тексты. В нашей работе их данные не очень помогли.
Ka_Wabanga
07.06.2019 14:23Средняя длина предложений в Jigsaw II (в словах) ~60.
Мне кажется можно натренировать что-то на полном «датасете» для понимания использования слова в контексте, а потом «отполировать» на урезанном «датасете» с длиной сообщения меньше X (20?).
С другой стороны основная проблема такой сети — специфический словарь в вашей конкретной области. Как пример — Bert, натренированный на Jigsaw I, дает всего 0.91 ROC AUC для Jigsaw II, но тот же Bert, натренированный на одинаковом по размеру «датасете» Jigsaw II, даст для него же 0.97 ROC AUC. Разница — словарная структура сообщений для модерации.
DrunkBear
false-positive срабатываний на фразы типа «хватит мне запрещать оскорблять употреблять» нет?
iwitaly Автор
Периодически бывают, но в оффлайн версии их сильно меньше. Сильно зависит от корпуса, на котором было обучение.