
(первая часть тут: https://habr.com/ru/post/456446/)
CEPH
Введение
Поскольку сеть является одним из ключевых элементов Ceph, а она в нашей компании немного специфична — расскажем сначала немного о ней.
Тут будет сильно меньше описаний самого Ceph, в основном сетевая инфраструктура. Описываться будут только сервера Ceph-а и некоторые особенности серверов виртуализации Proxmox.
Итак: Сама сетевая топология построена как Leaf-Spine. Классическая трехуровневая архитектура представляет из себя сеть, где есть Core (маршрутизаторы ядра), Aggregation (маршрутизаторы агрегации) и связанные напрямую с клиентами Access (маршрутизаторы доступа):
Трехуровневая схема
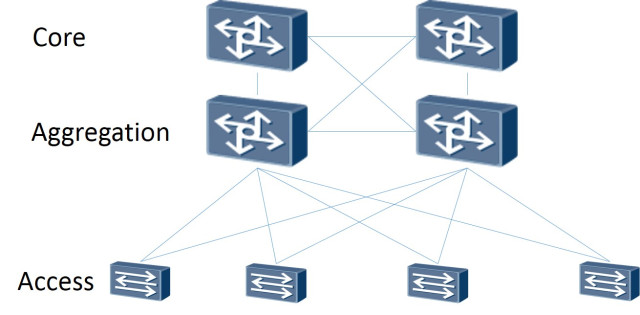
Топология Leaf-Spine состоит из двух уровней: Spine (грубо говоря основной маршрутизатор) и Leaf (ветви).
Двухуровневая схема

Вся внутренняя и внешняя маршрутизация построена на BGP. Основная система, которая занимается управлением доступами, анонсами и прочее — это XCloud.
Сервера, для резервирования канала (а так-же для его расширения) подключаются к двум L3 коммутаторам (большинство серверов включаются в Leaf коммутаторы, но часть серверов с повышенной сетевой нагрузкой включаются напрямую в Spine коммутатора), и через протокол BGP анонсируют свой unicast адрес, а так же anycast адрес для сервиса, если несколько серверов обслуживают трафик сервиса и им достаточно ECMP балансировки. Отдельной особенностью этой схемы, которая позволила нам сэкономить на адресах, но так же потребовала от инженеров познакомиться с миром IPv6, стало использование BGP unnumbered standard на основе RFC 5549. Какое-то время для обеспечения работы BGP в этой схеме для серверов применяли Quagga и периодически возникали проблемы с потерей пиров и связностью. Но после перехода на FRRouting (активными контрибьюторами которого являются наши поставщики ПО для сетевого оборудования: Cumulus и XCloudNetworks), больше таких проблем мы не наблюдали.
Всю эту общую схему для удобства называем "фабрика".
Поиск пути
Варианты настройки cluster network:
1) Вторая сеть на BGP
2) Вторая сеть на двух отдельных стекированных коммутаторах с LACP
3) Вторая сеть на двух отдельных изолированных коммутаторах с OSPF
Тесты
Тесты проводились двух типов:
а) сетевые, с помощью утилит iperf, qperf, nuttcp
b) внутренние тесты Ceph ceph-gobench, rados bench, создавали rbd и тестировали на них с помощью dd в один и несколько потоков, с помощью fio
Все тесты проводились на тестовых машинах с SAS дисками. На сами цифры в производительности rbd не сильно смотрели, использовали только для сравнения. Интересовали изменения в зависимости от типа подключения.
Первый вариант
Сетевые карты подключены к фабрике, настроены BGP.
Использовать эту схему для внутренней сети посчитали не самым лучшим выбором:
Во первых лишнее количество промежуточных элементов в виде коммутаторов, дающих дополнительные latency (это было основной причиной).
Во вторых первоначально для отдачи статики через s3 использовали anycast адрес, поднятый на нескольких машинах с radosgateway. Это выливалось в то, что трафик с фронтендовых машин до RGW распределялся не равномерно, а проходил по кратчайшему маршруту — то есть фронтовый Nginx всегда обращался к той ноде с RGW, которая была подключена к общему с ней leaf-у (это, конечно, был не основной аргумент — мы просто отказались в последствии от anycast адреса для отдачи статики). Но для чистоты эксперимента решили провести тесты и на такой схеме, чтоб иметь данные для сравнения.
Запускать тесты на всю полосу пропускания побоялись, поскольку фабрика используется prod серверами, и если бы мы завалили линки между leaf и spine — то это бы задело часть прода.
Собственно, это было еще одной из причин отказа от такой схемы.
Тесты iperf с ограничением BW в 3Gbps в 1, 10 и 100 потоков использовались для сравнения с другими схемами.
Тесты показали следующие результаты:
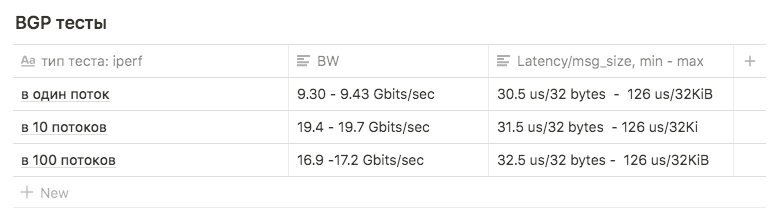
в 1 поток примерно 9.30 — 9.43 Gbits/sec (при этом сильно вырастает количество ретрансмитов, до 39148). Цифра оказалась приближенная к максимуму одного интерфейса говорит о том, что используется один интерфейс из двух. Количество ретрансмитов при этом примерно 500-600.
в 10 потоков 9.63 Gbits/sec на интерфейс, при этом количество ретрансмитов вырастало до среднего 17045.
в 100 потоков результат оказался хуже чем в 10, при этом количество ретрансмитов меньше: среднее значение 3354
Второй вариант
LACP
Нашлось два коммутатора Juniper EX4500. Собрали их в стек, подключили сервера первыми линками в один коммутатор, вторыми во второй.
Первоначальная настройка бондинга была такой:
root@ceph01-test:~# cat /etc/network/interfaces
auto ens3f0
iface ens3f0 inet manual
bond-master bond0
post-up /sbin/ethtool -G ens3f0 rx 8192
post-up /sbin/ethtool -G ens3f0 tx 8192
post-up /sbin/ethtool -L ens3f0 combined 32
post-up /sbin/ip link set ens3f0 txqueuelen 10000
mtu 9000
auto ens3f1
iface ens3f1 inet manual
bond-master bond0
post-up /sbin/ethtool -G ens3f1 rx 8192
post-up /sbin/ethtool -G ens3f1 tx 8192
post-up /sbin/ethtool -L ens3f1 combined 32
post-up /sbin/ip link set ens3f1 txqueuelen 10000
mtu 9000
auto bond0
iface bond0 inet static
address 10.10.10.1
netmask 255.255.255.0
slaves none
bond_mode 802.3ad
bond_miimon 100
bond_downdelay 200
bond_xmit_hash_policy 3 #(layer3+4 )
mtu 9000Тесты iperf и qperf показали Bw до 16Gbits/sec. Решили сравнить разные типа мода:
rr, balance-xor и 802.3ad. Так-же сравнивали разные типы хэширования layer2+3 и layer3+4 ( рассчитывая выгадать преимущество на вычислениях хэшей).
Ещё сравнили результаты при различных значениях sysctl переменной net.ipv4.fib_multipath_hash_policy, (ну и поиграли немного с net.ipv4.tcp_congestion_control, хотя она к бондингу отношения не имеет. По этой переменной есть хорошая статья ValdikSS)).
Но на всех тестах так и не получилось преодолеть порог в 18Gbits/sec (этой цифры достигли используя balance-xor и 802.3ad, между ними в результатах тестов разницы особо не было) и то это значение достигалось "в прыжке" всплесками.
Третий вариант
OSPF
Для настройки этого варианта убрали LACP с коммутаторов (стекирование оставили, но оно использовалось лишь для менеджмента). На каждом коммутаторе собрали по отдельному vlan-у для группы портов (с прицелом на будущее, что в эти же коммутаторы будут воткнуты как QA так и PROD сервера).
Настроили две плоских приватных сети для каждого vlan (по одному интерфейсу в каждый коммутатор). Поверх этих адресов идет анонсирование еще одного адреса из третьей приватной сети, которая и является cluster network для CEPH.
Поскольку public network (по которой мы ходим по SSH ) работает на BGP, то для настройки OSPF использовали frr, который уже стоит в системе.
10.10.10.0/24 и 20.20.20.0/24 — две плоских сети на коммутаторах
172.16.1.0/24 — сеть для анонсирования
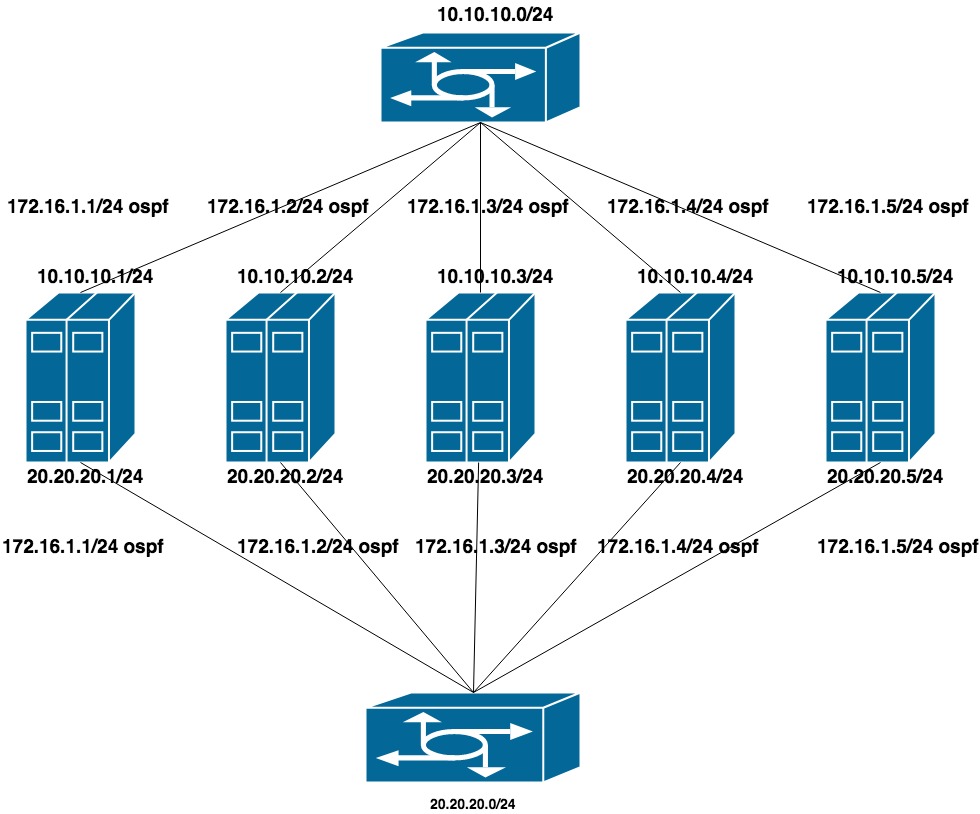
Настройка машины:
интерфейсы ens1f0 ens1f1 смотрят в приватную сеть
интерфейсы ens4f0 ens4f1 смотрят в публичную сеть
Конфиг сети на машине выглядит так:
oot@ceph01-test:~# cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
auto ens1f0
iface ens1f0 inet static
post-up /sbin/ethtool -G ens1f0 rx 8192
post-up /sbin/ethtool -G ens1f0 tx 8192
post-up /sbin/ethtool -L ens1f0 combined 32
post-up /sbin/ip link set ens1f0 txqueuelen 10000
mtu 9000
address 10.10.10.1/24
auto ens1f1
iface ens1f1 inet static
post-up /sbin/ethtool -G ens1f1 rx 8192
post-up /sbin/ethtool -G ens1f1 tx 8192
post-up /sbin/ethtool -L ens1f1 combined 32
post-up /sbin/ip link set ens1f1 txqueuelen 10000
mtu 9000
address 20.20.20.1/24
auto ens4f0
iface ens4f0 inet manual
post-up /sbin/ethtool -G ens4f0 rx 8192
post-up /sbin/ethtool -G ens4f0 tx 8192
post-up /sbin/ethtool -L ens4f0 combined 32
post-up /sbin/ip link set ens4f0 txqueuelen 10000
mtu 9000
auto ens4f1
iface ens4f1 inet manual
post-up /sbin/ethtool -G ens4f1 rx 8192
post-up /sbin/ethtool -G ens4f1 tx 8192
post-up /sbin/ethtool -L ens4f1 combined 32
post-up /sbin/ip link set ens4f1 txqueuelen 10000
mtu 9000
# Анонсируемые адреса висят на loopback-ах:
auto lo:0
iface lo:0 inet static
address 55.66.77.88/32
dns-nameservers 55.66.77.88
auto lo:1
iface lo:1 inet static
address 172.16.1.1/32Конфиги frr выглядят так:
root@ceph01-test:~# cat /etc/frr/frr.conf
frr version 6.0
frr defaults traditional
hostname ceph01-prod
log file /var/log/frr/bgpd.log
log timestamp precision 6
no ipv6 forwarding
service integrated-vtysh-config
username cumulus nopassword
!
interface ens4f0
ipv6 nd ra-interval 10
!
interface ens4f1
ipv6 nd ra-interval 10
!
router bgp 65500
bgp router-id 55.66.77.88 #поле необязательное, чуть ниже расскажем зачем его указали
timers bgp 10 30
neighbor ens4f0 interface remote-as 65001
neighbor ens4f0 bfd
neighbor ens4f1 interface remote-as 65001
neighbor ens4f1 bfd
!
address-family ipv4 unicast
redistribute connected route-map redis-default
exit-address-family
!
router ospf
ospf router-id 172.16.0.1
redistribute connected route-map ceph-loopbacks
network 10.10.10.0/24 area 0.0.0.0
network 20.20.20.0/24 area 0.0.0.0
!
ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
!
route-map ceph-loopbacks permit 10
match ip address prefix-list ceph-loopbacks
!
route-map redis-default permit 10
match ip address prefix-list default-out
!
line vty
!На этих настройках сетевые тесты iperf, qperf и т.д. показали максимальную утилизацию обоих каналов в 19.8 Gbit/sec, при этом latency упало до 20us
Поле bgp router-id: Используется для идентификации узла при обработке маршрутной информации и построении маршрутов. Если не указано в конфиге, то выбирается один из IP адресов узла. У разных производителей оборудования и ПО алгоритмы могут разниться, в нашем случае FRR использовал наибольший IP адрес на loopback. Это приводило к двум проблемам:
1) Если мы пытались повесить еще один адрес (например, приватный из сети 172.16.0.0) больше, чем текущий — то это приводило к смене router-id и, соответственно, к переустановке текущих сессий. А значит к кратковременному разрыву и потере сетевой связности.
2) Если мы пытались повесить anycast адрес, общий для нескольких машин и он выбирался в качестве router-id — в сети появлялись два узла с одинаковым router-id.
Часть 2
После тестов на QA приступили к модернизации боевого Ceph.
NETWORK
Переезд с одной сети на две
Параметр cluster network один из тех, которые нельзя поменять на лету, указав OSD его через ceph tell osd.* injectargs. Изменить его в конфиге и перезапустить весь кластер — терпимое решение, но очень не хотелось иметь даже небольшой даунтайм. Перезапускать по одной OSD с новым параметром сети тоже нельзя — в какой-то момент мы бы поимели два полкластера — старые OSD на старой сети, новые на новой. Благо, параметр cluster network (как, кстати, и public_network) это список, то есть можно указать несколько значений. Решили переезжать постепенно — сначала добавить в конфиги новую сеть, потом убрать старую. Ceph идет по списку сетей последовательно — OSD начинает работать сначала с той сетью, которая в списке указана первой.
Сложность заключалась в том, что первая сеть работала через bgp и была подключена к одним коммутаторам, а вторая — на ospf и подключена к другим, физически не связанным с первыми. На момент перехода необходимо было иметь временно сетевой доступ между двумя сетями. Особенность настройки нашей фабрики была в том, что ACLы невозможно настроить на сеть, если её нет в списке аннонсируемой (в этом случае она является "внешней" и ACL для нее может быть создан только вовне. Он создавался на spain-ах, но не приезжал на leaf-ы).
Решение было костыльным, сложным, но работало: анонсировать внутреннюю сеть через bgp, одновременно с ospf.
Последовательность перехода получилась такой:
1) Настраиваем cluster network для ceph на двух сетях: через bgp и через ospf
В конфигах frr менять ничего не пришлось, строка
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32не ограничивает нас в анонсируемых адресах, сам адрес для внутренней сети поднят на loopback интерфейсе, достаточно было на маршрутизаторах настроить приём анонса этого адреса.
2) Добавляем в конфиг ceph.conf новую сеть
cluster network = 172.16.1.0/24, 55.66.77.88/27и начинаем по одному перезапускать OSD, пока все не переходят на сеть 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout
# Что-бы не вызвать резкого всплеска нагрузки при рестарте большого количества OSD
# перезапускаем их с некоторой задержкой. Практика показала, что на наших дисках
# после старта, OSD заканчивает сверку данных примерно за 30 секунд.
root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done3) После чего убираем из конфига лишнюю сеть
cluster network = 172.16.1.0/24и повторяем процедуру.
Все, мы плавно переехали на новую сеть.
Ссылки:
https://shalaginov.com/2016/03/26/сетевая-топология-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench
Комментарии (18)

blackabdula
03.07.2019 13:16+1Какое-то странное решение, имея дц фабрику — выносить отдельные сервисы на свои собственные коммутаторы. Линки между лифами и спайнами же 40г? Нельзя было новых добавить? QoS никакого нет на фабрике, чтобы прод прикрыть?
Про ЛАСП все-таки интересно, в какую именно сторону ограничение было, от сервера к коммутатору или наоборот. Видимо, если тестировали между двумя серверами только, то ситуация симметричная и понять невозможно, но можно было бы еще с третьего сервера какой-нибудь трафик нагенерировать. А то непонятно, в чем проблема, со стороны коммутатора или со стороны сервера.
Еще по поводу теста, он проводился каким трафиком, юдп или тсп? Результаты приведенные — из iperf только? С загрузкой интерфейсов на коммутаторах и серверах сравнивали? Тому, что на 100 потоках результат сильно хуже, чем на 10 потоках, нашли обьяснение? В производительность сервера уперлись?DerekNN Автор
03.07.2019 21:38Выносить решили для того, чтоб не аффектить основной трафик. На момент написания 40Г было только между лифами, а между лифами и спайнами были две десятки.
Копать дальше в LACP не стали: покрутили только параметры, о которых я написал в статье и сравнили с ospf. Решили не углубляться дальше и просто использовали то, что показало себя лучше.
Тесты проводили в основном TCP (UDP гоняли пару раз всего). Результаты приведены из qperf — он показывает лэтэнси и bw в зависимости от размера пакета. Он умеет последовательно запускать их разного размера
qperf --time 10 -oo msg_size:1:64K:*2 -v --use_bits_per_sec ${test_address} tcp_lat tcp_bw
В итоге прогонялось по восходящей от 1 байта до 64 KiB
Наименьшее лэтэнси было обычно пакетами до 32 байт
На коммутаторах и интерфейсах bw показывалась одинаковая.
Разница в 10 и 100 потоков — на самом сервере упора в ресурсы не заметили. Прерывания были расбросаны по ядрам и ни одно не упиралось в потолок, памяти было достаточно, ошибок на сетевых интерфейсах или рост очереди не замечали.
Погрешили на коммутаторы.
Поскольку появилось время и возможность потестировать, думаем в ближайшее время разобраться с проблемой у LACP и падением производительности при росте потоков до 100.
blackabdula
03.07.2019 23:26+1ну получается какая-то слабенькая и не масштабируемая фабрика получилась, если нельзя несколько десяток трафика докинуть :)
А во время теста с ласп физические линки из бонда точно не выпадали на коммутаторе и\или со стороны сервера? lacp fast или slow? Может просто при заполнении порта дропались сообщения lacp, физический линк вылетал из бонда, потом обратно добавлялся, на усреднении вышло меньше, чем 20 гбит.
А джуниперу думаю все равно, что 10 потоков, что 100. Надо конечно попытаться понять, в обе ли стороны скорость ограничена, или в какую-то одну, тогда будет ясно, вина на стороне коммутатора или сетевухи.
DrunkBear
04.07.2019 17:16Слышал байку, что в Европе многие используют Hadoop-on-Ceph, но вменяемых подтверждений не нашёл.
На ваш взгляд, это реально, танцы с бубном или фантастика?yatheo
05.07.2019 13:20а в каком смысле «Hadoop-on-Ceph»? Если CephFS вместо HDFS, то мы так еще не пробовали, но идеологически выглядит нормальным решением. Но нужно проверить на практике как это будет работать. Если же просто держать данные в Ceph-е, то тут ломается основная идея близости данных к вычислительной ноде. Ну или нужен очень быстрый Ceph, чтобы нивелировать эту удаленность данных.
DrunkBear
05.07.2019 13:28+1Да, CephFS вместо HDFS.
Интересна скорость и возможные проблемыyatheo
05.07.2019 13:43+2Когда я смотрел на CephFS, там очень сильно пугало количество багов с ним связанных, и это останавливало от того, чтобы даже его посмотреть на QA. Но после чтения release notes от последних версий ceph-а, уже складывается ощущение что там стало сильно лучше. И когда Андрей нам обновит кластер до 13 или 14-ой версии, то еще раз посмотрим на применимость CephFS под наши задачи. Но как люди опытные, будем помнить о бэкапе и не будем туда класть данные которые нельзя потерять.
Опять же чисто на уровне идеи: мы получаем kernel module для CephFS вместо userland-а для HDFS, плюс мы все лучше и лучше умеем тюнить Ceph и его компоненты, так что такой эксперимент выглядит оправданным.
Но финальный ответ только по итогам тестов, причем как нагрузочных, так и функциональных. Мы не настолько хорошо знаем Ceph, чтобы давать какие-то теоретические оценки его надежности и производительности.DrunkBear
05.07.2019 14:12Пока что меня смущает память: 1 Гб за 1 тб дисков — дорого.
Есть кластер в 1 Пб (RF=3) — нужно будет выделить 1 ( или 3?) Тб оперативки под Ceph?
Да и стабильность: диски в кластере раз в пару месяцев умирают, по гарантии меняются за 2 часа. Как с этим с CephFS?yatheo
06.07.2019 12:37Про память я не согласен что дорого: сейчас память стоит порядка 5-10$ за гигабайт, у ssd порядок цен 100$ за терайбат. Ну то есть да, в Петабайтном кластере оперативной памяти будет на пару десятков тысяч долларов. Но это все-равно будут проценты от остальной стоимости кластера.
В зависимости от задач, можно перевести CAPEX в OPEX, но это тоже надо считать от проекта и задач, но как ориентир 1 PB в AWS S3 это порядка 25k $ в месяц.
А про диски я вот совсем не понял вопрос: ну умер физический диск, его надо так же заменить, ceph отреплицирует данные как в момент выхода диска из строя, так и после установки нового.
Варианта CephFS as a Service я пока не встречал, даже не буду гадать какие SLA и времена реакции там могут быть.DrunkBear
06.07.2019 18:04+1Дело не в цене, количество банков под память ограничено: на ноду полтора терабайта и лишней памяти особо нет, задачи ML сожрут всю память и ещё попросят.
Про диски — в hdfs диск меняется 2 часа, как по этому показателю в CephFS?yatheo
06.07.2019 19:15Либо я оптимист, либо не понимаю в чем сложность. Если мы имеем ноду, где Ceph сжирает терайбат оперативы, значит на этой ноде уже находится 1 PB данных на дисках. И даже в рекомендациях к Ceph-у говорится, что если данные умещаются на одну ноду, то лучше не городить Ceph, а собрать RAID.
Если на ноде данных меньше, и у нас кластер допустим на 20 узлов, то и памяти требуется в 20 раз меньше (ну или может в 10 если учитываем репликацию), и то есть от терабайта RAM мы на Ceph тратим только 5-10%, все остальное отдаем под ML.
А про замену диска: тут не про CephFS должна быть речь, за работу с диском отвечает Ceph. И сколько времени это займет, на зависит от объема и скорости диска и занятых данных. Я тут предпочитаю провести эксперимент и замеры, а не говорить оценочно. Но не вижу причин, почему Ceph может или должен быть медленее HDFS-а.
В общем, думаю ближе к 6 или 7-ой части дойдем и до экспериментов с Hadoop-ом и CephFS-ом, тогда замерим и сравним.DrunkBear
08.07.2019 12:08На самом деле это я не понимаю в чём возможная сложность, поэтому уточняю.
Работаю с вендорскими программно-аппаратными комплексами, сейчас в них HDFS, но прошёл слух, что могут сменить HDFS на Ceph ( CERN смог и мы сможем), поэтому решил заранее посмотреть, с чем едят Ceph.
a5b
06.07.2019 21:33+1Эта так называемая рекомендация "(НАПРИМЕР ~ 1 ГБ на 1ТБ)" = "however, during recovery they need significantly more RAM (e.g., ~1GB per 1TB of storage per daemon)" появилась в файле doc/start/hardware-recommendations.rst в далеком 2013 году, во времена ceph v0.73 (John Wilkins "doc: Updated docs for OSD Daemon RAM requirements. 4423"). Остается совершенно неясным как и откуда её посчитали, какие размеры дисков и ОЗУ были доступны в ту эпоху, в каких предположениях о числе PG, о числе объектов на PG, о размере объекта, о размере лога изменений и т.п. (зато такую рекомендацию легко копипастить в руководства и книги). До 2013 года там было безусловное 0.5-1ГБ "however, during recovery they need significantly more RAM (e.g., 500MB-1GB)".
В 2018 году рекомендацию поменял автор: https://github.com/ceph/ceph/pull/24247/files (повод для пересчета — issue 36163; обсуждение; commit 6af61277; ceph-13.2.3):
OSDs (ceph-osd) By default, OSDs that use the BlueStore backend require 3-5 GB of RAM. You can adjust the amount of memory the OSD consumes with the
osd_memory_targetconfiguration option when BlueStore is in use. When using the legacy FileStore backend, the operating system page cache is used for caching data, so no tuning is normally needed, and the OSD memory consumption is generally related to the number of PGs per daemon in the system.Обсуждение https://github.com/ceph/ceph/pull/24247
gregsfortytwo: Similarly we've been saying 1GB/TB on OSDs for a long time, but that messaging was quite confused for users of FileStore OSDs (I've certainly said on the list that I had no idea where it came from, since I think it was initially just made up without justification by some doc writer before we later decided it was a good idea?).
liewegas: The hardware recommendations definitely need a refresh--probably much more than I did here. (I would prefer not to block this critical fix to our defaults with a log conversation about the hardware recs, though!)Современное руководство RH не привязывается к объему диска — https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/3/html/red_hat_ceph_storage_hardware_selection_guide/ceph-hardware-min-recommend "Red Hat typically recommends a baseline of 16GB of RAM per OSD host, with an additional 2 GB of RAM per daemon" / Minimum of 5 GB of RAM per OSD container
CERN в 2015 году проверял работу вне этой рекомендации (еще на древнем Ceph firefly 0.80.8) и у них работало https://cds.cern.ch/record/2015206/files/CephScaleTestMarch2015.pdf "these machines are not within the recommended Ceph hardware spec, notably the RAM/TB ratio is far off the suggested 1GB/TB. However, this hardware is demonstrated to work well in our existing scaleout storage solution EOS"
edo1h
14.07.2019 12:34ЕМНИП, заметные случаи падения цефа с потерей данных были как раз вызываны нехваткой памяти
a5b
14.07.2019 16:54Да, при восстановлении цеф будет потреблять память; однако формула "например около 1 ГБ на 1 ТБ данных" не универсальна и получена неизвестно каким методом и из неизвестных "мнений"/ощущений по давним материалам рассылки. Реальное потребление будет зависеть не от объемов данных, а от настроек кластера, числа объектов (либо отношения между размером объекта и дисков), интенсивности записи, длительности восстановления, настроек восстановления. Можно придумать случаи, когда и 1 ГБ на 1 ТБ будет недостаточно. И понять реальное потребление можно только на тестах, приближенных к планируемому использованию.
dikkini
А где первая часть?
DerekNN Автор
habr.com/ru/post/456446
Поправил статью, добавил ссылку на первую часть в начало.
oller
Вы перевернули мой мир и представления о lacp и отказоустойчивости, спасибо вам огромное. Ospf настолько гениально, что пока не складывается в голову и хочется много тестировать.