
Тем более, что значительный поток инцидентов на вторую линию поддержки, это так называемые бизнес-инциденты, то есть инциденты, либо связанные с нарушением логики работы бизнес-процесса в сервисе, либо с некорректными действиями со стороны пользователя.
Мы смогли максимально снять со второй линии этот функционал, передав его в отдельную команду, собранную из сотрудников первой линии технической поддержки.
О том, как мы это делали и с какими трудностями столкнулись, мы расскажем вам в этой статье.
Традиционно решением инцидентов по системам у нас занимались команды второй линии технической поддержки, те которые обеспечивают сопровождение самого сервиса, выполняют настройки конфигурации продуктива, тестовых сред, мониторинга системы, производят установку патчей, участвуют в oncall-дежурствах и тд. И решение инцидентов в этих командах сопровождение часто проходило по «остаточному принципу» (если это конечно не инцидент с критическим приоритетом), тем не менее, в отведенные SLA в большинстве случаев они укладывались.
Осознавая, что за многими из инцидентов (а по фронт систем — за каждым) потенциально может стоят проблема Клиента Банка, мы решили минимизировать время выполнения этих запросов, но начали не с увеличения численности команд сопровождения, а с анализа каждого из этапов этого процессов.
Традиционный процесс поддержки в Банке был построен по классической схеме и выглядел следующим образом
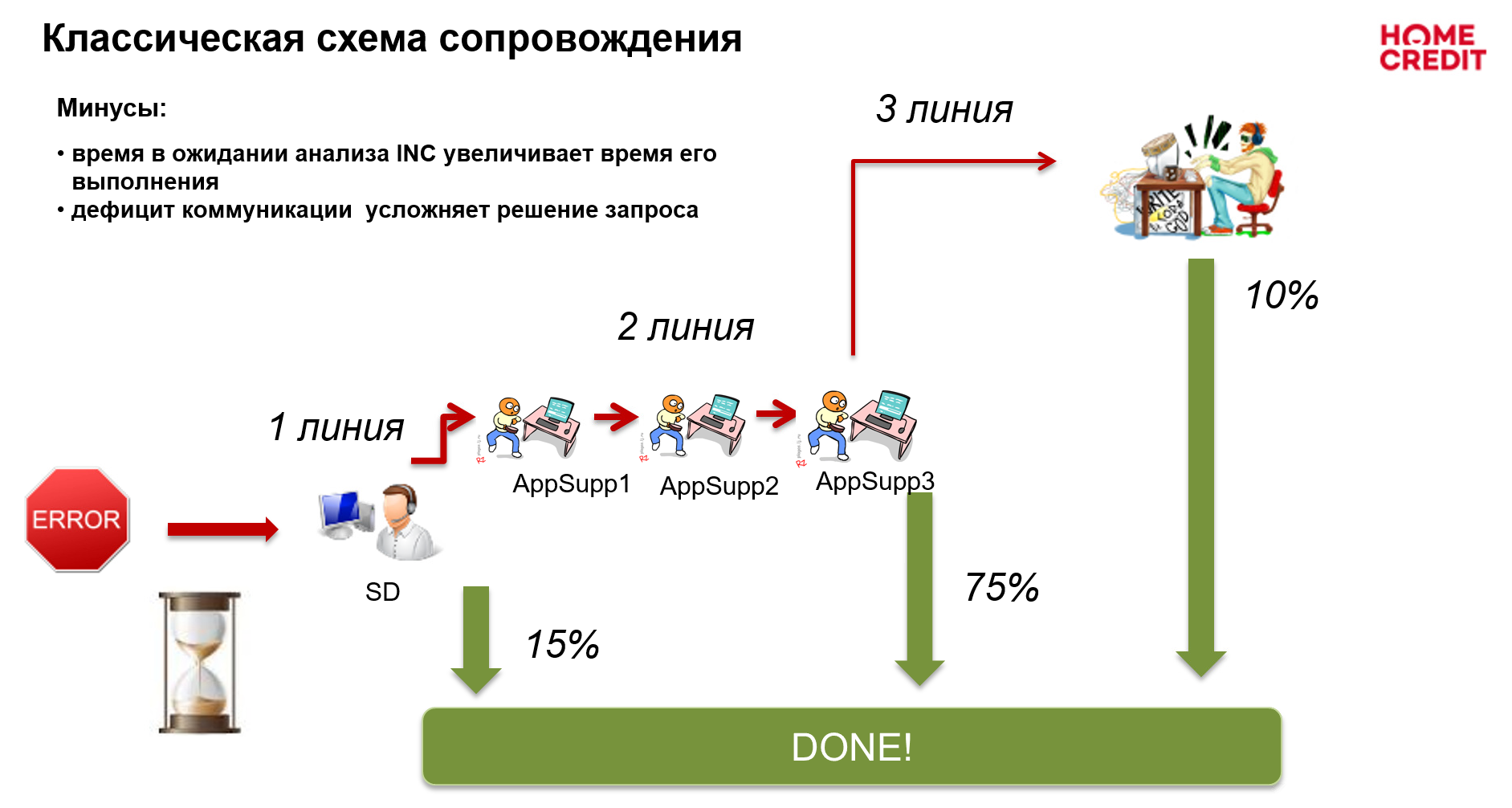
рис.1 Схема организации процесса сопровождения (было)
Запрос проходил через первую, вторую и третью линии поддержки, распределялась между ними в следующих пропорциях: 15:75:10.
Первая линия — Service Desk — прием, обработка, маршрутизация обращений с использованием следующих каналов коммуникации:
- телефон — 8% от всего количества обращений
портал самообслуживания — 83% от всего количества обращений
электронная почта — 4% от всего количества обращений
чат-бот в Viber и Telegram — 5 % от всего количества
Также первая линия занимается решением инцидентов удаленно на рабочих местах пользователей, предоставлением доступов в информационные системы Банка. О работе этого подразделения я написал в отдельной статье — ссылка здесь
Вторая линия — команды сопровождения прикладного ПО + инфраструктура + DBA + …,
Третья линия — это команды разработки.
Так как банковские системы интегрированы между собой, возникновение инцидента в одной из систем, часто бывает влиянием ошибки, возникшей в другой системе. И ошибки на “бэк системах” в первую очередь проявляются на “фронте”, оказывая непосредственное влияние на пользователей.
Выявление корневой причины возникновения в данном случае требует участия нескольких команд сопровождения, и, как следствие, череды маршрутизаций.
Взяв выборку из инцидентов за несколько месяцев и проведя анализ их жизненного цикла, мы выяснили, что большую часть своей жизни они проводит в очереди, в ожидании анализа сотрудником команды сопровождения второй линии (иногда до 80%), периодически, с переназначением между командами и продолжительной перепиской в теле запроса.
В процессе разбора и проведении анализа этих инцидентов, мы выяснили, что для решения интеграционных ошибок коллегам нужна информация со стороны смежных интеграционных систем (логи, анализ влияния и т.д.), за которой они и обращаются друг к другу, маршрутизируя инциденты.
В целях минимизации времени решения инцидентов, как пилотный проект, мы решили создать кроссфункциональную объединенную команду из сотрудников первой и второй линии для решения инцидентов в фронт системах Банка – интернет-банк, мобильный банк, сервисы отправки сообщений (sms и push) + основная фронт — офисная система Банка.
Эта команда является промежуточной между первой и второй линиями — полуторная линия поддержки, которую мы назвали “Frontline”.
Уже на стадии формирования этой команды мы столкнулись с определенными трудностями, в том числе, со стороны менеджеров второй линии, так передача даже одного сотрудника на этот проект от каждой из систем означала уменьшение капаситета текущей команды. Да и сами сотрудники второй линии, которые должны были участвовать в пилоте не горели желанием погрузиться с головой только лишь в решение инцидентов.
Путем итерационных переговоров, мы смогли договориться о том, что основная задача участников со второй линии в этом проекте — обучение сотрудников первой линии, совместное создание общей базы знаний, выстраивание процессов внутреннего взаимодействия, предоставление необходимых доступов, и после этого, постепенное возвращение обратно в свои подразделения.
Местом локации «Frontline» стал ИТ-Центр Банка в городе Обнинск.
Первый состав команды полуторной линии поддержки выглядел следующим образом:
- два сотрудника первой линии поддержки
- два сотрудника группы сопровождения фронт-офисной системы
- два сотрудника группы сопровождения Интернет-банка и мобильного банка
- один сотрудник группы сопровождения сервисов информирования клиентов (sms & push)
Основной фокус команды был сконцентрирован на 3-х показателях:
- СКОРОСТЬ — 70% запросов, поступающих в команду, необходимо решать не более чем за 8 рабочих часов
- КОЛИЧЕСТВО — команда может маршрутизировать на вторую линию поддержки не более 20% запросов
- КАЧЕСТВО — доля переоткрытых пользователями инцидентов не должна быть более 3%

рис. 2 Процесс обработки инцидентов с участием Frontline
Следующая трудность, с которой мы столкнулись в начале пилота, это — отсутствие команды в изначальном нашем ее понимании, при ее наличии.
Несмотря на то, что сотрудники «Frontline» находились рядом в одном помещении, попыток перехода к кроссфункциональности, обмена опытом, значительного взаимодействия внутри не возникало. Каждый участник, как и ранее, был сосредоточен на решении запросов по своей системе, в результате — кто-то был “завален” инцидентами, кто — то был явно более свободен.
Было решено «поменять системы» внутри команды, например, чтобы представитель сопровождения Интернет-банка больше не решал инциденты по своей системе, а начал обрабатывать запросы по фронт офисной системе, а представитель сопровождения фронт-офисной системы стал решать инциденты по сервисам оповещения и т.д.
Зачем?
- Попытаться прийти к универсальности, чтобы сотрудники могли переключаться между инцидентами разных систем, тем самым распределяя равномерно нагрузку на всех участников;
- Наделить ребят достаточными знаниями по смежным системам, которые помогут им быстрее выявлять причину возникновения интеграционной ошибки;
- Наладить коммуникации внутри команды;
Сделали необходимые учетные записи, предоставили достпы к логам приложений и баз данных, и вперед! :)
Сначала скорость решения инцидентов снизилась. Понятное дело, когда ты не знаешь тонкостей работы системы, а тебе еще и инциденты по ней решать надо — это задача непростая. Но ребята стали обращаться за помощью друг к другу, изучать и обновлять общую базу знаний и постепенно дело пошло.
Также каждый день мы стали проводить небольшие стендапы в начале каждого рабочего дня, около листов бумаги которые мы наклеили на стены и с ежедневными показателями. Мы обсуждали и дорисовывали их маркером, радуясь их выполнению или обсуждая причину неудачи, в случае если не смогли их достигнуть.
В последующем, конечно, мы заменили эти листы бумаги онлайн дашбордами.

рис.3 Дашборд эффективности Frontline
Здесь нужно сказать отдельное «спасибо» руководителю команды сопровождения фронт-офисной системы Банка, который взял на себя функции лидера и культивировал развитие командны изнутри — Алексей, спасибо! :)
В первые два месяца с поставленными таргетами команда не справлялась, шел процесс обучение, обновлялась база знаний.
Начиная с третьего месяца пилотного проекта, мы стали укладываться в таргеты, а спустя 6 месяцев стали даже их перевыполнять.
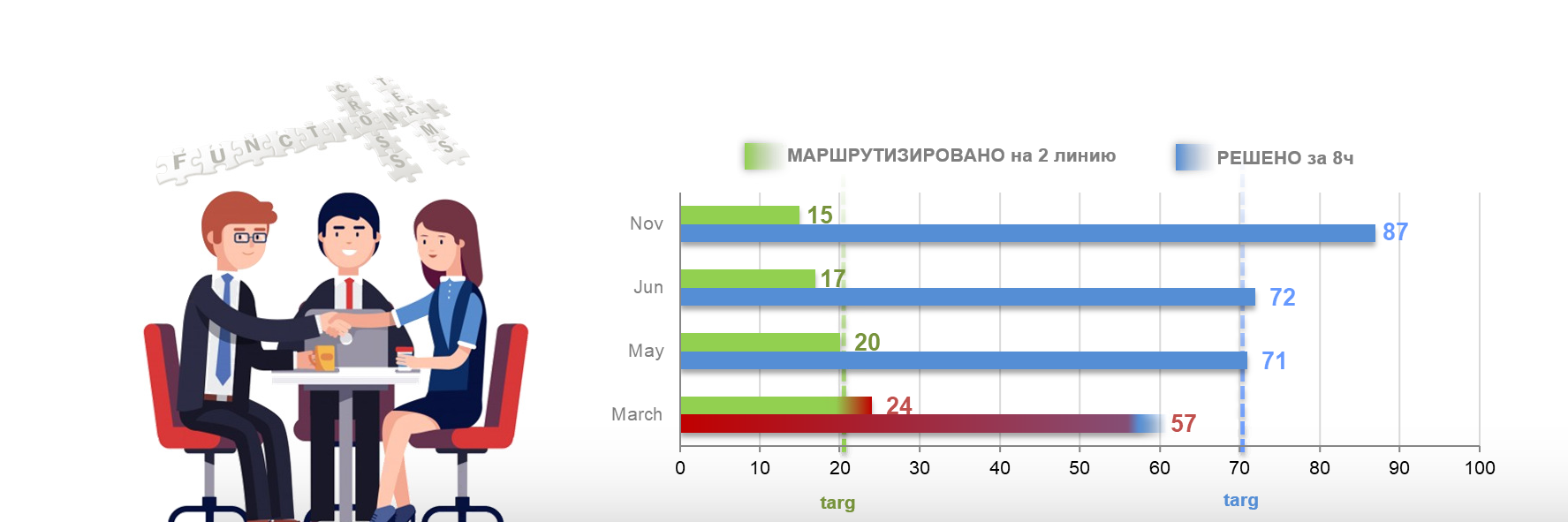
рис.4 Пилотный проект Frontline, первые показатели
Очень скоро стало понятно, что пилот успешно “взлетел”, и целесообразно проект масштабировать.
Постепенно, мы начали добавлять в команду компетенции по другим системам, выводить сотрудников второй линии и добавлять сотрудников из Service Desk.
Постепенно мы перешли к «Т — кроссфункциональности», когда за каждым участником закреплены одна основная система и две смежные.

рис. 4 Сравнительная статистика за 2018 год по времени решения запросов между Frontline и командами сопровождения второй линии
За 2018 год, команда Frontline закрыла больше инцидентов, чем любое другое подразделения сопровождения в Банке. Ребята значительно превысили установленные таргеты, в очередной раз показав, что командная работа и кроссфункциональные компетенции позволяют достигать значительных результатов.
Для второй линии поддержки «Frontline» сегодня — это надежный «щит», который значительно снижает поток обращений приходящий к ним.
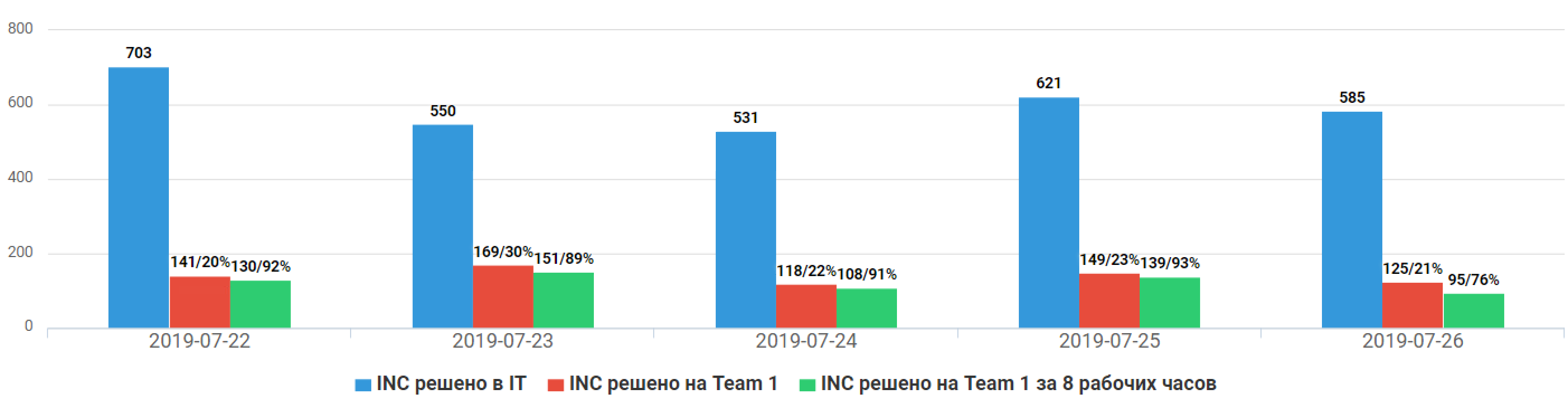
рис.5 Количество и доля инцидентов решенных во «Frontline» (на рис. — Team1) по отношению к инцидентам, решенным на второй линии по всем системам Банка
Сегодня все участники «Frontline» — это сотрудники из Service Desk, которые решают инциденты по основным фронт системам Банка, выдерживая заданные целевые показатели.
Так же «Frontline» — это следующая ступень для сотрудников Service Desk в нашей карьерной лестнице, перед переходом на вторую линию поддержки.
Комментарии (7)

badmilkman
01.09.2019 17:13+1Хоть кто-то дорос до понимания принципов работы хозрасчетной бригады.
А то куда ни позвони itil во всей красе, и пока доберешься до способного решить проблему специалиста отпадает желание работать с этой компанией.
Хотя, если в первой линии сидят не попугайчики, а способные оценить сложность проблемы специалисты по общению с клиентами. К тому-же знающие основы поддерживаемых систем, и регулярно информируемые последующими линиями о новых вариантах решений.
Но увы, техподдержка на удержание клиента не ориентирована. У них другие KPI, например скорость обработки заявки.
Barabek
01.09.2019 23:14Не кажется ли вам, что нормирование процента передачи на 2ю линию — зло? Ведь такая планка провоцирует фронтлайн применять быстрые сиюминутные меры, не доводя проблему до устранения корневой причины на 3L. А если в потоке тикетов так велика доля запросов, действительно не требующая вмешательства в код/конфиг, то это косвенно указывает на проблемы с продуктом в целом или с понятностью инструкций для пользователей.
serggvrn Автор
02.09.2019 10:59Не кажется ли вам, что нормирование процента передачи на 2ю линию — зло? Ведь такая планка провоцирует фронтлайн применять быстрые сиюминутные меры, не доводя проблему до устранения корневой причины на 3L.
Соглашусь с тем, что нормирование может быть злом, если оно под собой не имеет предварительного анализа и оснований, планка в 20% задана на основе анализа запросов за пол года, она не высока, так как ее чаще всего сотрудники Frontline перевыполняют.
Для себя мы решили, что на вторую линию должны попадать инциденты, решение которых требует какой — либо настройки продуктива.
Когда сотрудник Frontline видит ошибку в работе системы, исправление которой потребует доработку — он заводит тикет в Jira, привязывает его к инциденту в BMC Remedy и запрос в Jira назначает на команду развития, а сам инцидент оставляет в очереди Frontline и мониторит его выполнение. После того, как команда развития подготовила патч с исправлением и вторая линия поддержки его установила на продуктив, сотрудник Frontline проверяет исправление ошибки и после этого закрывает инцидент в BMC Remedy.
Каждый сотрудник Frontline закреплен за каким то подразделением второй линии и в случае возникновения каких либо вопросов и сомнений может обратиться к коллегам.
А если в потоке тикетов так велика доля запросов, действительно не требующая вмешательства в код/конфиг, то это косвенно указывает на проблемы с продуктом в целом или с понятностью инструкций для пользователей.
Особенность фронт систем в том, что на них «вылезает» всё — и ошибки в работе самой системы, ошибки на бэк системах, ошибки бизнес логики, ошибки сотрудников в процессе оформления продукта, особенности настройки маркетинговых акций и тд.
Мы используем дополнительную классификацию второго уровня в системе BMC Remedy и при закрытии запроса проставляем причину ее возникновения, так выявляя рост ошибок со стороны пользователей, мы можем передать информацию бизнес подразделениям, чтобы они провели доп обучение сотрудников розницы, если увеличивается количество интеграционных ошибок — мы так же сигнализируем об этом необходимым командам и т.д. Задача Frontline не просто закрыть инцидент, а сделать так чтобы их становилось меньше, своего рода Problem Management.

DarkWolf13
кирпич не конкретно к описанной команде, а в общем виденьи ситуации: иногда проблема бывает настолько витиевата, что первая линия её не понимает, ставит либо в ожидание, либо просит перезвонить… потом наконец кто-то начинает переключать на более квалифицированный уровень и вот тут то иногда либо специалисты сбрасывают (привет роботу РОМАНУ и подобным киберпопугайчикам) либо это другой специалист/старший специалист этого же уровня, не понимающий технической части вопроса (привет проводному… телекому) и в результате от продукта отказываются либо даже не приобретают… в некоторых случаяк бывает клиент получает возможность сразу проскочить 0-ой, 1-ый уровни при уде достаточном опыте общения, но подобное редкое исключение, которое иногда перестает работать при смене/модернизации менеджмента/рабочей бизнес модели
serraxes
Приобретают что? Нифига не понял полета мысли.
DarkWolf13
кредит, вклад, услуги связи это тоже товар который приобретают и если на этапе консультаций возникают проблемы, неважно до покупки или после, клиент в случае проблем буден настроен избежать дальнейшего контакта с организацией с таким проблемным сервисом/техподдержкой