
Начало проекта
Этот бенчмарк проект начался со статьи “Serializers in .NET v.2” на GeeksWithBlogs.net. В статье было рассмотрено довольно много имеющихся под .NET сериализаторов. Но, чтобы превратить эту статью и соответствующий код в настоящий бенчмарк, надо было сделать несколько улучшений.
Во-первых, сериализаторы надо было тестировать на нескольких типах данных. Есть универсальные сериализаторы, а есть специализированные. Специализированные очень хорошо работают только с несколькими типами данных, на других данных они работают намного хуже или совсем не работают. В чем мы в дальнейшем и убедились.
Во-вторых, сериализаторы сильно отличаются по интерфейсам. Наш бенчмарк не должен заставлять сериализатор следовать нашему выбору интерфейса. Наоборот, бенчмарк должен быть настолько гибким, чтобы каждый сериализатор мог бы использовать наиболее подходящий для него интерфейс. То есть надо передавать в бенчмарк дополнительные параметры конкретного сериализатора.
К автору статьи обратился автор одного из сериализаторов с предложением сделать усовершенствованный тест. Автор сериализатора был инициатором этого проекта, он же был и ведущим разработчиком. Сергей был разработчиком всей Web части проекта, всех великолепных отчетов. В качестве платформы для бенчмарка использовался NFX, позволивший сделать все планируемое (и многое-многое другое) очень быстро. NFX тянет на сотню подобных статей, надеюсь он вас тоже заинтересует.
Представление результаты тестов
Для начала я немножко остановлюсь на представлении результатов, на том, что требует особого внимания.
Для примера посмотрим на суммарную информацию одного из тестов:

Слева мы увидим по три победителя в двух наиболее важных категориях: в скорости и в размере сериализуемых данных. Сразу оговорюсь, что победителей может быть и больше, что победителями можно считать все сериализаторы, попавшие в синюю, зеленую и, в меньшей мере, светло-коричневую категории. Серая категория — это сериализаторы, не прошедшие данный тест.
В колонке скоростей вы можете кликнуть по названию сериализатора и получите расшифровку скорости с отдельными числами по сериализации и десериализации.
В качестве основной берется худшая скорость из сериализации и десериализации. Мы предполагаем, что вам важна суммарная производительность системы, а не производительность только сериализации или только десериализации. Ваш случай может быть другим, поэтому скорость другой операции тоже дана на графике тонкой палочкой.
На что обращать внимание:
- На сериализаторы, не прошедшие тест:
На некоторых тестах большая часть тестируемых сериализаторов теряли данные. Если вы выберете для работы “быстрый” сериализатор, а он будет портить ваши данные, это худшее, что можно представить. Вы затратите массу времени, пытаясь понять причину искаженных данных. И вам еще повезет, если вы наткнетесь на это в разработке, а не в продакшн.
- На соответствие ваших данных данным теста:
Наша рекомендация: загрузите код бенчмарка, измените тестовые данные или добавьте ваши данные и протестируйте их заново. Никогда не доверяйте вашей интуиции, не доверяйте экстраполяции. Практически любой сериализатор упадет на каком-то определенном размере данных. Мы не выполняли предельные тесты, делайте их сами под свои данные. Очень немногие сериализаторы прошли все наши тесты.
На что НЕ обращать внимание:
- Если тесты показывают разницу в числах в несколько раз, не стоит обращать внимание на разницу в проценты. Это не только бессмысленно, но и неправильно. Маленькие вариации в скоростях или размерах можно легко исказить, чуть-чуть изменив тестовые данные.
Тестовые данные
Мы постарались представить данные для наиболее используемых приложений. У нас нет статистики по использованию сериализаторов, поэтому мы выбирали данные, основываясь на собственном опыте. Если вы видите, что мы пропустили что-то важное, дайте нам знать или просто добавьте ваши тестовые данные в Serbench.
Типичные приложения мы видим в нескольких областях:
- распределенные, независимые системы (distributed systems). Программы работают независимо, в разных процессах или на разных машинах, и обмениваются данными. Программы обмениваются только контрактами, интерфейсами. Под этот тип попадают системы обмена сообщениями (messaging).
Данные, относящиеся к этому типу: Typical Person, Telemetry, EDI, Batching.
- распределенные, но сильно связанные системы. Отличие от предыдущего случая в том, что системы могут обмениваться не только контрактами, но и библиотеками. Чаще всего эти связанные системы разработаны в одном месте. Под этот тип попадают RPC (Remote Procedure Call) системы.
Данные, относящиеся к этому типу: Typical Person, Batching, Object Graph.
- системы хранения. Данные передаются между программами и хранилищами данных. Отличие от предыдущих случаев в том, что цикл сериализация-десериализация не происходит в течении микросекунд или секунд. Данные могут храниться и годами. В течение срока хранения контракты данных часто меняются, что порождает проблему версионности данных. Мы не тестировали сериалайзеры на работу с версиями. Любые из имеющихся тестовых данных могут работать с системами хранения. Но сериализаторы, поддерживающие версионность данных, могут быть более удобны в этом случае.
Typical Person
Здесь представлен простой класс без интерфейсов и без наследования. Почти все представленные сериализаторы проходят этот тест.
Telemetry
Подобные данные генерируются IoT (Internet of Things) устройствами. Их отличие — наличие числовой информации, временнЫе метки и несколько идентификаторов. Иногда данные очень короткие, когда пересылаются одно или несколько чисел; иногда пересылаются большие массивы чисел. Структура данных простая. Здесь важна скорость и плотность упаковки данных.
EDI
EDI (Electronic Data Interchange) данные являются эквивалентами документов. Для них характерна сложная иерархическая структура и вложенность классов. Присутствуют коллекции классов.
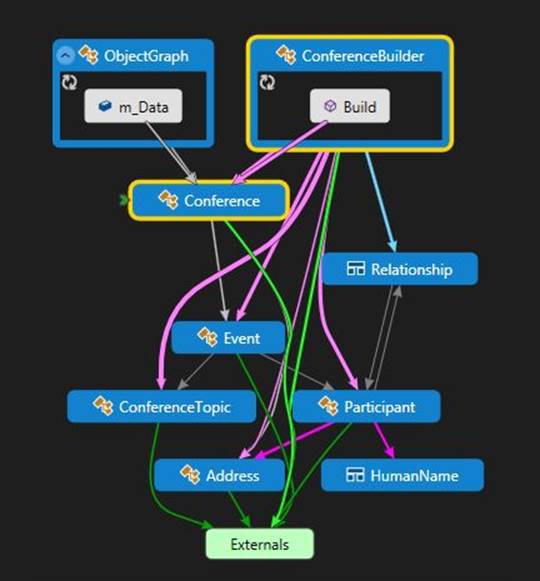
Object Graph
Если вы используете объектно-ориентированную разработку, вам наверняка приходилось иметь дело с подобными классами. Для них характерны сложные взаимосвязи между классами. Мы тестируем класс Конференция (Conference), в котором есть коллекция Событий (Event). В событии могут быть несколько Участников (Participant) и несколько Топиков (Conference Topic).
Интересно то, что участник может иметь несколько Связей (Relationship), каждая из которых ссылается на другого участника. В результате получаются циклические связи. Это обычная ситуация, но, оказывается, лишь очень немногие сериализаторы могут работать с циклическими связями.
Batching
Представьте ситуацию, когда вам надо переслать сразу несколько экземпляров объектов. Это типичная ситуация в распределенных системах. Объединяя несколько элементов данных в один пакет, который передается по сети за один шаг, мы можем значительно ускорить передачу. Пакет называется batch, отсюда и название — батчинг.
Обычно нам надо явным образом создавать пакет, вкладывая элементы данных в специальный класс-конверт (envelope). Некоторые сериализаторы позволяют обходиться без конвертов, что значительно упрощает разработку.
Процесс тестирования
Здесь все просто. За один тестовый цикл мы сериализуем объект или много объектов в случае батча, и сразу же дисериализуем его обратно. Конечный и исходные объекты сравниваются, чтобы отсеять ошибки. Сравнение делается быстрое, лишь по некоторым величинам. Мы не делаем полноценного сравнения, но все интерфейсы для полноценного сравнения есть в наличии.
Несколько тестовых циклов объединены в один проход (run), в начале которого генерируются тестируемые данные.
Несколько тестов объединены в последовательности, первым тестом в которых служит разогревочный (warmup) тест. Этот тест обычно состоит из одного цикла, цель которого — инициализировать все нужные данному сериализатору объекты.
Некоторые сериализаторы быстро инициализируются, но медленно сериализуют, некоторые — наоборот. Если вам надо использовать сериализатор один раз, то вам не стоит пренебрегать результатами разогревочных тестов, для вас они — главные.
Мы тестировали обычно сначала одиночный объект, а потом коллекцию объектов. Как оказалось, сериализаторы могут быть оптимизированы для работы с коллекциями. Тогда они могут пробиться из аутсайдеров в лидеры.
Любые данные, но обычно именно коллекции, могут быть очень большими, что может привести к резкому замедлению работы сериалайзера, либо привести к ошибкам. В некоторых неприятных случаях сериалайзер просто подвешивал систему.
Результаты тестирования
Мы перечисляем победителей в тестах, только в сумме по всем тестам. Победители в отдельных тестах очень хорошо представлены на страницах Результаты тестирования на сайте. Здесь мы сделаем некоторые выводы. Акцентирую ваше внимание на том, что мы не претендуем на истину в последней инстанции, мы только комментируем числа. Числа могут сильно измениться при будущих обновлениях тестов.
Typical Person
Результаты тестирования.
Этот тест я рассмотрю в подробностях. Остальные тесты — только в основном.
Все тесты
Практически все тесты выявили одни и те же самые быстрые сериализаторы: ProtoBuf, NFX Slim, MsgPack, NetSerializer. Разогревочные тесты дали очень большой разброс скоростей. Microsoft BinaryFormatter показал хорошую упаковку на коллекциях и худшие на одном объекте. К сожалению, Json.Net не пробился в лидеры ни в одном тесте.
Разогревочные тесты (Warmup)
Скорость
Наблюдается удивительный разброс скоростей. NFX Slim делает тысячи операций, а, к примеру, Jil только одну операцию в секунду. Основная масса сериализаторов делает один-два десятка операций в секунду, иногда несколько десятков. Что еще удивительнее, NFX Slim делает около 45 тысяч! десериализаций в секунду. Но мы по понятным причинам учитываем только самую медленную операцию.
Упаковка
Разброс не такой большой, как в скоростях. Несколько победителей показывают практически одинаковый результат и JSON сериализаторы, что естественно, показывают похожие результаты. Мы специально сделали два теста для одного из JSON сериализатора (NFX Json). Один из тестов выдает JSON текст в красивом формате, со всеми отступами и переводами строк, а другой тест выдает JSON без форматирования. Как видите, размеры для обоих случаев довольно сильно отличаются друг от друга.
Этот результат еще раз подтверждает известное правило: никогда не форматируйте сериализованные данные в канале! Делайте форматирование только для презентации и никогда — для передачи данных.
Batching
Результаты тестирования.
Только ProtoBuf, Microsoft BinaryFormatter и NFX Slim могут выполнять батчинг сериализацию. При этом Slim имеет специальный батчинг режим.
Здесь наблюдается большая вариация скоростей для разных типов данных. Победители меняются от ProtoBuf для Trading и EDI классов, до Slim для RPC and Personal классов. При этом ProtoBuf не смог сериализовать RPC класс, в котором встретилось object[] поле. Можно резюмировать, что только Microsoft BinaryFormatter и NFX Slim успешно прошли этот тест. Microsoft BinaryFormatter как всегда показал отличные результаты в разогревочных тестах и стабильно худшие результаты в упаковке, что не умаляет факта, что он отработал без ошибок.
Object Graph
Результаты тестирования.
Этот тест оказался самым сложным для сериализации. Много сериализаторов не прошли его. Многие прошли, но при этом показали ужасные скорости и упаковки. К примеру Jil на тесте ObjectGraph: Conferences: 1; Participants: 250; Events: 10 упаковал данные в 2.6 МВ, а лидеры упаковали данные в чуть более 100 КВ, то есть затратили в 26 раз меньше памяти.
В этом тесте мы видим несколько лидеров, которые побеждают с очень большим отрывом. Это ProtoBuf и NFX Slim. Microsoft BinaryFormatter неожиданно оказался среди этих лидеров по степени упаковки.
EDI X12
Результаты тестирования.
Интересным было то, как при росте объема данных все больше сериализаторов заканчивало работу с ошибками.
Как обычно на разогревочном тесте лидер — NFX Slim.
Похоже, что лидеры в упаковке: ProtoBuf, MsgPack, NetSerializer, NFX Slim — используют специальные методы упаковки для подобных случаев и эти методы работают очень хорошо.
Обращу ваше внимание, что XML, который часто используется для сериализации и обработки EDI документов, показал, в лице XmlSerializer, отвратительные результаты в упаковке, использовав в 8-9 раз больше места для сериализованных данных.
Выбор Сериализатора
Для чего нам надо выбирать сериализатор? Почему мы не можем обойтись сериализаторами из .NET Framework? (Microsoft поставляет несколько сериализаторов, некоторые из них появились совсем недавно, такие, как Bond и Avro.)
Дело в том, что сериализаторы становятся все более важным элементов распределенных систем. Медленный сериализатор может помешать достижению максимальной производительности, быстрый — может сделать вашу систему лучше, чем у конкурентов. Новые сериализаторы для .NET сейчас появляются с завидной постоянностью. Каждый из них рекламируется, как самый быстрый. В качестве доказательства создатели приводят результаты тестов.
Мы разработали собственную тестовую систему и провели независимое исследование. Сейчас же мы обсудим критерии, которые помогут вам сделать осознанный выбор сериализатора. Критерии выбора базируются на результатах проведенных тестов.
Надежность сериализации
Мы с удивлением обнаружили, что множество сериализаторов не проходят элементарных тестов. В лучшем случае мы получали ошибку в программе, в худшем случае данные терялись без всякого предупреждения, либо Windows зависал на неопределенное время. В промежуточном случае искажались объекты.
Внимательно ознакомьтесь с результатами наших тестов. Результаты эти очень сильно зависят от данных. Если данные простые по структуре, то практически любые сериализаторы справляются с работой. Если данные сложные либо большие по размерам, то, увы, все не так хорошо.
Я акцентирую на надежности, потому что вряд ли скорость работы или плотность упаковки данных будут оправданием к потерянным данным или к зависшей системе
Наверняка, самым надежным сериализатором является Microsoft BinaryFormatter. Он не из самых быстрых, но этому есть важная причина. Он сериализует практически всё без ошибок.
Сами ли вы выбираете формат данных?
К примеру, вы получаете данные от партнера в XML формате, и вы должны работать с XML. У вас нет никакой возможности изменить эту ситуацию. В этом случае ваш выбор ограничен XmlSerializer и Json.Net.
Если вы интегрируете свою систему с чужими системами, то выбор будет сделан за вас, и вам скорее всего придется использовать один из двух стандартных форматов: XML или JSON. В редких случаях вам придется работать с форматом CSV или с форматом какой-то определенной системы. Чаще всего это случается при интеграции с системами из прошлого тысячелетия.
Если вам нужно сериализовать простые .NET типы, такие как int, double, bool, то вам хватит элементарной функции ToString().
Сериализаторы, работающие с форматом JSON, более распространены. JSON намного проще XML, что в большинстве случаев является преимуществом.
Многие сериализаторы упаковывают данные в собственный бинарный формат. JSON формат обычно намного компактнее, чем XML. Бинарные форматы обычно компактнее, чем JSON.
Если вы можете сами выбирать формат данных, бинарный формат скорее всего будет лучшим выбором. Но помните, в этом случае, вы должны использовать один и тот же сериализатор и для сериализации, и для десериализации. На данный момент все бинарные форматы уникальны, ни один из них не стандартизован.
Плотность упаковки данных
Что важнее, скорость сериализации-десериализации или плотность упаковки данных?
Размер сериализованных данных обычно важнее, чем скорость процесса сериализации-десериализации. Связано это с тем, что скорость работы процессора (скорость, определяющая сериализацию-десериализацию) много выше скорости данных в сети, которая обычно напрямую связана с размером передаваемых данных. Уменьшение размера данных на 10% может привести к 10%-ому ускорению передачи данных, а двукратное увеличение скорости сериализации-десериализации — только к 1%-ому ускорению.
Вы пытаетесь выжать из своей системы максимальную производительность? А может для вас важнее производительность разработчиков?
Посмотрите, к примеру, на такие сериализаторы, как Bond, Thrift, Cap’n Proto. Вы не просто берете и сериализуете любые классы. Вам надо использовать специальный IDL язык и описывать на нет эти классы. Обычно вам помогут утилиты, генерирующие описания классов из самих классов. Но даже если они есть, вам надо разбираться с этим языком, отрывать время от непосредственно разработки.
Другие сериализаторы, к примеру, Slim из NFX, ничего от вас не требуют. Вы просто сериализуете любые классы. В промежуточных случаях сериализуемые классы надо украсить атрибутами. Наверняка вам знаком атрибут [Serializable].
Важно ли это? Да, это может быть важно. Особенно когда ваши классы не тривиальны по структуре. К примеру, в нашей тестовой системе вы встретите EDI тестовый класс, скомпонованный из десятков вложенных классов и сотен полей. Добавление атрибутов во все эти классы и поля было утомительной и долгой работой.
Еще это важно, когда вы сериализуете классы из библиотек, к коду которых у вас нет доступа. Вы не можете взять код и добавить туда атрибуты, код недоступен. Часто для обхода этой ситуации программисты используют так называемые DTO (Data Transfer Object). Их использование чревато усложнением программы и падением скорости разработки. Вместо работы над бизнес логикой, придется писать код, который не имеет к ней никакого отношения.
Вы выбираете сериализатор для сериализации и для десериализации или только для одной из этих операций?
Если ваша система является только принимающей или отправляющей стороной, то, согласитесь, это отличается от случая, когда вы отвечаете за обе операции.
Есть ли в ваших данных коллекции?
Сериализаторы могут быть оптимизированы для работы с коллекциями объектов. Другие сериализаторы никак не различают коллекции, поэтому они покажут много худшую скорость и упаковку.
Какой размер ваших данных?
Данные могут быть очень большими, что может привести к резкому замедлению работы сериалайзера либо привести к ошибкам в сериализации. Сериализатор может просто подвесить систему.
Большие данные в памяти могут влиять на сборку мусора, что в свою очередь, может вызвать долгие остановки в работе программ.
Вам надо сериализировать что-то очень неординарное?
И тут вам помогут сериализаторы, специализирующиеся именно на этой задаче. Вот к примеру, сериализатор занимающийся Linq expressions.
Вам нужна супер-супер производительность?
Тогда наилучшим вариантом будет написать свой собственный узкоспециализированный сериалайзер.
Если вы не хотите этим заниматься, то обратите внимание на дополнительные методы, используемые разными сериализаторами. К примеру, батчинг является великолепным методом увеличения скорости. К сожалению, только немногие сериализаторы могут использовать его без дополнительной кодировки.
Параллельная сериализация тоже является хорошим методом для достижения высоких скоростей. Если вы ее используете, для вас важна thread-safety сериализатора.
Комментарии (24)

notacodemonkey
28.07.2015 15:26-1В тесте отсутствуют zero-copy parsing библиотеки — например FlatBuffers для C# вполне можно юзать.
Десериализация за 0 сек — это серьёзно ))
Leo_Gan Автор
28.07.2015 19:13+1notacodemonkey: Да, это серьезно. В наших планах протестировать эти библиотеки.
Но надо понимать, что у них очень ограниченное применение. По сути вы явно выделяете память под объекты и сбрасываете копию памяти в эту выделенную область. Т.е. получается такая unmanaged область, где ваш объект. Вы byte[] выгружаете в эту область и называете это zero-copy.
Похоже, что при этом происходит подмена понятий.
Мы называем сериализацией-десериализацией процесс, в котором на одном конце находятся объекты. А тут — не объекты, а byte[], как и в канале, как и на другом конце. Естественно, время на это затрачивается — почти ничего. То, что приходится уже явно конвертировать этот byte[] в объект, не считается. Это уже не проблема сериализатора, это ваша проблема.
Нам говорят. Вот вам груда кирпичей. Это — дом, за который вы супер дешево заплатили.

itadapter
30.07.2015 00:05+1Flat buffers, CAPTN proto etc… these are not serializers, these are memory managers. You can not call them serializers as you can not use the «standard object» paradigm. In other words, you can not copy an instance of FileStream by just copying memory bytes. sorry for english i have little time to answer now
notacodemonkey
31.07.2015 14:57Для сценариев где данные изменять не нужно, и обьект доставать из этого буфера не нужно, потому что эти либы генерируют аксесоры прямо в этот буфер.
itadapter
01.08.2015 03:48da imenno,
eto kak kogda-to xranili v Delphi (naprimer) Dataset v binarnom file na diske. Rows[] — eto byl prosto (byte*)
kotoriy kastalsya cherez FiedlByName(«ColumnName»).
Eto ne serializaija. Eto format xraneniya dannix. On ne transparenten dlya raboti s obektami yazika kotorie na to i objects
chtobi s nimi rabotat (call methods, properties etc...)
itadapter
01.08.2015 03:52Ne zabudte — dostup cherez rekasti pointerov i transformaziju v buffer (byte*) — eto i est «psevdoserializaija» razmazannaya teper po business kody.
Kak skazal Leo_Gan, vam prodali ne dom a grudu kirpichei :)
Naprimer:
myData[«Age»] = 12345;
a esli v buffere xranitsya v BigEndian, a processor rabotaet v little endian? Eto znachit uje zamedlenie.
Tak chto nikakix chudes net i byt ne mojet. Skorost «zero-copy» resheniy eto ne skorost «write to stream» — nado meryat' vse i UCHITIVAT
«nepolnozennost buferov» — nevozmojnost rabotat s etimi dannimi cherez standartnie sredtsva yazika — a znachit eto DTO — a DTO eto govnokod :) (elsi ego mojno izbezhat')
Scratch
NFX разве можно без их фреймворка юзать?
Leo_Gan Автор
Scratch: В этом-то все и дело! Весь NFX — в одном dll. Он в этом каталоге.
Представляете, весь фрамеворк — в одном dll. Никаких проблем с версионностью, с потерянными ссылками и т.п.
Многие спросят, а зачем мне этот паравоз, мне только сериализатор нужен. А тут еще полноценная замена WCF на стероидах, доступ к базам, хостинг, кластеры… Можно ли оставить только сериализатор?
Ответ: нет. Вся суть этого подхода, Unistack, именно в этом. Попробуйте, может понравится. Все это хозяйство грузится за долю секунды и сразу же готово к работе. 1.5 МБ, — на мой взгляд, это небольшая плата.
lair
Вопрос не в том, «можно ли оставить», вопрос в том, что делать, если нужен только сериализатор.
dxwizard
Хм, помнится когда я описывал наш Walkable (LINQ для JS), все как раз настоятельно советовали юзать сторонние библиотеки невзирая на их избыточность )
lair
Вам далеко не только это советовали. Ну и вопрос же в соотношении пользы/избыточности — каждый для себя проводит границу комфорта.
dxwizard
Но и в веб-части данного проекта Walkable свою функцию выполнил. Причём без единого вопроса ко мне со стороны Сергея, который реализовал эту самую веб-часть, что всё-таки говорит о простоте.
lair
Да ни о чем это не говорит, будем честными.
dxwizard
Вы правы. Оно не говорит, оно делает )
Leo_Gan Автор
lair Честно говоря, не уверен, что сериализатор можно «вытащить» из NFX. Надо у его автора спросить.
Однозначно, это вытаскивание идет вразрез с идеей Unistack. Для работы с ним вам не надо подгружать никаких доп.библиотек. Это не идея швейцарского ножа с сотней мелочей. Это, скорее, "OK Google".
lair
Плохая метафора, «ок, гугл» может слишком много и поэтому все по отдельности делает плохо. Не согласны — попробуйте с его помощью проложить пеший трек по Исландии.
Я не хочу обсуждать достоинства/недостатки монолитных систем, я просто хочу понимать, что нужно, чтобы воспользоваться всеми сериализаторами, задействованными в сравнении.
Leo_Gan Автор
Согласен, универсальный тул по каждому входящему тулу хуже, чем специализированный тул. Поэтому мне аналогия со швейцарским ножом и не нравится.
Опять же согласен, что «ОК Google» тоже не совсем удачное сравнение.
Хммм… Попробую такое сравнение: топор, которым срубили Кижи. Или статуя, сделанная из глыбы, от которой отсекли все лишнее.
Или — LINQ.
Выбран самый нужный функционал для профи. Отброшено все, что упрощает работу для новичков. редко используемы сигнатуры, интерфейсы. Полученный концентрат можно использовать вдоль и поперек. Остался ограниченный набор. Сильно связанный набор! Выдернешь одно и порушишь все. Как болтик из ракеты. Все имеет свой смысл.
Этот набор сделан на общих принципах. Принципов, как и тулов, мало, но достаточно. Если освоишь, то оседлаешь ракету, похожую на топор с формами Венеры Милосской… эко меня понесло.
Или так: горная страна вся связана мостами. Но мосты переброшены только между основными вершинами. Ты можешь их использовать, только если обладаешь достаточными навыками, чтобы забраться хотя бы на одну вершину.
lair
А кто выбирал? Откуда мне знать, что его выбор подходит для моих задач?
Вы, вероятно, хотели сделать решению комплимент, но получилось строго наоборот.
Спасибо, но мне не надо забираться на вершину, мне надо добраться из точки А в точку Б. Поезд меня вполне устроит.
В этом проблема метафор — они больше выдают чувства автора, нежели описывают суть явления.
Leo_Gan Автор
Может и не подойдет. С сожалению, сейчас по NFX мало обзорных статей, мало доступных use cases. Use cases есть, но этот вопрос — к авторам NFX.
Намек на loose coupling? LC — хорошо,
LC— плохо. Выглядит, как догма.LC предполагает деление системы (модели) на подсистемы, которые уже и будут слабо связаны. NFX сильно связана, в том же смысле, как человек собран из разных частей. Посмотрим на человека, как систему костей и органов, будет одна модель. Посмотрим на человека, как на систему клеток, будет другая модель. NFX здесь больше на клетку похожа. Все в ней взаимно связано. Но при этом клетки объединяются. При этом клетки специализируются.
lair
Нет, намек на излишнюю хрупкость.
И с чем объединяется NFX?
Leo_Gan Автор
Про хрупкость… не понял, туплю.
В NFX есть библиотека Glue, которая Slim сериализатор использует. Что-то типа WCF. Чтобы рассыпать NFX приложения по серверам и связывать их. Представьте, что вам не надо заботиться о коммуникационном пакете, он есть всегда и везде.
lair
Я могу его использовать, чтобы связаться с мобильным приложением, написанным на Swift?
Leo_Gan Автор
Да, можете. Хотя придется данными обмениваться в JSON. Есть NFX JSON сериализатор, в тестах он тоже есть.
Но, естественно, придется на Swift писать кое-что от руки. Если связывать NFX приложение с NFX приложением, то это очень просто и быстро. Slim сериализатор использует свой бинарный формат. В тестах он есть.
lair
То есть, внезапно, коммуникационный пакет есть не всегда и везде, а только в таких же NFX-приложениях?