
Адепты функционального программирования любят завлекать новичков обещаниями идеальной выразительности кода, 100% корректностью, лёгкостью поддержки и простотой рефакторинга, а иногда даже пророчат высочайшую производительность. Однако, опытные разработчики знают, что такого не бывает. Программирование — это тяжёлый труд, а «волшебных таблеток» не существует.
С другой стороны, элементы функционального стиля программирования уже проникли в промышленные языки программирования, такие как Swift и Kotlin. Разработчики этих языков прекрасно знакомы с функциональным программированием, поэтому смогли применить его «в малом», предусмотрев многие, хотя и не все, необходимые компоненты. Чем дальше — тем больше части ФП внедряются в промышленные ЯП, и тем качественнее и полнее реализуется поддержка.
Уметь программировать в функциональном стиле полезно, чтобы упрощать себе работу, и сейчас мы посмотрим, как этим воспользоваться!
Виталий Брагилевский — преподаватель ФП, теории алгоритмов и вычислений, автор книги «Haskell in Depth» и участник комитетов Haskell 2020 и наблюдательного комитета компилятора GHC.
Истории о функциональном программировании не всегда правдивы. Часто о ФП говорят примерно так.
«Давным-давно в далекой-далекой галактике программирование было простым, понятным и хорошим. Алгоритмы и структуры данных запрограммировали и все прекрасно — никаких проблем!
Потом пришли ситхи страшные люди, которые решили, что все программы состоят из классов: «Объектно-ориентированное программирование для всех! Все нужно писать только такими методами.
Когда они набрали силу, разрабатывать ПО стало невозможно — появилась куча проблем. Чтобы спасти несчастных страдающих разработчиков, и существует функциональное программирование».
Главное в спасении — нарисовать красивую и бессмысленную картинку.
Когда вы примените все, что на картинке — наступит счастье, мир, покой, а проблемы разработки ПО будут решены.
История красивая, но на деле все обстоит иначе. Именно так я представляю функциональное и промышленное программирование.

В разговоре о промышленных языках программирования понятия, функциональны они или нет, используется там ФП или нет, подниматься не должны!
Желать пересадить всех на функциональные рельсы, все равно, что заставить ученых проводить эксперименты как Фарадей — бессмысленно. Никто сейчас не проводит опыты над электричеством такими устаревшими методами.
Рассмотрим на примерах.
Джон Маккарти один из создателей Лиспа.

65 лет назад основным языком программирования был Фортран. В нем есть условный оператор:
Если значение переменной I не равно 0, то переходим по метке «40».
В то время Джон создавал программу, которая программирует шахматы, и писать в подобном стиле ему было неудобно. Джон подумал, хорошо бы для решения конкретной задачи иметь функцию
Большой недостаток такой функции — одновременное вычисление N1 и N2. Зачем лишние вычисления, если нужно только одно значение?
Маккарти думал и над этой проблемой и пришел к условной тернарной операции:
В некоторых модных ЯП она считается устаревшей. Но этот элемент функционального программирования есть в любом мейнстримном языке. Мы везде его используем, и иногда вынуждены моделировать другими способами, чтобы все-таки получить условную операцию.
Джон Бэкус — создатель Фортрана и очень известный человек. В 1977 году получил премию Тьюринга в области информатики. На вручении награды произнес речь «Можно ли освободить программирование от стиля фон Неймана?». В ней создатель Фортрана — обратите внимание — призвал программировать не так, как мы привыкли.

Один из главных примеров в речи — код, который вычисляет скалярное произведение двух векторов.
Решение задачи можно найти циклом по классической фон-неймановской программе:
Здесь есть сумматор и аккумулятор — циклом перебираем значения и все комбинируем.
Решение этой же задачи можно найти функциональной программой. В качестве примера Джон показал код на выдуманном языке FP.
Джон предложил использовать композицию функций —
Два примера — классический и функциональный — выполняют одно и то же действие, но Бэкус считал, что правильнее писать во втором стиле.
Сейчас все так и пишут. Ваши программы скорее всего написаны в таком же стиле.
Многие напоминают мне, что когда-то я преподавал Java и студенты писали примерно так же на этом ЯП. Да, но это было давно, мы были молоды и не знали, как писать правильно.

Сейчас, оценивая этот код, я вижу много недостатков:
Именно так действительно никто не пишет, что хорошо.
Сейчас код выглядит подобным образом:
Это код на Kotlin, на не самом функциональном ЯП, но писать иначе уже нельзя. Как все работает?
На вход подается список имен файлов, считается количество строк в каждом из них, потом все суммируется и находится общее количество строк. Функциональный элемент — функция «map» — обрабатывает все элементы заданного списка имен файлов. Дальше котлиновское действие, которое мы производим с каждым файлом: считаем количество строк, файл читается и разбивается на строки. Переменная it — это имя конкретного файла на каждом шаге такого цикла. В конце считается сумма элементов — sum().
Если мы знаем, что такое
Но если приглядеться, то мы увидим Haskell.
Разница, конечно, есть. В Haskell я напишу две функции, а не одну, потому что это функциональное программирование.
Первая функция считает число строк в одном заданном файле. Мы сразу видим, что происходит: на входе имя файла, на выходе Int — целое число.
Контроль побочных эффектов. Мы используем «IO», потому что в Haskell нужно сигнализировать, что функция использует побочные эффекты и выполняется ввод-вывод. Это «нечистая функция», поэтому здесь не просто Int, а IO Int. Это сигнализирует, что число получено в результате исполнения побочных эффектов.
Вторая функция считает количество строк уже в нескольких файлах. Квадратные скобки — это список в Haskell. Мы берем список имен файлов — FilePath, и получаем тот же самый IO Int — суммирование. Следующая строка: сумма, traverse — обход по списку, а для каждого элемента списка выполняется действие «countLines».
Композиция функций. Везде используется операция «. » (у Бэкуса
«f. g» — это функция, которая по аргументу «x» возвращает значение «f(g(x))». Аргументов нигде нет, они будут подставлены сами. Я использую такую аннотацию, потому что для ФП она очень удобна. В этом мейнстримные языки пока отстают.
Если копнуть глубже, то видно, что особой разницы между ООП и ФП нет. ООП — практически то же, что и ФП.
Докажу утверждение на простом примере реализации UML-диаграммы. Классический пример: форма, круги, квадраты, наследование, виртуальные функции.
Я недавно узнал, что это уже не ООП, а протокол-ориентированное программирование. Но в Swift я ничего не понимаю, поэтому получилось, что получилось.
Вроде бы работает, но не ООП.
В реализации все просто: сериализация, методы, конструктор – все, как положено. Это классическое ООП в стиле Гради Буча.
Запустим этот код, например, на круге и на квадрате.
Получим результат. Все работает.
Здесь должен работать полиморфизм, но поскольку это ПОП, а не ООП, наверное, работает что-то другое. Но это не важно – главное, что работает.
Вот код на Haskell, который выполняет то же, что и код на Swift.
В ФП данные и функции существуют отдельно. В первой строке у нас тип данных, который мы называем «алгебраическим типом данных» — это круг или квадрат. Дальше операция «или» используется для построения типа данных. И пара функций считают площадь и диаметр.
Функции используют сопоставление с образцом — проверяют, круг это или квадрат, и выбирают соответствующую строчку. Так это работает в Haskell — отдельно. Функции вызываются для одного, для другого и считаются результаты.
Результат:
Понятие диаметра — расстояния между двумя самыми удаленными точками фигуры — используется для фигуры любой формы, в квадрате это диагональ.
Кажется, что в Swift и Haskell подходы противоположны. У нас есть класс и его наследники, которые мы реализуем, и два вида сущностей, для каждой из которых пишем функции. Однако, если представить наш код в виде таблицы, где столбцы — типы форм, а строки — функции, то видно, что разницы нет.
Какая разница, как работать с таблицей и как на нее смотреть: через строки или столбцы? Для соответствующих концепций это не имеет значение. Это важно только для нас как наблюдателей.
Разница есть техническая, когда мы проводим диспетчеризацию:
Идеологически — это просто работа с таблицей.
Известно, что алгебраические типы данных есть и в Swift.
Код в Haskell…
… в Swift будет немного многословнее.
Но идея та же. Не считая операции «или» для алгебраических типов данных, вместо которой в Swift используется «enum», реализация аналогична. Например, функцию можно оформить в виде метода расширения.
Код в Haskell…
… в Swift многословнее.
Но, опять же — идея та же.
Алгебраические типы данных присутствуют и в Kotlin:
Слов больше, но идеологически — аналогично.
После этого мы будем говорить, что Kotlin и Swift не функциональные ЯП? Они же используют эти элементы, потому что, неожиданно, это удобно. Элементы из ФП пришли в мейнстримные языки, и уже мейнстримные языки можно не называть объектно-ориентированными, потому что все самое хорошее из ФП они уже давно используют.
Есть еще одна разница между ООП и ФП. Существует ограничение в том, что если мы хотим расширить таблицу, добавить еще один столбец или строку, то выясняется, что некоторые способы расширить табличку в одной парадигме работают хорошо, а в другой плохо.
В ООП можно легко написать один класс, но чтобы добавить еще один метод, придется лезть в базовый класс, что-то добавлять — все перекомпилировать. Возникает масса сложностей. В ФП также: при добавлении нового объекта возникнет проблема — мы должны перекомпилировать определение базового типа. А функцию добавить, наоборот, легко.
В правом нижнем углу находится самое тяжелое для обоих способов. Невозможно это сделать красиво.
Исследователи уже двадцать лет бьются над проблемой расширения. Этой задачей часто тестируют выразительность ЯП. Основной пример — это что-то вроде задачи компиляции игрушечного языка программирования, когда мы хотим добавлять в него языковые конструкции — добавлять типы и расширять операции, статически контролировать типы. Но при этом мы не хотим ничего перекомпилировать и явно приводить типы — все должно выполняться компилятором автоматически.
У проблемы расширения — базовой дилеммы между ООП и ФП — решений много. Последние 20 лет они публикуются, и многие ЯП уже их внедряют.
Все перечисленные подходы, и даже решение с ужасным названием «Алгебры объектов», так или иначе решают проблему расширения. Подробно не будем останавливаться. Но если вам интересны именно языки программирования, а не само программирование — изучите самостоятельно, вам будет интересно.
Хочу поговорить не совсем об алгебрах, а вообще об этом слове.
Когда я встречаю функциональщика, то сразу слышу страшные слова: полугруппы, моноиды, функторы, монады. Иногда кажется, что функциональщики доказывают справедливость этой старой картинки.

Ее однозначно нарисовали адепты Haskell. Кто другой будет представлять себя в виде Эйнштейна, думать, что все представляют его Эйнштейном, и разговаривать «страшными» словами?
Каждое страшное слово, вроде «функтора» — это просто конкретная проблема в программировании и ничего больше.
Полугруппы и моноиды упрощают компоновку сущностей в сущности того же рода — паттерн «Composite». Есть моноиды и полугруппы. Мы просто берем сущности, компонуем их и получаем сущности того же рода для удобства обработки.
Например, операция конкатенации строк в Kotlin — это обычное использование моноида.
Когда я читаю лекции по общей алгебре, говорю: «Программисты, строки складывать умеете? Вот это и есть моноид». Можно дать формальное математическое определение, но кратко и без формализма — это компоновка двух строк во что-то одно.
Второй пример — компоновка свойств HTTP-запроса. В воображаемом Kotlin это выглядит так:
В реальном Haskell есть библиотека, которая выполняет ровно то же. Там свойства HTTP-объекта — это моноид. Мы складываем их и формируем из отдельных компонентов новый HTTP-запрос.
То же с монадами и функторами. Функторы и монады облегчают описание последовательности шагов вычисления в контексте. Шаги идут последовательно друг за другом и каким-то образом зависят друг от друга. Зависимость — не просто последовательное выполнение, но еще и некий контекст — то, что существует кроме этих шагов. Программисты на современных ЯП иногда используют «optional chaining», например, в Swift.
Мы пытаемся вычислить адрес, достать его из объекта. Есть объект «john» — извлекаем местожительство.
Вычисление идет последовательно: достаем из объекта сначала одно, потом другое, потом третье. Контекст здесь — возможность отсутствия соответствующего значения. Если оно отсутствует, то возвращаем ветку else — неуспешный результат в данном случае. Мы можем прерваться на любом шаге.
Создатели Swift не стали пугать программистов монадой. Они знают, что такое монада, и ввели в язык синтаксис, который выполняет монадические вычисления: последовательность шагов в контексте с отсутствием значения.
Если бы мы писали тот же самый код с монадой на Haskell, он бы выглядел так.
Обратите внимание, «>>=» — это главная операция монадического связывания. Но смысл кода от этого не меняется.
В Swift для «optional chaining» понадобилось вводить новую синтаксическую конструкцию. В Kotlin для корутин тоже нужно вводить кучу синтаксиса и понятий. В Haskell те же самые корутины неожиданно превращаются в те же самые монадические вычисления, с тем же самым оператором «>>=».
Есть два подхода к монаде:
Оба подхода хороши. Но идея выноса абстракции наверх в больших мейнстримных ЯП пока не считается хорошей. Считается, что лучше вводить много разных элементов синтаксиса и прятать от программиста единое понимание сути происходящего. Может быть, это и хорошо — так проще, чем подниматься на более высокий уровень абстракции.
Массу «алгебр» в своих мобильных разработках вы уже используете. Все программирование — это сущности, которые мы обрабатываем разными способами. Мы обычно не называем это «алгебрами», но это они и есть. Поэтому теперь понятие «алгебра объектов» не будет нас пугать.
Нет однозначного ответа на этот вопрос. Разработчики языков программирования самостоятельно принимают решение, что они делают — выносят абстракцию программистам или прячут ее за элементы синтаксиса.
Я считаю, что абстракция — это красиво. Покажу это на примере со сложным синтаксисом Haskell из работы «Build Systems a la Carte» Андрея Мохова из университета Ньюкасла и его соавторов. Соответствующая статья получила премию Distinguished Paper Award на International Conference on Functional Programming (ICFP) в Сент-Луисе осенью 2018 года. Эта замечательная работа посвящена Build-системам, которые все используют.
Авторы предлагают абстрагироваться от конкретных Build-систем и выражать разные Build-системы с помощью одной формализации — абстракции. Для этого они вводят понятие хранилища.
В нем есть параметры:
Хранилище — это абстракция. Один из примеров — файловая система с файлами, с дополнительной метаинформацией. У файлов есть имена и содержимое на диске.
Также есть зависимости. Мы хотим показать, что одни файлы зависят от других файлов, чтобы их собирать. Чтобы собрать объектный файл, нужно сначала найти на диске то-то и то-то, собрать, а потом это все вместе использовать.
Есть другая абстракция — «Task» — задание для системы сборки.
Здесь используется сложный синтаксис Haskell, потому что абстрагируется все. Например, монада — это частный случай «f», от которого происходит абстрагирование. Кроме монады, могут быть и другие способы описывать последовательности вычислений.
Что происходит? Функция «k -> fv» описывает зависимость между ключом и значением — это способ построить что-то одно. Эта функция играет роль параметра. В результате применения этой функции мы получаем итоговое значение. Так описывается сборка одного компонента Build-системы.
Выстраивание дерева выполняется уже следующим типом — набором заданий:
Это тоже функция, которая описывает, как от разных ключей зависят разные способы сборки. «Maybe» — это что-то вроде «optional». Мы описываем, как что-то от чего-то зависит, или не зависит.
В результате получаем окончательную абстракцию Build-системы:
На входе описание всей системы зависимостей. Затем идет ключ k, с которого начинается сборка. Дальше — начальное хранилище и хранилище с результатом функции с полностью собранной системой. Это пример абстракции, которая построена поверх других абстракций.
Андрей Мохов с соавторами выявили отличия и привели в статье формальное описание для четырех систем сборки.
Первые три системы сборки известны многим. Четвертая — Excel — это тоже система сборки. Excel тоже попадает под абстрактную формализацию — в нем клетки зависят друг от друга. Написали значение в одну клетку, пересчиталось что-то другое. Make и Excel имеют что-то общее, что можно описывать с помощью этой абстракции.
Это частая претензия к функциональному программированию.
— Ваш Haskell тормозит. Мы уже все давно посчитали, а вы все еще пишете свою программу и никак скомпилировать не можете.
Иногда да, иногда нет. Вообще-то быстродействие — это задача компилятора. В идеальной системе хороший компилятор должен построить хороший код, независимо от того, что написал программист. Если он строит плохой код, то это вина компилятора.
Например, высокодекларативный код на Haskell:
Можете считать это псевдокодом — я использую композицию функций. Я принимаю на вход какой-то список, а дальше:
Любой программист мейнстрим языка сразу начнет кричать:
— Ужас, сколько тут циклов, сколько промежуточных структур данных… Это вообще не программирование! Вон из профессии!
Просто потому, что компилятор слабоват.
В функциональных ЯП существует идея «fusion», которая потихоньку проникает в другие языки программирования.
Что такое «fusion»? По-простому: всю декларативную тщательно расписанную последовательность шагов можно превратить в императивный цикл:
Обращаю внимание, что цикл один (!), а промежуточных структур данных ноль (!). Задача компилятора в том, чтобы красивый и понятный код превратить в высокоэффективную программу, и скомпилировать это все в 2-3 ассемблерные команды.
Пусть разработчики компиляторов получше думают и пишут свои компиляторы так, чтобы код получался эффективным.
Еще один пример кода на Haskell, который считает скалярное произведение двух векторов:
Неважно, что происходит на Haskell: берем 2 вектора, покомпонентно перемножаем, находим сумму компонентов. Важно, что на Haskell этот код после компиляции работает непосредственно на GPU. Векторы размещены сразу на GPU, и графический ускоритель все сделает: скомпилирует CUDA, Open CL — все, что хотите. Библиотека Accelerate у Haskell скомпилирует — получится эффективный код.
На CUDA мы бы писали 100 лет, а здесь написали одну короткую строчку в функциональном стиле, и получили высокоэффективную программу. Все декларативно и быстро! Это ровно то, чего мы хотим от компилятора. Но есть проблемы, с которыми пока компиляторы не очень хорошо справляются.
Каррирование — это большая проблема. Что это такое? Есть функция с тремя параметрами типов a, b, c и результатом D.
Одно дело, когда мы работаем просто с этой функцией — передаем ее в качестве параметра. Другое дело, когда мы указали аргументы частично:
Во второй и третьей строчках мы часть аргументов указали, а часть нет. Если такую функцию, которая частично применена, будем куда-то передавать, то возникнут проблемы. Компиляторы пока не очень хорошо умеют это делать — создается замыкание, много всего требуется передавать, тратить массу времени.
Поэтому во многих языках, например, в Scala действуют по-другому.
Они говорят: «Это ты можешь откаррировать, а это нет. Эти два аргумента разделить нельзя, они должны всегда идти вместе. Тут скомпилируем, а здесь — нет». В результате ЯП ограничивает возможности программиста.
Это открытая проблема, которая пока еще не решена даже в функциональных языках.
Корректность хорошо работает в ФП. В Haskell 15 лет назад родилась библиотека QuickCheck, которая помогает в тестировании корректности.
Например, есть функция, которая оборачивает строку:
Мы ее тестируем, придумывая свойство этой функции. Если два раза применим ее к одной и той же строке, то получится исходная строка.
Да, это чистая функция и для нее можно придумать такое свойство. Библиотека генерирует случайным образом массу аргументов, в данном случае 100, на них прогоняет, и убеждается, что это свойство выполняется.
Мы проверяем работоспособность кода не на конкретных примерах, а формулируем свойство и говорим, что для всех аргументов это свойство должно выполняться. Работаем математически. Эта идея возникла в Haskell 15 лет назад. Сейчас подобные идеи проникают в другие языки. Уверен, что для Swift и Kotlin подобные библиотеки уже есть.
Как думаете, здесь произойдет ошибка?
Обратите внимание, функция в середине работает на непустом списке.
Если подали непустой список, функция
Попадем ли мы на «head», вызванный для пустого списка? Нет, и LiquidHaskell может это доказать. LiquidHaskell — это статический верификатор Haskell-кода.
Можно сказать, что у функции abs результатом будет всегда число, больше или равное n.
Здесь пишем, что функция определена на списке с некоторой длиной.
Здесь доказываем, что функция возвращает то, что ей передали. Функции передается x и возвращается также x.
Компилятор или его компонент может проверить вашу программу и доказать целый ряд свойств вашей программы, и она оказывается безопасной. Это пока еще функциональное программирование, потому что активно используется работа с чистыми функциями. Вполне возможно, что подобное когда-нибудь увидим и в мейнстримных языках. Какие-то попытки для объектно-ориентированных языков уже были, например, в Eiffel, значит что-то близкое можно сделать.
Это пример веб-разработки:
В Haskell есть библиотека Servant, которая может моделировать вызовы API с помощью типов. Например, в коде выше есть несколько url для конференции, для года, нравится она или нет, а результаты кодируются в JSON. Видно, что есть разные типы результатов: String», Int», Bool.
Мы пишем разные обработчики.
А библиотека контролирует всё — результаты такие, какими они должны быть.
Все работает, система типов охраняет корректность нашей программы. Мы не сможем при всем желании вернуть строку вместо целого числа в ответ на запрос о годе, просто потому, что компилятор не пропустит. Корректность — это очень хорошо.
Функциональное программирование — интересная штука. Не призываю всех переходить на него, но его элементы мигрируют во все обычные ЯП. И это прекрасно.
Если интересно — начните с книги Уилла Курта «Программируй на Haskell». На русском она вышла в ноябре 2018 года. Трое моих студентов ее перевели, а я подредактировал. Рекомендую книгу всем новичкам в Haskell. Когда освоите все 600 страниц, переходите к следующей.
«Haskell in Depth» за авторством некоего Виталия Брагилевского. Книга пока в раннем доступе, не закончена, но уже рекомендую. Промокод «slbragilevsky» дает скидку 42%.
С другой стороны, элементы функционального стиля программирования уже проникли в промышленные языки программирования, такие как Swift и Kotlin. Разработчики этих языков прекрасно знакомы с функциональным программированием, поэтому смогли применить его «в малом», предусмотрев многие, хотя и не все, необходимые компоненты. Чем дальше — тем больше части ФП внедряются в промышленные ЯП, и тем качественнее и полнее реализуется поддержка.
Уметь программировать в функциональном стиле полезно, чтобы упрощать себе работу, и сейчас мы посмотрим, как этим воспользоваться!
Виталий Брагилевский — преподаватель ФП, теории алгоритмов и вычислений, автор книги «Haskell in Depth» и участник комитетов Haskell 2020 и наблюдательного комитета компилятора GHC.
Краткая история
Истории о функциональном программировании не всегда правдивы. Часто о ФП говорят примерно так.
«Давным-давно в далекой-далекой галактике программирование было простым, понятным и хорошим. Алгоритмы и структуры данных запрограммировали и все прекрасно — никаких проблем!
Потом пришли ситхи страшные люди, которые решили, что все программы состоят из классов: «Объектно-ориентированное программирование для всех! Все нужно писать только такими методами.
Когда они набрали силу, разрабатывать ПО стало невозможно — появилась куча проблем. Чтобы спасти несчастных страдающих разработчиков, и существует функциональное программирование».
Главное в спасении — нарисовать красивую и бессмысленную картинку.
Когда вы примените все, что на картинке — наступит счастье, мир, покой, а проблемы разработки ПО будут решены.
История красивая, но на деле все обстоит иначе. Именно так я представляю функциональное и промышленное программирование.
Функциональное программирование это лаборатория Фарадея — место рождения идей, которые потом применяются в промышленном программировании.
В разговоре о промышленных языках программирования понятия, функциональны они или нет, используется там ФП или нет, подниматься не должны!
Главная миссия ФП — передавать хорошие элементы в мейнстримовые языки.
Желать пересадить всех на функциональные рельсы, все равно, что заставить ученых проводить эксперименты как Фарадей — бессмысленно. Никто сейчас не проводит опыты над электричеством такими устаревшими методами.
Рассмотрим на примерах.
Функция Джона Маккарти
Джон Маккарти один из создателей Лиспа.
65 лет назад основным языком программирования был Фортран. В нем есть условный оператор:
IF (I.NE.0) GOTO 40
STMT-1
STMT-2
40 STMT-3
Если значение переменной I не равно 0, то переходим по метке «40».
В то время Джон создавал программу, которая программирует шахматы, и писать в подобном стиле ему было неудобно. Джон подумал, хорошо бы для решения конкретной задачи иметь функцию
XIF(M, N1,N2), которая берет условие, и возвращает одно из двух значений: N1 или N2.Одна из первых идей ФП: от оператора с последовательностями действий «если… то» переходим к функции, и сразу получаем требуемое значение.
Большой недостаток такой функции — одновременное вычисление N1 и N2. Зачем лишние вычисления, если нужно только одно значение?
Маккарти думал и над этой проблемой и пришел к условной тернарной операции:
M==0 ? N1 : N2В некоторых модных ЯП она считается устаревшей. Но этот элемент функционального программирования есть в любом мейнстримном языке. Мы везде его используем, и иногда вынуждены моделировать другими способами, чтобы все-таки получить условную операцию.
Можно ли освободить программирование от стиля фон Неймана?
Джон Бэкус — создатель Фортрана и очень известный человек. В 1977 году получил премию Тьюринга в области информатики. На вручении награды произнес речь «Можно ли освободить программирование от стиля фон Неймана?». В ней создатель Фортрана — обратите внимание — призвал программировать не так, как мы привыкли.
Один из главных примеров в речи — код, который вычисляет скалярное произведение двух векторов.
Решение задачи можно найти циклом по классической фон-неймановской программе:
c := 0
for i := 1 step 1 until n do
c := c + a[i]*b[i]Здесь есть сумматор и аккумулятор — циклом перебираем значения и все комбинируем.
Решение этой же задачи можно найти функциональной программой. В качестве примера Джон показал код на выдуманном языке FP.
Def DotP = (Insert +) o (ApplyToAll x) o TransposeДжон предложил использовать композицию функций —
o, а функции, которые взаимодействуют между собой, писать декларативно.Два примера — классический и функциональный — выполняют одно и то же действие, но Бэкус считал, что правильнее писать во втором стиле.
Сейчас все так и пишут. Ваши программы скорее всего написаны в таком же стиле.
Как не надо писать
Многие напоминают мне, что когда-то я преподавал Java и студенты писали примерно так же на этом ЯП. Да, но это было давно, мы были молоды и не знали, как писать правильно.
Сейчас, оценивая этот код, я вижу много недостатков:
- используются циклы, которые вложены друг в друга;
- код совершенно нечитаем;
- некорректно проверяются концы строк;
- используются счетчики.
Именно так действительно никто не пишет, что хорошо.
Современный код
Сейчас код выглядит подобным образом:
fun countLinesInFiles(fnames: List<String>): Int
= fnames.map { File(it).readLines().size }
.sum()Это код на Kotlin, на не самом функциональном ЯП, но писать иначе уже нельзя. Как все работает?
На вход подается список имен файлов, считается количество строк в каждом из них, потом все суммируется и находится общее количество строк. Функциональный элемент — функция «map» — обрабатывает все элементы заданного списка имен файлов. Дальше котлиновское действие, которое мы производим с каждым файлом: считаем количество строк, файл читается и разбивается на строки. Переменная it — это имя конкретного файла на каждом шаге такого цикла. В конце считается сумма элементов — sum().
Если мы знаем, что такое
map и фигурные скобки в Kotlin, нам понятно, что выполняет код. Мы не гадаем, каким именно символом заканчивается строка в этой конкретной операционной системе. Это не важно — readLines все делает за нас.Почти как в Haskell
Но если приглядеться, то мы увидим Haskell.
countLines :: FilePath -> IO Int
countLines = fmap (length . lines) . readFile
countLinesInFiles :: [FilePath] -> IO Int
countLinesInFiles = fmap sum . traverse countLinesРазница, конечно, есть. В Haskell я напишу две функции, а не одну, потому что это функциональное программирование.
Первая функция считает число строк в одном заданном файле. Мы сразу видим, что происходит: на входе имя файла, на выходе Int — целое число.
Контроль побочных эффектов. Мы используем «IO», потому что в Haskell нужно сигнализировать, что функция использует побочные эффекты и выполняется ввод-вывод. Это «нечистая функция», поэтому здесь не просто Int, а IO Int. Это сигнализирует, что число получено в результате исполнения побочных эффектов.
Вторая функция считает количество строк уже в нескольких файлах. Квадратные скобки — это список в Haskell. Мы берем список имен файлов — FilePath, и получаем тот же самый IO Int — суммирование. Следующая строка: сумма, traverse — обход по списку, а для каждого элемента списка выполняется действие «countLines».
Композиция функций. Везде используется операция «. » (у Бэкуса
o) — это композиция функций. Мы пишем функции слева направо, но выполняются они справа налево.«f. g» — это функция, которая по аргументу «x» возвращает значение «f(g(x))». Аргументов нигде нет, они будут подставлены сами. Я использую такую аннотацию, потому что для ФП она очень удобна. В этом мейнстримные языки пока отстают.
Разница между ООП и ФП
Мы программируем практически в функциональном стиле на современных нефункциональных языках.
Если копнуть глубже, то видно, что особой разницы между ООП и ФП нет. ООП — практически то же, что и ФП.
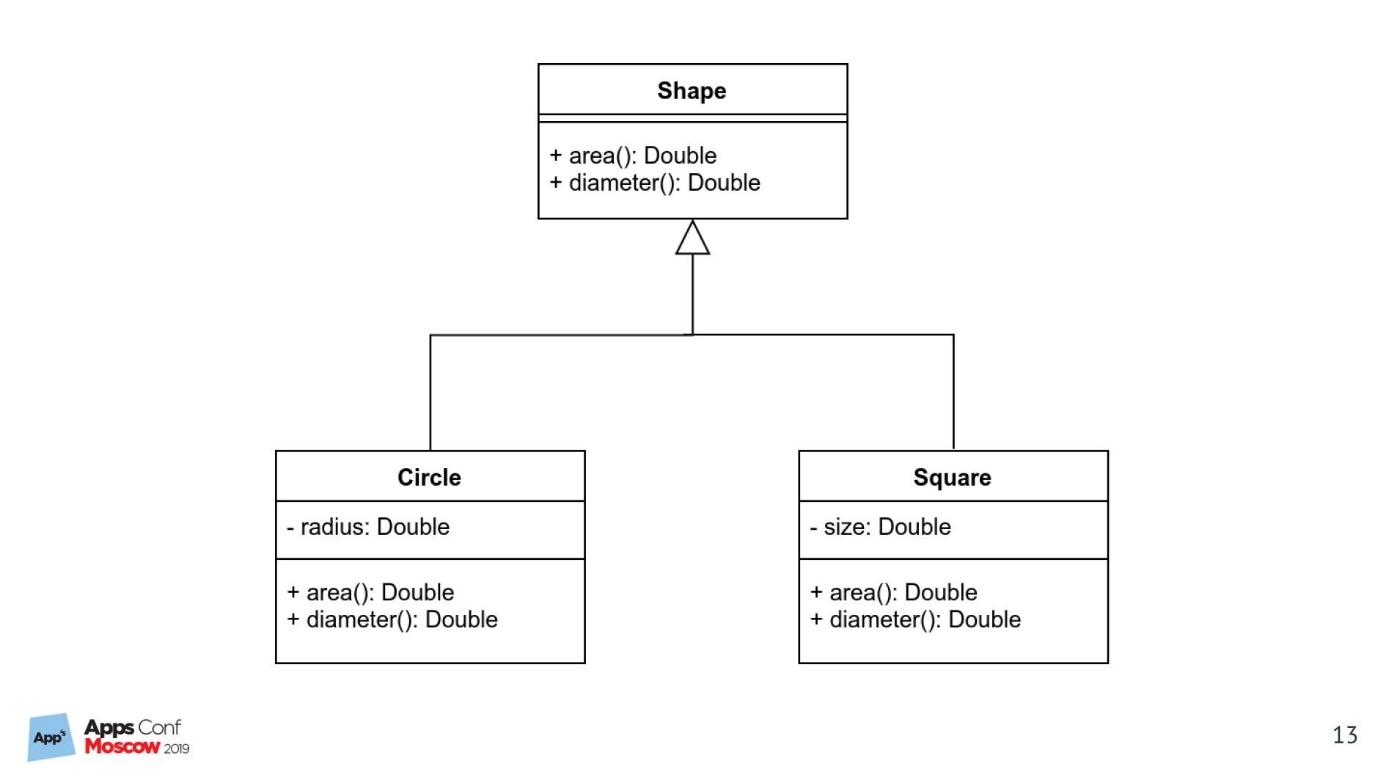
Докажу утверждение на простом примере реализации UML-диаграммы. Классический пример: форма, круги, квадраты, наследование, виртуальные функции.
Реализация на Swift
Я недавно узнал, что это уже не ООП, а протокол-ориентированное программирование. Но в Swift я ничего не понимаю, поэтому получилось, что получилось.
protocol Shape {
func area() -> Double
func diameter() -> Double
}
class Circle: Shape {
var r = 0.0
init(radius: Double) {
r = radius
}
func area() -> Double {
return 3.14 * r * r
}
func diameter() -> Double {
return 2 * r
}
}
class Square: Shape {
var s = 0.0
init(size: Double) {
s = size
}
func area() -> Double {
return s * s
}
func diameter() -> Double {
return sqrt(2) * s
}
}Вроде бы работает, но не ООП.
В реализации все просто: сериализация, методы, конструктор – все, как положено. Это классическое ООП в стиле Гради Буча.
Запустим этот код, например, на круге и на квадрате.
func testShape(shape: Shape) {
print(shape.area())
print(shape.diameter())
}Получим результат. Все работает.
testShape(shape: Circle(radius: 5))
testShape(shape: Square(size: 5))
78.5
10.0
25.0
7.0710678118654755Здесь должен работать полиморфизм, но поскольку это ПОП, а не ООП, наверное, работает что-то другое. Но это не важно – главное, что работает.
Реализация на Haskell
Вот код на Haskell, который выполняет то же, что и код на Swift.
data Shape = Circle Double | Square Double
area :: Shape -> Double
area (Circle r) = 3.14 * r * r
area (Square s) = s * s
diameter :: Shape -> Double
diameter (Circle r) = 2* r
diameter (Square s) = sqrt 2 * sВ ФП данные и функции существуют отдельно. В первой строке у нас тип данных, который мы называем «алгебраическим типом данных» — это круг или квадрат. Дальше операция «или» используется для построения типа данных. И пара функций считают площадь и диаметр.
Функции используют сопоставление с образцом — проверяют, круг это или квадрат, и выбирают соответствующую строчку. Так это работает в Haskell — отдельно. Функции вызываются для одного, для другого и считаются результаты.
Результат:
> area (Circle 5)
78.5
> diameter (Circle 5)
10.0
> area (Square 5)
25.0
diameter (Square 5)
7.0710678118654755Понятие диаметра — расстояния между двумя самыми удаленными точками фигуры — используется для фигуры любой формы, в квадрате это диагональ.
Кажется, что в Swift и Haskell подходы противоположны. У нас есть класс и его наследники, которые мы реализуем, и два вида сущностей, для каждой из которых пишем функции. Однако, если представить наш код в виде таблицы, где столбцы — типы форм, а строки — функции, то видно, что разницы нет.
| Circle | Square | |
| area | * | * |
| diameter | * | * |
ООП — это работа с этой таблицей по столбцам, где каждый столбец — один класс. ФП — это работа с таблицей по строкам, потому что речь идет о функциях.
Какая разница, как работать с таблицей и как на нее смотреть: через строки или столбцы? Для соответствующих концепций это не имеет значение. Это важно только для нас как наблюдателей.
Разница есть техническая, когда мы проводим диспетчеризацию:
- в ООП — до вызова функции по указателю на таблице виртуальных методов;
- в ФП — после вызова функции, когда мы смотрим, какая сущность пришла в функцию, и выбираем нужную строчку.
Идеологически — это просто работа с таблицей.
Алгебраические типы данных
Известно, что алгебраические типы данных есть и в Swift.
Код в Haskell…
data Shape = Circle Double | Square Double… в Swift будет немного многословнее.
enum Shape {
case Circle(radius: Double)
case Square(size: Double)
}Но идея та же. Не считая операции «или» для алгебраических типов данных, вместо которой в Swift используется «enum», реализация аналогична. Например, функцию можно оформить в виде метода расширения.
Код в Haskell…
area :: Shape -> Double
area (Circle r) = 3.14 * r * r
area (Square s) = s * s… в Swift многословнее.
extension Shape {
var area: Double {
switch self {
case .Circle(let r): return 3.14 * r * r
case .Square(let s): return s * s
}
}
}Но, опять же — идея та же.
Алгебраические типы данных присутствуют и в Kotlin:
sealed class Shape {
data class Circle(val radius: Double): Shape()
data class Square(val size: Double): Shape()
}
fun area(sh: Shape): Double {
return when (sh) {
is Shape.Circle -> 3.14 * sh.radius * sh.radius
is Shape.Square -> sh.size * sh.size
}
}Слов больше, но идеологически — аналогично.
После этого мы будем говорить, что Kotlin и Swift не функциональные ЯП? Они же используют эти элементы, потому что, неожиданно, это удобно. Элементы из ФП пришли в мейнстримные языки, и уже мейнстримные языки можно не называть объектно-ориентированными, потому что все самое хорошее из ФП они уже давно используют.
Проблема расширения
Есть еще одна разница между ООП и ФП. Существует ограничение в том, что если мы хотим расширить таблицу, добавить еще один столбец или строку, то выясняется, что некоторые способы расширить табличку в одной парадигме работают хорошо, а в другой плохо.
| Circle | Square | x | |
| area | * | * | ? |
| diameter | * | * | ? |
| f | ? | ? | ? |
В ООП можно легко написать один класс, но чтобы добавить еще один метод, придется лезть в базовый класс, что-то добавлять — все перекомпилировать. Возникает масса сложностей. В ФП также: при добавлении нового объекта возникнет проблема — мы должны перекомпилировать определение базового типа. А функцию добавить, наоборот, легко.
| Circle | Square | x | |
| area | * | * | + (ООП) |
| diameter | * | * | + (ООП) |
| f | + (ФП) | + (ФП) | ? |
В правом нижнем углу находится самое тяжелое для обоих способов. Невозможно это сделать красиво.
Исследователи уже двадцать лет бьются над проблемой расширения. Этой задачей часто тестируют выразительность ЯП. Основной пример — это что-то вроде задачи компиляции игрушечного языка программирования, когда мы хотим добавлять в него языковые конструкции — добавлять типы и расширять операции, статически контролировать типы. Но при этом мы не хотим ничего перекомпилировать и явно приводить типы — все должно выполняться компилятором автоматически.
Подходы к решению
У проблемы расширения — базовой дилеммы между ООП и ФП — решений много. Последние 20 лет они публикуются, и многие ЯП уже их внедряют.
- Паттерн «Visitor». Решение, которое возникло еще до того, как была сформулирована сама проблема. Метод хорошо работает, но с ограничениями.
- Мультиметоды.
- Открытые классы — методы расширения.
- Классы типов.
- Алгебры объектов.
Все перечисленные подходы, и даже решение с ужасным названием «Алгебры объектов», так или иначе решают проблему расширения. Подробно не будем останавливаться. Но если вам интересны именно языки программирования, а не само программирование — изучите самостоятельно, вам будет интересно.
Об алгебрах
Хочу поговорить не совсем об алгебрах, а вообще об этом слове.
Когда я встречаю функциональщика, то сразу слышу страшные слова: полугруппы, моноиды, функторы, монады. Иногда кажется, что функциональщики доказывают справедливость этой старой картинки.
Ее однозначно нарисовали адепты Haskell. Кто другой будет представлять себя в виде Эйнштейна, думать, что все представляют его Эйнштейном, и разговаривать «страшными» словами?
Каждое страшное слово, вроде «функтора» — это просто конкретная проблема в программировании и ничего больше.
Полугруппы и моноиды упрощают компоновку сущностей в сущности того же рода — паттерн «Composite». Есть моноиды и полугруппы. Мы просто берем сущности, компонуем их и получаем сущности того же рода для удобства обработки.
Например, операция конкатенации строк в Kotlin — это обычное использование моноида.
val a = "Hello "
val b = "world"
val c = a + bКогда я читаю лекции по общей алгебре, говорю: «Программисты, строки складывать умеете? Вот это и есть моноид». Можно дать формальное математическое определение, но кратко и без формализма — это компоновка двух строк во что-то одно.
Второй пример — компоновка свойств HTTP-запроса. В воображаемом Kotlin это выглядит так:
val a = HttpReq("f","v1")
val b = HttpReq("f2","v2")
val c = a + bВ реальном Haskell есть библиотека, которая выполняет ровно то же. Там свойства HTTP-объекта — это моноид. Мы складываем их и формируем из отдельных компонентов новый HTTP-запрос.
То же с монадами и функторами. Функторы и монады облегчают описание последовательности шагов вычисления в контексте. Шаги идут последовательно друг за другом и каким-то образом зависят друг от друга. Зависимость — не просто последовательное выполнение, но еще и некий контекст — то, что существует кроме этих шагов. Программисты на современных ЯП иногда используют «optional chaining», например, в Swift.
if let johnsStreet = john.residence?.address?.street
{ /* SUCCESS */ } else { /* FAILURE */ }Мы пытаемся вычислить адрес, достать его из объекта. Есть объект «john» — извлекаем местожительство.
?.значит, что местожительство может отсутствовать, в этом случае сразу получим false.- Но если местожительство присутствует, то достаем из него адрес.
- Адрес тоже может отсутствовать.
- Если присутствует — достаем строку.
Вычисление идет последовательно: достаем из объекта сначала одно, потом другое, потом третье. Контекст здесь — возможность отсутствия соответствующего значения. Если оно отсутствует, то возвращаем ветку else — неуспешный результат в данном случае. Мы можем прерваться на любом шаге.
Создатели Swift не стали пугать программистов монадой. Они знают, что такое монада, и ввели в язык синтаксис, который выполняет монадические вычисления: последовательность шагов в контексте с отсутствием значения.
Если бы мы писали тот же самый код с монадой на Haskell, он бы выглядел так.
case residence john >>= address >>= street of
Just johnsStreet -> -- SUCCESS
Nothing -> -- FAILUREОбратите внимание, «>>=» — это главная операция монадического связывания. Но смысл кода от этого не меняется.
В Swift для «optional chaining» понадобилось вводить новую синтаксическую конструкцию. В Kotlin для корутин тоже нужно вводить кучу синтаксиса и понятий. В Haskell те же самые корутины неожиданно превращаются в те же самые монадические вычисления, с тем же самым оператором «>>=».
Есть два подхода к монаде:
- Расширять языки программирования, прятать абстракцию монадического вычисления от программиста, давая ему при этом возможность этим пользоваться.
- Выпячивать абстракцию, как в Haskell.
Оба подхода хороши. Но идея выноса абстракции наверх в больших мейнстримных ЯП пока не считается хорошей. Считается, что лучше вводить много разных элементов синтаксиса и прятать от программиста единое понимание сути происходящего. Может быть, это и хорошо — так проще, чем подниматься на более высокий уровень абстракции.
Если у вас множество сущностей, и вы к ним применяете разные операции — это алгебра.
Массу «алгебр» в своих мобильных разработках вы уже используете. Все программирование — это сущности, которые мы обрабатываем разными способами. Мы обычно не называем это «алгебрами», но это они и есть. Поэтому теперь понятие «алгебра объектов» не будет нас пугать.
Абстракция — это хорошо или плохо?
Нет однозначного ответа на этот вопрос. Разработчики языков программирования самостоятельно принимают решение, что они делают — выносят абстракцию программистам или прячут ее за элементы синтаксиса.
Я считаю, что абстракция — это красиво. Покажу это на примере со сложным синтаксисом Haskell из работы «Build Systems a la Carte» Андрея Мохова из университета Ньюкасла и его соавторов. Соответствующая статья получила премию Distinguished Paper Award на International Conference on Functional Programming (ICFP) в Сент-Луисе осенью 2018 года. Эта замечательная работа посвящена Build-системам, которые все используют.
Авторы предлагают абстрагироваться от конкретных Build-систем и выражать разные Build-системы с помощью одной формализации — абстракции. Для этого они вводят понятие хранилища.
data Store i k vВ нем есть параметры:
- i — постоянная информация системы сборки;
- k — ключи зависимости, например, имена файлов в сборке;
- v — сами значения, то есть результаты сборки, например, собранные файлы.
Хранилище — это абстракция. Один из примеров — файловая система с файлами, с дополнительной метаинформацией. У файлов есть имена и содержимое на диске.
Также есть зависимости. Мы хотим показать, что одни файлы зависят от других файлов, чтобы их собирать. Чтобы собрать объектный файл, нужно сначала найти на диске то-то и то-то, собрать, а потом это все вместе использовать.
Есть другая абстракция — «Task» — задание для системы сборки.
newtype Task c k v = Task { run :: forall f. c f => (k -> f v) -> f v }Здесь используется сложный синтаксис Haskell, потому что абстрагируется все. Например, монада — это частный случай «f», от которого происходит абстрагирование. Кроме монады, могут быть и другие способы описывать последовательности вычислений.
Что происходит? Функция «k -> fv» описывает зависимость между ключом и значением — это способ построить что-то одно. Эта функция играет роль параметра. В результате применения этой функции мы получаем итоговое значение. Так описывается сборка одного компонента Build-системы.
Выстраивание дерева выполняется уже следующим типом — набором заданий:
type Tasks c k v = k -> Maybe (Task c k v) Это тоже функция, которая описывает, как от разных ключей зависят разные способы сборки. «Maybe» — это что-то вроде «optional». Мы описываем, как что-то от чего-то зависит, или не зависит.
В результате получаем окончательную абстракцию Build-системы:
type Build c i k v = Tasks c k v -> k -> Store i k v
-> Store i k vНа входе описание всей системы зависимостей. Затем идет ключ k, с которого начинается сборка. Дальше — начальное хранилище и хранилище с результатом функции с полностью собранной системой. Это пример абстракции, которая построена поверх других абстракций.
Андрей Мохов с соавторами выявили отличия и привели в статье формальное описание для четырех систем сборки.
- Make,
- Shake — аналог Make для Haskell,
- Bazel,
- Excel.
Первые три системы сборки известны многим. Четвертая — Excel — это тоже система сборки. Excel тоже попадает под абстрактную формализацию — в нем клетки зависят друг от друга. Написали значение в одну клетку, пересчиталось что-то другое. Make и Excel имеют что-то общее, что можно описывать с помощью этой абстракции.
ФП — это очень медленно
Это частая претензия к функциональному программированию.
— Ваш Haskell тормозит. Мы уже все давно посчитали, а вы все еще пишете свою программу и никак скомпилировать не можете.
Иногда да, иногда нет. Вообще-то быстродействие — это задача компилятора. В идеальной системе хороший компилятор должен построить хороший код, независимо от того, что написал программист. Если он строит плохой код, то это вина компилятора.
Декларативность не должна мешать производительности
Например, высокодекларативный код на Haskell:
h :: [a] -> Int
h = length . filter p . map g . map fМожете считать это псевдокодом — я использую композицию функций. Я принимаю на вход какой-то список, а дальше:
map f— применяю к каждому элементу функциюf;map g— к каждому элементу применяю функциюg;filter p— фильтрую все: применяю предикат, выкидываю все, что не удовлетворяет предикату;length— считаю длину получившегося списка — сколько элементов в результате удовлетворяет всем этим условиям.
Любой программист мейнстрим языка сразу начнет кричать:
— Ужас, сколько тут циклов, сколько промежуточных структур данных… Это вообще не программирование! Вон из профессии!
Просто потому, что компилятор слабоват.
Fusion
В функциональных ЯП существует идея «fusion», которая потихоньку проникает в другие языки программирования.
Что такое «fusion»? По-простому: всю декларативную тщательно расписанную последовательность шагов можно превратить в императивный цикл:
c := 0
foreach (x : xs)
if p(g(f(x)))
then c := c + 1Обращаю внимание, что цикл один (!), а промежуточных структур данных ноль (!). Задача компилятора в том, чтобы красивый и понятный код превратить в высокоэффективную программу, и скомпилировать это все в 2-3 ассемблерные команды.
Мы, как программисты, думаем, что это мы пишем медленные программы. Но это не наша вина — это компилятор виноват.
Пусть разработчики компиляторов получше думают и пишут свои компиляторы так, чтобы код получался эффективным.
Вычисления на GPU? Без проблем!
Еще один пример кода на Haskell, который считает скалярное произведение двух векторов:
dotp :: Acc (Vector Float) -> Acc (Vector Float) -> Acc (Scalar Float)
dotp xs ys = fold (+) 0 (zipWith (*) xs ys)Неважно, что происходит на Haskell: берем 2 вектора, покомпонентно перемножаем, находим сумму компонентов. Важно, что на Haskell этот код после компиляции работает непосредственно на GPU. Векторы размещены сразу на GPU, и графический ускоритель все сделает: скомпилирует CUDA, Open CL — все, что хотите. Библиотека Accelerate у Haskell скомпилирует — получится эффективный код.
На CUDA мы бы писали 100 лет, а здесь написали одну короткую строчку в функциональном стиле, и получили высокоэффективную программу. Все декларативно и быстро! Это ровно то, чего мы хотим от компилятора. Но есть проблемы, с которыми пока компиляторы не очень хорошо справляются.
Каррирование
Каррирование — это большая проблема. Что это такое? Есть функция с тремя параметрами типов a, b, c и результатом D.
f :: A -> B -> C -> D
f a b c = ...Одно дело, когда мы работаем просто с этой функцией — передаем ее в качестве параметра. Другое дело, когда мы указали аргументы частично:
f :: A -> B -> C -> Df a :: B -> C -> Df a b :: C -> Df a b c :: D
Во второй и третьей строчках мы часть аргументов указали, а часть нет. Если такую функцию, которая частично применена, будем куда-то передавать, то возникнут проблемы. Компиляторы пока не очень хорошо умеют это делать — создается замыкание, много всего требуется передавать, тратить массу времени.
Поэтому во многих языках, например, в Scala действуют по-другому.
f :: A -> (B , C) -> D
f a p = …
f :: A -> B -> C -> D
f a :: (B, C) -> D
f a p :: DОни говорят: «Это ты можешь откаррировать, а это нет. Эти два аргумента разделить нельзя, они должны всегда идти вместе. Тут скомпилируем, а здесь — нет». В результате ЯП ограничивает возможности программиста.
Это открытая проблема, которая пока еще не решена даже в функциональных языках.
В ФП проще гарантировать корректность
Корректность хорошо работает в ФП. В Haskell 15 лет назад родилась библиотека QuickCheck, которая помогает в тестировании корректности.
Например, есть функция, которая оборачивает строку:
reverse :: String -> String
reverse = ...Мы ее тестируем, придумывая свойство этой функции. Если два раза применим ее к одной и той же строке, то получится исходная строка.
> quickCheck (\s -> reverse (reverse s) == s)
+++ OK, passed 100 tests.Да, это чистая функция и для нее можно придумать такое свойство. Библиотека генерирует случайным образом массу аргументов, в данном случае 100, на них прогоняет, и убеждается, что это свойство выполняется.
Мы проверяем работоспособность кода не на конкретных примерах, а формулируем свойство и говорим, что для всех аргументов это свойство должно выполняться. Работаем математически. Эта идея возникла в Haskell 15 лет назад. Сейчас подобные идеи проникают в другие языки. Уверен, что для Swift и Kotlin подобные библиотеки уже есть.
Пример с ошибкой
Как думаете, здесь произойдет ошибка?
abs :: Int -> Int
abs x = if x < 0 then 0 - x else x
head :: [a] -> a -- Функция не определена на пустом списке!
head (x:_) = x
example :: Int -> Int
example x = if abs x < 0 then head [] else xОбратите внимание, функция в середине работает на непустом списке.
head :: [a] -> a -- Функция не определена на пустом списке!
head (x:_) = x Если подали непустой список, функция
head возвращает ее голову, а на пустом списке она просто не работает — должна вылететь.Попадем ли мы на «head», вызванный для пустого списка? Нет, и LiquidHaskell может это доказать. LiquidHaskell — это статический верификатор Haskell-кода.
{-@ abs :: Int -> { n : Int | 0 <= n } @-}
abs :: Int -> Int
abs x = if x < 0 then 0 - x else x
{-@ head :: { xs : [a] | 1 <= len xs } -> a @-}
head :: [a] -> a -- Функция не определена на пустом списке!
head (x:_) = x
{-@ head :: { xs : [a] | 1 <= len xs } -> a @-}
head :: [a] -> a -- Функция не определена на пустом списке!
head (x:_) = x Можно сказать, что у функции abs результатом будет всегда число, больше или равное n.
{-@ abs :: Int -> { n : Int | 0 <= n } @-}
abs :: Int -> Int
abs x = if x < 0 then 0 - x else xЗдесь пишем, что функция определена на списке с некоторой длиной.
{-@ head :: { xs : [a] | 1 <= len xs } -> a @-}
head :: [a] -> a -- Функция не определена на пустом списке!
head (x:_) = x Здесь доказываем, что функция возвращает то, что ей передали. Функции передается x и возвращается также x.
{-@ example :: x : Int -> { y : Int | x == y } @-}
example :: Int -> Int
example x = if abs x < 0 then head [] else xКомпилятор или его компонент может проверить вашу программу и доказать целый ряд свойств вашей программы, и она оказывается безопасной. Это пока еще функциональное программирование, потому что активно используется работа с чистыми функциями. Вполне возможно, что подобное когда-нибудь увидим и в мейнстримных языках. Какие-то попытки для объектно-ориентированных языков уже были, например, в Eiffel, значит что-то близкое можно сделать.
А это ещё что?
Это пример веб-разработки:
type MyAPI = Get '[PlainText] String
:<|> "conf" :> Get '[JSON] String
:<|> "year" :> Get '[JSON] Int
:<|> "like" :> Get '[JSON] Bool
myAPI :: Server MyAPI
= root :<|> year :<|> conf :<|> likeВ Haskell есть библиотека Servant, которая может моделировать вызовы API с помощью типов. Например, в коде выше есть несколько url для конференции, для года, нравится она или нет, а результаты кодируются в JSON. Видно, что есть разные типы результатов: String», Int», Bool.
Мы пишем разные обработчики.
root :: Handler String
root = pure "Welcome to my REST API"
conf :: Handler String
conf = pure "AppsConf"
year :: Handler Int
year = pure 2019 conf
like :: Handler Bool
like = pure TrueА библиотека контролирует всё — результаты такие, какими они должны быть.
Все работает, система типов охраняет корректность нашей программы. Мы не сможем при всем желании вернуть строку вместо целого числа в ответ на запрос о годе, просто потому, что компилятор не пропустит. Корректность — это очень хорошо.
Выводы
Функциональное программирование — интересная штука. Не призываю всех переходить на него, но его элементы мигрируют во все обычные ЯП. И это прекрасно.
Если интересно — начните с книги Уилла Курта «Программируй на Haskell». На русском она вышла в ноябре 2018 года. Трое моих студентов ее перевели, а я подредактировал. Рекомендую книгу всем новичкам в Haskell. Когда освоите все 600 страниц, переходите к следующей.
«Haskell in Depth» за авторством некоего Виталия Брагилевского. Книга пока в раннем доступе, не закончена, но уже рекомендую. Промокод «slbragilevsky» дает скидку 42%.
На Saint AppsConf мы рассчитываем, что в рамках нового Introductory-трека Виталий поможет нам определить раз и навсегда, с какого языка лучше начать изучать программирование. Но основной фокус конференции, конечно, будет на технологиях мобильной разработки. Подавайте заявки до конца августа, если у вас есть интересный опыт в iOS, Android, кросс-платформе или архитектуре — эта памятка поможет конкретизировать тему. Если знаете, о чем мобильным разработчикам стоит задуматься вне контекста программирования, тоже ждем тезисы.
За новостями программы следите в рассылке и telegram-канале, видео прошлых докладов смотрите здесь.
dimaaan
Эта реализация считывает все содержимое файлов в массив только для того, чтобы потом взять его размер, тогда как "неправильная реализация" читает посимвольно.
Вам стоит попробовать обе на папке с логами в пару гигабайт и подумать еще раз над тем, какая их них правильнее
Drag13
Так вам же сказали:
Надо кстати запомнить, если что — компилятор протестовать не будет.
algotrader2013
Понимаю сарказм. Самому гадко от такого отношения к написанию программ. Но, увы, говнокодеры, которые только и умеют винить компилятор в чем-то правы. С точки зрения заказчика, критерий правильности — это оптимизация функции от стоимости разработки, стоимости рантайма, стоимости поддержки, матожидания потерь от багов, и еще десятка фич в зависимости от специфики бизнеса. При чем, эти функции могут быть радикально разными в зависимости от решаемой задачи. К сожалению, большинство программистов работают в условиях, когда оптимизационная функция поощряет написание кода с неэффективным рантаймом. И такое решение выходит объективно правильным при конкретной ситуации.
ptyrss
Это чистое имхо, сильно серьёзно не воспринимайте.
Уже сейчас у программиста либо есть навык писать быстрый код, либо нет. Тех у кого он есть ждут в системах реального времени, высоконагруженных симтемах ну и подобное, для поиска таких людей проводят олимпиады и так далее. Но в других местах подобные люди либо становятся рок-звездой, не пуская никого в некорые части проектов (потому что реально оценивают уровень коллег), либо уходят потому что сложно работать, когда то что для тебя читаемо просят переписать, т.к. нипанятна, ну или деградируют (тут это слово не имеет негативного оттенка).
К чему это я, да к тому что тут причина и следствие вывернуты мне кажется, не бизнесу выгоден медленный код, а люди которые могут написать быстрый в этот бизннс не пошли. По скорост разработки, разница минимальная, что 10 уровней фора написать, что пару коллекций грамотно использовать.
iago
Честно сказать, за 12 лет я видел множество опытных разработчиков и множество джунов-мидов-звездочек. И чем опытнее становился разработчик, тем проще и читаемее становился его код. Хороший код реально просто читать, а написать что-то нечитаемое в одну строчку, состоящую из десятка оберток и вызовов функций — сомнительный скилл
DrPass
А могут и не быть радикально разными. И причём намного чаще так и есть. В подавляющем большинстве случаев паршивый код от вполне качественного отличается не затратами на разработку, а опытностью разработчика. Или просто степенью его ответственности.
Color
Так разрые притерии существуют
В одной разработке критерий заказчика — чтобы сделать быстро, дешево, выкатить на прод, а на поддержку взять индусов.
В другой разработке — сделать так, чтобы запрос обрабатывался на 30мс быстрее, чем у конкурента.
В обоих случаях заказчик мыслит понятными ему сущностями, за них же и готов платить. И он прав, ведь деньги то у него. Нам только остается выбирать тот проект, критерии оценки которого нам больше по вкусу.
Drag13
Написание кода с неэффективным рантаймом вряд ли может быть объективно правильным само по себе, правильно?
Т.е. на самом деле речь идет о том, что мы идем на компромис, жертвуя производительностью в угоду скорости разработки и/или читаемости. И тут я с вами согласен — ничего плохого тут нет. Но только пока это осознанное решение.
А в статье рецепт слишком уж прост: На проде умерла БД под нагрузкой — БД плохая потоиу что сама не создала индексы. И ORM плохой, потому что мы сделали .Include на всб таблицы в базе, а ORM не понял что мне нужен был только имейл пользователя.
DrunkBear
Насколько я помню, закрытие платформы Intanium — тоже вина компиляторов, которые не научились внятно оптимизировать код.
Чёртовы компиляторы!
Carburn
Тут дело не в компиляторе, а в реализации библиотеки.
TonyLorencio
Я люблю ФП, но то как это читается в Kotlin — по моему мнению, полная каша
Nick_Shl
А самое главное: подобные способы решения задачи даже не требуют понимания, что же там творится внутри. А если не надо знать и понимать, то и учить незачем. Не то нынче молодое поколение программистов, ох не то… а что будет дальше и подумать страшно.
ptyrss
— Вот я и говорю, — подавленно говорил он слегка заплетающимся языком. — Применение всех этих стандартных библиотек скотинит и развращает программиста. Низводит его до состояния быдла. Животного. Собаки Павлова. Загорелась зеленая лампочка — вызывай эту функцию. Загорелась синяя — другую. А почему?! П-почему лампочки загораются?!
Последнюю фразу Ксенобайт произнес с тоскливым надрывом. Гордо выпрямившись, ударил себя кулаком в грудь, потом снова сник.
— Н-никто не помнит. Никто не помнит, откуда там эти лампочки и почему горят. Ты меня понимаешь? Понимаешь, что я чувствую, когда смотрю на эти лампочки?
0xd34df00d
В каком смысле?
ptyrss
Для написания. В цепочках вызовов легко сделать что-то не так (прочитать весь файл целиком например), забыть обработчик исключений (привет реактивная Java, собраться соберётся, но упадёт потом если что), или просто перепутать функцию (использовать flatMap без побочных эффектов, забыть dispose сделать и так далее). Так же императивный стиль просто физически не даст сделать вложенность операций на 30 (в функциональном стиле занимало 10 полных строк).
Все эти примеры я встречал на одном проекте, после этого я понимаю что правильно использовать функциональный стиль сложнее чем писать императивно.
Ну и в целом, первый код понятен любому джуну, если что-то пойдёт не так — есть отладчик. А в функциональном стиле отладчик особо не поможет, джун пойдёт читать документации об потоках и застрянет надолго.
Это моё имхо, я могу и так и так, но предпочитаю писать проще, особенно если поддерживать не мне.
0xd34df00d
В императивном языке. С чем, конечно, трудно спорить.
А в циклах, как показывает мой опыт, и ошибок больше, и рефакторить сложнее, и размышлять о коде сложнее — глаз, конечно, всё равно вычленяет привычные паттерны, но на это затрачивается больше усилий.
sshikov
с каких это пор отладчик перестал помогать с лямбдами и стримами?
iit
На этом моменте пустил скупую слезу...
dimaaan
И еще один неприятный сюрприз ожидает пользователей "правильной" версии, когда выяснится, что эта реализация падает с арифметическим переполнением, если в файлах, суммарно, окажется < 2,147,483,647 строчек, а sum умеет возвращать только Int.
При этом в "неправильной" версии можно использовать BigInteger
balsoft
А что мешает использовать
Integerи соответствующую функцию (напримерGHC.List.sum)? Да, пока что программист ещё должен думать о пределах типов данных.xadd
Глянуть бы реализацию на хаскеле с посимвольным чтением
0xd34df00d
Можно взять, например, ленивую ByteString и получить ленивое (не посимвольное, но поблочное) чтение.
Fedorkov
В идеале перебор должен быть пословным (в смысле машинных слов).
0xd34df00d
Чтобы на каждое машинное слово делать сисколл?
Fedorkov
syscall заполняет буфер, а по буферу уже проходимся с uintptr_t*. И в конце ещё проверяем оставшиеся некратные символы.
0xd34df00d
Ну так и тут у вас заполняется буфер (ЕМНИП 32 килобайта), а по буферу вы уже можете проходиться посимвольно.
Только, естественно, никаких указателей в хаскеле нет.
Fedorkov
А мы всё ещё про хаскель говорим? :)
С аппаратной точки зрения лучше читать по словам, чем полагаться на кэш и эффективное обращение к невыровненным данным.
evocatus
В том же Python давно уже есть ленивые последовательности и они прекрасно подходят, в т.ч. для таких задач (потому что для таких абстракций как файл и пр. это реализовано)
Например этот же код будет выглядеть вот так:
В обоих вариантах ни о каком считывании полного файла в память не идёт и речи!
dimaaan
ленивые последовательности в c#
Revellion
Простите, но у readLines под капотом bufferedReader, который не грузит весь файл в память
А насчет ленивой последовательности — вот так будет лениво
Fedorkov
А
for line in fileразве не лениво?fogone
[deleted]
snamef
разве тут не формируется хотя бы ненужная строка каждый раз? Можно сравнить на Питоне с просто подсчётом сивмолов конца строки
evocatus
Не факт, что строка формируется — можно реализовать и без этого, но я, честно говоря, не знаю как оно на самом деле реализовано.
RandomInternetPerson
Можно написать иначе, чтобы было лениво, опции-то есть:
Но все равно речь была немного не о том.
MacIn
Более того, эта реализация скрывает реальный подсчет в библиотечном вызове.
Типа «ну, раз мы код не написали, а замели всё под ковер, то стало лучше».
Кто мешает подсчет в «плохой» функции также вынести «за скобки», в отдельную функцию? Это типичный прием, некорректный, который обычно применяют для демонстрации преимуществ stream-стиля: в итеративном стиле явно прописывается вся реализация, а в stream-примере кишки скрываются за фасадом библиотеки.
Yuuri
Так чтобы кишки один раз скрыть за удобными фасадами и потом легко, не обматывая дополнительными кишками, собирать из них что угодно, и нужен функциональный стиль (в идеале – чистый).
MacIn
Ничуть. Пихайте себе функционал «прошерстить стрим базового типа и посчитать црлфы» в обычную императивную функцию-процедуру и вызывайте. И вот тогда будет честным сравнение читаемости stream-стиля написания и императивного.
sshikov
Можно просто на папке с миллионами файлов. Тоже будет забавно.
NIKOSV
А вы не скажите какой вариант правильный не зная контекста. Все от задачи зависит. Если я знаю что функция будет применяться редко и (или) на малом количестве файлов, я забью на скорость и сделаю функцию максимально читабельной и friendly к дебагингу (к слову функциональный вариант не очень friendly).
Так же зависит от того, где будет функция находится. Если функция лежит где-то в тулзах и делает что-то очевидное что не зависит от бизнеса и никогда не будет меняться, то есть функция которая пишется раз и забывается (как в этом случае), то можно заморочиться часок другой и сделать ее правильно с точки зрения скорости.
dimaaan
Вы правы, не скажу. Зато автор безапелляционно утверждает, что циклы — неправильно, приводит пример в разделе "Как не надо писать" с подписью про "упоротость".
По сути, он взял эффективный, но сложный алгоритм, обозвал его упоротым и переписал, подняв читабельность и пожертвовав эффективностью.
Чуть выше, RandomInternetPerson привел вариант с ленивым построчным чтением, что, ИМХО, в 80% типовых случаев будет оптимальным
beeruser
Тут нет никаких требований читать файл целиком и держать строки в памяти.
Функциональный вид позволяет читать построчно и делать любые оптимизации, например SIMD / чтение через mmap, как лучше для конкретной ОС. Вопрос действительно в адекватном компиляторе / реализации библиотек.
Впрочем это уже написано в статье. Вы видимо пропустили часть про «fusion»?
Поэтому является довольно неторопливой.
Новые SSD на PCIe 4.0 обеспечат чтение 7ГБ/с. Вы продолжите дёргать read() по байтику? Ужас-ужас.
DrPass
У меня на SSD со скоростью 2.6Гб/с сообщения в Скайпе подлагивают, кнопка «Пуск» не мгновенно открывает меню, а браузер основательно залипает, когда открывает страничку Хабра с парой тысяч комментариев, и жрёт этак гигабайт памяти. При этом, я помню, почти двадцать лет назад Word легко справлялся с абсолютно такой же по сложности задачей (рендеринг «на лету» документа с полутора сотнями страниц, таблицами, рисунками) на Pentium-233 MMX с 64Мб ОЗУ и смешным винтом на 6Гб с недостижимой пиковой скоростью интерфейса 66 Мб/с.
У вас что, есть хоть капля сомнений, что пофигизм разработчиков легко справится с любым, даже самым производительным железом?
beeruser
А какая связь? Соседи, долбящиеся в стену по утрам, вряд ли являются причиной почему скисло молоко.
Маловероятно что Skype пишет гигабайты в секунду на диск?
В любом случае, вот поэтому и тормоза, потому что используют подходы «в лоб», как пример — посимвольное чтение файлов через getc() и подобное.
А те, кого волнует быстродействие, строят вот такие велосипеды.
github.com/lemire/simdjson
Это не просто так. Браузеры неплохо оптимизированы и пишут их умные люди.
Ну так смотрите интернеты в нём =)
sumanai
Firefox не тупит, если брать именно Хабр со статьёй в 3к комментариев. Хотя казалось бы, хром пишет большее число неглупых людей.
VladVR
можно ссылку на такую статью с комментариями? хочется тож посмотреть как тупит
sumanai
Ошибся, всего лишь 2439.
Gryphon88
beeruser
Какая?
1) Вы вызываете getc() 32 раза который по байтику читает из буфера, который каждые N байт вызывает fread() для чтения блока через системного кэша.
2) Читаете 256 бит одной инструкцией AVX2 из файла, отображенного на память.
Есть разница?
Gryphon88
Я про такую банальную вещь, чтоб на уровне ОС N чтений по байту превращалось в чтение области в N байт на диске.
MacIn
Так и есть — оно буферизовано, но все равно вы N раз вызовете функцию «прочитать байт из файла», которая вернет байт из буфера. Так что накладные расходы все равно будут — на вызов этой функции, проверку буфера и т.д.
DrPass
Это всего лишь другая сторона одной и той же «медали» — написанного через задницу кода. В случае Скайпа может быть даже основная глубина задницы находится не в самом коде Скайпа, а в Электроне, на котором его построили. Это даже хуже, так как код одного приложения — это проблемы одного приложения. А кривая архитектура библиотеки, это проблемы сотен приложений. В случае Электрона, например, главная проблема в том, что он вообще появился на свет.
Гы-гы.
Это просто замечание к тому, что все эти ваши «неплохо оптимизированы» — это ерунда. Они плохо оптимизированы. Очень плохо. Начиная даже ещё с самих стандартов, которые они реализуют. Например, CSS ведь почти все воспринимают как что-то само собой разумеющееся, разрабатывали их далеко не самые последние люди в индустрии. В результате мы получили дичайший механизм костылей. Хотите расположить элемент по центру по горизонтали в блоке? Есть свойство text-align, но о-па, работает только в инлайновых блоках. В обычном надо использовать свойства margin-left и margin-right со значением auto. Это ещё ладно, а для вертикальной центровки, минуточку, там вообще изначально нет выравнивания для обычного блока. Надо было переключать его в режим таблицы или прибивать границы сверху и снизу гвоздями, задавая их явно. А потом, лет через десять вместо того, чтобы просто добавить эту, вполне себе логичную, фичу в существующий набор атрибутов, ввели новый режим выравнивания, флексбоксы. И так везде. В CSS вообще правило «свойство = значение => эффект, который описывает значение» применимо только к простейшим свойствам вроде размеров и цвета. Основной принцип работы со стилями выглядит как «свойство 1 = значение 1; свойство 2 = значение 2… свойство N = значение N => получили производный эффект, зачастую побочный»
Поэтому не надо верить в умных чуваков, которые всё продумывают лучшим образом. Нифига. Даже в самых серьезных проектах за деревьями архитектуры никто не видит леса.
Cerberuser
С браузерами проблема ещё и в том, я так подозреваю, что требуется корректно отображать все сайты, включая самые старые, а это значит — тащить с собой лютейший багаж обратной совместимости (и лютейший багаж тех самых побочных эффектов этой самой обратной совместимости).
dimaaan
а) это очень поверхностное суждение, потому что:
Инами словами, "дёргать read() по байтику" совсем не означает считывать по байту за раз физически.
б) вы сами-то пробовали проверять?
у меня на самсунге 850 PRO (PCI-E 3.0) c тестовым набором в 43 128 файлов объемом 2.2 ГБ:
Как видите разница в скорости небольшая и зависит от кэширования.
Зато "правильная" версия скушала 500мб RAM, а неправильная 0 (по крайней мере "на глаз" не удалось заметить выделений памяти)
А при увеличении объема правильная упала с
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceededвот вам и "ужас-ужас"
nehaev
Название статьи не соответствует содержанию.
mapron
Почему нет? Просто оно неоконченное)
"..., это я вам буду морочить!"
amarao
Что-то не так у них с индустриальным программированием. При индустриальном программировании рабочий горячего Цеха направляет Ковш, который Отливает Чугун в Форму, после чего Форму Везут в Цех ковки, где Куют колёса. Потом колёса Везут в Цех шлифовки, где колёса Шлифуют.
Большими буквами выделены ключевые термины Индустриального Программирования. Вы сами можете догадаться какими примитивами реализовано Отлить, Цех и как реализовать процесс Ковки Кода.
nightwolf_du
Тогда уж:
Рабочий(abst.class) Горячего_Цеха(class) Направляет(func) Ковш(class), который Отливает(func) Чугун(class) в Форму(class),
после чего
Форму(class) Везут(func) в Цех_Ковки(class), где Куют(func) Колёса(class). Потом Колёса(class) Везут(func) в Цех_шлифовки(class), где колёса(class) Шлифуют(func).
А теперь определите, пожалуйста, в чьей ответственности операции «после того» и «Потом»
У кого определены функции Направляет и Отливает, и что делать если при вызове «Везут» случилась ошибка памяти, стека, сетевого вызова, и т.п.
Абстракции хороши, но они все равно текут.
KoCMoHaBT61
Это не классы, а объекты.
amarao
А почему вы считаете, что class и function — это основные примитивы? Ведь было время, и классов не было (а были структуры с указателями на ассоциированные функции), а было время — и функций не было.
Подумайте про альтернативную онтологическую модель. Попробуйте описать, что такое структура, класс и функция в терминах Цех, Плавильная печь и Ковка.
(Я даже и не знаю, троллю я или нет — потому что лямбда-калькулюс — это как раз попытка альтернативного описания того же, что описывает машина Тьюринга, в которой нет ни композиции, ни применения. Вполне можно представить себе альтернативную онтологическую модель, которая бы описывала работу устройства без деления на "код"/"данные" и/или концепции стрелочек из теории категорий).
sshikov
>потому что лямбда-калькулюс — это как раз попытка альтернативного описания того же, что описывает машина Тьюринга
Насколько я знаю, работа Чёрча появилась несколько раньше, чем Тьюринга. Так что это еще вопрос, чье описание альтернативное. Не настаиваю и могу ошибаться.
gearbox
Тьюринг — ученик Черча. Так же как и Клини, который описал все то же самое что и Тьюринг но чуть более элегантно (правда немного позже). А лямбда калькулус — частный случай term rewriting system, которые придумали вообще не для программирования.
amarao >в которой нет ни композиции, ни применения.
Прямо с вики:
Первое — это apply, второе — композиция. Просто другим способом (все через прямую подстановку) — но сути это не меняет.
amarao
На самом деле и модель Тьюринга, и работы Чёрча — теория, но Тьюринг реальную машину построил, так что он правее.
А потом пришёл фон Нейман, и все остальные модели под его вынуждены адаптироваться.
Напоминаю, что ни модель Тьюринга, ни лямбда-калькулюс не готовы к приходу прерываний. Что такое прерывание для лямбда-исчисления? Неконтролируемый рандомный сайд-эффект.
Gryphon88
Но это не повод переходить на автоматное программирование для прикладных программ.
gearbox
>Что такое прерывание для лямбда-исчисления? Неконтролируемый рандомный сайд-эффект.
Всего лишь символ на входе автомата. Все упирается в выбранную модель. Любое IO можно привести к строке символов на входе — надо лишь правильно задать алфавит.
amarao
Нет, нельзя. Прерывание происходит не тогда, когда компьютер его ожидает, а в любой момент времени. В буквальном смысле в любой — даже в середине привилегированной инструкции.
MacIn
Но в принципе мы же можем прерывание сделать детерминированным, чтобы оно обрабатывалось строго после инструкции? Задача прерывания же не в том, чтобы оборвать процессор на полу-слове, а в том, чтобы в принципе прервать выполнение. Да, для систем РВ это недопустимо, но теоретически-то?
amarao
Мы можем сделать так, чтобы прерывание выполнялось после текущей инструкции. Прерывание не будет детерминированным (мы не будем знать после какой инструкции оно произойдёт).
Ближайшей моделью детерминированного процессора, эквивалентной процессору с прерываниями будет процессор, каждая инструкция которого делает IO.
Каждая. Другими словами, чистых функций больше не будет от слова "совсем". Мы пишем
А эта функция — грязная, у неё есть сайд-эффекты. Да что там filterPrime, мы пишем a = 2 + 2, а эта функция — с сайд-эффектами.
Мне кажется, это не совсем модель в которой применим lambda-calculus.
Gryphon88
Поясните, пожалуйста, откуда в a=2+2 сайд эффекты. Используются два регистра, которые используются эксклюзивно в данный момент времени.
amarao
Если после каждой инструкции может произойти прерывание, которое не зависит от исполняемого кода, то для описания такой системы с помощью модели с чистыми функциями, надо предполагать, что все инструкции грязные. Вы делаете "+", а оно делает "+" и вызывает обработчик прерывания, когда вы этого не ожидаете.
Gryphon88
Разве чистота про время (и даже последовательность) исполнения? Вроде достаточно не изменять данные снаружи функции. Или вы предполагаете, что мы из функции изменили стек и контекст процессора (EDIT: даже если потом вернули как было) и таким образом «нагрязнили»?
amarao
Если мы пытаемся описать машину с прерываниями с помощью модели без прерываний, то у нас каждая операция вызывает грязную функцию, которая может сделать return, а может и значение на стеке по доброте душевной поменять.
Gryphon88
Можно сказать, что по планировщику у нас прерывается одна чистая функция и продолжается или начинается другая. Вопрос: можно ли написать «чистый» планировщик, потому что тут по-моему однозначно работа с глобальным состоянием.
amarao
А почему "другая" функция чистая, если она делает IO и меняет память чёрти где вне своего состояния?
Gryphon88
Если функция берёт что угодно, не обрабатывая, по адресу, а потом точно так же кладёт обратно, почему она не чистая? Для любого входа она вернёт True, если копирование удалось, или False, если что-то пошло не так.
amarao
Я не совсем понимаю о чём вы.
Вот, простой код:
foo — это чистая функция, судя по написанному. А теперь представим себе, что у нас в момент после выполнения второго
call fooслучилось прерывание, обработчик которого запрограммировал DMA-адреса, перекрывающие .bss секцию, и устройство записало туда 42.Дано: сработавший assert на ровном месте.
mayorovp
Это означает, что в системе есть UB. Наличие UB не нарушает чистоту функции.
Более того, так как из UB следует что угодно, наличие такого глючного обработчика прерываний делает любую функцию чистой (в случае гарантированного срабатывания прерывания, конечно же) :-)
amarao
Если верить документации процессора, то это не UB. Чтобы что-то объявить UB, нам надо иметь модель памяти (языка?) для которого это UB. С точки зрения документации к процессору (т.е. с точки зрения фон-неймановской архитектуры) у нас нет понятия "чистая функция", а есть конечный автомат процессора, в каждый момент времени которого у нас есть стрелочка на состояние "обработка прерываний", которая в свою очередь может делать что угодно.
mayorovp
Так ведь чистые функции именно что в языке существуют, а не в процессоре.
amarao
Понятие чистоты функции существует в модели, которая не может описать современные компьютеры.
Точнее, может, но моя версия почему-то у всех вызывает возмущение.
mayorovp
Потому что никому не интересно описывать этой моделью современные компьютеры. Интереснее решать обратную задачу — исполнение программы, описанной этой моделью, на современном компьютере.
Gryphon88
Значит, мы о несколько разных вещах беседовали, для меня ФП — это методология написания программ. Что существующие компьютеры и компиляторы, которые позволяют безнаказанно залезть в чужую область памяти, не могут быть полностью чистыми, полностью согласен.
Gryphon88
Мы про условную норму, или про случай, когда кто-то в обработчике ошибся?
amarao
См ниже, нам даже не нужны прерывания, в тёплом ламповом Си без borrow checker'а очень легко делать станное.
https://habr.com/en/company/oleg-bunin/blog/462505/?reply_to=20484899#comment_20484919
gearbox
Применимость лямбда калкулус — это все что на нем можно выразить. На нем не надо писать реальный софт — это мат аппарат упакованный под капот компилятора.
Далее. Прерывания. Есть программа которая выполняется на процессоре. Есть прерывания. Описываете модель процессора (с памятью и регистрами, да). Пишете программу. Пишете компилятор, который компиляет программу в последовательность символов которая принимается моделью процессора. Символы — команды процессора. Это все стандартно и существует в природе. Далее. Эксепшены в модели процессора — всего лишь новый символ, на который процессор как то реагирует. То есть ничем от команды не отличается. Просто команда в коде — и мы сами решаем где она появится, а прерывание прилетает снаружи. Да. Но для модели процессора это пофигу — оно должно уметь его отработать. Проблема не в том что это не выражаемо через лямбда калькулус (в metamath квантовую физику завезли, а он работает на той же прямой подстановке что и лямбда калькулус) так вот, проблема в том что без автоматического вывода доказательств этот пируэт не имеет смысла — раз. Во вторых — для реального программирования придется строить модель cpu+память+ось в которой будет крутится софт, а вот с моделированием оси — засада. Более менее (с долей оптимизма) это возможно на формально верифицированных операционках, но таких полторы на всю планету и кроме одной — это pet проекты. Так что промышленно использовать это сейчас нереально, да. Но утверждать что IO либо внешние эвенты невыразимы через лямбда калькулус — неверно, прекрасно оно выражается, без монад и прочего. Надо просто строить модель того в чем будет крутиться программа вместе с самой программой. В Certified Programming with Dependent Types первый же пример очень близко подходит к этой теме (не раскрывает полностью но очень близко).
0xd34df00d
Если вам вдруг действительно интересно, как всякие прерывания и экзепшоны сочетаются с чистотой...
В том же хаскеле чистые функции вообще ничего не знают про экзепшоны. Они могут их в том или ином виде кидать (например, неявно через incomplete pattern match или чуть более явно через какой-нибудь
error), но вот ловить не могут. Единственный, кто может поймать исключение — код, выполняемый в IO-монаде. Чистоту это, естественно, не нарушает: если чистая функция выдаёт значение, то оно всегда будет одним и тем же.При этом даже, например, убийство тредов сделано через кидание треду исключения, которое убивает любое происходящее в этом треде чистое вычисление (что делать можно всегда для любых вычислений, так как они, ну, чистые).
Так что всё прекрасно сочетается, я бы сказал.
amarao
Вот я про "чистоту" и хочу сказать.
Если у нас прерывание внешнее (т.е. не ошибка в программе, а просто пользователь неожиданно кнопку нажал), то у нас может быть чистая функция, значение которой зависит от того, было прерывание или нет. Потому что чистая функция, сама того не ожидая, из-за прерывания, "вызвала" грязную функцию, которая поменяла состояние, значение в регистрах и т.д.
mayorovp
Если обработчик прерывания поменял значения в регистрах и так и оставил — это просто кривой обработчик, а не грязная функция.
amarao
Что такое "обработчик прерывания" в контексте описания чистой функции и почему он был запущен изнутри чистой функции? Либо эта функция не "чистая", либо у нас модель чистых вычислений не работает на оборудовании с прерываниями.
Это, кстати, нифига не теоретический вопрос, ибо куча приложений по модели должна работать хорошо, а на практике имеет непонятные задержки в местах, где не ожидает. (Условно — "чистая функция" на языке с GC может получить неожиданный сайд-эффект от GC из-за сложной сборки).
mayorovp
Время выполнения не является результатом функции (любой, не только чистой), а значит и замедление из-за GC сайд-эффектом не является.
amarao
Даже если время становится бесконечным? Кажется, это называется bottom type.
mayorovp
Не совсем. Тип ? — это не просто бесконечное время работы или паника, а неизбежное бесконечное время работы или паника.
amarao
Давайте я скажу ещё хуже.
Вот у нас есть такая программа:
(Я использую alarm для имитации прерывания).
Какой возвращаемый тип у bottom? (Я понимаю, что в Си это всё равно void, но по логике?).
mayorovp
А что такое
aи как вы вызываете функцию не указывая её параметр?amarao
Опечатка, пардон.bottom(c), конечно. Вопроса проaя не понял.Адски кривой копипаст, поправил.
mayorovp
while(a==0)— что за переменная тут проверяется?mayorovp
IO Unit
sshikov
Хм. Когда это Тьюринг построил машину Тьюринга? Реальная машина, которую он построил, ничего общего с теоретической его же машиной не имеет. И вы, мне кажется, упоминали именно теоретическую его машину. Впрочем, это все равно были мелкие придирки к формулировкам, так что не важно
amarao
Не, я имел в виду, что он построил что-то работающее, так что его теории получают запас доверия больший, чем к теоретику, который не построил.
Грубо, но всё равно так.
KaminskyIlya
Deleted
gsedometov
Этот процесс отлично выражается в функциональном стиле:
СделатьКолёса Ковш =Направить Рабочий Ковш >>= Отлить Форма >>= Ковать ЦехКовки>>=Шлифовать ЦехШлифовки
amarao
Понятно, что все они описывают эквивалентный класс тьюринг-машины. Но я не уверен, что происходящее с колёсами в цехе ковки полностью описывается моделью ООП. Т.е., я совершенно уверен, что при ударе молота по заготовке никакие функции у колеса не вызываются, более того, если на месте колеса под гидравлическим молотом окажется не колесо, а объект с неправильным интерфейсом (не готовый коваться), то никакого эксепшена не будет, а будет лепёшка.
gsedometov
в таком случае, я не совсем понимаю, какой способ моделирования процессов вы предлагаете использовать вместо ООП и что конкретно предлагаете понимать под "ООП"
amarao
Ну, например, посмотрите на машину тьюринга. Где там классы и объекты? Там даже данных нет, только переход по ленте.
somurzakov
выглядит скорее как 1С
locutus
Все интересно, но под капотом всегда будут циклы, счётчики, системные вызовы. Каждому уровню свои инструменты. В примере с числом строк оба варианта зависят от функции чтения файла. Как осуществляется буферизация ввода-вывода, какие системные вызовы работают, как работает кэширование, как в принципе программа запустится и так далее.
Yuuri
А ещё ниже будет схемотехника, которая внезапно весьма ФП – у транзисторов нет состояния, а есть чистая зависимость выхода от входов, а состояние эмулируется, например, несколькими элементами, выходы которых поданы на вход друг другу – привет, рекурсия и tying the knot!
Только вот какая разница? Нам всё равно работать не под капотом, а наверху. А если уж порой приходится лазить под капот, стоит хотя бы пытаться минимизировать проведённое там время.
amarao
(вздох) У транзисторов есть состояние. С этим борятся, но оно есть. Ёмкость, распределение заряда в толще и т.д.
locutus
А ещё ниже работает квантовая электродинамика, в которой есть состояния (причем очень экзотические). Каждому уровню описания свои инструменты. Кто-то в верилоге делает логику, кто-то пишет операционные системы на Си, кто-то пишет бизнес-логику на языках высокого уровня в кровавом энтерпрайзе.
Cryvage
Сильное заявление. Даже если у нас будет чудесный компилятор, который «строит хороший код, независимо от того, что написал программист», то встанет вопрос о времени, и прочих ресурсах, затрачиваемых на саму компиляцию. Чудес ведь не бывает. Чтобы убрать сложность из одного места, придется перенести её в другое место. А для всяких JIT и интерпретаторов, эта проблема будет ещё актуальнее.
Помимо уже упомянутых затрат на компиляцию, надо ещё учитывать, что любые абстракции протекают. Любой существующий компилятор, умеет оптимизировать код, лишь при соблюдении определённых условий, следующих из внутренней логики этого компилятора. А значит, что для получения желаемого результата, программисту придётся знать, и соблюдать эти условия.
Помню, в том же prolog'е, приходилось держать в уме весь алгоритм машины вывода. А ведь он как раз и позиционировался как: «Пиши как хочешь, а машина разберётся как это выполнять». Но реальность жестока. Приходилось писать так, как хочет машина, и разбираться, как она будет это выполнять.
В общем, если уж требовать от компиляторов, чтобы они были идеальны, и любой код, написанный программистом, превращали в высокоэффективную программу, то надо хотя бы доказать, что идеальный компилятор, в принципе, возможен. У меня в этом есть большие сомнения. Да и как-то это расходится с тезисом, озвученным в начале статьи:
Разве идеальный компилятор, не будет той самой «волшебной таблеткой»?
KvanTTT
Идеальный компилятор возможен, если временя компиляции будет стремиться к бесконечности.
VladVR
Мне тоже интересно, если программист пишет квадратичный алгоритм там, где можно написать линейный, как поможет компилятор? Быстродействие кода в любом случае в первую очередь зависит от программиста, а лишь во вторую очередь от компилятора. Компилятор лишь инструмент. И этот инструмент нужно либо теоретически знать, либо практически исследовать его возможности. И не только компилятора, но и других низлежащих систем. Например операция создания объекта — дорогая. Операция же мутации поля в классе — дешевая. Я вот писал алгоритм с деревом, написал его и чистыми функциями и мутирующими. Тест производительности — вставляем миллион элементов в дерево. Максимальная глубина дерева при этом 20, средняя — 10. Т.е. для вставки мутирующему алгоритму надо создать 1 объект на итерацию, чистому — в среднем 10 на итерацию. Не считая балансировки. И на этой выборке, неожиданно, чистый код оказался чуть меньше чем в 10 раз медленнее. Как тут поможет компилятор реабилитировать ФП и чистые функции в частности? Непонятно.
algotrader2013
Кстати, о квадратичных алгоритмах: SQL — очень хороший пример. Join двух таблиц равных размеров — это математически квадратичный алгоритм. Но в зависимости от ряда условий там и линейное время может быть. Сама идея, что нечто неоптимальное, но понятное в рантайме под капотом превращается в быстрое, непонятное, но при этом эквивалентное — это уже мейнстрим. Достаточно, к примеру на принцип работы V8 посмотреть
sumanai
Для того, чтобы добиться этого линейного времени, нужно знать про индексы и их правильно использовать. То есть опять лезть под копот.
algotrader2013
Не всегда. Hash join дает линейное время и на неиндексированных полях.
sumanai
Вот про это и я не знаю. Но ведь это опять нужно знать внутрянку?
mayorovp
Нет, до этого СУБД сама догадается.
Тут скорее проблема в том, что в куче задач даже линейное время — это слишком много.
sshikov
Без гарантии.
algotrader2013
Гарантии О(1) и хеш таблицы в императивном коде не дают…
maxzh83
Ну так почему бы не написать сильный компилятор на ФП, всем бы сразу нос утерли? К слову, компилятор Паскаля был написан на Паскале.
0xd34df00d
Так ghc написан на хаскеле и спокойно это всё оптимизирует.
maxzh83
То есть, компилятор не слабоват на самом деле и автор заблуждается?
0xd34df00d
Код, подобный приведённому автором, в моём опыте отлично оптимизируется. Не знаю (и не особо хочу разбираться), заблуждается ли автор или же, например, это такая иллюстрация некоей мысли была.
В то же время случаи, когда мне оптимизация очевидна, а компилятор её не делает, конечно, бывают. Но это в любом языке так.
Yuuri
Будто сейчас этим кого-то удивишь.
maxzh83
Да я и не пытался, я про то, что почему бы не написать хороший компилятор на Haskel, раз нынешний слабоват
Neftedollar
вв статье не сказано, что это компилятор хаскеля слабый, там указано иное:
Про хаскель здесь не сказано ничего, но указан некий «программист мейстримового языка» который из своего опыта с мейнстримовым языком, произносит фразу про кучу циклов. Далее следует заключение, что говорит он это потому что компилятор слабоват.
Даю справку: имеется ввиду, что у этого самого мейнстримового языка компилятор слабоват.
Твиттер Брагилевского(автор текста) — хороший инструмент для понимания того когда произошел троллинг.
maxzh83
Это цитата из раздела «ФП — это очень медленно». Если это тоже троллинг, то так тонко, что порвалось.
Neftedollar
Где там сказано что хаскелл компилятор генерит медленный код?
В контексте этого параграфа, там сначала претензия, «мы уже посчитали — а вы скомпилировать не можете» это не про скорость бинаря скомпилированного хаскеллем, это про скорость разработки. А дальше говорится про идеальный мир в котором компилятор должен строить хороший код независимо от того что написал программист. Тут указывается на проблему копилятора хаскеля что ему требуется хороший код, чтоб быть скомпилированным. В противовес тому, что хотелось бы чтоб любой говнокод(«мы уже написали, а вы еще пишете») компилировался в хорший код.
Чтоб читать Брагилевского нужно знать Брагилевского. Море двусмысленности и троллинга. Да, тонко что рвется, просто потому что вы не в контексте и это нормально, что вы не в контексте. ТК этот товарищ хоть и забавный и титульный, но все же немного маргинальный.
И я не защищаю хачкель, просто перевожу с брагилевского на русский.
maxzh83
А где я утверждал, что компилятор хаскеля генерит медленный код? Сами придумали, сами ответили. Я только цитировал статью
Neftedollar
>Где там сказано что хаскелл компилятор генерит медленный код?
>что почему бы не написать хороший компилятор на Haskel, раз нынешний слабоват
ок, слабоват.
Но в статье к которой вы комментите
контекст в голове не удержали, бывает
теперь и разговора не получится
maxzh83
Вот опять, сами процитировали, а теперь мне приписываете. Слишком много контекстов в голове, бывает.
0xd34df00d
А зачем хаскелистам писать на хаскеле компилятор не хаскеля (и не какого-нибудь идриса или агды)?
То есть это весело, конечно, но для того, чтобы засунуть его в продакшен, придётся основательно позаниматься рутиной.
pin2t
На самом деле ничего хорошего. Потому что теперь у программиста появляется выбор. Раньше ему приходилось добавлять новый функционал, добавляя новые интерфейсы, методы и классы, а теперь он может добавить новый функционал используя паттерн матчинг и внешние (по отношению к классам) функции. Из-за этого фукнционал размазывается по разным местам и становится непонятно что и где происходит, код становится менее понятный и менее поддерживаемый (т.н. write-only код).
А это плохо, особенно если в команде больше одного программиста, или высокая текучка.
Поэтому — пишите в функциональном стиле на функциональных языках, ненадо тащить это в меинстрим.
user_man
>> фукнционал размазывается по разным местам и становится непонятно что и где происходит,
На функциональных языках пишут библиотеки с открытым кодом, а потому понимание можно получить просто поглядев исходник. Но такая стратегия неприемлема для бизнеса, поэтому да, переход на такой подход сделает жизнь хуже — он плохо дружит с модульностью при её закрытости.
pin2t
Я не про это понимание, я про понимание на кровне концепций и организации кода. Вот кстати хороший пример с библиотекой. Представьте, вы написали программу, разложили все по интерфейсам и объектам, придумали как это все должно быть организовано, реализовали. А потом вдруг решили использовать библиотеку, которая лезет в ваши объекты с помощью сопоставления с образцом, или рефлекшеном. Все, можно сказать ваш дизайн больше не ваш, вы вынуждены подстраиваться под то, как библиотека использует ваши объекты, под библиотечный дизайн кода, библиотека начинает диктовать вам как вам писать программу. И весь код превращается в кашу, потому что нет больше оригинального дизана. Никогда не используйте такие библиотеки, всегда делайте как минимум свои обертки, ну или свои библиотеки.
user_man
>> я про понимание на кровне концепций и организации кода
Люди привыкают мыслить в терминах целевого языка, поэтому такое непонимание проходит с накоплением опыта. Хотя да, отсутствие наследования данных в том же Хаскеле меня сильно напрягает, приходится городить избыточный огород, но это связано не с не пониманием, а с очевидной неэффективностью в ряде случаев.
>> Все, можно сказать ваш дизайн больше не ваш
Выбор библиотеки — ваше решение. Значит дизайн ваш. То есть вы согласились с насилием со стороны библиотеки и оправдываете её применение каким-то другим преимуществом.
mayorovp
А как это вообще возможно, хотя бы теоретически?
vassabi
если найти их положение и размеры в памяти
mayorovp
А дальше?
sshikov
Этому человеку уже один раз объяснили, что паттерн матчинг не имеет ничего общего с тем, чтобы лезть в потроха объектов. Но он не слышит, потому что не хочет. Ну не стоит оно того, чтобы убеждать.
tosha4encko
Сборщик мусора изначально появился в функциональном языке, и только спустя двадцать с хвостиком лет начал мигрировать во все обычные ЯП. Не надо обобщать.
pin2t
Сборщик мусора это другое дело, он же появился как замена, а не как дополнение. У программиста в Java нет выбора, использовать его или нет, он может его только натраивать.
tosha4encko
А у программиста python, например, такой выбор есть. Ну а тернарный оператор, или цикл foreach, или еще миллион плюшек, которые вы используете каждый день и не задумываетесь о фп, тоже зло?
nexmean
Ничего подобного. В ФП куда активнее используются абстракные интерфейсы, а паттерн-матчинг по заранее неизвестным типам невозможен за редкими исключениями (generics). Кроме того в ФП куда меньше распространён runtime reflection, который является верным путём к тому, чтобы сделать сложный, непонятный, магический, нечитаемый код.
sshikov
Вам уже один раз объясняли — не надо свое видение выдавать за мейнстрим. В нашем мейнстриме все наоборот. Не нравится — проходите, не мешайте нам говнокодить в том функциональном стиле, какой нам нравится.
user_man
Вам не стоит читать лекции по общей алгебре. Без понимания примитива типа «операция» и её свойств сразу кидать студентам пример гораздо более обвешанной ограничениями ситуации — это профанация. Математика не терпит поверхностности, а вы именно максимально поверхностно знакомите ваших студентов с предметом, что очень плохо. Кратко и без формализма вы лишь путаете студентов, создаёте ложное впечатление понимания. Нужно именно формально определить конкретную группу, а далее дать несколько примеров операций (включая ту же конкатенацию строк) и попросить доказать, каким ограничениям соответствуют предложенные операции, из чего вывести принадлежность к конкретной группе. Если же это кажется сложным, значит вашим студентам совершенно не нужна теория групп и абстрактная алгебра, ибо они её никогда не поймут по таким лекциям. Уж лучше не мучить людей лишними знаниями. Хотя конечно, если они платят за видимость образования, то…
Yuuri
Человеки обычно учатся индуктивно (от частного к общему), поэтому в знакомстве с абстрактной концепцией через конкретные примеры нет ничего плохого. Вы вот тоже сходу перешли от частного (пример автора из лекции) к общему (его умению преподавать).
user_man
>> Человеки обычно учатся индуктивно
Ну если вам нравится сначала изучить миллион примитивов, и только потом узнать, что все они сделаны по одному шаблону — учитесь так. Но на мой взгляд потеря времени будет совершенно бессмысленной, особенно если шаблон тривиален и укладывается в пару-тройку строк с определением.
И да, «индуктивно» учатся начинающие. После понимания дедукции взгляд на обучение сильно меняется, что я и рекомендую всем индуктивно мыслящим.
AlexeySoshin
Вопрос не в том, как кому-то нравится изучать материал. А как его эффективней преподавать.
Преподавать от простого к сложному эффективней, чем вываливать на студента ворох терминов в надежде, что он в них не захлебнется.
user_man
>> чем вываливать на студента ворох терминов в надежде, что он в них не захлебнется.
А с чего вы взяли, что я предлагаю вываливать ворох терминов? Я предлагаю не делать из людей идиотов попыткой убедить их в том, что они якобы с пользой отсидели в институтах 5 лет. И ворох терминов — один из вариантов получения идиотов на выходе. Только без понимания абстракций куча простеньких примеров точно так же делает из человека необразованного болванчика. Поэтому правильно учить людей «посередине», без вороха терминов, но и без потакания лени, когда ей не хочется учить абстракции.
mayorovp
А не надо изучать миллион, двух или даже одного примера достаточно. Но без них и правда плохо.
sshikov
Если отбросить субъективное мнение об умении преподавать, то по большей части останется чистая правда. Математические основы не терпят поверхностности. Программирование больше склонно прощать — но результатом является обычно нечто не очень хорошо пахнущее.
"Формальное математическое определение моноида, но кратко и без формализма" — это вообще перл.
При этом достаточно формальное определение моноида будет примерно таким — множество, с заданной на нем бинарной ассоциативной операцией (и немного про свойства операции), и так вполне простое, зачем его еще упрощать? Какое из четырех существенных слов в этом определении не очевидно?
AlexeySoshin
"Множество" — вообще неочевидно. Студент видел string'и, видел int'ы, видел class'ы. "Множества" студент не видел.
Что такое "ассоциативная операция" — тоже стоит пояснить.
Интуитивно можно понять только "бинарная операция", да и то не уверен, все ли студенты поймут это правильно.
В итоге вместо того, чтобы дать студенту чувство уверенности, такой формализм его только запутает.
sshikov
Не знаю как вам, а мне понятие множества давали в школе. Как и понятие ассоциативности, и бинарности. Если студент видел инты и стринги, но не учился в школе — ну пусть поучится. Такому моноиды точно пока не нужны.
AlexeySoshin
Моя цель как преподавателя — объяснить тему так, чтобы студент ее понял.
Стараюсь не решать за своих студентов, что им нужно, а что нет.
sshikov
А откуда вы знаете, что им нужно? И почему вы уверены, что они поняли? Я тут в общем не критикую ваш подход — в конце концов, это вы общаетесь со своими учениками, знаете их лучше. Что им моноиды не нужны — не более чем мое мнение, вполне возможно неправильное.
Так что тут вопрос совершенно без подвоха.
P.S. Когда я преподаватель — мой опыт обычно больше, чем у учеников. И в каком-то смысле я лучше знаю, что им нужно. Не вообще в жизни — а в рамках именно этого курса.
AlexeySoshin
Во первых по содержанию курса, раз уж они на него пришли :)
Во-вторых — по задаваемым вопросам.
Ниже в другой ветке уже написал, но повторюсь.
На мой взгляд, подход автора правилен в том, что нужно объяснить студенту, что моноиды, монады и прочие функторы, это то, с чем он скорее всего и так уже работает. А формальные объяснения из category theory этому мало помогут.
sshikov
>А формальные объяснения из category theory этому мало помогут.
На мой взгляд, за формальными объяснениями должны следовать либо доказанные полезные свойства (то есть, какие гарантии мы скажем имеем, если формально докажем, что тут имеет «моноид»), либо показывали бы, как эти свойства самостоятельно вывести. Ну или куда дальше копать, если понадобится.
faiwer
Вы уверены? Одну и ту же вещь можно объяснить как простым, так и сложным языком, как понятным, так и непонятным человеку. Я вот вышестоящее определение не понял (хотя и знаю эти слова по отдельности), но почти наверняка использую и моноиды и многие другие примитивы из ФП последние лет так 5. Выполняю задачи бизнеса.
А ещё через лет 5 практики я забуду те последние крохи формального языка, вбитого мне в школе и университете, что я ещё помню.
sshikov
Так, погодите, а зачем вам тогда формальное определение? Ну то есть, я его допустим знаю потому, что мне любопытно было. Но при этом к моноидам, композиции функций, монадам и пр. я пришел с чисто практической стороны, и вполне могу обходиться без формализма, выполняя те же задачи бизнеса.
Ну то есть, если у студента проблемы с восприятием довольно несложного формализма, которые в общем-то нужен не всем и не каждый день — ну зачем им его вообще давать?
faiwer
Да, это пожалуй тема для отдельного холивара. Подача материала. Как мне показалось именно матан страдает от этого в наибольшей степени. 90% времени при его изучении ты пытаешься понять что вообще автор учебника или твой препод имел ввиду, а по итогу задаёшься вопросом — неужели нельзя было эти, казалось бы не такие уж и сложные вещи, объяснить нормальным человеческим языком (а уже потом можно сформулировать "формальное" определение, а не наоборот). Зачем такой педагог вообще нужен. Правда это возможно только мой такой печальный опыт.
Мне нравится американский подход к подачи информации. Когда на простых примерах, простым языком объясняется как, что и почему работает. Не стесняются написать 10 абзацев вместо одного, убрав все головоломки. Примеров с edge case-ми побольше привести. Аналогий.
sshikov
Практические примеры это хорошо, но пожалуй при одном условии — что упрощение не делает пример неправильным. Как с тем же моноидом — что значит «компоновать строки»? Например, применение регулярного выражения (в виде строки) к строке — это что за операция? Получится ли у нас моноид, если мы в качестве операции возьмем эту, а не конкатенацию?
Ведь по большому счету, в программировании весь этот формализм нужен для того, чтобы убедиться (доказать), что наша композиция функций, к примеру, всегда будет вести себя правильно. Можно ли жить без этого? Естественно, ведь живут же, во многих случаях и на многих языках, заменяя доказательство скажем тестами. Но чем выше уровень абстракции конструкции — тем больше хочется доказательств.
AlexeySoshin
Не только :)
В моем случае (Тель Авив), такие педагоги были в основном профессорами, которых заставляли давать лекции, "отвлекая" их от "важных исследований".
AlexeySoshin
Собственно о чем я и писал — формальное определние давать не стоит, оно нужно не всем.
sshikov
Изначальная претензия к авторскому примеру неформального определения была не потому, что оно неформальное — а потому что оно, в общем-то, не совсем правильное. Произвольная композиция строк вполне может быть не ассоциативной, и не иметь «единицы». И не будет там никакого моноида.
А мое дополнение состоит ровно в том, что и нормальное-то формальное определение моноида — это математика, вполне доступная на уровне средней школы (7-8 класс), то есть несложная.
Можно-ли/нужно ли без формализма — ну опять же, я уже отвечал, что не знаю, зависит от целей, да. Но с другой стороны, хорошего и краткого неформального определения, из которого можно было бы делать полезные выводы о свойствах, я не припомню. Что возможно означает, что его не так просто придумать.
SirNickolas00
Да запросто.
Отрицательный модуль числа — вполне реальная штука, когда мы имеем дело с дополнительным кодом (two’s complement). И мне кажется, что это баг в статическом анализаторе, раз он считает, что
0 <= n.Cerberuser
Ну, скажем, в Rust такие вещи отлавливаются при компиляции (правда, только в константных функциях) и, если всё же просочились в код, приводят к панике в рантайме. В Си, если я правильно помню, отрицание с переполнением — это UB. Не берусь говорить про Haskell, но допускаю, что там такой код тоже будет семантически невалиден.
mayorovp
Тут фокус именно в том, что, насколько я знаю, в Haskell нет UB или исключения при переполнении, а значит код совершенно валиден...
arvitaly
В примере из статьи, ООП написано как ФП, поэтому не нашлось разницы.
На самом деле в описанном классе не хватает тех самых данных, которые будут отличать ООП от ФП, а конкретно — можно закешировать внутри объекта результаты вычислений радиуса. Именно это является ключевым отличием, а не синтаксис. В ФП нет таких отдельных маленьких сущностей с состоянием, его приходится хранить отдельно в глобальных структурах и прокидывать для вычислений внутрь каждой функции.
Конечно, если у нас в программе нет закешированных данных и есть лишь небольшой объем входных, т.е. каждое значение мы считаем заново, то использовать парадигмы, предназначенные для кеширования результатов вычисления глупо.
Например, во фронтенде сейчас это прекрасно видно на примере React+Redux, когда Store становится большим, он становится поистине God-object и весь выигрыш в чистых функциях и едином месте, где видно состояние всего приложения пропадает.
А когда в дело вступает многопоточность — идея глобальных хранилищ начинает еще сильнее трещать по швам, в случае редакса опять же прекрасно видно на примере асинхронных экшнов.
Идея ООП хранить данные не в одном месте, а в виде графа, распределенного по всей программе не лучше и не хуже идеи хранить данные в одном месте.
vassabi
arvitaly
Наверное тем, что каррированию, как хранилищу, нельзя дать имя, реализовать синглтон с произвольной точкой доступа таким образом тоже невозможно. В итоге все равно все сводится либо к прокидыванию аргументов через всю цепочку вызовов, либо к прокидыванию ссылки на именованное хранилище.
ООП не обязано, в отличии от ФП, быть деревом, оно может быть любым видом графа, а в случае метапрограммирования, еще и многомерным. (В функциональный Реакт это заставляет вводить Context, в дополнение к глобальному стору).
vassabi
эээ… а почему нельзя и невозможно?
sshikov
Вот интересно, каррированная функция — это такая же функция, как любая другая, она может быть безымянной — а может и не быть. Присоединюсь к вопросу — что вы имели в виду, когда сказали, что каррированию нельзя дать имя? Ну то есть, я может буду готов с этим согласиться, если вы говорите допустим только о React+Redux, но обобщать я бы не стал бы.
arvitaly
В случае класса со свойствами (или глобальными переменными, или переменными модуля), мы даем имя этим переменным и складываем туда результат вычислений. В случае ФП — это всегда константы, т.е. мы можем «сохранить» результат вычислений с помощью каррирования и дать на него ссылку, но не можем подменить находящееся там значение. В этом есть свои плюсы и минусы. Для программ с большим числом вычислений и малым хранилищем (по времени), это позволяет писать чистые функции, не беспокоясь, что кто-то где-то как-то подменит значение, не нужно мокать для тестов глобальные объекты, объекты по ссылкам и т.д.
Однако, для программ с необходимостью хранения множества объектов с часто изменяющимся внутренним состоянием — удобнее, когда имя дается один раз, а значения под этим именем меняются.
Это как если бы мы дали одно и то же название любому каррированию этой конкретной функции, вне зависимости от аргументов. Чего мы сделать в ФП не можем, да и зачем.
sshikov
Ну, да, в таком уточненном смысле — согласен.
geher
Хороший компилятор, внезапно, тоже программа. Если компилятор будут создавать программисты с таким мировоззрением, то он никогда не станет хорошим.
VladVR
Я даже больше скажу, если программист допустит ошибку, хороший компилятор должен догадаться, чего имел ввиду программист и исправить ее.
snamef
он имел ввиду что очень хороший компилятор построит свой хороший код и догадается где в своём коде ошибки))
sshikov
>В Haskell я напишу две функции, а не одну, потому что это функциональное программирование.
Я и в Java напишу две функции. Разделение на чистые функции и IO — оно вовсе не потому, что хаскель, а потому что это практично.
Nick_Shl
GeoSD
Кто-то должен писать хороший компилятор в идеальной системе.
maxpivovar
Шо опять ©
habr.com/ru/company/ruvds/blog/462483
rpiontik
Да этому стебу уже лет 25 на моей памяти. Уже что-то нового придумать очень сложно. И главное, смысла — ноль. Все как было, так и останется. Потому, что всему есть своя область применения. Отсюда разнообразие языков, стилей, методик, парадигм, методов и т.п.
kasyachitche
Очень тяжело читать, потому что видишь вот такое заявление:
и думаешь, вот сейчас то начнется, но потом появляется:
Оказывается, оба подхода — одно и то же потому что решают одну и ту же задачу? Или потому что на функциональном ЯП был реализован ООП подход? Мне кажется, что ФП заключается не в том, что функция определяет тип получаемого объекта и выбирает для этого нужный код. Я бы написал вот так:
Square=функция по определению хар-ых точек из длины стороныCircle=функция по определению хар-ых точек из радиуса и шага по углу
Area=функция по определению площади по хар-ым точкам
Diameter=функция по определению диаметра по хар-ым точкам
И в результате получается что площадь считается как:
Area(Square(5)). И заметьте, никаких равно, никуда мы это значение не сохраняем — площадь — это именно функция, а не цифра.Замечу, что подход для расчета в моем примере не самый оптимальный, но он определяется задачей и, и самое главное — такой подход функционален и тут видна разница между ФП и ООП.
mynameco
Все хорошо, но поддержка кода превращается в ад. Если в цепочке что то пошло не так, пропал элемент, или появились лишние, проверить это очень сложно. Не бряку поставить, ни код вписать для логирования, ни трай кетч. Учитывая что бывают случаи очень редкого бага, и попасть в него не так то просто, все становится еще хуже. Еще бывает что программист полюбил оператор .? и вставляет его в цепочку, усложняя понимание кода и добавляя неверную информацию о том что элемент может быть null так где этого не может быть, то все становится вообще плохо.
И чтобы поддерживать код, приходится — переписывать на понятный развернутый вариант по шагам, что как бы показывает насколько такой код понятен и поддерживаемый.
MilesSeventh
Что-то я не могу сообразить, как try/catch может помочь при отладке
AlexBin
Я мимо проходил, но в случае ошибки в catch можно прозрачно для внешнего кода вывести все нужные нам данные подробно, записать в лог или отправить почту.
balsoft
Так есть же всякие отладочные
traceи даже специальныйLoggerв Хаскеле для таких вещей.fori
А вдруг это все правда станет не нужно в настоящем ФЯ без mutable и прочего? Нет никакого зависимого окружения. Берешь любой кусок кода, отправляешь в REPL и получаешь результат работы. Не надо пол часа компилить, разворачивать базу нужной версии, поднимать инстанс, настраивать окружение, расставлять бряки чтобы отловить какую нибудь глупую ошибку в имени переменной.
xpoback
После таких статей все больше убеждаюсь в том, что чистое ФП — наследие прошлого.
Got_Oxidus
Пример можно?
snamef
fun countLinesInFiles(fnames: List String): Int
= fnames.map { File(it).readLines().size }
.sum()
причина по которой код так выглядит — потому что есть готовая функция readlines ещё и сама считает поэтому есть size, а если писать построчное чтение с нуля будет похожее мясо правда с 1 циклом.
Правда лучше написать сразу split или count chars
Разница между ООП и ФП
Чтоб закончить срач поповоду ФП, задолбали уже.
Самый весомый признак ФП — это возможность присвоения переменной значения «функции» и использование переменной-функции в функциях
высокого порядка (и ещё ф-я может возвращать ф-ю)
f = какая то функция
g (f,x,y...)
И ВСЁ
замысловатые нотации типа чточто-> ещё что то -> вырвиглаз могут присутствовать в ФП но совсем не обязательны, это скорее фича декларативного програмирования. Как и head — tail понятное дело не будет толком работать императивно. Тут путают понятия и доказывают что декл. язык низкого уровня не пригоден для индустиаальных проэктов, открыли америку.
впринципе момент старого доброго С где поинтер на функцию был void* и передавался и возвращался как переменная. Насколько я знаю, это используется сплошь и рядом в любой индустриальной либе на С
sumanai
Всегда знал, что PHP функциональный язык
Gryphon88
В любом тьюринг-полном языке можно писать в любой парадигме, вопрос только в количестве затраченных усилий. Например, с помощью сишного препроцессора можно программировать функционально, но обычно так делать не надо.
AlexBin
Совершенно верно, возможность создавать функции высшего порядка не делает язык пригодным для ФП. Помимо возможности должно быть еще удобство и читабельность.
TonyLorencio
Неверно. В ФП нет самого понятия присвоения. Всё иммутабельно.